AKDT: Adaptive Kernel Dilation Transformer for Effective Image
Denoising
Alexandru Brateanu
1 a
, Raul Balmez
1 b
, Adrian Avram
2
and Ciprian Orhei
2 c
1
University of Manchester, Manchester, U.K.
2
Politehnica University of Timis¸oara, Timis¸oara, Romania
{alexandru.brateanu, raul.balmez}@student.manchester.ac.uk, {adrian.avram, ciprian.orhei}@upt.ro
Keywords:
Image Denoising, Transformer Models, Dilated Convolutions, Deep Learning, Computer Vision.
Abstract:
Image denoising is a fundamental yet challenging task, especially when dealing with high-resolution images
and complex noise patterns. Most existing methods rely on standard Transformer architectures, which often
suffer from high computational complexity and limited adaptability to varying noise levels. In this paper,
we introduce the Adaptive Kernel Dilation Transformer (AKDT), a novel Transformer-based model that fully
harnesses the power of learnable dilation rates within convolutions. AKDT consists of several layers and
custom-designed blocks, including our novel Learnable Dilation Rate (LDR) module, which is utilized to
construct a Noise Estimator module (NE). At the core of AKDT, the NE is seamlessly integrated within
standard Transformer components to form the Noise-Guided Feed-Forward Network (NG-FFN) and Noise-
Guided Multi-Headed Self-Attention (NG-MSA). These noise-modulated Transformer components enable
the model to achieve unparalleled denoising performance while significantly reducing computational costs.
Extensive experiments across multiple image denoising benchmarks demonstrate that AKDT sets a new state-
of-the-art, effectively handling both real and synthetic noise. The source code and pre-trained models are
publicly available at https://github.com/albrateanu/AKDT.
1 INTRODUCTION
Image enhancement encompasses various techniques
aimed at improving the quality, clarity, and percep-
tibility of images. The main goal is to create visu-
ally appealing images, correct an image, or manip-
ulate certain features for specific use cases. Spe-
cific categories of enhancements can be highlighted
as such: image sharpening (Orhei and Vasiu, 2023;
Bogdan et al., 2024), low-light enhancement (Wang
et al., 2020; Brateanu et al., 2024), de-hazing (Ancuti
et al., 2017), denoising (Liang et al., 2021).
Image denoising is a crucial field within image
restoration which aims to enhance image quality by
eliminating noise introduced by digital and natural
factors alike. The noise, manifesting as random varia-
tions of brightness and color information, often com-
plicates the task of maintaining image characteristics
such as sharpness and texture. As such, the complex-
ity of this problem has led to the adoption of deep
a
https://orcid.org/0009-0001-2752-2357
b
https://orcid.org/0009-0003-6446-2669
c
https://orcid.org/0000-0002-0071-958X
neural networks, which have shown success in var-
ious image denoising tasks, as evidenced by recent
benchmarks
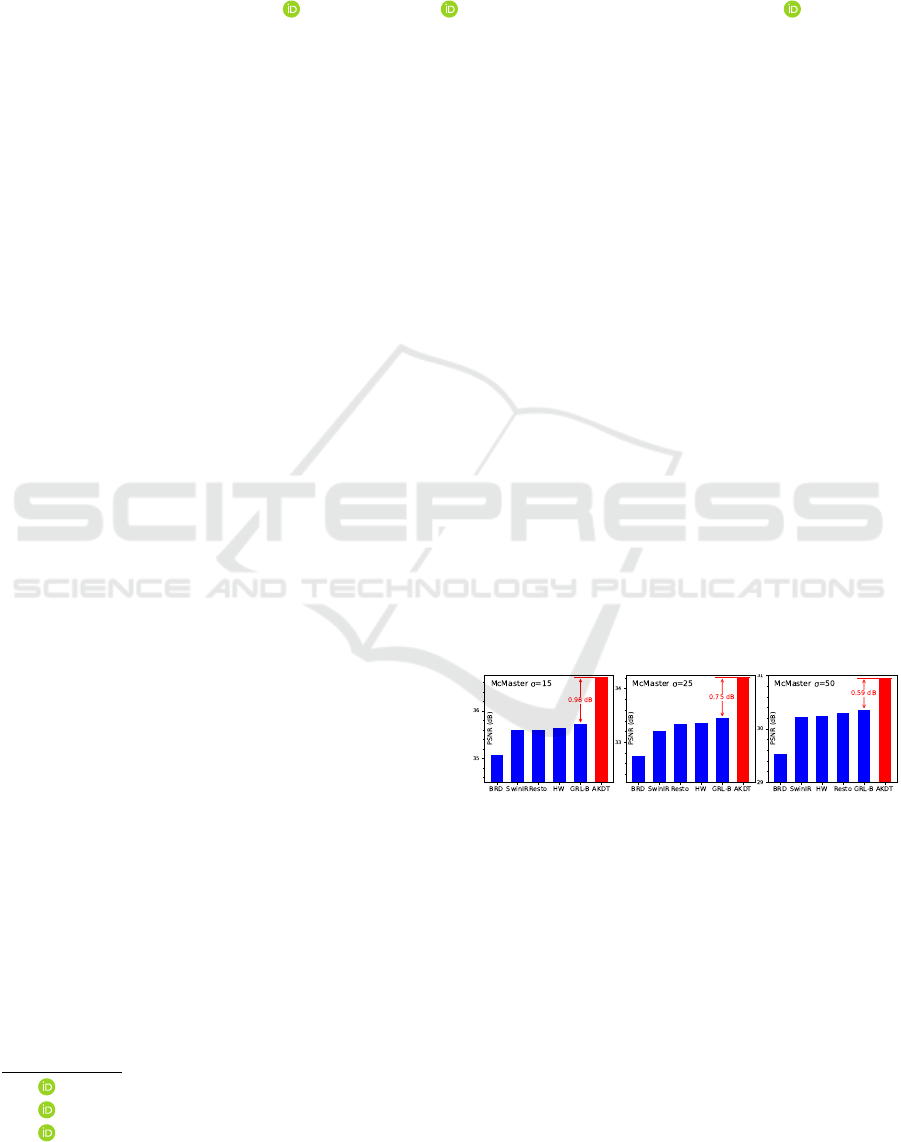
Figure 1: AKDT outperforms SOTA, including BRDNet
(Tian et al., 2020), SwinIR (Liang et al., 2021), and
Restormer (Zamir et al., 2022), GRL-B (Li et al., 2023),
and HWFormer (Tian et al., 2024) on denoising benchmark
McMaster at various noise levels.
The field of image denoising has seen a paradigm
shift with the introduction of Transformer models
(Dosovitskiy et al., 2021), which excel in capturing
extensive contextual information, having larger recep-
tive fields when compared to earlier Convolutional
Neural Networks (CNN) based methods. However,
the high computational cost of Transformer architec-
tures remains a barrier for high-resolution tasks such
as image denoising.
418
Brateanu, A., Balmez, R., Avram, A. and Orhei, C.
AKDT: Adaptive Kernel Dilation Transformer for Effective Image Denoising.
DOI: 10.5220/0013157700003912
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 3: VISAPP, pages
418-425
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

Dilated kernels, also known as atrous convolution
or convolution with holes, are a type of convolutional
kernel used in deep learning architectures or classi-
cal processing. The hypothesis behind this opera-
tion is that, by dilating, rather than expanding filters,
the region covered by the transformation increases in
terms of pixel distance and not pixel density. In re-
cent years, dilated filters proved particularly useful in
domains ranging from image segmentation (Yu and
Koltun, 2016; Yu et al., 2017) to edge detection (Bog-
dan et al., 2020; Orhei et al., 2021).
In this paper we propose the Adaptive Kernel Di-
lation Transformer (AKDT), a Transformer architec-
ture that incorporates convolutions within the stan-
dard Transformer components. AKDT innovates
through dilated convolutions that employ a mecha-
nism which allows them to learn and adapt the dila-
tion rate of kernels. Through the use of learnable di-
lation rate kernels, we can harness a weighted expan-
sion of the informational domain without increasing
computational cost.
Through the use of image denoising benchmarks,
with real and synthetic noise, we demonstrate AKDT
has state-of-the-art (SOTA) performance and high-
light its computational efficiency.
The main contributions of our work can be sum-
marized as follows:
• AKDT, a Transformer architecture tailored to per-
form highly-effective image denoising by em-
ploying the strengths of dilated convolutions.
• A novel approach of using dilated convolutions
in Transformer architectures in order to produce
dynamic and adaptable modules that tailor to the
specifics of the task.
• Two novel components in the Transformer ar-
chitecture: Noise-Guided Feed-Forward Network
(NG-FFN) and Noise-Guided Multi-Headed Self-
Attention (NG-MSA).
• Through quantitative and qualitative experiments,
AKDT demonstrates SOTA performance on stan-
dardized denoising benchmarks.
2 RELATED WORK
Image denoising is a critical area in computer vi-
sion that aims to remove noise from corrupted im-
ages to recover the original, uncorrupted content (Fat-
tal, 2007; HeK and SUNJ, 2011; Kopf et al., 2008;
Michaeli and Irani, 2013). Traditional approaches,
often based on CNNs, have been pivotal in advanc-
ing early image restoration techniques. These meth-
ods leverage spatial hierarchies of learned filters to
address various levels of degradation in images (Tu
et al., 2022; Zamir et al., 2022; Zhang et al., 2020;
Zamir et al., 2020b; Chen et al., 2021; Zamir et al.,
2020a). CNNs have been effective due to their ability
to enforce local connectivity and share weights across
spatial domains.
With the advent of Transformer architectures, the
computer vision paradigm has drastically shifted.
Originally developed for natural language processing
tasks (Vaswani et al., 2017), Transformers apply self-
attention mechanisms to capture long-range depen-
dencies in data, a significant advantage over CNNs
when dealing with complex image structures (Doso-
vitskiy et al., 2021; Ramachandran et al., 2017). In
image denoising, Transformers tokenize images and
learn intricate relationships, offering enhanced capa-
bilities for handling detailed textures and patterns in
high-resolution images (Touvron et al., 2021; Yuan
et al., 2021).
Despite their advantages, the computational de-
mands of Transformers increase quadratically with
the input size, presenting challenges for practical ap-
plications. Recent research has focused on developing
more efficient Transformer models to mitigate these
issues. Techniques such as locality-constrained self-
attention mechanisms introduced in Swin Transform-
ers (Liu et al., 2021) and innovative attention schemes
like those in CAT (Chen et al., 2022), which employ
rectangular-window self-attention, and channel-wise
attention, proposed in Restormer (Zamir et al., 2022),
have shown promising results in enhancing the com-
putational efficiency of Transformers.
3 PROPOSED METHOD
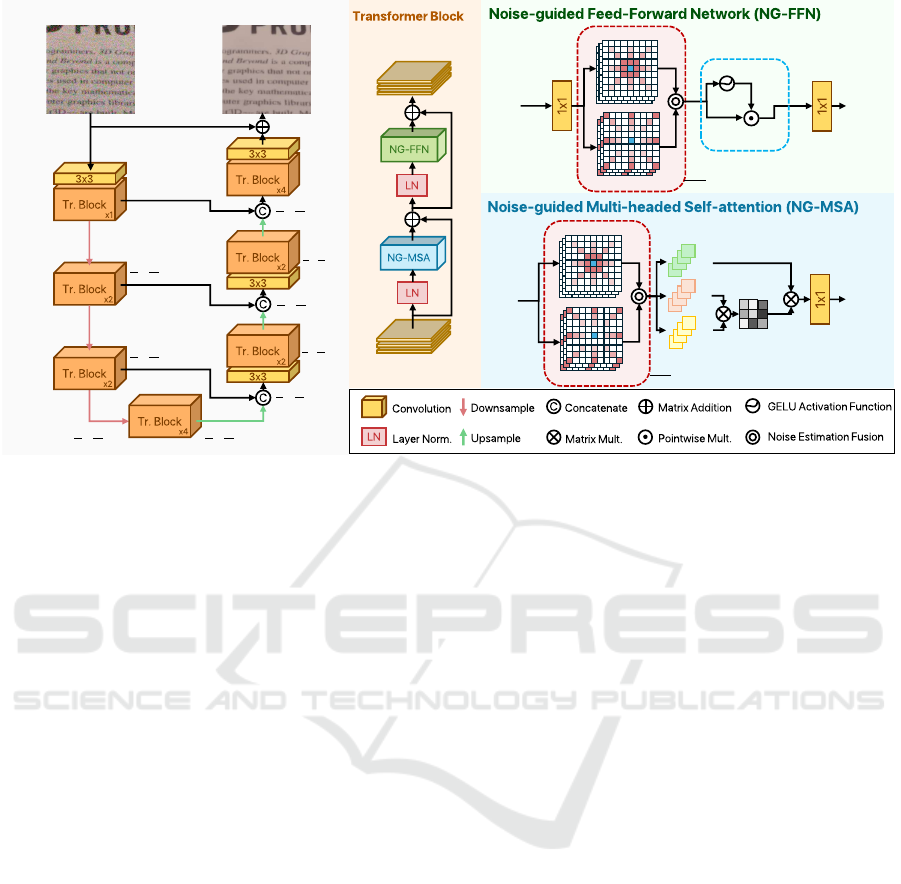
In Figure 2, we detail the architecture of AKDT,
which features a foundational Transformer struc-
ture. However, AKDT diverges from conventional
models by incorporating two novel components:
the Noise-Guided Multi-headed Self-attention (NG-
MSA) and the Noise-Guided Feed-Forward Network
(NG-FFN). Both blocks utilize our proposed Noise
Estimator Module (NE), which consists of two Learn-
able Dilation Rate (LDR) submodules.
The process begins as the input image in RGB
format is first subjected to a conv3×3 layer, which
projects the image into a high-dimensional feature
space, setting the stage for more complex trans-
formations. Following this initial projection, the
enhanced feature map is introduced into the core
of the Transformer architecture, which is organized
in a U-shaped configuration utilizing skip connec-
tions (Ronneberger et al., 2015). Up-sampling and
AKDT: Adaptive Kernel Dilation Transformer for Effective Image Denoising
419
Skip Connections
Noisy Input Denoised Image
𝐻 × W × 3
𝐻 × W × 𝐶
𝐻
2
×
𝑊
2
× 2𝐶
𝐻
4
×
𝑊
4
× 4𝐶
𝐻
8
×
𝑊
8
× 8𝐶
𝐻
4
×
𝑊
4
× 4𝐶
𝐻 × W × 3
Q
K
V
Softmax
LDR
Local
LDR
Global
F
in
F
out
𝐻 × W × 𝐶
𝐻 × W × 𝐶
𝐻 × W × 3𝐶
𝐶 × 𝐻𝑊
𝐻𝑊 × 𝐶
𝐶 × 𝐶
𝐻𝑊 × 𝐶
LDR
Local
LDR
Global
Gating Mechanism
𝐻 × W × 2𝐶
𝐻 × W × 𝐶
𝐻 × W × 𝐶
F
in
F
out
𝐻 × W × 𝐶
𝐻 × W × 𝐶
Noise Estimator Module
Noise Estimator Module
F
in
F
out
𝐻 × W × 𝐶
𝐻 × W × 𝐶
𝐻 × W × 𝐶
𝐻 × W × 𝐶
𝐻
4
×
𝑊
4
× 8𝐶
𝐻
4
×
𝑊
4
× 4𝐶
𝐻
2
×
𝑊
2
× 4𝐶
𝐻
2
×
𝑊
2
× 2𝐶
𝐻
2
×
𝑊
2
× 4𝐶
𝐻 × W × 𝐶
Figure 2: Framework of AKDT. Our Transformer architecture utilizes the proposed Noise Estimator module (NE) within the
Noise-Guided Feed-Forward Network (NG-FFN) and the Noise-Guided Multi-headed Self-attention (NG-MSA).
down-sampling are achieved through pixel-shuffle
and pixel-unshuffle operations (Shi et al., 2016).
After the feature map traverses through the U-
shaped Transformer sequence, it enters an advanced
refinement stage. This stage employs additional
Transformer blocks that further refine the features, en-
suring that even subtle nuances are captured and en-
hanced. This refinement is critical in restoration, par-
ticularly in the case of heavily degraded images.
The refined feature map is then processed through
another conv3×3 layer, which compresses the high-
dimensional features back into the standard RGB
color space. Additionally, a residual connection from
the original input is incorporated at this final stage.
This connection aids in preserving essential image de-
tails by allowing the original data to flow directly into
the output, thereby enhancing the fidelity of the re-
stored image and ensuring that important textural and
color details are maintained.
3.1 Learnable Dilation Rate Module
The LDR Module, is defined as the weighted concate-
nation (
c
⃝) of N convolutions with N different dilation
rates. The input feature map is first projected through
a conv1×1. The projected input F
in
∈ R
H×W ×C
is then
passed through multiple parallel dilated convolutions.
Each of the dilated convolution operations has a learn-
able weight that is adjusted during training. As such,
the output feature map F
LDR
can be expressed as:
F
LDR
=conv1×1
c
⃝
N
i=1
α
i
× conv3×3
i
(F
in
)
(1)
The choice of dilation rates in the LDR is impor-
tant, as they directly influence how the module cap-
tures and integrates information from different spa-
tial scales of the input data. This structured approach
to combining multiple dilated convolutions, each ad-
justed for a specific scale of feature extraction, en-
hances the ability of the model to discern finer details
and contributes to more robust and scale-invariant fea-
ture representations.
This implementation ensures that the LDR Mod-
ule is easily adjustable for different use-cases. In con-
sequence, our Global and Local LDR Modules have
the same implementation but employ different-scale
dilation rates.
3.2 Noise Estimator Module
The NE in the proposed architecture serves a critical
role by integrating both global and local context un-
derstanding through its unique structure. This mod-
ule consists of two distinct parallel components: the
Global and Local LDR modules.
The LDR
Global
module is designed to employ
higher-scale dilation rates, which enables it to grasp
the broader context and underlying patterns across the
entire image. We define F
Global
LDR
as follows:
F
Global
LDR
= LDR
Global
(F
in
), F
Global
LDR
∈ R
H×W×C
(2)
Conversely, the LDR
Local
module utilizes lower-
scale dilation rates, focusing on capturing finer, more
detailed aspects of the image. This attention to detail
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
420

Figure 3: Context captured by the NE at various levels.
is crucial for restoring specific features and textures.
F
Local
LDR
is defined as:
F
Local
LDR
= LDR
Local
(F
in
), F
Local
LDR
∈ R
H×W×C
(3)
Where F
in
∈ R
H×W ×C
is the input feature map in
both Equations 2 and 3.
Both of these modules operate in parallel, allow-
ing the NE to efficiently combine insights from both
the global and local perspectives. The resulting fea-
ture map F
NE
is represented in equation 4:
F
NE
=F
Global
LDR
o
⃝ F
Local
LDR
, F
NE
∈ R
H×W×C
(4)
Where
o
⃝ is the Noise Estimation Fusion opera-
tion, consisting of a convolutional block that merges
both local and global noise-modulated contexts.
In Figure 3, we illustrate the context captured by
the NE at various stages in the network. AKDT
leverages these NE across all stages of processing,
ensuring that both local nuances and global pat-
terns are consistently considered, preventing the over-
specialization of the model.
3.3 Noise-Guided Attention Block
Given an input image H × W × C, traditional atten-
tion mechanisms reach quadratic complexity with re-
spect to the spatial resolution (i.e., O(H
2
W
2
)). In
this work, we utilize a channel-wise attention mecha-
nism (Zamir et al., 2022) to reduce the complexity to
O(C
2
), allowing our model to work seamlessly with
high-resolution images.
In our novel transformer architecture, we prior-
itize the integration of the NE to refine the atten-
tion mechanism. Starting with a layer-normalized in-
put feature F
in
∈ R
H×W ×C
, we apply the NE to pro-
duce an enhanced feature representation F
NE
. Uti-
lizing F
NE
, we then compute the query (Q) key (K),
and value (V) components essential for the attention
mechanism as:
Q = W
Q
F
NE
, K = W
K
F
NE
, V = W
V
F
NE
, (5)
where W
Q
, W
K
, and W
V
denote the learnable pa-
rameters for projecting F
NE
into the respective com-
ponents.
This method underscores that our architecture
departs from conventional convolution-based ap-
proaches, spotlighting the NE role in facilitating a nu-
anced, context-aware generation of attention compo-
nents. Following the computation of Q, K, and V, the
attention operation is defined as:
Attention(Q, K, V) = V ⊙ Softmax
K
T
Q
α
, (6)
where α is a learnable scaling parameter that fine-
tunes the influence of the dot product between K and
Q prior to the softmax application. Channels are di-
vided into multiple ’heads’, resulting in multiple fea-
ture maps, as seen in the traditional multi-headed self-
attention (Dosovitskiy et al., 2021). This approach
ensures that our attention mechanism is both compu-
tationally efficient and capable of capturing extensive
contextual interactions within the input features.
3.4 Noise-Guided Feed-Forward
Network
Leveraging the NE to enrich the input features, our
NG-FFN significantly refines the feature transforma-
tion process. After applying the NE to the input fea-
ture map F
in
∈ R
H×W ×C
to obtain F
NE
= NE(F
in
),
the NG-FFN employs a gating mechanism (Zamir
et al., 2022) which enhances control over the feature
transformation. The gating mechanism is articulated
through the element-wise multiplication of two par-
allel transformation paths, where one of the paths in-
corporates the GELU (Hendrycks and Gimpel, 2016)
non-linearity.
The process is mathematically represented as:
F
NG-FFN
= φ(W
1
F
NE
) ⊙W
2
F
NE
+ F
NE
, (7)
where φ denotes the GELU activation function,
⊙ represents element-wise multiplication, and W
1
,
AKDT: Adaptive Kernel Dilation Transformer for Effective Image Denoising
421

Figure 4: Qualitative results on Color Gaussian Denoising - Urban100 dataset.
W
2
are the learnable parameters of the parallel paths.
Here, F
NG-FFN
symbolizes the output feature map of
the feed-forward network, showcasing an enhanced
representation for subsequent processing stages.
This approach distinctly bypasses the conven-
tional reliance on convolutions or fully-connected
layers, focusing instead on the synergy between the
NE-enhanced features and the gating mechanism.
4 EXPERIMENTS AND RESULTS
4.1 Implementation Details
In our evaluation, we select image denoising bench-
marks like CBSD68 (Martin et al., 2001), Urban100
(Huang et al., 2015), and McMaster (Zhang et al.,
2011) for synthetic cases, alongside SIDD (Abdel-
hamed et al., 2018) for real noise environments.
Our transformer-based model is architecturally
devised with a quad-level framework, hosting
[1, 2, 2, 4] transformer blocks, complemented by
[1, 2, 4, 8] attention heads at respective levels. The at-
tention dimensions are assigned as [34, 68, 134, 268]
across the levels. A set of 3 refinement blocks are
employed at the end of the encoder-decoder setup.
A distinctive feature of our methodology is the
adoption of progressive training, starting with image
patches of 128 × 128 pixels and gradually advancing
through sizes of 194 × 194, 256 × 256, 320 × 320,
and ultimately 384×384 pixels. This strategy accom-
modates a comprehensive learning spectrum from lo-
cal to global image characteristics and enhances the
model’s adaptability to diverse noise patterns.
To improve the training dynamics, random rota-
tions and flipping are employed as data augmenta-
tion techniques, strengthening the robustness of the
model. We utilize AdamW as the optimizer, parame-
terized by β
1
= 0.9, β
2
= 0.999, and a weight decay
of 1e − 4, across 300K iterations. The learning rate
begins at 3e − 4 and is methodically tapered to 1e − 6
via cosine annealing (Loshchilov and Hutter, 2017),
ensuring a smooth and effective model refinement.
Our evaluation framework employ the classical
PSNR (peak Signal-to-Noise Ratio) and SSIM (Struc-
tural Similarity Index Measure) metrics to quantita-
tively measure the denoising capability of the model,
ensuring a thorough appraisal of its capability to re-
construct clean images from noisy inputs. We also
utilize GMACs (Giga Multiply-Accumulate Opera-
tions) to highlight the computational complexity of
different methods.
4.2 Results
Real Image Denoising. Table 2 shows the per-
formance of multiple models on SIDD dataset.
Restormer achieves the highest PSNR of 40.02, mak-
ing it potentially the best choice. On the other hand,
our AKDT model showcases outstanding efficiency
with the lowest computational demand, measured at
56.15 GMACs, and the highest SSIM of 0.961. The
results highlight our method and showcase its SOTA
efficiency. Qualitative results in Fig. 4 further illus-
trate the performance of our method despite its re-
duced computational load.
Gaussian Denoising. Table 1 shows PSNR scores
of different models on various benchmark datasets.
We test color gaussian denoising capabilities, by in-
cluding well determined synthetic noise levels (σ) 15,
25 and 50. Qualitative results are presented in Fig. 5.
From the data presented we can conclude that
AKDT emerges as a standout, particularly in the
CBSD68, McMaster, and Urban100 datasets, where
it consistently outperforms other models across all
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
422

Table 1: Gaussian Color Denoising benchmarks results (PSNR). “-”: not reported. Red and blue represent best and second-
best values, respectively.
CBSD68 McMaster Urban100
Model
σ=15 σ=25 σ=50 σ=15 σ=25 σ=50 σ = 15 σ = 25 σ = 50
MACs
DnCNN(Zhang et al., 2017) 33.90 31.24 27.95 33.45 31.52 28.62 32.98 30.81 27.59 37 G
FFDNet(Zhang et al., 2018) 33.87 31.21 27.96 34.66 32.35 29.18 33.83 31.40 28.05 –
DSNet(Peng et al., 2019) 33.91 31.28 28.05 34.67 32.40 29.28 – – – –
BRDNet(Tian et al., 2020) 34.10 31.43 28.16 35.08 32.75 29.52 34.42 31.99 28.56 –
DRUNet(Zhang et al., 2021) 34.30 31.69 28.51 35.40 33.14 30.08 34.81 32.60 29.61 144 G
SwinIR(Liang et al., 2021) 34.42 31.78 28.56 35.61 33.20 30.22 35.13 32.90 29.82 759 G
Restormer(Zamir et al., 2022) 34.40 31.79 28.60 35.61 33.34 30.30 35.13 32.96 30.02 141 G
NAFNet-RCD(Zhang et al., 2023) 34.14 31.49 28.26 35.11 32.84 29.81 34.45 32.12 29.09 –
GRL-B(Li et al., 2023) 34.45 31.82 28.62 35.73 33.46 30.36 35.54 33.35 30.46 –
DCANet(Wu et al., 2024) 34.05 31.45 28.28 34.84 32.62 29.59 – – – 75 G
HWFormer(Tian et al., 2024) – – – 35.64 33.36 30.24 35.26 33.10 30.14 303 G
AKDT (Ours) 34.64 31.94 28.68 36.71 34.21 30.95 35.63 33.14 29.82 56 G
Figure 5: Qualitative results on Real Image Denoising - SIDD dataset.
Table 2: Performance of different models on the SIDD
dataset. Red and blue text indicate best and second-best
values, respectively.
Model PSNR ↑ SSIM ↑ GMACs ↓
MPRNet (Zamir et al., 2021) 39.17 0.958 588
CycleISP (Zamir et al., 2020a) 39.52 0.957 189.5
HINet (Chen et al., 2021) 39.99 0.23 170.7
MAXIM (Tu et al., 2022) 39.96 0.960 169.5
Restormer (Zamir et al., 2022) 40.02 0.960 141
MIRNet (Zamir et al., 2020b) 39.72 0.959 786
Uformer (Wang et al., 2021) 39.89 0.960 88.8
PCformer (Wan et al., 2023) 39.80 0.959 152
DCANet (Wu et al., 2024) 39.27 0.956 75.30
AKDT (Ours) 39.70 0.961 56.15
noise levels. This underscores the effectiveness of
AKDT in handling color denoising tasks, even in
challenging noisy environments.
The comparative analysis also brings to light the
trade-offs between performance and computational
efficiency. For instance, SwinIR, while achieving
near top marks, demands a substantial computational
cost with 759 GMACs, whereas AKDT maintains a
competitive edge with significantly lower computa-
tional needs (56 GMACs). This aspect is crucial for
practical applications where computational resources
are limited or cost-effectiveness is a priority. The data
suggests that AKDT not only provides denoising ca-
pabilities but does so with remarkable efficiency.
From a qualitative perspective, AKDT demon-
strates its superior performance by producing sharper
images while not introducing artifacts, as seen in the
outputs of DRUNet and SwinIR, while also not over-
smoothing details, as in the case of Restormer.
By leveraging our proposed NE, we construct
a robust and efficient Transformer architecture
(AKDT) that sets SOTA performance on various de-
noising benchmarks.
5 ABLATION STUDY
As ablation studies, we provide details into our archi-
tectural choices, accompanied by performance met-
rics on the SIDD dataset.
In Table 3 we present the impact of various LDR
configurations within the NE, employing specialized
paths for local and/or global context (i.e. Dual-
Path).The Dual-Path implementation enforces the im-
portance of specialization upon the model, by hav-
ing dedicated dilation rates for both types of contexts,
preventing excessive focus on one of the types of in-
formation.
Table 4 shows experiments with different com-
pression/expansion rates within the NE. C represents
the input dimensions of the NE. C×K means that the
NE has inner dimensions equal to those of the in-
put multiplied by a factor of K. As the results sug-
gest, performing feature compression within the NE
AKDT: Adaptive Kernel Dilation Transformer for Effective Image Denoising
423
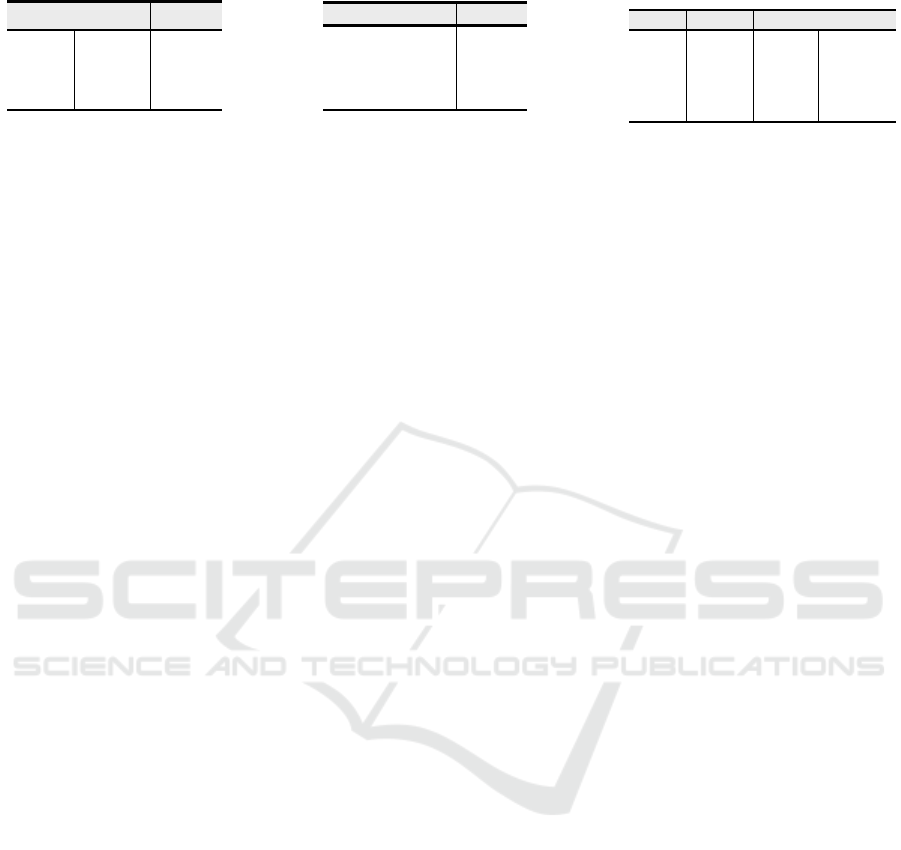
Table 3: Impact of LDR.
Local Global PSNR
✓ 39.47
✓ 39.32
✓ ✓ 39.70
Table 4: Impact of feature expansion.
Change PSNR
C → C × 0.125 39.28
C → C × 0.25 39.70
C → C × 0.5 39.67
C → C × 2 38.63
Table 5: Transformer Block varia-
tions impact.
MSA FFN PSNR GMACs
V V 35.29 51.13
NG V 37.48 53.27
V NG 36.46 65.35
NG NG 39.59 67.49
NG NG+G 39.70 56.16
performs better. This study suggests that the NE is
able to perform best by extracting only the most rele-
vant features from both the Global and Local contexts,
through the LDR
Global
and LDR
Local
respectively.
Table 5 presents a more extensive study on poten-
tial Transformer Block implementations. V represents
vanilla MSA/FFN implementations. NG is the noise-
guidance integration. +G represents the gating mech-
anism. As illustrated, the addition of the NE used for
the NG-MSA improves performance over the vanilla
(V) MSA by 2.19 dB. Similarly, the NG-FFN outper-
forms vanilla FFN by 1.17 dB. Furthermore, the gat-
ing mechanism (+G) improves performance over the
non-gated NG-FFN by 0.11 dB while also reducing
GMACs by 17%.
The ablation studies underscore the critical impact
of our architectural choices on the performance of the
Adaptive Kernel Dilation Transformer (AKDT).
6 CONCLUSION & FUTURE
WORKS
We introduced a novel approach of utilising learn-
able dilation convolutions, the LDR block, and used
it to develop a mechanism that is able to effectively
distinguish and learn between local and global noise
patterns, the NE. We proposed the integration of the
NE into the attention and feed-forward mechanisms
prevalent in Transformer architectures, producing an
efficient SOTA model.
Our comprehensive evaluation demonstrates that
our proposed method has superior performance and
computational efficiency in comparison to existing
denoising methods. Furthermore, our experiments
serve as theoretical backing to the proposed design,
thereby proving the positive impact of learnable dila-
tion rate convolutions in Transformer architectures.
REFERENCES
Abdelhamed, A., Lin, S., and Brown, M. S. (2018). A high-
quality denoising dataset for smartphone cameras. In
Proceedings of the IEEE conference on computer vi-
sion and pattern recognition, pages 1692–1700.
Ancuti, C. O., Ancuti, C., De Vleeschouwer, C., and
Bekaert, P. (2017). Color balance and fusion for un-
derwater image enhancement. IEEE Transactions on
image processing, 27(1):379–393.
Bogdan, V., Bonchis, C., and Orhei, C. (2024). An im-
age sharpening technique based on dilated filters and
2d-dwt image fusion. In Proceedings of the 19th
International Joint Conference on Computer Vision,
Imaging and Computer Graphics Theory and Applica-
tions - Volume 3: VISAPP, pages 591–598. INSTICC,
SciTePress.
Bogdan, V., Bonchis¸, C., and Orhei, C. (2020). Cus-
tom dilated edge detection filters. Journal of WSCG,
28:161–168.
Brateanu, A., Balmez, R., Avram, A., and Orhei, C. (2024).
Lyt-net: Lightweight yuv transformer-based network
for low-light image enhancement. arXiv preprint
arXiv:2401.15204.
Chen, L., Lu, X., Zhang, J., Chu, X., and Chen, C. (2021).
Hinet: Half instance normalization network for image
restoration. In Proceedings of the IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition
(CVPR) Workshops, pages 182–192.
Chen, Z., Zhang, Y., Gu, J., Kong, L., Yuan, X., et al.
(2022). Cross aggregation transformer for image
restoration. Advances in Neural Information Process-
ing Systems, 35:25478–25490.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn,
D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer,
M., Heigold, G., Gelly, S., et al. (2021). An image is
worth 16x16 words: Transformers for image recogni-
tion at scale. In ICLR.
Fattal, R. (2007). Image upsampling via imposed edge
statistics. In ACM SIGGRAPH 2007 papers, pages
95–es.
HeK, M. and SUNJ, T. X. O. (2011). Single image haze
removal using dark channel prior. IEEE Transac-
tionson Pattern Analysis and Machine Intelligence,
33(12):2341.
Hendrycks, D. and Gimpel, K. (2016). Gaussian error linear
units (GELUs). arXiv:1606.08415.
Huang, J.-B., Singh, A., and Ahuja, N. (2015). Single image
super-resolution from transformed self-exemplars. In
CVPR.
Kopf, J., Neubert, B., Chen, B., Cohen, M., Cohen-Or,
D., Deussen, O., Uyttendaele, M., and Lischinski, D.
(2008). Deep photo: Model-based photograph en-
hancement and viewing. ACM transactions on graph-
ics (TOG), 27(5):1–10.
Li, Y., Fan, Y., Xiang, X., Demandolx, D., Ranjan, R.,
Timofte, R., and Van Gool, L. (2023). Efficient
and explicit modelling of image hierarchies for im-
age restoration. In Proceedings of the IEEE/CVF Con-
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
424

ference on Computer Vision and Pattern Recognition,
pages 18278–18289.
Liang, J., Cao, J., Sun, G., Zhang, K., Van Gool, L., and
Timofte, R. (2021). SwinIR: Image restoration using
swin transformer. In ICCV Workshops.
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z.,
Lin, S., and Guo, B. (2021). Swin transformer: Hi-
erarchical vision transformer using shifted windows.
arXiv:2103.14030.
Loshchilov, I. and Hutter, F. (2017). SGDR: Stochastic gra-
dient descent with warm restarts. In ICLR.
Martin, D., Fowlkes, C., Tal, D., and Malik, J. (2001). A
database of human segmented natural images and its
application to evaluating segmentation algorithms and
measuring ecological statistics. In ICCV.
Michaeli, T. and Irani, M. (2013). Nonparametric blind
super-resolution. In Proceedings of the IEEE Inter-
national Conference on Computer Vision, pages 945–
952.
Orhei, C., Bogdan, V., Bonchis, C., and Vasiu, R. (2021).
Dilated filters for edge-detection algorithms. Applied
Sciences, 11(22):10716.
Orhei, C. and Vasiu, R. (2023). An analysis of extended and
dilated filters in sharpening algorithms. IEEE Access,
11:81449–81465.
Peng, Y., Zhang, L., Liu, S., Wu, X., Zhang, Y., and Wang,
X. (2019). Dilated residual networks with symmetric
skip connection for image denoising. Neurocomput-
ing.
Ramachandran, P., Zoph, B., and Le, Q. V. (2017).
Swish: a self-gated activation function. arXiv preprint
arXiv:1710.05941.
Ronneberger, O., Fischer, P., and Brox, T. (2015). U-Net:
convolutional networks for biomedical image segmen-
tation. In MICCAI.
Shi, W., Caballero, J., Husz
´
ar, F., Totz, J., Aitken, A. P.,
Bishop, R., Rueckert, D., and Wang, Z. (2016). Real-
time single image and video super-resolution using an
efficient sub-pixel convolutional neural network. In
CVPR.
Tian, C., Xu, Y., and Zuo, W. (2020). Image denoising
using deep cnn with batch renormalization. Neural
Networks.
Tian, C., Zheng, M., Lin, C.-W., Li, Z., and Zhang, D.
(2024). Heterogeneous window transformer for im-
age denoising. IEEE Transactions on Systems, Man,
and Cybernetics: Systems, 54(11):6621–6632.
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles,
A., and J
´
egou, H. (2021). Training data-efficient im-
age transformers & distillation through attention. In
ICML.
Tu, Z., Talebi, H., Zhang, H., Yang, F., Milanfar, P., Bovik,
A., and Li, Y. (2022). Maxim: Multi-axis mlp for
image processing. In Proceedings of the IEEE/CVF
Conference on Computer Vision and Pattern Recogni-
tion, pages 5769–5780.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I.
(2017). Attention is all you need. In NeurIPS.
Wan, Y., Shao, M., Cheng, Y., Meng, D., and Zuo, W.
(2023). Progressive convolutional transformer for im-
age restoration. Engineering Applications of Artificial
Intelligence, 125:106755.
Wang, W., Wu, X., Yuan, X., and Gao, Z. (2020). An
experiment-based review of low-light image enhance-
ment methods. Ieee Access, 8:87884–87917.
Wang, Z., Cun, X., Bao, J., and Liu, J. (2021). Uformer:
A general u-shaped transformer for image restoration.
arXiv:2106.03106.
Wu, W., Lv, G., Duan, Y., Liang, P., Zhang, Y., and Xia,
Y. (2024). Dual convolutional neural network with
attention for image blind denoising.
Yu, F. and Koltun, V. (2016). Multi-scale context aggrega-
tion by dilated convolutions. In International Confer-
ence on Learning Representations.
Yu, F., Koltun, V., and Funkhouser, T. (2017). Dilated
residual networks. In Proceedings of the IEEE con-
ference on computer vision and pattern recognition,
pages 472–480.
Yuan, L., Chen, Y., Wang, T., Yu, W., Shi, Y., Jiang, Z.,
Tay, F. E., Feng, J., and Yan, S. (2021). Tokens-to-
token vit: Training vision transformers from scratch
on imagenet. arXiv:2101.11986.
Zamir, S. W., Arora, A., Khan, S., Hayat, M., Khan,
F. S., and Yang, M.-H. (2022). Restormer: Efficient
transformer for high-resolution image restoration. In
CVPR.
Zamir, S. W., Arora, A., Khan, S., Hayat, M., Khan, F. S.,
Yang, M.-H., and Shao, L. (2020a). Cycleisp: Real
image restoration via improved data synthesis. In Pro-
ceedings of the IEEE/CVF conference on computer vi-
sion and pattern recognition, pages 2696–2705.
Zamir, S. W., Arora, A., Khan, S., Hayat, M., Khan, F. S.,
Yang, M.-H., and Shao, L. (2020b). Learning enriched
features for real image restoration and enhancement.
In ECCV.
Zamir, S. W., Arora, A., Khan, S., Hayat, M., Khan, F. S.,
Yang, M.-H., and Shao, L. (2021). Multi-stage pro-
gressive image restoration. In CVPR.
Zhang, K., Li, Y., Zuo, W., Zhang, L., Van Gool, L., and
Timofte, R. (2021). Plug-and-play image restoration
with deep denoiser prior. TPAMI.
Zhang, K., Luo, W., Zhong, Y., Ma, L., Stenger, B., Liu, W.,
and Li, H. (2020). Deblurring by realistic blurring. In
CVPR.
Zhang, K., Zuo, W., Chen, Y., Meng, D., and Zhang, L.
(2017). Beyond a gaussian denoiser: Residual learn-
ing of deep cnn for image denoising. TIP.
Zhang, K., Zuo, W., and Zhang, L. (2018). FFDNet: To-
ward a fast and flexible solution for CNN-based image
denoising. TIP.
Zhang, L., Wu, X., Buades, A., and Li, X. (2011). Color de-
mosaicking by local directional interpolation and non-
local adaptive thresholding. JEI.
Zhang, Z., Jiang, Y., Shao, W., Wang, X., Luo, P., Lin, K.,
and Gu, J. (2023). Real-time controllable denoising
for image and video. In Proceedings of the IEEE/CVF
Conference on Computer Vision and Pattern Recogni-
tion, pages 14028–14038.
AKDT: Adaptive Kernel Dilation Transformer for Effective Image Denoising
425
