
AGENTFORGE: A Flexible Low-Code Platform for Reinforcement
Learning Agent Design
Francisco E. Fernandes Jr.
a
and Antti Oulasvirta
b
Department of Information and Communications Engineering, Aalto University, Espoo, Finland
Keywords:
Reinforcement Learning, Agents, Bayesian Optimization, Particle Swarm Optimization.
Abstract:
Developing a reinforcement learning (RL) agent often involves identifying values for numerous parameters,
covering the policy, reward function, environment, and agent-internal architecture. Since these parameters are
interrelated in complex ways, optimizing them is a black-box problem that proves especially challenging for
nonexperts. Although existing optimization-as-a-service platforms (e.g., Vizier and Optuna) can handle such
problems, they are impractical for RL systems, since the need for manual user mapping of each parameter
to distinct components makes the effort cumbersome. It also requires understanding of the optimization pro-
cess, limiting the systems’ application beyond the machine learning field and restricting access in areas such
as cognitive science, which models human decision-making. To tackle these challenges, the paper presents
AGENTFORGE, a flexible low-code platform to optimize any parameter set across an RL system. Available at
https://github.com/feferna/AgentForge, it allows an optimization problem to be defined in a few lines of code
and handed to any of the interfaced optimizers. With AGENTFORGE, the user can optimize the parameters ei-
ther individually or jointly. The paper presents an evaluation of its performance for a challenging vision-based
RL problem.
1 INTRODUCTION
Developing reinforcement learning (RL) agents is im-
portant not only for advancements in machine learn-
ing (ML) but also for fields such as the cognitive sci-
ences, where RL increasingly serves as a computa-
tional framework to model human decision-making
mechanisms (Eppe et al., 2022). For example, RL can
help researchers understand how humans behave un-
der cognitive constraints (Chandramouli et al., 2024).
One of the challenging aspects of this development is
optimizing a broad array of parameters that influence
agent behavior and performance: this process repre-
sents a black-box optimization problem. Embodied
RL agents, modeled as partially observable Markov
decision processes (POMDPs) (Eppe et al., 2022),
highlight this complexity in tasks such as robotic nav-
igation (Shahria et al., 2022) and human–computer in-
teraction (Jiang et al., 2024). In contrast against ML
domains wherein the tuning focuses on a smaller set
of training-related parameters, RL requires optimiz-
ing explainable ones too (e.g., reward weights), to as-
a
https://orcid.org/0000-0003-2301-8820
b
https://orcid.org/0000-0002-2498-7837
sure of trustworthiness in artificial intelligence (AI)
systems.
We set out to give domain experts in cognitive
sciences, alongside other fields, the ability to opti-
mize all RL system parameters, either jointly or in-
dividually, as conditions dictate. This is essential,
since even small changes in an RL algorithm’s im-
plementation, such as its reward clipping, can signif-
icantly affect performance (Engstrom et al., 2020).
In some cases, careful parameter selection can im-
prove performance more than the choice of RL al-
gorithm itself (Andrychowicz et al., 2020). Embod-
ied RL agents in particular employ deep neural net-
works with numerous parameters highly sensitive to
optimization (Fetterman et al., 2023). These parame-
ters can be roughly categorized into three classes:
1. Agent Design: controls internal functions such as
the discount factor, entropy coefficient, and obser-
vation window size.
2. Environment Settings: define the task, including
the field of view and the reward structure.
3. Policy Parameters: encompass neural-network
architecture, learning rate, and activation func-
tions.
Fernandes Jr., F. E. and Oulasvirta, A.
AGENTFORGE: A Flexible Low-Code Platform for Reinforcement Learning Agent Design.
DOI: 10.5220/0013142900003890
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 1, pages 351-358
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
351

Against this backdrop, we present the ongoing work
on AGENTFORGE, a flexible low-code platform de-
signed for experts across disciplines to develop RL
systems without having to possess expertise in opti-
mization or ML. This domain-agnostic ability aligns
with the needs of cognitive scientists, who often re-
quire tailored experiment setups for testing hypothe-
ses about human cognition (Eppe et al., 2022; Noban-
degani et al., 2022). The development of low-code
platforms is relevant to many such fields. Also,
AGENTFORGE provides for rapid iteration by letting
users prototype RL designs, optimize them, and an-
alyze the results. It supports a wide range of RL
systems, from simple models to complex embodied
agents. Users need only define a custom environment,
an objective function, and parameters in two files,
where the objective function, which guides the opti-
mization process, can employ any criterion (e.g., av-
erage reward per episode). The platform then converts
these inputs into an optimization problem, automating
training and evaluation. AGENTFORGE’s current ver-
sion includes random search, Bayesian optimization
(BayesOpt), and particle swarm optimization (PSO),
with flexibility for adding more techniques.
Obviously, parameter optimization is a perennial
challenge in ML. Frameworks such as BoTorch (Ba-
landat et al., 2020), Optuna (Akiba et al., 2019), and
Google Vizier (Song et al., 2023) represent attempts
to address it. However, these tools are targeted at
users with advanced ML knowledge and are tricky
to apply to RL agents on account of the complexity
of defining objective functions for parameters across
system components. This shortcoming highlights the
need for low-code solutions, such as ours, that al-
low users to design effective agents without having
mastered the optimization techniques crucial for han-
dling high-dimensional inputs and dynamic RL envi-
ronments.
We tested AGENTFORGE by jointly optimizing
the parameters of a pixel-based Lunar Lander agent
from the Gymnasium library (Towers et al., 2024),
a POMDP in which the agent infers the state from
raw pixel values. Since this agent includes parameters
from all three categories – agent, environment, and
policy – it permitted testing AGENTFORGE’s ability
to handle complex parameter sets. Also, the paper
demonstrates how easily an optimization problem can
be defined, thus highlighting our platform’s simplicity
and flexibility.
2 RELATED WORKS
Among the many fields showing extensive use of RL
are robotics, cognitive science, and human–computer
interaction in general. Robotics focuses on optimiz-
ing real-world sensorimotor interactions (Shang and
Ryoo, 2023), while cognitive scientists model human
decision-making (Chandramouli et al., 2024). Table 1
highlights the breadth of tasks and needs in RL devel-
opment. Across the board, these share the challenge
of optimizing large parameter spaces and adapting to
dynamic environments, a goal that drives demand for
flexible, low-code platforms that simplify RL devel-
opment across disciplines.
The work in response forms part of the field
known as AutoRL, aiming to automate RL algorithm
and parameter optimization. While already show-
ing clear progress, AutoRL is in its infancy (Parker-
Holder et al., 2022; Afshar et al., 2022). Platforms
such as AutoRL-Sim (Souza and Ottoni, 2024) and
methods that use genetic algorithms (Cardenoso Fer-
nandez and Caarls, 2018) support simple RL tasks but
lack support for more complex real-world problems
with diverse parameters across agents, environments,
and policies. Among the optimization techniques
commonly employed in AutoRL are random search,
BayesOpt, and PSO, with the choice of technique de-
pending on task-specific requirements. Furthermore,
while such state-of-the-art RL solvers as Stable-
Baselines3 (Raffin et al., 2021) and CleanRL (Huang
et al., 2022) offer powerful tools for agent training,
they demand deep knowledge of RL’s internals, plus
extensive coding, and are not suitable for parameter
optimization.
Platforms of AGENTFORGE’s ilk can address
these challenges by simplifying RL agent design and
providing automated optimization for diverse needs.
Its provision for random search, BayesOpt, and PSO
furnishes a low-code interface for joint parameter op-
timization, whereby users become able to compare
and apply strategies for various RL agents with ease.
3 THE PROPOSED
FRAMEWORK
3.1 General Characterization
For enabling flexible low-code specification of an op-
timization problem in RL, the following engineering
objective guided the design of AGENTFORGE:
• A Low-Code Setting. Users provide simple con-
fig files that state optimization parameters and
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
352

Table 1: Example RL agents and corresponding parameterized modules – highlighting the diversity of parameter types, this
non-exhaustive list emphasizes the complexity of parameter optimization in RL systems.
Agent/env. Modules Use case Typical user
Gymnasium toy environments (Towers
et al., 2024)
- Environment dynamics
- Reward structure
- Policy network
- Value network
Achieving the highest reward in a
well-defined environment
- Machine learning researcher
- Robotics researcher
ActiveVision-RL (Shang and Ryoo, 2023)
- Observation window size
- Persistence of vision
- Sensorimotor reward
- Q-Network
Modeling visual attention in
complex environments
- Machine learning researcher
- Robotics researcher
CRTypist (Shi et al., 2024)
- Foveal vision
- Peripheral vision
- Finger movement
- Working memory
- Reward structure
- Neural networks
Simulating
touchscreen typ-
ing behavior
- Designer
- Accessibility researcher
- Cognitive scientist
- Behavioral scientist
Autonomous aircraft landing (Ladosz
et al., 2024)
- Descent velocity
- Frame stack
- Image resolution
- Q-Network
- Reward structure
Automating aircraft landings with
vision-based reinforcement
learning
- Machine learning researcher
- Robotics researcher
EyeFormer (Jiang et al., 2024)
- Inhibition of return (IoR)
- Vision encoder
- Fixation decoder
- Optimization constraints
- Neural networks
- Reward structure
Modeling visual attention and
eye-movement behavior for UI
optimization
- Designer
- Accessibility researcher
- Cognitive scientist
- Behavioral scientist
performance-evaluation methods. This approach
lets users exploit the platform without deep tech-
nical expertise.
• Integration. Support for custom RL environ-
ments compatible with the Gymnasium library en-
ables use across diverse application scenarios.
• Flexibility. Thanks to its multiple optimization
methods, users can easily swap and set up meth-
ods through config files without changing the core
code. This simplifies adaptation to various prob-
lem requirements.
• Parallelization. Allowing concurrent evaluation
of multiple solutions reduces optimization time.
By using Optuna’s parallelization and our custom
methods, the platform can explore many configu-
rations simultaneously, which is especially bene-
ficial for large-scale RL problems.
The overall optimization process comprises two
loops, illustrated in Figure 1. The outer loop opti-
mizes parameters via the chosen method, while the
inner one trains the RL agent through environment
interactions and performance evaluations. With the
next few sections, we give more details on using the
framework and on its optimization algorithms.
3.2 Specifying the Optimization Task
To use AGENTFORGE effectively, the user must fur-
nish three key components: configuration settings, a
customized environment, and an evaluation method.
Users start by providing a YAML configuration
file to define the optimization setup. This file spec-
ifies the parameters to be optimized, each categorized
as agent, environment, or policy, along with the type
for each (integer or float) and value ranges. It also
includes settings for agent training hyperparameters,
such as learning rates and discount factors, and the
choice of optimization algorithm: in the current im-
plementation random search, BayesOpt, or PSO. Ad-
ditionally, AGENTFORGE supports optimizing neural
network architectures for policy and value networks.
thereby letting users set the range for the number of
layers and of neurons per layer. Thus it enables a thor-
ough search for optimal structures.
Next, via a Python script, the user implements a
custom RL environment compatible with the Stable-
Baselines3 library. It must adhere to the standard in-
terface, defining action and observation spaces, and
include methods for resetting and stepping through
the environment. For this, the user writes a func-
tion that can create a training environment for the
agent. While AGENTFORGE currently supports only
the popular Python library Stable-Baselines3, future
versions may extend compatibility to other libraries.
Finally, users must implement an evaluation
method, again in a Python script, to assess the trained
agent’s performance. The function should calculate
and report metrics for factors such as reward, success
rate, etc., to make sure that AGENTFORGE can collect
and use these values during optimization. Optionally,
they may also provide a function that records a video
of the agent’s performance over a specified number of
AGENTFORGE: A Flexible Low-Code Platform for Reinforcement Learning Agent Design
353

Optimization results and
statistics
Optimization history
Parameters' history
Evaluation videos
Best Performing agent
Set of parameters
Agent model
Update optimization algorithm
with performance metrics
Observations
Agent
Learning
algorithm
Policy ( )
Actions
Rewards
Policy update
Environment
Optimizer
Train one agent for
each set of parameters
Generate sets of candidate parameters
(agent, environment, and policy)
b) AgentForge
c) Platform outputs
Customized environment
Action and observation space
Reset and step methods
Evaluation method
Performance metrics
Evaluation function
Optimization settings
Optimization algorithm
Agent training details
Parameters to optimize
Types of parameters
Parameters' boundaries
Neural network architecture
a) User inputs
Figure 1: The AGENTFORGE platform in overview. a) The inputs consist of three elements: optimization settings (including
search parameters), a customized environment, and an evaluation method. b) AGENTFORGE executes joint optimization of
RL parameters through a two-loop process. c) Then, AGENTFORGE provides the user with the best-performing agent along
with the optimization results and performance statistics.
episodes in the environment.
These three components are summarized in Fig-
ure 1 and in Listing 1.
3.3 Optimization Algorithms
AGENTFORGE supports several popular optimization
algorithms. While random search, BayesOpt, and
PSO form the set of default options, the framework
is flexible; it can be extended to include other meth-
ods, for various RL scenarios.
• Random search: is a simple baseline method that
randomly samples the parameter space. Useful
for initial comparisons in testing of more sophis-
ticated algorithms, it guarantees rich exploration
1 .. .
2 # T rai ni ng p ar am et er s
3 ga e_l am bd a :
4 ty pe : d ef aul t
5 s ear ch ab le : tr ue
6 in te ge r : fa lse
7 u se r_ pr ef er en ce : 0 .9
8 st art : 0. 9
9 st op : 0. 95
10 .. .
11 de f u se r_ t ra in _e nv ir on me nt ( seed , n_ tr ain _e nvs ,
** e nv _k wa rg s ):
12 "" "
13 Set up RL e nv ir on me nt f or tr ai ni ng .
14 Ar gs :
15 - s eed ( in t ) : R an dom se ed .
16 - n_ tr ai n_ en vs ( in t) : N um ber o f t rai ni ng e nvs .
17 - * * e nv _k war gs : A dd it io nal ar gs fo r en v
cr ea ti on .
18 Re tu rn s :
19 - tr ai n_ en v ( Ve cE nv ) : Co nf ig ur ed tr ai ni ng
en vi ro nm en t .
20 "" "
21 de f u se r_ e v a lu at e_ po li cy ( see d , m o d el , ** e nv_ kw ar gs ) :
22 "" "
23 Ev al ua te t he po li cy wi th a s epa ra te ev al ua ti on
en vi ro nm en t .
24 Ar gs :
25 - mo del ( B as eA lg or it hm ) : Mo de l to e va l .
26 Re tu rn s :
27 - m ea n_ ob je ct iv e_ va lu e ( f loa t ): Me an o bj ec tiv e
va lue ob ta in ed d ur ing e v al ua ti on .
28 - ex tr a_ in fo ( di ct ): A dd it io nal m etr ic s de fi ne d
by th e us er .
29 "" "
Listing 1: Sample code snippet illustrating parameter defi-
nition, creation of the environment, and evaluation setup.
but is less efficient at finding optimal regions.
• BayesOpt: is a structured approach using prob-
abilistic models (e.g., Gaussian processes) to fo-
cus on promising areas of the parameter space.
Our platform uses a tree-structured Parzen es-
timator (TPE), well suited to high-dimensional
spaces (Bergstra et al., 2011). It efficiently bal-
ances exploration and exploitation for fast conver-
gence.
• PSO: is a population-based approach suitable for
continuous optimization. Its stochastic nature aids
in escaping local optima. We use inertia (w),
cognitive (c
1
), and social (c
2
) weights of 0.9694,
0.099381, and 0.099381, respectively, for better
exploration of high-dimensional spaces, as rec-
ommended by (Oldewage et al., 2020).
In AGENTFORGE, Random search and BayesOpt
are implemented with Optuna, while PSO is custom-
designed. The mechanism of letting users select
and configure optimization strategies through a user-
defined configuration file (see the previous subsec-
tion) renders the framework adaptable to various ap-
plications.
3.4 Parallel Evaluation of Trials
Taking advantage of parallel evaluation improves the
efficiency and speeds up optimization. By running
each trial as an independent Python process, we avoid
issues with Python’s Global Interpreter Lock. For all
optimization methods, parameter sets are distributed
across nodes for evaluation, with multiple processes
accessing a centralized database to get a new set for
each trial. Parallelization is crucial since each trial in-
volves training agents for millions of timesteps, which
often takes hours. By utilizing parallel computing, the
platform significantly reduces the time required for a
full optimization loop, thus facilitating extensive RL
experimentation.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
354

Table 2: General optimization configuration, applied across
all experiments.
Training setup for each trial
Number of training timesteps 5,000,000
Evaluation frequency Every 10 batches
Maximum steps per episode 1024
Vectorized environments for training 10
Training algorithm PPO
Policy architecture CNN
Random search
Number of trials 400
Pruning of trials After 50 trials
Pruning strategy MedianPruner
Wait before trial is pruned At least 48 evaluations
BayesOpt
Number of trials 400
Number of initial random trials 50
Number of improvement candidates expected 80
Multivariate TPE Enabled
Pruning of trials After 50 trials
Pruning strategy MedianPruner
Wait before trial is pruned At least 48 evaluations
PSO
Number of generations 20
Population size 20
Inertia weight (w) 0.9694
Cognitive component weight (c
1
) 0.099381
Social component weight (c
2
) 0.099381
4 EVALUATION
We evaluated AGENTFORGE on the basis of agent
performance, judged in terms of the maximum mean
reward achieved by a pixel-based POMDP agent.
4.1 A Pixel-Based POMDP Agent
Our evaluation of AGENTFORGE used a pixel-based
version of the Lunar Lander environment from the
Gymnasium library (Towers et al., 2024), a POMDP
wherein the agent relies on raw-pixel observations in-
stead of state-based inputs. The agent processes four
stacked frames as visual input and uses continuous ac-
tions to control the main engine and lateral boosters.
Reward structure remains unchanged from the orig-
inal environment’s, with the task considered solved
when the agent reaches a reward of at least 200 in a
single episode.
This experiment demonstrated AGENTFORGE’s
flexibility in optimizing parameters across all three
categories (agent, environment, and policy), includ-
ing neural network architectures. The breadth of op-
timization attests to AGENTFORGE’s capacity to han-
dle complex RL configurations effectively. Below, we
provide details of its parameter optimization.
4.2 Optimization Configuration
The optimization configuration for all experiments,
covering the parameters for individual training trials
and the random search, BayesOpt, and PSO methods,
is detailed in Table 2. Each trial involved training for
five million timesteps, with performance evaluations
after every 10 batches. This setup used 10 parallel,
vectorized environments with the proximal policy op-
timization (PPO) algorithm and a convolutional neu-
ral network (CNN) feature extractor. Agent perfor-
mance was measured as the mean reward over 300
independent episodes. The table includes all the opti-
mization settings: the number of trials, pruning strate-
gies, and algorithm-specific parameters. All config-
urations can be easily customized through the user-
defined configuration file introduced in Section 3.
4.3 The Parameters Optimized
We optimized the parameters listed in Table 3. The
environment parameter chosen for optimization here
was the size of the field of view (in pixels). This pa-
rameter determines how much the original environ-
ment window is downsampled into a square window
suitable for the feature extractor. To define its di-
mensions, only one value is needed. Further param-
eters optimized were the discount factor (γ), gener-
alized advantage estimation (λ), learning rate, num-
ber of epochs, entropy coefficient, and clipping range.
These are critical for training because they influence
reward discounting, learning stability, and the effi-
ciency of policy updates. Also tuned were neural net-
work architecture parameters, such as the activation
function, number of layers, and number of neurons
per layer for the policy and value networks both. The
activation function was defined as a float in the range
[0.0, 1.0], with Tanh used for values below 0.5 and
ReLU for those of 0.5 or above.
4.4 Joint vs. Individual-Parameter
Optimization
The BayesOpt results presented below demonstrate
the flexibility of AGENTFORGE well. We report these
for three parameter-optimization configurations:
• Joint Optimization with NAS: Simultaneous op-
timization of all parameters listed in Table 3, ad-
dressing the policy and value networks’ architec-
ture
• Optimization Without NAS: Optimizing all pa-
rameters except for the network architecture (ac-
tivation function, number of layers, and neuron
AGENTFORGE: A Flexible Low-Code Platform for Reinforcement Learning Agent Design
355
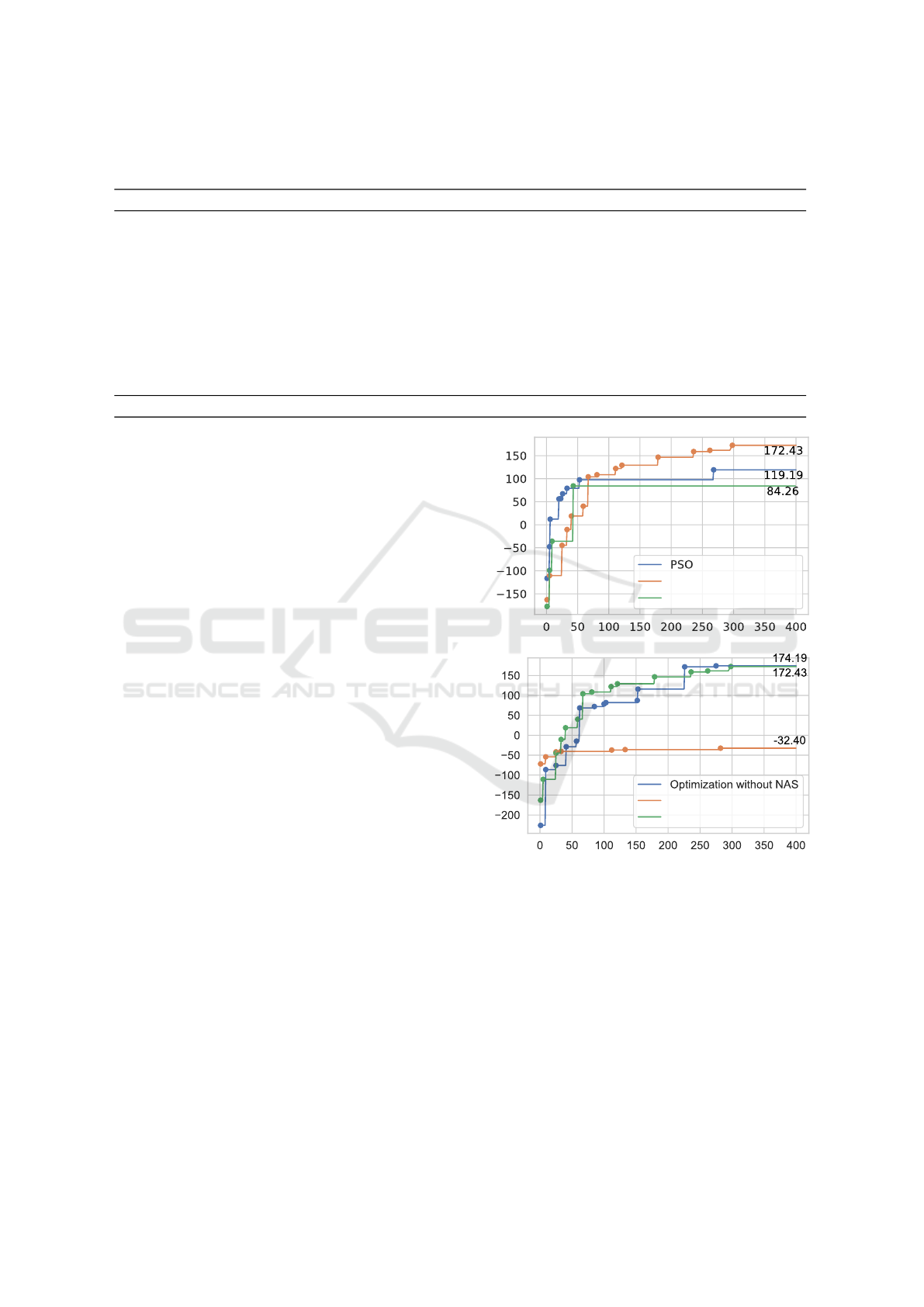
Table 3: The parameters optimized and the best values found for the pixel-based Lunar Lander agent – the wide range of
parameters being jointly optimized highlights the flexibility of AGENTFORGE.
Parameter Type Category Range Random search BayesOpt PSO
Field of view’s size (pixels) Integer Environment [40, 92] 71 92 92
Discount factor (γ) Float Agent [0.4, 0.8] 0.7934 0.7984 0.8
Generalized advantage estimation (λ) Float Agent [0.9, 0.95] 0.9433 0.9299 0.95
Learning rate Float Agent [3.5 · 10
−4
, 3.5 · 10
−3
] 0.0006 0.0034 0.0035
Number of epochs Integer Agent [3, 10] 6 3 5
Entropy coefficient Float Policy [0.01, 0.1] 0.0284 0.0279 0.1
Clipping range Float Policy [0.01, 0.3] 0.1407 0.0178 0.3
Activation function Float Policy [0.0, 1.0] 0.5478 0.9259 1.0
No. of layers in policy Integer Policy [1, 4] 1 3 4
No. of neurons per layer in policy Integer Policy [64, 128] 83 89 127
No. of layers in value network Integer Policy [2, 4] 4 2 4
No. of neurons per layer in value Integer Policy [64, 128] 100 89 128
Mean reward 84.26 172.43 119.19
count), which remain at their stable-baselines3
defaults
• NAS only: Optimization restricted to the network
architecture while all other parameters are fixed at
their Stable-Baselines3 defaults
5 RESULTS
5.1 Results from Joint Optimization
The upper pane of Figure 2 shows the evolution of the
mean reward in joint optimization over these episodes
for each trial under random search, BayesOpt, and
PSO. One can see that BayesOpt achieved the high-
est cumulative rewards while PSO showed the fastest
convergence. Table 3 lists the best parameters found
for this agent.
BayesOpt consistently outperformed random
search and PSO in terms of mean cumulative reward,
achieving a mean reward of 172.43. Though PSO
reached a lower final reward (mean reward: 119.19),
it demonstrated the fastest convergence. Random
search lagged behind with a mean reward of 84.26,
serving as a baseline for comparison. Notably, PSO
reached approximately 69% of BayesOpt’s mean re-
ward, while random search represented about 49% of
BayesOpt’s level. These results spotlight the effec-
tiveness of BayesOpt but also demonstrate AGENT-
FORGE’s flexibility in integrating multiple optimiza-
tion algorithms, which supports users’ selection of the
best approach for their specific RL agents.
Mean rewardMean reward
Trial number
Trial number
BayesOpt
Random search
NAS-Only
Joint optimization
Figure 2: Mean reward per episode for the pixel-based Lu-
nar Lander agent under different optimization strategies.
Top: Joint optimization of parameters and NAS using ran-
dom search, BayesOpt, and PSO. Bottom: A plot of joint vs.
individual-parameter optimization using BayesOpt, with
and without NAS, and NAS-only optimization.
5.2 Results of the Joint vs.
Parameter-Wise Optimization
Figure 2’s lower pane presents the results of joint
versus individual-parameter optimization. Joint op-
timization with and without NAS achieved mean
episode rewards of 172.43 and 174.19, respec-
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
356

tively, while the NAS-alone condition yielded a mean
episode reward of −32.40. These findings suggest
that network architecture is not the most critical pa-
rameter set to optimize for our agent. However, users
short on time can obtain satisfactory results by opting
for complete joint optimization.
5.3 Platform Overhead
AGENTFORGE introduces negligible overhead rela-
tive to the time required for evaluating RL agents.
A single candidate’s evaluation takes roughly three
hours on a consumer-grade Nvidia RTX 4090 GPU,
making any additional delays from the optimization
process insignificant. However, parallel evaluation is
vital; running 400 trials serially would take about 50
days. By evaluating eight trials in parallel, we can
complete the same 400 trials in just seven days.
6 DISCUSSION
Our results affirm AGENTFORGE’s effectiveness as a
flexible, low-code platform for RL agent design and
optimization. It addresses the challenge of optimiz-
ing interrelated parameters in large numbers across
the agent, environment, and policy classes by treating
this as a black-box optimization problem. We found
evidence that parameter optimization on its own can
improve the RL agent’s performance, without reliance
on changes to the training algorithms. All three op-
timization methods currently available with AGENT-
FORGE enhanced performance in our test case, with
BayesOpt arriving at the highest episode mean reward
observed. However, the platform’s key strength lies
in its support for joint and individual-level optimiza-
tion of RL agents’ parameters and neural network ar-
chitectures. This crystallizes the platform’s flexibility
for strongly supporting the study of critical interplay
among various aspects of RL agent design.
In principle, AGENTFORGE’s integration of vari-
ous optimization methods allows users to compare ap-
proaches and can streamline the prototyping and fine-
tuning of RL agents. By configuring optimization
settings through a simple YAML file and a Python
script, they can quickly customize their agents with-
out extensive coding. Thus helping pare back the
typical trial-and-error process in RL experimentation,
this frees more of practitioners’ time for refining their
problem models. While our results are encouraging,
further testing, with user studies and different RL sys-
tems, will be necessary to validate AGENTFORGE’s
broader impact. Still, it already offers a flexible solu-
tion to effectively tackle the unique challenges of RL
systems, overcoming several issues that practitioners
might face when using other platforms.
7 CONCLUSIONS AND FUTURE
WORK
With this short paper, we provided a glimpse at
AGENTFORGE, which simplifies joint optimization
of RL parameters, accelerating agent development –
especially for users with little optimization experi-
ence – through flexible optimization and easier de-
sign. Evaluation with a pixel-based POMDP agent
settings proved illuminating. The setup was simple
from a low-code perspective yet proved able to sup-
port finding a suitable balance (e.g., BayesOpt deliv-
ered the best optimization results, while PSO showed
faster convergence but requires further tuning). The
platform also gives users control over their experi-
ment setups: it demonstrated good flexibility for both
joint and individual parameters’ optimization.
This version does display several limitations,
which will be addressed in a follow-up paper. For in-
stance, we are developing a graphical interface to en-
able a comprehensive user study evaluating the ease
of use of our solution in comparison to preexisting
ones such as AutoRL-Sim. Also, the current interface
is designed to assist cognitive and behavioral scien-
tists in using RL to model human decision-making
processes more effectively. We plan to test use cases
additional to these, probe more agent designs, and
fully address the challenge of managing RL training
uncertainty during optimization.
ACKNOWLEDGEMENTS
This work was supported by the ERC AdG project
Artificial User (101141916) and the Research Coun-
cil of Finland (under the flagship program of the
Finnish Center for Artificial Intelligence, FCAI). The
calculations were performed via computer resources
provided by the Aalto University School of Science
project Science-IT. The authors also acknowledge
Finland’s CSC – IT Center for Science Ltd. for pro-
viding generous computational resources.
REFERENCES
Afshar, R. R., Zhang, Y., Vanschoren, J., and Kaymak,
U. (2022). Automated Reinforcement Learning: An
Overview. arXiv:2201.05000.
AGENTFORGE: A Flexible Low-Code Platform for Reinforcement Learning Agent Design
357

Akiba, T., Sano, S., Yanase, T., Ohta, T., and Koyama, M.
(2019). Optuna: A Next-Generation Hyperparameter
Optimization Framework. In Proceedings of the 25th
ACM SIGKDD International Conference on Knowl-
edge Discovery and Data Mining.
Andrychowicz, M., Raichuk, A., Sta
´
nczyk, P., Orsini, M.,
Girgin, S., Marinier, R., Hussenot, L., Geist, M.,
Pietquin, O., Michalski, M., Gelly, S., and Bachem,
O. (2020). What Matters in On-Policy Reinforce-
ment Learning? A Large-Scale Empirical Study.
arXiv:2006.05990.
Balandat, M., Karrer, B., Jiang, D. R., Daulton, S., Letham,
B., Wilson, A. G., and Bakshy, E. (2020). BoTorch: A
Framework for Efficient Monte-Carlo Bayesian Opti-
mization. arXiv:1910.06403.
Bergstra, J., Bardenet, R., Bengio, Y., and K
´
egl, B. (2011).
Algorithms for Hyper-parameter Optimization. In
Proceedings of the 24th International Conference on
Neural Information Processing Systems, NIPS ’11,
pages 2546–2554, Red Hook, NY, USA. Curran As-
sociates.
Cardenoso Fernandez, F. and Caarls, W. (2018). Parame-
ters [sic] Tuning and Optimization for Reinforcement
Learning Algorithms Using Evolutionary Computing.
In 2018 International Conference on Information Sys-
tems and Computer Science (INCISCOS), pages 301–
305, Quito, Ecuador. IEEE.
Chandramouli, S., Shi, D., Putkonen, A., De Peuter, S.,
Zhang, S., Jokinen, J., Howes, A., and Oulasvirta,
A. (2024). A Workflow for Building Computationally
Rational Models of Human Behavior. Computational
Brain & Behavior, 7:399–419.
Engstrom, L., Ilyas, A., Santurkar, S., Tsipras, D., Janoos,
F., Rudolph, L., and Madry, A. (2020). Implementa-
tion Matters in Deep RL: A Case Study on PPO and
TRPO. In 8th International Conference on Learning
Representations, ICLR 2020, Addis Ababa, Ethiopia,
April 26-30, 2020. OpenReview.net.
Eppe, M., Gumbsch, C., Kerzel, M., Nguyen, P. D. H., Butz,
M. V., and Wermter, S. (2022). Intelligent Problem-
Solving As Integrated Hierarchical Reinforcement
Learning. Nature Machine Intelligence, 4(1):11–20.
Fetterman, A. J., Kitanidis, E., Albrecht, J., Polizzi, Z.,
Fogelman, B., Knutins, M., Wr
´
oblewski, B., Simon,
J. B., and Qiu, K. (2023). Tune As You Scale: Hyper-
parameter Optimization For Compute Efficient Train-
ing. arXiv:2306.08055.
Huang, S., Dossa, R. F. J., Ye, C., Braga, J., Chakraborty,
D., Mehta, K., and Ara
´
ujo, J. G. M. (2022). CleanRL:
High-Quality Single-File Implementations of Deep
Reinforcement Learning Algorithms. The Journal of
Machine Learning Research, 23(1):12585–12602.
Jiang, Y., Guo, Z., Tavakoli, H. R., Leiva, L. A., and
Oulasvirta, A. (2024). EyeFormer: Predicting Per-
sonalized Scanpaths with Transformer-Guided Rein-
forcement Learning. arXiv:2404.10163.
Ladosz, P., Mammadov, M., Shin, H., Shin, W., and Oh, H.
(2024). Autonomous Landing on a Moving Platform
Using Vision-Based Deep Reinforcement Learning.
IEEE Robotics and Automation Letters, 9(5):4575–
4582.
Nobandegani, A. S., Shultz, T. R., and Rish, I. (2022).
Cognitive Models As Simulators: The Case of Moral
Decision-Making. In Proceedings of the 44th Annual
Conference of the Cognitive Science Society.
Oldewage, E. T., Engelbrecht, A. P., and Cleghorn, C. W.
(2020). Movement Patterns of a Particle Swarm
in High Dimensional Spaces. Information Sciences,
512:1043–1062.
Parker-Holder, J., Rajan, R., Song, X., Biedenkapp, A.,
Miao, Y., Eimer, T., Zhang, B., Nguyen, V., Calandra,
R., Faust, A., Hutter, F., and Lindauer, M. (2022). Au-
tomated Reinforcement Learning (AutoRL): A Survey
and Open Problems. Journal of Artificial Intelligence
Research, 74:517–568.
Raffin, A., Hill, A., Gleave, A., Kanervisto, A., Ernestus,
M., and Dormann, N. (2021). Stable-Baselines3: Re-
liable Reinforcement Learning Implementations. The
Journal of Machine Learning Research, 22(1):12348–
12355.
Shahria, M. T., Sunny, M. S. H., Zarif, M. I. I., Ghommam,
J., Ahamed, S. I., and Rahman, M. H. (2022). A Com-
prehensive Review of Vision-Based Robotic Applica-
tions: Current State, Components, Approaches, Barri-
ers, and Potential Solutions. Robotics, 11(6).
Shang, J. and Ryoo, M. S. (2023). Active Vision Rein-
forcement Learning under Limited Visual Observabil-
ity. In Oh, A., Neumann, T., Globerson, A., Saenko,
K., Hardt, M., and Levine, S., editors, Advances in
Neural Information Processing Systems, volume 36,
pages 10316–10338. Curran Associates.
Shi, D., Zhu, Y., Jokinen, J. P., Acharya, A., Putkonen,
A., Zhai, S., and Oulasvirta, A. (2024). CRTypist:
Simulating Touchscreen Typing Behavior via Compu-
tational Rationality. In Proceedings of the 2024 CHI
Conference on Human Factors in Computing Systems,
CHI ’24. ACM.
Song, X., Perel, S., Lee, C., Kochanski, G., and Golovin,
D. (2023). Open Source Vizier: Distributed Infras-
tructure and API for Reliable and Flexible Blackbox
Optimization. arXiv:2207.13676.
Souza, G. K. B. and Ottoni, A. L. C. (2024). AutoRL-
Sim: Automated Reinforcement Learning Simulator
for Combinatorial Optimization Problems. Modelling,
5(3):1056–1083.
Towers, M., Kwiatkowski, A., Terry, J., Balis, J. U.,
De Cola, G., Deleu, T., Goul
˜
ao, M., Kallinteris,
A., Krimmel, M., KG, A., Perez-Vicente, R., Pierr
´
e,
A., Schulhoff, S., Tai, J. J., Tan, H., and You-
nis, O. G. (2024). Gymnasium: A Standard In-
terface for Reinforcement Learning Environments.
arXiv:2407.17032.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
358
