
A2CT: Automated Detection of Function and Object-Level Access
Control Vulnerabilities in Web Applications
Michael Schlaubitz
a
, Onur Veyisoglu and Marc Rennhard
b
Institute of Computer Science (InIT), ZHAW Zurich University of Applied Sciences, Winterthur, Switzerland
Keywords:
Automated Web Application Security Testing, Access Control Vulnerabilities, Zero-Day Vulnerabilities.
Abstract:
In view of growing security risks, automated security testing of web applications is getting more and more
important. There already exist capable tools to detect common vulnerability types such as SQL injection
or cross-site scripting. Access control vulnerabilities, however, are still a vulnerability category that is much
harder to detect in an automated fashion, while at the same time representing a highly relevant security problem
in practice. In this paper, we present A2CT, a practical approach for the automated detection of access control
vulnerabilities in web applications. A2CT supports most web applications and can detect vulnerabilities in
the context of all HTTP request types (GET, POST, PUT, PATCH, DELETE). To demonstrate the practical
usefulness of A2CT, an evaluation based on 30 publicly available web applications was done. Overall, A2CT
managed to uncover 14 previously unknown vulnerabilities in two of these web applications, which resulted in
six published CVE records. To encourage further research, the source code of A2CT is made available under
an open-source license.
1 INTRODUCTION
Web applications are attractive attack targets (Veri-
zon, 2023). Consequently, they should be tested with
regard to security, with the goal to detect vulnerabil-
ities so they can be remedied. If possible, security
testing should be automated, as this allows for more
efficient and reproducible security tests.
A prominent automated security testing method is
vulnerability scanning. In web applications, vulner-
ability scanners can detect some vulnerability types
by sending HTTP requests to the running web appli-
cation and analyzing the received responses. There
exist several vulnerability scanners (Bennets, 2023;
OWASP, 2024) that can detect, e.g., SQL injection
and cross-site scripting vulnerabilities. A vulnerabil-
ity type that is much harder to detect is access control
vulnerabilities. The main challenge is that vulnerabil-
ity scanners usually do not know the access rights of
the different users, so there is no basis to determine
legitimate or illegitimate accesses during scanning.
Several approaches to automatically detect access
control vulnerabilities have been proposed (see Sec-
tion 6), but they typically have limitations that pre-
a
https://orcid.org/0009-0000-1796-9684
b
https://orcid.org/0000-0001-5105-3258
vent their adoption in practice. These limitations in-
clude, e.g., that significant manual work is required,
that a formal specification of an access control model
is needed (which is rarely available in practice), or
that the approach relies on a specific web application
technology (which limits its broad applicability).
This lack of a truly practical automated testing
methodology is in stark contrast to the relevance of
access control vulnerabilities. According to the Open
Worldwide Application Security Project (OWASP),
94% of web applications contain some form of ac-
cess control issue, more than any other vulnerability
type (OWASP, 2021a). As a result, the vulnerability
type broken access control climbed from fifth to first
place on OWASP’s current top ten list of the most crit-
ical vulnerability types in web applications (OWASP,
2021b). This underlines the need for automated de-
tection approaches for this vulnerability type.
In this paper, we present A2CT (Automated Ac-
cess Control Tester), an automated access control
vulnerability detection approach for web applica-
tions that overcomes the limitations of previous pro-
posals. A2CT supports all relevant HTTP request
types (GET, POST, PUT, PATCH, DELETE) and can
test web applications based on different technologies
and architectural styles. Our evaluation shows that
A2CT can detect previously unknown vulnerabilities.
Schlaubitz, M., Veyisoglu, O. and Rennhard, M.
A2CT: Automated Detection of Function and Object-Level Access Control Vulnerabilities in Web Applications.
DOI: 10.5220/0013092700003899
In Proceedings of the 11th International Conference on Information Systems Security and Privacy (ICISSP 2025) - Volume 2, pages 425-436
ISBN: 978-989-758-735-1; ISSN: 2184-4356
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
425

Specifically, 14 access control vulnerabilities in two
web applications were found, which resulted in six
newly published CVE records (MITRE, 2024). In
summary, our main contributions are the following:
• A2CT, a solution to automatically detect access
control vulnerabilities in web applications that re-
quires only minimal configuration and that does
not require a formal access control model.
• An evaluation of A2CT using 30 web applica-
tions, which revealed 14 access control vulnera-
bilities in two of these applications. This demon-
strates the practical value of A2CT.
• The source code of A2CT, made available to
the research community under an open-source li-
cense (ZHAW Infosec Research Group, 2024).
This work is based on a previous version devel-
oped by our research group (Kushnir et al., 2021;
Rennhard et al., 2022). However, the approach and
the evaluation have been significantly extended and
improved, and the previous limitations have been suc-
cessfully addressed (see Sections 3 and 4).
The remainder of this paper is organized as fol-
lows: In Section 2, an introduction to access con-
trol vulnerabilities in web applications is given. Next,
Section 3 explains how A2CT works to automatically
detect access control vulnerabilities. In Section 4, the
evaluation results are presented, followed by a discus-
sion of A2CT in Section 5, Related work is covered
in Section 6, and Section 7 concludes this work.
2 DETECTABLE ACCESS
CONTROL VULNERABILITIES
According to PortSwigger, “access control is the ap-
plication of constraints on who or what is authorized
to perform actions or access resources” (Portswigger,
2024). If the mechanisms to enforce this in a web ap-
plication contain vulnerabilities, users may be able to
act outside of their intended permissions.
The impacts of access control vulnerabilities can
be manifold. Examples include information disclo-
sure (e.g., an e-banking customer who can view ac-
count details of other customers), unauthorized ma-
nipulation of data (e.g., a user of a web shop who
can modify the shopping cart of other users), and get-
ting complete control of a web application (e.g., an
attacker manages to access the administrator panel).
There are different types of access control vul-
nerabilities, for an overview, see (Portswigger, 2024).
The two most prominent types are function-level and
object-level access control vulnerabilities. A2CT can
detect both types, and they are described as follows:
• A function-level access control vulnerability
means a user gets illegitimate access to a spe-
cific function in a web application. For example,
a URL like https://site.com/admin/view-users,
which provides the function to view all regis-
tered users, could be intended to be accessed only
by administrative users. If this resource admin/
view-users could also be accessed successfully
by non-administrators, this would correspond to
a function-level access control vulnerability.
• An object-level access control vulnerability
means a user has legitimate access to a function in
a web application, but can gain unauthorized ac-
cess to objects in the context of this function. For
instance, a seller in a web shop may have legit-
imate access to a function to edit his own prod-
ucts via the URL https://site.com/edit-product&
id=123 as the product with id 123 is one of his
own products. If the seller were to change the id in
the URL so that it corresponds to a product of an-
other seller (e.g., https://site.com/edit-product&
id=456), and if the seller gains illegitimate access
to edit this product, then this would correspond to
an object-level access control vulnerability.
3 A2CT: AUTOMATED ACCESS
CONTROL TESTER
A2CT uses a black box approach: a running web ap-
plication is tested by interacting with it from the out-
side, without any knowledge of internal information
such as the source code or the access control model.
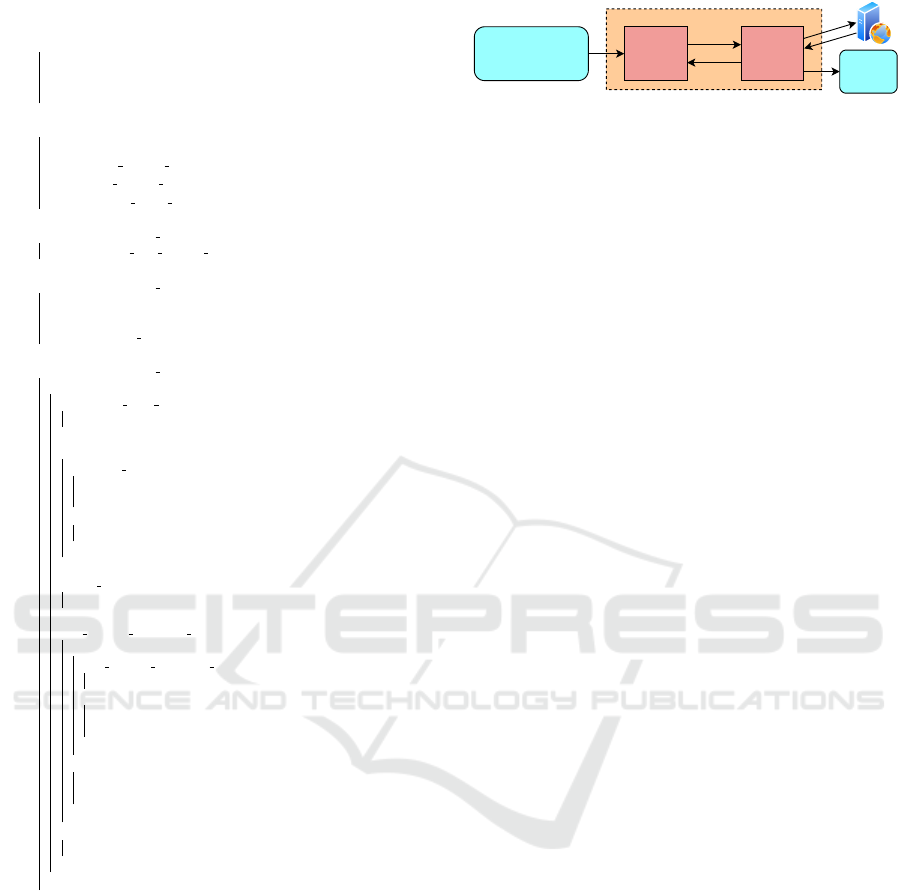
Figure 1 illustrates a typical setup how A2CT is used,
which corresponds to the setup we used during devel-
opment and for the evaluation (see Section 4).
Ubuntu Linux 22.04 / 16 Core CPU / 32 GB RAM / 500 GB Storage
Python / JavaScript Docker
A2CT
DB
SQLite
HTTP Requests
HTTP Responses
Figure 1: A2CT setup.
A2CT (implemented in Python and JavaScript)
and the web application under test run on the same
system, and the web application runs in a Docker
container (Docker, 2024). This setup allows to eas-
ily reset the web application during a test (see Sec-
tion 3.1). A2CT interacts with the web application
by sending HTTP requests and receiving HTTP re-
sponses. The request/response pairs are stored in an
SQLite database (SQLite, 2024). The underlying sys-
tem we used was based on Ubuntu Linux 22.04 with
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
426

a 16 core CPU, 32 GB RAM and 500 GB storage.
The fundamental idea how A2CT can determine
permitted access relies on the assumption that in many
web applications, the web pages presented to a user
contain only buttons, links and other navigation ele-
ments that correspond to functions that can be legiti-
mately accessed by this user. To illustrate this, assume
that the dashboard for administrators contains various
user interface (UI) elements to access different ad-
ministrator functions. Typically, access to the dash-
board and the included UI elements is only possible
after an administrator has logged in. Conversely, for a
standard (non-administrator) user, these UI elements
are typically not reachable. However, if a standard
user manages to successfully access an administrator
function by directly issuing the corresponding HTTP
request manually (i.e., without using the UI), then an
access control vulnerability is likely the cause. Based
on this assumption, web crawling can be used to au-
tomatically determine which requests can be legiti-
mately issued and which content can be legitimately
accessed by any given user, as crawlers follow links
and click buttons to emulate a human user interacting
with a web application.
As stated in Section 1, A2CT is based on a previ-
ous version developed by our research group that has
been significantly extended and improved. The im-
provements are mainly in the following areas, more
details will be provided in the following subsections:
• Improved Testing Coverage by Supporting all
HTTP Request Types: The previous version
supported only HTTP GET requests, i.e., re-
quests that read information from a web appli-
cation. This was extended to support also re-
quest types that modify the state of the web ap-
plication. Consequently, all relevant HTTP re-
quest types are now supported (GET, POST, PUT,
DELETE, PATCH) and as a result, it is now pos-
sible to detect vulnerabilities in the context of all
request types. This extension had an impact on
the requirements (see Section 3.1) and all compo-
nents of A2CT (see Sections 3.3-3.6).
• Improved Testing Coverage by Replacing and
Redesigning the Crawling Component: The
crawling component (see Section 3.3) of A2CT
has a big impact on the potential to detect vulner-
abilities. Compared to the previous version, this
component was redesigned and significantly en-
hanced. As a result, many more areas of a web
application can be reached by the crawling com-
ponent, making it possible to detect vulnerabili-
ties in areas that could not be tested previously.
• Improved Authentication Method of the
Crawling Component: Authenticating as a
specific user in the web application under test
has been moved to the browser instance which
also used to do the crawling. This ensures that
this browser instance is correctly initialized with
the authentication information before crawling
begins, which is more robust than the previous
version where authentication was done outside
this browser instance.
• Optimized Filtering Component: The filtering
component (see Section 3.4) was extended with a
new deduplication filter. This allows to remove
duplicate HTTP request/response pairs from the
crawling result and also helps to better understand
the results of the crawling process and why A2CT
has reported a specific vulnerability.
• More Efficient Overall Testing Process: The
previous version supported only two users at a
time and tests with more users required several in-
dividual test runs. The current version can include
any number of users in a test run, which is much
more efficient, as crawling with a particular user
must only be done once.
3.1 A2CT Requirements
To use A2CT, two requirements must be fulfilled:
• The authentication mechanism of the web appli-
cation under test can be automated using an au-
thentication script.
• The web application under test can be reset auto-
matically using a reset script.
The first requirement is because for every user in-
cluded in a test, A2CT must be able to log into the
web application with the user’s credentials (e.g., user
name and password). Otherwise, accessing the web
application using a specific user identity would not be
possible. The easiest way to create an authentication
script is by doing a manual login using the browser
and recording the login steps with a technology such
as Playwright codegen (Playwright, 2024b). Typi-
cally, these login steps include instructions to use a
URL to navigate to the login page of the web applica-
tion and to submit a POST request with the user cre-
dentials. The recorded login steps can then be added
to an authentication script template, and the resulting
script can be used to perform authentication directly
within a browser instance (see Section 3.3).
The second is a newly introduced requirement be-
cause A2CT now also supports request types (POST,
PUT, DELETE, PATCH) that can modify the state of
the web application under test, i.e., these requests may
create, change or delete data and resources. This re-
duces the reliability of A2CT because resources that
A2CT: Automated Detection of Function and Object-Level Access Control Vulnerabilities in Web Applications
427

were available when accessing the web application
with one user may be no longer be present (or contain
other data) when accessing them later with a differ-
ent user. To reduce the negative effects of such state
changes, the web application is reset to its initial state
whenever A2CT changes the user that is used to ac-
cess the web application. Resetting the web applica-
tion implies restoring the database to its original state
and restarting the web application. This is done by a
reset script, which executes the necessary commands.
The most robust way to do this is by containerizing
the web application with technologies like Docker (as
we did, see Figure 1).
For example authentication and reset scripts, refer
to (ZHAW Infosec Research Group, 2024).
3.2 A2CT Overview and Workflow
Besides the authentication and reset scripts, A2CT
also requires a configuration file. Listing 1 shows an
example configuration file for a web shop application.
1 t a r g e t :
2 t a r g e t u r l : h t t p : / / 1 7 2 . 1 7 . 0 . 1 : 8 0 8 0
3 a u t h s c r i p t : . / a u t h s c r i p t s / au t h . j s
4 r e s e t s c r i p t : . / r e s e t s c r i p t s / r e s e t . py
5 a u t h :
6 u s e r s :
7 − a dm in : Lo7Y . oCe ?ULa
8 − s e l l e r 1 : xIMp6aSTw −ue
9 − s e l l e r 2 : uGm natE&r2m
10 c o m b i n a t i o n s :
11 t y pe : s e l e c t e d
12 u s e r p a i r s :
13 − a dm in p u b l i c
14 − a dm in s e l l e r 1
15 − s e l l e r 1 p u b l i c
16 − s e l l e r 1 s e l l e r 2
17 o p t i o n s :
18 d o n o t c a l l p a g e s : l o g o u t | l o g i n | s ig n u p | p a s s w o r d
19 s t a t i c c o n t e n t e x t e n s i o n s : j s , c s s , img , j p g , png , svg , g i f
20 s t a n d a r d p a g e s : ab o u t . php , c r e d i t s . php
21 r e g e x t o m a t c h : a c c e s s d en i e d | u n a u t h o r i z e d
Listing 1: Configuration file example.
The configuration file uses YAML format. The
target node contains the base URL of the web ap-
plication under test and the file paths to the authen-
tication and reset scripts. The auth node contains the
users that should be included in the test and their pass-
words (users node). Here, three users are included: an
administrator of the web shop (admin) and two sell-
ers (seller1 and seller2). In addition, user public is
always included implicitly. The public user identifies
the non-authenticated user, i.e., the user that accesses
the web application without logging in.
The auth node also contains a combinations node
with the user combinations to be tested. By us-
ing type: all, all combinations of two users would
be tested. In this example, type: selected is used,
which allows to define the user combinations in the
user pairs node. Each entry contains two users and
specifies that it should be tested if the second user can
illegitimately access resources of the first user. For
instance, with admin public, it is tested if user pub-
lic can illegitimately access resources of user admin.
Likewise, admin seller1 tests if user seller1 can ac-
cess administrative resources that should not be acces-
sible, and seller1 public tests if user public can illegit-
imately access resources of user seller1. As these first
three entries include user pairs with different privilege
levels, they mainly serve to detect function-level ac-
cess control vulnerabilities. On the other hand, the
final entry seller1 seller2 includes two users of the
same privilege level (i.e., they have the same role) to
test if user seller2 can access resources of user seller1
that should not be accessible. This mainly allows
to uncover object-level access control vulnerabilities.
The options node contains further configurations that
will be explained in the following subsections.
Based on the configuration file and the authentica-
tion and reset scripts, the overall A2CT workflow con-
sists of four sequential components: crawling compo-
nent, filtering component, replaying component, and
validation component, as illustrated in Figure 2.
Input:
- Configuration File
- Authentication Script
- Reset Script
Filtering
Component
Crawling
Component
Validation
Component
Replaying
Component
Output:
- AccessControl
Vulnerabilities
Figure 2: The four components of the A2CT workflow.
In the first step of the workflow, the crawling com-
ponent crawls the web application with all users spec-
ified in the configuration file (and also the public user)
to record the reachable content of each user. Then, the
filtering component receives the data from the crawl-
ing component, filters out irrelevant entries, and pre-
pares the input for the next component. After that,
the replaying component uses each user pair defined
in the user pairs node in the configuration file to test
if resources that could be reached by the first but
not by the second user during crawling can be di-
rectly accessed by the second user. Finally, the val-
idation component assesses the results of the replay-
ing component to determine whether a potential ac-
cess vulnerability has been detected. The output of
the validation component are HTTP request/response
pairs where a potential access control vulnerability
has been detected. All four components will be ex-
plained in more detail in the following subsections.
Algorithm 1 describes the entire workflow in a
more formal way. When describing the four compo-
nents in the following subsections, we will refer to the
corresponding lines in this algorithm, and also to the
configuration file in Listing 1.
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
428
Input: configuration file, authentication script, reset script
Output: list of vulnerable request/response pairs
1 forall U
i
∈ users do
2 reset web application
3 B
U
i
← authenticate U
i
▷ authenticated browser instance B
U
i
4 C
U
i
← crawl(U
i
, B
U
i
) ▷ crawling results C
U
i
5 end
6 forall U
i
∈ users do
7 F
U
i
← deduplication-filter(C
U
i
)
8 F
U
i
← public content filter(F
U
i
)
9 F
U
i
← static content filter(F
U
i
)
10 F
U
i
← standard pages filter(F
U
i
) ▷ filtering results F
U
i
11 end
12 forall (U
1
,U
2
) ∈ user pairs do
13 F
U
1
,U
2
← other user content filter(F
U
1
, F
U
2
) ▷ filt. resuls F
U
1
,U
2
14 end
15 forall (U
1
,U
2
) ∈ user pairs do
16 reset web application
17 B
U
2
← authenticate U
2
18 R
U
1
,U
2
← replay requests(F
U
1
,U
2
, B
U
2
) ▷ replaying results R
U
1
,U
2
19 end
20 forall (U
1
,U
2
) ∈ user pairs do
21 forall R
U
1
,U
2
[i] ∈ R
U
1
,U
2
do
22 if not status code validator(R
U
1
,U
2
[i]) then
23 continue ▷ not vulnerable
24 end
25 if R
U
1
,U
2
[i] is HTTP 3xx then
26 if redirect validator(R
U
1
,U
2
[i]) then
27 flag vulnerability ▷ vulnerable
28 continue
29 else
30 continue ▷ not vulnerable
31 end
32 end
33 if regex validator(R
U
1
,U
2
[i]) then
34 continue ▷ not vulnerable
35 end
36 if U
1
content similarity validator(R
U
1
,U
2
[i]) then
37 if R
U
1
,U
2
[i] is HTTP GET then
38 if U
2
content similarity validator(R
U
1
,U
2
[i]) then
39 continue ▷ not vulnerable
40 else
41 flag vulnerability ▷ vulnerable
42 continue
43 end
44 else
45 flag vulnerability ▷ vulnerable
46 continue
47 end
48 else
49 continue ▷ not vulnerable
50 end
51 end
52 end
53 return request/response pairs flagged as vulnerable
Algorithm 1: A2CT workflow.
3.3 Crawling Component
As stated at the beginning of Section 3, A2CT re-
lies on the assumption that website elements that are
legitimately accessible for a user can be reached by
navigating the web application using the presented
UI. The purpose of the crawling component is to de-
rive the corresponding HTTP requests and responses
for all users included in the test by crawling the web
application. Figure 3 illustrates an overview of the
crawling component.
The inputs for the crawling component are the
Input:
- Configuration File
- Authentication Script
- Reset Script
Crawling Component
Crawler
(based on
Playwright)
Proxy
(based on
mitmproxy)
Requests
Responses
Output:
- Crawling
Results
Figure 3: Overview of the crawling component.
same as for the overall workflow (see Figure 2):
the configuration file and the authentication and re-
set scripts. The crawling component consists of two
parts: the actual crawler and a proxy. The crawler
executes the crawling of the web application under
test by interacting with it using HTTP requests and re-
sponses. All requests and responses are sent through
the proxy (based on mitmproxy (mitmproxy, 2024)),
which captures and stores them.
In Algorithm 1, the crawling component corre-
sponds to lines 1-5. Crawling is done for each user
included in the configuration file and for the public
user (line 1). Based on the example configuration in
Listing 1, crawling is done four times for users admin,
seller1, seller2 and public. For each user, the follow-
ing steps are done (lines 2-4): First, the web applica-
tion is reset using the reset script (line 2), which en-
sures the same initial state before crawling with a user
begins. Next, if the current user is not the public user,
the authentication script is executed within a browser
instance using the credentials from the configuration
file (line 3). After that, crawling of the web applica-
tion is done using this authenticated browser instance
(line 4). The output of the crawling component are the
crawling results, which consist of the crawled HTTP
request/response pairs for each user.
The previous version of the crawling compo-
nent was based on Scrapy (Scrapy, 2024) and Pup-
peteer (Puppeteer, 2024). The motivation for using
two technologies was to maximize crawling coverage,
as depending on the web application, one of them may
work better than the other. In reality, however, the us-
age of Scrapy provided almost no crawling coverage
benefits compared to Puppeteer. Therefore, it was de-
cided to stop using the Scrapy framework, and we also
replaced Puppeteer with the browser test automation
framework Playwright (Playwright, 2024a). The lat-
ter was mainly driven by the fact that Playwright pro-
vides additional flexibility over Puppeteer (e.g., multi
programming language and browser support). Other
than that, the two technologies, are similar.
Playwright uses a browser instance when crawl-
ing a web application. This means that web pages
received from the web application are rendered in this
browser instance and included JavaScript code is ex-
ecuted. Based on this, Playwright interacts with the
UI elements as a user would. As a result, Playwright
works well with both traditional and modern web ap-
A2CT: Automated Detection of Function and Object-Level Access Control Vulnerabilities in Web Applications
429

plications and the requests issued during crawling can
address, e.g., resources that serve entire HTML pages
or resources that correspond to REST API endpoints.
This is an important prerequisite for A2CT to detect
vulnerabilities in different resource types.
Another important change we did was to integrate
user authentication into the browser instance used
during crawling. In the previous version, authentica-
tion was done separately and the resulting authentica-
tion information such as cookies or tokens was added
to requests on the fly by the proxy during crawling,
but this was not always reliable and did not work with
every web application. By executing the authentica-
tion script directly within the browser instance that is
used for crawling afterwards, we get a truly authen-
ticated browser instance that correctly stores cookies
or tokens, and as a result of this, they are used cor-
rectly during crawling. This integration also makes
sure that cross-site request forgery (CSRF) counter-
measures such as CSRF tokens are handled correctly,
which is an important prerequisite when supporting
request types other than GET. As a final note, it is im-
portant that no accidental logout happen during crawl-
ing by clicking on a corresponding button or link, but
this can usually be avoided by blacklisted keywords,
which has the effect that requests where the URL con-
tains such a keyword are not executed during crawling
(see do not call pages option in Listing 1).
In addition, the actual crawling process was also
significantly redesigned and improved as with the pre-
vious version, we often observed limitations such as
UI elements that were not detected (and therefore web
application areas that could no be reached) and in-
finite crawling loops. In the following, some insights
into how the crawling component works are provided,
with a focus on the recent enhancements.
At the beginning of the crawling process, the main
page of the web application is requested and all nav-
igation elements are identified. We distinguish be-
tween link elements and clickable elements. For in-
stance, anchor tags (<a>) with an href attribute that
contains a URL are link elements that load a new
page. Examples of clickable elements are <button>
tags or input[type=submit] elements in forms. The
detected elements are converted to tasks and added to
a first in, first out (FIFO) task queue. After this initial
step, the tasks in the queue are processed. If the task
contains a link element, the corresponding resource
is requested and processed in the same way as with
the main page. If the task contains a clickable ele-
ment, processing is more complicated, as interacting
with such an element typically leads to one of two
outcomes: (1) changes in the document object model
(DOM) of the current page (e.g., new clickable ele-
ments are created, become actionable, change or even
disappear) or (2) a page navigation is initiated, which
loads a new page. The crawling component can de-
tect these two cases and reacts accordingly: If a page
navigation happens, the newly loaded page is imme-
diately processed, just like the main page. If no navi-
gation is detected, the state of the DOM is compared
with the previous state to detect new UI elements that
may have appeared. All newly detected link elements
and clickable elements are added to the task queue.
With this process, the crawling component gradually
explores the web application as it continuously pro-
cesses newly detected pages, follows link elements,
and interacts with clickable elements by processing
tasks from the task queue until it is empty.
Some clickable elements only become actionable
after other clickable elements have been clicked first.
For instance, there may be a navigation menu where
the buttons use multiple hierarchy levels where the
next next level is only shown after the button corre-
sponding to the parent menu entry has been clicked.
The crawling component supports this by implement-
ing a recursive clicking approach. This is done by per-
forming a series of clicks on already visible clickable
elements, which allows to access UI elements that are
only reached after a certain clicking depth. Compared
to the previous version, this newly introduced recur-
sive clicking approach was a major step to improve
crawling coverage in modern web applications as it
allows to detect significantly more UI elements and
therefore also web application areas.
Typically, the same elements will be found mul-
tiple times during crawling. Therefore, for efficiency
reasons and to prevent infinite crawling loops, an ele-
ment is only added to the task queue if it is considered
new. This is done by taking the CSS Path as well as
the outerHTML property of a UI element into con-
sideration, as these two values uniquely identify a UI
element in a web application. A newly detected UI
element is only added to the task queue if no task
with the same two values is already existing in the
task queue or has been processed before.
3.4 Filtering Component
The filtering component gets the configuration file
and the crawling results as inputs and uses five
sequential filters to remove HTTP request/response
pairs from the crawling results that are unnecessary
and to prepare the input for the following replaying
component. Figure 4 shows the filtering component.
In Algorithm 1, the filtering component corre-
sponds to lines 6-14. The first four filters are applied
to the crawling results per user (line 6). The first filter,
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
430
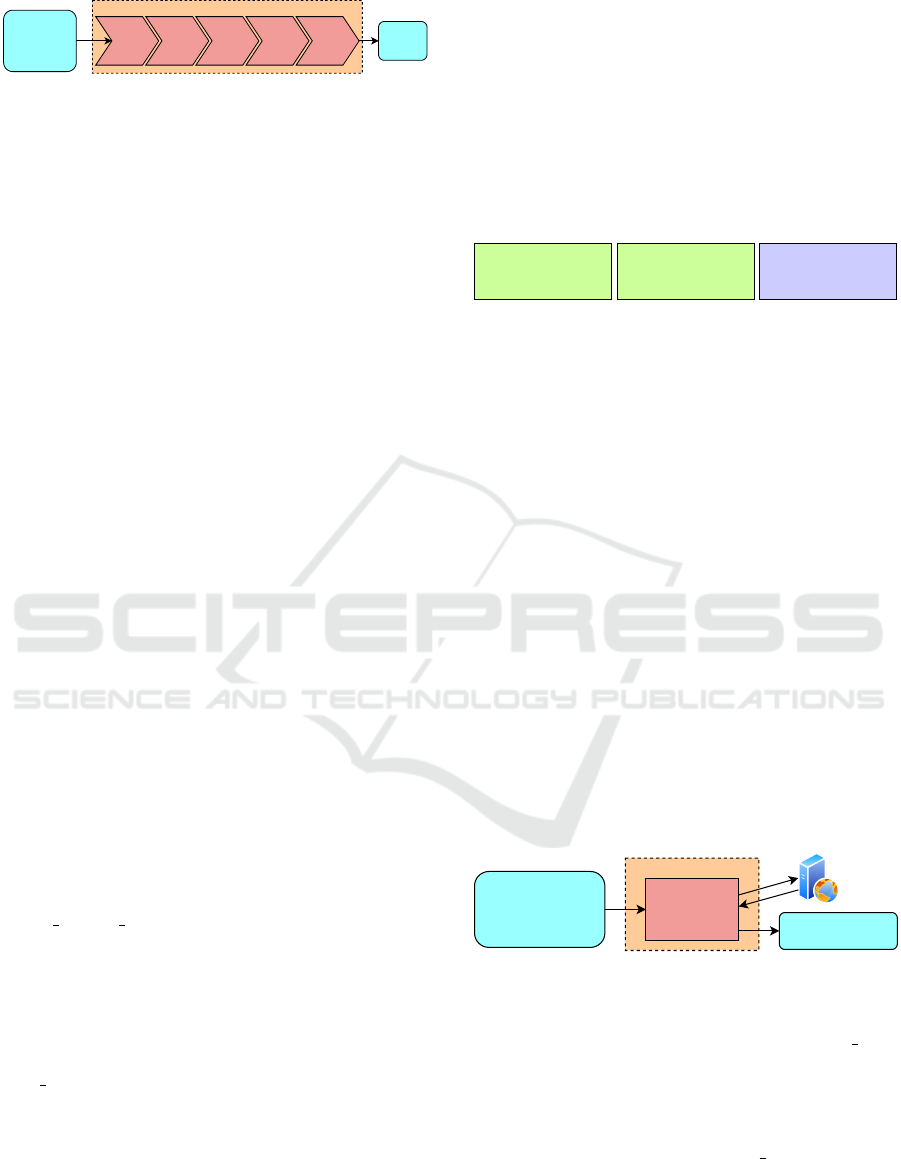
Dedup-
lication
Filter
Static
Content
Filter
Standard
Pages
Filter
Other
User
Content
Filter
Filtering Component
Input:
- Configuration
File
- Crawling
Results
Output:
- Filtering
Results
Public
Content
Filter
Figure 4: Overview of the filtering component.
the deduplication filter (line 7), removes duplicate re-
quest/response pairs from the crawling results. In the
previous version, duplicate checks were integrated in
the proxy of the crawling component before storing a
request/response pair. However, this had the conse-
quence that the complete crawling results were never
stored, which made it difficult to understand and im-
prove the crawling component during development.
Also, the complete crawling results can be helpful to
understand why a specific vulnerability was reported
by A2CT, as they allow to reconstruct the sequence
of requests that led to this result, and the final val-
idator of the validation component (see Section 3.6)
works most reliably if the complete crawling results
are available. The deduplication filter goes through
the crawled request/response pairs and removes an en-
try if the request is exactly the same or similar to a re-
quest that has been observed before. Specifically, two
requests are considered to be similar if they only dif-
fer in the value of a CSRF token or in the ordering of
parameter/value pairs (or key/value pairs with JSON
data) in the query string or request body.
The second filter, the public content filter (line 8),
removes entries from the crawling results that were
also found when crawling with the public user. As
these resources could be reached without logging in,
they are considered public content and not relevant in
the context of access control vulnerabilities.
The third filter, the static content filter (line 9), re-
moves entries that correspond to static content. Typi-
cal static content includes, e.g., JavaScript files, CSS
files, font files and – depending on the web ap-
plication – image files. This filter can be config-
ured by specifying the corresponding file extensions
(static content extensions option in Listing 1).
The fourth filter, the standard pages filter (line
10), removes entries that match certain standard
pages. Standard pages may include “About Us”
pages, contact forms, etc., that are not relevant
for access control tests. This filter can be config-
ured by specifying the corresponding resources (stan-
dard pages option in Listing 1).
The fifth filter, the other user content filter (lines
12-14), is applied in the context of each user pair
that is included in the test. As an example, consider
user pair admin seller1 from Listing 1. Assume that
F
admin
and F
seller1
contain the remaining request/re-
sponse pairs after the first four filtering stages (line
10). In this case, the request/response pairs in F
admin
are taken as a basis and all entries are removed from
this basis if the request is also included in F
seller1
,
because these resources can – according to the fun-
damental assumption – legitimately be accessed (by
crawling) by both users. The remaining request/re-
sponse pairs (identified as F
admin,seller1
, line 13), how-
ever, are candidates for access control vulnerabili-
ties if the resources can successfully be accessed by
seller1. As an example, consider Figure 5.
- GET /admin/dashboard
- POST /admin/createuser
- GET /seller/dashboard
- GET /seller/showproducts
- GET /seller/dashboard
- GET /seller/showproducts
- POST /seller/editproduct
- GET /admin/dashboard
- POST /admin/createuser
F
admin
F
seller1
F
admin,seller1
Figure 5: Example of the other user content filter.
In this example, after the first four filtering stages,
four entries are remaining in F
admin
and three in
F
seller1
(green boxes). For illustrative purposes, only
the request types and the URLs are shown here, but
in reality, the full request/response pairs are stored. In
F
admin,seller1
(purple box), only the two red requests
from F
admin
are remaining, because the two blue re-
quests from F
admin
are also in F
seller1
and are therefore
not included in F
admin,seller1
. The same is done for the
other three user pairs configured in Listing 1.
The output of the filtering component are the fil-
tering results, which consist of the filtered HTTP re-
quest/response pairs for each configured user pair.
3.5 Replaying Component
The replaying component takes the configuration file,
the authentication and reset scripts, and the filtering
results as inputs and replays each request in the filter-
ing results using the appropriate user identity. Figure
6 illustrates the replaying component.
Input:
- Configuration File
- Authentication Script
- Reset Script
- Filtering Results
Replaying Component
Replay filtered
requests of
each user-pair Output:
- Replaying Results
Figure 6: Overview of the replaying component.
In Algorithm 1, the replaying component corre-
sponds to lines 15-19. For each entry in the user pairs
node in the configuration file (line 15), the following
steps are performed: First, the web application is re-
set using the reset script (line 16), which ensures the
same initial state before replaying with a user begins.
If the second user in the current user pairs entry is not
the public user, the authentication script is executed
next (line 17), using the credentials of this second
user. This is done in the same way as in the crawling
component, i.e., directly within a browser instance.
A2CT: Automated Detection of Function and Object-Level Access Control Vulnerabilities in Web Applications
431
Next, the requests from the filtering results of the cur-
rent user pair are replayed (line 18). This is done by
taking the original request from the filtering results,
replacing authentication information (e.g., cookies or
tokens) in the original request with the fresh informa-
tion that is extracted from the authenticated browser
instance, sending the updated request to the web ap-
plication, and receiving the response. Recalling the
example in Figure 5 for user pair admin seller1, this
means that the two red requests in the purple box
would be replayed using the identity of seller1.
The output of the replaying component are the re-
playing results, which consist of the replayed HTTP
request/response pairs for each configured user pair.
3.6 Validation Component
The validation component takes the configuration file
and the replaying and crawling results as inputs and
uses a series of validators to determine which re-
played HTTP request/response pairs correspond to
access control vulnerabilities. Figure 7 illustrates
the validation component. At the top, a high-level
overview is shown, and at the bottom, the details how
the validators are applied to one request/response pair
from the replaying results are visualized.
Input:
- Configuration File
- Replaying Results
- Crawling Results
Validation Component
Series of
Validators
Status Code
Validator
no match
(not HTTP
2xx / 3xx)
Output:
- AccessControl
Vulnerabilities
Input:
- Replayed Request/
Response Pair
- User Pair U1U2
- Crawling Results
not
vulnerable
Regex
Validator
Redirect
Validator
match, HTTP 2xx
match,
HTTP 3xx
match
not
vulnerable
U1 Content
Similarity Validator
match
not
vulnerable
vulnerable
U2 Content
Similarity Validator
not
vulnerable
no match
match, GET request
match,
non-GET
request no match
vulnerable
not
vulnerable
no matchmatch
vulnerable
no match
Figure 7: Overview of the validation component (top) and
series of validators (bottom).
In Algorithm 1, the validation component corre-
sponds to lines 20-53. In the following, we focus
on the bottom part of Figure 7. The series of val-
idators is applied to each user pair U
1
U
2
defined in
the user pairs node in the configuration file (line 20)
and to each request/response pair from the replaying
results of this user pair (line 21). Recalling the exam-
ple in Figure 5 for user pair admin seller1, then U
1
corresponds to admin, U
2
corresponds to seller1, and
the series of validators is applied separately to the two
request/response pairs in the purple box.
First, the status code validator (line 22) checks
whether the HTTP status code of the response of the
replayed request indicates a successful access. Status
codes between 200-302 and status code 307 are con-
sidered potentially successful accesses, whereas any
other status code (e.g., 4xx and 5xx) is considered an
access denied decision by the web application, which
rules out the possibility of an access control vulner-
ability (line 23). Note that a 2xx status code alone
does not yet confirm that access was permitted since,
e.g., the content of the response may show a custom
error message that access is not allowed (instead of
responding, e.g., with a 403 status code).
In case of a redirection response (i.e., status code
3xx, line 25), the redirect validator is invoked next
(line 26). It compares the Location response header in
the replayed response of U
2
with the Location header
in the corresponding response in the crawling results
of U
1
. If they are equal, the request/response pair is
flagged as vulnerable (line 27). If they are different,
no vulnerability is reported (line 30). The rationale
here is that disallowed accesses are often redirected
to an error page or the login page, so they can be dis-
tinguished from permitted accesses by different URLs
in the Location header. As an example, consider the
POST request in the purple box of Figure 5. As-
sume that during crawling with admin, a redirection
response to https://site.com/admin/showusers was re-
ceived. If the same redirection response with the
same URL is received when replaying this request
as seller1 (i.e., the Location headers match), then
it is very likely a vulnerability has been detected.
On the other hand, if a redirection response to, e.g.,
https://site.com/error or https://site.com/login is re-
ceived (i.e., the Location headers differ), then it is
very likely that there is no vulnerability in the con-
text of this request/response pair.
In case of a response with status code 2xx, the
regex validator (line 33) is used after the status code
validator. It simply checks if the response body
matches a specific regular expression. This regu-
lar expression can optionally be configured with the
regex to match option in Listing 1. Its purpose is to
easily recognize specific strings (e.g., custom access
denied error messages) in the response body that in-
dicate a blocked access. If a match is detected, the
response of the replayed request is considered as a de-
nied access and no vulnerability is flagged (line 34).
Next, the U
1
content similarity validator (line 36)
checks if the response body in the replayed response
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
432

of U
2
is similar to the corresponding response body in
the crawling results of U
1
. If they are significantly dif-
ferent, no vulnerability is flagged (line 49) as the web
application very likely did not send back information
that should be inaccessible by U
2
. On the other hand,
if the response bodies are similar, a vulnerability may
have been detected as U
2
managed to access simi-
lar content as U
1
. For details about how the simi-
larity of the response bodies (e.g., HTML documents
or JSON data) is determined, we refer to our previ-
ous paper (Rennhard et al., 2022), but the basic idea
is that with HTML pages, the visible textual elements
are extracted and compared, and with JSON data, the
key/value pairs are compared. If there is an overlap of
80% or more, then the response bodies are considered
similar. As an example, consider the GET request
in the purple box of Figure 5. Assume that during
crawling with admin, an HTML page with the admin
dashboard is received. If the same or almost the same
dashboard is received when replaying the request as
U
2
, then the responses are considered similar and a
potential vulnerability has been detected. Conversely,
if a significantly different response is received by U
2
,
e.g., because it contains an access denied message or
only a skeleton HTML page without the actual dash-
board, the responses are not considered similar and no
vulnerability is flagged.
If the previous validator identified a potential vul-
nerability and if the request is a GET request (line 37),
the U
2
content similarity validator (line 38) is invoked
as a final check. It compares the response body in the
replayed response of U
2
with all response bodies in
the crawling results of U
2
. If any of these response
bodies is similar to the one of the replayed response,
then no vulnerability is flagged (line 39), otherwise a
vulnerability is flagged (line 41). The reasoning here
is that if U
2
can access the content of the replayed re-
sponse also by crawling (via a different URL), then
U
2
apparently has legitimate access to this content
and consequently, no vulnerability should be flagged.
The main purpose of this validator is to reduce false
positives. To illustrate this, assume that during crawl-
ing, U
1
and U
2
use different URLs to access the same
content, e.g., because the URL paths or a sorting pa-
rameter in the URL differ. In such cases, if we assume
that U
2
can indeed access the same content also with
the corresponding URL found during crawling with
U
1
, the U
1
content similarity validator flags this as a
potential vulnerability, i.e., a false positive. With the
U
2
content similarity validator, however, this is rec-
ognized and no vulnerability is reported.
Note that with non-GET requests (line 44), this fi-
nal validator is not used and a vulnerability is flagged
(line 45). To illustrate this, assume that both U
1
and
U
2
have legitimate access to the list of customers in a
web shop and can find this resource during crawling.
In addition, U
1
(but not U
2
) is also permitted to delete
a customer using a POST request, and as a response
to this request, U
1
gets the updated list of customers.
Now assume there is a vulnerability in the sense that
U
2
can also delete a customer by issuing the same
POST request and also getting the same response as
U
1
. The U
1
content similarity validator flags this cor-
rectly as a potential vulnerability. However, if the re-
ceived response – the updated list of customers – were
now compared with the crawling results of U
2
using
the U
2
content similarity validator, it would be very
likely that no vulnerability would be flagged as U
2
re-
ceived a very similar list of customers during crawl-
ing. To prevent such cases, the U
2
content similarity
validator is only used with GET requests.
The output of the validation component are the de-
tected access control vulnerabilities, i.e., the list of re-
quest/response pairs and the corresponding user pairs
that were flagged as vulnerable (line 53).
4 EVALUATION
In the evaluation of the previous version, we used only
a small set of web applications where we added spe-
cific vulnerabilities to show that the approach works
in principle. With the evaluation presented here, we
want to demonstrate that A2CT can indeed detect
previously unknown access control vulnerabilities to
prove its true value in practice.
To do this, A2CT was applied to several pub-
licly available open-source web applications. Over-
all, 30 web applications were tested and A2CT man-
aged to find 14 vulnerabilities in two of them. These
vulnerabilities resulted in six newly published CVE
records. Table 1 gives an overview of the vulnera-
bilities, including a number, the web application, the
affected version, the access control vulnerability type,
the CVE record, and the HTTP method and URL of
the vulnerable request. The remainder of this section
describes the vulnerabilities in detail.
4.1 Unifiedtransform
Unifiedtransform (Unifiedtransform, 2024) is an
open-source school management and accounting soft-
ware. Seven vulnerabilities were detected:
• No. 1: A student can view the grades of other
students. An object-level access control vulnera-
bility, which can be exploited by setting the URL
parameter student id to the ID of another student.
A2CT: Automated Detection of Function and Object-Level Access Control Vulnerabilities in Web Applications
433

Table 1: Detected vulnerabilities.
No. Web Version Access Control CVE HTTP URL path and parameters
Application Vulnerability Type Record Method
1 Object-level CVE-2024-12305 GET /marks/view?student id=<student id>&course id=...
2 Function-level CVE-2024-12306 GET /students/view/list
3 Object-level CVE-2024-12306 GET /students/view/profile/<student id>
4 Function-level CVE-2024-12306 GET /teachers/view/list
5 Function-level CVE-2024-12306 GET /teachers/view/profile/<teacher id>
6 Function-level CVE-2024-12307 GET /students/edit/<student id>
7
Unifiedtransform ≤2.0
Function-level CVE-2024-12307 POST /school/student/update
8 Object-level CVE-2024-2730 GET /page/preview/<incremented number>
9 Function-level & SSRF CVE-2024-3448 GET /s/ajax?action=plugin:focus:checkIframeAvailability&...
10 Function-level CVE-2024-2731 GET /s/contacts/quickAdd
11 Function-level CVE-2024-2731 GET /s/contacts/batchOwners
12 Function-level CVE-2024-2731 GET /s/monitoring
13 Function-level CVE-2024-2731 GET /s/companies/merge/<company id>
14
Mautic ≤4.4.9
Function-level CVE-2024-2731 POST /s/tags/edit/<tag id>
• No. 2,3: A student can view personal informa-
tion of other students. A function-level access
control vulnerability on page /students/view/list
allows students to list all other students. Also, de-
tailed personal information can be accessed with
/students/view/profile/<student id>, which is an
object-level access control vulnerability.
• No. 4,5: A student can view personal informa-
tion of teachers. Similar to No. 2,3, students
can access /teachers/view/list to get the list of all
teachers and /teachers/view/profile/<teacher id>
to reveal personal information of them.
• No. 6,7: A teacher can edit student data. A
function-level access control vulnerability allows
teachers to illegitimately access /students/ed-
it/<student id>. On this page, student data such
as name, date of birth, address, etc., can be mod-
ified, which sends a POST request to /school/stu-
dent/update to illegitimately save the changes.
4.2 Mautic
Mautic (Mautic, 2024) is an open-source marketing
automation software used by more than 200’000 or-
ganizations. Seven vulnerabilities were uncovered:
• No. 8: Previews of marketing campaigns can
be accessed by non-authenticated users. Mar-
keting campaigns created in Mautic can be pub-
lished as a preview, which can be accessed by a
public URL. The idea is that only recipients of the
URL can access the preview. A2CT reported that
this URL can illegitimately accessed by the pub-
lic user and further analysis revealed that guess-
ing valid URLs is easy, as the number to identify
a preview is assigned incrementally. This object-
level access control vulnerability allows competi-
tors to learn about upcoming campaigns and prod-
ucts, which can provide a competitive advantage.
• No. 9: Improper access control leads to
Server-Side Request Forgery (SSRF). This is a
function-level access control vulnerability where
A2CT found that the AJAX function identi-
fied with parameter action=plugin:focus:check-
IframeAvailability can be executed by low-
privileged users. This can be used to load any
HTML page within an iFrame. Further investiga-
tion revealed that this can be abused to carry out
an SSRF attack to execute, e.g., internal and exter-
nal port scans originating from the server where
the Mautic instance is running.
• No. 10-14: Low-privileged users can view
pages that expose sensitive information: These
are function-level vulnerabilities, which are all
similar. /s/contacts/quickAdd exposes all users’
full names, all company names, all stage names,
and all tags (the latter two are labels that can be as-
signed to contacts); /s/contacts/batchOwners ex-
poses all users’ full names; /s/monitoring exposes
all monitoring campaigns and their descriptions;
/s/companies/merge/<company
id> exposes all
company names; and /s/tags/edit/<tag id> ex-
poses tag names and descriptions and allows de-
scriptions to be edited.
4.3 Summary
The 14 vulnerabilities show the versatility of A2CT,
as they cover reading (GET) and modifying (POST)
requests, requests for HTML documents and to APIs,
and function- and object-level vulnerabilities.
Beyond the uncovered vulnerabilities, A2CT also
reported some false positives. Usually, they can be
quickly identified – in particular by a person who
has a good understanding of the web application
– by visually inspecting the requests, or by manu-
ally interacting with the web application, sending the
corresponding requests, and checking the responses.
In one case, however, we were convinced that we
detected two vulnerabilities that allowed so-called
worker users access to administrator functions, and
we reported this to the project maintainers. They
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
434

wrote us back that these are not vulnerabilities, but at
the same time they thanked us as our findings revealed
that there are functional bugs in their web applications
in the sense that the functionality to access these ad-
ministrative functions was missing in the UI presented
to worker users. This shows that while A2CT is de-
signed to detect access control vulnerabilities, it can
also uncover other issues in a web application.
5 DISCUSSION
Compared to our previous version, A2CT is a big step
forward. It removes the previous limitations in the
sense that it now supports all HTTP request types and
not only GET requests, that it copes much better with
the wide range of web application types (based on tra-
ditional and modern architectures), that testing cover-
age and robustness were significantly improved by re-
designing the crawling component, and that multiple
user combinations can be tested in one test run.
Beyond these technical improvements, the most
important step forward is the evaluation scope. Be-
fore, the evaluation was based solely on a small set
of web applications where we deliberately added vul-
nerabilities. With the evaluation presented here, we
have proven that A2CT can not only be applied to a
wide range of web applications, but that it can indeed
find previously unknown access control vulnerabili-
ties. This demonstrates the practical value of A2CT.
Some limitations remain. If the fundamental as-
sumption (see beginning of Section 3) on which
A2CT relies is not valid in a web application, then
A2CT will not work well and many false positives
may be reported. However, our evaluation demon-
strated that in most web applications, this assumption
is valid. Another limitation is that supporting modi-
fying HTTP requests during crawling can cause state
changes in the web application, which may affect the
results. This was partly remedied by resetting the web
application whenever crawling with a new user be-
gins, but state changes while crawling with a specific
user can of course still have an impact.
6 RELATED WORK
One way to find access control vulnerabilities in web
applications is to automatically extract the access con-
trol model, so it can be verified. In (Alalfi et al.,
2012), the source code of a web application is an-
alyzed to create a role-based access control model,
which is then manually checked for correctness. The
disadvantages of this approach are that it is depen-
dent on the used programming language and/or web
framework, meaning it has to be adapted for dif-
ferent technologies, and that manual checking is re-
quired. In (Le et al., 2015), a web application is
crawled with different users to create access spaces
per user. Next, a machine learning-based approach is
used to derive access rules from these access spaces.
These rules are then automatically compared against
an existing access control specification or manually
assessed. While this approach does not require access
to source code, it still requires an existing access con-
trol model for the approach to be automated.
Several approaches use replay-based vulnerabil-
ity detection. In (Li et al., 2014), an access control
model is extracted from a web application by crawl-
ing it with different users. During crawling, database
accesses by the web application are monitored to de-
rive an access control model that describes relation-
ships between users and permitted data accesses. This
model is then used to create test cases that check
whether users can access data that should not be
accessible by them. In (Noseevich and Petukhov,
2011), typical sequences of requests in web applica-
tions are compared with random sequences created by
crawlers. For this, a human first browses a web ap-
plication manually to record typical use cases, which
are represented as a graph. This graph is then used
as a basis to detect vulnerabilities when trying to ac-
cess resources that should not be accessible by non-
privileged users. The approach was applied to one
JSP-based web application, where it uncovered sev-
eral vulnerabilities. In (Xu et al., 2015), an approach
is described where a role-based access control model
of a program must first be defined manually. This
model is then used to create access control test cases,
which are transformed to code to execute the tests.
This approach was applied to three Java programs,
where it demonstrated that it could automatically cre-
ate a significant portion of the required test code and
that it could uncover vulnerabilities.
Some recent approaches focus on automated
REST API testing (Atlidakis et al., 2019; Viglianisi
et al., 2020; Liu et al., 2022; Deng et al., 2023). Based
on the OpenAPI specification, they generate request
sequences with the goal of triggering and detecting
bugs in the API. Although none of the works focus
solely on access control, Nautilus (Deng et al., 2023)
uncovered some privilege escalation vulnerabilities.
7 CONCLUSION
In this paper, we presented A2CT, a practical ap-
proach for the automated detection of function- and
A2CT: Automated Detection of Function and Object-Level Access Control Vulnerabilities in Web Applications
435

object-level access control vulnerabilities in web ap-
plications. A2CT can be applied to a wide range of
web applications, requires only a small configuration
effort, and can detect vulnerabilities in the context of
all relevant HTTP request types (GET, POST, PUT,
PATCH, DELETE). During our evaluation in the con-
text of 30 publicly available web applications, we
managed to detect 14 previously unknown vulnerabil-
ities in two of these applications, which resulted in six
newly published CVE records. This demonstrates the
soundness of the solution approach and the practical
applicability of A2CT.
To our knowledge, A2CT is the first approach that
combines a high degree of automation, broad applica-
bility, and demonstrated capabilities to detect access
control vulnerabilities in practice. To encourage fur-
ther research in this direction, A2CT is made avail-
able to the community under an open-source license.
ACKNOWLEDGEMENTS
This work was partly funded by the Swiss Confed-
eration’s innovation promotion agency Innosuissse
(project 48528.1 IP-ICT).
REFERENCES
Alalfi, M. H., Cordy, J. R., and Dean, T. R. (2012). Auto-
mated Verification of Role-Based Access Control Se-
curity Models Recovered from Dynamic Web Appli-
cations. In 2012 14th IEEE International Symposium
on Web Systems Evolution (WSE), pages 1–10, Trento,
Italy.
Atlidakis, V., Godefroid, P., and Polishchuk, M. (2019).
RESTler: Stateful REST API Fuzzing. In 2019
IEEE/ACM 41st International Conference on Soft-
ware Engineering (ICSE), pages 748–758.
Bennets, S. (2023). Open Source Web Scanners. https:
//github.com/psiinon/open-source-web-scanners.
Deng, G., Zhang, Z., Li, Y., Liu, Y., Zhang, T., Liu, Y.,
Yu, G., and Wang, D. (2023). NAUTILUS: Auto-
mated RESTful API Vulnerability Detection. In 32nd
USENIX Security Symposium (USENIX Security 23),
pages 5593–5609, Anaheim, CA. USENIX Associa-
tion.
Docker (2024). Docker. https://www.docker.com.
Kushnir, M., Favre, O., Rennhard, M., Esposito, D., and
Zahnd, V. (2021). Automated Black Box Detection
of HTTP GET Request-based Access Control Vulner-
abilities in Web Applications. In Proceedings of the
7th International Conference on Information Systems
Security and Privacy - ICISSP, pages 204–216.
Le, H. T., Nguyen, C. D., Briand, L., and Hourte, B. (2015).
Automated Inference of Access Control Policies for
Web Applications. In Proceedings of the 20th ACM
Symposium on Access Control Models and Technolo-
gies, SACMAT ’15, pages 27–37, Vienna, Austria.
Li, X., Si, X., and Xue, Y. (2014). Automated Black-Box
Detection of Access Control Vulnerabilities in Web
Applications. In Proceedings of the 4th ACM Confer-
ence on Data and Application Security and Privacy,
CODASPY ’14, pages 49–60, San Antonio, USA.
Liu, Y., Li, Y., Deng, G., Liu, Y., Wan, R., Wu, R., Ji, D.,
Xu, S., and Bao, M. (2022). Morest: Model-based
RESTful API Testing with Execution Feedback. ICSE
’22, page 1406–1417, New York, NY, USA. Associa-
tion for Computing Machinery.
Mautic (2024). Mautic. https://www.mautic.org.
mitmproxy (2024). mitmproxy. https://mitmproxy.org.
MITRE (2024). CVE – Common Vulnerabilities and Expo-
sures. https://www.cve.org.
Noseevich, G. and Petukhov, A. (2011). Detecting In-
sufficient Access Control in Web Applications. In
2011 First SysSec Workshop, pages 11–18, Amster-
dam, Netherlands.
OWASP (2021a). OWASP Top 10 – A01:2021 – Bro-
ken Access Control. https://owasp.org/Top10/A01
2021-Broken Access Control.
OWASP (2021b). OWASP Top 10:2021. https://owasp.org/
Top10.
OWASP (2024). Vulnerability Scanning Tools.
https://owasp.org/www-community/Vulnerability
Scanning Tools.
Playwright (2024a). Playwright. https://playwright.dev.
Playwright (2024b). Playwright Codgen. https://
playwright.dev/docs/codegen##running-codegen.
Portswigger (2024). Access Control Vulnerabilities
and Privilege Escalation. https://portswigger.net/
web-security/access-control.
Puppeteer (2024). Puppeteer. https://pptr.dev.
Rennhard, M., Kushnir, M., Favre, O., Esposito, D., and
Zahnd, V. (2022). Automating the Detection of Ac-
cess Control Vulnerabilities in Web Applications. SN
Computer Science, 3(5):376.
Scrapy (2024). Scrapy. https://scrapy.org.
SQLite (2024). SQLite. https://www.sqlite.org.
Unifiedtransform (2024). Unifiedtransform. https://
changeweb.github.io/Unifiedtransform.
Verizon (2023). 2023 Data Breach Investigation
Report. https://www.verizon.com/business/en-gb/
resources/reports/dbir.
Viglianisi, E., Dallago, M., and Ceccato, M. (2020).
RESTTESTGEN: Automated Black-Box Testing of
RESTful APIs. In 2020 IEEE 13th International Con-
ference on Software Testing, Validation and Verifica-
tion (ICST), pages 142–152.
Xu, D., Kent, M., Thomas, L., Mouelhi, T., and Traon,
Y. L. (2015). Automated Model-Based Testing of
Role-Based Access Control Using Predicate/Tran-
sition Nets. IEEE Transactions on Computers,
64(9):2490–2505.
ZHAW Infosec Research Group (2024). A2CT. https://
github.com/ZHAW-Infosec-Research-Group/A2CT.
ICISSP 2025 - 11th International Conference on Information Systems Security and Privacy
436
