
ForecastBoost: An Ensemble Learning Model for Road Traffic
Forecasting
Syed Muhammad Abrar Akber
1
, Sadia Nishat Kazmi
2
, Ali Muqtadir
3
and Syed Muhammad Zubair Akber
4
1
Department of Computer Graphics, Vision and Digital Systems, Faculty of Automatic Control, Electronics and Computer
Science, Silesian University of Technology, 44-100 Gliwice, Poland
2
Department of Distributed Computing and Informatic Devices, Faculty of Automatic Control, Electronics and Computer
Science, Silesian University of Technology, 44-100 Gliwice, Poland
3
School of Electronic and Electric Engineering, North China Electric Power University, Beijing 102206, China
4
Department of Electrical Engineering, University of Sialkot, 513010 Sialkot, Pakistan
Keywords:
Deep Learning, Ensemble Learning, Road Traffic, Time Series, Traffic Prediction.
Abstract:
Accelerated urbanization is causing ever-increasing road traffic around the world. This rapid increase in road
traffic is posing several challenges, such as road congestion, suboptimal emergency services due to inadequate
road infrastructure and lack of economic sustainability. To overcome such challenges, intelligent transporta-
tion systems have recently become increasingly popular. Traffic prediction is an important part of such intelli-
gent traffic management systems. Accurate traffic prediction leads to improved traffic flow, avoids congestion
and optimizes the timing of traffic signals, resulting in higher vehicle fuel efficiency. Lower fuel consump-
tion due to better fuel efficiency also limits the carbon footprints that help in combating global warming. To
accurately predict road traffic, this paper proposes the ForecastBoost model, which leverages an ensemble
learning approach to predict road traffic. ForecastBoost integrates two regression learning algorithms, namely
Extreme Gradient Boosting and Categorical Boosting, to predict road traffic. The first component handles
missing values and sparse data and the second handles categorical features without overfitting. We train the
proposed ForecastBoost with a publicly available real-world traffic dataset. The obtained results are evaluated
using similar state-of-the-art algorithms such as Neural Hierarchical Interpolation for Time Series Forecasting
(N-HiTS), Series-cOre Fused Time Series (SOFTS) and TimesNET. We use a well-known performance metrics
containing several performance parameters, including mean absolute error (MAE), mean absolute percentage
error (MAPE), and root mean square error (RMSE), to evaluate the performance of the proposed Forecast-
Boost. The evaluation results show that the proposed ForecastBoost outperforms the other models.
1 INTRODUCTION
A report published by the United Nations states that
more than half of the world’s population currently re-
sides in urban areas, and it is estimated that this pro-
portion will rise to 68% by 2050
1
. This rapid urban-
ization poses significant challenges for countries as
they strive to meet the needs of growing urban popula-
tions while ensuring sustainable development. Trans-
portation is one of the biggest challenges. Inrix re-
ports that drivers in Bucharest and Bogota lose an av-
erage of 134 and 133 hours per year respectively due
to traffic congestion (Zheng et al., 2023).
1
https://www.un.org/development/desa/en/news/popula
tion/2018-revision-of-world-urbanization-prospects.html
Rapidly growing urbanization is encouraging ve-
hicle manufacturers to increase the number of vehi-
cles they produce. Vehicle manufacturers are produc-
ing more advanced vehicles by taking advantages of
advances in Information and Communication Tech-
nologies (Akber et al., 2018), (Mohsin et al., 2021).
As a result, road traffic has increased significantly in
today’s modern world. We are witnessing an increas-
ing volume of traffic on the roads. This increased
volume of traffic needs to be managed effectively for
several reasons, such as improving safety, optimizing
urban infrastructure (roads, bridges, etc.) and ensur-
ing efficient emergency preparedness. Furthermore,
effective traffic management can lead to avoiding traf-
fic congestion, reducing fuel consumption and limit-
488
Akber, S. M. A., Kazmi, S. N., Muqtadir, A. and Akber, S. M. Z.
ForecastBoost: An Ensemble Learning Model for Road Traffic Forecasting.
DOI: 10.5220/0013155100003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 3, pages 488-495
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

ing the carbon footprint, thus making the environment
greener.
Traffic forecasting is an important aspect of mod-
ern intelligent traffic management systems. Traffic
forecasting provides valuable insights for decision
makers in urban planning and in the design of ef-
fective and timely emergency services. In addition,
accurate traffic forecasting can optimize the timing
of traffic signals, which can reduce waiting times
at intersections and significantly improve fuel effi-
ciency. Furthermore, predicting traffic patterns en-
ables proactive measures to be taken to ensure safety
in high-risk areas, which can reduce the number of
accidents. With the existence of smart cities and con-
nected vehicles, traffic prediction has become an inte-
gral part of the development of advanced transporta-
tion systems.
Anticipating the significance of traffic forecasting,
a lot of research efforts are underway in this domain.
The fundamental objective of traffic forecasting is to
predict future traffic volumes on road networks us-
ing historical traffic data. The wide popularity of
deep learning (DL) models in various domains (Ak-
ber et al., 2023) has encouraged their use for traf-
fic forecasting (Trachanatzi et al., 2020), (Liu et al.,
2023). These DL-based models are capable of ex-
amining spatio-temporal relationships to make more
accurate traffic forecasts (Chen et al., 2020). Accord-
ingly, such models are successfully being used to an-
alyze road traffic and predict future road traffic.
Several transformer-based neural network mod-
els, which have an enhanced capability of process-
ing input data in parallel, are also widely being
applied for forecasting (Guo et al., 2019) (Mohsin
et al., 2018). Such transformer-based models use self-
attention to capture temporal dependencies and spa-
tial correlations in the traffic data and make accurate
predictions (Jiang et al., 2023). In addition to DL-
and transformer-based models, time series forecast-
ing (TSF) models are also very popular for predict-
ing traffic (Zhang and Guo, 2020) (Shao et al., 2022).
Such models leverage historical traffic data to create
temporal patterns for predictions.
In recent decades, TSF solutions have evolved
rapidly. Initially, traditional statistical methods such
as ARIMA were very common. Later, machine learn-
ing techniques such as GBRT became increasingly
popular. Nowadays, DL models are widely used.
For predictive purposes, there has been a surge of
transformer-based solutions for time series analysis in
the recent past. However, there are several researchers
(Zhou et al., 2022) (Liu et al., 2021) who propose
models that focus on the challenges of the long-term
time series forecasting (LTSF) problem, an area that
is less explored. The objective of such models is to
identify and utilise temporal patterns from historical
traffic data and other relevant information to improve
predictions.
Transformer-based models, when making predic-
tions, focus multi-head self-attention mechanism for
identifying semantic connections between elements
in the data. However, this self-attention mechanism
ignores the order of elements and is permutation in-
variant and anti-order. Although various encoding
techniques can be applied to preserve the order in-
formation, still self-attention may potentially lose the
temporal details. This might be of lesser significance
for natural language processing (NLP) tasks, how-
ever, for TSF, preserving order becomes vital. Con-
sidering this fact, Zheng et al. (Zeng et al., 2023)
coined an intriguing argument Are transformers really
effective for long-term time series forecasting, which
has become very popular and attracted the attention
of researchers working on forecasting and prediction
domain.
Furthermore, Zheng and his colleagues (Zeng
et al., 2023) also presented a hypothesis that ”long-
term forecasting is only feasible for those time series
with a relatively clear trend and periodicity. As lin-
ear models can already extract such information”.
In support of this hypothesis, in this work, we pro-
pose ForecastBoost an ensemble learning model for
TSF that integrates two popular regression learning
algorithms, namely Extreme Gradient Boosting (XG-
Boost) (Li et al., 2024) and Categorical Boosting
(CatBoost) (Zhang and J
´
ano
ˇ
s
´
ık, 2024) (Fan et al.,
2024) for predicting road traffic. We train our pro-
posed approach by using a real-world traffic dataset.
The obtained results are evaluated with similar state-
of-the-art algorithms such as Neural Hierarchical
Interpolation for Time Series Forecasting (N-HiTS)
(Challu et al., 2023), Series-cOre Fused Time Series
(SOFTS) (Han et al., 2024) and TimesNET (Wu et al.,
2022). We use a well-known performance metrics
that contains several performance parameters, includ-
ing mean absolute error (MAE), mean absolute per-
centage error (MAPE) and root mean square error
(RMSE). The specific contributions of this work are
as follows;
• Propose ForecastBoost an ensemble learning TSF
model to predict the road traffic
• Train our proposed model by using a real-world
traffic dataset
• Evaluate the performance of the proposed model
by comparing it with state-of-the-art models by
considering several performance parameters such
as MAE, MAPE, and RMSE.
ForecastBoost: An Ensemble Learning Model for Road Traffic Forecasting
489

The rest of the paper is organized as follows: Sec-
tion 2 provides an insight into the existing literature
review of the domain. Section 3 briefly describes
the proposed approach, its working and the pseu-
docode. Section 4 presents the details of the experi-
ment, dataset, methodology and the obtained results
along with their evaluation. Lastly, section 5 con-
cludes the paper.
2 LITERATURE REVIEW
In recent years, several urban areas have suffered from
limited road networks due to ever-expanding road
traffic. This imbalance between road infrastructure
and road traffic leads to frequent congestion on roads,
which may also lead to accidents. In such a situa-
tion, the traffic management system becomes vital in
predicting road traffic and optimizing the decision-
making process. Time series forecasting is a funda-
mental forecasting approach that is widely used for
traffic forecasting. One possible reason for the wide
adoption of time series forecasting is its simplicity.
As a result, several authors utilize its capabilities in
designing advanced traffic forecasting models.
Zheng et al. (Zheng and Huang, 2020) use a deep
learning (DL) approach to perform traffic flow predic-
tion based on time series analysis, aiming to address
traffic congestion in urban areas. The authors employ
DL techniques to make predictions for traffic flow
through time series analysis Specifically, Zheng et al.
(Zheng and Huang, 2020) propose a traffic flow fore-
casting model based on the long short-term memory
(LSTM) network. The authors utilize the capabilities
of DL for handling large data volumes and observe
the patterns and consistency of traffic flow data to find
out the periodicity in a city in China. Subsequently,
Zheng et al. (Zheng and Huang, 2020) develop a traf-
fic flow prediction model using LSTM. By utilizing
massive raw data, this model outperforms classical
methods such as ARIMA and backpropagation neu-
ral networks (BPNN) in terms of prediction accuracy.
The experimental results show the superiority of the
LSTM network and provide valuable insights into the
dynamic development of traffic flow.
Luo et al. (Luo et al., 2019) propose a time series
prediction of the traffic flow by presenting a method-
ology to integrate K-nearest neighbors (KNN) and
LSTM networks. The proposed approach utilizes the
spatiotemporal correlation in the traffic data for mak-
ing traffic predictions with higher accuracy. The KNN
component of the proposed method identifies and ex-
tracts the neighbouring nodes in the traffic data and
the LSTM is used to make the predictions for the traf-
fic flow at the identified nodes. The individual predic-
tions of all these nodes are aggregated by weighting
the predicted values to produce the final prediction.
This approach also identifies the busiest traffic node
at a particular location.
The hybrid approach proposed by et al. (Luo
et al., 2019) effectively captures both temporal and
spatial dependencies in the traffic data. The KNN and
LSTM modules each individually identify the spatial
and temporal correlations in the traffic data. This en-
ables the approach to make more accurate traffic pre-
dictions.
In another work, Shao et al. (Shao et al., 2022)
propose a time series model for traffic prediction
called D
2
ST GNN. The authors focus on the chal-
lenges faced by Graph Neural Networks (GNNs)
in identifying spatio-temporal correlations in traf-
fic data. D
2
ST GNN improves the identification of
spatio-temporal correlations in traffic data by decou-
pling them into two distinct components: (i) the dif-
fusion model and (ii) the inherent model.. This de-
coupling enables the D
2
STGNN to effectively handle
the dynamic nature of traffic data and effectively learn
the spatio-temporal correlations. The diffusion model
and the inherent component of D
2
STGNN separate
the diffusion signal (which captures the propagation
of traffic conditions) from the inherent signal (which
represents direct spatiotemporal relationships), result-
ing in improved prediction accuracy.
Zheng et al. (Zhang and Guo, 2020) propose a
time series traffic forecasting model called GALSTM,
which uses a graph attention mechanism for traffic
prediction. This graph-attention approach in GA-
LSTM is applied within an LSTM network. The pro-
posed GA-LSTM combines the capabilities of LSTM
and spatio-temporal graph convolutional networks to
capture correlations in traffic data. GA-LSTM models
the road network as a graph, with nodes representing
road segments and edges indicating connections be-
tween them. The graph-attention mechanism of GA-
LSTM assigns weights to the nodes in the graph, en-
abling the learning and prediction of traffic patterns.
Shah et al (Shah et al., 2022) forecast traffic flow
using a functional time series (FTS) approach. The
proposed approach provides the traffic information
for the entire day and facilitates traffic prediction at
any desired time. The authors use a functional au-
toregressive (FAR) model to predict traffic flow for
the next day. The authors demonstrate the effective-
ness of their proposed approach by using the Dublin
airport link road traffic data and making the predic-
tion.
Chui et al (Cui et al., 2022) propose a two-stage
hybrid learning model to address the challenges such
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
490
as handling the nonlinear and stochastic nature of
traffic data associated with short-term traffic predic-
tion. The authors make a hybrid model by combining
Particle Swarm Optimization (PSO) and Gravitational
Search Algorithm (GSA) with the Extreme Learning
Machine (ELM). The PSO component of the model
identifies the population distribution for GSA that
helps achieve global optimum search. Afterwards,
ELM optimizes the results obtained by the PSO. The
authors test their approach using a real-world dataset
from Amsterdam and evaluate the model’s perfor-
mance using RMSE and MAPE values as the perfor-
mance metrics.
3 PROPOSED ForecastBoost
MODEL FOR ROAD TRAFFIC
FORECASTING
This section describes the details of the proposed
model and its working.
3.1 Overview of the Proposed
ForecastBoost
The proposed ensemble learning model, Forecast-
Boost, aims to predict road traffic by integrating XG-
Boost and CatBoost, which both are regression algo-
rithms. This makes ForecastBoost an ensemble learn-
ing model. ForecastBoost leverages the capabilities
of both XGBoost and CatBoost to make traffic predic-
tions with higher accuracy. XGBoost can efficiently
handle missing values and sparse data and CatBoost
is known to efficiently process categorical features
without overfitting. Consequently, ForecastBoost is
designed to achieve higher prediction performance in
traffic prediction tasks. After the model design, it is
trained on a comprehensive real-world traffic dataset.
The effectiveness of ForecastBoost is evaluated by a
comparative analysis with other state-of-the-art algo-
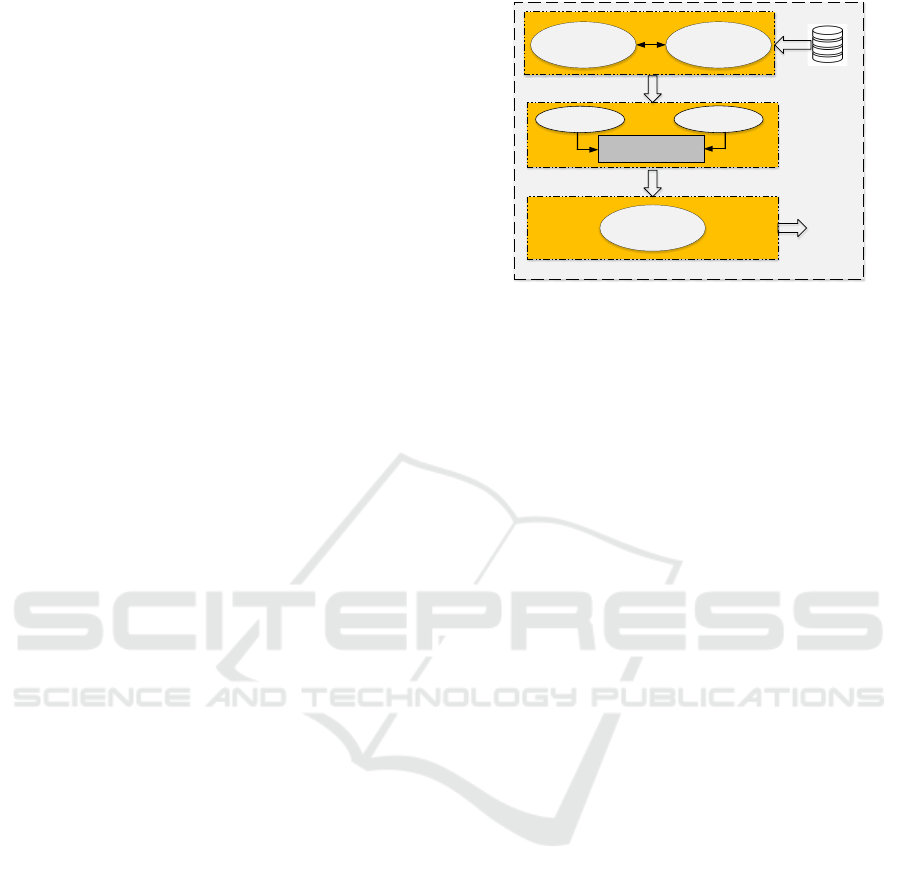
rithms. We present an overview of ForecastBoost in
Figure 1.
3.2 Mathematical Modelling of
ForecastBoost
This subsection presents the mathematical modelling
for the proposed ForecastBoost. Since ForecastBoost
integrates XGBoost and CatBoost, we present the
modelling of both components separately, followed
by their integration into ForecastBoost.
Feature extraction Data Pre processing
Train XGBoost
Train CatBoost
Model Integration
Model Evaluation
Input Data
Final
Prediction
Dataset Preparation
Model Training
Model Evaluation
Figure 1: An overview of ForecastBoost.
3.2.1 XGBoost Component
It is a powerful ensemble learning algorithm widely
being used for TSF. The mathematical modelling of
XGBoost includes an objective function that compen-
sates for the training loss and regularization to pre-
vent overfitting. The objective function of XGBoost
is shown in Eq.(1). It optimizes the following objec-
tive function to minimize the prediction errors:
O(χ) =
n
∑
i=1
l(x
i
, ˆx
i
) (1)
where O(χ) represents the overall loss function, and
l(x
i
, ˆx
i
) is the point-wise loss function. l is the mean
squared error as l(x
i
, ˆx
i
) = (x
i
− ˆx
i
)
2
and x
i
represents
the actual values, and ˆx
i
represents the predicted val-
ues. The modelling of regularization to prevent over-
fitting is presented in Eq. (2).
ϕ(χ) =
K
∑
k=1
ω( f
k
) (2)
where ϕ(χ) represents the regularization function,
ω( f
k
) is the regularization term that penalizes model
complexity to prevent the overfitting of the model.
The regularization term is defined as in Eq (3).
ω( f ) = γτ +0.5
λ
T
∑
j=1
µ
2
j
(3)
where τ is the number of leave nodes, µ
j
are the leaf
weights, and γ is the regularization parameter.
The XGBoost component in the proposed Fore-
castBoost is modelled in Eq. (4).
ρ(χ) = O(χ) + ϕ(χ) (4)
where ρ(χ) represents the loss function.
3.2.2 CatBoost Component
CatBoost minimizes the following objective function
while efficiently processing categorical features. The
ForecastBoost: An Ensemble Learning Model for Road Traffic Forecasting
491

Eq. (5) and Eq. (6) represent the equations for the
loss function and the regularization parameter for the
CatBoost component, respectively.
δ(χ) =
n
∑
i=1
δ(x
i
, ˆx
i
) (5)
where δ is the loss function component.
L(Θ) = κ
m
∑
j=1
∂ ˆy
i
∂x
i j
2
(6)
where Θ is the regularization parameter, and
∂ ˆy
i
∂x
i j
shows the sensitivity of model to feature j. We
present the CatBoost component in the proposed
ForecastBoost modelled in Eq. (7).
L(χ) = δ(χ) + L(Θ) (7)
3.2.3 Integration of XGBoost and CatBoost
Components
The final prediction ˆy of ForecastBoost is derived
from the weighted combination of the outputs from
XGBoost and CatBoost as modelled in Eq. (8).
ˆy = µ
1
· ˆy
XGB
+ µ
2
· ˆy
Cat
(8)
where ˆy
XGB
and ˆy
Cat
are the predictions from XG-
Boost and CatBoost, respectively, and µ
1
and µ
2
are
the weights assigned to XGBoost and CatBoost pre-
dictions respectively.
3.3 Working of the ForecastBoost
ForecastBoost is an ensemble architecture that aims to
increase prediction performance for road traffic pre-
diction by leveraging the capabilities of the XGBoost
and CatBoost algorithms. The detailed working of
ForecastBoost can be divided into several phases. In
the first phase, the data is pre-processed to remove
missing values and noise. In addition, feature ex-
traction is performed in this phase to extract tempo-
ral and event-related features. The final step in this
phase is the normalization of the data so that the data
may be scaled uniformly to achieve effective model
training and convergence. Once data prepossessing
is complete, ForecastBoost concurrently implements
the XGBoost and CatBoost algorithms. Both algo-
rithms are gradient-boosted decision trees (Zhang and
J
´
ano
ˇ
s
´
ık, 2024). XGBoost is a popular algorithm
for efficiently handling sparse data and missing val-
ues (Hakkal and Lahcen, 2024), while CatBoost is
known for effectively managing categorical features
and avoiding overfitting (Fan et al., 2024).
The third phase of ForecastBoost is the model
training phase, in which the model is trained with
the training dataset, which is a fraction of the input
dataset. Before training begins, hyperparameters are
set to achieve optimal model performance. The in-
dividual components of ForecastBoost are trained in-
dividually, then their outputs are integrated and syn-
chronized to obtain the final forecast values. The in-
dividual outputs of XGBoost and CatBoost are syn-
chronized using a weighted average approach.
3.4 Pseudocode for ForecastBoost
We present the pseudo-code for the proposed Fore-
castBoost as Algorithm 1.
Algorithm 1: ForecastBoost: An Ensemble Learning Model
for Road Traffic Prediction.
1: Input: Traffic dataset D
2: Output: Predicted traffic values
3: Divide D into D
train
, D
val
, and D
test
4: Initialize XGBoost with hyperparameters
5: Use D
train
to train XGBoost and get M
XGB
6: Use D
val
to optimize hyperparameters for XG-
Boost
7: Initialize CatBoost with hyperparameters
8: Use D
train
to train CatBoost and get M
Cat
9: Use D
val
to optimize hyperparameters CatBoost
10: Obtain predictions
ˆ
y
XGB
from M
XGB
11: Obtain predictions
ˆ
y
Cat
from M
Cat
12: Learn optimal weights µ
1
and µ
2
on D
val
13: Compute final predictions
ˆ
y as:
ˆ
y = µ
1
·
ˆ
y
XGB
+ µ
2
·
ˆ
y
Cat
14: Return Predicted traffic values
ˆ
y
The algorithm takes the preprocessed traffic
dataset D as the input. The input data contains fea-
ture vectors X and corresponding target values y. The
output of the algorithm is the predicted traffic values
ˆ
y. The dataset D is divided into three subsets: (i) a
training set D
train
, (ii) a test set D
test
, and (iii) a vali-
dation dataset D
test
. The training data is used to train
the model, validation data is employed for hyperpa-
rameter tuning and validation of the model and the
test data is used for final performance evaluation.
After dividing the dataset, the XGBoost compo-
nent of ForecastBoost is initiated and trained on the
D
train
and create XGBoost model M
XGB
. At the
same time, CatBoost is also inilize and trained in
analogous to XGBoost and produces CatBoost model
M
Cat
. The ForecastBoost optimizes the Hyperpa-
rameters for XGBoost and CatBoost model through
cross-validation on D
val
. Once the individual models
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
492
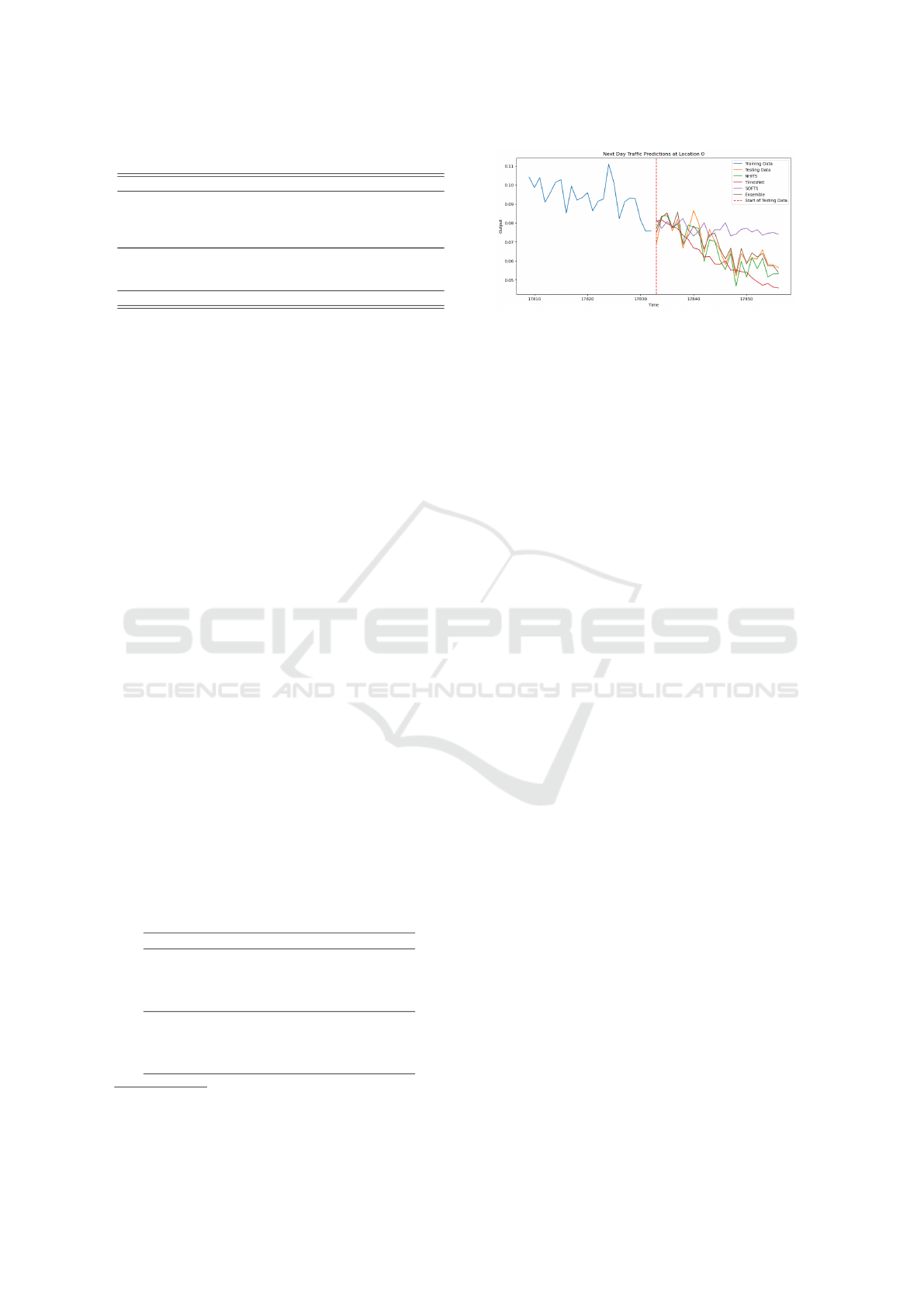
Table 1: Experimental Setup.
Description Details
Hardware
- CPU : Intel(R) core(TM) i7 920 @2.67 GHz
- RAM: 16 GB
- OS: Windows 10 (64 bits)
- Graphics Card: NVIDIA GeForce GT 440
Software
- Python 3.7.9 (64 bits)
- PyTorch
- VS Code 1.91.1
Baseline N-HiTS, SOFTS, TimeNet
have generated their outputs, predictions are gener-
ated
ˆ
y
XGB
and
ˆ
y
Cat
from the respective models. These
predictions are then integrated and synchronised to
identify the optimal weights µ
1
and µ
2
. The final pre-
diction
ˆ
y is performed by
ˆ
y = µ
1
·
ˆ
y
XGB
+ µ
2
·
ˆ
y
Cat
4 EXPERIMENT, RESULTS AND
EVALUATION
This section describes our experiments, obtained re-
sults and their evaluation for the proposed Forecast-
Boost. We first present the experiment environment.
4.1 Experiment Environment
We conduct practical experiments to verify the work-
ing of the ForecastBoost. All experiments are con-
ducted on a PC with Intel core i7 processor with 16
GB RAM. We use Python 3.7.9 (64-bit version) and
VS Code version 1.91.1 as the IDE. The detailed en-
vironment setup is presented in Table 1.
4.2 Dataset and Methodology
For the experiment, we use a real-world traffic
dataset, PEMS-08, obtained from a publicly available
repository from Kaggle
2
. The dataset contains infor-
mation about traffic flow, time step, location, speed of
vehicles, etc. To implement ForecastBoost, we first
pre-process the input traffic dataset and extract the
Table 2: Hyperparameters.
Model Hyperparameter Value
XGBoost
Learning Rate 0.1
Max Depth 6
Min Child Weight 1
Number of Estimators 100
CatBoost
Learning Rate 0.1
Max Depth 6
L2 Leaf Regularization 3
L2 Leaf Regularization 100
2
https://www.kaggle.com/datasets/elmahy/pems-
dataset
Figure 2: Training and testing of different models.
features, both temporal features and external features
(traffic flow and speed), for training. This feature ex-
traction phase is the key to capturing the temporal de-
pendencies. The target variable is separated from the
features, enabling the creation of a prediction model.
We then define the prediction horizon and the size of
the inputs such that the size of the inputs is twice the
size of the horizon to ensure a comprehensive set of
lagged inputs. The function is called to generate the
lagged dataset, which is then split into training and
testing sets, with 80% of the data used for training
and the remaining 20% for testing.
After feature extraction, we perform the normal-
ization process. Both components of ForecastBoost,
XGBoost and CatBoost, are trained independently
and their hyperparameters are optimized by cross-
validation on the validation data. We present the hy-
perparameters in Table 2. The individual predictions
of the two components are merged using a weighted
average to produce the final prediction. We evalu-
ate the performance of our proposed ForecastBoost
by comparing it with other similar models such as
NHITS, SOFTS and TimesNET. For the evaluation,
we use a well-known performance metrics consisting
of MAE, MAPE and RMSE.
4.3 Results and Evaluation
After training of the ForecastBoost is completed, we
record the results and perform the evaluation. We
present the training and testing of different models in
Figure 2. For the evaluation, we perform a compre-
hensive comparative analysis and compare our results
with the existing similar models. We compare our re-
sults with NHITS, TimesNet and SOFTS.
We present the details of our comparative analysis
and the results we obtained for the different models
in terms of all performance parameters are shown in
Figure 3. The values in Figure 3 show that the pro-
posed ForecastBoost outperforms the other models in
all performance parameters. Specifically, Forecast-
Boost achieves the lowest value for MAE of 0.0321,
outperforming NHITS (0.0387), SOFTS (0.0372) and
ForecastBoost: An Ensemble Learning Model for Road Traffic Forecasting
493
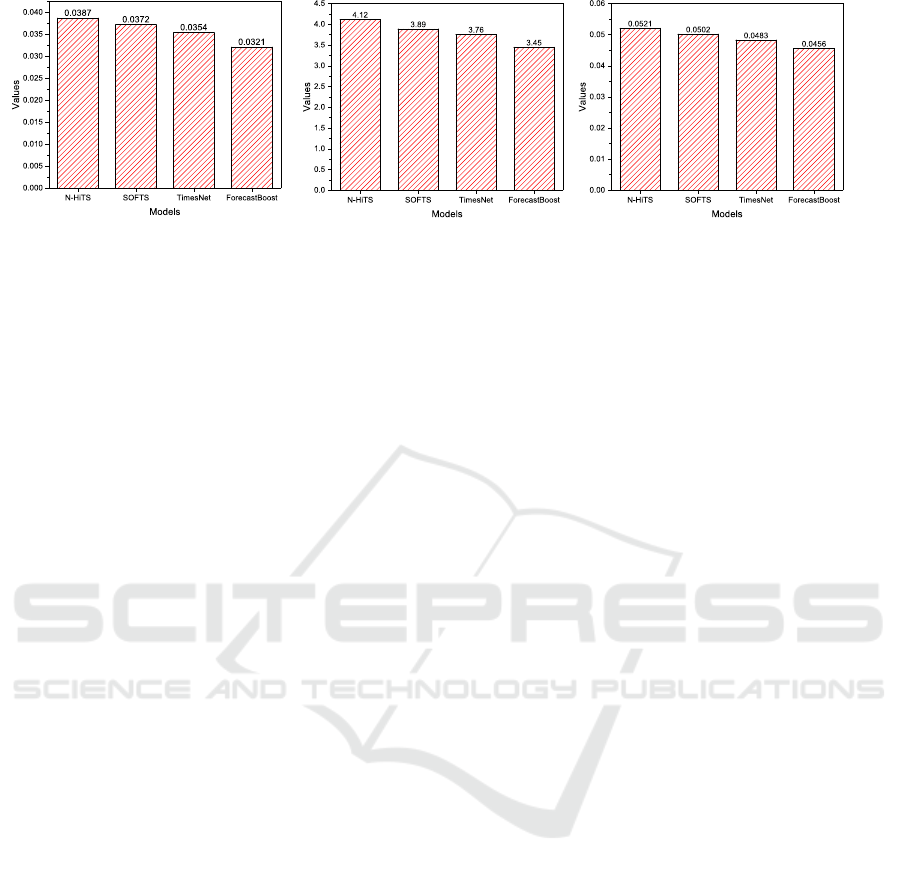
(a) MAE for different models
(b) MAPE for different models (c) RMSE for different models
Figure 3: Comparative Analysis for different models.
TimesNet (0.0354) as shown in Figure 3a.
Figure 3b shows the results obtained for MAPE
for different models. For MAPE, ForecastBoost
shows a value of 3.45%, while the values for MAPE
for NHITS, SOFTS and TimesNet are 4.12%, 3.89%
and 3.76% respectively. Figure 3c shows the values
obtained for the RMSE It can be seen that the RMSE
value for ForecastBoost is the lowest at 0.0456, while
the RMSE values for NHITS SOFTS, and TimesNet
are 0.0521, 0.0502, and 0.0483 respectively. The
comparative analysis shows that ForecastBoost is bet-
ter able to limit the deviations between the predicted
and actual traffic values, thus confirming the robust-
ness and effectiveness of the proposed ForecastBoost.
5 CONCLUSION
In this paper, we address the challenge of effec-
tive road traffic prediction to facilitate the decision-
making process for the provision of road infrastruc-
ture to cope with future traffic needs. Considering
the significance of traffic prediction, we propose Fore-
castBoost, an ensemble learning model for road traf-
fic forecasting. ForecastBoost integrates the capabil-
ities of two popular regression-based models, XG-
Boost and CatBoost, to produce time-series forecasts
for road traffic. The XGBoost component can effi-
ciently handle missing values and sparse data, while
CatBoost handles categorical features without overfit-
ting. The individual predictions of the two models are
integrated before ForecastBoost makes a final predic-
tion. We implement ForecastBoost and train it with
real traffic data.
We evaluate the performance of our proposed
ForecastBoost by comparing it with other similar
models such as NHITS, SOFTS and TimesNET. For
the evaluation, we use a well-known performance
metrics consisting of mean absolute error (MAE),
mean absolute percentage error (MAPE), and root
mean square error (RMSE). The evaluation results
show that the proposed ForecastBoost approach out-
performs the existing model. The comparative analy-
sis shows the higher performance of ForecastBoost in
limiting the deviations between the predicted and ac-
tual traffic values, thus confirming the robustness and
effectiveness of the proposed ForecastBoost.
ACKNOWLEDGMENT
This publication was supported by the pro-quality re-
search grant under the framework of the Excellence
Initiative - Research University programme, of the
Silesian University of Technology, Gliwice, Poland
under project number 32/014/SDU/10-22-66.
REFERENCES
Akber, S. M. A., Kazmi, S. N., Mohsin, S. M., and
Szczesna, A. (2023). Deep learning-based motion
style transfer tools, techniques and future challenges.
Sensors, 23(5).
Akber, S. M. A., Khan, I. A., Muhammad, S. S., Mohsin,
S. M., Khan, I. A., Shamshirband, S., and Chronopou-
los, A. T. (2018). Data volume based data gathering
in wsns using mobile data collector. In Proceedings of
the 22nd International Database Engineering & Ap-
plications Symposium, pages 199–207.
Challu, C., Olivares, K. G., Oreshkin, B. N., Ramirez, F. G.,
Canseco, M. M., and Dubrawski, A. (2023). Nhits:
Neural hierarchical interpolation for time series fore-
casting. In Proceedings of the AAAI conference on
artificial intelligence, volume 37, pages 6989–6997.
Chen, C., Li, K., Teo, S. G., Zou, X., Li, K., and Zeng, Z.
(2020). Citywide traffic flow prediction based on mul-
tiple gated spatio-temporal convolutional neural net-
works. ACM Transactions on Knowledge Discovery
from Data (TKDD), 14(4):1–23.
Cui, Z., Huang, B., Dou, H., Cheng, Y., Guan, J., and Zhou,
T. (2022). A two-stage hybrid extreme learning model
for short-term traffic flow forecasting. Mathematics,
10(12):2087.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
494

Fan, Z., Gou, J., and Weng, S. (2024). A feature
importance-based multi-layer catboost for student per-
formance prediction. IEEE Transactions on Knowl-
edge and Data Engineering.
Guo, S., Lin, Y., Feng, N., Song, C., and Wan, H. (2019).
Attention based spatial-temporal graph convolutional
networks for traffic flow forecasting. In Proceedings
of the AAAI conference on artificial intelligence, vol-
ume 33, pages 922–929.
Hakkal, S. and Lahcen, A. A. (2024). Xgboost to enhance
learner performance prediction. Computers and Edu-
cation: Artificial Intelligence, page 100254.
Han, L., Chen, X.-Y., Ye, H.-J., and Zhan, D.-C.
(2024). Softs: Efficient multivariate time series
forecasting with series-core fusion. arXiv preprint
arXiv:2404.14197.
Jiang, J., Han, C., Zhao, W. X., and Wang, J. (2023).
Pdformer: Propagation delay-aware dynamic long-
range transformer for traffic flow prediction. In Pro-
ceedings of the AAAI conference on artificial intelli-
gence, volume 37, pages 4365–4373.
Li, X., Shi, L., Shi, Y., Tang, J., Zhao, P., Wang, Y., and
Chen, J. (2024). Exploring interactive and nonlinear
effects of key factors on intercity travel mode choice
using xgboost. Applied Geography, 166:103264.
Liu, H., Dong, Z., Jiang, R., Deng, J., Deng, J., Chen,
Q., and Song, X. (2023). Spatio-temporal adaptive
embedding makes vanilla transformer sota for traffic
forecasting. In Proceedings of the 32nd ACM interna-
tional conference on information and knowledge man-
agement, pages 4125–4129.
Liu, S., Yu, H., Liao, C., Li, J., Lin, W., Liu, A. X.,
and Dustdar, S. (2021). Pyraformer: Low-complexity
pyramidal attention for long-range time series model-
ing and forecasting. In International conference on
learning representations.
Luo, X., Li, D., Yang, Y., and Zhang, S. (2019). Spatiotem-
poral traffic flow prediction with knn and lstm. Jour-
nal of Advanced Transportation, 2019(1):4145353.
Mohsin, S. M., Javaid, N., Madani, S. A., Akber, S. M. A.,
Manzoor, S., and Ahmad, J. (2018). Implementing
elephant herding optimization algorithm with differ-
ent operation time intervals for appliance scheduling
in smart grid. In 2018 32nd International Confer-
ence on Advanced Information Networking and Ap-
plications Workshops (WAINA), pages 240–249.
Mohsin, S. M., Khan, I. A., Abrar Akber, S. M., Shamshir-
band, S., and Chronopoulos, A. T. (2021). Exploring
the rfid mutual authentication domain. International
Journal of Computers and Applications, 43(2):127–
141.
Shah, I., Muhammad, I., Ali, S., Ahmed, S., Almazah,
M. M., and Al-Rezami, A. (2022). Forecasting day-
ahead traffic flow using functional time series ap-
proach. Mathematics, 10(22):4279.
Shao, Z., Zhang, Z., Wei, W., Wang, F., Xu, Y., Cao, X.,
and Jensen, C. S. (2022). Decoupled dynamic spatial-
temporal graph neural network for traffic forecasting.
arXiv preprint arXiv:2206.09112.
Trachanatzi, D., Rigakis, M., Marinaki, M., and Marinakis,
Y. (2020). An interactive preference-guided firefly
algorithm for personalized tourist itineraries. Expert
Systems with Applications, 159:113563.
Wu, H., Hu, T., Liu, Y., Zhou, H., Wang, J., and Long,
M. (2022). Timesnet: Temporal 2d-variation model-
ing for general time series analysis. arXiv preprint
arXiv:2210.02186.
Zeng, A., Chen, M., Zhang, L., and Xu, Q. (2023). Are
transformers effective for time series forecasting? In
Proceedings of the AAAI conference on artificial intel-
ligence, volume 37, pages 11121–11128.
Zhang, L. and J
´
ano
ˇ
s
´
ık, D. (2024). Enhanced short-term
load forecasting with hybrid machine learning mod-
els: Catboost and xgboost approaches. Expert Systems
with Applications, 241:122686.
Zhang, T. and Guo, G. (2020). Graph attention lstm: A
spatiotemporal approach for traffic flow forecasting.
IEEE Intelligent Transportation Systems Magazine,
14(2):190–196.
Zheng, G., Chai, W. K., Duanmu, J.-L., and Katos, V.
(2023). Hybrid deep learning models for traffic pre-
diction in large-scale road networks. Information Fu-
sion, 92:93–114.
Zheng, J. and Huang, M. (2020). Traffic flow forecast
through time series analysis based on deep learning.
IEEE Access, 8:82562–82570.
Zhou, T., Ma, Z., Wen, Q., Wang, X., Sun, L., and Jin,
R. (2022). Fedformer: Frequency enhanced decom-
posed transformer for long-term series forecasting. In
International conference on machine learning, pages
27268–27286. PMLR.
ForecastBoost: An Ensemble Learning Model for Road Traffic Forecasting
495
