
Advanced Techniques for Corners, Edges, and Stacked Gaps Detection
and Pose Estimation of Cardboard Packages in Automated Dual-Arm
Depalletising Systems
Santheep Yesudasu and Jean-Franc¸ois Breth
´
e
GREAH, Normandy University, Le Havre, France
Keywords:
Automated Depalletising, Cardboard Package Detection, Keypoint Detection, YOLOv8, Point Cloud Data,
3D Pose Estimation, Robotic Manipulation, Industrial Automation, Deep Learning, Computer Vision.
Abstract:
This paper introduces advanced methods for detecting corners, edges, and gaps and estimating the pose of
cardboard packages in automated depalletizing systems. Initially, traditional computer vision techniques such
as edge detection, thresholding, and contour detection were used but fell short due to issues like variable
lighting conditions and tightly packed arrangements. As a result, we shifted to deep learning techniques,
utilizing the YOLOv8 model for superior results. By incorporating point cloud data from RGB-D cameras, we
achieved better 3D positioning and structural analysis. Our approach involved careful dataset collection and
annotation, followed by using YOLOv8 for keypoint detection and 3D mapping. The system’s performance
was thoroughly evaluated through simulations and physical tests, showing significant accuracy, robustness,
and operational efficiency improvements. Results demonstrated high precision and recall, confirming the
effectiveness of our approach in industrial applications. This research highlights the potential of using different
sensors’ information to feed the deep learning algorithms to advance automated depalletizing technologies.
1 INTRODUCTION
Automated depalletizing systems play a crucial role
in modern logistics and manufacturing by improv-
ing package handling efficiency, accuracy, and safety.
With the growing demand for automation, there is an
increasing need for advanced techniques to enhance
the precise detection and manipulation of packages.
This paper presents the development of sophisticated
methods for detecting key features such as corners,
edges, and gaps and estimating the pose of cardboard
packages, common in industrial environments.
Traditional computer vision techniques for object
detection and pose estimation face challenges in sce-
narios involving partial occlusions, featureless ob-
jects, varying lighting, and tightly packed arrange-
ments, highlighting a critical gap in the automation
of depalletizing tasks. This research aims to over-
come these limitations and improve the performance
of automated depalletizing systems. Leveraging re-
cent advances in deep learning, specifically YOLOv8,
and the integration of point cloud data from RGB-D
cameras, we achieve more accurate 3D positioning
and structural analysis. Our approach significantly
enhances the detection and localization of cardboard
packages in complex industrial settings.
The contributions of this work are threefold:
1. We develop a novel methodology combining
YOLOv8 for keypoint detection with point cloud
data, enabling precise 3D localization and struc-
tural analysis of cardboard packages.
2. We create and annotate a dataset under diverse
conditions, focusing on keypoint detection to op-
timize model training.
3. We rigorously evaluate the system’s performance
using various metrics, showing significant im-
provements over traditional methods.
This paper details the methodology, including
dataset creation, YOLOv8-based keypoint detection,
point cloud integration, and the evaluation process.
We demonstrate substantial performance gains, ad-
dressing the identified challenges in automated depal-
letizing. The findings highlight the potential of inte-
grating deep learning and 3D data for complex tasks
in industrial automation, and we conclude by dis-
cussing real-world implications and future research
directions for further enhancement of these systems.
264
Yesudasu, S. and Brethé, J.
Advanced Techniques for Corners, Edges, and Stacked Gaps Detection and Pose Estimation of Cardboard Packages in Automated Dual-Arm Depalletising Systems.
DOI: 10.5220/0013016900003822
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 21st International Conference on Informatics in Control, Automation and Robotics (ICINCO 2024) - Volume 2, pages 264-273
ISBN: 978-989-758-717-7; ISSN: 2184-2809
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
2 RELATED WORK
2.1 Traditional Techniques
Traditional techniques for cardboard package detec-
tion and pose estimation have laid the groundwork
for modern advancements in automated depalletis-
ing systems. These methods, while foundational, of-
ten struggle with limitations in complex and dynamic
industrial environments. One of the primary tradi-
tional methods is RFID-based detection. RFID tags
are attached to packages to facilitate identification
and tracking throughout the logistics process. For
instance, (Bouzakis and Overmeyer, 2010) demon-
strated the use of RFID tags to describe the geome-
try of cardboard packages, enabling automated ma-
nipulation by industrial robots. Furthermore, RFID
systems can detect package tampering and openings
by analyzing changes in the radiation profile caused
by the movement of RFID-based antennas, as high-
lighted by (Wang et al., 2020).
Another technique involves terahertz imaging,
which utilizes terahertz waves to screen folded card-
board boxes for inserts or anomalies. This method
offers high-speed and unambiguous detection capa-
bilities, as noted by (Brinkmann et al., 2017). Vi-
sual monitoring and machine vision systems also play
a crucial role. (Casta
˜
no-Amoros et al., 2022) ex-
plored the use of low-cost sensors and deep learn-
ing techniques to detect and recognize different types
of cardboard packaging on pallets, optimizing ware-
house logistics. Electrostatic techniques, as described
by (Hearn and Ballard, 2005), leverage electrostatic
charges to identify and sort waste packaging mate-
rials, differentiating between plastics and cardboard.
Additionally, nonlinear ultrasonic methods, investi-
gated by (Ha and Jhang, 2005), are employed to de-
tect micro-delaminations in packaging by analyzing
harmonic frequencies generated by ultrasonic waves.
While these traditional methods provide valuable
insights and capabilities, they often face challenges
such as accuracy, speed, cost, and environmental in-
terference. These limitations have driven the devel-
opment and adoption of more advanced techniques,
particularly those based on deep learning.
2.2 Deep Learning Techniques
Deep learning techniques have revolutionized the
field of cardboard package detection and pose estima-
tion, offering significant improvements in accuracy,
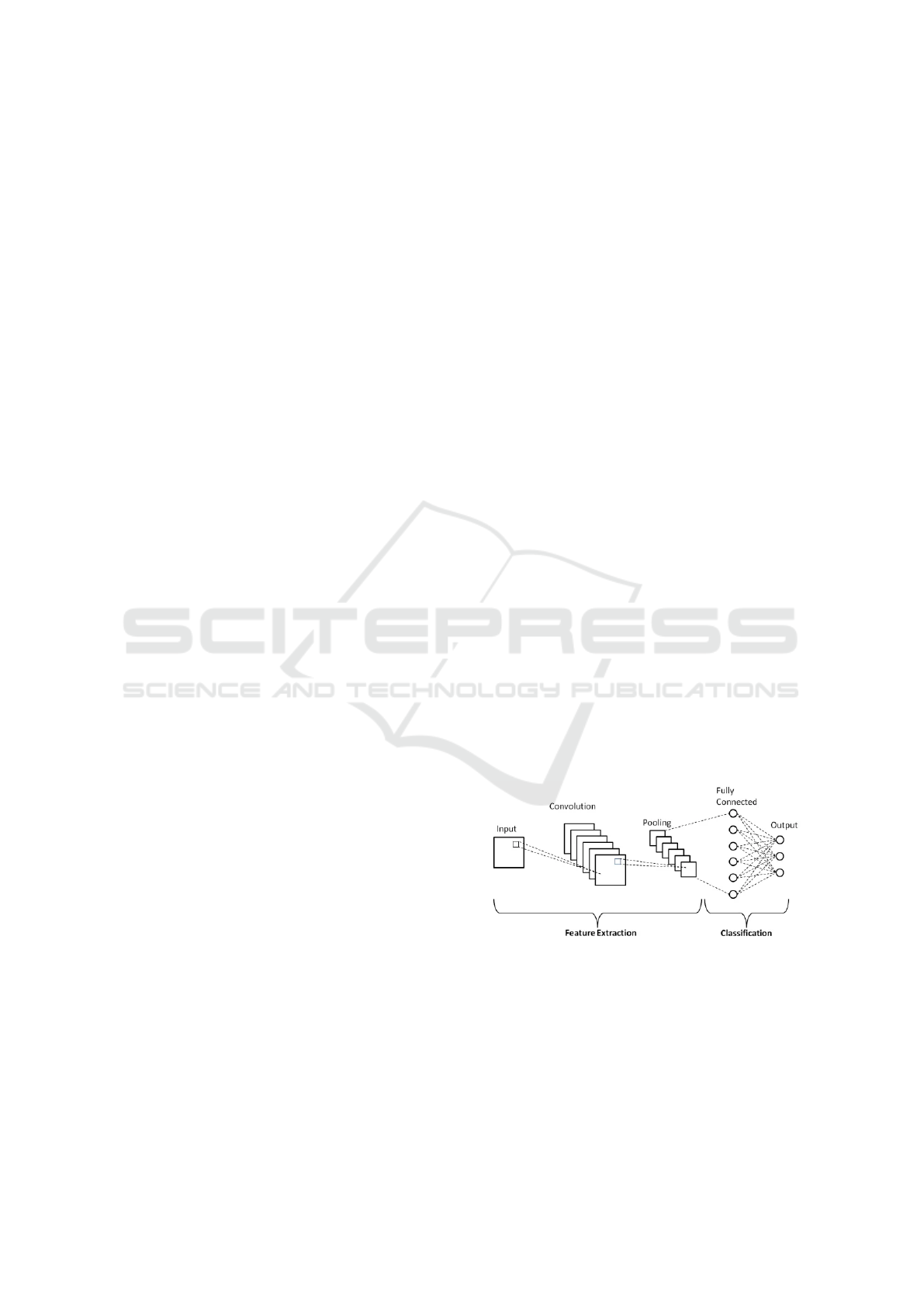
robustness, and efficiency. Convolutional Neural Net-
works (CNN) (Figure 1) form the backbone of these
advancements, enabling the development of sophisti-
cated models that can handle complex environments
with ease. Models like YOLO (You Only Look Once)
and SSD (Single Shot MultiBox Detector) have set
new benchmarks for real-time object detection. These
models balance speed and accuracy, making them
highly suitable for industrial applications where quick
and precise detection is crucial.
Our 2023 study, (Yesudasu et al., 2023) ex-
plores the application of YOLOv3 for object detec-
tion in automated depalletization systems. YOLOv3
is renowned for its speed and accuracy, making it
an ideal choice for real-time detection of cardboard
packages on a pallet. The detection process in their
study is seamlessly integrated with a pose estimation
algorithm, enabling the system to determine the ori-
entation and position of each package. This integra-
tion significantly enhances the efficiency and preci-
sion of the depalletization task. However, the pre-
vious system primarily handled free cardboard boxes
without addressing the complexities of varied box lo-
cations and orientations. Additionally, it had limita-
tions in detecting gaps between packages, a critical
factor for optimizing the depalletization process. By
learning hierarchical feature representations directly
from data, these models excel in identifying and lo-
calizing objects in diverse and challenging scenarios.
Deep learning extends beyond CNN to include archi-
tectures such as Deep Boltzmann Machines (DBM),
Deep Belief Networks (DBN), and Stacked Denois-
ing Autoencoders. These models have been success-
fully applied to various tasks, including face recogni-
tion, activity recognition, and human pose estimation.
The versatility of deep learning in handling different
computer vision challenges underscores its potential
in cardboard package detection and pose estimation.
Figure 1: Architecture of a typical Convolutional Neural
Network (Monica et al., 2020).
Significant strides have been made in object detec-
tion with models like Faster R-CNN, YOLOv3, and
SSD. These models use region proposal networks,
grid-based prediction, and multi-scale feature extrac-
tion to achieve high accuracy and efficiency. For ex-
ample, Faster R-CNN integrates a region proposal
network for efficient object detection, while YOLOv3
Advanced Techniques for Corners, Edges, and Stacked Gaps Detection and Pose Estimation of Cardboard Packages in Automated
Dual-Arm Depalletising Systems
265

achieves real-time performance by dividing the image
into grids and predicting bounding boxes and class
probabilities for each cell. Deep learning has also
found applications in robotics, enhancing perception,
decision-making, and control. CNN are widely used
for visual perception tasks, enabling robots to inter-
pret and understand their environment in real-time.
Recurrent Neural Networks (RNN), especially Long
Short-Term Memory (LSTM) networks, handle tem-
poral information, essential for tasks requiring se-
quence prediction and temporal context. Deep Re-
inforcement Learning (DRL) combines deep learning
with reinforcement learning, enabling robots to learn
optimal actions through trial and error. Generative
Adversarial Networks (GAN) are used for generating
synthetic data to train robots in simulation environ-
ments, improving the robustness of robotic perception
systems.
2.3 Object Pose Estimation Techniques
Object pose estimation is critical for robotic systems,
involving the determination of an object’s position
and orientation. Various advanced techniques have
been developed to enhance the accuracy and effi-
ciency of pose estimation in different applications.
RGB-D camera-based methods leverage depth in-
formation from sensors to enhance pose estimation.
The Hybrid Reprojection Errors Optimization Model
(HREOM) combines 3D-3D and 3D-2D reprojection
errors for robust pose estimation in texture-less and
structure-less scenes using RGB-D cameras (Yu et al.,
2019). Additionally, 3D human pose estimation tech-
niques use RGB-D images to estimate human poses
for robotic task learning, enhancing robots’ ability
to mimic human actions (Zimmermann et al., 2018).
Geometric and feature-based methods focus on ana-
lyzing the geometric properties of objects. The all-
geometric approach utilizes distances between fea-
ture pairs and image coordinates for pose estimation
with a single perspective view (Chandra and Abidi,
1990). Another technique, 6D pose estimation us-
ing Point Pair Features (PPF), employs multiple edge
appearance models to handle occlusion-free object
detection for robotic bin-picking (Liu et al., 2021).
Deep learning-based methods have significantly ad-
vanced pose estimation. Deep Object Pose Estima-
tion Networks use synthetic datasets and deep learn-
ing algorithms like CNN for 6-DOF pose estima-
tion, achieving high accuracy in complex environ-
ments (Zhang et al., 2022). Pruned Hough Forests
combine split schemes for effective pose estimation
in cluttered environments, enhancing performance for
robotic grasping tasks (Dong et al., 2021).
Pose estimation algorithms are crucial for various
robotic applications, including navigation, manipu-
lation, and human-robot interaction. Accurate pose
estimation enables robots to interact with objects in
their environment, perform tasks like assembly and
bin-picking, and collaborate effectively with humans.
In summary, the advancements in traditional, deep
learning, and object pose estimation techniques have
significantly enhanced the capabilities of automated
depalletising systems. These techniques address the
challenges of accuracy, robustness, and efficiency,
making them suitable for complex and dynamic in-
dustrial environments. Future research will continue
to refine these methods, further improving the perfor-
mance and reliability of automated depalletising sys-
tems.
3 METHODOLOGY
This section outlines the methodology used for de-
tecting corners, edges, gaps, and pose estimation of
cardboard packages in automated depalletising sys-
tems. Our approach leverages the advanced capabil-
ities of YOLOv8 and integrates point cloud data for
enhanced 3D analysis. Additionally, we explore tra-
ditional computer vision techniques and discuss their
limitations, which led to the adoption of deep learning
methods.
3.1 Classical Computer Vision Pipelines
3.1.1 Edge Detection
The initial phase of this research explored various
traditional computer vision techniques to detect and
grasp cardboard boxes. For edge detection, algo-
rithms such as the Canny Edge Detector and Sobel
Operator were employed. The Canny Edge Detector
identifies edges by detecting rapid intensity changes,
effectively outlining the boxes, while the Sobel Oper-
ator computes the gradient of the image intensity to
highlight regions with high spatial frequency corre-
sponding to edges.
3.1.2 Thresholding
Thresholding methods like Otsu’s Method and Adap-
tive Thresholding were used to separate cardboard
boxes from the background. Otsu’s Method auto-
matically finds the optimal threshold value, whereas
Adaptive Thresholding adjusts the threshold dynami-
cally for different image regions, useful under varying
lighting conditions.
ICINCO 2024 - 21st International Conference on Informatics in Control, Automation and Robotics
266

Figure 2: Traditional Computer Vision Techniques.
3.1.3 Contour Detection
Contour detection was implemented using OpenCV’s
FindContours function, which identifies the bound-
aries of boxes in a binary image. Shape analysis fol-
lowed, where bounding boxes were drawn around de-
tected contours (see Figure 2) to determine the lo-
cation and size of the boxes and aspect ratio analy-
sis was used to distinguish boxes from other objects
based on their width-to-height ratio.
3.1.4 Template Matching
Template matching involved techniques like cross-
correlation and normalized cross-correlation. Cross-
correlation matches a predefined template of a box to
the image to detect similar shapes, while normalized
cross-correlation provides a more refined match, less
affected by lighting and contrast changes.
3.1.5 Morphological Operations
Morphological operations, including erosion and dila-
tion, were applied to remove noise and small irregu-
larities in the binary image, making the boxes more
distinct. Additionally, opening and closing opera-
tions, which are combinations of erosion and dilation,
were used to clean up the image, filling small holes
and removing small objects.
3.1.6 Feature Detection
Feature detection methods such as the Harris Corner
Detector and FAST (Features from Accelerated Seg-
ment Test) were explored. The Harris Corner Detec-
tor identifies corners in the image which are common
features of rectangular boxes, while FAST provides a
quicker corner detection method suitable for real-time
applications.
3.1.7 Line Detection
Line detection was performed using the Hough Line
Transform and its probabilistic version. The Hough
Line Transform detects lines in an image, aiding in
identifying the edges and structure of the boxes, with
the probabilistic version being more efficient in de-
tecting line segments.
3.1.8 Color Segmentation
Finally, color segmentation was applied using the
HSV color space. By converting images to HSV, it
became easier to segment cardboard boxes based on
color, assuming the boxes had distinct color proper-
ties.
3.2 Limitations and Transition to Deep
Learning
3.2.1 Performance Issues
Despite extensive experimentation, traditional tech-
niques struggled with accuracy, robustness, and han-
dling occlusions, varying lighting conditions, and
featureless surfaces of the boxes. Additionally, the
tightly arranged boxes in pallets and the specific cam-
era angles, with the camera located above the head of
the robotic system, further complicated the detection
process.
3.2.2 Decision to Shift
These limitations highlighted the need for a more
advanced approach, prompting a transition to deep
learning-based methods. Deep learning techniques
offered superior performance in complex environ-
ments, providing enhanced accuracy and robustness
for cardboard box detection and pose estimation in
challenging conditions.
3.3 Dataset Collection and Annotation
To begin with, we collected and annotated 807 im-
ages of cardboard packages using the Computer Vi-
sion Annotation Tool (CVAT). The dataset was metic-
ulously labeled to capture the precise details required
for accurate detection and pose estimation. The key-
points were categorized into three classes based on
the number of visible faces on the boxes:
• boxF-1: Includes the top four corners as key-
points.
• boxF-2: Includes the top four corners plus the
bottom two corners of the visible side face.
Advanced Techniques for Corners, Edges, and Stacked Gaps Detection and Pose Estimation of Cardboard Packages in Automated
Dual-Arm Depalletising Systems
267

• boxF-3: Includes the top four corners, the bottom
two corners of the visible side face, and another
bottom corner of an additional visible side face.
Each keypoint was annotated with its position and a
visibility factor, indicating whether the keypoint was
fully visible, fully occluded, or not labeled. This de-
tailed annotation process ensures high-quality data for
training the neural networks.
3.4 Keypoint Detection with YOLOv8
The YOLOv8 model was then trained to detect key-
points and skeletons of cardboard boxes. The model
predicts keypoint coordinates and confidence scores,
forming the skeletons necessary for structural anal-
ysis. Anchor Points and Regression, YOLOv8 em-
ploys predefined anchor points for keypoints, facil-
itating the prediction of the exact positions of key-
points relative to these anchors. For each anchor
point, the network predicts parameters such as coor-
dinates (tx, ty), representing the keypoints relative to
the bounds of the grid cell, and a confidence score in-
dicating the likelihood of each keypoint’s presence.
YOLOv8 predicts bounding boxes around detected
cardboard boxes, including center coordinates, width
and height, objectness score, and class probabilities.
YOLOv8 also uses predefined anchor points for de-
tecting the skeletons of cardboard boxes, assisting in
predicting the key structural elements by providing
skeleton keypoint coordinates and a confidence score
for each skeleton keypoint.
3.5 Integration with Point Cloud Data
To enhance 3D positioning and structural analy-
sis, we integrated point cloud data from RGB-
D cameras with the detected keypoints and skele-
tons. This integration allows for precise calcula-
tion of box dimensions, gaps, and optimal grasp
points. Point cloud data (P) is obtained from RGB-
D cameras corresponding to the RGB images, where
each point p
i
in the point cloud is represented as
p
i
= (x
i
, y
i
, z
i
). The detected 2D keypoints from the
YOLOv8 model are mapped onto the point cloud to
determine their 3D coordinates. Detected 2D key-
points K = {k
1
, k
2
, . . . , k
n
}, where each k
i
= (u
i
, v
i
)
represents the pixel coordinates in the image, are
projected to 3D coordinates using the intrinsic cam-
era matrix. The depth (z-coordinate) from the point
cloud is matched to get the 3D coordinates K
3D
=
{(x
i
, y
i
, z
i
)}.
3.5.1 Edge and Face Estimation
Edges are calculated by connecting the projected 3D
keypoints, where an edge between two keypoints k
i
and k
j
is represented as a vector
−→
E
i j
=
−→
P
j
−
−→
P
i
. The
planes representing the box faces are determined us-
ing the 3D keypoints, where the plane equation is
given by Ax + By + Cz + D = 0. The normal vector
n to the plane is calculated using the cross product
of two vectors on the plane. For a plane defined by
three non-collinear points P
1
, P
2
, P
3
, the normal vector
n = (A, B, C), and the plane constant D is calculated
as D = −(Ax
1
+ By
1
+Cz
1
).
3.5.2 Box Size Calculation
To determine the dimensions (height, width, length)
of the boxes, we calculate the distances between the
identified 3D keypoints. The height (h) is the vertical
distance between the top and bottom keypoints on one
face, the width (w) is the horizontal distance between
the left and right keypoints on the same face, and the
length (l) is the depth distance between the front and
back keypoints of the box.
3.5.3 Gap Detection and Size Calculation
Gaps between boxes are identified by analyzing the
distances and spatial relationships between the edges
and faces of adjacent boxes. To identify gaps between
two parallel planes, the distance d between them is
calculated using
d =
|D
1
−D
2
|
√
A
2
+ B
2
+C
2
where D
1
and D
2
are the plane constants of two paral-
lel planes with normal vector n = (A, B, C). The size
of the gaps is measured by calculating the Euclidean
distance between the nearest edges or corners of adja-
cent boxes, where for two points P
i
and P
j
on adjacent
boxes, the gap size g is calculated as
g =
q
(x
j
−x
i
)
2
+ (y
j
−y
i
)
2
+ (z
j
−z
i
)
2
The predicted grasping approaches were tested in
a simulated environment to verify their effectiveness.
The simulation provided a controlled setting to refine
the algorithms and ensure they could handle various
scenarios encountered in real-world operations. Suc-
cessful simulations were followed by physical testing
using the dual-arm manipulator, further validating the
grasping strategies.
3.6 Performance Metrics
The system’s performance was evaluated using key
metrics: detection accuracy, grasping precision, and
ICINCO 2024 - 21st International Conference on Informatics in Control, Automation and Robotics
268

operational efficiency, showing significant improve-
ments over previous models. Mean Average Preci-
sion (mAP) measures detection accuracy by calculat-
ing average precision across classes:
AP =
N
∑
n=1
P(n) ·∆R(n)
N
Frames Per Second (FPS) gauges model speed:
FPS =
Number of Frames
Total Time Taken
Intersection over Union (IoU) assesses bounding box
overlap accuracy:
IoU =
Area of Overlap
Area of Union
Recall evaluates the model’s ability to detect all rel-
evant instances, and the F1 score balances precision
and recall:
F1 Score = 2 ·
Precision ·Recall
Precision + Recall
This methodology offers a comprehensive solu-
tion for detecting corners, edges, and gaps, as well
as estimating the pose of cardboard packages in auto-
mated depalletizing systems. By leveraging YOLOv8
and integrating point cloud data, we significantly im-
prove the accuracy, robustness, and efficiency of these
systems. Future work will focus on enhancing dataset
diversity, optimizing real-time performance, and inte-
grating real-time feedback mechanisms to further re-
fine and improve the system’s capabilities.
4 RESULTS AND DISCUSSION
This section presents the results of our methodology
for detecting corners, edges, gaps, and pose estima-
tion of cardboard packages in automated depalletis-
ing systems. We evaluate the system’s performance
using various metrics and discuss the implications of
these results for real-world applications. The com-
puter system has a high-performance Intel Core i7-
10875H processor, 32GB of RAM, and an NVIDIA
Quadro RTX 4000 GPU with 8GB of memory.
4.1 YOLOv8 Detection and Validation
The performance of the YOLOv8 model was eval-
uated across several object classes. As shown
3 Key metrics analyzed include F1-Confidence,
Precision-Confidence, Precision-Recall, and Recall-
Confidence, providing a comprehensive understand-
ing of the model’s accuracy and reliability at different
confidence thresholds.
4.1.1 F1-Confidence Analysis
The F1-Confidence metric is essential for evaluating
an object detection model’s performance, illustrating
the trade-offs between precision and recall. Our re-
sults show that the F1 score increases rapidly as the
confidence threshold rises from 0 to approximately
0.3, indicating high recall but moderate precision.
The F1 scores stabilize between 0.3 and 0.8 confi-
dence thresholds, with an average F1 score of 0.91
at a confidence threshold of 0.624 for all classes. As
the confidence threshold approaches 1.0, F1 scores
decline due to increased precision at the expense of
recall. BoxF-1 maintained the highest F1 scores, fol-
lowed by boxF-2 and boxF-3. The ’all classes’ curve
demonstrated consistent performance with a high F1
score.
4.1.2 Precision-Confidence Analysis
The Precision-Confidence metric evaluates the
model’s ability to correctly identify objects without
false positives. Precision increased rapidly as the
confidence threshold rose to 0.3, stabilized between
0.3 and 0.8, and further increased at high confidence
levels, minimizing false positives. BoxF-1 and
boxF-2 maintained higher precision levels compared
to boxF-3. The ’all classes’ curve showed perfect
precision (1.00) at a high confidence threshold
(0.975), validating YOLOv8’s robustness across
varying confidence thresholds and making it suitable
for tasks requiring high precision.
4.1.3 Precision-Recall Analysis
The Precision-Recall metric assesses the relation-
ship between precision and recall, with the area un-
der the curve (AUC) indicating overall performance.
High precision values close to 1.0 were observed at
lower recall levels, with a slight decline in precision
as recall increased, especially for boxF-2. The ’all
classes’ curve maintained a high mean average pre-
cision (mAP) of 0.939 at an IoU threshold of 0.5.
BoxF-1 maintained the highest precision-recall per-
formance, followed by boxF-3 and boxF-2, demon-
strating YOLOv8’s proficiency in balancing precision
and recall.
4.1.4 Recall-Confidence Analysis
The Recall-Confidence metric evaluates the model’s
ability to capture all relevant instances without miss-
ing any. High recall values close to 1.0 were observed
at lower confidence levels, stabilizing between 0.3
and 0.8 confidence thresholds, with a decline at high
Advanced Techniques for Corners, Edges, and Stacked Gaps Detection and Pose Estimation of Cardboard Packages in Automated
Dual-Arm Depalletising Systems
269

Figure 3: YOLOv8 pose estimation detection across different classes and keypoints. The graphs display various loss metrics,
precision, and recall over epochs.
confidence levels due to increased precision. BoxF-
1 maintained the highest recall scores, followed by
boxF-3 and boxF-2. The ’all classes’ curve showed
a high recall score (0.98) at a low confidence thresh-
old (0.000), demonstrating YOLOv8’s robustness in
capturing all relevant instances.
4.1.5 Validation and Test Metrics
Table 1 and Table 2 summarize the validation and test
metrics for YOLOv8 object detection. BoxF-1 ex-
hibited the highest precision, recall, and F1 scores,
followed by boxF-2 and boxF-3. The combined ’all
classes’ metrics confirmed YOLOv8’s excellent per-
formance across different object classes and confi-
dence thresholds.
Table 1: Validation Metrics for YOLOv8 Object Detection.
Class Precision Recall F1 Score
boxF-1 0.95 0.96 0.95
boxF-2 0.92 0.94 0.93
boxF-3 0.91 0.90 0.91
All Classes 0.93 0.93 0.93
Table 2: Test Metrics for YOLOv8 Object Detection.
Class Precision Recall F1 Score
boxF-1 0.93 0.94 0.94
boxF-2 0.90 0.91 0.91
boxF-3 0.88 0.89 0.88
All Classes 0.90 0.91 0.91
4.2 YOLOv8 Keypoints Detection
Results
The YOLOv8 model was trained to detect keypoints
on cardboard boxes, distinguishing between different
faces and edges of the boxes. Figures (5) illustrate
the model’s output on test images, with annotations
indicating the detected keypoints and the respective
confidence scores.
The results show high accuracy in detecting key-
points on various faces of the cardboard boxes, as ev-
idenced by the clear and precise annotations. The
keypoints, marked with different colors, correspond
to the corners and edges of the boxes, facilitating ac-
curate localization. The model effectively handles
occlusions and overlapping boxes, demonstrating ro-
bustness in detecting partially visible boxes and key-
points in complex arrangements. This capability is
crucial for real-world applications where boxes may
be tightly packed or partially obscured.
The precise detection of keypoints allows the sys-
tem to calculate the optimal grasping points and plan
the trajectories for the dual-arm manipulator. The
ability to identify gaps between boxes, as well as the
edges and corners, ensures that the robot can effec-
tively grasp and move the boxes without causing dam-
age or disrupting the arrangement.
The model was trained with the following hyper-
parameters: 2000 epochs, a batch size of 16, and an
input image resolution of 640x640 pixels. A warmup
phase of 3 epochs was applied to gradually ramp up
the learning rate. The initial learning rate was set to
0.01, with a linear decay to a final learning rate (LRF)
of 0.01. A momentum value of 0.937 and a weight
decay of 0.0005 were used to stabilize the optimiza-
tion process. During evaluation, an Intersection over
Union (IoU) threshold of 0.7 was employed to bal-
ance precision and recall in the model’s performance.
An important aspect of our approach was ensur-
ing robustness across diverse lighting conditions. Al-
though RGB-D cameras typically depend on optimal
lighting for accurate depth and RGB data, our model
mitigates this limitation by supporting low-light envi-
ronments. This was achieved by training the model
on datasets that included both normal and low-light
conditions, maintaining consistent detection accuracy
even in suboptimal lighting. This adaptability in-
ICINCO 2024 - 21st International Conference on Informatics in Control, Automation and Robotics
270

(a) (b)
(c) (d)
Figure 4: (a) & (c) The model’s output on test images, indicating the detected keypoints and the respective confidence scores
(b) & (d) The results of YOLOv8 skeleton detection for cardboard boxes, even if it is partially occluded.
creases the model’s effectiveness in real-world indus-
trial applications, where lighting conditions are often
uncontrolled.
4.3 Skeleton and Prioritized Gap
Detection Results
The skeleton detection results, with the identified pri-
oritized grasping points, provide several advantages.
The precise identification of keypoints and the prior-
itized grasping point allows for accurate calculation
of the optimal grasping strategy, ensuring secure han-
dling of the boxes. By focusing on the most suit-
able grasping point, the system can execute grasping
actions more quickly and effectively, improving the
overall efficiency of the depalletising process. The
ability to detect keypoints and determine the best
grasping point is robust to variations in box placement
and orientation, making the system adaptable to dif-
ferent scenarios and box arrangements.
While the current results are promising, further
improvements can be made by enhancing dataset di-
versity, including a wider variety of box types and
environments in the training dataset to improve the
model’s robustness and generalizability. Integrating
real-time force and torque feedback during grasping
can further enhance the precision and safety of the
manipulation process. Ensuring that the detection and
processing can be performed in real-time will be crit-
ical for deploying the system in dynamic industrial
settings.
5 CONCLUSION
In this study, we have introduced a comprehensive
methodology for detecting corners, edges, and gaps
and estimating the pose of cardboard packages in au-
tomated dual-arm depalletising systems. Leveraging
the advanced capabilities of the YOLOv8 model, cou-
Advanced Techniques for Corners, Edges, and Stacked Gaps Detection and Pose Estimation of Cardboard Packages in Automated
Dual-Arm Depalletising Systems
271

(a) (b)
(c) (d)
Figure 5: (a) YOLOv8 skeleton detection: Detecting boxes at different levels in the pallet, (b) Handling different lighting
conditions, (c) Adapting to different complex environments, (d) Managing rotated boxes and partially occluded boxes.
pled with point cloud data from RGB-D cameras, we
have addressed the significant challenges associated
with traditional computer vision techniques. Our ap-
proach demonstrated marked improvements in detec-
tion accuracy, robustness, and operational efficiency,
particularly in handling complex scenarios such as
occlusions, varying lighting conditions, and tightly
packed arrangements. The rigorous process of dataset
collection and annotation, combined with the use of
sophisticated detection algorithms, has facilitated pre-
cise calculations of box dimensions and optimal grasp
points. This has significantly enhanced the efficiency
and reliability of robotic manipulation, validating our
methodology through extensive simulation and phys-
ical testing.
While our results are promising, several areas war-
rant further investigation and enhancement. Expand-
ing the dataset to include a wider variety of box types,
colors, and environments will improve the model’s ro-
bustness and generalizability. Optimizing the model
for real-time processing is crucial for its deployment
in dynamic industrial settings, ensuring swift and ac-
curate detection and manipulation. Integrating real-
time force and torque feedback during grasping can
enhance precision and safety, reducing the likelihood
of errors and damage during manipulation. Inves-
tigating the system’s scalability for larger and more
varied industrial applications will help understand its
limitations and areas for improvement. Exploring the
potential for human-robot interaction and collabora-
tion in depalletising tasks can open new avenues for
efficiency and safety in industrial environments. In
conclusion, this research underscores the potential of
integrating deep learning with precise 3D data to ad-
vance automated depalletising systems. By contin-
uing to refine and build upon this work, we aim to
develop more adaptable, efficient, and reliable auto-
mated systems that can meet the evolving demands of
modern industries.
ICINCO 2024 - 21st International Conference on Informatics in Control, Automation and Robotics
272

REFERENCES
Bouzakis, A. and Overmeyer, L. (2010). Rfid-assisted de-
tection and handling of packages. In ROMANSY 18
Robot Design, Dynamics and Control: Proceedings
of The Eighteenth CISM-IFToMM Symposium, pages
367–374. Springer.
Brinkmann, S., Vieweg, N., G
¨
artner, G., Plew, P., and
Deninger, A. (2017). Towards quality control in phar-
maceutical packaging: Screening folded boxes for
package inserts. Journal of Infrared, Millimeter, and
Terahertz Waves, 38:339–346.
Casta
˜
no-Amoros, J., Fuentes, F., and Gil, P. (2022). Visual
monitoring intelligent system for cardboard packag-
ing lines. In 2022 IEEE 27th International Confer-
ence on Emerging Technologies and Factory Automa-
tion (ETFA), pages 1–8. IEEE.
Chandra, T. and Abidi, M. (1990). A new all-geometric
pose estimation algorithm using a single perspective
view. In Conference Proceedings.
Dong, H., Prasad, D. K., and Chen, I. (2021). Object pose
estimation via pruned hough forest with combined
split schemes for robotic grasp. IEEE Transactions on
Automation Science and Engineering, 18:1814–1821.
Ha, J. and Jhang, K. (2005). Nonlinear ultrasonic method
to detect micro-delamination in electronic packaging.
Key Engineering Materials, 297-300:813–818.
Hearn, G. and Ballard, J. R. (2005). The use of electro-
static techniques for the identification and sorting of
waste packaging materials. Resources Conservation
and Recycling, 44:91–98.
Liu, D., Arai, S., Xu, Y., Tokuda, F., and Kosuge, K.
(2021). 6d pose estimation of occlusion-free ob-
jects for robotic bin-picking using ppf-meam with
2d images (occlusion-free ppf-meam). IEEE Access,
9:50857–50871.
Monica, R., Aleotti, J., and Rizzini, D. L. (2020). Detection
of parcel boxes for pallet unloading using a 3d time-
of-flight industrial sensor. In 2020 Fourth IEEE In-
ternational Conference on Robotic Computing (IRC),
pages 314–318. IEEE.
Wang, W., Sadeqi, A., Nejad, H. R., and Sonkusale, S.
(2020). Cost-effective wireless sensors for detection
of package opening and tampering. IEEE access,
8:117122–117132.
Yesudasu, S., Sebbata, W., Breth
´
e, J.-F., and Bonnin, P.
(2023). Depalletisation humanoid torso: Real-time
cardboard package detection based on deep learning
and pose estimation algorithm. In 2023 27th Interna-
tional Conference on Methods and Models in Automa-
tion and Robotics (MMAR), pages 228–233. IEEE.
Yu, H., Fu, Q., Yang, Z., Tan, L., Sun, W., and Sun, M.
(2019). Robust robot pose estimation for challenging
scenes with an rgb-d camera. IEEE Sensors Journal,
19:2217–2229.
Zhang, H., Liang, Z., Li, C., Zhong, H., Liu, L., Zhao, C.,
Wang, Y., and Wu, Q. (2022). A practical robotic
grasping method by using 6-d pose estimation with
protective correction. IEEE Transactions on Indus-
trial Electronics, 69:3876–3886.
Zimmermann, C., Welschehold, T., Dornhege, C., Burgard,
W., and Brox, T. (2018). 3d human pose estimation in
rgbd images for robotic task learning. In 2018 IEEE
International Conference on Robotics and Automation
(ICRA), pages 1986–1992.
Advanced Techniques for Corners, Edges, and Stacked Gaps Detection and Pose Estimation of Cardboard Packages in Automated
Dual-Arm Depalletising Systems
273
