
Facial Empathy Analysis Through Deep Learning and Computer Vision
Techniques in Mixed Reality Environments
Insaf Setitra
1
, Domitile Lourdeaux
1
and Louenas Bounia
1, 2
1
UMR CNRS 7253 Heudiasyc, Sorbonne Universit
´
e, Universit
´
e de Technologie de Compi
`
egne,
57 avenue de Landshut, Compi
`
egne, France
2
Universit
´
e Sorbonne Paris Nord, Laboratoire d’Informatique de Paris-Nord (LIPN) - UMR-CNRS 7030, France
Keywords:
Empathy, Facial Expression, Emotion Detection, Valence and Arousal.
Abstract:
This paper introduces a novel approach for facial empathy analysis using deep learning and computer vision
techniques within mixed reality environments. The primary objective is to detect and quantify empathic re-
sponses based on facial expressions, establishing the link between empathy and facial expressions. We propose
the Deep Convolutional Neural Network with the Exponential Linear Unit activation function (ELU-DCNN).
We moreover design an augmented reality platform with two main features (i). virtual overlay of a VR head-
set on the user’s face and (ii). facial emotion recognition for users wearing the VR headset. Our target is
to analyse facial expressions in immersed environments in order to assess the empathy of users while being
immersed in specific environments. Our results analyse the feasibility and effectiveness of these models in
detecting and quantifying empathy through facial expressions. This work contributes to the growing field of
affective computing and highlights the potential of integrating advanced computer vision techniques in mixed
reality applications to better understand human emotional responses.
1 INTRODUCTION
Empathy is a fundamental element of human interac-
tions and plays a crucial role in communication and
interpersonal relationships. Understanding and an-
alyzing facial expressions associated with empathy
can offer profound perspectives not only in the field
of psychology, but also in various technological ap-
plications such as virtual reality, games and human-
machine interactions.
The state of the art hence analyzes both empathy
and facial expressions, with limited studies exploring
their interrelation in the context of historical empa-
thy. Some studies explore how empathy can improve
human-centered design by understanding user needs
and developing solutions accordingly (Zhu and Luo,
2023), (Somarathna et al., 2023), (Gareth W. Young
and Smolic, 2022), (Ventura and Martingano, 2023),
(Mathur et al., 2021), (Bang and Yildirim, 2018),
(Shin, 2018). In contrast, our work diverges by con-
centrating on the use of computer vision and deep
learning techniques to analyze empathic responses
in historical scenarios, aiming to adapt and enrich
these scenarios through advanced technological ap-
proaches. The main goal is to create a system that can
detect and analyze facial expressions to measure em-
pathy. The project contributes to the improvement of
virtual reality scenarios in a historical setting (mainly
in the memorial of Compi
`
egne) based on detected em-
pathy.
1.1 Empathy Detection
Empathy is divided into three distinct components:
affective, cognitive and associative empathy (Shen,
2010), (Ventura and Martingano, 2023). Affective
empathy is the ability to feel the emotions of an-
other person, cognitive empathy is the ability to un-
derstand the thoughts and feelings of others, and as-
sociative empathy combines the emotional and cog-
nitive aspects, allowing individuals to put themselves
completely in the other’s place. In our study, we are
mainly interested in cognitive empathy. Indeed, the
purpose of visiting a historical museum is to under-
stand historical events without directly feeling what
the individuals (deportees for instance) could have
felt. The study in (Hasan et al., 2024) revealed that
while empathy detection systems use various types of
signals, there is a predominance of empathy analysis
from texts as opposite to facial expressions. Question-
Setitra, I., Lourdeaux, D. and Bounia, L.
Facial Empathy Analysis Through Deep Learning and Computer Vision Techniques in Mixed Reality Environments.
DOI: 10.5220/0013057800003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 3, pages 31-39
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
31

naires allow to label the collected data. The Toronto
empathy questionnaire (Spreng et al., 2009) is fre-
quently cited in the literature. Shin (Shin, 2018) pro-
posed a model examining the relationships between
immersion, presence, flow, embodiment and empathy
in a virtual environment. Bang and Yildirim (Bang
and Yildirim, 2018) conducted a study to assess the
effectiveness of virtual reality storytelling in build-
ing user empathy. To do this, they compared two
groups of participants: the first watched the documen-
tary After Solitary
1
using a VR headset, while the sec-
ond one watched the same video in 360
o
format on a
desktop computer. In the context of measuring em-
pathy, researchers used the State Empathy Question-
naire (SEQ)(Shen, 2010). Leena et al.(Mathur et al.,
2021) conducted an experiment to collect a new set
of empathy data in an innovative interaction context,
where participants listened to stories told by the sto-
ryteller robot LuxAI. After listening to the three sto-
ries, participants completed the SEQ Questionnaire to
assess their empathic reactions. Video information
of participants was first extracted by OpenFace 2.0
(Baltrusaitis et al., 2018) to identify certain facial fea-
tures, including expression movement, eye angle and
head position. (Gareth W. Young and Smolic, 2022)
states that a good immersion creates an ”illusion of
body exchange” that facilitates the adoption of the
perspective of the incarnate character. Among sce-
narios that evoke empathy stands The Last Goodbye
2
,
a virtual reality experience that allows users to visit
the remains of a Nazi concentration camp in the com-
pany of a Holocaust survivor, Pinchas Gutter. This
scenario is intended to evoke intense emotions such
as sadness, anger and deep reflection. ”VR World
War II”
3
is another virtual reality scenario that im-
merses users in the events of World War II. In (Xue
et al., 2023)
4
, a database is presented which includes
73 extracts that induce valence variations and emo-
tional activation. A similar dataset is presented in (Li
et al., 2017)
5
with a set of 360
o
videos. AVDOS-
1
https://www.youtube.com/watch?v=G7 YvGDh9Uc&
t=14s
2
USC Shoah Foundation (2020, Septembre 18). The
last GOODBYE [VR documentary]. Gabo Arora and Ari
Palitz. https://sfi.usc.edu/lastgoodbye
3
World War II Foundation (2021-2024) VR video se-
ries. https://www.youtube.com/playlist?list=PL2A7-aRM
5qjU7KKRIdL-LsPObYfZHT7Od
4
https://www.dis.cwi.nl/ceap-360vr- dataset/, https:
//github.com/cwi-dis/CEAP-360VR-Dataset/tree/master?t
ab=readme-ov-file
5
https://vhil.stanford.edu/public-database-360-video
s-corresponding-ratings-arousal-and-valence
VR (Gnacek et al., 2024)
6
contains 30-second videos
with activation and valence information evaluated at
each second. Arousal and valence (positive/negative)
are often used to evaluate induced emotions. Self-
assessment by participants via the SAM scale is a
widespread method. Correlations are observed be-
tween head upward movements and high activation
levels (Somarathna et al., 2023). A subset of AVDOS-
VR is also presented in (Xue et al., 2023).
In our study we choose four scenarios from
AVDOS-VR (Gnacek et al., 2024) that are used us-
ing a desktop application we developed and two VR
scenarios (360
o
) from (Li et al., 2017). We use the
Toronto questionnaire (Spreng et al., 2009) before the
experiment and the SEQ questionnaire (Shen, 2010)
after the experience. We provide more details in the
following sections.
1.2 Facial Expression Recoginition
According to Rakibul et al. (Hasan et al., 2024), for
empathy detection in the deep learning category, mod-
els based on Convolutional Neural networks (CNN)
and Recurrent Neural Networks (RNN) are most fre-
quently used, while in the classical machine learn-
ing category, SVM is the most frequently used. Tra-
ditionally, seven basic emotions are classified: fear,
anger, disgust, happiness, neutrality, sadness and sur-
prise while the main datasets used in the literature are
FER2013, AffectNet, CK+, eNTERFACE’05 (Mar-
tin et al., 2006). Li and Deng (Li and Deng, 2022)
present a comprehensive review on Facial Expres-
sion Recognition (FER) and describes the standard
process of a deep FER system, including prepro-
cessing, learning of deep characteristics and classi-
fication. (Mohamed et al., 2022) presents a method
based on the association of a pre-trained CNN mod-
els (VGG16, ResNet50) used as a feature extractor
with a Multi-Layer Perceptron (MLP) classifier. (De-
mochkina and Savchenko, 2021) presents a method
to recognize facial expressions in videos, using the
proposed MobileEmotiFace netword. Kas et al. (Kas
et al., 2021) presents a framework that combines tex-
ture and shape characteristics from 49 landmarks de-
tected on a facial image. The shape is extracted us-
ing Histogram of Oriented Gradient (HOG) and the
texture using an Orthogonal and Parallel-based Di-
rections Generic Quad Map Binary Patterns (OPD-
GQMBP). Ezati et al. in (Ezati et al., 2024) highlight
the challenges posed by high computational com-
plexity and variations of multi-view poses in real-
6
https://github.com/michalgnacek/AVDOS-VR/tree/m
ain , https://www.gnacek.com/affective-video-database-onl
ine-study
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
32

world contexts and propose a Lightweight Attentional
Network incorporating Multi-Scale Feature Fusion
(LANMSFF). Ma et al (Ma et al., 2024) propose
the FER-YOLO-Mamba model, which integrates the
principles of Mamba and YOLO technologies to facil-
itate efficient recognition and localization of facial ex-
pressions. Sun et al. (Sun et al., 2023) propose a new
self-supervised approach called SVFAP that uses self-
supervised learning to overcome challenges related to
overfitting and the high cost of creating datasets. An-
other significant area of research examines how dif-
ferent facial regions contribute to the recognition of
facial expression. The observations of Wegrzyn et al.
(Wegrzyn et al., 2017) show that the lower part of the
face is about joy and disgust while the upper part in-
forms about anger, Fear, surprise and sadness. Win-
genbach (Wingenbach, 2023) shows the relationship
between facial muscles and facial expression. Using
facial electromyography
7
, it is possible to detect the
slightest muscle contractions and identify the charac-
teristic Action Units (AUs). In addition, it is possi-
ble to combine these AUs to determine an emotion.
The AU method has been used in several other stud-
ies such as (Yao et al., 2021). Huc et. al. (Huc
et al., 2023) studies the effects of emotional attribu-
tion errors on people with or without masks. This
work shows that the bottom of the face contributes
to the identification of emotions of joy, sadness and
surprise while the top of the face allows to recognize
fear which contradicts somewhat the (Wingenbach,
2023). Other confusions such as the confusion of fear
and surprise, anger and disgust and sadness and fear
and all with the neutral emotion are also described.
(Poux et al., 2020) is based on the propagation of fa-
cial movement to overcome difficulties related to oc-
clusions. (Minaee et al., 2021) presents an innovative
approach for facial expression recognition based on a
convolutional attentional network with a spatial atten-
tion mechanism. To validate the attentional approach,
a saliency map of important regions is generated. The
results confirmed that different expressions are indeed
sensitive to different parts of the face, for example the
mouth for joy and the eyes for anger.
2 OUR APPROACH
Our approach to facial empathy analysis is structured
into three key parts. The first part (Subsection 2.1)
focuses on facial expression recognition. We employ
a proposed neural network that fully predicts the ex-
pression from an image. This network is combined
7
A medical technique that studies the function of nerves
and muscles
with various feature extractors, including pixels, His-
togram of Oriented Gradients (HOG), MobileNet, and
VGG, along with classification algorithms such as K-
Nearest Neighbors (KNN) and Support Vector Ma-
chines (SVM). In the second part (Subsection 2.2),
we introduce a novel aspect of our dataset by adding a
mask to the expressions. This modification simulates
an environment where individuals are immersed in
Virtual Reality (VR), allowing us to analyze their fa-
cial expressions under these conditions. The last part
(Subsection 3.2) outlines our experimental setup. We
describe a series of scenarios designed to evoke em-
pathy, during which we capture video recordings of
participants’ reactions, both with and without wearing
a VR headset. Participants complete during the ex-
perimentation empathy questionnaires to provide ad-
ditional insights into their empathic responses. This
comprehensive approach enables us to analyze and
understand the relationship between facial expres-
sions and empathy in both traditional and VR envi-
ronments.
2.1 Facial Expression Recognition
The network we propose to classify facial expressions
is inspired of the work of Debnath et al.(Debnath
et al., 2022). Our proposed model consists of six con-
volution layers organized into three blocks:
• The first convolution block contains two layers us-
ing 5 filters with 64 filters each.
• The second block consists of two layers using 3 ×
3 filters with 128 filters.
• The third block has two convolution layers using
3 × 3 filters with 256 filters.
• Each convolution layer is followed by batch nor-
malization which helps to stabilize and accelerate
the drive. Moreover, an ELU (Exponential Linear
Unit) activation function is also applied after each
layer to improve network convergence.
• The model integrates MaxPooling layers after
each convolution layer block to reduce dimen-
sionality.
• Dropout layers prevent overfitting by ensuring
regularization as the number of parameters in-
creases.
• Flatten layer is finally used to convert the feature
maps into a one-dimensional vector followed by
a dense layer of 128 neurons with ELU activation
and batch normalization.
• The output layer uses a softmax activation for
multi-class classification.
Facial Empathy Analysis Through Deep Learning and Computer Vision Techniques in Mixed Reality Environments
33
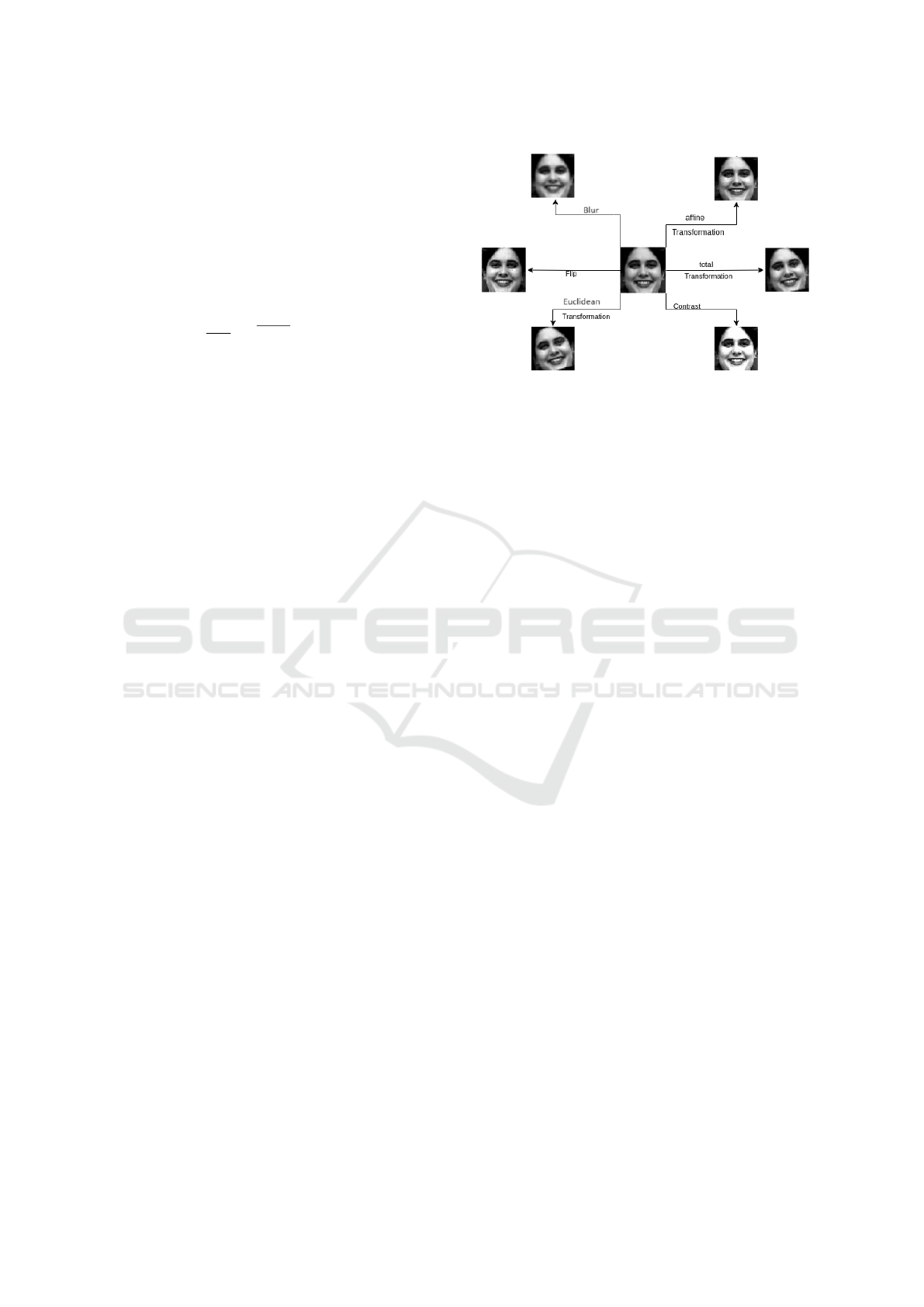
In addition, to improve the diversity and balance
of our training dataset, we have used a data augmen-
tation strategy shown in Figure 1. The set of augmen-
tations used are as follows given that x, y and x
′
, y
′
are
the image coordinates before and after the augmenta-
tion respectively:
• Gaussian blur: The weighted average of the
neighboring pixels for each pixel in the image is
applied. We use the Gaussian kernel to do so
(G(x, y) =
1
2πσ
2
exp
−x
2
+y
2
2σ
2
).
• Affine transformation: The combination of
translations, rotations, scaling and shears (bias
distortions) is applied
x
′
y
′
=
a b
c d
x
y
+
e
f
.
• Euclidean Transformation: includes
only rotations and translations
x
′
y
′
=
cosθ −sinθ
sinθ cosθ
x
y
+
t
x
t
y
with Where
θ is the angle of rotation and (t
x
, t
y
) is the
translation vector.
• Total Transformation: transformation of the
quadrilaterals into other quadrilaterals
x
′
y
′
w
′
=
a b c
d e f
g h i
x
y
1
.
• Contrast Modification: Higher contrast makes
light areas brighter and dark areas darker
I′(x, y) = αI(x, y) + β with I the image intensity
and α, β the contrast and brithness factors respec-
tively.
• Image Flipping (flip): either horizontal (x =
−x, y = y) or vertical (x = x, y = −y).
For the feature based facial expression recogni-
tion, we extract 4 types of features and use two
main classifiers. The feature extractors are described
briefly in the following:
• Pixels: each image is flattened into a vector of
pixels. Then, this vector is normalized to have an
average of 0 and a standard deviation of 1, which
improves the performance of machine learning al-
gorithms.
• Histogram of Oriented Gradient HOG: he his-
tograms of all cells are grouped together and used
as a feature vector.
• VGG Feature Extractor: in VGG16 (Simonyan
and Zisserman, 2014) we adopt the last layer
Figure 1: Examples of the used augmentations.
(4096 dimensional vector) as the feature vector
without any training.
• Mobile Net Feature Extractor: Similarily to
VGG, we use the last layer of MobileNet (Howard
et al., 2017) as a feature vector.
Finally we use SVM and KNN for classification
and use in our approach the cross-validation to deter-
mine the optimal number of neighbors.
2.2 Augmented Reality for Facial
Expression Recognition in
Immersion
Virtual reality headset overlay on faces via Aug-
mented Reality (AR) offers an innovative approach to
the study of emotion recognition in the context of ex-
periences in emotion recognition. This work also al-
lows to assess the potential impact of facial occlusion
by physical devices on the recognition of emotions.
The AR algorithm relies on two pre-prepared VR
headset images: a front view and a profile (sagittal)
view. The first crucial step in the process is to ana-
lyze the input image to detect and understand the face
geometry. This phase is fundamental because it pro-
vides the necessary information to position and ori-
ent the virtual VR headset correctly. The algorithm
operates in the following stages. (i) Face Detec-
tion:This process a machine learning-based method
known as BlazeFace (Bazarevsky et al., 2019), a
lightweight and efficient face detector designed for
real-time applications. BlazeFace leverages a single-
shot detection (SSD) architecture that quickly identi-
fies the bounding box of the face within the image,
enabling real-time face detection with high precision.
(ii). Face Mesh Generation: Within the Region Of
Interest (ROI), a mesh grid is generated, mapping out
the facial structure. This grid consists of numerous
points, known as landmarks, strategically positioned
to capture critical facial features such as the eyes,
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
34

nose, and mouth. (iii). Landmark Localization: The
algorithm uses the convolutional neural network Mo-
bileNetV2 (Sandler et al., 2019) to predict the precise
locations of these landmarks. (iv). Temporal Fil-
tering: For real-time applications, temporal filtering
is applied to stabilize the landmark positions across
consecutive frames. This reduces jitter and ensures
smooth tracking of facial movements.
From the set of detected landmarks, we selects
four specific points that will serve as a reference for
positioning the VR headset. These points are strategi-
cally chosen to frame the area where the helmet will
be placed, usually around the eyes and temple and de-
termine the geometric transformation applied to the
helmet. To determine the pitch, roll, and yaw angles
of the head, the pose can be calculated from 3D-2D
point correspondences using relevant algorithms and
facial landmarks. This problem involves solving for
the rotation (r) and translation (t) that minimize the
projection error from 3D-2D point correspondences.
The rotation vector r represents the axis of rotation in
3D space, and its magnitude represents the angle of
rotation. To convert this rotation vector into a rota-
tion matrix R, we use the Rodrigues’ rotation formula
(Hartley and Zisserman, 2003). The Rodrigues’ rota-
tion formula converts a rotation vector into a rotation
matrix through the following steps:
• Compute the angle of rotation θ as the magnitude
of the rotation vector: θ = ∥r∥.
• Compute the unit vector k =
r
θ
• Construct the skew-symmetric cross-product ma-
trix K of k : K =
0 −k
z
k
y
k
z
0 −k
x
−k
y
k
x
0
• Compute the rotation matrix R as R = I +
sin(θ)K + (1 − cos(θ))K
2
with I the identity ma-
trix.
• Finally, compute the Euler angles from the rota-
tion matrix R. The Euler angles (roll, pitch, and
yaw) describe the orientation of an object in three-
dimensional space. These angles are extracted
from the rotation matrix using as follows:
– Roll α : α = atan(R
32
, R
33
)
– Pitch β : β = atan(−R
31
,
q
R
2
32
+ R
2
33
)
– Yaw γ : γ = atan(R
21
, R
11
)
– R =
R
11
R
12
R
13
R
21
R
22
R
23
R
31
R
32
R
33
being the rotation ma-
trix.
Once calculated, the transformation matrix is applied
to the helmet image. This distorts the original image
according to the set parameters, producing a version
of the headset aligned with the face in the image.
2.3 Immersion Protocol and Empathy
Analysis
For the study of reactions, we have chosen four short
2D videos from AVDOS-VR (Gnacek et al., 2024)
and two virtual reality videos from (Li et al., 2017).
The scenarios are as follows:
• Police Helicopter Captures Armed Confronta-
tion (vid
´
eo 13 of AVDOS): 2D video of 30
seconds showing a police drill where an officer
comes to the aid of a colleague who was shot
2.659 and 6.652 for valence and arousal respec-
tively.
• Sick Boy Crying During an Interview (vid
´
eo 19
of AVDOS): 2D video of 30 seconds showing an
excerpt from an interview with a child suffering
from a serious illness 2.434 and 5.623 for valence
and arousal respectively.
• Soldiers Marching and Singing a Pop Song
(vid
´
eo 56 of AVDOS): 2D video of 30 seconds
showing a group of soldiers parading by singing
the song ”Barbie Girl” 6.283 and 5.975 for va-
lence and arousal respectively.
• Toddler Laughing at Torn Paper Pages (vid
´
eo
51 of AVDOS): 2D video of 30 seconds show-
ing a young child laughs when an adult tears up
a piece of paper with 7.07 and 6.429 for valence
and arousal respectively.
• Survive a Bear Attack in VR: a 360
o
video of 90
seconds showing a bear approaching dangerously
to a group of 3 campers, who decide to run away
in their car after having distracted the bear with
a cookie with 5.22 and 5 for valence and arousal
respectively.
• Solitary Confinement: a 360
o
video of 221 sec-
onds that puts the viewer in the shoes of an inmate
in isolation, while listening to a testimony from
a former prisoner 2.38 and 4.25 for valence and
arousal respectively.
Moreover, in the experimental protocol, we have
developed a Graphical User Interface (GUI) to allow
visualization the videos while simultaneously captur-
ing the webcam video stream. We use the Toronto
questionnaire (Spreng et al., 2009) before the exper-
iment to assess the empathy of the participant, fol-
lowed by the SEQ questionnaire (Shen, 2010) after
the experience. In order to collect responses of the
questionnaires, we use Google Forms in which we
used the same questions as the questionnaires. We
Facial Empathy Analysis Through Deep Learning and Computer Vision Techniques in Mixed Reality Environments
35

also add for the questionnaire a precision about which
individual in the video to rely for the empathic re-
sponse. For example, in the ”Police helicopter cap-
tures armed confrontation” scenario, we ask the par-
ticipant to choose which actor in the video to relate
to (the first policeman, the second, or the confronting
actor). More specifically, we provide the participants
with the following information:
• For the Preliminary Phase, Follow the Follow-
ing Steps:
– Inform the participant that they will be view-
ing a series of videos, each followed by a ques-
tionnaire. Also mention that some videos may
contain graphic scenes (notably video 13).
– Provide participants with contentment forms to
be filled, signed and returned.
– Place the participant in front of a computer in a
quiet room with a neutral background.
– Ask the participant to complete the Toronto
Questionnaire.
– Explain the operation of the graphical interface
used to view videos.
• For each 2D Video, Repeat the Following
Steps:
– The experimental staff leaves the room.
– The participant starts the video using the GUI.
– At the end of the video, the experimental staff
returns to the room and asks the participant to
complete the State Empathy Questionnaire cor-
responding to the video.
• For each 3D (360
o
) Video, Repeat the Follow-
ing Steps:
– The experimentation staff prepares the headset
with the video ready to be launched.
– The experimental staff leaves the room.
– At the end of the video, the experimental staff
returns to the room and asks the participant to
complete the State Empathy Questionnaire cor-
responding to the video.
After the experiment, we annotate the captured
videos with the appropriate facial expression. We
mainly select a representative image of the expres-
sions and reactions of the person being filmed, and
annotate the emotion observed among the following
seven labels: anger, disgust, fear, happiness, sadness,
surprise and neutrality. Finally, we crop the image to
retain only the participant’s face.
3 EXPERIMENTS
3.1 Facial Expression Recognition
Experiments
Experiments for facial expression recognition are
conducted on the Facial Expression Recognition 2013
(FER2013) database (Goodfellow et al., 2013). The
database includes 35.887 grayscale images of faces
with dimensions of 48 × 48 pixels. The images are
labeled in seven categories of emotions: anger, dis-
gust, fear, happiness, sadness, surprise and neutral.
Although FER2013 is particularly useful for training
and validating facial recognition models due to its
large size and the diversity of emotions represented,
classes in the database are not balanced. Particularly
the class ‘disgust’ has more than 16 times fewer sam-
ples than the class ‘happiness’. Figure 2 highlights the
imbalance in the distribution of emotion classes. We
therefore applied data augmentation described previ-
ously in order to balance the classes. 10.000 im-
ages were obtained for each class. We summarize
in Table 1 the different settings along with the ob-
tained accuracy. For our ELU-DCNN, the Dropout
layer has a rate of 0.6 to avoid overfitting and the
Adam optimizer is used. We used early stop callbacks
(EarlyStopping) to monitor the accuracy validation
metric, with a criterion of patience of 11 epochs and
a restoration of the best weights. Finally, we used a
scheduler of reduction of the learning rate (ReduceL-
ROnPlateau) in order to reduce the learning rate by
half after 7 epochs without improvement. The model
was trained for 100 epochs with lots (batch) of 32.
Table 1: Results of facial expression recognition using our
approach on the FER2013 dataset.
Approach Details Accuracy
Basic approach batch size = 64 0.63
Early stopping with p=5
Imbalanced classes
Data augmentation 10.000 images par classes 0.69
Reduced batch size batch size = 32 0.78
Early stopping with p=11
Nadam optimizer
Parameter refinement Adam Optimizer 0.81
As can be seen from the table, we obtain an ac-
curacy of 81% on our test data sample. Figure 3 also
shows that the accuracy is increasing and that it even-
tually stabilizes around 80% after the 40
th
epoch. Fi-
nally Figure 4 shows the confusion matrix for the val-
idation set. As can be seen, the model predicts in a
similar manner the different classes of expressions.
Hence, our model predicts 74% anger, 97% disgust,
68% fear, 85% happiness, 72% sadness, 90% surprise
and 77% neutral.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
36
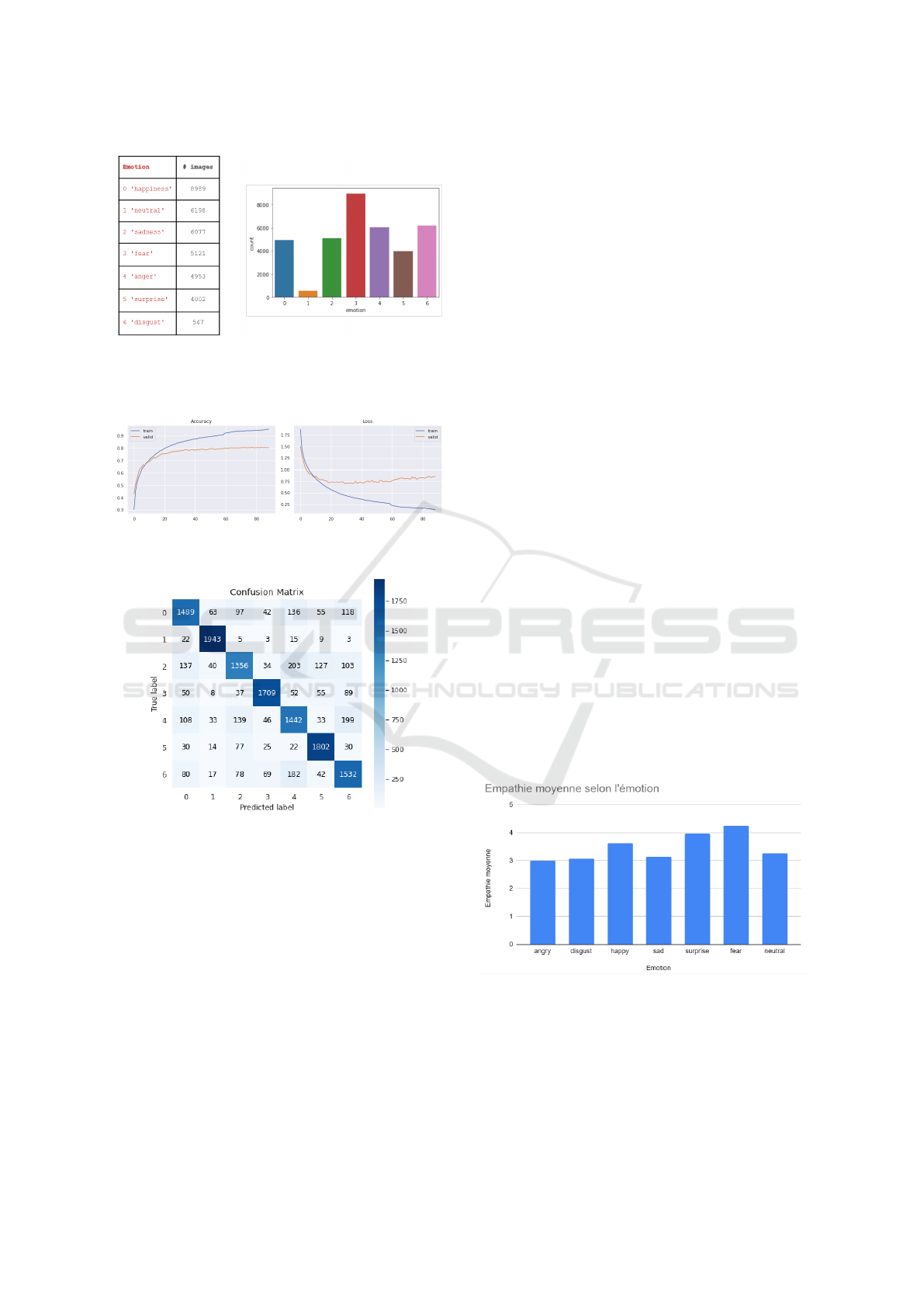
Figure 2: Distribution of Emotion Classes in the Dataset:
(left) Table of Emotion Names and Image Counts with
(right) Corresponding Histogram Illustrating Class Imbal-
ance.
Figure 3: Accuracy (left) and loss (right) with respect to
number of epochs (x-axis).
Figure 4: Confusion matrix for the validation set of
FER2013 dataset using our approach.
3.2 Empathy Analysis Experiments
In order to retrain our model on occluded faces and
hence simulate an environment where individuals are
immersed, we apply the augmented reality transfor-
mations on the FER dataset. This has the advantage
of training a facial expression classifier without the
need to re-annotate the data (as FER2013 is already
annotated with facial expression classes). However,
the accuracy drops to 67%. Some emotions without
the information from the top of the head struggle to be
recognized because of the lack of information. Some
emotions, such as anger, are strongly expressed in the
eye and eyebrow area, areas typically masked by a
VR headset. This occlusion can significantly reduce
the accuracy of emotional recognition.
We simultaneously performed the test protocol for
empathy analysis as described in Subsection . To
summarize, the protocol consists on:
• Ask participants to sign the consent form to use
their videos for this research.
• Ask participants to fill the Toronto form.
• Show scenarios (either 2D or 360
o
videos) to the
participants and capture their videos while they
watch the videos.
• After watching each scenario, ask participants to
fill the empathy SEQ quetionnaire that we repro-
duced in the google form.
•
By the end of the tests, We obtained a set of faces
of 8 individuals who participated in the experiments.
Each face was associated with emotions that we la-
belled manually and on which we were able to test
our different models of facial expression recognition.
Our classifier has achieved an accuracy of 20%. The
model correctly identified the expression of happi-
ness but failed to recognize the expression of surprise,
wrongly classifying it as anger. The main limitations
are glasses on the face, poor image quality and differ-
ent angles. Since the model did not perform to a high
extent on the captured videos, we analyzed empathy
based on the facial expressions that we manually an-
notated. We used the results of the questionnaires to
assess the level of empathy associated with different
emotions. As illustrated in Figure 5, different emo-
tions correspond to varying levels of empathic reso-
nance.
Figure 5: Confusion matrix for the validation set of
FER2013 dataset using our approch.
It is clear that fear and surprise have the high-
est empathy scores, while anger has the lowest score.
However, the differences in scores are not particularly
marked. This situation can be explained by several
factors. We depict some of them in the following:
Facial Empathy Analysis Through Deep Learning and Computer Vision Techniques in Mixed Reality Environments
37

• Participants’ Familiarity with the Videos:
Many participants had already participated in the
selection of the videos, their familiarity with
video content may lessen the intensity of their em-
pathic response, as they know what to expect and
are less surprised by the emotions depicted.
• Data Set Limitation: Our data set is still limited
in terms of diversity and quantity.
• Individual Variability: Empathic responses can
vary greatly from person to person based on indi-
vidual factors such as personal experiences, emo-
tional sensitivity, and innate empathic skills.
• Nature of Emotions: Some emotions can natu-
rally trigger stronger empathic reactions. For ex-
ample, fear and surprise are intense and often im-
mediate emotions, which may explain why they
score high. Other emotions, such as anger, can be
more complex and cause various reactions, some
people may feel empathy while others feel resis-
tance or rejection.
In order to overcome these limitations and achieve
more representative and generalizable results, we
can propose the following improvements. (i). In-
crease the scale of the experience: By expanding
the number of participants and diversifying demo-
graphic groups, we can get a better representation of
the empathic reactions. (ii). Diversification of emo-
tional stimuli: By using a greater variety of videos
and images to represent emotions, we can reduce the
familiarity effect and capture a wider range of reac-
tions. (iii). Improvement of Evaluation Condi-
tions: By standardizing the viewing conditions and
minimizing distractions, we can ensure that the reac-
tions of participants are as natural and authentic as
possible. (iv). Use of Advanced Empathy Measure-
ment Techniques: By integrating psychophysiologi-
cal measures such as eye movement tracking, By ana-
lyzing facial expressions in real time, and monitoring
physiological responses, we can obtain more accurate
and objective data on levels of empathy.
By implementing these strategies, we hope to gain
more accurate and reliable insights into the levels of
empathy associated with different emotions, and thus
improve our understanding of the mechanisms of em-
pathetic resonance.
4 CONCLUSION
In this work, we developed a comprehensive system
for facial empathy analysis using computer vision
and machine learning techniques. Our experimen-
tation setup included scenarios that evoke empathy,
capturing participants’ facial reactions through video
recordings, and subsequently measuring their empa-
thy levels using questionnaires. The findings from our
experiments indicate at some extent the correlation
between specific facial expressions and empathic re-
sponses. Overall, this work contributes to the field by
bridging the gap between facial expression analysis
and empathy detection, offering a novel approach that
can be applied in various domains, including psychol-
ogy, human-computer interaction, and virtual reality.
Future research could focus on refining the models
and algorithms for even greater accuracy and explor-
ing additional applications of this technology in real-
world scenarios.
REFERENCES
Baltrusaitis, T., Zadeh, A., Lim, Y. C., and Morency, L.-
P. (2018). Openface 2.0: Facial behavior analysis
toolkit. In 2018 13th IEEE International Confer-
ence on Automatic Face and Gesture Recognition (FG
2018), pages 59–66.
Bang, E. and Yildirim, C. (2018). Virtually empathetic?:
Examining the effects of virtual reality storytelling
on empathy. In Chen, J. Y. and Fragomeni, G., ed-
itors, Virtual, Augmented and Mixed Reality: Inter-
action, Navigation, Visualization, Embodiment, and
Simulation, pages 290–298, Cham. Springer Interna-
tional Publishing.
Bazarevsky, V., Kartynnik, Y., Vakunov, A., Raveendran,
K., and Grundmann, M. (2019). Blazeface: Sub-
millisecond neural face detection on mobile gpus.
Debnath, T., Reza, M., Rahman, A., Beheshti, A., Band, S.,
and Alinejad-Rokny, H. (2022). Four-layer convnet to
facial emotion recognition with minimal epochs and
the significance of data diversity. Scientific Reports,
12:1–18. Copyright the Crown 2022. Version archived
for private and non-commercial use with the permis-
sion of the author/s and according to publisher condi-
tions. For further rights please contact the publisher.
Demochkina, P. and Savchenko, A. V. (2021). Mobileemo-
tiface: Efficient facial image representations in video-
based emotion recognition on mobile devices. In Pat-
tern Recognition. ICPR International Workshops and
Challenges: Virtual Event, January 10–15, 2021, Pro-
ceedings, Part V, page 266–274, Berlin, Heidelberg.
Springer-Verlag.
Ezati, A., Dezyani, M., Rana, R., Rajabi, R., and Ayatol-
lahi, A. (2024). A lightweight attention-based deep
network via multi-scale feature fusion for multi-view
facial expression recognition. ArXiv, abs/2403.14318.
Gareth W. Young, N. O. and Smolic, A. (2022). Exploring
virtual reality for quality immersive empathy building
experiences. Behaviour and Information Technology,
41(16):3415–3431.
Gnacek, M., Quintero, L., Mavridou, I., Balaguer-Ballester,
E., Kostoulas, T., Nduka, C., and Seiss, E. (2024).
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
38

AVDOS-VR: Affective Video Database with Physio-
logical Signals and Continuous Ratings Collected Re-
motely in VR. Scientific Data, 11(1).
Goodfellow, I. J., Erhan, D., Carrier, P. L., Courville, A.,
Mirza, M., Hamner, B., Cukierski, W., Tang, Y.,
Thaler, D., Lee, D.-H., Zhou, Y., Ramaiah, C., Feng,
F., Li, R., Wang, X., Athanasakis, D., Shawe-Taylor,
J., Milakov, M., Park, J., Ionescu, R., Popescu, M.,
Grozea, C., Bergstra, J., Xie, J., Romaszko, L., Xu,
B., Chuang, Z., and Bengio, Y. (2013). Challenges
in representation learning: A report on three machine
learning contests. In Lee, M., Hirose, A., Hou, Z.-
G., and Kil, R. M., editors, Neural Information Pro-
cessing, pages 117–124, Berlin, Heidelberg. Springer
Berlin Heidelberg.
Hartley, R. and Zisserman, A. (2003). Multiple View Geom-
etry in Computer Vision. Cambridge University Press,
New York, NY, USA, 2 edition.
Hasan, M. R., Hossain, M. Z., Ghosh, S., Krishna, A., and
Gedeon, T. (2024). Empathy detection from text, au-
diovisual, audio or physiological signals: Task formu-
lations and machine learning methods.
Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D.,
Wang, W., Weyand, T., Andreetto, M., and Adam,
H. (2017). Mobilenets: Efficient convolutional neu-
ral networks for mobile vision applications.
Huc, M., Bush, K., Atias, G., Berrigan, L., Cox, S., and
Jaworska, N. (2023). Recognition of masked and un-
masked facial expressions in males and females and
relations with mental wellness. Frontiers in Psychol-
ogy, 14.
Kas, M., merabet, Y. E., Ruichek, Y., and Messoussi, R.
(2021). New framework for person-independent facial
expression recognition combining textural and shape
analysis through new feature extraction approach. In-
formation Sciences, 549:200–220.
Li, B. J., Bailenson, J. N., Pines, A., Greenleaf, W. J., and
Williams, L. M. (2017). A public database of immer-
sive vr videos with corresponding ratings of arousal,
valence, and correlations between head movements
and self report measures. Frontiers in Psychology, 8.
Li, S. and Deng, W. (2022). Deep facial expression recogni-
tion: A survey. IEEE Transactions on Affective Com-
puting, 13(3):1195–1215.
Ma, H., Lei, S., Celik, T., and Li, H.-C. (2024). Fer-yolo-
mamba: Facial expression detection and classification
based on selective state space.
Martin, O., Kotsia, I., Macq, B., and Pitas, I. (2006). The
enterface’ 05 audio-visual emotion database. In 22nd
International Conference on Data Engineering Work-
shops (ICDEW’06), pages 8–8.
Mathur, L., Spitale, M., Xi, H., Li, J., and Matari
´
c, M. J.
(2021). Modeling user empathy elicited by a robot sto-
ryteller. In 2021 9th International Conference on Af-
fective Computing and Intelligent Interaction (ACII),
pages 1–8.
Minaee, S., Minaei, M., and Abdolrashidi, A. (2021). Deep-
emotion: Facial expression recognition using atten-
tional convolutional network. Sensors, 21(9).
Mohamed, B., Daoud, M., Mohamed, B., and taleb ahmed,
A. (2022). Improvement of emotion recognition from
facial images using deep learning and early stopping
cross validation. Multimedia Tools and Applications,
81.
Poux, D., Allaert, B., Mennesson, J., Ihaddadene, N., Bi-
lasco, I. M., and Djeraba, C. (2020). Facial expres-
sions analysis under occlusions based on specificities
of facial motion propagation. Multimedia Tools and
Applications, 80(15):22405–22427.
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., and
Chen, L.-C. (2019). Mobilenetv2: Inverted residuals
and linear bottlenecks.
Shen, L. (2010). On a scale of state empathy during mes-
sage processing. Western Journal of Communication,
74:504–524.
Shin, D. (2018). Empathy and embodied experience in vir-
tual environment: To what extent can virtual reality
stimulate empathy and embodied experience? Com-
puters in Human Behavior, 78:64–73.
Simonyan, K. and Zisserman, A. (2014). Very deep con-
volutional networks for large-scale image recognition.
CoRR, abs/1409.1556.
Somarathna, R., Bednarz, T., and Mohammadi, G. (2023).
Virtual reality for emotion elicitation – a review. IEEE
Transactions on Affective Computing, 14(4):2626–
2645.
Spreng, R. N., Mckinnon, M., Mar, R., and Levine, B.
(2009). The toronto empathy questionnaire: Scale de-
velopment and initial validation of a factor-analytic
solution to multiple empathy measures. Journal of
personality assessment, 91:62–71.
Sun, L., Lian, Z., Wang, K., He, Y., Xu, M., Sun, H., Liu,
B., and Tao, J. (2023). Svfap: Self-supervised video
facial affect perceiver.
Ventura, S. and Martingano, A. J. (2023). Roundtable:
Raising empathy through virtual reality. In Ventura,
S., editor, Empathy, chapter 3. IntechOpen, Rijeka.
Wegrzyn, M., Vogt, M., Kireclioglu, B., Schneider, J., and
Kissler, J. (2017). Mapping the emotional face. how
individual face parts contribute to successful emotion
recognition. PLOS ONE, 12.
Wingenbach, T. S. H. (2023). Facial EMG – Investigating
the Interplay of Facial Muscles and Emotions, pages
283–300. Springer International Publishing, Cham.
Xue, T., Ali, A. E., Zhang, T., Ding, G., and Cesar, P.
(2023). Ceap-360vr: A continuous physiological and
behavioral emotion annotation dataset for 360
◦
vr
videos. IEEE Transactions on Multimedia, 25:243–
255.
Yao, L., Wan, Y., Ni, H., and Xu, B. (2021). Action unit
classification for facial expression recognition using
active learning and svm. Multimedia Tools and Appli-
cations, 80.
Zhu, Q. and Luo, J. (2023). Toward artificial empathy for
human-centered design: A framework.
Facial Empathy Analysis Through Deep Learning and Computer Vision Techniques in Mixed Reality Environments
39
