
Rethinking Model Selection Beyond ImageNet Accuracy for Waste
Classification
Nermeen Abou Baker
a
and Uwe Handmann
b
Computer Science Institute, Ruhr West University of Applied Science, Luetzowstr. 5, Bottrop, Germany
Keywords:
Transfer Learning, Pretrained Model Selection, Transferability Metrics, Waste Classification.
Abstract:
Waste streams are growing rapidly due to higher consumption rates, and they present repeating patterns that
can be classified with high accuracy due to advances in computer vision. However, collecting and annotating
large datasets is time-consuming, but transfer learning can overcome this problem. Selecting the most appro-
priate pretrained model is critical to maximizing the benefits of transfer learning. Transferability metrics pro-
vide an efficient way to evaluate pretrained models without extensive retraining or brute-force methods. This
study evaluates six transferability metrics for model selection in waste classification: Negative Conditional
Entropy (NCE), Log Expected Empirical Prediction (LEEP), Logarithm of Maximum Evidence (LogME),
TransRate, Gaussian Bhattacharyya Coefficient (GBC), and ImageNet accuracy. We evaluate these metrics
on five waste classification datasets using 11 pretrained ImageNet models, comparing their performance for
finetuning and head-training approaches. Results show that LogME correlates best with transfer accuracy for
larger datasets, while ImageNet accuracy and TransRate are more effective for smaller datasets. Our method
achieves up to 364x speed-up over brute-force selection, which demonstrates significant efficiency in practical
applications.
1 INTRODUCTION
It is estimated that by 2050, waste generation will in-
crease by 70% due to the increasing consumption of
consumers(Statista, 2023). Automating waste classi-
fication using a combination of AI and robotics will
be critical to keep up with this growth. Waste pat-
terns are difficult to sort because they can come in
different shapes, colors, and states, and the scarcity of
this data can limit the accuracy of the classification.
Therefore, this study introduces transfer learning to
overcome this challenge. Moreover, the growing need
to save computational complexity and energy costs in
the training phase is necessary for industrial applica-
tions.
Transfer learning leverages knowledge from a
source domain/task and applies it to a related target
domain/task (Thrun and Pratt, 1998). Pretrained mod-
els are deep learning architectures trained on large
datasets, such as ImageNet (Deng et al., 2009). Task
adaptation depends on the characteristics of both the
pretrained model and the target task. Since different
a
https://orcid.org/0000-0002-9683-5920
b
https://orcid.org/0000-0003-1230-9446
tasks require different pretrained models, this study
limits the target datasets to a set of waste classifica-
tion datasets to reduce domain shift. Specifically, five
datasets from Kaggle and GitHub are used, with im-
ages crawled from search engines. Transfer learning
from ImageNet is appropriate, as these datasets con-
sist of natural images from real-world applications.
There are two ways to implement transfer learn-
ing:
• Retrain head (or feature extractor): This approach
preserves the weights of the source features by
freezing the feature extractor layer, which is a
task-related layer, and retraining it using the tar-
get dataset.
• Finetuning: This technique involves replacing the
task-related layer with a new one, and then fine-
tuning the whole model.
Recently, several pretrained models have been stud-
ied, such as model hubs, model zoos, and model
pools. This variety raises the following research ques-
tion:
Which pretrained model should be selected with-
out prior training on a classification task for a
waste dataset?
Baker, N. A. and Handmann, U.
Rethinking Model Selection Beyond ImageNet Accuracy for Waste Classification.
DOI: 10.5220/0013111200003905
In Proceedings of the 14th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2025), pages 223-234
ISBN: 978-989-758-730-6; ISSN: 2184-4313
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
223

Although ImageNet accuracy is commonly used as a
transferability metric, the performance of a model that
excels on ImageNet does not necessarily indicate that
it will perform best on other datasets. The effective-
ness of a pretrained model can vary depending on the
specific characteristics of the target task and dataset.
In domain-specific applications, such as waste classi-
fication in this study, other transferability metrics may
provide different insights. This work aims to answer
the previous research question by adding the follow-
ing contributions:
1. This study provides a thorough comparative anal-
ysis of six transferability metrics, including Im-
ageNet accuracy correlation, NCE (Tran et al.,
2019), LEEP (Nguyen et al., 2020), GBC (P’andy
et al., 2021), TransRate (Huang et al., 2021), and
LogME (You et al., 2021), specifically applied to
five waste classification datasets, demonstrating
their utility for this task.
2. This work shows that the effectiveness of these
metrics varies with dataset size and compares
their performance in feature extraction versus
finetuning scenarios, emphasizing the importance
of model selection over brute-force methods in
transfer learning.
3. Performing a quantitative evaluation of the com-
putational efficiency of these metrics, particularly
the significant speed-ups compared to brute-force
methods, while also providing insights into why
certain metrics perform better in specific contexts.
The transferability scores should be taken without
training on the target task. The best score must be
effective, easily applicable to most pretrained mod-
els, and computationally efficient without training on
the target data. Figure 1 shows the evaluation of the
transferability metrics method in the selection of pre-
trained models for a target dataset.
This paper is structured to provide an analysis of
transferability metrics in waste classification. Fol-
lowing this introduction, Section 2 reviews the ex-
isting literature on model selection strategies to pro-
vide the context for our research. Section 3 details our
methodological approach, including dataset selection
criteria, pre-processing techniques, and experimental
design. In Section 4, we present our results, critically
analyzing the performance of six transferability met-
rics in different waste classification datasets. Section
5 provides insights derived from our results, and the
conclusion summarizes our main contributions and
suggests directions for future research. By systemati-
cally evaluating these metrics, we aim to provide both
theoretical insights and practical guidance for transfer
learning researchers and practitioners on waste classi-
fication.
2 RELATED WORK
Previous work has attempted to evaluate the selec-
tion of pretrained models for supervised classification
tasks in two approaches (Renggli et al., 2020):
• Task Agnostic Model Search Strategies: it
ranks pretrained models before observing the tar-
get datasets. However, they used brute-force,
which is expensive, and trained these models ex-
tensively on benchmark datasets to provide some
guidelines for selecting the best models. The work
of (Kornblith et al., 2018) compared 16 pretrained
models on 12 datasets, and the authors found that
there is a strong correlation between ImageNet ac-
curacy and transfer accuracy in general, but not
on fine-grained datasets. In addition, our previous
work presented guidelines and evaluated how to
select the most appropriate pretrained model that
matches the target domain for image classification
tasks based on application requirements by mea-
suring accuracy, accuracy density, training time,
and model size (Abou Baker et al., 2022).
• Task-Aware Model Search Strategies: Taskon-
omy used the loss (Zamir et al., 2018) and
Task2Vec used the target dataset with additional
computation by extracting learned representations
from the pretrained model, then training a linear
or K-Nearest Neighbour (KNN) classifier on these
representations, and selecting the model with the
highest accuracy using the Fisher information ma-
trix after fully finetuning the pretrained model on
the target dataset (Achille et al., 2019).
While these methods can provide some guid-
ance in selecting the appropriate model source, they
are computationally expensive. In addition, with a
large number of pretrained models available on open-
source frameworks such as PyTorch, TensorFlow,
Hugging Face, Caffe, MATLAB, etc., it is becom-
ing increasingly difficult to select the best pretrained
model to meet the application requirements. These
requirements vary in accuracy, energy, and computa-
tional cost in terms of memory (FLOPS) and training
time. Brute-force is therefore not an efficient method.
Overall, this suggests the need for a better under-
standing of the pretrained model selection to evalu-
ate the model pool. To determine source-task learn-
ing representations, a few scores have been intro-
duced to assess the transferability measure that elim-
inates the need for training models and is therefore
computationally efficient. Therefore, a fast, accurate,
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
224
Figure 1: Evaluating pretrained model selection for a target dataset.
and generic assessment method is needed to solve
the problem. The following transferability measures
can be considered as a starting point for selecting
the model among several others to achieve the best
performance on a target task. Related works assess
model selection (You et al., 2022), (Agostinelli et al.,
2022), and (Renggli et al., 2020). However, all of
them evaluate model ranking on fine-grained datasets
or datasets with different label representations.
To estimate the transferability score of the tested
candidates and to select the one with the maximum
transferable score based on the available methods,
there are two types of quantifying transferability mea-
sures (Bolya et al., 2021):
• Label comparison-based (or probability-
based) methods that compute the dependence of
the source and target label spaces. These methods
assume equivalence between labels in the source
and target domains or compute pseudo-labels by
passing the source model to the target domain
once, such as NCE and LEEP.
• Source embedding-based methods rely only on
the feature extractor to embed labels from the tar-
get domain. Scores are then computed using these
embeddings and their corresponding labels, such
as LogME, TransRate, and GBC.
In addition, recent work has standardized the eval-
uation of transferability scores for pretrained model
selection across 11 general vision datasets and eval-
uated 14 transferability scores using CNN and ViT
models. The study evaluates both accuracy and com-
putational complexity, using the weighted Kendall
Tau score to efficiently rank models (Abou Baker
and Handmann, 2024). While focused on general vi-
sion datasets, our waste classification study provides
a more focused, empirical validation of transferability
metrics for a specific domain.
2.1 Negative Conditional Entropy
(NCE)
This method quantifies the amount of information
from the source to the target domain, based on an
information-theoretic quantity to assess transferabil-
ity between tasks. The NCE score is shown to be re-
lated to the loss of the transferred model. It assumes
that the training labels are random variables and in-
vestigates their statistics as follows: NCE estimates
the joint distribution P(y
t
,y
s
) with one-hot labels and
predictions, then computes NCE as −H(y
t
|y
s
) which
represents the negative conditional entropy of the
target labels y
t
given the predictions y
s
as ground
truth source (Tran et al., 2019). The authors assume
cross-entropy as the loss function and then show that
the conditional entropy between the label sequences
of their training sets for two tasks can define how
well (or the likelihood of success) the representation
learned from one task will perform on another task.
This avoids training models and is therefore compu-
tationally efficient.
2.2 Log Expected Empirical Prediction
(LEEP)
The idea behind the LEEP score is to measure the
resonance between a pretrained model and a target
dataset. The log-likelihood of the empirical condi-
tional distribution is measured by calculating the av-
Rethinking Model Selection Beyond ImageNet Accuracy for Waste Classification
225

erage log-likelihood of the source and target labels
(Nguyen et al., 2020). LEEP scores are calculated
in three steps:
• Compute the dummy label distributions of the in-
puts by making a single forward pass of the pre-
trained model through the target dataset.
• Compute the empirical conditional distribution of
the target label given the source label. This step
estimates the joint distribution of the predicted
and the true labels to compute an empirical pre-
dictor.
• The LEEP score is calculated by estimating the
likelihood of an empirical predictor that maps
the target labels to the predictions of the source
model.
LEEP uses indirect representations of distributions,
where the output label distribution is a linear trans-
formation of the features, and the dummy labels con-
tain information about the input features. The au-
thors show that LEEP can also predict the conver-
gence speed when finetuning the model. The scores
are obtained without training on the target task, thus
avoiding parameter optimization. LEEP uses the soft-
max output layer, which limits this score to classifica-
tion tasks only.
2.3 The Logarithm of Maximum
Evidence (LogME)
It is introduced to estimate the compatibility between
source models and target datasets. LogME score esti-
mates the accuracy of the target dataset using the fol-
lowing steps:
• The target images are embedded using the source
feature extractor.
• The LogME score computes the probability con-
dition (which is the evidence) of the target labels
over these embeddings.
• To compute this evidence, the authors set up a
graphical model that assumes the samples are in-
dependent.
LogME ranges in [−1,1], where the closest value to
−1 indicates the worst transferability values, and the
value closest to +1 indicates the best. LogME doesn’t
require a softmax output layer, which makes it a can-
didate score for regression and unsupervised learning.
Since LogME is generic, it can be used for classifi-
cation and regression. However, this study focuses
only on classification tasks. The original paper re-
ports that compared to brute-force finetuning, com-
puting the LogME provides at most a 3700 speed-up
in wall-clock time and requires 1% of the memory.
2.4 TransRate
The TransRate score is designed to measure trans-
ferability by using the mutual information between
target labels and features extracted by a pretrained
model. Unlike many existing approaches, TransRate
computes transferability in a single pass across all in-
stances of the target dataset. Its key advantages in-
clude eliminating the need for computationally inten-
sive modeling or training, significantly reducing com-
putational costs by using coding rate as a proxy for
entropy, and maintaining effectiveness even with fi-
nite datasets.
TransRate could also be used to compare trans-
ferability between source tasks, source models, and
layers. Furthermore, this comparison is applied to su-
pervised and self-supervised trained models for clas-
sification and regression tasks.
2.5 Gaussian Bhattacharyya Coefficient
(GBC)
The GBC score measures the overlap between target
classes in the source feature space. It measures how
well a pretrained model transfers to the target dataset.
According to the GBC score, the more classes over-
lap in the feature space, the more difficult it is to
finetune the pretrained model for high accuracy. The
GBC score is measured as follows: All target im-
ages are embedded in the feature space defined by the
source model and represented with a per-class Gaus-
sian, then the pairwise separability is estimated by
the Bhattacharyya coefficient. According to the GBC
score, the more classes overlap in the feature space,
the more difficult it is to finetune the pretrained model
for high accuracy. The authors applied the GBC score
to semantic segmentation, where GBC outperformed
state-of-the-art metrics.
3 METHODS
This study aims to evaluate the effectiveness of differ-
ent transferability metrics in selecting optimal source
models for transfer learning without the need for ex-
tensive training. We evaluated five transferability
metrics, as well as the ImageNet accuracy correlation
proposed by (Kornblith et al., 2018), on five different
waste classification datasets. Our evaluation uses 11
models pretrained on the ImageNet Large Scale Vi-
sual Recognition Challenge (ILSVRC) 2012 classifi-
cation task, providing a robust foundation for compar-
ison.
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
226

Our experimental framework is designed to sys-
tematically evaluate the performance of each transfer-
ability metric under different conditions. We consider
two primary transfer learning scenarios: The retrain
head and finetuning. For each scenario, we compute
the correlation between the values of the transferabil-
ity metrics and the ground truths of the target datasets.
This approach allows us to assess not only the predic-
tive performance of each metric but also its consis-
tency in different transfer learning experiments.
3.1 Datasets
3.1.1 Selection Criteria
The selection of appropriate datasets is important for
a comprehensive assessment of transferability met-
rics. We used the following criteria to ensure the rel-
evance and diversity of our benchmark:
• Domain Relevance: Waste classification is a crit-
ical challenge that intersects environmental sus-
tainability and computer vision. The selected
datasets include diverse waste shapes, color vari-
ations, and spatial origins. This experimental
framework goes beyond the traditional brute-force
method. It provides a controlled representative
domain for testing transferability metrics.
• Label Diversity: The datasets span a wide range
of classifications. They include broad categories
like glass, plastic, and metal, as well as fine-
grained material identification of specific packag-
ing types. This variety supports a thorough evalu-
ation of transfer learning methods. It highlights
how knowledge representations adapt to differ-
ent levels of semantic granularity and contextual
specificity.
• Vision Complexity: The datasets vary greatly in
size. Smaller collections like Manon include 320
images, while large repositories like GarbageFine
have 23,715 images. This scale diversity offers
a robust platform for benchmarking. It demon-
strates how transferability metrics perform under
different data constraints and computational chal-
lenges.
• Replicability and Accessibility: The datasets
are publicly available on platforms like Kaggle
and Github, and were obtained through system-
atic web crawling. This ensures a transparent
and replicable research pipeline. These web-
derived image collections reflect real-world com-
putational environments where transfer learning
technologies will be deployed. This approach en-
sures scientific validity and practical relevance.
Table 1: The tested datasets of waste classification that
come from web crawling.
Dataset # of classes Train size Test size
Manon str (Yacharki, 2013) 5 320 83
Trashnet (Thung, 2018) 6 2,019 508
Trahbox (TrashBox, 2024) 7 16,060 1,793
WasteFine (WasteFine, 2023) 34 17,873 5,756
GarbageFine (GarbageFine, 2023) 58 23, 715 5, 958
Figure 2: Sample images (with their corresponding label)
for each dataset.
3.1.2 Dataset Overview
Table 1 provides a summary of the selected datasets,
indicating the number of classes and sample sizes
for training and testing. Figure 2 illustrates sam-
ple images with their corresponding labels from each
dataset, to provide visual context for the classification
tasks.
3.1.3 Data Pre-Processing
To improve the generalization capabilities of our
models and to ensure consistency across experiments,
we applied several data pre-processing and augmen-
tation techniques:
• Dataset splitting: For datasets without predefined
splits, we used an 80:20 ratio for training and test
sets. Where original training and validation splits
existed, we merged them to form the training set,
while retaining the original test set for evaluation.
• Data augmentation: We implemented several aug-
mentations to the training and test sets, including
random resized crop, random horizontal flip, and
image normalization using the mean and standard
deviation of the ImageNet dataset to ensure con-
sistency with the pretraining data distribution.
These pre-processing and augmentation steps are es-
sential to improve model generalization and allow fair
comparison between different pretrained models and
datasets.
3.1.4 Scope and Limitations
Our focus on waste classification is motivated by the
critical global challenge of waste management and re-
cycling. The increasing volume of waste and the need
for efficient sorting technologies make waste classifi-
cation a crucial area of research with significant en-
Rethinking Model Selection Beyond ImageNet Accuracy for Waste Classification
227

vironmental and economic implications (Abou Baker
et al., 2023).
Although our study provides insight into trans-
ferability metrics specific to waste classification
datasets, we acknowledge the domain-specific nature
of our research. The selected datasets, ranging from
5 to 58 classes and representing different waste sort-
ing scenarios, provide a comprehensive exploration
within the waste classification domain. However, the
results are not intended to be universally applicable to
all image classification tasks.
3.2 Models
In this study, we evaluate 11 Convolutional Neu-
ral Networks (CNN) architectures that cover a wide
range of model complexities and ImageNet accura-
cies. These architectures represent the current state
of image classification models and can be categorized
into four groups based on their architectural design:
Resnets as skip connections (ResNet-34, ResNet-
50, ResNet-101, ResNet-152 (He et al., 2016)),
parallel convolution filters (Inception-V3 (Szegedy
et al., 2016), and GoogleNet (Szegedy et al., 2015)),
densely connected blocks (DenseNet-121, DenseNet-
169, DenseNet-201 (Huang et al., 2016)), or convolu-
tional neural networks designed for mobile and edge
devices (MnasNet1 − 0 (Tan et al., 2018), MobileNet-
V2(Sandler et al., 2018)).
We use these pretrained models in two transfer
learning methods: full model tuning and retrain head.
This allows a comprehensive evaluation of the cor-
relation between transferability scores and test accu-
racy.
For transfer learning experiments, we use a stan-
dardized training protocol to ensure fair comparisons.
We use Stochastic Gradient Descent (SGD) optimiza-
tion with a momentum of 0.9, an initial learning rate
of 10
−
3, initial learning rate with 0.1 step weight de-
cay every 7 epochs. We use a batch size of 16 for all
experiments, which were run on NVIDIA RTX8000
GPU.
Although we understand that optimal hyperpa-
rameters may vary significantly between models and
datasets, we choose this uniform setup to maintain
consistency and facilitate direct comparisons. This
approach is consistent with common practices in
transfer learning research, although we recognize that
performance could potentially be improved through
extensive hyperparameter tuning and advanced train-
ing strategies.
3.3 Model Selection Process
To systematically evaluate the effectiveness of dif-
ferent transferability metrics and to simplify the pre-
trained model selection process, we present the fol-
lowing workflow:
• Feature extraction: Features are extracted from
the penultimate layer of each model to capture
high-level representations for transfer learning.
These features are inputs to the tested transferabil-
ity metrics, which are used to calculate scores and
to measure computation time.
• Evaluation of the transferability metrics: The ap-
proach validates each metric by computing the
Pearson correlation coefficient between the values
of the transferability scores and the ground truth
for each dataset. The Pearson correlation, which
ranges from −1 to +1, measures the strength and
direction of the linear relationship, with values
near −1 indicating a strong negative correlation,
near 0 indicating no linear correlation, and near
+1 indicating a strong positive correlation. This
analysis ranks the pretrained models and identifies
the most appropriate metric for each data set.
• Model selection and correlation analysis: The out-
put includes the selected models, correlation coef-
ficients, and computation times, providing a struc-
tured and objective approach to simplify model
selection in transfer learning without training.
The rationale for this approach addresses the limi-
tation of using ImageNet accuracy as the only pre-
dictor of model transferability. By evaluating multi-
ple transferability metrics and correlating their values
with ground truth performance, the method provides a
more robust strategy for selecting pretrained models.
This approach challenges the assumption that Ima-
geNet performance universally indicates transferabil-
ity and provides a practical methodology for assessing
feature transferability across diverse waste datasets.
The algorithm 1 shows the steps in the process.
4 RESULTS AND DISCUSSION
Our analysis focuses on the correlation between 6
transferability metrics and actual transfer learning
performance in different datasets and transfer learning
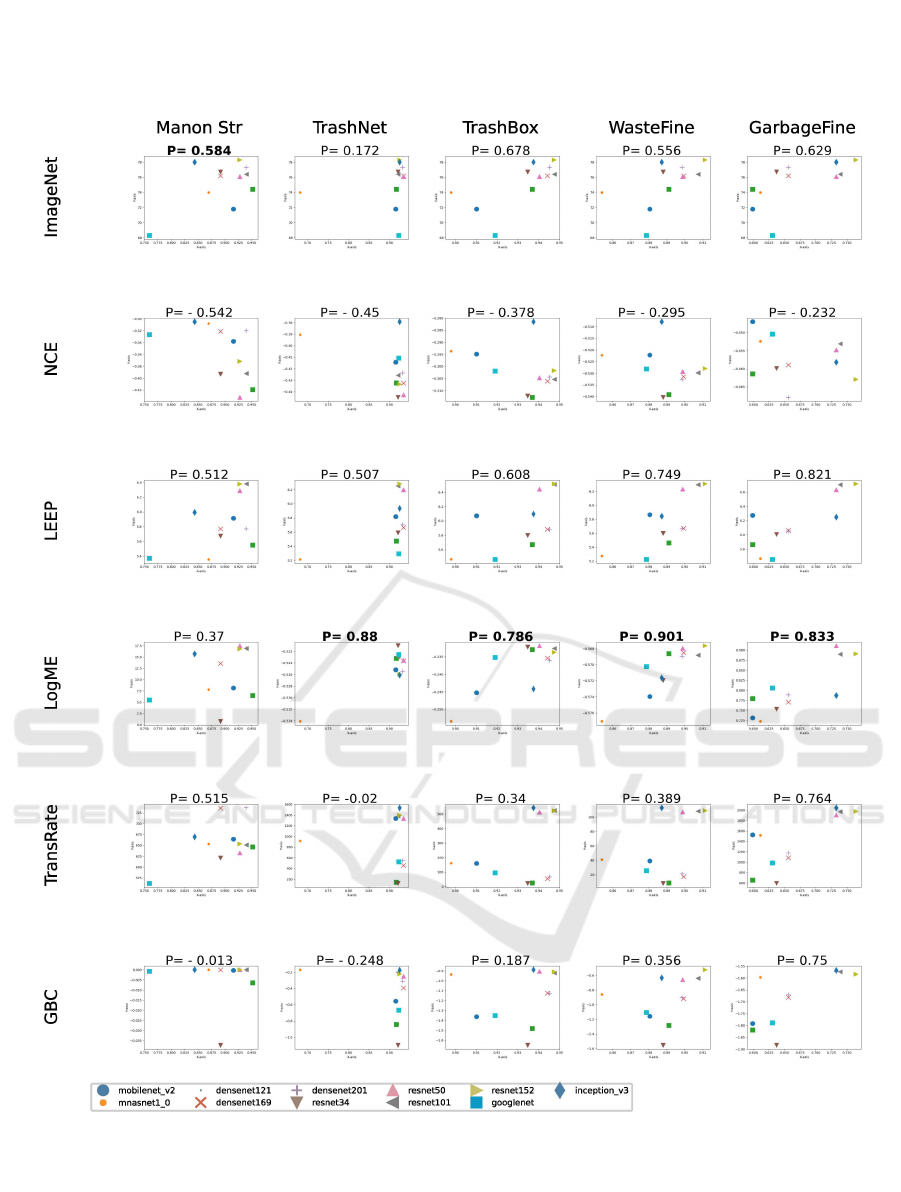
strategies. Figures 3 and 4 present a comprehensive
view of these correlations for the feature extraction
(retrain-head) and full model finetuning approaches,
respectively.
In Figure 3, we observe the performance of our
transferability metrics when applied to the retrain
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
228

Algorithm 1: Model selection and evaluation for transfer
learning.
Input:
• Target datasets {D
1
,D
2
,D
3
,D
4
,D
5
}
• Pretrained models M = {m
j
}
11
j=1
• Model selection metrics Φ = {φ
i
}
6
i=1
• Ground truth performance values {A
d
}
5
d=1
, where
each A
d
= {a
d j
}
11
j=1
Output:
• Selected models {m
∗
d
}
5
d=1
for each dataset
• Pearson correlation coefficients {ρ
d
}
5
d=1
• Computation times {T
d
}
5
d=1
Procedure:
1. Feature extraction
• For each dataset D
d
and model m
j
∈ M :
– Extract representations from penultimate layer:
f
d j
= ℓ
p
(m
j
(D
d
))
• Set F
d
= { f
d j
}
11
j=1
for each dataset
2. Evaluate model selection metrics
• For each dataset D
d
:
– For each metric φ
i
∈ Φ and model m
j
∈ M :
*
Start timer t
start
*
Calculate transferability score:
σ
di j
= φ
i
( f
d j
,D
d
)
*
Record time: τ
di j
= t
current
−t
start
• Set S
d
= {σ
di j
} and T
d
= {τ
di j
} for each dataset
3. Model selection and correlation analysis
• For each dataset D
d
:
– For each metric φ
i
∈ Φ:
*
Let σ
di
= [σ
di1
,.. . ,σ
di11
]
*
Calculate Pearson correlation:
ρ
di
=
Cov(σ
di
,A
d
)
s
σ
di
s
A
d
– Set ρ
d
= [ρ
d1
,.. . ,ρ
d6
]
T
– Select best metric i
∗
d
= argmax
i
ρ
di
– Select best model m
∗
d
= argmax
m
j
∈M
σ
di
∗
d
j
Return:
• Selected models {m
∗
d
}
5
d=1
• Correlation coefficients {ρ
d
}
5
d=1
• Computation times {T
d
}
5
d=1
head method. The columns represent our 5 target
waste classification datasets, while the rows corre-
spond to the 6 transferability metrics under evalua-
tion: NCE, LEEP, LogME, TransRate, GBC, and Im-
ageNet accuracy. Each individual subplot illustrates
the correlation between a specific transferability met-
ric (y-axis) and the ground truth accuracy (x-axis)
achieved by our 11 pretrained models on a particular
dataset, with the best correlation in bold.
Following the same visualization structure as in
Figure 3, we extend our analysis to the full model
finetuning method in Figure 4. As described in the
section 3, all scores are based on the training set only.
We find that the datasets do not consistently fol-
low the correlation patterns expected from ImageNet
accuracy. This observation challenges the common
assumption that performance on ImageNet is a reli-
able predictor of transferability across visual tasks.
The inconsistency demonstrates the task-specific na-
ture of transfer learning and suggests that the features
learned on ImageNet may not be equally relevant or
transferable to all target tasks. For smaller datasets
such as Manon Str, the accuracy correlation of Im-
ageNet proves to be a useful metric, ranking first in
the Pearson correlation for finetuning the full model
and third for retrain-head. This suggests that for tasks
with limited data, the broad feature representations
learned on ImageNet can provide a strong starting
point. The effectiveness here is due to the diversity
and scale of ImageNet, which allows models to learn
general visual features, which can be particularly ben-
eficial when target data is scarce.
In contrast, LogME proves to be a strong per-
former, showing a high correlation with most datasets,
except for the small Manon Str dataset. The effective-
ness of LogME is attributed to its probabilistic ap-
proach to estimating the compatibility between source
models and target datasets. By modeling the evidence
of target labels given the embeddings of the source
model, LogME captures a more detailed representa-
tion of transferability.
Interestingly, TransRate demonstrates a good cor-
relation with the Manon Str dataset, especially in the
retrain head scenario. This is consistent with Tran-
sRate’s theoretical foundation, which is well-suited
for finite examples as shown in section 2.4. Using
the coding rate as an alternative to entropy allows it
to efficiently capture essential information for trans-
fer, which makes it particularly effective for smaller
datasets.
On the other hand, NCE and LEEP do not perform
well across experiments. These label comparison-
based methods, which rely on retraining a linear clas-
sifier to estimate joint distributions between source
and target labels, appear prone to overfitting. In waste
classification, where class definitions are often am-
biguous or overlapping, the assumption of a direct re-
lationship between label spaces does not work, which
Rethinking Model Selection Beyond ImageNet Accuracy for Waste Classification
229

.µ
Q)
z
Q)
Cl
ro
E
UJ
u
z
c..
UJ
UJ
...J
UJ
:E
Cl
3
Q)
.µ
i!i.
l/)
c
ro
F
Manon Str
Trash
Net
Trash
Box
Waste
Fine
GarbageFine
·n
P=
0.417
.. ·n
P=
0.245
...
·n
P=
0.46
·n
P=
0.356
• • ·o
P=
0.506
••
,.
"'
"\.
+x
,.
•
xi
,.
• x
""
._
,.
..,
:4
,.
..,
+
'4
( . . ( . . ( . .
...
( . . ( . .
" . " . ,, . " . " .
" "
'"
" "
..
.
..
.
..
.
..
.
..
.
><
0..1
°'
QJ
o.a
O•
Q70
O"
UO
o.r; O.
<>O
o.a.
Q"°
Oil
'"
0.01
'"
o,,;
01'
0.1'
0
00
0 .
.,
...
0.
..
U I
0..
'·"
'
01,;o
O.
n>
OllOO
O.t>
,
"'''
o.>1'
O.>O
- - - - -
..
-.
P=
-0.
236
1
..
·.·r
P=
-0.
485
• x
-.
..
.
.
..
.
....
..
~
i •
.,
• •
...
...
.., +
...
•
x..
.
..
. . ..
~...
~
...
P=
0.369
•
-"'
"'
• +
x
•
•
_,,
,,,,
""'·"
'
. "."'
!~"
'
n
P=0.854
~"'
P=
0.787
~-n
P=
0.858
.
~
·
~
,.,D
P=
0.754
,
~
.
1"
~- "
°"
-o.>ro •
-"
·'"
•
._,,,,,,
...
. .
J J
o.m
•
_,,,,,.
.
_,,,,.,,
.
_,,,,,.
--0."1
. .
'"
'"
'·"
' ·"
0.00
--------
--------
..
,~
..
,
~
i·" .
P=
0.525
•
+x
• •
. . .
•
:
:n
P=
0.077
•
-u
P=
0.538
~
.
-n
P=
0.259
••
"D
P=
0.304
•
- .
~~ ~
~
'"""
• • : lOO :
"'
ii
: • +x
""'
• •
.,
• •
.,
• •
lllQ
• •
5t
" •
no
Q70
Q1'
O.IO 0.0>
0.00
. 0 0
...
QIO
O
.U
n•
~
~
X
QI<
Ot>
'°
•.
,.
O.JO
QIO
O.Ol 0.1< 0
...
,,
"!'
....
'·'"
0750
0.11>
0000
'·°''
'-'"
~
~
>i:.>
- - - -
·.··~
P
=:,
• 0.
05
•
.~
~
.. *
~.-~
P=
-0.
053
1
.,
"""·"''
• +
- - x
t
_,,~,,
• 0 0 •
:--0= = •
- - .
- ... ...
><
O..
•
°'
0.1
QI
>O
070
'"
UO
O.
t'I
0 .
..,
mobilenet_v2
mnasnetl_O
~
..
~ ~
..
~
densenetl21
X densenetl69
+ densenet201
T resnet34
resnetso
resnetlOl
P=
0.
13
•
•
•
. :
...
resnet152
googlenet
~
.
..
~
P
.
=
.
0 ..
129
.J
.:
::i-
P .= 0.
12
-1
8 ...
i
~
:
• *
I:::
+x
'·:
: '.
'::
. . .
-
1.1
~"
'·
"
~""
'·"
~
..
'·
"'
.,
;
uo
-
l>O
'·"'
~'"
'·'"
·-
' ·
"'
°'"'
~
"
°'""
~
..
~ ~
..
~
inception_v3
Figure 3: Pearson correlation (P) for retrain-head between ground truth accuracy (X-axis) and 6 transferability metrics (Y-
axis) with 11 pretrained model selection for 5 target datasets.
leads to unreliable transferability estimates.
Additionally, the GBC score shows mixed results,
with negative correlations for smaller datasets such as
Manon Str and TrashNet. This behavior shows the
limitations of assuming Gaussian distributions and
linear separability in feature spaces, especially for
complex tasks or limited data scenarios. In waste clas-
sification, where object appearance can vary signifi-
cantly within classes, feature distributions may be far
from Gaussian, further invalidating the assumptions
of GBC.
Surprisingly, NCE shows a negative correlation
across experiments, which challenges the straightfor-
ward application of information-theoretic principles
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
230
.µ
Q)
z
Q)
Cl
ro
E
UJ
u
z
c..
UJ
UJ
...J
UJ
:E
Cl
3
Q)
.µ
i!i.
l/)
c
ro
F
Manon Str
Trash
Net
P=
0.584
·n P=0.172 •
+
. 1.
( . .
" .
..
.
•
•
..
.
O.JO
~1'
OllO
O.
"
~00
,,
,
0
P=
.0.
37
h
~,,,n
P=0.88
~
.
::
: x _::::
..
:
l _,, • •
J~,,.
. . .
~
o.
~,,.,
o.m
o.ooo
0.
01>
o.o:;o
,.,,
~
''"
o.m
'·"'
'·'
'°
• o.ro
il>
ooo
0.1>
i,.,
..
,~
..
,~
""
.
i
Trash
Box
P=
0.678
•
•
P=
0.786
Waste
Fine
P=
0.556
+
" .
""
.
•
i
•
•
~-n
P=
0.9
~
~
. •
-o.>ro •
§"'"
~
--0"'
•
D.10 ' "
...
,_.,
Q
to
~"
P=
0.515
x
•
•
•••
..
:
=n
P=
-0.02
, . _
0
P=
0.
34
• _
-n
P=
0.389
• ••
- .
~
"""
• : lOO :
"'
:
"!<
: • •
..
• :
.
~
.
~
no
o.
ro
il>
ooo
0.1>
i,.,
..
0
..
..,
001
" " o
.u
111
..
,. '·"
o..oo
' "
.,.
·
,..
~
o.
to
~"
- - -
GarbageFine
P=
0.629
" .
j'·
""''
o.m
•
..
,,,
..
+
• x
• •
..
•
P=
0.833
•
+
x
P=
0.764
•
.
• •
:
...
...
-. .
,
...
[
P=
-
,.
o ..
.0~
:3
~
..
~
••.
[
P=
- 0.
248
1
.
- • t
--0.0 lO --0.4 x
t
-"~"
• ' ' •
,_
' .
--0-
M •
- . .
'
!
-1
•
P=
0.
187
.
1
*_
.:.l
P=
0:
56
:
..
1
l
P
~
0
75
• •
1
. . .
'·::
..
. '
::
: .
~~
~~
=
..
.,
~
·
~
..
~
,
--C
, .
.,,
-
1.1
'-''
'"
uo
~
..
.. ..,
'"
-
1>0
'""'
..
,,,,
1'
'·
'"'
'·'"
o."
" °'"
''"'
.. ,,,.,
o.m
o.
OM
'·*''
u"
''"
'""'
' ·
"'
''
'" 0.10
'"
,.,,
0.
1>
'""
mobilenet_v2
mnasnetl_O
~
..
~ ~
..
~
densenetl21
X densenet169
+ densenet201
T resnet34
resnetso
resnetlOl
- - -
resnetl52
googlenet
inception_v3
Figure 4: Pearson correlation (P) for finetuning between ground truth accuracy (X-axis) and 6 transferability metrics (Y-axis)
with 11 pretrained model selection for 5 target datasets.
to transfer learning. This consistent negative correla-
tion suggests that the assumptions underlying NCE,
particularly, the relationship between conditional en-
tropy and transferability, may not apply uniformly
across different tasks and datasets.
When comparing the computational efficiency of
model selection metrics, LogME demonstrates sig-
nificant advantages over brute-force finetuning. For
example, in experiments on the Manon Str dataset,
LogME is computed in just 5 minutes for 11 pre-
trained models, achieving a speed-up of 42.6x over
the brute-force method, which takes almost 3.5 hours.
For the larger GarbageFine dataset, LogME takes 7
minutes compared to almost 42 hours for brute-force,
Rethinking Model Selection Beyond ImageNet Accuracy for Waste Classification
231

resulting in a remarkable speed-up of 363.7x. This
efficiency is due to the ability of LogME to filter out
redundant information in features, combined with its
strong performance. This makes it particularly attrac-
tive for fast and efficient model selection in transfer
learning scenarios.
These findings demonstrate the need for a model
selection metric to assess transferability in image
classification. While ImageNet accuracy correlation
can provide useful insights, especially for smaller
datasets, it should not be relied upon as the only indi-
cator of transferability. The success of metrics such as
LogME in certain scenarios suggests the importance
of considering feature space structure and target task
characteristics when assessing transferability.
5 INSIGHTS FROM METRIC
PERFORMANCE ACROSS
MODELS AND DATASETS
The following key takeaways summarise the findings
from analyzing various transferability metrics, focus-
ing on their performance, stability, and sensitivity
across different models and datasets in the feature ex-
traction and the finetuning scenarios.
• The Consistent Performance of LogME: The
LogME metric performs consistently well in
feature extraction and finetuning scenarios (ex-
cept for the Manon Str dataset). Its robustness
in estimating compatibility between models and
datasets suggests that it captures essential aspects
of transferability, regardless of the transfer learn-
ing method. On the other hand, the GBC shows
consistently lower correlation coefficients com-
pared to other metrics. This may indicate that
class separability in feature space, as measured by
the GBC, may not be a useful factor for transfer
success in these specific tasks.
• Improved Metric Correlations After Finetuning:
Finetuning leads to improved correlation coeffi-
cients for many metrics, particularly for LogME
and LEEP. This indicates that these metrics have
improved predictive performance after finetuning
the models, demonstrating the value of finetun-
ing for a better understanding of transferability.
However, the varying degrees of improvement
across metrics and datasets suggest a complex,
task-dependent relationship between initial trans-
ferability estimates and performance after finetun-
ing.
• Dataset-Dependent Metric Performance: Trans-
ferability metrics such as LogME and GBC show
significant variability across datasets, suggesting
that transferability is not just a property of mod-
els, but also depends on model-dataset interac-
tions. This variability emphasizes the importance
of dataset characteristics in transfer learning out-
comes.
• Influence of Model Architectures: Certain archi-
tectures, such as Inception_v3 and Mobilenet_v2,
perform consistently well across metrics and
datasets, especially after finetuning. This suggests
that some architectures have inherent character-
istics that make them more adaptable to transfer
learning.
• Metrics Variability: Metrics such as GBC and
TransRate show variability, with the sensitivity of
the TransRate to the mutual information between
target labels and features leading to fluctuations
between feature extraction and finetuning. While
some metrics, like LogME, remain stable, others
show higher sensitivity, suggesting the need for
a combination of metrics to get a comprehensive
evaluation of transferability.
6 CONCLUSIONS
This study investigates the effectiveness of trans-
ferability metrics in selecting pretrained models for
waste classification, which is a critical challenge in
representation learning. Six metrics (NCE, LEEP,
LogME, TransRate, GBC, and ImageNet accuracy)
are evaluated by transferring knowledge from Ima-
geNet to five datasets of varying size, label density,
and diversity. The analysis examines performance for
full model finetuning and head-only retraining, pro-
viding practical insights into the utility of metrics in
different scenarios.
The results challenge the assumption that Ima-
geNet accuracy reliably predicts transferability across
datasets and tasks. While ImageNet accuracy remains
effective for smaller datasets and overall model tun-
ing, its correlation with transfer performance is incon-
sistent for larger datasets. In contrast, LogME shows
stronger and more stable performance and emerges
as a robust metric for model selection. Additionally,
TransRate shows particular promise in head-training
scenarios. These results demonstrate the need for a
detailed approach to model selection, considering the
dataset’s characteristics and the considered task.
Although the experimental results focus on waste
classification, they show the limitations of Ima-
geNet’s accuracy and highlight the need for broader
validation. Extending this evaluation framework
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
232

to other domain-specific classification tasks, cross-
domain experiments, and diverse dataset characteris-
tics will be important for generalizing these results.
Future research should extend beyond the current
scope by exploring several promising avenues. First,
including Vision Transformer (ViT) models, or fine-
tuning large pretrained models (Abou Baker et al.,
2024) would provide insight into how newer archi-
tectural paradigms perform in transfer learning sce-
narios. Second, developing more advanced hyperpa-
rameter optimization techniques could further refine
model selection strategies. Third, expanding the di-
versity of datasets to include more domain-specific
and cross-domain challenges would test the general-
izability of our findings. In addition, exploring the in-
teraction between transferability metrics and emerg-
ing techniques such as few-shot learning could pro-
vide new approaches for efficient machine learning
model adaptation.
In conclusion, effective transferability metrics
must balance speed and accuracy to identify appro-
priate pretrained models without extensive finetuning.
This research contributes to a deeper understanding of
transferability in deep learning, providing a founda-
tion for broader evaluations and practical guidance in
waste classification and beyond.
ACKNOWLEDGEMENTS
This work has been funded by the Ministry of Econ-
omy, Innovation, Digitization, and Energy of the
State of North Rhine-Westphalia, Germany, within
the project Digital.Zirkulär.Ruhr.
REFERENCES
Abou Baker, N. and Handmann, U. (2024). One size does
not fit all in evaluating model selection scores for im-
age classification. Scientific Reports, 14(1):30239.
Abou Baker, N., Rohrschneider, D., and Handmann,
U. (2024). Parameter-efficient fine-tuning of
large pretrained models for instance segmentation
tasks. Machine Learning and Knowledge Extraction,
6(4):2783–2807.
Abou Baker, N., Stehr, J., and Handmann, U. (2023). E-
waste recycling gets smarter with digitalization. In
2023 IEEE Conference on Technologies for Sustain-
ability (SusTech), pages 205–209.
Abou Baker, N., Zengeler, N., and Handmann, U. (2022).
A transfer learning evaluation of deep neural net-
works for image classification. Machine Learning and
Knowledge Extraction, 4(1):22–41.
Achille, A., Lam, M., Tewari, R., Ravichandran, A., Maji,
S., Fowlkes, C., Soatto, S., and Perona, P. (2019).
Task2vec: Task embedding for meta-learning. In
ICCV 2019.
Agostinelli, A., Pándy, M., Uijlings, J., Mensink, T., and
Ferrari, V. (2022). How stable are transferability
metrics evaluations? In Computer Vision – ECCV
2022: 17th European Conference, Tel Aviv, Israel, Oc-
tober 23–27, 2022, Proceedings, Part XXXIV, page
303–321, Berlin, Heidelberg. Springer-Verlag.
Bolya, D., Mittapalli, R., and Hoffman, J. (2021). Scalable
diverse model selection for accessible transfer learn-
ing. In Neural Information Processing Systems.
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-
Fei, L. (2009). Imagenet: A large-scale hierarchical
image database. In 2009 IEEE Conference on Com-
puter Vision and Pattern Recognition, pages 248–255.
GarbageFine (2023). Garbage dataset. https://www.
kaggle.com/datasets/mrk1903/garbage. Ac-
cessed: 2024-09-27.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
ual learning for image recognition. In 2016 IEEE Con-
ference on Computer Vision and Pattern Recognition
(CVPR), pages 770–778.
Huang, G., Liu, Z., and Weinberger, K. Q. (2016). Densely
connected convolutional networks. 2017 IEEE Con-
ference on Computer Vision and Pattern Recognition
(CVPR), pages 2261–2269.
Huang, L.-K., Wei, Y., Rong, Y., Yang, Q., and Huang, J.
(2021). Frustratingly easy transferability estimation.
In International Conference on Machine Learning.
Kornblith, S., Shlens, J., and Le, Q. V. (2018). Do better im-
agenet models transfer better? 2019 IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition
(CVPR), pages 2656–2666.
Nguyen, C. V., Hassner, T., Archambeau, C., and Seeger,
M. W. (2020). Leep: A new measure to evaluate trans-
ferability of learned representations. In International
Conference on Machine Learning.
P’andy, M., Agostinelli, A., Uijlings, J. R. R., Ferrari, V.,
and Mensink, T. (2021). Transferability estimation us-
ing bhattacharyya class separability. 2022 IEEE/CVF
Conference on Computer Vision and Pattern Recogni-
tion (CVPR), pages 9162–9172.
Renggli, C., Pinto, A. S., Rimanic, L., Puigcerver, J.,
Riquelme, C., Zhang, C., and Lucic, M. (2020).
Which model to transfer? finding the needle in the
growing haystack. 2022 IEEE/CVF Conference on
Computer Vision and Pattern Recognition (CVPR),
pages 9195–9204.
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., and
Chen, L.-C. (2018). Mobilenetv2: Inverted residu-
als and linear bottlenecks. In 2018 IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition,
pages 4510–4520.
Statista (2023). Global waste generation: statistics and
facts. https://www.statista.com/topics/4983/
waste-generation-worldwide/topicOverview.
Accessed: 2024-09-27.
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S.,
Anguelov, D., Erhan, D., Vanhoucke, V., and Rabi-
novich, A. (2015). Going deeper with convolutions. In
Rethinking Model Selection Beyond ImageNet Accuracy for Waste Classification
233

2015 IEEE Conference on Computer Vision and Pat-
tern Recognition (CVPR), pages 1–9.
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., and Wojna,
Z. (2016). Rethinking the inception architecture for
computer vision. In 2016 IEEE Conference on Com-
puter Vision and Pattern Recognition (CVPR), pages
2818–2826.
Tan, M., Chen, B., Pang, R., Vasudevan, V., and Le, Q. V.
(2018). Mnasnet: Platform-aware neural architec-
ture search for mobile. 2019 IEEE/CVF Conference
on Computer Vision and Pattern Recognition (CVPR),
pages 2815–2823.
Thrun, S. and Pratt, L. (1998). Learning to Learn: Introduc-
tion and Overview, pages 3–17. Springer US, Boston,
MA.
Thung, G. (2018). Trashnet: A dataset of images
of garbage. https://github.com/garythung/
trashnet. Accessed: 2024-09-27.
Tran, A., Nguyen, C., and Hassner, T. (2019). Transfer-
ability and hardness of supervised classification tasks.
In 2019 IEEE/CVF International Conference on Com-
puter Vision (ICCV), pages 1395–1405.
TrashBox (2024). Trashbox. https://github.
com/nikhilvenkatkumsetty/TrashBox. Accessed:
2024-09-27.
WasteFine (2023). Waste pictures dataset. https:
//www.kaggle.com/datasets/wangziang/
waste-pictures. Accessed: 2024-09-27.
Yacharki (2013). Manon str cleaned dataset.
https://www.kaggle.com/datasets/yacharki/
manon-str-cleaned-dataset. Accessed: 2024-
09-27.
You, K., Liu, Y., Long, M., and Wang, J. (2021). Logme:
Practical assessment of pre-trained models for trans-
fer learning. In International Conference on Machine
Learning.
You, K., Liu, Y., Zhang, Z., Wang, J., Jordan, M. I., and
Long, M. (2022). Ranking and tuning pre-trained
models: A new paradigm for exploiting model hubs.
JMLR.
Zamir, A. R., Sax, A., Shen, W., Guibas, L. J., Malik, J., and
Savarese, S. (2018). Taskonomy: Disentangling task
transfer learning. In Proceedings of the IEEE Con-
ference on Computer Vision and Pattern Recognition
(CVPR).
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
234
