
Neural Network Meta Classifier:
Improving the Reliability of Anomaly Segmentation
Jurica Runtas
a
and Tomislav Petkovi
´
c
b
University of Zagreb, Faculty of Electrical Engineering and Computing, Unska 3, 10000 Zagreb, Croatia
Keywords:
Computer Vision, Semantic Segmentation, Anomaly Segmentation, Entropy Maximization, Meta
Classification, Open-Set Environments.
Abstract:
Deep neural networks (DNNs) are a contemporary solution for semantic segmentation and are usually trained
to operate on a predefined closed set of classes. In open-set environments, it is possible to encounter seman-
tically unknown objects or anomalies. Road driving is an example of such an environment in which, from a
safety standpoint, it is important to ensure that a DNN indicates it is operating outside of its learned semantic
domain. One possible approach to anomaly segmentation is entropy maximization, which is paired with a
logistic regression based post-processing step called meta classification, which is in turn used to improve the
reliability of detection of anomalous pixels. We propose to substitute the logistic regression meta classifier
with a more expressive lightweight fully connected neural network. We analyze advantages and drawbacks of
the proposed neural network meta classifier and demonstrate its better performance over logistic regression.
We also introduce the concept of informative out-of-distribution examples which we show to improve training
results when using entropy maximization in practice. Finally, we discuss the loss of interpretability and show
that the behavior of logistic regression and neural network is strongly correlated. The code is publicly avail-
able at https://github.com/JuricaRuntas/meta-ood.
1 INTRODUCTION
Semantic segmentation is a computer vision task in
which each pixel of an image is assigned into one of
predefined classes. An example of a real-world appli-
cation is an autonomous driving system where seman-
tic segmentation is an important component for vi-
sual perception of a driving environment (Biase et al.,
2021; Janai et al., 2020).
Deep neural networks (DNNs) are a contemporary
solution to the semantic segmentation task. DNNs
are usually trained to operate on a predefined closed
set of classes. However, this is in a contradiction
with the nature of an environment in which afore-
mentioned autonomous driving systems are deployed.
Such systems operate in a so-called open-set environ-
ment where DNNs will encounter anomalies, i.e., ob-
jects that do not belong to any class from the prede-
fined closed set of classes used during training (Wong
et al., 2019).
From a safety standpoint, it is very important that
a DNN classifies pixels of any encountered anomaly
a
https://orcid.org/0009-0003-0505-2889
b
https://orcid.org/0000-0002-3054-002X
as anomalous and not as one of the predefined classes.
The presence of an anomaly indicates that a DNN is
operating outside of its learned semantic domain so a
corresponding action may be taken, e.g., there is an
unknown object on the road and an emergency brak-
ing procedure is initiated.
One approach to anomaly segmentation is entropy
maximization (Chan et al., 2020). It is usually paired
with a logistic regression based post-processing step
called meta classification, which is used to improve
the reliability of detection of anomalous pixels in the
image, driving subsequent anomaly detection.
In this paper, we explore entropy maximization
approach to anomaly segmentation where we pro-
pose to substitute the logistic regression meta clas-
sifier with a lightweight fully connected neural net-
work. Such a network is more expressive than the lo-
gistic regression meta classifier, so we expect an im-
provement in anomaly detection performance. Then,
we provide additional analysis of the entropy maxi-
mization that shows that caution must be taken when
using it in practice in order to ensure its effectiveness.
To that end, we introduce the concept of informative
out-of-distribution examples which we show to im-
348
Runtas, J. and Petkovi
´
c, T.
Neural Network Meta Classifier: Improving the Reliability of Anomaly Segmentation.
DOI: 10.5220/0013143000003912
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 2: VISAPP, pages
348-355
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

prove training results. Finally, we discuss the loss of
interpretability and show that the behavior of logistic
regression and neural network is strongly correlated,
suggesting that the loss of interpretability may not be
a significant drawback after all.
2 RELATED WORK
The task of identifying semantically anomalous re-
gions in an image is called anomaly segmentation or,
in the more general context, out-of-distribution (OoD)
detection. Regardless of a specific method used for
anomaly segmentation, the main objective is to obtain
an anomaly segmentation score map. The anomaly
segmentation score map a indicates the possibility
of the presence of an anomaly at each pixel location
where higher score indicates more probable anomaly
(Chan et al., 2022). Methods described in the litera-
ture differ in the ways how such a map is obtained.
The methods described in the early works are
based on the observation that anomalies usually re-
sult in low confidence predictions allowing for their
detection. These methods include thresholding the
maximum softmax probability (Hendrycks and Gim-
pel, 2017), ODIN (Liang et al., 2018), uncertainty es-
timation through the usage of Bayesian methods such
as Monte-Carlo dropout (Gal and Ghahramani, 2016;
Kendall et al., 2015), ensembles (Lakshminarayanan
et al., 2017) and distance based uncertainty estima-
tion through Mahalanobis distance (Denouden et al.,
2018; Lee et al., 2018) or Radial Basis Function Net-
works (RBFNs) (Li and Kosecka, 2021; van Amers-
foort et al., 2020). These methods do not rely on
the utilization of negative datasets containing images
with anomalies so they are classified as anomaly seg-
mentation methods without outlier supervision.
However, methods such as entropy maximization
(Chan et al., 2020) use entire images sampled from a
negative dataset. Some methods cut and paste anoma-
lies from images in the chosen negative dataset on
the in-distribution images (Bevandi
´
c et al., 2019; Be-
vandi
´
c et al., 2021; Grci
´
c et al., 2022). The nega-
tive images are used to allow the model to learn a
representation of the unknown; therefore, such meth-
ods belong to the category of anomaly segmentation
methods with outlier supervision.
Finally, there are methods that use generative
models for the purpose of anomaly segmentation (Bi-
ase et al., 2021; Blum et al., 2019; Grci
´
c et al., 2021;
Lis et al., 2019; Xia et al., 2020), usually through the
means of reconstruction or normalizing flows, with or
without outlier supervision. Current state-of-the-art
anomaly segmentation methods (Ackermann et al.,
2023; Rai et al., 2023; Nayal et al., 2023; Deli
´
c
et al., 2024) utilize mask-based semantic segmenta-
tion (Cheng et al., 2021; Cheng et al., 2022).
3 METHODOLOGY
In this section, we describe a method for anomaly
segmentation called entropy maximization. Then, we
describe a post-processing step called meta classifi-
cation, which is used for improving the reliability of
anomaly segmentation. Finally, we describe our pro-
posed improvement to the original meta classifica-
tion approach (Chan et al., 2020). All methods de-
scribed in the following two subsections are intro-
duced and thoroughly described in (Chan et al., 2020;
Chan et al., 2022; Oberdiek et al., 2020; Rottmann
et al., 2018; Rottmann and Schubert, 2019).
3.1 Notation
Let x ∈ [0, 1]
H×W ×3
denote a normalized color image
of spatial dimensions H ×W . Let I = {1, 2, ..., H} ×
{1, 2, ...,W } denote the set of pixel locations. Let C =
{1, 2, ...,C} denote the set of |C | predefined classes.
We define a set of training data used to train a se-
mantic segmentation neural network in a supervised
manner as D
train
in
=
(x
j
, m
j
)
N
train
in
j=1
, where N
train
in
de-
notes the total number of in-distribution training sam-
ples and m
j
= (m
i
)
i∈I
∈ C
H×W
is the correspond-
ing ground truth segmentation mask of x
j
. Let
F : [0, 1]
H×W ×3
→ [0, 1]
H×W ×|C |
be a semantic seg-
mentation neural network that produces pixel-wise
class probabilities for a given image x.
3.2 Anomaly Segmentation via Entropy
Maximization
Let p
i
(x) =
p
i
(c|x)
i∈I ,c∈C
∈ [0, 1]
|C |
denote a vec-
tor of probabilities such that the p
i
(c|x) is a probabil-
ity of a pixel location i ∈ I of a given image x ∈ D
in
being a pixel that belongs to the class c ∈ C . We de-
fine p(x) =
p
i
(x)
i∈I
∈ [0, 1]
H×W ×|C |
, the probabil-
ity distribution over images in D
in
. When using D
train
in
to train a semantic segmentation neural network F,
one can interpret that the network is being trained to
estimate p(x), denoted by
ˆ
p(x). For a semantic seg-
mentation network in the context of anomaly segmen-
tation, it would be a desirable property if such net-
work could output a high prediction uncertainty for
OoD pixels which can in turn be quantified with a per-
pixel entropy. For a given image x ∈ [0, 1]
H×W ×3
and
Neural Network Meta Classifier: Improving the Reliability of Anomaly Segmentation
349

a pixel location i ∈ I , the per-pixel prediction entropy
is defined as
E
i
ˆ
p
i
(x)
= −
∑
c∈C
ˆp
i
(c|x)log
ˆp
i
(c|x)
, (1)
where E
i
ˆ
p
i
(x)
is maximized by the uniform (non-
informative) probability distribution
ˆ
p
i
(x) which
makes it an intuitive uncertainty measure.
We define a set of OoD training samples as
D
train
out
=
(x
j
, m
j
)
N
train
out
j=1
where N
train
out
denotes the to-
tal number of such samples. In practice, D
train
out
is a
general-purpose dataset that contains diverse taxon-
omy exceeding the one found in the chosen domain-
specific dataset D
train
in
and it serves as a proxy for im-
ages containing anomalies.
It has been shown (Chan et al., 2020) that one can
make the output of a semantic segmentation neural
network F have a high entropy on OoD pixel loca-
tions by employing a multi-criteria training objective
defined as
L = (1 − λ)·E
(x,m)∈D
train
in
h
l
in
F(x), m
i
+
λ·E
(x,m)∈D
train
out
h
l
out
F(x), m
i
,
(2)
where λ ∈ [0, 1] is used for controlling the impact of
each part of the overall objective.
When minimizing the overall objective defined by
Eq. (2), a commonly used cross-entropy loss is ap-
plied for in-distribution training samples defined as
l
in
F(x), m
= −
∑
i∈I
∑
c∈C
1
m
i
=c
· log
ˆp
i
(c|x)
, (3)
where 1
c=m
i
∈ {0, 1} is the indicator function being
equal to one if the class index c ∈ C is, for a given
pixel location i ∈ I , equal to the class index m
i
de-
fined by the ground truth segmentation mask m and
zero otherwise. For OoD training samples, a slightly
modified cross-entropy loss defined as
l
out
F(x), m
= −
∑
i∈I
out
∑
c∈C
1
|C |
log
ˆp
i
(c|x)
(4)
is applied for pixel locations i ∈ I labeled as OoD
in the ground truth segmentation mask m. It can be
shown (Chan et al., 2020) that minimizing l
out
defined
by Eq. (4) is equivalent to maximizing per-pixel pre-
diction entropy E
i
ˆ
p
i
(x)
defined by Eq. (1), hence
the name entropy maximization. The anomaly seg-
mentation score map a can then be obtained by nor-
malizing the per-pixel prediction entropy, i.e.,
a = (a
i
)
i∈I
∈ [0, 1]
H×W
, a
i
=
E
i
ˆ
p
i
(x)
log(|C |)
. (5)
3.3 Meta Classification
Meta classification is the task of discriminating be-
tween a false positive prediction and a true positive
prediction. Training a network with a modified en-
tropy maximization training objective increases the
network’s sensitivity towards predicting OoD objects
and can result in a substantial number of false positive
predictions (Chan et al., 2019; Chan et al., 2020). Ap-
plying meta classification in order to post-process the
network’s prediction has been shown to significantly
improve the network’s ability to reliably detect OoD
objects. For a given image x, we define a set of pixel
locations being predicted as OoD as
I
ˆ
out
(x, a) =
i ∈ I | a
i
≥ t, t ∈ [0, 1]
(6)
where t represents a fixed threshold and a is computed
using Eq. (5). Based on I
ˆ
out
(x, a), a set of connected
components representing OoD object predictions de-
fined as
ˆ
K (x, a) ⊆ P
I
ˆ
out
(x, a)
is constructed. Note
that P
I
ˆ
out
(x, a)
denotes the power set of I
ˆ
out
(x, a).
Meta classifier is a lightweight model added on
top of a semantic segmentation network F. After
training F for entropy maximization on the pixels of
known OoD objects, a structured dataset of hand-
crafted metrics is constructed. For every OoD ob-
ject prediction
ˆ
k ∈
ˆ
K (x, a), different pixel-wise un-
certainty measures are derived solely from
ˆ
p(x) such
as normalized per-pixel prediction entropy of Eq. (1),
maximum softmax probability, etc. In addition to
metrics derived from
ˆ
p(x), metrics based on the OoD
object prediction geometry features are also included
such as the number of pixels contained in
ˆ
k, various
ratios regarding interior and boundary pixels, geomet-
ric center, geometric features regarding the neighbor-
hood of
ˆ
k, etc. (Chan et al., 2020; Rottmann et al.,
2018).
After a dataset with the hand-crafted metrics is
constructed, a meta classifier is trained to classify
OoD object predictions in one of the following two
sets,
C
T P
(x, a) =
ˆ
k ∈
ˆ
K (x, a) | IoU(
ˆ
k, m) > 0
and
C
FP
(x, a) =
ˆ
k ∈
ˆ
K (x, a) | IoU(
ˆ
k, m) = 0
,
(7)
where C
T P
represents a set of true positive OoD ob-
ject predictions, C
FP
a set of false positive OoD object
predictions and IoU represents the intersection over
union of a OoD object prediction
ˆ
k with the corre-
sponding ground truth segmentation mask m. Each
(x, m) ∈ D
meta
out
is an element of a dataset containing
known OoD objects used to train a meta classifier.
During inference, a meta classifier predicts
whether an OoD object predictions obtained from F
are false positive. Certainly, the prediction is done
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
350

without the access to the ground truth segmentation
mask m and is based on learned statistical and geo-
metrical properties of the OoD object predictions ob-
tained from the known unknowns. OoD object pre-
dictions classified as false positive are then removed
and the final prediction is obtained.
3.4 Neural Network Meta Classifier
In (Chan et al., 2020), authors use logistic regression
for the purpose of meta classifying predicted OoD ob-
jects. Their main argument for the use of logistic re-
gression is that since it is a linear model, it is possi-
ble to analyze the impact of each hand-crafted met-
ric used as an input to the model with an algorithm
such as Least Angle Regression (LARS) (Efron et al.,
2004). However, we argue that even though it is desir-
able to have an interpretable model in order to analyze
the relevance and the impact of its input, it is possi-
ble to achieve a significantly greater performance by
employing a more expressive type of model such as a
neural network.
Let
ˆ
K be a set containing OoD object pre-
dictions for every (x, m) ∈ D
meta
out
defined as
ˆ
K =
S
(x,m)∈D
meta
out
ˆ
K (x, a). We formally define
the aforementioned hand-crafted metrics dataset as
µ ⊂ R
|
ˆ
K|×N
m
, where N
m
is the total number of hand-
crafted metrics derived from each OoD object predic-
tion.
We propose that instead of logistic regression as
a meta classifier, a lightweight fully connected neu-
ral network is employed. Let F
meta
: µ → [0, 1] denote
such a neural network. We can interpret that F
meta
outputs the probability of a given OoD object predic-
tion being false positive based on the corresponding
derived hand-crafted metrics according to Eq. (7). Let
p
F
denote such probability. Since F
meta
is essentially
a binary classifier, we can train it using the binary
cross-entropy loss defined as
L
meta
= −
N
∑
i=1
y
i
log
p
F
i
+(1−y
i
)log
1 − p
F
i
, (8)
where N represents the number of OoD object predic-
tions included in a mini-batch and y
i
represents the
ground truth label of a given OoD object prediction
and is equal to one if given OoD object prediction is
false positive and zero otherwise.
4 EXPERIMENTS
In this section, we briefly describe the experimen-
tal setup and evaluate our proposed neural network
meta classifier.
4.1 Experimental Setup
For the purpose of the entropy maximization, we
use DeepLabv3+ semantic segmentation model (Chen
et al., 2018) with a WideResNet38 backbone (Wu
et al., 2016) trained by Nvidia (Zhu et al., 2018).
The model is pretrained on Cityscapes dataset (Cordts
et al., 2016). The pretrained model is fine-tuned ac-
cording to Eq. (2). We use Cityscapes dataset (Cordts
et al., 2016) as D
train
in
containing 2,975 images while
for D
train
out
we use a subset of COCO dataset (Lin et al.,
2014) which we denote as COCO-OoD. For the pur-
pose of D
train
out
, we exclude images containing class
instances that are also found in Cityscapes dataset.
After filtering, 46,751 images remain. The model is
trained for 4 epochs on random square crops of height
and width of 480 pixels. Images that have height
or width smaller than 480 pixels are resized. Before
each epoch, we randomly shuffle 2,975 images from
Cityscapes dataset with 297 images randomly sam-
pled from the remaining 46,751 COCO images. Hy-
perparameters are set according to the baseline (Chan
et al., 2020): loss weight λ = 0.9, entropy threshold
t = 0.7. Adam optimizer (Kingma and Ba, 2017) is
used with learning rate η = 1 × 10
−5
.
4.2 Evaluation of Neural Network Meta
Classifier
We use (Chan et al., 2020) as a baseline. We substitute
the logistic regression with a lightweight fully con-
nected neural network whose architecture is shown in
Table 1. The proposed meta classifier is trained on the
hand-crafted metrics derived from OoD object predic-
tions of the images in LostAndFound Test (Pinggera
et al., 2016). Derived hand-crafted metrics, i.e., cor-
responding OoD object predictions are leave-one-out
cross validated according to Eq. (7). The meta clas-
sifier is trained using Adam optimizer with learning
rate η = 1 × 10
−3
and weight decay γ = 5 × 10
−3
for 50 epochs with a mini-batch size N = 128. Note
that in our case, the total number of hand-crafted met-
rics N
m
= 75. Also note that the logistic regression
meta classifier has 76 parameters. The results are
shown in Table 2 and Fig. 1. In our experiments, the
improved performance is especially noticeable when
considering OoD object predictions consisting of a
very small number of pixels.
5 DISCUSSION
In this section, we introduce the notion of high and
low informative OoD proxy images, and we show
Neural Network Meta Classifier: Improving the Reliability of Anomaly Segmentation
351
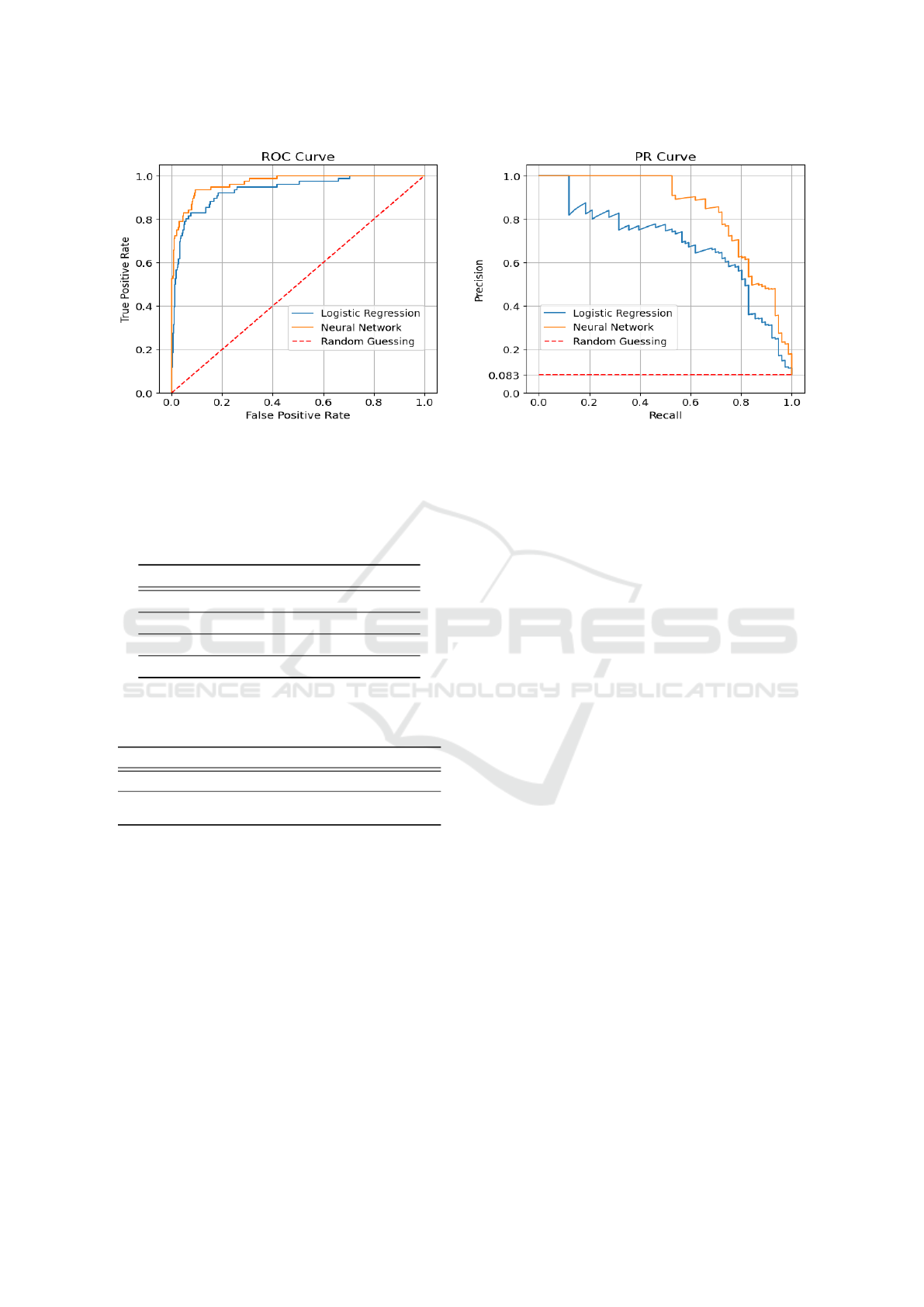
Figure 1: ROC and PR meta classifier curves for OoD object predictions of LostAndFound Test images. On the PR curve,
random guessing is represented as a constant dashed red line whose value is equal to the ratio of the number of OoD objects
and the total number of predicted OoD objects.
Table 1: Architecture of the neural network meta classifier.
All layers are fully connected and a sigmoid activation is
applied after the last layer. The total number of parameters
is 17,176.
Layer # of neurons # of parameters
Input layer 75 5,700
1. layer 75 5,700
2. layer 75 5,700
Output layer 1 76
Table 2: Performance comparison of meta classifiers. Note
that the given results are based on OoD object predictions
obtained with entropy threshold t = 0.7 of Eq. (6).
Model Type Logistic Regression Neural Network
Source Baseline Reproduced Ours
AUROC 0.9444 0.9342 0.9680
AUPRC 0.7185 0.6819 0.8418
that the high informative proxy OoD images are the
ones from which the semantic segmentation network
can learn to reliably output high entropy on OoD pix-
els of images seen during inference. Then, we dis-
cuss the loss of interpretability, a drawback of using
the proposed neural network meta classifier instead
of the interpretable logistic regression meta classifier
and show that it may not be a significant drawback
after all.
5.1 On Outlier Supervision of the
Entropy Maximization
We introduce the notion of high informative and low
informative proxy OoD images. What we mean by
high and low informative is illustrated with Fig. 2.
We have noticed empirically that high informative
proxy OoD images have two important characteristics
that differentiate them from the low informative proxy
OoD images: spatially clear separation between ob-
jects and clear object boundaries.
Our conjecture is that the low informative proxy
OoD images have little to no impact on the entropy
maximization training or can even negatively impact
the training procedure. On the other hand, high infor-
mative proxy OoD images are the ones from which
the semantic segmentation network can learn to re-
liably output high entropy on OoD pixels of im-
ages seen during inference, denoted by D
out
\ D
train
out
,
where \ represents the set difference.
To investigate our conjecture, we perform the en-
tropy maximization training on subsets of COCO-
OoD. We consider it difficult to universally quan-
tify the mentioned characteristics of high informa-
tive proxy OoD images, however, we notice a signifi-
cant correlation between the percentage of the labeled
OoD pixels and the desirable properties found in high
informative OoD proxy images. We use COCO-OoD
proxy for the creation of the two disjoint sets such that
the first contains images from COCO-OoD that have
at most 20% of pixels labeled as OoD (denoted as L-
20%-OoD) and the second that contains images from
COCO-OoD that have at least 80% of pixels labeled
as OoD (denoted as M-80%-OoD). Table 3 shows that
performing the entropy maximization training using
M-80%-OoD results in a little to no improvement in
comparison to the model trained exclusively on the
in-distribution images. On the other hand, using L-
20%-OoD produced even better results than the ones
obtained with the usage of COCO-OoD.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
352

(a) Examples of high informative proxy OoD images. (b) Examples of low informative proxy OoD images.
Figure 2: Examples of high and low informative proxy OoD images. The first row contains the proxy OoD images while the
second row contains ground truth segmentation masks such that the white regions represent pixels labeled as OoD for which
Eq. (4) is applied.
Table 3: Results for the entropy maximization training using COCO-OoD subsets. Column DLV3+W38 contains the results
obtained from the model used for fine-tuning (Zhu et al., 2018) which was trained exclusively on the in-distribution images.
Other columns contain results obtained from the best model after performing the entropy maximization training numerous
times with a given subset.
Metric FPR
95
AUPRC
Source DLV3+W38 COCO-OoD L-20%-OoD M-80%-OoD DLV3+W38 COCO-OoD L-20%-OoD M-80%-OoD
LostAndFound Test 0.35 0.15 0.09 0.13 0.46 0.75 0.78 0.48
Fishyscapes Static 0.19 0.17 0.12 0.31 0.25 0.64 0.73 0.25
5.2 Interpretability of Neural Network
Meta Classifier
A drawback of using a neural network as a meta clas-
sifier is the loss of interpretability. However, we at-
tempt to further understand the performance of our
proposed meta classifier. Fig. 3 shows LARS path for
ten hand-crafted metrics most correlated with the re-
sponse of logistic regression, i.e., the ones which con-
tribute the most in classifying OoD object predictions.
One can interpret LARS as a way of sorting the hand-
crafted metrics based on the impact on the response of
logistic regression. Algorithm 1 offers a way to lever-
age this kind of reasoning in order to gain a further
insight in how neural network meta classifier behaves
in comparison to logistic regression. Note that we
assume that LARS sorts hand-crafted metrics in de-
scending order with respect to the correlation. Fig. 4
shows results of executing Algorithm 1 for both meta
classifiers.
For the logistic regression meta classifier, after we
take a subset of µ containing 21 most correlated hand-
crafted metrics according to LARS, adding remaining
hand-crafted metrics results in little to no improve-
ment in performance. We can see that the neu-
ral network meta classifier exhibits a similar behav-
ior, although in a more unstable manner. The ob-
vious difference in performance can be most likely
attributed to the fact that neural network meta clas-
sifier is more expressive and better aggregates the
hand-crafted metrics. We argue that the hand-crafted
metrics having the most impact on the performance
of logistic regression meta classifier also do so in
the case of neural network meta classifier. Such in-
sight could alleviate presumably the most significant
drawback of using neural network meta classifier in-
stead of logistic regression meta classifier - the loss of
interpretability.
Figure 3: LARS path for the hand-crafted metrics at t = 0.7.
A detailed description of the hand-crafted metrics can be
found in (Chan et al., 2020).
Neural Network Meta Classifier: Improving the Reliability of Anomaly Segmentation
353
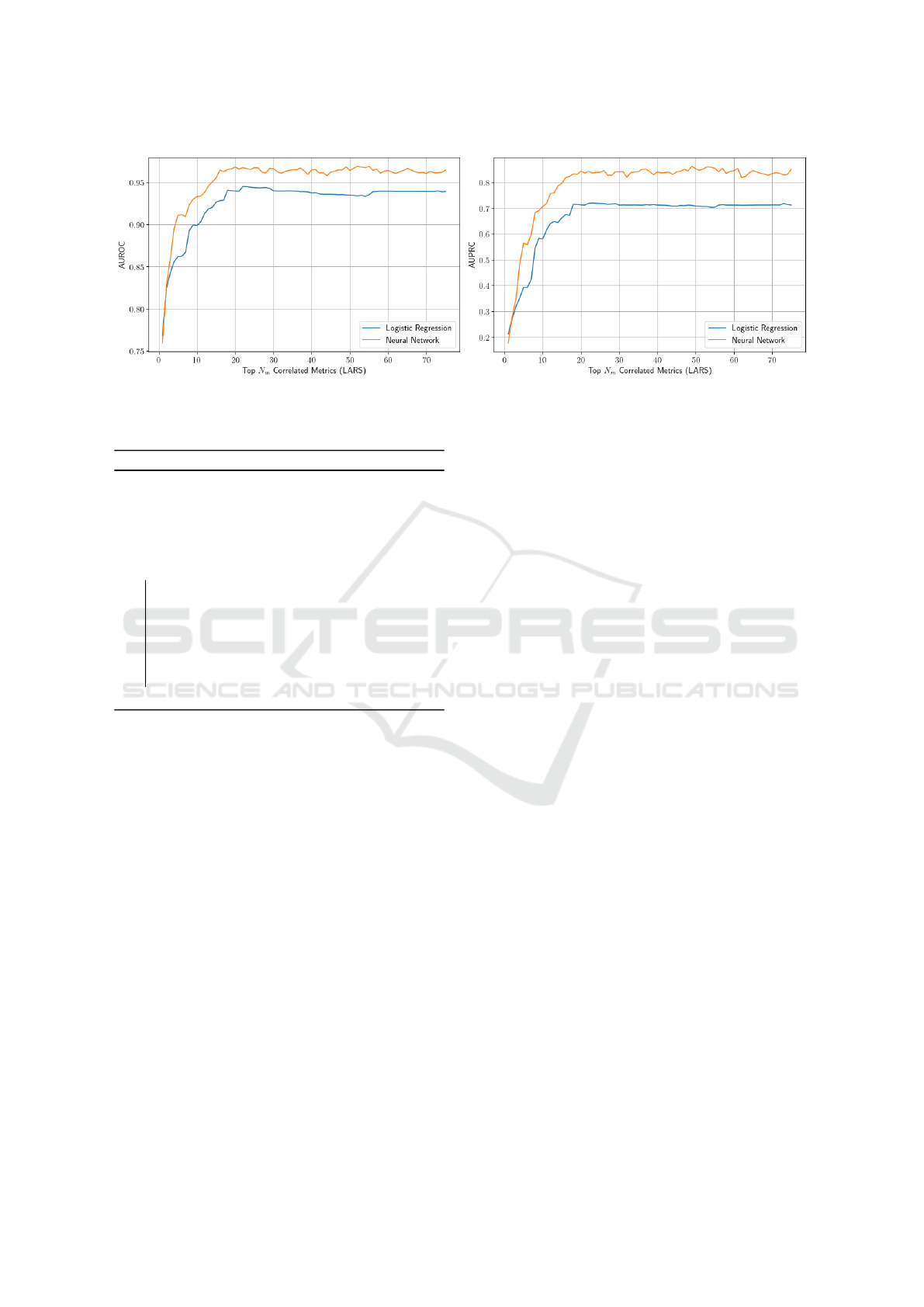
Figure 4: Performance comparison of logistic regression meta classifier and neural network meta classifier when trained on
subsets of the hand-crafted metrics dataset µ. For each value N
m
on the x-axis, we train the meta classifiers on the subset of µ
such that we take the first N
m
metrics having the most correlation with the response according to LARS.
Algorithm 1: Incremental meta classifier evaluation.
Input : F
meta
, µ, N
m
Output: lists of AUROC and AUPRC metrics
AUROC ←− [ ];
AUPRC ←− [ ];
MetricsSortedByCorrelation ←− LARS(µ);
for i = 1 to N
m
do
ξ ←− MetricsSortedByCorrelation[:i];
initializeModel(F
meta
);
trainModel(F
meta
, ξ);
(m
1
, m
2
) ←− evaluateModel(F
meta
, ξ);
AUROC.append(m
1
);
AUPRC.append(m
2
);
end
6 CONCLUSION
In this paper, we explored the anomaly segmenta-
tion method called entropy maximization which can
increase the network’s sensitivity towards predicting
OoD objects, but which can also result in a substantial
number of false positive predictions. Hence, the meta
classification post-processing step is applied in or-
der to improve the network’s ability to reliably detect
OoD objects. Our experimental results showed that
employing the proposed neural network meta classi-
fier results in a significantly greater performance in
comparison to the logistic regression meta classifier.
Furthermore, we provided additional analysis of
the entropy maximization training which showed that
in order to ensure its effectiveness, caution must be
taken when choosing which images are going to be
used as proxy OoD images. Our experimental results
demonstrated that high informative proxy OoD im-
ages are the ones from which the semantic segmen-
tation network can learn to reliably output high en-
tropy on OoD pixels of images seen during inference
and are therefore more beneficial to the entropy max-
imization training in terms of how well a semantic
segmentation neural network can detect OoD objects
afterwards.
Finally, a drawback of using the neural network
meta classifier is the loss of interpretability. In our
attempt to further analyze the performance of the pro-
posed neural network meta classifier, we found that
the behavior of logistic regression and neural network
is strongly correlated, suggesting that the loss of inter-
pretability may not be a significant drawback after all.
REFERENCES
Ackermann, J., Sakaridis, C., and Yu, F. (2023).
Maskomaly:zero-shot mask anomaly segmentation.
Bevandi
´
c, P., Krešo, I., Orši
´
c, M., and Šegvi
´
c, S.
(2019). Simultaneous semantic segmentation and out-
lier detection in presence of domain shift. CoRR,
abs/1908.01098.
Bevandi
´
c, P., Krešo, I., Orši
´
c, M., and Šegvi
´
c, S. (2021).
Dense outlier detection and open-set recognition
based on training with noisy negative images. CoRR,
abs/2101.09193.
Biase, G. D., Blum, H., Siegwart, R., and Cadena, C.
(2021). Pixel-wise anomaly detection in complex
driving scenes. CoRR, abs/2103.05445.
Blum, H., Sarlin, P., Nieto, J. I., Siegwart, R., and Ca-
dena, C. (2019). The fishyscapes benchmark: Mea-
suring blind spots in semantic segmentation. CoRR,
abs/1904.03215.
Chan, R., Rottmann, M., and Gottschalk, H. (2020). En-
tropy maximization and meta classification for out-
of-distribution detection in semantic segmentation.
CoRR, abs/2012.06575.
Chan, R., Rottmann, M., Hüger, F., Schlicht, P., and
Gottschalk, H. (2019). Metafusion: Controlled false-
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
354

negative reduction of minority classes in semantic seg-
mentation.
Chan, R., Uhlemeyer, S., Rottmann, M., and Gottschalk,
H. (2022). Detecting and learning the unknown in se-
mantic segmentation.
Chen, L., Zhu, Y., Papandreou, G., Schroff, F., and Adam,
H. (2018). Encoder-decoder with atrous separable
convolution for semantic image segmentation. CoRR,
abs/1802.02611.
Cheng, B., Misra, I., Schwing, A. G., Kirillov, A., and Gird-
har, R. (2022). Masked-attention mask transformer for
universal image segmentation.
Cheng, B., Schwing, A. G., and Kirillov, A. (2021). Per-
pixel classification is not all you need for semantic
segmentation.
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler,
M., Benenson, R., Franke, U., Roth, S., and Schiele,
B. (2016). The cityscapes dataset for semantic urban
scene understanding. CoRR, abs/1604.01685.
Deli
´
c, A., Grci
´
c, M., and Šegvi
´
c, S. (2024). Outlier detec-
tion by ensembling uncertainty with negative object-
ness.
Denouden, T., Salay, R., Czarnecki, K., Abdelzad, V., Phan,
B., and Vernekar, S. (2018). Improving reconstruction
autoencoder out-of-distribution detection with maha-
lanobis distance. CoRR, abs/1812.02765.
Efron, B., Hastie, T., Johnstone, I., and Tibshirani, R.
(2004). Least angle regression. The Annals of Statis-
tics, 32(2).
Gal, Y. and Ghahramani, Z. (2016). Dropout as a bayesian
approximation: Representing model uncertainty in
deep learning.
Grci
´
c, M., Bevandi
´
c, P., and Šegvi
´
c, S. (2021). Dense
anomaly detection by robust learning on synthetic
negative data. ArXiv, abs/2112.12833.
Grci
´
c, M., Bevandi
´
c, P., and Šegvi
´
c, S. (2022). Dense-
hybrid: Hybrid anomaly detection for dense open-set
recognition.
Hendrycks, D. and Gimpel, K. (2017). A baseline for de-
tecting misclassified and out-of-distribution examples
in neural networks. In 5th International Conference
on Learning Representations, ICLR 2017, Toulon,
France, April 24-26, 2017, Conference Track Pro-
ceedings. OpenReview.net.
Janai, J., Güney, F., Behl, A., and Geiger, A. (2020).
Computer vision for autonomous vehicles: Problems,
datasets and state of the art. Found. Trends. Comput.
Graph. Vis., 12(1–3):1–308.
Kendall, A., Badrinarayanan, V., and Cipolla, R. (2015).
Bayesian segnet: Model uncertainty in deep convolu-
tional encoder-decoder architectures for scene under-
standing. CoRR, abs/1511.02680.
Kingma, D. P. and Ba, J. (2017). Adam: A method for
stochastic optimization.
Lakshminarayanan, B., Pritzel, A., and Blundell, C. (2017).
Simple and scalable predictive uncertainty estimation
using deep ensembles.
Lee, K., Lee, K., Lee, H., and Shin, J. (2018). A simple uni-
fied framework for detecting out-of-distribution sam-
ples and adversarial attacks.
Li, Y. and Kosecka, J. (2021). Uncertainty aware proposal
segmentation for unknown object detection. CoRR,
abs/2111.12866.
Liang, S., Li, Y., and Srikant, R. (2018). Enhancing
the reliability of out-of-distribution image detection
in neural networks. In 6th International Conference
on Learning Representations, ICLR 2018, Vancouver,
BC, Canada, April 30 - May 3, 2018, Conference
Track Proceedings. OpenReview.net.
Lin, T., Maire, M., Belongie, S. J., Bourdev, L. D., Girshick,
R. B., Hays, J., Perona, P., Ramanan, D., Dollár, P.,
and Zitnick, C. L. (2014). Microsoft COCO: common
objects in context. CoRR, abs/1405.0312.
Lis, K., Nakka, K. K., Fua, P., and Salzmann, M.
(2019). Detecting the unexpected via image resyn-
thesis. CoRR, abs/1904.07595.
Nayal, N., Yavuz, M., Henriques, J. F., and Güney, F.
(2023). Rba: Segmenting unknown regions rejected
by all.
Oberdiek, P., Rottmann, M., and Fink, G. A. (2020). De-
tection and retrieval of out-of-distribution objects in
semantic segmentation. CoRR, abs/2005.06831.
Pinggera, P., Ramos, S., Gehrig, S., Franke, U., Rother, C.,
and Mester, R. (2016). Lost and found: Detecting
small road hazards for self-driving vehicles. CoRR,
abs/1609.04653.
Rai, S. N., Cermelli, F., Fontanel, D., Masone, C., and Ca-
puto, B. (2023). Unmasking anomalies in road-scene
segmentation.
Rottmann, M., Colling, P., Hack, T., Hüger, F., Schlicht,
P., and Gottschalk, H. (2018). Prediction error meta
classification in semantic segmentation: Detection via
aggregated dispersion measures of softmax probabili-
ties. CoRR, abs/1811.00648.
Rottmann, M. and Schubert, M. (2019). Uncertainty mea-
sures and prediction quality rating for the semantic
segmentation of nested multi resolution street scene
images. CoRR, abs/1904.04516.
van Amersfoort, J., Smith, L., Teh, Y. W., and Gal, Y.
(2020). Simple and scalable epistemic uncertainty es-
timation using a single deep deterministic neural net-
work. CoRR, abs/2003.02037.
Wong, K., Wang, S., Ren, M., Liang, M., and Urtasun,
R. (2019). Identifying unknown instances for au-
tonomous driving. CoRR, abs/1910.11296.
Wu, Z., Shen, C., and van den Hengel, A. (2016). Wider or
deeper: Revisiting the resnet model for visual recog-
nition. CoRR, abs/1611.10080.
Xia, Y., Zhang, Y., Liu, F., Shen, W., and Yuille, A. L.
(2020). Synthesize then compare: Detecting fail-
ures and anomalies for semantic segmentation. CoRR,
abs/2003.08440.
Zhu, Y., Sapra, K., Reda, F. A., Shih, K. J., Newsam, S. D.,
Tao, A., and Catanzaro, B. (2018). Improving seman-
tic segmentation via video propagation and label re-
laxation. CoRR, abs/1812.01593.
Neural Network Meta Classifier: Improving the Reliability of Anomaly Segmentation
355
