
HTEKG: A Human-Trait-Enhanced Literary Knowledge Graph with
Language Model Evaluation
Sreejith Sudhir Kalathil
1
, Tian Li
1
, Hang Dong
2
and Huizhi Liang
1
1
Newcastle University, Newcastle upon Tyne, U.K.
2
University of Exeter, Exeter, U.K.
Keywords:
Knowledge Graph, Literary Analysis, Language Model.
Abstract:
Knowledge Graphs (KGs) are a crucial component of Artificial Intelligence (AI) systems, enhancing AI’s
capabilities in literary analysis. However, traditional KG designs in this field have focused more on events,
often ignoring character information. To tackle this issue, we created a comprehensive Human-Trait-Enhanced
Knowledge Graph, HTEKG, which combines past event-centered KGs with general human traits. The HTEKG
enhances query capabilities by mapping the complex relationships and traits of literary characters, thereby
providing more accurate and context-relevant information. We tested our HTEKG on three typical literary
comprehension methods: traditional Cypher query, integration with a BERT classifier, and integration with
GPT-4, demonstrating its effectiveness in literary analysis and its adaptability to different language models.
1 INTRODUCTION
The advent of Artificial Intelligence (AI) has signifi-
cantly revolutionized our ability to analyze, interpret,
and interact with human literature, offering several
powerful tools for studying vast volumes of literary
data, including summarization, topic and relationship
mining, entity extraction, information structuring, and
retrieval. Meanwhile, these technologies facilitate re-
searchers in achieving advancements in domains such
as human-computer interaction, role-play generation,
and creative writing assistance. However, despite its
prosperity, AI systems still encounter challenges in
approaching the human level. This is because current
NLP technology mainly focuses on information and
knowledge while overlooking personal trait and rela-
tion aspects. For example, prior works (Van Hage and
Ceolin, 2013; Lombardo et al., 2018; Kozaki et al.,
2023; P. Wilton, 2013; Khan et al., 2016; Yeh, 2017;
Lisena et al., 2023) have concentrated on author-
centric and event-centric knowledge points, such as
authorship, content summaries, genre information,
story elements, event timelines, and their interrela-
tions. The forced application of knowledge-centered
schemas to character analysis inevitably leads to the
loss of nuanced information about individuals and
the complex relationships between them (Ugai et al.,
2024; Ugai, 2023). Consequently, it constrains the
AI potential in tasks such as character analysis and
role-playing, hindering AI’s application in fields like
creative writing, game development, AI in education,
and person-centered recommendations.
To address these issues, this paper aims to
construct a comprehensive, Human-Trait-Enhanced
Knowledge Graph with a new backbone ontology
schema to depict human and contextual attributes
across various literary pieces. We name the knowl-
edge graph built upon this ontology HTEKG. By ex-
tracting relevant entities and information from vari-
ous literary datasets (such as Project Gutenberg
1
and
Goodreads
2
) according to our proposed ontology, we
build HTEKG on the Neo4j platform. To evaluate
the effectiveness of our system for character under-
standing and its compatibility with cutting-edge NLP
models, we employed three different methods, Neo4j
Cypher, BERT classification (Devlin et al., 2018), and
GPT-4 (Achiam et al., 2023), to assess HTEKG on
multiple dimensions.
Our key contributions are as follows:
• We pioneered a Human-Trait-Enhanced Knowl-
edge Graph schema and extraction process, in-
corporating character attributes, emotions, and re-
lational dynamics into the knowledge graph in
a standardized manner. This endows AI frame-
works with more comprehensive literary character
1
https://www.gutenberg.org
2
https://www.goodreads.com
Kalathil, S., Li, T., Dong, H. and Liang, H.
HTEKG: A Human-Trait-Enhanced Literary Knowledge Graph with Language Model Evaluation.
DOI: 10.5220/0013013600003838
In Proceedings of the 16th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2024) - Volume 2: KEOD, pages 207-215
ISBN: 978-989-758-716-0; ISSN: 2184-3228
Copyright © 2024 by Paper published under CC license (CC BY-NC-ND 4.0)
207

analysis capabilities, and the standardization and
generality of our approach ensure its scalability to
the vast amount of literature.
• Our detailed evaluation on integrating HTEKG
with BERT and GPT-4 showcases not only its cor-
rectness and relatedness (Nguyen et al., 2023) in
character understanding but also its flexibility in
integrating with the language models.
2 RELATED WORK
We define Knowledge Graphs (KGs) based on the
various definitions in the field (Ehrlinger and W
¨
oß,
2016), as schema (or a backbone ontology) of classes
with their data instances. The schema provides high-
level terms (corresponding to TBox in an OWL on-
tology (Grau et al., 2008)) and the facts provide in-
stance level information (corresponding to ABox). A
KG can be represented as a set of triples (s, p, o) of
subject, predicate, and object.
KGs have been extensively applied in various nar-
rative text scenarios to manage information and as-
sist tasks such as reading comprehension, logical rea-
soning, and literary creation (Hitzler and Janowicz,
2013; Lehmann, 2015; Lee and Chang, 2019). There
is a substantial amount of prior work on the de-
sign of ontologies for narrative text scenarios. The
Simple Event Model (SEM) (Van Hage and Ceolin,
2013) was one of the earliest attempts to construct a
unified ontology for narrative texts, focusing on the
chronological order of events and forming their on-
tology around temporal sequences. However, their
work neglected the characterization of people, thus
omitting attributes like “who and how”. The work
(Lombardo et al., 2018) proposed another ontology,
Drammar, that included human attributes, but it was
fiction-specific, lacking standardization and general-
izability. The KG Reasoning Challenge (Kozaki et al.,
2023) provided a KG for Sherlock Holmes novels,
but its characterization of characters was too sim-
plistic, missing information such as character mo-
tivations, opportunities, and means of crime. Ad-
ditionally, many ontology works for narrative con-
tent (P. Wilton, 2013; Khan et al., 2016; Yeh, 2017;
Lisena et al., 2023) opted for event-centric construc-
tion schemes. These studies focus on addressing the
challenges of constructing nonlinear narratives using
KGs rather than on character and relationship depic-
tion.
In terms of KGs usage, early approaches mainly
involved retrieval reasoning and embedding tech-
niques. In the KG Reasoning Challenge, Ugai
(Ugai et al., 2024; Ugai, 2023) constructed a KG
encompassing character motives, opportunities, and
methods, coupling it with an event-centered KG to
achieve interpretable crime predictions. Kurokawa
(Kurokawa, 2021) used various KG embeddings to
perform crime prediction and summarization through
link prediction. Nguyen (Nguyen et al., 2023) em-
ployed BERT classification to test their biological
KG. In recent years, with the rise of large language
models (LLMs), graph-based retrieval-augmented
generation (RAG) systems that integrate KGs and
LLMs have become increasingly popular. Ashby
(Ashby et al., 2023) utilizes KGs to assist LLMs in
procedural content generation. Mindmap (Wen et al.,
2023) and GraphRAG (Edge et al., 2024) constructs
multi-level natural language summaries (also named
“community”) for KG retrieval to facilitate the use of
KG information by LLMs. The core objective of these
approaches is to leverage the topological information
of KGs to represent complex relationships, thereby
enhancing the effectiveness of the final system. To
demonstrate the adaptability of our ontology to dif-
ferent approaches, we selected one representative ap-
proach from each of the three categories above (Neo4j
Cypher, BERT-based classification, and GPT-4 API)
and coupled it with our HTEKG for evaluation.
3 METHODOLOGY
In this section, we elaborate on the following three
topics to create our HTEKG including schema design,
construction, and evaluation:
• Schema Design of the HTEKG. How to de-
sign a Human-Trait-Enhanced backbone ontology
to represent character information, particularly
the complex relationships and interaction features
among characters.
• Construction of the HTEKG from Texts. How
to utilize NLP techniques to extract the corre-
sponding entities and populate the final HTEKG
with the backbone ontology. This involves named
entity recognition (NER) and subject-verb-object
(SVO) methods for character identification, geo-
graphic detection, and relationships.
• Evaluation of the HTEKG. How to couple our
HTEKG with different language models (BERT
and GPT-4) to give predictions of detailed charac-
ter attributes and relationships, or generations for
evaluation purposes.
KEOD 2024 - 16th International Conference on Knowledge Engineering and Ontology Development
208
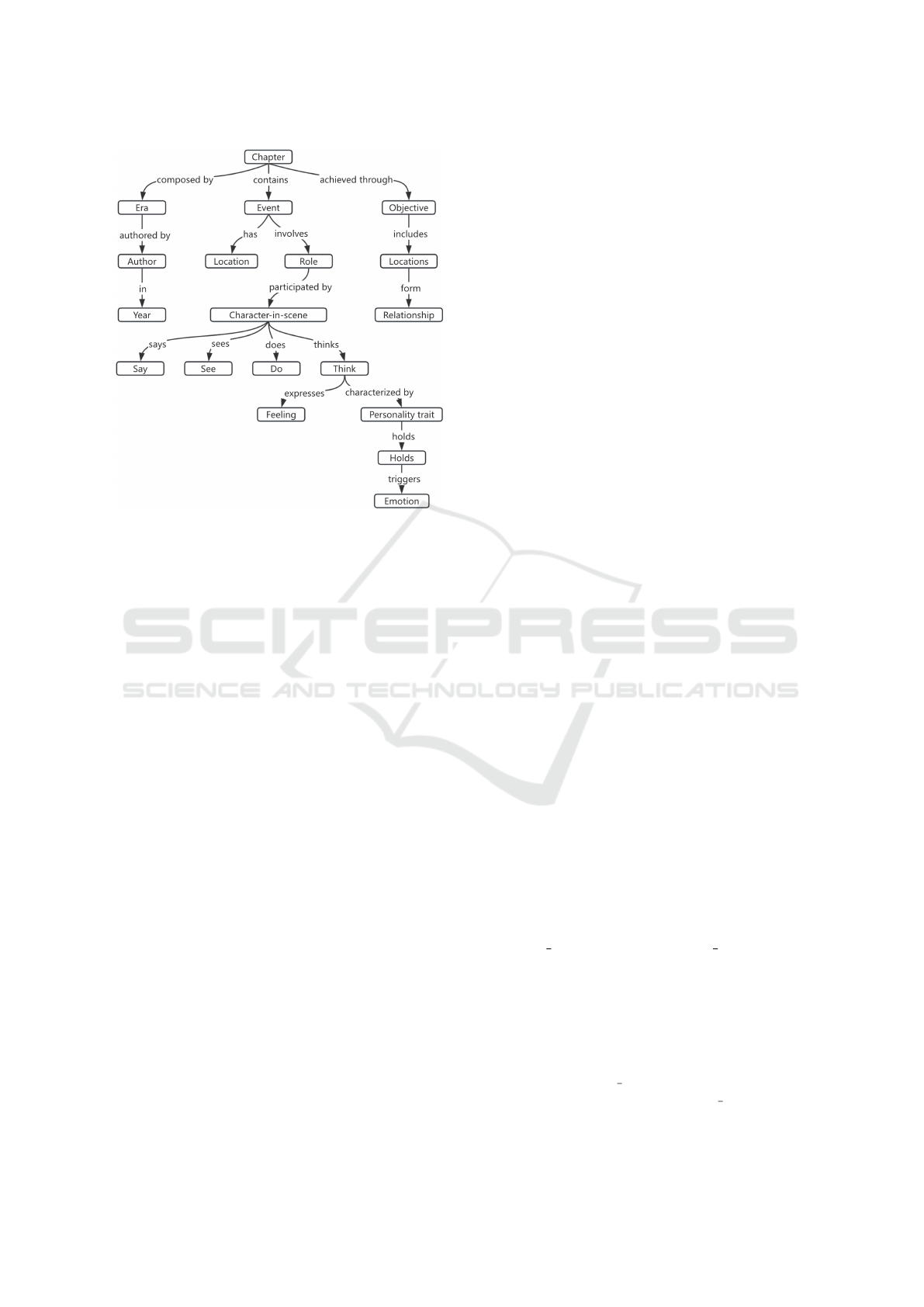
Figure 1: Human-Trait-Enhanced KG schema.
3.1 Schema Design of the HTEKG
To build a unified literary ontology, we integrated
the Simple Event Model (SEM) (Van Hage and Ce-
olin, 2013; Gottschalk and Demidova, 2018), Empa-
thy Knowledge Representation (Pileggi, 2021), ABC
Model of Personality (Ellis, 1991), and theory of
mind for cognitive KG (Wu et al., 2023), and make
adjustments to better depict character traits and rela-
tionships. Our goal is to provide a hierarchical and in-
terconnected framework containing semantically rich
character attributes and narrative elements, thereby
promoting a deeper and more comprehensive litera-
ture analysis through the KG.
The overall schema is illustrated in Figure 1. It
has several key design objectives. First, it provides
enhanced character and narrative integration, which
includes the following features:
• Chapter and Contextual Data. The schema be-
gins with the class “Chapter”, which then con-
textualizes the narrative by including “Era”, “Au-
thor”, and “Year”. This foundational layer sets the
stage for a deeper understanding of the narrative
and its historical or stylistic settings.
• Events and Settings.: Each “Event” within a
chapter includes the “Location” where it unfolds,
providing spatial context that influences character
interactions and developments.
• Role Dynamics. The roles that characters play
within these events are depicted as the flow,
changing from one event to another, reflecting the
evolving nature of their interactions and the sig-
nificance within the narrative.
Second, the backbone ontology is designed to pro-
vide detailed character-in-scene depiction, as listed
below:
• Actions and Beliefs. The “Character-in-scene”
component captures what characters see, say, and
do, along with their thoughts and beliefs. These
elements are crucial for illustrating “Personality
Traits” and how these traits manifest in different
situations (Lehmann, 2015).
• Emotions. Characters’ emotions are intricately
linked to events, showcasing how different scenar-
ios influence their emotional responses. This dy-
namic portrayal helps in understanding how char-
acters react under varying circumstances.
Third, this schema displays linkages of several
narrative elements, including the linking between
the chapter and its main objectives and the relation-
ships among characters within that chapter. Such
linkages also provide more in-depth social fabric vi-
sualization based on the interactions between charac-
ters, such as friendships, rivalries, alliances, and fa-
milial bonds. This feature adds ontological signifi-
cance to the characters, enriching the potential to de-
pict their human traits.
These three features are vital to illustrate how
characters’ goals and interactions drive the narrative
forward and affect their development, and is some-
thing that previous work has overlooked.
3.2 Construction of the HTEKG
This section introduces two parts: (i) the extended set-
tings used to construct the HTEKG; (ii) the NLP tech-
niques employed for various information extraction.
3.2.1 Extended Settings to Construct HTEKG
For the definition of nodes, each of them has multiple
attributes, such as character and emotional states. For
example:
• Character Nodes. Attributes include roles
(“HAS ROLE”) and traits (“HAS TRAIT”), pro-
viding a dynamic representation of character de-
velopment.
• Scene Nodes. Attributes related to characters and
settings, reflecting the spatial dynamics and emo-
tional textures of the narrative.
For the definition of edges, we use relationships
such as “INCLUDES SCENE” (between “Chapter”
and “Scene” nodes) or “FEATURES IN” (between
“Chapter” nodes) to connect different nodes.
HTEKG: A Human-Trait-Enhanced Literary Knowledge Graph with Language Model Evaluation
209

3.2.2 Techniques for Information Extraction
Before performing all extraction steps, we prepro-
cessed the data by removing disturbing symbols and
irrelevant information (such as project introductions
and copyright statements) that could interfere with
subsequent operations. By identifying specific chap-
ter markers, we divided the data into different chap-
ters. This approach facilitates targeted extraction of
the content, themes, and objectives within each chap-
ter in the subsequent steps (Siahaan et al., 2023).
For entities such as names, locations, and dates,
we utilized SpaCy with their official English NER
model for extraction. For character traits, emotions,
and personality characteristics, we first located them
using SpaCy’s tags and then matched and identified
these features using a predefined sentiment lexicon.
To extract character relationships, we employ an-
other lexicon dictionary (a small number of pre-
prepared words and use WordNet (Miller, 1995) to
enumerate all their synonyms) to match and map the
results to predefined relationships. This approach mit-
igates the omission caused by unconventional expres-
sions of some relationships.
3.3 Evaluation of the HTEKG
The evaluation compares the results of the querying
of the HTEKG (e.g. with a KG querying language:
Cypher) with pre-prepared answers. We calculated
the accuracy (Acc), precision (Prec), recall (Rec), and
F1 score of the retrieval results, thus reflecting the ef-
fectiveness of our HTEKG in literary analysis.
We also tested fusing HTEKG with two language
models: GPT-4 and BERT (Nguyen et al., 2023). This
provides further insights into our HTEKG’s adapta-
tion to cutting-edge models. Their processes are in-
troduced in the following sections.
3.3.1 Integration with GPT-4
For the integration with GPT-4, the overall process is
divided into three steps:
1. We concatenated the natural language require-
ment query and the structural description of KG
and input them into GPT4 to generate the corre-
sponding Cypher query. An example is shown in
Table 1.
2. We execute the Cypher query on Neo4j to retrieve
the corresponding search results.
3. We concatenate the query and the Cypher query
results and input them into GPT-4 to obtain the
final output. An example is shown in Table 2.
We assess the quality of the generated content
through manual annotation. For information of the
test samples and the GPT version, please refer to Sec-
tion 4.
3.3.2 Integration with BERT
For the integration with BERT, the overall process in-
volves training and evaluation phases, as we convert
it into multiple classification tasks and achieve it by
fine-tuning BERT. The using of fine-tuned BERT for
KG evaluation is inspired by the previous work in
(Nguyen et al., 2023). Four classifiers are prepared,
including Traits Classifier, Relationships Classifier,
Emotions Classifier, and Events Classifier. The task
of each classifier is a binary classification task. The
meaning of the label is defined as follows:
• Correct Information (Label = 1). This la-
bel signifies that the extracted attribute (such as
traits, relationships, emotions, or events) accu-
rately matches the information from the novel.
For example, if the classifier correctly identifies
“Sherlock Holmes” as “intelligent”, it is labeled
as correct.
• Incorrect Information (Label = 0). This la-
bel indicates that the attribute is either incorrect
or inconsistent with the known data. For in-
stance, if the dataset incorrectly states that “Sher-
lock Holmes” is “fearful”, it is labeled as incor-
rect.
After manually collecting the samples required for
each task, the entire dataset is divided into two parts:
a training set, used for fine-tuning the classifiers, and
a test set, used to evaluate their performance. For
meta information and statistical information about the
dataset, please refer to Section 4.
4 EXPERIMENTS
We used Neo4j as the platform to construct our
HTEKG. It leverages a graph model to represent and
navigate relationships between data points, making it
ideal for applications that require connected data in-
sights. Meanwhile, it employs Cypher, a powerful
and expressive query language specifically designed
for working with graph data. Additionally, it has sev-
eral build-in tools to visualize the database.
We used the novel “The Hound of the
Baskervilles” from the Gutenberg dataset to con-
struct the HTEKG. This knowledge graph contains
239 nodes and 683 relationships. The statistics of
entities extracted during the NER phase are shown in
KEOD 2024 - 16th International Conference on Knowledge Engineering and Ontology Development
210
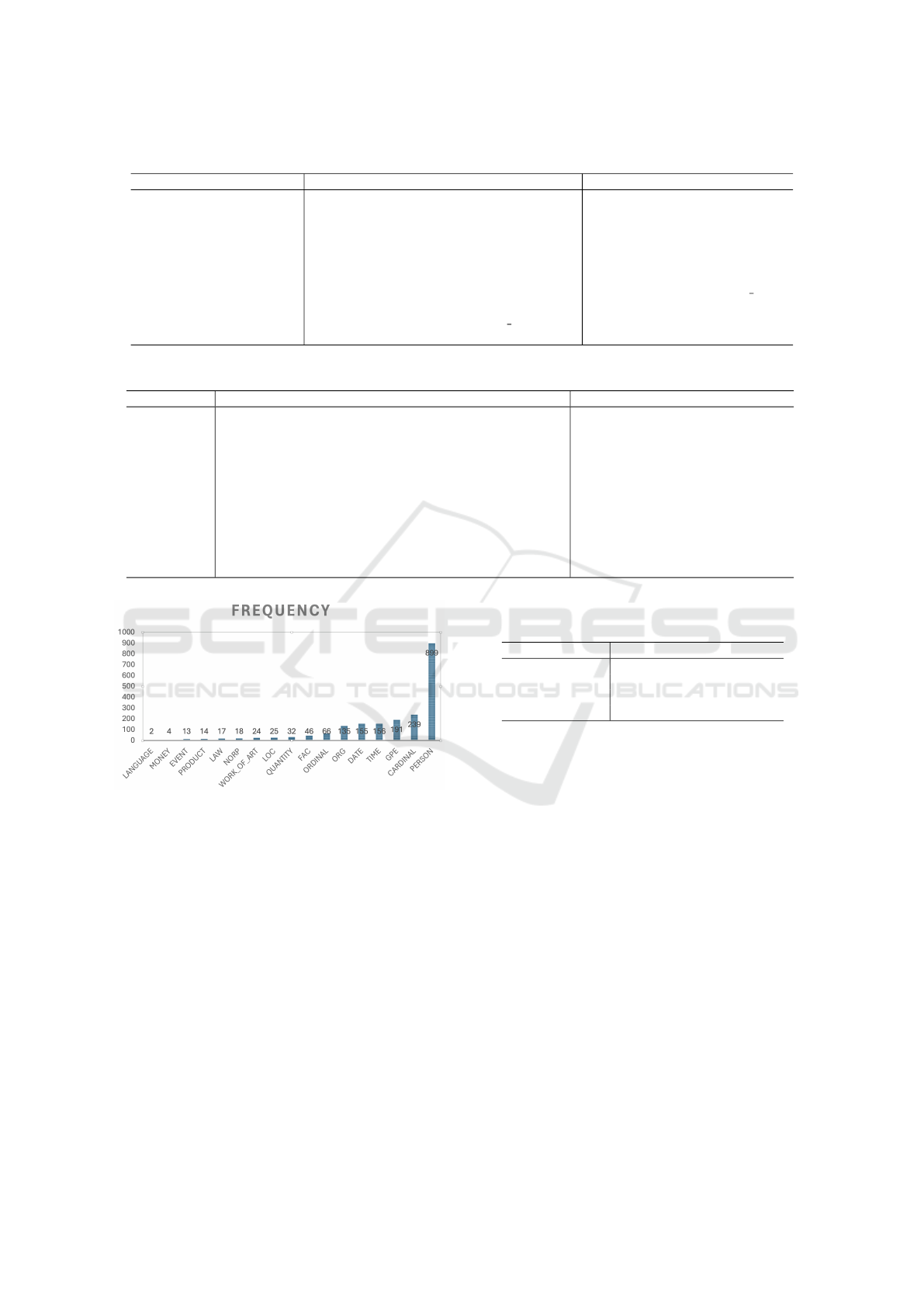
Table 1: The sample to prompt GPT-4 to convert natural language query plus graph structure information into Cypher query.
Query Graph Structure Description Response
Given the context of ‘The
Hound of the Baskervilles’
by Sir Arthur Conan Doyle,
generate a Cypher query
to find the characters who
are friends of Dr. Watson.
Return the query in JSON
format.
Nodes: Character, Book, Chapter, Location,
Event, Scene
Character nodes have properties: name, ...
Book nodes have properties: title, ...
Relationships:
Character nodes are connected to Book, ...
Character nodes can have relationships
with each other (e.g., FRIENDS WITH, ...).
...
MATCH (c:Character)-
[r:FRIEND]->(w:Character
{name: ‘Dr. Watson’})
RETURN c.name AS friend name
Table 2: The sample to prompt GPT-4 to generate the answer based on query and KG information.
Query Cypher Result Response
Describe the
relationship
between Dr.
Watson and
Sherlock
Holmes.
{‘characterProfile’: {‘name’: ‘Sherlock Holmes’, ‘roles’:
[(‘role’: ‘Detective’,‘description’: ‘Holmes uses his
remarkable deductive reasoning skills to solve complex
and mysterious cases.’), (‘role’: ‘Friend’, ‘description’:
‘Holmes is a close friend and flatmate to Dr. John
Watson, often working together on various cases.’}],
‘traits’: [‘Intellectual’, ‘Observant’, ‘Analytical’,‘Eccentric’,
‘Unemotional’], ‘emotionalExperiences’: [‘experience:
‘Frustration’, ‘description’:‘Holmes often shows
frustration when people fail to see what he considers
obvious clues.’}, ...
Dr. Watson and Sherlock Holmes
share a deep, rich friendship and
an incredibly strong professional
relationship as well. Introduced
in Arthur Conan Doyle’s novel,
“A Study in Scarlet,” Dr. John
Watson meets Sherlock Holmes
when both are looking for affordable
lodgings, leading to them sharing
rooms at 221B Baker Street...
Figure 2: Statistics of entities for “The Hound of the
Baskervilles”.
Figure 2. Figures 3 and 4 illustrate how the HTEKG
represents Jack Stapleton and the relationship
between Dr. John Watson and Dr. James Mortimer.
For the traditional Cypher queries and BERT clas-
sification scenarios, we prepared 500 samples across
4 categories, with no fewer than 100 samples per cat-
egory. Since the BERT classifiers require training, the
dataset was split into a 7:3 ratio for training and eval-
uation. The evaluation for both Cypher queries and
BERT classifiers was conducted on the evaluation set.
The detailed statistics are shown in Table 3.
For training the BERT model, we used Bert-base-
uncased as our base model and fine-tuned it to create
the four classifiers as needed.
For the dataset used to test the integration with
Table 3: The dataset statistics for Cypher queries and BERT
classifiers.
Classifier Train Evaluation Total
Character Traits 105 45 150
Relationships 70 30 100
Emotions 84 36 120
Events 91 39 130
GPT-4, we manually prepared 24 queries for evalua-
tion. For the GPT-4 version, we used the GPT-4-0613
model. This is the standard version provided by Ope-
nAI, supporting a token length of 8K.
5 RESULTS
We report results based on the three evaluation strate-
gies, comparing KG query (with Cypher language) to
predefined answers, comparing fine-tuned BERT re-
sults with the HTEKG, and integrating HTEKG with
prompting GPT-4.
5.1 Results of Querying HTEKG
Table 4 demonstrates the results of using Cypher
queries to retrieve relevant characters, emotions, re-
lationships, and events. It showcases the HTEKG’s
ability to structurally extract and present complex
character dynamics from literary texts.
HTEKG: A Human-Trait-Enhanced Literary Knowledge Graph with Language Model Evaluation
211
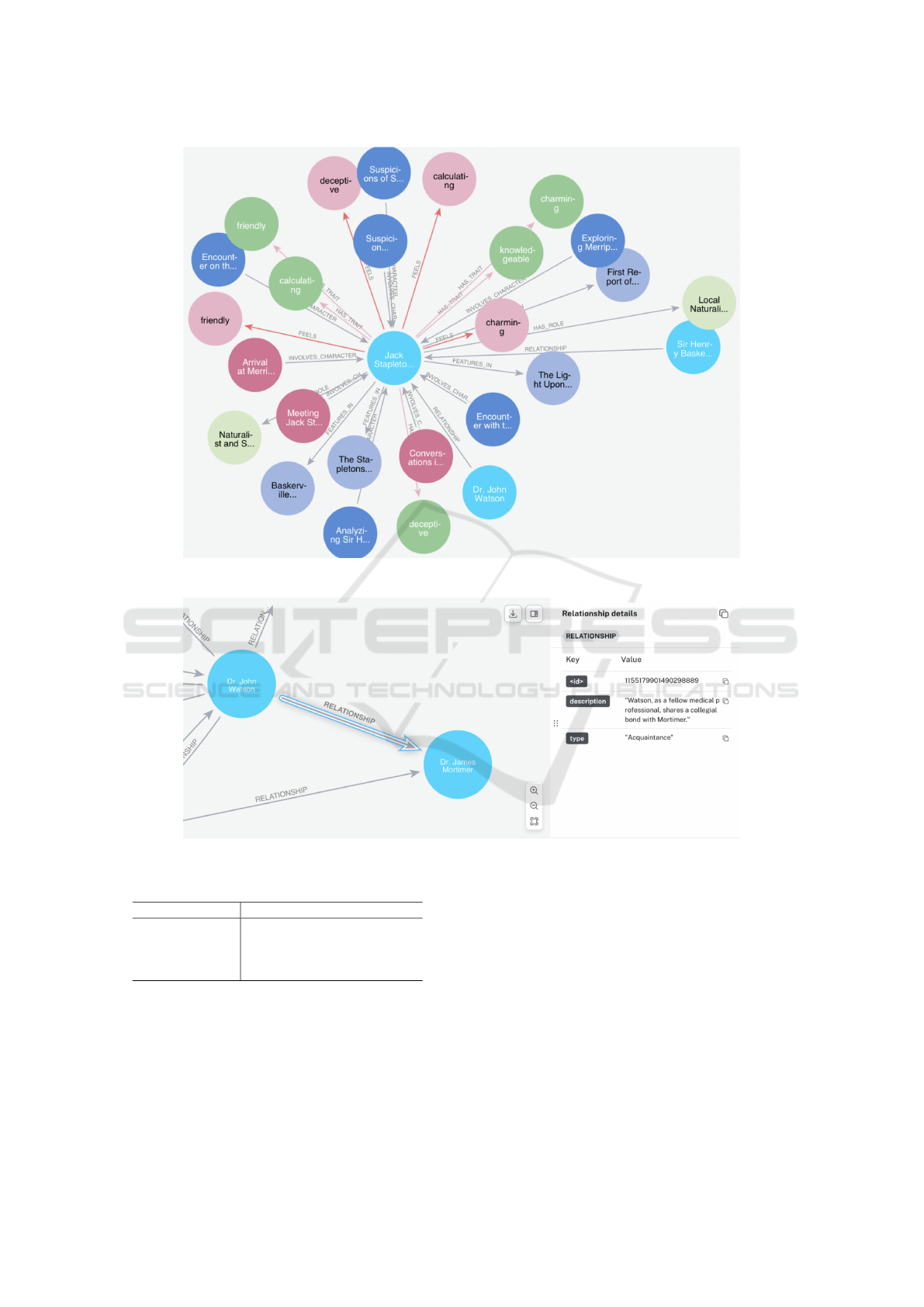
Figure 3: The demonstration subgraph of Jack Stapleton extracted from the HTEKG.
Figure 4: The demonstration of the “acquaintance” relationship between Dr. John Watson and Dr. James Mortimer.
Table 4: Results of querying HTEKG using Cypher.
Category Acc Prec Rec F1
Character Traits 0.91 0.90 0.91 0.90
Relationships 0.77 0.74 0.76 0.75
Emotions 0.86 0.84 0.83 0.83
Events 0.87 0.85 0.86 0.85
5.2 Result of Integrating HTEKG with
BERT
Table 6 shows the performance of integrating HTEKG
with BERT in predicting different attributes. It excels
in predicting traits. However, it performs moderately
in predicting attributes with complex relations, such
as character relationships, emotions, and the associ-
ated events.
5.3 Result of Integrating HTEKG with
GPT-4
Table 5 displays a full GPT-4 respond to the query
based on the HTEKG content, and Table 7 provides
metrics proving that the HTEKG integrates well with
GPT-4. It can be observed that even when concatenat-
ing long Cypher results, GPT-4 can still understand
the content and extract relevant information to gener-
KEOD 2024 - 16th International Conference on Knowledge Engineering and Ontology Development
212
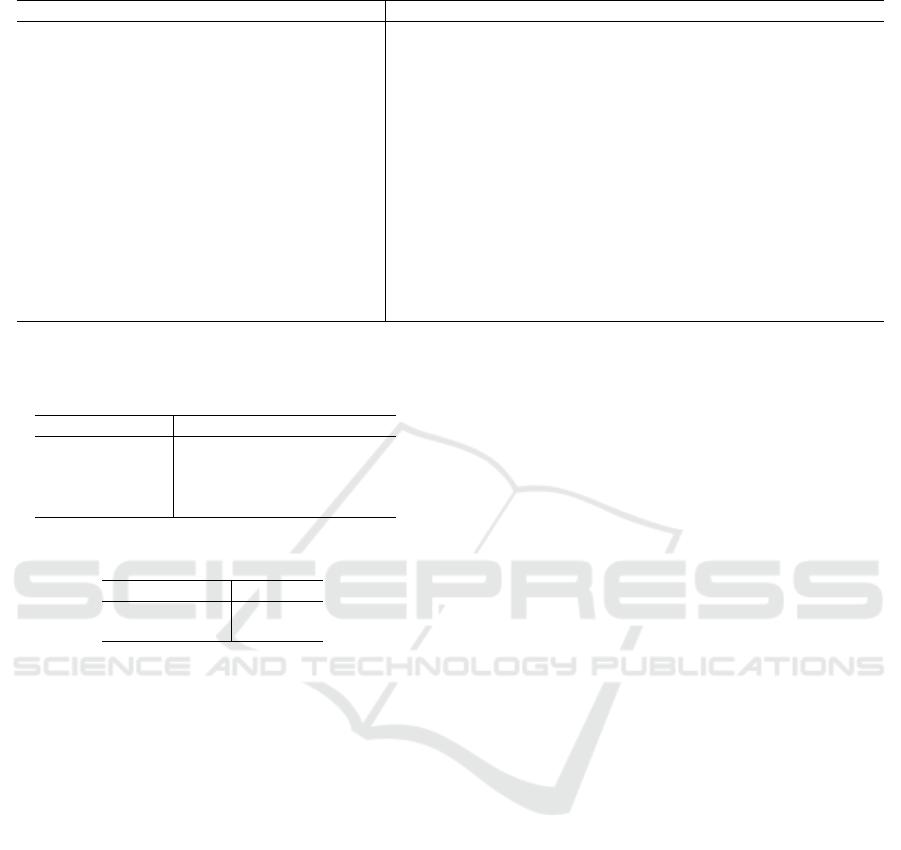
Table 5: An example of GPT-4’s response.
Input Reponse
List the implications of this narrative element in
bullet points: Sir Charles Baskerville’s death.
+ ${Cypher Result}
The death of Sir Charles Baskerville kick-starts the main storyline
of the novel “The Hound of the Baskervilles” by Arthur Conan
Doyle involving a legendary beast supposedly haunting the
Baskerville family.
- It brings into focus the supposed curse on the Baskerville
family which becomes a subject of investigation and interest.
- Sir Charles’s death leads to the introduction of Sherlock Holmes
and Dr. John Watson, the main characters, who are brought in to
investigate the mysterious circumstances surrounding his death.
- After his death, the heir apparent, Sir Henry Baskerville, is
introduced, which adds another layer of suspense and intrigue to
the plot.
- It leads to the exploration of the Baskerville Hall and its
surrounding moor.
Table 6: Results of BERT classifiers.
Category Acc Prec Rec F1
Character Traits 0.87 0.85 0.84 0.84
Relationships 0.67 0.65 0.66 0.65
Emotions 0.75 0.73 0.74 0.73
Events 0.77 0.76 0.77 0.77
Table 7: Results using GPT-4-0613.
Query Method Accuracy
GPT-4 0.63
+ HTEKG 0.85
ate context-rich and correct responses. The generated
content includes a great deal of detail, which is not
visible when querying GPT-4 without the HTEKG.
The results highlight the HTEKG’s potential to im-
prove AI tools for literary analysis.
5.4 Discussion
Beyond the evaluation metrics presented above, we
also observed that integrating HTEKG with GPT-4
enhanced GPT-4’s ability to provide more detailed
and nuanced explanations. This opens up new av-
enues for interpretability in future research, allowing
researchers to monitor the internal thought processes
of GPT-4 more effectively. Also, GPT-4 excels at us-
ing HTEKG to generate coherent predictions when
dealing with complex narrative elements such as rela-
tionships. In contrast, BERT may give contradictory
results when predicting the relationship between two
people using different person’s subgraphs.
6 CONCLUSION
In this work, we propose a novel standardized
Human-Trait-Enhanced Knowledge Graph, HTEKG.
Our ontology highlights the nuanced interplay of
character traits and relationships, showcasing the po-
tential of KGs to capture complex human interactions
within the literature. We evaluated HTEKG in three
scenarios: Cypher query, integration with BERT, and
integration with GPT-4. Our evaluation demonstrates
the role of HTEKG in literary understanding and its
flexibility in coupling with different AI frameworks.
However, this work has the following limitations:
• Comprehensive Knowledge Coverage. This work
primarily focuses on integrating general human
attributes with past event-centered ontology, lack-
ing coverage in areas such as temporal knowl-
edge. Additionally, there is a lack of specific re-
search on idioms and metaphors in literary works,
which may result in some knowledge missing.
• Evaluation Method Limitations. The three eval-
uation scenarios used in this work are basic and
general practices compared to the real-world ap-
plication. More evaluation methods need to be
attempted to verify the effectiveness of HTEKG
with various cutting-edge technologies. More-
over, the current HTEKG evaluation lacks stan-
dardized metrics, so we devised different evalua-
tion schemes based on usage scenarios. This must
be tackled in the future.
For future work, we propose the following direc-
tions:
• More Advanced Knowledge Extraction Tech-
niques. We aim to introduce more advanced and
automated technologies, leveraging graph under-
HTEKG: A Human-Trait-Enhanced Literary Knowledge Graph with Language Model Evaluation
213

standing AI frameworks, to standardize and ac-
celerate the knowledge extraction process.
• Broader Corpus Coverage. We plan to build our
HTEKG on a larger scale corpus.
• Clearer Downstream Application Scenarios. Be-
sides analysis, we will also explore using the
HTEKG to assist in tasks such as role-playing and
procedural content generation. For instance, in
role-playing scenarios, current systems that com-
bine LLMs with agent-based design are highly
disorganized, with each implementation using its
own unique memory design. However, since our
ontology encompasses detailed role information
(including states, goals, emotions, and past ac-
tions), our HTEKG can be applied to standard-
ize the design of agent systems in this domain,
thereby enhancing and scaling up the role-playing
capabilities of existing LLMs.
REFERENCES
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I.,
Aleman, F. L., Almeida, D., Altenschmidt, J., Altman,
S., Anadkat, S., et al. (2023). Gpt-4 technical report.
arXiv preprint arXiv:2303.08774.
Ashby, T., Webb, B. K., Knapp, G., Searle, J., and Fulda,
N. (2023). Personalized quest and dialogue genera-
tion in role-playing games: A knowledge graph-and
language model-based approach. In Proceedings of
the 2023 CHI Conference on Human Factors in Com-
puting Systems, pages 1–20.
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K.
(2018). Bert: Pre-training of deep bidirectional trans-
formers for language understanding. arXiv preprint
arXiv:1810.04805.
Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody,
A., Truitt, S., and Larson, J. (2024). From local to
global: A graph rag approach to query-focused sum-
marization. arXiv preprint arXiv:2404.16130.
Ehrlinger, L. and W
¨
oß, W. (2016). Towards a definition
of knowledge graphs. SEMANTiCS (Posters, Demos,
SuCCESS), 48(1-4):2.
Ellis, A. (1991). The revised abc’s of rational-emotive ther-
apy (ret). Journal of rational-emotive and cognitive-
behavior therapy, 9(3):139–172.
Gottschalk, S. and Demidova, E. (2018). Eventkg: A multi-
lingual event-centric temporal knowledge graph. In
The Semantic Web: 15th International Conference,
ESWC 2018, Heraklion, Crete, Greece, June 3–7,
2018, Proceedings 15, pages 272–287. Springer.
Grau, B. C., Horrocks, I., Motik, B., Parsia, B., Patel-
Schneider, P., and Sattler, U. (2008). Owl 2: The next
step for owl. Journal of Web Semantics, 6(4):309–322.
Semantic Web Challenge 2006/2007.
Hitzler, P. and Janowicz, K. (2013). Linked data, artifi-
cial intelligence, and the semantic web. AI Magazine,
34(2):63–72.
Khan, A. F., Bellandi, A., Benotto, G., Frontini, F., Giovan-
netti, E., and Reboul, M. (2016). Leveraging a narra-
tive ontology to query a literary text. In 7th Workshop
on Computational Models of Narrative (CMN 2016).
Schloss-Dagstuhl-Leibniz Zentrum f
¨
ur Informatik.
Kozaki, K., Egami, S., Matsushita, K., Ugai, T., Kawamura,
T., and Fukuda, K. (2023). Datasets of mystery stories
for knowledge graph reasoning challenge. In ESWC
Workshops.
Kurokawa, M. (2021). Explainable knowledge reasoning
framework using multiple knowledge graph embed-
ding. In Proceedings of the 10th International Joint
Conference on Knowledge Graphs, pages 172–176.
Lee, Y. and Chang, H. (2019). The role of ontology in un-
derstanding human relations. Cognitive Science Quar-
terly, 39(1):45–65.
Lehmann, J. (2015). Dbpedia – a large-scale, multilingual
knowledge base extracted from wikipedia. Semantic
Web, 6(2):167–195.
Lisena, P., Schwabe, D., van Erp, M., Leemans, I., Tul-
lett, W., Troncy, R., Ehrich, S. C., and Ehrhart, T.
(2023). An ontology for creating hypermedia stories
over knowledge graphs. In SWODCH 2023, Workshop
on Semantic Web and Ontology Design for Cultural
Heritage.
Lombardo, V., Damiano, R., and Pizzo, A. (2018). Dram-
mar: A comprehensive ontological resource on drama.
In The Semantic Web–ISWC 2018: 17th International
Semantic Web Conference, Monterey, CA, USA, Octo-
ber 8–12, 2018, Proceedings, Part II 17, pages 103–
118. Springer.
Miller, G. (1995). Wordnet: A lexical database for english.
Communications of the ACM, 38(11):39–41.
Nguyen, H., Chen, H., Chen, J., Kargozari, K., and Ding,
J. (2023). Construction and evaluation of a domain-
specific knowledge graph for knowledge discovery.
P. Wilton, J. Tarling, J. M. (2013). Storyline ontology - an
ontology to represent news storylines.
Pileggi, S. F. (2021). Knowledge interoperability and re-
use in empathy mapping: An ontological approach.
Expert Systems with Applications, 180:115065.
Siahaan, D., Raharjana, I., and Fatichah, C. (2023). User
story extraction from natural language for require-
ments elicitation: Identify software-related informa-
tion from online news. Information and Software
Technology, 158:107195.
Ugai, T. (2023). Criminal investigation with augmented on-
tology and link prediction. In 2023 IEEE 17th Inter-
national Conference on Semantic Computing (ICSC),
pages 288–289. IEEE.
Ugai, T., Koyanagi, Y., and Nishino, F. (2024). A logical ap-
proach to criminal case investigation. arXiv preprint
arXiv:2402.08284.
Van Hage, W. R. and Ceolin, D. (2013). The simple event
model. In Situation awareness with systems of sys-
tems, pages 149–169. Springer.
KEOD 2024 - 16th International Conference on Knowledge Engineering and Ontology Development
214

Wen, Y., Wang, Z., and Sun, J. (2023). Mindmap:
Knowledge graph prompting sparks graph of
thoughts in large language models. arXiv preprint
arXiv:2308.09729.
Wu, J., Chen, Z., Deng, J., Sabour, S., and Huang,
M. (2023). Coke: A cognitive knowledge graph
for machine theory of mind. arXiv preprint
arXiv:2305.05390.
Yeh, J.-h. (2017). Storyteller: An event-based story ontol-
ogy composition system for biographical history. In
2017 International Conference on Applied System In-
novation (ICASI), pages 1934–1937. IEEE.
HTEKG: A Human-Trait-Enhanced Literary Knowledge Graph with Language Model Evaluation
215
