
Spiideo SoccerNet SynLoc: Single Frame World Coordinate Athlete
Detection and Localization with Synthetic Data
H
˚
akan Ard
¨
o
1 a
, Mikael Nilsson
2 b
, Anthony Cioppa
4 c
, Floriane Magera
4
, Silvio Giancola
3 d
,
Haochen Liu
1
, Bernard Ghanem
3 e
and Marc Van Droogenbroeck
4 f
1
Spiideo, Malm
¨
o, Sweden
2
Centre for Mathematical Sciences, Lund University, Sweden
3
Center of Excellence for Generative AI, KAUST, Saudi Arabia
4
Montefiore Institute, Open-SportsLab, University of Li
`
ege, Belgium
fl
Keywords:
Synthetic, Dataset, Sports, 3D, Human, Detection, Localization.
Abstract:
Currently, most research and public datasets for video sports analytics are base on detecting players as bound-
ing boxes in broadcast videos. Going from there to precise locations on the pitch is however hard. Modern
solutions are making dedicated static cameras covering the entire pitch more readily accessible, and they are
now used more and more even in lower tiers. To promote research that can take benefits of such cameras
and produce more precise pitch locations, we introduce the Spiideo SoccerNet SynLoc dataset. It consists of
synthetic athletes rendered on top of images from real world installation of such cameras. We also introduce
a new task of detecting the players in the world pitch coordinate system and a new metric based solely on
real world physical properties where the representation in the image is irrelevant. The dataset and code are
publicly available at https://github.com/Spiideo/sskit.
1 INTRODUCTION
The object detection research field has seen a lot of
successes using bounding-boxes to represent the de-
tected object and evaluate the performance of detec-
tors c.f. (Wang et al., 2024). This particular repre-
sentation has proven effective for a lot of downstream
tasks and applications, but it is not sufficient for all of
them. For instance, several applications require to in-
fer information about the physical world by analysing
captured images of the scene. However, the image
itself is only an intermediate representation, and eval-
uations in image-space is therefore not representative
of the physical detection of the object. In those cases,
evaluations in physical-space are critical, i.e., to mea-
sure the localisation errors in meters instead of pixels.
Sports analytics often requires player localization
a
https://orcid.org/0000-0001-6214-3662
b
https://orcid.org/0000-0003-1712-8345
c
https://orcid.org/0000-0002-5314-9015
d
https://orcid.org/0000-0002-3937-9834
e
https://orcid.org/0000-0002-5534-587X
f
https://orcid.org/0000-0001-6260-6487
Figure 1: Example synthetic image form our proposed Spi-
ideo SoccerNet SynLoc public dataset. The players are 3D
generated on a real-captured image of a soccer pitch. The
proposed task is to detect and locate the player on the pitch
(purple) given the image and the camera calibration.
on the pitch to analyze their positions relative to each
other, the ball, and the field. Applications include shot
and goal locations, ball possession losses, heatmaps,
and Game State Recognition (GSR).
Such analytics can be conducted using broad-
cast video streams with moving cameras or dedicated
static cameras covering the entire pitch. Historically,
278
Ardö, H., Nilsson, M., Cioppa, A., Magera, F., Giancola, S., Liu, H., Ghanem, B. and Van Droogenbroeck, M.
Spiideo SoccerNet SynLoc: Single Frame World Coordinate Athlete Detection and Localization with Synthetic Data.
DOI: 10.5220/0013108200003912
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 2: VISAPP, pages
278-285
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

static cameras were rare and costly, so most datasets
and research relied on broadcast video. However,
modern solutions have made static cameras more ac-
cessible, even in lower tiers, increasing their rele-
vance for research.
A first step toward physical-space evaluation was
made with SoccerNet-GSR (Somers et al., 2024), but
the dataset is finite and was expensive to produce. It
defines the player’s physical location as the projec-
tion of the image bounding box’s bottom edge center
onto the ground. How this relate to any physical prop-
erty of the players is unclear. In this paper, we define
the physical location as the orthogonal projection of
the player pelvis onto the ground plane, and shows
in Section 7.1, that the SoccerNet-GSR definition is a
poor approximation of this.
World-space evaluation datasets are more com-
plex than standard image-bounding-box datasets,
requiring precise camera calibration and physical
ground truth data. While self-driving car datasets of-
ten use expensive sensors like radars and lidars, re-
search shows synthetic data can effectively train sys-
tems that generalize to real data (Rematas et al., 2018;
Black et al., 2023). Synthetic data is now also used
in sports analytics training (Leduc et al., 2024; Zhu
et al., 2020), with ground truth extracted from 3D ren-
dering models.
Team clothing is crucial in sports analytics, mak-
ing parametric clothed human models valuable for
generating diverse subjects. Layered human repre-
sentations like SynBody (Yang et al., 2023) and BED-
LAM (Black et al., 2023), are particularly relevant.
In this work we propose a new public dataset,
called Spiideo SoccerNet SynLoc, designed for soc-
cer player analytics. The dataset proposed is based on
real world installations of dedicated static cameras.
Contributions. The main contributions are as fol-
lows. (i) A Bird’s-Eye View (BEV) detection and
localization task for players using real world loca-
tions on a pitch. (ii) A publicly released synthetic
dataset, called Spiideo SoccerNet SynLoc, of soccer
scenes with static, calibrated cameras covering the en-
tire pitch. (iii) A new metric, called mAP-LocSim,
for evaluating player localization in real world pitch
space. (iv) A baseline detector based on YOLOX-
pose (Maji et al., 2022; Ge et al., 2021).
Table 1: Comparing the proposed dataset, Spiideo Soccer-
Net SynLoc, with other popular 3D human datasets. The
numbers refers to the numer of training images (Imgs), im-
age width in pixesl (Width), number of annotated humans
(Hum) and maximum camera height (MaxH). Bold faced
names are synthetic datasets.
Imgs Width Hum MaxH
Kitti 14K 1224 4K 2m
nuScenes 204K 1600 11K 2m
Human3.6M 5.8M 1000 1.4M 2m
MPI-INF3DHP 102K 2048 102K 3m
JTA 230K 1920 300M N/A
SynBody 1.2M 1024 2.7M 5m
BEDLAM 285K 1280 750K 6m
Proposed 65K 3840 668K 29m
2 RELATED WORK
2.1 Datasets
Publicly available datasets for sports analytics, such
as those released by SoccerNet (Giancola et al., 2018;
Deli
`
ege et al., 2021; Cioppa et al., 2022a; Cioppa
et al., 2022b; Mkhallati et al., 2023; Held et al., 2023;
Somers et al., 2024)
1
, are often based on broadcast or
single-view video. This means that the cameras are
in motion, which makes them hard to calibrate due
to limited visual cues and motion blur. That makes
it challenging to get accurate real-world ground truth.
These datasets have driven research for a lot of dif-
ferent analytics tasks as shown by the success of the
SoccerNet challenges (Giancola et al., 2022; Cioppa
et al., a; Cioppa et al., b). However, for some sports
analytics, more precise locations of all players in the
real world are needed, and in those cases, dedicated
static calibrated cameras covering the entire pitch are
an interesting alternative. Hence, in this work, we
capture data from single static cameras covering half
a pitch each, that we release publicly.
Lots of efforts have been put into producing
datasets with 3D information about humans, as illus-
trated in Table 1, leveraging both annotated real world
footage and rendered synthetic data. The level of de-
tails of the 3D information in those datasets varies
from full 3D meshes based on the SMPL (Loper et al.,
2015) model to 3D pose keypoints to 3D bounding
boxes. These datasets can aid sports analytics training
but require bridging a domain gap. For example, in
autonomous driving, Kitti (Geiger et al., 2012; Menze
and Geiger, 2015) and nuScenes (Caesar et al., 2020)
datasets use car-mounted cameras with low viewing
angles, unlike typical soccer analytics setups.
1
www.soccer-net.org
Spiideo SoccerNet SynLoc: Single Frame World Coordinate Athlete Detection and Localization with Synthetic Data
279

Figure 2: Example of image data annotations available in our proposed Spiideo SoccerNet SynLoc dataset. These are only
provided for convenience as the evaluation is performed entirely in world pitch coordinates. Our annotations comprise i)
bounding boxes (red), ii) ground position, defined as the orthogonal projection of the pelvis onto the ground (light blue) and
iii) pelvis (blue). To show that the ground position does not always align with center of bottom edge of the bounding box it is
also shown (orange).
Then there are the studio datasets such as Hu-
man3.6M (Ionescu et al., 2014) and MPI-INF3DHP
(Mehta et al., 2017) that use actors in a studio
recorded by multiple cameras and some motion cap-
ture system for generating ground truth. These
datasets only contains small scenes with one or a few
humans. Setting up such a capturing system for an
entire soccer pitch would be almost impossible.
A more promising approach consists in rendering
synthetic datasets. This can be achieved by intercept-
ing the 3D data passing through the graphics hard-
ware while playing computer games. Examples of
this are the JTA (Fabbri et al., 2018), NBA2K (Zhu
et al., 2020) and SoccerNet-Depth (Leduc et al., 2024)
datasets. However, this limits the variability of the
produced datasets to that of the game as it is hard to
extend them beyond their original framework.
There are also approaches that build up the 3D
models explicitly in layers such, as BEDLAM (Black
et al., 2023) and SynBody (Yang et al., 2023). Here,
each sample is constructed by randomly choosing an
combination of 3D models from large pools of mod-
els representing different aspects of the scene, such
as background, body shapes, cloths, hair styles, tex-
tures and motions. This can create large variations in
the datasets as the different aspects can be combined
in several different ways. The randomly created 3D
model is then rendered using photorealistic rendering
engines such as Blender (Blender Online Community,
2018) or Unreal. By choosing which models are avail-
able for each aspect it is also possible to control the
kind of scenes produced, and it is also easy to extend
by adding more 3D models. In this work, we lever-
age this last approach by superimposing 3D paramet-
ric athlete models over a real stadium.
2.2 Metrics
When it comes to metrics, the classical way to mea-
sure how well a detected object fits the ground truth
annotations is to look at the Intersection over Union
(IoU) between the detected image-bounding-box and
the ground truth image-bounding-box. This IoU value
is typically thresholded to get a criteria specifying if
an object have been detected or not. For some use-
cases, such as sports analytics, a more relevant detec-
tion criteria is to threshold the distance between the
estimated location in the real world and the ground
truth location.
In tasks where a more detailed representation of
the objects is available, this IoU can be replaced with
other similarity measures. In pose keypoint detectors
for example, the COCO Object Keypoint Similarity,
OKS, (Lin et al., 2015a) is typically used instead. It
is defined as the mean similarity over all visible key-
points. It does however still measure the similarity in
pixels in the image space and not in the real world.
The SoccerNet Game State dataset (Somers et al.,
2024) introduces a tracking metric called GS-HOTA.
It is based on the HOTA (Luiten et al., 2020) met-
ric, but replaces the IoU similarity measure used there
with another measure called LocSim. It is based on
the distance, d, between a detected objects location
and its ground truth location in the real world ground
plane, and defined as
e
ln0.05
d
2
τ
2
, (1)
where τ is a constant distance tolerance set to 5 in
their work. This similarity measure allows the sim-
ilarity to be measured in the real world, but HOTA
is a tracking metric not suitable to evaluate a single
frame detector. However the same approach of re-
placing the IoU with LocSim can be applied to the
common detection metric mAP, which then becomes
the proposed metric mAP-LocSim.
This gives a single metric that allows a whole
parametric ensemble of detectors to be evaluated as
a single entity. The different detectors in the ensem-
ble are formed by varying the score threshold used to
discard week detections. However, for a practical us-
age, this threshold has to be chosen and a single met-
ric does not describe all aspects of a model. Also, it’s
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
280

hard to interpret what the exact values represent. This
prompts for the use of additional metrics whose val-
ues are more intuitively interpretable. In this work,
we propose to choose the final threshold that maxi-
mizes the F1-score on the validation-set and use the
classical precision, recall and F1-score as additional
metrics together with the frame accuracy metric, de-
fined in Section 5.
3 TASK DEFINITION: ATHLETE
DETECTION AND
LOCALIZATION
In this paper a new athlete detection and localization
task is proposed. It focuses on the real world problem
of detecting players, referees, and bystanders and lo-
cating them on a soccer-pitch. More precisely, given
an image and the camera calibration parameters relat-
ing the image to the real world coordinate system, the
objective is to locate each athlete based on the pro-
jection of its pelvis onto the ground plane. How the
player is represented in the image is irrelevant to the
task. The entire evaluation is performed in the real
world pitch coordinate system. This allows differ-
ent representations in the image (bounding-box, pose-
keypoints, pixel segmentations, etc.) to be utilized
while solving the task.
4 PROPOSED DATASET: SPIIDEO
SOCCERNET SYNLOC
To support this task we release a new dataset with
ground-truth locations of players in the real world.
The data consists of background images from real
world installation with synthetic players rendered on
top.
4.1 Data Generation
The 3D rendering technique used to render the Spi-
ideo SoccerNet SynLoc dataset is based on a com-
bination of the techniques used in BEDLAM (Black
et al., 2023) and HeNIT (Ard
¨
o et al., 2022). Each
scene to render is created from an random combina-
tion of different assets which leads to an exponential
combination of possible scenes. The tools used (with
the exception of the cloth 3D models) are available as
open-source
2
.
2
https://github.com/AxisCommunications/
blenderset-addon
Figure 3: Example renderings of the different cloths 3D
models used with one of the teams textures applied to all
of them.
At the base real world installations are used to
form the background and camera placements. In-
stallations at 17 different arenas with two 4K cam-
eras covering half the pitch each have been used, c.f.
Fig. 1. From these scenes, background images were
constructed from 134 different games by taking the
temporal median over several minutes of video to get
rid of any moving objects.
Lighting is applied to the scene by randomly
choosing one of 683 different HDRI sky images as
described in HeNIT (Ard
¨
o et al., 2022), and player
bodies (shapes and poses) are sampled from the BED-
LAM (Black et al., 2023) dataset. The clothing in
BEDLAM is unsuitable for soccer players or referees,
so a 3D artist designed custom models (Fig. 3). These
included three upper-body, three lower-body, and two
sock variations, along with a procedural texture for
customizable player names, jersey numbers, colors,
stripes, and badges. This allowed for the creation
of home and away uniforms for 11 teams, including
players and goalkeepers, totaling 44 uniforms. Addi-
tionally, three referee uniforms were designed.
For each scene two teams are then randomly cho-
sen, including 10 players and one goalkeeper each.
The goalkeeper location is chosen randomly using a
Gaussian distribution centered at the center of the goal
with a standard deviation σ = 2 meters. For the play-
ers a ball position is chosen randomly using a uniform
distribution over the entire pitch, then the player po-
sitions are chosen from a Gaussian distribution, trun-
cated to the pitch and centered around this point with
σ = 10 meters.
In addition to the players, the referees are placed
in the scene. The main referee position is chosen us-
ing the same distribution as the players while the two
side line referees are placed along the long sides with
a center position chosen uniformly along the line and
then drawn from a Gaussian distribution centered at
that point with σ = 1 meter. Outside the pitch 4 by-
standers are placed at a distance from the pitch uni-
formly chosen between 0 and 2 meters and positioned
uniformly along the edge of the pitch. The bystander
model uses cloths from the BEDLAM dataset.
Spiideo SoccerNet SynLoc: Single Frame World Coordinate Athlete Detection and Localization with Synthetic Data
281

4.2 Dataset Annotations
Annotations in the Spiideo SoccerNet SynLoc dataset
are the players ground locations in world space and
camera calibrations. All the annotations are presented
in a format compatible with the COCO annotations
format (Lin et al., 2015b). That is a list of images and
a list of athletes.
For each image a camera calibration consisting of
a camera matrix, P, a distortion polynomial, p
dist
and
an undistortion polynomial, p
undist
is provided. The
camera matrix,
P = [R t] , (2)
specifies the orientation, R, and translation t of the
camera related to the ground plane with the origin at
the pitch center and the x-axis along the center line
and the y-axis perpendicular to it in the ground plane.
The distortion polynomial models the entire lens,
including all the intrinsic parameters of the camera,
using an industrial distortion model (Trioptics, ). This
means no intrinsic parameters, K, are present in the
camera matrix. The polynomial relates pixels dis-
tance from the principal point to the angle of the world
ray that is projected onto that pixel. It assumes that
the principal point is centered in the image and is here
defined on normalized image coordinates,
(u
n
, v
n
) =
1
w
u −
w
2
, v −
h
2
, (3)
where (u, v) are pixel coordinates in the camera im-
age and (w, h) its size in pixels. It is a radial distor-
tion model and the distortion polynomial, p
dist
relates
the magnitude of the normalized image coordinates,
r
n
=
p
u
2
n
+ v
2
n
to the magnitude of the undistorted co-
ordinates, r
u
=
p
u
2
u
+ v
2
u
as
r
n
= p
dist
(arctan(r
u
)). (4)
For convenience there is also an undistortion polyno-
mial fitted to the inverse of this function,
r
u
= tan(p
undist
(r
n
)). (5)
For each athlete, the annotations consists of both
image and world information. In the image there is a
bounding-box, the area of a pixelwise segmentation
and two 2D keypoints, the pelvis and the physical
location on the pitch, projected into the image, see
Fig. 2. The world data consists of two 3D keypoints,
the pelvis and the physical location on the pitch, see
Fig. 1.
Annotations are stored in JSON format, with poly-
nomials as coefficient lists in decreasing monomial
degree. Keypoints and the camera matrix are stored
as lists of lists, and the image bounding box is repre-
sented as (u, v, w
box
, h
box
), denoting the top-left corner
and box dimensions.
4.3 Dataset Statistics
The Spiideo SoccerNet SynLoc dataset has been split
into 42 504 training images, 6 777 validation im-
ages, 9 309 test images and 11 352 challenge im-
ages. Among the 17 arenas used, two have been solely
dedicated to the test-set and two to the challenge-set.
About half the images in the test and the challenge
sets are based on those dedicated arenas. The other
half is based on the same arenas as is present in the
training data, but from different games. In total, the
entire dataset consists of 1 107 009 annotated humans.
5 EVALUATION METRICS
The main metric proposed for this task is called mAP-
LocSim and it is based on the common detection met-
ric mAP, but replaces the IoU similarity measure with
the LocSim similarity measure defined in Equation 1.
The entire evaluation, using mAP-LocSim, is per-
formed in world space and, since the image represen-
tation is irrelevant for the metric, the algorithms are
freed from using a specific representation there (i.e.
bounding boxes). This allows other representations to
be explored.
In the benchmark presented, the LocSim param-
eter τ was chosen to 1 m based on empirical exper-
iments. This is in contrast to SoccerNet-GSM that
used 5. This allows the proposed task to focus on
more precise localisation, which is made possible by
using real 3D information.
This approach evaluates the model without requir-
ing a final threshold, but one must be selected for
practical use. Since false positives and negatives are
equally problematic in many sports analytics cases,
the final threshold is typically chosen by maximizing
the F1-score on the validation set post-training. Us-
ing this threshold, we propose frame accuracy, a more
interpretable metric measuring the percentage of im-
ages with perfect predictions—no false positives or
negatives, with all players correctly detected. Detec-
tion is defined by a LocSim similarity below 0.5, cor-
responding to a 0.48-meter distance. Figure 5 shows
this is achievable across the pitch without sub-pixel
image localization precision.
To give an even more detailed picture of the ca-
pabilities of different algorithms it is also proposed to
use other metrics that show different aspects of their
performance. The additional metrics are F1-score,
precision and recall.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
282
6 BASELINE METHOD
As a baseline, an off-the-shelf 2D keypoint detec-
tor will be used to detect two points: the pelvis and
its projection onto the ground plane (player location
on the pitch). Each detection provides an estimated
image location, projected back to world coordinates
using the camera calibration. Image bounding-box
bottom-line-centers will also be projected for compar-
ison, highlighting the benefits of 3D information over
bounding boxes. The architecture used is YOLOX-
pose (Maji et al., 2022; Ge et al., 2021), which con-
sists of a CNN backbone that extracts features directly
from the images, followed by a head that for a set of
anchor-boxes detects bonding box coordinates, pose
point coordinates and scores. A non maximum sup-
pression algorithm is used to suppress similar detec-
tions, and then a score threshold can be used to prune
week and negative detections.
7 EXPERIMENTS
7.1 Baseline Experimental Setup
The 2D pose detector implementation is based on
mmpose (Contributors, 2020) with code released on
github
3
. It was trained on the training set of the Spi-
ideo SoccerNet SynLoc dataset and evaluated on the
test set. The original YOLOX-Pose uses a learning
rate of 4 · 10
−3
and introduces an auxiliary loss with
a second-stage preprocessing after 280 epochs. This
training schedule did not converge when applied to
the proposed dataset. Instead the learning rate had
to be reduced to 10
−4
and the auxiliary loss intro-
duced already after 200 epochs. Experiments were
performed with training detectors for different resolu-
tions, 640 × 640 and 960 × 960. Otherwise the train-
ing process was not altered. Results are shown in Ta-
ble 2 and Fig. 4.
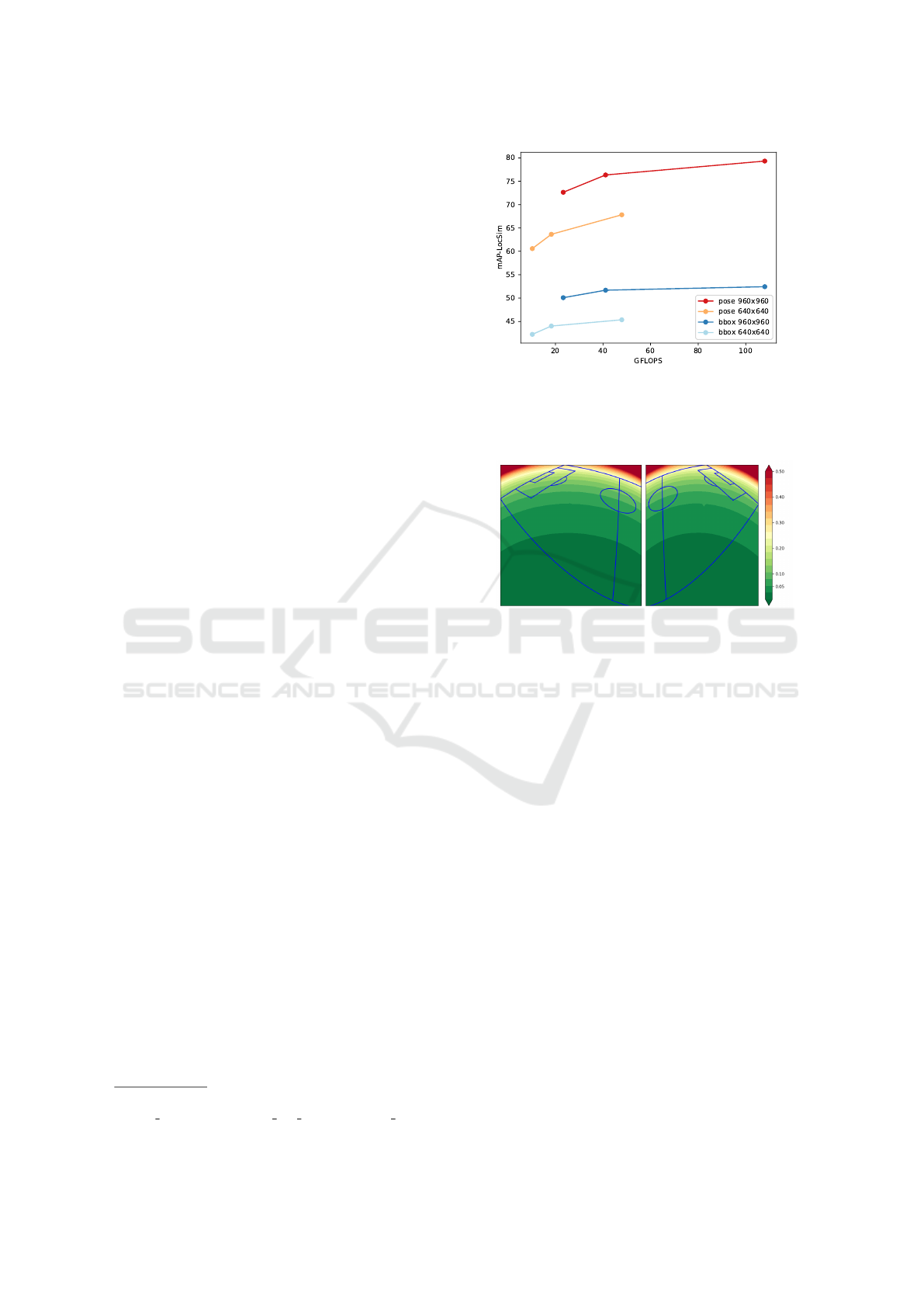
The models regressing the location significantly
outperforms the models that use the center of the bot-
tom edge of the bounding box as the location in all
the metrics investigated. Also, increasing the reso-
lution gives a more significant performance boost as
compared to increasing the model size. This is most
likely due the fact that the athletes are small compared
to the image size, and therefore they will consist of
very few pixel when the image is scaled down. That
means that there is not enough information to distin-
guish them from the background and thus increasing
3
https://github.com/Spiideo/mmpose/tree/
spiideo scenes/configs/body bev position/spiideo scenes
Figure 4: Results of different detectors with different input
resolutions on the Spiideo SoccerNet SynLoc dataset. The
bbox models uses the center of the bottom edge of the image
bounding box as the player position while the pose models
are regressing the position as a keypoint in the pose detector.
Figure 5: Localisation errors in meters in different parts of
the pitch corresponding to a pixel error of one pixel for a
some of the real world installations the Spiideo SoccerNet
SynLoc dataset is based on.
the model size will not help. Also, the performance of
the model using the bounding box flattens out, which
probably means that increasing the model size even
more will not improve the performance for it.
7.2 Pitch Location Uncertainty
Since the camera rig is located on one side of the
pitch, a one pixel detection error has a different met-
ric impact depending on the distance of its real world
location with respect to the camera.
In order to highlight this impact, for each pixel be-
longing to the pitch image, we simulate a confusion
with one of its direct neighbouring pixels and com-
pute the distance in meters between the deprojection
of the pixel on the pitch and its neighbour. For a pixel
that is not located on the edges of the image, this gives
us 8 metric distances that are averaged and plotted in
Fig. 5. The resulting errors in meters remain low and
does not exceed 30 cm for pixels corresponding to the
opposite side of the pitch. Note that the pixels here
refer to the pixels in the original 4k images, which
are scaled down 6 respective 4 times in the baseline
experiments presented in Table 2.
Spiideo SoccerNet SynLoc: Single Frame World Coordinate Athlete Detection and Localization with Synthetic Data
283

Table 2: Results of different detectors with different input resolutions on the Spiideo SoccerNet SynLoc dataset. Mean
average precision, mAP, metrics are presented for two different cases: IoU - standard intersection over union based image
bounding box similarity and LocSim - proposed world distance based similarity of predicted pitch location. The YOLOX-
pose architecture is used with the bbox models using the center of the bottom edge of the image bounding box as the player
location while the pose models are regressing the location as a keypoint in the pose detector. To give a more detailed picture,
the classical Precision, Recall and F1 metrics are also reported, and to give a metric that is easier to interpret intuitively,
Frame Accuracy is proposed. It presents the amount of images for with a perfect result in terms of false positives/negatives is
predicted.
mAP Frame
Model Input Res. GFLOPS IoU LocSim Precision Recall F1 Accuracy
yolox-tiny bbox 640 × 640 10.3 50.2 42.2 77.9 70.0 73.7 6.2
yolox-s bbox 640 × 640 18.3 54.5 44.0 79.7 72.0 75.7 6.8
yolox-m bbox 640 × 640 47.9 59.2 45.4 82.1 74.0 77.9 9.2
yolox-tiny bbox 960 × 960 23.3 61.3 50.1 84.8 80.0 82.3 13.6
yolox-s bbox 960 × 960 41.1 65.7 51.7 85.6 82.0 83.7 15.6
yolox-m bbox 960 × 960 108.0 69.5 52.4 87.8 83.0 85.3 17.1
yolox-tiny pose 640 × 640 10.3 50.2 60.6 81.7 75.0 78.2 10.0
yolox-s pose 640 × 640 18.3 54.5 63.6 84.9 77.0 80.8 11.3
yolox-m pose 640 × 640 47.9 59.2 67.8 87.5 80.0 83.6 15.4
yolox-tiny pose 960 × 960 23.3 61.3 72.6 90.4 84.0 87.1 20.9
yolox-s pose 960 × 960 41.1 65.7 76.3 88.0 88.0 88.0 28.0
yolox-m pose 960 × 960 108.0 69.5 79.3 92.8 89.0 90.9 31.6
8 CONCLUSIONS
In this work we introduce and publish a new synthetic
dataset for soccer analytics. It is based on background
images from real world installations on top of which
synthetic players are rendered. This allows the ground
truth annotations to consist of precise 3D camera cal-
ibrations and pitch locations of the athletes. Baseline
experiments show that this kind of data can improve
localisation of players on a pitch significantly com-
pared to using the center of the bottom edge of the
image bounding box as the players location projected
into the camera image. We also present a new task
for detecting and locating players on a pitch and pro-
pose a new metric, mAP-LocSim, for evaluation per-
formed entirely in the world pitch coordinate system.
We see this dataset as a first step towards opening
up new research opportunities for the field without
the limitations imposed by using broadcast video as
source. Potential future steps could involve extracting
more annotations from the rendering pipeline, such
as keypoint poses, athlete classes (player, referee, by-
stander), Jersey numbers, names, pixel segmentations
or pixel depths.
ACKNOWLEDGEMENTS
This research has been supported by VINNOVA
project 2023-02689 ”DAIDESS”. The rendering of
the synthetic data were enabled by the Berzelius re-
source provided by the Knut and Alice Wallenberg
Foundation at the National Supercomputer Centre.
The training of the baseline models were enabled
by resources provided by Chalmers e-Commons at
Chalmers. Anthony Cioppa is funded by the F.R.S-
FNRS (https://www.frs-fnrs.be/en/).
REFERENCES
Ard
¨
o, H., Ahrnbom, M., and Nilsson, M. (2022). Height
normalizing image transform for efficient scene spe-
cific pedestrian detection. In 2022 18th IEEE Inter-
national Conference on Advanced Video and Signal
Based Surveillance (AVSS), pages 1–11.
Black, M. J., Patel, P., Tesch, J., and Yang, J. (2023).
BEDLAM: A synthetic dataset of bodies exhibiting
detailed lifelike animated motion. In Proceedings
IEEE/CVF Conf. on Computer Vision and Pattern
Recognition (CVPR), pages 8726–8737.
Blender Online Community (2018). Blender - a 3D mod-
elling and rendering package. Blender Foundation,
Stichting Blender Foundation, Amsterdam.
Caesar, H., Bankiti, V., Lang, A. H., Vora, S., Liong, V. E.,
Xu, Q., Krishnan, A., Pan, Y., Baldan, G., and Bei-
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
284

jbom, O. (2020). nuscenes: A multimodal dataset for
autonomous driving. In CVPR.
Cioppa, A., Deli
`
ege, A., Giancola, S., Ghanem, B., and
Van Droogenbroeck, M. (2022a). Scaling up Soc-
cerNet with multi-view spatial localization and re-
identification. 9(1):1–9.
Cioppa, A., Giancola, S., Deliege, A., Kang, L., Zhou, X.,
Cheng, Z., Ghanem, B., and Van Droogenbroeck, M.
(2022b). SoccerNet-tracking: Multiple object track-
ing dataset and benchmark in soccer videos. pages
3490–3501.
Cioppa, A., Giancola, S., Somers, V., and et al. SoccerNet
2023 challenges results.
Cioppa, A., Giancola, S., Somers, V., and et al. Soccernet
2024 challenges results.
Contributors, M. (2020). Openmmlab pose estimation tool-
box and benchmark. https://github.com/open-mmlab/
mmpose.
Deli
`
ege, A., Cioppa, A., Giancola, S., Seikavandi, M. J.,
Dueholm, J. V., Nasrollahi, K., Ghanem, B., Moes-
lund, T. B., and Van Droogenbroeck, M. (2021).
SoccerNet-v2: A dataset and benchmarks for holis-
tic understanding of broadcast soccer videos. pages
4503–4514.
Fabbri, M., Lanzi, F., Calderara, S., Palazzi, A., Vezzani, R.,
and Cucchiara, R. (2018). Learning to detect and track
visible and occluded body joints in a virtual world. In
European Conference on Computer Vision (ECCV).
Ge, Z., Liu, S., Wang, F., Li, Z., and Sun, J. (2021). Yolox:
Exceeding yolo series in 2021.
Geiger, A., Lenz, P., and Urtasun, R. (2012). Are we ready
for autonomous driving? the kitti vision benchmark
suite. In Conference on Computer Vision and Pattern
Recognition (CVPR).
Giancola, S., Amine, M., Dghaily, T., and Ghanem, B.
(2018). SoccerNet: A scalable dataset for action spot-
ting in soccer videos. pages 1792–179210.
Giancola, S., Cioppa, A., Deli
`
ege, A., and et al. (2022).
SoccerNet 2022 challenges results. pages 75–86.
ACM.
Held, J., Cioppa, A., Giancola, S., Hamdi, A., Ghanem, B.,
and Van Droogenbroeck, M. (2023). VARS: Video
assistant referee system for automated soccer decision
making from multiple views. pages 5086–5097.
Ionescu, C., Papava, D., Olaru, V., and Sminchisescu, C.
(2014). Human3.6m: Large scale datasets and pre-
dictive methods for 3d human sensing in natural envi-
ronments. IEEE Transactions on Pattern Analysis and
Machine Intelligence, 36(7):1325–1339.
Leduc, A., Cioppa, A., Giancola, S., Ghanem, B., and
Van Droogenbroeck, M. (2024). Soccernet-depth: a
scalable dataset for monocular depth estimation in
sports videos. In Proceedings of the IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition
(CVPR) Workshops, pages 3280–3292.
Lin, T.-Y., Maire, M., Belongie, S., Bourdev, L., Girshick,
R., Hays, J., Perona, P., Ramanan, D., Zitnick, C. L.,
and Doll
´
ar, P. (2015a). Microsoft coco: Common ob-
jects in context.
Lin, T.-Y., Maire, M., Belongie, S., Bourdev, L., Girshick,
R., Hays, J., Perona, P., Ramanan, D., Zitnick, C. L.,
and Doll
´
ar, P. (2015b). Microsoft coco: Common ob-
jects in context.
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., and
Black, M. J. (2015). SMPL: A skinned multi-person
linear model. ACM Trans. Graphics (Proc. SIG-
GRAPH Asia), 34(6):248:1–248:16.
Luiten, J., Osep, A., Dendorfer, P., Torr, P., Geiger, A.,
Leal-Taix
´
e, L., and Leibe, B. (2020). HOTA: A
higher order metric for evaluating multi-object track-
ing. 129(2):548–578.
Maji, D., Nagori, S., Mathew, M., and Poddar, D. (2022).
Yolo-pose: Enhancing yolo for multi person pose es-
timation using object keypoint similarity loss. pages
2636–2645.
Mehta, D., Rhodin, H., Casas, D., Fua, P., Sotnychenko, O.,
Xu, W., and Theobalt, C. (2017). Monocular 3d hu-
man pose estimation in the wild using improved cnn
supervision. In 3D Vision (3DV), 2017 Fifth Interna-
tional Conference on. IEEE.
Menze, M. and Geiger, A. (2015). Object scene flow for
autonomous vehicles. In Conference on Computer Vi-
sion and Pattern Recognition (CVPR).
Mkhallati, H., Cioppa, A., Giancola, S., Ghanem, B., and
Van Droogenbroeck, M. (2023). SoccerNet-caption:
Dense video captioning for soccer broadcasts com-
mentaries. pages 5074–5085.
Rematas, K., Kemelmacher-Shlizerman, I., Curless, B., and
Seitz, S. (2018). Soccer on your tabletop. In CVPR.
Somers, V., Joos, V., Giancola, S., Cioppa, A.,
Ghasemzadeh, S. A., Magera, F., Standaert, B., Man-
sourian, A. M., Zhou, X., Kasaei, S., Ghanem,
B., Alahi, A., Van Droogenbroeck, M., and
De Vleeschouwer, C. (2024). SoccerNet game state
reconstruction: End-to-end athlete tracking and iden-
tification on a minimap.
Trioptics. Imagemaster.
https://www.trioptics.com/products/imagemaster-
hr-tempcontrol-universal-image-quality-mtf-testing/.
Wang, A., Chen, H., Liu, L., Chen, K., Lin, Z., Han, J.,
and Ding, G. (2024). Yolov10: Real-time end-to-end
object detection. arXiv preprint arXiv:2405.14458.
Yang, Z., Cai, Z., Mei, H., Liu, S., Chen, Z., Xiao, W.,
Wei, Y., Qing, Z., Wei, C., Dai, B., Wu, W., Qian,
C., Lin, D., Liu, Z., and Yang, L. (2023). Synbody:
Synthetic dataset with layered human models for 3d
human perception and modeling. In Proceedings of
the IEEE/CVF International Conference on Computer
Vision (ICCV), pages 20282–20292.
Zhu, L., Rematas, K., Curless, B., Seitz, S., and
Kemelmacher-Shlizerman, I. (2020). Reconstructing
nba players. In Proceedings of the European Confer-
ence on Computer Vision (ECCV).
Spiideo SoccerNet SynLoc: Single Frame World Coordinate Athlete Detection and Localization with Synthetic Data
285
