
Self-Supervised Partial Cycle-Consistency for Multi-View Matching
Fedor Taggenbrock
1,2 a
, Gertjan Burghouts
1 b
and Ronald Poppe
2 c
1
Utrecht University, Utrecht, Netherlands
2
TNO, The Hague, Netherlands
Keywords:
Self-Supervision, Multi-Camera, Feature Learning, Cycle-Consistency, Cross-View Multi-Object Tracking.
Abstract:
Matching objects across partially overlapping camera views is crucial in multi-camera systems and requires
a view-invariant feature extraction network. Training such a network with cycle-consistency circumvents the
need for labor-intensive labeling. In this paper, we extend the mathematical formulation of cycle-consistency
to handle partial overlap. We then introduce a pseudo-mask which directs the training loss to take partial
overlap into account. We additionally present several new cycle variants that complement each other and
present a time-divergent scene sampling scheme that improves the data input for this self-supervised setting.
Cross-camera matching experiments on the challenging DIVOTrack dataset show the merits of our approach.
Compared to the self-supervised state-of-the-art, we achieve a 4.3 percentage point higher F1 score with our
combined contributions. Our improvements are robust to reduced overlap in the training data, with substantial
improvements in challenging scenes that need to make few matches between many people. Self-supervised
feature networks trained with our method are effective at matching objects in a range of multi-camera settings,
providing opportunities for complex tasks like large-scale multi-camera scene understanding.
1 INTRODUCTION
Matching people and objects across cameras is essen-
tial for multi-camera understanding (Hao et al., 2023;
Loy et al., 2010; Zhao et al., 2020). Matches are
commonly obtained by solving a multi-view match-
ing problem. One crucial factor that determines the
quality of the matching is the feature extractors’ gen-
eralization to varying appearances as a result of ex-
pressiveness and view angle (Ristani and Tomasi,
2018). Feature extractors can be trained in a super-
vised setting, which requires labor-intensive data la-
beling (Hao et al., 2023). The lack or scarcity of la-
beled data for novel domains is a limiting factor. Self-
supervised techniques thus offer an attractive alterna-
tive because they can be trained directly on object and
person bounding boxes without labels.
Effective, view-invariant feature networks have
been learned with self-supervision through cycle-
consistency, for use in multi-view matching, cross-
view multi-object tracking, and re-identification (Re-
ID) (Gan et al., 2021; Wang et al., 2020). Training
a
https://orcid.org/0009-0002-6166-0865
b
https://orcid.org/0000-0001-6265-7276
c
https://orcid.org/0000-0002-0843-7878
these networks only requires sets of objects where
there is a sufficient amount of overlap between sets
of objects between views. For multi-person matching
and tracking, sets are typically detections of people
from multiple camera views (Gan et al., 2021; Hao
et al., 2023). When the overlapping field of view
between cameras decreases in the training data, self-
supervised cycle-consistency methods have a diluted
learning signal.
In this work, we address this situation and ex-
tend the theory of cycle-consistency for partial over-
lap with a new mathematical formulation. We then
implement this theory to effectively handle partial
overlap in the training data through a pseudo-mask,
and introduce trainable cycle variations to obtain a
richer learning signal, see Figure 1. Consequently,
we can get more out of the training data, thus provid-
ing a stronger cycle-consistency learning signal. Our
method is shown to be robust in more challenging set-
tings, with less overlap between cameras and fewer
matches in the training data. It is especially effective
for challenging scenes where few matches need to be
found between many people. The additional informa-
tion from partial cycle-consistency thus leads to sub-
stantial improvements, as shown in the experimental
Taggenbrock, F., Burghouts, G. and Poppe, R.
Self-Supervised Partial Cycle-Consistency for Multi-View Matching.
DOI: 10.5220/0013080900003912
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 3: VISAPP, pages
19-29
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
19
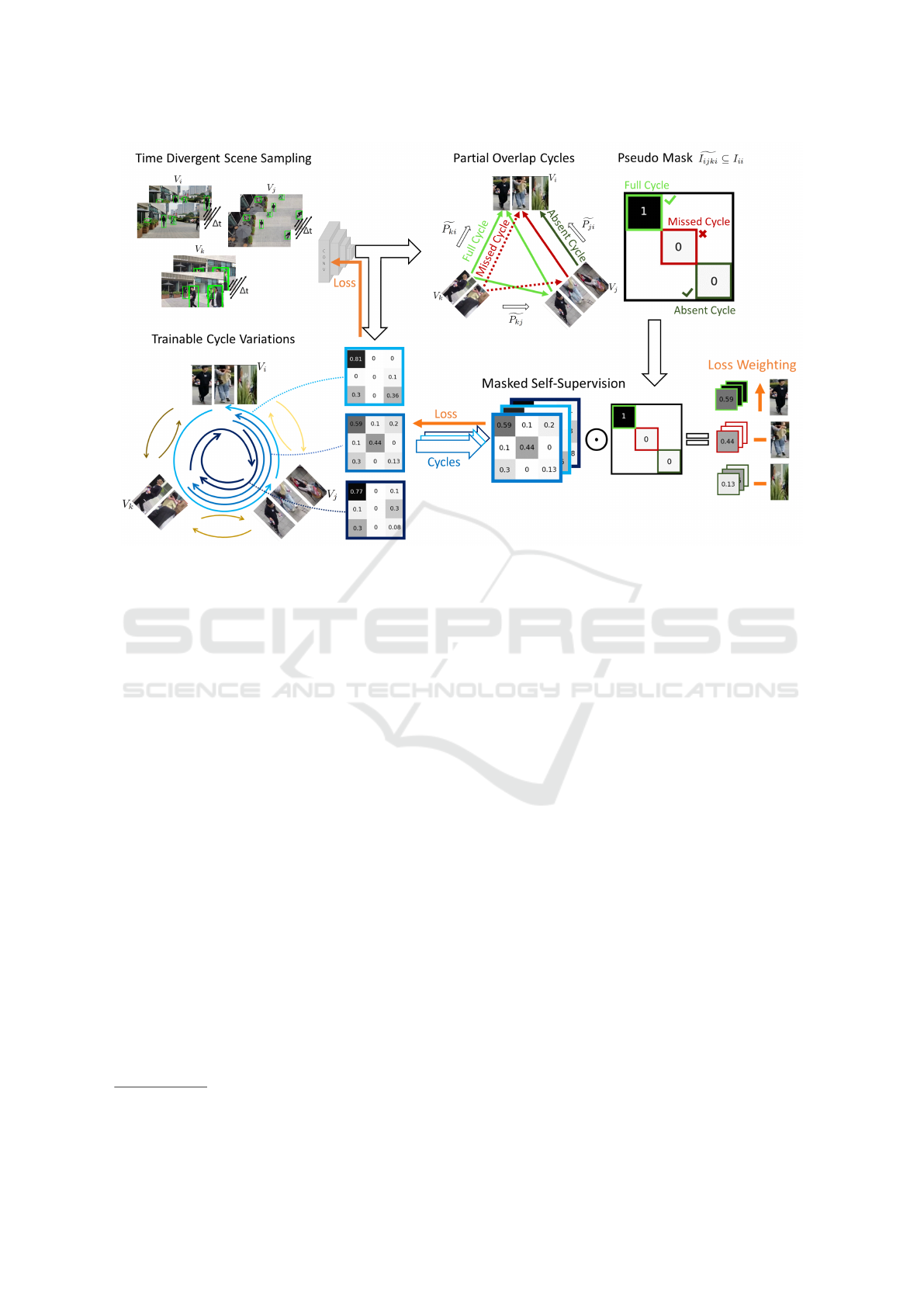
Figure 1: Overview of our self-supervised cycle-consistency training method. Trainable cycle variations (left bottom) are
constructed from sampled batches (left top). Cycle matrices represent chains of matches starting and ending in the same view.
With partial overlap, however, we construct a pseudo-mask of the identity matrix (top right) to determine which specific cycles
should be trained due to partial overlap. This pseudo-mask is then used to provide a weighted loss signal with more emphasis
on the positive predicted cycles (right bottom).
section. The code is also made open source
1
Our contributions are as follows:
1. We extend the mathematical formulation of
cycle-consistency to handle partial overlap, lead-
ing to a new formulation for partial cycle-
consistency.
2. We use pseudo-masks to implement partial cycle-
consistency and introduce several cycle variants,
motivating how these translate to a richer self-
supervision learning signal.
3. We experiment with cross camera matching on
the challenging DIVOTrack dataset, and obtain
systematic improvements. Our experiments high-
light the merits of using a range of cycle variants,
and indicate that our approach is especially effec-
tive in more challenging scenarios.
Section 2 covers related works on self-supervised
feature learning. Section 3 summarizes our
mathematical formulation and derivation of cycle-
consistency with partial overlap. Section 4 details our
self-supervised method. We discuss the experimental
validation in Section 5 and conclude in Section 6.
1
For the open source code and theoretical analysis, see
the Supplementary Materials available at Github.
2 RELATED WORK
We first address the general multi-view matching
problem, and highlight its application areas. Sec-
tion 2.2 summarizes supervised feature learning,
whereas Section 2.3 details self-supervised alterna-
tives.
2.1 Multi-View Matching
Many problems in computer vision can be framed
as a multi-view matching problem. Examples in-
clude keypoint matching (Sarlin et al., 2020), video
correspondence over time (Jabri et al., 2020), shape
matching (Huang and Guibas, 2013), 3D human pose
estimation (Dong et al., 2019), multi-object track-
ing (MOT) (Sun et al., 2019), re-identification (Re-
ID) (Ye et al., 2021), and cross-camera matching
(CCM) (Han et al., 2022). Cross-view multi-object
tracking (CVMOT) combines CCM with a tracking
algorithm (Gan et al., 2021; Hao et al., 2023). The
underlying problem is that there are more than two
views of the same set of objects, and we want to find
matches between the sets. For MOT, detections be-
tween two subsequent time frames are matched (Wo-
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
20

jke et al., 2017). Instead, in CCM, detections from
different camera views should be matched. One par-
ticular challenge is that the observations have signif-
icantly different viewing angles. Such invariancies
should be handled effectively through a feature ex-
traction network. Such networks can be trained us-
ing identity label supervision but obtaining consistent
labels across cameras is labor-intensive (Hao et al.,
2023), highlighting the need for good self-supervised
alternatives.
2.2 Supervised Feature Learning
Supervised Re-ID methods (Wieczorek et al., 2021;
Ye et al., 2021) work well for CCM. With labels, fea-
ture representations from the same instance are metri-
cally moved closer, while pushing apart feature repre-
sentations from different instances. Other approaches
such as joint detection and Re-ID learning (Hao et al.,
2023), or training specific matching networks (Han
et al., 2022) have been explored. Supervised meth-
ods for CCM typically degrade in performance when
applied to unseen scenes, indicating issues with over-
fitting. Self-supervised cycle-consistency (Gan et al.,
2021) has been shown to generalize better (Hao et al.,
2023).
2.3 Self-Supervised Feature Learning
Self-supervised feature learning algorithms do not
exploit labels. Rather, common large-scale self-
supervised contrastive learning techniques (Chen
et al., 2020) rely on data augmentation. We argue that
the significant variations in object appearance across
views cannot be adequately modeled through data
augmentations, meaning that such approaches can-
not achieve view-invariance. Clustering-based self-
supervised techniques (Fan et al., 2018) are also not
designed to deal with significant view-invariance. An-
other alternative is to learn self-supervised features
through forcing dissimilarity between tracklets within
cameras while encouraging association with track-
lets across cameras (Li et al., 2019). Early work on
self-supervised cycle-consistency has shown that this
framework significantly outperforms clustering and
tracklet based self-supervision methods (Wang et al.,
2020). Self-supervision with cycle-consistency is es-
pecially suitable for multi-camera systems because
it enables learning to associate consistently between
the object representations from different cameras and
at different timesteps. Trainable cycles can be con-
structed as series of matchings that start and end at
the same object. Each object should be matched back
to itself as long as the object is visible in all views. If
an object is matched back to a different one, a cycle-
inconsistency has been found which then serves as a
learning signal (Jabri et al., 2020; Wang et al., 2020).
Given the feature representations of detections in
two different views, a symmetric cycle between these
two views can be constructed by combining two soft-
maxed similarity matrices, matching back and forth.
The feature network can then be trained by forc-
ing this cycle to resemble the identity matrix with
a loss (Wang et al., 2020). This approach can be
extended to transitive cycles between three views,
which is sufficient to cover cycle-consistency between
any number of views (Gan et al., 2021; Huang and
Guibas, 2013). With little partial overlap in the train-
ing data, forcing cycles to resemble the full identity
matrix (Gan et al., 2021; Wang et al., 2020) provides
a diluted learning signal that trains many non-existent
cycles without putting proper emphasis on the actual
cycles that should be trained. To effectively handle
partial overlap, it is therefore important to differen-
tiate between possibly existing and absent cycles in
each batch. To this end, we implement a strategy that
makes this differentiation. A work that was developed
in parallel to ours (Feng et al., 2024) has also found
improvements with a related partial masking strategy.
Our work confirms their observations that consider-
ing partial overlap improves matching performance.
In addition, we provide a rigid mathematical under-
pinning for our method, introduce more cycle varia-
tions, and trace back improvements to characteristics
of the scene including the amount of overlap between
views.
Learning with cycle-consistency is not exclu-
sive to CCM. Cycles between detections at different
timesteps can be employed to train a self-supervised
feature extractor for MOT (Bastani et al., 2021), and
cycles between image patches or video frames can
serve to learn correspondence features at the image
level (Dwibedi et al., 2019; Jabri et al., 2020; Wang
et al., 2019). This highlights the importance of a rigid
mathematical derivation of partial cycle-consistency
in a self-supervised loss.
3 PARTIAL
CYCLE-CONSISTENCY
We summarize the main contributions from our the-
oretical extension of partial cycle-consistency, which
appears in full in the supplementary materials
1
. Given
are pairwise similarities S
i j
∈ R
n
i
×n
j
∀i, j between the
views V
i
,V
j
, that contain n
i
, n
j
bounding boxes. Par-
tial multi-view matching aims to obtain the optimal
partial matching matrices P
i j
∈ {0, 1}
n
i
×n
j
∀i, j, given
Self-Supervised Partial Cycle-Consistency for Multi-View Matching
21
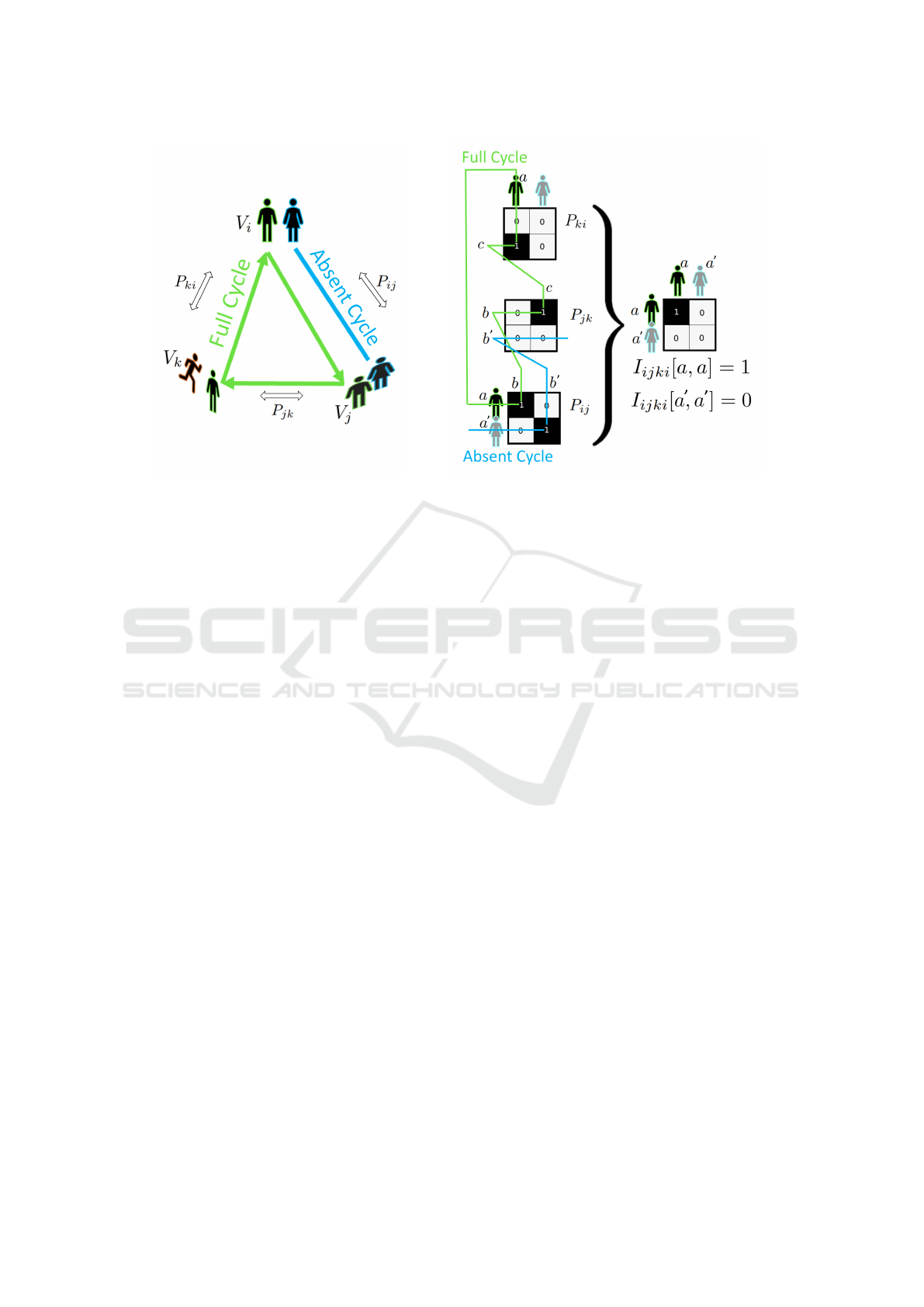
Figure 2: Partial cycle-consistency and an interpretation of Equation 5. I
i jki
[a, a] = 1 because a is matched to b, matched to c
which is then matched back to a. The same does not hold for a
′
, so this cycle is absent.
the S
i j
that are partially cycle-consistent with each
other. See also Figure 2. Partial cycle-consistency
implies that, among others, matching from view V
i
to view V
j
and then to view V
k
should be a sub-
set of the direct matching between V
i
and V
k
. We
make this subset relation explicit, pinpointing which
matches get lost through view V
j
by inspecting the
pairwise matches, proving equivalence to the orig-
inal definition. We then prove that partial cycle-
consistency in general implies the most usable form
of self-supervision cycle-consistency, where matches
are combined into full cycles that start and end in
the same view and should thus be a subset of the
identity matrix. We are able to explicitly define this
usable form of partial cycle-consistency in proposi-
tion 1. Based on this insight, in Section 4, we con-
struct subsets of the identity matrix during training to
serve as pseudo-masks, improving the training pro-
cess with partially overlapping views. Our explicit
cycle-consistency proposition is as follows:
Proposition 1 (Explicit partial cycle-consistency).
If a multi-view matching {P
i j
}
∀i, j
is partially cycle-
consistent, it holds that:
P
ii
= I
n
i
×n
i
∀i ∈ {1, . . . , N}, (1)
P
i j
P
ji
= I
i ji
∀i, j ∈ {1, . . . , N}, (2)
P
i j
P
jk
P
ki
= I
i jki
∀i, j, k ∈ {1, . . . , N}, (3)
where I
i ji
⊆ I
n
i
×n
i
is the identity map from view i
back to itself, filtering out matches that are not seen
in view V
j
:
I
i ji
[a, c] =
(
1 if a = c & ∃b s.t. P
i j
[a, b] = 1.
0 else,
(4)
and where I
i jki
⊆ I
n
i
×n
i
is the identity mapping
from view i back to itself, filtering out all matches that
are not seen in views V
j
and V
k
:
I
i jki
[a, d] =
1 if a = d & ∃b, c s.t. P
i j
[a, b]
= P
jk
[b, c] = P
ki
[c, d] = 1.
0 else.
(5)
The notation X[·,·] is used for indexing a matrix X.
The intuition behind Equation 5 can be best un-
derstood through the visualization in Figure 2. Here,
I
i jki
[a
′
, a
′
] = 0 because there is a detection of a
′
absent
in view V
k
, while I
i jki
[a, a] = 1 because a full cycle
is formed from the corresponding pairwise matches.
The proofs with detailed explanations are given in the
supplementary materials
1
.
4 SELF-SUPERVISION WITH
PARTIAL
CYCLE-CONSISTENCY
The theory of cycle-consistency and its relation to
partial overlap can be translated into a self-supervised
feature network training strategy. The main chal-
lenges are to determine which cycles to train, which
loss to use, and how to implement the findings from
Proposition 1 to handle partial overlap. Section 4.1
explores what cycles to train and how to construct
them. Section 4.2 explores how to obtain partial
overlap masks for the cycles that approximate the
I
i ji
, I
i jki
⊆ I
n
i
×n
i
from Proposition 1. It also explores
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
22

how these masks can be incorporated in a loss to deal
with partial overlap during training.
4.1 Trainable Cycle Variations
Given are the pairwise similarities S
i j
between all
view pairs, obtained from the feature extractor φ that
we wish to train. The idea is to combine softmax
matchings of the S
i j
into cycles, similar to Equations 2
and 3. For this we use the temperature-adaptive row-
wise softmax f
τ
(Wang et al., 2020) on a similar-
ity matrix S to perform a soft row-wise partial match-
ing. This function has the differentiability needed to
train a feature network and the flexibility to make non-
matches for low similarity values. We get:
f
τ
(S[a, b]) =
exp(τS[a, b])
∑
b
′
exp(τS[a, b
′
])
, (6)
where the notation S[·, ·] is used for matrix index-
ing. The temperature τ depends on the size of S as
in (Wang et al., 2020).
4.1.1 Pairwise Cycles
The pairwise cycles need to be constructed from just
S
i j
= S
T
ji
. To this end, we take:
A
i j
= f
τ
(S
i j
), A
ji
= f
τ
(S
T
i j
), A
i ji
= A
i j
A
ji
. (7)
The pairwise cycle A
i ji
, originally proposed in (Wang
et al., 2020), represents a trainable variant of the pair-
wise cycle P
i j
P
ji
from Equation 2, and so a learn-
ing signal is obtained by forcing it to resemble I
i ji
.
Note that the A
i j
and A
ji
differ because they match the
rows and columns of S
i j
, respectively. This is impor-
tant because the loss then forces these different soft
matchings to be consistent with each other, modelling
the partial cycle-consistency constraint in Equation 2.
The loss will be the same for A
i ji
and A
T
i ji
= A
T
ji
A
T
i j
, so
just Equation 7 suffices.
4.1.2 Triplewise Cycles
The triplewise cycles are constructed from S
i j
, S
jk
and
S
ki
, and should resemble the P
i j
P
jk
P
ki
from Equa-
tion 3. The authors in (Feng et al., 2024) propose to
use:
A
0
i jki
= A
i j
A
jk
A
ki
, (8)
while in (Gan et al., 2021), the similarities are com-
bined first so that:
S
i jk
= S
i j
S
jk
, A
i jk
= f
τ
(S
i jk
), (9)
with which their triplewise cycle is created as:
A
1
i jki
= A
i jk
A
k ji
. (10)
We discovered that using multiple triplewise cycle
constructions in the training improves the results.
Each of the constructed cycles exposes a different in-
consistency in the extracted features, so that a combi-
nation of cycles provides a robust training signal. We
propose to use the following four triplewise cycles:
A
0
i jki
= A
i j
A
jk
A
ki
, (11)
A
1
i jki
= A
i jk
A
k ji
, (12)
A
2
i jki
= A
i jk
A
ki
, (13)
A
3
i jki
= A
i jk
A
ki j
A
jki
. (14)
The cycles from Equation 12-14 are also visualized
in Figure 1 as the three blue swirls. In the following,
A
i jki
can be used to refer to any of the four triplewise
cycles in Equations 11- 14, and additionally A
i ji
when
assuming j = k. The symmetric property of the loss
makes transposed versions of Equations 11 - 14 re-
dundant.
4.2 Masked Partial Cycle-Consistency
Loss
The A
i jki
can be directly trained to resemble the iden-
tity matrix I
ii
, by training each diagonal element in
A
i jki
to be a margin m greater than their correspond-
ing maximum row and column values, similar to the
triplet loss (Wang et al., 2020; Gan et al., 2021). This
is achieved through:
L
m
(A
i jki
) =
n
i
∑
i=1
relu(max
b̸=a
(A
i jki
[a, b])−A
i jki
[a, a]+m).
(15)
The following loss enforces this margin over both the
rows and columns:
L
m
(A
i jki
) =
1
2
(L
m
(A
i jki
) + L
m
(A
T
i jki
)). (16)
This loss, however, does not distinguish between ab-
sent and existing cycles that occur with partial over-
lap. Note that the ground truth I
i jki
are masks (or sub-
sets) of the I
ii
that exactly filter out such absent cy-
cles, while keeping the existing cycles, according to
Equation 5 and visualized in Figure 2. In this figure,
detections of the blue person form an absent cycle be-
cause the pairwise matches are not connected. The
I
i jki
are constructed based on the ground truth matches
P
i j
. We therefore propose to construct pseudo-masks
e
I
i jki
from pseudo-matches
e
P
i j
that are available during
self-supervised training. For this we use:
e
P
i j
=
(
[ f
τ
(S
i j
) > 0.5] if |V
i
| < |V
j
|,
h
f
τ
(S
T
i j
)
T
> 0.5
i
if |V
j
| < |V
i
|,
(17)
Self-Supervised Partial Cycle-Consistency for Multi-View Matching
23

where the Iverson bracket [Predicate(X)] binarizes
matrix X, with elements equal to 1 for which the pred-
icate is true, and 0 otherwise. In
e
P
i j
, each element in
a view with fewer elements can be matched to at most
one element in the other view, as desired for a partial
matching. We construct the pseudo-masks as:
e
I
i jki
[a, a] =
1 if ∃b, c s.t.
e
P
i j
[a, b]
=
e
P
jk
[b, c] =
e
P
ki
[c, a] = 1.
0 else.
(18)
e
I
i jki
is invariant to the order in the i, j, k sequence, and
independent of the cycle variant for which it is used
as a mask. Equation 18 can be vectorized as:
e
I
i jki
=
h
e
P
i j
e
P
jk
e
P
ki
⊙ I
ii
≥ 1
i
. (19)
Our masked partial cycle-consistency loss extends
the loss from Equation 16 with the pseudo-masks
e
I
i jki
,
for which only the diagonal elements of predicted ex-
isting cycles are 1. The absent cycles have diagonal
elements of 0. The loss uses two different margins
m
+
> m
/
0
> 0, where m
+
is used for cycles that are
predicted to exist with
e
I
i jki
, and m
/
0
is used for the cy-
cles predicted to be absent:
L
explicit
=
L
m
+
(
e
I
i jki
⊙ A
i jki
) + L
m
/
0
((I
ii
−
e
I
i jki
) ⊙ A
i jki
)
2
.
(20)
5 RESULTS AND EXPERIMENTS
We demonstrate the merits of a stronger self-
supervised training signal from the addition of our
cycle variations and partial cycle-consistency mask.
We introduce the training setting, before detailing our
quantitative and qualitative results.
Dataset and Metrics. DIVOTrack (Hao et al., 2023)
is a large and varied dataset of time-aligned overlap-
ping videos with consistently labeled people across
cameras. The train and testset are disjoint sets with 9k
frames from three overlapping camera’s each. Three
time-aligned overlapping frames are one matching in-
stance. Frames from 10 different scenes are used,
equally distributed over the train and test set. Our self-
supervised feature network trains with the 9k match-
ing instances of the trainset without its labels. We re-
port the average cross-camera matching precision, re-
call and F1 score (Han et al., 2022) over the 9k match-
ing instances of the test set, averaged over five train-
ing runs with standard deviation. The average number
of people per matching instance is around 19, but this
varies per scene
1
.
Implementation Details. Our contributions ex-
tends the state-of-the-art in self-supervised cycle-
consistency (Gan et al., 2021). Our cycle varia-
tions from Equations 11-14 are used instead of theirs,
providing a diverse set of cycles to capture differ-
ent cycle-inconsistencies. Previous methods with-
out masking (Wang et al., 2020) (Gan et al., 2021)
use the loss from Equation 16. Our partial masking
strategy instead constructs pseudo-masks with Equa-
tion 18 and uses these in our explicit partial masking
loss from Equation 20, with m
+
= 0.7 and m
/
0
= 0.3.
We use the same training setup as (Gan et al., 2021)
for fair comparison. Specifically, we use annotated
bounding boxes without identity labels to extract fea-
tures and train a ResNet-50 (He et al., 2016) for 10
epochs with an Adam optimizer with learning rate
1e − 5. Matching inference uses the Hungarian algo-
rithm between all view pairs, with an optimized par-
tial overlap parameter to handle non-matches.
Time-Divergent Scene Sampling. Detections from
multiple cameras at two timesteps are used in a batch
such that cycles are constructed and trained between
the pairs and triples for 2C views of the same scene,
with C the number of cameras (Feng et al., 2024; Gan
et al., 2021). Time-divergent scene sampling gradu-
ally increases the interval ∆t between timesteps dur-
ing training, with ∆t equal to the current epoch num-
ber. It also uses fractional sampling to obtain a bal-
anced batch order, such that the local distribution of
scenes resembles the average global distribution of
scenes.
5.1 Main Results
We show the overall effectiveness of our cycle varia-
tions and partial masking as additions to the existing
SOTA within the framework of self-supervised cycle-
consistency (Gan et al., 2021) in Table 1.
The first paper in this framework (Wang et al.,
2020) used a simple baseline approach with just
pairwise cycles, and showed the effectiveness com-
pared to multiple other self-supervised feature learn-
ing methods using clustering (Fan et al., 2018) and
tracklet based techniques (Li et al., 2019) among oth-
ers. The authors in (Gan et al., 2021) and (Feng
et al., 2024) expanded upon this framework, where
(Feng et al., 2024) is not open source. We report
the results in our paper both with and without time-
divergent scene sampling, as this simply makes the
data input richer, improving performance regardless
of which cycle-consistency method is used. We find
that combining cycle variations, partial masking and
Time Divergent Scene Sampling boosts the F1 match-
ings score of the previous SOTA by 4.3 percentage
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
24

Table 1: Cycle variations and partial masking together improve the overall matching performance by 2.5-2.1 percentage
points. Every method benefits from time-divergent scene sampling, and combining everything boosts the previous SOTA by
4.3 percentage points, also improving stability.
Model Standard Time-Div. Scene Sampling
Precision Recall F1 Precision Recall F1
MvMHAT (Gan et al., 2021) 66.3 60.1 63.1±1.7 68.0 62.8 65.3±1.3
Cycle variations (CV) 68.8 61.1 64.7±1.9 70.4 62.3 66.1±1.4
CV + Partial masking 71.0 61.0 65.6±1.1 71.7 63.6 67.4±0.9
Table 2: Results per scene. Our methods improve the average F1 score on every scene. Crowded challenging test scenes like
Ground, Side and Shop benefit most, with improvements of 9.1, 5.6 and 4.7 percentage points respectively.
Methods Gate2 Square Moving Circle Gate1
MvMHAT (Gan et al., 2021) 88.1 73.3 73.1 67.4 67.2
Ours w\o Masking 88.3(+0.2) 74.9(+1.6) 74.9(+1.8) 68.7(+1.3) 69.6(+2.4)
Ours 88.3(+0.2) 74.9(+1.6) 76.2(+3.1) 69.9(+2.5) 70.4(+3.2)
Methods Floor Park Ground Side Shop
MvMHAT (Gan et al., 2021) 64.7 58.2 56.9 56.0 42.1
Ours w\o Masking 65.2(+0.5) 58.4(+0.2) 64.5(+7.6) 58.9(+2.9) 45.5(+3.4)
Ours 66.8(+2.1) 60.4(+2.2) 66.0(+9.1) 61.6(+5.6) 46.8(+4.7)
points, and that this combination is also the most con-
sistent of all approaches. To put the results of Table
1 in perspective, we report that the F1 matching score
of a Resnet pretrained on ImageNet is 16.8, while a
supervised SOTA Re-ID model (Ye et al., 2021) with
an optimized network architecture and hard negative
mining is able to obtain a matching score of 82.28.
This illustrates the strength of self-supervised cycle-
consistency in general, showcasing its ability to sig-
nificantly improve the feature quality of a pretrained
ResNet. It also shows that our unoptimized self-
supervised method is not to far from an optimized su-
pervised baseline.
5.1.1 Results per Scene
The 10 scenes in the train and test data provide dif-
ferent challenges. During training, scenes with lit-
tle overlap provide a worse learning signal for the
overall model. During testing, scenes that require
few matchings between many people are significantly
more challenging. Insights into the overlap and num-
ber of people per scene is provided in the supplemen-
tary materials
1
. The scenes Ground, Side and Shop
contain the highest number of people, around 24-32
per frame on average. The scenes Side and Shop
also have little overlap, so that few matches needed
to be correctly found from many possible ones. These
scenes can thus be considered as the most challenging
test set scenes. Table 2 reports the matching results
per scene. Our methods outperform (Gan et al., 2021)
on every test set, with the largest (relative) gains on
Ground, Side and Shop, with 9.1, 5.6 and 4.7 percent-
age points, respectively, highlighting the improved
expressiveness of our feature network.
5.1.2 Partial Overlap Experiments
We experiment with artificially reducing the field of
view in the training data by 20-40%. We implement
this by reducing the actual width of each camera view
starting from the right, throwing away the bounding
boxes outside this reduced field of view. We train on
these reduced overlap datasets and measure the ro-
bustness for each method, because self-supervision
through cycle-consistency learns from overlap. An
overlap analysis for the original and reduced datasets
is provided in Table 3, and the evaluation results when
training with the reduced data are shown in Table 4.
We observe that our method is robust and contributes
to the performance even in these harder training sce-
narios.
5.1.3 Cycle Variations Ablation
Our cycle variations use Equations 11- 14 to construct
multiple trainable cycles to obtain a richer learning
signal. We perform an ablation study on the effec-
tiveness of each cycle, with and without masking, in
Table 5. We find that our new A
i jk
A
ki
and A
i jk
A
ki j
A
jki
cycles from Equations 13 and 14 perform well on
their own and even better when combined with the cy-
cles from Equations 11 and 12. We observe that mul-
tiple cycle variations work especially well in the pres-
Self-Supervised Partial Cycle-Consistency for Multi-View Matching
25

Figure 3: Qualitative example during training. Each of the blue swirls, representing Equations 12-14, constructs a cycle matrix
with various cycle-inconsistencies. Partial overlap requires that only some of the diagonal elements are trained as cycles. The
pseudo-mask correctly finds the existing cycles, except for a heavily occluded one. A strong learning signal is obtained from
one of the diagonals of the dark blue cycle.
Table 3: The original train dataset has an average of 40% IoU between any two cameras, 26% people visible in all three
cameras, and 18.4 unique people per frame. We reduce the FOV to simulate harder train data with less overlap.
Jaccard Index Full Train|Test 80% Train Overlap 60% Train Overlap
Two Cameras 0.40|0.38 0.37 0.29
Three Cameras 0.26|0.23 0.24 0.15
Num People 18.4|19.4 16.5 14.0
Table 4: Our methods consistently improve performance, even with sparser training data that is reduced in partial overlap.
Full Train 80% Train Overlap 60% Train Overlap
Methods test set F1 score
MvMHAT (Gan et al., 2021) 63.1±1.7 60.6±1.6 55.0±2.3
Ours w\o Masking 66.1±1.4 63.0±1.9 56.5±2.3
Ours 6
6
67
7
7.
.
.4
4
4±0
0
0.
.
.9
9
9 6
6
63
3
3.
.
.8
8
8 ± 1
1
1.
.
.2
2
2 5
5
57
7
7.
.
.9
9
9 ± 1
1
1.
.
.5
5
5
ence of masking, showing that these methods partly
complement each other.
5.2 Qualitative Results
Figure 3 illustrates the contribution of the various cy-
cles and pseudo-mask during training. In this specific
example, it can be seen how the varied cycle construc-
tions are cycle-inconsistent in different ways. Con-
sequently, a robust learning signal is obtained from
combining these cycle variants. The figure also shows
the pseudo-mask I
i jki
that is constructed for this batch,
where the existing cycles are correctly found with the
exception of a severely occluded one in the top left,
which you would not want to train anyway. The low
value of 0.36 on the diagonal of the dark blue cycle
means that a strong self-supervised learning signal is
obtained from the masking, forcing the model to out-
put more similar features for the different views of the
person in pink.
Figure 4 provides insight into the test set match-
ing performance of our model compared to (Gan
et al., 2021). It shows how our model effectively
finds the pairwise matches at test time in a crowded
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
26

Table 5: Ablation of the cycle variations, also linking the Equations with illustrations. Our new A
i jk
A
ki
and A
i jk
A
ki j
A
jki
cycles
work well individually, and even better in combination with the other cycle variations. Partial masking is also most effective
when combined with multiple cycle variations. Our final method uses the setup from the bottom row with masking.
A
i jk
A
k ji
A
i jk
A
ki
A
i jk
A
ki j
A
jki
A
i j
A
jk
A
ki
w\o with
Eq 12 (Gan et al., 2021) Eq 13 [Ours] Eq 14 [Ours] Eq 11 (Feng et al., 2024) Masking Masking
✓ 65.1 ± 0.9 66.7± 0.6
✓ 6
6
66
6
6.
.
.4
4
4 ± 1
1
1.
.
.0
0
0 66.2±1.5
✓ 65.6 ± 1.8 66.4±1.2
✓ 57.7 ± 1.5 55.9±1.2
✓ ✓ 65.6 ± 1.5 66.7 ± 0.9
✓ ✓ ✓ 66.2 ± 1.2 66.9 ± 0.7
✓ ✓ ✓ ✓ 66.3 ± 1.0 6
6
67
7
7.
.
.2
2
2 ± 1
1
1.
.
.1
1
1
Figure 4: Qualitative example during matching inference for a difficult frame in the test set. Our model is able to match with
significantly fewer false positives. The matches found with our method are based on subtle clothing details, and have been
correctly found in the presence of significant view angle differences and occlusion, significantly improving over the previous
SOTA
scene. Note the difficulty of the matching problem,
and how our method has significantly fewer false pos-
itive matches. The figure also demonstrates that our
method is able to match significantly different repre-
sentations of the same person across cameras, while
differentiating between very similar looking people
based on subtle clothing details.
Self-Supervised Partial Cycle-Consistency for Multi-View Matching
27

6 CONCLUSIONS
We have extended the mathematical formulation of
cycle-consistency to partial overlaps between views.
We have leveraged these insights to develop a self-
supervised training setting that employs multiple
new cycle variants and a pseudo-masking approach
to steer the loss function. The cycle variants ex-
pose different cycle-inconsistencies, ensuring that the
self-supervised learning signal is more diverse and
therefore stronger. We also presented a time di-
vergent batch sampling approach for self-supervised
cycle-consistency. Our methods combined improve
the cross-camera matching performance of the cur-
rent self-supervised state-of-the-art on the challeng-
ing DIVOTrack benchmark by 4.3 percentage points
overall, and by 4.7-9.1 percentage points for the most
challenging scenes.
Our method is effective in other multi-camera
downstream tasks such as Re-ID and cross-view
multi-object tracking. One limitation of self-
supervision with cycle-consistency is its dependence
on bounding boxes in the training data. Detections
from an untrained detector could be used to train with
instead, but this would likely degrade performance.
Another area for improvement is to take location and
relative distances into account both during training
and testing, as this provides informative identity in-
formation.
Self-supervision through cycle-consistency is ap-
plicable to many more settings than just learning
view-invariant object features. We believe the tech-
niques introduced in this paper also benefit works that
use cycle-consistency to learn image, patch, or key-
point features from videos or overlapping views.
REFERENCES
Bastani, F., He, S., and Madden, S. (2021). Self-supervised
multi-object tracking with cross-input consistency.
Advances in Neural Information Processing Systems,
34:13695–13706.
Chen, T., Kornblith, S., Norouzi, M., and Hinton, G. (2020).
A simple framework for contrastive learning of visual
representations. In International conference on ma-
chine learning, pages 1597–1607. PMLR.
Dong, J., Jiang, W., Huang, Q., Bao, H., and Zhou, X.
(2019). Fast and robust multi-person 3d pose esti-
mation from multiple views. In Proceedings of the
IEEE/CVF conference on computer vision and pattern
recognition, pages 7792–7801.
Dwibedi, D., Aytar, Y., Tompson, J., Sermanet, P., and Zis-
serman, A. (2019). Temporal cycle-consistency learn-
ing. In Proceedings of the IEEE/CVF conference on
computer vision and pattern recognition, pages 1801–
1810.
Fan, H., Zheng, L., Yan, C., and Yang, Y. (2018). Un-
supervised person re-identification: Clustering and
fine-tuning. ACM Transactions on Multimedia Com-
puting, Communications, and Applications (TOMM),
14(4):1–18.
Feng, W., Wang, F., Han, R., Qian, Z., and Wang, S. (2024).
Unveiling the power of self-supervision for multi-
view multi-human association and tracking. arXiv
preprint arXiv:2401.17617.
Gan, Y., Han, R., Yin, L., Feng, W., and Wang, S. (2021).
Self-supervised multi-view multi-human association
and tracking. In Proceedings of the 29th ACM Inter-
national Conference on Multimedia, pages 282–290.
Han, R., Wang, Y., Yan, H., Feng, W., and Wang, S. (2022).
Multi-view multi-human association with deep as-
signment network. IEEE Transactions on Image Pro-
cessing, 31:1830–1840.
Hao, S., Liu, P., Zhan, Y., Jin, K., Liu, Z., Song, M., Hwang,
J.-N., and Wang, G. (2023). Divotrack: A novel
dataset and baseline method for cross-view multi-
object tracking in diverse open scenes. International
Journal of Computer Vision, pages 1–16.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
ual learning for image recognition. In Proceedings of
the IEEE conference on computer vision and pattern
recognition, pages 770–778.
Huang, Q.-X. and Guibas, L. (2013). Consistent shape maps
via semidefinite programming. Computer graphics fo-
rum, 32(5):177–186.
Jabri, A., Owens, A., and Efros, A. (2020). Space-time cor-
respondence as a contrastive random walk. Advances
in neural information processing systems, 33:19545–
19560.
Li, M., Zhu, X., and Gong, S. (2019). Unsupervised tracklet
person re-identification. IEEE transactions on pattern
analysis and machine intelligence, 42(7):1770–1782.
Loy, C. C., Xiang, T., and Gong, S. (2010). Time-delayed
correlation analysis for multi-camera activity under-
standing. International Journal of Computer Vision,
90:106–129.
Ristani, E. and Tomasi, C. (2018). Features for multi-target
multi-camera tracking and re-identification. In Pro-
ceedings of the IEEE conference on computer vision
and pattern recognition, pages 6036–6046.
Sarlin, P.-E., DeTone, D., Malisiewicz, T., and Rabinovich,
A. (2020). Superglue: Learning feature matching
with graph neural networks. In Proceedings of the
IEEE/CVF conference on computer vision and pattern
recognition, pages 4938–4947.
Sun, S., Akhtar, N., Song, H., Mian, A., and Shah, M.
(2019). Deep affinity network for multiple object
tracking. IEEE transactions on pattern analysis and
machine intelligence, 43(1):104–119.
Wang, X., Jabri, A., and Efros, A. A. (2019). Learning cor-
respondence from the cycle-consistency of time. In
Proceedings of the IEEE/CVF Conference on Com-
puter Vision and Pattern Recognition, pages 2566–
2576.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
28

Wang, Z., Zhang, J., Zheng, L., Liu, Y., Sun, Y., Li, Y., and
Wang, S. (2020). Cycas: Self-supervised cycle as-
sociation for learning re-identifiable descriptions. In
Computer Vision–ECCV 2020: 16th European Con-
ference, Glasgow, UK, August 23–28, 2020, Proceed-
ings, Part XI 16, pages 72–88. Springer.
Wieczorek, M., Rychalska, B., and D ˛abrowski, J. (2021).
On the unreasonable effectiveness of centroids in im-
age retrieval. In Neural Information Processing: 28th
International Conference, ICONIP 2021, Sanur, Bali,
Indonesia, December 8–12, 2021, Proceedings, Part
IV 28, pages 212–223. Springer.
Wojke, N., Bewley, A., and Paulus, D. (2017). Simple on-
line and realtime tracking with a deep association met-
ric. In 2017 IEEE international conference on image
processing (ICIP), pages 3645–3649. IEEE.
Ye, M., Shen, J., Lin, G., Xiang, T., Shao, L., and Hoi, S. C.
(2021). Deep learning for person re-identification: A
survey and outlook. IEEE transactions on pattern
analysis and machine intelligence, 44(6):2872–2893.
Zhao, J., Han, R., Gan, Y., Wan, L., Feng, W., and Wang,
S. (2020). Human identification and interaction detec-
tion in cross-view multi-person videos with wearable
cameras. In Proceedings of the 28th ACM Interna-
tional Conference on Multimedia, pages 2608–2616.
Self-Supervised Partial Cycle-Consistency for Multi-View Matching
29
