
SwarmPrompt: Swarm Intelligence-Driven Prompt Optimization Using
Large Language Models
Thilak Shekhar Shriyan
1
, Janavi Srinivasan
2
, Suhail Ahmed
2
, Richa Sharma
3 a
and Arti Arya
3 b
1
Couchbase, Bangalore, India
2
Hewlett Packard Enterprise, Bangalore, India
3
PES University, Bangalore, India
Keywords:
Swarm Intelligence Algorithms, Prompt Optimization, Prompt Evaluation, Prompt Engineering, Discrete
Prompt Optimization, Particle Swarm Optimization, Grey Wolf Optimization.
Abstract:
The advancement of generative AI and large language models (LLMs) has made developing effective text
prompts challenging, particularly for less experienced users. LLMs often struggle with nuances, tone, and
context, necessitating precise prompt engineering for generating high-quality outputs. Previous research has
utilized approaches such as gradient descent, reinforcement learning, and evolutionary algorithms for optimiz-
ing prompts. This paper introduces SwarmPrompt, a novel approach that employs swarm intelligence-based
optimization techniques, specifically Particle Swarm Optimization and Grey Wolf Optimization, to enhance
and optimize prompts. SwarmPrompt combines the language processing capabilities of LLMs with swarm
operators to iteratively modify prompts and identify the best-performing ones. This method reduces human
intervention, surpasses human-engineered prompts, and decreases the time and resources required for prompt
optimization. Experimental results indicate that SwarmPrompt outperforms human-engineered prompts by
4% for classification tasks and 2% for simplification and summarization tasks. Moreover, SwarmPrompt con-
verges faster, requiring half the number of iterations while providing superior results. This approach offers an
efficient and effective alternative to existing methods. Our code is available at SwarmPrompt.
1 INTRODUCTION
The art of prompt engineering lies in crafting the
right questions to maximize the output of large lan-
guage models (LLMs). By facilitating direct commu-
nication with LLMs through simple natural language
commands, prompt engineering enables better re-
sponses. However, creating effective text prompts that
yield high-quality outputs is a skill with a steep learn-
ing curve, especially for novice and non-technical
users.
Automated prompt optimization offers key advan-
tages over manual methods, especially in scenarios
requiring scalability, efficiency, and precision. Un-
like labor-intensive manual approaches prone to hu-
man biases, automated methods use algorithms to sys-
tematically explore and refine prompts. This data-
driven process evaluates numerous variations quickly,
enabling faster and more accurate identification of op-
timal prompts.
a
https://orcid.org/0000-0002-4539-7051
b
https://orcid.org/0000-0002-4470-0311
Various prompt engineering methods include
zero-shot prompting (no examples provided) and few-
shot or multi-shot prompting (using multiple exam-
ples to guide the model). Techniques like Chain of
Thought (COT) prompting help LLMs reason through
responses, enhancing performance on complex tasks.
However, human expertise remains essential for craft-
ing effective prompts. Prompt engineers require a
deep understanding of language syntax, semantics,
pragmatics, and model-specific characteristics, often
relying on iterative experiments to achieve optimal
results. This paper aims to eliminate human depen-
dency by automating the evaluation and optimization
of user-provided prompts.
Prompt tuning can be performed in two primary
ways to enhance prompt quality:
• Soft Prompt Tuning: This approach utilizes gra-
dient descent and requires the computation of
internal gradients within LLMs. The resulting
prompts are often not human-readable.
• Discrete Prompt Tuning: This method mod-
ifies concrete tokens from a predefined vocab-
86
Shriyan, T. S., Srinivasan, J., Ahmed, S., Sharma, R. and Arya, A.
SwarmPrompt: Swarm Intelligence-Driven Prompt Optimization Using Large Language Models.
DOI: 10.5220/0013090300003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 3, pages 86-93
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

ulary, exploring the search space to improve
prompts. Discrete prompt optimization, however,
is challenging because the prompts are generated
through ”enumeration-then-selection” heuristics,
which may not cover the entire search space.
Recently, various methods for discrete prompt op-
timization have emerged, including Reinforcement
Learning (Pang and Lee, 2005) and Evolutionary Al-
gorithms (Guo et al., 2023a).
In prior work (Guo et al., 2023b) leading up to our
study, discrete prompt optimization is performed us-
ing Genetic Algorithms (GA) and Differential Evolu-
tion (DE), a subset of Evolutionary Algorithms. Here
it proposes to connect evolutionary operators with
LLMs, which proves to be very powerful as imple-
menting evolutionary algorithms conventionally will
alter tokens individually, without considering the se-
mantics between the tokens, to generate new can-
didate solutions for the next iterations. Hence, the
LLMs act as evolutionary operators and modify the
prompts to preserve their semantic meaning, thus
yielding human-understandable prompts.
Regarding the choice of algorithms for this paper,
GA mimics natural selection by selecting the fittest
individuals for reproduction, involving operations like
selection, crossover, and mutation. However, GA can
suffer from premature convergence to local optima in
complex, multi-modal landscapes, primarily due to
the loss of population diversity or suboptimal param-
eter settings. GA also has high computational costs.
On the other hand, DE iteratively improves candidate
solutions by leveraging differences between randomly
selected individuals, proving effective for continuous
optimization with fewer parameters to tune compared
to GA. Despite its benefits, DE can stagnate and strug-
gle with noisy fitness landscapes.
Swarm intelligence algorithms, inspired by the
collective behaviour of social organisms like ant
colonies and bird flocks, use interactions between in-
dividual agents to solve optimisation problems. Each
swarm agent interacts with others and the environ-
ment to explore the solution space, guided by swarm
operators’ rules that dictate interaction, position up-
dates, and the balance between exploration and ex-
ploitation.
These algorithms offer fast convergence, robust-
ness to local optima, parallelism, and decentraliza-
tion. Particle Swarm Optimization (PSO) and Grey
Wolf Optimization (GWO) have gained attention for
their efficiency. PSO, inspired by particle move-
ment in nature, often outperforms Genetic Algorithms
(GA) and Differential Evolution (DE) with faster con-
vergence and fewer parameters. GWO, modelled on
grey wolf social behaviour, achieves a strong bal-
ance between exploration and exploitation with sim-
ple implementation. While GA and DE are effec-
tive, PSO and GWO address their limitations, making
them ideal for complex optimization problems.
This paper introduces SwarmPrompt, a frame-
work for discrete prompt optimization leverag-
ing swarm intelligence. Here, swarm agents
represent candidate prompts, and swarm oper-
ators—implemented via LLMs—iteratively refine
prompts while maintaining semantic meaning. This
integration ensures human-readable outputs and en-
hanced optimization performance. The main contri-
butions of this paper are:
• A novel framework called SwarmPrompt, which
leverages swarm intelligence algorithms such as
PSO and GWO to iteratively optimize the popula-
tion of prompts, ultimately yielding an optimized
discrete prompt.
• Conducted multiple experiments on various tasks
such as classification, simplification, and summa-
rization on different population sizes and budgets
and compared these results with existing meth-
ods of prompt optimization, such as Genetic Al-
gorithms (GA) and Differential Evolution (DE).
• In comparison to existing methods, this work
achieves superior results for the classification task
and comparable results for the simplification and
summarization tasks while running for half the it-
erations, therefore taking less resources and time
to converge.
2 RELATED WORK
P. Liu et al. (Liu et al., 2023) provides a compre-
hensive review of prompt-based learning, categoriz-
ing key concepts and methodologies. The study cov-
ers fundamental techniques, including the creation of
prompt templates and formulating prompt responses,
alongside advanced strategies such as multi-prompt
learning and prompt-aware training. Additionally, the
authors discuss practical applications and the impact
of different prompting methods on task outcomes.
B. Lester et al. (Lester et al., 2021) intro-
duces soft prompts, which are continuous vectors op-
timized through backpropagation to adapt pre-trained
LLMs efficiently. Unlike traditional fine-tuning, soft
prompts require fewer parameter updates and demon-
strate scalability as model sizes increase. The study
also shows that soft prompts generalize well across
tasks, supporting domain transferability.
R. Ma et al. (Ma et al., 2024) investigates prompt
optimization mechanisms for LLMs, revealing chal-
SwarmPrompt: Swarm Intelligence-Driven Prompt Optimization Using Large Language Models
87

lenges such as the inability of LLMs to recognize mis-
takes or generate optimal prompts in a single refine-
ment step. To address this, the authors propose an
Automatic Behavior Optimization framework that em-
ploys resampling-based and reflection-based prompt
regeneration techniques to optimize model behavior
effectively.
Y. Zhou et al. (Zhou et al., 2022) propose the
Automatic Prompt Engineer (APE) for generating
and selecting task-specific instructions. APE opti-
mizes instruction candidates using zero-shot perfor-
mance evaluation from another LLM. Results demon-
strate that automatically generated instructions sur-
pass human-crafted prompts and existing LLM base-
lines.
C. Yang et al. (Yang et al., 2023) present an iter-
ative optimization approach where LLMs act as opti-
mizers for generating task solutions. At each stage,
new prompts are created based on previous solutions
and their evaluations. The approach effectively opti-
mizes tasks like linear regression and combinatorial
problems, such as the traveling salesman problem.
X. Wang et al. (Wang et al., 2023) address lim-
itations in prior prompt optimization methods, par-
ticularly the underutilization of expert-level prompt
knowledge. The authors introduce PromptAgent,
which formulates prompt optimization as a strategic
planning problem and uses Monte Carlo Tree Search
(MCTS) to explore high-reward prompts. PromptA-
gent leverages expert insights, detailed error reflec-
tion, and constructive feedback to refine prompts iter-
atively.
Q. Guo et al. (Guo et al., 2023a) propose EVO-
PROMPT, an evolutionary algorithm-based approach
for prompt optimization. EVOPROMPT begins with
an initial population of prompts and iteratively re-
fines them using evolutionary operators and LLM-
generated variations. By ensuring coherence and
fast convergence without relying on gradients, EVO-
PROMPT achieves notable performance gains.
M. Janga Reddy et al. (Janga Reddy and
Nagesh Kumar, 2020) highlight the significance of
swarm intelligence (SI) algorithms, which leverage
collective group intelligence and self-organization to
evolve global-level solutions from local interactions.
SI methods, often termed behaviorally inspired al-
gorithms, have gained considerable attention, with
over 500 metaheuristic algorithms (MAs) introduced
to date, including 350 in the last decade (Rajwar et al.,
2023).
Although research on swarm intelligence in
NLP remains limited, studies suggest that SI algo-
rithms offer substantial benefits for optimization tasks
(Bharambe et al., 2024). Specifically, SI techniques
enhance feature selection and parameter tuning, lead-
ing to improved performance in tasks such as text
clustering (Selvaraj and Choi, 2021). Their inherent
parallelism also facilitates scalability, enabling effi-
cient handling of large datasets and complex models
(Bharti et al., 2022).
Despite advancements in prompt-based learning
and optimization, key challenges persist:
• Uncontrolled LLM Behavior. LLMs often pro-
duce unpredictable outputs, including deviations
from desired structures and irrelevant or redun-
dant information.
• Resource Constraints. Existing methods can be
computationally expensive, requiring extensive it-
erations and large budgets to achieve optimal re-
sults.
To address these limitations, swarm intelligence
algorithms present a promising alternative. By con-
straining the search space and leveraging structured
templates, swarm-based methods can effectively con-
trol LLM outputs. Additionally, their ability to con-
verge rapidly enables resource-efficient optimization,
achieving high-quality results with fewer iterations
and reduced computational costs.
3 PROPOSED APPROACH
3.1 General Framework of
SwarmPrompt
This paper presents an approach that integrates swarm
optimization algorithms, specifically PSO and GWO,
with LLMs to optimize prompts for tasks like clas-
sification, summarization, and simplification. The it-
erative optimization process enhances prompt quality,
achieving significant performance improvements over
baseline methods.
Unlike evolutionary algorithms, swarm intelli-
gence algorithms maintain a constant population
size, with in-place mutations. As shown in Fig. 1,
the framework consists of three main components:
prompt instantiation, prompt evolution, and evalua-
tion and update.
The initial prompt set combines human-
engineered and LLM-generated prompts to ensure
diversity and incorporate prior knowledge. These
prompts are paraphrased using an LLM, and the
new candidates are evaluated using task-specific
metrics. Their effectiveness is validated as discrete
prompts for the corresponding task, with the LLM’s
performance serving as a measure of prompt quality.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
88
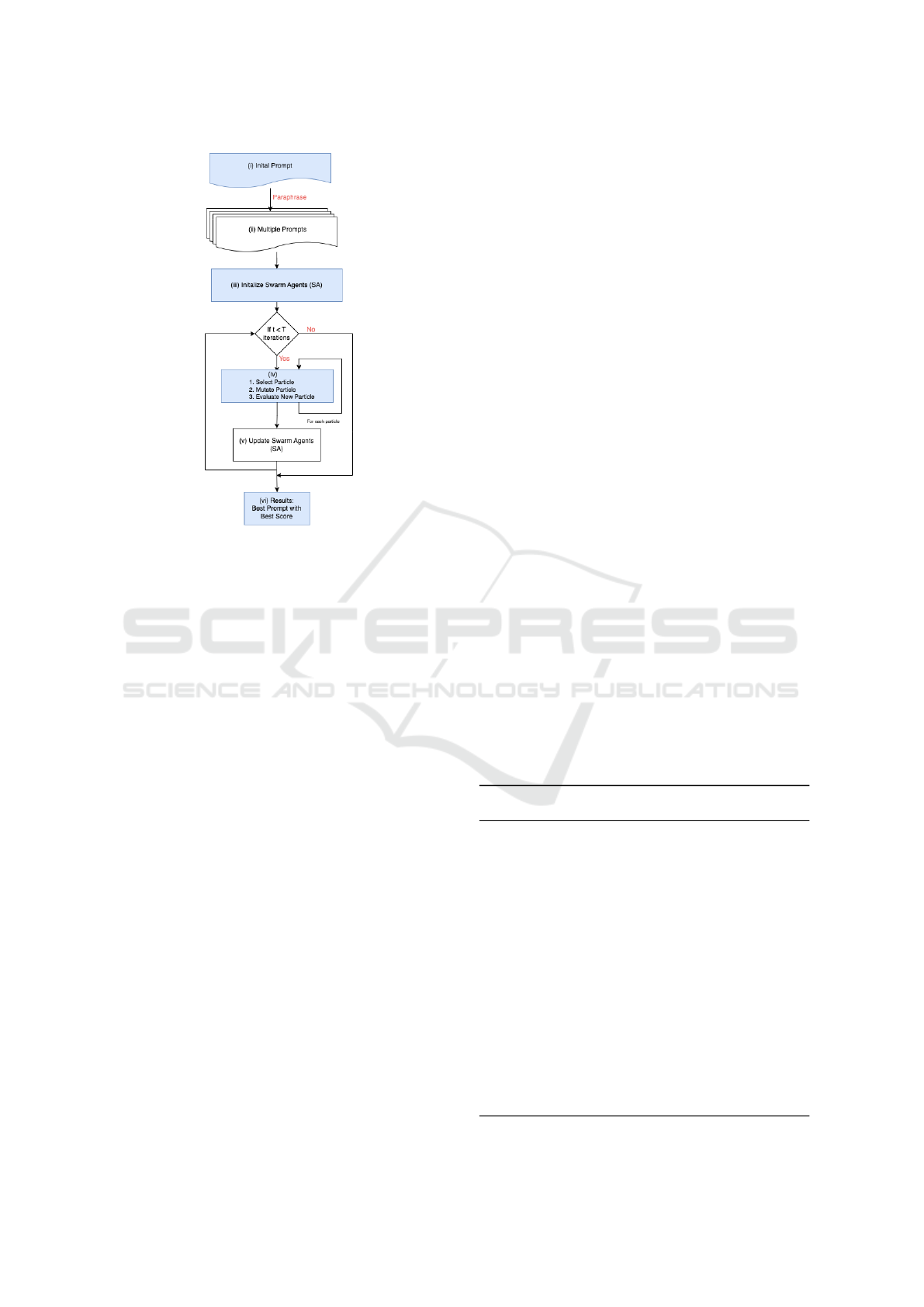
Figure 1: General workflow of swarm intelligence algo-
rithms for optimizing prompts.
This iterative process refines prompts to achieve
task-specific goals effectively.
Swarm agents are initialized with algorithm-
specific parameters. For PSO, this includes popula-
tion size, inertia weight, and cognitive and social co-
efficients; for GWO, parameters include the number
of wolves, convergence factor, and hunting behavior.
Since LLMs handle the updates, explicit coefficient
adjustments are not performed.
The evolutionary process runs for a fixed number
of iterations (T ), also referred to as the budget (Guo
et al., 2023b). Each iteration involves the following
steps:
• Selection. A particle (prompt) is selected from
the population.
• Mutation. The particle undergoes mutation using
a swarm intelligence mutation function. In PSO,
this involves updating velocity and position based
on cognitive and social components. In GWO, po-
sitions are updated relative to the alpha, beta, and
delta wolves.
• Evaluation. The mutated particle is evaluated
using fitness metrics: accuracy for classification,
ROUGE-n for summarization, and SARI for sim-
plification.
• Update. Swarm agents are updated based on par-
ticle performance. In PSO, global and personal
best positions are updated; in GWO, the wolf po-
sitions adjust based on the top three solutions.
For simplicity, the LLM adjusts parameters dy-
namically during optimization using a predefined
template, as detailed in the experimental setup.
The objective is to evolve prompts using PSO and
GWO for optimal task performance, rather than mak-
ing minor tweaks. This iterative update mechanism
steers the search towards improved solutions by lever-
aging swarm intelligence principles, enabling effec-
tive exploration of the search space and generating
high-quality, diverse prompts.
The process terminates after T iterations, identify-
ing the best-performing prompt with the highest score
as the output. Fig. 1 illustrates the entire workflow.
3.2 SwarmPrompt Using Particle
Swarm Optimization
In PSO, we begin with a population of N prompts,
iteratively refining them based on a fitness function
evaluated on the development set. SwarmPrompt us-
ing PSO follows these steps:
• Evolution. Each prompt is modified using the
LLM, acting as the PSO operator, to move closer
to the global best prompt and its own previous best
prompt.
• Update. The new prompts are evaluated on the
development set. The global best prompt is up-
dated to the highest-performing prompt, and each
prompt’s personal best is updated accordingly.
The process terminates after a fixed number of it-
erations, returning the global best prompt from the fi-
nal iteration. The detailed algorithm is provided in
Algorithm 1.
Algorithm 1: Optimizing Prompts using Particle Swarm
Optimization (PSO).
Require: Initial set of prompts, population size, de-
velopment dataset
1: Initialize: evaluate initial prompts on the dataset
2: Initialize personal best P
best
for each prompt and
global best P
global
3: for each iteration do
4: for each prompt in the population do
5: Generate a new prompt using P
best
, P
global
,
and the current prompt
6: Evaluate the new prompt on the dataset
7: Update P
best
if the new prompt performs bet-
ter
8: end for
9: Update P
global
with the best P
best
prompt
10: end for
11: return P
global
as the best prompt
SwarmPrompt: Swarm Intelligence-Driven Prompt Optimization Using Large Language Models
89

3.3 SwarmPrompt Using Grey Wolf
Optimization
Algorithm 2: Optimizing Prompts using Grey Wolf Opti-
mization (GWO).
Require: Initial set of prompts, population size, de-
velopment dataset
1: Initialize: evaluate initial prompts on the dataset
2: Initialize alpha P
α
, beta P
β
, and delta P
δ
prompts
3: for each iteration do
4: for each prompt in the population do
5: Generate a new prompt using P
α
, P
β
, P
δ
, and
the current prompt
6: Evaluate the new prompt on the dataset
7: end for
8: Update P
α
(best prompt), P
β
(second-best), and
P
δ
(third-best)
9: end for
10: return P
α
as the best prompt
In GWO, we start with a population of N prompts,
refining them iteratively based on a fitness function
evaluated on the development set. SwarmPrompt us-
ing GWO follows these steps:
• Evolution. Each prompt is modified using the
LLM, acting as the GWO operator, to move closer
to the alpha, beta, and delta prompts (the best,
second-best, and third-best prompts).
• Update. New prompts are evaluated on the devel-
opment set, and the alpha, beta, and delta prompts
are updated as the top three performing prompts.
The process terminates after a fixed number of
iterations, returning the alpha prompt as the best
prompt. The detailed algorithm is provided in Algo-
rithm 2.
4 EXPERIMENTAL SETUP
4.1 Datasets
PSO and GWO algorithms were evaluated on three
datasets, corresponding to distinct tasks: classifica-
tion (cls), simplification (sim), and summarization
(sum). The datasets used are as follows:
• MR Dataset (Pang and Lee, 2005). Developed
by Pang and Lee, it consists of movie reviews la-
beled on a multi-point scale (1–5 stars), enabling
nuanced sentiment classification beyond binary
analysis.
• ASSET Dataset (Alva-Manchego et al., 2020).
Created by Alva-Manchego et al., it includes mul-
tiple simplified versions of complex sentences,
supporting diverse simplification tasks such as
lexical replacement and sentence splitting.
• SAMSum Dataset (Gliwa et al., 2019). Designed
by Gliwa et al., this dataset comprises human-
annotated dialogues for abstractive summariza-
tion, enabling concise conversational text summa-
rization.
The optimized prompts are evaluated as discrete
inputs to the LLM for each task, and the LLM’s per-
formance serves as the metric for assessing the opti-
mization process.
4.2 Experiments Conducted
• Population sizes of 4, 6, 8, and 10 were tested with
a budget of 5 iterations for classification, simplifi-
cation, and summarization tasks.
• Additional experiments with population sizes of 4
and 8 were conducted with a budget of 10 itera-
tions for classification and simplification tasks.
4.3 Templates
Templates for prompt mutation in PSO and GWO are
provided to the LLM during each iteration.
• PSO Template. Fig. 2 shows the template for
PSO. Here, Prompt 1 refers to the global best
prompt, Prompt 2 to the personal best prompt, and
Prompt 3 to the current prompt being modified.
The example task in Fig. 2 is classification.
Figure 2: Template for PSO-based prompt mutation.
• GWO Template. Fig. 3 illustrates the template
for GWO. Here, Prompt 1 is the alpha prompt,
Prompt 2 the beta prompt, Prompt 3 the delta
prompt, and Prompt 4 the current prompt being
modified. The example task in Fig. 3 is simplifi-
cation.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
90

Figure 3: Template for GWO-based prompt mutation.
4.4 Hyperparameters
To conduct experiments on PSO and GWO algo-
rithms, prompts are modified using predefined tem-
plates. In PSO, adjustments are based on the per-
sonal best and global best prompts, while in GWO,
they depend on the Alpha, Beta, and Delta prompts.
These adjustments correspond to key parameters: in-
ertia weight, cognitive and social coefficients (PSO),
and hunting behavior coefficients a, A, and C (GWO).
For simplicity, the parameters are hardcoded into
template files. Figures 2 and 3 illustrate the hyperpa-
rameters: in PSO, 10% of the current prompt is re-
tained, modified by 70% of the global best and 20%
of the personal best. For GWO, 20% of the current
prompt is retained, adjusted by 30% of the Alpha, and
25% each of the Beta and Delta prompts. A higher
weight is allocated to the global best (PSO) and Alpha
(GWO) prompts, as they guide the mutation towards
better-performing prompts.
The hyperparameters were selected empirically to
balance performance and computational efficiency.
While they provided satisfactory results, they can be
refined or dynamically adjusted in future work to bet-
ter align with specific experimental objectives.
5 RESULTS & DISCUSSION
5.1 SwarmPrompt Using PSO
In the SwarmPrompt (PSO) framework, each parti-
cle tracks its personal best position across iterations,
while the global best prompt is updated and used
for subsequent mutations. Our observations high-
light that with a smaller budget and larger population,
PSO efficiently explores the search space, converging
rapidly to near-optimal results.
5.2 SwarmPrompt Using GWO
In the SwarmPrompt (GWO) approach, the optimiza-
tion process relies on three primary swarm agents: Al-
pha, Beta, and Delta, along with one particle undergo-
ing mutation. Notably, the minimum population size
for GWO is four. Experimental results show that in-
creasing the population size expands the search space,
which can negatively impact accuracy. However, in-
creasing the budget allows GWO to refine its search
more effectively over iterations.
Table 1: Model Accuracy for Different Tasks and Optimiza-
tion Techniques.
Method Classification (MR) Simplification (ASSET) Summarization (SAMSum)
Human-Engineered Prompts 88.75 43.03 26.25
Evoprompt (DE) 90.22 46.21 29.62
Evoprompt (GA) 90.07 46.43 28.67
SwarmPrompt (PSO) 91.5 44.81 28.23
SwarmPrompt (GWO) 92.2 45.06 28.95
Table 1 shows that SwarmPrompt outperforms
Evoprompt by 2% and human-engineered prompts by
4% in the classification task (MR dataset). In the sim-
plification task (ASSET dataset), Evoprompt slightly
exceeds SwarmPrompt by 1%, but SwarmPrompt still
outperforms human-engineered prompts by 2%. For
summarization (SAMSum dataset), Evoprompt (DE)
achieves the highest accuracy, followed by Swarm-
Prompt (GWO), with SwarmPrompt outperforming
human-engineered prompts by 2%.
These results indicate that SwarmPrompt excels
in classification but is less effective for simplification
and summarization, likely due to the higher complex-
ity and dimensionality of these tasks, where PSO and
GWO struggle to maintain diversity. In contrast, Dif-
ferential Evolution (DE) in Evoprompt performs bet-
ter in high-dimensional spaces.
Notably, Evoprompt’s results were achieved with
a budget of 10, while SwarmPrompt achieved similar
accuracy with a budget of just 5, demonstrating its
greater resource efficiency.
5.3 Impact of Population Size on Task
Accuracy
Figs. 4, 5, and 6 provide detailed insights into the
relationship between population size and accuracy
for SwarmPrompt across classification, simplifica-
tion, and summarization tasks, respectively, under a
constant budget of 5.
SwarmPrompt: Swarm Intelligence-Driven Prompt Optimization Using Large Language Models
91
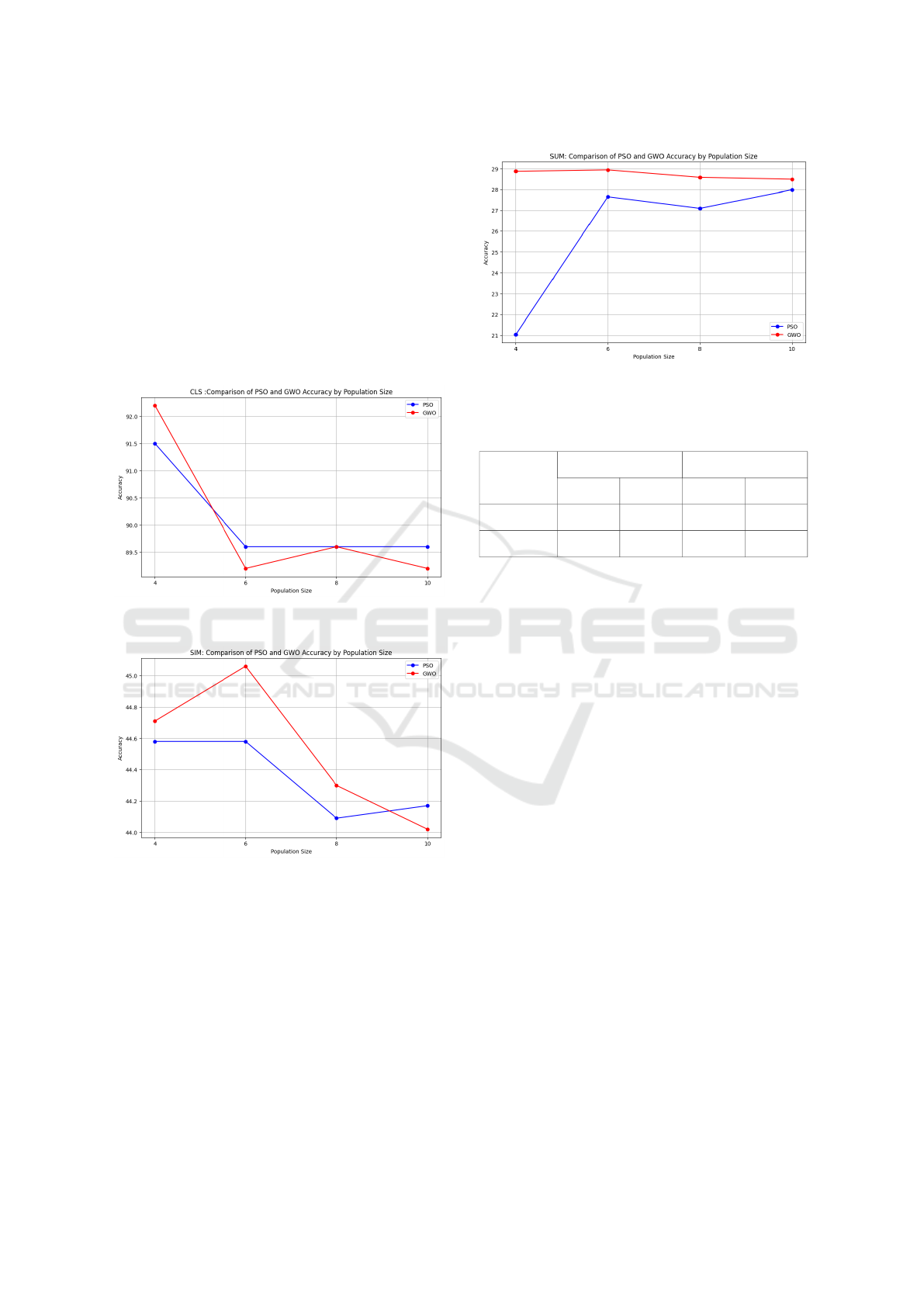
• Classification Task (MR Dataset). As shown in
Fig. 4, both PSO and GWO achieve peak accuracy
with a population size of 4. Further increases in
population size result in stagnation of accuracy.
• Simplification Task (ASSET Dataset). Fig. 5
indicates that PSO achieves maximum accuracy
with a population size of 4, while GWO performs
best with a population size of 6.
• Summarization Task (SAMSum Dataset). In
Fig. 6, GWO consistently outperforms PSO
across all population sizes, demonstrating its su-
perior performance for summarization tasks.
Figure 4: Accuracy trends for PSO and GWO with Popula-
tion Size for Classification.
Figure 5: Accuracy trends for PSO and GWO with Popula-
tion Size for Simplification.
5.4 Impact of Budget on Task Accuracy
Table 2 presents results for classification and simplifi-
cation tasks with a higher budget (10) for population
sizes of 4 and 8. The findings suggest that increasing
the budget has minimal impact on accuracy, reiterat-
ing that SwarmPrompt achieves effective results even
with a smaller budget.
Figure 6: Accuracy trends for PSO and GWO with Popula-
tion Size for Summarization.
Table 2: Accuracy for PSO and GWO with Budget 10 on
CLS and SIM Tasks.
Method CLS Accuracy SIM Accuracy
Population Size 4 Population Size 8 Population Size 4 Population Size 8
SwarmPrompt (PSO) 89.6 89.6 44.81 44.58
SwarmPrompt (GWO) 90.0 89.6 27.96 44.31
These results confirm that SwarmPrompt achieves
stable accuracy with reduced computational re-
sources, making it a highly efficient optimization
method.
6 CONCLUSION & FUTURE
SCOPE
In this study, we proposed SwarmPrompt, leveraging
swarm intelligence algorithms (PSO and GWO) as
optimization operators for LLM prompt optimization.
Our experiments demonstrate that SwarmPrompt con-
sistently outperforms human-engineered prompts and
achieves competitive performance against existing
evolutionary methods like Evoprompt, but with sig-
nificantly lower resource requirements.
Key observations include:
• SwarmPrompt excels in classification tasks but
shows minor limitations for high-dimensional
tasks like simplification and summarization.
• Smaller population sizes (4–6) and lower budgets
(5) are sufficient to achieve optimal results, ensur-
ing computational efficiency.
While our work explored a fixed set of hyper-
parameters, future research can investigate dynamic
hyperparameter tuning and other swarm intelligence
techniques like Ant Colony Optimization. Addition-
ally, this study focused on Alpaca, an open-source
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
92

LLM. Future experiments can extend to closed-source
LLMs such as GPT to further validate the approach.
In conclusion, integrating Swarm Intelligence Al-
gorithms with LLMs has proven to be a powerful
method for prompt optimization, offering substan-
tial performance gains with reduced resource con-
sumption. This work lays the foundation for further
advancements in efficient LLM optimization tech-
niques.
ACKNOWLEDGEMENTS
We would like to extend our thanks to Guo Qingyan,
who collaborated on the paper (Guo et al., 2023b)
with Microsoft and provided essential insights and
guidance on the feasibility of extending this project
to further ventures.
REFERENCES
Alva-Manchego, F., Martin, L., Bordes, A., Scarton, C.,
Sagot, B., and Specia, L. (2020). Asset: A dataset
for tuning and evaluation of sentence simplification
models with multiple rewriting transformations. arXiv
preprint arXiv:2005.00481.
Bharambe, U., Ramesh, R., Mahato, M., and Chaudhari,
S. (2024). Synergies between natural language pro-
cessing and swarm intelligence optimization: A com-
prehensive overview. In Advanced Machine Learn-
ing with Evolutionary and Metaheuristic Techniques,
pages 121–151.
Bharti, V., Biswas, B., and Shukla, K. (2022). Swarm intel-
ligence for deep learning: Concepts, challenges and
recent trends. In Advances in Swarm Intelligence:
Variations and Adaptations for Optimization Prob-
lems, pages 37–57. Springer International Publishing.
Gliwa, B., Mochol, I., Biesek, M., and Wawer, A.
(2019). Samsum corpus: A human-annotated dia-
logue dataset for abstractive summarization. arXiv
preprint arXiv:1911.12237.
Guo, Q., Wang, R., Guo, J., Li, B., Song, K., Tan, X.,
Liu, G., Bian, J., and Yang, Y. (2023a). Connecting
large language models with evolutionary algorithms
yields powerful prompt optimizers. arXiv preprint
arXiv:2309.08532.
Guo, Q., Wang, R., Guo, J., Li, B., Song, K., Tan, X.,
Liu, G., Bian, J., and Yang, Y. (2023b). Connecting
large language models with evolutionary algorithms
yields powerful prompt optimizers. arXiv preprint
arXiv:2309.08532.
Janga Reddy, M. and Nagesh Kumar, D. (2020). Evolution-
ary algorithms, swarm intelligence methods, and their
applications in water resources engineering: a state-
of-the-art review. H2Open Journal, 3(1):135–188.
Lester, B., Al-Rfou, R., and Constant, N. (2021). The power
of scale for parameter-efficient prompt tuning. arXiv
preprint arXiv:2104.08691.
Liu, P., Yuan, W., Fu, J., Jiang, Z., Hayashi, H., and Neubig,
G. (2023). Pre-train, prompt, and predict: A system-
atic survey of prompting methods in natural language
processing. ACM Computing Surveys, 55(9):1–35.
Ma, R., Wang, X., Zhou, X., Li, J., Du, N., Gui, T.,
Zhang, Q., and Huang, X. (2024). Are large language
models good prompt optimizers? arXiv preprint
arXiv:2402.02101.
Pang, B. and Lee, L. (2005). Seeing stars: Exploiting class
relationships for sentiment categorization with respect
to rating scales. arXiv preprint cs/0506075.
Rajwar, K., Deep, K., and Das, S. (2023). An exhaustive
review of the metaheuristic algorithms for search and
optimization: Taxonomy, applications, and open chal-
lenges. Artificial Intelligence Review, 56(11):13187–
13257.
Selvaraj, S. and Choi, E. (2021). Swarm intelligence algo-
rithms in text document clustering with various bench-
marks. Sensors, 21(9):3196.
Wang, X., Li, C., Wang, Z., Bai, F., Luo, H., Zhang, J.,
Jojic, N., Xing, E., and Hu, Z. (2023). Prompta-
gent: Strategic planning with language models en-
ables expert-level prompt optimization. arXiv preprint
arXiv:2310.16427.
Yang, C., Wang, X., Lu, Y., Liu, H., Le, Q., Zhou, D., and
Chen, X. (2023). Large language models as optimiz-
ers. arXiv preprint arXiv:2309.03409.
Zhou, Y., Muresanu, A., Han, Z., Paster, K., Pitis, S.,
Chan, H., and Ba, J. (2022). Large language mod-
els are human-level prompt engineers. arXiv preprint
arXiv:2211.01910.
SwarmPrompt: Swarm Intelligence-Driven Prompt Optimization Using Large Language Models
93
