
Experience Replay and Zero-Shot Clustering for Continual Learning in
Diabetic Retinopathy Detection
Gusseppe Bravo-Rocca
1 a
, Peini Liu
1 b
, Jordi Guitart
1,2 c
, Ajay Dholakia
3 d
,
David Ellison
3 e
and Rodrigo M. Carrillo-Larco
4 f
1
Barcelona Supercomputing Center, Barcelona, Spain
2
Universitat Politècnica de Catalunya, Barcelona, Spain
3
Lenovo Infrastructure Solutions Group, Morrisville, NC, U.S.A.
4
Emory University, GA, U.S.A.
Keywords:
Zero-Shot Clustering, Experience Replay, Diabetic Retinopathy Detection, Privacy-Preserving Learning,
Medical Imaging.
Abstract:
We present an approach to mitigate catastrophic forgetting in Continual Learning (CL), focusing on domain
incremental scenarios in medical imaging. Our method leverages Large Language Models (LLMs) to generate
task-agnostic descriptions from multimodal inputs, enabling zero-shot clustering of tasks without supervision.
This clustering underpins an enhanced Experience Replay (ER) strategy, strategically sampling data points to
refresh the model’s memory while preserving privacy. By incrementally updating a multi-head classifier using
only data embeddings, our approach maintains both efficiency and data confidentiality. Evaluated on a chal-
lenging diabetic retinopathy dataset, our method demonstrates significant improvements over traditional CL
techniques, including Elastic Weight Consolidation (EWC), Gradient Episodic Memory (GEM), and Learn-
ing Without Forgetting (LWF). Extensive experiments across Multi-Layer Perceptron (MLP), Residual, and
Attention architectures show consistent performance gains (up to 3.1% in Average Mean Class Accuracy) and
reduced forgetting, with only 6% computational overhead. These results highlight our approach’s potential
for privacy-preserving, efficient CL in sensitive domains like healthcare, offering a promising direction for
developing adaptive AI systems that can learn continuously while respecting data privacy constraints.
1 INTRODUCTION
Continual Learning (CL) aims to develop AI systems
capable of acquiring and refining knowledge over
time, mirroring human-like adaptive learning (Parisi
et al., 2019). Unlike conventional Machine Learn-
ing approaches that separate training and inference
phases, CL models must adapt to evolving real-world
data and tasks (Wang et al., 2024). This adaptation is
crucial in scenarios with blurred task boundaries (Koh
et al., 2022) and in environments requiring continuous
learning without catastrophic forgetting (De Lange
et al., 2022; Kirkpatrick et al., 2017; Robins, 1993).
a
https://orcid.org/0000-0001-6824-1124
b
https://orcid.org/0000-0003-0058-8732
c
https://orcid.org/0000-0003-0751-3100
d
https://orcid.org/0009-0007-8973-6063
e
https://orcid.org/0000-0002-0752-5569
f
https://orcid.org/0000-0002-2090-1856
A significant challenge in CL is maintaining con-
sistent performance across changing multimodal data
distributions, particularly in domains like medical
imaging where privacy concerns and data mutability
are paramount. Domain Incremental Learning (DIL)
faces acute challenges with domain shifts, such as
variations in lighting, population characteristics, or
noise in medical image classifiers. Traditional re-
training approaches are often infeasible due to pri-
vacy constraints in healthcare (Kumar and Srivas-
tava, 2018; Kumari and Singh, 2024; Lenga et al.,
2020), leading to performance degradation on previ-
ously learned tasks (Khan et al., 2024; Kuang et al.,
2018).
To address these challenges, we present a
novel unsupervised learning framework that leverages
Large Language Models (LLMs) for CL in privacy-
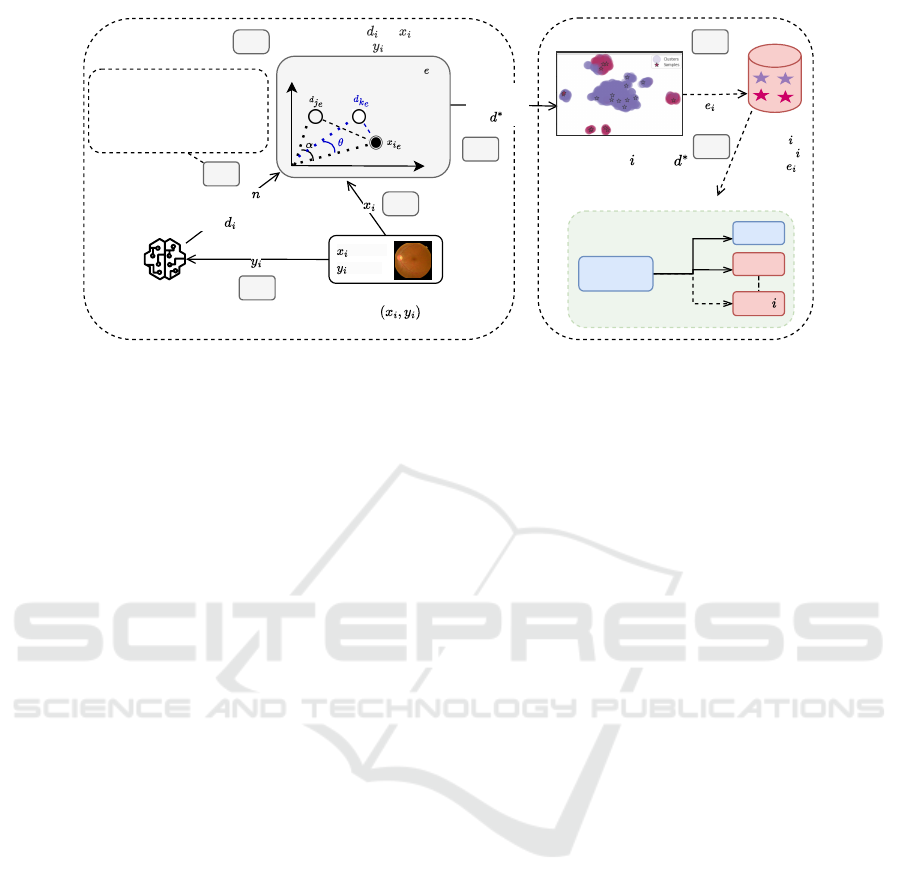
sensitive domains. As shown in Figure 1, our ap-
proach uses LLMs to generate textual descriptions
from multimodal inputs (images, labels), enabling
Bravo-Rocca, G., Liu, P., Guitart, J., Dholakia, A., Ellison, D. and Carrillo-Larco, R. M.
Experience Replay and Zero-Shot Clustering for Continual Learning in Diabetic Retinopathy Detection.
DOI: 10.5220/0013128600003912
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 2: VISAPP, pages
81-92
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
81

zero-shot clustering without predefined task bound-
aries. That is, once we get the LLM-generated de-
scriptions, we map them to embeddings. On the same
space, we compare these embeddings with the im-
ages’ embeddings to perform the clustering. This
method is particularly well-suited for medical imag-
ing scenarios, such as Diabetic Retinopathy (DR) de-
tection from fundus images, where data privacy and
distribution shifts are critical concerns.
Our approach extends the concept of ER (Riemer
et al., 2019) by integrating a strategic sampling
methodology derived from zero-shot clusters. This
new ER strategy refreshes the neural network’s mem-
ory, mitigating knowledge degradation across tasks.
The model architecture employs a multi-head classi-
fier that expands incrementally with new tasks, each
head containing a simple linear layer for adaptation.
Key features of our approach include:
• Privacy Preservation. By operating on embed-
dings rather than raw images, our method ad-
dresses critical privacy concerns in sensitive do-
mains like healthcare.
• Resource Efficiency. Designed to function on
CPUs using embeddings, our approach is compu-
tationally efficient and suitable for deployment in
resource-constrained environments.
• Adaptability. The ER strategy, free from fixed
task definitions, improves adaptability to evolv-
ing data distributions in medical imaging scenar-
ios (Zhang et al., 2024; Serra et al., 2018).
• Foundation Model Integration. We leverage
CLIP (Radford et al., 2021) to produce robust im-
age embeddings, enhancing the zero-shot cluster-
ing process.
Our method seamlessly integrates with and en-
hances established CL strategies, including Elas-
tic Weight Consolidation (EWC) (Kirkpatrick et al.,
2017), Gradient Episodic Memory (GEM) (Lopez-
Paz and Ranzato, 2017), and Learning Without For-
getting (LWF) (Li and Hoiem, 2017). We demon-
strate its effectiveness on a challenging DR dataset
(Karthik, 2019), showcasing improved robustness
against forgetting and significant performance boosts
over existing techniques.
The main contributions of our paper are:
1. A novel zero-shot clustering framework using
LLM-generated descriptions for unsupervised im-
age clustering, enhancing ER in CL.
2. A privacy-preserving, CPU-based ER strategy
leveraging zero-shot clusters for efficient incre-
mental learning in sensitive domains.
3. Comprehensive experiments demonstrating our
method’s efficacy in preventing catastrophic for-
getting and enhancing existing CL performance
across multiple model architectures (MLP, Resid-
ual, and Attention).
4. A generalizable approach to CL that addresses
key challenges in medical imaging while show-
ing potential applicability to other domains with
similar privacy and distribution shift concerns.
2 RELATED WORK
LLMs for Zero-Shot Learning. LLMs have dra-
matically transformed machine capabilities for under-
standing and generating human-like text, notably en-
hancing zero-shot learning (Brown and et al., 2020).
Our research leverages these capabilities, using LLMs
to create descriptive embeddings for images. These
embeddings, when integrated with the visual embed-
dings from CLIP, facilitate effective zero-shot clus-
tering. This method represents a departure from the
usual applications of LLMs, which typically direct
task execution. Instead, we use their generative power
to enhance data organization for CL.
Experience Replay. ER is rooted in the aspiration to
emulate aspects of human memory processes, where
past experiences are occasionally revisited to solidify
learning. The canonical form of ER (Riemer et al.,
2019) involves interleaved training of new tasks with
memory samples, seeking to approximate the joint
distribution of tasks. Variants like Dark ER (Buzzega
et al., 2020) have added layers of complexity, employ-
ing distillation loss to enforce output consistency. Re-
cent trends in ER have seen the incorporation of dual-
memory architectures, such as approaches mirroring
the interplay between fast and slow learning processes
by maintaining two semantic memories (Arani et al.,
2022). While such architectures provide novel mech-
anisms to handle forgetting, the optimal way to struc-
ture and utilize these memories remains an open chal-
lenge. In our work, we use this idea to incorporate
past data points to inform the replay, based on the data
properties.
Privacy-Preserving Exemplars. ER is essential for
mitigating catastrophic forgetting, typically involving
raw data samples from previous tasks. Our method
enhances privacy by storing only the embeddings of
exemplars, not the raw images. This modification
ensures data privacy while maintaining ER effective-
ness. By fine-tuning zero-shot clustering on train-
ing datasets, we refine exemplar selection, ensuring
the memory buffer contains the most representative
embeddings (Rebuffi et al., 2017; Shin et al., 2017).
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
82
Inference (for Task 1, ..., Task N)
Custom Experience Replay
Training (for Task 0)
Multimodal
input
: Image
: Label
Multi-head
classifier
Base model
Head 0
Head 1
Head
Train a new
head
for Task
using
Zero-shot clustering
for any Task using
Large
Language
Model
Best
descriptions
Find best for
given
Language-image embedding ( )
Generate
pairs of descriptions
Sample
each
cluster
2
1
2
4
5
6
Positive: "[Optical image
shows] {an iris with retinal
disease}"
Negative: "[Optical image
shows] {normal retina}"
Closest
candidate
3
Memory Buffer
Figure 1: Our method uses a Large Language Model (LLM) to generate descriptions d
i
for each image x, using its label y for
initial domain learning in Task 0. These descriptions underpin unsupervised zero-shot clustering, forming clusters x
i
. Key
points from these clusters are buffered for replay. A multi-head classifier leverages this buffer in an Experience Replay (ER)
strategy, learning the pertinent head i for predictions y, thus preserving knowledge across successive tasks.
This approach addresses privacy concerns in medical
image analysis by storing embeddings instead of ac-
tual images, complying with privacy regulations and
addressing security concerns (Shokri and Shmatikov,
2015). Our strategy meets the growing demand for
privacy-preserving ML techniques.
CLIP Embeddings in CL. Our methodology re-
purposes CLIP as an embedder within a CL frame-
work, eschewing the common practice of fine-tuning
CLIP on downstream tasks. This strategy retains the
model’s zero-shot learning capabilities while avoid-
ing the pitfalls of catastrophic forgetting inherent
in direct fine-tuning scenarios (Garg et al., 2023).
By comparing LLM-generated descriptions, our zero-
shot clustering fine-tuning process identifies optimal
exemplars for memory storage, facilitating more ef-
fective learning across sequential tasks.
Continual Learning in Medical Imaging. CL in
medical imaging presents unique challenges due to
privacy concerns and data distribution shifts. Recent
work has explored continuous domain adaptation for
healthcare applications (Venkataramani et al., 2018),
addressing the evolving nature of medical data. Addi-
tionally, domain adaptation techniques have been ap-
plied to medical image segmentation tasks (Valindria
et al., 2018), demonstrating the potential of transfer
learning in this field. Our work builds upon these
foundations, introducing a novel approach that com-
bines zero-shot learning with ER, specifically tailored
to handle the privacy and distribution shift issues in
medical imaging scenarios.
3 PROBLEM STATEMENT
Challenges and Requirements. The primary chal-
lenges in DIL include:
• Catastrophic Forgetting. New knowledge acqui-
sition leads to the erosion of previously learned
information.
• Dynamic Data Distributions. The data distribu-
tion D
i
changes over time, necessitating continual
model adaptation.
• Privacy Preservation. Direct access to raw data
is often restricted, especially in sensitive applica-
tions like healthcare.
• Task Boundary Ambiguity. In real-world sce-
narios, clear task boundaries may not exist, re-
quiring models to adapt without explicit task de-
lineation.
Formal Definition. DIL involves training a model H
on a sequence of tasks {T
1
, T
2
, . . . , T
n
}, where the data
distribution for each task may change over time. In
our context, a task T
i
represents a specific domain or
data distribution, such as fundus images with particu-
lar lighting conditions or noise levels. The model H
consists of a base network b(x;θ
b
) shared across tasks
and a set of task-specific heads {g
k
(z;θ
k
)}, where
z = b(x; θ
b
) is the shared representation. The objec-
tive is to minimize the cumulative loss:
min
θ
b
,{θ
k
}
n
∑
i=1
L(H (D
i
;θ
b
, θ
i
), Y
i
), (1)
where θ
b
are the parameters of the base network,
θ
i
are the parameters of the head for task T
i
, D
i
and
Experience Replay and Zero-Shot Clustering for Continual Learning in Diabetic Retinopathy Detection
83

Y
i
are the data and labels for task T
i
, respectively, and
L denotes the loss function.
During training on a new task T
n
, a new head
g
n
(z;θ
n
) is added to the model:
H (x; θ
b
, {θ
k
}
n
k=1
) = g
n
(b(x;θ
b
);θ
n
). (2)
The goal is to optimize the parameters θ
b
and {θ
k
}
such that the performance on all previously learned
tasks {T
1
, T
2
, . . . , T
n−1
} is maintained while learning
the new task T
n
.
Task Iteration. In our approach, tasks are presented
sequentially, with each task representing a distinct do-
main or data distribution. The model is trained on
these tasks in order, without revisiting previous tasks
except through the ER mechanism. This setup sim-
ulates real-world scenarios where data distributions
evolve over time and previous data may not be fully
accessible.
Significance and Impact. Addressing these chal-
lenges will enable the development of more robust
and adaptive AI systems. In medical imaging, for
instance, this means more accurate and timely diag-
noses despite evolving data distributions, all while
preserving patient privacy. Successfully solving this
problem will also advance the broader field of CL,
providing insights and techniques applicable to var-
ious dynamic environments where data distributions
shift over time and privacy is a concern.
4 APPROACH
We propose a framework that synergizes LLMs,
specifically GPT-4 (OpenAI, 2023), with vision-
language models like CLIP to enhance CL through
zero-shot clustering and ER. Our approach addresses
key challenges in CL, particularly in privacy-sensitive
domains like medical imaging, by leveraging GPT-
4-generated descriptions and CLIP embeddings for
zero-shot clustering. This method enables the iden-
tification of exemplars for ER without storing raw
images, ensuring privacy preservation and efficient
learning across sequential tasks.
4.1 Zero-Shot Clustering with LLM
and CLIP
Our zero-shot clustering method harnesses the com-
bined strengths of GPT-4 and CLIP to cluster im-
ages into predefined classes without explicit training.
This approach is particularly valuable in CL scenarios
where task boundaries are ambiguous and data distri-
butions evolve over time.
Given a set of images {I
1
, I
2
, . . . , I
n
} and their as-
sociated labels (’Retinopathy’ and ’No Retinopathy’),
we employ GPT-4 to generate a set of textual de-
scriptions {D
1
, D
2
, . . . , D
m
}. These descriptions cap-
ture various aspects of the images, including poten-
tial class information (e.g., presence or absence of
retinopathy) and other relevant features. We then uti-
lize CLIP (ViT-L/14@336px configuration) to obtain
embeddings for both images and textual descriptions,
leveraging its ability to create a shared embedding
space for multimodal data.
4.1.1 Embedding Generation
The embedding process consists of two key steps:
1. Textual Description Generation and Tokenization:
GPT-4 generates descriptions based on image labels,
which are then tokenized for CLIP input.
2. CLIP Encoding: Both tokenized descriptions and
images are processed by CLIP to obtain normalized
embeddings, denoted as X
i
for images and T
j
for text
descriptions.
Formally, we represent this process as:
X
i
=
CLIP
image
(I
i
)
|CLIP
image
(I
i
)|
, T
j
=
CLIP
text
(D
j
)
|CLIP
text
(D
j
)|
(3)
where CLIP
image
(·) and CLIP
text
(·) are CLIP’s im-
age and text encoding functions, respectively. Nor-
malization ensures all embeddings lie on the unit
sphere, facilitating similarity computations.
4.1.2 Similarity Computation and Clustering
We perform zero-shot clustering by computing cosine
similarities between image and text embeddings. For
each image embedding X
i
, we calculate its similarity
to all text embeddings T
j
:
S
i j
= cos(X
i
, T
j
) =
X
i
· T
j
|X
i
||T
j
|
(4)
Label assignment for each image is determined
by the text description yielding the highest similar-
ity score: L
i
= argmax
j
S
i j
. This process effectively
assigns each image to the class best represented by
its most similar text description, achieving zero-shot
classification without task-specific training.
4.1.3 Optimizing Description Selection
To maximize the effectiveness of zero-shot cluster-
ing, we optimize the selection of textual descriptions.
We experiment with various templates and descrip-
tion sets (see Table 1), evaluating their clustering per-
formance using F1-score (due to imbalanced data).
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
84
Algorithm 1 outlines this optimization process, and
Figure 2 presents the results.
Data: Image set I , class labels L = {0, 1}, set of
description sets D, set of templates T
Result: Optimal template T
∗
, optimal description
set D
∗
foreach template t ∈ T do
foreach description set d ∈ D do
Generate text prompts using template t
and description set d;
Obtain text embeddings T
j
using the
CLIP model;
foreach image I
i
∈ I do
Compute similarity scores S
i j
between image I
i
and all
embeddings T
j
;
Assign label L
i
to image I
i
based on
the highest similarity score S
i j
;
end
Evaluate the F1-score for the current
combination of t and d;
if current scores are higher than the best
previous scores then
Update T
∗
and D
∗
with the current
template t and description set d;
end
end
end
Algorithm 1: Optimizing Description Selection for Zero-
shot Clustering.
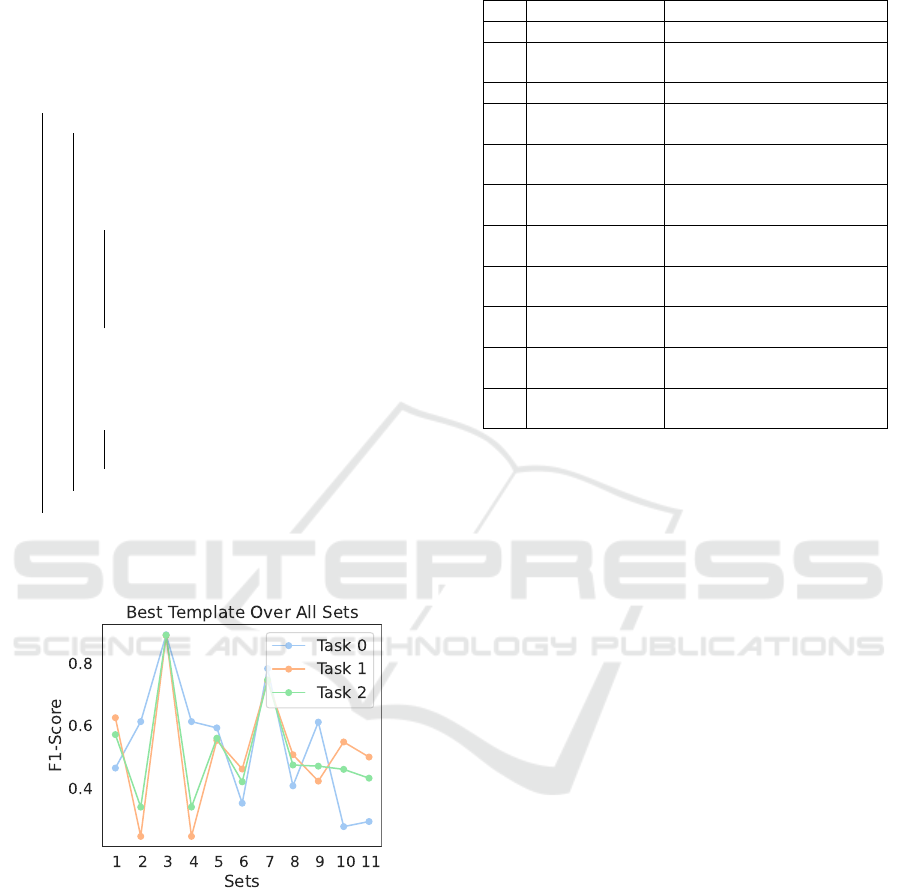
Figure 2: Optimal template against all the sets. We can
see that ’Set 3’ gets the highest score for Task 0 and also
for Task 1 and Task2, indicating a useful description and
template for zero-shot clustering at inference time.
We task GPT-4 to generate 11 description sets for
the classes No Retinopathy and Retinopathy, paired
with 10 templates for constructing prompts. These
sets vary in detail, from technical terms (e.g., "Mild
to Severe non-proliferative diabetic retinopathy") to
simpler descriptions (e.g., "Signs of diabetic retinopa-
thy"). Templates such as "An iris with {}", "A human
eye with {}", and "An ocular image with {}" were
used to form the final prompts.
Table 1: 10 Templates and 11 Description Sets optimized
for Zero-shot Clustering.
# Templates Binary Description Sets
1 An iris with Healthy / Diabetic damage
2 A human eye
with
No damage / Diabetic signs
3 no template Normal / Retinal disease
4 An ocular im-
age with
No issues / Retinopathy
5 A retinal photo
with
Clear fundus / Fundus
changes
6 A fundus image
displaying
No retinopathy / Mild-
severe incl. laser
7 Visible symp-
toms suggest
Normal fundus / Retinopa-
thy incl. laser
8 Retinal scan re-
veals
No abnormalities / Non-
proliferative
9 Optical image
shows
No pathology / Mild-severe
incl. laser
10 The condition
of the retina is
Healthy / Mild-severe incl.
laser
11 No disease / Various stages
incl. laser
This comprehensive generation enables our
method to adapt to the nuances of DR detection.
4.2 Stratified Sampling for Experience
Replay
After optimizing the textual descriptions and tem-
plates for zero-shot clustering, we employ stratified
sampling to ensure balanced representation of each
class within the ER buffer. This approach is crucial
for constructing a diverse and representative collec-
tion of multimodal inputs, each containing an embed-
ding, label, ensuring effective and privacy-preserving
ER while promoting generalization across tasks and
minimizing catastrophic forgetting.
4.2.1 Sampling Procedure
Given a collection of multimodal inputs M , where
each input m
i
∈ M is characterized by its embedding
E
i
, zero-shot label z
i
, we define a stratified sampling
strategy to select a subset S ⊆ M with proportional
representation across the zero-shot classified labels.
For each distinct zero-shot label l ∈ Z derived
from the clustering process, we define a subset M
l
⊂
M containing inputs with label l. We then sample
n
neighbors
inputs from each subset M
l
:
S
l
=
(
sample(M
l
, n
neighbors
), if |M
l
| > n
neighbors
M
l
, otherwise
(5)
Experience Replay and Zero-Shot Clustering for Continual Learning in Diabetic Retinopathy Detection
85
The final sample set S is the union of all samples
across the labels:
S =
[
l∈Z
S
l
(6)
This stratified sampling strategy ensures a bal-
anced replay buffer, critical for maintaining diversity
during ER and reducing the risk of catastrophic for-
getting while reinforcing learning across tasks.
4.2.2 Clustering+Sampling Performance
We evaluate our zero-shot clustering and stratified
sampling approach across three tasks of increasing
complexity (described in Section 5.2.1). Some key
insights can be derived from our results, which are
shown in Table 2.
Table 2: Zero-shot clustering and sampling results across
tasks 0, 1, and 2.
Task Class 0 Class 1 Samples F1-score
0 387 653 20 (1.92%) 0.892
1 1732 890 20 (0.76%) 0.890
2 2120 1542 20 (0.55%) 0.891
• Class Distribution. There is significant class im-
balance across tasks, mirroring real-world med-
ical imaging scenarios where pathological cases
are less frequent.
• Sampling Efficiency. Consistent selection of 20
samples per task (1.92% to 0.55% of total data),
demonstrating compact yet representative mem-
ory buffer maintenance as the dataset grows.
• Performance Stability. F1-scores remain consis-
tent (0.89) across tasks despite increasing com-
plexity and imbalance, highlighting the robust-
ness of our approach in evolving data distribu-
tions.
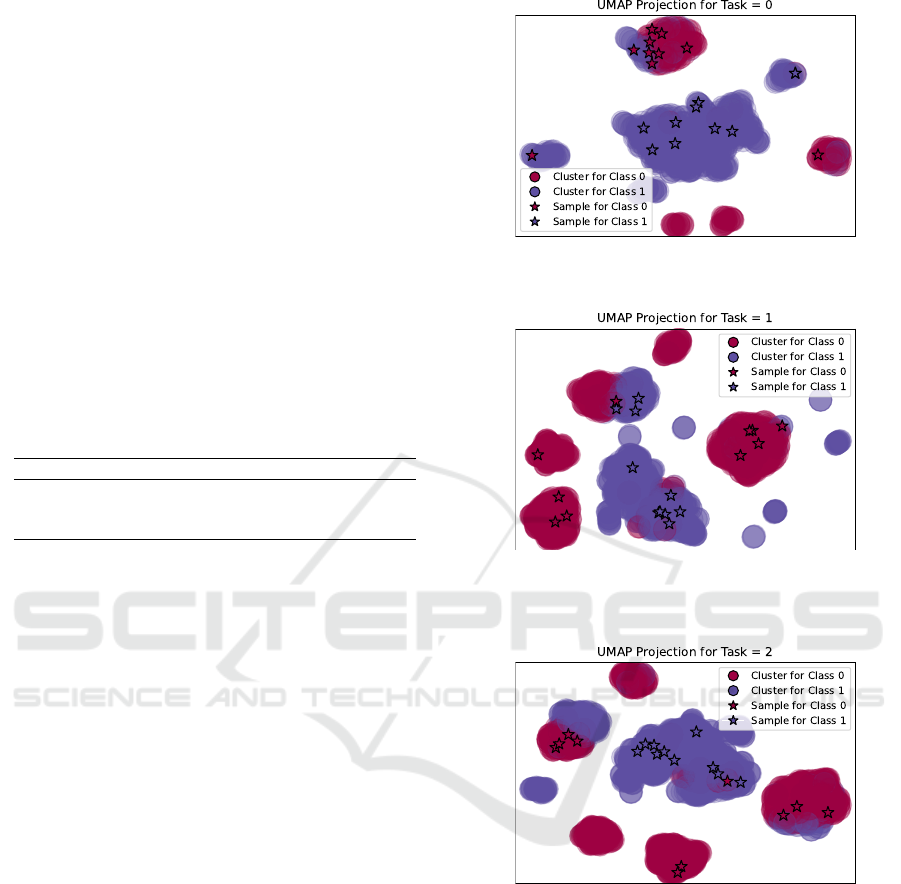
These quantitative results are further illustrated
by the qualitative analysis shown in Figure 3, which
presents UMAP projections of clusters and selected
samples for each task.
4.2.3 Template and Description Set Performance
We evaluate the performance of various templates and
description sets for zero-shot clustering across tasks.
Figure 4 presents the top-performing combinations
for each task.
The key findings from our template and descrip-
tion set analysis are as follows:
• Across all tasks, the template "Optical image
shows" combined with description Set 3 ("Normal
(a) Task 0: Clusters with uniform image quality. The model
successfully differentiates between Class 0 and Class 1,
with well-separated cluster shapes.
(b) Task 1: Clusters impacted by lighting variation. Light-
ing variations cause more overlap between clusters, making
classification harder, yet most sample points are still cor-
rectly clustered.
(c) Task 2: Clusters with Gaussian noise applied. Noise
increases cluster overlap significantly. Despite the noise,
some samples remain distinguishable, demonstrating mod-
erate model robustness.
Figure 3: UMAP projections of clusters for embeddings
across the three tasks. Each projection includes clusters and
10 samples from the memory buffer for both Class 0 and
Class 1. These projections illustrate how the model adapts
to progressively increasing task complexity.
/ Retinal disease") consistently achieves the high-
est F1-scores (0.892, 0.890, and 0.891 for Tasks
0, 1, and 2, respectively).
• Set 3 demonstrates robust performance across
all tasks, indicating its effectiveness in zero-shot
clustering for DR detection.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
86
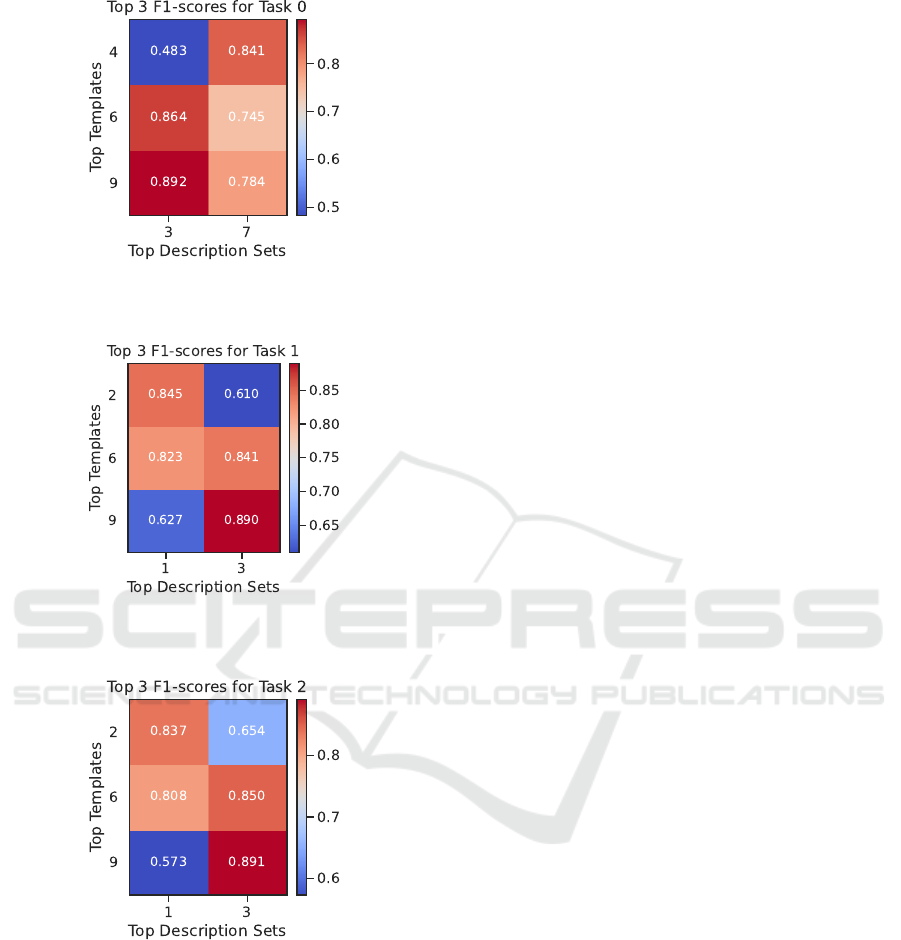
(a) Task 0: Top 3 templates and description sets. The best-
performing pair is {Template 9, Set 3}, achieving an F1-
score of 0.892.
(b) Task 1: Top 3 templates and description sets. The best-
performing pair is {Template 9, Set 3}, achieving an F1-
score of 0.890.
(c) Task 2: Top 3 templates and description sets. The best-
performing pair is {Template 9, Set 3}, achieving an F1-
score of 0.891.
Figure 4: Top 3 templates and description sets for each task,
highlighting the highest F1-scores for zero-shot clustering
across Tasks 0, 1, and 2. Set 3 consistently shows top per-
formance in combination with different templates across all
tasks.
• Sets 1 ("Healthy / Diabetic damage") and 7 ("Nor-
mal fundus / Retinopathy incl. laser") also show
promising performance, highlighting the impor-
tance of carefully crafted descriptions in zero-shot
learning scenarios.
These results highlight the robustness of our
method, which consistently adapts to increasing task
complexity (e.g., uniform quality, lighting variation,
Gaussian noise) while maintaining high performance
in zero-shot clustering and sample selection for ER.
This demonstrates its effectiveness in real-world sce-
narios where image quality varies significantly.
4.3 Experience Replay Algorithm
We propose an enhanced ER algorithm that leverages
zero-shot clustering and stratified sampling to address
catastrophic forgetting in CL. Our method comprises
two key components: a zero-shot exemplars buffer
and an ER strategy.
4.3.1 Zero-shot Exemplars Buffer
The zero-shot exemplars buffer maintains a balanced
set of exemplars based on zero-shot clustering out-
comes. It is updated as shown in Algorithm 2.
Input: Max buffer size max_size, neighbors
n_neighbors, strategy S
Output: Updated replay buffer B
D ← {CreateMultimodalInput(d) | d ∈
S.experience.dataset};
C , Z ←
ZEROSHOTCLUSTERING(D,text_embs_best);
S ← STRATIFIEDSAMPLING(C , Z, n_neighbors);
B ← {(E
s
, y
s
,t
s
) | s ∈ S, (E
s
, y
s
,t
s
) =
ExtractFeatures(s)};
Update B in strategy S, respecting max_size;
Algorithm 2: Updating Replay Buffer with Zeroshot Exem-
plars.
Key features of our zero-shot exemplars buffer
include: multimodal input creation encapsulating
embeddings and labels, unsupervised clustering us-
ing pre-computed text embeddings, stratified sam-
pling for balanced cluster representation, privacy-
preserving updates using embeddings instead of raw
data and dynamic buffer group adjustment based on
clustering outcomes.
This approach ensures diverse sample representa-
tion while maintaining privacy and efficiency. The use
of zero-shot labels enhances applicability in scenarios
with scarce ground truth.
4.3.2 Experience Replay Strategy
Our ER strategy integrates the zero-shot exemplars
buffer into the training process as shown in Algorithm
3. This strategy addresses key CL challenges through
several mechanisms. It employs adaptive sampling
via zero-shot clustering, mitigating task boundary am-
biguity, while ensuring balanced class and task repre-
Experience Replay and Zero-Shot Clustering for Continual Learning in Diabetic Retinopathy Detection
87

sentation through stratified sampling. The approach
maintains privacy preservation by operating on em-
beddings, and achieves computational efficiency with
a compact, diverse replay buffer.
Input: Training strategy S, Storage policy P (with
zero-shot exemplars buffer B)
Output: Updated training strategy with ER
Attach P to S ;
while training do
if B ∈ P is not empty then
S.dataloader ←
Combine(S.adapted_dataset, B);
end
ExecuteTrainingExperience();
B ← P .update(S);
end
Algorithm 3: Experience Replay Strategy.
5 EXPERIMENTAL EVALUATION
We rigorously evaluate our proposed CL approach on
the challenging task of DR detection, assessing its
efficacy under various conditions that simulate real-
world scenarios.
5.1 Experimental Setup
5.1.1 Testbed
Our experiments were conducted on a CPU-based
platform with comprehensive specifications. The
hardware configuration consists of Dual Intel Xeon
Platinum 8360Y CPUs operating at 2.40GHz with
256 GB RAM, running on Ubuntu 22.04 LTS.
Our software stack includes the Intel AI Analyt-
ics Toolkit (Docker image: intel/oneapi-aikit:devel-
ubuntu22.04)
1
, Avalanche 0.3.1 for CL
2
, Intel Exten-
sion for PyTorch 1.12.100+cpu
3
, and Intel Extension
for Scikit-learn 2023.0.1
4
. This environment ensures
reproducibility and leverages optimized libraries for
enhanced performance on CPU architectures.
5.1.2 Dataset
We utilize the APTOS 2019 Blindness Detection
dataset (Karthik, 2019), comprising 3,662 high-
resolution retinal images. This dataset, developed
in collaboration with Aravind Eye Hospital in India,
captures real-world clinical complexities and image
1
https://hub.docker.com/r/intel/oneapi-aikit
2
https://avalanche.continualai.org/
3
https://github.com/intel/intel-extension-for-pytorch
4
https://github.com/intel/scikit-learn-intelex
quality variations, providing a robust testbed for our
CL approach. Figure 5 presents sample images from
this dataset, illustrating the diversity in image quality
and pathological conditions.
Figure 5: Representative fundus images from different
tasks, showcasing varying image quality and conditions.
Left: Task 0 - uniform image quality; Center: Task 1 - vari-
ation in lighting; Right: Task 2 - artificially added Gaussian
noise to simulate challenging imaging conditions.
5.2 Experimental Methodology
5.2.1 Task Design
We construct three distinct tasks to assess our model’s
performance under progressively challenging condi-
tions:
• Task 0 (Baseline). Uniform image quality, repre-
senting ideal clinical conditions.
• Task 1 (Lighting Variation). Introduces varia-
tions in lighting, simulating different imaging en-
vironments.
• Task 2 (Noise Addition). Incorporates Gaussian
noise, emulating low-quality or degraded images.
This task progression allows us to evaluate our
model’s robustness to common real-world variations
in medical imaging.
5.2.2 Model Architectures
To rigorously evaluate the generalizability and robust-
ness of our approach, we employ three distinct neural
network architectures, each chosen to address specific
aspects of CL in medical imaging:
• Multi-Layer Perceptron (MLP). A baseline ar-
chitecture with one hidden layer, selected for its
simplicity and efficiency. This model serves as
a litmus test for our method’s ability to enhance
even basic architectures in CL scenarios.
• Residual Network. Incorporating skip connec-
tions, this architecture mitigates the vanishing
gradient problem, crucial for maintaining perfor-
mance across multiple tasks in CL. Its ability to
learn residual functions is particularly relevant for
detecting subtle changes in medical images across
different domains.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
88

• Attention-based Network. Leveraging self-
attention mechanisms, this model excels at cap-
turing complex, long-range dependencies in data.
In the context of medical imaging, it can focus
on the most relevant features for diagnosis, poten-
tially enhancing the model’s adaptability to new
tasks.
All architectures are designed to process 768-
dimensional CLIP embeddings as input, outputting
binary classifications for DR. This unified input-
output structure allows for fair comparison across ar-
chitectures while leveraging the rich semantic infor-
mation captured by CLIP embeddings.
5.2.3 Continual Learning Strategies
We benchmark our approach against a diverse set of
state-of-the-art CL strategies, each addressing differ-
ent aspects of the catastrophic forgetting problem:
• Naive (fine-tuning). Serves as a baseline, high-
lighting the severity of catastrophic forgetting in
the absence of specialized CL techniques.
• Elastic Weight Consolidation (EWC). A
regularization-based approach that selectively
slows down learning on important parameters,
crucial for preserving knowledge in medical
imaging tasks where certain features may be
universally important.
• Learning without Forgetting (LwF). Employs
knowledge distillation to retain previous task
information, potentially beneficial in scenarios
where task boundaries in medical imaging are not
clearly defined.
• Gradient Episodic Memory (GEM). Constrains
gradient updates to maintain performance on pre-
vious tasks, offering insights into the trade-offs
between stability and plasticity in medical AI
models.
Each strategy is evaluated in its original form and
enhanced with our proposed zero-shot clustering and
stratified sampling approach. This comprehensive
evaluation not only benchmarks our method against
established techniques but also demonstrates its po-
tential as a complementary enhancement to existing
CL strategies in the challenging domain of medical
image analysis.
5.2.4 Evaluation Metric
We employ the Average Mean Class Accuracy
(AMCA) as our primary evaluation metric:
AMCA =
1
T
T
∑
t=1
1
C
C
∑
c=1
a
c,t
!
(7)
where T = 3 (number of tasks) and C = 2 (num-
ber of classes: with and without DR). This metric en-
sures robustness against class imbalance and distribu-
tion shifts across tasks.
5.3 Experimental Protocol
To ensure robust and generalizable results, we im-
plemented a rigorous experimental protocol. Our
approach included extensive hyperparameter explo-
ration, varying the number of neighbors (15, 20, 25,
30, 50) in our stratified sampling approach to assess
sensitivity. For stochastic control, we utilized differ-
ent random seeds for each run, ensuring statistical
validity. We conducted a comprehensive evaluation
across multiple architectures, including MLP, Resid-
ual, and Attention-based networks. These were tested
with various CL strategies: Naive, EWC, LwF, and
GEM, both in their original form and enhanced with
our approach. For each configuration, we recorded
key performance metrics, focusing on AMCA and
Forgetting scores. This comprehensive evaluation
framework enables us to draw statistically significant
conclusions about our method’s efficacy across di-
verse scenarios in medical imaging CL.
5.4 Results and Discussion
We evaluate our approach across multiple architec-
tures (MLP, Residual, Attention) and continual learn-
ing strategies (Naive, GEM, LwF, EWC), compar-
ing performance and computational efficiency against
baseline methods.
5.4.1 Performance Analysis
Table 3 presents Average Mean Class Accuracy
(AMCA) scores and Forgetting metrics across differ-
ent configurations. Our method consistently outper-
forms baselines across all architectures and strategies.
• Architectural Robustness. Performance im-
provements range from 0.8% to 3.1% in AMCA
across all architectures, with the most signifi-
cant gains observed in complex models (Residual:
+2.8% for Naive, Attention: +3.1% for LwF).
• Strategy Enhancement. Our approach amplifies
the strengths of existing CL strategies. For in-
stance, it reduces Forgetting in Naive learning (8.5
to 5.2 in Residual models) and enhances knowl-
edge distillation in LwF (3.1% AMCA increase
in Attention models).
Experience Replay and Zero-Shot Clustering for Continual Learning in Diabetic Retinopathy Detection
89
• Forgetting Mitigation. We observe consistent
reductions in Forgetting metrics, particularly no-
table in the Naive strategy across all architectures,
indicating improved knowledge retention.
These results suggest that our zero-shot cluster-
ing and stratified sampling approach provides a more
diverse and representative set of samples, enhancing
both learning and retention in CL scenarios.
5.4.2 Hyperparameter Sensitivity
The number of neighbors in KNN has a significant
impact on both performance and forgetting. The
Mean AMCA shows peak performance at around 25
neighbors, followed by a slight decline and stabiliza-
tion between 30 and 50 neighbors. Similarly, forget-
ting is reduced most significantly at around 25 neigh-
bors, after which it gradually decreases as the number
of neighbors increases.
Figure 6: Both metrics reach optimal values around 25-
30 number of neighbors (NN), illustrating the trade-off be-
tween performance and retention.
This highlights a sweet spot between 25 and 30
neighbors, where both performance (Mean AMCA)
and retention (reduced forgetting) are optimized.
Tuning within this range balances sample diversity
and computational efficiency, ensuring high perfor-
mance with minimal forgetting, as shown in Figure 6.
5.4.3 Computational Efficiency
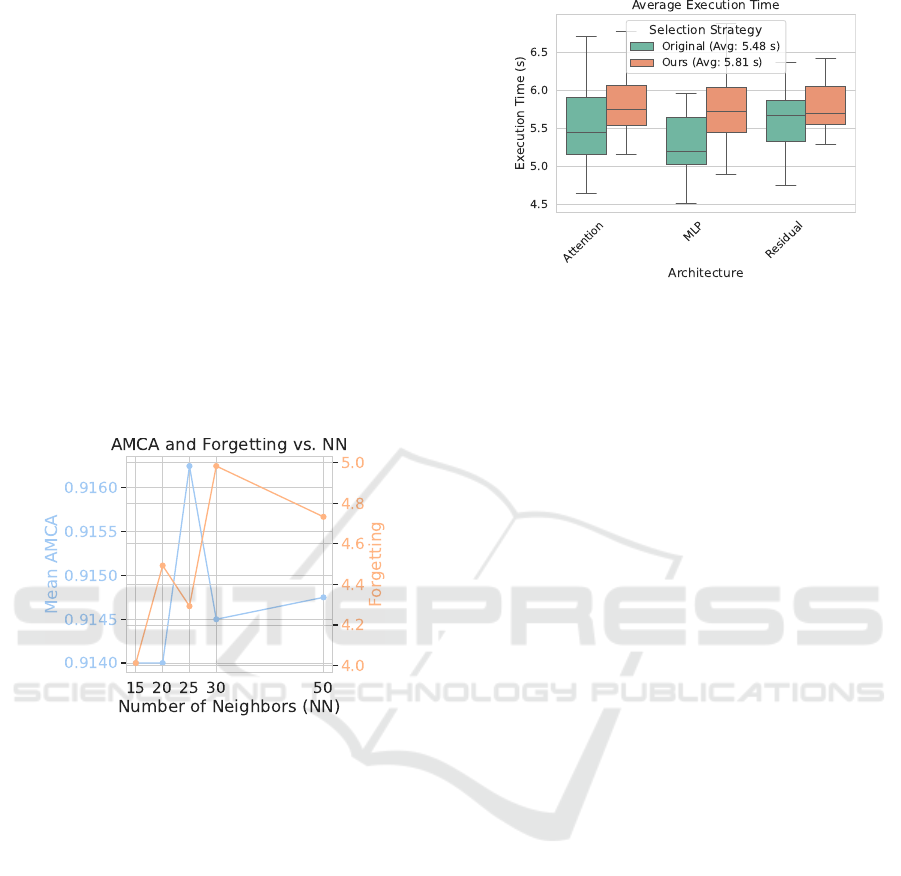
Figure 7 compares the execution times between our
method and the original strategy. Our approach in-
curs a minimal 6% increase in average execution time
(5.81 s vs. 5.48 s). This negligible overhead is con-
sistent across all architectures, with Attention models
showing the highest variability due to their complex-
ity.
The marginal increase in computational cost, cou-
pled with significant performance gains, positions our
method as an efficient in-place replacement for exist-
ing strategies. This balance is particularly valuable
Figure 7: Average execution time comparison across archi-
tectures. Box plots show distribution of execution times,
with mean values in the legend.
in time-sensitive applications like medical imaging,
where improved accuracy without substantial compu-
tational overhead is crucial.
6 CONCLUSION
This study introduced a framework integrating zero-
shot learning with Experience Replay for CL in med-
ical imaging, with a focus on DR detection. Our ap-
proach, leveraging LLMs for DIL, demonstrated sev-
eral key achievements. We observed consistent per-
formance improvements across diverse model archi-
tectures and CL strategies, with AMCA increases up
to 3.1%. The system showed effective mitigation of
catastrophic forgetting, evidenced by reduced Forget-
ting metrics, particularly in naive learning scenarios.
Additionally, we achieved this with negligible com-
putational overhead (6% increase in execution time),
enabling seamless integration into existing systems.
These results highlight the potential of our method
to enhance the adaptability, efficiency, and privacy-
preservation of AI systems in healthcare. The frame-
work’s ability to maintain performance across varying
data distributions while operating on embeddings ad-
dresses critical challenges in medical AI deployment.
Future research directions encompass several key
areas. We aim to scale to more complex, multi-
modal medical datasets and develop adaptive cluster-
ing algorithms for dynamic medical imaging scenar-
ios. Additionally, we plan to explore applicability in
other domains with similar privacy and distribution
shift concerns. A crucial component of future work
involves conducting rigorous ethical analyses, partic-
ularly regarding data privacy and algorithmic bias in
diverse patient populations.
While our work represents a step towards more ro-
bust and adaptable AI in healthcare, realizing its full
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
90

Table 3: Comparison of Mean AMCA scores and forgetting (parentheses) for different base models and strategies. Boldface
indicates superior performance between Ours and Original strategies based on Mean AMCA. Averages are computed across
different NN values for each base model.
Model NN Naive GEM LwF EWC
Ours Original Ours Original Ours Original Ours Original
Attention
15 0.936(3.7) 0.929(3.4) 0.967(3.5) 0.965(3.4) 0.823(4.8) 0.793(5.3) 0.930(4.1) 0.928(3.1)
20 0.938(4.2) 0.926(4.3) 0.968(4.2) 0.965(3.2) 0.816(5.8) 0.793(5.3) 0.934(3.7) 0.919(4.4)
25 0.939(4.7) 0.922(4.9) 0.967(3.3) 0.965(3.2) 0.826(5.5) 0.789(5.4) 0.933(3.6) 0.915(4.2)
30 0.937(4.5) 0.930(2.5) 0.967(4.2) 0.961(3.4) 0.825(5.3) 0.792(5.5) 0.929(5.9) 0.918(4.1)
50 0.938(4.3) 0.932(2.6) 0.965(4.1) 0.960(3.8) 0.824(5.7) 0.791(5.0) 0.932(4.8) 0.911(5.7)
Avg 0.938(4.3) 0.928(3.5) 0.967(3.9) 0.963(3.4) 0.823(5.4) 0.792(5.3) 0.932(4.4) 0.918(4.3)
Residual
15 0.913(5.1) 0.880(9.7) 0.941(2.6) 0.934(2.8) 0.940(4.6) 0.928(4.5) 0.939(3.8) 0.933(3.7)
20 0.912(5.0) 0.879(9.7) 0.942(2.8) 0.935(2.9) 0.934(4.5) 0.930(4.5) 0.938(4.3) 0.932(4.1)
25 0.913(5.3) 0.879(9.7) 0.942(1.7) 0.938(2.8) 0.933(4.6) 0.928(4.4) 0.938(3.9) 0.926(4.5)
30 0.912(5.7) 0.879(9.6) 0.940(3.9) 0.937(2.7) 0.938(4.4) 0.928(4.5) 0.938(4.9) 0.914(6.7)
50 0.912(5.0) 0.903(3.8) 0.941(3.1) 0.935(2.6) 0.936(4.8) 0.929(4.5) 0.932(6.7) 0.901(10.0)
Avg 0.912(5.2) 0.884(8.5) 0.941(2.8) 0.936(2.8) 0.936(4.6) 0.929(4.5) 0.937(4.7) 0.921(5.8)
MLP
15 0.915(5.1) 0.899(3.2) 0.931(5.1) 0.923(3.8) 0.942(4.8) 0.940(4.8) 0.930(6.9) 0.917(5.8)
20 0.914(5.3) 0.897(4.3) 0.931(5.1) 0.923(3.7) 0.941(5.0) 0.940(4.5) 0.892(5.2) 0.874(5.4)
25 0.914(5.2) 0.900(3.8) 0.931(5.1) 0.922(4.0) 0.944(5.0) 0.937(5.0) 0.891(5.6) 0.875(4.1)
30 0.914(5.6) 0.896(4.2) 0.930(5.2) 0.923(3.8) 0.944(4.8) 0.937(5.3) 0.892(5.5) 0.879(3.2)
50 0.911(5.5) 0.893(5.1) 0.927(5.3) 0.921(3.9) 0.948(4.9) 0.936(5.3) 0.890(5.9) 0.872(4.7)
Avg 0.914(5.4) 0.897(4.1) 0.930(5.1) 0.922(3.9) 0.944(4.9) 0.938(5.0) 0.899(5.8) 0.883(4.6)
potential requires extensive clinical validation. As
we progress towards real-world applications, address-
ing scalability, generalizability, and ethical consider-
ations will be paramount.
ACKNOWLEDGEMENTS
We thank Lenovo for providing the technical in-
frastructure to run the experiments in this paper.
This work was partially supported by Lenovo and
Intel as part of the Lenovo AI Innovators Uni-
versity Research program, by the Spanish Min-
istry of Science (MICINN), the Research State
Agency (AEI) and European Regional Develop-
ment Funds (ERDF/FEDER) under grant agreements
PID2019-107255GB-C22 and PID2021-126248OB-
I00, MCIN/AEI/10.13039/ 501100011033/FEDER,
UE, and by the Generalitat de Catalunya under con-
tract 2021-SGR-00478.
REFERENCES
Arani, E., Sarfraz, F. B., and Zonooz, B. (2022). Learn-
ing fast, learning slow: A general continual learn-
ing method based on complementary learning system.
arXiv preprint abs/2201.12604.
Brown, T. B. and et al., M. (2020). Language models are
few-shot learners. In Proceedings of the 34th Interna-
tional Conference on Neural Information Processing
Systems, NIPS’20. Curran Associates Inc.
Buzzega, P., Boschini, M., Porrello, A., Abati, D., and
Calderara, S. (2020). Dark experience for general
continual learning: a strong, simple baseline. In Pro-
ceedings of the 34th International Conference on Neu-
ral Information Processing Systems, NIPS’20. Curran
Associates Inc.
De Lange, M., Aljundi, R., Masana, M., Parisot, S., Jia,
X., Leonardis, A., Slabaugh, G., and Tuytelaars, T.
(2022). A continual learning survey: Defying forget-
ting in classification tasks. IEEE Transactions on Pat-
tern Analysis and Machine Intelligence, 44(7):3366–
3385.
Garg, S., Farajtabar, M., Pouransari, H., Vemulapalli, R.,
Mehta, S., Tuzel, O., Shankar, V., and Faghri, F.
(2023). TiC-CLIP: Continual Training of CLIP Mod-
els. arXiv preprint abs/2310.16226.
Karthik, Maggie, S. D. (2019). APTOS 2019 Blindness De-
tection. https://kaggle.com/competitions/aptos2019-
blindness-detection.
Khan, V., Cygert, S., Deja, K., Trzcinski, T., and Twar-
dowski, B. (2024). Looking through the past: Better
knowledge retention for generative replay in continual
learning. IEEE Access, 12:45309–45317.
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J.,
Desjardins, G., Rusu, A. A., Milan, K., Quan, J.,
Ramalho, T., Grabska-Barwinska, A., et al. (2017).
Overcoming catastrophic forgetting in neural net-
works. Proceedings of the national academy of sci-
ences, 114(13):3521–3526.
Experience Replay and Zero-Shot Clustering for Continual Learning in Diabetic Retinopathy Detection
91

Koh, H., Kim, D., Ha, J.-W., and Choi, J. (2022). Online
continual learning on class incremental blurry task
configuration with anytime inference. arXiv preprint
abs/2110.10031.
Kuang, K., Cui, P., Athey, S., Xiong, R., and Li, B. (2018).
Stable prediction across unknown environments. In
Proceedings of the 24th ACM SIGKDD International
Conference on Knowledge Discovery & Data Mining,
KDD’18, pages 1617–1626, New York, NY, USA. As-
sociation for Computing Machinery.
Kumar, P. and Srivastava, M. M. (2018). Example min-
ing for incremental learning in medical imaging. In
2018 IEEE Symposium Series on Computational In-
telligence (SSCI), pages 48–51.
Kumari, S. and Singh, P. (2024). Deep learning for unsuper-
vised domain adaptation in medical imaging: Recent
advancements and future perspectives. Computers in
Biology and Medicine, 170:107912.
Lenga, M., Schulz, H., and Saalbach, A. (2020). Con-
tinual learning for domain adaptation in chest x-ray
classification. In Proceedings of the Third Confer-
ence on Medical Imaging with Deep Learning, PMLR
121:413-423, 2020.
Li, Z. and Hoiem, D. (2017). Learning without forgetting.
IEEE Transactions on Pattern Analysis and Machine
Intelligence, 40(12):2935–2947.
Lopez-Paz, D. and Ranzato, M. (2017). Gradient episodic
memory for continual learning. In Proceedings of the
31st International Conference on Neural Information
Processing Systems, NIPS’17, pages 6470–6479. Cur-
ran Associates Inc.
OpenAI (2023). GPT-4 Technical Report.
https://openai.com/research/gpt-4.
Parisi, G. I., Kemker, R., Part, J. L., Kanan, C., and
Wermter, S. (2019). Continual Lifelong Learning
with Neural Networks: A Review. Neural Networks,
113:54–71.
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh,
G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P.,
Clark, J., Krueger, G., and Sutskever, I. (2021). Learn-
ing transferable visual models from natural language
supervision. In Meila, M. and Zhang, T., editors, Pro-
ceedings of the 38th International Conference on Ma-
chine Learning, ICML 2021, 18-24 July 2021, Virtual
Event, volume 139 of Proceedings of Machine Learn-
ing Research, pages 8748–8763. PMLR.
Rebuffi, S.-A., Kolesnikov, A., Sperl, G., and Lampert,
C. H. (2017). iCaRL: Incremental Classifier and Rep-
resentation Learning. In 2017 IEEE Conference on
Computer Vision and Pattern Recognition (CVPR),
pages 5533–5542.
Riemer, M., Cases, I., Ajemian, R., Liu, M., Rish, I., Tu,
Y., and Tesauro, G. (2019). Learning to learn with-
out forgetting by maximizing transfer and minimizing
interference. arXiv preprint abs/1810.11910.
Robins, A. (1993). Catastrophic forgetting, rehearsal and
pseudorehearsal. Connection Science, 5(2):123–146.
Serra, J., Suris, D., Miron, M., and Karatzoglou, A. (2018).
Overcoming catastrophic forgetting with hard atten-
tion to the task. In International Conference on Ma-
chine Learning, pages 4548–4557. PMLR.
Shin, H., Lee, J. K., Kim, J., and Kim, J. (2017). Con-
tinual learning with deep generative replay. In Pro-
ceedings of the 31st International Conference on Neu-
ral Information Processing Systems, NIPS’17, pages
2994–3003. Curran Associates Inc.
Shokri, R. and Shmatikov, V. (2015). Privacy-preserving
deep learning. In 2015 53rd Annual Allerton Con-
ference on Communication, Control, and Computing
(Allerton), pages 909–910.
Valindria, V. V., Lavdas, I., Bai, W., Kamnitsas, K.,
Aboagye, E. O., Rockall, A. G., Rueckert, D., and
Glocker, B. (2018). Domain Adaptation for MRI Or-
gan Segmentation using Reverse Classification Accu-
racy. arXiv preprint abs/1806.00363.
Venkataramani, R., Ravishankar, H., and Anamandra, S.
(2018). Towards continuous domain adaptation for
healthcare. arXiv preprint abs/1812.01281.
Wang, L., Zhang, X., Su, H., and Zhu, J. (2024). A Com-
prehensive Survey of Continual Learning: Theory,
Method and Application. IEEE Transactions on Pat-
tern Analysis and Machine Intelligence, 46(8):5362–
5383.
Zhang, J., Fu, Y., Peng, Z., Yao, D., and He, K. (2024).
CORE: Mitigating Catastrophic Forgetting in Contin-
ual Learning through Cognitive Replay. arXiv preprint
abs/2402.01348.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
92
