
Cross-Domain Generalization with Reverse Dynamics Models in Offline
Model-Based Reinforcement Learning
Yana Stoyanova and Maryam Tavakol
Eindhoven University of Technology, Eindhoven, The Netherlands
Keywords:
Offline Model-Based Reinforcement Learning, Reverse Dynamics Models, Cross-Domain Generalization,
Context-Awareness.
Abstract:
Recent advancements in offline reinforcement learning (RL) have enabled automation in many real-world
applications, where online interactions are often infeasible or costly, especially in high-stakes problems like
healthcare or robotics. However, most algorithms are developed and evaluated in the same environment, which
does not reflect the ever-charging nature of our world. Hence, beyond dealing with the distributional shift be-
tween the learning policy and offline data, it is crucial to account for domain shifts. Model-based offline
RL (MBORL) methods are generally preferred over model-free counterparts for their ability to generalize
beyond the dataset by learning (forward) dynamics models to generate new trajectories. Nevertheless, these
models tend to overgeneralize in out-of-support regions due to limited samples. In this paper, we present
a safer approach to balance conservatism and generalization by learning a reverse dynamics model instead,
that can adapt to environments with varying dynamics, known as cross-domain generalization. We introduce
CARI (Context-Aware Reverse Imaginations), a novel approach that incorporates context-awareness to capture
domain-specific characteristics into the reverse dynamics model, resulting in more accurate models. Experi-
ments on four variants of Hopper and Walker2D demonstrate that CARI consistently matches or outperforms
state-of-the-art MBORL techniques that utilize a reverse dynamics model for cross-domain generalization.
1 INTRODUCTION
Reinforcement learning stands at the forefront of con-
temporary research in the fields of artificial intelli-
gence, captivating the attention of scientists, engi-
neers, and practitioners alike. This paradigm repre-
sents a pivotal departure from traditional approaches,
introducing a dynamic framework that enables intel-
ligent agents to learn from interaction with their envi-
ronment. Specifically, in online reinforcement learn-
ing, agents learn and adapt in real time, by continu-
ously interacting with the environment and updating
their strategies as new information becomes available
(Sutton and Barto, 2018). However, despite its huge
prospects to revolutionize different fields and indus-
tries, RL has remained mainly in the realm of research
and experimentation. This is because in most real-
world scenarios, simulation or online interaction with
the environment is usually impractical, costly and/or
dangerous (Prudencio et al., 2022). Therefore, of-
fline reinforcement learning (Sutton and Barto, 2018),
where the agent learns from a precollected offline
dataset, is an appealing alternative especially in high-
stakes domains such as healthcare (Liu et al., 2020a)
or robotics (Singh et al., 2021). However, learning
from such a static dataset is a very challenging task,
because the agent needs to find a balance between in-
creased generalization and avoiding unwanted behav-
iors outside of distribution (distributional shift) (Pru-
dencio et al., 2022).
Usually, RL agents are broadly separated into
two different categories, namely model-free rein-
forcement learning (MFRL) agents and model-based
reinforcement learning (MBRL) agents (Sutton and
Barto, 2018), and each category tackles the distribu-
tional shift issue in various ways. Importantly, most
MFRL approaches introduce policy constrains and
aggressive regularization techniques, therewith lim-
iting their task generalization. On the other hand,
MBRL methods are shown to exhibit better gener-
alization abilities over their model-free counterparts,
but they usually depend on (accurate) uncertainty es-
timation. A way to refrain from such unwanted be-
haviors is to learn a reverse dynamics model for gen-
erating reverse imaginations, which has been shown
to provide informed data augmentation and enable
Stoyanova, Y. and Tavakol, M.
Cross-Domain Generalization with Reverse Dynamics Models in Offline Model-Based Reinforcement Learning.
DOI: 10.5220/0013097200003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 2, pages 57-68
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
57

conservative generalization beyond the offline dataset
(Wang et al., 2021; Lyu et al., 2022). Nonetheless,
in the offline MBRL context this line of work is very
recent and more research is needed to explore its full
potential.
Having the ability to generalize to new scenarios
is one of the most important requirements for the safe
deployment of RL agents, particularly in high-stakes
domains. However, in the majority of research works,
agents are trained and tested on offline datasets that
focus on singleton environments, where all trajecto-
ries are from the same environment with the same dy-
namics (Mediratta et al., 2023). Thus, the general-
ization capabilities of offline RL agents to new envi-
ronments (with different initial states, transition func-
tions, or reward functions), also referred to as cross-
domain generalization, remain underexplored. In fact,
this makes RL agents practically ill-equipped and un-
prepared for the ever-changing world.
So far offline MBRL approaches that incorporate
learning a reverse dynamics model have not yet been
studied in the context of cross-domain generalization,
despite emerging as a promising direction. Motivated
by this lack of research and driven by the urge to
contribute making RL agents reliable for real-life de-
ployment, the goal of this work is to bridge the gap
between cross-domain generalization and MBORL
approaches that learn reverse dynamics models by
proposing a novel framework. Therefore, the contri-
butions of this work are two-fold:
• Performance comparison between existing of-
fline MBRL approaches that learn reverse dynam-
ics models, namely Reverse Offline Model-based
Imagination (ROMI), Confidence-Aware Bidirec-
tional offline model-based Imagination (CABI)
and Backwards Model-based Imitation Learning
(BMIL), with respect to cross-domain generaliza-
tion on Hopper and Walker2D environments (Fig-
ure 1). An in-depth analysis of the findings is
performed, focusing on the specific characteristics
inherent to each approach that either facilitate or
impede generalization.
• A novel offline MBRL framework, based on re-
verse dynamics models, named Context-Aware
Reverse Imagination (CARI), for improved cross-
domain generalization.
2 RELATED WORK
Reinforcement learning is typically conceptualized in
two main settings, namely online and offline. In on-
line RL, agents learn by directly interacting with the
(a) Hopper (b) Walker2D
Figure 1: Experimental environments.
environment in real-time. The agent takes actions
based on its current policy, observes the resulting state
transitions, and receives immediate feedback in the
form of rewards. These experiences are then used to
update the agent’s policy or value function, driving
iterative learning. However, online RL poses safety
concerns in certain domains, making it very restricted
or even infeasible to use for some real-world applica-
tions (Dulac-Arnold et al., 2019; Levine et al., 2020).
In contrast, offline RL operates on fixed datasets
of previously collected experiences, without the need
for direct interaction with the environment during the
learning process (Levine et al., 2020). These datasets
are typically pre-collected from sources such as his-
torical data or unknown behavioural policies. Con-
trary to its online counterpart, offline RL is particu-
larly suitable for the real world as there is no need
for access to the environment. Nonetheless, one of
the main challenges of this setting, known as distri-
butional shift, is finding a balance between increased
generalization and avoiding previously unseen (out-
of-distribution) states and actions (Levine et al., 2020;
Wang et al., 2021; Kidambi et al., 2020).
In this paper, the focus is on offline reinforce-
ment learning, due to its practical applicability in real-
world scenarios.
2.1 Model-Based versus Model-Free
Methods in Offline RL
Generally, reinforcement learning algorithms are sep-
arated into two main categories, namely model-free
and model-based (Remonda et al., 2021). These two
methodologies diverge in their strategies for acquir-
ing and utilizing information to optimize decision-
making processes within an environment. Model-free
reinforcement learning prioritizes empirical learn-
ing through direct interaction with the environment.
Rather than formulating an explicit representation of
the environment’s dynamics, model-free algorithms
focus on learning optimal policies solely based on ob-
served experiences. Although generally favoured due
to its simplicity, MFRL has major limitations when
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
58

it comes to sample efficiency, as such algorithms of-
ten require extensive exploration or datasets to con-
verge to optimal policies, leading to slow learning
rates (Luo et al., 2022; Remonda et al., 2021). Some
offline model-free RL algorithms deal with out-of-
distribution (OOD) actions by constraining the policy
search within the support of the static offline dataset
via importance sampling (Precup et al., 2001; Sutton
et al., 2015; Liu et al., 2019; Nachum et al., 2019;
Gelada and Bellemare, 2019) or policy constraints
(Fujimoto et al., 2018; Kumar et al., 2020; Wu et al.,
2019; Peng et al., 2019; Kostrikov et al., 2021; Wang
et al., 2020; Laroche and Trichelair, 2017; Liu et al.,
2020b). Other algorithms learn conservative critics
(Lu et al., 2021; Ma et al., 2021b; Kumar et al., 2021;
Ma et al., 2021a), quantify uncertainty (Wu et al.,
2021; Zanette et al., 2021; Deng et al., 2021) or model
the trajectories in a sequential manner (Chen et al.,
2021; Meng et al., 2021). Nonetheless, due to the
heavy constraints and the sample complexity issue,
these methods have poor generalization capabilities
(Wang et al., 2021; Yarats et al., 2019).
Model-based RL, on the other hand, emphasizes
the construction of an explicit model representing the
environment’s dynamics. This model captures the
transitions between states and the corresponding re-
wards, enabling agents to simulate potential trajecto-
ries and plan actions accordingly. Such methods at-
tain excellent sample efficiency. By leveraging the
learned model, model-based methods can perform
more effective planning and decision-making, leading
to potentially faster convergence (Luo et al., 2022).
Moreover, MBRL algorithms have the added bene-
fit of generalizing knowledge more effectively across
similar states or tasks, as the learned model encap-
sulates the underlying dynamics of the environment
(Wang et al., 2021). Nonetheless, such algorithms are
generally more computationally expensive and their
performance heavily relies on the accuracy of the dy-
namics model (Remonda et al., 2021).
As distributional shift remains the most influential
problem in offline model-based reinforcement learn-
ing, recent advancements in the field have focused on
addressing namely this issue. Some offline MBRL
algorithms handle it by introducing constraints on
the model through modifications in state transition
dynamics, reward functions, or value functions (He,
2023; Janner et al., 2021; Li et al., 2022; Matsushima
et al., 2020; Yu et al., 2021; Rigter et al., 2022; Bhard-
waj et al., 2023). Another widely adopted strategy in
recent model-based RL literature is to further mitigate
distributional shift by learning ensembles of (typically
forward) dynamics models, used to estimate uncer-
tainty (Yu et al., 2020; Yu et al., 2021; Kidambi et al.,
2020; Rigter et al., 2022; Lowrey et al., 2018; Ovadia
et al., 2019; Diehl et al., 2021). These uncertainty es-
timates encourage the agent to stay in states of low un-
certainty by heavily penalizing it when visiting areas,
where the model is uncertain. However, (inaccurate)
uncertainty estimates can lead to overgeneralization
in out-of-support regions (Wang et al., 2021). In other
words, such conservatism quantifications can over-
estimate some unknown states and mislead forward
model-based imaginations to undesired areas (Wang
et al., 2021). A newly researched way of mitigating
distributional shift in the context of offline MBRL is
the learning of reverse dynamics models (Wang et al.,
2021; Lyu et al., 2022; Park and Wong, 2022; Jain
and Ravanbakhsh, 2023), as it adds a new layer of
conservatism.
2.2 Reverse Dynamics Models
The idea of learning a reverse dynamics model (also
called backward dynamics model) to generate imag-
ined reversed samples first emerged in the literature
of online RL algorithms (Holyoak and Simon, 1999;
Goyal et al., 2018; Edwards et al., 2018; Lai et al.,
2020; Lee et al., 2020). It has been shown to speed up
learning, improve sample efficiency by aimed explo-
ration, benefit planning for credit assignment (Hasselt
et al., 2019; Chelu et al., 2020) and robustness (Jaf-
ferjee et al., 2020). Lai et al. (2020) (Lai et al., 2020)
utilize a reverse model to reduce the dependence on
accuracy in forward model predictions. Having sim-
ilar motivation, Lee et al. (2020) (Lee et al., 2020)
learn a backward dynamics model to capture contex-
tual information while mitigating the risk of overly
focusing on predicting only the forward dynamics. In
contrast to the backward model in online RL, Wang
et al. (2021) (Wang et al., 2021) propose to diver-
sify the offline dataset with reverse imaginations to in-
duce conservatism bias with data augmentation. Their
proposed framework, called Reverse Offline Model-
based Imagination (ROMI) marks the start of reverse
dynamics modelling in the realm of MBORL.
ROMI learns a reverse dynamics model in con-
junction with a novel reverse policy, which can gen-
erate rollouts leading to the target goal states within
the offline dataset. The authors show that these re-
verse imaginations provide informed data augmenta-
tion, therewith diversifying the offline dataset. Based
on this idea, Lyu et al. (2022) (Lyu et al., 2022) de-
veloped a method, that incorporates learning both a
forward and a reverse dynamics model (also known
as bidirectional dynamics model) with the purpose of
introducing conservatism into transition. Their frame-
work, called Confidence-Aware Bidirectional offline
Cross-Domain Generalization with Reverse Dynamics Models in Offline Model-Based Reinforcement Learning
59

model-based Imagination (CABI) is based on a dou-
ble checking mechanism, which ensures the forward
imagination is reasonable by generating a reverse
imagination from it. In other words, only samples
that both the forward and reverse models agree on
are trusted and therefore, included in the augmented
dataset. Park & Wong (2022) (Park and Wong, 2022),
propose a method for goal-conditioned RL, called
Backwards Model-based Imitation Learning (BMIL),
which utilizes a reverse-time generative dynamics
model that can generate possible paths leading the
agent back onto the dataset trajectories. BMIL pairs
a backwards dynamics model with a policy and is be-
ing trained on both offline data and imagined model
rollouts. These reverse rollouts provide useful infor-
mation since every rollout ends within the support of
the offline dataset.
2.3 Cross-Domain Generalization
Another area of research, primary explored in on-
line RL, is the topic of cross-domain generaliza-
tion, defined as generalization across environments
with varying transition dynamics, initial states or re-
ward functions (Mediratta et al., 2023). One note-
worthy contribution to the field is a method called
Context-aware Dynamics Model (CaDM), where con-
text refers to the dynamics of the environment (e.g.
pole lengths in CarPole or body mass in Hopper, Fig-
ure 2) (Lee et al., 2020). First, it uses a context en-
coder to capture the contextual information from a re-
cent experience. Then, an online adaptation to the
unseen environment dynamics is performed by con-
ditioning the forward dynamics model on the con-
text. While there is a large body of work focused
on evaluating and improving the generalization of on-
line RL approaches (Packer et al., 2018; Cobbe et al.,
2018; Zhang et al., 2018; Cobbe et al., 2019; Kuttler
et al., 2020; Raileanu et al., 2021; Jiang et al., 2021;
Raileanu and Fergus, 2021), just recently it began at-
tracting more research interest in the offline setting,
which is particularly suitable for the real-world de-
ployment of RL. Specifically, the majority of current
research is centralized around developing better per-
forming offline RL methods (Mediratta et al., 2023;
Levine et al., 2020; Prudencio et al., 2022; Fujimoto
et al., 2018; Wu et al., 2019; Agarwal et al., 2019;
Nair et al., 2020; Fujimoto and Gu, 2021; Zanette
et al., 2021; Rashidinejad et al., 2021; Zhang et al.,
2021; Lambert et al., 2022; Yarats et al., 2022; Brand-
fonbrener et al., 2022; Cheng et al., 2022), rather
than better generalizable offline RL agents. Mediratta
et al. (2023) (Mediratta et al., 2023) demonstrated
that some benchmarked offline RL methods, namely
Batch-Constrained deep Q-learning (BCQ) (Fujimoto
et al., 2018), Conservative Q-Learning (CQL) (Kumar
et al., 2020), Implicit Q-Learning (IQL) (Kostrikov
et al., 2021), Behavioral Cloning Transformer (BCT)
(Chen et al., 2021), and Decision Transformer (DT)
(Chen et al., 2021), exhibit poor cross-domain gener-
alization capabilities, highlighting the need for devel-
oping offline learning methods which generalize bet-
ter to new environments. Another important finding
of this work is that the diversity of the data, rather
than its size, improves performance on new environ-
ments (Mediratta et al., 2023).
To bridge the gap between cross-domain general-
ization and offline RL, Liu et al. (2022) (Liu et al.,
2022) propose Dynamics-Aware Rewards Augmenta-
tion (DARA). DARA is evaluated according to their
newly introduced cross-domain setup, consisting of
offline RL datasets with dynamics (mass, joint) shift
compared to the original D4RL datasets. The modi-
fied datasets are used for training, while the original
D4RL datasets are used for testing, therewith eval-
uating cross-domain generalization capabilities due
to the varying transition dynamics. By augmenting
rewards in the training dataset, DARA can acquire
an adaptive policy in testing time, which results in
consistently stronger performance when compared to
prior offline RL methods (Liu et al., 2022). DARA
is similar to another method designed for the cross-
domain setup it introduces, namely Beyond OOD
State Actions (BOSA). The core concept of BOSA is
to address the intrinsic offline extrapolation error by
focusing on OOD state-actions and OOD transition
dynamics. The aim is to filter out offline transitions
that could lead to a shift in state-actions or a mismatch
in transition dynamics (Liu et al., 2023).
3 THEORETICAL BACKGROUND
This section outlines the theoretical background rele-
vant to the newly proposed method, Context-Aware
Reverse Imagination (CARI). Consequently, a use
case describing the general idea of ROMI is provided,
as CARI is largely based on ROMI.
3.1 Preliminaries
In general, reinforcement learning addresses the prob-
lem of learning to control a dynamical system. The
dynamical system is defined by a fully-observed or
partially-observed Markov decision process (MDP).
Following the definitions in Sutton and Barto
(1998) (Sutton and Barto, 2018), the Markov deci-
sion process is defined as a tuple M = (S, A, p, r, γ, ρ
0
),
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
60
(a) Thin (b) Normal (c) Thick
Figure 2: Different body masses of Hopper.
where S is a set of states s ∈ S, which may be ei-
ther discrete or continuous (i.e. multi-dimensional
vectors), A is a set of actions a ∈ A, which similarly
can be discrete or continuous, p defines a conditional
probability distribution of the form p(s
′
|s, a), which
describes the dynamics of the system, where s
′
is the
next state after taking action a at the current state s.
r : S × A → R defines a reward function, γ ∈ (0, 1] is
a scalar discount factor and ρ
0
defines the initial state
distribution. In the case of offline RL, the trajecto-
ries represented by the tuples (s, a, r, s
′
) are stored in
a static dataset D
env
. The goal of RL is to optimize a
policy π(a|s) that maximizes the expected discounted
return defined as E
π
[
∑
∞
t=0
γ
t
r(s
t
, a
t
)].
3.2 Problem Formulation
The standard offline RL framework is considered,
where an agent learns from an offline static dataset.
Formally, the problem is formulated as an MDP, fol-
lowing the definitions introduced in Section 3.1. This
is further tackled in the context of model-based RL
by learning either a forward dynamics model f =
ˆp(s
′
|s, a) or a reverse (backward) dynamics model
b = ˆp(s|s
′
, a), which approximate the true transition
dynamics p(s
′
|s, a) and p(s|s
′
, a), respectively. In or-
der to address the problem of cross-domain general-
ization, the distribution of MDPs is further consid-
ered, where the transition dynamics p
c
(s
′
|s, a) varies
according to a context c. For instance, consider a
change in the transition dynamics of Hopper by modi-
fying its environment parameters (e.g.mass, Figure 2).
This study concerns the development of an of-
fline MBRL approach that learns a reverse dynamics
model, capable of generalization, which is robust to
such dynamics changes, i.e., approximating a distri-
bution of transition dynamics. Specifically, given a
set of training environments with contexts sampled
from p
train
(c), the aim is to learn a reverse dynam-
ics model that can retain good cross-domain general-
ization, i.e. produce accurate predictions for test envi-
ronments with unseen contexts sampled from p
test
(c).
Goal
Offline Dataset
Target Goal State
Dataset Trajectory
Forward Imagination
Reverse Imagination
Agent
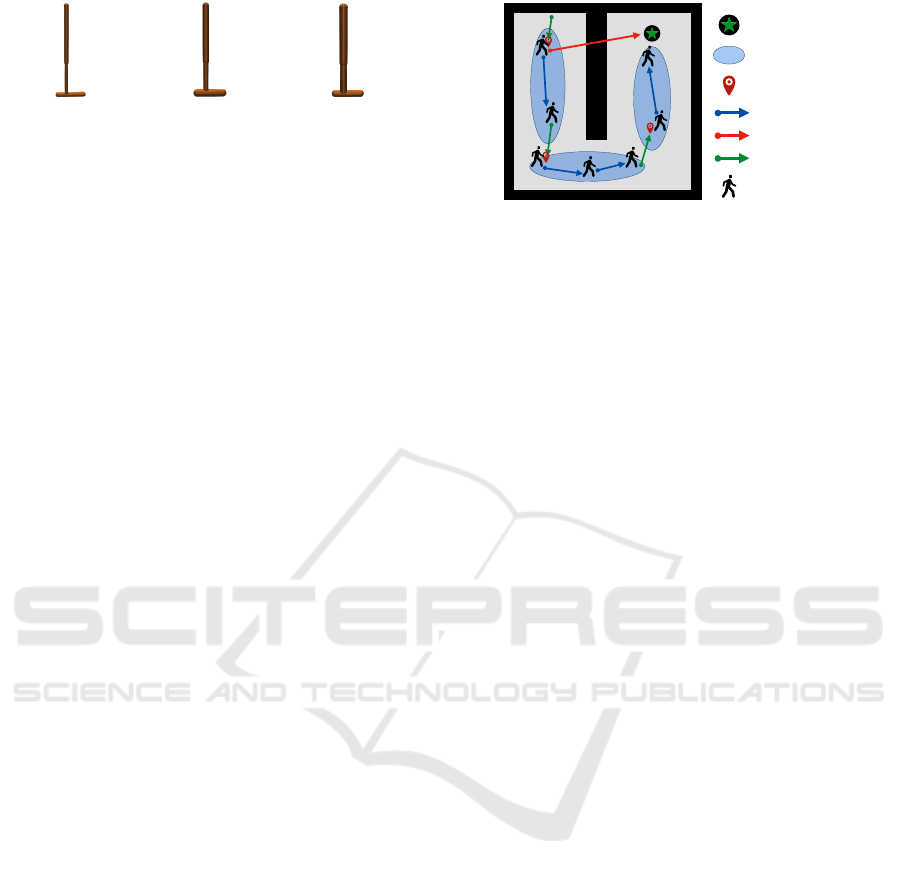
Figure 3: General idea of ROMI.
3.3 General Idea of ROMI
To illustrate the general idea of ROMI, consider Fig-
ure 3. The agent navigates in a U-shaped maze to
reach the goal. The precollected offline dataset is rep-
resented by the blue ovals and its trajectories are de-
noted by blue arrows. This dataset does not contain
any trajectories that hit the walls and thus, the agent
will be unaware of them during the learning process.
Hence, in this scenario, a standard (forward) dynam-
ics model might greedily generate an invalid imagina-
tion with overestimated value with the aim of finding
a better route to the goal state (red arrow). Contrary
to forward imaginations, ROMI generates trajectories
that lead to the target goal states within the offline
dataset (green arrows). Further, those reverse imag-
inations can be connected with the dataset trajectories
to create more diverse or even optimal policies.
Translating this example to a real-world scenario,
consider an offline dataset collected by an expert be-
haviour policy, where the agent is a vacuum cleaning
robot. The robot’s task is to learn to reach its charg-
ing station (i.e. the goal state) when its battery life is
low. Thus, in this case, the agent has to learn this task
only from successful trajectories that avoid bumping
into walls or furniture. When using a forward dy-
namics model, the agent can generate aggressive roll-
outs from the dataset to outside areas. Such forward
imaginations can potentially discover better routes to
the charging station, but can also guide the vacuum
cleaner towards an obstacle, rather than the charger,
due to overestimation. If the agent has learned a re-
verse dynamics model instead, then the reverse imag-
inations generate possible traces leading to targeted
states inside the offline dataset, therefore providing
a conservative way of augmenting the offline dataset.
These are useful not only because the agent will not be
guided towards obstacles, which in turn will impede
learning, but also because such conservative rollouts
can merge existing trajectories eventually composing
an optimal path to the charger.
Cross-Domain Generalization with Reverse Dynamics Models in Offline Model-Based Reinforcement Learning
61

4 TOWARD CROSS-DOMAIN
GENERALIZATION
In the offline RL setting, the agent has access only to a
given dataset, without the option to perform online ex-
ploration. In this setting, MBRL algorithms are usu-
ally challenged by (i) the limited samples of the given
dataset, (ii) the uncertainties in the out-of-support ar-
eas and (iii) the inability to correct model inaccuracies
by online interaction. Thus, it is of great importance
to augment the dataset, while also keeping conserva-
tive generalization, as increasing the diversity of the
data, rather than its size, is shown to improve per-
formance with respect to generalization (Mediratta
et al., 2023). In this section, Context-Aware Re-
verse Imagination (CARI) framework is introduced,
that combines model-based imaginations with model-
free offline policy learners. CARI builds upon ROMI
by incorporating context-awareness into the dynam-
ics model, while keeping the other two components,
namely reverse rollout policy and the generation of
rollouts for augmenting the offline dataset (see Fig-
ure 4). Thus, both frameworks promote diverse aug-
mentation of model-based rollouts and enable conser-
vative generalization of the generated imaginations.
However, CARI captures the local dynamics (i.e. the
context), and then predicts the previous state condi-
tioned on it. This is favorable because learning a
global model that can generalize across different dy-
namics is a challenging task.
4.1 Illustrative Example
As mentioned CARI is based on ROMI, which means
that the augmentation properties of the latter are
preserved. Hence why CARI retains the same superi-
ority as ROMI, compared to a method that generates
forward imaginations, as illustrated in Section 3.3
(see Figure 3). To demonstrate this further, consider
the following example: Assume state s
in
has a dataset
trajectory leading to the goal (denoted by s
goal
):
Dataset trajectory: 〈s
in
, · · ·, s
goal
〉
Suppose s
in
is part of a forward imaginary trajec-
tory (s
in
is the starting state of the trajectory, while s
4
is the last state) and its reverse counterpart (s
4
is the
starting state of the trajectory and s
in
is the last state).
Formally:
Forward imagination: 〈s
in
, a
f
1
, s
1
, a
f
2
, s
2
, a
f
3
, s
3
, a
f
4
, s
4
〉
Reverse imagination: 〈s
4
, a
b
4
, s
3
, a
b
3
, s
2
, a
b
2
, s
1
, a
b
1
, s
in
〉
Note that both trajectories visit the same sequence
of states but in reversed order, hence why the actions
differ. During the training process, the reverse rollout
will expand the dataset trajectory from 〈s
in
, · · ·, s
goal
〉
to 〈s
4
, · · ·, s
in
, · · ·, s
goal
〉. In other words, the sequence
〈s
1
: s
4
〉 can now reach the goal. Thus, the policy
learning in this task can be enhanced by the reverse
rollout through the reverse imagination of 〈s
1
: s
4
〉.
However, for the forward rollout, there are three cases
for the state s
4
:
(i) State s
4
is out-of-support and its value is over-
estimated: If this is the case, the forward rollout can
mislead the policy from s
in
to s
4
and impede the learn-
ing process by diverging from the goal. On the other
hand, the reverse trajectory cannot make such a neg-
ative impact since s
in
does not reach s
4
(but rather, s
4
reaches s
in
).
(ii) State s
4
is out-of-support and its value is not
overestimated: In this case, the forward trajectory
does not impact the policy learning, as the policy will
not go to s
4
with a lower value. As elaborated above,
the reverse rollout will benefit the learning, because
of its effective trajectory expansion.
(iii) State s
4
is in the support of the dataset: If s
4
has a trajectory leading to the goal, then the forward
imaginary trajectory can improve the learning by se-
lecting the better trajectory between 〈s
in
, ···, s
goal
〉 and
〈s
in
, · · ·, s
4
, · · ·, s
goal
〉. In this case, the reverse aug-
mentation has a single successful trajectory starting
at state s
in
, 〈s
in
, · · ·, s
goal
〉. However, for this situa-
tion neither of the models has to deal with the conser-
vatism issue, since s
4
is within the dataset support.
4.2 Context-Aware Reverse Imagination
(CARI)
Training the Context-Aware Reverse Dynamics
Model. To make the dynamics model context-aware,
CARI separates the task of reasoning about the en-
vironment dynamics into (i) learning the dynamics-
specific information (a latent vector c), and (ii) pre-
dicting the next state conditioned on the latent vector
(transition inference). This is done by introducing an
additional neural network head to the standard two-
head architecture (one head for transition inference
and one for the variance). The loss function puts pres-
sure on the context head to produce a context vector
that improves prediction accuracy, as similarly done
in (Lee et al., 2020). The reverse model estimates
the reverse dynamics model ˆp(s|s
′
, a, c) and rewards
model ˆr(s, a) simultaneously. For simplicity, the dy-
namics and reward function are unified into the re-
verse model p(s, r|s
′
, a, c). The output predictions are
explicitly conditioned on the context vector. If the
context vector does not capture relevant information,
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
62

the model’s predictions will be inaccurate, leading to
higher loss (Eq. 1). This unified model represents
the probability of the current state and immediate re-
ward conditioned on the next state, current action and
learned context. It is parameterized by φ and opti-
mized by maximizing the log-likelihood:
L
bwd
(φ) = E
(s,a,r,s
′
)∼D
env
[−log ˆp
φ
(s, r, |s
′
, a, c)] (1)
Training the Reverse Rollout Policy. Just like
ROMI, diversity in reverse model-based imaginations
near the dataset is encouraged by training a genera-
tive model
ˆ
G
θ
(a|s
′
), which samples diverse reverse
actions from D
env
using stochastic inference. Specifi-
cally, a conditional variational autoencoder is utilized
to train the diverse rollout policy , represented by
ˆ
G
θ
(a|s
′
). The rollout policy is trained to maximize
the variational lower bound:
L
bvae
(θ) = E
(s,a,r,s
′
)∼D
env
,z∼
ˆ
E
ω
(s
′
,a)
h
a−
ˆ
D
ζ
(s
′
, z)
2
+
D
KL
ˆ
E
ω
(s
′
, a)∥N (0, I)
i
, (2)
where
ˆ
E
ω
(s
′
, a) is an action encoder that produces
latent vector z under the multivariate normal distri-
bution N (0, I) with I being an identity matrix, and
ˆ
D
ζ
(s
′
, z) is the action decoder.
Combination with Model-Free Algorithms. Based
on the learned context-aware reverse dynamics model
and the reverse rollout policy, CARI can generate re-
verse rollouts. These reverse imaginations are col-
lected and stored in a model-based buffer D
model
.
This buffer is further combined with the original of-
fline dataset D
env
to compose the final augmented
dataset D
total
, i.e. D
total
= D
env
∪ D
model
. By
design, D
total
is obtained before the policy learn-
ing stage, therefore CARI can be combined with any
model-free offline RL algorithm such as BCQ (Fuji-
moto et al., 2018).
Figure 4 illustrates the CARI framework, while
Algorithm 1 details its training procedure.
5 EMPIRICAL EVALUATION
This section outlines the conducted experiments and
provides an answer to the following questions: (i)
How well do existing offline MBRL approaches, that
learn reverse dynamics models, perform with respect
to cross-domain generalization (see Table 1)? (ii)
What approach-specific characteristics hinder or con-
tribute to cross-domain generalization abilities, and
what are the associated trade-offs (see Section 5.2.1)?
(iii) Does CARI outperform all methods considered
in this study (see Table 1)?
Input: Offline dataset D
env
, rollout horizon h,
the number of iterations C
φ
, C
θ
, T ,
learning rates α
φ
, α
θ
, offline MFRL
algorithm
Result: π
out
Randomly initialize reverse model params φ;
for i = 0, ..., C
φ
− 1 do
Prepare inputs (s
′
, a) and targets (s, r)
from the dataset D
env
;
Get context latent vector c;
Condition the next state prediction on the
context latent vector c;
Compute L
bwd
;
Update φ ← φ − α
φ
∆
φ
L
bwd
;
end
Randomly initialize rollout policy params θ;
for i = 0, ..., C
θ
− 1 do
Compute L
bvae
using the dataset D
env
;
Update θ ← θ − α
θ
∆
θ
L
bvae
;
end
Initialize the replay buffer D
model
←
/
0;
for i = 0, ..., T − 1 do
Sample target state s
t+1
from D
env
;
Generate {(s
t−i
, a
t−i
, r
t−i
, s
t+1−i
)}
h−1
i=0
from
s
t+1
by drawing samples from the
dynamics model and rollout policy;
D
model
←
D
model
∪ {(s
t−i
, a
t−i
, r
t−i
, s
t+1−i
)}
h−1
i=0
;
end
Compose the final D
total
← D
env
∪ D
model
;
Combine the offline MFRL algorithm to
derive the final policy π
out
using D
total
;
Algorithm 1: CARI.
5.1 Experimental Setup
The considered methods, namely ROMI, CABI and
BMIL, and the proposed framework, CARI, are eval-
uated against each other in cross-domain offline RL
settings, following (Liu et al., 2022; Liu et al., 2023).
Importantly, ROMI, CABI and CARI are model-
based methods that incorporate a model-free compo-
nent. Thus, for the aims of this study all three meth-
ods are combined with BCQ as a model-free policy
learner. All methods share the same values for the
same set of hyperparameters across all environment
variants. The rollout length is set to 5 for all envi-
ronments and all methods. The study focuses on two
Gym-MuJoCo environments, Hopper and Walker2D
(see Figure 1), such that each environment has four
versions: Random, Medium, Medium-Expert and
Medium-Replay. The Random datasets contain expe-
riences collected with a random policy. The Medium
datasets contain experiences from an early-stopped
Cross-Domain Generalization with Reverse Dynamics Models in Offline Model-Based Reinforcement Learning
63

Backbone
Context
Output
Variance
Encoder
Decoder
Experience
Agent
Augmented
dataset
c
σ
̂
p(s,r
|
s′ ,a,c)
𝒟
total
z
̂
E
ω
(s′ ,a)
̂
D
ζ
(s′ ,z)
(s′ ,a)
Input
Figure 4: Illustration of CARI. First a context-aware reverse dynamics model is learned (left), which takes the next state and
current action as input. Then a diverse rollout policy, used to sample diverse rollouts, is trained, represented by a CVAE
(middle). Finally, the generated rollouts serve as augmentations to the original dataset, used by a MFRL algorithm to train the
learning policy (right).
SAC policy. The Medium-Replay datasets record
the samples in the replay buffer during the training
of the Medium SAC policy. The Medium-Expert
datasets mix sub-optimal samples with samples gen-
erated from an expert policy. As the main idea of
cross-domain generalization is to have the ability to
retain strong performance in previously unseen en-
vironmental settings, then the experimental setup in-
volves both a source and a target dataset. The source
dataset is used for training, while the target one is
used for testing, such that both datasets differ in terms
of their environmental dynamics. This study adopts
the proposed setup by Liu et al. (2022) (Liu et al.,
2022), which involves using offline samples from
D4RL as target offline dataset. For the source dataset,
the authors have changed the body mass of agents or
added joint noise to the motion, and, similar to D4RL,
collected the Random, Medium, Medium-Replay and
Medium-Expert offline datasets for the environments
(Liu et al., 2022). However, for the purposes of this
study only the datasets with shifted body masses are
considered for both Hopper and Walker2D. Specifi-
cally, the source datasets are comprised of 10% D4RL
data and 100% of the collected source offline data
(Liu et al., 2022).
Each of the methods is evaluated on the eight vari-
ants on five different random seeds. The evaluation
criterion is the normalized scores metric, suggested
by D4RL benchmark (Fu et al., 2020), where 0 in-
dicates a random policy performance and 100 corre-
sponds to an expert performer. The code of this work
is available at https://github.com/YanasGH/CDG.
5.2 Overall Performance
The three baselines that learn a reverse dynamics
model, namely BMIL, CABI and ROMI, are com-
pared against a cross-domain baseline, DARA. Like
CABI and ROMI, DARA can incorporate a model-
free part. Thus, DARA+BCQ (referred to as DARA)
is selected to ensure fair comparison, as both ROMI
and CABI are combined with BCQ for the purposes
of this study. The results for DARA are directly ob-
tained from the source paper (Liu et al., 2022).
For seven out of the eight environment vari-
ants, DARA outperforms BMIL. Only for Walker2D
Medium-Expert the performance of BMIL exceeds
the one of DARA. CABI performs better than BMIL
and manages to improve the scores achieved by
DARA on four environments. However, it matches
the performance of DARA for one environment, while
it underperforms for the three left. ROMI, on the
other hand, strongly outperforms DARA for all en-
vironments.
Compared to the strongest performer of the three
reverse baselines, namely ROMI, CARI manages to
further improve the score for both Hopper Medium-
Expert and Walker2D Medium-Replay. Complete re-
sults of all methods considered are given in Table 1,
while the following sections contain an elaborate dis-
cussion.
5.2.1 Approach-Specific Characteristics
Influencing Cross-Domain Generalization
To provide a multifaceted view of the algorithms’
cross-domain generalization capabilities, four ver-
sions of each environment are considered. The ver-
sion with the most unstructured data is the Random
one. Hence why the goal-conditioned method, BMIL,
fails. BMIL relies on successful trajectories to learn a
task effectively. For this reason, it is expected that this
method fails to score high in general. CABI, on the
contrary, manages to improve the performance com-
pared to BMIL, especially in Medium and Medium-
Expert environments. Notably, these respectively
high scores highlight CABI’s ability to leverage more
structured datasets effectively. However, CABI still
does not convincingly outperform DARA. One pos-
sible explanation for this could be the influence of
the forward dynamics model in CABI in combination
with the fact that CABI is not specifically designed
for cross-domain settings, unlike DARA. CABI incor-
porates a double-checking mechanism to perform the
data augmentation such that the only admitted imag-
inations are the ones confirmed by both the forward
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
64

Table 1: Performance of BMIL, CABI, ROMI, DARA and CARI for each of the environments, on the normalized return
metric. Results are averaged over five random seeds and standard deviation is reported (highest scores in bold). Also, results
of FOMI are included, such that its scores are compared only against ROMI’s and FOMI’s outperforming results are in italic.
Environment BMIL CABI ROMI DARA CARI FOMI
Hopper
Random 2.3 ± 0.0 13.1 ± 0.3 24.2 ± 3.5 9.7 27.3 ± 2.3 12.7 ± 1.8
Medium 14.5 ± 0.1 40.6 ± 2.7 47.1 ± 5.2 38.4 46.3 ± 0.9 70.1 ± 8.7
Medium-Expert 48.4 ± 1.2 63.6 ± 3.5 106.3 ± 1.4 84.2 110.1 ± 0.5 95.2 ± 6.3
Medium-Replay 12.3 ± 0.1 30.3 ± 1.1 46.2 ± 3.4 32.8 48.3 ± 1.9 42.6± 5.8
Walker2D
Random 1.4 ± 0.0 0.9 ± 0.2 12.4 ± 8.0 4.8 9.9 ± 4.5 5.4 ± 0.2
Medium 37.0 ± 2.5 80.5 ± 0.8 87.0 ± 0.5 52.3 87.5 ± 0.3 87.2 ± 0.2
Medium-Expert 61.9 ± 3.8 88.3 ± 0.3 93.3 ± 0.3 57.2 92.8 ± 0.6 93.1 ± 0.3
Medium-Replay 10.0 ± 0.0 62.6 ± 2.7 84.1 ± 0.5 15.1 85.9 ± 1.2 84.3± 1.5
and reverse dynamics models. Therefore, this added
conservatism can serve as an explanation of the ques-
tionable performance of CABI.
On the other hand, the most distinguished method,
ROMI, does not depend only on successful trajecto-
ries, neither does it learn a forward dynamics. No-
tably, in the Random environments, ROMI performs
impressively well. This serves as an indication that
this method learns to generalize very well despite
unstructured data. Importantly, the strong cross-
generalization abilities of ROMI are present even in
structured data, as it is the case for the Medium and
Medium-Expert environments for both Hopper and
Walker2D. These overall high scores serve as a proof
of concept that the combination of learning a reverse
dynamics model and diverse generative rollout policy
leads to an augmented dataset with extreme diversity,
needed for strong cross-domain generalization.
In analyzing the comparative performance of
CARI against the reverse baselines across Hopper and
Walker2D domains, several noteworthy observations
arise that highlight its relative strengths and weak-
nesses in terms of cross-domain generalization ca-
pabilities. The results from the Hopper domain un-
derscore CARI’s superior performance across varying
dataset conditions. Specifically, CARI achieves the
highest performance in the Medium-Expert condition
(110.1 ± 0.5), demonstrating a marked advantage over
BMIL, CABI, ROMI, and DARA in this engineered
data scenario. This robust performance suggests that
CARI is particularly adept at leveraging the structural
insights provided by structured data, thereby achiev-
ing higher efficacy in task execution. Since CARI is
incremental work of ROMI, these results showcase
the positive impact of context-awareness. In compari-
son, while ROMI also exhibits strong performance in
the Medium-Expert condition, its results are charac-
terized by higher variability. This variability points to
potential sensitivity to data randomness, which CARI
appears to handle more effectively.
Notably, CARI maintains a more stable perfor-
mance profile across all conditions, indicating a bal-
anced trade-off between adaptability and consistency.
CABI does not reach the same level of excellence
as CARI, regardless of its strong performance in
Walker2D Medium and Walker2D Medium-Expert
variants. Similarly, the results of BMIL, despite being
the most stable of all, are not comparable to the ones
of CARI, as the performance gap is quite pronounced
in every setting.
In summary, CARI demonstrates a clear edge over
the other methods in terms of cross-domain general-
ization abilities due to its consistently high perfor-
mance across both domains. While other methods
like ROMI and CABI show strong performance in
specific conditions, their variability and sensitivity to
data structure limit their overall efficacy compared to
CARI. These findings highlight CARI’s superior bal-
ance of performance, adaptability, and consistency,
thereby making it a preferred choice for tasks requir-
ing robust cross-domain generalization.
5.3 Ablation
Two ablation studies are performed to provide a
deeper insight into (i) the effect of a reverse dynamics
model (versus its forward counterpart), as well as (ii)
the influence of rollout length on CARI.
5.3.1 Ablation Study with Model-Based
Imagination
To investigate whether ROMI’s strong performance is
only due to the reverse model-based imagination, an
ablation study is performed to compare ROMI with its
forward counterpart, namely Forward Offline Model-
based Imagination (FOMI). Specifically, the reverse
imaginations are substituted with ones in the forward
direction. To study the performance of FOMI, the
same two environments with the same four variants
are used. To ensure fair comparison, FOMI is com-
bined with BCQ, as done in ROMI.
Table 1 shows that ROMI consistently matches or
outperforms FOMI for all environments except for
Cross-Domain Generalization with Reverse Dynamics Models in Offline Model-Based Reinforcement Learning
65

Figure 5: Performance comparison between ROMI and
CARI with varying rollout length for Walker2D Medium.
Hopper Medium. This performance gap is particu-
larly pronounced in the Random environments, under-
scoring the limitations of forward dynamics models in
handling unstructured settings. These overall results
imply that the reverse imaginations play a crucial role
for ROMI when it comes to cross-domain generaliza-
tion. However, it should be noted that although FOMI
comes generally short compared to ROMI, it still re-
tains very strong performance. The most plausible
reason for this is the diverse rollout policy.
5.3.2 Rollout Horizon Length Experimentation
Additional experiments are conducted to investigate
the effect of rollout length more clearly. This hyper-
parameter is varied on the Walker2D Medium envi-
ronment, as the results for CARI and ROMI are com-
parable. The results are vizualized in Figure 5, which
illustrates the aggregated normalized scores over five
runs, where the error bars are the standard deviation.
The findings point that both methods follow the same
trend, and their respective performances peak at roll-
out length of 5. Nonetheless, it can be seen that
CARI performs slightly better compared to ROMI for
shorter rollout length, while ROMI seems to have a
more accurate model for longer horizon imagination.
It should be noted that for this specific environment
it seems the learning of the context does not provide
a significant impact on the performance for any hori-
zon length, possibly due to the transitions being more
predictable.
6 CONCLUSION
This paper investigates the cross-domain generaliza-
tion capabilities of BMIL, CABI and ROMI. While
BMIL struggled to outperform the cross-domain
baseline DARA, CABI and ROMI showed consistent
improvements. Most notably, ROMI with its combi-
nation of learning a reverse dynamics model and di-
verse generative rollout policy lead to an augmented
dataset with extreme diversity, needed to ensure
strong generalization abilities. These results serve as
a proof of concept that offline MBRL methods that
learn a reverse dynamics model exhibit overall good
capabilities with respect to cross-domain generaliza-
tion. Importantly, this paper introduces CARI, a novel
MBORL framework, that builds on ROMI by making
the reverse dynamics model context-aware, therewith
improving its cross-domain generalization.
As future work, one potential direction is to com-
bine CARI with other MFRL algorithms, such as
CQL, as this can further improve its performance.
Another interesting possibility is to explore trajectory
augmentation techniques for further diversification of
the augmented dataset.
REFERENCES
Agarwal, R., Schuurmans, D., and Norouzi, M. (2019).
An Optimistic Perspective on Offline Reinforcement
Learning. In International Conference on Machine
Learning.
Bhardwaj, M., Xie, T., Boots, B., Jiang, N., and Cheng, C.-
A. (2023). Adversarial Model for Offline Reinforce-
ment Learning. ArXiv, abs/2302.11048.
Brandfonbrener, D., Bietti, A., Buckman, J., Laroche, R.,
and Bruna, J. (2022). When does return-conditioned
supervised learning work for offline reinforcement
learning? ArXiv, abs/2206.01079.
Chelu, V., Precup, D., and Hasselt, H. V. (2020). Fore-
thought and Hindsight in Credit Assignment. ArXiv,
abs/2010.13685.
Chen, L., Lu, K., Rajeswaran, A., Lee, K., Grover, A.,
Laskin, M., Abbeel, P., Srinivas, A., and Mordatch, I.
(2021). Decision Transformer: Reinforcement Learn-
ing via Sequence Modeling. In Neural Information
Processing Systems.
Cheng, C.-A., Xie, T., Jiang, N., and Agarwal, A. (2022).
Adversarially Trained Actor Critic for Offline Rein-
forcement Learning. ArXiv, abs/2202.02446.
Cobbe, K., Hesse, C., Hilton, J., and Schulman, J. (2019).
Leveraging Procedural Generation to Benchmark Re-
inforcement Learning. In International Conference on
Machine Learning.
Cobbe, K., Klimov, O., Hesse, C., Kim, T., and Schulman,
J. (2018). Quantifying Generalization in Reinforce-
ment Learning. In International Conference on Ma-
chine Learning.
Deng, Z.-H., Fu, Z., Wang, L., Yang, Z., Bai, C., Wang,
Z., and Jiang, J. (2021). SCORE: Spurious COrrela-
tion REduction for Offline Reinforcement Learning.
ArXiv, abs/2110.12468.
Diehl, C. P., Sievernich, T., Kr
¨
uger, M., Hoffmann, F., and
Bertram, T. (2021). UMBRELLA: Uncertainty-Aware
Model-Based Offline Reinforcement Learning Lever-
aging Planning. ArXiv, abs/2111.11097.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
66

Dulac-Arnold, G., Mankowitz, D. J., and Hester, T. (2019).
Challenges of Real-World Reinforcement Learning.
ArXiv, abs/1904.12901.
Edwards, A. D., Downs, L., and Davidson, J. C. (2018).
Forward-Backward Reinforcement Learning. ArXiv,
abs/1803.10227.
Fu, J., Kumar, A., Nachum, O., Tucker, G., and Levine, S.
(2020). D4RL: Datasets for Deep Data-Driven Rein-
forcement Learning. ArXiv, abs/2004.07219.
Fujimoto, S. and Gu, S. S. (2021). A Minimalist Ap-
proach to Offline Reinforcement Learning. ArXiv,
abs/2106.06860.
Fujimoto, S., Meger, D., and Precup, D. (2018). Off-Policy
Deep Reinforcement Learning without Exploration.
In International Conference on Machine Learning.
Gelada, C. and Bellemare, M. G. (2019). Off-Policy Deep
Reinforcement Learning by Bootstrapping the Covari-
ate Shift. In AAAI Conference on Artificial Intelli-
gence.
Goyal, A., Brakel, P., Fedus, W., Singhal, S., Lillicrap, T. P.,
Levine, S., Larochelle, H., and Bengio, Y. (2018). Re-
call Traces: Backtracking Models for Efficient Rein-
forcement Learning. ArXiv, abs/1804.00379.
Hasselt, H. V., Hessel, M., and Aslanides, J. (2019). When
to use parametric models in reinforcement learning?
ArXiv, abs/1906.05243.
He, H. (2023). A Survey on Offline Model-Based Rein-
forcement Learning. ArXiv, abs/2305.03360.
Holyoak, K. J. and Simon, D. (1999). Bidirectional
reasoning in decision making by constraint satisfac-
tion. Journal of Experimental Psychology: General,
128:3–31.
Jafferjee, T., Imani, E., Talvitie, E. J., White, M., and
Bowling, M. (2020). Hallucinating Value: A Pitfall
of Dyna-style Planning with Imperfect Environment
Models. ArXiv, abs/2006.04363.
Jain, V. and Ravanbakhsh, S. (2023). Learning to Reach
Goals via Diffusion. ArXiv, abs/2310.02505.
Janner, M., Li, Q., and Levine, S. (2021). Offline Rein-
forcement Learning as One Big Sequence Modeling
Problem. In Neural Information Processing Systems.
Jiang, M., Dennis, M., Parker-Holder, J., Foerster, J. N.,
Grefenstette, E., and Rocktaschel, T. (2021). Replay-
Guided Adversarial Environment Design. In Neural
Information Processing Systems.
Kidambi, R., Rajeswaran, A., Netrapalli, P., and Joachims,
T. (2020). MOReL : Model-Based Offline Reinforce-
ment Learning. ArXiv, abs/2005.05951.
Kostrikov, I., Nair, A., and Levine, S. (2021). Offline Rein-
forcement Learning with Implicit Q-Learning. ArXiv,
abs/2110.06169.
Kumar, A., Agarwal, R., Ma, T., Courville, A. C., Tucker,
G., and Levine, S. (2021). DR3: Value-Based Deep
Reinforcement Learning Requires Explicit Regular-
ization. ArXiv, abs/2112.04716.
Kumar, A., Zhou, A., Tucker, G., and Levine, S. (2020).
Conservative Q-Learning for Offline Reinforcement
Learning. ArXiv, abs/2006.04779.
Kuttler, H., Nardelli, N., Miller, A. H., Raileanu, R.,
Selvatici, M., Grefenstette, E., and Rockt
¨
aschel, T.
(2020). The NetHack Learning Environment. ArXiv,
abs/2006.13760.
Lai, H., Shen, J., Zhang, W., and Yu, Y. (2020). Bidi-
rectional Model-based Policy Optimization. ArXiv,
abs/2007.01995.
Lambert, N., Wulfmeier, M., Whitney, W. F., Byravan, A.,
Bloesch, M., Dasagi, V., Hertweck, T., and Ried-
miller, M. A. (2022). The Challenges of Explo-
ration for Offline Reinforcement Learning. ArXiv,
abs/2201.11861.
Laroche, R. and Trichelair, P. (2017). Safe Policy Improve-
ment with Baseline Bootstrapping. In International
Conference on Machine Learning.
Lee, K., Seo, Y., Lee, S., Lee, H., and Shin, J. (2020).
Context-aware Dynamics Model for Generalization
in Model-Based Reinforcement Learning. ArXiv,
abs/2005.06800.
Levine, S., Kumar, A., Tucker, G., and Fu, J. (2020). Offline
Reinforcement Learning: Tutorial, Review, and Per-
spectives on Open Problems. ArXiv, abs/2005.01643.
Li, G., Shi, L., Chen, Y., Chi, Y., and Wei, Y. (2022). Set-
tling the Sample Complexity of Model-Based Offline
Reinforcement Learning. ArXiv, abs/2204.05275.
Liu, J., Zhang, H., and Wang, D. (2022). DARA:
Dynamics-Aware Reward Augmentation in Offline
Reinforcement Learning. ArXiv, abs/2203.06662.
Liu, J., Zhang, Z., Wei, Z., Zhuang, Z., Kang, Y., Gai,
S., and Wang, D. (2023). Beyond OOD State Ac-
tions: Supported Cross-Domain Offline Reinforce-
ment Learning. ArXiv, abs/2306.12755.
Liu, S., See, K. C., Ngiam, K. Y., Celi, L. A., Sun, X., and
Feng, M. (2020a). Reinforcement Learning for Clini-
cal Decision Support in Critical Care: Comprehensive
Review. Journal of Medical Internet Research, 22.
Liu, Y., Swaminathan, A., Agarwal, A., and Brunskill, E.
(2019). Off-Policy Policy Gradient with Stationary
Distribution Correction. ArXiv, abs/1904.08473.
Liu, Y., Swaminathan, A., Agarwal, A., and Brunskill, E.
(2020b). Provably Good Batch Off-Policy Reinforce-
ment Learning Without Great Exploration. In Neural
Information Processing Systems.
Lowrey, K., Rajeswaran, A., Kakade, S. M., Todorov, E.,
and Mordatch, I. (2018). Plan Online, Learn Offline:
Efficient Learning and Exploration via Model-Based
Control. ArXiv, abs/1811.01848.
Lu, C., Ball, P. J., Parker-Holder, J., Osborne, M. A., and
Roberts, S. J. (2021). Revisiting Design Choices in
Offline Model Based Reinforcement Learning. In In-
ternational Conference on Learning Representations.
Luo, F., Xu, T., Lai, H., Chen, X.-H., Zhang, W., and Yu,
Y. (2022). A Survey on Model-based Reinforcement
Learning. Sci. China Inf. Sci., 67.
Lyu, J., Li, X., and Lu, Z. (2022). Double Check Your
State Before Trusting It: Confidence-Aware Bidi-
rectional Offline Model-Based Imagination. ArXiv,
abs/2206.07989.
Ma, X., Yang, Y., Hu, H., Liu, Q., Yang, J., Zhang, C.,
Zhao, Q., and Liang, B. (2021a). Offline Reinforce-
ment Learning with Value-based Episodic Memory.
ArXiv, abs/2110.09796.
Cross-Domain Generalization with Reverse Dynamics Models in Offline Model-Based Reinforcement Learning
67

Ma, Y. J., Jayaraman, D., and Bastani, O. (2021b). Conser-
vative Offline Distributional Reinforcement Learning.
In Neural Information Processing Systems.
Matsushima, T., Furuta, H., Matsuo, Y., Nachum, O., and
Gu, S. S. (2020). Deployment-Efficient Reinforce-
ment Learning via Model-Based Offline Optimiza-
tion. ArXiv, abs/2006.03647.
Mediratta, I., You, Q., Jiang, M., and Raileanu, R. (2023).
The Generalization Gap in Offline Reinforcement
Learning. ArXiv, abs/2312.05742.
Meng, L., Wen, M., Yang, Y., Le, C., Li, X., Zhang, W.,
Wen, Y., Zhang, H., Wang, J., and Xu, B. (2021). Of-
fline Pre-trained Multi-Agent Decision Transformer:
One Big Sequence Model Tackles All SMAC Tasks.
ArXiv, abs/2112.02845.
Nachum, O., Chow, Y., Dai, B., and Li, L. (2019).
DualDICE: Behavior-Agnostic Estimation of Dis-
counted Stationary Distribution Corrections. ArXiv,
abs/1906.04733.
Nair, A., Dalal, M., Gupta, A., and Levine, S. (2020). Ac-
celerating Online Reinforcement Learning with Of-
fline Datasets. ArXiv, abs/2006.09359.
Ovadia, Y., Fertig, E., Ren, J. J., Nado, Z., Sculley, D.,
Nowozin, S., Dillon, J. V., Lakshminarayanan, B., and
Snoek, J. (2019). Can You Trust Your Model’s Un-
certainty? Evaluating Predictive Uncertainty Under
Dataset Shift. In Neural Information Processing Sys-
tems.
Packer, C., Gao, K., Kos, J., Kr
¨
ahenb
¨
uhl, P., Koltun, V., and
Song, D. X. (2018). Assessing Generalization in Deep
Reinforcement Learning. ArXiv, abs/1810.12282.
Park, J. Y. and Wong, L. L. S. (2022). Robust Imitation of a
Few Demonstrations with a Backwards Model. ArXiv,
abs/2210.09337.
Peng, X. B., Kumar, A., Zhang, G., and Levine, S.
(2019). Advantage-Weighted Regression: Simple and
Scalable Off-Policy Reinforcement Learning. ArXiv,
abs/1910.00177.
Precup, D., Sutton, R. S., and Dasgupta, S. (2001). Off-
Policy Temporal Difference Learning with Function
Approximation. In International Conference on Ma-
chine Learning.
Prudencio, R. F., Maximo, M. R., and Colombini, E. L.
(2022). A Survey on Offline Reinforcement Learning:
Taxonomy, Review, and Open Problems. IEEE trans-
actions on neural networks and learning systems, PP.
Raileanu, R. and Fergus, R. (2021). Decoupling Value and
Policy for Generalization in Reinforcement Learning.
ArXiv, abs/2102.10330.
Raileanu, R., Goldstein, M., Yarats, D., Kostrikov, I., and
Fergus, R. (2021). Automatic Data Augmentation for
Generalization in Reinforcement Learning. In Neural
Information Processing Systems.
Rashidinejad, P., Zhu, B., Ma, C., Jiao, J., and Russell,
S. J. (2021). Bridging Offline Reinforcement Learning
and Imitation Learning: A Tale of Pessimism. IEEE
Transactions on Information Theory, 68:8156–8196.
Remonda, A., Veas, E. E., and Luzhnica, G. (2021). Act-
ing upon Imagination: when to trust imagined trajec-
tories in model based reinforcement learning. ArXiv,
abs/2105.05716.
Rigter, M., Lacerda, B., and Hawes, N. (2022). RAMBO-
RL: Robust Adversarial Model-Based Offline Rein-
forcement Learning. ArXiv, abs/2204.12581.
Singh, B., Kumar, R., and Singh, V. P. (2021). Reinforce-
ment learning in robotic applications: a comprehen-
sive survey. Artificial Intelligence Review, 55:945 –
990.
Sutton, R. S. and Barto, A. G. (2018). Reinforcement Learn-
ing: An Introduction. A Bradford Book, Cambridge,
MA, USA.
Sutton, R. S., Mahmood, A. R., and White, M. (2015).
An Emphatic Approach to the Problem of Off-policy
Temporal-Difference Learning. J. Mach. Learn. Res.,
17:73:1–73:29.
Wang, J., Li, W., Jiang, H., Zhu, G., Li, S., and Zhang, C.
(2021). Offline Reinforcement Learning with Reverse
Model-based Imagination. In Neural Information Pro-
cessing Systems.
Wang, Z., Novikov, A., Zolna, K., Springenberg, J. T.,
Reed, S. E., Shahriari, B., Siegel, N., Merel, J.,
Gulcehre, C., Heess, N. M. O., and de Freitas,
N. (2020). Critic Regularized Regression. ArXiv,
abs/2006.15134.
Wu, Y., Tucker, G., and Nachum, O. (2019). Behavior
Regularized Offline Reinforcement Learning. ArXiv,
abs/1911.11361.
Wu, Y., Zhai, S., Srivastava, N., Susskind, J. M., Zhang,
J., Salakhutdinov, R., and Goh, H. (2021). Uncer-
tainty Weighted Actor-Critic for Offline Reinforce-
ment Learning. In International Conference on Ma-
chine Learning.
Yarats, D., Brandfonbrener, D., Liu, H., Laskin, M.,
Abbeel, P., Lazaric, A., and Pinto, L. (2022). Don’t
Change the Algorithm, Change the Data: Exploratory
Data for Offline Reinforcement Learning. ArXiv,
abs/2201.13425.
Yarats, D., Zhang, A., Kostrikov, I., Amos, B., Pineau, J.,
and Fergus, R. (2019). Improving Sample Efficiency
in Model-Free Reinforcement Learning from Images.
In AAAI Conference on Artificial Intelligence.
Yu, T., Kumar, A., Rafailov, R., Rajeswaran, A., Levine, S.,
and Finn, C. (2021). COMBO: Conservative Offline
Model-Based Policy Optimization. In Neural Infor-
mation Processing Systems.
Yu, T., Thomas, G., Yu, L., Ermon, S., Zou, J. Y., Levine,
S., Finn, C., and Ma, T. (2020). MOPO: Model-based
Offline Policy Optimization. ArXiv, abs/2005.13239.
Zanette, A., Wainwright, M. J., and Brunskill, E. (2021).
Provable Benefits of Actor-Critic Methods for Offline
Reinforcement Learning. In Neural Information Pro-
cessing Systems.
Zhang, A., Ballas, N., and Pineau, J. (2018). A Dissection
of Overfitting and Generalization in Continuous Rein-
forcement Learning. ArXiv, abs/1806.07937.
Zhang, C., Kuppannagari, S. R., and Prasanna, V. K.
(2021). BRAC+: Improved Behavior Regularized Ac-
tor Critic for Offline Reinforcement Learning. ArXiv,
abs/2110.00894.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
68
