
Application of Machine Learning Models to Predict e-Learning
Engagement Using EEG Data
Elias Dritsas
1 a
, Maria Trigka
1 b
and Phivos Mylonas
2 c
1
Industrial Systems Institute, Athena Research and Innovation Center, Patras, Greece
2
Department of Informatics and Computer Engineering, University of West Attica, Greece
Keywords:
e-Learning, EEG, Machine Learning, Classification.
Abstract:
The rapid evolution of e-learning platforms necessitates the development of innovative methods to enhance
learner engagement. This study leverages machine learning (ML) techniques and models to predict e-learning
engagement with the aid of Electroencephalography (EEG). Various ML models, including Logistic Regres-
sion (LR), Support Vector Machine (SVM), Random Forest (RF), Gradient Boosting Machine (GBM), and
Neural Networks (NN), were applied to a dataset comprising EEG signals collected during e-learning ses-
sions. Among these models, NN demonstrated the highest accuracy (90%), with precision and F1-score of
88%, a recall of 89%, and an Area Under the Curve (AUC) of 0.92 for predicting engagement levels. The
results underscore the potential of EEG-based analysis combined with advanced ML techniques to optimize
e-learning environments by accurately monitoring and responding to learner engagement.
1 INTRODUCTION
The advent of e-learning has significantly trans-
formed the educational landscape, offering unprece-
dented opportunities for flexible and accessible learn-
ing experiences. However, this paradigm shift has
brought about new challenges, especially in maintain-
ing learner concentration on a task. Engagement is a
critical factor in educational success, influencing both
the retention of information and the overall learning
experience. Traditional methods of assessing engage-
ment, such as self-reports and behavioural observa-
tions, are often subjective and prone to biases. Con-
sequently, there is a growing interest in leveraging ob-
jective physiological measures to gain deeper insights
into learner engagement (Herbig et al., 2020; Mejbri
et al., 2022).
In this context, EEG, a neuroimaging technique
that records human brain activity, has emerged as a
promising tool. EEG can provide real-time knowl-
edge of cognitive and emotional states by capturing
brainwave patterns across different frequency bands.
These patterns can indicate various cognitive and
mental states (Trigka et al., 2023a; Maimaiti et al.,
a
https://orcid.org/0000-0001-5647-2929
b
https://orcid.org/0000-0001-7793-0407
c
https://orcid.org/0000-0002-6916-3129
2022), including attention, relaxation, and cognitive
load, which are all relevant to engagement in learning
activities. By analyzing EEG data, researchers can
obtain a more accurate and dynamic understanding of
how learners interact with online materials (Chrysan-
thakopoulou et al., 2023; Trigka et al., 2023b).
In recent years, ML has gained significant traction
as a powerful approach for analyzing complex physi-
ological data, including EEG signals. ML algorithms
can identify patterns and correlations in large-scale
datasets, making them well-suited for predicting en-
gagement levels based on EEG recordings. With the
increasing prevalence of online education, the motiva-
tion for this research stems from the need to enhance
the effectiveness of e-learning platforms by develop-
ing methods that monitor learners’ status to ensure
that they remain engaged and motivated (Trigka et al.,
2024).
Hence, this study explores the application of var-
ious ML models to predict engagement using EEG
data in an e-learning context. The contributions are
threefold:
• A meticulous description of all involved compo-
nents in an EEG-based framework that exploits
the Emotiv Epoc-X device, for collecting, pro-
cessing and extracting accurate EEG features for
e-learning engagement modelling.
Dritsas, E., Trigka, M. and Mylonas, P.
Application of Machine Learning Models to Predict e-Learning Engagement Using EEG Data.
DOI: 10.5220/0013016000003825
In Proceedings of the 20th International Conference on Web Information Systems and Technologies (WEBIST 2024), pages 323-330
ISBN: 978-989-758-718-4; ISSN: 2184-3252
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
323

• Spectral features analysis is applied to reveal
potential differences between engaged and non-
engaged states. Understanding these differences
will provide insights into the neural mechanisms
underlying engagement and their connection to
lecture comprehension.
• Evaluation of ML models’ effectiveness in pre-
dicting engagement levels from EEG data, offer-
ing insights into their relative performance. These
findings highlight the potential for such predic-
tions to inform the design of adaptive e-learning
systems making them responsive to learners’ cog-
nitive and mental state in real-time, ultimately
enhancing personalized learning experiences and
improving educational outcomes.
The rest of this paper is organized as follows. Section
2 presents related works for the subject under con-
sideration. In Section 3, the adopted methodology is
outlined, while Section 4 discusses the experimental
results. Finally, in Section 5 the conclusions are out-
lined.
2 RELATED WORKS
Capturing attention in educational settings has seen
significant advancements with the application of
EEG-based brain-computer interface (BCI) systems
(Trigka et al., 2022). Numerous studies have explored
various computational methods and classification ap-
proaches to effectively monitor and enhance student
engagement in both traditional and e-learning envi-
ronments.
Firstly, in (Nandi et al., 2021), a novel ap-
proach was presented for real-time emotion classifi-
cation leveraging EEG data streams. The proposed
system called the ”Real-time Emotion Classification
System” (RECS), employed LR trained online with
the Stochastic Gradient Descent (SGD) algorithm.
The research used the DEAP dataset for validation,
demonstrating that RECS could classify emotional
states more effectively in real-time compared to exist-
ing offline and online classifiers, including Hoeffding
Tree (HT), Adaptive Random Forest (ARF), and oth-
ers. The system was designed for practical applica-
tions, particularly in e-learning environments, where
real-time emotional feedback can enhance learning.
The authors in (Trigka et al., 2023a) introduced an
ML methodology by comparing various classifiers
trained and tested on EEG data, specifically focus-
ing on band power, attention, and mediation fea-
tures collected by the MindSet device. The goal was
to effectively differentiate between ”Confused” and
”Not-Confused” individuals. Notably, the J48 model
emerged as the most effective, achieving optimal per-
formance with accuracy, precision, and recall rates of
99.9%, and an AUC of 1.
Moreover, (Al-Nafjan and Aldayel, 2022) pro-
posed a BCI system to enhance the quality of distance
education by using EEG signals to detect students’
attention during online classes. The study extracted
power spectral density (PSD) features from a public
dataset and calculated various attention indexes us-
ing the fast Fourier transform (FFT). K-nearest neigh-
bours (KNN), SVM, and RF models were employed
to assess their performance in recognizing students’
attentive states. The results showed that the RF clas-
sifier achieved the highest accuracy of 96%, indicat-
ing its effectiveness in distinguishing attention states
in online learning environments.
In (Pathak and Kashyap, 2023), a novel solu-
tion that employed real-time EEG data collected
from individuals wearing EEG headsets during on-
line courses was presented. This method focuses on
a convolutional neural network (CNN) model, which
efficiently classifies these EEG signals with an ac-
curacy rate of 70%. The performance highlighted
the speed of processing and accuracy of the devel-
oped models, offering a promising solution to cur-
rent e-learning validation challenges. Research work
(Pathak and Kashyap, 2022) introduced deep learn-
ing (DL) model to address the limitations of existing
ones in ML, which rely on manual feature extraction
and training with limited data. Real-time e-learning
data was gathered from students wearing EEG head-
sets during online classes. This approach overcame
the challenges associated with traditional ML models
and historical data. The proposed CNN model clas-
sified students into different grade levels, aiding in
the creation of an automated system to monitor stu-
dent learning progress and provide recommendations
to enhance e-learning course materials.
Also, (Daghriri et al., 2022) presented a novel ap-
proach utilizing Probability-Based Features (PBF) de-
rived from RF and GBM models to enhance the per-
formance of ML classifiers for detecting confusion in
students during online learning sessions. The study
evaluated various classifiers, including RF, GBM, LR,
SVC, and Extra Trees Classifier (ETC), achieving an
accuracy, precision, recall and f1-score of 100%, with
the proposed PBF approach. Additionally, the ap-
proach was validated using a separate EEG dataset,
demonstrating superior performance compared to ex-
isting methodologies. The best-performing model nu-
merically was the proposed PBF using RF and GBM
features, achieving consistent top scores across all
evaluation metrics.
Finally, (Aggarwal et al., 2021) evaluated learn-
WEBIST 2024 - 20th International Conference on Web Information Systems and Technologies
324

ers’ attention levels in MOOC (Massive Open On-
line Courses) environments and compared them with
traditional classroom settings using brain signals.
The proposed approach involved capturing EEG fre-
quency bands from various subjects during short lec-
tures in both e-learning and classroom environments.
An SVM model was employed to classify students’
mental states as either attentive or non-attentive.
3 METHODOLOGY
In this section, we analyze the dataset’s characteris-
tics in which our ML models were evaluated. Also,
we describe the adopted methodology, and finally, we
capture the ensemble models we experimented with,
as well as the metrics for their evaluation.
3.1 Experiment and Dataset Collection
The dataset used in this study comprised EEG record-
ings collected from participants engaged in an e-
learning activity. More specifically, 8 students, with
varying levels of education (High school, Middle
school, Undergraduate) were invited to watch 11 on-
line video lectures (e.g., Quantum Physics, Statistics,
String Theory, Photosynthesis, Linear Algebra, Bi-
ology, Numbers and Operations, Computational Ge-
ometry, Mythology). During these lectures, the stu-
dent’s EEG brain waves were recorded using a multi-
channel EEG system, the Emotiv Epoc X 14-channel
headset with a sampling rate of 128/256 Hz (Dade-
bayev et al., 2022).
The dataset contained preprocessed data from the
channels AF3, F7, F3, FC5, T7, P7, O1, O2, P8, T8,
FC6, F4, F8, and AF4, as shown in Figure 1. The
letters in the electrode names indicate the lobe loca-
tions: F (frontal), P (parietal), T (temporal), O (occip-
ital), and C (central). Odd numbers correspond to the
right hemisphere and even numbers to the left hemi-
sphere. Also, for each of the 14 channels, the PSD
was estimated in five different frequency bands (i.e.,
θ (4-8Hz), α (8-12Hz), low β (12 - 20Hz), high β
(20-30 Hz), γ (30 - 45 Hz)) providing a quantitative
measure of the brain’s electrical activity. The target
class captures whether a student understood the lec-
ture or not. In total, the dataset consists of 85 features,
54370 samples in class “engaged” and 14461 samples
in class “non-engaged”.
3.2 Dataset Preprocessing
Effective preprocessing of EEG data is essential for
accurate and reliable analysis. Raw EEG signals often
contain noise and artifacts that can obscure the neu-
ral activity related to engagement. To address this, a
multi-step preprocessing framework is considered to
clean and prepare the data for ML analysis.
To extract PSD features, the Emotiv Epoc-X used
specific digital filters that preprocessed and properly
prepared the raw EEG data. Firstly, band-pass filter-
ing was applied to retain frequencies within the range
of 0.2 to 45 Hz, which are most relevant for cognitive
and emotional state analysis. This step effectively re-
moves high-frequency noise and low-frequency drifts
that are not informative for the study. Also, this de-
vice includes built-in digital notch filters at 50 Hz
and 60 Hz to eliminate power line interference, which
could otherwise contaminate the EEG signal and af-
fect the accuracy of the PSD calculation. The Sinc
filter is used to smooth the signal and remove high-
frequency noise and aliasing artefacts. The built-in
digital 5th-order Sinc filter helps to refine the EEG
data by providing a sharp cutoff for unwanted high-
frequency components, ensuring that only the fre-
quencies of interest are retained for PSD analysis.
Next, artefact removal was performed using In-
dependent Component Analysis (ICA) to eliminate
physiological artefacts like eye blinks, muscle move-
ments, and heartbeats, preserving the true neural sig-
nals relevant to engagement. Following artefact re-
moval, the EEG signals were normalized to reduce
inter-subject variability. Z-score normalization is ap-
plied to each EEG channel, transforming the data
to have a zero mean and a standard deviation of
one. This standardization ensures that the features ex-
tracted from the EEG data are on a comparable scale,
facilitating better performance of the machine learn-
ing models.
After normalization, band-pass filters were ap-
plied to extract features from specific frequency bands
of the EEG signals to derive meaningful information.
These filters are essential for accurate PSD calcula-
tion by keeping frequencies in the desired band. The
PSD was computed using the FFT and/or other related
methods. These frequency bands are known to corre-
late with various cognitive states, such as attention,
relaxation, and cognitive load, which are critical for
assessing engagement.
3.3 Spectral Features Analysis
To gain a deeper understanding of the dataset, an ex-
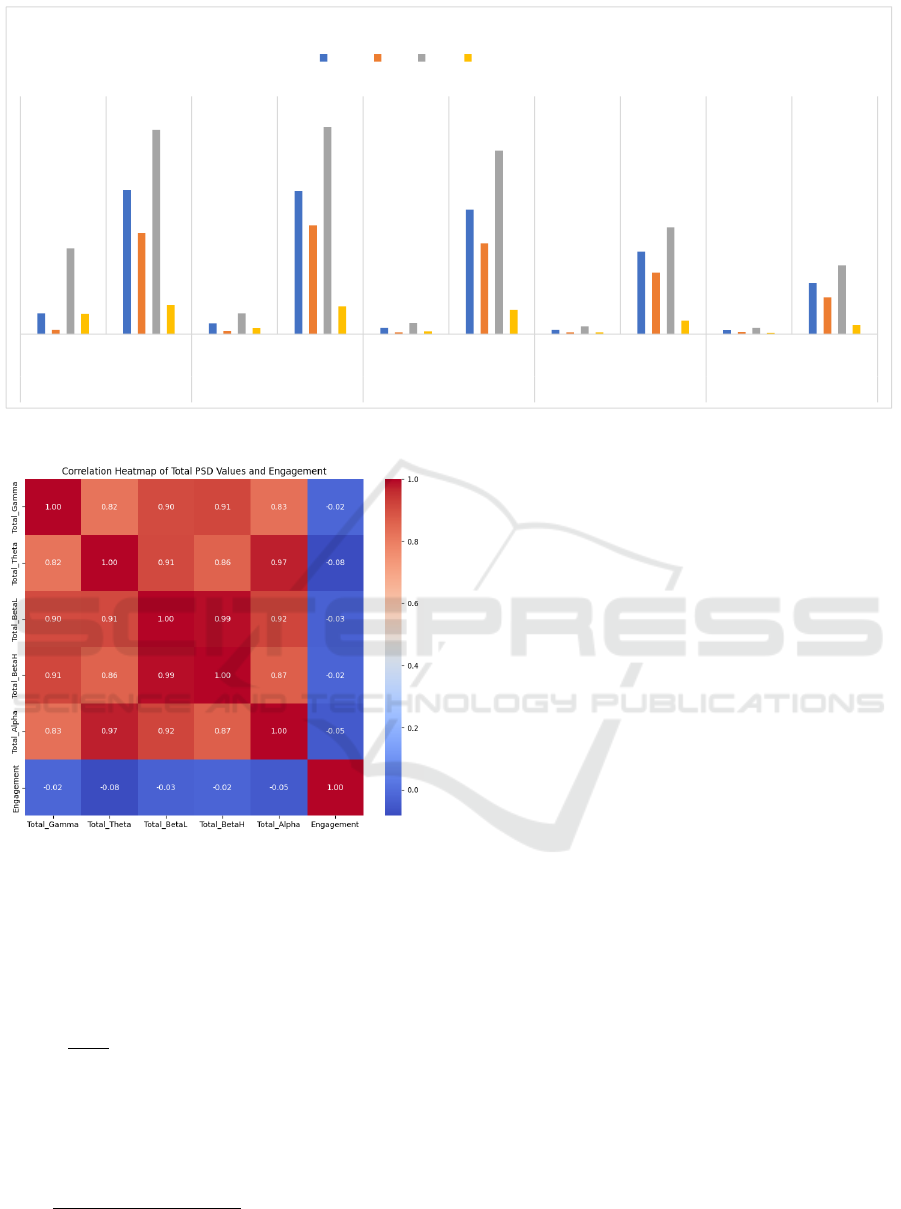
ploratory data analysis was conducted. Figure 2 sum-
marizes, across all participants, the statistical mea-
sures of PSD, namely, mean, minimum, maximum
and standard deviation values across different fre-
quency bands per engagement class, allowing for easy
Application of Machine Learning Models to Predict e-Learning Engagement Using EEG Data
325

Rereferencing
Common Average
Referencing
Artifacts Removal
ICA
Powerline Noise
Interference
Removal
Notch
Filtering at 50/60 Hz
Band-pass Filter
PSD
δ, θ, α, β, γ
Band-pass
Filtering
(0.2 - 45) Hz
EEG Raw
Data
Preprocessing
Data Acquisition
Features
Extraction
High-frequency noise,
other unwanted signals
5
th
order Sinc filter
Emotiv Epoc-X 14 channels
Data
Normalization
Figure 1: EEG-based processing pipeline in multi-channel
Emotiv Epoc-X device.
comparison. In the following, such an analysis is pre-
sented.
In the non-engaged group, the θ band exhibited
significantly higher mean (12111.71) and maximum
(17170.77) PSD values compared to the engaged
group, which had a mean of 1758.19 and a maximum
of 7214.34. This suggested that higher θ activity in
the non-engaged group might indicate increased cog-
nitive effort without effective engagement or compre-
hension. Additionally, the standard deviation in the
non-engaged group (2440.01) was higher than that in
the engaged group (1709.85), reflecting greater vari-
ability in cognitive processing.
The α band activity in the non-engaged group
showed a higher mean PSD (12022.24) and maximum
PSD (17418.27) than the engaged group, which had
a mean of 915.58 and a maximum of 1748.40. The
increased α activity might indicate a state of relax-
ation or inattentiveness, which is counterproductive
to effective learning. The variability in α band ac-
tivity was also greater in the non-engaged group, as
indicated by the standard deviation (2342.06 versus
501.08).
For the β low band, the non-engaged group
displayed significantly higher mean (10466.68) and
maximum (15438.50) PSD values than the engaged
group (mean: 521.01, maximum: 924.49). This
suggested that while the non-engaged individuals
might be concentrated in cognitive processes, these
processes are not effectively directed towards un-
derstanding the lesson. The higher standard de-
viation in the non-engaged group (2051.02 versus
241.23) indicated more unstable cognitive activity.
In the β high band, the non-engaged group’s mean
(6925.70) and maximum (8995.99) PSD values were
markedly higher than those of the engaged group
(mean: 359.02, maximum: 657.95). This further
supported the notion that the non-engaged group was
experiencing cognitive activity that was not aligned
with effective learning. The standard deviation was
also higher in the non-engaged group (1141.96 versus
152.38), reflecting less consistent cognitive concen-
tration.
Finally, γ band activity was associated with infor-
mation processing and integration. The non-engaged
group showed higher mean (4295.32) and maximum
(5796.70) PSD values compared to the engaged group
(mean: 330.62, maximum: 519.33). This suggested
that while the non-engaged individuals may have been
processing information, they were not effectively in-
tegrating it in a manner conducive to understanding
the lesson. The higher standard deviation in the non-
engaged group (759.34 versus 108.39) demonstrated
greater fluctuations in cognitive processing. Overall,
these results highlighted significant differences in the
PSD values across various frequency bands between
the engaged and non-engaged groups, pointing to dif-
ferences in cognitive activity and engagement levels.
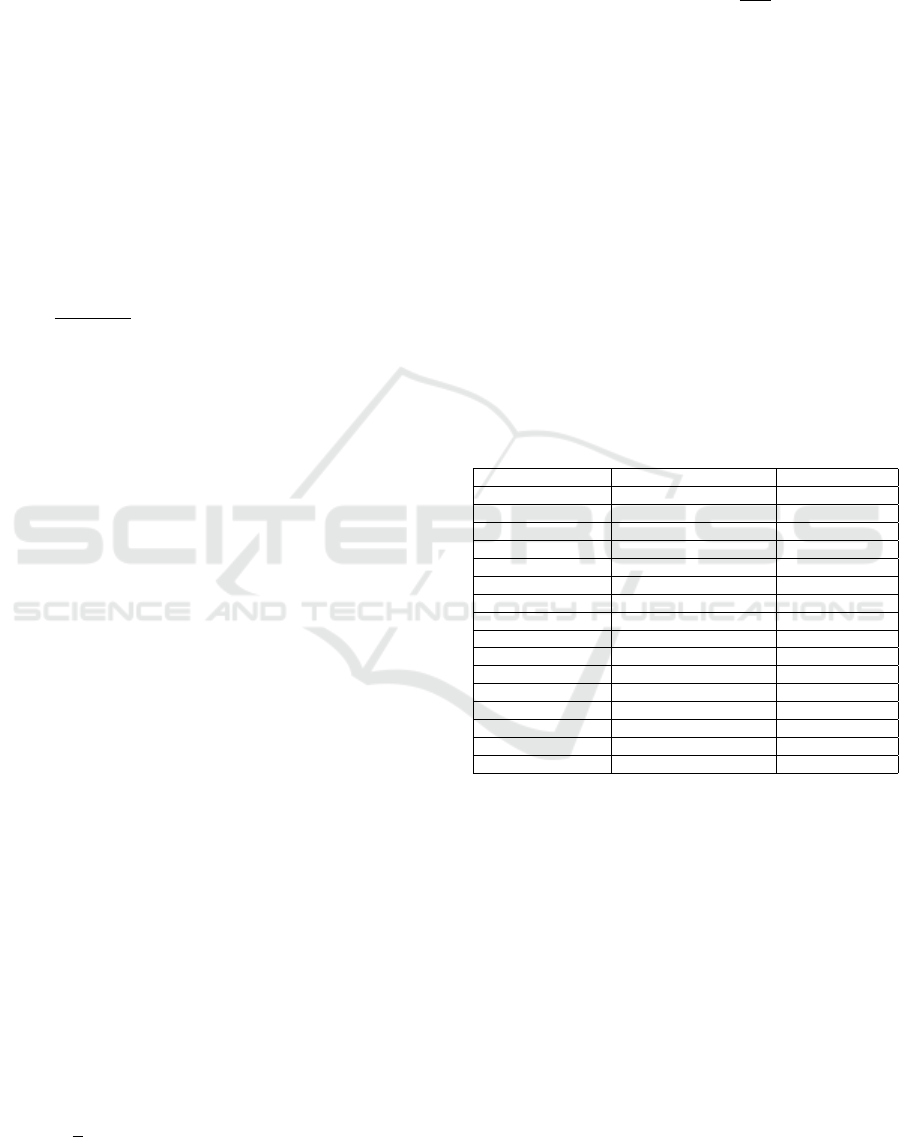
Additionally, Figure 3 depicts the correlation (or
linear dependency) between PSD features including
engagement class (engaged, non-engaged) using a
heatmap. The heatmap visually represents the Pear-
son correlation coefficients (PCCs), with colour inten-
sity indicating the strength of the correlation. Positive
correlations are shown in shades of red, while nega-
tive correlations are in shades of blue. Also, this vi-
sualization helps identify which frequency bands are
most closely associated with the engagement class.
It was observed that power-based features are
highly linear-dependent on one another, but, their im-
portance in improving the predictive performance of
the ML models is low according to the PCCs in the
blue area of the heatmap. Hence, further and exten-
sive analysis should be conducted to understand the
features’ importance and apply proper selection tech-
niques to indicate the most important ones that raise
the model’s performance while reducing complexity.
3.4 Machine Learning Models
The selection of appropriate ML models is critical
to the successful prediction of e-learning engagement
using EEG data. In this work, several ML models
were investigated, each with distinct strengths and ca-
pabilities, to determine the most effective approach
for this task. The models evaluated include LR, SVM,
RF, GBM, and NNs. In the following, a detailed de-
scription of each model and the rationale behind their
selection are provided.
WEBIST 2024 - 20th International Conference on Web Information Systems and Technologies
326
1758.19
12111.71
915.58
12022.24
521.01
10466.68
359.02
6925.7
330.62
4295.32
359.55
8482.53
243.66
9157.45
156.47
7636.93
150.62
5167.12
167.54
3091.71
7214.34
17170.77
1748.4
17418.27
924.49
15438.5
657.95
8995.99
519.33
5796.7
1709.85
2440.01
501.08
2342.06
241.23
2051.02
152.38
1141.96
108.39
759.34
ENGAGED NOT-
ENGAGED
ENGAGED NOT-
ENGAGED
ENGAGED NOT-
ENGAGED
ENGAGED NOT-
ENGAGED
ENGAGED NOT-
ENGAGED
THETA (4-8 HZ) ALPHA (8-13 HZ) BETAL (13-20 HZ) BETAH (20- 30 HZ) GAMMA (30 -45 HZ )
PSD STATISTICS PER FREQUENCY BAND
Mean Min Max Standard Deviation
Figure 2: Statistics of PSD per frequency band and engagement state.
Figure 3: Correlation between PSD features and engage-
ment class.
LR (Lu and Wang, 2024) model is based on the
logistic function (a special case of sigmoid function),
which maps any real-valued number to a value be-
tween 0 and 1. This function is particularly use-
ful for binary classification tasks. The LR equa-
tion can be expressed as follows: P(y = 1 | X) =
σ(z) =
1
1+e
−z
, where P(y = 1 | X ) is the probabil-
ity that the output y is 1 (engaged) given the input
features X. Also, z is defined as z = β
0
+ β
1
X
1
+
β
2
X
2
+. . . +β
n
X
n
, where σ(z) is the logistic function,
(β
0
, β
1
, β
2
, . . . , β
n
) are the coefficients of the model
and (X
1
, X
2
, . . . , X
n
) are the input features. Putting it
all together, the LR model can be written as P(y = 1 |
X) =
1
1+e
−(β
0
+β
1
X
1
+β
2
X
2
+...+β
n
X
n
)
. This equation calcu-
lates the probability that the input X belongs to class
1 “engaged”. The predicted class label can be deter-
mined by applying a threshold (typically 0.5) to this
probability.
SVM (Pisner and Schnyer, 2020) with a radial ba-
sis function (RBF) kernel, mainly aims to find the
optimal hyperplane that separates the classes with
the maximum margin. The mathematical formula-
tion involves solving a quadratic optimization prob-
lem. The decision function for SVM is given by:
f (X) = sign(
∑
n
i=1
α
i
y
i
K(X
i
, X) + b), where α
i
are the
Lagrange multipliers, y
i
are the class labels, K(X
i
, X)
is the kernel function and b is the bias term.
Our focus here is on the RBF kernel whose func-
tion K is defined as: K(X
i
, X) = exp
−γ∥X
i
− X∥
2
,
where γ is a parameter that determines the spread
of the kernel. Summarizing these together, the
decision function with the RBF kernel is f (X) =
sign
∑
n
i=1
α
i
y
i
exp
−γ∥X
i
− X∥
2
+ b
.
RF (Genuer et al., 2020) is an ensemble learn-
ing method that combines multiple decision trees to
improve the robustness and generalizability of the
model. The overall prediction of the RF model is
obtained by aggregating the predictions of individual
trees, often by taking the mode (majority vote) in clas-
sification tasks. Here’s the mathematical formulation
for RFs:
1. Individual Decision Tree Prediction - Let h
m
(X)
be the prediction of the m-th decision tree in the
forest for input X.
2. Random Forest Prediction - The final prediction
H(X) of the RF is obtained by taking the ma-
jority vote of all M trees’ predictions: H(X) =
mode{h
1
(X), h
2
(X), . . . , h
M
(X)}.
GBM (Ayyadevara and Ayyadevara, 2018) is an en-
Application of Machine Learning Models to Predict e-Learning Engagement Using EEG Data
327
semble learning technique that builds models sequen-
tially, with each new model correcting errors made by
the previous ones. The goal is to optimize the over-
all prediction by minimizing the loss function. Here’s
the mathematical formulation for GBMs:
1. Model Initialization F
0
(X) =
argmin
γ
∑
n
i=1
L(y
i
, γ), where L is the loss
function, and y
i
are the actual target values.
2. Additive Model - The model is built in a stage-
wise manner. At each stage m, a new model
h
m
(X) is added to minimize the loss: F
m
(X) =
F
m−1
(X) + ηh
m
(X), where η is the learning rate,
and h
m
(X) is the new model fitted to the residuals
of the previous model.
3. Residual Calculation - For each stage
m, compute the residuals r
im
: r
im
=
−
∂L(y
i
,F(X
i
))
∂F(X
i
)
F(X
i
)=F
m−1
(X
i
)
4. Fit New Model h
m
(X) to the residuals: h
m
(X) =
argmin
h
∑
n
i=1
(r
im
− h(X
i
))
2
5. Update the Model with the new fitted model:
F
m
(X) = F
m−1
(X) + ηh
m
(X).
NNs (Gurney, 2018) are DL models that use multi-
ple layers of neurons to capture intricate patterns in
data. In a feedforward neural network, the data flows
from the input layer through multiple hidden layers to
the output layer. Each neuron computes a weighted
sum of its inputs, applies an activation function, and
passes the result to the next layer. The training pro-
cess involves backpropagation to adjust the weights.
The mathematical formulation for a feedforward neu-
ral network is as follows:
1. Weighted Sum and Activation for a Single Neu-
ron - For each neuron in layer l, the output a
(l)
i
is
computed as: z
(l)
i
=
∑
n
(l−1)
j=1
w
(l)
i j
a
(l−1)
j
+ b
(l)
i
, a
(l)
i
=
σ(z
(l)
i
), where z
(l)
i
is the weighted sum of inputs
to the i-th neuron in layer l, w
(l)
i j
are the weights
from neuron j in layer l − 1 to neuron i in layer l,
b
(l)
i
is the bias term for the i-th neuron in layer l,
σ is the activation function (e.g., ReLU, sigmoid,
tanh), and a
(l−1)
j
is the activation of the j-th neu-
ron in the previous layer.
2. Output Layer, the process is similar: z
(L)
k
=
∑
n
(L−1)
j=1
w
(L)
jk
a
(L−1)
j
+ b
(L)
k
, ˆy
k
= σ(z
(L)
k
), where L is
the final layer, and ˆy
k
is the predicted output.
3. Loss Function L measures the difference between
the predicted outputs ˆy and the true targets y.
For example, using Mean Squared Error (MSE):
L =
1
N
∑
N
i=1
(y
i
− ˆy
i
)
2
, where N is the number of
training examples.
4. Backpropagation: During this step, gradients of
the loss with respect to the weights and biases are
computed and used to update the parameters. For
weights w
(l)
i j
: w
(l)
i j
← w
(l)
i j
− η
∂L
∂w
(l)
i j
, where η is the
learning rate.
3.5 Model Training and Optimization
The ML modelS’ evaluation was carried out using
WEKA (WEK, ), a free software suite offering a
range of tools for data preprocessing, classification,
regression, clustering, and visualization. The experi-
ments were executed on an Apple MacBook Pro with
a 13.3” Retina Display, equipped with an M2 chip,
16GB of RAM, and a 256GB SSD. Each model was
trained on the preprocessed EEG dataset using a strat-
ified 10-fold cross-validation to ensure robust perfor-
mance evaluation. Hyperparameter tuning was per-
formed using grid search to identify the optimal pa-
rameter settings for each model as shown in Table 1.
Table 1: Optimal Hyperparameter Tuning for Machine
Learning Models.
Model Hyperparameter Optimal Value
Logistic Regression Regularization (C) 1.0
SVM Kernel Type RBF
Kernel Coefficient (γ) 0.01
Regularization (C) 10
RF Number of Trees 100
Maximum Depth None (unlimited)
Minimum Samples Split 2
GBM Number of Estimators 200
Learning Rate 0.1
Maximum Depth 3
NN Number of Layers 3
Neurons per Layer [64, 128, 64]
Activation Function ReLU
Learning Rate 0.001
Batch Size 32
Epochs 150
3.6 Evaluation Metrics
Several metrics were used to evaluate the perfor-
mance of the ML models, accuracy, precision, recall,
F1-score, and AUC (Naidu et al., 2023). These met-
rics provide insights into various aspects of models’
performance, ensuring a robust assessment of their
predictive capabilities. It should be noted that the ul-
timate value in each metric was derived by averaging
the outcomes of both classes from all folds. The def-
inition of these metrics is based on the confusion ma-
trix consisting of the elements true-positive (Tp), true-
negative (Tn), false-positive (Fp) and false-negative
(Fn). Below is a brief description of each metric:
• Accuracy is the proportion of correctly predicted
WEBIST 2024 - 20th International Conference on Web Information Systems and Technologies
328
instances out of the total instances. It is a straight-
forward metric indicating the overall correctness
of the model. Accuracy =
Tp+Tn
Total Instances
.
• Precision is the ratio of correctly predicted pos-
itive observations to the total predicted positives.
It reflects the accuracy of the positive predictions
made by the model. Precision =
Tp
Tp+Fp
.
• Recall is the ratio of correctly predicted positive
observations to all the observations in the actual
class. It measures the model’s ability to capture
all relevant instances. Recall =
Tp
Tp+Fn
.
• F1-score is the harmonic mean of Precision and
Recall. It provides a single metric that balances
the trade-off between Precision and Recall, espe-
cially useful when the class distribution is imbal-
anced: F1-Score = 2 ×
Precision×Recall
Precision+Recall
.
• AUC measures the ability of the model to distin-
guish between classes. It represents the degree of
separability achieved by the model. An AUC of
1 indicates a perfect model, while an AUC of 0.5
suggests no discriminative power.
These metrics provided a comprehensive view of the
model performance, enabling the identification of the
most effective model for predicting e-learning en-
gagement based on EEG data.
4 RESULTS AND DISCUSSION
The performance results are summarized in Table
2. The NN model outperformed all other models,
achieving the highest scores across all evaluation met-
rics. The GBM also showed strong performance, in-
dicating its effectiveness in handling complex, non-
linear relationships in the EEG data.
Table 2: Performance of Machine Learning Models.
Model Accuracy Precision Recall F1-Score AUC
LR 0.78 0.75 0.76 0.75 0.8
SVM 0.82 0.80 0.81 0.80 0.84
RF 0.85 0.83 0.84 0.83 0.87
GBM 0.87 0.85 0.86 0.85 0.89
NN 0.90 0.88 0.89 0.88 0.92
The NN model achieved an accuracy of 90%, pre-
cision of 88%, recall of 89%, F1-score of 88%, and an
AUC of 0.92. These results demonstrated the model’s
superior ability to accurately predict learner engage-
ment. The high AUC value indicated excellent dis-
crimination between engaged and not-engaged states.
The GBM also performed well, with an accuracy of
87%, precision of 85%, recall of 86%, F1-score of
85%, and an AUC of 0.89. The ensemble nature of
this model allows it to capture complex patterns and
interactions in the data, contributing to its robust per-
formance. RF, while slightly less accurate than GBM,
still showed strong performance with an accuracy of
85%, precision of 83%, recall of 84%, F1-score of
83%, and an AUC of 0.87. Its ability to handle high-
dimensional data and reduce overfitting by averaging
multiple trees makes it a reliable choice for EEG data
analysis.
The RBF-based SVM model achieved an accuracy
of 82%, precision of 80%, recall of 81%, F1-score of
80%, and an AUC of 0.84. Its performance demon-
strated the effectiveness of kernel methods in captur-
ing non-linear relationships in the EEG data. LR, de-
spite being the simplest model, performed reasonably
well with an accuracy of 78%, precision of 75%, re-
call of 76%, F1-score of 75%, and an AUC of 0.8.
This indicated that even linear models can provide
valuable insights when applied to EEG data.
The results of this study are expected to have sig-
nificant implications for the design and implementa-
tion of e-learning systems. By integrating EEG-based
engagement prediction models, e-learning platforms
can adapt in real-time to the learners’ cognitive and
emotional states. This personalization can enhance
learner engagement, improve learning outcomes, and
reduce dropout rates.
5 CONCLUSIONS
This study demonstrated the efficacy of various ML
models in predicting e-learning engagement using
EEG data, with NN emerging as the most effective
model. The experimental results underscored the su-
periority of NN, which achieved the highest metrics
across all evaluation parameters; an accuracy of 90%,
a precision and F1-score of 88%, a recall equal to
89%, and an AUC of 0.92. These results indicated
that NN provides a robust model for accurately pre-
dicting learner engagement.
The findings reveal that the most significant EEG
features contributing to engagement predictions were
the power spectral densities in the alpha and beta fre-
quency bands. These bands are well-documented in
literature for their associations with relaxation, atten-
tion, and cognitive processing, respectively. The im-
plications of this research are substantial for the de-
sign and implementation of adaptive e-learning sys-
tems. By incorporating EEG-based engagement pre-
diction models, e-learning platforms can dynamically
adapt to the cognitive and emotional states of learn-
ers, thereby enhancing engagement, improving learn-
ing outcomes, and potentially reducing dropout rates.
Application of Machine Learning Models to Predict e-Learning Engagement Using EEG Data
329

In future research, we aim to expand the analy-
sis to datasets that include a broader range of physi-
ological signals, enhancing the robustness and gener-
alizability of the engagement prediction models. Ad-
ditionally, exploring the real-time implementation of
these models within e-learning platforms will be a
crucial step towards creating more personalized and
responsive learning environments.
REFERENCES
Weka. https://www.weka.io/. (accessed on 17 July 2024).
Aggarwal, S., Lamba, M., Verma, K., Khuttan, S., and Gau-
tam, H. (2021). A preliminary investigation for assess-
ing attention levels for massive online open courses
learning environment using eeg signals: An experi-
mental study. Human Behavior and emerging tech-
nologies, 3(5):933–941.
Al-Nafjan, A. and Aldayel, M. (2022). Predict students’
attention in online learning using eeg data. Sustain-
ability, 14(11):6553.
Ayyadevara, V. K. and Ayyadevara, V. K. (2018). Gradient
boosting machine. Pro machine learning algorithms:
A hands-on approach to implementing algorithms in
python and R, pages 117–134.
Chrysanthakopoulou, A., Dritsas, E., Trigka, M., and My-
lonas, P. (2023). An eeg-based application for real-
time mental state recognition in adaptive e-learning
environment. In 2023 18th International Workshop
on Semantic and Social Media Adaptation & Person-
alization (SMAP) 18th International Workshop on Se-
mantic and Social Media Adaptation & Personaliza-
tion (SMAP 2023), pages 1–6. IEEE.
Dadebayev, D., Goh, W. W., and Tan, E. X. (2022). Eeg-
based emotion recognition: Review of commercial
eeg devices and machine learning techniques. Jour-
nal of King Saud University-Computer and Informa-
tion Sciences, 34(7):4385–4401.
Daghriri, T., Rustam, F., Aljedaani, W., Bashiri, A. H., and
Ashraf, I. (2022). Electroencephalogram signals for
detecting confused students in online education plat-
forms with probability-based features. Electronics,
11(18):2855.
Genuer, R., Poggi, J.-M., Genuer, R., and Poggi, J.-M.
(2020). Random forests. Springer.
Gurney, K. (2018). An introduction to neural networks.
CRC press.
Herbig, N., D
¨
uwel, T., Helali, M., Eckhart, L., Schuck, P.,
Choudhury, S., and Kr
¨
uger, A. (2020). Investigating
multi-modal measures for cognitive load detection in
e-learning. In Proceedings of the 28th ACM confer-
ence on user modeling, adaptation and personaliza-
tion, pages 88–97.
Lu, W. and Wang, Y. (2024). Logistic regression. In
Textbook of Medical Statistics: For Medical Students,
pages 181–189. Springer.
Maimaiti, B., Meng, H., Lv, Y., Qiu, J., Zhu, Z., Xie, Y.,
Li, Y., Zhao, W., Liu, J., Li, M., et al. (2022). An
overview of eeg-based machine learning methods in
seizure prediction and opportunities for neurologists
in this field. Neuroscience, 481:197–218.
Mejbri, N., Essalmi, F., Jemni, M., and Alyoubi, B. A.
(2022). Trends in the use of affective computing in
e-learning environments. Education and Information
Technologies, pages 1–23.
Naidu, G., Zuva, T., and Sibanda, E. M. (2023). A review of
evaluation metrics in machine learning algorithms. In
Computer Science On-line Conference, pages 15–25.
Springer.
Nandi, A., Xhafa, F., Subirats, L., and Fort, S. (2021). Real-
time emotion classification using eeg data stream in
e-learning contexts. Sensors, 21(5):1589.
Pathak, D. and Kashyap, R. (2022). Electroencephalogram-
based deep learning framework for the proposed so-
lution of e-learning challenges and limitations. In-
ternational Journal of Intelligent Information and
Database Systems, 15(3):295–310.
Pathak, D. and Kashyap, R. (2023). Evaluating e-learning
engagement through eeg signal analysis with convo-
lutional neural networks. In International Conference
on Computer & Communication Technologies, pages
225–239. Springer.
Pisner, D. A. and Schnyer, D. M. (2020). Support vector
machine. In Machine learning, pages 101–121. Else-
vier.
Trigka, M., Dritsas, E., and Fidas, C. (2022). A survey on
signal processing methods for eeg-based brain com-
puter interface systems. In Proceedings of the 26th
Pan-Hellenic Conference on Informatics, pages 213–
218.
Trigka, M., Dritsas, E., and Mylonas, P. (2023a). Mental
confusion prediction in e-learning contexts with eeg
and machine learning. In Novel & Intelligent Digital
Systems Conferences, pages 195–200. Springer.
Trigka, M., Dritsas, E., and Mylonas, P. (2024). New per-
spectives in e-learning: Eeg-based modelling of hu-
man cognition individual differences. In IFIP Inter-
national Conference on Artificial Intelligence Appli-
cations and Innovations, pages 290–299. Springer.
Trigka, M., Papadoulis, G., Dritsas, E., and Fidas, C.
(2023b). Influences of cognitive styles on eeg-based
activity: An empirical study on visual content com-
prehension. In IFIP Conference on Human-Computer
Interaction, pages 496–500. Springer.
WEBIST 2024 - 20th International Conference on Web Information Systems and Technologies
330
