Fine-Grained Self-Localization from Coarse Egocentric Topological
Maps
Daiki Iwata, Kanji Ta naka, Mitsuki Yoshida , Ryogo Ya mamoto, Yuudai Morishita and Tomoe Hiroki
University of Fukui, 3-9-1 Bunkyo, Fukui City, Fukui 910-0017, Japan
Keywords:
Active Topological Navigation, Ego-Centric Topological Maps, Incremental Planner Retraining.
Abstract:
Topological maps are increasingly favored in robotics for their cognitive relevance, compact storage, and ease
of transferability to human users. While these maps provide scalable solutions for navigation and action plan-
ning, they present challenges for tasks requiring fine-grained self-localization, such as object goal navigation.
This paper investigates the action planning problem of active self-localization from a novel perspective: can
an action planner be trained to achieve fine-grained self-localization using coarse topological maps? Our
approach acknowledges the inherent limitations of topological maps; overly coarse maps lack essential infor-
mation for action planning, while excessively high-resolution maps diminish the need for an action planner.
To address these challenges, we propose the use of egocentric topological maps to capture fine scene varia-
tions. This representation enhances self-localization accuracy by integrating an output probability map as a
place-specific score vector into the action planner as a fixed-length state vector. By leveraging sensor data
and action feedback, our system optimizes self-localization performance. For the experiments, the de facto
standard particle filter-based sequential self-localization fr amework was slightly modified to enable the trans-
formation of ranking results from a graph convolutional network (GCN)-based topological map classifier into
real-valued vector state inputs by utilizing bag-of-place-words and reciprocal rank embeddings. Experimental
validation of our method was conducted in the Habitat workspace, demonstrating the potential for effective
action planning using coarse maps.
1 INTRODUCTION
Topological maps are widely utilized in robotics due
to their h igher cognitive relevance compared to ge-
ometric maps, compact storage requireme nts, and
ease of transferability to human users. Numerous
researchers have investigated methods for creating
topological maps and applying them to navigation and
action planning. These maps offer lightweight, scal-
able so lutions that are simpler than geometr ic maps
and require significantly less storage. A topological
map typically consists of coarsely quantized region
nodes and a set of edges representing relationship be -
tween the se regions, providing a c oncise representa-
tion of the workspace. This region-based rep resenta-
tion is robust against minor errors in self-localization,
and as long as the estimation remains within the same
region node, the impact on navigation performance is
minimal (Ulrich and Nourbakhsh, 2000; Ranganathan
and D e llaert, 20 08; Lui and Jarvis, 2010). However,
this error toleran ce poses c hallenges for tasks requir-
ing fine-grained self-localization, such as safe driv-
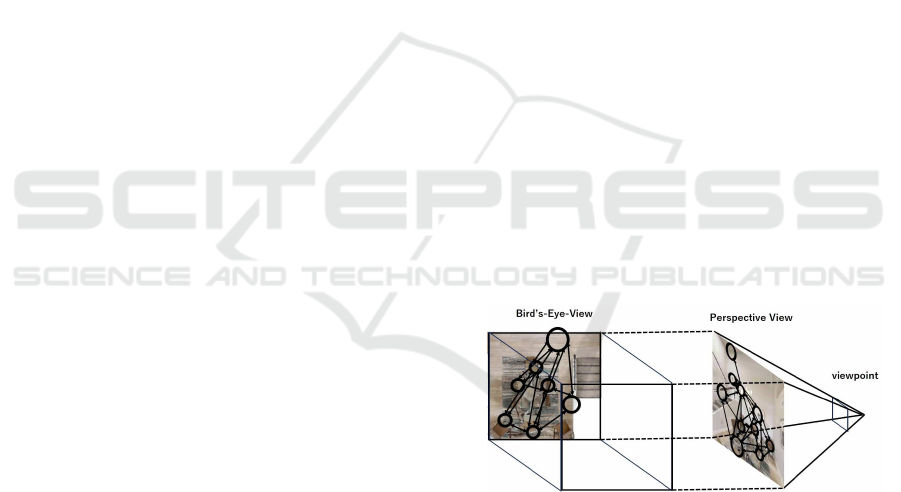
Figure 1: Topological navigation using ego-centric topolog-
ical maps. Left: Conventional world-centric map. Right:
The proposed ego-centric map.
ing. In fact, much of the past research on topological
navigation has relied on the combined use of accurate
metric maps or assumed the availability of infrastruc-
ture such as Global Positioning Systems (GPS). Lit-
tle progress has been made in achieving fine-grained
self-localization using only coarse topological maps,
with (Chaplot et al., 202 0) being a notable exception,
though its active vision does not primarily focus on
active localization.
In this paper, we focus on the action planning
problem active self-localization from the novel per-
810
Iwata, D., Tanaka, K., Yoshida, M., Yamamoto, R., Morishita, Y. and Hiroki, T.
Fine-Grained Self-Localization from Coarse Egocentric Topological Maps.
DOI: 10.5220/0013098000003912
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 2: VISAPP, pages
810-819
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

spective of topological map-based self-localization,
specifically exploring the research question: “Can an
action planne r be tr ained to achieve fine-grained self -
localization using coarse topological m a ps?” This ap-
proach is not universally applicab le, as the effec-
tive range of the given topological map has its lim-
its: On on e hand, overly coarse topological maps fail
to provide useful information for the action planner.
Conversely, when the resolution is already fine, self-
localization becomes accurate enough to make action
planning trivial.
Thus, we aim to develop an excellent action plan-
ner while also investigating its limitations. Regard-
ing the developmen t, our key insight is to use egocen-
tric topological maps—rather than traditional world-
coordinate-based maps—to capture fine scene varia-
tions and achieve fine-grained self-localization (Fig.
1). Then, the output probability map in the form of a
place-specific score vector is integrated into the action
planner as a fixed-length state vector. By leveraging
sensor data and action feedback, the system improves
self-localization accuracy and converges toward an
optimal estimation.
As a technical contribution, we present a novel
self-localization framework that employs a classifier
as the front-end and a sequential state estimator as the
back-end. This approach enables the integratio n of
graph convolutional network (GCN) classifiers, typi-
cally used for topological map recognition, with the
de facto standard particle filter for sequential self-
localization into a unified pipeline. This integration is
achieved by utilizing bag-of-place-words and recipro -
cal ran k vectors as intermediate representations. The
experimental inve stig a tion has been validated in the
Habitat workspace (Szot et al., 2021).
The contributions of this paper are summarized
as follows: (1) We formalize the active localiza-
tion problem based on a novel egocentric topologi-
cal map that does not require pre-computation and
maintenan ce of world-ce ntric maps. (2) This ap-
proach enables fully incremental re al-time active lo-
calization, allowing loc alization, planning, and plan-
ner training to be completed within the real-time bud-
get of each v iewpoint. (3) By utilizing coarse, region-
based topological m aps, we achieve fine-grained self-
localization beyond the region level, demo nstrating
state-of-the-art self-localization per formance as val-
idated through expe riments.
2 RELATED WORK
Topological n avigation is a behavior adopted by var-
ious animal species, including humans (Leonard and
Durrant- Whyte, 1991)( Thrun et al., 2 002). A topo-
logical map models the environment as a graph,
where only characteristic scene parts are en coded;
thus, it provides a much more compact representation
than metric map s. This is in contrast to geometric
map models, suc h as grid maps, where r aw data and
geometric features (lines, edges, etc.) are used to rep-
resent the e nvironment as a set of coordinates o f ob-
jects or obstacles. Furthermore, topological maps are
one of the most effective means of dealing with uncer-
tainties in visual robot navigation (Brooks, 1985), and
various frameworks have been proposed, including
geometric features ( Stankiewicz and Kalia, 2007)(Ta-
pus an d Siegwart, 2008)(N¨uchter and Hertzberg,
2008)(Tapus and Siegwart, 2008), appearance fea-
tures (L ui and Jarvis, 2010)(Lowe, 1999) (Ulrich and
Nourbakhsh, 2000)(Mikolajczyk et al., 2005), vi-
sual pedestrian loca liza tion (Zha and Yilmaz, 2021),
and matching tech niques (Li and Olson, 201 2)(Cum-
mins and Newman, 2008)(Ranganath an and Dellaert,
2008)(Aguilar et al., 2009)(Neira and Tard´os, 2 001).
However, most rely on globally consistent world-
centric maps; thus, they are not applicable to egocen-
tric maps. Recently, impressive methods for active
localization have b e en proposed for cases using gr id
data, such as images (Chaplot et al., 2018); however,
active localization for non-gr id data, such as topologi-
cal maps, is still largely unexplored. To the best of our
knowledge, this is th e first study to develop a fully
incrementa l, real-time active localization framewo rk
that d oes not rely on any globally consistent world-
centric models to be pre-computed or maintained.
The localization applicatio ns considered in this
study pe rtain prim a rily to semantic localization , a r e-
cently emerging domain-invariant localization appli-
cation (Sch¨onberger et al., 2018) . In (Sch¨onberger
et al., 201 8), 3D poin t clouds and semantic features
were used for highly robust and accurate sem antic
localization, and novel deep neural networks were
employed to embed the geometric and semantic fea-
tures. In contrast, we explored a purely mo nocular
localization problem that did not rely on 3D mod-
els/measuremen ts. In (Yu et al., 2018), the sema n-
tic region edges provided by semantic segmentation
were used as features. In contrast, we d o not r ely
on the availability of precise semantic segmentation;
instead, we use only the coarse semantic, size, and
location attributes of the scene parts. In (Gawel
et al., 2018), a semantic g raph was employed as a
scene model to achieve accurate localization via graph
matching in outdoor scenes. However, this method as-
sumes p erfect semantic segmentation. Furthermore,
they rely on costly graph matching, and their con -
siderable com putational burden may limit their scal-
Fine-Grained Self-Localization from Coarse Egocentric Topological Maps
811

ability. In (Guo et al., 2021a), semantic histograms
were extracted from a semantic graph map to achieve
a highly efficient topological localiza tion. However,
this method assumes the availability of discrimina-
tive scene graphs an d may encounter difficulties in se-
mantically poor doma ins (also known as bucolic en-
vironm ents (Benbihi et al., 2020)). In contrast, ou r
active localization approa ch relies only on very sim-
ple semantic and spatial features, and therefore robust
against segmentation noise and has good generaliza-
tion performance. Importan tly, egocentric topolog i-
cal maps do not require the management of maps in a
world-centered coordinate system, making them na t-
urally compatible with map-le ss navigation (e.g., ob-
ject goal navigation) ( Ch aplot et al., 2020).
3 APPROACH
3.1 System Overview
Active localization typically com prises two main
modules: passive localization and action planning.
Passive localization is responsible for estimating the
robot’s state (e.g., viewpoint) g iven th e latest ego-
motion and pe rceptual measurements. The action
planner is responsible for determ ining the optimal
next-best-view action , give n the latest state e stima te ,
by simulating possible future robot-environmen t in-
teractions. These two submodules are described as
follows:
We formulate passive localization as a place clas-
sification problem to classify a given egocentric topo-
logical map into predefined place classes. Note that
this is one of the most scalable formulations of the
self-localization problem (Lowry et al., 2015), among
other formulations such as image retrieval, multiple
hypothesis tracking, geometric matching , and view-
point regression. For example, in (Weyand et al.,
2016), a planet-scale place classification problem was
considered using adaptive partitioning of a large-scale
workspace (i.e., planet) into place classes. For sim-
plicity, in this study, the grid-based place partition-
ing in (Kim et al., 2019) is ad opted, as it allows the
incrementa l addition/deletion of place classes and is
thus more suitable for autonomous robo tics applica -
tions. As the inp ut modality for the robot, (Kim et al.,
2019) assumes the use of 3D LiDAR, whereas we use
an RGB camera. Nevertheless, the movement of the
robot on a two-dimensional plane in a top-down view
coordinate system is common to both, and thus the
2D grid partitioning from (Kim et al., 2019) can be
directly applied to our grid partitio ning.
Action planning is fo rmulated as a discrete time-
Figure 2: Scene parsing. Left: SGB (Tang et al., 2020).
Right: Ours.
discounted Mar kov decision process (MDP) (Sutton
and Barto, 1998). A discrete time-discounted MDP is
a general formulation consisting of a set of states S,
a set of actions A, a state-transition distribution P, a
reward function R, and a discount rate γ. In our par-
ticular scenario, the state s ∈ S was estimated using
a passive loca lization module. An action consists of
turns with a ro tation angle r and f orward movements
by a distance f . A reward was provided for success-
ful loc alization at the end of each training episode.
Specifically, an episode consists of L=4 repetitions of
sense-plan-action cycles, and the agent receives at the
final viewpoint in each episod e, a reward value of r=1
if the top-1 ranked place c la ss is co nsistent with the
ground truth or r=-1 otherwise.
3.2 Active Localization with
Ego-Centric Topological Maps
Similarity-pre serving mapping from an image to a
scene descriptio n is an important requirement for ac-
tive localization. For our egocentr ic topological map,
graphs with sim ilar node/edge attributes must be re-
produced from similar view points.
This issue is most relevant to scene -graph gener-
ation (Tang et al., 2020), which aims to parse an im-
age into a scene graph. However, most of these exist-
ing approaches are optimized for scene understanding
and related applications an d not for localization appli-
cations. In fact, our preliminary experiments reve aled
that their performance in localization application s is
often extremely limited.
Figure 2 shows the results of our evalu ation of
the state-of-the-art scene parsing in (Tang et al., 2020)
and the results of our three-step approach. Although
the former method can precisely describe the causal
relationships between parts, it is often not invariant
across different viewpoints. By contrast, our ap-
proach is designed to increase invariance at the ex-
pense of distinctiveness.
We f ocused on invariance rather than translation
accuracy to cross-view domain changes, and we f ol-
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
812

lowed a conservative three-step heuristic method (Zhu
et al., 2022), includin g (1) im a ge segmentation into
part regions (i.e., nodes), (2) part region descriptions,
and (3) inter-part relationsh ip infer ences (i.e., edges),
as detailed below.
The part segmentation step segments an input im-
age of size 256×256 pixels into subregions using the
semantic segmentation mod e l in (Zhou et al., 2017).
This model consisted of a ResNet module (Cao et al.,
2010) and a pyramid pooling modu le (Zhao et al. ,
2017) trained on the ADE20K dataset.
The pa rt description step describes each part of
a r egion using a combination of semantic and spa-
tial descriptors. Then, we further categorize the se-
mantic labels output using the semantic segmentation
method in (Zhou et al., 2017) into 10 coarser meta cat-
egories, including “wall, ” “floor, ” “ceiling , ” “bed,
” “door, ” “table, ” “sofa, ” “refrigera tor”, “TV, ”
and “Other.” Regions sm aller than 100 pixels in area
were co nsidered dummy objects and were not used
as graph nodes. For the spatial descriptor, the spatial
attributes of a part region are compactly rep resented
by a “size/location” categor y (Cao et al., 2010). First,
each part was categor iz ed into one of three categories
with respect to the “size” category. A size category
is determ ined according to the area of the bound-
ing box, including “small (0)” S < S
o
, “medium (1)”
S
o
≤ S < 6S
o
, and “large (2)” 6S
o
≤ S.” S
o
is a con-
stant c orresponding to 1/16 of the image area, set
based on the simple idea of dividing the image into a
4x4 grid. Then, the bounding box center location was
discretized using a grid of 3×3=9 cells, and w e used
the cell ID (∈ [0, 8]) as the location category. Note
that the above attributes are all huma n-interpretable
semantic ca tegories and do not introduce complex ap-
pearances or spatial attributes, such as real-valued de-
scriptors. Finally, a node featur e is defined as a one-
hot vector of dime nsions 10 ×3 ×9 = 270 in the com-
bined space of the semantic, size, and location cate -
gories.
The edge connection step connects no de pairs that
are spatially c lose to each other with ed ges. Specifi-
cally, a part pair was considered to be in spatial prox-
imity if the bounding boxes overlapped. A training set
of ego-centric topological maps was then fed into the
training set of a graph neural network. For the net-
work architecture, a graph convolutional neural net-
work (GCN) in a deep graph library (Wang et al.,
2019) was employed. The nu mber of lay ers of the
GCN was set to two. This GCN is specifically used to
classify input, place -specific ego- centric topological
maps into several prototype place classes. This clas-
sification task essentially follows the c lassical proto-
type method in the field of computer vision. However,
in our application, an explicit set of prototype classes
is not manually provided, so the robot must define
them in an unsupervised ma nner. The simple way
to define th is is to perform unsupervised clustering
of the training ego-centric topological maps, sampled
from the target workspace, into K groups, treating
each cluster as a prototype class. Following this sim-
ple idea, we define K prototype p la c e classes. As a re-
sult, the classification output from methods like GCN
is typically represented as class-specific rank vectors.
From the perspective of inf ormation fusion, it is com-
mon to express this a s a class-spec ific reciprocal rank
vector. This can be considered as a score-based bag-
of-place-words representation, where the score values
in this case are recipro cal r a nk values. Specifically,
in our implementation, we generate place prototypes
by dividing the workspace into K coarse gr id cells
in an overhead coordinate system. Figure 3 shows
the test view sequence and the classification results
of the graph neura l network. It can be observed that
prototy pe places with sim ilar scores are included for
spatially ad jacent viewpoints, and they exhibit high
similarity. We exploit this fact to compress the in-
finitely growing ego-centric topological maps into a
graph neural network.
It can be seen that prototyp es with similar score
values are included for spatially adjacent viewpoints,
and have high similarity. We exploit this fact to com-
press an infinitely increa sin g egocentric topolog ical
map into a graph neural network. Nevertheless, it can
be also seen that there are subtle differences in the
relative strengths of the scores betwee n the different
views. We utilize such subtle differences as cues to
discriminate between different scenes.
Another issue is that the outputs of the graph neu-
ral network are usually not calibrated as a proper
probability function. Here, we propose a graph neu-
ral mo del as the ranking f unction. This is motivated
by the fact that it is common to use a neural network
as a classifier o r r anking function rather than a proba-
bility regressor, and there is c onsiderable experimen-
tal evidence for its effectiveness (Krizhevsky et al.,
2012). Specifically, we interpr e t the class-spe cific
probability map output from the graph neur a l network
as a cla ss-spe cific reciprocal rank (RR) vector derived
from the field of multimodal information fusion (Cor-
mack et al., 2009). Th e RR vector is a class-specific
score vector and can be used as a state vector of the
given input graph. Note that the time cost for trans-
forming a class-specific probability vector into a re-
ciprocal rank vector is on the order of the number of
place classes and is very low.
A pa rticle filter-based sequential passive localiza-
tion method was employed to update the belief of
Fine-Grained Self-Localization from Coarse Egocentric Topological Maps
813

Figure 3: Seven spatially adjacent input images along the
robot trajectory and their bag-of-words representation: The
graph shows the time difference of bag-of-words histogram
h[t](t = 1, 2,3,4,5,6,7) of viewpoint sequence of length 7.
∆h[t]=h[t + 1] − h[t](t=1,2,3,4,5,6). Among the elements of
∆h[t], three visual words with small absolute values of time
difference are chosen, and their prototype ego-centric topo-
logical maps are shown in the figure.
the robot’s state (i.e., 3dof pose) incrementally in r eal
time, given the latest observations and actions at each
viewpoint. We slightly mo dified the standard imple-
mentation of the particle filter localization (Dellaert
et al., 1999) for our application. First, because the
measurement is a class-specific reciprocal rank vec-
tor and not a likelihood vector, the weight of each
particle was updated using the reciprocal rank fusion
rule (Cormack et al., 2009) rather than the Bayesian
rule. N ext, the classification results were obtained for
each class by max pooling the weights of the par ticles
belonging to that class, regardless of their bearing at-
tributes. The number of particles was set to 10,000
for eve ry Ha bitat workspace. The detailed algorithm
of r eciprocak rank-based particle filter (RRPF) is pro-
vided in Algorithm 1.
3.3 Incremental Training of Action
Planner
In this section, the integration of incremental pla n-
ner train ing into an active localization pipeline is
described. First, we extended the BoW concept
such that the output of the graph neural network
can b e interpreted as a BoW descriptor. Subse-
quently, we refor mulated the planner training task
as nearest-neighbor-based Q-learning in (Sutton and
Barto, 199 8), and further extended it to an incre-
mental training scheme by introducing an incremen-
tal BoW-based nearest-neighbor engine. As a result,
we ob ta in a novel fully-incremental framework that is
able to complete not only visual reco gnition and ac-
tion p la nning, but also planner training c an also be
completed within each viewpoint’s real-time budge t.
BoW is a popular scene descriptor in robotics. It
describes a given input scene using an unordered col-
lection of visual words {(w
i
,s
i
)}
N
i=1
. A vocabulary
function f , typically a k-me a ns dictionary (Sivic and
Zisserman, 2003), sh ould be pretrained to m ap an
ego-centric topological map to visual words {w
i
}
N
i=1
with its importance score s
i
representin g how mu ch
each word w
i
contributes to the scene representation.
However, applying a Bo W descriptor to structured
scene models like ego-centric topological maps is not
a trivial task, as the BoW descriptors always ignore
the relationship between scene parts. Typical vocab-
ularies such as the k-means dictionary (Cummins and
Newman, 2008) assume one-to-one mapping from a
scene part to a visual word and are thus not applica-
ble to structured data. Here, we propose to reuse the
graph neural network as the vocabulary. Specifically,
we viewed a collection of N place classes {w
i
}
N
i=1
,
with class-specific reciprocal rank scores {s
i
}
N
i=1
pro-
vided by the graph neural network as a collec tion of
visual words. Note that the resulting BoW descriptor
is now a fixed-length vector and transferable to many
other machine learning frameworks.
Q-learning is a standard RL fr amework for rein-
forcement learning (Sutton and Barto, 1998). It aims
to learn an optimal state-action map through robot-
environment interactions with delay ed rewards. The
naive implementation of the state-action-value func-
tion requ ires una cceptable spatial costs, particularly
when the state space becomes high dimensional. To
address this issue, researchers have developed fast ap-
proxim ation variants for Q-fu nction. Nearest neigh-
bor Q-learning (NNQL) (Shah and Xie, 2018) is a re-
cent example of such a variant. It approximates the
state-action value fun ction using the nearest neighbor
search. Recall that the Q-function is updated in the
following form ula (Sutton and Barto, 1998): Q(s
t
,a)
← Q(s
t
,a) + α [r
t+1
+ γ max
p∈A
Q(s
t+1
, p) - Q(s
t
,a)].
In this updated formu la , the number of times that
the Q function is referenced is on c e for calculat-
ing Q(s
t
,a) and |A| times for calculating Q(s
t+1
, p).
Therefore, the nearest-neighb or search must be per-
formed (|A| + 1) times for each viewpoint.
We replaced the nearest neighbor search in NNQL
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
814

Algorithm 1: Reciprocal Rank-based Particle Filter Algorithm.
1: Initialization:
2: Randomly generate particles from a uniform distribution (e.g., 10,000 particles).
3: Initialize each particle’s pose as (location,orientation), and set the initial score to 0.
4: Motion Model Application:
5: Update the origin pose based on the action index.
6: Apply the same transformation to each pa rticle to generate new po se hypotheses.
7: Convert rotation angles to radians.
8: Compute the new positions using trigonometric functions.
9: Observation Model Application:
10: For each particle, determ ine the class ID within the environment based on the p article’s new
pose (location and orientation).
11: Update the particle’s score based on the observations.
12: Score Update:
13: For each class, update the score using the Reciprocal Rank Fusion (RRF) formula:
score +=
1
RANK + 1
14: Where RANK is the ranking position of the class.
15: Reflect the updated scores in the reciprocal r a nk vector.
16: Resampling:
17: Generate a new set of particles based on the updated scores.
with BoW retrieval. Specifically, each database ele-
ment is represented by a triplet consisting o f state s,
action a, and value q. Then, the Q-value for a given
state-action pair (s,a) is stored in an inverted index,
which is built independently for e ach possible action
a, using each word w that makes up the state s as
an index. The optimal next-best-view action a
∗
for
some state s is chosen in the following steps. First,
the database for each action a was retrieved using s as
a query, yielding a shor tlist of the most relevant k = 4
database items. The value of each state-action pair
(s,a) was then computed by averaging the k Q-values.
As mentioned above, the Q- value is obtained for ea ch
candidate of the state-action pair (s,a). Note that by
building a temporary hash table that m aps score val-
ues to items given a search result, the shortlist length
and cost for finding the top-k n e arest neighbor items
can be made independent of the database size an d
very small, respectively.
4 EXPERIMENTS
In this section, we describe the experiments we per-
formed and report and analyze the results. In sum -
mary, we evalu a te d active localization frameworks in
a variety of challenging and crowded indoor environ-
ments and found that the proposed method with the
simplest ego-centric topological maps alr eady signif-
icantly outperformed state-of-the-art techniques for
semantic localization.
Figure 4: Experimental environments.
Experiments were performed using the 3D pho-
torealistic simulator Habitat-Sim (Szot et al., 2021).
Five workspaces, “00800-TEEsavR23oF,” “00801-
HaxA7YrQdEC,” “00802-wcojb4TFT35,” “00806-
tQ5s4ShP627,” an d “00808-y9hTuugGdiq,” fro m the
Habitat-Matterp ort3D Research Dataset (HM3D) was
imported into H abitat-Sim. The robot workspace is
partitioned by a grid-based partitioning method with
spatial re solution of 2 [m] and 30 [deg]. As a results,
the above workspaces are partitione d in to 576, 648,
720, 336 , and 576 place classes, respe ctively. A bird’s
eye view of the robot workspaces are shown in Fig. 4.
The localization performance was evaluated using
top-1 a c curacy. Recall that the particle filter is em-
ployed to extend the single -view GCN-based place
classification to sequential localization (III-C). The
top-1 accuracy was calculated by evaluating wheth e r
the top-1 classes of the class-specific rank values out-
put by the particle filter were consistent with the
ground-truth class for each test sample.
The number of epochs was set to 5. The batch size
was 32. The learning rate was 0.001. For eac h dataset,
Fine-Grained Self-Localization from Coarse Egocentric Topological Maps
815
the GCN classifier was trained using a training set
consisting of ego-centric topological maps with c la ss
labels as supervision. In rein forcement learning, the
planner is trained using 1 0,000 training episodes by
default. The number of sense-plan-action cycles per
episode was L=4. At the final viewpoint in each
episode, the reward function returns a reward of +1
if the class top -1 ranked by the particle filter is con-
sistent with the ground truth; otherwise it returns a re-
ward of -1. The hyperpa rameters for the NNQL train-
ing were set as follows: The number of iterations is
10,000. The learning rate α is 0.1. The discount fac-
tor γ is 0.9. During actio n planning, the action with
the highest Q valu e is usually selected, but actions are
randomly selected until the 25th episode, and there-
after, actions are d etermined by the ε-greedy algo-
rithm, where ε = 1/(0.1 ∗ ([episodeID] + 1) + 1).
The proposed method was compared with the
baseline and ab lation meth ods. To date, active lo-
calization using first-person- view scene graphs like
ego-centric topological maps has not been explored.
To ad dress this, the baseline method was built by re-
placing an essential module of the proposed frame-
work, the GCN with ego-centric topological map,
with a state-of-the-art semantic h isto gram embedding
in (Guo et al., 2021b). In the semantic histogram
method, each graph node votes to gen erate a his-
togram of length D
3
, where D = 10 denotes the num-
ber of semantic labe ls. The histogram bin ID is deter-
mined by concatenating the leng th three sequence of
semantic labels f rom three graph no des: the node of
interest, an adjacent node ( a child), and the child’s
adjacent node (a grand c hild). Our own implemen -
tation of the Python code was used. Two ablation
methods, single-view localization and passive multi-
view localization fr ameworks, were compar e d with
the proposed active localization (i.e., active multi-
view frameworks). The passive multi-view frame -
work differs from the proposed framewo rk in that it
does not perform action planning but determines a c-
tions ran domly. The single-view framework termi-
nated the localization task from the first viewpoint for
each episode.
The pe rformance resu lts are summar iz e d in Ta-
ble 1. As expected, the proposed a ctive localiza-
tion framework clearly outperformed the two abla-
tion methods in all Habitat workspaces. The pro-
posed method is competitive and outperforms state-
of-the- a rt passive localization, although it uses a sim-
ple to pological map as the input modality. Further-
more, the proposed method exhibits a more stable
active localization performance than the baseline se-
mantic histogram framework. This may be because
the combination of graph neural network s and ego-
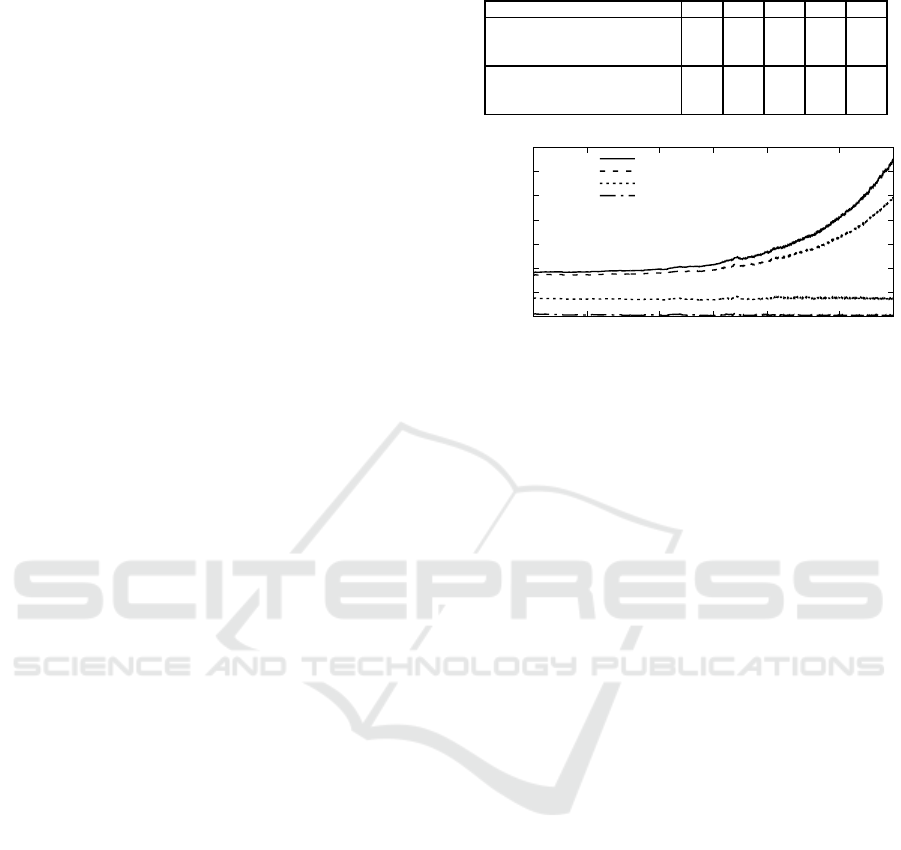
Table 1: Performance results.
800 801 802 806 808
GCN
active (Ours.)
67.8 69.2 68. 3 68.8 61.6
passive 58.7 57.0 51. 5 62.3 52.4
single-view 50.6 50.2 39. 1 50.9 38.4
sem. histo.
(Guo et al.,
2021b)
active
N/A 40.4 39.3 54.3 N/A
passive N/A 34.4 32.7 48.6 N/A
single-view N/A 26.0 19.0 31.6 N/A
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
1000 2000 5000 10000 20000 50000
time [sec]
#episode
A+B+C+D
A+B+C
A+B
A
Figure 5: Time cost per sense-plan-acition cycle. A : Prepro-
cessing. B: Particle filter. C: Action planning. D: Planner
retraining.
centric topological maps c aptures better contextual
informa tion from simple semantic scene graphs.
Figure 5 shows timing performance. perfor-
mance (CPU: Core i7-11700K, programming lan-
guage: C++) As can be seen, the computational cost
of the proposed method is sub-constant and real-time,
at least up to 10000 e pisodes. As expected, fully-
incrementa l and real-time processing is achieved.
Figure 6 shows examples of success and failure.
As shown in the figure, the robot’s movement to -
ward viewpoints with a high concentration of natu-
ral landmark objects often improves the localization
performance. For example, from the first viewpoint,
the robot was facing a wall and could not observe
any valid landmarks, but from the next viewpoint, by
changin g the direction of travel, it was able to detect
a door, improving the self-localization accuracy using
this landmark object. A typical example of a failure
is shown in Fig. 6. In this case, the majority of view-
points in the episode faced nondescript objects, suc h
as walls and windows. Nota bly, the recog nition suc-
cess ra te tended to decrease when the viewpoint was
too close to the object and the field of view was nar-
rowed.
One of the novelties of the proposed framework
is that it allows n ot only visual recognition and ac-
tion p la nning but also planner training to be com-
pleted within the real-time budget of each viewpoint.
We cond ucted addition a l experiments to demonstrate
this performa nce. In this additional experiment, plan-
ner training is performed while the robot perform s
long-ter m navigation using a random environment ex-
ploration algorithm . At that time, as in the previ-
ous expe riments, we will repeat an episode consist-
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
816

(a) success examples.
(b) failure examples.
Figure 6: Examples of L repetitions of sense-plan-action
cycles.
ing of L = 4 sense-plan- a ction cycles. Also, at the
beginning of the episode, the particle filter is in itial-
ized. Note that, unlike the previous experiments, the
final robot pose of one i-th episode becomes the initial
robot pose of the next (i + 1)-th episode. After d evel-
oping the first version of the long-term exploration al-
gorithm, it was obser ved that the robot freq uently gets
stuck in a n arrow depression formed by an obstacle in
the workspace, a nd wasted many training episodes.
Therefore, we modified the exploration algorithm so
as to reduce the chance of getting stuck. Specifically,
we modified the action set to include more translation
actions among the nine actions, by replacing some ro-
tate actions with translation actions. The modified ac-
tion set consists of the following pairing of rotate r
[deg] and forward f [m]: (r, f )∈{ ( 0, 0.5), (0, 1.5),
(30, 0.3), (-35, 0.3), (80, 1 ), (-85, 1), (140, 0), (-145,
0), (180, 0)}. We traine d over 10,000 episodes and
evaluated over 1000 episodes, using the workspace
“0080 1-HaxA7Yr Q dEC”. The top- 1 accuracy result
was 69.2. By modifying the a ction set, we were able
to explore th e map evenly, which resulted in high re-
sults. A closer look at the results shows that when
the test was perform e d only with coordinates that the
robot had experienced, the r e sult was 78.2, and in all
other cases it was 65.1.
The total distance traveled by the robot during this
training was 4598.3 meters. This time, we have fine-
tuned the action set to get good results on the cur-
rent workspace, so it is not clear whether this method
generalizes to other environments and it is a subject
for future resear ch. A future challenge is to develop
a general-purpose action set that can be generalize d
to various environments. An other challenge is to de-
velop a method that allows the robot to successfully
pass thro ugh narrow passages. Ensemble learning is
a promising direction for further improving perfor-
mance (Islam et al., 2003).
In conclusion, the pro posed method with fully
incrementa l real-time planner training outperforms
state-of-the-art approache s despite the fact that it uses
simple semantic features.
5 CONCLUSIONS
In this pa per, we proposed a practical solution for
trainable active localization using topological maps.
The key idea of the pr oposed method is to employ
a novel ego-centric topological map rather than re-
quiring precomputatio n and mainten ance of a world-
centric map. The collection of ego-centric maps,
which increases incrementally an d unlimitedly in
proportion to the robot’s travel distance, is com-
pressed to a fixed size using a graph neural net-
work, and then transferred to a novel incremental
action planner and planner training module. As a
result, fully-incremental real-time active localization
was achieved, allowing localization, planning, and
planner training to be complete d within the real-time
budget of ea ch viewpoint. We verified the scala-
bility, incrementality, real-time nature, and robust-
ness of our method through training scenarios involv-
ing many intermittent navigations and unprecedented
long-distance navigations.
REFERENCES
Aguilar, W., Frauel, Y., Escolano, F., Mart´ınez-P´erez, M. E.,
Espinosa-Romero, A., and Lozano, M. A. (2009). A
robust graph transformation matching for non-rigid
registration. Image Vis. Comput., 27(7):897–910.
Benbihi, A., Arravechia, S., Geist, M., and Pradalier, C.
(2020). Image-based place recognition on bucolic
environment across seasons from semantic edge de-
scription. In 2020 IEEE International Conference on
Robotics and Automation, ICRA 2020, Paris, France,
May 31 - August 31, 2020, pages 3032–3038. IEEE.
Brooks, R. A. (1985). Visual map making f or a mobile
robot. In Proceedings of the 1985 IEEE International
Conference on Robotics and Automation, St. Louis,
Missouri, USA, March 25-28, 1985, pages 824–829.
IEEE.
Cao, Y., Wang, C., Li, Z., Zhang, L., and Zhang, L. (2010).
Spatial-bag-of-features. In The Twenty-Third IEEE
Fine-Grained Self-Localization from Coarse Egocentric Topological Maps
817

Conference on Computer Vision and Pattern Recog-
nition, CVPR 2010, San Francisco, CA, USA, 13-18
June 2010, pages 3352–3359. IEEE Computer Soci-
ety.
Chaplot, D. S., Parisotto, E., and Salakhutdinov, R. (2018).
Active neural localization. In 6th International Con-
ference on Learning Representations, ICLR 2018,
Vancouver, BC, Canada, April 30 - May 3, 2018, Con-
ference Track Proceedings. OpenReview.net.
Chaplot, D. S., Salakhutdinov, R., Gupta, A., and Gupta, S.
(2020). Neural topological slam for visual navigation.
In Proceedings of the IEEE/CVF conference on com-
puter vision and pattern recognition, pages 12875–
12884.
Cormack, G. V., Clarke, C. L. A., and B¨uttcher, S. (2009).
Reciprocal rank fusion outperforms condor cet and in-
dividual rank learning methods. In A llan, J., Aslam,
J. A., Sanderson, M., Zhai, C., and Zobel, J., editors,
Proceedings of the 32nd Annual International ACM
SIGIR Conference on Research and Development in
Information Retrieval, SIGIR 2009, Boston, MA, USA,
July 19-23, 2009, pages 758–759. ACM.
Cummins, M. J. and Newman, P. M. (2008). FAB-MAP:
probabilistic localization and mapping in the space of
appearance. Int. J. Robotics Res., 27(6):647–665.
Dellaert, F., Fox, D., Burgard, W., and Thrun, S. (1999).
Monte carlo localization for mobile robots. In 1999
IEEE International Conference on Robotics and Au-
tomation, Marriott Hotel, Renaissance Center, De-
troit, Michigan, USA, May 10-15, 1999, Proceed-
ings, pages 1322–1328. IEEE R obotics and Automa-
tion S ociety.
Gawel, A., Don, C. D., Siegwart, R., Nieto, J. I., and
Cadena, C. (2018). X-view: Graph-based semantic
multiview localization. IEEE Robotics Autom. Lett.,
3(3):1687–1694.
Guo, X., Hu, J., Chen, J., Deng, F., and Lam, T. L. (2021a).
Semantic histogram based graph matching for real-
time multi-robot global localization in large scale en-
vironment. IEEE Robotics Autom. Lett., 6(4):8349–
8356.
Guo, X., Hu, J., Chen, J., Deng, F., and Lam, T. L. (2021b).
Semantic histogram based graph matching for real-
time multi-robot global localization in large scale en-
vironment. IEEE Robotics Autom. Lett., 6(4):8349–
8356.
Islam, M. M., Yao, X., and Murase, K. (2003). A construc-
tive algorithm for t raining cooperative neural network
ensembles. IEEE Transactions on neural networks,
14(4):820–834.
Kim, G., Park, B., and Kim, A. (2019). 1-day learning,
1-year localization: Long-term lidar localization us-
ing scan context image. IEEE Robotics Autom. Lett.,
4(2):1948–1955.
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). Im-
agenet classification with deep convolutional neural
networks. In Bartlett, P. L., Pereira, F. C. N ., Burges,
C. J. C., Bottou, L., and Weinberger, K. Q., edi-
tors, Advances in Neural Information Processing Sys-
tems 25: 26th Annual Conference on Neural Informa-
tion Processing Systems 2012. Proceedings of a meet-
ing held December 3-6, 2012, Lake Tahoe, Nevada,
United States, pages 1106–1114.
Leonard, J. J. and Durrant-Whyte, H. F. (1991). Mo-
bile robot localization by tracking geometric beacons.
IEEE Trans. Robotics Autom., 7(3):376–382.
Li, Y. and Olson, E. B. (2012). IPJC: the incremental pos-
terior joint compatibility test for fast feature cloud
matching. In 2012 IEEE/RSJ International Confer-
ence on Intelligent Robots and Systems, IROS 2012,
Vilamoura, Algarve, Portugal, October 7-12, 2012,
pages 3467–3474. IEEE.
Lowe, D. G. (1999). Object recognition from local scale-
invariant features. In Proceedings of the International
Conference on Computer Vision, Kerkyra, Corfu,
Greece, September 20-25, 1999, pages 1150–1157.
IEEE Computer Society.
Lowry, S., S¨underhauf, N. , Newman, P., Leonard, J. J., Cox,
D., Corke, P., and Milf ord, M. J. (2015). Visual place
recognition: A survey. ieee transactions on robotics,
32(1):1–19.
Lui, W. L. D. and Jarvis, R. A. (2010). A pure vision-based
approach to topological SLAM. In 2010 IEEE/RSJ
International Conference on Intelligent Robots and
Systems, October 18-22, 2010, Taipei, Taiwan, pages
3784–3791. IEEE.
Mikolajczyk, K., Tuytelaars, T., Schmid, C. , Zisserman, A.,
Matas, J., Schaffalitzky, F., Kadir, T., and Gool, L. V.
(2005). A comparison of affine region detectors. Int.
J. Comput. Vis., 65(1-2):43–72.
Neira, J. and Tard´os, J. D. (2001). Data association in
stochastic mapping using the joint compatibility test.
IEEE Trans. Robotics Autom., 17(6):890–897.
N¨uchter, A. and Hertzberg, J. (2008). Towards seman-
tic maps for mobile robots. Robotics Auton. Syst.,
56(11):915–926.
Ranganathan, A. and Dellaert, F. (2008). Automatic
landmark detection for topological mapping using
bayesian surprise. Technical report, Georgia Institute
of Technology.
Sch¨onberger, J. L ., Pollefeys, M., Geiger, A., and Sattl er, T.
(2018). Semantic visual localization. In 2018 IEEE
Conference on Computer Vision and Pattern Recogni-
tion, CVPR 2018, Salt Lake City, UT, USA, June 18-
22, 2018, pages 6896–6906. Computer Vision Foun-
dation / IEEE Computer Society.
Shah, D. and Xie, Q. (2018). Q-learning with nearest neigh-
bors. I n Bengio, S., Wallach, H. M., Larochelle, H.,
Grauman, K., Cesa-Bianchi, N., and G arnett, R., edi-
tors, Advances in Neural Information Processing Sys-
tems 31: Annual Conference on Neural Information
Processing Systems 2018, NeurIPS 2018, December
3-8, 2018, Montr´eal, Canada, pages 3115–3125.
Sivic, J. and Zisserman, A. (2003). Video google: A text
retrieval approach to object matching in videos. In
9th IEEE International Conference on Computer Vi-
sion (ICCV 2003), 14-17 October 2003, Nice, France,
pages 1470–1477. IEEE Computer Society.
Stankiewicz, B. J. and Kalia, A. A. (2007). Acquistion of
structural versus object landmark knowledge. Journal
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
818

of Experimental Psychology: Human Perception and
Performance, 33(2):378.
Sutton, R. S. and Barto, A. G. (1998). Reinforcement learn-
ing: An introduction. IEEE Trans. Neural Networks,
9(5):1054–1054.
Szot, A., Clegg, A., Undersander, E., Wijmans, E., Zhao,
Y., Turner, J., Maestre, N., Mukadam, M., Chaplot,
D. S., Maksymets, O., Gokaslan, A., Vondrus, V.,
Dharur, S., Meier, F., Galuba, W., Chang, A. X., Kira,
Z., Kolt un, V., Malik, J., Savva, M., and Batra, D.
(2021). Habitat 2.0: Training home assistants to rear-
range their habitat. In Ranzato, M., Beygelzimer, A.,
Dauphin, Y. N., Liang, P., and Vaughan, J. W., editors,
Advances in Neural Information Processing Systems
34: Annual Conference on Neural Information Pro-
cessing Systems 2021, NeurIPS 2021, December 6-14,
2021, virtual, pages 251–266.
Tang, K., Niu, Y., Huang, J., Shi, J., and Zhang, H. (2020).
Unbiased scene graph generation from biased train-
ing. In 2020 IEEE/CVF Conference on Computer Vi-
sion and Pattern Recognition, CVPR 2020, Seattle,
WA, USA, June 13-19, 2020, pages 3713–3722. Com-
puter Vision Foundation / IEEE.
Tapus, A. and Siegwart, R. (2008). Topological SLAM.
In Bessi`ere, P., Laugier, C., and Siegwart, R., edi-
tors, Probabilistic Reasoning and Decision Making in
Sensory-Motor Systems, volume 46 of Springer Tracts
in Advanced Robotics, pages 99–127.
Thrun, S . et al. (2002). Robotic mapping: A survey.
Ulrich, I. and Nourbakhsh, I. R. (2000). Appearance-based
place recognition for topological localization. In Pro-
ceedings of the 2000 IEEE International Conference
on Robotics and Automation, ICRA 2000, April 24-
28, 2000, San Francisco, CA, USA, pages 1023–1029.
IEEE.
Wang, M., Yu, L., Zheng, D. , Gan, Q., Gai, Y., Ye, Z., Li,
M., Zhou, J., Huang, Q., Ma, C., Huang, Z., Guo, Q.,
Zhang, H., Li n, H., Zhao, J., Li, J., Smola, A. J., and
Zhang, Z. (2019). Deep graph library: Towards ef-
ficient and scalable deep learning on graphs. CoRR,
abs/1909.01315.
Weyand, T., Kostrikov, I., and Philbin, J. (2016). Planet
- photo geolocation with convolutional neural net-
works. In Leibe, B., Matas, J., Sebe, N., and Welling,
M., editors, Computer Vision - ECCV 2016 - 14th
European Conference, Amsterdam, The Netherlands,
October 11-14, 2016, Proceedings, Part VIII, volume
9912 of Lecture Notes in Computer Science, pages
37–55. Springer.
Yu, X., Chaturvedi, S., Feng, C., Taguchi, Y. , Lee, T., Fer-
nandes, C., and Ramalingam, S. (2018). VLASE: ve-
hicle localization by aggregating semantic edges. In
2018 IEEE/RSJ International Conference on Intelli-
gent Robots and Systems, IROS 2018, Madrid, Spain,
October 1-5, 2018, pages 3196–3203. IEEE.
Zha, B. and Yilmaz, A. (2021). Map-based temporally con-
sistent geolocalization through l earning motion trajec-
tories. In 2020 25th International Conference on Pat-
tern Recognition (ICPR), pages 2296–2303. IEEE.
Zhao, H., Shi, J., Qi, X. , Wang, X., and Jia, J. (2017). Pyra-
mid scene parsing network. In 2017 IEEE Conference
on Computer Vision and Pattern Recognition, CVPR
2017, Honolulu, HI, USA, July 21-26, 2017, pages
6230–6239. IEEE Computer Society.
Zhou, B., Zhao, H., Puig, X., Fidler, S., Barri uso, A., and
Torralba, A. (2017). Scene parsing through ADE20K
dataset. In 2017 IEEE Conference on Computer Vi-
sion and Pattern Recognition, CVPR 2017, Honolulu,
HI, USA, July 21-26, 2017, pages 5122–5130. IEEE
Computer Society.
Zhu, G., Zhang, L. , Jiang, Y., Dang, Y., Hou, H., Shen, P.,
Feng, M., Zhao, X., Miao, Q., Shah, S. A. A., and
Bennamoun, M. (2022). Scene graph generation: A
comprehensive survey. CoRR, abs/2201.00443.
Fine-Grained Self-Localization from Coarse Egocentric Topological Maps
819
