
CTypiClust: Confidence-Aware Typical Clustering for Budget-Agnostic
Active Learning with Confidence Calibration
Takuya Okano
a
, Yohei Minekawa
b
and Miki Hayakawa
c
Hitachi High-Tech Corporation, Japan
Keywords:
Deep Learning, Active Learning, Confidence Calibration.
Abstract:
Active Learning (AL) has been widely studied to reduce annotation costs in deep learning. In AL, the ap-
propriate method varies depending on the number of annotatable data (budget). In low-budget settings, it is
appropriate to priorit ize sampling typical data, while in high-budget settings, it is better to prioritize sampling
data with high uncertainty. This study proposes Confidence-aware Typical Clustering (CTypiClust), an AL
method t hat performs well regardless of the budget. CTypiClust dynamically swit ches between typical data
sampling and low-confidence data sampling based on confidence. Additionally, to mitigate t he overconfidence
problem in low-budget settings, we propose a new confidence calibration method Cluster-Enhanced Confi-
dence (CEC). By applying CEC to CTypiClust, we suppress the occurrence of overconfidence in low- budget
settings. To evaluate the effectiveness of the proposed method, we conducted experiments using multiple
benchmark datasets, and confirmed that C TypiClust consistently shows high performance regardless of the
budget.
1 INTRODUCTION
Reducing annotation costs is on e of the critical chal-
lenges in deep learning. To enhanc e the performance
of deep learning models, a large amount of data is re -
quired, but annotating all the data is very costly. This
problem is particularly severe in fields requiring ex-
pertise, such as manufacturing and healthcare, where
accurate labeling demands enormous costs and time.
Active Learning (AL) h a s been widely studied as
a method to minimize annotatio n costs (Ren et al.,
2021). In AL, a fixed budget of data is sampled from
a large pool of un la beled data, based on its useful-
ness for improving model performance. This process
is repeated to optimize the model with minimal la-
beled data. Traditional methods include AL methods
using un certainty (low confidence) (Roth a nd Small,
2006; Gal et al., 2017; Pop and Fulop, 2018), meth-
ods considering data diversity (Sener and Savarese,
2018; Zhdanov, 2019), and methods considering both
uncertainty and diversity (Sinh a et al., 2019). T hese
methods assum ed relatively high-budget settings, but
recent advances in self-supervised learning (Jaiswal
a
https://orcid.org/0009-0006-3749-3883
b
https://orcid.org/0009-0006-8980-4356
c
https://orcid.org/0009-0004-3547-8896
et al., 2021) have led to the d evelopment of AL meth-
ods in cold -start settings with no labeled data (Chen
et al., 2023; Yi et al., 2022), and research on AL in
low-budget settings (Hacohen et al., 2022).
However, (Hacohen et al., 2022) shows that the
optimal method varies depending on th e budget. In
low-budget settings, it is necessary to learn from lim-
ited data, so prioritizing typical data makes it easier to
capture the overall characteristics of the dataset, lead-
ing to faster model accuracy improvement. On the
other hand, in high-budget settings, the main features
of the dataset can be lear ned from a large amount of
data, so learn ing data with high un certainty near the
decision boundary is effective fo r improving accuracy
(Hacohen et al., 2022).
Therefore, in this study, we propose Confidence-
aware Typical Clustering (CTypiClust), which per-
forms highly regardless of the budget. This method
extends Typical Clustering(TypiClust)(Haco hen
et al., 2022), a method for low-budget settin gs, by
dynamically switching between sampling typical
data and low-confidence data based on confidence,
making it effective in high-budget settings as well.
Additionally, to address the issue of overconfi-
dence in low-budget settings, we propose a new
confidence calibration method Cluster-Enhanced
Confidence(CEC) and apply it to CTypiClust. To
340
Okano, T., Minekawa, Y. and Hayakawa, M.
CTypiClust: Confidence-Aware Typical Clustering for Budget-Agnostic Active Learning with Confidence Calibration.
DOI: 10.5220/0013139400003912
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 2: VISAPP, pages
340-347
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

confirm that CTypiClust performs well regardless
of the budget, we evaluate its effectiveness using
CIFAR-10, CIFAR-100, and STL-10.
The contributions of this paper are as follows:
1. We propose an AL method CTypiClust that con-
sistently de monstrates high performance regard-
less of budget constraints.
2. A confidence calibration metho d CEC is pro-
posed, which effectively mitigates overconfidence
eve n in low-budget setting s.
3. The e ffectiveness of CTypiClust and CEC is
demonstra te d through experiments using multiple
benchm ark datasets.
2 RELATED WORK
2.1 Active Learning
High-Budget Active Learning. Many AL methods
typically assume a high-budget setting, where meth-
ods that sample data with high unce rtainty (Roth and
Small, 2006; Gal et al., 2017; Pop and Fulop, 2018) ,
methods that consider diversity (Sener and Savarese,
2018; Zhda nov, 2019), and methods that consider
both unc ertainty and dive rsity have been proposed
(Kirsch et al., 2019; Sinha et al., 2019).
Among these, methods that sample data with high
uncertainty have been widely proposed (Roth and
Small, 2006; Gal et al., 2017; Pop and Fulop, 2018) .
(Roth a nd Small, 2006) pro posed Margin, which pri-
oritizes sampling data with a small difference b e-
tween the highest and second-highest predic ted prob-
abilities, considering such data as having high uncer-
tainty. (Gal et al., 2017) proposed DBAL, which uti-
lizes a Bayesian approach.
(Sener and Savarese, 2018) proposed Co reSet,
an AL method that prioritizes diversity. CoreSet
achieves diversity-aware sampling by sampling rep-
resentative da ta based on the core-set app roach. (Zh-
danov, 2019) proposed a mini-batch active learn-
ing method that incorporates data diversity using K-
means clustering to enhance the efficiency of label se-
lection in large-scale datasets.
Approac hes that consider both uncertainty and di-
versity have also been proposed (Kirsch et al., 2019;
Sinha et al., 2019). (Kirsch et al., 2019) proposed
BALD, which balances uncertainty a nd diversity by
sampling to maximize mutual informatio n among
data points within a b a tc h, in add ition to a Bayesian
approa c h. (Sinha et al., 2019) introduced VAAL, a
method that focuses on both diversity and unc e rtainty
using a variational autoencoder.
Cold and Low-Budget Active Learning. In settings
like cold-start and low-budget, where there is little or
no labeled data, methods effective in high-budget set-
tings perform worse than random sampling (Hacohen
et al., 2022). As an effective method in cold-start set-
tings, (Yi et al. , 2022) introduce d a method that sam-
ples data w ith high loss in pretext tasks, considering
it to have high learning efficiency. (Chen et al., 2023)
proposed a method based on contrastive learning that
samples data that is difficult to distinguish as typical
data. In cold-start and low-budget settings, (Hacohen
et al., 2022) proposed TypiClust. TypiClust priori-
tizes samplin g data with hig h density in the feature
space of unlabeled data as typical data.
Typicality-prioritized AL meth ods like TypiClust
perform poorly in high-budget settings. Therefore , in
this study, we propose CTypiClust, which p e rforms
highly regardless of the budget by combining meth-
ods based on uncer ta inty. Uncertainty is generally
calculated from the model’s confiden c e, but in low-
budget settings, there is a problem of overconfidence ,
where the model becomes excessively confident.
2.2 Confidence Calibration
Deep learning models are known to exhibit overcon-
fidence, wh e re the predicted confidence significantly
exceeds the a ctual accuracy. This issue is particu-
larly prevalent in low-budget settings with very lim-
ited training data. To address this problem, numer-
ous calibration methods have been proposed to align
predicted probabilities with actu a l accuracies (Wang,
2024).
Calibration methods can be broadly categorized
into post-hoc methods and regularization methods.
Post-hoc methods perform calibration using a large
amount of data after the model has been trained. For
example, temperature scaling (Platt, 2000; Mozafari
et al., 2019) op timizes the temperature parameter of
the softmax function using validation data. On the
other hand, regularization methods add penalties to
the model’s loss function to suppress overconfide nce
(Guo et al., 2017; Pereyra et al., 2017).
Many calibration methods assume settings with a
large a mount of labeled data or aim to improve the
model itself o r the loss function. However, they do
not consider special settin gs like low-budget, where
labeled data is extremely limited.
In this study, we propose a new calibration method
CEC to mitigate overconfidence in low-budget set-
tings and apply it to CTypiClust. CEC c orrects the
model’s con fidence based on the clustering results of
intermediate layer features.
CTypiClust: Confidence-Aware Typical Clustering for Budget-Agnostic Active Learning with Confidence Calibration
341

Figure 1: Illustration of CTypiClust and CEC. (a) CTypiClust, similarly to TypiClust, obtains features fr om the unlabeled
dataset U and performs clustering. From each cl uster K
i
, it r et r ieves the data with the highest typicality x
t
and the data with
the lowest CEC x
c
. It decides whether to sample x
t
or x
c
based on the CEC(x
t
) of the data with the highest typicality. (b)
In CEC, the input data x is fed into the model to obtain the features f (x) (black circle) and the output of the classification
model g(y | f (x)). From g(y | f (x)), the pseudo-label ˆy and the confidence ˆc are calculated. The features of the unlabeled
data are clustered, and the cluster to which x belongs is assigned the pseudo-label ˜y. The confidence ˜c is calculated based on
the relative distance to the center µ
i
(star) of each cluster. Finally, CEC(x) is calculated from the two pseudo-labels and the
confidence.
3 METHOD
In this section, we introduce Confiden ce-aware Typi-
cal Clustering (CTypiClust). The detailed methodol-
ogy of CTypiClust is explained in Section 3.2. Ad-
ditionally, we propose a new confidence calibration
method called Cluster-Enhance d Confidence (CEC),
which is used in CTypiClust and is discussed in Sec-
tion 3.3. The methods are illustrated in Figure 1.
3.1 Notation
Let X be the set of all input data, and each data point
x ∈ X is included in the unlabeled dataset U ⊆ X.
Although the data in the unlabeled dataset U are
not labeled, there exists a set of class labels Y =
{1, 2, . . . , |Y |} corresponding to the data. Each data
point x has a corr esponding label y ∈ Y . The model
used in this study is divided into a feature extractor
f (·) and a classifier g(·). First, the feature extractor
f extracts features f (x) from the input x. The classi-
fier g takes the featu res f (x) as input and ou tputs the
probability distribution g(y | f (x)) for the label y.
3.2 Confidence-Aware Typical
Clustering
We propose CTypiClust, an extension of TypiClust
(Hacohen et al., 2022) that considers confidence .
While TypiClust samples data with hig h typicality
as is, CTypiClust determines whether to sample data
with high typicality or low -confidence data based on
the confidence of the data with high typicality. If
the confidence of the data with h igh typicality is
high, CTypiClust assumes that the learning efficiency
of typical data is low and samples low-confidence
data. As a result, in immature stages like low-budge t
settings, typicality-prio ritized sampling is expected,
while in mature stages like high-budget settin gs, low-
confidence-prior itized sampling is expected. Addi-
tionally, CTypiClust uses CEC as the c onfidence mea-
sure to mitigate overconfidence in low-budget set-
tings.
The specific steps of CTypiClust are explained be-
low. CTyp iClust consists of four steps. Steps 1 and 2
are the same as in TypiClust.
Step1: Pre-train the model f using the unlabeled data
U with Self-Supervised Learnin g methods (e.g., Sim-
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
342

CLR (Chen et al., 2020)).
Step2: Input the unlabe le d data U into the model f
pre
trained in Step 1 to obtain features. Perform cluster-
ing on the obtained features using a me thod such as
K-means.
Step3: Extract data with high typicality x
t
=
argmax
x∈K
i
{Typicality(x)} and data with low CEC
x
c
= arg min
x∈K
i
{CEC(x)} from each cluster K
i
. The
calculation method of CEC is explained in Sectio n
3.3. Typicality(x) is calculated as the local density
in the feature spa ce of x, as in (Hacohen et al., 2022).
Specifically, it is defined by the following equation:
Typicality(x) =
1
K
∑
x
i
∈K -NN(x)
kx − x
i
k
2
!
−1
.
Here, K is the number of data points in the K -nearest
neighbors (K - NN ) of x, and x
i
is one of the data
points in th e neighborho od. kx−x
i
k
2
is the Euclidean
distance between the data point x and its neighboring
point x
i
.
Step4: If the CEC(x
t
) of the data with high typical-
ity x
t
is below th e threshold T
c
, sample x
t
as is. If
CEC(x
t
) is h igher than the threshold T
c
, sample the
data x
c
with the lowest CEC in the same cluster.
The algorithm of CTypiClust is shown in Algo-
rithm 1.
Data: Unlabele d pool U, Budget B
Result: Queries
Embedding ← Representation
Learning(U);
Clust ← Clustering
algorithm (Embedding,
B);
Queries ←
/
0;
for i = 1 to B do
x
t
← argmax
x∈K
i
{Typicality(x)} ;
x
c
← argmin
x∈K
i
{CEC(x)} ;
if CEC(x
t
) > T
c
then
Add x
c
to Queries ;
else
Add x
t
to Queries ;
end
end
Algorithm 1: CTypiClust.
3.3 Cluster-Enhanced Confidence
In low-budget settings, where the amount of train-
ing data is limited, the model tends to overfit and be-
come overconfident. To mitigate overconfidence, we
propose a confidence ca libration method CEC, which
corrects the confidence of the cla ssification model’s
output using the c lustering results of intermediate
layer features.
The pseud o-label obtained from the classifier g
is ˆy = arg max
y
g(y | f (x)), and the confidence is
ˆc = max
y
g(y | f (x)). Additionally, the features of
the unlab eled d ata U are clustered, and the center of
each cluster K
i
is µ
i
=
1
|K
i
|
∑
x∈K
i
f (x). The pseu do-
label ˜y is the label obtained from clustering. In K-
means, ˜y = argmin
i
D(x, µ
i
). D represents any dis-
tance function (e.g., Euclidean distance, Cosine sim-
ilarity). The correspondenc e between the model’s
pseudo- la bel ˆy and the clu ster ing pseudo-label ˜y is
based on the frequency of label occurr ence within
each cluster. Specifically, after each data x is assigned
a pseudo-label ˜y by the clustering method, the model’s
pseudo- la bel ˆy that appears most frequently within
each c luster K
i
is assign ed as the representative label
of that cluster. The confidence ˜c is calculated based
on the relative distance to the center of each cluster,
similar to Prototypical Networks (Snell et al., 2017).
˜c = max
k
exp(−D( f (x), µ
k
))
∑
i
exp(−D( f (x), µ
i
))
.
By using these values, CEC(x) is defined a s follows:
CEC(x) = 1
[ ˆy= ˜y]
· ˆc · ˜c. (1)
Here, 1
[ ˆy= ˜y]
is an indicator function that returns 1 if
the two pseu do-labels match and 0 if they do not. The
number of clusters |K| is set to be equa l to th e number
of classes |Y |. This function ensures that if the labels
do no t match, CEC becomes 0, and unless both confi-
dences are high, the confidence will not be high. The
algorithm of CEC is shown in Algorithm 2 .
Data: Data x, Clust K, Models f , g
Result: CEC(x)
for i = 1 to |K| do
µ
i
←
1
|K
i
|
∑
x∈K
i
f (x) ;
end
ˆy ← argmax
y
g(y | f (x));
˜y ← argmin
i
D(x, µ
i
) ;
ˆc ← max
y
g(y | f (x));
˜c ← max
k
exp(−D(f (x),µ
k
))
∑
i
exp(−D(f (x),µ
i
))
;
CEC(x) ← 1
[ ˆy= ˜y]
· ˆc · ˜c ;
Algorithm 2: CEC.
4 EXPERIMENT AND
DISCUSSION
To verify whether CTypiClust performs superiorly re-
gardless of th e budget, we use multiple datasets and
compare it with related methods under various budget
settings. Additionally, we conduct an ablation stu dy
of CTypiClust and CEC using the CIFA R-10 dataset.
CTypiClust: Confidence-Aware Typical Clustering for Budget-Agnostic Active Learning with Confidence Calibration
343
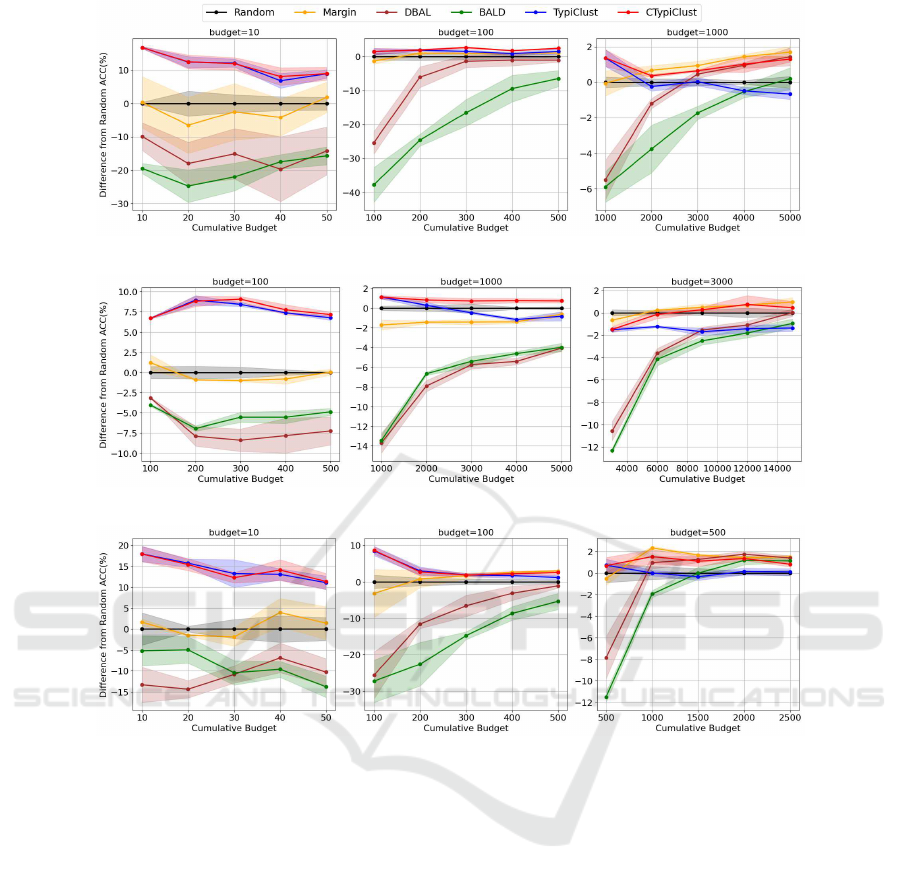
(a) CIFAR-10
(b) CIFAR-100
(c) STL-10
Figure 2: Comparison of the ACC difference between each method and Random for each dataset. Results are shown from left
to right for low, medium, and high budgets. The shaded area reflects standard error.
4.1 Experimental Settings
In this experiment, we evaluate based on the AL pro-
gram proposed by (Munjal et al., 2022). The datasets
used for evaluation ar e CIFAR-10 (Krizhevsky and
Hinton, 2009), CIFAR-100 (Krizhevsky and Hin-
ton, 2009), and STL-10 (Coates et al., 2011). Th e
compariso n meth ods are TypiClust(Hacohen e t al.,
2022), Margin(Ro th and Small, 2006), DBAL(Gal
et al., 2017), BALD(K irsch et al., 2019), and Ran-
dom. We set three types of budgets (low, medium,
and hig h) and configure them for each da ta set as fol-
lows: low=10, medium =100, high=1000 for CIFAR-
10; low=100, medium=1000, high=3000 for CIFAR-
100; and low=10, medium=100, high=500 for STL -
10. We use ResNet-18 (He et al., 2016) as the model.
For TypiClust and CTypiClust, we use feature s ex-
tracted from models pre-trained with SimCLR (Chen
et al., 2020). The models for learning each dataset ar e
also pr e-trained with SimCLR. Th e parameter T
c
for
CTypiClust is set to 0.8, and the distance function D
is th e Euclidean distanc e. The evaluation metrics are
accuracy (ACC) and Area Under the Budge t Curve
(AUBC) (Z han et al., 2021). AUBC is a metric that
calculates the area under the ACC curve for each bud-
get. Other detailed settings are described in the Ap-
pendix.
4.2 Performance Comparison of
Different Methods
To evaluate whether CTypiClust performs highly re -
gardless of the budget compared to other methods, we
compare it with related methods under various budget
settings for m ultiple datasets.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
344
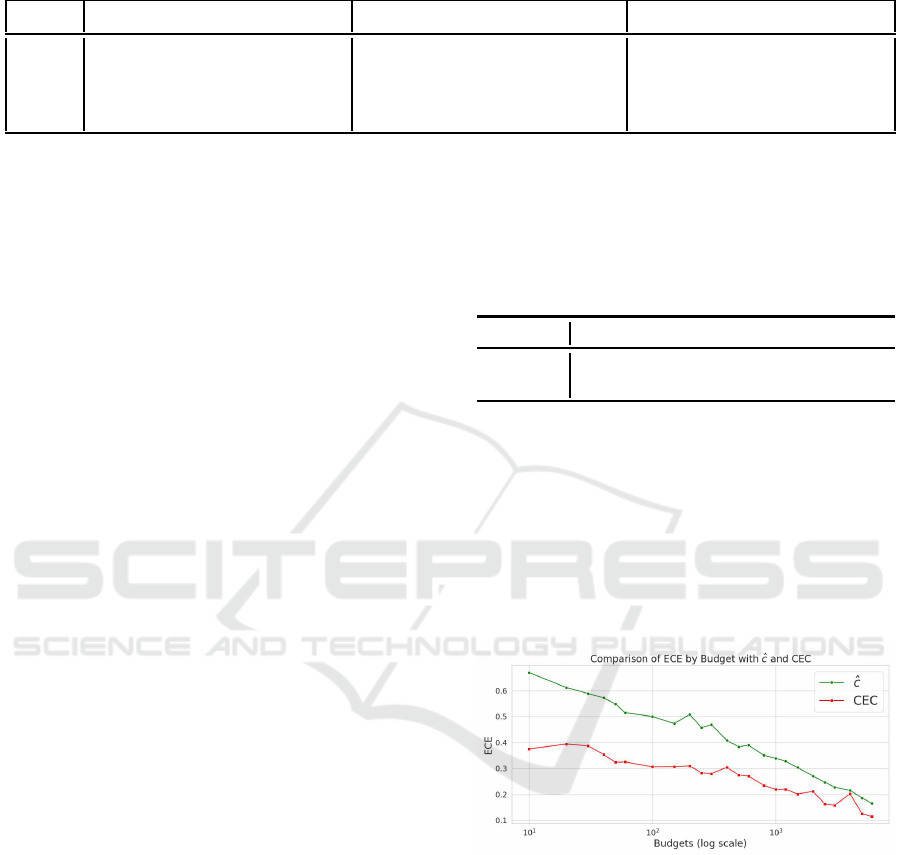
Table 1: Mean and standard deviation of AUBC for each method under low, medium, and high budgets. The numbers in
parentheses indicate the budget size. The highest performance is shown in red, and the second highest in blue.
CIFAR-10 CIFAR-100 STL-10
Budget Low(10) Medium(100) High(1000) Low(100) Medium(1000) High(3000) Low(10) Medium(100) High(500)
Random 49.77 (±1.67) 74.20 (±0.70) 82.56 (±0.12) 20.90 (±0.44) 44. 83 (±0.13) 53.94 (±0.20) 41.88 (±1.98) 71.00 (±0.8 5) 83.67 (±0.42)
Margin 46.78 (±7.11) 74.89 (±0.05) 83.52 (±0.20) 20.37 (±0.16) 43. 48 (±0.13) 54.33 (±0.18) 42.39 (±1.83) 72.21 (±1.6 6) 85.14 (±0.08)
DBAL 33.58 (±6.65) 68.75 (±1.97) 82.10 (±0.07) 13.58 (±1.38) 37. 84 (±0.43) 51.05 (±0.26) 30.89 (±1.06) 62.30 (±1.8 2) 83.85 (±0.35)
BALD 29.32 (±2.86) 56.03 (±1.46) 80.34 (±0.27) 15.28 (±0.43) 38. 48 (±0.16) 50.16 (±0.35) 33.24 (±2.45) 55.38 (±1.7 3) 82.17 (±0.14)
TypiClust 60.84 (±1.28) 75.66 (±0.26) 82.47 (±0.18) 28.77 (±0.15) 44. 53 (±0.11) 52.48 (±0.19) 56.00 (±1.26) 73.83 (±0.4 9) 83.72 (±0.24)
CTypiClust 61.13 (±1.70) 76.29 (±0.22) 83.3 9 (±0.12) 29.04 (±0.24) 45. 63 (±0.14) 54.03 (±0.42) 55.97 (±0.59) 74.07 (±0.2 8) 84.84 (±0.17)
Figure 2 compare s each method with Random un -
der different budgets for each dataset. TypiClust per-
forms well when the budget is small, such as in low-
budget settings, but it performs worse than Random
as the budget increases. On the other hand, Margin,
which samples data with high u ncertainty, performs
better than Random in high-budget settings but worse
than Random in low-budget settings. The proposed
method CTypiClust per forms better than Random in
most cases regardless of the budget.
Table 1 compares the results of each method
in term s of AUBC. Sim ilar to Figure 2, TypiClust
performs well in low-budget settings but poorly in
high-budget settings. Margin performs well in high-
budget settings but relatively poorly in low-budget
and medium-budget settings. CTyp iClust ranks first
or second in all budget settings, demonstrating high
performance regardless of the budget.
4.3 Ablation Study
In this section, we conduc t an ablation study on CTyp -
iClust and CEC using the CIFAR-10 dataset. First, we
compare CTypiClust using confidence ˆc and CEC to
evaluate the necessity of CEC in CTypiClust . Next,
we assess whether CEC mitigates the issue of over-
confidence. Finally, we examine the performance dif-
ferences based o n the parameter T
c
in CTypiClust.
Comparison of CTypiClust Using Confidence ˆc
and CEC. To evaluate the necessity of CEC in CTyp-
iClust, we compare the perfor mance of CTypiClust
using simple c onfidence ˆc (w/o CEC) and CTypiClust
using CEC (w/ CEC). Table 2 shows the AUBC of
w/o CEC a nd w/ CEC. In low-budget settings, the
AUBC of w/o CEC is 59.34%, that of w/ CEC is
61.13%, approximately 1.79% imp rovement by using
CEC. In high-budget settings, the AUBC of w/o CEC
is 83.43%, slightly better than the 83.39% of w/ CEC,
but the difference of 0 .04% is very small, with almost
no difference between them. This is likely because
in high-budget settin gs, the model’s ACC improves,
and overconfidence is mitigated, allowing w/o CEC
to perform well. Thus, in scenarios with relatively
low overconfidence like high-budget settings, the ne-
cessity of CEC is low, but in scenarios prone to over-
confidence like low-budget settings, the n ecessity of
CEC is high.
Table 2: Comparison of AUBC for CTypiClust without
CEC (w/o CEC) and with CEC (w/ CEC) . The numbers in
parentheses indicate the budget size. The highest value for
each budget is shown in bold.
Budget Low (10) Medium(100) High(1000)
w/o CEC 59.34 75.81 83.43
w/ CEC
61.13 76.29 83.39
Verificat ion of Overconfidence Mitigation by CEC.
To verify the extent to which CEC mitigates over-
confidence, we compare the overco nfidence of simple
confidence ˆc and CEC. We use Expected Calib ration
Error (ECE) (Pakdaman Naeini et al. , 2015) to quanti-
tatively evaluate overco nfidence. ECE ranges from 0
to 1, with lower ECE indicating less overconfidence.
Figure 3 compares ECE for each budget between con-
fidence ˆc and CEC on the CIFAR-10 test data.
Figure 3: Comparison of ECE between confidence ˆc and
CEC.
Figure 3 shows that CEC has smaller ECE than
ˆc f or all budgets. This indicates that CEC re duces
overconfidence compared to ˆc. The difference in ECE
between CEC and ˆc is particularly large in settings
with small budgets of 10 to 100.
The reason CEC mitigates overconfidence is
likely due to the use of the agreement between the
pseudo- la bel ˆy obtained from the classifier g and the
pseudo- la bel ˜y obtained by clustering the features.
When the budget is low and learning is insufficient
(low ACC), features are not well-separated by class,
leading to many mismatched pseudo-lab e ls and CEC
CTypiClust: Confidence-Aware Typical Clustering for Budget-Agnostic Active Learning with Confidence Calibration
345

values of 0 (fro m Equation 1). As the budget and
ACC increase, features separate better, pseudo-labe ls
match more, a nd CEC values rise.
To verify this, we visualized the re lationship be-
tween ACC, test data feature space, and the two
pseudo- la bels. Figu re 4 shows that with low ACC (as
shown on the left side of Figure 4), features are poorly
separated and pseudo-labels often mismatch, result-
ing in ma ny CEC values of 0. With higher budgets
and ACC (as shown on the right side of Figure 4), fea-
tures sepa rate better, pseudo-labels match mo re, and
CEC values increase. Confidence ˜c also rises as clu s-
ters become more distinct.
Figure 4: Visualization of CIFAR-10 test data features using
t-SNE (Laurens and Hinton, 2008) and labeling the features
with ˆy and ˜y. ˆc
mean
represents the mean of ˆc for the test
data, and CEC
mean
represents the mean of CEC for the test
data. The left and right halves show the feature space when
ACC is low and high, respectively. The top row represents
the unlabeled feature space, the middle row represents the
feature space labeled by ˆy, and the bottom row represents
the feature space labeled by ˜y.
Comparison of CTypiClust Performance for Dif-
ferent T
c
. To investigate the impact of the param-
eter T
c
on the performance of CTypiClust, we eval-
uate CTy piClust using various T
c
values. In CTyp-
iClust, the confidence CEC o f typical data x
t
deter-
mines whether x
t
is used for training. The thresh old
for this decision is T
c
, so we compare values from 0.5
to 0.9, excluding T
c
= 1 as it corresponds to Typi-
Clust. Figure 5 shows the perfo rmance differences
of CTy piClust for each T
c
on CIFAR-10. From Fig-
ure 5, CTypiClust performs better than Random for
all budgets from low-budget to high- budge t for any
T
c
. This is likely because, in CEC, 1
[ ˆy= ˜y]
in Equation
1 becomes 0 when the labels d o not match, a nd CEC
functions regardless of T
c
when CEC is 0.
Figure 5: Graph show ing the difference between CTypi-
Clust and Random for each threshold T
c
. Results are show n
from left to right f or low, medium, and high budgets.
Additionally, Table 3 shows the AUBC for each
T
c
. The difference between the maximum a nd mini-
mum values for each budget is 0.12% (63.35-63.23)
for low-budget, 0.71% (77.13-76.42) for medium-
budget, and 0.27% (83.62-83.35) for high-budge t, in-
dicating that CTyp iClust performs stab ly regardless of
the parameter.
Table 3: AUBC for each T
c
under different budgets. T he
numbers in parentheses indicate the budget size. The high-
est value f or each budget is shown in bold.
T
c
0.5 0.6 0.7 0.8 0.9
Low (10) 63.25 63.25 63.35 63.23 63.23
Medium(100) 77.13 76.92 76.53 76.48 76.42
High(1000) 83.50 83.61 83.55 83.35 83.62
4.4 Limitations
Since CEC used in CTypiClust depends on the agree-
ment between th e model’s classification results and
the clustering results of the features, CTypiClust is
specialized for classification problems and cannot b e
easily applied to regression tasks.
In the futu re, we aim to overcome these limitation s
and extend the method to make it applicable to various
tasks, including r egression tasks.
5 CONCLUSION
We proposed CTypiClust, which per forms highly re-
gardless of the budget. CTypiClust performs well in
both low-budget an d high-budget settings by consid-
ering confidence in TypiClust. Additionally, to ad-
dress overcon fidence in immature models like in low-
budget settings, w e pro posed a confidence calibra-
tion method CEC a nd applied it to CTypiClust. We
evaluated CTypiClust on CIFAR-10, CIFAR-100, and
STL-10, and fo und that it performs well across var-
ious budgets. We also experimentally verified that
CEC mitig ates overconfidence. Sin c e CTypiClust is
specialized f or classification problems, we p la n to
extend CTy piClust to make it applicable to various
tasks, including r egression tasks, in the future.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
346

REFERENCES
Chen, L., Bai, Y., Huang, S., Lu, Y., Wen, B., Yuille, A. ,
and Zhou, Z. (2023). Making your first choice: To
address cold start problem in medical active learning.
In Medical Imaging with Deep Learning.
Chen, T., Kornblith, S., Norouzi, M., and Hinton, G. (2020).
A simple framework for contrastive learning of visual
representations. In Proceedings of the 37th Interna-
tional Conference on Machine Learning.
Coates, A., Ng, A., and Lee, H. (2011). An analysis of
single-layer networks in unsupervised feature learn-
ing. In Proceedings of the Fourteenth International
Conference on Artificial Intelligence and Statisti cs.
Gal, Y., Islam, R. , and G hahramani, Z. (2017). Deep
Bayesian active learning with i mage data. In Proceed-
ings of the 34th International Conference on Machine
Learning.
Guo, C., P leiss, G., Sun, Y., and Weinberger, K. Q. (2017).
On calibration of modern neural networks. In Pro-
ceedings of the 34th International Conference on Ma-
chine Learning.
Hacohen, G., Dekel, A., and Weinshall, D. ( 2022). Active
learning on a budget: Opposite strategies suit high and
low budgets. In Proceedings of t he 39th International
Conference on Machine Learning.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
ual learning for image recognition. In Proceedings
of the IEEE/CVF Conference on Computer Vision and
Pattern R ecognition (CVPR).
Jaiswal, A., Babu, A. R., Zadeh, M. Z., Banerjee,
D., and Makedon, F. (2021). A survey on con-
trastive self-supervised learning. arXiv preprint
arXiv:2011.00362.
Kirsch, A., van Amersfoort, J., and Gal, Y. (2019). Batch-
bald: Efficient and diverse batch acquisition for deep
bayesian active learning. In Advances in Neural Infor-
mation Processing Systems.
Krizhevsky, A. and Hinton, G. (2009). Learning multiple
layers of features from tiny images. Technical report,
University of Toronto. Online.
Laurens, v. d. M. and Hinton, G. ( 2008). Visualizing data
using t-sne. Journal of Machine Learning R esearch,
9.
Mozafari, A. S., Gomes, H. S., Le˜ao, W., Janny, S., and
Gagn´e, C. (2019). Attended temperature scaling: A
practical approach for calibrating deep neural net-
works. arXiv preprint arXiv:1810.11586.
Munjal, P., Hayat, N., Hayat, M., Sourati, J., and Khan,
S. ( 2022). Towards robust and reproducible active
learning using neural networks. In Proceedings of the
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition (CVPR ).
Pakdaman Naeini, M., Cooper, G., and Hauskrecht, M.
(2015). Obtaining well calibrated probabilities using
bayesian binning. Proceedings of the AAAI C onfer-
ence on Artificial Intelligence, 29.
Pereyra, G., Tucker, G., Chorowski, J., Łukasz Kaiser,
and Hinton, G. (2017). Regularizing neural networks
by penalizing confident output distributions. arXiv
preprint arXiv:1701.06548.
Platt, J. (2000). Probabilistic outputs for support vector
machines and comparisons to regularized likelihood
methods. In Advances in Large Margin Classifiers.
Pop, R. and Fulop, P. (2018). Deep ensemble bayesian ac-
tive learning : Addressing the mode collapse issue in
monte carlo dropout via ensembles. arXiv preprint
arXiv:1811.03897.
Ren, P., Xiao, Y., Chang, X., Huang, P.-Y., Li, Z.,
Gupta, B. B., Chen, X., and Wang, X. (2021).
A survey of deep active learning. arXiv preprint
arXiv:2009.00236.
Roth, D. and Small, K. (2006). Margin-based active learn-
ing for structured output spaces. In Proceedings of the
European Conference on Machine Learning.
Sener, O. and Savarese, S. (2018). Active learning for con-
volutional neural networks: A core-set approach. In
6th International Conference on Learning Represen-
tations, ICLR 2018.
Sinha, S., Ebrahimi, S., and Darrell, T. (2019). Varia-
tional adversarial active learning. In Proceedings of
the IEEE/CVF International Conference on Computer
Vision ( I CCV).
Snell, J., Swersky, K., and Zemel, R. (2017). Prototypical
networks for few-shot learning. In Advances in Neural
Information Processing Systems.
Wang, C. (2024). Calibration in deep learning: A survey of
the state-of-the-art. arXiv preprint arXiv:2308.01222.
Yi, J. S. K., Seo, M., Park, J., and Choi, D.-G. (2022). Us-
ing self-supervised pretext tasks for active learning.
In Proceedings of the European Conference on Com-
puter Vision(ECCV).
Zhan, X., Liu, H., Li, Q., and Chan, A. B. (2021). A com-
parative survey: Benchmarking for pool-based active
learning. In Proceedings of the Thirtieth I nternational
Joint Conference on Artificial Intelligence.
Zhdanov, F. (2019). Diverse mini-batch active learning.
arXiv preprint arXiv:1901.05954.
CTypiClust: Confidence-Aware Typical Clustering for Budget-Agnostic Active Learning with Confidence Calibration
347
