
A Hybrid Approach for Detecting SQL-Injection Using Machine
Learning Techniques
Hari Krishna
1
, Jared Oluoch
1 a
and Junghwan Kim
2
1
Department of Electrical Engineering & Computer Science, University of Toledo,
2801 W. Bancroft Street, Toledo OH, U.S.A.
2
Department of Engineering Technology, University of Toledo, 2801 W. Bancroft Street, Toledo OH, U.S.A.
Keywords:
SQL Injection Detection, Machine Learning, Naive Bayes Algorithm, Long Short-term Memory, Random
Forest classifier, Cybersecurity, Algorithm Integration.
Abstract:
SQL injection is a common web hacking technique that allows hackers to gain unauthorized access to a
database. These database breaches may have far-reaching financial consequences to individuals, organiza-
tions, and the society. This paper introduces an innovative approach that combines Naive Bayes, Long Short-
Term Memory (LSTM), and Random Forest to enhance the detection and mitigation of SQL injections. By
extracting and analyzing data through the sequential application of Naive Bayes and LSTM algorithms, the
proposed methodology uniquely synthesizes their outputs to inform a Random Forest classifier, aiming to
optimize accuracy in identifying potential threats. The efficacy of this approach is validated through compre-
hensive testing, yielding a significant improvement in detection accuracy compared to conventional methods.
Findings demonstrate the potential of integrating diverse machine learning techniques for cybersecurity ap-
plications and pave the way for future advancements in the automated detection of SQL injection and other
similar cyber threats. The implications of this research extend to developing more secure web environments,
ultimately contributing to the broader field of information security.
1 INTRODUCTION
Web applications have become part of nearly every
aspect of modern life, ranging from business opera-
tions to personal data management. This prolifera-
tion of web-based applications comes with the need
for enhanced security to protect the confidentiality, in-
tegrity, and availability of data. One of the most com-
mon security threats for web applications is Struc-
tured Query Language Injection (SQLi). These SQLi
threats stand out due to their frequency, simplicity
of execution, and potential for severe impact. More
often, they lead to unauthorized access to and/or de-
struction of data.
SQLi attacks exploit vulnerabilities in web appli-
cations that use SQL databases, allowing attackers to
execute malicious SQL code through improperly san-
itized input fields. Traditional defenses mechanisms
against such attacks involve signature-based detection
systems and manual coding practices. However, at-
tackers continuously evolve strategies to bypass these
measures, leaving systems vulnerable to exploitation.
a
https://orcid.org/0000-0002-9840-8180
Machine learning (ML) has emerged as a power-
ful tool in cybersecurity, offering the ability to learn
from and adapt to new data patterns and anomalies.
Leveraging ML for the detection and prevention of
SQLi presents a promising solution to the problem of
constantly evolving attack vectors. By analyzing pat-
terns within requests, ML-based systems can identify
malicious behavior that deviates from the norm, in-
cluding sophisticated attacks that would go unnoticed
by traditional defenses.
This manuscript explores the efficacy of ML tech-
niques in detecting SQLi attacks. It begins by exam-
ining the nature of SQLi attacks and existing detection
methods. It then proposes a framework that employs
a range of feature extraction methods and ML clas-
sifiers to differentiate between benign and malicious
SQL queries. This paper’s methodology focuses on
detection accuracy and the system’s ability to gener-
alize, thus maintaining high performance in the face
of new, previously unseen attack patterns. The paper
hypothesizes that an ML-based approach can outper-
form traditional SQLi detection methods and provide
enhanced security for web applications. To test this
Krishna, H., Oluoch, J. and Kim, J.
A Hybrid Approach for Detecting SQL-Injection Using Machine Learning Techniques.
DOI: 10.5220/0013078100003899
In Proceedings of the 11th International Conference on Information Systems Security and Privacy (ICISSP 2025) - Volume 2, pages 15-23
ISBN: 978-989-758-735-1; ISSN: 2184-4356
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
15

hypothesis, we implemented a series of experiments
using various ML algorithms, creating a benchmark
with a vast dataset(SHAH, ) of almost 30,000 mali-
cious and benign SQL queries. We rigorously evalu-
ated the performance of the proposed method to check
for its reliability and validity.
The novelty of our work is its combination of
Naive Bayes, Long Short-Term Memory (LSTM),
and Random Forest algorithms to detect SQLi.
Specifically, it leverages the strengths of each algo-
rithm - Naive Bayes for its efficiency and ability to
handle large datasets, LSTM for its prowess in pro-
cessing sequential data, and Random Forest for its ac-
curacy in classification tasks. This proposed hybrid
model significantly enhances detection accuracy. The
proposed approach not only contributes to the theoret-
ical understanding of ML applications in cybersecu-
rity, but also provides a practical framework for devel-
oping more resilient web applications against SQLi
attacks.
1.1 Motivation and Problem Definition
Developing machine learning-based defenses against
SQLi attacks is important. Traditional security mech-
anisms are proving insufficient against the sophisti-
cation and evolving nature of SQLi, which remains a
top threat in the Open Worldwide Application Secu-
rity Project (OWASP) top 10 list for web application
security risks(OWASP, ). The potential damage from
these attacks is substantial, including data breaches,
loss of customer trust, financial liabilities, and, in ex-
treme cases, complete operational shutdown. Figure1
shows an SQLi workflow.
1.1.1 SQLi Attacks Overview
SQLi is a code injection technique that exploits a se-
curity vulnerability in an application’s database layer.
The vulnerability occurs when user inputs are either
incorrectly filtered for string literal escape charac-
ters embedded in SQL statements or are not strongly
typed and thereby unexpectedly executed. This can
allow attackers to execute arbitrary SQL code on the
database, leading to unauthorized access or manipu-
lation of data. The basic concept of SQL injection
revolves around the attacker’s ability to insert or “in-
ject” a malicious SQL query via the input data from
the client to the application. A successful injection
can lead to data leakage, deletion, or modification,
among other impacts. Below is a simple example to
illustrate how an SQL injection can occur: Suppose
a web application uses the following SQL query to
authenticate users:
SELECT ∗ FROM usersWHEREusername =
′
$username
′
AND password =
′
$password
′
;
(1)
In this scenario 1, $username and $password are
placeholders for user inputs. An attacker can inject
SQL code if the application does not properly sanitize
the user input.
Ex: 1- Username: admin’ – Password: [left blank]
Resulting SQL Query:
SELECT ∗ FROM usersWHEREusername
=
′
admin
′
− −
′
AND password =
′ ′
;
(2)
The attacker inputs admin’ – in the username field.
The apostrophe (’) ends the username string, and the
double hyphen (–) comments out the rest of the SQL
statement 2. This manipulation effectively removes
the password check from the SQL query because ev-
erything after the – is considered a comment. If the
admin username exists, the database processes the
query as a legitimate request for the user named “ad-
min” without verifying the password. Ex: 2- User-
name: ‘OR ‘1’=’1 Password: [not required for this
injection] Resulting SQL Query:
SELECT ∗ FROM usersWHERE
username =
′ ′
OR
′
1
′
=
′
1
′
;
(3)
The attacker’s input ends the username crite-
rion and adds a new condition that always evalu-
ates to true (‘1’=‘1’) 3. Because the OR operator
is used, the query will return true for every row, ef-
fectively bypassing any need for specific user creden-
tials(Sadeghian et al., 2013).
Furthermore, the automation of attacks and the
emergence of SQLi-as-a-Service offerings on the dark
web have made these types of attacks accessible
to non-skilled individuals, exacerbating the problem.
Therefore, enhancing SQLi detection has technical
significance and a broad socio-economic impact. Au-
tomating machine learning into SQLi detection is mo-
tivated by the need for a dynamic, robust, scalable so-
lution that can adapt over time and detect even the
most cunning attacks. The core problem addressed in
this research is detecting SQLi attacks in web applica-
tions with greater accuracy and efficiency than current
methods. Traditional pattern-matching and signature-
based systems are limited by the need for constant
updates and their inability to detect novel or obfus-
cated attacks. Moreover, they often suffer from high
false-positive rates, causing unnecessary disruption to
legitimate users and consuming valuable human and
computational resources.
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
16
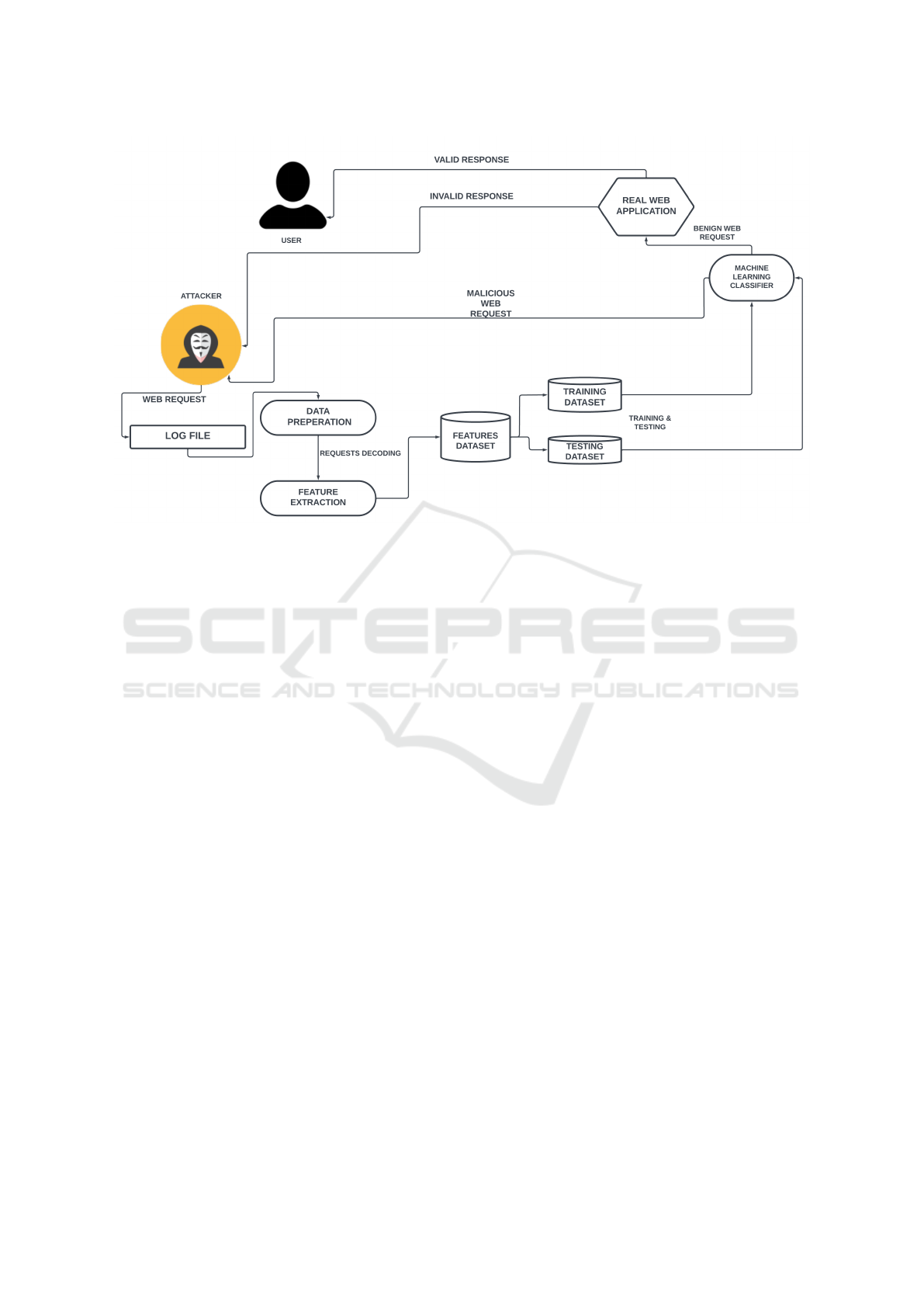
Figure 1: SQLi Workflow.
1.1.2 Research Questions
This paper addresses the following research ques-
tions.
• How can machine learning algorithms be effec-
tively trained to distinguish between benign and
malicious SQL queries with high accuracy?
• What feature extraction techniques can best cap-
ture the characteristics of SQLi to facilitate this
classification?
• Can a machine learning-based system generalize
from known attacks to detect zero-day SQLi at-
tacks?
• How can such a system be designed to minimize
false positives while maintaining an optimal de-
tection rate?
This research seeks to define a machine learning-
based approach that can autonomously adapt to the
evolving landscape of SQLi threats without frequent
rule updates or manual intervention. It uses ML’s pat-
tern recognition and generalization capabilities to cre-
ate a more resilient web application infrastructure.
The rest of this paper is organized as follows. Sec-
tion 2 discusses literature that closely relates to our
work. Section 3 presents the system design. Section 4
outlines the performance metrics. Section 5 discusses
results of our work. Finally, we conclude our work in
Section 6.
2 RELATED WORK
SQLi attacks pose a persistent threat to the security of
web applications, necessitating ongoing research into
effective detection and mitigation strategies. Over the
years, various approaches have been explored, rang-
ing from traditional signature-based detection to more
recent machine learning (ML) techniques. In Na-
tional Language Processing (NLP), various feature
engineering methods exist, yet for detecting SQLi at-
tacks, Word Level term frequency-inverse document
frequency (TF-IDF) vectors stand out as particularly
effective. TF-IDF plays a crucial role in search and
relevance determination of specific words within a
document. Term Frequency measures the frequency
of a word’s appearance in a single document, whereas
Document Frequency assesses the prevalence of a
word across a collection of documents(Oudah et al.,
2022). The primary benefit of using TF-IDF is its
assumption that documents are merely collections
of individual words without any interrelation. This
simplicity yet effectiveness is especially suitable for
our scenario because SQL lacks the grammatical and
tense structures found in natural languages(Krishnan
et al., 2021).
In their work (Alghawazi et al., 2022) conducted
a systematic review, emphasizing the role of machine
learning and deep learning models in detecting SQL
injection attacks. Their paper highlights the promis-
ing results AI and ML techniques have shown in con-
trolling SQLi, underscoring the intersection between
A Hybrid Approach for Detecting SQL-Injection Using Machine Learning Techniques
17

artificial intelligence fields and cybersecurity mea-
sures against SQLi attacks (Alghawazi et al., 2022).
SQL injection attacks fall into seven distinct cat-
egories: tautologies, illegal or logically incorrect
queries, piggy-backed queries, stored queries, infer-
ence, and alternate encodings. In such attacks, a
harmful script is inserted into a web application with
weak security through an entry point, which is then
relayed to the database at the back end (Farooq,
2021).
Attackers target vulnerabilities in management
APIs, which, if exploited, can lead to successful at-
tacks and compromise an organization’s assets. Sub-
sequently, attackers may use the compromised cloud
to launch additional attacks on other cloud users. Ex-
ploiting vulnerabilities in the systems, software, or
applications that facilitate multi-tenancy in cloud in-
frastructure can disrupt the separation between ten-
ants. This disruption allows an attacker to access one
organization’s resources and potentially reach another
user’s or organization’s data. The nature of multi-
tenancy expands the potential attack surface, raising
the likelihood of data leakage if separation controls
are inadequate(Tripathy et al., 2020).
Most existing countermeasures against SQL injec-
tion rely on syntax-based detection methods or a set
of pre-defined rules to identify such attacks. While
these solutions may be effective against basic forms
of SQLi, they are less effective against more advanced
and sophisticated attacks. This vulnerability arises
because attackers can devise new strategies to bypass
detection, leveraging their understanding of how con-
ventional detection mechanisms, which primarily fo-
cus on analyzing SQL syntax, operate(Abdulmalik,
2021).
A lot of research has been done on Semantic
Learning-Based Detection Model. A study intro-
duced synBERT, a semantic learning-based model for
SQLi attack detection. This model embeds sentence-
level semantic information from SQL statements into
embedding vectors, which can be mapped to SQL
syntax tree structures(Lu et al., 2023a). The research
showcased synBERT’s capability to outperform pre-
vious models, demonstrating over 90% accuracy in
detecting SQLi on a wide range of datasets(Lu et al.,
2023b).
The application of deep learning technologies has
been explored to address the challenges traditional
SQLi detection methods face. One framework in-
volves offline training and online testing stages, pro-
cessing samples through encoding, generalization,
and tokenization before training a classifier that can
efficiently identify SQLi attacks(Sun et al., 2023).
Other research work has been done in Probabilis-
tic Neural Networks (PNN) in SQLi Detection. For
instance, Fawaz Khaled Alarfaj and Nayeem Ahmad
Khan proposed using a PNN optimized by the BAT
algorithm for detecting SQLi attacks. By extracting
features from SQL queries and employing Chi-Square
testing for feature selection (Alarfaj and Khan, 2023),
their PNN model achieved an accuracy of 99.19%,
demonstrating the effectiveness of deep learning and
optimization algorithms in SQLi detection.
A deep neural network-based model, SQLNN, has
been designed to detect SQL injection statements ef-
fectively. This model utilizes TF-IDF for data pro-
cessing, highlighting the importance of filtering out
common words to focus on significant terms for SQLi
detection(Zhang et al., 2022).
Building on these insights, our work introduces a
hybrid approach that combines the strengths of Naive
Bayes, LSTM, and Random Forest algorithms. This
combination seeks to address the individual limita-
tions of each method—leveraging Naive Bayes for
its efficiency with large datasets, LSTM for its deep
learning capabilities in recognizing complex patterns,
and Random Forest for its robustness and accuracy in
classification tasks. To the best of our knowledge,this
is the first study to explore such an integrated ap-
proach for SQLi detection, promising enhanced ac-
curacy and greater adaptability to the evolving land-
scape of SQLi threats.
3 SYSTEM DESIGN
Various datasets are used to train an algorithm for de-
tecting SQLi attacks. These datasets typically consist
of a mix of normal and malicious SQL queries, al-
lowing the algorithm to learn patterns associated with
SQL injection attacks.
1. Annotated Data: The queries are usually labeled
as normal or malicious. This annotation is crucial
for supervised learning methods, where the model
learns from labeled examples.
2. Diversity of SQL Queries: The dataset includes
a wide range of SQL queries, both legitimate and
malicious. This variety helps the model to differ-
entiate between normal operations and SQLi at-
tacks.
3. Malicious SQL Samples: These include typi-
cal SQL injection patterns like tautologies, il-
legal/logically incorrect queries, union queries,
piggy-backed queries, and stored procedures ex-
ploitation.
4. Normal SQL Samples: These are regular, non-
malicious SQL queries that an application would
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
18

typically process. Including these helps to reduce
false positives, where legitimate queries are incor-
rectly flagged as SQLi.
5. Parameterized Data: Datasets often include
queries with various parameters and structures to
mimic real-world scenarios where inputs vary sig-
nificantly.
These datasets are vital for machine learning models
to effectively learn and distinguish between normal
behavior and potential security threats from SQLi at-
tacks. They are usually sourced from public repos-
itories or cybersecurity organizations or generated
through controlled penetration testing on the web.
This study proposes a novel methodology for de-
tecting SQLi attacks by harnessing the strengths of
Naive Bayes, Long Short-Term Memory (LSTM) net-
works, and Random Forest classifiers. Our approach
is designed to optimize detection accuracy while mit-
igating common limitations associated with each al-
gorithm when used in isolation. Below, we detail the
dataset preparation, feature selection, individual al-
gorithm implementation, and the integration strategy
that forms the core of our detection framework. Al-
gorithm 1 present the algorithm for our framework.
Data Preparation df ← load csv“dataset”)
queries ← df“query”] labels ← df“label”]
TF-IDF Vectorization vectorizer ←
create tfidf vectorizer() X tfidf ←
vectorizer.fit transform(queries)
while there are more training data do
Train Naive Bayes nb model ←
create multinomial nb()
nb model.fit(X tfidf, labels)
Train LSTM lstm model ←
create lstm model(tokenizer,
max sequence length)
lstm model.fit(X train lstm, y train lstm)
Combine Naive Bayes and LSTM
Features combined features train ←
concatenate(nb probs train,
lstm features train)
Train Random Forest on Combined
Features rf model ←
create random forest()
rf model.fit(combined features train,
labels)
Evaluate Random Forest predictions rf ←
rf model.predict(combined features test)
accuracy ← calculate accuracy(y test nb,
predictions rf)
end
Algorithm 1: Proposed Model Algorithm.
3.1 Dataset Preparation and
Pre-Processing
Our methodology consists of a comprehensive
dataset derived from (SHAH, ), with legitimate and
malicious SQL query samples. We pre-process this
data to ensure it is suitable for machine learning
analysis. The dataset is then divided into training and
testing sets, with 70% allocated for training and 30%
reserved for validation purposes. The process begins
with transforming the text data (SQL queries) into a
numerical format that machine learning algorithms
can process. This is done using the TF-IDF vectorizer.
• Term Frequency(TF) measures how frequently
a term occurs in a document. Since every doc-
ument is different in length, it is possible that a
term would appear many more times in long doc-
uments than in shorter ones. Thus, the term fre-
quency is often divided by the document length
(the total number of terms in the document) as a
way of normalization:
TF(t) =
Number of times term t appears in a document
Total number of terms in the document
(4)
• Inverse Document Frequency (IDF) measures
how important a term is. While computing TF,
all terms are considered equally important. How-
ever, certain terms, such as “is,” “of,” and “that,”
may appear many times but have little importance.
Thus, we need to weigh down the frequent terms
while scaling up the rare ones by computing:
IDF(t) =
Total number of documents
Number of documents with term t in it
(5)
each word or term is then represented by TF-IDF
score, which is the multiplication of TF and IDF. Fig-
ure 2 shows the workflow of the model.
3.2 Feature Selection and Extraction
Given the diverse nature of SQLi attacks, selecting
relevant features is crucial for effective detection. We
employ selection techniques, such as TF-IDF and
word embeddings, to extract features that capture syn-
tactical and semantic nuances of SQL queries. This
process enhances our models’ learning efficiency and
reduces false positive rates.
Figure 2 represents the overall workflow of our ap-
proach, showcasing each step from initial data collec-
tion to the final analysis.
A Hybrid Approach for Detecting SQL-Injection Using Machine Learning Techniques
19
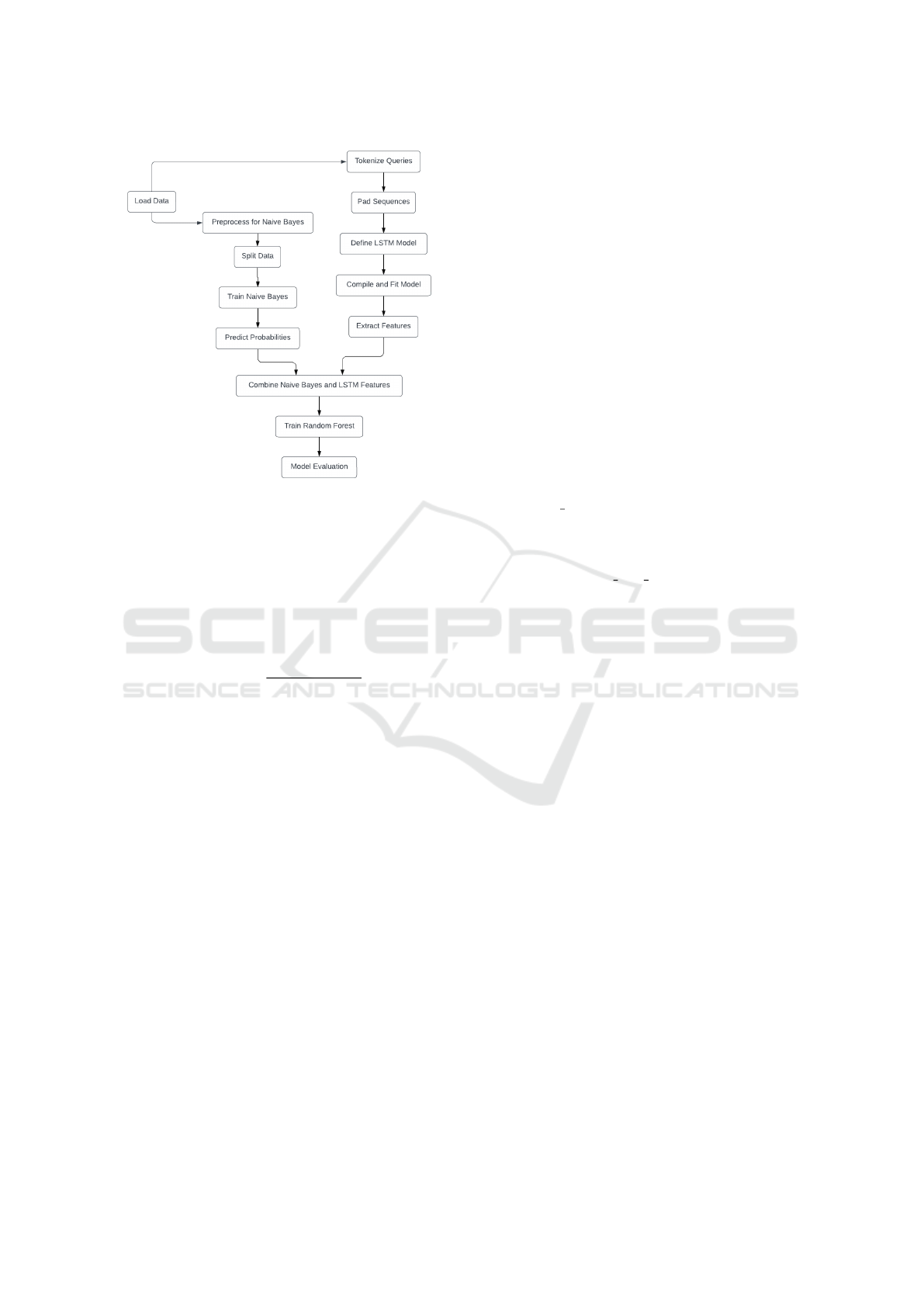
Figure 2: WorkFlow.
3.3 Model Training and Feature
Integration
Naive Bayes Model. The MultinomialNB classifier
was trained on the TF-IDF-transformed dataset 45.
The classifier calculates the probability of each class
given a set of inputs:
P(y | X ) =
P(X | y) × P(y)
P(X)
(6)
where:
y is the class variable,
X represents features,
P(y | X) is the posterior probability,
P(X | y) is the likelihood,
P(y) is the class prior probability, and
P(X) is the predictor prior probability.
These probabilities represent how likely each
query is thought to be malicious or regular, based
on the frequency and distribution of words within
the text, adjusted by the overall importance of these
words in the dataset. The output probabilities, P
NB
,
served as one component of the feature set for the in-
tegrated model.
LSTM Model. The LSTM (Long Short-term Mem-
ory model is a type of recurrent neural network(RNN)
that is particularly designed for learning from se-
quences, such as time-series data or text. In our study,
a bidirectional LSTM architecture is utilized. A bidi-
rectional LSTM processes data in both forward and
reverse directions, effectively increasing the informa-
tion available to the network and improving the con-
text for each point in the sequence.
The model is enhanced with dropout and L2 regu-
larization—methods used to prevent overfitting when
a model learns the training data too well, including
the noise, and performs poorly on new data. Dropout
works by randomly setting a fraction of the output
units of the layer to 0 at each update during training
time, which helps to prevent overfitting by making the
network’s cells less sensitive to the weights of other
cells. L2 regularization, also known as weight decay,
adds a penalty term to the loss function proportional
to the sum of the squares of the weights, which en-
courages the model weights to be small and, in turn,
simplifies the model.
Regularization Loss = λ
n
∑
i=1
w
2
i
(7)
where λ is the regularization factor (0.001 here) and
w
i
are the weights of the kernel in the LSTM layer.
EarlyStopping is configured to monitor the valida-
tion loss (val loss) in this setup. The patience param-
eter is set to 5, which means training will continue
until the validation loss fails to improve for five con-
secutive epochs. When this condition is met, training
stops, and to restore best weights=True, the model
weights are rolled back to the point where the vali-
dation loss was at its minimum.
The bidirectional LSTM model is trained on the
dataset to recognize patterns indicative of SQL injec-
tion. As it processes the input sequences (i.e., the tok-
enized SQL queries), it builds up a state that captures
information about the sequences seen so far. After
training, the model can extract feature representations
from sequences, essentially high-level data abstrac-
tions.
The features are extracted from the final dense
layer of the LSTM model. In neural networks, the
penultimate layer is just before the final output layer.
This layer captures the input data’s most informative
and discriminative representations, which are crucial
for the subsequent classification task.
Random Forest Classifier. The Random Forest
model integrated the Naive Bayes probabilities and
LSTM-derived features, creating a combined feature
set, F
combined
= [P
NB
⊕ F
LSTM
], where ⊕ denotes con-
catenation. When constructing each decision tree
within the Random Forest, the algorithm iteratively
chooses the best feature to split the data at each node.
The “best” feature is determined based on which fea-
ture split maximizes the Information Gain. The algo-
rithm compares the Information Gain of splits using
different features and chooses the feature that pro-
vides the highest gain. This process is repeated for
each node in each tree until a stopping criterion is met
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
20

(e.g., maximum tree depth, minimum node size).
IG(D
p
, f ) = I(D
p
) −
N
le f t
N
I(D
le f t
) +
N
right
N
I(D
right
)
(8)
where:
IG is information gain
I is the impurity measure,
D p, D left, D right are the datasets of the parent and
two child nodes,
N is the total number of samples,
N left and N right are the number of samples in the
left
and right child nodes,
f is the feature to split on.
In Random Forest, not all features are considered for
splitting at each node. Instead, a random subset of
features is selected. This adds diversity to the model,
crucial for improving generalization over fitting in-
dividual decision trees. The ensemble’s final predic-
tion is typically more robust and less prone to overfit-
ting than a single decision tree. Each tree votes for a
class, and the class with the most votes becomes the
model’s prediction. The final prediction is based on
the combined features by constructing multiple deci-
sion trees during training and outputs the class, which
is the mode of the classes (classification) of the indi-
vidual trees.
This ensemble approach leverages the predictive
capabilities of both algorithms, aiming to harness
their complementary strengths for enhanced detection
accuracy.
4 PERFORMANCE METRICS
The performance of the integrated model was evalu-
ated using accuracy, precision, recall, and F-1 score
to provide a comprehensive view of its effectiveness.
Accuracy is defined as the proportion of true re-
sults (both true positives and true negatives) among
the total number of cases examined. Formally, it is
represented as:
Accuracy =
T P + T N
T P + T N + FP + FN
(9)
Where T P, T N, FP, and FN represent the true pos-
itives, true negatives, false positives, and false nega-
tives, respectively.
Precision is the ratio of correctly predicted posi-
tive observations to the total predicted positives. It is
also known as the Positive Predictive Value.
Precision =
True Positives (TP)
True Positives (TP)+False Positives (FP)
(10)
Recall, also known as Sensitivity or True Positive
Rate, is the ratio of correctly predicted positive obser-
vations to all observations in an actual class.
Recall =
True Positives (TP)
True Positives (TP) + False Negatives (FN)
(11)
The F1 Score is the weighted average of Precision
and Recall. Therefore, this score takes both false pos-
itives and false negatives into account.
F1-Score = 2 ·
Precision × Recall
Precision + Recall
(12)
5 RESULTS
The evaluation of our integrated model for SQL injec-
tion detection, combining Naive Bayes, LSTM, and
Random Forest algorithms, demonstrates a signifi-
cant advancement in detection accuracy. As shown
in Table 1, our combined approach achieved bet-
ter results compared to existing work. The LSTM
model, tailored for sequence processing and aug-
mented with bidirectional layers and regularization
techniques, reached a training accuracy of 99.83%
and a validation accuracy of 99.07% by the final
epoch. This high accuracy on the validation set un-
derscores the model’s ability to generalize well to un-
seen data, a critical aspect of effective SQL injection
detection.
Upon integrating the outputs from the Naive
Bayes and LSTM models with the Random For-
est classifier, our system attained a final detection
accuracy of 99.89% on the test set. This perfor-
mance marks a substantial improvement over our
initial benchmarks, where accuracy hovered around
96%. The accuracy progression indicates the syn-
ergistic effect of combining these diverse machine-
learning strategies.
The enhancement in detection accuracy from ap-
proximately 96% to 99.89% underscores our hybrid
approach’s effectiveness. By leveraging the proba-
bilistic outputs of Naive Bayes, the sequential data
processing capability of LSTM, and the ensemble
decision-making power of Random Forest, our model
effectively captures the complex patterns and anoma-
lies characteristic of SQL injection attacks. This im-
provement validates the potential of integrating mul-
tiple machine learning paradigms and highlights the
adaptability and robustness of our detection system
against a wide array of attack vectors. These results
underscores the potential of our hybrid approach to
adapt and respond to the evolving dynamics of SQL
injection threats, outperforming models reliant on sin-
gular methodologies.
A Hybrid Approach for Detecting SQL-Injection Using Machine Learning Techniques
21

Table 1: Performance metrics of the methods on the individual test runs.
Method Accuracy Precision Recall F1 TP TN FP FN
Na
¨
ıve Bayes 0.8619 0.9028 0.8122 0.892 1950 2054 210 432
SVM 0.9723 0.96218 0.9951 0.9807 1956 2088 40 75
LSTM 0.9925 0.991 0.9878 0.9865 2045 2548 15 19
Random Forest 0.9723 0.9621 0.9527 0.9807 2156 3545 55 107
Paper(Tasdemir et al., 2023) 0.9986 0.9996 0.9966 0.9981 2259 3854 1 8
Paper(Lu et al., 2023a) 0.9974 0.9968 0.9952 0.9960
Combined Approach 0.9987 0.9991 0.9973 0.9981 2241 3896 2 6
5.1 Discussion
The integrated model’s high accuracy rate highlights
the efficacy of combining probabilistic, sequential,
and ensemble learning techniques in detecting SQLi
attacks. By leveraging the distinct advantages of
Naive Bayes, LSTM, and Random Forest classifiers,
our approach addresses the limitations inherent in us-
ing these algorithms in isolation. Furthermore, the
evaluation underscores the importance of feature ex-
traction and selection in enhancing the model’s detec-
tion capabilities, as evidenced by the significant role
played by TF-IDF vectorization and LSTM-derived
features.
6 CONCLUSION AND FUTURE
WORK
The study of machine learning algorithms in the con-
text of SQLi detection has yielded promising results.
Decision Trees and SVMs offer decent accuracy and
balance between precision and recall, making them
suitable for scenarios where computational efficiency
is crucial. In contrast, Random Forests and Neural
Networks demonstrate superior performance in ac-
curacy and F1-score, indicating their effectiveness
in complex SQLi detection scenarios. These results
highlight the potential of machine learning in enhanc-
ing cybersecurity measures against SQLi attacks.
However, the performance of these algorithms can
be influenced by factors such as the dataset’s quality,
feature selection, and algorithm configuration. Con-
sidering that the dynamic and evolving nature of cy-
ber threats like SQLi requires continuous adaptation,
and the improvement of these models is crucial.
Future work should focus on utilizing more di-
verse and comprehensive datasets, including the lat-
est types of SQLi attacks. Data augmentation tech-
niques can also be explored to enhance the model’s
generalizability and performance in real-world sce-
narios. There is scope for improving the algo-
rithms, especially in reducing false positives and neg-
atives. Advanced machine learning and deep learn-
ing techniques, such as convolutional neural networks
(CNNs) and recurrent neural networks (RNNs), could
be explored. Implementing these algorithms in real-
time SQLi detection systems would be a signifi-
cant step forward. This includes integrating machine
learning models into existing database management
systems or web application frameworks.
As machine learning models become more com-
plex, ensuring the explainability and interpretability
of these models is crucial. This is important for
trust and accountability, especially in security-critical
applications. Investigating hybrid models that com-
bine the strengths of different machine learning algo-
rithms could improve performance in detecting SQLi
attacks. Developing models that can continuously
learn and adapt to new types of SQLi attacks over
time would be invaluable, ensuring that the detec-
tion mechanisms remain effective as attack patterns
evolve.
By pursuing these avenues, we can enhance the ef-
fectiveness of machine learning in cybersecurity, par-
ticularly in the crucial area of SQLi detection, thereby
making digital spaces more secure against these per-
vasive threats.
REFERENCES
Abdulmalik, Y. (2021). An improved sql injection at-
tack detection model using machine learning tech-
niques. International Journal of Innovative Comput-
ing, 11(1):53–57.
Alarfaj, F. K. and Khan, N. A. (2023). Enhancing the perfor-
mance of sql injection attack detection through prob-
abilistic neural networks. Applied Sciences, 13(7).
Alghawazi, M., Alghazzawi, D., and Alarifi, S. (2022). De-
tection of SQL injection attack using machine learn-
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
22

ing techniques: A systematic literature review. Jour-
nal of Cybersecurity and Privacy, 2(4):764–777.
Farooq, U. (2021). Ensemble machine learning approaches
for detection of sql injection attack. Tehni
ˇ
cki glasnik,
15(1):112–120.
Krishnan, S. A., Sabu, A. N., Sajan, P. P., and Sreedeep, A.
(2021). Sql injection detection using machine learn-
ing. Revista Geintec-Gestao Inovacao E Tecnologias,
11(3):300–310.
Lu, D., Fei, J., and Liu, L. (2023a). A semantic Learning-
Based SQL injection attack detection technology.
Electronics, 12(6):1344.
Lu, D., Fei, J., and Liu, L. (2023b). A semantic learning-
based sql injection attack detection technology. Elec-
tronics, 12(6).
Oudah, M. A., Marhusin, M. F., and Narzullaev, A. (2022).
Sql injection detection using machine learning with
different tf-idf feature extraction approaches.
OWASP. Owasp top 10:2021 a03:2021 - injection. https:
//owasp.org/Top10/A03 2021-Injection. Accessed:
August 20 2023.
Sadeghian, A., Zamani, M., and Abdullah, S. M. (2013). A
taxonomy of sql injection attacks. In 2013 Interna-
tional Conference on Informatics and Creative Multi-
media, pages 269–273.
SHAH, S. S. H. Sql injection dataset, kaggle.
https://www.kaggle.com/datasets/syedsaqlainhussain/
sql-injection-dataset. Accessed: Jan 20 2023.
Sun, H., Du, Y., and Li, Q. (2023). Deep learning-based de-
tection technology for sql injection research and im-
plementation. Applied Sciences, 13(16).
Tasdemir, K., Khan, R., Siddiqui, F., Sezer, S., Kurugollu,
F., Yengec-Tasdemir, S. B., and Bolat, A. (2023). Ad-
vancing sql injection detection for high-speed data
centers: A novel approach using cascaded nlp.
Tripathy, D., Gohil, R., and Halabi, T. (2020). Detecting sql
injection attacks in cloud saas using machine learn-
ing. In 2020 IEEE 6th Intl Conference on Big Data
Security on Cloud (BigDataSecurity), IEEE Intl Con-
ference on High Performance and Smart Computing,
(HPSC) and IEEE Intl Conference on Intelligent Data
and Security (IDS), pages 145–150.
Zhang, W., Li, Y., Li, X., Shao, M., Mi, Y., Zhang, H.,
and Zhi, G. (2022). Deep neural Network-Based SQL
injection detection method. Security and Communica-
tion Networks, 2022.
A Hybrid Approach for Detecting SQL-Injection Using Machine Learning Techniques
23
