
STEP: SuperToken and Early-Pruning for Efficient Semantic
Segmentation
Mathilde Proust
1 a
, Martyna Poreba
1 b
, Michal Szczepanski
1 c
and Karim Haroun
1,2 d
1
Universit ´e Paris-Saclay, CEA, List, F -91120, Palaiseau, France
2
Universit´e Cˆote d’Azur, Sophia Antipolis, France
Keywords:
Visi on Transformer, Token Pruning, Token Merging, Semantic Segmentation, Supertoken, Computational
Efficiency, Optimization.
Abstract:
Visi on Transformers (ViTs) achieve state-of-the-art accuracy in numerous vision tasks, but their heavy com-
putational and memory requirements pose significant challenges. Minimising token-related computations is
critical to alleviating this computational burden. This paper introduces a novel SuperToken and Early-Pruning
(STEP) approach that combines patch merging along with an early-pruning mechanism to optimize token
handling in ViTs for semantic segmentation. The improved patch merging method is developed t o effectively
address the diverse complexities of images. It features a dynamic and adaptive system, dCTS, which employs
a CNN-based policy network to determine the quantity and size of patch groups that share the same superto-
ken during inference. With a flexible merging strategy, it handles superpatches of varying sizes: 2×2, 4×4,
8×8, and 16×16. Early in the network, high-confidence tokens are discarded and preserved from subsequent
processing stages. This hybrid approach reduces both computational and memory requirements without signif-
icantly compromising segmentation accuracy. It is shown through experimental results that, on average, 40%
of tokens can be predicted from the 16th layer onwards when using ViT-Large as the backbone. Additionally,
a reduction of up to 3× in computational complexity is achieved, with a maximum drop in accuracy of 2.5%.
1 INTRODUCTION
Recently, Vision Transformers (ViTs) (Dosovitskiy
et al., 2021) have emerged as highly promising al-
ternatives to Convolutional Neura l Networks (CNN)
models (He et al., 2016)(Sandler et al., 2018). They
are pushing the boundaries of existing knowledge
in several computer vision tasks, such as classifica-
tion (Touvron et al., 2021), object detection (Car-
ion et al., 202 0) and semantic segmentation (Zhang
et al., 2022)(Zheng et al., 2021). ViTs leverage self-
attention to capture global contextual relationships,
enabling precise under standing of spatial object dis-
tributions. Their ability to model long-range de pen-
dencies makes them particularly effective for seman-
tic segmentation, esp ecially in complex scenes where
accurate boundary deline a tion is cr itica l.
This advantage positions ViTs as strong con-
a
https://orcid.org/0009-0003-5610-7624
b
https://orcid.org/0000-0002-5102-7735
c
https://orcid.org/0009-0000-9061-4396
d
https://orcid.org/0009-0000-6972-6019
1
2
3
4
5
N
N patches N tokens
ViT Blocks
1
2
3
4
5
M
M<N patches M<N tokens
ViT Block
ViT Block
K<M<N tokens
Vision Transformer with STEP
Standard Vision Transformer
N-1
M-1
Figure 1: SuperToken and Early-Pruning (STEP) added to
Visi on Transformer. Semantically similar patches are dy-
namically merged via our token-sharing policy network to
form superpatches. Early-pruned supertokens (black filled)
are masked and discarded, and only the remaining tokens
are processed in the subsequent layers. STEP boosts effi-
ciency without significant loss in quality.
50
Proust, M., Poreba, M., Szczepanski, M. and Haroun, K.
STEP: SuperToken and Early-Pruning for Efficient Semantic Segmentation.
DOI: 10.5220/0013132800003912
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 3: VISAPP, pages
50-61
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

tenders in tasks where traditional CNNs often struggle
to capture global features. Researchers have explored
semantic segmentation using vision tran sf ormers in
a variety of ways. One approach involves develop-
ing custom transformer architectur e s specifically de-
signed to address the task of semantic segmentation
(Wang et al., 20 21)(Zheng et al., 2021). Another
common approach focuses on enhancing either the
transformer-based backbone (Liu et al., 2021 )(Wang
et al., 2021) or the ta sk-specific decoder (Strudel
et al., 2021) (Zhan g et al., 202 1). Specifically, Seg-
Former (Xie et al., 2021) enhances the basic archi-
tecture by incorporating pyr amid features, allowing it
to capture multi-scale contexts. Segmenter (Strudel
et al., 2021) leverages learnable class tokens in com-
bination with encoder outputs to generate segmen-
tation masks, making the process data-dependent.
SegViT (Zhan g et al., 2022) advances the study of the
self-attention mechanism by introducing an innova-
tive attention-to-mask (ATM) module, which dyn am-
ically generates accurate segmentation masks.
Despite their promising performance, ViTs
present significant com putational challenges. One
major issue is the quadratic complexity of the self-
attention mechanism, which scales poorly with im-
age resolution. As the size of input images increases,
the computational cost and memory requirements rise
significantly, making ViTs deployment challenging.
Efforts to improve their efficiency still struggle to
balance computational complexity, latency, and per-
formance. Reducing complexity or improving in-
ference speed often compromises segmentation ac-
curacy, while optimizing performance can increase
computation and slow down inf erence. Achieving
an optimal trade-off between the se factors remains a
key challenge, particu la rly in real-time or resource-
constrained applications.
In this context, our work intr oduces SuperToken
and E arly-Pruning (STEP), a novel token optimiza-
tion mechanism that dynamically merges semanti-
cally similar, neighbo ring p a tc hes into superpatches
via a class-agnostic policy network. Unlike traditional
grid-b a sed patch processing, this method generates
superpatches of different sizes, enabling the numb er
of tokens to adjust according to the complexity of
the image content. Additionally, STEP in corpor ates
an early-pru ning m echanism where certain tokens are
masked and discarded early in the network, further
reducing the number of tokens processed in later la y-
ers. We can summ arize this work’s contributions as
follows:
• We introduce STEP, a hybrid to ken optimiza-
tion mechanism tailore d for semantic segmenta-
tion that generates sup erpatches and a dapts the
token pruning paradigm based on early -pruning
strategy.
• We analyze patch merging and token discarding
methods, evaluating their impact on latency, com-
putational cost, and accuracy. Our focus is on op-
timizing these techniques to achieve a balance be-
tween efficiency and performance.
• We a pply STEP to a mainstream semantic seg-
mentation transformer model (ViT-Large) and
condu c t extensive experiments on two challeng-
ing benchmarks using an A100 GPU. The results
show that STEP can reduce computational costs
by up to 66% witho ut a significant drop in accu-
racy.
2 RELATED WORK
Traditionally, ViTs create vision patches by dividing
an image into a uniform, fixed grid, with each grid
cell treated as a to ken . However, not all region s of
an image are equally cruc ia l for specific tasks. For
example, de ta iled analysis o f facial fe a tures may re-
quire many tokens for ac c urate representation, while
broade r regions such as the sky or large uniform sur-
faces may need only a few tokens. This leads to the
question: is it really necessary to process that many
tokens at every layer? Given the high computational
demand s of vision transforme rs, reducin g the number
of tokens is a stra ightforward way to lower computa-
tion costs. There are many techniques that can be used
to a ccelerate the inference speed of the ViT mode l, in-
cluding qua ntization ( Lin et al., 2022), (Yuan et al.,
2022), (Li and Gu, 2023), distillation (Wu et al.,
2022), (Yang et al., 2024), and pruning (merging or
discarding ). Key studie s have shown that such re-
duction techniques can lead to substantial decreases
in model size an d computational cost, making ViTs
more feasible for deployment on resource- constrained
devices o r in large-scale a pplications. Pruning in-
volves, based on certain criteria, definitely discarding
or merging tokens. However, identifying which to-
kens are less important or similar can be complex and
vary across different layers, as ViTs may focus on dif-
ferent regions at each layer. Addressing these chal-
lenges requires advanced pruning techniques. Fac-
tors like task-specific requ irements, token importance
metrics, and retraining strategies are crucial for ensur-
ing the effectiveness o f token pruning methods. Ad-
ditionally, aggressive prun ing might lead to the loss
of cr itical information, resultin g in degraded model
performance. Balancing the intensity of pruning with
performance preservation is crucial. Another chal-
lenge is the dyna mic nature of token importance,
STEP: SuperToken and Early-Pruning for Efficient Semantic Segmentation
51

which can vary acr oss different images or tasks, ne-
cessitating adaptive pruning strategies that can dy-
namically adjust based on the input.
2.1 Token Discarding
There are different pruning approaches that involve
discarding to kens such as 1) heuristic token reduc -
tion like importance scoring-based pruning, which
removes tokens based on their relevance assessed
through attention weights or entropy; 2) learned prun-
ing, which trains the model to identify less impor-
tant tokens using auxiliary networks; and 3) gradual
pruning, which prunes tokens incr e mentally acr oss
layers to balance efficiency and accuracy. Learned
token reduction (Michel et al., 2019), (Kong et al.,
2022), (Meng et al., 202 2), (Song et al., 2022), (Hao
and Jianxin, 2023) typically requires training auxil-
iary models to rank the importance of tokens in the
input data, w hich is often viewed as a drawback. In
contrast, several works have proposed heuristic token
reduction that can be applied to the off-the-shelf ViTs
without further finetuning. For instance, ATS (Fayyaz
et al., 2022) serves as a plug-and-play modu le that
samples tokens based on their similarity to other to-
kens in the attention map. However, a limitation of
this method is its reliance on the class token (cls),
which might not be applicable or present in dense pre-
diction tasks such as segmenta tion or object detec tion.
Many token removal strategies are mainly tai-
lored for image classification, based on th e idea
that eliminating uninformative tokens, suc h a s back -
grounds, h a s minimal impact on rec ognition perfor-
mance. This is effective because classification tasks
focus on global features for single-class predictio ns.
In this vein, A-ViT (Yin et al., 2022) computes halt-
ing p robability score to recognize tokens to be dis-
carted and in this manner perform dense compute
only on the active tokens deemed info rmative. CP-
ViT (So ng et al., 2022) defines the cu mulative score
to dynam ic a lly locate the informative pa tc hes and
heads across the ViT model, according to their max-
imum value in attention probability. DynamicViT
(Rao et al., 2021) add an extra learnable neural net-
work to remove redundant tokens progressively and
dynamically. The proposed pred ic tion m odule esti-
mates token’s importance score with a ML P (Vaswani
et al., 2017). AdaViT (Meng et al., 2022) integrates
a jointly optimized lightweight decision n e twork into
every transformer block of the ViT backbone to de-
rive inference strategies. Its purpose is to determine
which pa tches to retain, which self-attention hea ds to
activate, and which transformer bloc ks to b ypass for
each image.
A slightly different way of proceeding is soft
pruning. Instead of discarding less informative tokens
completely, they are integrated into a consolidated
package token . For instance, SP-ViT (Kong et al.,
2022) proposes an attention-based multi-h ead token
selector, which is inserted multip le times through-
out the model, to rank, consolidate an d prune tokens
based on their importance scores. Similarly, EViT
(Liang et al., 2022) focuses on the prog ressive selec-
tion of info rmative tokens during training. It m a sks
and fuses regions that represent the inattentive tokens
to expedite computations. The attentiveness value is
chosen as a criterion to identify the top -k attentive to-
kens and fuse the rest. E vo-ViT (Xu et al., 2022) pro-
poses an unstructured instance-wise token selection
and a slow-fast token updating module. Informative
tokens and placeholder tokens are determined by the
evolved g lobal class attention. Both informative and
non-informative token s are then updated in different
manners. Unlike the previous discarding methods,
this makes it possible to main tain the complete spa-
tial structure and information.
To ken pruning c a n improve computational e ffi-
ciency, but it has notable dr awbacks. Primarily, it
risks information loss, w hich may decrease accuracy.
The variability in the number of tokens across dif-
ferent inputs complicates batched inference, leading
to inefficient re source utilization and increased over-
head in managing token counts. Additionally, the pro -
cess often require s extra training to determine which
tokens to retain, adding complexity and prolonging
overall training time. To address this issue, zero-shot
token pruning methods, such as Zero-TPrune (Wang
et al., 2023), can prune large architectures at negligi-
ble cost, seamlessly switch between pruning c onfigu-
rations, and efficiently tune hyperparameters. How-
ever, it is important to note that excessive p runing
may lead to overfitting, causing the model to become
overly specialized to the training data.
2.2 Token Merging
Merging com bines tokens to create fewer, more com-
prehen sive ones, effectively red ucing the overall to-
ken count while retaining essential informa tion. To-
kens can b e merged based on various criteria such as
spatial proxim ity, semantic similarity, or their contri-
bution to the final predictions. One approac h to merg-
ing is spatial ag gregation, which combines tokens rep-
resenting nearby regions. Another method is feature
aggregation, where tokens with similar features or
activations are me rged. To tackle these cha llenges,
various concepts can b e employed, inc luding tradi-
tional pooling operations, convolutional integration
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
52

within transformers, attention pooling, grid-based to-
ken merging, and cluster-based merging. Combining
tokens in a way th at retains the original information
content can be challenging. Merging tokens risks los-
ing fine-grained inform a tion encode d by individual
tokens, which can affect the model’s a bility to cap-
ture subtle details. Poor aggregation can result in sig-
nificant information loss, leading to degraded model
performance.
As with discarding-based prun ing, the common
approa c h in merging is to process in multiple stages,
gradua lly reducing the sequence length while preserv-
ing infor mation. For instance, ToMe (Bolya et a l.,
2023) and (Bolya and Hoffman, 2023) introduce a
novel non-train ing method which averages similar to-
kens based on the efficient bipartite matching algo-
rithm. Inform ation aggregation from neighboring to-
ken is done using a pooling-like operation that com-
bines th e features of multiple tokens into a single r ep-
resentative token. This ap proach is related to DT M
(Zizheng et al., 2022), where tokens based on ob-
jects scales and shap es are dynam ic ally merged. In
contrast, TokenLearner (Ryoo et al., 2021) uses a
relatively small number of tokens, learned through
the aggregation of the entire feature map, which is
weighted by a dynamic attention map conditioned on
the feature map. This sophisticated method for tok-
enizing the input employs a spatial attention mech-
anism designed to adaptively identify important re-
gions and generate tokens from them. Token Pool-
ing (Marin et al., 2023) addresses the proble m using
a cost-efficient clustering-based downsampling oper-
ator. Following each transformer block, it ide ntifies
a subset of tokens that best approximates th e under-
lying con tinuous signal, thereby capturing redundant
features. For token downsampling, Token Pooling
employs K-Means or K-Medoids algor ithms, or their
weighted versions, WK-Means or WK-Medoids, re-
spectively. TCFormer ( Zeng et al., 2022) merges
tokens from different locations through progre ssive
clustering, generating new tokens with flexible shapes
and sizes. STViT (H uang et al., 2022) proposes
a per-token attention me chanism consisting of three
processes: aggregating tokens into super to ken s via
the soft k-means, modeling g lobal dependencies in
the super token space, a nd then upsampling the su-
per tokens. PeToMe (Tran et al., 2 024) emphasizes
preserving informative tokens through an additiona l
metric called the energy score. This score identi-
fies large clusters of similar tokens as high-e nergy,
making them potential candidates f or merging, while
smaller, unique, and isolated clusters are considered
low-energy an d are preserved.
2.3 Hybrid Token Reduction
Choosing between token discarding and merging
strategies can be intric ate, leading to the question of
whether one technique may be more effective than the
other for a particular task. In this context, ToFu (Kim
et al., 2024) ama lgamates the benefits of both token
pruning and token merging. In practice, the depth
of the layer determines the chosen merging strategy:
early layers use pruned me rging, while later layers
transition to average (or MLERP) me rging. DiffRate
(Chen et al., 2023) includes both token discarding
and m erging, and formulates token compression as
an optimization problem. LTMP (Bonnaerens and
Dambre, 2023) adds merging and discarding c om-
ponen ts with lear ned threshold masking modules in
each transformer block between the Multi-head Self-
Attention (MSA) and MLP co mponents. In the same
vein, PPT (Wu et al., 2023) combines token pruning
for inattentive tokens an d token pooling for attentive
tokens. It is achieved via an adaptive token compres-
sion module inserted inside the standard transformer
block.
2.4 Token Pruning in Dense Tasks
In classification tasks, token pruning meth ods o ften
permane ntly remove tokens since they no longer af-
fect the outco me. This is because the classification
relies primarily on the class token, which is always
retained. In dense pre diction task like semantic seg-
mentation, patches ca nnot be discarded entirely, as
informa tion from all patches must be retained to en-
sure accurate pixel-level predictions. ViTs handle this
by proce ssing a large number of tokens, which need
to be merged effectively to maintain fine-grained de-
tails while reduc ing computational complexity. Con-
sequently, on ly two of the previously mentioned token
reduction methods are suitable for dense prediction
tasks, which require high spatial resolution, detailed
informa tion, and precise preservation of contextual
relationships. For instance, the work of Dynam ic ViT
(Rao et al., 2021) has been extend to mo re network
architecture s inclu ding hierarchical vision transf orm-
ers as well as more complex dense prediction tasks
like object detection and semantic segmentation (Rao
et al., 2023). ToFu (Kim et al., 2024) produce promis-
ing results for image generation task. The authors
of TCFormer (Zeng et al., 2022) envision the pro-
posed me thod as general and applicable to a wide
range of vision tasks, su ch as object detection and
semantic segmentation. However, the major limi-
tation of TCFormer is that the computational com-
plexity of the KNN-DPC algorithm is qua dratic with
STEP: SuperToken and Early-Pruning for Efficient Semantic Segmentation
53

respect to the number of tokens, which limits TC-
Former’s speed when dealing with large input reso-
lutions. Among the methods specially desig ned for
the segmentation task we can cite Content-aware To-
ken Sharing (CTS) (Lu et al., 2023), Dynamic To-
ken Pruning (DToP) (Tang et al., 2023), an d SVIT
(Liu et al., 2024). CTS proposes a class-agnostic pol-
icy network trained separately fro m ViT to predict if
neighbouring image patches co ntain th e same seman-
tic class. DToP utilizes early-pruning for high- con-
fidence tokens, enabling the p rediction of simpler to-
kens to be completed earlier without requiring a full
forward pass through the entire network. Recently,
SVIT introduced a ligh tweight, 2- la yer MLP to ef-
fectively choose tokens to be p rocessed in the trans-
former block. The pruned token s are preserved in fea-
ture maps and can be reactivated in later layers.
3 METHODOLOGY
In this work, we propose a novel hybrid token r educ-
tion mechanism aime d at e nhancing the efficiency of
ViTs for semantic segmentation tasks. Our method,
called STEP (SuperToken and Early-Pruning), com -
bines two advanced techniques: supertoken process-
ing and early-pruning (Figure 2). This integration
effectively reduces token redundancy while preserv-
ing essential image details. The STEP approa ch en-
sures optimal allocation of computational resources
by dynamically adapting the merging and discarding
processes. The flexibility of this method allows for
the preservation of important details in complex im-
ages while simplify ing the processing of less com-
plicated ones. Following the content-aware patch
merging process, the image is split into a grid of
superpatches with non-unifo rm sizes, facilitating dy-
namic scalab ility tailo red to the image co ntent. Fig-
ure 3 shows that regions with higher sem a ntic homo-
geneity produce larger superpatches, whereas regions
with greater complexity lead to smaller superpatche s.
The token-sharin g module then transforms the cre-
ated superpatches into supertokens. This conversion
is performed by applying a linear embedding function
f
embed
, wh ic h maps the superpatch es into their corr e -
sponding token representations:
Z = f
embed
(P
′
)
where P
′
represents the set of super patches, and
f
embed
is the linear embedding fu nction that g enerates
supertokens Z. The transformer-based ViT models
process th e resulting supertokens and produce the fi-
nal output through per-token predictions.
Additionally, we integrate an early-pruning sys-
tem, as introduce d in DToP. This strategy allows con-
fidently pr edicted tokens in the early lay ers to exit the
network sooner, thereby lowering overall computa-
tional costs without compromising segmentation ac-
curacy. Only the most challen ging tokens continue
to propa gate through the deeper layers of th e trans-
former.
3.1 Content-Aware Patch Merging
The STEP method begins with the cla ss-agnostic pol-
icy network, de sig ned to determine wh ich patches
can be combined into a superpatch, merging them
only when they belong to the same semantic class.
This d raws inspiration from CTS, which utilizes a
lightweight CNN to produce probability scores for
each 2×2 patch group. Subsequently, the k super-
patches are generated based on the highest-ranked
probabilities (Figure 3). We advocate for a merg-
ing process that takes into account the complexity of
the ima ge. Thus, fixing the number and size of su-
perpatch es as a hyper parameter is a limitatio n of the
CTS method. For complex images, this approach may
force the merging of patc hes that should remain sep-
arate. Conversely, f or simpler images, the number of
merged zon es could be larger.
STEP introduces an improved method that more
effectively addresses the diverse complexities of im -
ages, thereby overcoming th e limitations of the orig-
inal CTS approach. We integrate a dynamic, adap-
tive system (dCTS) based on the EfficientNetLite0
model (Tan and Le, 2019), pre-trained on ImageNet-
1K (Russakovsky et al., 2015). It employs a more
adaptable merging strategy, which involves the use of
patch windows of varying size, including 2×2, 4×4,
8×8, and 16×16 patche s. For any given win dow of n
neighboring patches W = {p
1
, p
2
, . . . , p
n
}, the class-
agnostic policy network predicts a similarity score S
for W:
S = σ
W
⊤
p
(W )
where W
p
is the lear ned weight matrix of the pol-
icy network and σ is the sigmoid activation func-
tion. Additio nally, we employ a threshold-based sy s-
tem rath er than relying on a prede te rmined number
of me rges. Our policy network evaluates the patch
groups to estimate the likelihood that they belong to
the same class. If the similarity score S ≥ τ, where
τ is a predefined thresho ld, the patc h window W is
concatenate d to form a superpatch as follows:
p
sp
= concat(p
1
, p
2
, . . . , p
n
)
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
54

N patches
M <N patches
M <N
tokens
Auxiliary head
K<M tokens
ViT
W<K<M tokens
1
2
3
4
5
M
M-1
Auxiliary head
Multi Head Self Attention (MSHA)
Feed Forward Network (FFN)
Network Stage
Decode Head
Token
Unsharing
1
2
3
4
5
M
M-1
1
2
3
4
5
M
M-1
Multi Head Self Attention (MSHA)
Feed Forward Network (FFN)
Multi Head Self Attention (MSHA)
Feed Forward Network (FFN)
Token sharing
dCTS
Figure 2: S TEP Overview. After dividing the image into patches, our dCTS policy network predicts which groups can form
superpatches, which are then transformed into supertokens. Similar to DToP, the Vi T model, composed of M attention blocks,
is divided into K stages, wi th built-in auxiliary heads. On this diagram, 3 stages finalize tokens with a high level of certainty.
The final decode head combines forecasts from all stages to create t he final results.
361 patches 172 patches
715 patches 715 patches
Figure 3: Class-agnostic policy network generates super-
paches from neighboring similar patches. The number of
tokens to process in the ViT is indicated below each image,
relative to the original 1 024 patches. Top: Results obtained
after applying the CTS method, with k fixed at 103 as the
number of merged groups of 2×2 patches; Bottom: Results
after applying our dCTS policy network, allowing dynamic
token merging up to groups of 16×16 patches.
3.2 Early Token Pruning
DTo P offers an early stopping mechanism that masks
and discards high-confident tokens, yet keeps them
accessible for later processing stages and final class
estimation. As a resu lt, we structure the model into
M stages. The model directs tokens to an auxiliary
head after a predetermine d number of attention b lock
layers and employs a stopping criterion based on its
confidence in the predictions. Specifically, at stage
M, a con fidence score c
(m)
i
is computed f or each token
z
i
. Tokens with confidenc e scores greater than a pre-
defined threshold θ are considered hig h-confid ence
tokens and are discarded, while the remaining low-
confidence tokens continue through the network:
Z
(m+1)
= {z
i
| c
(m)
i
< θ}
where Z
(m+1)
represents the set of tokens passed
to the next stage .
Each auxiliary he ad adopts attention-to-mask
module (ATM) (Zhang et al., 2022) as the segmen-
tation head. The core concept of DToP is to iden-
tify easy tokens in th e intermediate layers and ex-
clude them from furthe r computations by assessing
the difficulty level of all tokens. This hig hlights the
importance of strategically placing auxiliary heads. If
they a re positioned too early in the network, the model
may struggle to predict the class of any tokens. The
STEP: SuperToken and Early-Pruning for Efficient Semantic Segmentation
55
authors of DToP suggest that dividing the backbone
into three stag e s with token pruning at the 6th and 8th
layers for ViT-Base an d 8th and 16th for ViT-Large
achieves a desirable trade-off between computational
cost and segmentation accuracy. However, we ques-
tion this choice, especially since the inference time
was not considered. Furthermo re, with this configu-
ration, the re duction in computational complexity for
ViT-Large is negligible compared to utilizing just the
auxiliary head at the 6th layer. We advocate for addi-
tional studies to improve our g uidelines on the posi-
tioning of auxiliary heads.
4 EXPERIMENTS
We implement STEP within the semantic segmenta-
tion framework SegViT (Zhang et a l., 2022). All
experiments are cond ucted usin g MMSegmentation
(mmseg)(MMSegmen tation Contributors, 2020)
1
, an
open-so urce toolbo x based on PyTorch, which facili-
tates easy model custom ization by enabling the com-
bination of various backbones. We incorpora te the
ViT-Large model, which featur e s 24 e ncoder layers,
a 1024 -dimensional hidden layer, a nd 16 attention
heads. The model processes images by dividing them
into 16×1 6 pixel patches.
We conduct extensive exper iments on two widely
used semantic segmentation da ta sets: COCOStuff10k
(Caesar et al., 2018), which co ntains a diverse
range of objects in complex, real-world scenes, and
ADE20k (Zhou et al., 2017), which is a compre-
hensive dataset for scene parsing. The image sizes
are 512×51 2 for COCOStuff10k, a nd 640×640 for
ADE20K. For DToP, we set a fixed confidence thr e sh-
old θ at 0.95 for the COCOStuff10k dataset, and 0.9
for the ADE20K dataset. We employ an AdamW op-
timizer with an initial learning rate of 6e-5, weigh t de-
cay of 0.01, and a cosine learn ing rate schedule. We
follow the standard mmseg training settings. We train
the mo dels for 160K iterations on ADE20K, 80K on
COCOStuff10k, using a batch size of 4. Data aug-
mentation in c ludes random horizontal flipping, ran-
dom resizing (ra tio 0.5 to 2.0), and random c ropping.
The mean intersection over union (mIoU) evaluates
segmentation accuracy, the q uantity of floating-point
operations in giga FLOPS (GFLOPs) indicates the
complexity of the model, whereas frames per second
(FPS) m easures the throughpu t on a single NVIDIA
A100 GPU. We use the fvcore package
2
to compute
GFLOPs for all configurations.
1
https://github.com/open-mmlab/mmsegmentation
2
https://github.com/facebookresearch/fvcore
4.1 Ablation for Confidence Threshold
We conduct a series of expe riments to id entify th e op-
timal thresholds for different superpa tc h sizes in our
dCTS approach. Durin g this process, we evaluate the
model’s performance in terms of mI oU and GFLOPs.
This allowed us to determine the optimal balance be-
tween computational efficiency and segmentation ac-
curacy for each superpatch size. For example, when
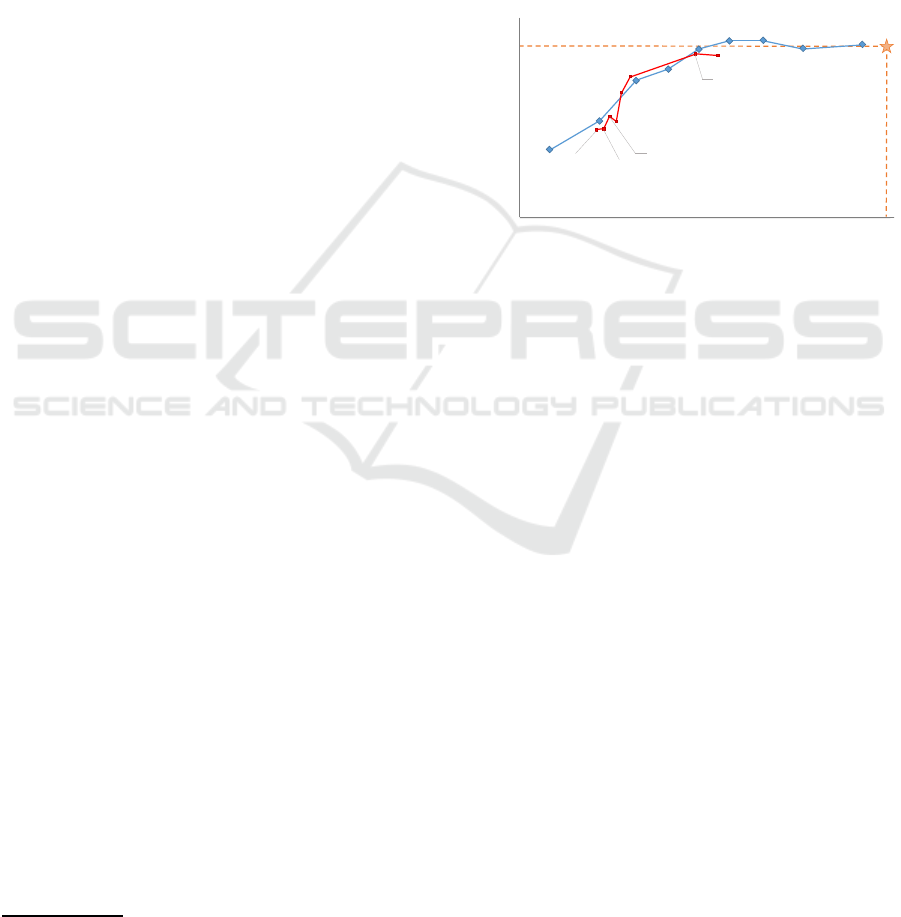
merging only groups of 2×2 patches, Figure 4 clearly
shows that a thr eshold τ of 0 .4 for tokens belonging
to the same class ach ieves the best balan ce b e tween
accuracy and co mputational complexity.
0,9
0,8
0,7
0,6
0,5
0,4
0,3
0,2
0,1
47,00
46,00
45,00
44,00
43,00
42,00
41,00
120 140
160 180
200
220
240
GFLOPs
mIoU
6,9,9,9
4,4,9,9
4,5,9,9
4,7,9,9
4,8,9,9
4,9,9,9
6,8,9,9
4,6,9,9
Figure 4: Adjusting the merging t hreshold hyperparameter
affects both accuracy and computational complexity when
using the ViT-Large backbone with the COCOSt uff10k
dataset. The blue curve demonstrates t he effect of merging
only groups of 2×2 patches, while the red curve depicts the
use of varying thresholds that depend on the size of the su-
perpatches. The orange star represents CTS’s performance
when fixing 103 merged patches of size 2×2.
Table 1 summarizes the results obtained for sev-
eral threshold configurations. Each patch size is as-
signed with a unique threshold value τ. We set
the threshold probability at 0.9 for larger groups of
patches while adjusting its values for smaller groups.
This is driven by the need to avoid errors in crea ting
large superpatches, as such mistakes would signifi-
cantly compromise the quality of the final segmen-
tation. We determine the optimal combination to be
τ-4999 or τ-6899 for the 2× 2, 4×4, 8×8, and 16×16
superpatch sizes, respectively. Compared to the CTS,
the first configuration allows no loss in segmenta-
tion accuracy while reducing computational complex-
ity by 27%. The second is less strict on segmentation
quality, allowing a potential 1% loss in mIoU, but re-
ducing complexity by 36%.
Throu gh an adaptive approach, we allow for a
more per sonalized merging process tailored to each
image. Our dCTS method achieves a significant re-
duction in the number of tokens compared to CTS.
For example, as shown in Figure 3, a complex image
can achieve a token reductio n by a factor of 2, while
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
56
a simpler image can see a reduction by a factor of 4.
This decline in tokens explains the decreased compu-
tational complexity, allowing for more efficient pro-
cessing.
Table 1: E xperiments on COCOStuff10k dataset. The
dCTS method applies thresholds τ according to the size of
the superpatches. The values are decimal numbers for the
2×2, 4×4, 8×8, and 16×16 superpatch sizes, respectively.
Threshold τ mIoU GFLOPs
CTS (τ not relevant) 46.1 248
.6 .9 .9 .9 45.9 189
.6 .8 .9 .9 46.0 181
.4 .9 .9 .9 45.3 159
.4 .8 .9 .9 44.8 156
.4 .7 .9 .9 43.9 153
.4 .6 .9 .9 44.1 151
.4 .5 .9 .9 43.7 149
.4 .4 .9 .9 43.7 147
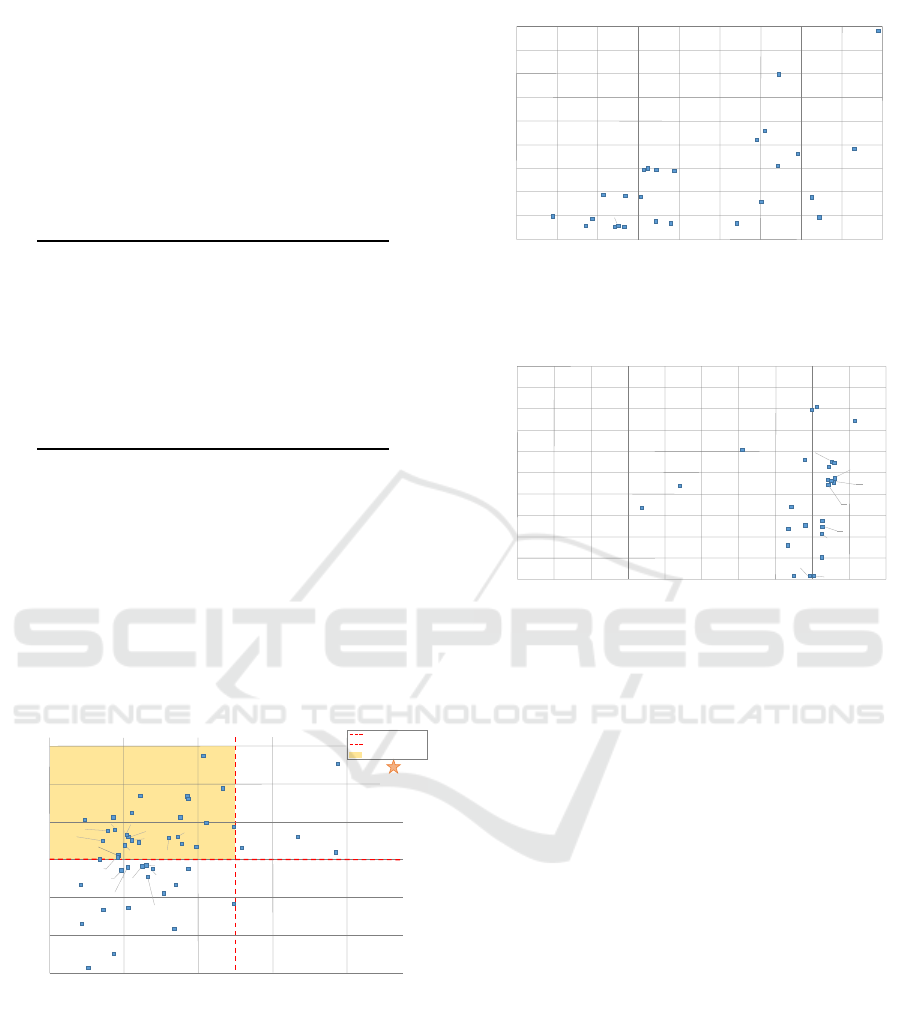
4.2 In-Depth Exploration of Pruning
Positions
We explore alternative positions for the auxiliary
head by dividing the ViT model into two or three
stages. For each config uration, we measur e the im-
pact on segmentation accuracy, computational com-
plexity (Figure 5), inference time (Figur e 6), and the
percentage of pruned tokens (Figure 7) to establish
the most effective placement strategy.
2,22
280
GFLOPs
mIoU
300
320
340
360
45,5
45
46,5
46
47,5
47
48
SegViT
GFLOPs=330
mIoU=46,5
Area of Interest
3,21
1,5
2,18
18,19
18,18
2,17
4,18
12,18
16,16
9,9
2,15
2,16
4,17
2,14
7,9
4,16
8,12
10,14
8,17
8,14
10,15
7,14
8,15
10,17
9,19
12,15
13,18
10,12
4,14
4,15
6,17
6,14
8,18
10,16
10,18
8,16
6,16
12,17
6,15
15,22
6,18
13,13
7,7
12,14
12,16
5,14
Figure 5: Exploration of the pruning head configuration on
the COCOStuff10k dataset. The numbers represent the po-
sitions of the auxiliary heads, with the red star marking per-
formance relative to the reference SegViT, where no prun-
ing is applied. The plot compares computational complex-
ity (GFLOP s) to segmentation accuracy (mIoU). The yel-
low rectangle highlights the configurations selected for fur-
ther analysis, as they achieve at least a 10% reduction in
GFLOPs with a maximum accuracy loss of 1.5%.
The results dem onstrate that the number of aux-
iliary heads impac ts computatio nal complexity and
285
GFLOPs
FPS
295 305
315
320
12
290
300
310
325
330
14
16
18
20
22
24
26
28
30
18,18
16,16
13,13
15,22
2,16
2,15
4,18
7,7
2,17
9,9
6,18
6,17
12,18
10,18
5,14
8,16
6,14
6,16
7,14
8,18
6,15
10,16
10,17
12,14
12,16
12,17
Figure 6: Exploration of the pruning head configuration on
the COCOStuff10k dataset. The plot compares throughput
(FPS) to computational cost (GFLOPs).
0
Aux Head 1: Average % Pruned Tokens
AuxHead 0: Average %PrunedTokens
10
20
30
35
12
5
15
25
40
50
14
16
18
20
22
24
26
28
30
45
7,7
9,9
c
v
18,18
13,13
16,16
12,14
15,22
7,14
2,15
2,16
2,17
4,18
6,18
5,14
6,14
6,16
6,15
12,18
12,17
12,16
10,16
8,16
8,18
10,17
10,18
6,17
Figure 7: Exploration of the pruning head configuration on
the COCOStuff10k dataset. The plot shows t he average per-
centage of pruned tokens achieved.
inference speed. For example, placin g the pruning
heads at positions 8th and 16th resu lts in a gain of
22% (289 vs. 373) GFLOPs while maintaining seg-
mentation accuracy com pared to the SegVit, whe re
no tokens have been pruned. However, adding ex-
tra he ads also contributes to longe r inference times.
Placing the pruning heads at the 8th and 16th layers
slows down the process by a factor of four, while us-
ing a single head at either the 16th or 18th layer re-
sults in a twofold increase in inference time. Given
this observation, a single auxiliary head presents the
best trade-off between reducing complexity and en-
suring real-time inference. This level of throughput
can only be attained by placing the auxiliary he ad
deeper in the network. As we proceed, th e percent-
age of pruned tokens rises linearly with the use of
only one auxiliary head for pru ning, reaching an aver-
age of approx imately 40% after the 16th position. At
this stage, th e pruning rates attain levels comparab le
to those achieved with two auxiliar y heads, irrespec-
tive o f th eir configuration.
Identify ing the ideal configuration is not an easy
task and is fairly nuanced. If the primary g oal is to
minimize com putational complexity, we suggest di-
STEP: SuperToken and Early-Pruning for Efficient Semantic Segmentation
57

viding the network into two stages and positioning th e
auxiliary heads for pruning after the 8th and 16th lay-
ers. Conversely, if inference time is the critical crite-
rion, we recommend using only a single head, posi-
tioned as early as the 16th layer.
4.3 Comparative Study
We use SegViT, which performs no mergin g or to-
ken pruning, as a baseline fo r co mparison. We also
create its variants by seq uentially applying different
optimization techniques: first, merging patches using
the CTS method, then implementing token pruning
with DToP, and finally combining both techniques.
The latest is the preliminary version of our STEP
mechanism. Througho ut this process, we adhered
to the baseline configurations and parameters estab-
lished by the authors. We combine a fixed number
of 2 × 2 patches for CTS, specifically merging 103
patches, and position the auxiliary heads at the 8th
and 16th layers for DToP. In our STEP method, we ap-
ply the previously described threshold configura tion
for dCTS. We choose to divide the ViT-Large model
into two and three stages, naming them STEP@[18]
and STEP@[8,16], re spectively. The values in brack-
ets indicate the pruning heads positions.
Figure 8: Distribution of pruned tokens with STEP@[8,16]
and segmentation results on COC O Stuff10k dataset at each
stage of the pruning process highlighting varying image
complexities. From left to right: few tokens pruned, an av-
erage number pruned, and most token pruned.
Tables 2 and 3 summarize the perform a nce
achieved. The results indicate that incorporating
STEP into SegViT enables us to maintain a com-
parable mIoU, with the segmentation accuracy loss
Table 2: Performance evaluation of our STEP mechanism,
integrated into ViT-Large, on the ADE20K dataset.
Method mIoU GFLOPs FPS
SegViT 53.0 624 37.7
+CTS 52.0 410 41.1
+DToP 52.3 465 6.3
+CTS&DToP 51.2 334 12.5
+STEP@[8,16]τ-6899 51.2 224 13.9
+STEP@[8,16]τ-4999 50.8 209 14.8
+STEP@[18]τ-6899 51.7 395 21.7
+STEP@[18]τ-4999 50.4 261 26.5
not exceeding 2.5%, depending on the chosen con-
figuration . Our STEP yields a notable reduction in
GFLOPs; for instance, STEP@[18]τ-4999, achieves
a decrease of 5 8% on ADE20K and 52% on CO-
COStuff10k. Implementing two a uxiliary heads leads
to a greater reductio n in GFLOPs c ompared to hav-
ing a single pruning head af ter layer 18th. However,
in this case, the throughput is twice as slow. In our
STEP mechanism, since we also use the configuration
[8, 16], which is the sam e as in the original DToP,
we clearly see tha t our dCTS p rovides a significant
reduction in computationa l complexity compared to
CTS, reducing it by 37% for ADE20 K and 28% for
COCOStuff10k.
Table 3: Performance evaluation of our STEP mechanism,
integrated into ViT-Large, the COCOStuff10k dataset.
Method mIoU GFLOPs FPS
SegViT 46.7 373 44.6
+ CTS 46.2 251 40.3
+ D ToP 46.6 290 15.0
+CTS& DToP 45.4 210 17.3
+STEP@[8,16]τ-6899 46.0 173 17.9
+STEP@[8,16]τ-4999 45.3 150 20.1
+STEP@[18]τ-6899 46.0 201 30.2
+STEP@[18]τ-4999 45.1 177 29.2
Figure 8 illustrates how tokens are pruned across
images by each auxiliary head, revealing that most to-
kens are pruned early in simple scenarios, while they
are r e ta ined until the final prediction phase in mo re
complex scenes. Figure 9 a nd Figure 10 display sam-
ple visualizations of predictions with STEP integrated
into ViT-Large.
5 CONCLUSION
We presented a novel token reduc tion method called
SuperToken and Early-Pruning (STEP) that enhances
token man agement in ViTs for semantic segmen tation
by integrating p atch merging with an early-pruning
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
58

Figure 9: Visualized results on COCO Stuff10K
STEP@[8,16]τ-4999 added to ViT-Large. Left: Ground
truth; Right: Predicted segmentation.
mechanism. Our approach employs a versatile merg-
ing strategy that utilizes superpatches of varying sizes
and introduces an improved patch merging technique
to effectively handle diverse image complexities. Ex-
tensive experimental tests we re conducte d to estab-
lish optimal parameters for creating superpatch es. We
also explored the advantages of pruning tokens within
the network, finding that starting from the 16th layer
of ViT-Large, 40% of tokens can be classified with
high accuracy. While using auxiliary heads to prune
high-confidence tokens reduces computational com-
Figure 10: Visualized results on ADE20K with
STEP@[8,16]τ-6899 added to ViT-Large. Left: Ground
truth; Right: Predicted segmentation.
plexity, it significantly slows down inference. We rec-
ommend that f uture resear c h focus on the examina-
tion of auxiliary heads, as pruning tokens using seg-
mentation heads with ATM modules has been shown
to be excessively slow.
REFERENCES
Bolya, D., Fu, C.-Y., Dai, X., Zhang, P., Feichtenhofer, C .,
and Hoffman, J. (2023). Token merging: Your ViT
STEP: SuperToken and Early-Pruning for Efficient Semantic Segmentation
59

but faster. In International Conference on Learning
Representations.
Bolya, D. and Hoffman, J. (2023). Token merging for fast
stable diffusion. CVPR Workshop on E fficient Deep
Learning for Computer Vi sion.
Bonnaerens, M. and Dambre, J. (2023). Learned thresh-
olds token merging and pruning for vision transform-
ers. Transactions on Machine Learning Research.
Caesar, H., Uij lings, J., and Ferrari, V. (2018). Coco-stuff:
Thing and stuff classes in context. In 2018 IEEE/CVF
Conference on Computer Vision and Pattern R ecog-
nition (CVPR), pages 1209–1218, Los Alamitos, CA,
USA. IEEE Computer Society.
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov,
A., and Zagoruyko, S . (2020). End-to-end object de-
tection with tr ansformers. In European conference on
computer vision, pages 213–229. Springer.
Chen, M., Shao, W., Xu, P., Lin, M., Zhang, K., Chao, F., Ji,
R., Qiao, Y., and Luo, P. (2023). Diffrate : Differen-
tiable compression rate f or efficient vision transform-
ers. arXiv preprint arXiv:2305.17997.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn,
D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer,
M., Heigold, G., G elly, S., Uszkoreit, J., and Houlsby,
N. (2021). An image is worth 16x16 words: Trans-
formers for image recognition at scale. In Interna-
tional Conference on Learning Representations.
Fayyaz, M., Abbasi Kouhpayegani, S., Rezaei Jafari, F.,
Sommerlade, E., Vaezi Joze, H. R ., Pirsiavash, H., and
Gall, J. (2022). Adaptive token sampling for efficient
vision transformers. European Conference on Com-
puter Vision (ECCV).
Hao, Y. and Jianxin, W. (2023). A unified pruning frame-
work for vision transformers. Science C hina Informa-
tion Sciences, 66:1869–1919.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
ual learning for image recognition. In Proceedings of
the IEEE Conference on C omputer Vision and Pattern
Recognition ( CVPR).
Huang, H., Zhou, X., Cao, J., He, R., and Tan, T. (2022).
Visi on transformer with super token sampling. ArXiv,
abs/2211.11167.
Kim, M., Gao, S., Hsu, Y.-C., Shen, Y., and Jin, H. (2024).
Token fusion: Bri dging the gap between token prun-
ing and token merging. In 2024 IEEE/CV F Win-
ter Conference on Applications of Computer Vision
(WACV), pages 1372–1381.
Kong, Z., Dong, P., Ma, X., Meng, X., Niu, W., Sun, M.,
Shen, X., Yuan, G., Ren, B. , Tang, H., et al. (2022).
Spvit: E nabling faster vision transformers via latency-
aware soft token pruning. I n Computer Vision–ECCV
2022: 17th European Conference, Tel Aviv, Israel, Oc-
tober 23–27, 2022, Proceedings, Part XI, pages 620–
640. Springer.
Li, Z. and Gu, Q. (2023). I-vit: Integer-only quantization for
efficient vision transformer inference. In Proceedings
of the IEEE/CVF International Conference on Com-
puter Vision, pages 17065–17075.
Liang, Y., Ge, C., Tong, Z., Song, Y., Wang, J., and Xie, P.
(2022). Not all patches are what you need: Expediting
vision transformers via token reorganizations. In In-
ternational Conference on Learning Representations.
Lin, Y., Zhang, T., Sun, P., L i, Z., and Zhou, S. (2022). Fq-
vit: Post-training quantization for fully quantized vi-
sion transformer. In Proceedings of the Thirty-First
International Joint Conference on Art ificial Intelli-
gence, IJCAI-22, pages 1173–1179.
Liu, Y., Gehrig, M., Messikommer, N., Cannici, M., and
Scaramuzza, D. (2024). Revisiting token pruning
for object detection and instance segmentation. In
2024 IEEE/CVF Winter Conference on Applications
of Computer Vision (WACV), pages 2646–2656, Los
Alamitos, CA, USA. IEEE Computer Society.
Liu, Z., L in, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin,
S., and Guo, B. (2021). Swin transformer: Hierarchi-
cal vision transformer using shifted windows. In Pro-
ceedings of the IEEE/CVF International Conference
on Computer Vision (ICCV), pages 10012–10022.
Lu, C., de Geus, D., and Dubbelman, G. (2023). Content-
aware Token Sharing for Efficient Semantic Segmen-
tation with Vision Transformers. In IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition
(CVPR).
Marin, D., Chang, J.-H. R., Ranjan, A., Prabhu, A., Raste-
gari, M., and Tuzel, O. (2023). Token pooling
in vision transformers for image classification. In
2023 IEEE/CVF Winter Conference on Applications
of Computer Vision (WACV), pages 12–21.
Meng, L., Li, H., Chen, B.-C., Lan, S., Wu, Z., Jiang, Y.-
G., and Lim, S.-N. (2022). Adavit: Adaptive vision
transformers for efficient image recognition. In 2022
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition (CVPR), pages 12309–12318.
Michel, P., Levy, O., and Neubig, G. (2019). Are si x-
teen heads really better than one? In Wallach, H. ,
Larochelle, H ., Beygelzimer, A., d'Alch´e-Buc, F.,
Fox, E., and Garnett, R., editors, Advances in Neural
Information Processing Systems, volume 32. Curran
Associates, Inc.
MMSegmentation Contributors (2020). MMSegmenta-
tion: Openmmlab semantic segmentation toolbox
and benchmark. https://github.com/open-mmlab/
mmsegmentation.
Rao, Y., Liu, Z. , Zhao, W., Zhou, J., and Lu, J. (2023). Dy-
namic spatial sparsification for efficient vision trans-
formers and convolutional neural networks. IEEE
Transactions on Pattern Analysis and Machine Intel-
ligence, 45(9):10883–10897.
Rao, Y., Zhao, W., Liu, B., Lu, J., Z hou, J., and Hsi eh,
C.-J. (2021). Dynamicvit: Efficient vision transform-
ers with dynamic token sparsification. In Advances in
Neural I nformation Processing Systems (NeurIPS).
Russakovsky, O., Deng, J. , Su, H., Krause, J., Satheesh,
S., Ma, S., Huang, Z., Karpathy, A., Khosla, A.,
Bernstein, M., Berg, A. C. , and Fei-Fei, L. (2015).
ImageNet Large Scale Visual Recognition Challenge.
International Journal of C omputer Vision (IJCV),
115(3):211–252.
Ryoo, M. S ., Pi ergiovanni, A. J., Arnab, A., Dehghani, M.,
and Angelova, A. (2021). Tokenlearner: What can
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
60

8 learned tokens do for images and videos? CoRR,
abs/2106.11297.
Sandler, M., Howard, A. , Zhu, M., Zhmoginov, A., and
Chen, L.-C. (2018). Mobilenetv2: Inverted residu-
als and linear bottlenecks. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recogni-
tion (CVPR).
Song, Z., Xu, Y., He, Z., Jiang, L., Jing, N., and Liang, X.
(2022). Cp-vit: Cascade vision transformer pruning
via progressive sparsity prediction.
Strudel, R., Garcia, R., Laptev, I., and Schmid, C. (2021).
Segmenter: Transformer for semantic segmentation.
In Proceedings of the IEEE/C VF international con-
ference on computer vision, pages 7262–7272.
Tan, M. and Le, Q. V. (2019). Efficientnet: Rethink-
ing model scaling for convolutional neural networks.
ArXiv, abs/1905.11946.
Tang, Q., Zhang, B. , Liu, J., Liu, F., and Liu, Y. (2023). Dy-
namic token pruning in plain vision transformers for
semantic segmentation. In 2023 IEEE/CVF Interna-
tional Conference on Computer Vision (ICCV), pages
777–786, Los Alamitos, CA, USA. IEEE Computer
Society.
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles,
A., and J´egou, H. (2021). Training data-efficient im-
age transformers & distillation through attention. In
International conference on machine learning, pages
10347–10357. PMLR.
Tran, H.-C., Nguyen, D., Nguyen, D., Nguyen, T., Lˆe, N.,
Xie, P., Sonntag, D., Zou, J., Nguyen, B., and Niepert,
M. (2024). Accelerating transformers with spectrum-
preserving token merging.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., Kaiser, L. u., and Polosukhin,
I. (2017). Attention is all you need. I n Guyon,
I., Luxburg, U. V., Bengio, S., Wallach, H., Fer-
gus, R., Vishwanathan, S., and Garnett, R., editors,
Advances in Neural Information Processing Systems,
volume 30. Curran Associates, Inc.
Wang, H., Dedhia, B., and Jha, N. K. (2023). Zero-
tprune: Zero-shot token pruning through leveraging of
the attention graph in pre-trai ned transformers. arXiv
preprint arXiv:2305.17328.
Wang, W., Xie, E., Li, X., Fan, D.-P., Song, K., Liang, D.,
Lu, T., Luo, P., and Shao, L. (2021). Pyramid vi-
sion transformer: A versatile backbone for dense pre-
diction without convolutions. In Proceedings of the
IEEE/CVF international conference on computer vi-
sion, pages 568–578.
Wu, K., Zhang, J., Peng, H., Liu, M., Xiao, B., Fu, J., and
Yuan, L. (2022). Tinyvit: Fast pretraining distillation
for small vision transformers. In European conference
on computer vi sion (ECCV).
Wu, X., Zeng, F., Wang, X., Wang, Y., and Chen, X. (2023).
Ppt: Token pruning and pooling for efficient vision
transformers. arXiv preprint arXiv:2310.01812.
Xie, E., Wang, W., Yu, Z., Anandkumar, A., Al varez, J. M.,
and Luo, P. (2021). Segformer: Simple and efficient
design for semantic segmentation with transformers.
Advances in neural information processing systems,
34:12077–12090.
Xu, Y., Zhang, Z., Zhang, M., Sheng, K ., Li, K., Dong, W.,
Zhang, L., Xu, C., and Sun, X. (2022). Evo-vit: S low-
fast token evolution for dynamic vision transformer.
In Proceedings of the AAAI Conference on Artificial
Intelligence, volume 36, pages 2964–2972.
Yang, Z., Li, Z., Zeng, A., Li, Z., Yuan, C., and Li, Y.
(2024). ViTKD: Feature-based knowledge distil lation
for vision transformers.
Yin, H., Vahdat, A., Alvarez, J., Mallya, A., Kautz, J., and
Molchanov, P. (2022). A-ViT: Adaptive tokens for
efficient vision transformer. In Proceedings of the
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition.
Yuan, Z., Xue, C., Chen, Y., Wu, Q., and Sun, G. (2022).
Ptq4vit: Post-training quantization for vision trans-
formers with twin uniform quantization. In Computer
Vision – ECCV 2022: 17th European Conference,
Tel Aviv, Israel, October 23–27, 2022, Proceedings,
Part XII, page 191–207, Berli n, Heidelberg. Springer-
Verlag.
Zeng, W., Jin, S., Liu, W., Qian, C., Luo, P., Ouyang,
W. , and Wang, X. (2022). Not all tokens are equal:
Human-centric visual analysis via token clustering
transformer. In Proceedings of the IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition,
pages 11101–11111.
Zhang, B., Tian, Z., Tang, Q., Chu, X., Wei, X., S hen, C.,
and Liu, Y. (2022). Segvit: Semantic segmentation
with plain vision transformers. NeurIPS.
Zhang, W., Pang, J., Chen, K., and Loy, C. C. (2021). K-
net: Towards unified image segmentation. Advances
in Neural Information Processing Systems, 34:10326–
10338.
Zheng, S., Lu, J., Zhao, H., Zhu, X., Luo, Z., Wang, Y., Fu,
Y., Feng, J., Xiang, T., Torr, P. H., et al. (2021). Re-
thinking semantic segmentation from a sequence-to-
sequence perspective with transformers. In Proceed-
ings of the IEEE/CVF conference on computer vision
and pattern recognition, pages 6881–6890.
Zhou, B., Zhao, H., Puig, X., Fidler, S., Barri uso, A., and
Torralba, A. (2017). Scene parsing through ade20k
dataset. In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition.
Zizheng, P., Bohan, Z., Haoyu, H., Jing, L. , and Jianfei,
C. (2022). Less is more: Pay less attention in vision
transformers. In The Thirty-Sixth AA AI Conference on
Artificial Intelligence, pages 2035–2043.
STEP: SuperToken and Early-Pruning for Efficient Semantic Segmentation
61
