
Examination of Document Clustering Based on Independent Topic
Analysis and Word Embeddings
Riku Yasutomi
1a
, Seiji Yamada
2b
and Takashi Onoda
1c
1
Aoyama Gakuin University School of Science and Engineering, 5-10-1 Huchinobe, Chuo, Sagamihara, Kanagawa, Japan
2
National Institute of Informatics 2-1-2 Hitotsubashi, Chiyoda, Tokyo, Japan
Keywords: Topic Model, NLP, Independent Topic Analysis, ITA, Word Embedding, Word2vec, Machine Learning,
Document Clustering, News Paper.
Abstract: In recent years, research on text mining, which aims to extract useful information from textual data, has been
actively conducted. This paper focuses on document classification methods that extract topics from textual
data and assign documents to the extracted topics. Among these methods, the most representative is Latent
Dirichlet Allocation (LDA). However, it has been pointed out that LDA often extracts similar topics due to
the high amount of shared information between topics. Therefore, this paper proposes a document classifica-
tion method based on Independent Topic Analysis (ITA), which extracts topics based on the independence of
topics, and on Word Embedding, which learn word co-occurrence. This approach aims to avoid extracting
similar topics and to achieve information grouping that is closer to human intuition. As a comparative metric,
we used the agreement rate between the results of manually classifying documents into topics and those clas-
sified by each method. The results of the comparative experiment showed that the agreement rate for docu-
ment classification based on ITA and Word Embedding was the highest. From these results, it was suggested
that the proposed method could achieve document classification closer to human perception.
1 INTRODUCTION
In recent years, the widespread use of mobile devices
and laptops, as well as rapid advancements in infor-
mation technology, have been remarkable. As a result,
anyone can now easily disseminate large volumes of
textual data. These data are being accumulated daily,
and the amount of available textual data continues to
increase. In fact, the document information manage-
ment service market is on a steady path of growth.
Ministry of Internal Affairs and Communications of
Japan has projected an increase in the volume of dig-
ital data. The amount of digital data worldwide is ex-
pected to expand fourfold over the five-year period
since 2011. (MIC, 2012). However, on the other hand,
there is a limit to human information processing ca-
pacity. Therefore, research on text mining, which
aims to extract useful information from such data, has
been actively conducted (Shinobu, 2015).
In particular, various studies have been conducted
a
https://orcid.org/0009-0008-2675-4982
b
https://orcid.org/0000-0002-5907-7382
c
https://orcid.org/0000-0002-5432-0646
on methods for extracting topics from document data
and classifying documents, including hierarchical
clustering techniques applied to word embeddings
(Grootendorst, 2022) and methods utilizing word dis-
tributions. Grouping a large amount of information
into topics that align with human intuition is highly
sought after (Vivek, 2024).
Among these document classification methods,
the most representative approach is Latent Dirichlet
Allocation (LDA), proposed by Blei et al. (Blei,
2003). LDA is a distribution-based method, but many
studies have pointed out the problem of extracting
highly similar topics (Section 2.2).
Therefore, this paper focuses on Independent
Topic Analysis (ITA), proposed by Shinohara (Shino-
hara, 1999), which performs topic extraction with
high independence. However, since ITA is a topic ex-
traction method primarily used for topic tracking, it
must be adapted to document classification problems
by leveraging
word embeddings (Takahiro, 2020).
Yasutomi, R., Yamada, S. and Onoda, T.
Examination of Document Clustering Based on Independent Topic Analysis and Word Embeddings.
DOI: 10.5220/0013104100003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 3, pages 185-192
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
185

As a method for obtaining word embeddings,
this paper employs Word2Vec, which is the simplest
in structure and facilitates analysis. The objective of
this study is to achieve document classification that
aligns closely with human intuition by focusing on
topic independence while utilizing word embed-
dings
.
The remainder of this paper is organized as fol-
lows: Section 2 explains LDA as the baseline method
and reviews related works. Section 3 presents the pro-
posed method for document classification. Section 4
describes the evaluation experiments of the proposed
method. Finally, Section 5 discusses comparisons
with methods other than LDA, highlights the limita-
tions of the proposed method, and outlines future
challenges, concluding the paper.
2 RELATED RESEARCH
This section discusses the most common document
classification method, LDA, its issues, and the objec-
tive of this study.
2.1 LDA (Latent Dirichlet Allocation)
In LDA, documents are represented as random mix-
tures of latent topics. The graphical model is shown
in Fig 1. In this model, 𝑀 represents the number of
documents. 𝑁 denotes the number of words. 𝐾 stands
for the number of topics. Each plate represents re-
peated structures. Furthermore, 𝛼 is the parameter of
the Dirichlet distribution, which serves as the prior
distribution of the topic distribution 𝜃
for each doc-
ument. And 𝛽 is the parameter of the Dirichlet distri-
bution, which serves as the prior distribution of the
word distribution 𝜙
for each topic. 𝑧
,
denotes the
topic assignment corresponding to the 𝑛-th word in
document 𝑚, indicating from which topic each word
Figure 1: Graphical Model of LDA.
was generated. 𝑤
,
represents the actual observed
word in the 𝑛-th position of document 𝑚. Fig 1 illus-
trates the LDA process. The topic distribution per
document and the word distribution per topic are con-
trolled by the values of the Dirichlet parameters 𝛼
and 𝛽. First, the latent topic 𝑧 of a word is determined
from the document-specific topic distribution 𝜃
through a multinomial distribution. Then, using the
latent topic of the word and the word distribution 𝜙
for each topic, the observed word 𝑤 (bag of words) is
generated. In other words, LDA performs topic ex-
traction and classification. The probabilistic genera-
tive model of words and documents forms the basis
of LDA, allowing it to extract topics and classify doc-
uments effectively.
2.2 LDA Challenges
Many studies have pointed out the problem of extract-
ing highly similar topics with LDA. Mu et al. (2024)
discussed the limitations of traditional topic modeling
methods like LDA, highlighting issues such as the ex-
traction of similar topics and the difficulty in inter-
preting topics. As a result, it can become challenging
to interpret the topics (Aletras and Stevenson, 2014),
often leading to inaccurate topic labels during label
assignment (Gillings and Hardie, 2023). To make the
results interpretable by humans, post-processing of
the model's output may sometimes be required
(Vayansky and Kumar, 2020).
Due to these issues, there is a possibility that the
classification results deviate from human intuition.
Section 3 will provide an explanation of the proposed
method, which focuses on ensuring independence be-
tween topics.
3 PROPOSED METHOD
In this section, we propose a document classification
method that addresses the objective stated in Section
2.1 by utilizing ITA and Word2Vec. Section 3.1 ex-
plains ITA, Section 3.2 describes Word2Vec, and
Section 3.3 provides an explanation of the document
classification method that combines these approaches.
3.1 ITA
We introduce Independent Topic Analysis (ITA),
proposed by Shinohara (Shinohara, 1999). As illus-
trated in Fig 2, ITA is a method for extracting topics
with high independence. Highly independent topics
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
186
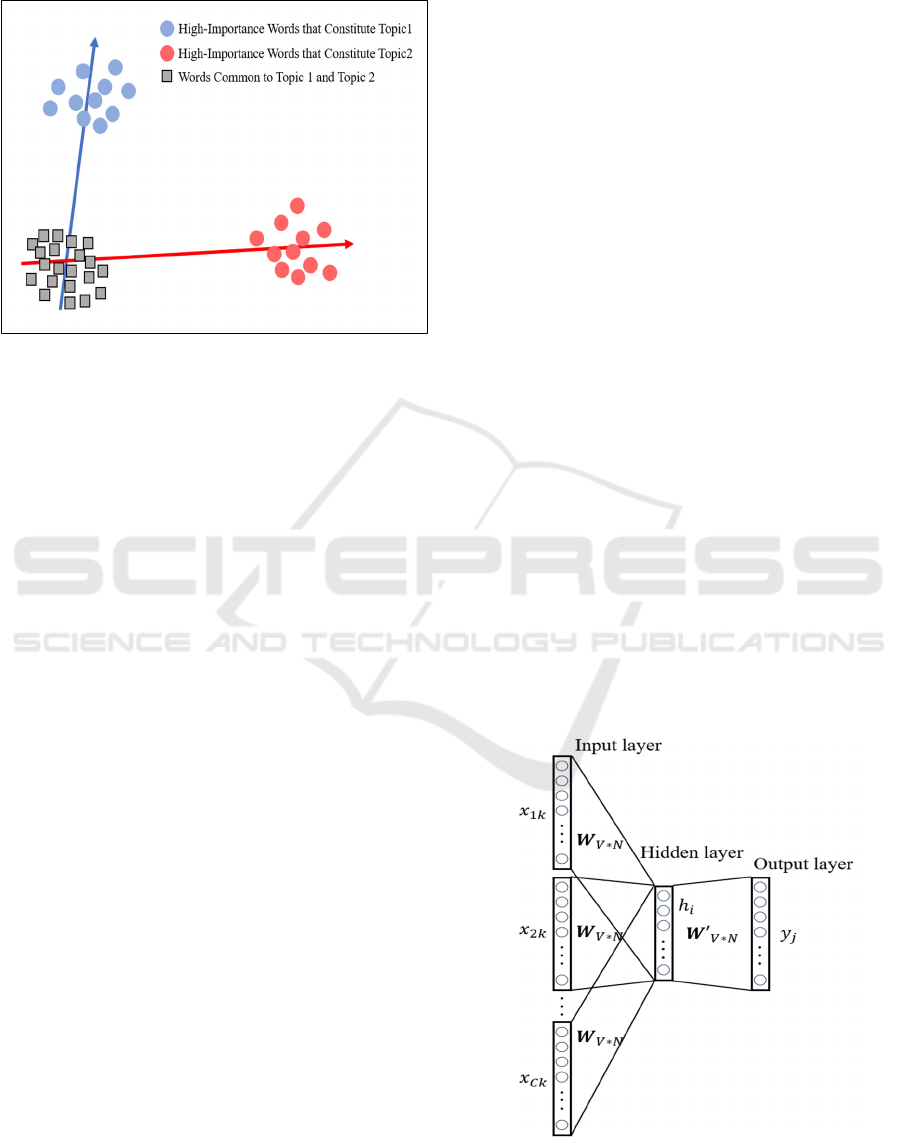
are those that share a small amount of mutual infor-
mation with each other. In other words, this method
Figure 2: Image Diagram of Independent Topic Analysis
(ITA).
aims to avoid the extraction of similar topics and an-
alyse the overall topic structure of documents. Let 𝑡∈
1,...,𝑘 denote the topic, 𝑑 ∈1,...,𝑛 the docu-
ment, and 𝑤∈
1,...,𝑚
the word, which are the
common variables used in this method. ITA performs
Singular Value Decomposition (SVD). On the word
frequency matrix 𝐴 of the documents to determine
the significance of word 𝑤 in topic 𝑡 and the signifi-
cance of document 𝑑 in topic 𝑡. To evaluate the inde-
pendence between topics, we use the kurtosis of
higher-order statistics as a metric. Kurtosis is calcu-
lated as the difference between the fourth moment
and a normal distribution with the same mean and
variance. From this value, we calculate the concentra-
tion of words for the topics being used.
ITA seeks to extract topics from document data
such that the word concentration of topics is maxim-
ized and the independence between topics is maxim-
ized. Moreover, since ITA is a topic extraction
method, it requires a document classification method
to utilize these extracted topics. In Section 3.2, we ex-
plain Word2Vec, which is used for document classi-
fication.
3.2 Word2Vec
We classify documents based on the topics extracted
using ITA by employing Word2Vec, proposed by To-
mas et al. (Tomas, 2013). Word2Vec is a model used
to learn vector space representations of vocabulary in
natural language processing. In this paper, we utilize
the Continuous Bag of Words (CBOW) model, as il-
lustrated in Fig 3. CBOW is a neural network com-
prising an input layer, hidden layer, and output layer.
For each of the C words in document 𝑘 , a one-hot
vector is formed and used as the input. The error be-
tween the predicted output and the correct labels
(one-hot vectors) for the actual target words are com-
puted using the cross-entropy loss function. The
weights 𝒘′ of the output layer are obtained through
weight updates via backpropagation. Each column of
these weights represents the distributed representa-
tion of each word. In other words, CBOW is a model
that predicts the central word from its surrounding
context. Consequently, this model captures the se-
mantic similarity between words through co-occur-
rences, representing it as a low-dimensional continu-
ous vector.
3.3 ITA+Word2Vec
As mentioned in Section 3.1, ITA uses the frequency
of word occurrences as input. From this, ITA seeks to
identify topics that maximize the concentration of
words and the independence of each topic from the
document data. Due to this characteristic, there is a
possibility that rare words, which appear only in spe-
cific articles, are preferentially extracted. Addition-
ally, the co-occurrence of words is not taken into ac-
count during the topic extraction process. Therefore,
we want to classify rare words that are assigned high
importance within each topic while considering co-
occurring words. To achieve this, we will introduce
word embeddings. This classification method will
henceforth be referred to as the "Vector Classifica-
tion." By adopting this approach, it becomes possible
Figure 3: Image Diagram of ITA (Independent Topic Anal-
ysis).
Examination of Document Clustering Based on Independent Topic Analysis and Word Embeddings
187
to discover documents that include semantically sim-
ilar words. Even if they don’t contain rare, highly im-
portant words within the topics. The process of docu-
ment classification using Vector Classification is il-
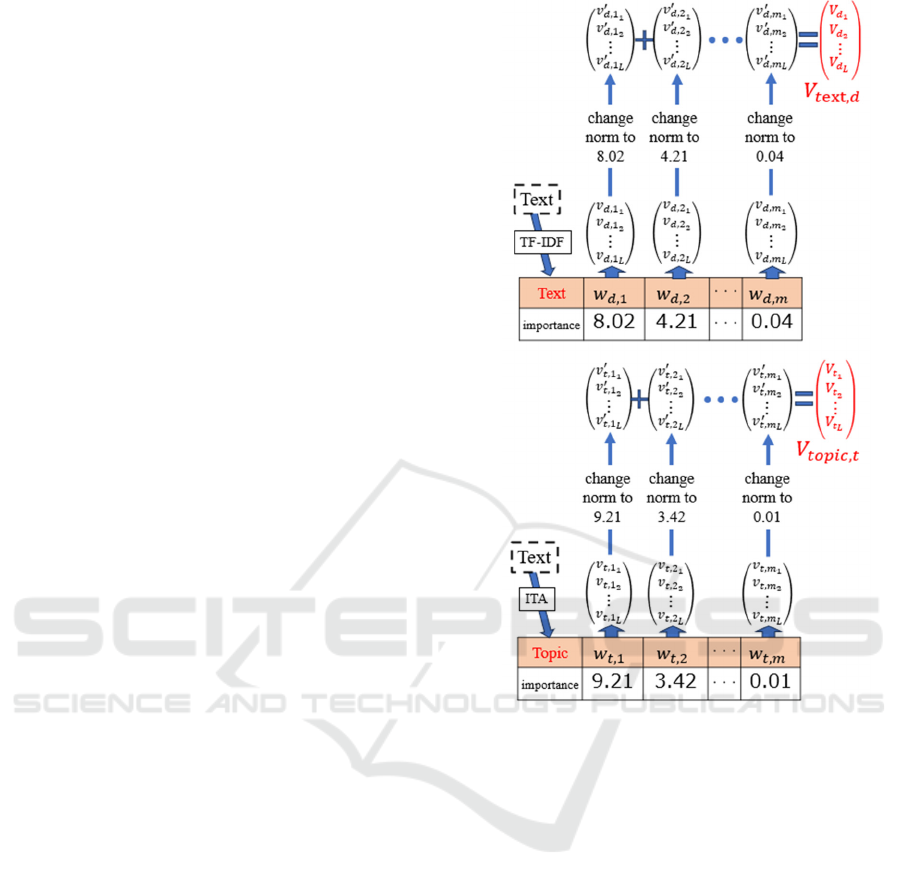
lustrated below (Figure 4).
I. Perform the following process for topic 𝑡∈
1,...,𝑘
.
(a) Convert all constituent words 𝑤∈
1,...,𝑚
of each topic into word embed-
ings.
(b) Convert the magnitude of each word embed-
ing into the importance of word 𝑤 in topic 𝑡.
(c) Add up all word embeddings for each topic
to generate the word embedding 𝑉
,
for
topic 𝑡.
II. Perform the following process for document
𝑑∈
1,...,𝑛
.
(a) Apply weighting to each word using TF-IDF.
(b) Similarly to step I. convert the constituent
words into word embeddings, adjust their
magnitudes, and sum them to generate the
word embedding 𝑉
,
for document 𝑑.
III. Calculate the cosine similarity cos(𝑉
,
,
𝑉
,
) between the 𝑉
,
of each document
and the 𝑉
,
of all topics.
IV. Assign the document to the topic with the
highest similarity.
Through the aforementioned process, we classify
documents into topics using the
word embeddings
obtained by Word2Vec. Word embeddings are learned
based on word co-occurrences. ITA is a method that
utilizes word occurrence frequencies and leverages
relationships among topics. But it does not take word
co-occurrences into consideration. Therefore, we in-
corporate word embeddings in the process of classi-
fying articles into topics.
4 EVALUATION EXPERIMENT
In the evaluation experiments, we will compare the
classification results obtained using LDA with the re-
sults from the proposed method, Vector Classification.
We will also assess these results against human clas-
sification results. Based on these results, we will ex-
amine methods that are closer to human intuition.
Figure 4: The method for converting documents and topics
into word embeddings in vector classification.
4.1 Used Data and Evaluation Method
In the experiments, we utilize weekly article data
from the Mainichi Shimbun in Japan for the year 2017
(The Mainichi, 2017). The data comprises articles
from weeks 1, 2, 3, 4, 5, 10, 20, 30, 40, and 50. Ini-
tially, we extract and classify 13 topics for each week
using LDA. Subsequently, we extract the same num-
ber of topics from the same data using Independent
Topic Analysis. For these topics, we perform classifi-
cations using both a topic-article classification based
on word importance (hereafter referred to as TF Clas-
sification) and the proposed method, Vector Classifi-
cation.
TF Classification calculates the cosine similarity
between the word importance derived from the topics
extracted through ITA. And the word importance of
each article, weighted using TF-IDF. The cosine sim-
ilarity between vectors 𝑥
⃗
and 𝑥
⃗
is computed using
the following formula.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
188
𝑐𝑜𝑠(𝒙
⃗
,𝒙
⃗
)=
𝒙
⃗
∙ 𝒙
⃗
|𝒙
⃗
| | 𝒙
⃗
|
This represents the cosine of the angle between the
two vectors, where a larger value indicates a greater
similarity between the topic and the article. We cal-
culate the cosine similarity for all topics and articles,
assigning each article to the topic with the highest
similarity. The number of extracted topics is set to 13.
It is consistent with the number of article categories
in the Mainichi Shimbun. Additionally, the parame-
ters for LDA are set to 𝛼 = 50/𝑘 and 𝛽 = 0.01, fol-
lowing the research by Steyvers et al. (Steyvers,
2007) They are implemented using the Gensim li-
brary in Python. Parameter exploration is conducted
based on coherence values to confirm the differences
in results due to parameter settings. The parameters
for Word2Vec were set to size=600 and window=10,
based on the study by Oren et al. (Oren, 2016).
By comparing the classification results of ITA,
LDA and human classification, we aim to investigate
which method aligns more closely with human per-
ception. The human classification involves the author
manually assigning articles to topics extracted by
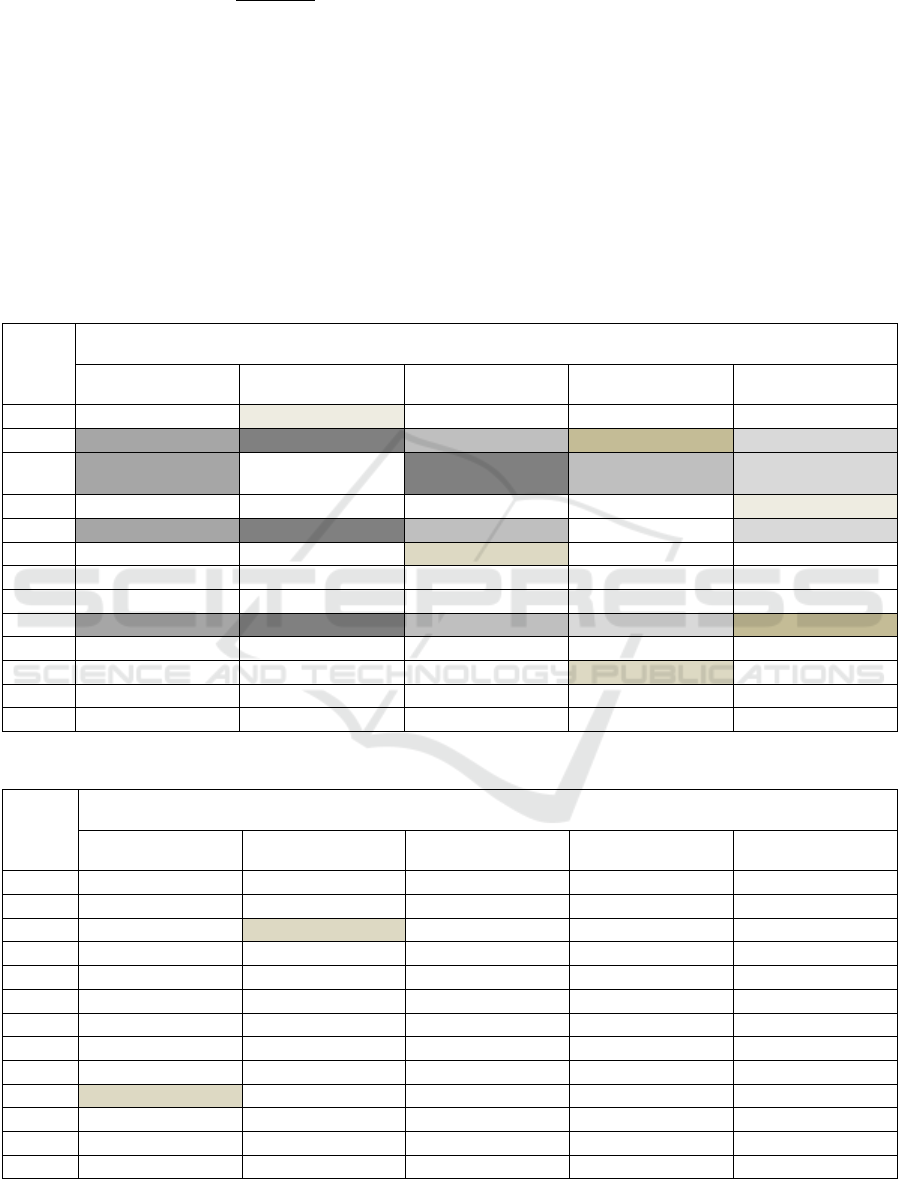
Table 1: The overlap of the top five words by probability for the 13 topics extracted using LDA.
topic
𝑡
probability
𝑤=1 𝑤=2 𝑤=3 𝑤=4 𝑤=5
1 scorers Tokyo Hyogo Osaka Chiba
2 cooperation Saito funeral art museum newspaper
3 cooperation
voluntary evacua-
tion
Saito funeral newspaper
4 Japan America picture world Tokyo
5 cooperation Saito funeral mother newspaper
6 defense Tanaka opponent champion judgement
7 party chairman constituency incumbent case party
8 Kawasaki Kashima match Urawa Yokohama ma
9 cooperation Saito funeral newspaper art museum
10 joint research suspect bribe arrest university
11 Higashifukuoka Toukaidai final opponent victory
12 fertilized egg transplant consent IVF man
13 Aogakudai Soudai stage prize victory Jundai
Table 2: The overlap of the top five words by importance for the 13 topics extracted using ITA.
topic
𝑡
importance
𝑤=1 𝑤=2 𝑤=3 𝑤=4 𝑤=5
1 opponent Toyko Tanaka champion defense
2 man woman fertilized egg transplant IVF
3 China America Japan Taiwan Takahara
4 dissolution prime minister reporter Suzuki this year
5 Koike laugh decision Tomin-first political
6 Goyoukai Nihon-buyo everyone recital musical
7 Higashifukuoka Toukaidai final Toin Gakuin semifinal
8 abdication emperor citizens coverage constitution
9 Aogakudai stage prize victory Soudai outward way
10 America company influence UK production
11 party chairman case constituency incumbent party
12 Kashima Kawasaki Yokohama ma Urawa Iwata
13 Saitama Hyogo Kyoto Chiba Okayama
Examination of Document Clustering Based on Independent Topic Analysis and Word Embeddings
189
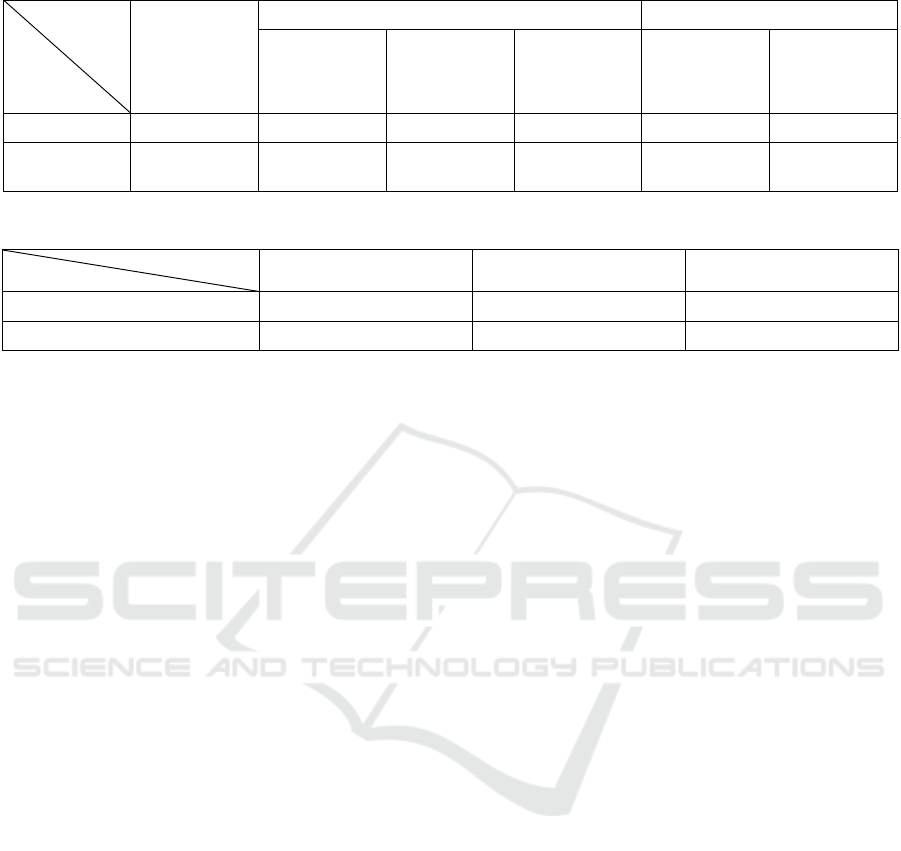
Table 3: Comparison of the matching rates between article classifications by each method and human classifications.
average num-
ber of articles
ITA LDA
The number
of articles
classified
manuall
y
Agreement
rate with vec-
tor classifica-
tion (%)
Agreement
rate with TF
classification
(%)
The number
of articles
classified
manuall
y
Agreement
rate with LDA
(%)
1-5 weeks
1423.8 423.0 64.8 81.0 439.4 40.6
10-50
weeks
※1
1680.0 505.8 69.9 83.8 518.2 43.8
Table 4: Comparison of the matching rates between the top 10 articles and topics for each method.
number of
articles
number of
matched articles
matching rate
(%)
Vector classification
129 98 76.0
LDA (coherence)
88 52 59.1
both LDA and ITA. During this process, only assign
articles that are clearly determined to belong to each
topic. Articles that are judged not to belong to any
topic or those that are determined to belong to multi-
ple topics are excluded. We had other experiment par-
ticipants perform a similar assignment task before-
hand. As a result, the agreement rate with the author's
classification was 85.6%. Therefore, we confirmed in
advance that there was no significant bias in classifi-
cation accuracy.
From these results, we will compare LDA, a topic
extraction and classification method that utilizes a
probabilistic generative model, with ITA, which lev-
erages the relationships between the extracted topics.
Furthermore, we will compare the TF classification
method that uses word importance with the Vector
Classification method that employs distributed repre-
sentations obtained from word co-occurrences.
4.2 Results
Table 1 presents the 13 topics extracted by LDA from
the article data of the first week of 2017. The param-
eters used are those that yielded the best coherence
values. Table 2 displays the topics extracted by ITA
from the same data. As shown in Table 2, ITA assigns
importance to all constituent words of each topic. Al-
lowing the user of the method to infer meaning from
the most important words of each topic, similar to
LDA. LDA exhibits a high degree of commonality in
words across topics, suggesting a substantial amount
of mutual information. In contrast, ITA extracts top-
ics with high independence, resulting in fewer com-
mon words among topics compared to LDA. Similar
results were obtained with other datasets.
Next, Table 3 shows the average number of arti-
cles and the number of articles assigned to the 13 top-
ics by human classification. And the average agree-
ment rates between classifications by each method
and human classification for the article data over one
year. Specifically for weeks 1-5 (one week each) and
weeks 10-50 (every ten weeks). The average number
of articles assigned to each topic by human classifiers
was 423.0 and 505.8 for ITA. While for LDA, the
numbers were 439.4 and 518.2, indicating no signifi-
cant difference. Furthermore, the agreement rates be-
tween articles assigned by each method and those as-
signed by human classifiers were 64.8% and 69.9%
for TF Classification. 81.0% and 83.8% for Vector
Classification, while LDA yielded 40.6% and 43.8%.
Thus, Vector Classification achieved the highest
agreement rates with human classification, whereas
LDA yielded the lowest.
Table 4 presents the results of the agreement rates
for the top 10 articles assigned to each topic when
LDA parameters were determined based on coher-
ence values. It also includes the results when using
Vector Classification. In this case, the agreement rate
for Vector Classification was again the highest. This
indicates that the results did not significantly vary
with different LDA parameters.
4.3 Discussion
From the results in Tables 1 and 2, it is evident that
the amount of common information between topics is
lower in ITA compared to LDA. However, it is also
apparent that there are topics with overlapping con-
tent between the two methods. Figure 5 illustrates the
number of matching top ten words between the 13
topics extracted by LDA and ITA. The top ten words
of topics 6, 7, 8, 11, 12, and 13 extracted by LDA
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
190

match over 70% with those of topics 1, 2, 7, 9, 11, and
12 in ITA. This suggests that the granularity of topics
extracted by ITA is not significantly different from
that of LDA. Simultaneously, it can be inferred that
the issue of redundant topics with a high number of
common words in LDA is mitigated. This allows for
a more multifaceted understanding of the overall
topic structure of the documents.
In the comparative experiment with human classi-
fication using newspaper articles, it was found that
the results of ITA and the Vector Classification based
Figure 5: The number of matching top ten words between
topics extracted by LDA and ITA.
on word2vec exhibited the highest agreement rates
with human classification. This indicates the potential
for achieving document classification that aligns
more closely with human perception through ITA and
document classification based on word embeddings.
Moreover, the lack of significant differences in the
average number of articles assigned to each topic by
humans between LDA and Independent Topic Anal-
ysis implies that there is no substantial difference in
the granularity of the extracted topics. This finding
can also be understood from the comparison in Figure
5. Specifically, it appears that discrepancies in preci-
sion arise during the classification process of articles
into topics beyond the common content identified by
LDA and ITA. The number of articles classified by
humans for each topic accounted for approximately
30% of the total articles. This characteristic of news-
paper articles, which comprehensively documents
events occurring each day, likely contributes to the
difficulty in extracting large topics with a high num-
ber of assigned articles.
Additionally, the agreement rate of TF Classifica-
tion was lower compared to Vector Classification.
ITA aims to minimize the common information
among topics in its extraction method. Consequently,
rare words that appear in a limited number of docu-
ments may be assigned a higher level of importance.
However, when calculating the similarity between
topics and documents using the TF Classification
method, it may only be high for a few documents con-
taining these important yet rare words. This can lead
to classification results that diverge from human per-
ception. Simultaneously, the similarity to articles
containing important words within the topics consist-
ently produces high values. This characteristic could
explain why the results for agreement rates were
higher than those of LDA.
While LDA estimates the agreement rates with
each topic based on word distribution, the proposed
method calculates the agreement rates between topics
and the constituent words of articles. This is achieved
using word embeddings derived from co-occurrence
learning. Methods utilizing probabilistic generative
models are known to achieve high precision in group-
ing documents. However, due to the abundance of
common words among the extracted topics and high
mutual information, a single document may corre-
spond to multiple topics. Therefore, when evaluated
based on proximity to human perception, it is plausi-
ble that precision may be lower.
Regarding the number of articles classified by hu-
mans, ITA showed little variation across weeks, while
LDA exhibited variability in its values. A common
characteristic attributed to LDA is the difficulty in de-
termining optimal parameters. Since the optimal so-
lution varies depending on the dataset and purpose,
adjustments are required for each application. Conse-
quently, experience and trial-and-error may be neces-
sary. In this study, the parameters for LDA were de-
termined based on prior research; however, the output
of LDA is highly sensitive to its parameters. There-
fore, changing the parameters could potentially alter
the experimental results. The same applies to
Word2Vec. In contrast, the results of ITA do not fluc-
tuate significantly based on user input. It is believed
that the minimal variability in the number of articles
classified by humans is a result of this characteristic.
5 CONCLUSIONS
In this paper, we conducted a classification of news-
paper articles into various topics using ITA, a method
known for its high independence in topic extraction,
along with word embeddings. We compared the clas-
sification results of our proposed method with those
obtained through LDA, a widely used topic extraction
Examination of Document Clustering Based on Independent Topic Analysis and Word Embeddings
191

method, as well as with results manually classified by
humans. The findings revealed that our proposed
method demonstrated a higher accuracy in terms of
the agreement rate between the extracted topics and
the assigned articles compared to existing methods.
This suggests that our approach effectively avoids the
extraction of topics characterized by a high number
of common words, which is a noted issue with LDA,
allowing for a more multifaceted representation of
document topic structures.
The number of words in the topics extracted by
ITA corresponds to the number of constituent words
in the input documents, resulting in a high computa-
tional cost for calculating the similarity between top-
ics and documents. Consequently, there are current
limitations in applying ITA to larger-scale document
datasets.
In this study, LDA, the most representative
method for document classification, was chosen as a
comparison benchmark. However, recent models
such as BERTopic, which employs BERT and hierar-
chical clustering (Grootendorst, 2022), and LDA2vec,
which integrates word embeddings prior to LDA ap-
plication (Akihiro, 2019), have also been extensively
studied. Future work must include comparisons with
these state-of-the-art methods. Additionally, it is nec-
essary to explore the use of word embeddings before
applying ITA.
In the present experiment, Japanese newspaper ar-
ticles were used as the dataset. Newspaper articles
were chosen because they cover a wide variety of top-
ics, making it challenging to categorize them into a
small number of groups. As future work, we plan to
explore the application of comparison methods to
other datasets, such as review sites or documents
maintained by companies, as well as to English doc-
uments.
REFERENCES
Ministry of Internal Affairs and Communications (MIC).
(2012). Information and Communications White Paper,
2024 edition (in Japanese)
Shinobu, O. (2015). Technologies and Trends in Text Min-
ing. Japanese Journal of Statistics and Data Science
(JJSD). 28-1, pp.31‒40 (in Japanese)
Grootendorst Maarten. (2022). BERTopic : Neural topic
modeling with a class-based TF-IDF procdure. arXiv :
2203.05794
Vivek M., Mohit A., Rohit K. K. (2024). A comprehensive
and analytical review of text clustering techniques. In-
ternational Journal of Data Science and Analytics.
18:239–258
David M. Blei. Andrew Y. Ng. Michael I. Jordan. (2003).
Latent Dirichlet Allocation. The Journal of Machine
Learning Research. Vol.3, pp993-1022
Yasushi Shinohara. (1999). Independent Topic Analysis -
Extraction of Distinctive Topics through Maximization
of Independence. Communications Techniques.
OFS99-14 (in Japanese)
Takahiro Nishigaki. Kenta Yamamoto. Takashi Onoda.
(2020). Topic Tracking and Visualization Method using
Independent Topic Analysis. AIRCC Publishing Cor-
poration. Vol.10, No.3, pp. 1-18
Yida Mu. Chun Dong. Kalina Bontcheva. Xingyi Song.
(2024). Large Language Models Offer an Alternative to
the Traditional Approach of Topic Modelling
Nikolaos Aletras. Mark Stevenson. (2014). Labelling topics
using unsupervised graph-based methods. In Proceed-
ings of the 52nd Annual Meeting of the Association for
Computational Linguistics. Vol.2, pp.631–636
Mathew Gillings. Andrew Hardie. (2023). The interpreta-
tion of topic models for scholarly analysis: An evalua-
tion and critique of current practice. Digital Scholarship
in the Humanities, 38(2):530–543
Ike Vayansky. Sathish AP Kumar. (2020). A review of
topic modeling methods. Information Systems, 94:
101582
Tomas Mikolov. Kai Chen. Greg Corrado. Jeffrey Dean.
(2013). Efficient Estimation of Word Representations
in Vector Space
Provider: The Mainichi - Japan Daily News. Released by:
Nikkai Associates. (2017). CD - Mainichi Shimbun
Data Collection
Mark Steyvers. Tom Griffiths. (2007). Probabilistic Topic
Models. Lawrence Erbaum Associates
Oren Melamud. David McClosky. Siddharth Patwardhan.
(2016). Mohit Bansal:The Role of Context Types and
Dimensionality in Learning Word Embeddings.
NAACL-HLT 2016. pp.1030–1040
Akihiro Ito. Rina Shirai. Hiroshi Uehara. (2019). Topic Ex-
traction Using Similar Vocabulary with Word2Vec.
IPSJ SIG Technical Report. Vol.2019-ITS-77, No.21
(in Japanese).
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
192
