
Swarm Behavior Cloning
Jonas N
¨
ußlein, Maximilian Zorn, Philipp Altmann and Claudia Linnhoff-Popien
Institute of Computer Science, LMU Munich, Germany
fi
Keywords:
Reinforcement Learning, Imitation Learning, Ensemble, Robustness.
Abstract:
In sequential decision-making environments, the primary approaches for training agents are Reinforcement
Learning (RL) and Imitation Learning (IL). Unlike RL, which relies on modeling a reward function, IL lever-
ages expert demonstrations, where an expert policy π
e
(e.g., a human) provides the desired behavior. Formally,
a dataset D of state-action pairs is provided: D = (s,a = π
e
(s)). A common technique within IL is Behavior
Cloning (BC), where a policy π(s) = a is learned through supervised learning on D. Further improvements can
be achieved by using an ensemble of N individually trained BC policies, denoted as E = {π
i
(s)}
1≤i≤N
. The
ensemble’s action a for a given state s is the aggregated output of the N actions: a =
1
N
∑
i
π
i
(s). This paper
addresses the issue of increasing action differences—the observation that discrepancies between the N pre-
dicted actions grow in states that are underrepresented in the training data. Large action differences can result
in suboptimal aggregated actions. To address this, we propose a method that fosters greater alignment among
the policies while preserving the diversity of their computations. This approach reduces action differences and
ensures that the ensemble retains its inherent strengths, such as robustness and varied decision-making. We
evaluate our approach across eight diverse environments, demonstrating a notable decrease in action differ-
ences and significant improvements in overall performance, as measured by mean episode returns.
1 INTRODUCTION
Reinforcement Learning (RL) is a widely recognized
approach for training agents to exhibit desired behav-
iors by interacting with an environment over time.
In RL, an agent receives a state s, selects an action
a, and receives feedback in the form of a reward,
learning which behaviors are beneficial (high reward)
and which are detrimental (low reward) based on the
reward function provided by the environment (Sut-
ton and Barto, 2018). While RL has shown great
promise, designing an effective reward function can
be highly challenging. A well-designed reward func-
tion must satisfy several criteria: (1) the optimal be-
havior should yield the maximum possible return R
∗
(the sum of all rewards in an episode); (2) subopti-
mal behaviors must be penalized, resulting in a return
R < R
∗
, ensuring that shortcuts or unintended strate-
gies are discouraged; (3) the reward function should
be dense, providing informative feedback at every
step of an episode rather than just at the end; (4) the
reward should support gradual improvement, avoid-
ing overly sparse rewards such as those that assign 1
to the optimal trajectory and 0 to all others, which can
hinder exploration and learning (Eschmann, 2021;
Knox et al., 2023).
Due to the inherent complexity of crafting such
reward functions, the field of Imitation Learning (IL)
has emerged as an alternative approach (Zheng et al.,
2021; Torabi et al., 2019b). Instead of relying on
an explicitly defined reward function, IL uses ex-
pert demonstrations to model the desired behavior.
This paradigm has proven effective in various real-
world applications, such as autonomous driving (Bo-
jarski et al., 2016; Codevilla et al., 2019) and robotics
(Giusti et al., 2015; Finn et al., 2016). A prominent
method within IL is Behavior Cloning (BC), where
supervised learning is applied to a dataset of state-
action pairs D = {(s,a = π
e
(s))}, provided by an ex-
pert policy π
e
. Compared to other IL methods like In-
verse Reinforcement Learning (Zhifei and Meng Joo,
2012; N
¨
ußlein et al., 2022) or Adversarial Imitation
Learning (Ho and Ermon, 2016; Torabi et al., 2019a),
BC has the advantage of not requiring further inter-
actions with the environment, making it particularly
suitable for non-simulated, real-world scenarios.
A straightforward extension of BC is the use of an
ensemble of N individually trained policies. In this
approach, the ensemble action is computed by aggre-
gating the N predicted actions as a =
1
N
∑
i
π
i
(s). Al-
though ensemble methods often improve robustness,
they can encounter challenges when states in the train-
Nüßlein, J., Zorn, M., Altmann, P. and Linnhoff-Popien, C.
Swarm Behavior Cloning.
DOI: 10.5220/0013086600003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 1, pages 23-32
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
23

ing data D are underrepresented. For these states,
the N policies may predict actions {a
i
}
1≤i≤N
that di-
verge significantly, leading to suboptimal aggregated
actions.
In this paper, we address the problem of in-
creasing action differences in such underrepresented
states. Specifically, we propose a new loss func-
tion that encourages greater alignment among the N
policies in the ensemble while preserving the diver-
sity of their computations. This approach reduces ac-
tion differences and ensures that the ensemble retains
its inherent strengths, such as robustness and varied
decision-making. As illustrated in Figure 1, this ap-
proach—termed Swarm Behavior Cloning—leads to
more consistent predictions across the ensemble, with
the N predicted actions (gray dots) clustered more
closely together compared to standard Ensemble Be-
havior Cloning (middle plot). By minimizing action
divergence, our approach improves the quality of the
aggregated action and enhances performance in di-
verse environments.
2 BACKGROUND
2.1 Reinforcement Learning
Reinforcement Learning (RL) problems are often
modeled as Markov Decision Processes (MDP). An
MDP is represented as a tuple M = ⟨S,A, T, r, p
0
,γ⟩
where S is a set of states, A is a set of actions, and
T (s
t+1
|s
t
,a
t
) is the probability density function (pdf)
for sampling the next state s
t+1
after executing action
a
t
in state s
t
. It fulfills the Markov property since this
pdf solely depends on the current state s
t
and not on a
history of past states s
τ<t
. r : S × A → R is the reward
function, p
0
is the start state distribution, and γ ∈ [0; 1)
is a discount factor which weights later rewards less
than earlier rewards (Phan et al., 2023).
A deterministic policy π : S → A is a mapping from
states to actions. Return R =
∑
∞
t=0
γ
t
· r(s
t
,a
t
) is the
(discounted) sum of all rewards within an episode.
The task of RL is to learn a policy such that the ex-
pected cumulative return is maximized:
π
∗
= argmax
π
J
p
0
(π,M) = argmax
π
E
"
∑
∞
t=0
γ
t
· r(s
t
,a
t
) | π
#
Actions a
t
are selected following policy π. In Deep
Reinforcement Learning the policy π is represented
by a neural network
ˆ
f
φ
(s) with a set of trainable pa-
rameters φ (Sutton and Barto, 2018).
2.2 Imitation Learning
Imitation Learning (IL) operates within the frame-
work of Markov Decision Processes, similar to Re-
inforcement Learning (RL). However, unlike RL, IL
does not rely on a predefined reward function. In-
stead, the agent learns from a dataset of expert demon-
strations consisting of state-action pairs:
D = {(s
i
,a
i
= π
e
(s
i
))}
i
where each a
i
represents the expert’s action π
e
(s
i
) in
state s
i
. IL is particularly useful in situations where
demonstrating the desired behavior is easier than de-
signing a corresponding reward function.
IL can be broadly divided into two main cate-
gories: Behavior Cloning (BC) and Inverse Rein-
forcement Learning (IRL). Behavior Cloning focuses
on directly mimicking the expert’s actions by training
a policy through supervised learning on the provided
dataset D (Torabi et al., 2018). In contrast, Inverse
Reinforcement Learning seeks to infer the underlying
reward function r
e
(s,a) that would make the expert’s
behavior optimal, using the same dataset D.
The key advantage of BC over IRL is that BC does
not require further interactions with the environment
during training. This makes BC more applicable to
real-world (non-simulated) scenarios, where collect-
ing new trajectories can be costly, time-consuming,
or even dangerous due to the exploratory actions in-
volved (Zheng et al., 2021; Torabi et al., 2019b).
In addition to BC and IRL, there are adversarial
approaches to IL that do not neatly fit into these two
categories. These methods also necessitate environ-
ment rollouts for training. The core idea behind ad-
versarial methods is to frame the learning process as
a zero-sum game between the agent and a discrimi-
nator. The discriminator’s objective is to distinguish
between state-action pairs generated by the agent and
those produced by the expert, while the agent tries to
generate actions that fool the discriminator (Ho and
Ermon, 2016; Torabi et al., 2019a).
3 PROBLEM ANALYSIS: ACTION
DIFFERENCE IN ENSEMBLE
BEHAVIOR CLONING
When training an ensemble of N policies, denoted as
{π
i
}
1≤i≤N
, on a given dataset D = {(s
t
,a
t
)}
t
consist-
ing of state-action pairs, each policy π
i
is trained inde-
pendently to predict actions based on the input states.
Due to differences in the training paths and the in-
herent variability in the learning process, the ensem-
ble members typically produce different action pre-
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
24
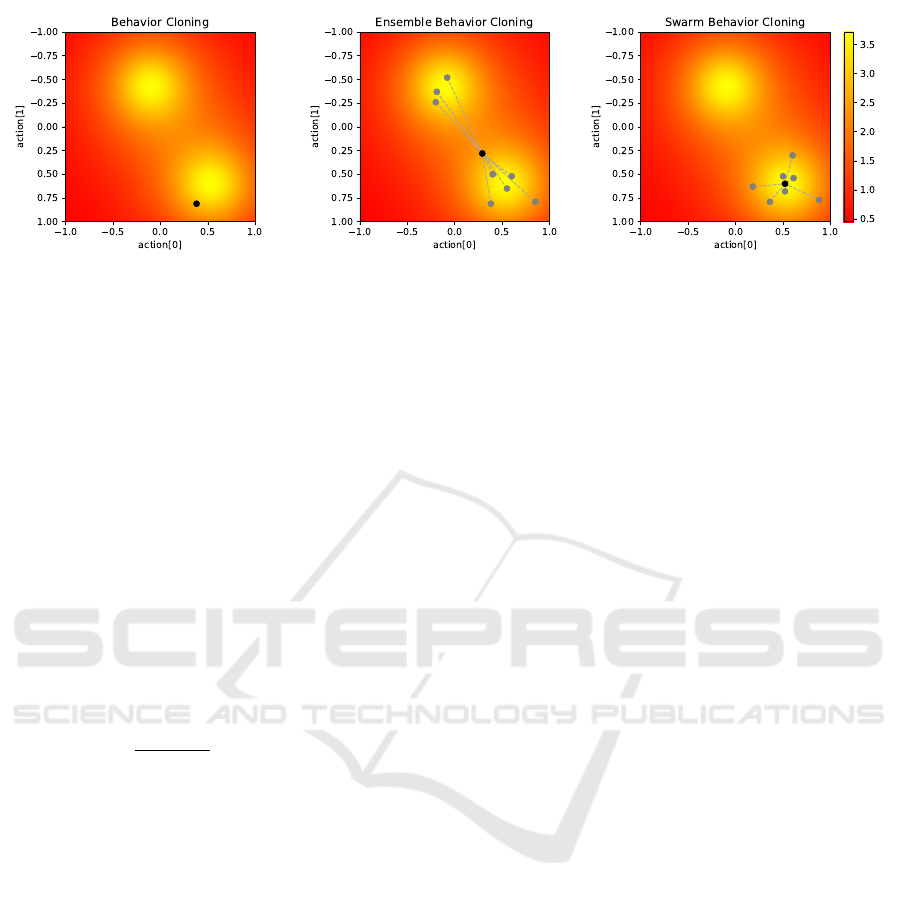
Figure 1: This figure visualizes schematically the predicted actions of three different Behavior Cloning approaches, repre-
sented as black dots, in a 2-dim action space for some state s
t
. The heatmap represents the Q-values Q(a
t
,s
t
). (Left) the left
plot shows plain Behavior Cloning. A policy π was trained using supervised learning on some training data D. The black dot
is the predicted action a
t
= π(s
t
). (Middle) in Ensemble Behavior Cloning an ensemble of N policies is trained individually
on D. The N predicted actions {a
i
= π
i
(s
t
)} (gray dots) are then aggregated to the ensemble action (black dot). (Right) in our
approach Swarm Behavior Cloning an ensemble of N policies is trained as well. However, they are not trained individually but
using a modified loss function, see formula (2). The effect is a smaller difference between the N predicted actions, resembling
a swarm behavior. Similar to Ensemble Behavior Cloning the ensemble action (black dot) is then aggregated from the N
predicted actions (gray dots).
dictions for the same state s. This divergence can be
quantified through the concept of mean action differ-
ence, which we formally introduce in Definition 3.1.
Definition 1 (Mean Action Difference). Let E =
{π
i
}
1≤i≤N
represent an ensemble of N policies, and
let s be a given state. For the ensemble E, we can
compute N action predictions, denoted as A = {a
i
=
π
i
(s)}
1≤i≤N
. The mean action difference, d, is defined
as the average pairwise L2-norm between the actions
in A. Formally, the mean action difference d is given
by:
d =
2
N(N − 1)
∑
i
∑
j>i
∥a
i
− a
j
∥
This measure quantifies the average difference be-
tween the action predictions of the ensemble members
for a particular state s. A higher value of d indi-
cates greater divergence in the actions predicted by
the policies, whereas a lower value suggests that the
ensemble members are more consistent in their pre-
dictions.
In Figure 2 (left), we illustrate the mean ac-
tion difference across an entire episode within the
LunarLander-continuous environment. The ensem-
ble in this experiment consisted of six policies trained
on a dataset D derived from a single expert demon-
stration. The expert used for this demonstration was
a fully-trained Soft-Actor-Critic (SAC) model from
Stable-Baselines 3 (Raffin et al., 2021). The figure
highlights areas with both high and low mean action
differences. In regions with high mean action dif-
ference, the ensemble members produce actions that
are quite divergent, whereas regions with low mean
action difference show greater agreement among the
predictions.
To explore this phenomenon further, we analyzed
two specific timesteps, t = 120 and t = 225, where
we visualized the actions predicted by the N = 6 poli-
cies (represented by gray dots) alongside the aggre-
gated action (black dot) on the 2D action space of
this environment. The Q-value heatmap, provided by
the expert SAC critic network, is also displayed. No-
tably, in the upper-right plot, we observe a scenario
where the Q-value of the aggregated action, Q(a,s), is
lower than the Q-values of all individual actions, i.e.,
Q(a,s) < Q(a
i
,s) for all i. This phenomenon is more
prevalent in states where the mean action difference
is large, leading to suboptimal aggregated actions due
to the inconsistency among the policies.
In Chapter 5, we present a modified training loss
designed to tackle the problem of divergent action
predictions within the ensemble. This new loss func-
tion encourages the individual policies in the en-
semble to learn more similar hidden feature repre-
sentations, effectively reducing the mean action dif-
ference. By fostering greater alignment among
the policies while preserving the diversity of their
computations, the ensemble retains its inherent
strengths—such as robustness and varied decision-
making—while producing more consistent actions.
This reduction in action divergence improves the
quality of the aggregated actions, ultimately leading
to enhanced overall performance.
4 RELATED WORK
Imitation Learning is broadly divided into Behavior
Cloning (BC) and Inverse Reinforcement Learning
Swarm Behavior Cloning
25
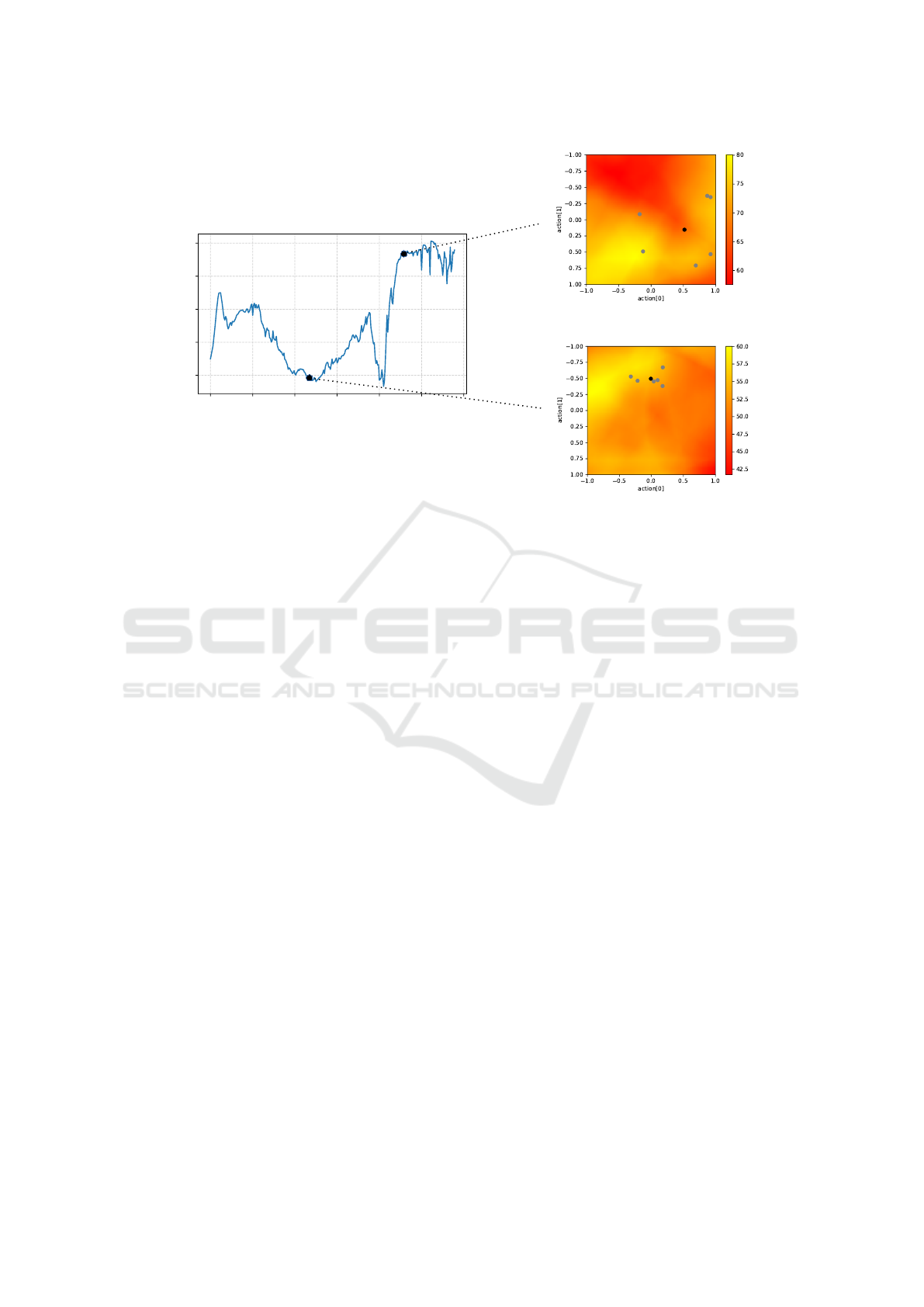
0 50 100 150 200 250 300
Step in Episode
0.2
0.3
0.4
0.5
0.6
Mean Action Dierence
Figure 2: This figure visualizes exemplarily the mean action difference for an entire episode of an ensemble containing N = 6
policies. We used the LunarLander-continuous environment since it has a 2-dim action space that can be easily visualized.
The x-axis in the left plot represents the timestep in the episode. For two interesting timesteps, we have visualized the
predicted actions of the N policies {a
i
t
= π
i
(s
t
)} (gray dots) as well as the aggregated action (black dot) on a 2-dim map (the
complete action space). The underlying heatmap represents the Q-values from the expert critic (a fully-trained SAC model
from Stable-Baselines 3).
(IRL) (Zheng et al., 2021; Torabi et al., 2019b). While
in Behavior Cloning the goal is to learn a direct map-
ping from states to actions (Bain and Sammut, 1995;
Torabi et al., 2018; Florence et al., 2022), IRL is a
two-step process. First, the missing Markov Deci-
sion Process (MDP) reward function is reconstructed
from expert data, and then a policy is learned with
it using classical reinforcement learning (Arora and
Doshi, 2021; Ng et al., 2000). Besides BC and IRL,
there are also adversarial methods such as GAIL (Ho
and Ermon, 2016) or GAIfO (Torabi et al., 2019a).
BC approaches cannot be adequately compared to
IRL or adversarial methods, since the latter two re-
quire access to the environment for sampling addi-
tional episodes. Therefore, we compare our approach
only against other Behavior Cloning approaches: BC
(Bain and Sammut, 1995) and Ensemble BC (Yang
et al., 2022).
Besides these approaches, other Behavior Cloning
algorithms exist which, however, require additional
inputs or assumptions. In (Brantley et al., 2019) the
algorithm Disagreement-regularized imitation learn-
ing is presented that first learns a standard BC ensem-
ble. In the second phase, another policy is learned by
using a combination of BC and RL, in which the re-
ward function is to not drift into states where the vari-
ance of the ensemble action predictions is large. The
policy therefore has two goals: (1) it should act simi-
larly to the expert (2) the policy should only perform
actions that ensure the agent doesn’t leave the expert’s
state distribution. However, this approach also re-
quires further interactions with the environment mak-
ing it inappropriate to compare against a pure Behav-
ior Cloning algorithm. The similarity to our approach
Swarm BC is that both algorithms try to learn a policy
that has a low mean action difference. Our algorithm
can therefore be understood as a completely offline
version of Disagreement-regularized imitation learn-
ing.
In (Smith et al., 2023) the proposed algorithm IL-
BRL requires an additional exploration dataset be-
yond the expert dataset and subsequently uses any
Offline RL algorithm. In (Hussein et al., 2021) a
data-cleaning mechanism is presented to remove sub-
optimal (adversarial) demonstrations from D before
applying BC. (Torabi et al., 2018) proposes a state-
only BC approach using a learned inverse dynamics
model for inferring the executed action.
In (Shafiullah et al., 2022) Behavior Transformers
are introduced for learning offline from multi-modal
data. The authors in (Wen et al., 2020) present a BC
adaption for combating the ”copycat problem” that
emerges if the policy has access to a sliding win-
dow of past observations. In this paper, we assume
a Markov policy that only receives the last state as in-
put. Therefore the ”copycat problem” does not apply
here.
There is much literature on ensemble methods
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
26

(Dong et al., 2020; Sagi and Rokach, 2018; Diet-
terich et al., 2002; Zhou and Zhou, 2021; Webb and
Zheng, 2004). The main difference of current en-
semble methods to our approach is that we encourage
the ensemble members to reduce the output diversity,
while current methods try to increase the output di-
versity. We show that in Markov Decision Problem
environments, ensembles with large action diversities
can lead to poor aggregated actions. In the next chap-
ter, we therefore present an algorithm that reduces the
mean action difference.
5 SWARM BEHAVIOR CLONING
In this section, we introduce our proposed approach,
Swarm Behavior Cloning (Swarm BC), which aims to
reduce the divergence in action predictions among en-
semble policies by encouraging them to learn similar
hidden feature representations.
We assume that each of the N policies in the en-
semble E = {π
i
}
1≤i≤N
is modeled as a standard Mul-
tilayer Perceptron (MLP). The hidden feature activa-
tions of policy π
i
at hidden layer k, given input state s,
are represented as h
ik
(s) ∈ R
m
, where m is the number
of neurons in that hidden layer. These hidden activa-
tions form the basis of the ensemble’s predictions.
Consider a training data point (s,a) ∈ D, where s
is the state and a is the expert’s action. In standard
Behavior Cloning (BC), each policy in the ensem-
ble is trained individually using a supervised learning
loss function. The goal is to minimize the difference
between each policy’s predicted action π
i
(s) and the
corresponding expert action a. The standard loss for
training a BC ensemble is given by:
L(s,a) =
∑
i
(π
i
(s) − a)
2
(1)
This formulation treats each policy independently,
which can lead to divergence in their predicted ac-
tions, especially in underrepresented states, resulting
in a high mean action difference.
The core idea behind Swarm BC is to introduce
an additional mechanism that encourages the poli-
cies to learn more similar hidden feature activations,
which in turn reduces the variance in their predicted
actions. This is achieved by modifying the standard
loss function to include a regularization term that pe-
nalizes large differences in hidden feature activations
between policies. The adjusted loss function is:
L(s,a) =
∑
i
(π
i
(s) − a)
2
+ τ
∑
k
∑
i< j
h
ik
(s) − h
jk
(s)
2
(2)
Algorithm 1: Swarm Behavior Cloning.
Input: expert data D = {(s,a = π
e
(s))}
Parameters:
τ (regularization coefficient)
N (number of policies in the ensemble)
Output: trained ensemble E = {π
i
}
1≤i≤N
. Pre-
dict an action a for a state s using formula
(3)
1: initialize N policies E = {π
i
}
1≤i≤N
2: train ensemble E on D using loss (2)
3: return trained ensemble E
The first term is the standard supervised learn-
ing loss, which minimizes the difference between the
predicted action π
i
(s) and the expert action a. The
second term introduces a penalty for dissimilarity be-
tween the hidden feature activations of different poli-
cies at each hidden layer k. The hyperparameter τ
controls the balance between these two objectives: re-
ducing action divergence and maintaining accuracy in
reproducing the expert’s behavior.
By incorporating this regularization term, the
individual policies in the ensemble are encouraged
to align their internal representations of the state
space, thereby reducing the mean action difference.
At the same time, the diversity of the ensemble is
preserved to some extent, allowing the individual
policies to explore different solution paths while
producing more consistent outputs.
The final action of the ensemble, known as the en-
semble action, is computed as the average of the ac-
tions predicted by the N policies, following the stan-
dard approach in ensemble BC:
a =
1
N
∑
i
π
i
(s) (3)
This averaging mechanism allows the ensemble to
benefit from the collective knowledge of all policies,
while the regularization ensures that the predictions
remain aligned.
The overall procedure for Swarm BC is summa-
rized in Algorithm 1. The algorithm takes as input
the expert dataset D = (s,a = π
e
(s)), the number of
ensemble members N, and the hyperparameter τ. It
outputs a trained ensemble E = {π
i
}
1≤i≤N
capable
of making robust action predictions by computing the
ensemble action as shown in Equation (3).
6 EXPERIMENTS
In this experiments section, we want to verify the fol-
lowing two hypotheses:
Swarm Behavior Cloning
27

• Using our algorithm Swarm Behavior Cloning we
can reduce the mean action difference as defined
in Definition 3.1 compared to standard Ensemble
Behavior Cloning.
• Swarm Behavior Cloning shows a better perfor-
mance compared to baseline algorithms in terms
of mean episode return.
For testing these hypotheses we used a large set of
eight different OpenAI Gym environments (Brock-
man et al., 2016): HalfCheetah, BipedalWalker,
LunarLander-continuous, CartPole, Walker2D, Hop-
per, Acrobot and Ant. They resemble a large and
diverse set of environments containing discrete and
continuous action spaces and observation space sizes
ranging from 4-dim to 27-dim.
To examine if Swarm BC improves the test perfor-
mance of the agent we used a similar setting as in (Ho
and Ermon, 2016). We used trained SAC- (for con-
tinuous action spaces) and PPO- (for discrete action
spaces) models from Stable-Baselines 3 (Raffin et al.,
2021) as experts and used them to create datasets D
containing x ∈ [1, 8] episodes. Then we trained our
approach and two baseline approaches until conver-
gence. We repeated this procedure for 5 seeds. The
result is presented in Figure 3.
For easier comparison between environments, we
scaled the return. For this, we first determined
the mean episode return following the expert pol-
icy R
expert
and the random policy R
random
. Then we
used the formula R
scaled
= (R − R
random
)/(R
expert
−
R
random
) for scaling the return into the interval [0,1]. 0
represents the performance of the random policy and
1 of the expert policy.
The solid lines in Figure 3 show the mean test per-
formance for 20 episodes and 5 seeds. The shaded
areas represent the standard deviation.
The main conclusion we can draw from this ex-
periment is that Swarm BC was nearly never worse
than BC or Ensemble BC and in larger environments
significantly better. In HalfCheetah, for example, the
agent achieved a mean scaled episode return of 0.72
using Swarm BC for datasets D containing 8 expert
episodes and just 0.17 using Ensemble BC. Ensemble
BC still performed better than single BC in most en-
vironments.
To test whether our approach does reduce the
mean action difference as introduced in Definition 3.1
we used the same trained models from the previous
experiment and calculated the mean action difference
for each timestep in the test episodes. The x-axes in
Figure 4 represent the timestep and the y-axes repre-
sent the mean action difference. The plots show the
average for 20 episodes and 5 seeds. Swarm Behav-
ior Cloning did reduce the mean action difference, but
not always to the same extend. In the BipedalWalker
environment it was reduced by almost 44% while in
Ant it was only reduced by 11%.
Nevertheless, we can verify the hypothesis that
Swarm BC does reduce the mean action difference.
Swarm BC shows significantly better performance
compared to baseline algorithms with nearly no com-
putational overhead. The main disadvantage however
is the introduction of another hyperparameter τ. To
test the sensitivity of this parameter we conducted an
ablation study regarding τ and also about N (the num-
ber of policies in the ensemble E). The results are
plotted in Figure 5. For this ablation study, we used
the Walker2D environment and again scaled the return
for better comparison. For τ we tested values within
{0.0,0.25,0.5, 0.75,1.0}. The main conclusion for
the ablation in τ is that too large values can decrease
the performance. τ = 0.25 worked best so we used
this value for all other experiments in this paper.
For the ablation on N we tested values in the set
{2,4,6, 8}. For N = 2 the test performance was sig-
nificantly below the test performance for N = 4. For
larger ensembles (N = 6 and N = 8) the performance
did not increase significantly anymore. But since the
training time scales linearly with the number of poli-
cies N we chose N = 4 for all experiments.
As a conclusion of this experiments section we
can verify both hypotheses that Swarm BC increases
test performance and decreases the mean action dif-
ference. In the next chapter, we provide a theoretical
analysis of our approach.
7 THEORETICAL ANALYSIS
Let (s,a) ∈ D be a random but fixed state-action tuple
out of the training dataset D. Let E = {π
i
}
1≤i≤N
be an
ensemble of N policies, each represented as an MLP
containing K hidden layers. For state s the ensemble
E produces N hidden feature activation h
i,k
for each
layer k ∈ [1, K].
The basic idea of our approach Swarm BC is to
train an ensemble E that produces similar hidden fea-
tures:
∀ (i, j) ∈ [1,N]
2
,k ∈ [1,K] : h
i,k
≈ h
j,k
By doing so the ensemble tries to find features h
i,k
that can be transformed by at least N different trans-
formations to the desired action a since we have no
restriction regarding the weights W, b:
h
i,k+1
= σ(W
i,k
· h
i,k
+ b
i,k
)
Training a single neural net f
φ
with parameters φ on
D with some fixed hyperparameters Q corresponds to
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
28
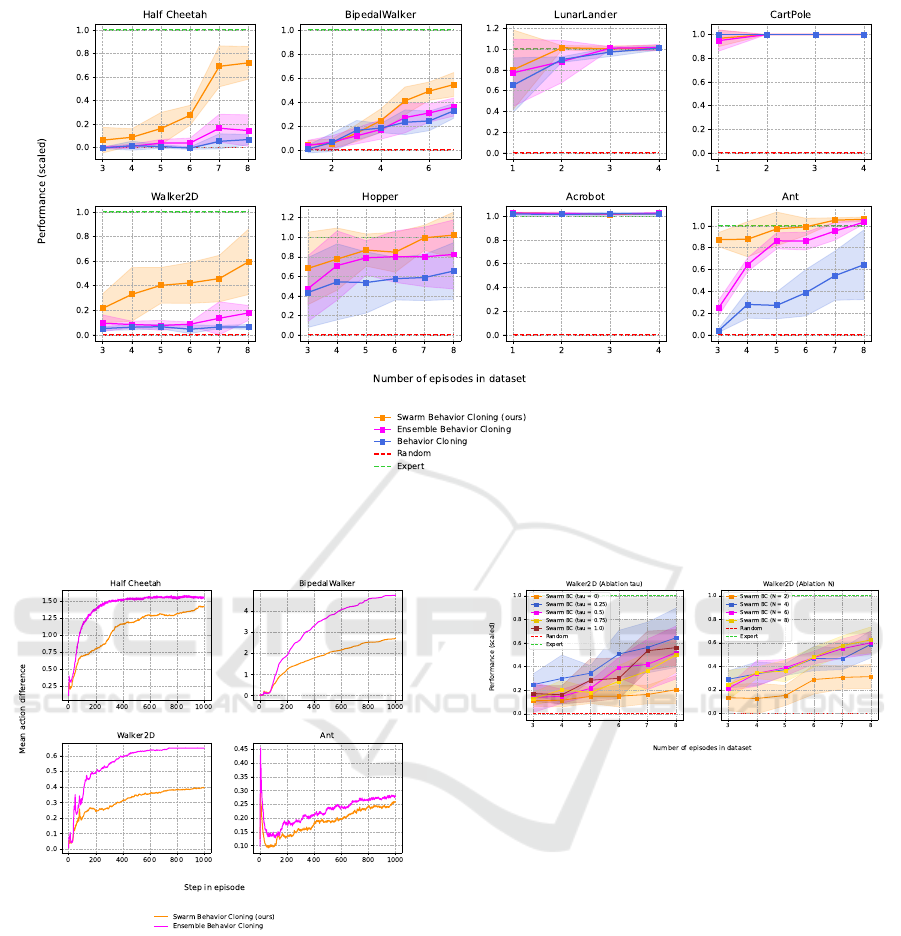
Figure 3: These plots show the mean normalized test returns of our approach Swarm BC and two baseline algorithms on eight
different OpenAI Gym environments. The graphs represent the mean over 20 episodes and 5 seeds. The x-axes represent the
number of expert episodes in the training data D. The results show a significant performance improvement in environments
with larger observation- and action spaces.
Figure 4: In this figure we are evaluating whether Swarm
BC can reduce the mean action difference as defined in Def-
inition 3.1, which is the difference between the N predicted
actions {a
i
= π
i
(s)}
1≤i≤N
of an ensemble E containing N
policies. The results show that our approach does indeed
reduce it but depending on the environment not always to
the same extent. The x-axes in these plots represent the
timestep in the test episodes and the y-axes represent the
mean action difference. The graphs are the mean over 20
episodes and 5 seeds.
sampling from the probability density function (pdf):
φ ∼ p(φ | D, Q)
Since D and Q are fixed we can shorten this expres-
Figure 5: To examine the sensitivity of the two hyperpa-
rameters τ and N we did an ablation study. (Left) choosing
τ too large or too small can reduce the test performance in
terms of mean episode return. For Walker2D the best value
was τ = 0.25. Thus, we chose this value for all experiments
in this paper. (Right) the conclusion of the ablation on the
ensemble size N is that larger N are better, but this comes
at the expense of longer runtime. For N > 4, however, the
performance does not increase significantly anymore. Thus
we chose N = 4 for all experiments in this paper.
sion to p(φ). The pdf for hidden features h
k
for state
s corresponds to the integral over all weights that pro-
duce the same feature activations:
p(h
k
| s) =
Z
φ
1[
ˆ
f
k
φ
(s) = h
k
] · p(φ)
For a fixed state s we can shorten this expression to
p(h
k
).
We now show that training an ensemble with sim-
ilar feature activations corresponds to finding the
global mode of the pdf p(h
k
).
If we are training a standard ensemble, we are sam-
pling N times independently from the pdf p(h
k
). But
Swarm Behavior Cloning
29

the pdf for sampling N times the same hidden feature
activation corresponds to:
p
N
(h
k
) =
p(h
k
)
N
R
ϕ
p(ϕ)
N
with
p(h
k
)
N
=
N
∏
i=1
p(h
k
)
For N → ∞ the pdf p
N
(h
k
) corresponds to the Dirac
delta function being p
N
(h
k
) = +∞ for the mode h
+
k
of
p(h
k
) and 0 elsewhere (if there is just one mode). So
we just need to sample once from p
N
(h
k
) to get the
mode h
+
k
. Note that the probability density p(h
k
) is
not the probability for sampling h
k
. The probability
for sampling a specific h
k
is always 0. The probabil-
ity can just be inferred by integrating the density over
some space. We use as a space the hypercube T of
length τ around activation h
k
:
P
N
τ
(h
k
) =
Z
T
p
N
(h
k
)
Proposition: For τ → 0 and N → ∞, the probability
for sampling the global mode with maximum error τ
from p
N
(h
k
) is P
N
τ
(h
+
k
) = 1 if p(h
k
) is continuously
differentiable, there is just a single mode h
+
k
and the
activation space H
k
∋ h
k
is a bounded hypercube.
Proof : By assumption we know that the activation
space H
k
is a bounded hypercube of edge length l and
number of dimensions m. We further know that h
+
k
is the only mode of p(h
k
) and p(h
k
) is continuously
differentiable (i.e. p(h
k
) is differentiable and its devi-
ation is continuous which implies that there is a max-
imum absolute gradient).
For a given τ ∈ (0; ∞) we split the hypercube
H
k
in each dimension into
l
τ
parts. Thus H
k
is
split into
l
τ
m
sub-hypercubes. Each of them has
maximum volume τ
m
. If the mode h
+
k
lies on the
edge between two sub-hypercubes we move all sub-
hypercubes by τ/2. So we need a maximum of
l
τ
+ 1
m
sub-hypercubes to ensure that h
+
k
lies in ex-
actly one sub-hypercube. We name it H
+
and all
other sub-hypercubes are labeled {H
−
i
}
1≤i<
l
τ
+1
m
.
We can calculate the mode for p(h
k
) in the remaining
space of H
k
without H
+
as follows:
h
#
k
= argmax
h
k
∈H
k
\H
+
p(h
k
)
Now we can calculate the upper bound for the proba-
bility mass in each H
−
sub-hypercube by integrating
the maximal possible density p(h
#
k
) over the maximal
possible volume τ
m
:
P(H
−
) ≤ τ
m
· p(h
#
k
)
Since h
+
k
is the only mode, H
k
is bounded and p(h
k
)
is continuously differentiable there is a β ∈ R
+
such
that: p(h
+
k
) = p(h
#
k
) + β. This implies that there is
a sub-hypercube H
∗
inside of H
+
with edge length
˜
τ < τ such that:
∀ h
k
∈ H
∗
: p(h
k
) > p(h
#
k
) +
1
2
·
p(h
+
k
) − p(h
#
k
)
Thus we can calculate a lower bound for the probabil-
ity mass in H
+
:
P(H
+
) ≥
˜
τ
m
·
p(h
#
k
) +
1
2
·
p(h
+
k
) − p(h
#
k
)
=
=
˜
τ
m
2
p(h
#
k
) + p(h
+
k
)
We can generalize both bounds to P
N
(H) :
P
N
(H
−
) ≤
τ
m
· p(h
#
k
)
N
Z
P
N
(H
+
) ≥
˜
τ
m
·
p(h
#
k
)
N
+ p(h
+
k
)
N
2Z
with Z being the normalization constant:
Z =
Z
h
k
∈H
k
p(h
k
)
N
Let α ∈ [0;∞) be a threshold. To proof that P
N
τ
(h
k
)
approximates the global mode of p(h
k
) for τ → 0 and
N → ∞ we need to show that for any α and any τ ∈
(0;∞) we can choose N ∈ N such that:
P
N
(H
+
)
l
τ
+ 1
m
· P
N
(H
−
)
≥ α
Because this would mean we can shift arbitrarily
much probability mass into the sub-hypercube H
+
by
increasing N. For that let’s consider the ratio:
P
N
(H
+
)
P
N
(H
−
)
≥
˜
τ
m
· p(h
#
k
)
N
+
˜
τ
m
· p(h
+
k
)
N
2τ
m
· p(h
#
k
)
N
=
=
˜
τ
m
2τ
m
|{z}
≡c
·
1 +
p(h
+
k
)
p(h
#
k
)
N
!
Since h
+
k
is the only mode the density p(h
+
k
) is larger
than p(h
#
k
). We can therefore see that the ratio gets
arbitrarily large for N → ∞. So we can choose N ac-
cording to:
P
N
(H
+
)
l
τ
+ 1
m
· P
N
(H
−
)
≥
c
l
τ
+ 1
m
·
"
1 +
p(h
+
k
)
p(h
#
k
)
N
#
!
≥ α
⇒ N =
&
ln
l
τ
+1
m
·α
c
− 1
ln
p(φ
+
)
p(φ
#
)
'
□
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
30

8 CONCLUSION
Behavior Cloning (BC) is a crucial method within Im-
itation Learning, enabling agents to be trained safely
using a dataset of pre-collected state-action pairs pro-
vided by an expert. However, when applied in an en-
semble framework, BC can suffer from the issue of in-
creasing action differences, particularly in states that
are underrepresented in the training data D = (s
t
,a
t
)
t
.
These large mean action differences among the en-
semble policies can lead to suboptimal aggregated ac-
tions, which degrade the overall performance of the
agent.
In this paper, we proposed Swarm Behavior
Cloning (Swarm BC) to address this challenge. By
fostering greater alignment among the policies while
preserving the diversity of their computations, our ap-
proach encourages the ensemble to learn more similar
hidden feature representations. This adjustment effec-
tively reduces action prediction divergence, allowing
the ensemble to retain its inherent strengths—such as
robustness and varied decision-making—while pro-
ducing more consistent and reliable actions.
We evaluated Swarm BC across eight diverse
OpenAI Gym environments, demonstrating that it ef-
fectively reduces mean action differences and signif-
icantly improves the agent’s test performance, mea-
sured by episode returns.
Finally, we provided a theoretical analysis show-
ing that our method approximates the hidden fea-
ture activations with the highest probability den-
sity, effectively learning the global mode h
∗
k
=
argmax
h
k
; p(h
k
;|; D) based on the training data D. This
theoretical insight further supports the practical per-
formance gains observed in our experiments.
REFERENCES
Arora, S. and Doshi, P. (2021). A survey of inverse
reinforcement learning: Challenges, methods and
progress. Artificial Intelligence, 297:103500.
Bain, M. and Sammut, C. (1995). A framework for be-
havioural cloning. In Machine Intelligence 15, pages
103–129.
Bojarski, M., Del Testa, D., Dworakowski, D., Firner,
B., Flepp, B., Goyal, P., Jackel, L. D., Monfort,
M., Muller, U., Zhang, J., et al. (2016). End to
end learning for self-driving cars. arXiv preprint
arXiv:1604.07316.
Brantley, K., Sun, W., and Henaff, M. (2019).
Disagreement-regularized imitation learning. In
International Conference on Learning Representa-
tions.
Brockman, G., Cheung, V., Pettersson, L., Schneider, J.,
Schulman, J., Tang, J., and Zaremba, W. (2016). Ope-
nai gym. arXiv preprint arXiv:1606.01540.
Codevilla, F., Santana, E., L
´
opez, A. M., and Gaidon,
A. (2019). Exploring the limitations of behavior
cloning for autonomous driving. In Proceedings of
the IEEE/CVF International Conference on Computer
Vision, pages 9329–9338.
Dietterich, T. G. et al. (2002). Ensemble learning.
The handbook of brain theory and neural networks,
2(1):110–125.
Dong, X., Yu, Z., Cao, W., Shi, Y., and Ma, Q. (2020). A
survey on ensemble learning. Frontiers of Computer
Science, 14:241–258.
Eschmann, J. (2021). Reward function design in reinforce-
ment learning. Reinforcement Learning Algorithms:
Analysis and Applications, pages 25–33.
Finn, C., Levine, S., and Abbeel, P. (2016). Guided cost
learning: Deep inverse optimal control via policy op-
timization. In International conference on machine
learning, pages 49–58. PMLR.
Florence, P., Lynch, C., Zeng, A., Ramirez, O. A., Wahid,
A., Downs, L., Wong, A., Lee, J., Mordatch, I.,
and Tompson, J. (2022). Implicit behavioral cloning.
In Conference on Robot Learning, pages 158–168.
PMLR.
Giusti, A., Guzzi, J., Cires¸an, D. C., He, F.-L., Rodr
´
ıguez,
J. P., Fontana, F., Faessler, M., Forster, C., Schmidhu-
ber, J., Di Caro, G., et al. (2015). A machine learning
approach to visual perception of forest trails for mo-
bile robots. IEEE Robotics and Automation Letters,
1(2):661–667.
Ho, J. and Ermon, S. (2016). Generative adversarial imi-
tation learning. Advances in neural information pro-
cessing systems, 29.
Hussein, M., Crowe, B., Petrik, M., and Begum, M. (2021).
Robust maximum entropy behavior cloning. arXiv
preprint arXiv:2101.01251.
Knox, W. B., Allievi, A., Banzhaf, H., Schmitt, F., and
Stone, P. (2023). Reward (mis) design for autonomous
driving. Artificial Intelligence, 316:103829.
Ng, A. Y., Russell, S., et al. (2000). Algorithms for inverse
reinforcement learning. In Icml, volume 1, page 2.
N
¨
ußlein, J., Illium, S., M
¨
uller, R., Gabor, T., and Linnhoff-
Popien, C. (2022). Case-based inverse reinforcement
learning using temporal coherence. In International
Conference on Case-Based Reasoning, pages 304–
317. Springer.
Phan, T., Ritz, F., Altmann, P., Zorn, M., N
¨
ußlein, J.,
K
¨
olle, M., Gabor, T., and Linnhoff-Popien, C. (2023).
Attention-based recurrence for multi-agent reinforce-
ment learning under stochastic partial observability.
In International Conference on Machine Learning,
pages 27840–27853. PMLR.
Raffin, A., Hill, A., Gleave, A., Kanervisto, A., Ernestus,
M., and Dormann, N. (2021). Stable-baselines3: Reli-
able reinforcement learning implementations. Journal
of Machine Learning Research, 22(268):1–8.
Swarm Behavior Cloning
31

Sagi, O. and Rokach, L. (2018). Ensemble learning: A sur-
vey. Wiley Interdisciplinary Reviews: Data Mining
and Knowledge Discovery, 8(4):e1249.
Shafiullah, N. M., Cui, Z., Altanzaya, A. A., and Pinto, L.
(2022). Behavior transformers: Cloning k modes with
one stone. Advances in neural information processing
systems, 35:22955–22968.
Smith, M., Maystre, L., Dai, Z., and Ciosek, K. (2023).
A strong baseline for batch imitation learning. arXiv
preprint arXiv:2302.02788.
Sutton, R. S. and Barto, A. G. (2018). Reinforcement learn-
ing: An introduction. MIT press.
Torabi, F., Warnell, G., and Stone, P. (2018). Be-
havioral cloning from observation. arXiv preprint
arXiv:1805.01954.
Torabi, F., Warnell, G., and Stone, P. (2019a). Adversarial
imitation learning from state-only demonstrations. In
Proceedings of the 18th International Conference on
Autonomous Agents and MultiAgent Systems, pages
2229–2231.
Torabi, F., Warnell, G., and Stone, P. (2019b). Recent ad-
vances in imitation learning from observation. arXiv
preprint arXiv:1905.13566.
Webb, G. I. and Zheng, Z. (2004). Multistrategy ensem-
ble learning: Reducing error by combining ensemble
learning techniques. IEEE Transactions on Knowl-
edge and Data Engineering, 16(8):980–991.
Wen, C., Lin, J., Darrell, T., Jayaraman, D., and Gao, Y.
(2020). Fighting copycat agents in behavioral cloning
from observation histories. Advances in Neural Infor-
mation Processing Systems, 33:2564–2575.
Yang, Z., Ren, K., Luo, X., Liu, M., Liu, W., Bian, J.,
Zhang, W., and Li, D. (2022). Towards applicable
reinforcement learning: Improving the generalization
and sample efficiency with policy ensemble. arXiv
preprint arXiv:2205.09284.
Zheng, B., Verma, S., Zhou, J., Tsang, I., and Chen, F.
(2021). Imitation learning: Progress, taxonomies and
challenges. arXiv preprint arXiv:2106.12177.
Zhifei, S. and Meng Joo, E. (2012). A survey of in-
verse reinforcement learning techniques. Interna-
tional Journal of Intelligent Computing and Cybernet-
ics, 5(3):293–311.
Zhou, Z.-H. and Zhou, Z.-H. (2021). Ensemble learning.
Springer.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
32
