
Improving Periocular Recognition Accuracy: Opposite Side Learning
Suppression and Vertical Image Inversion
Masakazu Fujio, Yosuke Kaga and Kenta Takahashi
Research and Development Group Hitachi Ltd., 292 Yoshida-cho, Totsuka-ku, Yokohama-shi, Japan
{masakazu.fujio.kz, yosuke.kaga.dc, kenta.takahashi.bw}@hitachi.com
Keywords:
Periocular Recognition, CNN, Suppress Backpropagation.
Abstract:
Periocular recognition has emerged as an effective biometric identification method in recent years, particularly
when the face is partially occluded, or the iris image is unavailable. This paper proposes a deep learning-based
periocular recognition method specifically designed to address the overlooked issue of simultaneously training
left and right periocular images from the same person. Our proposed method enhances recognition accuracy by
identifying the eye side, applying a vertical flip during training and inference, and stopping backpropagation
for the opposite side of the current periocular. Experimental results on visible and NIR image datasets, using
six different off-the-shelf deep CNN models, demonstrate an approximate 1∼2% improvement in recognition
accuracies compared to conventional approaches that employ horizontal flip to align the appearance of the
right and left eyes. The proposed approach’s performance was compared with state-of-the-art methods in
the literature on three unconstrained periocular datasets: CASIA-Iris-Distance, UBIPr. The experimental
results indicated that our approach consistently outperformed the state-of-the-art methods on these datasets.
From the perspective of implementation costs, the proposed method is applied during training and does not
affect the computational complexity during inference. Moreover, during training, the method only sets the
gradient values of the periocular image class of the opposite side to zero, thus having a minimal impact on the
computational cost. It can be combined easily with other periocular authentication methods.
1 INTRODUCTION
In the era of rapidly evolving technology, biometric
authentication has emerged as an essential security
measure. Among various biometric modalities, facial
recognition has been widely adopted due to its nonin-
vasive nature and ease of implementation. However,
the recent global pandemic has necessitated the use
of facial masks, thereby obscuring significant parts
of the face and hampering the effectiveness of facial
recognition systems. This has prompted researchers
to explore alternate biometric modalities that are re-
silient to such challenges. One such promising tech-
nique is periocular authentication. Such as periocular
recognition focuses on the region around the eye, in-
cluding the eyelashes, eyelids, and surrounding skin
(Kumari and Seeja, 2022). Periocular recognition
holds promise as it can be used even when the rest
of the face is obscured, making it particularly rele-
vant in the current context. Iris recognition is another
method that has been considered, but it brings its own
set of challenges. These include sensitivity to lighting
conditions and the need for user cooperation in posi-
tioning the eye accurately for the scanner (Tan and
Kumar, 2013).
Our study aims to explore and enhance the accu-
racy of periocular recognition as a viable alternative
or complement to existing biometric techniques. We
investigate a deep learning method in improving the
accuracy of periocular recognition, particularly focus-
ing on enhancing the discriminative capacity of re-
sembling classes (the left and right periocular regions
of the same individual). This, in turn, improves user
authentication accuracy. Our approach involves ap-
plying a simple vertical image inversion and suppress-
ing the learning of the opposite side periocular.
While it is also possible to train separate recog-
nition models for the right eye and the left eye, the
reduction in training samples could decrease the ac-
curacy of identification.
The remainder of this paper is structured as fol-
lows: Section II contains a literature review, Sec-
tion III presents the methodology and implementation
method, Section IV presents the results, and finally,
Section V provides the conclusion and future direc-
tions.
298
Fujio, M., Kaga, Y. and Takahashi, K.
Improving Periocular Recognition Accuracy: Opposite Side Learning Suppression and Vertical Image Inversion.
DOI: 10.5220/0013123400003912
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 2: VISAPP, pages
298-305
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

2 RELATED WORK
Periocular recognition is a rapidly evolving field
within biometrics, with numerous studies exploring
different methodologies to improve recognition ac-
curacy and robustness. In early works, researchers
focused on hand-crafted descriptors such as Local
Binary Patterns (LBP), Histogram of Oriented Gra-
dients (HOG), and Scale-Invariant Feature Trans-
form (SIFT) for feature extraction (Park et al., 2009)
(Miller et al., 2010) (Adams et al., 2010) (Santos and
Hoyle, 2012) (Ambika et al., 2017). These descrip-
tors are designed to capture specific patterns within
periocular images. For instance, Park et al. (Park
et al., 2009) utilized these descriptors to prove the
high discriminative nature of the periocular region un-
der different conditions. Bharadwaj et al. (Bharad-
waj et al., 2010) proposed a global description for
periocular images using GIST and circular LBP op-
erators, and Mahalingam and Ricanek (Mahalingam
and Ricanek, 2013) implemented data alignment with
the iris as the center for feature representation with
multi-scale and patch-based LBP descriptors. These
traditional methods, however, were found to be sen-
sitive to various factors such as noise, rotation, and
blur. To overcome these limitations, some researchers
proposed the fusion of features from multiple descrip-
tors or using novel descriptors that analyze images in
a multi-resolution and multi-orientation manner (Cao
and Schmid, 2016).
With the advent of deep learning, Convolutional
Neural Networks (CNNs) have been increasingly em-
ployed for periocular recognition. CNNs have the
advantage of automatically learning relevant features
from data, leading to significant improvements in
recognition accuracy. Researchers have explored var-
ious methods to improve the performance of CNNs
in the field of periocular recognition. Zhao and Ku-
mar (Zhao and Kumar, 2016) proposed a Semantics-
Assisted CNN, which uses not only identity labels
but also explicit semantic information such as gender
and side information of the eyes for more compre-
hensive periocular feature extraction. Similarly, the
ADPR model proposed by (Talreja et al., 2022) si-
multaneously jointly trains periocular recognition and
soft biometrics prediction. In contrast with previous
methods, their method fuses the predicted soft bio-
metrics features with periocular features in the train-
ing step to improve the overall periocular recogni-
tion performance. Proenc¸a and Neves (Proenca and
Neves, 2018) proposed Deep-PRWIS, a deep CNN
model trained in such a way that the recognition is
based exclusively on information surrounding the eye,
with the iris and sclera regions features degraded dur-
ing learning. Recent advancements have seen the
fusion of hand-crafted and deep-learning methods
to enhance periocular recognition performance. For
instance, the Adaptive Spatial Transformation Net-
works proposed by (Borza et al., 2023) combines the
advantages of both hand-crafted and deep learning
features. The LDA-CNN model proposed by (Alah-
madi et al., 2022) enhances periocular recognition by
handling unconstrained variations such as illumina-
tion and pose. Their model incorporated an LDA
layer after the last convolutional layer of the back-
bone model, then fine-tuned in an end-to-end manner.
They evaluated the model using benchmark periocu-
lar datasets, indicating outperformed results than sev-
eral state-of-the-art methods, even in difficult cross-
conditions such as cross-eye and cross-pose.
Despite the considerable progress made by using
deep learning methods, the literature overlooks the
adverse effect of training left and right periocular im-
ages from the same person simultaneously. Our pro-
posed method enhances recognition accuracy by iden-
tifying the eye side, applying a vertical flip during
training and inference, and stopping backpropagation
for the opposite side of the current periocular.
3 PROPOSED METHOD
A pivotal study examining the potential of employing
the periocular region for human identification under
various conditions is presented in (Park et al., 2009).
Consistent with prior research (Park et al., 2009) (Ku-
mari and Seeja, 2020) (Alahmadi et al., 2022), we
consider each side of the periocular images as distinct
identities. Subsequently, the user’s identity is deter-
mined based on the authentication results or scores
obtained from the left and right periocular images.
To amplify the number of training samples and
enhance the precision of periocular authentication,
we incorporate both left and right periocular features
into a single Convolutional Neural Network (CNN)
model. However, this approach raises several chal-
lenges concerning authentication accuracy. Specifi-
cally, it becomes more complex to differentiate the
same individual’s left and right periocular images
compared to distinguishing another person’s left or
right perioculars
1
.
When training with the left periocular samples of
1
The similarity scores of the left and right periocular
images are lower than those of the right-to-right and left-to-
left periocular images. However, they remain significantly
higher than those of the periocular images of others, closely
resembling identity pairs (Kumari and Seeja, 2020) (Alah-
madi et al., 2022).
Improving Periocular Recognition Accuracy: Opposite Side Learning Suppression and Vertical Image Inversion
299

a given user (User1), treating the right-side periocu-
lar samples of the same user (User1) as general im-
postor samples (periocular images from other users)
could potentially have adverse effects on the training
of the right-side periocular classes for the same user.
An alternative strategy could involve applying aug-
mentation with a horizontal flip (Ahuja et al., 2016).
Nonetheless, we propose that this approach may ob-
scure the innate characteristics of the periocular re-
gion, blur the subtle differences between the right and
left periocular images, and consequently reduce accu-
racy.
Prompted by these findings, we propose a novel
CNN model training method designed to mitigate the
adverse effects caused by training the other side of
periocular classes. Our proposed method centers on
two key approaches:
• Identify the left or right eye and apply a vertical
flip during training and inferencing.
• Cease the backpropagation of the current perioc-
ular’s opposite side.
By implementing these initial approaches, we ex-
pect that the model will easily distinguish periocular
images of the same individual.
3.1 Overall Process of Periocular
Recognition
Periocular authentication is a process that identi-
fies individuals based on the distinctive features
surrounding their eye region, including the eyelids,
eyelashes, and eyebrows. The overall process of
periocular CNN model training and inferencing,
comprises the following steps:
[Training Phase]
Step 1: Region of Interest (ROI) Extraction. The
Periocular images are extracted by using the OSS
tools Media Pipe Facemesh
2
.
Step 2: Image Preprocessing. If the input periocu-
lar image is from the left-side (or right-side), the
image is flipped vertically.
Step 3: Data Augmentation. Data augmentation
techniques (Chatfield et al., 2014) are employed
to increase the number of training samples,
excluding horizontal and vertical flips.
2
https://nemutas.github.io/app-mediapipe-facemesh-
demo/. We used following landmark IDs. Left: 244, 190,
56, 28, 27, 29, 30, 247, 226, 25, 110, 24, 23, 22, 232, 233,
Right: 464, 414, 286, 258, 257, 259, 260, 467, 446, 255,
339, 254, 253, 252, 452, 453.
Step 4: Feature Extraction. Feature extraction is
conducted using CNNs, such as Resnet18.
Step 5: Loss Calculation. The loss value is calcu-
lated using cross-entropy loss.
Step 6: Backpropagation. Perform backpropaga-
tion, excluding the opposite side of the current
periocular (explained later).
[Inference Phase]
Step 1: ROI Extraction. Periocular images are ex-
tracted from facial images.
Step 2: Image Preprocessing. If the input periocu-
lar image is from the left-side (or right-side), the
image is flipped vertically.
Step 3: Feature Extraction. Feature extraction is
conducted using CNNs, such as Resnet18, with-
out the final Fully Connected (FC) layer.
Step 4: Inferencing. The cosine similarity is calcu-
lated. Samples are accepted as genuine if the
similarity is greater than or equal to a predefined
threshold.
3.2 Image Preprocessing
As discussed in the previous subsection, our proposed
method, in Step 2, flips the input images if they origi-
nate from a predefined side (either the left-side or the
right-side). In our experiments, we compared the ac-
curacies derived from three different scenarios: The
first scenario does not involve any flips (Top); the sec-
ond scenario involves a horizontal flip of the right
periocular images (Middle); and the third scenario
involves a vertical flip of the left periocular images
(Bottom), as depicted in Fig.1.
Figure 1: Variations of image flips. Top: w/o flips, Middle:
horizontal flip of right perioculars, Bottom: vertical flip of
left perioculars.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
300

3.3 Training with Opposite Eye
BackProp Suppression
As discussed in the previous subsection 3.1, our pro-
posed method carries out backpropagation, except on
the opposite side of the current periocular region (Step
6).
Fig. 2 depicts stopping the backpropagation for
the opposite side of the current periocular region. The
input image serves as an illustration of periocular im-
ages. The user ID ”002” corresponds to the user ID
of the input image, while the side ID ”L” indicates
whether the image originates from the right (”R”) or
left (”L”) eye. The Convolutional Neural Network
(CNN) model illustrates an inference model currently
under training that accepts an image as input and
yields features as output.
These features are utilized to estimate the user ID
+ side ID of the input image. The classifier can be
composed of a fully connected layer, with the fea-
ture’s dimensionality serving as the input dimension
and the count of user ID + side ID types serving as
the output dimension.
’Class logits’ refers to the output vector produced
by the classifier with dimensions corresponding to the
user ID + side ID. The softmax function normalizes
the class logits into probability values between 0 and
1. Class probability distribution signifies the distri-
bution of vectors with a dimensionality equal to the
number of user ID + side ID types.
The teacher probability distribution possesses a
one-hot vector, where the correct data corresponding
to user ID + side ID is marked as 1 and all other val-
ues are set to 0. Cross-entropy can be employed as a
loss function to measure the discrepancy between the
teacher and estimated class distribution.
The ’Target class’ represents the input image’s ID
(user ID + side ID), while the ’Opposite side class’
corresponds to the user ID + opposite side ID. The
black dashed arrow illustrates the state of the back-
propagation for the nodes corresponding to the user
ID + side ID of the Target class. The gray dashed ar-
row depicts the state of the backpropagation for the
nodes corresponding to the user ID + opposite side
ID.
In Step 5, the discrepancy between the class and
teacher probability distributions is computed. Subse-
quently, in Step 6, all gradients of the edges connected
to the node of user ID + opposite side ID in the class
logits are set to 0. Backpropagation for other nodes is
then conducted as usual.
This methodology suppresses updates to param-
eters associated with user ID + side ID during the
image learning phase for user ID + opposite side ID.
Then, it enhances the estimation precision of the class
ID for left and right periocular images in the post-
training inference model.
Figure 2: Outline of Training with Opposite Eye BackProp
Suppression.
Algorithm 1 outlines the training process utilizing
OEBS (Opposite Periocular BackProp Suppression).
During each training iteration, a batch of samples X
is initially passed through the CNN model to generate
embeddings (F). These embeddings are then passed
through the classifier to generate class logits (Y ). Fol-
lowing this, the loss between the estimated class logit
Y (class logits of the Y are normalized using a soft-
max operation in the criterion function) and the gen-
uine one-hot labels y is calculated. Subsequently, the
gradient of the edges connected to the node of user
ID + opposite side ID within the class logits is set to
’0.0’, and backpropagation is performed as usual.
The proposed method is applied during training
and does not affect the computational complexity dur-
ing inference. Moreover, during training, the method
only sets the gradient values of the periocular image
class of the opposite side to zero, thus having a mini-
mal impact on the computational cost.
4 EVALUATION
In this section, we assess the authentication accura-
cies of periocular recognition with and without our
proposed method, which incorporates OEBS (Oppo-
site Eye Backpropagation Suppression) and vertical
image flips. To determine the efficacy of our method,
we employ various state-of-the-art CNN models, in-
cluding ResNet, SE-Resnet, and Mobilenet, among
others, as described in the existing literature.
4.1 Database
We used four datasets to evaluate our method: one
consists of IR face images (publicly available at
CASIA-Iris-Distance, and the other comprises visi-
ble face images (purchased from the Datatang Face
Improving Periocular Recognition Accuracy: Opposite Side Learning Suppression and Vertical Image Inversion
301

Data: X ∈ R
T,B,C,W,H
images (T number of
batches, B batch size, C channels, W
width, H height), model CNN model,
e epochs, y correct eye classes
(one-hot encoding), y
′
opposite eye
classes (one-hot encoding)
Result: trained CNN model
initialization;
for i ← 0 to e do
for j ← 0 to T do
X ← D[ j], F ←model(X ),
Y ←metric(F), loss ←criterion(Y, y)
for k ← 0 to len(y
′
) do
if y
′
[k] = 1 then
model.fc.weight.grad[k] = 0
end
end
▷ Apply backprop.
end
if No improvement in loss then
return model;
else
continue;
end
end
Algorithm 1: Training with Opposite Eye Back- Prop Sup-
pression.
Dataset
3
) and UBIPR (Proenca et al., 2010). These
datasets span both visible and NIR spectrums. Further
information about the databases used and the division
of training and test sets is provided in Table 1.
Table 1: Summary of the employed databased for training
and testing.
DB Name CASIA-Iris Datatang UBIPr
-Distance
# of subjects 142 4742 344
#. of classes 284 9484 688
#. of images 2,567 43,813 10,252
Resolution 2352 2976 500∼1000
x1728 x3968 x 400∼800
DB Type Public Paied Public
Features NIR Visible Visible
Train set 4,678 35,120 8,882
Test set 456 8,693 2,136
4.2 Recognition Accuracy: Periocular
ID Evaluation
This section presents the tests’ results to validate
the proposed methods. Table 2∼4 provides a brief
overview of the performance of various CNN mod-
els when evaluated on test data. For instance, the
3
https://datatang.co.jp/dataset/1402
’Model ’ column denotes the name of the CNN mod-
els we used for the accuracy evaluation. We evaluated
six different off-the-shelf DCNNs. The ’Method’ col-
umn displays the method we introduced. ’Flip’ refers
to the types of image flips used, while the ’OEBS
(Opposite Eye Backpropagation Suppression)’ col-
umn indicates whether OEBS was utilized. ’H-flip,’
’NO-flip,’ and ’V-flip’ correspond to each image flip
type as shown in Fig. 1. Then there are six (three ×
two) evaluation patterns in each CNN model. ’EER’
stands for ’Equal Error Rate.’ Each value in the Ta-
ble represents the error rate (%) obtained under each
setting. The underlined values signify the best re-
sult (minimum error) among each model’s six eval-
uation patterns in each column (evaluation metrics).
The boldface values indicate that the ’OEBS’ method
affected accuracy improvements.
Table 2: Comparison Results for the CASIA-IRIS-
Distance. We employed EER (Equal Error Rate) (%) for
the periocular ID.
Method Model Name
resnet se-resnet mobilenet
Flip OEBS 18 18 V2
V w/o 3.06 3.57 2.61
w/ 2.71 3.23 3.36
H w/o 12.89 3.37 3.09
w/ 3.88 4.55 3.86
NO w/o 9.34 3.34 2.72
w/ 2.77 3.51 2.81
Table 3: Comparison Results for Datatang. We employed
EER (Equal Error Rate) (%) for the periocular ID.
Method Model Name
resnet se-resnet mobilenet
Flip OEBS 18 18 V2
V w/o 1.52 2.14 1.49
w/ 1.50 1.54 1.49
H w/o 2.12 1.89 2.56
w/ 1.90 1.62 2.38
NO w/o 2.11 1.49 1.64
w/ 1.55 1.33 1.09
When comparing the FLIP method, the H-flip
approach consistently underperforms in each CNN
model in each dataset as we expected. However, V-
flip and NO-flip do not show clear superiority. In the
UBIPR dataset, the NO-flip approach demonstrated
better results than V-flip (2 out of 3 models in the
UBIPR). There was a significant variation in the sub-
ject–camera poses (0-degree pose; 30-degree pose; -
30-degree pose), so it may have been easier to dis-
tinguish between the left and right eye areas without
flipping the image.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
302
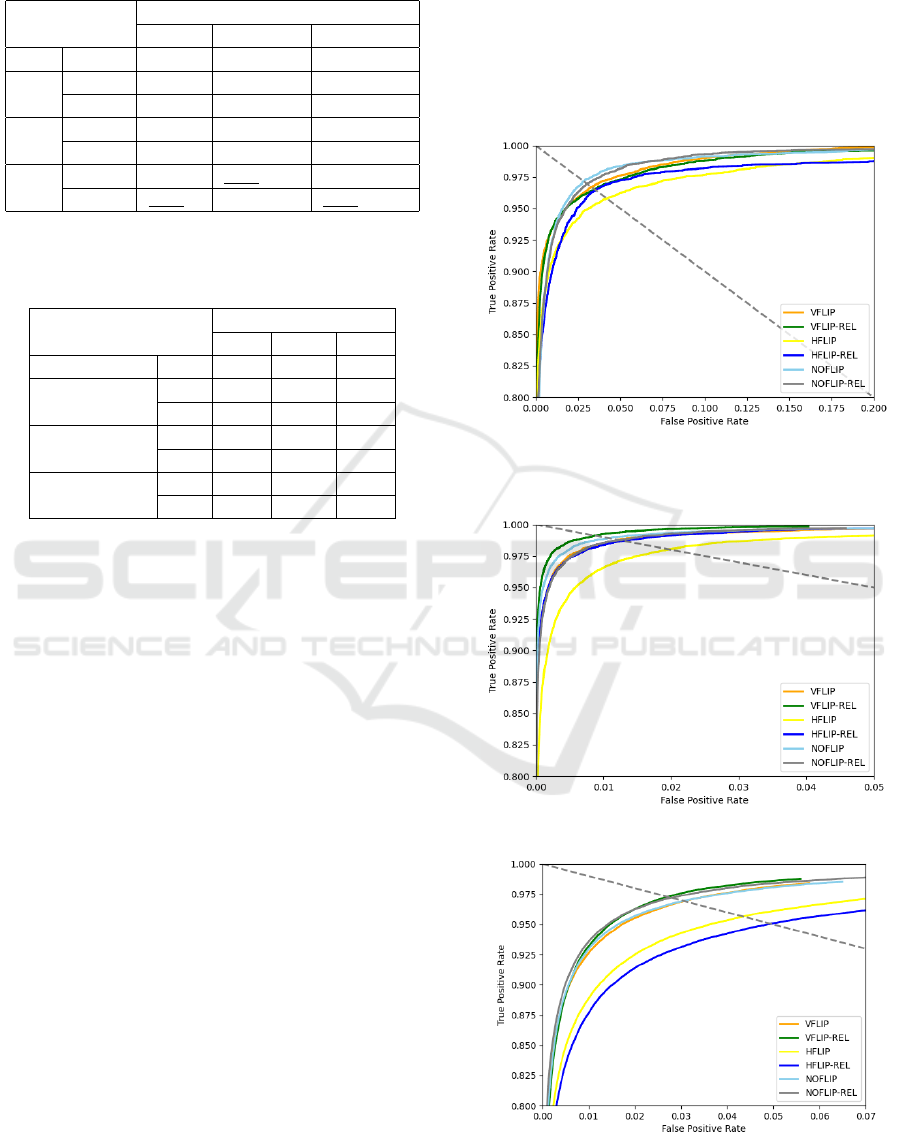
Table 4: Comparison Results for UBIPR. We employed
EER (Equal Error Rate) (%) for the periocular ID.
Method Model Name
resnet se-resnet mobilenet
Flip OEBS 18 18 V2
V w/o 3.05 3.01 2.82
w/ 2.65 2.83 2.45
H w/o 3.90 3.74 2.83
w/ 4.84 4.99 3.7
NO w/o 2.51 2.28 2.26
w/ 2.31 2.85 2.24
Table 5: Comparison with separate network training. We
employed EER (Equal Error Rate) (%) for the periocular
ID. res:Resnet, seres:SeResnet, mn:Mobilenet.
Method Model Name
res seres mn
DB L/R 18 18 V2
CASIA-IRIS L 3.18 4.02 3.58
Distance R 4.42 3.82 5.18
Datatang L 2.08 2.04 2.21
R 1.89 1.94 2.31
UBIPR L 4.16 4.63 3.58
R 3.38 3.45 3.10
In the case of the OEBS method, for the CASIA-
IRIS-Distance dataset, 4 out of 9 experimental set-
tings (3 models × 3 flip types) exhibited positive ef-
fects (boldface characters); for the Datatang dataset,
8 out of 9 experimental settings exhibited positive ef-
fects, for the UBIPR dataset, 5 out of 9 experimental
settings exhibited positive effects.
Figure 3, 4 and 5 shows the Roc curves for each
database when using the SE-Resnet34 model. The x-
axis stands for the FAR (False Acceptance Rate), and
the y-axis stands for the TAR (True Acceptance Rate).
The dashed gray line represents the EER (Equal Er-
ror Rate) points. From the Roc curves, we can also
see that the NO-flip or the V-flip outperforms the H-
flip. On the UBIPR dataset, the highest accuracy is
achieved by V-flip/NO-flip with OEBS, followed by
V-flip/NO-flip without OEBS. Next in accuracy are
H-flip with OEBS, and lastly, H-flip without OEBS.
While it is also possible to train separate models
for the right and the left periocular, the reduction in
training samples could decrease the accuracy of iden-
tification. Table 5 shows the results with alternative
strategies; separate network training. In some cases
(with the MobilenetV2 (Datatang), with the Resnet
(UBIPR)), separate network training approach outper-
forms the H-flip method. But for each database, the
EER is worth than our methods (V-flip, NO-flip).
Using the samples from CASIA-IRIS-Distance,
we will illustrate top-scoring imposter pair samples
for each of the H-flip, NO-flip, and V-flip methods.
Fig. 6 and Fig. 7 illustrate the examples of FA (False
Acceptance) images. As expected, most high-scoring
error instances in the H-flip method occur with pairs
of left and right periocular images from the same user.
On the other hand, in the case of the NO-flip and V-
flip, most images are periocular images between dif-
ferent users.
Figure 3: Roc curves of for CASIA-IRIS-Distance. Six
experimental settings (3 fliptypes × 2 OEBS types) were
trained with the SE-Resnet-34 model.
Figure 4: Roc curves of for Datatang.
Figure 5: Roc curves of for UBIPR.
Improving Periocular Recognition Accuracy: Opposite Side Learning Suppression and Vertical Image Inversion
303
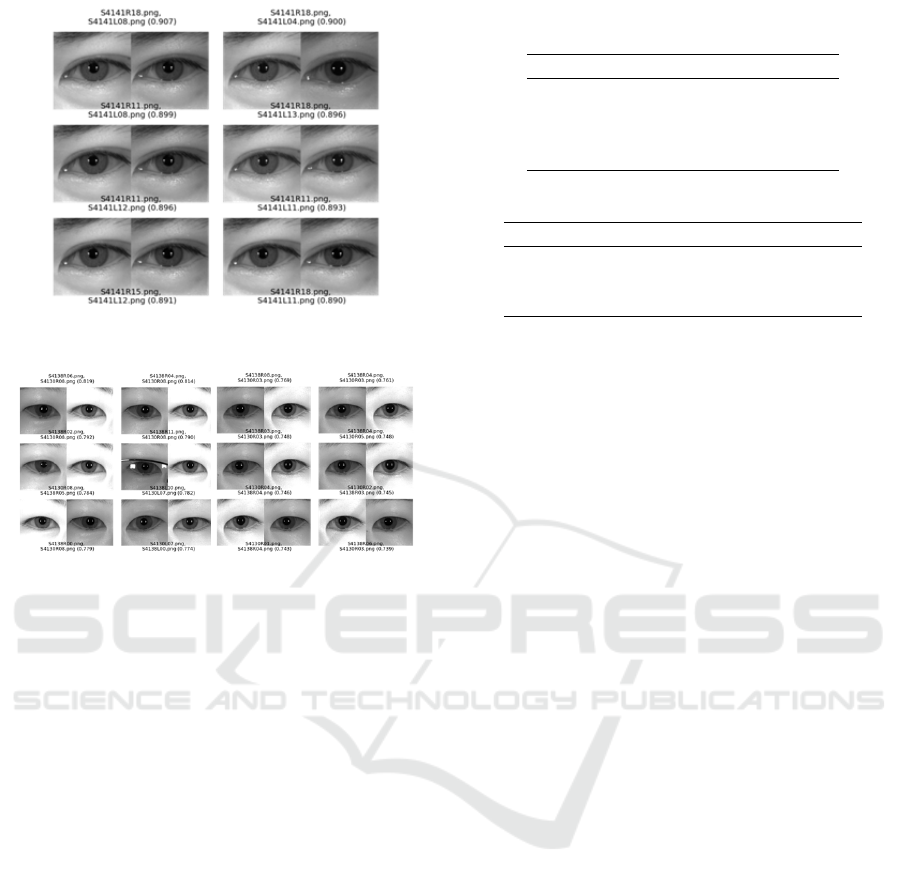
Figure 6: False Acceptance Examples with High Score: H-
flip.
(a) NO-flip (b) V-flip
Figure 7: False Acceptance Examples with High Score.
4.3 Comparison with Other Existing
Methods
The proposed approach’s performance was compared
with state-of-the-art methods in the literature on three
unconstrained periocular datasets: CASIA Iris Dis-
tance, UBIPr, and UBIPR.v2. Following the same
protocol (Kumari and Seeja, 2020) and (Zhou et al.,
2024), 80% of the dataset was used for training,
and the remaining 20% was used for testing all the
datasets. Using SE-Resnet18 (with the NO-flip and
the OEBS) as an example, we will demonstrate the
performance of our proposed method.
Table 6 provides the identification result on CA-
SIA Iris Distance (EER:0.65%) compared to (Zhao
and Kumar, 2016), (Zou et al., 2022) and (Zhou et al.,
2024). Table 7 compares the identification result of
UBIPr (RANK1: 99.73%) to those of (Kumari and
Seeja, 2020), and (Alahmadi et al., 2022).
From these results, it can be observed that our ap-
proach consistently outperformed the state-of-the-art
methods on these datasets. Although there is some
overlap in the confidence intervals in the Table 7, the
superiority of the proposed method is generally rec-
ognized.
Table 6: Comparison with other existing methods: CASIA-
Iris-Distance.
Method EER(%)
(Zhao and Kumar, 2016) 6.61
(Zou et al., 2022) 7.74
(Zhou et al., 2024) 6.22
OURS 1.18
Table 7: Comparison with other existing methods: UBIPR.
Method RANK1(%)
(Kumari and Seeja, 2020) 93.33 ± 1.06
(Alahmadi et al., 2022) 99.17 ± 0.39
OURS 99.73 ± 0.22
5 CONCLUSIONS
To improve the accuracy of the periocular authenti-
cation, we introduced two new methods that are de-
signed to reflect the difference between the left and
right periocular of the same person. Our proposed
method employs two fundamental approaches to en-
hance periocular recognition. First, during training
and inference, the system identifies whether an im-
age is of the left or right eye and applies a vertical
flip. Second, we stop backpropagation for the same
individual’s opposite side of the periocular region. In
the experiments carried out on four datasets (visible
and NIR images) with the six different off-the-shelf
DCNNs, we achieved about 1 ∼ 2% improvements in
the periocular recognition accuracies compared with
the conventional horizontal flip approach. This was
also true in the case of the user authentication evalu-
ations (with score fusion of left and right periocular
authentication scores). The proposed approach’s per-
formance was compared with state-of-the-art meth-
ods in the literature on three unconstrained peri-
ocular datasets: CASIA-Iris-Distance, UBIPr, and
UBIPRv2. The experimental results indicated that our
approach consistently outperformed the state-of-the-
art methods on these datasets. From the perspective
of implementation costs, the proposed method is ap-
plied during training and does not affect the computa-
tional complexity during inference. Moreover, during
training, the method only sets the gradient values of
the periocular image class of the opposite side of the
same individual to zero, thus having a minimal im-
pact on the computational cost. Furthermore, it can
be combined easily with other periocular authentica-
tion methods. In future studies, we plan to extend this
approach to other biometrics of left and right pairs or
some dependent class pairs.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
304

ACKNOWLEDGEMENTS
We want to acknowledge the support of the indi-
viduals at Hitachi-LG Data Storage and the Hitachi
R&D members for sharing and providing us with
the data for facial and periocular recognition exper-
iments. Their contribution has been invaluable in ad-
vancing this research.
REFERENCES
Adams, J., Woodard, D. L., Dozier, G., Miller, P., Bryant,
K., and Glenn, G. (2010). Genetic-based type ii fea-
ture extraction for periocular biometric recognition:
Less is more. In 2010 20th International Conference
on Pattern Recognition, pages 205–208.
Ahuja, K., Islam, R., Barbhuiya, F. A., and Dey, K. (2016).
A preliminary study of cnns for iris and periocular ver-
ification in the visible spectrum. In 2016 23rd Inter-
national Conference on Pattern Recognition (ICPR),
pages 181–186.
Alahmadi, A., Hussain, M., and Aboalsamh, H. (2022).
Lda-cnn: Linear discriminant analysis convolution
neural network for periocular recognition in the wild.
Mathematics, 10(23).
Ambika, D., Radhika, K., and Seshachalam, D. (2017). Fu-
sion of shape and texture for unconstrained periocu-
lar authentication. International Journal of Computer
and Information Engineering, 11(7):831–837.
Bharadwaj, S., Bhatt, H. S., Vatsa, M., and Singh, R.
(2010). Periocular biometrics: When iris recogni-
tion fails. In 2010 Fourth IEEE International Confer-
ence on Biometrics: Theory, Applications and Systems
(BTAS), pages 1–6.
Borza, D. L., Yaghoubi, E., Frintrop, S., and Proenca, H.
(2023). Adaptive spatial transformation networks for
periocular recognition. Sensors, 23(5).
Cao, Z. and Schmid, N. A. (2016). Fusion of operators
for heterogeneous periocular recognition at varying
ranges. Pattern Recognition Letters, 82:170–180. An
insight on eye biometrics.
Chatfield, K., Simonyan, K., Vedaldi, A., and Zisserman,
A. (2014). Return of the devil in the details: Delving
deep into convolutional nets.
Kumari, P. and Seeja, K. (2020). Periocular biometrics
for non-ideal images: with off-the-shelf deep cnn
and transfer learning approach. Procedia Computer
Science, 167:344–352. International Conference on
Computational Intelligence and Data Science.
Kumari, P. and Seeja, K. (2022). Periocular biometrics: A
survey. Journal of King Saud University - Computer
and Information Sciences, 34(4):1086–1097.
Mahalingam, G. and Ricanek, K. (2013). Lbp-based
periocular recognition on challenging face datasets.
EURASIP Journal on Image and Video processing,
2013:1–13.
Miller, P. E., Rawls, A. W., Pundlik, S. J., and Woodard,
D. L. (2010). Personal identification using periocular
skin texture. In Proceedings of the 2010 ACM sympo-
sium on Applied Computing, pages 1496–1500.
Park, U., Ross, A., and Jain, A. K. (2009). Periocular bio-
metrics in the visible spectrum: A feasibility study. In
2009 IEEE 3rd International Conference on Biomet-
rics: Theory, Applications, and Systems, pages 1–6.
Proenca, H. and Neves, J. C. (2018). Deep-prwis: Perioc-
ular recognition without the iris and sclera using deep
learning frameworks. IEEE Transactions on Informa-
tion Forensics and Security, 13(4):888–896.
Proenca, H., Filipe, S., Santos, R., Oliveira, J., and Alexan-
dre, L. (2010). The UBIRIS.v2: A database of visi-
ble wavelength images captured on-the-move and at-
a-distance. IEEE Trans. PAMI, 32(8):1529–1535.
Santos, G. and Hoyle, E. (2012). A fusion approach to un-
constrained iris recognition. Pattern Recognition Let-
ters, 33(8):984–990.
Talreja, V., Nasrabadi, N. M., and Valenti, M. C. (2022).
Attribute-based deep periocular recognition: Lever-
aging soft biometrics to improve periocular recogni-
tion. In 2022 IEEE/CVF Winter Conference on Ap-
plications of Computer Vision (WACV), pages 1141–
1150.
Tan, C.-W. and Kumar, A. (2013). Towards online iris
and periocular recognition under relaxed imaging con-
straints. IEEE Transactions on Image Processing,
22:3751–3765.
Zhao, Z. and Kumar, A. (2016). Accurate periocular
recognition under less constrained environment us-
ing semantics-assisted convolutional neural network.
IEEE Transactions on Information Forensics and Se-
curity, 12(5):1017–1030.
Zhou, Q., Zou, Q., Xuliang, G., Liu, C., Feng, C., and Chen,
B. (2024). Low-resolution periocular images recogni-
tion using a novel cnn network. Signal, Image and
Video Processing, 18:1–13.
Zou, Q., Wang, C., Yang, S., and Chen, B. (2022).
A compact periocular recognition system based
on deep learning framework attenmidnet with the
attention mechanism. Multimedia Tools Appl.,
82(10):15837?15857.
Improving Periocular Recognition Accuracy: Opposite Side Learning Suppression and Vertical Image Inversion
305
