
On the Text-to-SQL Task Supported by Database Keyword Search
Eduardo R. Nascimento
1 a
, Caio Viktor S. Avila
1,4 b
, Yenier T. Izquierdo
1 c
, Grettel M. Garc
´
ıa
1 d
,
Lucas Feij
´
o L. Andrade
1 e
, Michelle S. P. Facina
2
, Melissa Lemos
1 f
and Marco A. Casanova
1,3 g
1
Instituto Tecgraf, PUC-Rio, Rio de Janeiro, RJ, CEP 22451-900, Brazil
2
Petrobras, Rio de Janeiro, RJ, CEP 20231-030, Brazil
3
Departamento de Inform
´
atica, PUC-Rio, Rio de Janeiro, RJ, CEP 22451-900, Brazil
4
Departamento de Computac¸
˜
ao, UFC, Fortaleza, CEP 60440-900, Brazil
Keywords:
Text-to-SQL, Database Keyword Search, Large Language Models, Relational Databases.
Abstract:
Text-to-SQL prompt strategies based on Large Language Models (LLMs) achieve remarkable performance on
well-known benchmarks. However, when applied to real-world databases, their performance is significantly
less than for these benchmarks, especially for Natural Language (NL) questions requiring complex filters
and joins to be processed. This paper then proposes a strategy to compile NL questions into SQL queries
that incorporates a dynamic few-shot examples strategy and leverages the services provided by a database
keyword search (KwS) platform. The paper details how the precision and recall of the schema-linking process
are improved with the help of the examples provided and the keyword-matching service that the KwS platform
offers. Then, it shows how the KwS platform can be used to synthesize a view that captures the joins required
to process an input NL question and thereby simplify the SQL query compilation step. The paper includes
experiments with a real-world relational database to assess the performance of the proposed strategy. The
experiments suggest that the strategy achieves an accuracy on the real-world relational database that surpasses
state-of-the-art approaches. The paper concludes by discussing the results obtained.
1 INTRODUCTION
The Text-to-SQL task is defined as “given a relational
database D and a natural language (NL) sentence
Q
N
that describes a question on D, generate an SQL
query Q
SQL
over D that expresses Q
N
” (Katsogiannis-
Meimarakis and Koutrika, 2023; Kim et al., 2020).
Numerous tools have addressed this task with rel-
ative success (Affolter et al., 2019; Katsogiannis-
Meimarakis and Koutrika, 2023; Kim et al., 2020;
Shi et al., 2024) over well-known benchmarks, such
as Spider – Yale Semantic Parsing and Text-to-SQL
Challenge (Yu et al., 2018) and BIRD – BIg Bench for
LaRge-scale Database Grounded Text-to-SQL Eval-
a
https://orcid.org/0009-0005-3391-7813
b
https://orcid.org/0009-0002-3899-0014
c
https://orcid.org/0000-0003-0971-8572
d
https://orcid.org/0000-0001-9713-300X
e
https://orcid.org/0009-0006-4763-8564
f
https://orcid.org/0000-0003-1723-9897
g
https://orcid.org/0000-0003-0765-9636
uation (Li et al., 2024). The leaderboards of these
benchmarks point to a firm trend: the best text-to-
SQL tools are all based on Large Language Models
(LLMs) (Shi et al., 2024).
Text-to-SQL tools must face several challenges, as
a consequence of the complexity of SQL (Yu et al.,
2018) and of the database itself. In particular, real-
world databases raise challenges for several reasons,
among which: (1) The relational schema is often
large; (2) The relational schema is often an inappro-
priate specification of the database from the point of
view of the LLM; (3) The data semantics are often
complex; (4) Metadata and data are often ambiguous.
Indeed, the performance of some of the best LLM-
based text-to-SQL tools on real-world databases is
significantly less than that observed for the Spider
and BIRD benchmarks (Nascimento et al., 2024a; Lei
et al., 2024).
This paper then addresses the real-world text-to-
SQL problem, which is the version of the text-to-SQL
problem for real-world databases. Albeit the origi-
nal problem has been investigated for some time, this
Nascimento, E. R., Avila, C. V. S., Izquierdo, Y. T., García, G. M., Andrade, L. F. L., Facina, M. S. P., Lemos, M. and Casanova, M. A.
On the Text-to-SQL Task Supported by Database Keyword Search.
DOI: 10.5220/0013126300003929
In Proceedings of the 27th International Conference on Enterprise Information Systems (ICEIS 2025) - Volume 1, pages 173-180
ISBN: 978-989-758-749-8; ISSN: 2184-4992
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
173

version is considered far from solved, as argued in
(Floratou et al., 2024; Lei et al., 2024).
The first contribution of the paper is a novel
strategy to compile NL questions into SQL queries
that leverages the services provided by a database
keyword search (KwS) platform, called DANKE
(Izquierdo et al., 2021; Izquierdo et al., 2024). The
proposed strategy is the first one to explore a sym-
biotic combination of a KwS platform and a prompt
strategy to process NL questions.
The second contribution of the paper is a set of
experiments with a real-world benchmark to assess
the performance of the proposed strategy. The bench-
mark is built upon a relational database with a chal-
lenging schema, which is in production at an en-
ergy company, and a set of 100 NL questions care-
fully defined to reflect the NL questions users submit
and to cover a wide range of SQL constructs (Spi-
der and BIRD, two of the familiar text-to-SQL bench-
marks, were not adopted for the reasons explained in
Section 2.1). These new results, combined with re-
sults from (Nascimento et al., 2024a), indicate that
the proposed strategy performs significantly better
on the real-world benchmark than LangChain SQL-
QueryChain, SQLCoder
1
, “C3 + ChatGPT + Zero-
Shot” (Dong et al., 2023), and “DIN-SQL + GPT-4”
(Pourreza and Rafiei, 2024).
The paper is organized as follows. Section 2 cov-
ers related work. Section 3 describes the database
keyword search platform adopted in the paper. Sec-
tion 4 details the proposed text-to-SQL strategy. Sec-
tion 5 presents the experiments, including the real-
world benchmark used. Finally, Section 6 contains
the conclusions.
2 RELATED WORK
2.1 Text-to-SQL Datasets
The Spider – Yale Semantic Parsing and Text-to-SQL
Challenge (Yu et al., 2018) defines 200 datasets, cov-
ering 138 different domains, for training and testing
text-to-SQL tools. Most databases in Spider have very
small schemas – the largest five databases have be-
tween 16 and 25 tables, and about half have schemas
with five tables or fewer. Furthermore, all Spider NL
questions are phrased in terms used in the database
schemas. These two limitations considerably reduce
the difficulty of the text-to-SQL task. Therefore, the
results reported in the Spider leaderboard are biased
toward databases with small schemas and NL ques-
1
https://huggingface.co/defog/sqlcoder-34b-alpha
tions written in the schema vocabulary, which is not
what one finds in real-world databases.
BIRD – BIg Bench for LaRge-scale Database
Grounded Text-to-SQL Evaluation (Li et al., 2024)
is a large-scale, cross-domain text-to-SQL benchmark
in English. The dataset contains 12,751 text-to-SQL
data pairs and 95 databases with a total size of 33.4
GB across 37 domains. However, BIRD still does not
have many databases with large schemas – of the 73
databases in the training dataset, only two have more
than 25 tables, and, of the 11 databases used for de-
velopment, the largest one has only 13 tables. Again,
all NL questions are phrased in the terms used in the
database schemas.
Despite the availability of these benchmark
datasets for the text-to-SQL task, and inspired by
them, Section 5.1 describes a benchmark dataset con-
structed specifically to test strategies designed for the
real-world text-to-SQL task. The benchmark dataset
consists of a relational database and a set of 100
test NL questions and their ground-truth SQL trans-
lations. The database schema is inspired by a real-
world schema and is far more challenging than most
of the database schemas available in Spider or BIRD.
The database is populated with real data with a se-
mantics which is sometimes not easily mapped to the
semantics of the terms the users adopt (such as “crit-
icity level = 5” encodes “critical orders”), which is
a challenge for the text-to-SQL task not captured by
unpopulated databases, as in Spider. Finally, the NL
questions mimic those posed by real users, and cover
a wide range of SQL constructs.
2.2 Text-to-SQL Tools
A comprehensive survey of text-to-SQL strategies can
be found in (Shi et al., 2024), including a discussion
of benchmark datasets, prompt engineering, and fine-
tuning methods, partly covered in what follows.
Several text-to-SQL tools were tested in (Nasci-
mento et al., 2024a) against the benchmark used in
this paper – SQLCoder, LangChain SQLQueryChain,
C3, and DIN+SQL. Despite the impressive results of
C3 and DIN on Spider, and of SQLCoder on a spe-
cific benchmark, the performance of these tools on the
benchmark used in this paper was significantly lower
(Nascimento et al., 2024a), and much less than that of
the strategy described in Section 4. A similar remark
applies to LangChain SQLQueryChain, whose results
are shown in Line 1 of Table 2.
Lastly, a text-to-SQL tool that leverages dynamic
few-show examples was introduced in (Coelho et al.,
2024). Line 4 of Table 2 shows the results the tool
achieved on the benchmark used in this paper.
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
174

3 A DATABASE KEYWORD
QUERY PROCESSING TOOL
DANKE is the keyword search platform currently de-
ployed for the industrial database described in Sec-
tion 5.1 and used for the experiments. The reader is
referred to (Izquierdo et al., 2021; Izquierdo et al.,
2024) for the details of the platform.
DANKE operates over both relational databases
and RDF datasets, and is designed to compile a key-
word query into an SQL or SPARQL query that re-
turns the best data matches. For simplicity, the de-
scription that follows uses the relational terminology.
DANKE’s architecture comprises three main com-
ponents: (1) Storage Module; (2) Preparation Mod-
ule; and (3) Data and Knowledge Extraction Module.
The Storage Module houses a centralized re-
lational database, constructed from various data
sources. The database is described by a concep-
tual schema, treated in what follows as a relational
schema, again for simplicity.
The Storage Module also holds the data indices
required to support the keyword search service. The
indexing process is enriched to create a keyword dic-
tionary.
The Preparation Module has tools for creating the
conceptual schema and for constructing and updat-
ing the centralized database through a pipeline typ-
ical of a data integration process. The conceptual
schema is defined by de-normalizing the relational
schemas of the underlying databases and indicating
which columns will have their values indexed.
The Data and Knowledge Extraction Module
has two main sub-modules, Query Compilation and
Query Processing.
Let R be the referential dependencies diagram of
the database schema in question, where the nodes of R
are the tables and there is an edge between nodes t and
u iff there is a foreign key from t to u or vice-versa.
Given a set of keywords K, let T
K
be a set of table
schemes whose instances match the largest set of key-
words in K. The query compilation sub-module first
constructs a Steiner tree S
K
of R whose end nodes are
the set T
K
. This is the central point since it guarantees
that the final SQL query will not return unconnected
data, as explored in detail in (Garc
´
ıa et al., 2017). If
R is connected, then it is always possible to construct
one such Steiner tree; overwise, one would have to
find a Steiner forest to cover all tables in T
K
.
Using the Steiner tree, the Query Compilation
sub-module compiles the keyword query into an SQL
query that includes restriction clauses representing
the keyword matches and join clauses connecting
the restriction clauses. Without such join clauses,
an answer would be a disconnected set of tuples,
which hardly makes sense. The generation of the join
clauses uses the Steiner tree edges.
Lastly, DANKE’s internal API was expanded to
support the text-to-SQL strategy described in Section
4. Briefly, it now offers the following services:
• Keyword Match Service: receives a set K of key-
words and returns the set K
M
of pairs (k, d
k
) such
that k ∈ K and d
k
is the dictionary entry that best
matches k. The dictionary entry d
k
will be called
the data associated with k.
• View Synthesis Service: receives a set S
′
of tables
and returns a view V that best joins all tables in S
′
,
using the Steiner tree optimization heuristic men-
tioned above.
4 A TEXT-TO-SQL STRATEGY
The proposed text-to-SQL strategy comprises two
modules, schema linking and SQL query compilation.
The two modules use a dynamic few-shot examples
strategy that retrieves a set of samples from a synthetic
dataset. The key point is the use of services provided
by DANKE to enhance schema linking and simplify
SQL query compilation. In particular, DANKE will
generate a single SQL view containing all data and
encapsulating all joins necessary to answer the input
NL question.
The synthetic dataset D for the database DB con-
tains pairs (Q
N
, Q
SQL
), where Q
N
is an NL question
and Q
SQL
is its SQL translation. Such pairs should
provide examples that help the LLM understand how
the database schema is structured, how the user’s
terms map to terms of the database schema, and how
NL language constructions map to data values. The
synthetic dataset construction process is described in
detail in (Coelho et al., 2024).
Let DB be a relational database with schema S and
D be the synthetic dataset created for DB. Let Q
N
be
an NL question over S.
The schema linking module finds a minimal set
S
′
⊂ S such that S
′
has all tables in S required to an-
swer Q
N
. It has the following components (see Figure
1): Keyword Extraction and Matching; Dynamic Few-
shot Examples Retrieval (DFE); Schema Linking.
Keyword Extraction and Matching receives Q
N
as
input; calls the LLM to extract a set K of keywords
from Q
N
; calls the DANKE Keyword Matching ser-
vice to match K with the dictionary, creating a final
set K
M
of keywords and associated data.
Dynamic Few-shot Examples Retrieval (DFE) re-
ceives Q
N
as input; retrieves from the synthetic
On the Text-to-SQL Task Supported by Database Keyword Search
175

dataset D a set of k examples whose NL ques-
tions are most similar to Q
N
, generating a list T =
[(Q
1
, F
1
), ..., (Q
k
, F
k
)], where F
i
is the set of tables in
the FROM clause of the SQL query associated with Q
i
in D.
Schema Linking receives as input Q
N
, K
M
, and T ;
retrieves the set of tables in S and their columns; calls
the LLM to create S
′
prompted by Q
N
, K
M
, S, and T ;
returns S
′
and K
M
.
Figure 1: Schema linking module.
The SQL query compilation module receives as
input the NL question Q
N
, the set of tables S
′
, and the
set K
M
of keywords and associated data, and returns
an SQL query Q
SQL
. It has the following major com-
ponents (see Figure 2): View Synthesis; Question De-
composition; Dynamic Few-shot Examples Retrieval
(DFE); SQL Compilation.
Figure 2: SQL query compilation module.
View Synthesis receives the set of tables S
′
as in-
put; calls the DANKE View Synthesis service to syn-
thesize a view V that joins the tables in S
′
; returns V .
Question Decomposition receives Q
N
as input; de-
composes Q
N
into sub-questions Q
1
, ..., Q
m
; returns
Q
1
, ..., Q
m
.
Dynamic Few-shot Examples Retrieval (DFE) re-
ceives the list Q
1
, ..., Q
m
as input; for each i ∈ [1, m],
retrieves from the synthetic dataset D a set of p ex-
amples whose NL questions are most similar to Q
i
and whose SQL queries are over S
′
, generating a list
L
i
= [(Q
i
1
, SQL
i
1
), ..., (Q
i
p
, SQL
i
p
)] in decreasing or-
der of similarity of Q
i
j
to Q
i
; creates the final list L,
with k elements, by intercalating the lists L
i
and re-
taining the top-k pairs.
SQL Compilation receives as input Q
N
, V , K
M
,
and L; retrieves from DB a set M of row samples of
V ; calls the LLM to compile Q
N
into an SQL query
Q
SQL
over V , when prompted with Q
N
, V , K
M
, M and
L
′
; returns Q
SQL
.
5 EXPERIMENTS
5.1 A Benchmark Dataset
This section describes a benchmark to help inves-
tigate the real-world text-to-SQL task. The bench-
mark consists of a relational database, a set of 100
test NL questions and their SQL ground-truth transla-
tions, and a set of partially extended views.
The selected database is a real-world relational
database that stores data related to the integrity man-
agement of an energy company’s industrial assets.
The relational schema of the adopted database con-
tains 27 relational tables with, in total, 585 columns
and 30 foreign keys (some multi-column), where the
largest table has 81 columns.
The benchmark contains a set of 100 NL ques-
tions that consider the terms and questions experts use
when requesting information related to the mainte-
nance and integrity processes. The ground-truth SQL
queries were manually defined so that the execution
of a ground-truth SQL query returns the expected an-
swer to the corresponding NL question.
An NL question is classified into simple, medium,
and complex, based on the complexity of its corre-
sponding ground-truth SQL query, as in the Spider
benchmark. The set contains 33 simple, 33 medium,
and 34 complex NL questions.
Lastly, table and column names in the relational
schema use terms based on an internal naming con-
vention for database objects, which makes it hard for
end-users, including non-human users such as LLMs,
to directly use the relational schema. To address this
fact, the benchmark also includes a set of partially ex-
tended views (Nascimento et al., 2024b) that rename
table and column names of the relational schema to
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
176

end users’ terms. Such views also have new columns
that pre-define joins that follow foreign keys and im-
port selected columns from the referenced tables to
facilitate SQL query compilation.
5.2 Evaluation Procedure
The experiments used an automated procedure to
compare the predicted and the ground-truth SQL
queries, entirely based on column and table values,
and not just column and table names. Therefore, a
predicted SQL query may be compared with the cor-
responding ground-truth SQL query based on the re-
sults they return. The results of the automated pro-
cedure were manually checked to eliminate false pos-
itives and false negatives. The reader is referred to
(Nascimento et al., 2024a) for the details.
5.3 Experiments with Schema Linking
5.3.1 Experimental Setup
The first set of experiments evaluated several alterna-
tives for performing the schema linking task.
The experiments adopted the benchmark de-
scribed in Section 5.1. For each NL question, the
ground-truth minimum sets of tables necessary to an-
swer the NL question is the set of tables in the FROM
clause of the ground-truth SQL query. The experi-
ments used GPT-3.5 Turbo and GPT-4, but only the
results obtained with GPT-4 were noteworthy.
Table 1 presents the results of the experiments for
the following alternatives:
1. (LLM): A strategy that prompts an LLM with Q
N
and S to find the set of tables S
′
.
2. (DANKE): A strategy that, first, uses DANKE to
extract a set of keywords K from Q
N
, and then
extracts the set of tables S
′
from the information
associated with K in DANKE’s dictionary.
3. (LLM+DFE): A strategy that, first, finds a set of
examples T from D using Q
N
, and then prompts
an LLM with Q
N
, S, and T to find the set of tables
S
′
.
4. (LLM+DANKE): A strategy that, first, uses an
LLM to extract a set K of keywords from Q
N
, and
then extracts the set of tables S
′
from the informa-
tion associated with K in DANKE’s dictionary.
5. (LLM+DANKE+DFE): A strategy that, first, uses
an LLM to extract a set K of keywords from Q
N
,
retrieves the information associated with K from
DANKE’s dictionary, creating a set K
M
, finds a set
of examples T from D using Q
N
, and then prompts
an LLM with Q
N
, S, K
M
, and T to find the set of
tables S
′
.
6. (Complete): The entire Schema Linking process.
5.3.2 Results
Table 1 presents the precision, recall, and F1-score for
the experiments using the Schema Linking process.
Briefly, the results show that:
1. (LLM): Alternative 1 obtained an F1-score of
0.851. It had a performance poorer than Alter-
native 2, which used just DANKE.
2. (DANKE): Alternative 2 obtained an F1-score of
0.900. Note that DANKE achieved a better re-
sult than Alternatives 1 and 3 (which do not use
DANKE), although DANKE does no syntactic or
semantic processing of the user question Q
N
, and
may incorrectly match terms in Q
N
to terms in the
database schema or to data values.
3. (LLM+DFE): Alternative 3 obtained an F1-score
of 0.868. The use of DFE improved the results
achieved by Alternative 1, but the results were still
lower than those of Alternative 2.
4. (LLM+DANKE): Alternative 4 increased the F1-
score to 0.930. Enriching the prompt with the
keywords extracted by DANKE from Q
N
yielded
consistent improvements in both precision and re-
call. This is due to DANKE’s ability to find refer-
ences to column values, associating them with the
table/column where the value occurs. This fea-
ture allowed DANKE to find implicit references
that were previously impossible for the LLM to
discover since it had no knowledge about the
database instances.
5. (LLM+DANKE+DFE): Alternative 5 increased
the F1-score to 0.950.
6. (Complete – GPT-4): The complete Schema Link-
ing process achieved an F1-Score of 0.996, the
best result. Using the LLM to extract keywords
from Q
N
improved the results of DANKE. Al-
though DANKE may still return incorrect terms,
the LLM corrects them.
7. (Complete – GPT-4o): Using GPT-4o resulted in
a slight decrease in the F1-score to 0.995.
In general, these results show that DANKE, to-
gether with the LLM, performed effectively in the
Schema Linking process for NL questions. Con-
sidering that the complete Schema Linking process
achieved a recall of 1.0, it returned all tables required
to answer each NL question. Thus, the Schema Link-
ing process does not impact the SQL Query Compila-
tion step, although the extra tables may create distrac-
tions for the LLM (see Section 5.4).
On the Text-to-SQL Task Supported by Database Keyword Search
177

Table 1: Results for the schema linking alternatives (all with
GPT-4, except the last line).
# Method Precision Recall F1-score
1 LLM 0.864 0.886 0.851
2 DANKE 0.860 0.983 0.900
3 LLM+DFE 0.940 0.843 0.868
4 LLM+DANKE 0.930 0.930 0.930
5 LLM+DFE+DANKE 0.993 0.983 0.950
6 Complete – GPT-4 0.993 1.000 0.996
7 Complete – GPT-4o 1.000 0.995 0.995
5.4 Experiments with SQL Query
Compilation
5.4.1 Experimental Setup
The experiments were based on LangChain SQL-
QueryChain, which automatically extracts metadata
from the database, creates a prompt with the meta-
data and passes it to the LLM. This chain greatly sim-
plifies creating prompts to access databases through
views since it passes a view specification as if it were
a table specification.
The experiments executed the 100 questions intro-
duced in Section 5.1 in nine alternatives:
1. (Relational Schema): SQLQueryChain executed
over the relational schema of the benchmark
database.
2. (Partially Extended Views): SQLQueryChain ex-
ecuted over the partially extended views of the
benchmark database.
3. (Partially Extended Views and DFE): SQL-
QueryChain executed over the partially extended
views using only the DFE technique.
4. (Partially Extended Views, DFE, and Question
Decomposition): SQLQueryChain executed over
the partially extended views, using Question De-
composition and the DFE technique.
5. (The Proposed Text-to-SQL Strategy – GPT-4):
The proposed Text-to-SQL Strategy, using GPT-
4-32K.
6. (The Proposed Text-to-SQL Strategy – GPT-4o):
The proposed Text-to-SQL Strategy, using GPT-
4o.
7. (The Proposed Text-to-SQL Strategy – LLaMA
3.1-405B-Instruct): The proposed Text-to-SQL
Strategy, using LLaMA 3.1-405B-Instruct.
8. (The Proposed Text-to-SQL Strategy – Mistral
Large): The proposed Text-to-SQL Strategy, us-
ing Mistral Large.
9. (The Proposed Text-to-SQL Strategy – Claude
3.5-Sonnet): The proposed Text-to-SQL Strategy,
using Claude 3.5-Sonnet.
Alternatives 1–6 ran on the OpenAI platform, and
Alternatives 7–9 on the AWS Bedrock platform.
5.4.2 Results
Table 2 summarizes the results for the various alter-
natives. Columns under “#Correct Predicted Ques-
tions” show the number of NL questions per type cor-
rectly translated to SQL (recall that there are 33 sim-
ple, 33 medium, and 34 complex NL questions, with a
total of 100); columns under “Accuracy” indicate the
accuracy results per NL question type and the overall
accuracy; the last column shows the total elapsed time
to run all 100 NL questions.
The results for Alternatives 1, 2, and 3 were
reported in (Nascimento et al., 2024a; Nascimento
et al., 2024b; Coelho et al., 2024), respectively. They
are repeated in Table 2 for comparison with the results
of this paper.
The results for Alternative 4 show that Question
Decomposition produced an improvement in total ac-
curacy from 0.79 to 0.84. This reflects the diversity
of examples passed to the LLM when they are re-
trieved for each sub-question, as already pointed out
in (Oliveira et al., 2025).
The results for Alternative 5 show that the key
contribution of this paper, the text-to-SQL strategy
described in Section 4, indeed leads to a significant
improvement in the total accuracy for the case study
database, as well as the accuracies for the medium and
complex NL questions.
The results for Alternative 6 indicate a slight de-
crease in the total accuracy to 0.90 when GPT-4o is
adopted, possibly due to the non-deterministic behav-
ior of the models. However, while GPT-4-32K took
17 minutes to run all 100 questions, GPT-4o took only
7 minutes.
The results for Alternatives 7–9 show a decrease
in the total accuracy to 0.81%, 0.77%, and 0.74%,
respectively, with a much higher total elapsed time,
when compared with GPT-4o, but comparable to that
of GPT-4-32K.
5.4.3 Discussion
The results in Table 2 show that the proposed strategy
(Line 5) correctly processed four more medium NL
questions and six more NL complex questions than
the previous best strategy (Line 4). However, these
results hide the fact that the proposed strategy pro-
cessed four complex NL questions that none of the
strategies previously tested on the same database and
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
178
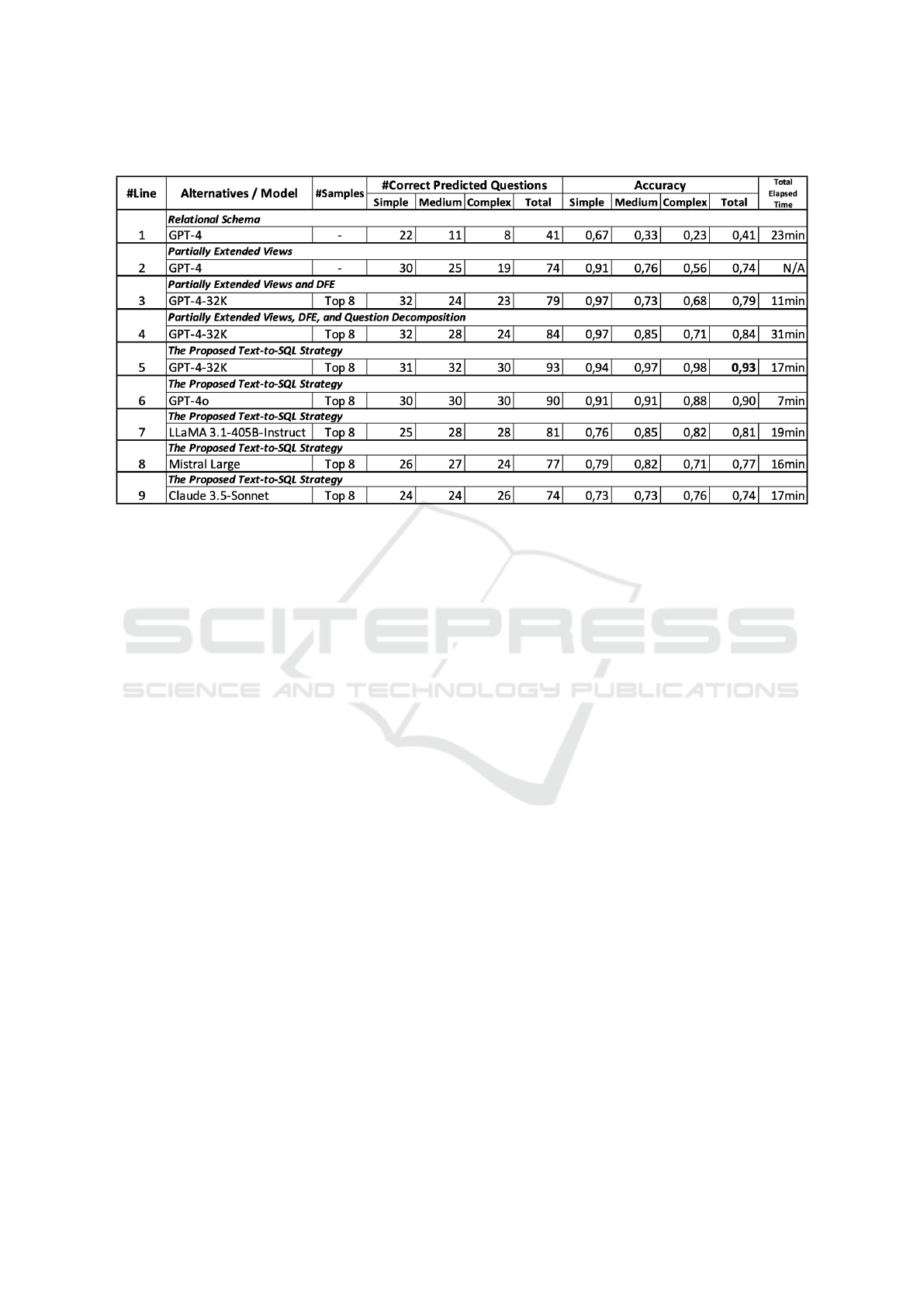
Table 2: Summary of the results.
set of questions have correctly handled, including C3
and DIN.
As for the other models – Llama 3.1-405B In-
struct, Mistral Large, and Claude 3.5 Sonnet – the
most common source of error was the use of the CON-
TAINS function, which requires the target column to
be indexed, but this was not always the case; the cor-
rect filter would have to use LIKE.
6 CONCLUSIONS
This paper proposed a text-to-SQL strategy that lever-
ages the services provided by DANKE, a database
keyword search platform.
The paper detailed how the schema-linking pro-
cess can be improved with the help of the keyword
extraction service that DANKE provides. Then, it
showed how DANKE can be used to synthesize a
view that captures the joins required to process an in-
put NL question and thereby simplify the SQL query
compilation step.
The paper included experiments with a real-world
relational database to assess the performance of the
proposed strategy. The results in Section 5.3 showed
that the precision and recall of the schema-linking
process indeed improved with the help of the keyword
extraction service that DANKE provides. The discus-
sion in Section 5.4 suggested that creating a view with
the help of DANKE also helped with the SQL query
compilation process. In conjunction, these results in-
dicated that the proposed strategy achieved a total ac-
curacy in excess of 90% over a benchmark built upon
a relational database with a challenging schema and
a set of 100 questions carefully defined to reflect the
questions users submit and to cover a wide range of
SQL constructs. The total accuracy was much higher
than that achieved by SQLCoder, LangChain SQL-
QueryChain, C3, and DIN+SQL on the same bench-
mark, as reported in (Nascimento et al., 2024a).
As for future work, the proposed strategy should
be tested and compared against other strategies us-
ing additional databases and test questions. A sec-
ond demand is to address the problem that Natu-
ral Language questions are intrinsically ambiguous.
DANKE’s matching process helps but should be com-
plemented with a different approach, perhaps incor-
porating the user in a disambiguation loop.
ACKNOWLEDGEMENTS
This work was partly funded by FAPERJ under
grant E-26/204.322/2024; by CNPq under grant
302303/2017-0; and by Petrobras, under research
agreement 2022/00032-9 between CENPES and
PUC-Rio.
REFERENCES
Affolter, K., Stockinger, K., and Bernstein, A. (2019). A
comparative survey of recent natural language inter-
faces for databases. The VLDB Journal, 28:793–819.
Coelho, G., Nascimento, E. S., Izquierdo, Y., Garc
´
ıa, G.,
Feij
´
o, L., Lemos, M., Garcia, R., de Oliveira, A., Pin-
On the Text-to-SQL Task Supported by Database Keyword Search
179

heiro, J., and Casanova, M. (2024). Improving the
accuracy of text-to-sql tools based on large language
models for real-world relational databases. In Strauss,
C., Amagasa, T., Manco, G., Kotsis, G., Tjoa, A.,
and Khalil, I., editors, Database and Expert Systems
Applications, pages 93–107, Cham. Springer Nature
Switzerland.
Dong, X., Zhang, C., Ge, Y., Mao, Y., Gao, Y.,
Chen, L., Lin, J., and Lou, D. (2023). C3:
Zero-shot text-to-sql with chatgpt. arXiv preprint.
https://doi.org/10.48550/arXiv.2307.07306.
Floratou, A. et al. (2024). Nl2sql is a solved problem... not!
In Conference on Innovative Data Systems Research.
Garc
´
ıa, G., Izquierdo, Y., Menendez, E., Dartayre, F.,
and Casanova, M. (2017). Rdf keyword-based query
technology meets a real-world dataset. In Proceed-
ings of the 20th International Conference on Extend-
ing Database Technology (EDBT), pages 656–667,
Venice, Italy. OpenProceedings.org.
Izquierdo, Y., Garc
´
ıa, G., Lemos, M., Novello, A., Nov-
elli, B., Damasceno, C., Leme, L., and Casanova, M.
(2021). A platform for keyword search and its appli-
cation for covid-19 pandemic data. Journal of Infor-
mation and Data Management, 12(5):521–535.
Izquierdo, Y., Lemos, M., Oliveira, C., Novelli, B., Garc
´
ıa,
G., Coelho, G., Feij
´
o, L., Coutinho, B., Santana, T.,
Garcia, R., and Casanova, M. (2024). Busca360: A
search application in the context of top-side asset in-
tegrity management in the oil & gas industry. In Anais
do XXXIX Simp
´
osio Brasileiro de Bancos de Dados,
pages 104–116, Porto Alegre, RS, Brasil. SBC.
Katsogiannis-Meimarakis, G. and Koutrika, G. (2023). A
survey on deep learning approaches for text-to-sql.
The VLDB Journal, 32(4):905–936.
Kim, H., So, B.-H., Han, W.-S., and Lee, H. (2020). Natural
language to sql: Where are we today? Proc. VLDB
Endow., 13(10):1737–1750.
Lei, F. et al. (2024). Spider 2.0: Evaluat-
ing language models on real-world enter-
prise text-to-sql workflows. arXiv preprint.
https://doi.org/10.48550/arXiv.2411.07763.
Li, J., Hui, B., Qu, G., Yang, J., Li, B., Li, B., Wang, B.,
Qin, B., Geng, R., Huo, N., Zhou, X., Ma, C., Li, G.,
Chang, K., Huang, F., Cheng, R., and Li, Y. (2024).
Can llm already serve as a database interface? a big
bench for large-scale database grounded text-to-sqls.
In Proceedings of the 37th International Conference
on Neural Information Processing Systems, NIPS ’23,
Red Hook, NY, USA. Curran Associates Inc.
Nascimento, E., Garc
´
ıa, G., Feij
´
o, L., Victorio, W.,
Izquierdo, Y., Oliveira, A., Coelho, G., M., L., Garcia,
R., Leme, L., and Casanova, M. (2024a). Text-to-sql
meets the real-world. In Proceedings of the 26th Inter-
national Conference on Enterprise Information Sys-
tems - Volume 1: ICEIS, pages 61–72, Set
´
ubal, Portu-
gal. INSTICC, SciTePress.
Nascimento, E., Izquierdo, Y., Garc
´
ıa, G., Coelho, G.,
Feij
´
o, L., Lemos, M., Leme, L., and M.A., C.
(2024b). My database user is a large language model.
In Proceedings of the 26th International Confer-
ence on Enterprise Information Systems - Volume 1:
ICEIS, pages 800–806, Set
´
ubal, Portugal. INSTICC,
SciTePress.
Oliveira, A., Nascimento, E., Pinheiro, J., Avila, C., Coelho,
G., Feij
´
o, L., Izquierdo, Y., Garc
´
ıa, G., Leme, L.,
Lemos, M., and Casanova, M. (2025). Small, medium,
and large language models for text-to-sql. In Maass,
W., Han, H., Yasar, H., and Multari, N., editors, Con-
ceptual Modeling, pages 276–294, Cham. Springer
Nature Switzerland.
Pourreza, M. and Rafiei, D. (2024). Din-sql: decomposed
in-context learning of text-to-sql with self-correction.
In Proceedings of the 37th International Conference
on Neural Information Processing Systems, NIPS ’23,
Red Hook, NY, USA. Curran Associates Inc.
Shi, L., Tang, Z., Zhang, N., Zhang, X., and Yang,
Z. (2024). A survey on employing large lan-
guage models for text-to-sql tasks. arXiv preprint.
https://doi.org/10.48550/arXiv.2407.15186.
Yu, T., Zhang, R., Yang, K., Yasunaga, M., Wang, D., Li,
Z., Ma, J., Li, I., Yao, Q., Roman, S., Zhang, Z.,
and Radev, D. (2018). Spider: A large-scale human-
labeled dataset for complex and cross-domain seman-
tic parsing and text-to-sql task. In Riloff, E., Chiang,
D., Hockenmaier, J., and Tsujii, J., editors, Proc. 2018
Conference on Empirical Methods in Natural Lan-
guage Processing, pages 3911–3921, Brussels, Bel-
gium. Association for Computational Linguistics.
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
180
