
SMVLift: Lifting Semantic Segmentation to 3D on XR Devices
Marcus Valtonen
¨
Ornhag
a
, P
¨
uren G
¨
uler
b
,
Anastasia Grebenyuk
c
, Hiba Alqaysi
d
and Tobias Widmark
Ericsson Research, Lund, Sweden
Keywords:
Semantic Segmentation, XR Devices.
Abstract:
Creating an immersive mixed-reality experience, where virtual objects are seamlessly blending into physical
environments, requires a careful integration of 3D environmental understanding with the underlying contex-
tual semantics. State-of-the-art methods in this field often rely on large and dense 3D point clouds, which
are not feasible for real-time performance in standalone XR headsets. We introduce Sparse Multi-View Lift-
ing (SMVLift), a lightweight 3D instance segmentation method capable of running on constrained hardware,
which demonstrates on par or superior performance compared to a state-of-the-art method while being signif-
icantly less computationally demanding. Lastly, we use the framework in downstream XR applications with
satisfactory performance on real hardware.
1 INTRODUCTION
High demand for processing power, especially for
tasks involving 3D computations such as dense re-
constructions, creates a bottleneck for most mobile
devices (Wu et al., 2020), which typically lack the
necessary computational resources. This limitation
is especially pronounced in resource-constrained de-
vices like XR headsets, where traditional 3D compu-
tational methods are not feasible for real-time, on-
device processing. These devices require more ef-
ficient, lightweight solutions that can achieve simi-
lar results without the overhead of heavy processing
loads.
To overcome these challenges, we propose a novel
approach that leverages sparse 3D data combined with
2D image-based semantic segmentation, significantly
reducing the computational burden. Our solution pro-
cesses 2D images for semantic segmentation and then
“lifts” the extracted semantic information from multi-
ple views into a sparse 3D point cloud, utilizing a new
lightweight component we developed called SMVLift.
This approach not only alleviates the computational
demands but also retains the precision needed for XR
systems, offering a more efficient and scalable solu-
a
https://orcid.org/0000-0001-8687-227X
b
https://orcid.org/0000-0001-6254-5135
c
https://orcid.org/0009-0002-6503-9494
d
https://orcid.org/0000-0001-9319-1413
tion for object detection and interaction in augmented
environments. Our main contributions are threefold:
• A fast incremental algorithm (SMVLift) for lift-
ing multi-view 2D semantics to 3D on constrained
hardware,
• A thorough comparison with the state-of-the-art
learning-based method,
• We showcase the applicability of the proposed
method on real XR hardware for downstream
tasks by placing a virtual object in a physical
scene.
2 RELATED WORK
2.1 2D to 3D Semantic Segmentation
By leveraging existing advancements in 2D im-
age analysis, these methods offer a computationally
lighter alternative for segmenting 3D point clouds,
and as such are well-suited for resource constrained
devices.
Wang et al. (2019) introduce the Label Diffusion
Lidar Segmentation (LDLS) technique, which tackles
the challenge of 3D object segmentation in lidar point
clouds by using the semantic segmentation results of
2D images. LDLS employs a semi-supervised learn-
ing framework, creating a graph that bridges the 2D
Örnhag, M. V., Güler, P., Grebenyuk, A., Alqaysi, H. and Widmark, T.
SMVLift: Lifting Semantic Segmentation to 3D on XR Devices.
DOI: 10.5220/0012982800003905
In Proceedings of the 14th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2025), pages 555-562
ISBN: 978-989-758-730-6; ISSN: 2184-4313
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
555
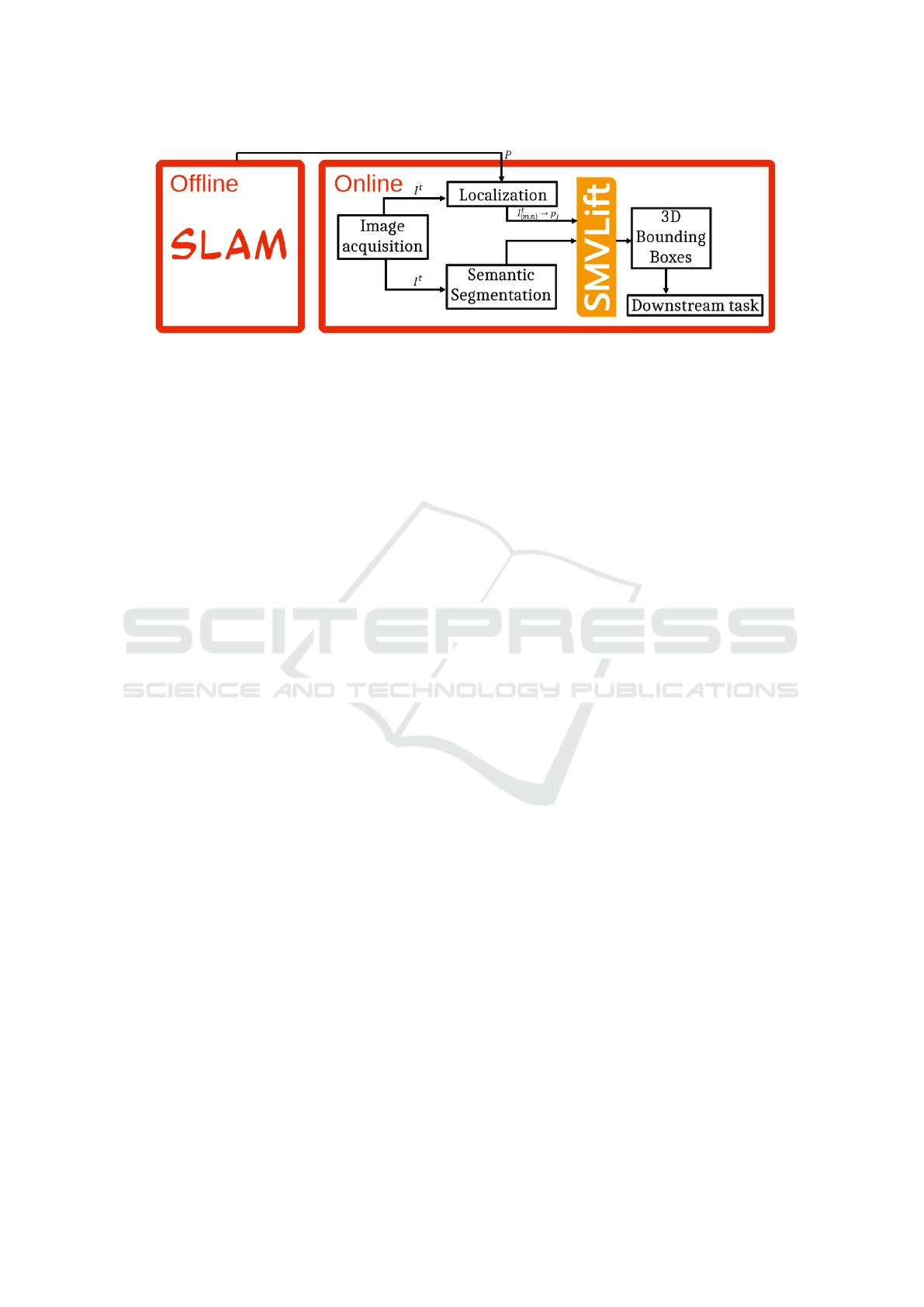
Figure 1: Illustration of general workflow. From an offline module, a map is calculated and 3D point cloud P is given to
the online module to extract 3D instances from the map. The online module starts with image acquisition I
t
at time t. Then
“Localization” module extracts the 2D-3D correspondences I
t
m,n
→ p
j
, where I
t
m,n
∈ I
t
is a pixel in image I
t
at coordinates
m ∈ {0, 1, . . . , W − 1} and n ∈ {0, 1, . . . , H − 1}, and p
j
∈ P is a corresponding point in a set P. In parallel, “Semantic
Segmentation” module calculates 2D semantics for each image I
t
as object class c
t
, object mask m
t
, and class label score s
t
.
Using 2D-3D projections and 2D semantics, “SMVLift” module lifts 2D semantics to 3D instance semantics using a novel
set-based instance assignment algorithm. Finally, we calculate 3D bounding boxes to be used by downstream tasks.
pixel space with the 3D point space. This graph facil-
itates the diffusion of labels from the 2D image seg-
mented using Mask R-CNN (He et al., 2017) to the
unlabeled 3D point cloud. The nodes of the graph
consist of 2D image pixels and 3D lidar points, while
the edges connect corresponding pixels and points
based on their projections and 3D proximity. The
initial labels from the 2D segmentation are diffused
through this graph to the 3D points, utilizing the geo-
metric relationships encoded in the graph to refine the
segmentation boundaries. The process iterates until
convergence, resulting in a finely segmented 3D point
cloud.
Some authors fuse semantic information from
multiple views, e.g., running semantic segmentation
on images (RGB or RGB-D) captured from known
poses and making use of multi-view geometric rela-
tionships to project the predicted semantic labels into
the 3D space. Mascaro et al. (2021) presented a multi-
view fusion framework for semantic scene segmenta-
tion. The framework addresses the 3D semantic seg-
mentation challenge by using 2D semantic segmen-
tation of multiple image views to produce a consis-
tent and refined 3D segmentation. This approach for-
mulates the 3D segmentation task as a label diffusion
problem on a graph, leveraging multi-view data and
3D geometric properties to propagate semantic labels
from 2D image space to the 3D map.
Wang et al. (2018) introduced PointSeg which
uses spherical images derived from 3D lidar point
clouds. The 2D spherical images are fed to a CNN
that predicts point-wise semantic masks. The pre-
dicted masks are then transformed back to 3D space.
2.2 3D Instance Segmentation
In this category, the detection and segmentation are
made directly on large and dense 3D point clouds.
The semantic predictions are usually done point-wise
using a deep neural network, followed by clustering
the points into object instances. Due to the large size
and density of the 3D point clouds required for these
methods to perform well, they should be considered
infeasible for device implementation.
Current state-of-the-art methods in 3D semantic
segmentation mostly rely on neural networks and con-
duct the detection and segmentation directly on the
map, i.e., these methods do not propagate class la-
bels from the 2D images to the 3D map. Typically,
pixel-wise semantic feature extraction is aggregated
on extremely dense 3D point clouds and uses compu-
tationally expensive models to regularize the result-
ing 3D segmentation. Although these learning-based
methods generally achieve better results, they require
labeled 3D data for training and do not scale to XR
devices.
Existing 3D instance segmentation methods, pri-
marily bottom-up and cluster-based, struggle with
closely packed objects or loosely connected large
objects. To overcome these issues, ISBNet (Ngo
et al., 2023) proposed a cluster-free method for 3D
instance segmentation using Instance-aware Farthest
Point Sampling to sample candidates and leverage the
local aggregation layer to encode candidate features
and box-aware dynamic convolution.
To reduce memory usage and inference time of
segmenting 3D point clouds, Zhang et al. (2020) pro-
posed to reduce the number of input points before
feeding them to the segmentation model.
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
556

2.3 Spatial Computing on XR Devices
XR devices leverage spatial perception to support var-
ious tasks; however, the limited computational power
available on such devices makes it a challenging task
to realize. Many have considered offloading com-
putationally expensive tasks to remote edge devices
or cloud services, e.g., GPU servers, allowing for
real-time processing (Heo et al., 2023). In Wu et al.
(2020), the Microsoft HoloLens is used to recognize
objects in an environment with object detection per-
formed on 2D images. This data is subsequently
mapped to a reconstructed 3D space.
In Hau et al. (2022), the authors proposed a
method for 3D semantic mapping using a network of
smart edge sensors for object pose estimation and re-
finement. The proposed method distributes a multi-
view 3D semantic mapping system over multiple
smart edge sensors to include object-level informa-
tion for downstream tasks. According to their exper-
iments, semantic tasks such as object detection and
tracking can be executed at an update rate of 1 Hz
while object pose estimation and refinement are per-
formed online and in real-time. They conclude that
the overall latency in such applications is highly de-
pendent on the amount of processing needed to dis-
play the result.
In challenging network conditions, it is not feasi-
ble to rely on offloading and certain spatial perception
tasks should be performed on device in order to guar-
antee a satisfactory user experience. However, it is
not possible to run state-of-the-art 3D semantic tasks
on device due to hardware limitations. This requires
a different data flow to be realized in practice, e.g., by
working with significantly sparser 3D data.
3 SYSTEM OVERVIEW
We propose to use object detection on multiple 2D
images and lift these to a sparse point cloud. In our
framework, we assume that the 3D reconstruction of
the scene is computed offline, e.g., using available
SLAM frameworks, and can be downloaded from the
cloud or edge to the XR device. In real-time, images
are captured on device and are parsed by a seman-
tic segmentation algorithm in parallel to a localiza-
tion framework. These are later merged in our pro-
posed component, called Sparse Multi-View Lifting
(SMVLift), and from the semantically enhanced point
cloud we extract 3D bounding boxes, see Figure 1.
Assume a 3D map of an environment represented
by a sparse point cloud P ∈ R
3×N
created through im-
age views I = {I
t
} where t ∈ {0, ..., T }. In the on-
Figure 2: 2D-3D correspondences between images (with
instance semantic masks visible) and point cloud from the
Lounge 2 of the S3DIS dataset. We will use a heavily down-
sampled point cloud, only keeping 0.3 % of the points, in
order for us to work on XR devices.
line module, we run multi-view object detection in 2D
images I and map these tentative labels to the corre-
sponding points from the obtained 2D-3D correspon-
dences using the localization module of the pipeline,
see Figure 2. Then through a novel set-based instance
assignment algorithm, we cluster the 3D points based
on the semantic content of instances. After post-
processing of instances to filter out noisy data, the
final 3D bounding boxes can be extracted.
The current framework is assuming a static scene;
however, for future applications, this can be extended
to dynamic environments.
3.1 Aggregating Multi-View Semantic
Masks to Sparse 3D Points
An image I
t
∈ R
W ×H
at time t is fed to a 2D in-
stance segmentation method which outputs class pre-
dictions c(I
t
m,n
) ∈ N
N
, mask confidences m(I
t
m,n
) ∈
R
N×W×H
and label scores s(I
t
m,n
) ∈ R
N
for each im-
age pixel I
t
m,n
at coordinates m ∈ {0, 1, . . . , W − 1}
and n ∈ {0, 1, . . . , H − 1}, assuming N objects are
found. Given an image I
t
, there is a set of 2D-3D
point correspondences, and for each detected object
the 3D point indices belonging to the view are col-
lected together with the label as a local instance L
t
i
for i ∈ {0, . . . , N −1} as a part of a preprocessing step.
This can efficiently be implemented on GPU.
3.2 Set-Based Instance Assignment
Without applying tracking to semantic segmentation
masks, the order in which the masks are labeled will
be different between views, e.g., an object assigned
instance number M in one view will be assigned in-
stance N in another, and there is no clear way of map-
ping the two together. The primary reason to not use
tracking is that we want to aggregate views from mul-
tiple locations of a room, without having to track im-
SMVLift: Lifting Semantic Segmentation to 3D on XR Devices
557

Ground truth LDLS (Mask R-CNN) Our (Mask R-CNN) LDLS (YOLOv8n) Our (YOLOv8n)
Conference Room 1
3823 points
(1 table, 17 chairs)
Lounge 1
3223 points
(6 tables, 7 chairs, 4 sofas)
Lounge 2
6016 points
(2 tables, 8 chairs)
Office 3
2388 points
(2 tables, 2 chairs, 4 sofas)
Figure 3: Experiment on a heavily downsampled point clouds of S3DIS. Bounding boxes for the two different classes are
colored as follows: tables (red) and “sittable” objects (chairs, armchairs and sofas) (blue).
Table 1: Comparison on the S3DIS dataset. Values in bold indicate the better-performing method for each metric and room.
Mask R-CNN YOLOv8n
Precision Recall IoU Precision Recall IoU
LDLS Our LDLS Our LDLS Our LDLS Our LDLS Our LDLS Our
Conference Room 1 0.62 0.68 0.57 0.73 0.16 0.38 0.69 0.82 0.68 0.73 0.21 0.52
Lounge 1 0.60 0.17 0.41 0.34 0.11 0.11 0.62 0.60 0.21 0.32 0.05 0.08
Lounge 2 0.73 0.66 0.55 0.62 0.29 0.17 0.78 0.84 0.57 0.60 0.29 0.25
Office 3 0.88 0.90 0.11 0.49 0.18 0.20 0.84 0.92 0.38 0.38 0.21 0.24
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
558

ages in between, i.e., the localization should work
even though the images are not taken within a short
time frame of each other. To this end, an efficient
way of finding corresponding instances across views
is necessary. We will outline our novel approach next.
For each view at time t, local instances L
t
i
are
created. The next step is to merge these to global
instances G
i
which are independent of the view.
The first set of local instances are directly mapped
to global instances, i.e., G
i
= L
0
i
; however, subse-
quent masks are merged based on a set-based in-
stance assignment heuristic, outlined in Algorithm
1. In essence, when a new set of local instances
{L
t
i
}
i=1,...,N
t
are found by the semantic segmenation
algorithm, each local instance L
t
i
is assigned to a cor-
responding global instance. We select the global in-
stance which has the highest number of common ele-
ments, i.e., G
k
:
= G
k
∪ L
t
∗
, where
L
t
∗
= argmax
i=1,...,N
t
|G
k
∩ L
t
i
| . (1)
If there are no common elements, a new global in-
stance is created. Furthermore, to avoid merging of
instances due to noisy segmentation masks we de-
mand that the intersection between the instances is
proportionally large with respect to the cardinality of
the local and global sets considered. However, we
only do this if the class labels are the same. If instead,
the class labels are different, we assume these come
from noise and remove them from the global instance.
3.3 Post-Processing
After creating the global instances, we apply post-
processing to remove noisy points, by treating each
global instance as a sub-point cloud. We apply DB-
SCAN to cluster the sub-point cloud and proceed
by removing points that are further away from their
neighbors compared to the average of the cluster. For
smaller sub-point clouds, we found experimentally
that one may directly use statistical filtering on the
entire sub-point cloud without clustering. The bound-
ing boxes are then computed as the convex hull of the
3D points, and the final label is taken to be the most
common label from the local instances used to create
the sub-point cloud.
4 EXPERIMENTS
We compare our method to LDLS (Wang et al., 2019),
a state-of-the-art method in the category utilizing 2D
image segmentation. We would like to emphasize that
LDLS is not a feasible option for XR devices as it is
Algorithm 1: Set-based instance assignment.
Match local instances L
t
i
to global
instances G
k
(1);
if No match then
Create new global instance from local
instance;
else
if Same label between local and global
instance then
Merge instances if |G
k
∩ L
t
∗
| is sufficiently
large compared to |L
t
∗
| and |G
k
|;
else
Remove common elements G
k
:
= G
k
\ L
t
∗
;
end
end
Extract 3D bounding boxes from the global
instances, see Section 3.3;
too computationally demanding, which we will dis-
cuss further in Section 4.3. Furthermore, it should
be noted that LDLS only handles single-view infor-
mation, i.e., it does not aggregate data over multiple
views.
The goal of the comparisons is not only to show
that we can get similar and sometimes better perfor-
mance, but to emphasize that our method scales well
to current XR devices. Three datasets were used in
the experiments: S3DIS (Armeni et al., 2017), a syn-
thetically generated dataset, and a real-world dataset
collected using a Varjo XR-3 headset, with a scenario
of placing an avatar in a physical environment. Fur-
thermore, we show that it is possible to run our algo-
rithm on an embedded device (Jetson Xavier NX).
LDLS is not designed for multi-view scenarios
and performs 3D point cloud segmentation by lever-
aging semantic segmentation from a single 2D image
taken by an aligned camera. For a fair comparison, we
let LDLS process each view independently, resulting
in multiple different potential labelings of the input
point cloud, and pick the best label with respect to
each ground truth object from all outputs. Bounding
boxes are then computed by taking the convex hull of
the points for each instance.
Evaluation Metrics. we use commonly occurring
quality metrics used in semantic segmentation to eval-
uate our method. Precision and recall are computed
point-wise over all classes and IoU score is reported
with respect to the predicted 3D axis-aligned bound-
ing boxes that the methods output. The mean scores
are averaged over all classes.
4.1 Experiments on S3DIS
The S3DIS dataset (Armeni et al., 2017) is used to
compare our framework with LDLS. S3DIS contains
six large-scale indoor areas with 271 rooms. For the
SMVLift: Lifting Semantic Segmentation to 3D on XR Devices
559

evaluation, we specifically focused on Area 3, which
consists of many environments including Conference
Room 1, Lounge 1, Lounge 2, and Office 3, which we
have used in these experiments. These environments
are chosen as they capture a variety of different con-
stellations. Furthermore, the S3DIS dataset contains
larger object classes than the ones that Mask R-CNN
and YOLO are trained on and as a result, the com-
parison to ground truth had to be limited to “sittable
objects” and tables; however, these are important ob-
jects for interaction in XR environments.
The S3DIS data contains highly dense point
clouds, while our framework is constructed to work
on sparse 3D data. We subsample the point clouds and
retain only 0.3% of the original data by randomly se-
lecting points from each object in each scene. We use
Mask R-CNN which was originally used and trained
with LDLS, and YOLOv8 (Jocher et al., 2023) as our
instance segmentation algorithms of choice. We use
YOLOv8n—the smallest model—as it is most likely
to run on an XR device. The output is shown in Fig-
ure 3 and the corresponding results in Table 1.
In Conference Room 1, our method outperforms
LDLS in all metrics for both models. In Lounge
1, LDLS demonstrates superior or comparable per-
formance in precision and IoU using Mask R-CNN,
whereas our method shows improvement in recall
with YOLOv8n. The significant decrease in precision
for our method with Mask R-CNN in Lounge 1 is due
to challenges in accurately detecting tables. Unlike
the LDLS method, which effectively captures the en-
tire height of the bounding boxes, our approach tends
to recognize only the tabletops, leading to this dispar-
ity in performance. This specific limitation in detect-
ing the full 3D structure of tables leads to a lower pre-
cision score in this particular scenario. On the other
hand, this is not crucial for XR applications, as it is
often the tabletop that one uses for interaction. In
Lounge 2, LDLS has higher precision and IoU with
Mask R-CNN, while our method shows better recall
with both models. In Office 3, our method generally
outperforms LDLS, particularly in recall.
The results suggest that the performance varies
significantly depending on the room and the specific
metric, with our method showing notable improve-
ments in several cases.
4.2 Experiments on Synthetic Dataset
To overcome the issue of having 2D object detec-
tion algorithms that have been trained on different
data, we created a synthetic dataset with objects that
are present in the COCO dataset, which was used in
training Mask R-CNN and YOLOv8. In this exper-
iment, we use YOLOv8x the most powerful model
in the series, as it is better at finding smaller ob-
jects, which makes the comparison more interesting.
In Section 4.3 we discuss the feasibility of using such
a comparatively heavy algorithm on device.
Table 2: Class-wise comparison on the synthetic dataset ob-
jects. Values in bold indicate best performance.
Precision Recall IoU
LDLS Our LDLS Our LDLS Our
Bottle 0.63 1.00 0.01 0.37 0.24 0.34
Bowl 0.53 1.00 0.13 0.76 0.37 0.60
Chair 0.35 0.99 0.04 0.19 0.02 0.11
Clock 1.00 1.00 0.26 0.80 0.05 0.90
Fridge 1.00 1.00 0.11 0.49 0.04 0.22
Glass 0.00 1.00 0.00 0.18 0.00 0.07
Jar 0.63 1.00 0.02 0.20 0.01 0.12
Sink 0.60 0.65 0.13 0.47 0.06 0.39
Table 0.95 0.33 0.07 0.30 0.04 0.06
Wine glass 0.99 0.99 0.53 0.51 0.61 0.35
Furthermore, the dataset shares many similarities
with SLAM-generated dataset where the points orig-
inate from keypoint descriptors. For example, large
untextured objects (e.g., the table) have very few
points, while smaller objects (e.g., bottles) can have
many. This is not the case for lidar-scanned datasets
and other techniques used in the S3DIS where the
points are more uniformly spread.
The results are shown in Table 2. For smaller ob-
jects, our method significantly outperforms LDLS in
all metrics. Larger objects, e.g., clock and fridge, both
methods achieve perfect precision, but our method
shows a considerably higher recall and IoU. How-
ever, in the case of larger objects like tables, our
method, despite showing improved recall, tends to
have lower precision compared to LDLS. As dis-
cussed in the previous section, this is related to the
limitation in detecting the full 3D structure of ta-
bles. Overall, the superior performance in recall and
IoU across most classes shows the effectiveness of
our approach in broader object identification contexts,
and LDLS does not work well for non-uniformly dis-
tributed point clouds as is common in image-based
SLAM-generated datasets.
4.3 SMVLift on Real XR Hardware
As previously mentioned, LDLS is too computation-
ally demanding. When executed on the synthetic
dataset in Section 4.2 on a computer equipped with
a GeForce RTX 3090 (24 GB) GPU, the average run-
time was 241 ms excluding the object detection algo-
rithm. Even for such powerful hardware, this cannot
be considered for real-time applications. In this sec-
tion, we demonstrate that SMVLift is capable of real-
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
560

Figure 4: (Left): Experimental setup of our scene. A user is scanning the scene with a Varjo XR-3. (Mid) Example screenshot
from the Varjo XR-3 view where the three detected objects are present. (Right) The Varjo XR-3 is tethered, but future
generations of XR hardware could (at least mechanically) fit more powerful hardware such as the Jetson Xavier NX 8 GB.
Figure 5: (Left): The sparse point cloud (1028 points) and the corresponding 3D bounding boxes aggregated from three views.
(Right): An avatar is placed on the chair based on the bounding boxes computed in 3D space. The banana and apple are also
known and could be tagged for interaction by a downstream task.
Object Detection
Preprocessing
Set-based instance assignment
Post-Processing
Calculate bounding boxes
0
20
40
60
80
100
92.3
23.12
3.74
68.44
3.03
17.84
2.04
0.18
2.06
0.41
Execution time (ms)
Scenario 1 Scenario 2
Figure 6: Profiling on a Jetson showing execution time for
different configurations and parts of the pipeline.
time performance on limited hardware. To do so, we
created a small dataset using the Varjo XR-3 head-
set, see Figure 4. A total of 33 images were captured
from different positions in a room, facing a test scene.
To simulate the offline SLAM process, c.f., Figure 1,
we used COLMAP to generate the sparse point cloud.
As the scene is poorly textured, with lots of neutral
background, the SIFT keypoint extractor had trouble
matching descriptors between frames, resulting in a
final point cloud of only 1028 points. We argue that
this is representative of many indoor scenarios, and
regardless of the low-quality 3D reconstruction, the
results are still usable for XR applications, as will be
demonstrated.
In the online part of the pipeline, three images,
previously not used by the framework, are used to es-
timate the pose and the 2D-3D correspondences in the
localization part of the pipeline. Simultaneously the
images are processed by the light-weight object detec-
tor YOLOv8n and the labels and segmentation masks
are sent to the SMVLift block for processing. The
corresponding 3D bounding boxes are shown in Fig-
ure 5. Furthermore, we use the computed bounding
boxes to position an avatar on the chair to simulate its
applicability in an XR application, see Figure 5. Note
that the apple and the banana are correctly recognized
and could be used by the avatar or the user for inter-
action.
Since the Varjo XR-3 is one of the most advanced
PCVR mixed reality headsets available on the market
and is tethered to a powerful computer with GPU sup-
port, it cannot be considered to have limited compu-
tational power. In order to get a reasonable measure-
ment of the real-time performance of the proposed
SMVLift: Lifting Semantic Segmentation to 3D on XR Devices
561

pipeline for a standalone XR device, we use a Jetson
Xavier NX 8 GB for benchmarking. This system-on-
module device comes in a small form factor with GPU
support and is widely used as an AI edge device, due
to its cloud-native support and hardware acceleration
made possible with the NVIDIA software stack. We
consider two different scenarios:
Scenario 1. The synthetic dataset setup:
YOLOv8x, 8 images, 22474 points, with 36
objects.
Scenario 2. The setup used in this section:
YOLOv8n, 3 images, 1028 points, with 3 objects.
To utilize the most of the hardware, the device is
configured to run in the maximum performing power
mode (20 W) and the object detection models are con-
verted to quantized TensorRT-optimized model files
using INT8 precision. The preprocessing is done on
GPU and the set-based instance assignment algorithm
is implemented on CPU, while the post-processing is
done using Open3D compiled with CUDA support.
The results are shown in Figure 6. The total execu-
tion time for Scenario 1 is 190.63 ms per frame and
22.53 ms per frame in Scenario 2. Keep in mind that
the localization part of the pipeline is not taken into
account; however, it should be noted that it can be
executed in parallel to the object detector.
5 DISCUSSION
Our approach shows notable strengths in identifying
smaller objects and in scenarios where comprehen-
sive detection is crucial. However, there are limita-
tions in detecting the full structure of larger objects,
like tables, which affect the precision in specific con-
texts. This insight is not problematic for applications
in XR environments, where interaction often focuses
on object surfaces like tabletops. Overall, the findings
highlight the potential of our method in diverse ap-
plications, balancing between detailed detection and
practical constraints in real-world scenarios.
6 CONCLUSIONS
In this work, we introduced a fast incremental algo-
rithm (SMVLift) for lifting 2D semantics to 3D on
constrained hardware. By working with sparse point
clouds, on-device performance is made possible. For
robustness, we aggregated the semantic masks from
multiple views, by using a novel set-based instance
segmentation algorithm. Our method was compared
to a state-of-the-art algorithm and showed compara-
ble or superior results despite being significantly more
lightweight. In addition, we showed that our method
can be incorporated into a real XR application by
positioning an avatar on a chair using a Varjo XR-3
headset. Finally, we showed that the method is capa-
ble of real-time performance on a Jetson Xavier NX
and argued that, due to the mechanical form factor
of such devices, the computational capacity of future
generations of XR devices are likely to be running al-
gorithms such as the one proposed in the paper.
REFERENCES
Armeni, I., Sax, A., Zamir, A. R., and Savarese, S. (2017).
Joint 2D-3D-Semantic Data for Indoor Scene Under-
standing. https://arxiv.org/abs/1702.01105.
Hau, J., Bultmann, S., and Behnke, S. (2022). Object-level
3D semantic mapping using a network of smart edge
sensors. In IEEE International Conference on Robotic
Computing (IRC), pages 198–206. IEEE.
He, K., Gkioxari, G., Doll
´
ar, P., and Girshick, R. (2017).
Mask R-CNN. In IEEE International Conference on
Computer Vision (ICCV), pages 2980–2988.
Heo, J., Bhardwaj, K., and Gavrilovska, A. (2023). FleXR:
A system enabling flexibly distributed extended real-
ity. In Proceedings of the Conference on ACM Multi-
media Systems, pages 1–13.
Jocher, G., Chaurasia, A., and Qiu, J. (2023). Ultralytics
YOLOv8. https://github.com/ultralytics/ultralytics.
Mascaro, R., Teixeira, L., and Chli, M. (2021). Dif-
fuser: Multi-view 2D-to-3D label diffusion for seman-
tic scene segmentation. In IEEE International Con-
ference on Robotics and Automation (ICRA), pages
13589–13595.
Ngo, T. D., Hua, B.-S., and Nguyen, K. (2023). ISBNet:
A 3D point cloud instance segmentation network with
instance-aware sampling and box-aware dynamic con-
volution. In Proceedings of the IEEE/CVF Conference
on Computer Vision and Pattern Recognition (CVPR),
pages 13550–13559.
Wang, B. H., Chao, W.-L., Wang, f. Y., Hariharan, B., Wein-
berger, K. Q., and Campbell, M. (2019). LDLS: 3-D
object segmentation through label diffusion from 2-
D images. IEEE Robotics and Automation Letters,
4(3):2902–2909.
Wang, Y., Shi, T., Yun, P., Tai, L., and Liu, M.
(2018). PointSeg: Real-time semantic seg-
mentation based on 3D LiDAR point cloud.
https://arxiv.org/abs/1807.06288.
Wu, Z., Zhao, T., and Nguyen, C. (2020). 3D reconstruction
and object detection for HoloLens. In Digital Image
Computing: Techniques and Applications (DICTA),
pages 1–2. IEEE.
Zhang, H., Han, B., Ip, C. Y., and Mohapatra, P. (2020).
Slimmer: Accelerating 3D semantic segmentation for
mobile augmented reality. In IEEE International
Conference on Mobile Ad Hoc and Sensor Systems
(MASS), pages 603–612.
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
562
