
Obstacle Detection and Ship Recognition System for
Unmanned Surface Vehicles
Sevda Sayan
1,2 a
and Hazım Kemal Ekenel
2,3 b
1
ASELSAN, Defense System Technologies, Turkey
2
Istanbul Technical University, Department of Computer Engineering, Turkey
3
New York University Abu Dhabi, Division of Engineering, U.A.E.
Keywords:
Obstacle Detection, Ship Classification, Vision Transformers, Maritime.
Abstract:
This study investigates obstacle detection and ship classification via cameras to ensure safe navigation for
Unmanned Surface Vehicles. A two-stage approach was employed to achieve these goals. In the first stage, the
focus was on detecting ships, humans, and other obstacles in maritime environments. Models based on the You
Only Look Once architecture, specifically YOLOv5 and its variant TPH-YOLOv5 —specialized for detecting
small objects— were optimized using the MODS dataset. This dataset contains labeled images of dynamic
obstacles, such as ships, humans, and static obstacles, e.g., buoys. TPH-YOLOv5 performed well in detecting
small objects, crucial for collision avoidance in Unmanned Surface Vehicles. In the second stage, the study
addressed the ship classification problem, using the MARVEL dataset, which contains over two million images
across 26 ship subtypes. A comparative analysis was conducted between Convolutional Neural Networks and
Vision Transformer based models. Among these, the Data-efficient Image Transformer achieved the highest
classification accuracy of 92.87%, surpassing the previously reported state-of-the-art performance. In order
to further analyze the classification results, this study introduced a generic method for generating attention
heatmaps in vision transformer based models. Unlike related works, this method is applicable not only to
Vision Transformer but also to its variants. Additionally, pruning techniques were explored to improve the
computational efficiency of Data-efficient Image Transformer model, reducing inference times and moving
closer to the speed required for real-time applications, though Convolutional Neural Networks remain faster
for such tasks.
1 INTRODUCTION
Unmanned Surface Vehicles (USVs) are types of
robotic vehicles that can operate autonomously or by
remote control in marine environments, performing
tasks without human intervention. Today, the expand-
ing operational areas of USVs have marked a turn-
ing point in the maritime sector. They are effectively
used in various fields such as marine research, en-
vironmental monitoring, military reconnaissance and
surveillance, and search and rescue operations. Ob-
ject detection and ship classification in marine en-
vironments are challenging tasks that are critical for
maritime safety and navigation. This requires han-
dling image distortions caused by factors such as
changing weather conditions, wave motion, reflec-
tions, and lighting. These factors can significantly im-
a
https://orcid.org/0009-0005-1121-8974
b
https://orcid.org/0000-0003-3697-8548
pact the accuracy and reliability of the systems. Ship
classification becomes even more complex due to the
diversity, sizes, and movements of ships on the sea.
Advanced image processing technologies and
deep learning methods are employed to overcome
these challenges. In recent years, object detection al-
gorithms like YOLO (You Only Look Once) (Red-
mon et al., 2016) and innovative approaches such
as Vision Transformers (ViTs) have made significant
progress in this field. These methods make object
detection and ship classification in marine environ-
ments faster, more accurate, and more effective, open-
ing new horizons for maritime safety and navigation.
YOLOv5 (Jocher, 2020) is an advanced version of
the original YOLO, renowned for its speed and accu-
racy in real-time object detection. It has gained sig-
nificant traction in the field of marine object detec-
tion due to its several key advantages. Its lightweight
architecture allows it to perform detections quickly,
Sayan, S. and Ekenel, H. K.
Obstacle Detection and Ship Recognition System for Unmanned Surface Vehicles.
DOI: 10.5220/0013152000003912
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 3: VISAPP, pages
113-122
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
113

which is crucial for the dynamic and challenging envi-
ronment where objects such as ships, buoys, and ma-
rine life need to be identified promptly.
Recent advancements in maritime surveillance
have necessitated more effective object detection
methodologies, particularly for small, difficult-to-
detect objects. The TPH-YOLOv5 (Zhu et al., 2021)
is an enhanced version of the YOLOv5 model, in-
corporates Transformer Prediction Heads (TPH) and
the Convolutional Block Attention Module to address
these challenges. CBAM aids the model in focus-
ing on relevant areas within dense scenes, thereby
enhancing detection accuracy. This model signifi-
cantly improves the detection of small-scale objects
by leveraging the self-attention mechanism of trans-
formers, which provides superior feature representa-
tion.
Vision Transformers (Dosovitskiy et al., 2021),
Data-efficient image Transformers (DeiT) (Touvron
et al., 2021), Swin Transformers (Liu et al., 2021),
and ConvNeXt (Woo et al., 2023) are recent advance-
ments in neural network architectures that have trans-
formed how we approach image classification tasks.
ViT applies transformers directly to image patches
and treats them as tokens. It offers a different ap-
proach compared to CNNs, achieving excellent re-
sults when pre-trained on large datasets. DeiT fur-
ther optimizes this approach by introducing tech-
niques like distillation to train more data-efficient
models without reliance on extensive computational
resources. Swin Transformers introduce a hierar-
chical structure that uses shifted windows to limit
self-attention computation to local windows while al-
lowing cross-window connection. Lastly, ConvNeXt
modernizes the traditional CNN architecture by inte-
grating transformer-like elements, such as layer scale
and inverted bottlenecks, improving performance on
par with more advanced transformer models. These
architectures offer powerful options for handling var-
ious image classification tasks.
This study first concentrates on object detection
within marine environments utilizing YOLOv5 based
models. Our study shows TPH-YOLOv5’s better per-
formance on the MODS (Bovcon et al., 2022) dataset,
highlighting its potential to detecting small objects in
USVs for maritime surveillance. Subsequently, we
performed ship classification using the increasingly
prominent vision transformer based models and com-
pared their class-specific accuracies. To the best of
our knowledge, this is the first study to use vision
transformers for ship classification. With this ap-
proach, we outperformed the state-of-the-art. Addi-
tionally, we utilized the attention layers within these
models to generate attention flow maps —a special-
ized type of heatmap designed to visualize the fo-
cused areas by the transformers. This study also pro-
poses a general method for applying attention maps
to different versions of the ViT model. These visu-
alizations provide crucial insights into the regions of
the images that the models primarily target during the
classification process. Furthermore, we show the af-
fect of post-training pruning techniques on inference
times without significantly affecting accuracy.
All experiments in this study were conducted
on the NVIDIA Orin AGX Developer Kit, a high-
performance computing platform designed for edge
AI and robotics applications. This platform’s ad-
vanced GPU architecture and efficient parallel pro-
cessing capabilities were essential for training and
evaluating the deep learning models used in this re-
search.
The remainder of this paper is structured as fol-
lows: Section 2 presents a review of the literature rel-
evant to this field. Section 3 describes the datasets
employed in our analysis. Section 4 details the imple-
mentation and results, which are divided into object
detection and ship classification. Finally, Section 5
summarizes the findings.
2 RELATED WORKS
When examining the current literature on object de-
tection and classification in marine environments, it
is evident that Convolutional Neural Network (CNN)-
based learning algorithms are predominantly pre-
ferred. In this context, most researchers initially ad-
dress the problem from the perspective of object de-
tection. Moreover, in their studies, authors frequently
emphasize that factors such as reflections and adverse
environmental conditions posed by the marine envi-
ronment negatively impact the results. This section
will examine and discuss the methodologies and re-
sults of similar studies.
MODS is a dataset presented at the MaCVi’23
(Kiefer et al., 2023) competition. This competition
holds a central position in demonstrating the latest
methods in the field of marine environment object
detection and segmentation. The participating teams
faced the necessity to establish a crucial balance be-
tween achieving high accuracy and reasonable infer-
ence speeds. Most approaches focused on improving
the detection of small objects, which is of critical im-
portance in maritime surveillance. In USV object de-
tection challenge, teams improved upon the baseline
method, Mask R-CNN (He et al., 2017), using ad-
vanced models. The Fraunhofer IOSB team took first
place with their DetectorRS model, noted for its abil-
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
114

ity to detect smaller objects in aquatic environments,
although it sometimes misidentified water reflections
as objects.
Another prominent study involves the use of
WaSR (Water Segmentation and Refinement) (Bov-
con and Kristan, 2022), an advanced network focused
on detecting obstacles in water environments using
semantic segmentation. It effectively distinguishes
between water, obstacles, and sky in images. An-
other study, eWaSR (Ter
ˇ
sek et al., 2023), is a variant
of WaSR designed for computationally limited em-
bedded devices. It maintains similar detection per-
formance with a very minor decrease in F1 score
(0.52% less than WaSR) but significantly reduces
computational requirements, operates 10 times faster
on a standard GPU, and can work on embedded sen-
sors where WaSR cannot due to memory constraints.
Lastly, WaSR-T (
ˇ
Zust and Kristan, 2022) enhances
WaSR by incorporating texture information over time,
better handling challenges such as reflections. This
version improves performance in challenging lighting
and water conditions, making it more robust in dy-
namic marine environments.
The study (Aguiar et al., 2023) explores obsta-
cle detection and avoidance in USVs using CNNs
and semantic segmentation. It utilizes the Mastr1325
dataset (Bovcon et al., 2019), containing 1,325 pixel-
wise annotated images for semantic segmentation,
and the Marine Obstacle Detection Dataset (MODD)
(Bovcon et al., 2018), consisting of 12 videos (4,454
frames) captured by real USVs under diverse con-
ditions. These datasets allow the study to ex-
plore semantic segmentation for identifying obsta-
cles and calculating safe routes based on regions of
interest within segmented images. This study em-
phasizes reducing computational complexity through
pre-segmentation and horizon line detection. Their
method uses semantic segmentation to distinguish be-
tween sky and water regions, enabling more efficient
processing and reducing false positives. The method
achieves over 90% accuracy in identifying obstacles
under various environmental conditions, including di-
verse lighting, weather, and high maritime traffic sce-
narios. These results show the applicability of their
methodology for real-time navigation, emphasizing
its practical utility in improving the safety and auton-
omy of USVs in complex maritime environments.
When we look at the ship classification task, the
largest and most detailed dataset, MARVEL (Gun-
dogdu et al., 2017), stands out. The creators of
this dataset have performed ship classification using
a deep learning model called AlexNet (Krizhevsky
et al., 2012). Despite class imbalances in the dataset,
equal numbers of examples from each class were se-
Figure 1: Sample images from the MARVEL (Gundogdu
et al., 2017) dataset and their classes. From left to right
classes container, fishing vessel, dredger and tug.
lected to build training and testing sets, 8192 and
1024, respectively. The model’s classification accu-
racy for 26 classes was found to be 73.14%, a signifi-
cant improvement over the 53.89% accuracy obtained
using a Support Vector Machine (Hearst et al., 1998).
An optimized CNN-based system for classify-
ing marine vehicles using deep learning and transfer
learning is presented in (Salem et al., 2023). Vari-
ous CNN models, including MobileNetV2 (Sandler
et al., 2018) and EfficientNet (Tan and Le, 2019),
were trained on the Game of Deep Learning Ship
dataset available on Kaggle
1
, and the top-performing
model was further tested on MARVEL. The results,
with a total of 10,000 images across 5 classes (cargo,
military, cruise, carrier, and tanker), demonstrated a
high classification accuracy of 97.04%, outperform-
ing other methods. (Salem et al., 2022) also worked
on MARVEL by utilizing pre-trained models like Ef-
ficientNet (B0-B5) (Tan and Le, 2019), ResNet-152
(He et al., 2016), and InceptionV3 (Szegedy et al.,
2015). The researchers aim to reduce training time
and resource consumption without compromising the
performance of image classification tasks for 26 ship
classes. Their experiments demonstrate that the Effi-
cientNet B5 architecture is superior to the other mod-
els, achieving a top accuracy of 91.60%. This im-
provement is notable as it exceeds previous best re-
sults in maritime vessel image classification.
The enhancement of ship classification accuracy
through deep learning methods, specifically CNNs, is
explored in (Leclerc et al., 2018). The study focuses
on the maritime domain, employing transfer learning
with pre-trained CNN architectures, such as Incep-
tion (Szegedy et al., 2015) and ResNets (He et al.,
2016), to adapt to a limited dataset of maritime vessel
images. These models were initialized with weights
from ImageNet (Deng et al., 2009), enabling them
to refine and build upon prior work more effectively.
This approach demonstrates a substantial improve-
ment over the existing state-of-the-art methods.
1
Kaggle dataset: https://www.kaggle.com/datasets/
arpitjain007/game-of-deep-learning-ship-datasets
Obstacle Detection and Ship Recognition System for Unmanned Surface Vehicles
115
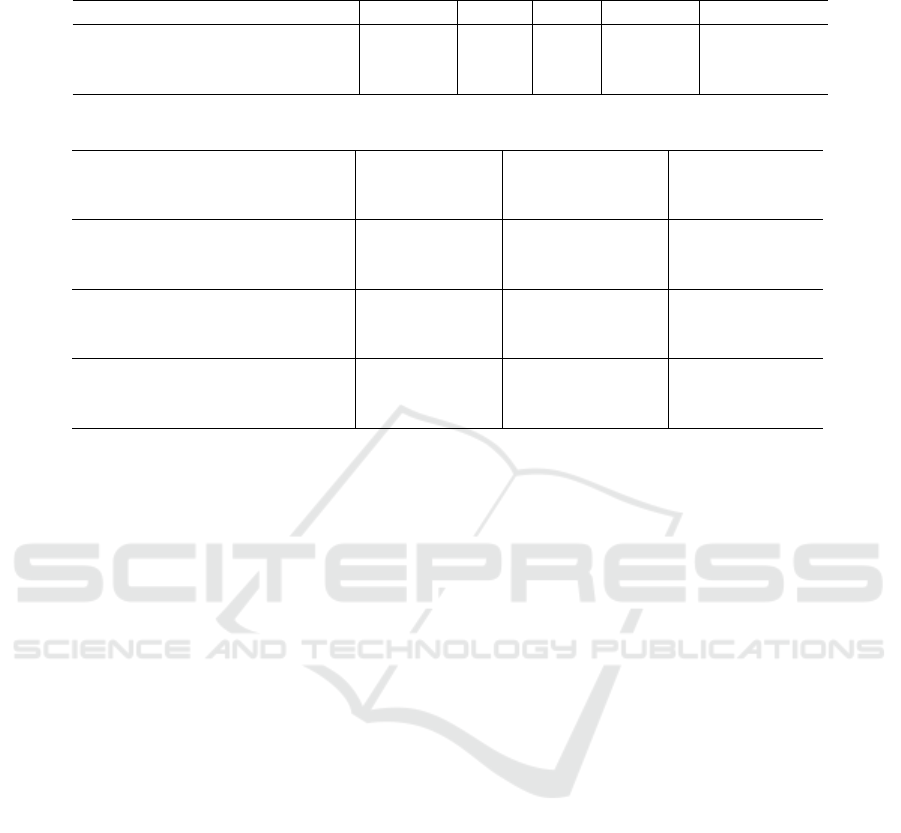
Table 1: Detailed comparison of performance metrics for various YOLOv5 models on the MODS (Bovcon et al., 2022)
dataset.
Precision Recall F1 mAP@.5 mAP@.5:.95
YOLOv5-s (Jocher, 2020) 0.845 0.745 0.791 0.793 0.403
YOLOv5-l (Jocher, 2020) 0.897 0.812 0.852 0.844 0.487
TPH-YOLOv5 (Zhu et al., 2021) 0.894 0.830 0.860 0.863 0.493
Table 2: Class-specific performance metrics for YOLOv5 models on the MODS dataset.
Pr / ship Pr / person Pr / other
Re / ship Re / person Re / other
mAP@.5 / ship mAP@.5 / person mAP@.5 / other
YOLOv5-s
(Jocher, 2020)
0.924 0.714 0.812
0.923 0.625 0.484
0.947 0.687 0.607
YOLOv5-l
(Jocher, 2020)
0.919 0.916 0.799
0.938 0.818 0.545
0.95 0.824 0.648
TPH-YOLOv5-s
(Zhu et al., 2021)
0.915 0.895 0.794
0.920 0.818 0.609
0.941 0.852 0.666
3 DATASETS
This study is conducted on two datasets, MODS
(Bovcon et al., 2022) and MARVEL (Gundogdu et al.,
2017), which offer comprehensive benchmarks for
object detection and segmentation in maritime envi-
ronments and ship classification, respectively. The
MODS dataset is specifically designed for USV op-
erations, focusing on obstacle detection and segmen-
tation in real-world maritime scenarios. It includes
stereo images captured from a USV navigating di-
verse coastal areas. Each image in the dataset is an-
notated to include dynamic obstacles, such as ships,
swimmers, and other moving objects, using bounding
boxes. Additionally, static obstacles, such as buoys
are carefully annotated. This detailed annotation en-
sures precise evaluation of both dynamic and static
obstacle detection, which is critical for USV naviga-
tion and collision avoidance. Images were captured
under varying weather conditions and includes chal-
lenging features such as sun-glitter, sea foam, and
dense object scenarios. The MODS dataset includes
detailed labels for both detection and segmentation
tasks. It is particularly used for detecting obstacles
that USVs may encounter, especially in small sizes.
On the other hand, the MARVEL dataset stands
out as the most extensive and comprehensive dataset
ever created for ship classification. This dataset, host-
ing about 2 million images, divides five main ship
types (cargo, military, carrier, cruise, and tanker) into
26 different subtypes. Figure 1 shows some sam-
ple images from the dataset. The dataset’s large
size and diversity make it ideal for exploring ad-
vanced deep learning architectures, including CNNs
and ViTs. MARVEL not only supports the develop-
ment of high-accuracy models for ship classification
but also contributes to maritime safety and monitoring
applications.
Preprocessing and Dataset Adaptation
Both datasets required preprocessing to align with the
goals of this study:
• MODS: The annotations were converted into a
YOLO-compatible format to optimize the training
of YOLOv5-based models. Around 9,000 images
have been divided into approximately 80% train-
ing, 10% validation, and 10% test data.
• MARVEL: To address the inherent class im-
balance in the MARVEL dataset and enhance
model generalization, data augmentation tech-
niques were employed. These techniques in-
cluded horizontal flipping, translation, random
brightness and contrast adjustments, and scal-
ing, all aimed at diversifying the training data
and ensuring equitable representation across ves-
sel classes. This preprocessing step was crucial
for maintaining the dataset’s robustness and pre-
venting model overfitting.
For experimentation, the dataset was structured
to include 3,600 training images, 800 validation
images, and 800 test images per class, ensuring
consistency and reliability in model evaluation.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
116

Figure 2: Comparison of object detection performance across three YOLO model variants (YOLOv5-s (Jocher, 2020),
YOLOv5-l (Jocher, 2020), TPH-YOLOv5 (Zhu et al., 2021)) on the MODS (Bovcon et al., 2022) dataset, illustrating de-
tection outcomes in various maritime scenes (best viewed in digital format zoomed in).
This balanced approach allowed for comprehen-
sive testing of classification algorithms, particu-
larly for less frequent vessel types, while main-
taining high generalizability and accuracy.
4 OBJECT DETECTION
One of the objectives of this study is to detect ships,
humans, and objects in the marine environment. After
reviewing the literature and conducting preliminary
analyses, object detection was chosen over segmen-
tation due to the need for fast and accurate responses
in real-time, critical for USVs operating in dynamic
and hazardous conditions.
Based on the analysis of the MODS dataset,
the problem was defined as detection of small ob-
jects. TPH-YOLOv5, optimized for small objects,
was compared with YOLOv5, which was chosen for
its balance of accuracy, speed, and efficiency, espe-
cially for real-time applications. TPH-YOLOv5 was
included due to its specialized design for this prob-
lem. Both models were initialized with pre-trained
ImageNet weights and fine-tuned for 130 iterations on
the MODS dataset.
Table 1 provides a detailed comparative evaluation
of the overall performances using metrics such as pre-
cision, recall, F1 score, and mean average precision
(mAP) at two intersection over union (IoU) thresh-
olds. Here, TPH-YOLOv5 emerges as the superior
model, demonstrating higher F1 scores and mAP val-
ues, which indicates its robustness in detecting ob-
jects with greater accuracy and consistency. Table 2
further delves into class-specific performance, high-
lighting how each model performs in detecting dif-
ferent objects like ships and persons. If we look at
the increase in score for the person and other classes
compared to other models, we can conclude that the
Figure 3: Graphical representation of training process of the
vision transformers on MARVEL dataset.
ability to detect small objects has improved.
Figure 2 presents a comparative visualization of
detection performance using three variants, as ap-
plied to the MODS dataset in diverse maritime set-
tings. Each row corresponds to a different model,
showing their efficiency in identifying and classify-
ing objects under varying environmental conditions.
Notably, TPH-YOLOv5 demonstrates a marked im-
provement in detecting smaller objects compared to
the other models. This enhancement is attributed to
the integration of Transformer Prediction Heads in
the TPH-YOLOv5 architecture, which enhances the
model’s sensitivity to smaller-scale features and dy-
namic obstacles. This capability is critical for appli-
cations requiring high accuracy in cluttered and chal-
lenging environments, such as navigation and surveil-
lance in maritime domains.
5 SHIP CLASSIFICATION
Traditional methods predominantly employ CNNs,
which, while effective, are primarily designed to cap-
ture spatial hierarchies in images. Recent advance-
ments in deep learning have introduced transformer-
based models, which leverage self-attention mecha-
nisms to process data in a manner that could poten-
tially outperform conventional CNNs in terms of both
accuracy and efficiency in certain tasks.
Obstacle Detection and Ship Recognition System for Unmanned Surface Vehicles
117

Table 3: Performance Comparison of Various Neural Network Architectures on the MARVEL(Gundogdu et al., 2017) Dataset,
Evaluating Classification Accuracy Across Different Methods and Class Sizes.
Study #class method acc.type acc.(%)
Erhan et al.(Gundogdu et al., 2017) 26 AlexNet (Krizhevsky et al., 2012) Val 73.14
Erhan et al.(Gundogdu et al., 2017) 26 SVM (Hearst et al., 1998) Val 53.89
Leclerc et al.(Leclerc et al., 2018) 26 Inception-v3 (Szegedy et al., 2015) Val 78.73
Leclerc et al.(Leclerc et al., 2018) 26 ResNet (He et al., 2016) Val 75.84
Salem et al.(Salem et al., 2023) 5 EfficientNetB2 (Tan and Le, 2019) Test 97.04
Salem et al.(Salem et al., 2022) 26 EfficientNet-B5 (Tan and Le, 2019) Val 91.60
This study 26 ResNet50 (He et al., 2016) Test 91.76
This study 26 ResNet101 (He et al., 2016) Test 89.87
This study 26 ViT-B (Dosovitskiy et al., 2021) Test 82.68
This study 26 DeiT-B (Touvron et al., 2021) Test 92.87
This study 26 Swin-T (Liu et al., 2021) Test 87.72
This study 26 Swin-B (Liu et al., 2021) Test 90.44
This study 26 ConvNext-v2 (Woo et al., 2023) Test 90.07
Table 4: Comparison of Image Classification Models Based
on Standardized Image Size of 224x224, Floating Point Op-
erations per Second (FLOPs) and Frame per Second (FPS).
Model FLOPs FPS
ResNet50 (He et al., 2016) 4.1G 52.66
ResNet101 (He et al., 2016) 7.8G 54.00
ViT-B (Dosovitskiy et al., 2021) 55.4G 0.95
DeiT-B (Touvron et al., 2021) 17.5G 1.31
Swin-B (Liu et al., 2021) 15.4G 0.51
Swin-T (Liu et al., 2021) 4.5G 1.14
ConvNext-v2 (Woo et al., 2023) 115G 0.13
In this study, we explore the applications of ViT
(Dosovitskiy et al., 2021), DeiT (Touvron et al.,
2021), Swin Transformers (Liu et al., 2021), and
ConvNext-v2 (Woo et al., 2023) for the task of ship
classification, utilizing the MARVEL dataset. Due to
the large size of the MARVEL dataset, previous stud-
ies have typically used random subsets of the data,
making direct comparisons across different models
challenging. To maintain consistency in our exper-
iments and ensure a fair evaluation, we followed a
similar approach by utilizing a random subset of the
dataset. Although our dataset size is similar to those
in other studies, the processes we applied to reduce
data size and address class imbalance issues intro-
duced differences in our datasets. Due to these dif-
ferences, we fine-tuned convolution-based networks
to allow for a fair comparison with our transformer-
based models. Additionally, we conduct a detailed
analysis of each model’s performance, focusing on
accuracy and computational speed.
Figure 3 illustrates the training process of Vision
Transformers (ViTs), where an input image is divided
into smaller patches, flattened into vectors, and then
embedded with positional information to retain the
spatial arrangement of the patches. These patch em-
beddings are passed through a transformer encoder,
which applies self-attention mechanisms to capture
global relationships between different parts of the im-
age. By doing so, the model can identify dependen-
cies across patches, even if they are far apart in the
original image, which is crucial for understanding the
overall context. The output from the transformer en-
coder is then fed into a multilayer perceptron (MLP)
head for classification, where the final decision is
made based on the global information gathered from
the attention layers. The attention mechanism, in par-
ticular, allows the model to focus on the most rele-
vant patches, effectively classifying images without
relying on traditional convolutional layers, which are
commonly used in CNNs for local feature extrac-
tion. ViTs thus enable efficient image classification
by modeling long-range dependencies across patches,
making them a powerful alternative to convolution-
based models.
The methodology includes resizing images
to 224x224x3 pixels, and employs an AdamW
(Loshchilov and Hutter, 2019) optimizer with a linear
learning rate (LR) scheduler. The hyperparameters
are optimized values tailored for each model to
achieve optimal performance. ViT, DeiT, SwinT-
base, and ConvNext-T all share an optimized learning
rate of 1e-4, a weight decay of 0.01, and a linear LR
schedule. SwinT-Tiny uses a slightly lower learning
rate of 5e-5. All models, except ViT and DeiT,
include a 0.1 warmup ratio. Each model is trained for
15 epochs with a batch size of 10 for training and 4
for evaluation. These configurations reflect careful
tuning to align with the architectural differences and
training requirements of each model, ensuring the
best possible performance on the given tasks.
Table 3 presents the performance of various neu-
ral network architectures on the MARVEL dataset.
While most previous studies, such as (Gundogdu
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
118
et al., 2017), (Leclerc et al., 2018), and (Salem et al.,
2023), reported their models’ performance on the val-
idation set, we conducted evaluations on the test set.
Notably, our method, using the DeiT model, achieved
a test-set accuracy of 92.87%, surpassing the previous
best score of 91.60%, which was recorded by (Salem
et al., 2023) with the EfficientNet-B5. Both this study
and the two previous works involved the classifica-
tion of 26 distinct classes. This result highlights the
potential benefits of transformer-based architectures,
like DeiT, over conventional CNNs, particularly in
handling complex image classification tasks within a
challenging dataset like MARVEL.
When we examine the detailed comparison of sev-
eral neural network models used for ship classifica-
tion, Table 4 highlights computational characteristics
and response times which are key metrics for real-
time maritime operations. Traditional CNN models
like ResNet50 and ResNet101, which showed good
frame per second (FPS), also achieve high accuracy.
This makes ResNet architectures a solid choice for
balancing both speed and performance.
Transformer-based models, while having lower
FPS—show promising accuracy, with DeiT-B achiev-
ing the highest accuracy of 92.87%. However, the
high FLOPs and low FPS of these models indicate
that they are more suited for scenarios where accuracy
is prioritized over speed. ConvNext-v2, despite being
the most computationally expensive, still manages to
offer a strong accuracy of 90.07%. Thus, when con-
sidering both response times and accuracy, traditional
CNN models remain more practical for real-time ap-
plications, while transformer models excel in accu-
racy but are better suited for offline tasks.
5.1 Pruning
Pruning is a model compression technique used in
deep learning to reduce the size and computational
requirements of large neural networks by removing
redundant parameters. This process helps maintain
high accuracy while cutting down on the storage and
processing power needed, making the models more
efficient. Pruning involves identifying and discard-
ing low-impact weights and neurons, often those with
low magnitude or similar activations. The result is a
lighter model with improved generalization, and bet-
ter suitability for deployment on low-resource devices
like embedded systems.
We observed that Vision Transformers, are not
suitable for real-time applications due to their low
FPS. Therefore, we experimented with various prun-
ing techniques to enhance their efficiency. Among
the models we tested, DeiT had the highest accuracy,
Figure 4: Sparsity vs Accuracy and Inference time change
when apply pruning to our finetuned DeiT model (best
viewed in digital format zoomed in).
which is why we focused our pruning experiments on
this model. We applied various post-training prun-
ing techniques on the DeiT model to assess their im-
pact on the efficiency and accuracy of ship classifica-
tion systems. These experiments used both local and
global pruning strategies. Local pruning targeted spe-
cific model components, including the classification
layer, the first attention layer, and all attention lay-
ers. Global pruning was applied across the model as a
whole. Despite DeiT being the best model in terms of
accuracy, its FPS was extremely low, making it inef-
ficient for real-time applications. Pruning was neces-
sary to reduce the model’s computational load, aiming
to provide a balance between maintaining high classi-
fication accuracy and improving inference speed.
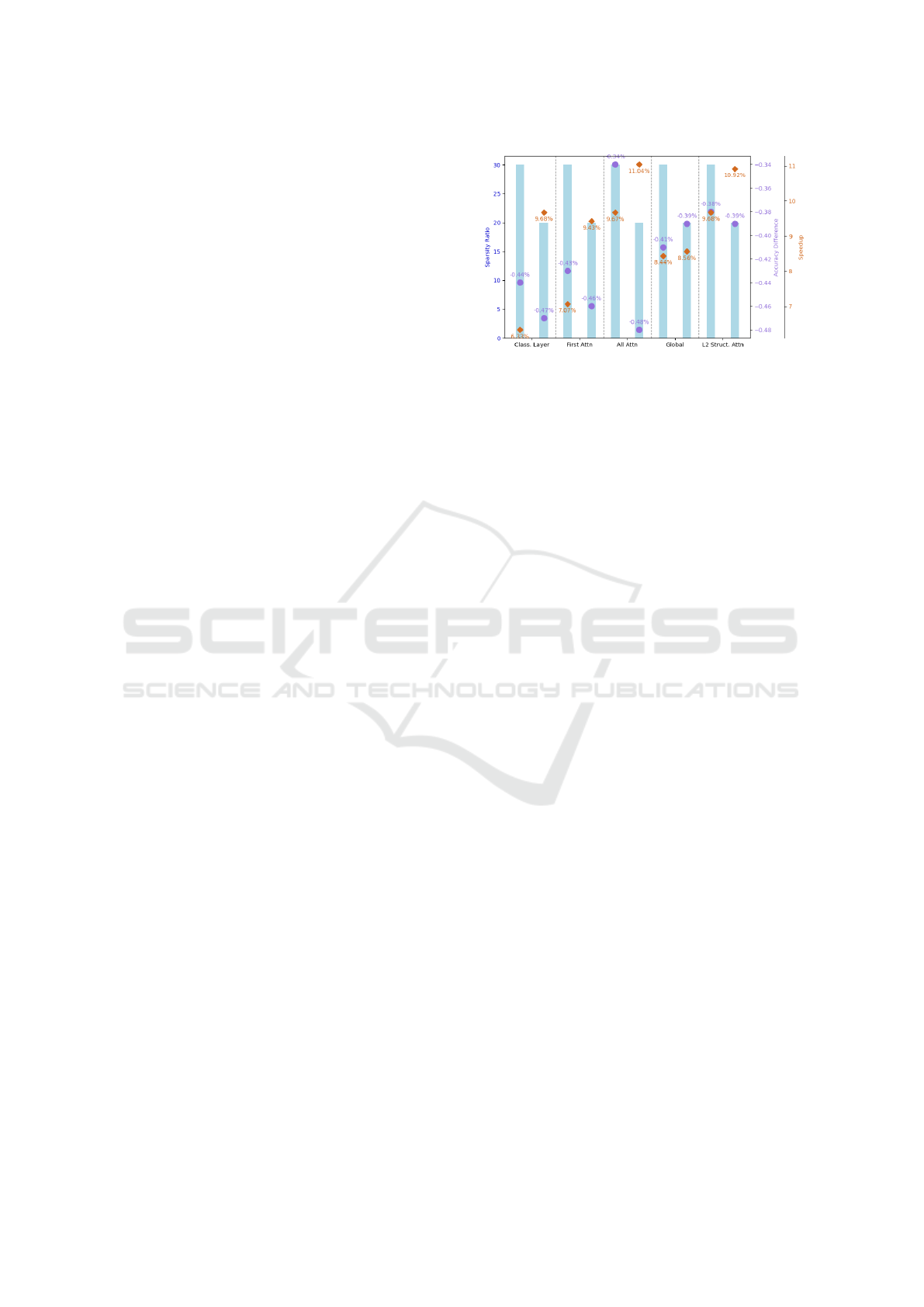
Figure 4 illustrates the effects of various prun-
ing strategies on the DeiT model, specifically target-
ing different components. For each pruning method,
the sparsity ratio (in blue bars), speedup (in orange
diamonds), and accuracy difference (in purple dots)
are compared. The results reveal subtle changes in
model performance, with accuracy reductions rang-
ing from 0.34% to 0.48%. Meanwhile, inference time
showed notable improvements, with speedups rang-
ing from 6.33% to 11.04%, reflecting an important
improvement in computational efficiency. The fig-
ure indicates that L2 structured pruning with 20% pa-
rameter reduction has optimal balance between max-
imum speedup and minimal accuracy degradation. It
achieves a 10.92% speedup while maintaining a small
accuracy drop of only 0.39%. However, despite the
improvements, the speed-up achieved with DeiT still
falls short of reaching the FPS seen in CNNs.
5.2 Attention Rollout
Heatmaps are visual tools used to highlight the re-
gions within an image that a model focuses on dur-
ing its decision-making process. They provide insight
Obstacle Detection and Ship Recognition System for Unmanned Surface Vehicles
119

Figure 5: Attention rollout maps for true and false predicted
samples on vision transformer models.
into the inner workings of machine learning models
by revealing which features or areas are most influ-
ential in generating predictions. They are commonly
used in image classification and text analysis to show
which parts of the input the model focuses on. Col-
ors typically range from cool (blue) for less atten-
tion to warm (red) for high influence. Heatmaps en-
hance transparency, making AI models easier to un-
derstand, helping identify biases or errors, and im-
proving trust and performance by showing how the
model processes inputs.
In this work, heatmaps are derived from the atten-
tion mechanisms of Vision Transformers (ViTs) and
their variants, enabling the visualization of how these
models process and prioritize different parts of an im-
age. This approach helps identify whether the mod-
els are correctly focusing on relevant features, such
as the shape or size of ships, while ignoring back-
ground noise like waves or reflections. Unlike pre-
vious work (Abnar and Zuidema, 2020), which of-
ten generated heatmaps specific to ViT, this study in-
troduces a generic method that can be applied across
various transformer architectures, including DeiT and
Swin Transformers. This generalization allows for
consistent interpretability and model validation for
maritime applications.
To better understand which parts of an image
the vision transformer models focus on, we used
the attention layers to create rollout maps, a type of
heatmap. These maps highlight the regions of the im-
age that the model pays the most attention to during
classification. By analyzing these visualizations, we
gain valuable insights into how the model processes
and prioritizes different parts of the image when mak-
ing decisions.
In our exploration of the attention rollout tech-
nique (Abnar and Zuidema, 2020), we adopted a
methodology for quantifying attention flow in trans-
formers that significantly enhances our understanding
of how information propagates through the model’s
layers. This approach presents novel post-hoc meth-
ods to approximate attention to input tokens using at-
tention weights. These techniques, referred to as ”at-
tention rollout” and ”attention flow”.
Let A
i
= attention matrix for layer i, (1)
ˆ
A
i
= max(A
i
) (Fused Attention) (2)
A
′
i
=
ˆ
A
i
+ I
∑
(
ˆ
A
i
+ I)
(Normalized) (3)
Rollout
i
= A
′
i
· Rollout
i−1
(4)
The implementation involved manipulating atten-
tion matrices, to remove less informative attention
scores based on a specified discard ratio. Among the
provided three options (max, min and mean) on the at-
tention heads, we employed a maximum fusion strat-
egy in Eq. 2 to better capture significant areas that any
single head may highlight. This was complemented
by a strategy to discard lower attention values, which
significantly improved the clarity of attention maps
by highlighting the strongest or most activated fea-
tures. Additionally, residual connections are included
by adding the identity matrix I to the attention ma-
trix of each layer. To capture the cumulative attention
across layers, the final attention map was generated by
multiplying the refined attention matrices, as shown
in Eq. 4, and then normalizing to maintain a consis-
tent distribution of attention across the image.
This methodology allowed for a more focused
and interpretable visualization of where the model di-
rects its attention, providing insights into its decision-
making process. By employing this technique, we ef-
fectively address the challenge of visualizing atten-
tion in deeper layers of the model. Our modified at-
tention rollout method can be applied not only to the
original ViT but also to its variants, such as DeiT and
Swin Transformers.
For models like DeiT that include a classification
token (CLS token), we extracted this token from all
attention layers before combining them, as seen in
Eq. 5. In this equation, the number of CLS tokens
is represented by the variable k. This operation in-
dicates that we select all elements from the last two
dimensions starting from the index k onwards, effec-
tively skipping or ignoring the first k entries in both
dimensions.
˜
A
i
= A
i
[..., k :, k :] (5)
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
120

Similarly, for Swin Transformers, we averaged
across the batch dimension to reduce window size, as
shown in Eq. 6. This process takes the mean of the
attention across the batch dimension (dimension 0).
˜
A
i
= mean(A
i
, dim = 0, keepdim = True) (6)
This enhanced method not only aligns with the
findings from (Abnar and Zuidema, 2020) but also
adapts their insights to improve the interpretability
of deeper layers in other vision transformer models.
This adaptation ensures that the attention mechanisms
in ViTs and other transformer-based architectures can
be effectively visualized, offering more intuitive ex-
planations of model behavior across various vision
tasks.
Figure 5 illustrates several input images that were
correctly or incorrectly predicted. The rows corre-
spond to specific vessel types, with the true class la-
bels indicated on the far left of each row. Each col-
umn represents the output of a different model: the
first shows the input image, and the remaining four
columns show the outputs of ViT, DeiT, Swin-T, and
Swin-B models, respectively. The maps in each cell
represent the regions of the image where each model
focused during classification, highlighting the areas
that were most important in the model’s decision-
making process. Below each image, the predicted
class for that specific model is displayed, showing
how each model classified the vessel.
It is observed that inaccuracies in predictions are
usually due to the models focusing on incorrect areas
of the images. However, the rollout maps highlight
the models’ ability to focus on the relevant parts of the
images without being distracted by background ob-
jects, particularly in correct predictions. This visual-
ization helps in understanding how the models’ atten-
tion mechanisms are engaged during prediction, con-
firming that they correctly identify and concentrate on
pertinent features within the images.
6 CONCLUSION
This paper presents a comprehensive study on object
detection and ship classification for Unmanned Sur-
face Vehicles. By utilizing the MODS and MARVEL
datasets, we applied advanced deep learning models,
such as YOLOv5 and Vision Transformers, to address
the challenges of detecting and classifying ships and
other obstacles in dynamic maritime conditions. Our
results demonstrate that the TPH-YOLOv5 model sig-
nificantly outperformed other variants of YOLOv5,
particularly in detecting small objects, achieving a
high mAP score of 0.863.
For ship classification, Vision Transformer mod-
els, especially DeiT, achieved state-of-the-art perfor-
mance with a classification accuracy of 92.87% on
the MARVEL dataset. Although the DeiT model
achieved a high classification accuracy of 92.87%
on the MARVEL dataset, its low FPS performance
makes it less suitable for real-time applications. The
high computational demands of Vision Transformers
can result in slower inference times, which is a critical
limitation for time-sensitive tasks like ship classifica-
tion in maritime environments. To address this, post-
training pruning techniques were employed, reducing
the model’s complexity and improving its speed by up
to 11%, with minimal impact on accuracy. Despite the
improvements from post-training pruning, the speed
and accuracy trade-off still led to the conclusion that
ResNet-based CNN models are more practical for
real-world applications.
Moreover, this research introduces an approach to
visualize the attention areas on images, applicable not
only to ViT but also its derivative models. The study
also proposes strategies to improve response times,
aiming to make these models more suitable for time-
sensitive tasks in real-world maritime applications.
For future work, we plan to explore the integra-
tion of detection and classification tasks into a uni-
fied framework, leveraging the strengths of our mod-
els. Additionally, we aim to further optimize model
performance through advanced techniques such as
quantization and knowledge distillation, with a fo-
cus on improving real-time capabilities. Expanding
the datasets and incorporating more challenging mar-
itime conditions will also be key to enhancing model
robustness.
REFERENCES
Abnar, S. and Zuidema, W. (2020). ”Quantifying Attention
Flow in Transformers”. In Proceedings of the 58th
Annual Meeting of the Association for Computational
Linguistics, pages 4190–4197.
Aguiar, R., Bertini, L., Copetti, A., Clua, E. W. G.,
Gonc¸alves, L. M. G., and Moreira, L. B. (2023).
Semantic Segmentation and Regions of Interest for
Obstacles Detection and Avoidance in Autonomous
Surface Vessels. In 2023 Latin American Robotics
Symposium (LARS), 2023 Brazilian Symposium on
Robotics (SBR), and 2023 Workshop on Robotics in
Education (WRE), pages 403–408.
Bovcon, B. and Kristan, M. (2022). WaSR—A Water Seg-
mentation and Refinement Maritime Obstacle Detec-
tion Network. IEEE Transactions on Cybernetics,
52(12):12661–12674.
Bovcon, B., Mandeljc, R., Per
ˇ
s, J., and Kristan, M.
(2018). Stereo obstacle detection for unmanned sur-
Obstacle Detection and Ship Recognition System for Unmanned Surface Vehicles
121

face vehicles by IMU-assisted semantic segmentation.
Robotics and Autonomous Systems, 104:1–13.
Bovcon, B., Muhovi
ˇ
c, J., Per
ˇ
s, J., and Kristan, M. (2019).
The MaSTr1325 dataset for training deep USV obsta-
cle detection models. In 2019 IEEE/RSJ International
Conference on Intelligent Robots and Systems (IROS),
pages 3431–3438.
Bovcon, B., Muhovi
ˇ
c, J., Vranac, D., Mozeti
ˇ
c, D., Per
ˇ
s,
J., and Kristan, M. (2022). MODS—A USV-Oriented
Object Detection and Obstacle Segmentation Bench-
mark. IEEE Transactions on Intelligent Transporta-
tion Systems, 23(8):13403–13418.
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei,
L. (2009). ImageNet: A large-scale hierarchical im-
age database. In 2009 IEEE Conference on Computer
Vision and Pattern Recognition, pages 248–255.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn,
D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer,
M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby,
N. (2021). An Image is Worth 16x16 Words: Trans-
formers for Image Recognition at Scale. In 9th In-
ternational Conference on Learning Representations,
ICLR 2021.
Gundogdu, E., Solmaz, B., Y
¨
ucesoy, V., and Koc¸, A.
(2017). MARVEL: A Large-Scale Image Dataset for
Maritime Vessels. In Computer Vision – ACCV 2016,
pages 165–180.
He, K., Gkioxari, G., Doll
´
ar, P., and Girshick, R. B. (2017).
Mask R-CNN. In ICCV, pages 2980–2988.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep Resid-
ual Learning for Image Recognition. In Proceedings
of 2016 IEEE Conference on Computer Vision and
Pattern Recognition, CVPR ’16, pages 770–778.
Hearst, M., Dumais, S., Osuna, E., Platt, J., and Scholkopf,
B. (1998). Support Vector Machines. IEEE Intelligent
Systems and their Applications, 13(4):18–28.
Jocher, G. (2020). ultralytics/yolov5: v3.1 - Bug Fixes
and Performance Improvements. https://github.com/
ultralytics/yolov5.
Kiefer, B. et al. (2023). 1st Workshop on Maritime Com-
puter Vision (MaCVi) 2023: Challenge Results. In
Proceedings of the IEEE/CVF Winter Conference on
Applications of Computer Vision (WACV) Workshops,
pages 265–302.
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). Im-
ageNet Classification with Deep Convolutional Neu-
ral Networks. In Advances in Neural Information Pro-
cessing Systems, volume 25.
Leclerc, M., Tharmarasa, R., Florea, M. C., Boury-Brisset,
A.-C., Kirubarajan, T., and Duclos-Hindi
´
e, N. (2018).
Ship Classification Using Deep Learning Techniques
for Maritime Target Tracking. In 2018 21st Interna-
tional Conference on Information Fusion (FUSION),
pages 737–744.
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S.,
and Guo, B. (2021). Swin Transformer: Hierarchical
Vision Transformer using Shifted Windows. CoRR,
abs/2103.14030.
Loshchilov, I. and Hutter, F. (2019). Decoupled Weight De-
cay Regularization. In International Conference on
Learning Representations.
Redmon, J., Divvala, S., Girshick, R., and Farhadi, A.
(2016). You Only Look Once: Unified, Real-Time
Object Detection. In 2016 IEEE Conference on Com-
puter Vision and Pattern Recognition (CVPR), pages
779–788.
Salem, M. H., Li, Y., and Liu, Z. (2022). Transfer Learning
on EfficientNet for Maritime Visible Image Classifica-
tion. In 2022 7th International Conference on Signal
and Image Processing (ICSIP), pages 514–520.
Salem, M. H., Li, Y., Liu, Z., and AbdelTawab, A. M.
(2023). A Transfer Learning and Optimized CNN
Based Maritime Vessel Classification System. Applied
Sciences, 13(3).
Sandler, M., Howard, A. G., Zhu, M., Zhmoginov, A., and
Chen, L. (2018). Inverted Residuals and Linear Bot-
tlenecks: Mobile Networks for Classification, Detec-
tion and Segmentation. CoRR, abs/1801.04381.
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., and Wojna,
Z. (2015). Rethinking the Inception Architecture for
Computer Vision. 2016 IEEE Conference on Com-
puter Vision and Pattern Recognition (CVPR), pages
2818–2826.
Tan, M. and Le, Q. (2019). EfficientNet: Rethinking Model
Scaling for Convolutional Neural Networks. In Pro-
ceedings of the 36th International Conference on Ma-
chine Learning, volume 97 of Proceedings of Machine
Learning Research, pages 6105–6114.
Ter
ˇ
sek, M.,
ˇ
Zust, L., and Kristan, M. (2023). eWaSR
– An Embedded-Compute-Ready Maritime Obstacle
Detection Network. Sensors, 23(12):5386.
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles,
A., and Jegou, H. (2021). Training data-efficient im-
age transformers & distillation through attention.
Woo, S., Debnath, S., Hu, R., Chen, X., Liu, Z., Kweon,
I. S., and Xie, S. (2023). ConvNeXt V2: Co-designing
and Scaling ConvNets with Masked Autoencoders. In
2023 IEEE/CVF Conference on Computer Vision and
Pattern Recognition (CVPR), pages 16133–16142.
Zhu, X., Lyu, S., Wang, X., and Zhao, Q. (2021). TPH-
YOLOv5: Improved YOLOv5 Based on Transformer
Prediction Head for Object Detection on Drone-
captured Scenarios. In 2021 IEEE/CVF International
Conference on Computer Vision Workshops (ICCVW),
pages 2778–2788.
ˇ
Zust, L. and Kristan, M. (2022). Temporal Context for Ro-
bust Maritime Obstacle Detection. In 2022 IEEE/RSJ
International Conference on Intelligent Robots and
Systems (IROS), pages 6340–6346.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
122
