
InfoGenie: A Chatbot that Enhances Information Extraction Using
Modern Natural Language Processing Techniques
Yerram Deekshith Kumar
a
, Manash Pratim Lahkar
b
, Aditya Kumar Singh
c
, Biki Dey
d
and Utpal Sharma
e
Department of Computer Science and Engineering, Tezpur University, Napaam, Assam, India
Keywords: Question Answering, Sentence Embeddings, Answer Generation, Information Extraction, PDF Processing.
Abstract: Information extraction and question-answering systems face challenges in efficiently extracting information
from large repositories, particularly when dealing with PDF files. In response, this paper presents an innova-
tive application of Natural language processing (NLP) techniques. We address these challenges by developing
an intelligent chatbot tailored for streamlined Information extraction. Leveraging established language mod-
els and embeddings, including the Hugging Face Transformers library and Sentence Transformer models, our
solution seamlessly integrates with the Chroma vector store. We outline a robust data ingestion process en-
compassing Portable Document Format(PDF) document parsing, text segmentation, and document embedding
creation. These embeddings serve as the foundation for a resilient vector store, enhancing Information extrac-
tion efficiency. The chatbot’s underlying model is fine-tuned for sequence-to-sequence learning, enabling it to
generate coherent responses to user queries. Implemented through a user-friendly web interface powered by
Streamlit, users can interact seamlessly with the chatbot, upload PDF documents, and ask queries based on
those PDF documents. Evaluation on a crowdsourced dataset collected by us demonstrates a 95% cosine simi-
larity between generated and ground truth answers. This research advances NLP-based Information extraction
systems, offering practical solutions and insights for future enhancements.
1
INTRODUCTION
The volume and diversity of textual material in the
digital world has risen considerably in recent years,
and an increasing number of papers in various forms
are being generated and exchanged. This flow of
data presents possibilities and problems, particularly
in the fields of information extraction and question-
and-answer systems. Despite the abundance of data
that might give insightful knowledge, users may find
it challenging to locate and extract the specific infor-
mation they seek owing to the volume and variety of
documents.
Traditional keyword-based search engines and in-
formation extraction systems, although occasionally
successful, usually struggle to understand the nu-
ances of human language and accurately interpret
a
https://orcid.org/0009-0001-1647-8522
b
https://orcid.org/0009-0008-7244-1653
c
https://orcid.org/0009-0009-3588-1366
d
https://orcid.org/0009-0000-4342-854X
e
https://orcid.org/0000-0002-9210-7168
user requests. The proliferation of unstructured ma-
terial, such as PDF documents, exacerbates the prob-
lem, since standard search algorithms struggle to sort
through its complexities.
In this research project, we developed an intelli-
gent chatbot capable of understanding user requests
and responding in natural language. The project’s
purpose is to bridge the knowledge gap between con-
sumers and the massive amounts of information con-
cealed behind digital archives. The chatbot’s goal is
to improve users’ access to relevant information by
utilizing sophisticated language understanding skills
and innovative document processing techniques. This
allows consumers to make more educated judgments
and gain deeper insights from textual data.
2
APPLICATIONS
Our study has broad applicability in numerous sec-
tors. Some of the main applications are:
Kumar, Y. D., Lahkar, M. P., Singh, A. K., Dey, B. and Sharma, U.
InfoGenie: A Chatbot that Enhances Information Extraction Using Modern Natural Language Processing Techniques.
DOI: 10.5220/0013312500004646
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Cognitive & Cloud Computing (IC3Com 2024), pages 239-247
ISBN: 978-989-758-739-9
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
239

2.1
Information Extraction
•
The key use case for our chatbot is information
extraction, which allows users to quickly search
through a library of papers for relevant informa-
tion.
•
This tool is beneficial in academic contexts, cor-
porate settings, research, and any other circum-
stance in which quick access to certain informa-
tion is required.
2.2
Document Summarizing
•
Our chatbot can simplify and summarize long-
form papers, allowing users to rapidly compre-
hend the essential arguments and conclusions
without having to read the entire thing.
•
This tool is beneficial for professionals that need
to quickly extract critical data from long reports
or research papers.
2.3
Customer Support and Faqs
•
Businesses may provide 24-hour customer service
by incorporating our chatbot into their customer
care systems.
•
The chatbot may react to customer queries regard-
ing goods, services, rules, and troubleshooting in
a timely and accurate manner, relieving the bur-
den on human support representatives.
2.4
Educational Tools
•
In the field of education, our chatbot might func-
tion as a virtual study assistant or tutor, assist-
ing students in identifying relevant literature, re-
sponding to questions, and offering clarification
on a number of issues.
•
Furthermore, it may assist teachers in creating in-
teractive lectures and determining how effectively
their pupils understand the subject taught in class.
2.5
Legal and Compliance
•
The chatbot can be used by law firms and le-
gal departments to look up pertinent precedents,
rules, or legal interpretations by searching through
statutes, legal documents, and case law.
•
Law companies and legal departments can utilize
the chatbot to search for relevant precedents, regu-
lations, or legal interpretations in legislation, legal
documents, and case law.
Although this kind of automated chatbot seems
promise, there are a few issues that need to be re-
solved. One of the main challenges is creating pre-
cise algorithms to examine the intricate structure of
digital documents, especially PDF files. Maintaining
real-time responsiveness while effectively and scal-
able managing massive amounts of data is a major
technical issue.
3
LITERATURE REVIEW
The following section covers research articles from
areas like NLP, Information extraction and Informa-
tion retrieval:
3.1
Research on Document Similarity,
Summarization, and Retrieval
Our chatbot system’s primary tasks are retrieval, sum-
marization, and document similarity. Here, we exam-
ine a number of studies that investigate methods for
these assignments:
Ascione and Sterzi conduct a comparative analy-
sis of embedding models for measuring patent simi-
larity (Ascione and Sterzi, 2023). The selection of an
appropriate model for our chatbot to evaluate docu-
ment relevance can be informed by embedding mod-
els, which capture semantic relationships between
documents. (Ascione and Sterzi, 2023).
Sequence-to-sequence Recurrent neural networks
(RNNs) are the means by which Nallapati et al.
propose an abstractive text summarization approach
(Nallapati et al., 2016). Abstractive summarization is
the process of creating fresh, succinct summaries that
highlight the key ideas in a work. Although our first
focus is on retrieval, adding abstractive summariza-
tion to our chatbot might be a useful addition in the
future(Nallapati et al., 2016).
For retrieval tasks, Askari et al. provide an effec-
tive transformer-based re-ranker (Askari et al., 2023).
Re-ranking is the process of picking the best papers
from a set of candidate documents that a previous
system had obtained. According to their research,
transformer-based models may significantly increase
the information extraction accuracy of our chatbot
(Askari et al., 2023).
Jiang et al. offer a technique for rating large
texts using query-directed sparse transformers (Jiang
et al., 2023). Ranking refers to the process of sort-
ing returned documents based on their relevance to
IC3Com 2024 - International Conference on Cognitive & Cloud Computing
240

the user’s query. Jiang’s work on sparse transform-
ers provides excellent ways for handling long doc-
uments when our chatbot works with huge datasets
(Jiang et al., 2023).
Together, these studies provide innovative ap-
proaches for increasing the efficiency and quality of
information extraction, which is critical for our chat-
bot’s ability to identify relevant material for users.
3.2
Integration of Language Models and
Artificial Intelligence(Ai) in
Educational and Enterprise Settings
Several studies explore integrating large language
models and AI services into educational and en-
terprise applications, demonstrating the potential of
these technologies in real-world settings:
Hsain and El Housni (Hsain and El Housni, 2023)
investigate the use of large language model-powered
chatbots to support students in higher education.
Their work suggests that large language models can
be beneficial for educational chatbots, providing a
foundation for our chatbot’s ability to interact with
users and answer their questions .
Jeong (Jeong, 2023) explores the implementation
of generative AI services in enterprise applications.
Generative AI models can be used for various tasks,
including text generation and chatbot development.
Jeong’s work highlights the potential for generative
AI to enhance the capabilities of enterprise chatbots,
providing insights for us to consider as we develop
our own chatbot .
Taipalus (Taipalus, 2023) discusses fundamen-
tal concepts and challenges associated with vector
database management systems, which are essential
for storing and retrieving high-dimensional data like
document embeddings. Efficient storage and retrieval
of document embeddings are crucial for our chatbot’s
performance. Taipalus’s work highlights the impor-
tance of considering appropriate data storage solu-
tions for our chatbot .
Shen et al. (Shen et al., 2023) propose a frame-
work for memory augmentation using language mod-
els, offering insights for enhancing the chatbot’s
knowledge retention and retrieval capabilities. Mem-
ory augmentation techniques can improve a chatbot’s
ability to access and process information, potentially
benefiting our chatbot’s ability to answer follow-up
questions and engage in multi-turn conversations .
Van de Cruys et al. (Van de Cruys et al., 2022) in-
vestigate question-answering techniques for technical
documents. While our initial focus might be on Infor-
mation extraction, incorporating question-answering
capabilities could be a valuable future extension for
our chatbot. Van de Cruys et al.’s work provides in-
sights into techniques for enabling our chatbot to an-
swer user questions directly within retrieved docu-
ments.
Adiba et al. (Adiba et al., 2023) propose meth-
ods for unsupervised domain adaptation in question-
answering systems. Unsupervised domain adaptation
allows a model to be trained on data from one domain
(e.g., general knowledge) and then applied to a dif-
ferent domain (e.g., legal documents) where labeled
data is scarce. While our initial focus might be on re-
trieval, incorporating question-answering capabilities
could be a valuable future extension for our chatbot,
especially when dealing with domain-specific docu-
ments. Adiba et al.’s work suggests that unsupervised
domain adaptation techniques could help enable our
chatbot to answer questions about these specialized
documents even if limited training data is available in
that specific domain (Adiba et al., 2023).
Cohan et al. (Cohan et al., 2023) explore the use of
pre-trained language models for sequential sentence
classification tasks. Sentence classification involves
categorizing sentences based on their meaning. While
our initial focus might be on retrieval, incorporating
functionalities like sentiment analysis or topic classi-
fication could be valuable extensions for our chatbot.
Cohan et al.’s work suggests that pre-trained language
models can be effective for these tasks, providing a
foundation for us to explore adding such functionali-
ties in the future .
Kamma (Kamma, 2023) discusses language mod-
eling for intelligent Information extraction systems.
Kamma’s work emphasizes the role of language mod-
els in understanding the semantics of documents and
queries, which is essential for effective retrieval.
Their insights can inform our selection and applica-
tion of language models within our chatbot’s retrieval
system .
Lappalainen and Narayanan (Lappalainen and
Narayanan, 2023) describe Aisha, a custom AI library
chatbot built using the ChatGPT API. While this work
directly utilizes an existing API, it showcases the po-
tential for building custom chatbots with capabilities
similar to our envisioned intelligent Information ex-
traction chatbot .
Trust et al. (Trust et al., 2024) explore techniques
for augmenting large language models to enhance in-
teraction with government data repositories. While
their focus is on a specific domain (government data),
their work highlights the potential for ongoing re-
search and development in large language models,
InfoGenie: A Chatbot that Enhances Information Extraction Using Modern Natural Language Processing Techniques
241

Tex
t
chunck
s
-
2
Embedding
s
-
2
Tex
t
chunck
s
-
3
LLM Generativ
e
AI
Knowledg
e
bas
e
Ranked Result s
Embeddings-3
Build Semantic
Index
Embeddings-1 Text chuncks -1
Semantic Search
Query
Embeddings
Split in Chuncks
PDF Files
Extract
Data/context
Question
which can inform future advancements in our own
chatbot’s capabilities .
Vaswani et al. (Vaswani et al., 2017) introduce the
Transformer architecture, a neural network architec-
ture that has become foundational for many state-of-
the-art NLP models, including some of the works dis-
cussed previously (e.g., Askari et al. 2023). Under-
standing the core principles of the Transformer archi-
tecture can provide valuable background knowledge
for us as we develop our chatbot.
Wang et al. (Wang et al., 2019) discuss language
Input
Text chuncks -n
Embeddings-n
Figure 1: System Architecture.
models with transformers, providing a more in-depth
exploration of this architecture and its applications in
various NLP tasks. Similar to Vaswani et al. (2017),
this work can provide a deeper understanding of the
technical foundations underlying some of the recent
advancements in NLP relevant to our chatbot devel-
opment.
In conclusion, this review has explored a wide
range of advancements in NLP, Information extrac-
tion, and chatbot systems. The referenced studies of-
fer valuable insights into methodologies that can be
harnessed to enrich the capabilities of our intelligent
Information extraction chatbot. Key takeaways in-
clude:
Building an effective chatbot requires mastery of
essential information extraction methodologies. Em-
bedding models and abstractive summarization aid in
understanding PDF information and condensing large
documents into concise, understandable summaries.
Transformer-based models improve retrieval, provid-
ing for rapid access to important information. Inte-
grating massive language models with AI characteris-
tics such as instructional chatbots and generative AI
enhances capabilities for question response and so-
phisticated information processing. Keeping up with
NLP breakthroughs enables constant progress. Un-
derstanding Transformer architecture helps you make
educated decisions about how to deploy these tech-
nologies, such as creating a robust, user-friendly chat-
bot that successfully answers questions and offers im-
portant information.
4
SYSTEM ARCHITECTURE
Our system’s functionalities include processing user
queries quickly, retrieving pertinent data from a
knowledge base, and producing context-aware re-
sponses. Figure 1 shows the information flow from
user queries to the creation of ranked results, repre-
senting the system architecture. Important parts of the
architecture include the generative model, knowledge
base, text chunking, and embeddings generation.
Algorithm 1 describes the system’s workflow.
Algorithm 1 NLP-based Query Chatbot
Require: User query q, PDF documents D
=
{d
1
, d
2
, ..., d
n
}
Ensure: Context-aware response r
0: function C
HATBOT
(q, D)
0:
Extract text chunks: T ← {}
0: for d
i
∈ D do T ← T ∪ E
XTRACT
C
HUNKS
(d
i
)
0: end for
0:
Embed chunks: E ← {}
0: for t
j
∈ T do E ← E ∪ E
MBEDDING
(t
j
)
0: end for
0: Create semantic index I from E
0: Transform query: q
embed
← E
MBEDDING
(q)
0: Retrieve relevant embeddings:
rel emb ← S
EMANTIC
S
EARCH
(I, q
embed
)
0: Rank results: ranked res ← R
ANK
(rel emb)
0: Generate response:
r ← G
ENERATE
R
ESPONSE
(ranked
res)
0: return r
0: end function=0
4.1
SYSTEM COMPONENT
The system is made up of a number of interrelated
components, each of which plays an important part in
obtaining chatbot functionality. Table 1 presents an
overview of these components and their interconnec-
tions.
4.2
Components of the Language Model
Pipeline
The Language Model Pipeline consists of following
key components:
•
MiniLM Model: HuggingFace Transformers’
MiniLM model, a transformer-based language
model, serves as the pipeline’s primary compo-
nent. MiniLM was chosen because it excels in un-
derstanding the context of user requests and pro-
viding well-reasoned responses. The model un-
derstands complicated linguistic patterns since it
has been pre-trained on a large corpus.
IC3Com 2024 - International Conference on Cognitive & Cloud Computing
242

Table 1: System Components Overview.
Component Description
User Initiates queries and interacts with
the chatbot.
Question User’s input in the form of a query.
ment d
i
in D. To extract the associated text chunks T
i
,
each document d
i
in D is iterated over and analysed
individually. It is possible to put this this way:
Text
Chunks
Segments of text extracted from
PDF files.
T
i
= ExtractChunks(d
i
) (1)
Sentences are added to the text chunks T
i
once
Embeddings Numerical representations of text
chunks.
PDF Files Source documents containing rele-
vant information.
they have been collected for each document d
i
. Let
S
i
be the collection of sentences that were taken out
of each of the text chunks T
i
. To do this, each text
Knowledge
Base
LLM Gen-
erative
Model
Semantic
Search
Ranked Re-
sults
Repository of text chunks and em-
beddings.
Language model for context-aware
response generation.
Process of retrieving information
based on semantic similarity.
Ordered list of relevant results.
chunk t
j
in T
i
is divided into separate sentences s
k
.
This might be shown as:
S
i
=
[
{
s
k
| s
k
is a sentence in t
j
}
(2)
t
j
∈T
i
After obtaining the collection of sentences S
i
for
each document d
i
, embeddings are created for each
sentence to aid in semantic analysis. E
i
should be the
•
Tokenizer: Tokenization is the process of trans-
forming input text into units that the MiniLM
model understands. This pipeline uses Hug-
gingFace’s AutoTokenizer, making it straight-
forward to load the MiniLM model’s pre-trained
tokenizer.
•
Pipeline Parameters: A variety of settings may
be configured to optimize the behavior and per-
formance of the Language Model Pipeline. Table
2 summarizes the parameters utilized in the Lan-
guage Model Pipeline.
Table 2: Language Model Pipeline Parameters
Parameter Description
Model MiniLM
Max Length 256
Sampling True
Temperature 0.3
5
METHODOLOGY
The procedures for text preparation, indexing,
query processing, and result display are as follows:
5.1
TEXT PREPROCESSING AND
REPRESENTATION
PDF files are processed using PyPDFLoader and
PDFMinerLoader. Textual data is extracted from PDF
files. The retrieved text has been divided into manage-
able chunks.
Let D be the collection of PDF documents, and let
T
i
be the set of text excerpts extracted from each docu-
collection of embeddings corresponding to the sen-
tences in S
i
. As part of the embedding process, each
phrase s
k
in S
i
is iterated over, and the appropriate
embedding e
k
is calculated. This can be displayed as:
E
i
= {e
k
| s
k
∈ S
i
} (3)
To generate a semantic index I for efficient infor-
mation extraction, each document d
i
has its embed-
dings E
i
used.
Finally, the text segments, phrases,
and embeddings in each document are ready to be em-
ployed in responses to user queries.
5.2
INDEXING AND STORAGE
We save the sentence embeddings with a semantic in-
dex (e.g., Chroma). The accuracy and speed of in-
formation extraction are improved by integrating with
Chroma. In order for the system to efficiently and cor-
rectly retrieve data based on the semantic knowledge
embedded in the vectors, the vector storage is essen-
tial to similarity searches.
5.3
QUERY PROCESSING
To get ready for processing, a user query q is tok-
enized when it is received. Let q
embedding
stand for
the query’s embedding, which was acquired by using
the same procedure as the text chunks. To obtain rele-
vant results, relevant embeddings, a semantic search
is run on the stored embeddings in Chroma.
5.4
RESULT PRESENTATION
Based on how well the returned results match the
query semantically, they are ordered. The ordered
list of pertinent results from the semantic search
InfoGenie: A Chatbot that Enhances Information Extraction Using Modern Natural Language Processing Techniques
243

may be represented as follows: ranked results =
{r
1
, r
2
, ..., r
k
}, where r
i
indicates the i-th result. A
tuple (text
i
, score
i
), with text
i
denoting the result’s
text content and score
i
denoting its semantic similar-
ity score with the query, makes up each result r
i
.
The last response is produced using a Language
Model (LM) Generative AI. The function that pro-
duces the response based on the query q and the
ranked results is denoted by A(q, ranked results).
The following yields the answer a:
44 questions on average per PDF file and responses
that were around 18.14 words long. We carefully ex-
amined and verified the annotations during the data
gathering procedure to ensure their validity. The eval-
uation dataset
1
was enhanced with a multitude of
viewpoints and insights by our crowdsourcing tech-
nique, which was made possible by the wide range
of questions and answers from human annotators.
We intend to increase the scope of our crowdsourced
dataset by include a greater variety of document for-
a = Restructure(argmax
r
In this notation:
i
∈ranked results
Score(r
i
)) (4)
mats and query types, in recognition of its limitations.
This will entail gathering information from a variety
of sources and making sure that our dataset accurately
•
a represents the final answer.
•
The function argmax selects the result r
i
with the
highest score from the ranked results.
•
Score(r
i
) denotes the score assigned to each result
r
i
.
•
Restructure represents the function that restruc-
tures the selected answer before presenting it as
the final response.
5.5
DATASET
We decided to use Google Forms for our assessment
dataset annotations, employing a crowdsourcing ap-
proach. Participants received the PDF documents for
the evaluation task and were asked to come up with
questions and answers based on the content. The goal
was to directly collect these annotations through the
form.In order to guarantee that the annotations were
excellent and pertinent, we took care to specify stan-
dards including clarity, correctness, and alignment
with the PDF text.
Distribution of Questions Across PDF Files
6.pdf
5.pdf
4.pdf
3.pdf
2.pdf
1.pdf
0 10 20 30 40 50
Number of Questions
Figure 2: Count of questions for each document
Six PDF files make up our dataset, which has
2,295 tokens and 982 unique words in total.
Each
reflects a range of real-world circumstances. Our goal
is to increase the assessment dataset’s diversity in or-
der to enhance the chatbot’s resilience and generaliz-
ability when processing various kinds of documents
and questions.
6
EXPERIMENTS AND RESULTS
We conduct a comprehensive investigation of the
chatbot’s performance in the Colab environment us-
ing scores from the Recall-Oriented Understudy for
Gisting Evaluation (ROUGE) and a range of word
embedding models to determine how effectively the
bot understands user queries and generates relevant
responses.
Table 3 shows that the average cosine simi-
larity scores for the various embeddings (GloVe,
Word2Vec, FastText, and BERT) vary from 0.82 to
0.95. The produced responses’ semantic closeness to
the ground truth answers may be inferred from these
ratings. We use four different embeddings: GloVe
(glove-wiki-gigaword-300), Word2Vec (word2vec-
google-news-300), FastText (fasttext-wiki-subwords-
300), and BERT (bert-base-uncased) to turn the
ground truth response and the anticipated answer into
vectors.
Following conversion, the similarity between the
ground truth answer’s and the anticipated answer’s
vectors was measured using cosine similarity. Fig. 3
displays the document-wise cosine similarity of the
anticipated responses with the ground truth.
Additionally, we evaluated the chatbot’s quality of
answer using ROUGE scores, a widely used natural
language processing metric. The following were the
acquired ROUGE scores:
•
ROUGE-1: Recall (r) = 0.54, Precision (p) =
0.44, F1-score (f) = 0.46
paragraph has around 382.5 tokens on average, dis-
persed over 14 phrases, or roughly 27.32 tokens per
sentence. We collected 264 submissions in all, with
1
https://drive.google.com/drive/folders/1B
H
Uw0u2 jb
9 f CIS5RWJcrweD9s4KSAgt?usp = sharing
24
45
50
47
4
9
49
PD
F
Files
IC3Com 2024 - International Conference on Cognitive & Cloud Computing
244
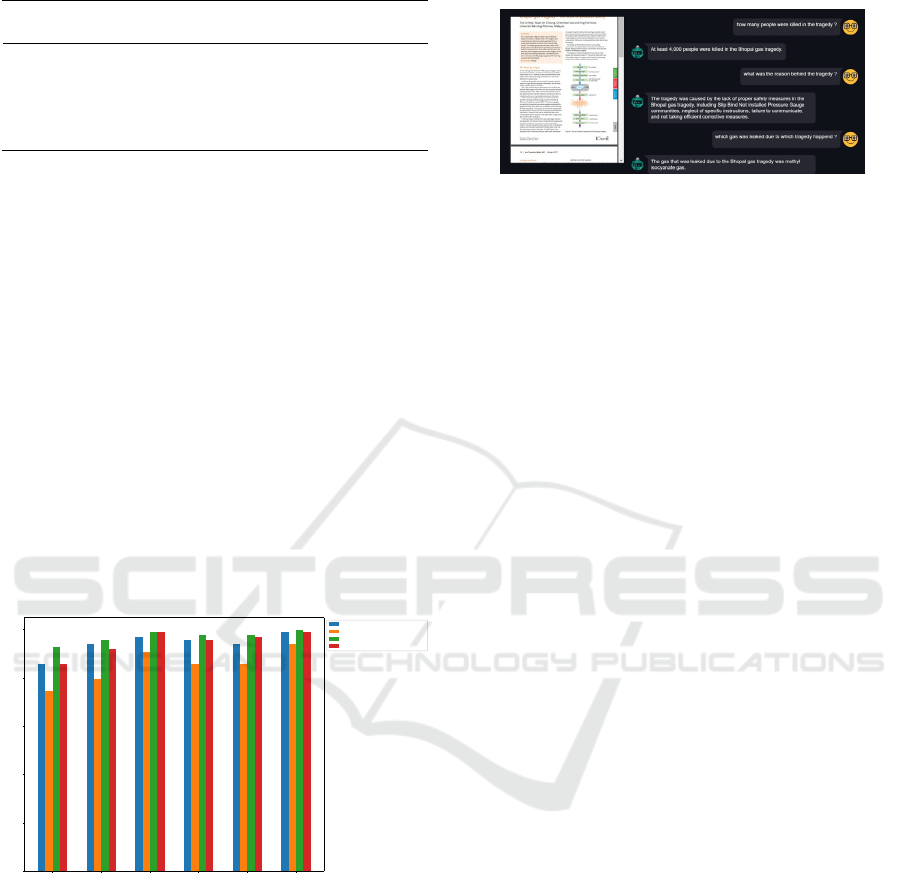
Table 3: Average Cosine Similarity Scores for Different
Embeddings
Doc No. Embeddings
glove-wiki word2vec fasttext-wiki bert-base
-gigaword-300 -google-news-300 -subwords-300 -uncased
1.pdf 0.8
4
0.73 0.91 0.8
4
2.pdf 0.92 0.78 0.9
4
0.9
0
3.pdf 0.95 0.89 0.97 0.97
4.pdf 0.9
4
0.8
4
0.96 0.9
4
5.pdf 0.92 0.8
4
0.96 0.95
6.pdf 0.97 0.92 0.98 0.97
Average 0.92 0.82 0.95 0.92
•
ROUGE-2: Recall (r) = 0.31, Precision (p) =
0.28, F1-score (f) = 0.28
•
ROUGE-L: Recall (r) = 0.48, Precision (p) =
0.40, F1-score (f) = 0.42
The reported ROUGE scores show that the chat-
bot’s capacity to create replies with significant lexical
and semantic overlap with ground truth answers still
needs to be improved. Additional improvements are
required to improve the relevancy and accuracy of the
chatbot’s answers. By combining the ROUGE score
evaluation with the examination of average cosine
similarity scores, we can gain a comprehensive un-
derstanding of the chatbot’s ability to answer to user
inquiries in a relevant and accurate manner. These
measures are useful for determining the quality and
usefulness of a chatbot’s replies in real-world circum-
stances.
Cosine Similarity Scores for Each PDF Document
1.0
0.8
the interface’s development to ensure that users could
easily query information from documents.
Figure 4: User Interface of Chatbot Web Application.
7.1
Article Display
The article about the Bhopal gas tragedy is displayed
on the left side of the interface. The causes of the
incident, the number of casualties, and other relevant
details are all covered in detail in this article. Users
can consult the original content while interacting with
the chatbot because the article is presented in an easily
readable format.
7.2
Chatbot Interaction Panel
Users can interact with the chatbot through the chat
interface on the right side. Users are intended to
ask questions about the article’s content using this
panel. Utilising sophisticated natural language pro-
cessing methods, the chatbot retrieves pertinent data
from the document in response to user inquiries.
0.6
0.4
0.2
0.0
1.pdf 2.pdf 3.pdf 4.pdf 5.pdf 6.pdf
PDF Documents
7.3
Illustrative Interaction
A typical user interface interaction is shown in Figure
4. In this instance, the user poses particular queries
regarding the Bhopal gas tragedy, and the chatbot pro-
vides precise answers taken directly from the article.
The exchange shows off the chatbot’s abilities to:
Figure 3: Document wise average Cosine similarity of the
answers.
7
WEB-BASED USER INTERFACE
FOR ENHANCED
INTERACTION
This section introduces our chatbot application’s
web-based user interface, which is intended for inter-
active information retrieval and question-answering.
Streamlit and simple HTML templates were used in
•
Accurately identify and retrieve key details such
as the number of casualties.
•
Explain the reasons behind the tragedy, including
safety failures and procedural neglect.
•
Specify the type of gas involved in the incident.
The seamless user experience is made possible
by the interface’s aesthetic appeal and functionality,
which are ensured by the integration of HTML tem-
plates and Streamlit. We carried out official user test-
ing sessions to make sure the interface satisfies user
expectations and demands. A wide range of individ-
uals engaged with the chatbot throughout these ses-
g
love-wiki-
g
i
g
aword-300
word2vec-google-news-300
fasttext-wiki-news-subwords-300
bert-base-uncased
Cosi ne Similarity
InfoGenie: A Chatbot that Enhances Information Extraction Using Modern Natural Language Processing Techniques
245

sions, offering qualitative input on the usability, navi-
gation, and general performance of the interface. The
input received was crucial in directing more improve-
ments. Our system serves as an example of how con-
temporary chatbots can greatly improve information
extraction and retrieval, enabling users to more effec-
tively extract specific details from lengthy texts.
7.4
Proof of Concept
It is important to note that this interface is intended
as a proof of concept. While it demonstrates the po-
tential capabilities and effectiveness of the chatbot,
further development and refinement would be neces-
sary for practical deployment and broader application
across different domains and types of documents.
8
LEGAL AND ETHICAL ISSUES
The use of automated information extraction and
question-answering systems in sensitive sectors
presents significant legal and ethical concerns. These
systems must adhere to privacy standards, ensuring
that consumers are aware of data usage and provide
explicit consent. Data anonymization and encryption
are critical for ensuring user privacy. Furthermore,
NLP models might perpetuate biases found in their
training data, resulting in biassed outputs. To limit
this risk, employ diversified datasets, fairness-aware
algorithms, and conduct frequent bias checks. Trans-
parency helps foster trust by helping users to under-
stand how decisions are made, and developers must
accept responsibility for the system’s consequences,
including methods for fixing failures. Automated
technologies should support rather than replace hu-
man decision-making, especially in vital sectors such
as healthcare and finance. Ethical norms must be set
to avoid misuse and promote beneficial societal con-
sequences. Addressing these legal and ethical con-
cerns is critical for the proper development and de-
ployment of NLP-based information extraction sys-
tems, which will increase their value and adoption in
real-world applications.
9
CONCLUSION AND FUTURE
WORKS
In conclusion, our research demonstrates a signifi- cant
advancement in natural language processing and
Information extraction through the development of an
effective chatbot. Employing various word embed-
ding models and evaluating the chatbot’s performance
using average cosine similarity scores and ROUGE
scores, we have shown its ability to comprehend user
queries and provide accurate responses from a docu-
ment corpus. Despite constraints on directly applying
traditional metrics like precision and recall, our focus
remains on optimizing user experience and facilitat-
ing meaningful interactions. The analysis of average
cosine similarity scores across different embeddings
provides insights into the semantic similarity between
generated responses and ground truth answers. Fur-
thermore, ROUGE scores offer valuable indications
of lexical and semantic overlap, contributing to our
understanding of the chatbot’s performance. These
findings underscore the chatbot’s efficacy in generat-
ing relevant and accurate responses, laying a strong
foundation for future advancements in intelligent doc-
ument querying systems.
Looking ahead, future enhancements aim to en-
hance the system’s power and adaptability. Integrat-
ing advanced language models, exploring diverse vec-
tor store options, and extending features to support
multimedia content will contribute to the continuous
evolution of the chatbot.
A significant avenue for future development in-
volves customizing the system to be organization-
specific. Tailoring the chatbot to address the unique
queries and requirements of different organizations
aims to provide a valuable tool for enhancing Infor-
mation extraction in professional settings.
In summary, the chatbot not only achieves its pri-
mary goal of efficient Information extraction but also
lays the groundwork for further advancements in nat-
ural language processing. This project serves as a
foundation for ongoing research and application de-
velopment, contributing to the continuous evolution
of intelligent systems for document querying.
9.1
Future Directions
We will execute domain-specific assessments in the
financial, legal, and healthcare sectors to give a thor-
ough study of the chatbot’s performance across sev-
eral domains. This will evaluate how well the chat-
bot can handle language unique to its domain, adapt,
and deliver trustworthy information. We will also as-
sess the system’s performance in managing massive
amounts of data and real-time processing, addressing
scalability and efficiency issues. We will investigate
optimisation strategies including model compression
and parallel processing. Formal user testing sessions
will be carried out to improve the user experience by
collecting qualitative input on the usability and in-
IC3Com 2024 - International Conference on Cognitive & Cloud Computing
246

terface of the chatbot, which will direct future im-
provements. Finally, by applying sophisticated nat-
ural language understanding algorithms and context
management strategies, we will handle technical is-
sues including managing complicated queries, docu-
ment parsing failures, and keeping context throughout
multi-turn interactions. With these improvements, In-
foGenie should be a more reliable and adaptable tool
for automated information extraction, increasing its
wider application and practicality.
REFERENCES
Adiba, A. I., Homma, T., and Sogawa, Y. (2023). Unsuper-
vised domain adaptation on question-answering sys-
tem with conversation data.
Ascione, G. S. and Sterzi, V. (2023). A comparative analysis
of embedding models for patent similarity.
Askari, A., Verberne, S., A bolghasemi, A., Kraaij, W., and
Pasi, G. (2023). Retrieval for extremely long queries
and documents with rprs: a highly efficient and effec-
tive transformer-based re-ranker.
Cohan, A., Beltagy, I., King, D., Dalvi, B., and Weld, D. S.
(2023). Pretrained language models for sequential
sentence classification.
Hsain, A. and El Housni, H. (2023). Large language model-
powered chatbots for internationalizing student sup-
port in higher education.
Jeong, C. (2023). A study on the implementation of gen-
erative ai services using an enterprise data-based llm
application architecture.
Jiang, J.-Y., Xiong, C., Lee, C.-J., and Wang, W. (2023).
Long document ranking with query-directed sparse
transformer.
Kamma, A. (2023). An approach to language modelling for
intelligent document retrieval system.
Lappalainen, Y. and Narayanan, N. (2023). Aisha: A cus-
tom ai library chatbot using the chatgpt api.
Nallapati, R., Zhou, B., dos Santos, C., Gu¨lc¸ehre, , and Xi-
ang, B. (2016). Abstractive text summarization using
sequence-to-sequence rnns and beyond. IBM Watson.
Shen, J., Dudley, J. J., and Kristensson, P. O. (2023).
Encode-store-retrieve: Enhancing memory augmenta-
tion through language-encoded egocentric perception.
Taipalus, T. (2023). Vector database management systems:
Fundamental concepts, use-cases, and current chal-
lenges.
Trust, P., Omala, K., and Minghim, R. (2024). Augment-
ing large language models for enhanced interaction
with government data repositories. University College
Cork, Cork, Ireland.
Van de Cruys, T., Vanroy, B., and Peirsman, Y. (2022).
Question answering on technical documents.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., Kaiser, , and Polosukhin, I. (2017).
Attention is all you need. Google Research.
Wang, C., Li, M., and Smola, A. J. (2019). Language mod-
els with transformers. Amazon Web Services.
InfoGenie: A Chatbot that Enhances Information Extraction Using Modern Natural Language Processing Techniques
247
