
FAIRlead: A Conceptual Framework for a Model Driven Software
Development Approach in the Field of FAIR Data Management
Andreas Schmidt
1,2 a
, Mohamed Anis Koubaa
1 b
, Nan Liu
1 c
, Philipp Schmurr
1 d
,
Karl-Uwe Stucky
1 e
and Wolfgang S
¨
uß
1 f
1
Institute for Automation and Applied Computer Science, Karlsruhe Institute of Technology (KIT), Karlsruhe, Germany
2
Department of Computer Science and Business Information Systems, Karlsruhe University of Applied Sciences,
Karlsruhe, Germany
{andreas.schmidt, mohamed.koubaa, nan.liu, philipp.schmurr, karl-uwe.stucky, wolfgang.suess}@kit.edu
Keywords:
Code Generation, Metadata, Ontology Based Engineering, FAIR.
Abstract:
The publication of scientific results together with the underlying experiments is an important source of further
research. In 2016, the “FAIR Guiding Principles for scientific data management and stewardship” were pub-
lished, in which the authors postulate a series of guidelines for improving the (F)indability, (A)ccessibility,
(I)nteroperability and (R)eusability of digital information (FAIR). The point (I)nteroperability deals with the
prerequisites for the reusability of digital objects. The central point here is the need to have a common under-
standing of the meaning of digital objects. This understanding is provided by formal languages of knowledge
representation (ontologies), which describe the actual data. These descriptions of data are also known as
metadata. As part of our current work at the Institute for Automation and Applied Computer Science (IAI) at
KIT, we are implementing novel concepts and technologies for the sustainable handling of research data using
high-quality metadata. As part of this work, we plan to develop a software tool that can be used to enrich data
with suitable metadata and thus automate the process of making research results available. A key requirement
is that the tool must be independent of the underlying domain. In order to be able to deal with data from any
domain, we have opted for a model-driven approach in which an ontology, and possibly other platform-specific
information, are input for a software generator, which then generates an (interactive) tool for specifying the
metadata and linking it to the data itself. The generated tool includes the complete software stack, starting with
a user interface, programmatic APIs for connecting additional application logic, and a persistence component.
How these individual layers are realized is not specified, but defined by the mapping rules of the software
generator, which also opens up the possibility of generating and evaluating different variants of the software.
1 INTRODUCTION
In computer science, an ontology is the formal nam-
ing and definition of the concepts, categories, proper-
ties and relationships between the concepts, data or
entities of a particular domain (Ont, 2024). These
basic concepts for ontologies are also the basic el-
ements of Conceptual Models (CM), like the ER-
Model (Chen, 1976) and UML (OMG, 2011). So, to
that extend, languages and tools from both worlds can
be used interchangeably. In the ontology context there
a
https://orcid.org/0000-0002-9911-5881
b
https://orcid.org/0000-0001-8552-2008
c
https://orcid.org/0009-0005-8768-7072
d
https://orcid.org/0009-0004-2324-7839
e
https://orcid.org/0000-0002-0065-0762
f
https://orcid.org/0000-0003-2785-7736
are e.g. languages like OWL, RDF(S), and SHACL
(Shapes Constraint Language) (SHACL, 2017). Hav-
ing this in mind, the paper on hand generally uses on-
tology terminology and employs the CM terms only
where more suitable for understanding.
1.1 Metadata
Scientific experiments take place in a specific context
and it is within this context that data, parameters and
results obtained have a practical meaning. In order to
be able to interpret the underlying data and results in
retrospect, detailed knowledge of this context is re-
quired. Data and its context form a unit that can be
described by ontologies and their instantiations. This
additional data is referred to as metadata, as it pro-
vides data about data.
Schmidt, A., Koubaa, M., Liu, N., Schmurr, P., Stucky, K. and Süß, W.
FAIRlead: A Conceptual Framework for a Model Driven Software Development Approach in the Field of FAIR Data Management.
DOI: 10.5220/0013013700003838
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 16th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2024) - Volume 3: KMIS, pages 323-330
ISBN: 978-989-758-716-0; ISSN: 2184-3228
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
323

In the context of FAIR (Wilkinson et al.,
2016), the present work deals with the aspect of
(I)nteroperability, which intends the enrichment of
data with rich metadata.
Due to the exponentially growing amount of sci-
entific data, the enrichment with metadata must be au-
tomated by using suitable tools.
1.2 Example Scenario
In order to get a clearer picture of the requirements for
such software, a concrete scenario will be presented
here. The Institute for Automation and Applied In-
formatics (IAI) at KIT operates an experimental pho-
tovoltaic system (PV), consisting of a large number
of panels that are connected together as an array (in
parallel) or string (in series). Additional components
of this PV system include power inverters, batter-
ies, measuring equipment, and so on. An overview
of the concepts and their relationships are shown in
Figure 1. By reconfiguring the components, a large
number of experiments can be carried out in order to
achieve certain goals (e.g. maximum average elec-
tricity yield), or to observe the behavior under certain
effects (e.g. partial shading).
As part of an experiment that is carried out with
a specific interconnection of the components over a
specific time interval and under specific weather con-
ditions, a series of result data is generated that is
stored in a time series database. In order to be able
to interpret the measurement results, it is necessary to
know the components’ connectivity and the weather
condition at this time. This is an example for meta
information that has to be managed by our tool, to-
gether with the information on where the result values
are stored.
1.3 Requirements for a Metadata
Management Component
In order to fulfill this task, the software must have
a persistence component that allows the specific test
setup (the metadata) to be saved. Since we are talking
about ontology-based metadata the database schema
will be derived from the ontology. In addition, the
component must have an interface through which the
information can be entered. This can be, for exam-
ple, a simple web-based CRUD (Create, Read, Up-
date, and Delete) interface via which the individual
components of the system can be specified, or a dedi-
cated graphical editor with which the panels and other
components can be graphically created and linked to-
gether.
The software must also maintain the connection
between data and metadata. Data can be available in
a variety of formats, such as measurement data in a
time series database, relational data, parameter sets
of a learned neural network, as well as a variety of
proprietary data formats. Therefore, a component that
establishes this data-metadata connection is needed.
Such a tool can provide the data of the experi-
ment as well as the concrete setup (the metadata).
By preparing this information according to existing
standard formats, it is now able to export the data to-
gether with its metadata, or directly write it into a pre-
viously specified repository like the databus (Hoyer-
Klick et al., 2023). This repository than covers the
FAIR aspects (F)indable and (A)ccessible.
In contrast, in today’s reality, the information
about a specific experimental setup frequently is only
implicitly available in configuration files, installation
scripts or makefiles, which makes it almost impossi-
ble to extract this meta information.
The general functionality of the component just
described is therefore not only useful for the publi-
cation of semantically enriched FAIR data, but also
offers valuable services as an electronic notebook of
the experiments carried out.
In addition, it is not limited to the PV domain used
here as an example. The statements made here are
valid for any domain. While the general functional-
ity of the application is the same for all domains, the
structure of the metadata will be different. It depends
on the specific entities or concepts that describe the
specific application. These are described by CMs or
by the ontologies that describe the applications’ do-
mains.
1.4 Approach
And this brings us to the core idea of our research ap-
proach, the generation of an application, as described
in the previous section, on the basis of the available
domain information. We use a Model-Driven Soft-
ware Development (MDSD) approach (see Section 2
for details). The application to be realized is gener-
ated from a model description (the ontology) and a
number of transformation rules, which map the model
information to source code for a specific target plat-
form. In addition to the model information in the form
of an ontology, the generator can process further in-
formation such as a specific GUI layout or informa-
tion on the underlying software platform during the
generation process.
The rest of the paper is structured as follows:
Next, in Section 2 the basic terms and the methodol-
ogy of MDSD are presented. Then the concept of our
FAIRlead generator is presented in Section 3. Having
KMIS 2024 - 16th International Conference on Knowledge Management and Information Systems
324
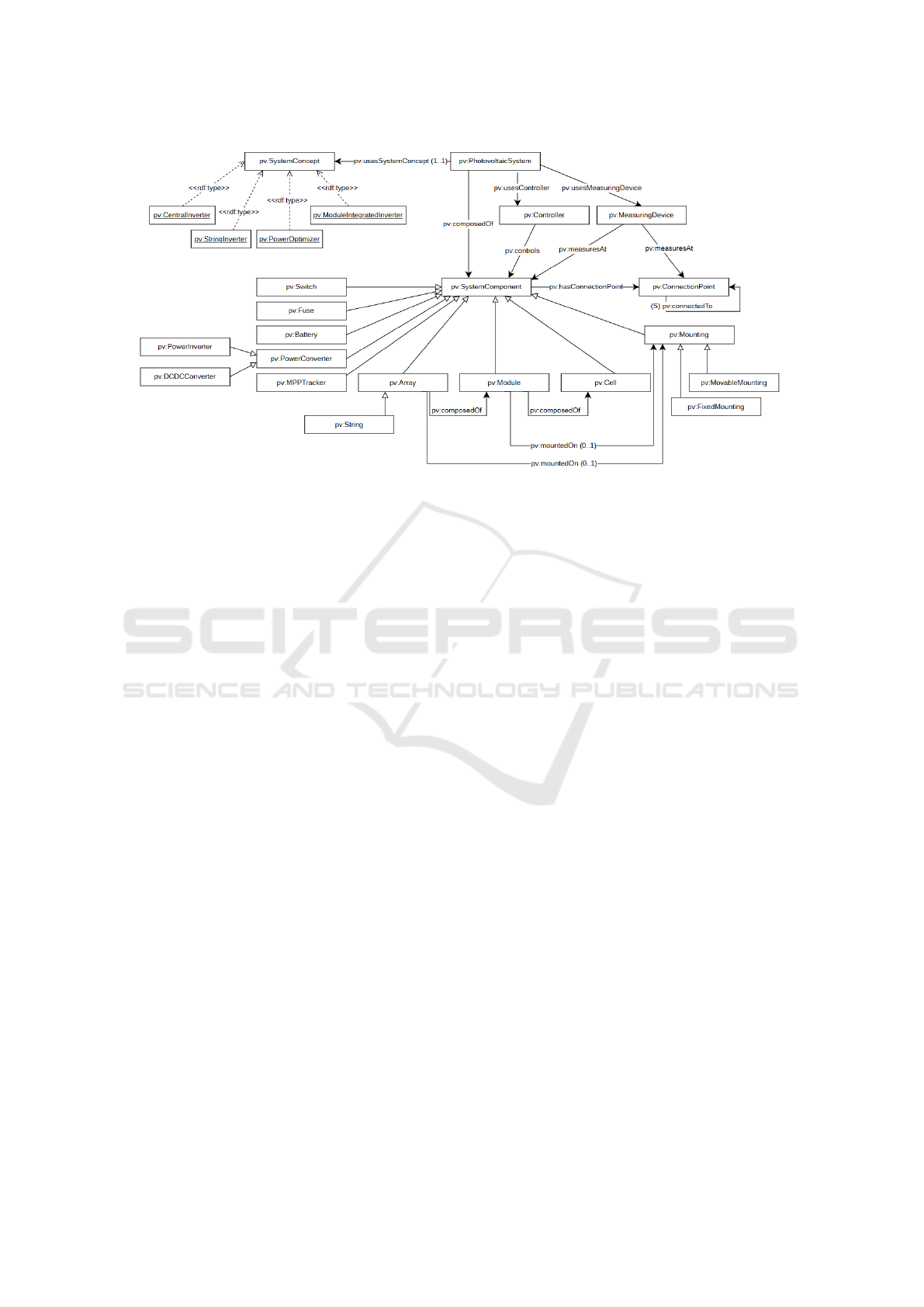
Figure 1: PV ontology (from (Schweikert et al., 2023)).
developed the concept so far, the following steps that
we plan to take will be explained in Section 3. In Sec-
tion 4, we take a closer look at the benefits we expect
from the use of our generator, before giving a brief
summary and outlook in Section 5.
2 MODEL DRIVEN SOFTWARE
DEVELOPMENT
The basic idea of MDSD is the generation of source
code from model information that describe the soft-
ware to be developed (see Figure 2). Model descrip-
tions are compact, abstract, formal, and platform-
independent. As an example, the following is an ab-
stract model description of the class Person:
<class Person(name: string(40),
birthday: date,
mother: Person,
father: Person)>
Transformation rules are needed to map this ab-
stract representation of the problem space onto pro-
gramming code. These are usually provided in the
form of templates and add the platform-specific in-
formation to the model. The following code fragment
shows an example of a transformation rule that trans-
forms the above model description into executable
PHP code (specifically: a class description with con-
structor and setter methods). To do this, a template
language (language elements shown in red) is used to
integrate the variable parts from the model into the
static code framework (in black).
<? foreach ($model->classes as $class) { ?>
// class generated, do not edit !!!
// timestamp: <?= date(DATE_RFC2822); ?>
class <?= $class->name; ?> {
<? foreach ($class->properties as $p) { ?>
protected $<?= $p ?>;
<? } ?>
function __construct() { }
<? foreach ($class->properties as $p) { ?>
function set<?= ucfirst($p) ?>($v) {
$this-><?= $p ?> = $v;
}
<? } ?>
}
<? } ?>
The code generated from the model and the trans-
formation rule with the help of the generator then, af-
ter an additional code formatting step (not shown in
Figure 2), looks like this:
// class generated, do not edit !!!
// timestamp: Tue, 24 Sep 2024 14:49:37 +0200
class Person {
protected $name;
protected $birthday;
protected $mother;
protected $father;
function __construct() { }
function setName($value) {
$this->name = $value;
}
function setBirthday($value) {
$this->birthday = $value;
}
// more code folows here ...
}
FAIRlead: A Conceptual Framework for a Model Driven Software Development Approach in the Field of FAIR Data Management
325
Typically, 60% to 80% of an application’s code
can be generated (Stahl and V
¨
olter, 2006). The basic
functionality of the intended application can even be
generated almost by 100%. In addition to the higher
development speed, this code typically has a higher
quality, as the transformation rules are centrally de-
fined in the generator templates and are consistently
applied to the generated platform code. Even the
quality of the software architecture is usually higher,
as more thought is given to the underlying architec-
ture during the template development. Furthermore,
there is a clear separation of functional and technolog-
ical aspects, so that the transition from one technolog-
ical platform to another only requires an adaptation of
the templates, but the model remains untouched.
Figure 2: Principle function of a software generator. The
input for the generator is the abstract, platform-neutral de-
scription of the application to be realized, as well as the
platform-specific transformation rules. The result is the
generated source code, which is then compiled in a further
step or executed directly by an interpreter.
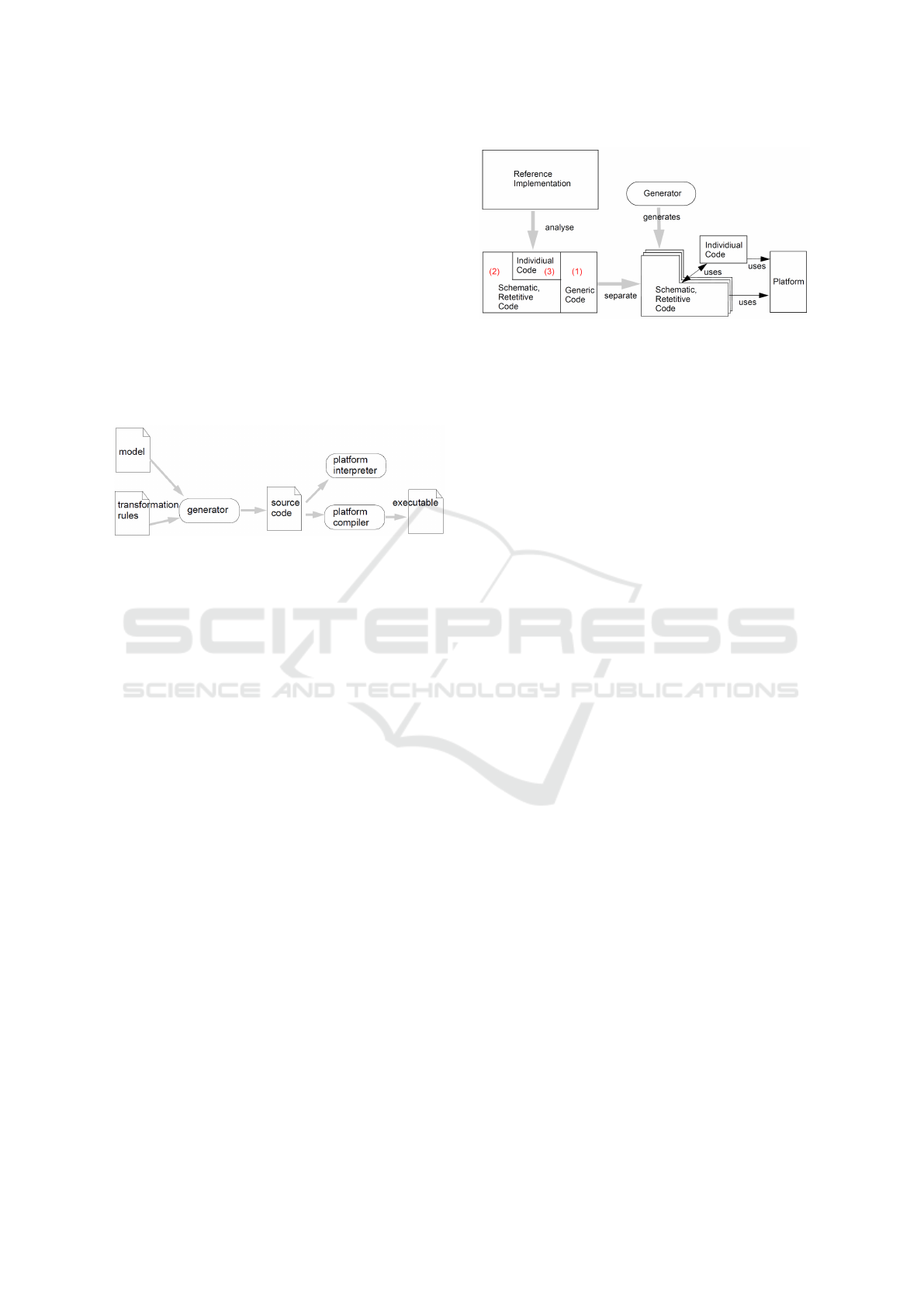
Starting point of an MDSD project is a reference
implementation that is as lean as possible but exe-
cutable. It serves as the basis for the development
of the generator templates, which perform the trans-
formation into source code. Once the reference im-
plementation has been created, it is analyzed and the
code is broken down according to the following crite-
ria (Stahl and V
¨
olter, 2006):
1. generic code, that is the same for all possible ap-
plications
2. schematic, repetative code, which is individual for
each application but has the same schematic struc-
ture
3. application-specific code (individual code)
This approach is illustrated in Figure 3. The
generic, repetetive code (1) can simply be used, while
the schematic code (2) is the starting point for creating
the transformation rules in the generator templates.
For this purpose, the code fragments are generalized
into transformation rules and merged with the model
information, as shown in Figure 2.
Figure 3: Principle of MDSD (adapted from (Stahl and
V
¨
olter, 2006)).
3 FAIRlead APPROACH
In a preliminary step, we choose the target platform.
This is the platform on which the generated applica-
tion must be able to run. This can be a programming
language such as PHP or a platform such as .net. A
framework such as django (Vincent, 2019) or sym-
fony (Zaninotto and Potencier, 2008) can also serve
as a target platform. The use of a framework has the
advantage that some of the tasks that would otherwise
have to be covered by the generator are already cov-
ered by the framework (e.g. creation of CRUD in-
terfaces for the concepts occurring in the ontology,
creation of database schemas, object-relational map-
ping).
In line with the MDSD approach presented in the
previous section, we will develop a simple reference
implementation for our PV domain in a first step. The
functionality of the application corresponds to that
described in Section 1.3. We then identify both the
generic part and the repetitive schematic part. The ref-
erence implementation can be very simple, as it only
serves to verify the functionality of the generator. In
the case that one or more components support intro-
spection, generic approaches can also be pursued, as
the meta information (e.g. properties of a class and
their types) can be read and analyzed at runtime. This
is especially important in order to implement com-
munication interfaces for domain components, and
also for the generic creation and extension of database
schemas.
The next step is to analyze whether the input on-
tology provides enough information for generation
of the schematic code part, or if additional infor-
mation must be supplied to the generator. An ex-
ample are SHACL definitions that extend OWL on-
tologies with the definitions of necessary properties,
cardinality constraints or value ranges. Furthermore,
platform-specific information, such as the graphical
layout of the GUI, etc., will certainly be added. How-
ever, it remains to be seen to what extent this will be
KMIS 2024 - 16th International Conference on Knowledge Management and Information Systems
326

necessary.
A further task is the selection of a suitable gener-
ator.
The spectrum here ranges from in-house develop-
ment with a scripting language such as PHP or Python
together with a templating module available for the
programming language, such as twig (Twig, 2024) or
smarty (Smarty, 2024) for PHP, mako (Mako, 2024)
or jinia2 (Jin, 2024) (for Python), to the use of a
tool such as the modeling workflow engine (MWE,
2024) in the Eclipse Modeling Project (EMP, 2024).
The decisive factor is which information the abstract
metamodel of the generator already contains and how
flexibly the metamodel can be extended to meet the
application’s requirements. If a suitable generator is
not available, an abstract metamodel with all the nec-
essary properties has to be developed programmati-
cally (i.e. as a set of Java classes) and then combined
with an existing template framework in the selected
language to be used as a software generator. Fig-
ure 4 shows the dependencies when selecting a suit-
able generator. In order to map the concepts described
in the ontology, the generator’s internal meta model
must support them, or one must be able to extend the
existing meta model to do so. Only under this condi-
tion is it possible to address the aspects described in
the ontology within the templates and thus implement
them in the generated application.
Figure 4: Dependencies between ontologies, generator and
generated application. The concepts from the ontology can
only be implemented in the application to be generated if
the generator’s internal meta-model supports them.
Once the generator is chosen, templates are cre-
ated to regenerate the code of the reference implemen-
tation.
In a further step, the reference implementation is
extended. This includes domain-specific tasks like
the connection of external components such as pro-
prietary systems or real time measurement software
(i.e. Beckhoff automatisation software (Beck, 2024))
as well as the integration of already established repos-
itories and registries following with the FAIR prin-
ciples. The aim of this step is to establish mean-
ingful extension interfaces that behave independently
of the domain (i.e. the time series exporter tool
Zeitgeist (Schmidt et al., 2023)). The newly estab-
lished extension interface can then also become the
starting point for a plug-in architecture of the gener-
ated code.
Our plan is to develop a generator framework
which, in a first stable version, provides a web-based
interface with CRUD functionality. This framework
will allow the integration of meta information and
also enables the referencing of primary data in vari-
ous data sources (e.g. relational databases, time se-
ries databases, ...). At this time, the framework is also
planned to be released as a GitHub project to gain in-
put and enhancements from the community.
Figure 5 gives an overview of the architecture. In-
put for the FAIRlead generator are the ontologies and
the generator templates, which define the transforma-
tions on the target platform. Further input can come
from SHACL files, which further specify the input on-
tologies. In addition to the source code for GUI and
CRUD functionality, the database schema is also gen-
erated. On the right-hand side you will find manually
created application logic. The arrows that originate
from the application logic represent the connection of
the manually created code to the extension interfaces
of the generated code. Patterns on how this can be
done can be found in (Stahl and V
¨
olter, 2006). The
database with the meta information, which is linked
to the actual data (bottom), is located near the center
of the figure. Since we want to support the widest
possible range of data sources, we need to find an
API that is as generic as possible. However, there are
already approaches here, such as (DTP, 2024; ODC,
2024; Beam, 2024), which we will examine for their
suitability.
Further research steps include:
• finding interfaces between the individual parts of
the application so that the individual components
are as interchangeable as possible (i.e. exchange a
simple web-basd formular with a graphical editor
for specifying the instances of domain concepts).
• Mechanisms for the connection between metadata
and data.
• Detection of inconsistencies between data and
metadata (consistency checks).
Figure 6 shows a flowchart of the individual activ-
ities we have defined so far, along with their depen-
dencies.
FAIRlead: A Conceptual Framework for a Model Driven Software Development Approach in the Field of FAIR Data Management
327
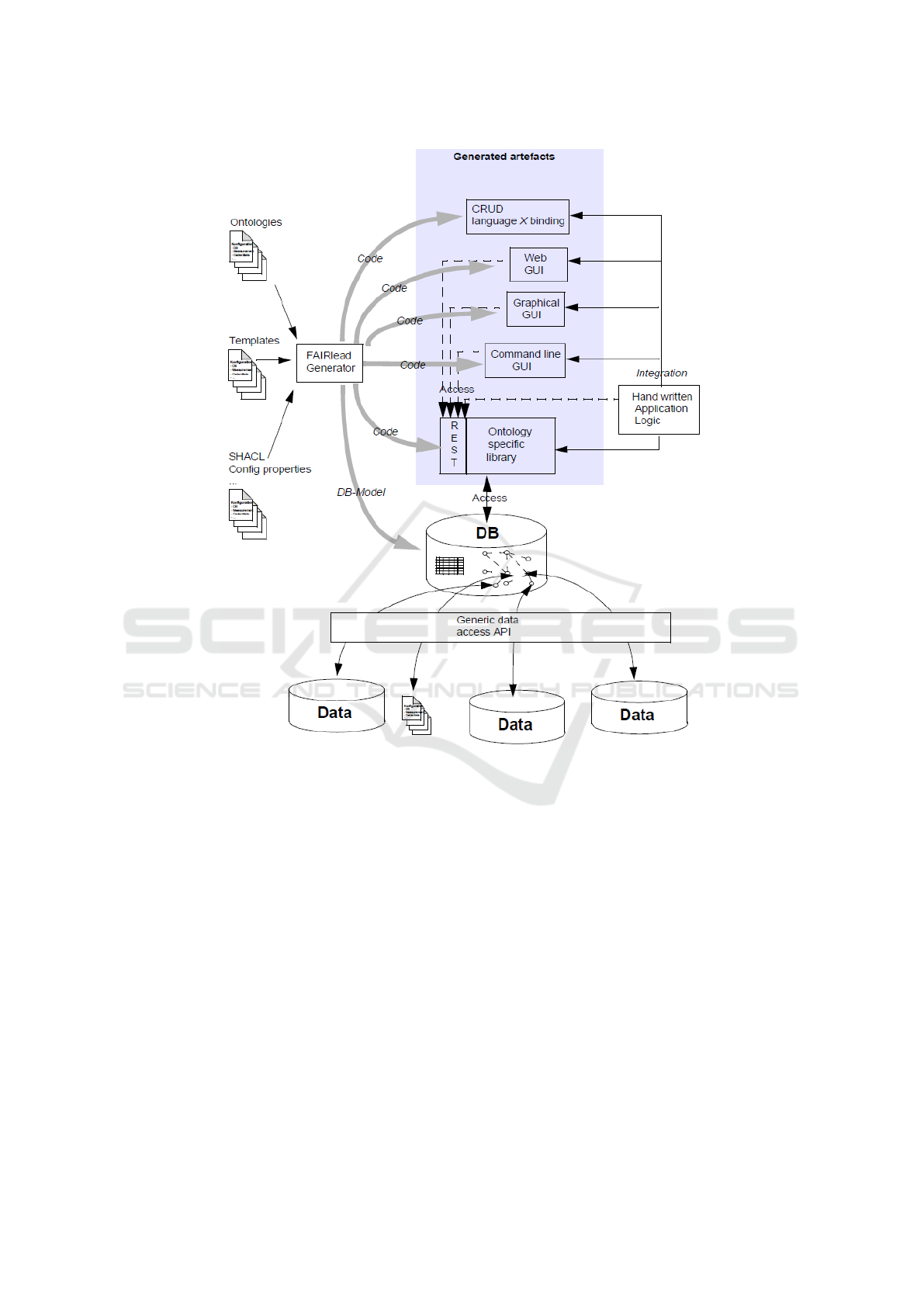
Figure 5: FAIRLead Generator architecture.
4 ADVANTAGES OF THE
FAIRlead APPROACH
In the FAIR community, there are currently a number
of alternative concepts for implementing the princi-
ples. An Example is given by FAIR Digital Objects
(FDO) which, e.g., have been compared to Linked
Data approaches in (Soiland-Reyes et al., 2024). Web
Frameworks are available as well as systems based on
Web Components (Schmidt and Tobias, 2024). As
with respect to storage, Triple-Store-based solutions
exist beside alternative persistence concepts. With
our approach, it is easy to compare and evaluate all
those different implementation variants in an overall
system, since only the corresponding additional tem-
plates have to be developed for the different imple-
mentations.
The generic approach shifts a significant propor-
tion of the application implementation to the concep-
tual, technology-independent part - defined by on-
tologies - and therefore takes place at a higher level
of abstraction. As a result, design decisions like
those mentioned in the preceding paragraph can be
made later or realized in parallel and comparatively
with minimum effort. The only prerequisite for this
is the development of one or more corresponding
technology-specific templates (see Figure 3).
In addition, once the software generator has been
fully developed, it is easier to involve technical ex-
perts in the creation of new application systems, as
discussions can take place at a purely conceptual level
and the target architecture is generated by the genera-
tor and the templates already developed at this stage.
We plan to make the generator we have developed
KMIS 2024 - 16th International Conference on Knowledge Management and Information Systems
328

Figure 6: Flowchart of the activities we have defined and are implementing.
available to the FAIR community as open source.
This will enable researchers around the world to use
our tool by using their ontologies as input for the gen-
erator and generating the domain-specific application
for linking data and metadata.
This application can then be integrated into the re-
spective laboratory infrastructure and used, for exam-
ple, as an electronic laboratory notebook and, on the
other hand, make the step towards publishing their re-
search results much easier.
However, the functionality of the generated ap-
plication can easily extend by developing new gen-
erator templates or adapting the templates to your
own requirements. This is not particularly compli-
cated if you use the existing generator templates as a
blueprint.
5 CONCLUSION AND OUTLOOK
The enrichment of data with associated metadata is
seen as a necessary step to make research results re-
producible, to verify scientific experiments or to build
on the results of these. In this context, we pre-
sented the conceptual framework FAIRlead, which is
designed to support scientists in enriching data with
metadata. To support people from different domains,
we have chosen a model-driven approach that gen-
erates software artifacts to enrich data with metadata
based on an ontology description of the domain.
The functionality of the generated software in-
cludes the specification of a scientific experiment
based on the concepts defined in the ontology and
their relationships to each other as well as the link-
ing to the actual data. Now that we have defined the
conceptual framework for our future work, we will
next carry out a reference implementation based on
the PV ontology we have developed in order to derive
our generator templates, which form the core of the
FAIRlead generator. An important future step is the
establishment of a clean interface architecture in the
generated application so that different possible im-
plementation variants can be easily exchanged. The
same applies to the interface for connecting the busi-
ness logic and external systems.
REFERENCES
Beam (2024). Apache beam i/o connectors. https://beam.
apache.org/documentation/io/connectors/. (Accessed
on 2024-09-24).
Beck (2024). Beckhoff new automatision technol-
ogy. https://www.beckhoff.com/en-en/products/
automation/twincat/. (Accessed on 2024-09-24).
Chen, P. P. (1976). The entity-relationship model - toward
a unified view of data. ACM Trans. Database Syst.,
1(1):9–36.
DTP (2024). Eclipse data tools platform. https://projects.
eclipse.org/projects/tools.datatools. (Accessed on
2024-09-24).
EMP (2024). Eclipse modeling project. https://projects.
eclipse.org/projects/modeling. (Accessed on 2024-09-
24).
Hoyer-Klick, C., Blesl, M., von Bremen, L., Frey, U.,
Gainnousakis, A., H
¨
ulk, L., Kronshage, S., Kuck-
FAIRlead: A Conceptual Framework for a Model Driven Software Development Approach in the Field of FAIR Data Management
329

ertz, P., Lohmann, G., Muschner, C., Pehl, M., and
Schroedter-Homscheidt, M. (2023). Fair data in en-
ergy systems analysis. In Proceedings of the Interna-
tional Conference on Energy Meterology.
Jin (2024). Template designer documentation. https://jinja.
palletsprojects.com/en/3.0.x/templates/. (Accessed on
2024-09-24).
Mako (2024). Mako templates for python. https://www.
makotemplates.org/. (Accessed on 2024-09-24).
MWE (2024). Eclipse modeling workflow engine. https:
//projects.eclipse.org/projects/modeling.emf.mwe.
(Accessed on 2024-09-24).
ODC (2024). Open data connector. https:
//www.dataspaces.fraunhofer.de/en/software/
connector/open data connector.html. (Accessed
on 2024-09-24).
OMG (2011). Unified modeling language™ (uml®).
Ont (2024). Ontology (information science). https://en.
wikipedia.org/wiki/Ontology (information science).
(Accessed on 2024-09-24).
Schmidt, A., Koubaa, M. A., Schweikert, J., Stucky, K.-
U., S
¨
uß, W., and Hagenmeyer, V. (2023). Zeitgeist
- A Generic Tool Supporting the Dissemination of
Time Series Data following FAIR Principles. In Pro-
ceedings of the International Conference on Knowl-
edge Management and Information Systems. Insticc,
SCITEPRESS.
Schmidt, A. and Tobias, M. (2024). Web Components for
Database Developers. In Proceedings of the Sixteenth
International Conference on Advances in Databases,
Knowledge, and Data Applications. ThinkMind.
Schweikert, J., Stucky, K.-U., S
¨
uß, W., and Hagenmeyer, V.
(2023). A photovoltaic system model integrating fair
digital objects and ontologies. Energies, 16(3).
SHACL (2017). Shapes Constraint Language (SHACL).
(Accessed on 2024-09-24).
Smarty (2024). Smarty template engine. https://www.
smarty.net/. (Accessed on 2024-09-24).
Soiland-Reyes, S., Goble, C., and Groth, P. (2024). Evalu-
ating fair digital object and linked data as distributed
object systems. PeerJ Computer Science, 10:e1781.
Stahl, T. and V
¨
olter, M. (2006). Model-Driven Software De-
velopment: Technology, Engineering, Management.
Wiley, Chichester, UK.
Twig (2024). Twig for template designers. https://twig.
symfony.com/doc/3.x/templates.html. (Accessed on
2024-09-24).
Vincent, W. S. (2019). Django for Professionals: Produc-
tion websites with Python & Django. Independently
published.
Wilkinson, M. D., Dumontier, M., Aalbersberg, I. J., Apple-
ton, G., Axton, M., Baak, A., Blomberg, N., Boiten,
J.-W., da Silva Santos, L. B., Bourne, P. E., et al.
(2016). The fair guiding principles for scientific data
management and stewardship. Scientific data, 3.
Zaninotto, F. and Potencier, F. (2008). The Definitive Guide
to symfony. apress.
KMIS 2024 - 16th International Conference on Knowledge Management and Information Systems
330
