
A Taxonomy for Complexity Estimation of Machine Data in Machine
Health Applications
Lukas Meitz
1 a
, Michael Heider
2 b
, Thorsten Sch
¨
oler
1 c
and J
¨
org H
¨
ahner
2 d
1
Hochschule Augsburg, An der Hochschule 1, Augsburg, Germany
2
Universit
¨
at Augsburg, Am Technologiezentrum 8, Augsburg, Germany
Keywords:
Predictive Maintenance, Condition Monitoring, Complexity, Taxonomy, Product Automation Systems.
Abstract:
The Machine Health (MH) sector—which includes, for example, Predictive Maintenance, Prognostics and
Health Management, and Condition Monitoring—has the potential to improve efficiency and reduce costs for
maintenance and machine operation. This is achieved by data-driven analytics applications, utilising the vast
amount of data collected by sensors during machine runtime. While there are numerous possible fields of ap-
plication, the overall complexity of machines and applications in scientific publications is still low, preventing
MH technologies from being implemented in many real-world scenarios. This may be the result of a diffuse
understanding of the term complexity in the publications of this field, which results in a lack of focus towards
the core problems of real-world MH applications. This article introduces a new way of discerning complexity
in data-driven MH applications, enabling an effective discussion and analysis of present and future MH ap-
plications. This is achieved by creating a new taxonomy based on observations from relevant literature and
substantial domain knowledge. Using this newly introduced taxonomy, we categorise recent applications of
MH to demonstrate the usefulness of our approach and illustrate a still-prevalent research gap based on our
findings.
1 INTRODUCTION
The sector of Machine Health (MH), whose more
prominent elements are, for example, Predictive
Maintenance (PdM), Prognostics and Health Man-
agement, and Condition Monitoring, has the potential
to revolutionise modern machinery-related applica-
tions. In theory, MH technologies, such as estimating
a machine’s Remaining Useful Lifetime (RUL), are
able to reduce downtime, cost, and resource consump-
tion of maintenance and can improve overall machine
efficiency by using data that is continuously collected
and analysed (Serradilla et al., 2022).
However, as current surveys repeatedly find, there
are still numerous open challenges and research gaps
in the domain, preventing its technologies from be-
ing widespread and commonplace (Nunes et al.,
2023)(Gashi and Thalmann, 2020)(Serradilla et al.,
2022). Most important, there is a lack of generalisa-
a
https://orcid.org/0000-0001-7409-2401
b
https://orcid.org/0000-0003-3140-1993
c
https://orcid.org/0000-0001-5487-1862
d
https://orcid.org/0000-0003-0107-264X
tion in current research, with each research project be-
ing a solution to the specific machine at hand (Nunes
et al., 2023). Applications that are reported in sci-
entific literature are not as diverse as they could be;
published articles are still mostly staying at the level
of system components (Gashi and Thalmann, 2020).
The overall complexity of actual MH applications is
often said to be low, while—at the same time—there
is a lack of common understanding of the term com-
plexity in MH.
For the scope of this article, a first definition of
complex applications references applications, that are
hard or impossible to implement using existing stan-
dard components and algorithms. To aid future re-
search on implementing this type of applications, the
aim of this article is to further refine this definition,
and describe what exactly makes an application com-
plex. This refined definition is presented and intro-
duced as a new taxonomy in Section 4.
This taxonomy allows identifying and addressing
the parts of an application that introduce the most
complexity, thereby guiding the research field towards
removing the most relevant barriers to the adoption of
MH methods in practice.
Meitz, L., Heider, M., Schöler, T. and Hähner, J.
A Taxonomy for Complexity Estimation of Machine Data in Machine Health Applications.
DOI: 10.5220/0012994900003822
In Proceedings of the 21st International Conference on Informatics in Control, Automation and Robotics (ICINCO 2024) - Volume 1, pages 341-350
ISBN: 978-989-758-717-7; ISSN: 2184-2809
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
341

The contributions of this article are:
• Collection of related articles dealing with com-
plexity
• Introduction of a taxonomy for the term complex-
ity
• Categorisation of multiple applications using this
taxonomy
• Discussion of current applications, their complex-
ity level and research gaps
The structure of this work is the following: In Sec-
tion 2 the foundations for the remainder of this article
are introduced to enable an effective discussion. Sec-
tion 3 comprises a review of how the term complexity
has been used in recent applications, and summarises
the building blocks of related work. Afterwards, the
proposed taxonomy is explained in detail in Section 4
and used to classify multiple recent applications and
illustrate the findings in Section 5. Lastly, a discus-
sion about the selected applications and the usage of
the taxonomy is provided in Section 6 followed by an
outlook to future research.
2 FOUNDATIONS AND
PROBLEM DEFINITION
An application is a concrete implementation of a
paradigm, such as Predictive Maintenance, for a given
machine. Applications differ from machines in that
different applications are possible for one machine.
One application of MH for CNC Mill’s might be RUL
estimation of the used tool. Another application may
be the monitoring of vibrations from the same CNC
mill’s spindle. As can be seen from this, application
complexity is related not only to a machine, but to
each specific application.
In the context of this paper, we define Machine
Data as data that is created by or related to the oper-
ation of machinery. This not only encompasses pro-
duction machinery, but any type of machine that is
subject to continuous monitoring. Mostly, this data
is gathered by connected sensors attached to or built
into the machine or by logging signals that control the
machine or parts of it. However, different additional
sources of information can be present in an MH appli-
cation, such as meta-information about the operation
of the machinery. The data usually takes the form of
time series, as samples are recorded periodically from
sensors and other information sources.
We assume that the collection of data follows a
purpose beyond purely internal use, e.g. for control
systems: Engineers and/or Data Scientists want
to use that data for a variety of applications. Here,
extracting machine-related information from the
collected data is the main goal of MH. We can
distinguish between direct consumption by humans,
e.g. for remote condition monitoring, dashboarding,
or remote control, and (semi-)intelligent data-driven
applications, such as Prognostics and Health Man-
agement, which is often also known under the
term Predictive Maintenance and the main type of
application we focus on in this study.
To give an intuitive understanding of the problem
found in recent literature, we give a short example of
what complexity encompasses. One prominent appli-
cation example in the MH domain is fault detection
on ball bearings of rotating machinery. This can be a
straightforward affair and has seen exhaustive atten-
tion in recent publications, which are summarised for
example in (Farooq et al., 2024). The vibration data
in form of time series, generated by the ball bearing
in operation, can be analysed using off-the-shelf mod-
els. However, implementing the same fault detection
application is not as straightforward for more complex
machinery. Take the example of a robotic arm, which
consists of multiple jointed components monitored by
sensors. This setup is generating multiple different
time series with additional dependencies, in contrast
to the ball bearings application. Naturally, providing
the same fault detection mechanism for such an arm is
much more difficult and comes with more challenges
than in the simple ball-bearing application. In other
words, the robotic arm application is more complex,
but the way in which it is more complex is not prop-
erly defined.
This lack of specific understanding of complex-
ity leads to problems for implementing Predictive
Maintenance for sophisticated machinery. Solving
the example application with existing off-the-shelf so-
lutions is unlikely but of course highly desired. In
recent literature every application needed its own re-
search for finding suitable methods, as there is no
detailed description of the problem of complexity at
hand and comparison of different machines is not triv-
ial.
In this context, the consideration of data properties
is an important aspect, as we presume that it will aid
further research. Considering the sources and type of
complexity of an application can be used to estimate
the complexity of an application, help focus on the
core problems for implementation, and enables the
comparison of different settings. This in turn lends
an idea of what models or modelling approaches and
pipelines are applicable for any specific use case. To
achieve all this, we propose the creation of a new tax-
ICINCO 2024 - 21st International Conference on Informatics in Control, Automation and Robotics
342

onomy that enables a mapping of complexity levels to
ways to process and model data.
3 DISCUSSION OF THE TERM
COMPLEXITY
Complexity is a term regularly used in multiple publi-
cations, especially to characterise systems that cannot
be easily described. In consequence, there are varying
definitions of the term complex in the context of MH.
To shed some light and give an overview of popular
definitions, we dive into the relevant literature based
on a short survey we performed.
3.1 Usage in Related Literature
In their work, Gashi et al. (Gashi and Thalmann,
2020) state that recent PdM applications mostly con-
sists of single-component-system solutions, which
neglect the dependency of components on each other
and therefore lacking complexity. The authors coint
the term multi-component systems (MCS) and give
four types of component interdependence, in order to
communicate which type of complexity could be part
of future research. Some publications use the term
complexity without explicit definition, such as Fos-
sier et al. (Fossier and Robic, 2017) and Dai et al. (Dai
et al., 2008), missing out on the opportunity to clarify
the exact challenges faced in their work.
In contrast to these, there are articles which ex-
plicitly deal with the term complexity and establish
isolated descriptions. Miller and Dubrawski (Miller
and Dubrawski, 2020) for example give an overview
of multiple different applications and group them by
similarity, which is useful for illustrating the range
of different implementations. As an additional re-
sult of their work, they analyse research gaps regard-
ing the complexity of current scenarios. To better
communicate their findings, they introduce the terms
component-level and system-level Predictive Main-
tenance, referring to the scope of implementations.
They find two gaps: First, in component-level scenar-
ios, there is mostly two distinct states of operation,
which are faulty and healthy. Second, most of the
more elaborate applications do not incorporate the in-
terdependence of components into their analysis and
fail to observe the system as a whole. Their termi-
nology using component-level and system-level gives
a solid starting point to where complexity might be
introduced in applications.
Nguyen et al. (Nguyen et al., 2015) set the focus
of their article on a decision policy rather than data
analysis. They introduce their own description of sys-
tem complexity as being inter-dependencies of differ-
ent kinds for a MCS.
Van Horenbeek et al. (Van Horenbeek and Pin-
telon, 2013) similarly introduce complexity in the
form of MCS with different kinds of dependencies
between components. They further state that there
are stochastic, structural and economic dependencies
between components of one machine. In their pa-
per, they address the problem of modelling such types
of dependencies and choosing a maintenance strategy
suited for a given system.
The approach of considering component depen-
dencies is adapted in a clear definition by Ahmed et
al. (Ahmed et al., 2021). They describe complex sys-
tems as systems with multiple components with de-
pendencies that are either unknown or hard to incor-
porate into a model. As examples of domains con-
taining complex applications they mention aerospace,
automotive, oil and gas, as well as industrial applica-
tions.
3.2 Basic Aspects of Complexity in
Applications
There are multiple publications that describe small as-
pects of complexity in the context of MH, whose in-
sights form a solid basis for discussion. To under-
stand their impact onto the proposed taxonomy, they
are referenced and described shortly.
Klein et al. (Klein and Bergmann, 2019) worked
on the subject of complexity in machines from the
perspective of data. Their publication tackles the
problem of complex data generation for PdM ap-
plications, with complexity being defined as multi-
variability. They give an overview of datasets that
are commonly used for benchmark purposes, describe
their attributes and finally introduce their own method
of generating multivariate time series data based on
a Fischertechnik factory model. The main aspect of
complexity they introduced is the use of multivariate
time series, which is considered an important attribute
in the further scope this article.
Blancke and Combette (Blancke et al., 2019) use
the term complex to mean that there are many possi-
ble modes of failure for the equipment being moni-
tored. They used expert knowledge to create a causal
graph of failure causes and symptoms in order to im-
plement PdM. They intuitively refer to complexity as
a high variance of possible machine states, but do
not give a formal definition. We, too, incorporate the
amount and difference in possible failure modes into
our taxonomy.
Lee and Pan (Lee and Pan, 2017) published a
A Taxonomy for Complexity Estimation of Machine Data in Machine Health Applications
343

way of implementing PdM for complex systems with
probabilistic dependencies. They list publications
addressing PdM for multi-component machines and
single-component applications, and give a possible
implementation of PdM. While their dataset does not
consist of time series data and is quite outdated, they
do define their understanding of a complex system
explicitly: They characterise it as multi-leveled hi-
erarchical system with multiple components and un-
known component dependencies. These dependen-
cies are another way of introducing complexity to a
multi-component system, which will be relevant in
the course of this article as well.
Z
¨
ufle et al. (Z
¨
ufle et al., 2021) also deal with the
complexity of data, but do not explicitly explain their
understanding of it. They introduce a workflow for
anomaly detection on machine tool data. Instead of
relying on benchmark datasets, they use real-world
data collected from a machining centre and process it
in order to implement supervised anomaly detection.
To achieve this, they used a segmentation approach on
the complex real-world data to make it suitable for the
anomaly detection task. Their publication introduces
a conception of especially relevant in real-world PdM
applications, which is variance in form of multiple
steps in a process.
As can be seen, all named publications implic-
itly or explicitly deal with data complexity, but they
lack a common understanding in their applications.
The majority only take the mechanical properties of
a machine into account when referring to complex-
ity, making them too specific for comparison among
different MH applications. However, as stated in the
foundations section, different applications can be im-
plemented for a given machine, introducing complex-
ity in a second field: the process being executed by
the machine.
There is still a lack of sophisticated applications,
as stated for example by (Z
¨
ufle et al., 2021) or (Gashi
and Thalmann, 2020). We think this is a direct result
of the research gap at hand, which is the matter of
clearly describing complexity in MH. In order to fill
this research gap, our article will further characterise
the term complexity and provide a way of estimating
and comparing application complexity by introducing
a novel taxonomy that can be used for all types of MH
applications.
3.3 Challenges of Complexity
Complexity influences not only the feasibility of im-
plementation for some applications, but also the nec-
essary steps for properly working with the data. More
complexity in the data generally means models might
not perform well or at all. More complexity in terms
of machine hardware will introduce more feature di-
mensions, data types, component dependencies and
general data heterogeneity. Higher complexity in the
observed process also leads to longer time series,
possible deviations in length, more possible machine
states, different types of machine states and more pos-
sible environmental influences. Increased complexity
in either attribute means more states and variance to
consider, with only a small part of the data relevant to
maintenance decisions, bringing off-the-shelf models
to their performance limit. Most models cannot work
well with high amounts of variance, as they are only
trained to learn one specific function or classification,
not a combination of multiple ones. The taxonomy,
which will be now introduced, can be used for a cat-
egorisation of an application in terms of its complex-
ity, and therefore help with selecting the proper opera-
tions for actual data preprocessing and models for the
implementation, mitigating some of these challenges.
4 A NOVEL TAXONOMY FOR
COMPLEXITY
Essentially, the previously mentioned publications re-
ferring to complexity describe attributes like volume
and variance in the application’s data. This is already
a common understanding in the domain of big data,
where the five Vs (Volume, Velocity, Veracity, Vari-
ety, and Value) are often addressed as the main chal-
lenges (Naeem et al., 2022).
However, in contrast to the specific definitions of
our related work, the definition given in Big Data pub-
lications is too general for the subject of Machine
Health. There is no deeper look at where the volume
or variance is introduced, missing out on the possibil-
ity of solving problems at their core. The core prob-
lem of complex applications is handling or reducing
the complexity in/to a form that existing models can
handle. To successfully achieve this, the source and
type of complexity needs to be found and dealt with
in the implementation.
When looking at the data recorded from Ma-
chines, two major factors contribute to an applica-
tion’s complexity: the machine and the process be-
ing implemented. The first factor solely describes the
hardware aspect of an application, while the second
one focuses on the technical process that is imple-
mented by the machine.
To illustrate this, we get back to the previously in-
troduced example of Section 2. By being a machine
consisting of more than one component, the robot arm
introduces more volume of data, simply by needing
ICINCO 2024 - 21st International Conference on Informatics in Control, Automation and Robotics
344

Figure 1: Machine Complexity Illustration.
more sensors to monitor all of its components. Ad-
ditionally, the robot arm can perform tasks that are
more complicated or inherently different from each
other, which increases the variance in recordings for
each process. While this is intuitively understood, a
definition of the two factors machine and process will
help in aiding the discussion about complexity.
4.1 Machine-Induced Complexity
By looking at the hardware part of an application,
complexity can be found in the number and type of
components that are the building blocks of the ma-
chine or system. With more components, there are
more possible interactions and dependencies. Addi-
tionally, with many different components there are
a wider variety of observable properties. Differ-
ent types of sensors create heterogeneous time se-
ries data, with multiple observations that have to be
treated differently. This increases volume and vari-
ance of the recorded data, creating the aforemen-
tioned challenges.
Depending on the application setup, a single ma-
chine or a batch of machines can be subject to the
approach. For a single machine, an observation of op-
erating condition over time is the only way to imple-
ment monitoring. This way, degradation and trends
over time can be extracted from the observations. For
multiple machines, deviations from the behaviour of
the bulk of machines can be the mode for detection.
This enables detection of failures without trend or
degradation attributes, as there is no need to compare
a history of observations.
Another factor to consider is that machine degra-
dation is not always linear. Components can fail spon-
taneously or degrade exponentially, among other pos-
sibilities, which may not be easily modelled. Differ-
ent components may fail differently, all inside of one
machine, which makes the task of failure detection
and diagnosis even harder for complex machines. For
this taxonomy, the type of degradation is not among
the properties for complexity estimation, as the inter-
actions of components are considered the prime cause
for complexity.
The scale of machine complexity ranges from a
single component to a system of multiple different
interdependent components, with single component
machines being the least complex type of applica-
tions. This scale is further defined in Table 1 and is
illustrated in Figure 1.
Machine complexity in PdM applications is cru-
cial to incorporate into preprocessing. As machine
complexity increases, so does the possible depen-
dence and interaction of the components. With high
machine complexity, components may not be able to
be monitored separately, but need to be seen as a
whole system. In addition, some models may not be
able to learn the complexity of circular dependencies.
The complexity of the monitored machine is the
main focus of relevant publications. While this is one
big aspect of complexity, there is another important
factor which has not seen too much attention in recent
research.
4.2 Process-Induced Complexity
In addition to the machine complexity, the imple-
mented process itself has significant impact on data
complexity and needs to be considered as an addi-
tional source of complexity in applications. The main
influence on process complexity is the number of ma-
chine states that can be observed in the data.
Simple processes can range from stamping or
pressing a part to driving a shaft or tool. For these
cases, only a single state is enough to define the nor-
mal operating conditions of the process. However, in
most real-world applications the processes have more
than one or two states. For example, the manufac-
turing of a complicated shape from a piece of stock
involves manipulating material in a sequence of dif-
ferent operations. For sequences with multiple steps,
there are multiple different states for each one, result-
ing in turn in a higher complexity of the application.
In recording or monitoring, the process can have
an influence on the form of data. Some processes or
segments can deviate in their length, making direct in-
stance comparison infeasible. Processes can, depend-
ing on their nature, produce periodic and non-periodic
data. For some algorithms or models, non-periodicity
can be a problem during learning or inference.
Control signals recorded in the time series data,
can be beneficial and enable more sophisticated anal-
ysis approaches. In the absence control signals, a
black box approach is used, where measurements, or
observations, depict to the machine condition. With
the presence of control signals a grey-box approach
can be implemented, in which the desired machine
state can (partially) be extracted from control signals
and more precise assumptions about the normality are
possible. However, another form of information/data
A Taxonomy for Complexity Estimation of Machine Data in Machine Health Applications
345
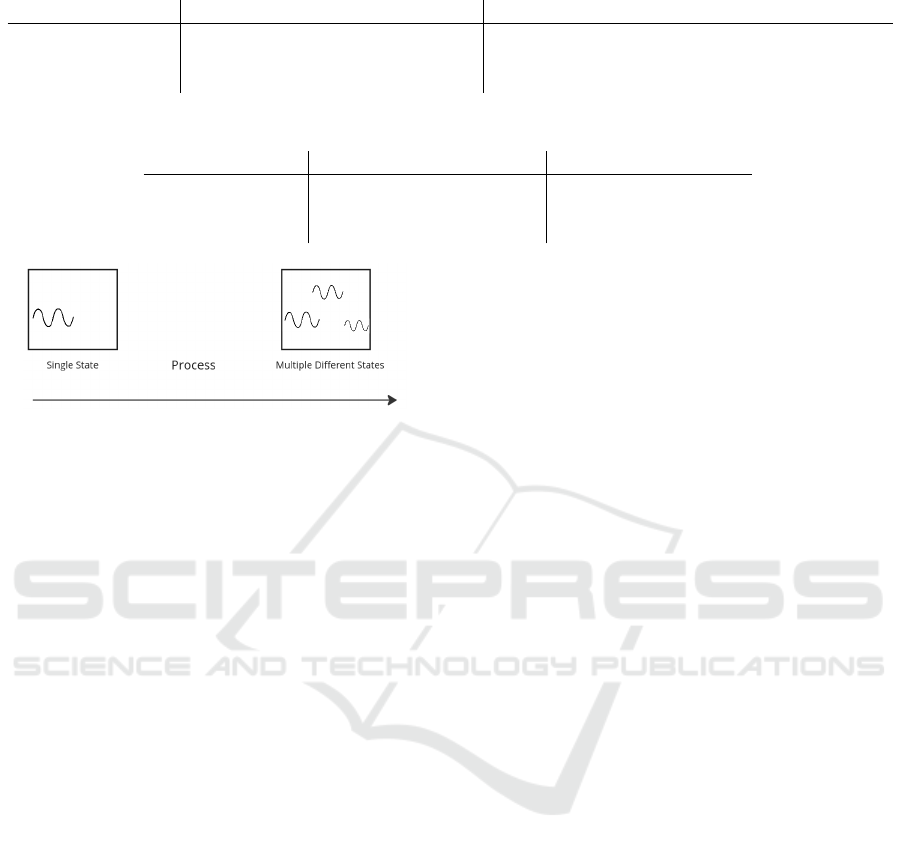
Table 1: Scale of complexity for the Machine Part.
Low Complexity Medium Complexity High Complexity
Single Component Multiple Independent Components Many inter-dependent Components
Single Sensor Multiple Sensors Many Heterogeneous Sensors
Single Machine Multiple similar Machines Multiple Machines w/ Environmental Influences
Table 2: Scale of complexity for the Process Part.
Low Complexity Medium Complexity High Complexity
Single State Multiple known States Many Unknown States
Uniform Length Uniform Length Non-Uniform Length
Periodic Data Periodic and Non-Periodic Non-Periodic
Figure 2: Process Complexity Illustration
introduces even further complexity to the application.
The levels of process complexity range from a
single-state, continuous process up to a multi-state se-
quenced process containing multiple modes of failure.
The summary of these levels can be found in Table 2
and are illustrated in Figure 2.
Process-attributes contribute a lot to the overall
complexity of an application, but has not seen at-
tention in related publications. By considering this
second aspect as an important one, our taxonomy
presents a new and effective way of describing the
overall complexity of a MH application.
5 USING THE PROPOSED
TAXONOMY
After introducing and explaining the two types of
complexity sources, this section will demonstrate the
usage of the taxonomy on different published applica-
tions to give a brief overview over recent research ef-
forts. By using it to categorise and compare multiple
data sets, a better overview of the current complex-
ity of applications can be given for the set of selected
applications.
5.1 Literature Search for Applications
The next goal of this article is to give an overview of
some of the existing applications and categorise them
using the proposed taxonomy. In order to give an un-
biased image, a structured literature search for appli-
cation publications is needed to create a dataset that
can be used as a basis for the demonstration.
One method of looking for applications is to ap-
ply numerous keyword-searches to scientific search
engines. However there are existing surveys that col-
lect applications in PdM or CM in order to give an
overview of the recent advances. For the purpose of
this article, taking a collection of applications from an
already published survey-paper is sufficient.
In the following, the findings of Mallioris et
al. (Mallioris et al., 2024) will be used for further dis-
cussion. Using the proposed approach, a set of appli-
cations has been collected from their survey and will
be described in the following subsection. As there
were multiple similar listings in their overview tables,
representative examples have been selected to be in-
cluded in this illustration of our taxonomy.
Table 3 gives an overview of all the selected appli-
cations for the scope of this article. On the first col-
umn of the table, the referenced application is named
and cited. In the next column, the used features are
presented to give an impression of the application
scope.
For the application of our taxonomy, one column
per feature is present in the table. The estimations
were retrieved by comparing the authors description
in the publications with our introduced scales for
machine- and process-induced complexity. The first
aspect, machine complexity, is described by the Ma-
chine Setup column. Here, a brief description of the
selected machine components and used sensors are
given, followed by an estimation of the complexity
based on these attributes. Process complexity is pre-
sented in another dedicated column named Process
Setup. Here, the type of process is described briefly,
how many different states it involves and if it is con-
tinuous or periodic. This column also contains the
complexity estimation for the given process.
ICINCO 2024 - 21st International Conference on Informatics in Control, Automation and Robotics
346
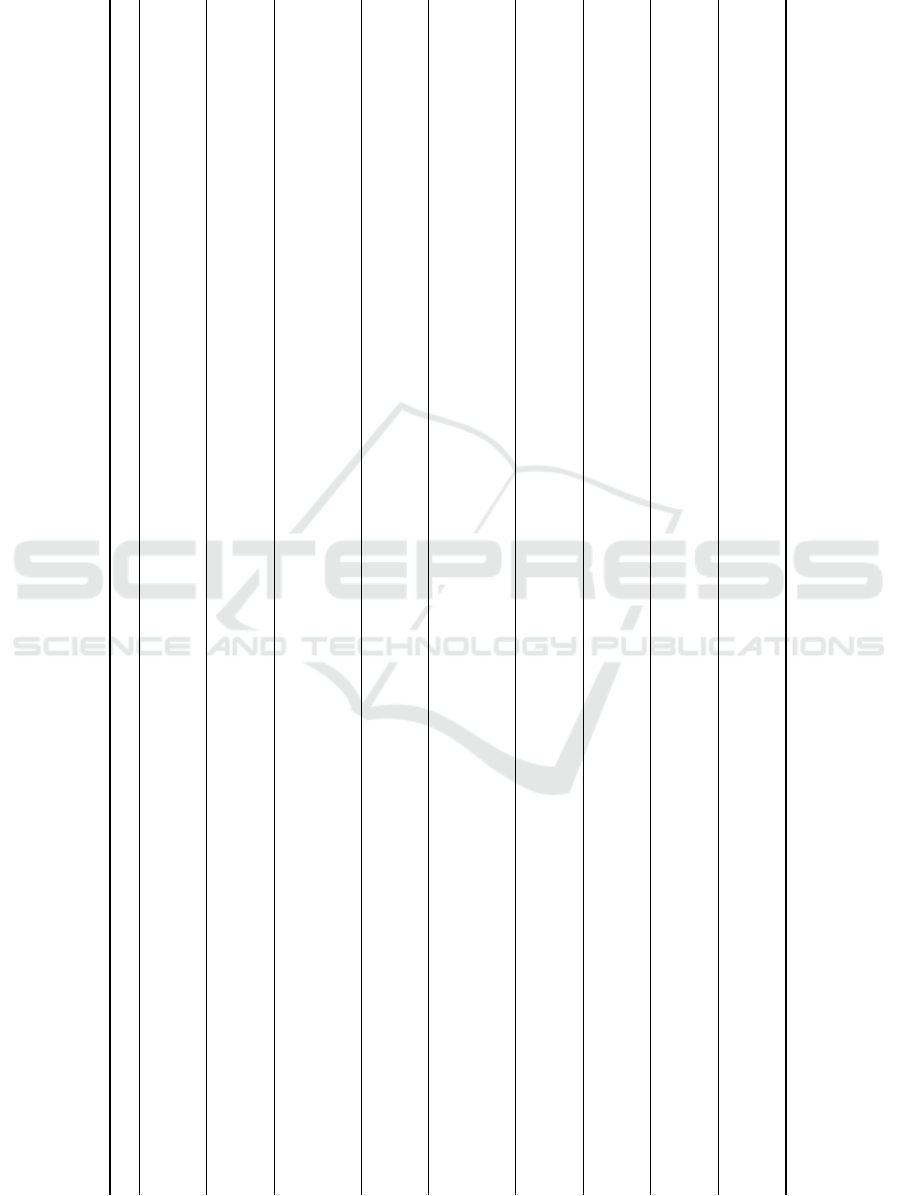
Table 3: Overview of the selected applications with the taxonomy applied. The Machine Setup and Process Setup columns
describe and categorise the two complexity sources.
Machine Type Data Features Machine Setup Process Setup
Pressing Machine
(Serradilla et al., 2021)
Rotational Speed,
Power Consumption,
Force, Position
Motor Connected over Gearbox to friction clutch;
Multiple Sensors of different kind;
Medium Complexity
Stamping a Part in one Motor Rotation;
Non-periodic time series and Single Normal State;
Low Complexity
Centrifugal Fan
(Lis et al., 2021)
Vibration
Single Motor driving a Fan;
Single Component and Sensor;
Low Complexity
Turning a Fan at constant RPM;
Single Normal State of a constant signal;
Low Complexity
Conveyor Belt
(Elahi et al., 2022)
Power Consumption
Single Motor driving a conveyor
belt with tensioning mechanism;
Single Component and Measurement;
Low Complexity
Turning a Conveyor Belt at constant speed;
Low Complexity
Hydraulic Machinery
(Roosefert Mohan et al., 2023)
Vibration, Oil Pressure,
Contamination
Motor Driving hydraulic Pump
Single Measurement and Autoregression;
Low Complexity
Hydraulic system monitoring (e.g. oil pressure);
Single healthy state with degradation;
Low Complexity
CNC Milling Machine
(Z
¨
ufle et al., 2021)
Vibration, movements,
temperature, speed, torque,
power, acoustics
3 Axis CNC Machine with one spindle;
Monitoring Sensor with multiple different signals;
incorporation of control signals;
Medium Complexity
Manufacturing Process with multiple steps;
multiple possible states;
Medium to High Complexity
CNC Spindle
(Hesser and Markert, 2019)
Vibration
CNC Machine Spindle;
Single vibration sensor;
Low Complexity
Test Process with single healthy state;
Low Complexity
Industrial Robot Joint
(Izagirre et al., 2020)
Torque Signal
Robot arm with multiple Joints;
Torque Readings from Two joints;
Low to Medium Complexity
Fixed test trajectory on the same Machine;
Non-periodic time series;
Medium Complexity
Nasa Turbofan
(Wang and Zhao, 2022)
Temperature, pressure,
ratio flow, fan speed,
coolant bleed
Turbofan Engine with many components
Multiple heterogeneous sensor signals;
High Complexity
Continuous usage in varying conditions;
Single Healthy State with Degradation and RUL;
Low to Medium Complexity
CFRP Drilling Machine
(Dom
´
ınguez-Monferrer
et al., 2022)
Energy Consumption,
Cutting Time
Drill with different Tool inserts;
Power Consumption and Statistical Features;
Low to Medium Complexity
Drilling Operation with 4 Phases;
Non-Periodic Time Series;
Medium Complexity
A Taxonomy for Complexity Estimation of Machine Data in Machine Health Applications
347
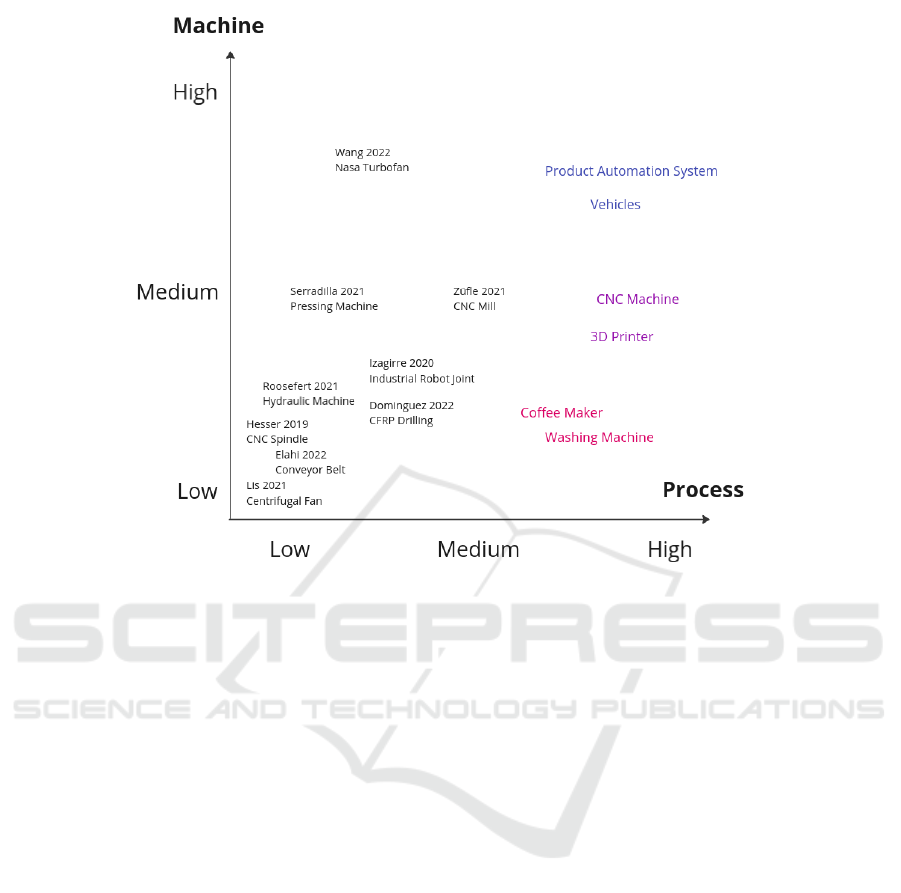
Figure 3: Complexity of related applications.
5.2 Illustration of the Dataset
In order to get a comprehensive illustration of the
complexity of different applications, it is useful to
combine the two introduced factors, machine and pro-
cess, into a two-dimensional plot. When applied to
multiple data points, this creates an illustrative way of
comparing complexity among the given applications.
For each application, an estimate of relative com-
plexity in Machine and Process has been made. These
data points have been placed in a graph displaying the
machine complexity in its X-axis and process com-
plexity in its Y -axis. Figure 3 shows the plot of the se-
lected and classified applications. Applications from
the list of selected publications are shown in black.
Additionally, there are coloured data points, which
are examples of possible future applications and will
be introduced in the following discussion.
6 DISCUSSION
The illustration of our proposed taxonomy yields in-
teresting insights into the current application spec-
trum as given by (Mallioris et al., 2024). In this sec-
tion, a discussion of the findings will be presented, as
well as a discussion of the approach itself.
6.1 Observations from the Taxonomy
When looking at Figure 3, two conclusions can be
drawn from the illustration: 1. Clusters of similarly
complex applications can be established, and 2. There
is a lack of applications with high process complex-
ity. These two observations are an important subject
for further discussion.
First, by using the taxonomy on a set of applica-
tions, clusters of similar complexity have been cre-
ated. This enables the observer, or an interested en-
terprise, to find similar solutions to their own prob-
lem, based on the characteristics of the application. It
therefore aids the development of real-world imple-
mentations by giving a starting point to look for when
it comes to preprocessing techniques and model se-
lection.
Second, evident through a lack of data points on
the right side of the graph, process complexity in the
observed applications is still low. This means that the
currently published types of solutions are only suit-
able for simple processes or kept simple for ease of
implementation. Processes of such type have only
few known states or a single healthy state, which is
distinctly different to most real-world scenarios.
Figure 3 illustrates the complexity of selected ap-
plications in black. In addition to those points, there
are coloured instances, which are examples of pos-
ICINCO 2024 - 21st International Conference on Informatics in Control, Automation and Robotics
348

sible applications that could be implemented to fit
those complexity. These can be summarised as a spe-
cific type of machinery, called Product Automation
Systems (PAS). PAS automate a technical process for
manufacturing or production of goods in a single ma-
chine. As can be seen in the illustration, this can
be simple machines such as a washing machine or
a coffee maker, but is also true for 3d printers and
CNC machines. What these machines introduce by
automating a complicated technical process is a high
complexity in the process-axis. The difference of the
examples in the illustration to existing research is the
scope of the application, which often does not con-
sider all of the possible process-induced complexity.
6.2 Identified Research Gap and
Relevance
The main research gap that can be observed by ap-
plying the proposed taxonomy to recent implementa-
tions in the MH setting is a lack of process-induced
complexity.
A possible cause of this could be the lack of
process-complex datasets in the field. Benchmark
datasets are popular and seen as a solid way to com-
pare performance over different models. However,
these benchmark datasets are neither optimised to be
as close as possible to real scenarios, nor complex
enough to make current algorithms struggle, as has
been demonstrated for the case of time series anomaly
detection (Wu and Keogh, 2022). Without read-
ily available datasets only industry-partnered projects
have access to complex data, which are then often re-
stricted by NDA policies. The result of such a lack
in complex datasets is a lack of research concerning
process complexity. Exactly this complexity is an es-
sential part and challenge of using MH technology in
real-world scenarios. Without being able to research
this field, complex applications will ultimately stay
out of reach for the MH community, and applications
will stay on the component level of machinery.
In order to mitigate this scarcity, some preliminary
steps should be taken. First, industrial co-operations
should be able to publish and share their data in a
scope that allows researchers from different institu-
tions to work together and compare their results, or to
develop methods for dealing with complex applica-
tions. Second, the creation of synthetic data based on
real-world applications should be researched to cre-
ate publicly available benchmark datasets that con-
tain various aspects process complexity. Third, the
effort to implement MH applications for PAS ma-
chinery should be increased. This type of machine
is widespread and not only reserved for big indus-
trial partnerships. Small machines such as CNC ma-
chines, 3d printers or coffee makers are available for
consumers and can build an important foundation for
research applications. Improvements in these areas
would foster the efforts of dealing with the process-
induced complexity and aid future efforts of imple-
menting sophisticated real-world applications.
6.3 Limits of the Proposed Approach
There are some fields of machinery, where this taxon-
omy is more suitable than for others. Industrial ma-
chinery, especially PAS are now part of the discus-
sion in MH. Overall, the taxonomy can be used for
comparing most applications that can be found in the
domain of Machine Health, as it is general enough to
encompass not only industrial machines.
Additionally, unsupervised learning is the mode of
operation for most applications. For supervised learn-
ing, the complexity of the application is not the first
consideration. When labels are present, most of the
issues that arise through complexity become less im-
portant.
One limitation of our taxonomy is that there is
no exact numerical quantification of complexity, but
more of a continuous scale that can vary slightly de-
pending on the observer. This makes it hard to give
a precise estimation for some applications, which can
however be resolved in discussions.
7 CONCLUSION
This article introduced a novel way of characterising
machine data in the context of Machine Health appli-
cations, which was described in detail as a two-feature
taxonomy containing machine- and process-induced
complexity. Using this taxonomy, selected applica-
tions from a well-crafted survey article have been
classified and illustrated using a two-dimensional
plot.
Based on observations from the plot, two impor-
tant topics have been identified and discussed: The
possibility to find clusters of similar applications in
the illustration, as well as the lack of high-complexity
processes in recent publications. The type of ma-
chines and research that could fill this gap in the future
have been introduced as Product Automation Systems.
The introduced taxonomy is an important step to-
wards fostering the discussion about complex, real-
world Machine Health applications. Using this well-
defined baseline for discussion, two improvements to
the state of the art are now possible. First, comparing
existing applications to another and to planned imple-
A Taxonomy for Complexity Estimation of Machine Data in Machine Health Applications
349

mentations of MH. Second, applications with previ-
ously unsolved challenges can be identified as such
and targeted specifically in future research. Imple-
mentation can focus on core sources of complexity
for tackling future problems.
REFERENCES
Ahmed, U., Carpitella, S., and Certa, A. (2021). An inte-
grated methodological approach for optimising com-
plex systems subjected to predictive maintenance. Re-
liability Engineering & System Safety, 216:108022.
Blancke, O., Combette, A., Amyot, N., and Komljenovic,
D. (2019). A predictive maintenance approach for
complex equipment based on a failure mechanism
propagation model. International Journal of Prognos-
tics and Health Management, 10.
Dai, J., Chen, C. L. P., Xu, X.-Y., and Hu, P. (2008). Condi-
tion monitoring on complex machinery for predictive
maintenance and process control. In 2008 IEEE Inter-
national Conference on Systems, Man and Cybernet-
ics, pages 3595–3600.
Dom
´
ınguez-Monferrer, C., Fern
´
andez-P
´
erez, J., De Santos,
R., Migu
´
elez, M., and Cantero, J. (2022). Machine
learning approach in non-intrusive monitoring of tool
wear evolution in massive cfrp automatic drilling pro-
cesses in the aircraft industry. Journal of Manufactur-
ing Systems, 65:622–639.
Elahi, M., Afolaranmi, S. O., Mohammed, W. M., and Mar-
tinez Lastra, J. L. (2022). Energy-based prognostics
for gradual loss of conveyor belt tension in discrete
manufacturing systems. Energies, 15(13).
Farooq, U., Ademola, M., and Shaalan, A. (2024). Compar-
ative analysis of machine learning models for predic-
tive maintenance of ball bearing systems. Electronics,
13(2).
Fossier, S. and Robic, P.-O. (2017). Maintenance of com-
plex systems — from preventive to predictive. In 2017
12th International Conference on Live Maintenance
(ICOLIM), pages 1–6.
Gashi, M. and Thalmann, S. (2020). Taking complex-
ity into account: A structured literature review on
multi-component systems in the context of predictive
maintenance. In Themistocleous, M. and Papadaki,
M., editors, Information Systems, pages 31–44, Cham.
Springer International Publishing.
Hesser, D. F. and Markert, B. (2019). Tool wear monitor-
ing of a retrofitted cnc milling machine using artificial
neural networks. Manufacturing Letters, 19:1–4.
Izagirre, U., Andonegui, I., Egea, A., and Zurutuza, U.
(2020). A methodology and experimental implemen-
tation for industrial robot health assessment via torque
signature analysis. Applied Sciences, 10(21).
Klein, P. and Bergmann, R. (2019). Generation of complex
data for ai-based predictive maintenance research with
a physical factory model. In ICINCO (1), pages 40–
50. Scitepress.
Lee, D. and Pan, R. (2017). Predictive maintenance
of complex system with multi-level reliability struc-
ture. International Journal of Production Research,
55(16):4785–4801.
Lis, A., Dworakowski, Z., and Czubak, P. (2021). An
anomaly detection method for rotating machinery
monitoring based on the most representative data.
Journal of Vibroengineering.
Mallioris, P., Aivazidou, E., and Bechtsis, D. (2024). Pre-
dictive maintenance in industry 4.0: A systematic
multi-sector mapping. CIRP Journal of Manufactur-
ing Science and Technology, 50:80–103.
Miller, K. and Dubrawski, A. (2020). System-level predic-
tive maintenance: Review of research literature and
gap analysis.
Naeem, M., Jamal, T., Diaz-Martinez, J., Butt, S. A., Mon-
tesano, N., Tariq, M. I., De-la Hoz-Franco, E., and
De-La-Hoz-Valdiris, E. (2022). Trends and future per-
spective challenges in big data. In Pan, J.-S., Balas,
V. E., and Chen, C.-M., editors, Advances in Intelli-
gent Data Analysis and Applications, pages 309–325,
Singapore. Springer Singapore.
Nguyen, K.-A., Do, P., and Grall, A. (2015). Multi-level
predictive maintenance for multi-component systems.
Reliability Engineering & System Safety, 144:83–94.
Nunes, P., Santos, J., and Rocha, E. (2023). Challenges in
predictive maintenance – a review. CIRP Journal of
Manufacturing Science and Technology, 40:53–67.
Roosefert Mohan, T., Preetha Roselyn, J., and Annie Uthra,
R. (2023). Lstm based predictive maintenance ap-
proach for zero breakdown in foundry line through in-
dustry 4.0. In Kumar, H., Jain, P. K., and Goel, S., ed-
itors, Recent Advances in Intelligent Manufacturing,
pages 29–51, Singapore. Springer Nature Singapore.
Serradilla, O., Zugasti, E., Ramirez de Okariz, J., Ro-
driguez, J., and Zurutuza, U. (2021). Adaptable and
explainable predictive maintenance: Semi-supervised
deep learning for anomaly detection and diagnosis in
press machine data. Applied Sciences, 11(16).
Serradilla, O., Zugasti, E., Rodriguez, J., and Zurutuza,
U. (2022). Deep learning models for predictive
maintenance: a survey, comparison, challenges and
prospects. Applied Intelligence, 52.
Van Horenbeek, A. and Pintelon, L. (2013). A dynamic
predictive maintenance policy for complex multi-
component systems. Reliability Engineering & Sys-
tem Safety, 120:39–50.
Wang, Y. and Zhao, Y. (2022). Multi-scale remaining useful
life prediction using long short-term memory. Sustain-
ability, 14(23).
Wu, R. and Keogh, E. J. (2022). Current time series
anomaly detection benchmarks are flawed and are cre-
ating the illusion of progress (extended abstract). In
2022 IEEE 38th International Conference on Data
Engineering (ICDE), pages 1479–1480.
Z
¨
ufle, M., Moog, F., Lesch, V., Krupitzer, C., and Kounev,
S. (2021). A machine learning-based workflow for au-
tomatic detection of anomalies in machine tools. ISA
Transactions, 125.
ICINCO 2024 - 21st International Conference on Informatics in Control, Automation and Robotics
350
