
Improving Controlled Text Generation
via Neuron-Level Control Codes
Jay Orten and Nancy Fulda
Brigham Young University, Provo, Utah, U.S.A.
Keywords:
Language Modeling, Statistical and Machine Learning Methods, Semi-Supervised, Weakly-Supervised and
Unsupervised Learning.
Abstract:
Task-specific text generation is a highly desired feature for language models, as it allows the production of
text completions that are either broadly or subtly aligned with specific objectives. By design, many neural
networks switch between multiple behaviors during inference - for example, when selecting a target language
in many-to-many translation systems. Such task-specific information is usually presented to the network as an
augmentation of its input data. In this work, we explore an alternate approach: transmitting task information
directly to each neuron in the network. This removes the need for task information to propagate forward during
training, a particularly critical advantage in low-resource settings where maximum benefit must be extracted
from each training example. To test this approach, we train over 160 language models from scratch with a large
variety of architectures and configurations. Our results show that models with neuron-level augmentation can
experience increased learning speed, improved final generation accuracy, and even novel learning capabilities,
with greater benefits as network depth increases.
1 INTRODUCTION
Deep neural networks are capable of learning rich fea-
ture spaces containing complex information of rele-
vance to many tasks. For this reason, it is often more
efficient to train a single model to perform many re-
lated tasks than it would be to train a model for each
task in isolation. Given a broad task range, it is de-
sirable to have the ability to guide model output ac-
cording to the objectives of the user. This is typi-
cally accomplished by including additional input in-
formation. The CTRL language model (Keskar et al.,
2019) performs controlled generation by appending
task-specific tokens to the beginning of input prompts.
A related method is employed by Meta’s M2M-100
model, in which target language data is added as an
additional token of the decoder rather than the en-
coder (Fan et al., 2021). Similar to these approaches
is the method used implicitly by large-scale text gen-
eration models such as GPT-4 (OpenAI, 2023), which
rely completely on prompt engineering to perform a
wide variety of unique tasks.
The referenced methods for controlled generation
are effective in part because many deep learning sys-
tems leverage residual connections to allow more effi-
cient transmission of feature representations between
layers (He et al., 2016), meaning that task informa-
tion has the ability to propagate throughout the entire
network.
We theorize that task-specific behaviors in neural
networks with generalized internal feature representa-
tions could be learned more quickly and successfully
by passing task-specific information directly to the in-
terior layers of the network. To test this theory, we
connect a task embedding vector directly to the neu-
rons in the network’s hidden layers. Proven effective,
this approach would boost efficient training of smaller
models while retaining nuanced control over text gen-
eration.
The core contributions of this work are: (1) a
framework for applying control codes at the neuron
level on both small-scale Transformer networks and
simple gated recurrent unit (GRU) neural networks,
(2) a structured analysis of this augmentation obtained
by training over 160 models from scratch with a vari-
ety of datasets and configurations, and (3) the discov-
ery that, within certain constraints on relative depth of
the network, the neuron-level control codes can sig-
nificantly improve learning speed, increase final per-
formance, and even enable new learning capabilities.
574
Orten, J. and Fulda, N.
Improving Controlled Text Generation via Neuron-Level Control Codes.
DOI: 10.5220/0013160100003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 3, pages 574-581
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

2 BACKGROUND
Language Model Architectures: Language model-
ing can be described as a task whereby the next token
in a sequence is repeatedly predicted. Well-known ar-
chitectures for language modeling include Recurrent
Neural Networks (RNNs) and Transformers.
RNNs operate on sequential data via the combi-
nation of the current input vector with a hidden state
representing salient information from all previous in-
puts. Formally,
h
t
= RU(x
t
, h
t−1
) (1)
ˆy
t
= softmax(W
o
· h
t
) (2)
where h
t
represents the hidden state, ˆy
t
the out-
put of the network, x
t
the input of the network, and
t the time step. The matrix W
o
is a final linear layer.
The components of a recurrent unit (RU) function can
vary. Popular implementations include Long Short-
Term Memory (LSTM) (Hochreiter and Schmidhu-
ber, 1997) and Gated Recurrent Units (GRU) (Cho
et al., 2014).
Recently, auto-regressive decoder-only Trans-
former networks have become popular for novel text
generation tasks. The Transformer architecture con-
sists of sequential layers, each containing a multi-
head attention block followed by a feed-forward net-
work block, as described by Vaswani et al. (2017).
Transformer models such as GPT-4 (OpenAI, 2023),
although powerful, require extraordinary compute re-
sources to train. Our work seeks to reduce the time
and energy consumption required to train such mod-
els for multi-task frameworks.
Controllable Text Generation. Vanilla language
models function as next-word prediction tasks, where
the probability of the next token x is determined by all
previous tokens as per the chain rule of probability:
p(x) =
n
∏
t=1
p(x
t
|x
<t
) (3)
Conditional language models invoke additional
conditioning on some context c:
p(x|c) =
n
∏
t=1
p(x
t
|x
<t
, c) (4)
The conditioning context c represents additional
information upon which generation is conditioned.
Commonly, c is implemented as an additional token
in the input prompt. Keskar et al. (2019) refers to
this token as a control code, and explored a variety of
novel approaches to using control codes, such as us-
ing web-page links as codes or mixing codes in order
to generate cross-over behavior.
The usage of control codes as a conditioning con-
text is common in machine translation, specifically
for multilingual translation with a single model (Ha
et al., 2016). For example, Johnson et al. (2017)
achieved remarkable multilingual zero-shot transla-
tion by introducing a token signifying the target lan-
guage to the beginning of each input sentence.
The conditional context c may also be interpreted
as a vector of information. For example, Ficler and
Goldberg (2017) achieved controllable generation by
simultaneously conditioning on multiple parameters
involving stylistic properties. This was accomplished
by creating a conditional vector consisting of multiple
embedding vectors concatenated together. Sennrich
et al. (2016) controlled the level of politeness in gen-
erations by utilizing what they term ‘side constraints’
appended to the end of the source text.
A primary contribution of models such as GPT-
4 is that increased model sizes and huge amounts of
data allow models to implicitly learn controlled gener-
ation (OpenAI, 2023). Because these models are very
effective few-shot learners, controlled generation can
be accomplished via prompt-engineering alone. How-
ever, because an explicit context c is absent, it is dif-
ficult to control for specific desired attributes during
training and usage.
More recently, Plug and Play Language Models
(Dathathri et al., 2020) enable controlled text gen-
eration for any pre-trained language model via ad-
ditional attribute classifier models. While this ap-
proach requires no modification to the base model,
it is intended for use on very large pre-trained lan-
guage models, and is not suited for low-resource set-
tings where efficient training from scratch on specific
tasks is highly desirable.
3 METHODOLOGY
Our core contribution, and the foundation for this
research, is the idea that models can learn more
quickly if each neuron has direct access to informa-
tion about the current text-generation task. To enable
this, we propose an alternative architecture for condi-
tioned language models that distributes task informa-
tion throughout the entire network. We compare this
alternative method to a default architecture and report
results in Section 5 below.
3.1 Definition of Control Codes
We define the conditional context as a control code,
c, represented by a special token of a unique form,
e.g. ‘〈shakespeare〉’. This token is embedded as an n-
Improving Controlled Text Generation via Neuron-Level Control Codes
575

dimensional vector, as with all other tokens in a given
prompt. Most conditional language models simply in-
clude c as an additional token in the prompt; our ap-
proach, however, utilizes the embedded vector of c at
each linear layer throughout the entire network.
Figure 1: Methods for controlled generation with multi-
layer RNNs. The alternative approach involves concatena-
tion of a special vector before every layer in the RNN, not
just the first.
3.2 Applying Neuron-Level Control
Codes in RNNs
With RNNs, the default method for controlled gener-
ation involves concatenating c with each input token
x
t
in the sequence (See Figure 1). This is a known
method for controlled generation (Ficler and Gold-
berg, 2017). Where n is the number of layers in the
RNN:
h
n
t
= RU((x
t
⊕ c), h
n
t−1
) for n = 1 (5)
h
n
t
= RU(h
n−1
t
, h
n
t−1
) for n > 1 (6)
ˆy
t
= softmax(W
o
· h
n
t
) (7)
Our alternative architecture concatenates c to the
input of every RNN cell in each layer, rather than just
before the first layer of RNN cells:
h
n
t
= RU((h
n−1
t
⊕ c), h
n
t−1
) for n > 1 (8)
The control information is also concatenated to
the final output from the last layer, before it is passed
through a final fully connected feed-forward layer:
ˆy
t
= softmax(W
o
· (h
n
t
⊕ c)) (9)
This is done for each point in the sequence (See
Fig. 1).
3.3 Applying Neuron-Level Control
Codes in Transformers
The default approach for controlled generation in
Transformers is achieved by concatenating the em-
bedded vectors for both the input sequence and the
embedded control code c, such that the embedded
control token information is represented at the begin-
ning of each sequence in a batch. This combined vec-
tor is then passed through positional encoding as de-
scribed in Vaswani et al. (2017).
Figure 2: Alternative Transformer architecture. The control
information is concatenated at key points within the linear
layers of every decoder cell.
To apply the control codes to every neuron, we
take advantage of the position-wise fully connected
feed-forward network that follows the self-attention
block within a Transformer decoder layer:
FFN(x) = max(0,W
1
x + b
1
)W
2
+ b
2
(10)
This block consists of two linear transformations
with a ReLU activation in between.
In this approach, our control token vector, c, is
not concatenated with the input sequence. Rather, af-
ter the attention block, c is concatenated before each
layer in the feed-forward block. Thus, we are directly
augmenting each point in the linear layers with con-
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
576

Table 1: Datasets used to train RNNs.
Dataset Description Tokens
Languages Combined full text of two literary sources, one in English and one in Tagalog. The Great
Gatsby by F. Scott Fitzgerald and Bulalakaw ng P
´
ag-Asa by Ismael A. Amado (Project
Gutenberg, 2024).
89,564
Books Combined full text of two literary sources, both in English. The Great Gatsby by F. Scott
Fitzgerald and a collection of works from Shakespeare (Project Gutenberg, 2024).
116,232
Table 2: Datasets used to train Transformer-based models.
Dataset Description Tokens
Books-2 Combined full text of two literary sources, both in English. The Great Gatsby by F. Scott
Fitzgerald and a collection of works from Shakespeare (Project Gutenberg, 2024).
116,232
Books-3 Combined full text of three literary sources, all in English. All sources used in Books-2,
with the addition of A Tale of Two Cities by Charles Dickens (Project Gutenberg, 2024).
276,985
Books-6 Combined full text of six literary sources, all in English. All sources used in Books-3, with
the addition of Alice in Wonderland by Lewis Carroll, The Iliad by Homer, and Moby Dick
by Herman Melville (Project Gutenberg, 2024).
780,658
Reviews English Amazon reviews for two different kinds of topics: outdoor equipment and music
(Ni et al., 2019).
1,183,235
Scripts English text from two differently styled sources: news articles and blog posts. News ar-
ticles from BBC Business (Greene and Cunningham, 2006), and blog posts from Blog
Authorship Corpus (J. Schler and Pennebaker, 2006).
115,286
trol information:
FFN(x) = (max(0, (x ⊕c)W
1
+b
1
)⊕c)W
2
+b
2
(11)
Finally, c is concatenated to the output of the final
decoder cell before it is passed through a final linear
layer, which decodes to output (see Fig. 2).
In this manner, control information is directly
fed to all weights except those in multi-head atten-
tion. Efforts to integrate control information in self-
attention, such as token-wise concatenation before ap-
plying self-attention, led to a significant performance
drop.
Our method differs from the default method in that
we concatenate the control vector with each sequence
element’s vector space, injecting control information
throughout the entire sequence rather than just at the
start. This approach accounts for the Transformer
decoder’s batch processing of entire sequences. In
contrast, the default control architecture prepends the
control vector solely at the sequence’s outset, like
adding a token to a prompt’s beginning. We hypothe-
size that this difference enables our network to much
more directly receive and incorporate control infor-
mation during training and inference, providing a sig-
nificant benefit.
4 EXPERIMENTAL SETUP
We train 160 models on several datasets to test our al-
ternative method. All models were trained on a single
11 GB NVIDIA GeForce GTX 1080 Ti, with a batch
size of 16 and a sequence length of 256.
4.1 Datasets
Various datasets were tested to introduce variety to the
experimental trials. Each dataset contains unique text
styles. It is intended that this will test the capabilities
of the models to generate text in different domains.
Datasets chosen are relatively small, but contain con-
trolled content for testing conditional generation.
All experiments were done on datasets consisting
of at least two topics, or sources. Every epoch, a
model would be trained on all data from each source
in the specific dataset. Special tokens such as ‘〈mu-
sic〉’ and ‘〈garden〉’ were used to differentiate be-
tween the different sources. At evaluation time, con-
trolled generation for the desired generation type was
accomplished via the corresponding control token.
RNN architectures were trained on two small
datasets extracted from Project Gutenberg (Project
Gutenberg, 2024), one monolingual and one bilin-
gual. Transformer-based architectures were trained
Improving Controlled Text Generation via Neuron-Level Control Codes
577

and tested using five datasets with varying sizes and
content styles. See Tables 1 and 2. These datasets are
relatively small compared to benchmark datasets for
large language models. Using these smaller datasets
allowed us faster training time and more flexibility in
testing.
4.2 RNN Experimental Setup
Both default and alternative RNN architectures were
trained on identical setups for direct comparison
against each other. RNNs consisted of three layers
of GRU cells. Hidden sizes of 256, 512, and 1024
were tested. All networks were trained on the ‘Books’
dataset for 50 epochs. Models were trained on the
‘Languages’ dataset for 150 epochs. Cross-entropy
loss was used as the loss function, and Adam as the
optimizer. A learning rate of 0.001 was used.
4.3 Transformer Experimental Setup
All Transformer models were trained with 2 attention
heads and an embedding dimension of 200, both ar-
bitrary decisions. Hidden sizes of 128, 256, 512, and
1024 were tested. Layer sizes of 2, 4, 6, and 8 were
tested. The purpose of this was to explore how model
size may effect results for both architectures. Conse-
quently, 160 models were trained, each with a differ-
ent architecture, dataset, hidden size, and number of
layers.
A learning rate initializing at 5 was used for all
training runs. A learning rate scheduler was used with
a gamma of 0.95 every epoch. Cross-entropy loss was
used as the loss function, and stochastic gradient de-
scent as the optimizer. Models were trained for 50
epochs, regardless of configuration. While 50 epochs
is a relatively short training time, it allowed us to ex-
plore a large variety of models.
4.4 Evaluation
A variety of methods were used for evaluation. Loss
was the only metric used to evaluate RNNs, as RNNs
were simply used for preliminary tests. In contrast,
the Transformer models were evaluated using loss,
perplexity, BERTScore (Zhang et al., 2020), a sim-
ple Variance metric, and a Degeneracy metric. The
BLEU score (Papineni et al., 2002) was also calcu-
lated, using SacreBLEU (Post, 2018). In practice,
BLEU scores did not display any meaningful trends
during the short training time.
BERTScores were calculated using baseline
rescaling, as suggested by its creators, resulting in
mostly negative values for many generations. This is
to be expected considering the quality of initial text
generations and the nature of baseline rescaling for
BERTScore (Hanna and Bojar, 2021).
A simple variation metric was used to monitor the
generic fluency a model may produce. Variation was
calculated by dividing the number of unique tokens in
a prediction by the number of total tokens in a predic-
tion, averaged across n predictions. A higher variance
score indicates higher vocabulary variation. In test-
ing, this simple metric showed correlation with gen-
erational fluency in testing.
Degeneracy represents the average frequency of
the most common word across n generations; lower
is better. Additionally, test generations were recorded
every epoch in order to observe generational quality
from a human standpoint. Predictions were selected
through greedy sampling of the token that was given
the highest probability in the sampling distribution.
5 EXPERIMENTAL RESULTS
Figure 3: Loss from RNNs with various hidden layer sizes
on ‘Languages’ dataset. For smaller hidden sizes, the alter-
native models outperformed the default models. Results on
‘Books’ dataset are similar.
5.1 RNN Results
Initial RNN tests indicated that the alternative archi-
tecture may offer training advantages. As shown in
Figure 3, the alternative RNN achieves a lower loss
faster than the default model for smaller hidden sizes
of 512 and 256. In most cases, both model types
converge to the same loss value. As hidden size in-
creases, the alternative method resulted in poorer per-
formance compared to the default. For larger hid-
den sizes, such as 1024, the alternative models do not
learn as quickly.
These results may indicate that the alternative ar-
chitecture could provide a speedup in training, but not
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
578
necessarily a final advantage, over the default archi-
tecture. This only occurs, however, for small network
sizes.
5.2 Transformer Results
Table 3: Averaged BLEU, BERTScore, and Degeneracy
scores from five different tests with different initialization
seeds for default and alternative architectures (ours), across
50 epochs. Bold represents better score. The alternative
method shows improvement over the default in BERTScore
and Degeneracy, but not in BLEU.
Model Epoch Bleu BERTScore Deg.
Default
1 0.52 -0.28 4.1
5 0.48 -0.29 4.1
10 0.58 -0.28 4.09
25 0.52 -0.28 4.08
50 0.46 -0.29 4.09
Altern.
(ours)
1 0.45 -0.34 3.91
5 0.43 -0.28 5.15
10 0.48 -0.15 2.93
25 0.42 -0.15 2.73
50 0.45 -0.14 2.79
Experiments with Transformer models demonstrate
that, on average, across various datasets and model
sizes, the alternative model outperforms the corre-
sponding default model (Figure 4). Interestingly, in
contrast to results for RNNs, the alternative method
becomes more effective over the default method as
model size increases.
Figure 4: Average loss of all Transformer model sizes per
dataset. All datasets tested achieved similar results: on av-
erage, across all model sizes, the alternative architecture
reached a lower loss value.
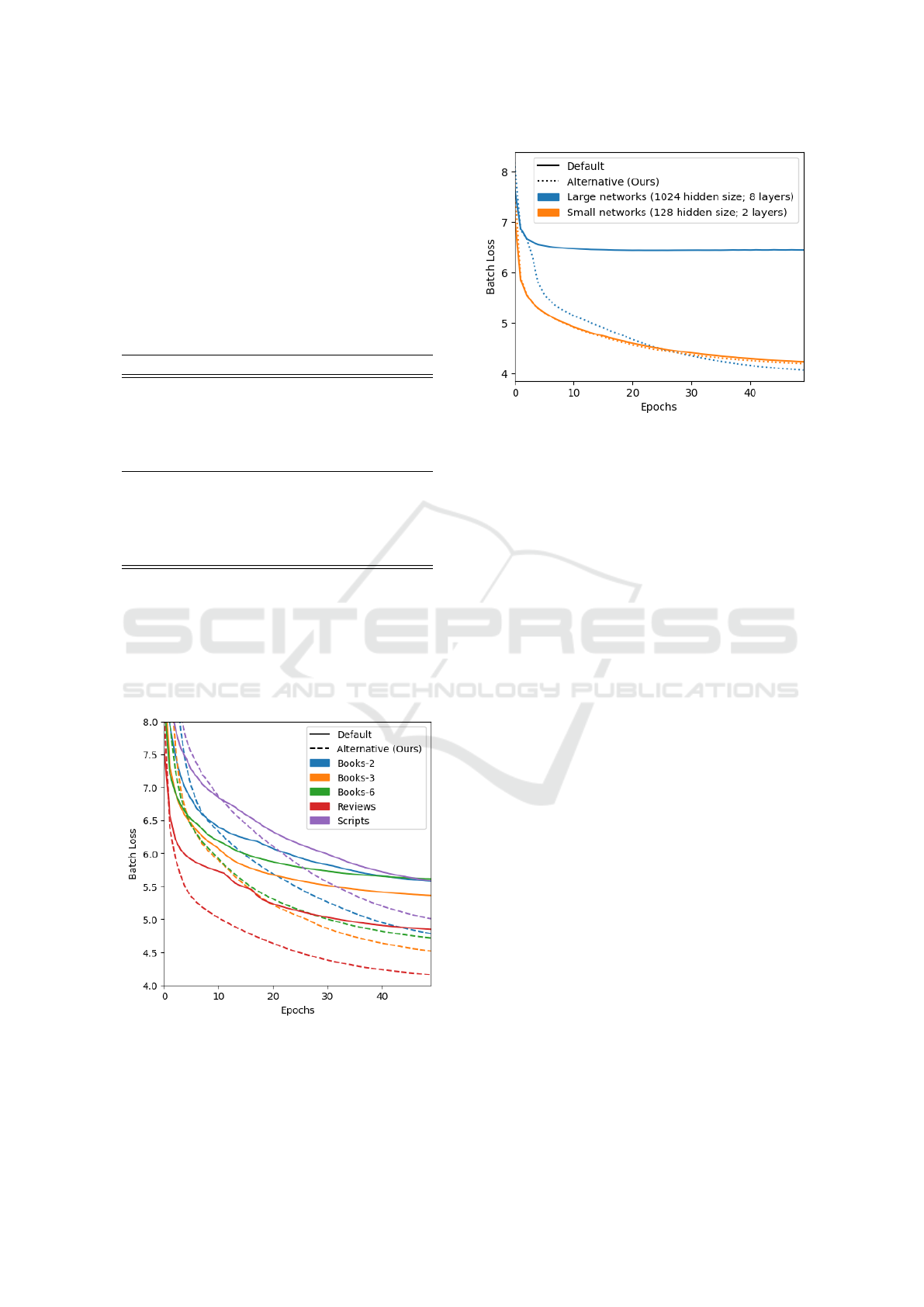
Figure 5: Batch loss on large and small networks for the
‘Reviews’ dataset. The alternative architecture with larger
models would achieve similar performance to the models
with only 2 layers, where the default architecture would
simply not learn, indicating that the alternative method ben-
efits training for large models.
• For larger networks, the alternative architecture
would very often find ‘breakthroughs’, resulting
in dramatic boosts in training, where the default
architecture would not. See Figure 5.
• There was never an instance where the default
architecture learned and the alternative did not.
In these tests, if a model did not learn, the vari-
ance would remain around .5, indicating that the
final generation quality is equivalent to the ini-
tial generation quality: unintelligible and repet-
itive. While there were instances for large net-
works where the default architecture would not
learn while the alternative architecture would, the
opposite never occurred. This suggests that the
alternative method only ever acted as an enhance-
ment, and never as a complete detriment to learn-
ing.
• The difference in performance between default
and alternative models grew more pronounced as
layer count increased. As seen in Figure 6, there
is an increasing gap between default and alterna-
tive method performance as the models go from 4
to 6 layers, with an expanding early learning ad-
vantage of 4 to 10 epochs. This may show that
a primary benefit of the alternative method is a
speedup in training.
• For small networks with a hidden size of 128 and
2 layers, the default architecture generally learned
slightly faster than the alternative. However, both
networks would arrive at the same level of loss,
variation, and perplexity. This suggests that, for
small networks, the alternative approach slows
Improving Controlled Text Generation via Neuron-Level Control Codes
579
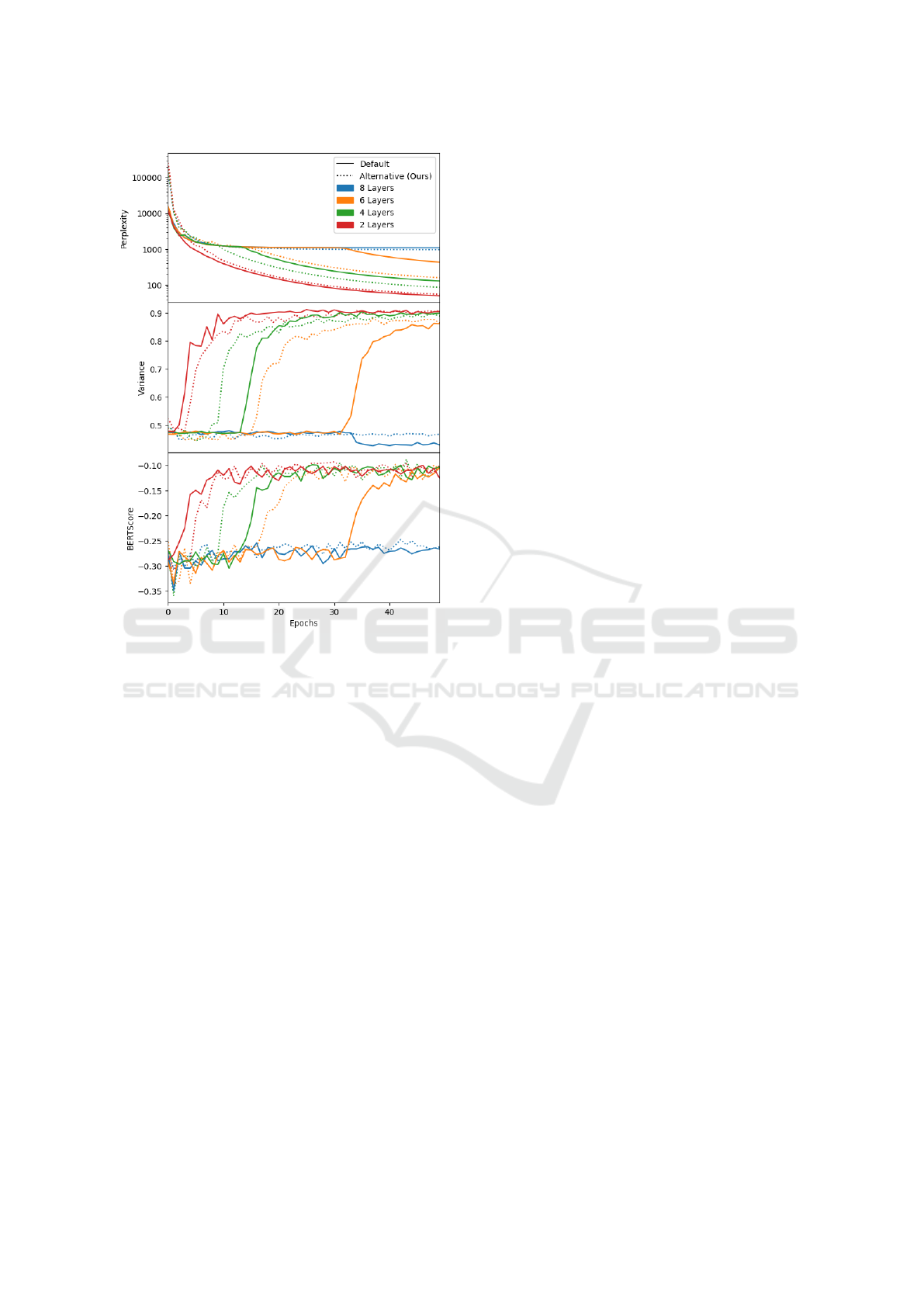
Figure 6: Perplexity, variance, and BERTScore for differ-
ent model sizes on ‘Scripts’ dataset. Larger models using
the alternative method achieve a boost in performance much
sooner than their default counterparts, indicating that the al-
ternative method enables faster learning for larger models.
down learning slightly.
• Large networks consisting of 8 layers would
sometimes not learn with either architecture. This
may be a result of short training time, sub-optimal
learning rate, and dataset size.
• The number of layers in a model had a much
greater impact on performance than the size of the
hidden layers. Different hidden sizes did not seem
to significantly impact model performance for ei-
ther architecture.
• Tests were conducted to establish how consis-
tently the models would achieve results. Over
five runs with each architecture and a randomized
initialization, results consistently appear to follow
the same trend.
6 DISCUSSION
We observe from our results that the training benefits
of neuron-level control codes emerge as model size
grows, specifically in the layer dimension. While net-
works consisting of only 2-4 layers are generally hin-
dered by the alternative approach, larger models with
more than 6 layers show valuable performance im-
provements during training, both in terms of training
speedup and emergent learning abilities. The models
train faster, perform better, and are in some cases able
to learn tasks that the default architecture was unable
to master.
We attribute our method’s success to the fact that
control information is not being lost or diluted via
propagation through the network. This is in some
ways comparable to the role played by skip connec-
tions in deep learning architectures (He et al., 2016).
However, in this case we ensure that control informa-
tion is distributed directly to each neuron in the net-
work rather than simply making it easier to propagate
forward. It therefore follows intuitively that models
with more layers take greater benefit from this ap-
proach.
Thus far, our research has been restricted to small-
scale language models with 8 or fewer layers. While
this is a key limitation of our work, it also allowed us
to iterate efficiently and avoid unnecessary compute
usage as we sought an optimal configuration. We note
in particular that the goal of this research was to iden-
tify a novel machine learning architecture with pow-
erful forward possibilities in the domain of multi-task
text generation. Our goal is not to achieve flawless
text generation, but rather to compare learning speed
and final text quality across many model sizes and
architectures. It was expected that if the alternative
method proved effective in small learning architec-
tures, it would also be effective in their state-of-the-
art cousins. A full-scale application of this method to
large-scale language models, while enticing, lies be-
yond the scope of this work.
7 CONCLUSION
This work presents a novel technique for multi-task
language models in which a task-specific embedding
is appended to the input of each hidden layer in
the network, thus facilitating effective distribution of
task-specific information to all neurons. We apply
this method to two common neural network architec-
tures used in language-based tasks – Transformer net-
works and RNNs – and find that, with models contain-
ing greater depth layer-wise, our method significantly
improves training performance and in some cases en-
ables models to learn where they otherwise wouldn’t.
We posit that this method exhibits great potential
for improving model control and, ultimately, safety.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
580

Future research should include further exploration of
hyper-parameters, the investigation of hybrid methods
wherein task-specific information is injected into only
a subset of hidden layers, and the application of this
method to large-scale models for machine translation
and text generation.
REFERENCES
Cho, K., van Merri
¨
enboer, B., Gulcehre, C., Bahdanau, D.,
Bougares, F., Schwenk, H., and Bengio, Y. (2014).
Learning phrase representations using RNN encoder–
decoder for statistical machine translation. In Mos-
chitti, A., Pang, B., and Daelemans, W., editors, Pro-
ceedings of the 2014 Conference on Empirical Meth-
ods in Natural Language Processing (EMNLP), pages
1724–1734, Doha, Qatar. Association for Computa-
tional Linguistics.
Dathathri, S., Madotto, A., Lan, J., Hung, J., Frank, E.,
Molino, P., Yosinski, J., and Liu, R. (2020). Plug
and play language models: A simple approach to con-
trolled text generation. In International Conference
on Learning Representations.
Fan, A., Bhosale, S., Schwenk, H., Ma, Z., El-Kishky, A.,
Goyal, S., Baines, M., Celebi, O., Wenzek, G., Chaud-
hary, V., et al. (2021). Beyond english-centric multi-
lingual machine translation. The Journal of Machine
Learning Research, 22(1):4839–4886.
Ficler, J. and Goldberg, Y. (2017). Controlling linguis-
tic style aspects in neural language generation. In
Brooke, J., Solorio, T., and Koppel, M., editors,
Proceedings of the Workshop on Stylistic Variation,
pages 94–104, Copenhagen, Denmark. Association
for Computational Linguistics.
Greene, D. and Cunningham, P. (2006). Practical solutions
to the problem of diagonal dominance in kernel doc-
ument clustering. In Proc. 23rd International Confer-
ence on Machine learning (ICML’06), pages 377–384.
ACM Press.
Ha, T.-L., Niehues, J., and Waibel, A. (2016). Toward mul-
tilingual neural machine translation with universal en-
coder and decoder. In Proceedings of the 13th Interna-
tional Conference on Spoken Language Translation,
Seattle, Washington D.C. International Workshop on
Spoken Language Translation.
Hanna, M. and Bojar, O. (2021). A fine-grained analysis of
BERTScore. In Proceedings of the Sixth Conference
on Machine Translation, pages 507–517, Online. As-
sociation for Computational Linguistics.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
ual learning for image recognition. In Proceedings of
the IEEE conference on computer vision and pattern
recognition, pages 770–778.
Hochreiter, S. and Schmidhuber, J. (1997). Long short-term
memory. Neural Computation, 9(8):1735–1780.
J. Schler, M. Koppel, S. A. and Pennebaker, J. (2006). Ef-
fects of age and gender on blogging. AAAI Spring
Symposium on Computational Approaches for Analyz-
ing Weblogs.
Johnson, M., Schuster, M., Le, Q. V., Krikun, M., Wu, Y.,
Chen, Z., Thorat, N., Vi
´
egas, F., Wattenberg, M., Cor-
rado, G., Hughes, M., and Dean, J. (2017). Google’s
multilingual neural machine translation system: En-
abling zero-shot translation. Transactions of the Asso-
ciation for Computational Linguistics, 5:339–351.
Keskar, N. S., McCann, B., Varshney, L. R., Xiong, C., and
Socher, R. (2019). Ctrl: A conditional transformer
language model for controllable generation.
Ni, J., Li, J., and McAuley, J. (2019). Justifying recom-
mendations using distantly-labeled reviews and fine-
grained aspects. In Proceedings of the 2019 Con-
ference on Empirical Methods in Natural Language
Processing and the 9th International Joint Conference
on Natural Language Processing (EMNLP-IJCNLP),
pages 188–197, Hong Kong, China. Association for
Computational Linguistics.
OpenAI (2023). Gpt-4 technical report.
Papineni, K., Roukos, S., Ward, T., and Zhu, W.-J. (2002).
Bleu: a method for automatic evaluation of machine
translation. In Proceedings of the 40th Annual Meet-
ing of the Association for Computational Linguistics,
pages 311–318, Philadelphia, Pennsylvania, USA.
Association for Computational Linguistics.
Post, M. (2018). A call for clarity in reporting BLEU scores.
In Proceedings of the Third Conference on Machine
Translation: Research Papers, pages 186–191, Bel-
gium, Brussels. Association for Computational Lin-
guistics.
Project Gutenberg (2024).
Sennrich, R., Haddow, B., and Birch, A. (2016). Control-
ling politeness in neural machine translation via side
constraints. In Proceedings of the 2016 Conference
of the North American Chapter of the Association for
Computational Linguistics: Human Language Tech-
nologies, pages 35–40, San Diego, California. Asso-
ciation for Computational Linguistics.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., Kaiser, L., and Polosukhin, I.
(2017). Attention is all you need. In Guyon, I.,
Luxburg, U. V., Bengio, S., Wallach, H., Fergus,
R., Vishwanathan, S., and Garnett, R., editors, Ad-
vances in Neural Information Processing Systems,
volume 30. Curran Associates, Inc.
Zhang, T., Kishore, V., Wu, F., Weinberger, K. Q., and
Artzi, Y. (2020). Bertscore: Evaluating text genera-
tion with bert. In International Conference on Learn-
ing Representations.
Improving Controlled Text Generation via Neuron-Level Control Codes
581
