
Enhancing LULC Classification with Attention-Based Fusion of
Handcrafted and Deep Features
Vian Abdulmajeed Ahmed
a
, Khaled Jouini
b
and Ouajdi Korbaa
c
MARS Research Lab, LR17ES05, ISITCom, University of Sousse, Sousse, Tunisia
Keywords:
Land Use and Land Cover Classification, Attention-Based Fusion, Early and Late Fusion, Multi-Modal
Learning.
Abstract:
Satellite imagery provides a unique perspective of the Earth’s surface, pivotal for applications like environ-
mental monitoring and urban planning. Despite significant advancements, analyzing satellite imagery remains
challenging due to complex and variable land cover patterns. Traditional handcrafted descriptors like Scale-
Invariant Feature Transform (SIFT) excel at capturing local features but often fail to capture the global context.
Conversely, Convolutional Neural Networks (CNNs) excel at capturing rich contextual information but may
miss crucial local features due to limitations in capturing small and subtle spatial arrangements. Most exist-
ing Land Use and Land Cover (LULC) classification approaches heavily rely on fine-tuning large pretrained
models. While this remains a powerful tool, this paper explores alternative strategies by leveraging the com-
plementary strengths of handcrafted and CNN-learned features. Specifically, we investigate and compare three
fusion strategies: (i) early fusion, where handcrafted and CNN-learned features are merged at the input level;
(ii) late fusion, where attention mechanisms dynamically integrate salient features from both CNN and SIFT
modalities; and (iii) mid-level fusion, where attention is used to generate two feature maps: one prioritizing
global context and another, weighted by SIFT features, emphasizing local details. Experiments on the real-
world EuroSAT dataset demonstrate that these fusion approaches exhibit varying levels of effectiveness and
that a well-chosen fusion strategy not only substantially outperforms the underlying methods used separately
but also offers an interesting alternative to solely relying on fine-tuning pre-trained large models.
1 INTRODUCTION
Satellite imagery underpins critical applications like
land cover mapping, environmental monitoring, dis-
aster response, and urban planning (Ahmed et al.,
2024). At the heart of these applications lies Land
Use and Land Cover (LULC) classification, which
involves assigning predefined semantic classes to re-
mote sensing images. Effective LULC classification
requires the capability to discern complex spatial pat-
terns while maintaining robustness against variations
in scale, atmospheric conditions, and noise (Xia and
Liu, 2019). Early methods in LULC classification
relied heavily on handcrafted descriptors like Scale-
Invariant Feature Transform (SIFT) (Lowe, 2004)
and similar approaches, which excel at capturing dis-
tinctive local features such as edges and textured re-
gions. These methods, however, often struggle to cap-
a
https://orcid.org/0009-0002-5924-6139
b
https://orcid.org/0000-0001-5049-4238
c
https://orcid.org/0000-0003-4462-1805
ture the complex spatial and contextual information
present in remote sensing images due to their local
nature (Cheng et al., 2019). The advent of deep learn-
ing and its models trained on large datasets has rev-
olutionized image classification, achieving accuracy
levels far beyond traditional methods. The impres-
sive performance of these models, coupled with their
data-intensive nature, has directed much of the cur-
rent work on LULC classification towards transfer
learning (Dewangkoro and Arymurthy, 2021; Helber
et al., 2019; Wang et al., 2024; Neumann et al., 2020),
which involves fine-tuning pre-trained large models
on remote sensing datasets.
The convolutional layers of deep models operate
by applying learned filters (small grids of weights)
that slide across the image. As these filters move,
their weights are multiplied element-wise with pixel
values, and the results are summed to create a fea-
ture map. The stacking of convolutional layers en-
ables deep models to learn increasingly complex pat-
terns: early layers typically capture basic elements
Ahmed, V. A., Jouini, K. and Korbaa, O.
Enhancing LULC Classification with Attention-Based Fusion of Handcrafted and Deep Features.
DOI: 10.5220/0013098500003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 2, pages 69-78
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
69

like edges and corners, while subsequent layers inter-
pret these elements to recognize objects. This hierar-
chical learning process allows Convolutional Neural
Networks (CNNs) to excel at capturing global con-
texts and spatial relationships. Despite these capabili-
ties, CNNs can struggle to preserve very fine-grained
details like small textures or subtle variations in color
due to the pooling operations that often follow convo-
lutional layers.
In this work, we aim to investigate and quantify
the potential benefits of synergizing the complemen-
tary strengths of handcrafted SIFT descriptors and
features learned from CNNs. Fusing these features
is intended to leverage both the local detailed cues
provided by SIFT and the global context captured
by CNNs. Specifically, we investigate three fusion
strategies: a straightforward early fusion approach,
and novel late and mid-level fusion approaches inte-
grating attention mechanisms. Attention mechanisms
enable neural networks to prioritize informative input
elements by assigning them weights that reflect their
relative importance. The late fusion approach uses
attention to dynamically weigh and integrate salient
features from both the CNN and SIFT modalities be-
fore making final classification decisions.The mid-
level fusion approach generates two distinct feature
maps: one prioritizing global context and another
locally-attended feature map weighted according to
SIFT features, emphasizing local details. Our exper-
imental study on the real-world EuroSAT dataset re-
veals that the different fusion approaches vary in ef-
fectiveness. Our study also suggests, that while the
prevalent fine-tuning of pre-trained models remains
a powerful tool for LULC classification, alternatives
such as integrating handcrafted and CNN-learned fea-
tures warrant exploration.
The remainder of this paper is organized as fol-
lows. Section 2 provides a concise overview of previ-
ous research. Section 3 introduces our features fusion
approaches. Section 4 presents a comparative experi-
mental analysis. Finally, Section 5 concludes the pa-
per.
2 RELATED WORK
The EuroSAT dataset (Helber et al., 2018) is a widely
recognized and extensively used dataset for LULC
classification. It includes 27,000 geotagged image
patches, each covering an area of 64x64 meters with
a spatial resolution of 10 meters. The dataset com-
prises ten distinct classes, with each class including
2,000 to 3,000 images. As illustrated in Figure 1,
these classes represent a diverse range of land use and
land cover types. For the sake of conciseness and due
to lack of space, we mainly focus in the sequel on ap-
proaches presenting similarities with our work or that
use EuroSAT. Existing remote sensing image classifi-
cation approaches and studies can be broadly classi-
fied into two families: Machine Learning (ML)-based
and Deep Learning (DL)-based methods.
The study by Chen & Tian (Chen and Tian, 2015),
and Thakur & Panse (Thakur and Panse, 2022) are
representative of ML-based approaches. (Chen and
Tian, 2015) introduced the Pyramid of Spatial Rela-
tions (PSR) model, designed to incorporate both rela-
tive and complete spatial information into the BoVW
(i.e. Bag of Visual Words) framework. Experiments
conducted on a high-resolution remote sensing im-
age revealed that the PSR model achieves an aver-
age classification accuracy of 89.1%. In (Thakur and
Panse, 2022), the performance of four machine learn-
ing algorithms was evaluated on the EuroSAT dataset:
Decision Tree (DT), K-Nearest Neighbour (KNN),
Support Vector Machine (SVM), and Random Forest
(RF). The study revealed distinct performance levels
among the algorithms: RF achieved the highest over-
all accuracy of 56.70%, significantly outperforming
DT and KNN.
The studies (Temenos et al., 2023), (Dewangkoro
and Arymurthy, 2021), (Helber et al., 2019), (Wang
et al., 2024) and (Neumann et al., 2020) are rep-
resentative of DL-based approaches. In (Temenos
et al., 2023), the authors introduce an interpretable
DL framework for LULC classification using SHap-
ley Additive exPlanations (SHAPs). They employ
a compact CNN model for image classification, fol-
lowed by feeding the results to a SHAP deep ex-
plainer, achieving an overall accuracy of 94.72% on
EuroSAT. The approach in (Dewangkoro and Ary-
murthy, 2021) utilizes different CNN architectures for
feature extraction, including VGG19, ResNet50, and
InceptionV3. These extracted features are then recal-
ibrated using the Channel Squeeze & Spatial Excita-
tion (sSE) block, with Twin SVM (TWSVM) serving
as classifier, achieving an accuracy of 94.39% on Eu-
roSAT. In (Helber et al., 2019), various CNN archi-
tectures were compared, including a shallow CNN,
a ResNet50-based model, and a GoogleNet-based
model. The achieved classification accuracies on Eu-
roSAT were 89.03%, 98.57%, and 98.18%, respec-
tively. (Neumann et al., 2020) explored in-domain
fine-tuning using five diverse remote sensing datasets
and the ResNet50V2 architecture. (Neumann et al.,
2020) demonstrated that models fine-tuned on in-
domain datasets significantly outperform those pre-
trained on general purpose datasets like ImageNet.
The pretrained ResNet50v2 fine-tuned on in-domain
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
70

Figure 1: Sample Images Extracted from the EuroSAT Dataset (Helber et al., 2019).
datasets achieved an overall accuracy of 99.2% on Eu-
roSAT.
While transfer learning typically involves adapt-
ing a pre-trained model to improve performance on
a related dataset, knowledge transfer involves train-
ing a single model on multiple tasks simultaneously
and leveraging shared representations and knowledge
across these tasks. (Gesmundo and Dean, 2022) used
knowledge transfer and employed a multitask learn-
ing framework in which the model learns from di-
verse remote sensing datasets concurrently. The evo-
lutionary “mutant multitask network” (µ2Net), in-
troduced by (Gesmundo and Dean, 2022), enhances
model efficiency and quality through effective knowl-
edge transfer mechanisms while addressing common
challenges such as catastrophic forgetting and neg-
ative transfer. Empirical results demonstrate that
µ2Net can achieve competitive performance across
various image classification tasks. Specifically, on
EuroSAT, µ2Net achieved a high classification accu-
racy of 99.2%. Knowledge transfer is also used by
(Wang et al., 2024), where Vision Transformers (ViT)
(Steiner et al., 2021) with Rotatable Variance Scaled
Attention (RVSA) are used as part of a Multi-Task
Pretraining (MTP) framework. When evaluated on
EuroSAT, the MTP-enhanced model achieved a high
accuracy of 99.2%.
As outlined in this section, most existing LULC
classification approaches typically focus on either
classical ML or DL methods. Studies (Tianyu et al.,
2018) and (Ahmed et al., 2024) have demonstrated the
benefits of combining handcrafted and CNN-learned
features on the general-purpose CIFAR dataset and
EuroSAT dataset, respectively. However, these stud-
ies only explored a straightforward early fusion ap-
proach. Our work proposes more advanced attention-
based fusion methods that can potentially learn to
focus on more discriminative features for improved
LULC classification accuracy.
3 SYNERGIZING
HANDCRAFTED AND CNN
LEARENED FEATURES
As mentioned earlier, SIFT is adept at capturing intri-
cate local details and textures but falls short in inter-
preting broader scene contexts. In contrast, CNNs ex-
cel at understanding contextual information and spa-
tial relationships, yet they may overlook fine-grained
details. Integrating these features potentially allows
the model mitigating the limitations of each method
when used alone.
The remainder of this section explores three dis-
tinct fusion strategies: (straightforward) early fusion,
and novel late and mid-level fusion with attention
mechanisms. Broadly, early fusion directly combines
features extracted from different modalities before
feeding them into a classifier. Conversely, late fusion
extracts features independently using separate models
for each modality and then fuses these features before
classification. Mid-level fusion partially extracts fea-
tures from each modality before allowing information
exchange between them, enabling them to influence
each other’s feature learning process.
Enhancing LULC Classification with Attention-Based Fusion of Handcrafted and Deep Features
71

3.1 Baseline Models and Early Fusion
Approach
This section provides an overview of the baseline
models and the early fusion approach used in our ex-
periments, establishing a foundation for understand-
ing the more advanced late and mid-level fusion ap-
proaches discussed later in this paper.
SIFT identifies keypoints in an image that remain
stable under scale, rotation, and illumination changes.
Initially, SIFT creates a scale-space representation of
the image by convolving it with Gaussian filters at
multiple scales. Keypoints are then localized as lo-
cal extrema (peaks or valleys) in the Difference-of-
Gaussian (DoG) images computed across these scales
(Lowe, 2004). Keypoints are typically found at cor-
ners, edges, or distinct texture patterns (Lowe, 2004)
and in areas with significant variations in intensity
across different directions. In the context of satel-
lite images, keypoints often correspond to transitions
between different land covers. To enhance accuracy,
each keypoint’s precise position and scale are refined
through interpolation to achieve subpixel accuracy.
Once keypoints are identified, SIFT computes a de-
scriptor for each of them. This descriptor encapsu-
lates information about the gradients or directional
changes in intensity surrounding that keypoint within
a localized patch of the image (Lowe, 2004). The
standard SIFT descriptor is generated by creating a
histogram of gradient orientations within this patch,
divided into a 4 × 4 grid, with each of the 16 cells
contributing eight orientation bins, resulting in a 128-
element descriptor vector. SIFT identifies potentially
hundreds or thousands of keypoints per image. To
simplify data representation and ensure compatibility
with most machine learning algorithms, all individual
keypoint descriptors are typically concatenated into a
single row vector (flattening).
Figures 2 and 3 illustrate the baseline models em-
ployed in our work. The first baseline model is a neu-
ral network that takes SIFT descriptors as input. It
follows a common architecture with two dense layers
for feature processing, using ReLU (Rectified Linear
Unit) activation functions to introduce non-linearity.
Batch normalization is incorporated to stabilize train-
ing, and dropout with L2 regularization are applied
to prevent overfitting. The second baseline model
is a convolutional neural network (CNN) that takes
RGB images as input. It features a standard architec-
ture comprising convolutional layers for feature ex-
traction, pooling layers for downsampling, a flatten-
ing layer for feature vector transformation, and fully-
connected layers for classification. ReLU activation
functions are used throughout the network to intro-
duce non-linearity, and dropout with L2 regulariza-
tion are applied to prevent overfitting.
Figure 4 illustrates the early fusion model used in
our work. Early fusion is a prevalent approach for
combining features extracted from different modali-
ties (Ahmed et al., 2024) and consists in combining
these features before feeding them into the higher-
level layers of a neural network. Despite its sim-
plicity, early fusion can achieve good accuracy be-
cause it enables the model to learn a unified repre-
sentation that leverages information from both RGB
images and SIFT descriptors during the training pro-
cess (Ahmed et al., 2024). As shown in Figure 4,
the early fusion model we employed comprises two
distinct branches, each processing a different modal-
ity. After feature extraction in each branch, the model
concatenates them. This fused feature vector is then
passed through standard neural network layers that in-
tegrate regularization techniques (dropout, L2). The
final layer employs a softmax activation function for
multi-class classification.
3.2 Late Fusion: Attention-Enhanced
Dual Learning (ADL)
Attention mechanisms enable neural network mod-
els to selectively focus on informative aspects within
the input data. They achieve this by learning a set
of weights for different parts of the input, indicating
their relative importance. Broadly, attention mech-
anisms operate by calculating scores (e.g., element-
wise multiplication, dot products) reflecting the po-
tential relevance of each element in the input. These
scores are learned dynamically based on the context.
A softmax function is then applied to the scores, nor-
malizing them into a probability distribution. The re-
sulting weights sum to 1 and represent the relative im-
portance of each element as a probability. Finally,
the original input elements are multiplied by their
corresponding weights and then summed. This cre-
ates a weighted representation of the input, emphasiz-
ing informative aspects based on the learned attention
weights.
As depicted in Figure 5, in our proposed late fu-
sion model, features are extracted from each modal-
ity independently using separate models, and then the
outputs of the branches are fused at the very end of
the network before classification. To improve fea-
ture learning, our late fusion model leverages ad-
equate attention mechanisms in both branches. A
channel-wise attention is integrated into the CNN
of the RGB branch through Squeeze-and-Excitation
(SE) (Hu et al., 2018) blocks. The SE block dynam-
ically adjusts the importance of each channel within
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
72
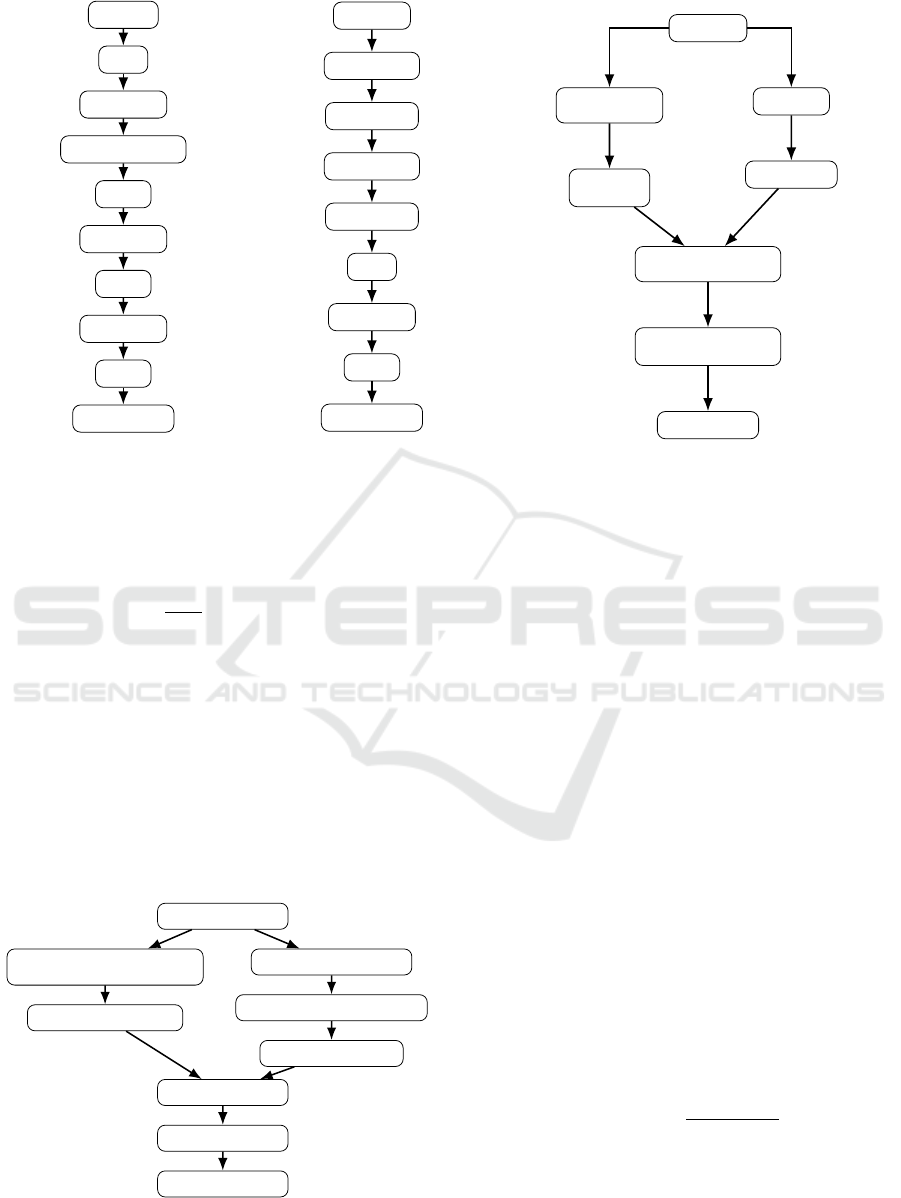
SIFT Input
Flatten
Dense, ReLU
Batch Normalization
Dropout
Dense, ReLU
Dropout
Dense, ReLU
Dropout
Dense, Softmax
Figure 2: Baseline SIFT-NN
Model
RGB Image
Conv2D, ReLU
MaxPooling2D
Conv2D, ReLU
MaxPooling2D
Flatten
Dense, ReLU
Dropout
Dense, Softmax
Figure 3: Baseline Shallow CNN
Model
Input Image
SIFT Descriptors
Extraction
Flatten SIFT
Descriptors
CNN Model
CNN Features
Concatenated
Feature Vector
Dense/ReLU,
Dropout Layers
Dense, Softmax
Figure 4: Early Fusion of SIFT and CNN Features.
the feature maps. The process involves the following
steps (Hu et al., 2018):
1. Squeeze: Global average pooling is applied to
each feature map, reducing each channel to a sin-
gle value: z
c
=
1
H×W
∑
H
i=1
∑
W
j=1
x
i, j,c
, where x
i, j,c
represents the value at position (i, j) in channel c,
and H and W are the height and width of the fea-
ture map.
2. Excitation: A gating mechanism with a bottle-
neck structure (two fully connected layers) is ap-
plied to capture channel-wise dependencies: s =
σ(W
2
δ(W
1
z)), where W
1
and W
2
are the weight
matrices, δ denotes the ReLU activation function,
and σ denotes the sigmoid activation function.
3. Recalibration: The original feature map is scaled
by the learned channel weights: ˜x
i, j,c
= s
c
·x
i, j,c
Input Image
CNN with Squeeze-and-Excitation
(Channel-Wise Attention)
Refined CNN Feature Map
SIFT Descriptors Extraction
NN with Feature-Wise Attention
Weighted SIFT Features
Combined Features
Dense, Dropout
Dense, Softmax
Figure 5: Late Fusion Approach : Attention-Enhanced Dual
Learning (ADL).
In the SIFT branch, SIFT descriptors are pro-
cessed using a neural network integrating a feature-
wise attention layer that assigns weights to descrip-
tors to emphasize the most informative ones. By as-
signing higher weights to relevant SIFT descriptors,
the attention mechanism emphasizes features that are
particularly informative for specific LULC classes.
This complements the focus on global spatial rela-
tionships learned by the CNN in the RGB branch.
Formally, each SIFT descriptor x
i
is transformed into
query Q
i
, key K
i
, and value V
i
vectors using learned
linear transformations:
Q
i
= W
Q
x
i
+b
Q
, K
i
= W
K
x
i
+b
K
, V
i
= W
V
x
i
+b
V
where W
Q
, W
K
, W
V
are weight matrices and b
Q
, b
K
, b
V
are bias vectors. These transformations enable
the network to effectively compute attention scores,
which measure the relevance of each feature within
the descriptor relative to others. The attention score
for each feature within the SIFT descriptor is com-
puted as the dot product of the query vector with all
key vectors: score
i j
= Q
i
·K
j
. This results in a matrix
of attention scores indicating the relevance of each
feature with respect to all others. The subsequent
softmax normalization of these scores produces at-
tention weights that denote the significance of each
descriptor element: α
i j
=
exp(score
i j
)
∑
k
exp(score
ik
)
. Ultimately, a
weighted sum of the value vectors, weighted by these
attention weights, results in a refined representation
of the SIFT descriptors. The final output of the at-
tention mechanism is the weighted sum of the value
vectors, where the weights are the normalized atten-
Enhancing LULC Classification with Attention-Based Fusion of Handcrafted and Deep Features
73

Figure 6: Example Illustrating SIFT-Guided Attention.
tion scores: attended f eatures
i
=
∑
j
α
i j
V
j
.
After the independent processing in each branch,
the enriched feature outputs from the RGB branch
(with channel-wise attention) and the SIFT branch
(with feature-wise attention) are concatenated. The
fused features combine the spatial relationships cap-
tured by the CNN with the local variations captured
by the SIFT descriptors, enriched by their respective
attention mechanisms. The concatenated feature vec-
tor serves as input to dense layers with regularization
techniques (dropout, L2).
3.3 Mid-Level Fusion: Fusion of Local
Attended CNN Features and Global
CNN Features (LFGF) with Gating
Mechanism
Early fusion as well as late fusion combine indepen-
dent feature representations from CNN and SIFT for
classification, considering both global and local fea-
tures equally important and informative. In this sec-
tion, we propose a novel mid-level fusion approach
with the same aim of leveraging local SIFT cues to
help identify potentially informative regions, but with
a different rationale.
Instead of concatenating separate SIFT and CNN
features, the proposed mid-level approach fuses CNN
global features, which capture the global context,
with localized, attention-weighted CNN features that
specialize in capturing finer-grained local details. To
achieve this, we use a custom SIFT-guided dynamic
and adaptive attention mechanism.
As illustrated in the example of Figure 6 (ex-
tracted from our experiments), within this attention
mechanism, SIFT descriptors and keypoints act as
guides, highlighting potentially informative regions
within the image that are likely to hold discriminative
power for distinguishing between different land cover
types. The attention mechanism subsequently focuses
on these highlighted areas, selectively amplifying the
detailed features captured by the CNN within those
specific patches. Most importantly, this approach in-
tegrates, rather than discards, the rich feature set ex-
tracted by the CNN from the entire image and fuses it
Input Image
CNN Model
Global CNN Feature Map
SIFT Keypoints and
Descriptors Extraction
SIFT-Guided Attention Layer
Attended CNN Feature Map
Concatenate Global and Attended Feature Maps
Gating Mechanism
Dense and Dropout Layers
Dense Layer, Softmax
Figure 7: Mid-Level Fusion Approach: Fusion of Local At-
tended CNN Features and Global CNN Features (LFGF)
with Gating Mechanism
with the attended CNN features.
As depicted in Figure 7, the feature map extracted
by the RGB branch along with the keypoints and de-
scriptors extracted by the SIFT branch form the input
of the attention layer. The attention layer acts as a
bridge between the global CNN features and localized
SIFT information. It has three key components: pro-
jection layers, scaled dot-product attention (Vaswani
et al., 2017), and weighting and aggregation.
Projection Layer: The first step involves projecting
the CNN features, SIFT descriptors, and keypoints
into a common latent space. This is achieved through
the use of separate fully connected (dense) layers for
each feature type. These projection layers transform
the input features into vectors of the same dimen-
sionality, enabling subsequent similarity calculations.
Formally, let F
CNN
denote the CNN features, F
SIFT
the SIFT descriptors, and K
SIFT
the SIFT keypoints.
The projection layers can be represented as:
P
CNN
= W
CNN
F
CNN
+ b
CNN
P
SIFT
= W
SIFT
F
SIFT
+ b
SIFT
P
KP
= W
KP
K
SIFT
+ b
KP
where W and b are the weights and biases of the
respective projection layers, and P
CNN
, P
SIFT
, and
P
KP
are the projected features.
Scaled Dot-Product Attention (Vaswani et al., 2017):
The projected features are next fed into a scaled dot-
product attention mechanism. This attention mech-
anism computes a score that measures the similarity
between the SIFT-derived features (descriptors and
keypoints) and the CNN features. These scores de-
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
74

termine the importance of each region in the CNN
feature map relative to the SIFT keypoints. The simi-
larity scores are computed using a scaled dot-product
operation: Score(i, j) =
P
SIFT,i
·P
T
CNN, j
√
d
, where d is the
dimensionality of the projected features, and · denotes
the dot product.
The attention weights are then obtained by
applying a softmax function to the similarity scores:
α
i j
= so ftmax(Score(i, j)) =
exp(Score(i, j))
∑
k
exp(Score(i,k))
. These
attention weights indicate the degree of relevance of
each CNN feature region to the SIFT keypoints.
Weighting and Aggregation: Finally, the attention
weights are used to modulate the CNN features.
The original CNN feature map is element-wise mul-
tiplied by the attention weights, effectively high-
lighting regions deemed important by the SIFT key-
points/descriptors. The refined features, referred to as
”Attended CNN Features” are computed as follows:
F
Attended CNN Features
= α ⊙F
CNN
where α represents the attention weights and ⊙ de-
notes the element-wise multiplication.
After obtaining the ”Attended CNN Features” these
are concatenated with the original CNN features to
form a comprehensive feature vector. As depicted in
Figure 7 our model integrates a gating mechanism and
L1 regularization to reduce redundancy in the con-
catenated feature map. The gating mechanism selec-
tively combines the original and attended CNN fea-
tures by learning to scale the importance of each fea-
ture through a sigmoid-activated gate, thus enhancing
feature discrimination. L1 regularizations are applied
to the dense layers projecting the SIFT descriptors
and CNN features, as well as the gating layer, to pro-
mote sparsity in the learned weights. This encourages
the model to utilize a smaller, more informative sub-
set of features, improving generalization and reducing
the risk of overfitting.
4 EXPERIMENTAL STUDY
4.1 Experimental Setup
This section evaluates the performance of the pro-
posed fusion strategies on the EuroSAT real-world
dataset. The experiments include baseline models,
the early fusion model, and the proposed late and
mid-level fusion models. Fusion approaches are im-
plemented using both, the shallow CNN described
earlier, and a pre-trained, fine-tuned MobileNetV2
model (Qamar and Bawany, 2023). While not the
Table 1: Accuracy achieved by the studied models.
Model Accuracy
Baseline
SIFT-NN model 0.619
Shallow CNN 0.845
Fine-tuned MobileNetV2 0.966
Early Fusion
Shallow CNN 0.887
Fine-tuned MobileNetV2 0.976
Proposed Late Fusion Approach (ADL)
Shallow CNN 0.911
Fine-tuned MobileNetV2 - SIFT 0.984
Proposed Mid-Level Fusion Approach (LFGF)
Shallow CNN 0.924
Fine-tuned MobileNetV2 0.985
most accurate pre-trained model, MobileNetV2 of-
fers a good trade-off between accuracy and speed.
To avoid functional redundancy, we opted for a spa-
tial attention mechanism instead of channel-wise at-
tention in our late fusion approach using MobileNet.
This choice allows the network to focus not only on
the significance of features across channels (a task al-
ready managed by the depthwise separable convolu-
tions) but also on their spatial importance.
All models were implemented using Keras and
TensorFlow (Abadi et al., 2015). SIFT keypoints
and descriptors were extracted using OpenCV (Culjak
et al., 2012). To enhance the robustness of our mod-
els, we applied common image augmentation tech-
niques, including random flips, random jitters, ran-
dom rotations, random crop, noise injections for SIFT
descriptors, etc.. The EuroSAT images were stratified
by land cover class and split into a 70/15/15 training,
validation, and test set. Each model was trained for
100 epochs with early stopping and learning rate re-
duction on plateau strategies.
4.2 Results & Discussion
The results presented in Table 1 confirm the poten-
tial benefits of synergizing handcrafted features with
learned CNN features for LULC classification. No-
tably, all the fusion approaches outperform the SIFT-
NN and CNN baseline models. The results also
show that not all fusion approaches are equally effec-
tive. The late fusion approach achieves an improve-
ment of 47.17% over the baseline SIFT-NN and of
7.68% over the baseline CNN, demonstrating the ad-
vantage of applying attention mechanisms to dynam-
ically weigh and integrate salient features from both
the CNN and SIFT branches before final classifica-
tion decisions are made. The mid-level fusion ap-
proach, which fuses the original CNN-learned feature
map with the SIFT-based attended CNN feature map,
achieves a 49.27% improvement over SIFT-NN and a
Enhancing LULC Classification with Attention-Based Fusion of Handcrafted and Deep Features
75

Table 2: Accuracy Achieved by Main Existing Approaches.
Model Accuracy
SVM (Thakur and Panse, 2022) 0.509
Random Forest (Thakur and Panse, 2022) 0.567
SIFT-SVM (Helber et al., 2018) 0.701
SIFT-CNN (Ahmed et al., 2024) 0.916
Pretrained VGG19 with TWSVM (Dewangkoro and Arymurthy, 2021) 0.946
SHapley Additive exPlanations (SHAPs) (Temenos et al., 2023) 0.947
Pretrained GoogleNet (Helber et al., 2019) 0.960
Pretrained ResNet50 (Helber et al., 2019) 0.964
ResNet50 pretrained on in-domain datasets (Neumann et al., 2020) 0.992
µ2Net (Gesmundo and Dean, 2022) 0.992
Multi-Task Pretraining with Vision Transformers (ViT) (Wang et al., 2024) 0.992
Our Mid-Level Fusion Approach - Shallow CNN 0.924
Our Mid-Level Fusion Approach - MobileNetV2 0.985
9.22% improvement over the baseline CNN. The late
and mid-level fusion approaches outperform the more
common early fusion approach, which merges infor-
mation at the initial stages of processing and might
discard some feature details before the network can
learn their importance.
The improvements achieved by late and mid-level
fusion observed with the pre-trained MobileNetV2
are smaller than with the shallow CNN. This is
likely because MobileNetV2’s pre-trained features al-
ready achieve a high baseline performance, leaving
less room for enhancement by additional features.
However, gains observed across both models demon-
strate the generalizability of the proposed fusion ap-
proaches.
As shown in Table 2, existing work heavily re-
lies on fine-tuning pre-trained large models such as
ResNet50 (Helber et al., 2019; He et al., 2016),
Googlenet (i.e. InceptionV1,) (Gesmundo and Dean,
2022), and Vision Transformers (ViT) (Wang et al.,
2024). These models deliver very high performance,
with accuracies ranging from 96.0% to 99.2%. Our
proposed mid-level fusion approach with a shallow
CNN achieved an accuracy of 92.4%, which sur-
passes many traditional approaches and is competi-
tive with some pre-trained deep learning approaches.
Furthermore, our mid-level fusion with MobileNetV2
reached an accuracy of 98.5%, which is competitive
with high-performance models, and only slightly be-
low the top-performing models at 99.2% (Neumann
et al., 2020; Wang et al., 2024). Table 2 highlights
that, beyond the prevalent fine-tuning of pre-trained
large models, alternative approaches such as the inte-
gration of handcrafted features deserve exploration.
As mentioned earlier, our mid-level approach
fuses two feature maps: the original CNN-learned
feature map and a SIFT-based attended CNN feature
map. The original feature map captures the broader
context, while the attended feature map prioritizes lo-
cal details. Figure 8 shows the distribution of atten-
tion weights in the attended feature map within the
mid-level approach. The peaks around zero suggest
that the model still relies on the global context pro-
vided by the original CNN feature map. The pres-
ence of non-zero peaks in attention weights across
classes indicates that the mid-level fusion approach
effectively utilizes local features captured by SIFT de-
scriptors. This is crucial for enhancing the model’s
ability to capture fine-grained details that CNNs may
not prioritize.
The distribution patterns also reflect the nature
of each LULC class, with more complex classes
like Industrial showing a broader spread of attention
weights. This indicates a more nuanced use of lo-
cal features. Homogeneous classes like Forest and
SeaLake show a narrow distribution, suggesting a
consistent pattern of local feature importance, align-
ing with their more uniform textures.
The analysis of attention weight distributions
highlights the potential of the mid-level fusion ap-
proach for integrating local details captured by SIFT
descriptors with the global context learned by CNNs.
This approach demonstrably enhances the model’s
ability to capture fine-grained information crucial for
accurate LULC classification. However, further in-
vestigation is necessary to determine the generaliz-
ability of these findings across various datasets and
LULC tasks. Additionally, exploring alternative at-
tention mechanisms or feature extraction techniques
might be beneficial for capturing even more nuanced
local features or handling situations where SIFT de-
scriptors might not be optimal.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
76
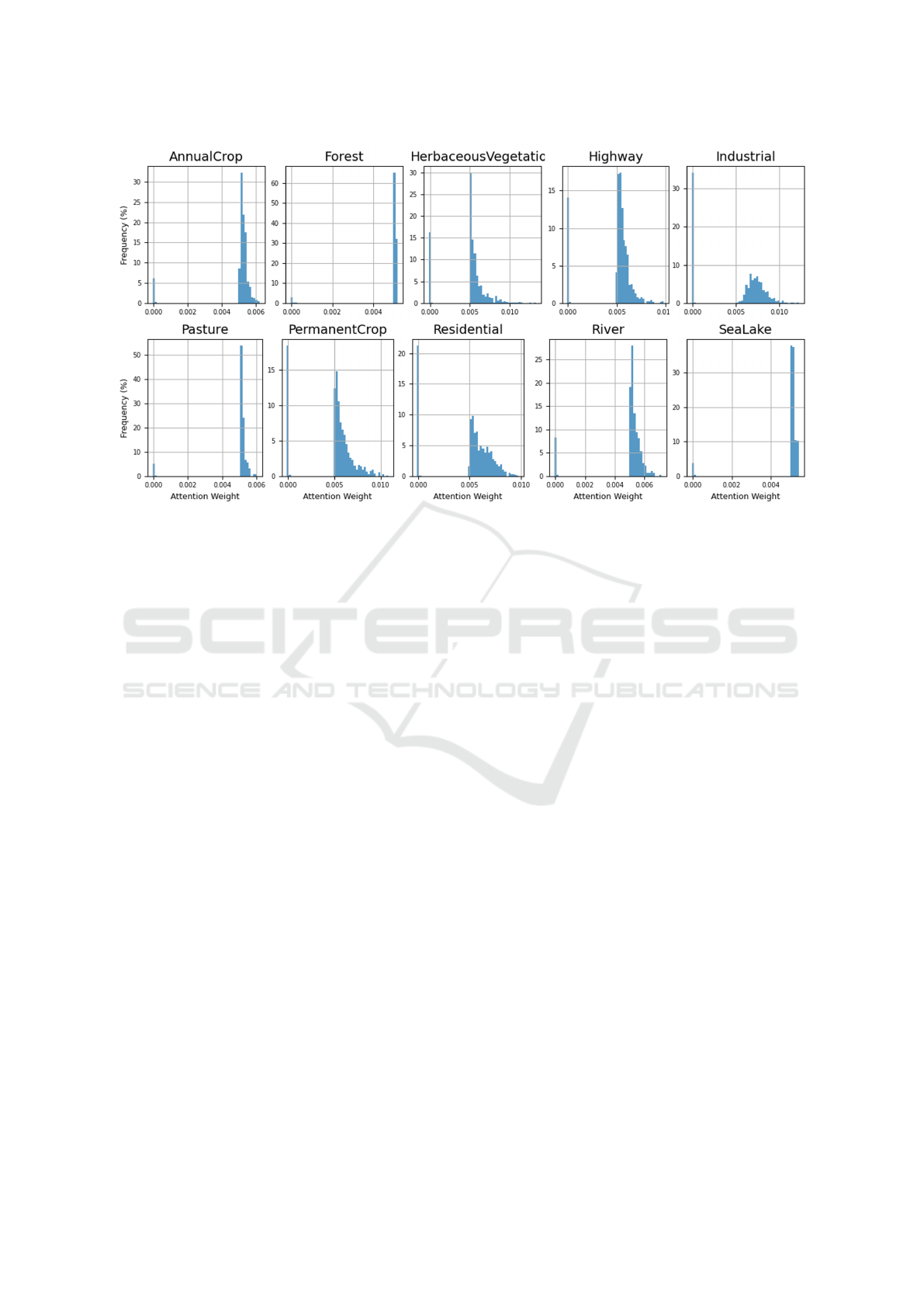
Figure 8: Distribution of Attention Weights (LFGF-CNN).
5 CONCLUSION AND FUTURE
WORK
This paper investigated the synergistic integration of
handcrafted SIFT descriptors with CNN-learned fea-
tures for improved LULC classification accuracy. We
compared three fusion strategies: early, late, and mid-
level fusion. Late fusion dynamically weighs salient
features from both modalities before classification.
Mid-level fusion further refines this by using a custom
SIFT-guided attention mechanism, selectively ampli-
fying detailed features while preserving the rich CNN
features. Experiments on real-world data showed that
late and mid-level fusion outperform the conventional
early fusion approach, demonstrating their efficacy in
capturing both fine-grained local details and broader
scene context.
The encouraging results of fusion approaches
pave the way for several research directions. Mov-
ing forward, we plan to delve deeper into the realm
of attention-based methods and dynamic fusion ap-
proaches. We also envision exploring the application
of the proposed method to land-use change detection
by analyzing time series data. Another interesting di-
rection involves investigating the generalizability and
adaptability of our proposed fusion approaches by ap-
plying them to various data-intensive tasks beyond
LULC classification.
REFERENCES
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z.,
Citron, C., Corrado, G., Davis, A., Dean, J., Devin,
M., and et. al. (2015). Tensorflow: Large-scale ma-
chine learning on heterogeneous systems.
Ahmed, V. A., Jouini, K., Tuama, A., and Korbaa, O.
(2024). A fusion approach for enhanced remote sens-
ing image classification. In Radeva, P., Furnari, A.,
Bouatouch, K., and de Sousa, A. A., editors, Pro-
ceedings of the 19th International Joint Conference
on Computer Vision, Imaging and Computer Graph-
ics Theory and Applications, VISIGRAPP 2024, Vol-
ume 2: VISAPP, Rome, Italy, February 27-29, 2024,
pages 554–561. SCITEPRESS.
Chen, S. and Tian, Y. (2015). Pyramid of spatial relatons
for scene-level land use classification. IEEE Trans.
Geosci. Remote Sens., 53(4):1947–1957.
Cheng, G., Xie, X., Han, J., Guo, L., and Xia, G. S. (2019).
Remote sensing image scene classification meets deep
learning: Challenges, methods, benchmarks, and op-
portunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote
Sens., 13(X):3735–3756.
Culjak, I., Abram, D., Pribanic, T., Dzapo, H., and Cifrek,
M. (2012). A brief introduction to opencv. In 35th
International Convention MIPRO, page 1725–1730.
Dewangkoro, H. I. and Arymurthy, A. M. (2021). Land
use and land cover classification using cnn, svm, and
channel squeeze & spatial excitation block. IOP Conf.
Ser. Earth Environ. Sci., 704(1).
Gesmundo, A. and Dean, J. (2022). An evolutionary ap-
proach to dynamic introduction of tasks in large-scale
multitask learning systems.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
ual learning for image recognition. In Proceedings of
Enhancing LULC Classification with Attention-Based Fusion of Handcrafted and Deep Features
77

the IEEE conference on computer vision and pattern
recognition, pages 770–778.
Helber, P., Bischke, B., Dengel, A., and Borth, D. (2018).
Introducing eurosat: A novel dataset and deep learn-
ing benchmark for land use and land cover classifica-
tion. In IGARSS, page 204–207.
Helber, P., Bischke, B., Dengel, A., and Borth, D. (2019).
Eurosat: A novel dataset and deep learning bench-
mark for land use and land cover classification.
IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens.,
12(7):2217–2226.
Hu, J., Shen, L., and Sun, G. (2018). Squeeze-and-
excitation networks. In 2018 IEEE/CVF Conference
on Computer Vision and Pattern Recognition, pages
7132–7141.
Lowe, D. G. (2004). Distinctive image features from scale-
invariant keypoints. International Journal of Com-
puter Vision, 60(2):91–110.
Neumann, M., Pinto, A. S., Zhai, X., and Houlsby, N.
(2020). In-domain representation learning for remote
sensing. CoRR, abs/1911.06721.
Qamar, T. and Bawany, N. Z. (2023). Understanding the
black-box: towards interpretable and reliable deep
learning models. PeerJ Comput. Sci., 9.
Steiner, A., Kolesnikov, A., Zhai, X., Wightman, R., Uszko-
reit, J., and Beyer, L. (2021). How to train your vit?
data, augmentation, and regularization in vision trans-
formers. CoRR, abs/2106.10270.
Temenos, A., Temenos, N., Kaselimi, M., Doulamis, A.,
and Doulamis, N. (2023). Interpretable deep learning
framework for land use and land cover classification
in remote sensing using shap. IEEE Geosci. Remote
Sens. Lett., 20:1–5.
Thakur, R. and Panse, P. (2022). Classification perfor-
mance of land use from multispectral remote sens-
ing images using decision tree, k-nearest neighbor,
random forest and support vector machine using eu-
rosat da. Orig. Res. Pap. Int. J. Intell. Syst. Appl.
Eng. IJISAE, 2022(1s):67–77. [Online]. Available:
https://github.com/phelber/EuroSAT.
Tianyu, Z., Zhenjiang, M., and Jianhu, Z. (2018). Combin-
ing cnn with hand-crafted features for image classifi-
cation. In 2018 14th IEEE International Conference
on Signal Processing (ICSP), pages 554–557.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., Kaiser, L., and Polosukhin, I.
(2017). Attention is all you need. In Proceedings of
the 31st International Conference on Neural Informa-
tion Processing Systems, NIPS’17, page 6000–6010,
Red Hook, NY, USA. Curran Associates Inc.
Wang, D., Zhang, J., Xu, M., Liu, L., Wang, D., Gao, E.,
Han, C., Guo, H., Du, B., Tao, D., and Zhang, L.
(2024). Mtp: Advancing remote sensing foundation
model via multi-task pretraining.
Xia, H. and Liu, C. (2019). Remote sensing image deblur-
ring algorithm based on wgan. In Liu, X., Mrissa,
M., Zhang, L., Benslimane, D., Ghose, A., Wang, Z.,
Bucchiarone, A., Zhang, W., Zou, Y., and Yu, Q.,
editors, Service-Oriented Computing – ICSOC 2018
Workshops, pages 113–125, Cham. Springer Interna-
tional Publishing.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
78
