
Optimizing Sensor Redundancy in Sequential Decision-Making Problems
Jonas N
¨
ußlein, Maximilian Zorn, Fabian Ritz, Jonas Stein, Gerhard Stenzel, Julian Sch
¨
onberger,
Thomas Gabor and Claudia Linnhoff-Popien
Institute of Computer Science, LMU Munich, Germany
fi
Keywords:
Reinforcement Learning, Sensor Redundancy, Robustness, Optimization.
Abstract:
Reinforcement Learning (RL) policies are designed to predict actions based on current observations to max-
imize cumulative future rewards. In real-world, i.e. not simulated, environments, sensors are essential for
measuring the current state and providing the observations on which RL policies rely to make decisions. A
significant challenge in deploying RL policies in real-world scenarios is handling sensor dropouts, which can
result from hardware malfunctions, physical damage, or environmental factors like dust on a camera lens. A
common strategy to mitigate this issue is to use backup sensors, though this comes with added costs. This
paper explores the optimization of backup sensor configurations to maximize expected returns while keeping
costs below a specified threshold, C. Our approach uses a second-order approximation of expected returns
and includes penalties for exceeding cost constraints. The approach is evaluated across eight OpenAI Gym
environments and a custom Unity-based robotic environment (RobotArmGrasping). Empirical results demon-
strate that our quadratic program effectively approximates real expected returns, facilitating the identification
of optimal sensor configurations.
1 INTRODUCTION
Reinforcement Learning (RL) has emerged as a
prominent technique for solving sequential decision-
making problems, paving the way for highly au-
tonomous systems across diverse fields. From
controlling complex physical systems like tokamak
plasma (Degrave et al., 2022) to mastering strategic
games such as Go (Silver et al., 2018), RL has demon-
strated its potential to revolutionize various domains.
However, when transitioning from controlled envi-
ronments to real-world applications, RL faces sub-
stantial challenges, particularly in dealing with sen-
sor dropouts. In critical scenarios, such as healthcare
or autonomous driving, the failure of sensors can re-
sult in suboptimal decisions or even catastrophic out-
comes.
The core of RL decision-making lies in its reliance
on continuous, accurate observations of the environ-
ment, often captured through sensors. When these
sensors fail to provide reliable data — whether due to
hardware malfunctions, environmental interference,
or physical damage — the performance of RL policies
can degrade significantly (Dulac-Arnold et al., 2019).
In domains such as aerospace, healthcare, nuclear en-
ergy, and autonomous vehicles, the consequences of
sensor failures are particularly severe. This vulner-
ability highlights the importance of addressing sen-
sor dropout to ensure the robustness of RL systems
in real-world applications. Thus, improving the re-
silience of RL systems to sensor dropouts is not just
desirable—it is critical for ensuring their safe and re-
liable deployment in mission-critical applications.
One common approach to mitigate the risks of
sensor dropouts is the implementation of redundant
backup sensors. These backup systems provide an ad-
ditional layer of security, stepping in when primary
sensors fail, thereby maintaining the availability of
crucial data. While redundancy can enhance system
resilience, it also introduces significant costs, and not
all sensor dropouts result in performance degrada-
tion severe enough to justify the investment in back-
ups. This paper presents a novel approach to op-
timizing backup sensor configurations in RL-based
systems. Our method focuses on balancing system
performance — quantified by expected returns in a
Markov Decision Process (MDP) — and the costs as-
sociated with redundant sensors.
1
1
This publication was created as part of the Q-Grid
project (13N16179) under the “quantum technologies –
from basic research to market” funding program, supported
by the German Federal Ministry of Education and Research.
Nüßlein, J., Zorn, M., Ritz, F., Stein, J., Stenzel, G., Schönberger, J., Gabor, T. and Linnhoff-Popien, C.
Optimizing Sensor Redundancy in Sequential Decision-Making Problems.
DOI: 10.5220/0013086700003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 1, pages 245-252
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
245

2 BACKGROUND
2.1 Markov Decision Processes (MDP)
Sequential Decision-Making problems are frequently
modeled as Markov Decision Processes (MDPs). An
MDP is defined by the tuple E = ⟨S, A,T, r, p
0
,γ⟩,
where S represents the set of states, A is the set of
actions, and T (s
t+1
| s
t
,a
t
) is the probability density
function (pdf) that governs the transition to the next
state s
t+1
after taking action a
t
in state s
t
. The pro-
cess is considered Markovian because the transition
probability depends only on the current state s
t
and
the action a
t
, and not on any prior states s
τ<t
.
The function r : S ×A → R assigns a scalar reward
to each state-action pair (s
t
,a
t
). The initial state is
sampled from the start-state distribution p
0
, and γ ∈
[0,1) is the discount factor, which applies diminishing
weight to future rewards, giving higher importance to
immediate rewards.
A deterministic policy π : S → A is a mapping
that assigns an action to each state. The return R =
∑
∞
t=0
γ
t
· r(s
t
,a
t
) is the total (discounted) sum of re-
wards accumulated over an episode. The objective,
typically addressed by Reinforcement Learning (RL),
is to find an optimal policy π
∗
that maximizes the ex-
pected cumulative return:
π
∗
= argmax
π
E
p
0
"
∞
∑
t=0
γ
t
· r(s
t
,a
t
) | π
#
Actions a
t
are selected according to the policy π.
In Deep Reinforcement Learning (DRL), where state
and action spaces can be large and continuous, the
policy π is often represented by a neural network
ˆ
f
φ
(s)
with parameters φ, which are learned through training
(Sutton and Barto, 2018).
2.2 Quadratic Unconstrained Binary
Optimization (QUBO)
Quadratic Unconstrained Binary Optimization
(QUBO) is a combinatorial optimization problem
defined by a symmetric, real-valued (m × m) matrix
Q, and a binary vector x ∈ B
m
. The objective of
a QUBO problem is to minimize the following
quadratic function:
x
∗
= argmin
x
H(x) = argmin
x
m
∑
i=1
m
∑
j=i
x
i
x
j
Q
i j
(1)
The function H(x) is commonly referred to as the
Hamiltonian, and in this paper, we refer to the matrix
Q as the “QUBO matrix”.
The goal is to find the optimal binary vector x
∗
that minimizes the Hamiltonian. This task is known
to be NP-hard, making it computationally intractable
for large instances without specialized techniques.
QUBO is a significant problem class in combinato-
rial optimization, as it can represent a wide range of
problems. Moreover, several specialized algorithms
and hardware platforms, such as quantum annealers
and classical heuristics, have been designed to solve
QUBO problems efficiently (Morita and Nishimori,
2008; Farhi and Harrow, 2016; N
¨
ußlein et al., 2023b;
N
¨
ußlein et al., 2023a).
Many well-known combinatorial optimization
problems, such as Boolean satisfiability (SAT), the
knapsack problem, graph coloring, the traveling
salesman problem (TSP), and the maximum clique
problem, have been successfully reformulated as
QUBO problems (Choi, 2011; Lodewijks, 2020;
Choi, 2010; Glover et al., 2019; Lucas, 2014). This
versatility makes QUBO a powerful tool for solving a
wide variety of optimization tasks, including the one
addressed in this paper.
3 ALGORITHM
3.1 Problem Definition
Let π be a trained agent operating within an MDP E.
At each timestep, the agent receives an observation
o ∈ R
u
, which is collected using n sensors {s
i
}
1≤i≤n
.
Each sensor s
i
produces a vector o
i
, and the full ob-
servation o is formed by concatenating these vectors:
o = [o
1
,o
2
,.. . ,o
n
]. The complete observation o has
dimension |o| =
∑
i
|o
i
|.
At the start of an episode, each sensor s
i
may drop
out with probability d
i
∈ [0,1], meaning it fails to pro-
vide any meaningful data for the entire episode. In the
event of a dropout, the sensor’s output is set to o
i
= 0
for the rest of the episode.
If π is represented as a neural network, it is evident
that the performance of π, quantified as the expected
return, will degrade as more sensors drop out. To mit-
igate this, we can add backup sensors. However, in-
corporating a backup sensor s
i
incurs a cost c
i
∈ N,
representing the expense associated with adding that
redundancy.
The task is to find the optimal backup sensor con-
figuration that maximizes the expected return while
keeping the total cost of the backups within a prede-
fined budget C ∈ N. Let x ∈ B
n
be a vector of binary
decision variables, where x
i
= 1 indicates the inclu-
sion of a backup for sensor s
i
. If E
d,π,x
[R] represents
the expected return while using backup configuration
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
246

x, the optimization problem can be formulated with
both a soft and hard constraint:
x
∗
= argmax
x
E
d,π,x
[R] s.t.
n
∑
i=1
x
i
c
i
≤ C (2)
An illustration of this problem is provided in Fig-
ure 1. In the next section, we describe a method to
transform this problem into a QUBO representation.
3.2 SensorOpt
There are potentially 2
n
possible combinations of sen-
sor dropout configurations, making it computationally
expensive to evaluate all of them directly. Since we
only have a limited number of episodes B ∈ N to sam-
ple from the environment E, we opted for a second-
order approximation of E
d,π,x
[R] to reduce the com-
putational burden while still capturing meaningful in-
teractions between sensor dropouts.
To compute this approximation, we first calculate
the probability q(d) that at most two sensors drop out
in an episode:
q(d) =
n
∏
i=1
(1 − d
i
) +
n
∑
i=1
d
i
·
n
∏
j̸=i
(1 − d
j
)
+
n
∑
i=1
n
∑
j<i
d
i
d
j
·
n
∏
l̸=i, j
(1 − d
l
)
Next, we estimate the expected return
ˆ
R
(i, j)
for
each pair of sensors (s
i
,s
j
) dropping out. This can
be efficiently achieved using Algorithm 1, which
samples the episode return E
(i, j)
(π) using policy π
with sensors s
i
and s
j
removed. The algorithm be-
gins by calculating two return values for each sen-
sor pair. It then iteratively selects the sensor pair
with the highest momentum of the mean return, de-
fined as |R
(i, j)
[: −1] − R
(i, j)
|. Here, R
(i, j)
[: −1] de-
notes the mean of all previously sampled returns for
the sensor pair (s
i
,s
j
), excluding the most recent re-
turn, while R
(i, j)
represents the mean including the
most recent return. The difference between these two
values measures the momentum, capturing how much
the expected return is changing as more episodes are
sampled.
We base the selection of sensor pairs on mo-
mentum rather than return variance to differen-
tiate between aleatoric and epistemic uncertainty
(Valdenegro-Toro and Mori, 2022). Momentum is
less sensitive to aleatoric uncertainty, making it a
more reliable indicator in this context.
A simpler, baseline approach to estimate
ˆ
R
(i, j)
would be to divide the budget B of episodes evenly
across all sensor pairs (s
i
,s
j
). In this Round Robin ap-
proach, we sample k =
B
n(n+1)/2
episodes for each sen-
sor pair and estimate
ˆ
R
(i, j)
as the empirical mean. In
the Experiments section, we compare our momentum-
based approach from Algorithm 1 against this naive
Round Robin method to highlight its efficiency and
accuracy.
Once we have estimated all the values of
ˆ
R
(i, j)
,
we can compute the overall expected return
ˆ
R(d) for
a given dropout probability vector d, again using a
second-order approximation:
ˆ
R(d) =
1
q(d)
"
ˆ
R
0
n
∏
i=1
(1 − d
i
) +
n
∑
i=1
ˆ
R
(i,i)
d
i
n
∏
j̸=i
(1 − d
j
)
+
n
∑
i=1
n
∑
j<i
ˆ
R
(i, j)
d
i
d
j
n
∏
l̸=i, j
(1 − d
l
)
#
Now we can calculate the advantage of using a backup
for sensor s
i
vs. using no backup sensor for s
i
:
∆
ˆ
R
(i,i)
(d) =
ˆ
R(d
{i}
) −
ˆ
R(d)
with
d
A
=
(
d
2
i
if i ∈ A,
d
i
if i /∈ A.
When a backup sensor is used for sensor s
i
, the new
dropout probability for s
i
becomes d
i
← d
2
i
, since
the system will only fail to provide an observation if
both the primary and backup sensors drop out. We
adopt the notation d
A
to represent the updated dropout
probabilities when backup sensors from set A are in
use. For example, if the dropout probability vector is
d = (0.2,0.5,0.1) and a backup is used for sensor 1,
the updated vector becomes d
1
= (0.2,0.25, 0.1), as
the backup reduces the dropout probability for sensor
1 while sensors 0 and 2 remain unchanged.
We can now compute the joint advantage of using
backups for both sensors s
i
and s
j
. This joint advan-
tage is not simply the sum of the individual advan-
tages of using backups for each sensor in isolation:
∆
ˆ
R
(i, j)
(d) =
ˆ
R(d
{i, j}
)−
ˆ
R(d) −∆
ˆ
R
(i,i)
(d) −∆
ˆ
R
( j, j)
(d)
This formula accounts for the interaction between
the two sensors, reflecting the fact that their joint con-
tribution to the expected return is influenced by how
the presence of both backup sensors affects the system
as a whole, beyond just the sum of their individual
contributions. This interaction term is crucial when
optimizing backup sensor configurations, as it helps
Optimizing Sensor Redundancy in Sequential Decision-Making Problems
247
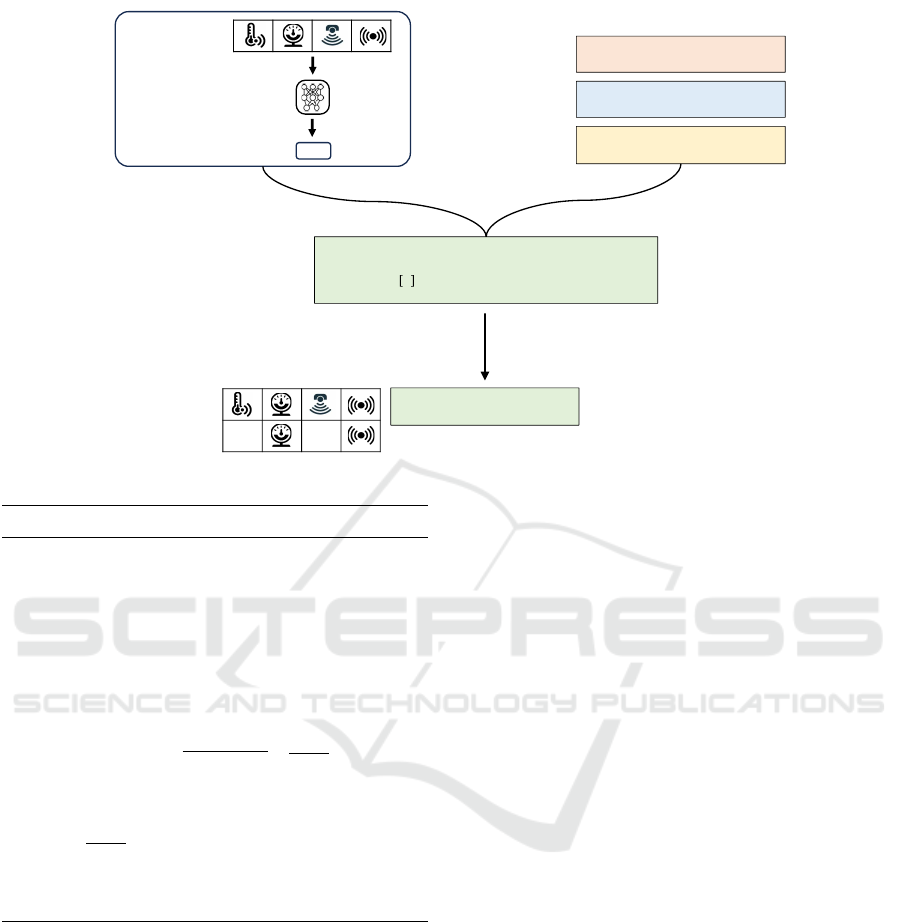
Objective:
s.t.
(maximally allowed costs)
Costs for adding a backup sensor:
Probability for each sensor to drop out:
Binary decision variables for using
backup sensors:
solve this NP-hard problem using
any QUBO solver
optimal set of backup sensors:
observation
(here via
sensors)
action
policy
trained
Figure 1: An illustration of our approach for optimizing the backup sensor configuration.
Algorithm 1: Estimating
ˆ
R
(i, j)
.
Input: budget of episodes to run B ∈ N
# sensors n ∈ N
MDP E
trained policy π
R
(i, j)
= [E
(i, j)
(π),E
(i, j)
(π)] ∀i < j,(i, j) ∈ [1,n]
2
for e = 1 to B − n(n + 1) do
(i, j) = arg max
(i, j)
| R
(i, j)
[: −1] − R
(i, j)
|
R
(i, j)
.append
E
(i, j)
(π)
end for
ˆ
R
(i, j)
= R
(i, j)
// expected return = mean
empirical return
return all
ˆ
R
(i, j)
capture the diminishing or synergistic returns that can
occur when multiple sensors are backed up together.
With these components in hand, we can now for-
mulate the QUBO problem for the sensor optimiza-
tion task defined in (2). The soft constraint H
so f t
cap-
tures the optimization of the expected return, approxi-
mated by the change in return ∆
ˆ
R
(i,i)
(d) for individual
sensors and ∆
ˆ
R
(i, j)
(d) for sensor pairs:
H
so f t
=
n
∑
i=1
x
i
· ∆
ˆ
R
(i,i)
(d) +
n
∑
i< j
x
i
x
j
· ∆
ˆ
R
(i, j)
(d)
Here, x
i
are binary decision variables where x
i
= 1
indicates that a backup sensor is added for sensor s
i
.
This formulation ensures that the algorithm optimizes
the expected return based on the specific backup con-
figuration.
To enforce the cost constraint, we introduce a
hard constraint H
hard
, which penalizes configurations
where the total cost exceeds the specified budget C:
H
hard
=
n
∑
i=1
x
i
c
i
+
n+1+⌈log
2
(C)⌉
∑
i=n+1
x
i
2
(i−n−1)
−C
!
2
The expression
∑
n
i=1
x
i
c
i
represents the total cost
of the selected backup sensors, and the second term
accounts for the binary encoding of the cost con-
straint, ensuring that no configuration exceeds the
budget C.
Finally, we introduce a scaling factor α to balance
the contributions of the soft and hard constraints:
α =
n
∑
i=1
|∆
ˆ
R
(i,i)
(d)| +
n
∑
i< j
|∆
ˆ
R
(i, j)
(d)|
The overall QUBO objective function is then
given by:
H = −H
so f t
+ β · α · H
hard
(3)
Here, H
so f t
approximates the expected return
E
d,π,x
[R], while H
hard
ensures that the total cost re-
mains within the allowable budget. The parameter
β is a hyperparameter that controls the trade-off be-
tween maximizing the expected return and enforcing
the cost constraint.
Algorithm SensorOpt summarizes our approach
for optimizing sensor redundancy configurations.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
248

This algorithm uses the QUBO formulation to find the
optimal backup sensor configuration, balancing per-
formance improvements with budget constraints.
Algorithm 2: - SensorOpt: Calculating best sensor backup
configuration.
Input: # sensors n ∈ N
dropout probability for each sensor d ∈
[0,1]
n
costs for each backup sensor c ∈ N
maximally allowed costs C ∈ N
budget of episodes to run B ∈ N
MDP E
trained policy π
ˆ
R
0
← E(π) // expected return with no sensor
dropouts
ˆ
R
(i, j)
← use Algorithm 1 (B,n,E,π)
Q ← create QUBO-matrix using formula (3)
x
∗
= argmin
x
x
T
Qx // solve using any QUBO
solver,
e.g. Tabu Search
// x ∈ B
m
, m = n + ⌈log
2
(C)⌉
return x
∗
[: n] // first n bits of x
∗
encode the
optimal
sensor backup configuration
For a given problem instance (n,d,c,C,B, E,π),
α is a constant while β ∈ [0,1] is a hyperparameter
we need to choose by hand. The number of boolean
decision variables our approach needs is determined
by m = n + ⌈log
2
(C)⌉.
Proposition 1. The optimization problem described
in (2) belongs to complexity class NP-hard.
Proof. We can prove that the problem described in
(2) belongs to NP-hard by reducing another prob-
lem W , that is already known to be NP-hard, to
it. Since this would imply that, if we have a
polynomial algorithm for solving (2), we could
solve any problem instance w ∈ W using this algo-
rithm. We choose W to be Knapsack (Salkin and
De Kluyver, 1975) which is known to be NP-hard.
For a given Knapsack instance (n
(1)
,v
(1)
,c
(1)
,C
(1)
)
consisting of n
(1)
items with values v
(1)
, costs c
(1)
and maximal costs C
(1)
we can reduce this to a
problem instance (n
(2)
,d
(2)
,c
(2)
,C
(2)
,E) from (2)
via: n
(2)
= n
(1)
, d
(2)
= 0, c
(2)
= c
(1)
, C
(2)
= C
(1)
.
For each possible x we define an individual MDP
E
x
: S = {s
0
,s
terminal
},A = {a
0
},T (s
terminal
|s
0
,a
0
) =
1,r(s
0
,a
0
) = x · v, p
0
(s
0
) = 1, γ = 1. The expected
return E
d,π,x
[R] will therefore be E
d,π,x
[R] = x · v.
4 RELATED WORK
Robust Reinforcement Learning (Moos et al., 2022;
Pinto et al., 2017) is a sub-discipline within RL that
tries to learn robust policies in the face of several
types of perturbations in the Markov Decision Process
which are (1) Transition Robustness due to a proba-
bilistic transition model T (s
t+1
|s
t
,a
t
) (2) Action Ro-
bustness due to errors when executing the actions (3)
Observation Robustness due to faulty sensor data.
There is a bulk of papers dealing with Observation
Robustness (L
¨
utjens et al., 2020; Mandlekar et al.,
2017; Pattanaik et al., 2017). However, the vast ma-
jority is about handling noisy observations, meaning
that the true state lies within an ε-ball of the perceived
observation. In these scenarios, an adversarial an-
tagonist is usually used in the training process that
adds noise to the observation, trying to decrease the
expected return, while the agent tries to maximize it
(Liang et al., 2022; L
¨
utjens et al., 2020; Mandlekar
et al., 2017; Pattanaik et al., 2017). In our problem
setting, however, the sensors are not noisy in the sense
of ε-disturbance, but they can drop out entirely.
Another line of research is about the framework
Action-Contingent Noiselessly Observable Markov
Decision Processes (ACNO-MDP) (Nam et al., 2021;
Koseoglu and Ozcelikkale, 2020). In this framework,
observing (measuring) the current state s
t
comes with
costs. The agent therefore needs to learn when ob-
serving a state is crucially important for informed ac-
tion decision making and when not. The action space
is extended by two additional actions {observe, not
observe} (Beeler et al., 2021). Not observe, however,
affects all sensors.
Important other related work comes from Safe Re-
inforcement Learning (Gu et al., 2022; Dulac-Arnold
et al., 2019). In (Dulac-Arnold et al., 2019) the prob-
lem of sensors dropping out is already mentioned and
analyzed. However, they only examine the scenario in
which the sensor drops out for z ∈ N timesteps. There-
fore they can use Recurrent Neural Networks for rep-
resenting the policy that mitigates this problem.
Our approach for optimizing the sensor redun-
dancy configuration given a maximal cost C bears
similarity to Knapsack (Salkin and De Kluyver, 1975;
Martello and Toth, 1990). In (Lucas, 2014) a QUBO
formulation for Knapsack was already introduced and
(Quintero and Zuluaga, 2021) provides a study re-
garding the trade-off parameter for the hard- and soft-
constraint. The major difference between the original
Knapsack problem and our problem is that in Knap-
Optimizing Sensor Redundancy in Sequential Decision-Making Problems
249
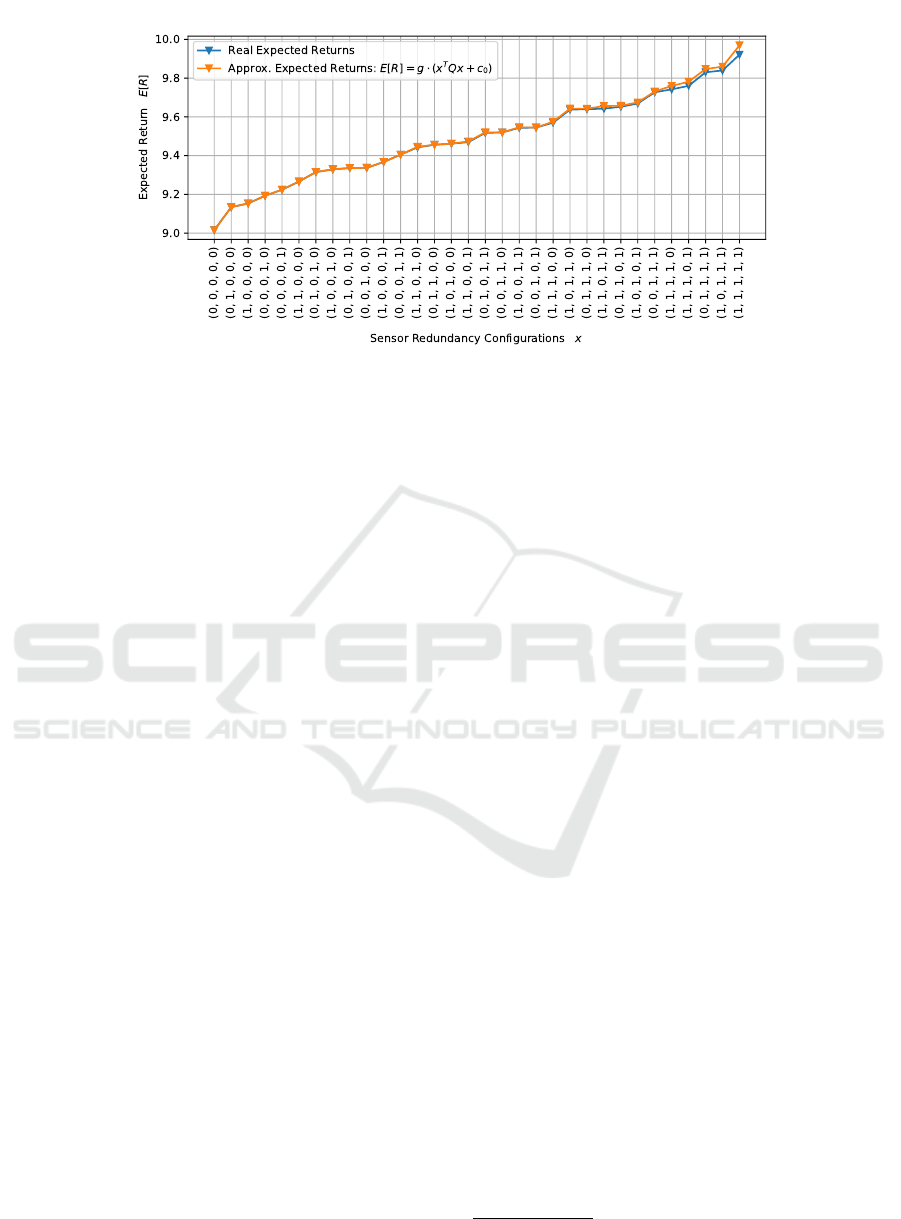
Figure 2: Proof-of-concept: this plot shows the real expected return and the approximated expected return E
d,π,x
[R] ≈
− x
T
Q x +
ˆ
R(d) when using a backup sensor configuration x. The configurations (x-axis) are sorted according to the real
return.
sack, the value of a collection of items is the sum of
all item values: W =
∑
i
w
i
x
i
. In our problem formu-
lation this, however, doesn’t hold. We therefore pro-
posed a second-order approximation for representing
the soft-constraint.
To the best of our knowledge, this paper is the first
to address the optimization of sensor redundancy in
sequential decision-making environments.
5 EXPERIMENTS
In this Experiments section we want to evaluate our
algorithm SensorOpt. Specifically, we want to exam-
ine the following hypotheses:
1. Hamiltonian H of formula (3) approximates the
real expected returns.
2. Our algorithm SensorOpt can find optimal sensor
backup configurations.
3. Algorithm 1 approximates the expected returns
R
(i, j)
faster than with Round Robin.
5.1 Proof-of-Concept
To test how well our QUBO formulation (a second-
order approximation) approximates the real expected
return for each possible sensor redundancy configu-
ration x we created a random problem instance and
determined the Real Expected Returns E
d,π,x
[R] and
the Approximated Expected Returns:
E
d,π,x
[R] ≈ − x
T
Q x +
ˆ
R(d)
Note that in general a QUBO-matrix can be lin-
early scaled by a scalar g without altering the order
of the solutions regarding solution quality. Figure
2 shows the two resulting graphs where the x-axis
represents all possible sensor backup configurations
x and the y-axis the expected return. We have sorted
the configurations according to their real expected re-
turns. The key finding in this plot is that the ap-
proximation is quite good even though it is not per-
fect for all x. But the relative performance is still in-
tact, meaning especially that the best solution in our
approximation is also the best solution regarding the
real expected returns. We can therefore verify the first
hypothesis that our Hamiltonian H approximates the
real expected returns. But as with any approximation,
it can contain errors.
5.2 RobotArmGrasping Environment
The RobotArmGrasping domain is a robotic simula-
tion based on a digital twin of the Niryo One
2
which is
available in the Unity Robotics Hub
3
. It uses Unity’s
built-in physics engine and models a robot arm that
can grasp and lift objects.
5.3 Main Experiments
Next, we tested if SensorOpt can find optimal sensor
backup configurations in well-known MDPs. We used
8 different OpenAI Gym environments (Brockman
et al., 2016). Additionally, we created a more realistic
and industry-relevant environment RobotArmGrasp-
ing based on Unity. In this environment, the goal of
the agent is to pick up a cube and lift it to a desired lo-
cation. The observation space is 20-dimensional and
the continuous action space is 5-dimensional.
2
https://niryo.com/niryo-one/
3
https://github.com/Unity-Technologies/
Unity-Robotics-Hub
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
250

Table 1: Results of our algorithm SensorOpt on 9 different environments compared against the true optimum, determined via
brute force and the baselines when using no additional backup sensors and all possible backup sensors. We solved the QUBO
created in SensorOpt using Tabu Search. Note that All Backups is not a valid solution to the problem presented in formula (2),
since the cost of using all backup sensors exceeds the threshold C. Due to the exponential complexity of conducting a brute
force search for the optimal configuration, it was feasible to apply this approach only to the first four environments.
ENVIRONMENT SENSOROPT OPTIMUM* NO BACKUPS ALL BACKUPS
CARTPOLE-V1 493.3 493.3 424.0 498.7
ACROBOT-V1 -86.73 -86.73 -91.38 -83.01
LUNARLANDER-V2 241.5 241.5 200.1 249.5
HOPPER-V2 2674 2674 1979 3221
HALFCHEETAH-V2 9643 - 8119 10711
WALKER2D-V2 3388 - 2402 4097
BIPEDALWALKER-V3 215.5 - 160.2 273.0
SWIMMER-V2 329.6 - 272.6 341.7
ROBOTARMGRASPING 29.41 - 22.27 30.41
In all experiments, we sampled each dropout prob-
ability d
i
, cost c
i
, and maximum costs C uniformly out
of a fixed set. For simplicity, we restricted the costs c
i
in our experiments to be integers.
For the 8 OpenAI Gym environments we used
as the trained policies SAC- (for continuous action
spaces) or PPO- (for discrete action spaces) models
from Stable Baselines 3 (Raffin et al., 2021). For our
RobotArmGrasping environment we trained a PPO
agent (Schulman et al., 2017) for 5M steps. We
then solved the sampled problem instances using Sen-
sorOpt. We optimized the QUBO in SensorOpt using
Tabu Search, a classical meta-heuristic. Further, we
calculated the expected returns when using no backup
sensors (No Backups) and all n backup sensors (All
Backups). For the four smallest environments Cart-
Pole, Acrobot, LunarLander and Hopper we also de-
termined the true optimal backup sensor configuration
x
∗
using brute force. This was however not possible
for larger environments.
For each environment, we sampled 10 problem in-
stances. Note that using all backup sensors is not a
valid solution regarding the problem definition in for-
mula (2) since the costs would exceed the maximally
allowed costs
∑
i
c
i
> C. All results are reported in
Table 2.
The results show that SensorOpt found the op-
timal sensor redundancy configuration in the first
four environments for which we were computation-
ally able to determine the optimum using brute force.
6 CONCLUSION
Sensor dropouts present a major challenge when de-
ploying reinforcement learning (RL) policies in real-
world environments. A common solution to this prob-
lem is the use of backup sensors, though this approach
introduces additional costs. In this paper, we tackled
the problem of optimizing backup sensor configura-
tions to maximize expected return while ensuring the
total cost of added backup sensors remains below a
specified threshold, C.
Our method involved using a second-order ap-
proximation of the expected return, E
d,π,x
[R] ≈
−x
T
Qx +
ˆ
R(d), for any given backup sensor config-
uration x ∈ B
n
. We incorporated a penalty for config-
urations that exceeded the maximum allowable cost,
C, and optimized the resulting QUBO matrices Q us-
ing the Tabu Search algorithm.
We evaluated our approach across eight OpenAI
Gym environments, as well as a custom Unity-based
robotic scenario, RobotArmGrasping. The results
demonstrated that our quadratic approximation was
sufficiently accurate to ensure that the optimal con-
figuration derived from the approximation closely
matched the true optimal sensor configuration in prac-
tice.
REFERENCES
Beeler, C., Li, X., Bellinger, C., Crowley, M., Fraser, M.,
and Tamblyn, I. (2021). Dynamic programming with
incomplete information to overcome navigational un-
certainty in a nautical environment. arXiv preprint
arXiv:2112.14657.
Brockman, G., Cheung, V., Pettersson, L., Schneider, J.,
Schulman, J., Tang, J., and Zaremba, W. (2016). Ope-
nai gym. arXiv preprint arXiv:1606.01540.
Choi, V. (2010). Adiabatic quantum algorithms for the
NP-complete maximum-weight independent set, ex-
act cover and 3SAT problems.
Choi, V. (2011). Different adiabatic quantum optimization
algorithms for the NP-complete exact cover and 3SAT
problems.
Degrave, J., Felici, F., Buchli, J., Neunert, M., Tracey, B.,
Carpanese, F., Ewalds, T., Hafner, R., Abdolmaleki,
A., de Las Casas, D., et al. (2022). Magnetic con-
Optimizing Sensor Redundancy in Sequential Decision-Making Problems
251

trol of tokamak plasmas through deep reinforcement
learning. Nature, 602(7897):414–419.
Dulac-Arnold, G., Mankowitz, D., and Hester, T. (2019).
Challenges of real-world reinforcement learning.
arXiv preprint arXiv:1904.12901.
Farhi, E. and Harrow, A. W. (2016). Quantum supremacy
through the quantum approximate optimization algo-
rithm. arXiv preprint arXiv:1602.07674.
Glover, F., Kochenberger, G., and Du, Y. (2019). Quantum
bridge analytics I: A tutorial on formulating and using
QUBO models.
Gu, S., Yang, L., Du, Y., Chen, G., Walter, F., Wang, J.,
Yang, Y., and Knoll, A. (2022). A review of safe re-
inforcement learning: Methods, theory and applica-
tions. arXiv preprint arXiv:2205.10330.
Koseoglu, M. and Ozcelikkale, A. (2020). How to miss
data? reinforcement learning for environments with
high observation cost. In ICML Workshop on the Art
of Learning with Missing Values (Artemiss).
Liang, Y., Sun, Y., Zheng, R., and Huang, F. (2022). Ef-
ficient adversarial training without attacking: Worst-
case-aware robust reinforcement learning. Advances
in Neural Information Processing Systems, 35:22547–
22561.
Lodewijks, B. (2020). Mapping NP-hard and NP-complete
optimisation problems to quadratic unconstrained bi-
nary optimisation problems.
Lucas, A. (2014). Ising formulations of many NP problems.
L
¨
utjens, B., Everett, M., and How, J. P. (2020). Certified ad-
versarial robustness for deep reinforcement learning.
In conference on Robot Learning, pages 1328–1337.
PMLR.
Mandlekar, A., Zhu, Y., Garg, A., Fei-Fei, L., and Savarese,
S. (2017). Adversarially robust policy learning:
Active construction of physically-plausible perturba-
tions. In 2017 IEEE/RSJ International Conference on
Intelligent Robots and Systems (IROS), pages 3932–
3939. IEEE.
Martello, S. and Toth, P. (1990). Knapsack problems: algo-
rithms and computer implementations. John Wiley &
Sons, Inc.
Moos, J., Hansel, K., Abdulsamad, H., Stark, S., Clever, D.,
and Peters, J. (2022). Robust reinforcement learning:
A review of foundations and recent advances. Ma-
chine Learning and Knowledge Extraction, 4(1):276–
315.
Morita, S. and Nishimori, H. (2008). Mathematical founda-
tion of quantum annealing. Journal of Mathematical
Physics, 49(12).
Nam, H. A., Fleming, S., and Brunskill, E. (2021). Re-
inforcement learning with state observation costs in
action-contingent noiselessly observable markov deci-
sion processes. Advances in Neural Information Pro-
cessing Systems, 34:15650–15666.
N
¨
ußlein, J., Roch, C., Gabor, T., Stein, J., Linnhoff-Popien,
C., and Feld, S. (2023a). Black box optimization using
qubo and the cross entropy method. In International
Conference on Computational Science, pages 48–55.
Springer.
N
¨
ußlein, J., Zielinski, S., Gabor, T., Linnhoff-Popien,
C., and Feld, S. (2023b). Solving (max) 3-sat via
quadratic unconstrained binary optimization. In Inter-
national Conference on Computational Science, pages
34–47. Springer.
Pattanaik, A., Tang, Z., Liu, S., Bommannan, G., and
Chowdhary, G. (2017). Robust deep reinforcement
learning with adversarial attacks. arXiv preprint
arXiv:1712.03632.
Pinto, L., Davidson, J., Sukthankar, R., and Gupta, A.
(2017). Robust adversarial reinforcement learning.
In International Conference on Machine Learning,
pages 2817–2826. PMLR.
Quintero, R. A. and Zuluaga, L. F. (2021). Characterizing
and benchmarking qubo reformulations of the knap-
sack problem. Technical report, Technical Report.
Department of Industrial and Systems Engineering,
Lehigh . . . .
Raffin, A., Hill, A., Gleave, A., Kanervisto, A., Ernestus,
M., and Dormann, N. (2021). Stable-baselines3: Reli-
able reinforcement learning implementations. Journal
of Machine Learning Research, 22(268):1–8.
Salkin, H. M. and De Kluyver, C. A. (1975). The knapsack
problem: a survey. Naval Research Logistics Quar-
terly, 22(1):127–144.
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and
Klimov, O. (2017). Proximal policy optimization al-
gorithms. arXiv preprint arXiv:1707.06347.
Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai,
M., Guez, A., Lanctot, M., Sifre, L., Kumaran, D.,
Graepel, T., et al. (2018). A general reinforcement
learning algorithm that masters chess, shogi, and go
through self-play. Science, 362(6419):1140–1144.
Sutton, R. S. and Barto, A. G. (2018). Reinforcement learn-
ing: An introduction. MIT press.
Valdenegro-Toro, M. and Mori, D. S. (2022). A deeper look
into aleatoric and epistemic uncertainty disentangle-
ment. In 2022 IEEE/CVF Conference on Computer
Vision and Pattern Recognition Workshops (CVPRW),
pages 1508–1516. IEEE.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
252
