
Stateful Monitoring and Responsible Deployment of AI Agents
Debmalya Biswas
Wipro AI, Switzerland
Keywords:
Multi-Agent Systems, Autonomous Agents, Agent Architecture, Monitoring, Stateful Execution, Responsible
AI.
Abstract:
AI agents can be disruptive given their potential to compose existing models and agents. Unfortunately,
developing and deploying multi-agent systems at scale remains a challenging problem. In this paper, we
specifically focus on the challenges of monitoring stateful agents and deploying them in a responsible fashion.
We introduce a reference archi tecture for AI agent platforms, highli ghting the key components to be considered
in designing the respective solutions. From an agent monitoring perspective, we show how a snapshot based
algorithm can answer different types of agent execution state related queries. On the responsible deployment
aspect, we show how responsible AI dimensions relevant to AI agents can be integrated in a seamless fashion
with the underlying AgentOps pipelines.
1 INTRODUCTION
In the generative AI context, Auto-GPT (Significant
Gravitas, 2023) is representative o f an autonomous
AI agent that can execute complex tasks, e.g., make
a sale, plan a trip, make a flight booking, bo ok a con-
tractor to do a hou se job , o rder a pizza. Given a user
task, Auto-GPT a ims to identify (compose) an agent
(group of agents) capable to executing the given task.
AI agents (Park et al., 20 23) follow a long
history of research around multi-agent systems
(MAS) (Weiss, 2016), esp., goal oriented agents (Bor-
des et al., 2017 ; Yan et al., 2015). A high-level a p-
proach to solving such complex tasks involves: ( a )
decomp osition of th e given co mplex task into (a hi-
erarchy or workflow of) simple tasks, followed by
(b) composition of agents able to execute the simpler
tasks. This can be achieved in a dy namic or static
manner. In the dynamic approach, given a c omplex
user task, the system comes up with a plan to fulfill
the request dependin g on the capabilities of available
agents at run-time. In the static approach, give n a set
of agents, composite agents are defined manua lly at
design-time combining their cap abilities.
Unfortu nately, designing and deploying AI agents
remains challenging in practice. In this pape r, we fo-
cus o n primarily two asp e cts of AI agent platforms:
• given the complex and long-running nature of AI
agents, we discuss app roaches to ensure a reliable
and stateful AI agent execution.
• adding the responsible AI dimension to AI agents.
We highlight issues specific to AI agents and
propose approaches to establish an integrated AI
agent platform governed by responsible AI prac-
tices.
The r e st of the paper is organized as follows. In
Section 2, we introduce a refere nce architecture for
AI agent platforms, highlighting the key components
to be conside red in designing the following solutions.
In Section 3, we identify the key challenges to moni-
tor stateful AI agents, and outline a snapshot based al-
gorithm that can answer the relevan t age nt execution
state related queries. We consider responsible deploy-
ment of agents in Section 4, showing how responsi-
ble AI dimensions can be integrated in the underlying
AgentOps pipelines. Finally, Section 5 con c ludes the
paper and provides some directions for future work.
2 AGENT AI PLATFORM
REFERENCE ARCHITECTURE
In this section, we focus on identifying the key com-
ponen ts of a refe rence AI agent platform illustrated in
Fig. 1:
• Reasoning layer
• Agent marketplace
• Integration layer
Biswas, D.
Stateful Monitoring and Responsible Deployment of AI Agents.
DOI: 10.5220/0013160300003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 1, pages 393-399
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
393

• Shared mem ory layer
• Governance la yer, including expla inability, pri-
vacy, security, etc.
Given a u ser task, th e goal of an AI agen t pla tform
is to identify (compose) an agent (group of agents)
capable to executing the given task. So the first com-
ponen t that we need is a reasoning layer capable of
decomp osing a task into sub-tasks, with execution of
the respective agen ts orchestrated by an orch estration
engine.
Chain of Thought (CoT) (Wei et al., 2022) is
the most widely used decomposition framework to-
day to transform complex tasks into multiple manage-
able ta sks and shed light into an interpretation of the
model’s thinking process. CoT can be implemented
using two approaches: user prompting and automated
approa c h.
• User Prompting: Here, during prompting, user
provides the lo gic about how to appr oach a certain
problem and LLM will solve similar problem s us-
ing same logic and return the output a long with
the logic.
• Automating Chain of Thought Prompting: Manu-
ally handcrafting CoT can be time consuming and
provide sub-optimal solution, Auto matic Chain of
Thought (Auto -CoT) (Zhang et al., 2022) can be
leveraged to generate the r easoning chain s auto-
matically thus eliminating the human interven-
tion.
Tree of Thoughts (Yao et al., 2023) extends CoT
by exploring multiple deco mposition possibilities in
a structured way. Fr om each thought, it can branch
out and generate multiple next-level thou ghts, creat-
ing a tree-like structure that can be explored by BFS
(breadth-first search) o r DFS (depth-first search) with
each state evaluated by a classifier (via a prompt) or
majority vote.
Agent composition implies the existence of an
agent marketplace / registry of agents - with a well-
defined descrip tion of the agent capabilities and con-
straints. For example, let u s consider a house painting
agent C whose services can be reserved online (via
credit card). Given this, the fact that the user requires
a valid c redit card is a constrain t, and the fact that
the user’s house will be painted within a certain time-
frame are its capabilities. In addition, we also need
to consider any constraints of C during the actual ex-
ecution phase, e.g., the fact that C can only provide
the service on weekdays (and not on weekends). In
general, constraints refer to the conditions that need
to be satisfied to initiate an execution and capabilities
reflect the expected outcome after the execution ter-
minates.
In the context of MAS, specifically, previous
works (Capezzuto et al., 2021; Trabelsi et al., 2022;
Veit et al., 2001) have conside red agent limitations
during the discovery process. (Veit et al., 2001) pro-
poses a con figurable XML based framework called
GRAPPA (Generic Request Architecture for Passive
Provider Agents) for agent matchmaking. (Capez-
zuto et al., 2021) specifies a compact formulation for
multi-agent task allocation with spatial and tempo-
ral constraints. (Trabelsi et al., 2022) considers agent
constraints in the form of incompatib ility with re-
sources. The au thors then propose an optimal match-
making algorithm that allows the agents to relax their
restrictions, within a budget. Refer to (Biswas., 2024)
for a detailed discussion on the discovery aspect of AI
agents.
Given the need to orchestrate multiple agen ts, we
also need an integration layer supportin g different
agent interaction patterns, e. g., agen t-to-agen t API,
agent API providing output for human consump tion,
human triggering an AI agent, AI agent-to-agent with
human in the loop. The integration patterns need to
be supp orted by the underlying AgentOps platform.
To accommodate multiple lon g-running agents,
we a lso need a shared long-term mem ory layer en-
abling d ata transfer between agents, storing interac-
tion data such tha t it can be used to persona lize future
interactions. The standard approa ch here is to save th e
embedd ing representation of agent in formation into
a vector database that can support maximum inner
product sear ch ( MIPS). For fast retrieval, the approx-
imate nearest neighbors (ANN) algorithm is used that
returns approximately top k-nearest neighbor s with an
accuracy trade-off versus a huge speed ga in.
Finally, the governance layer. We need to ensure
that data shared by the user specific to a task, or user
profile data that cuts across tasks; is only shared with
the relevant agents (authenticatio n and access con-
trol). We further consider the different responsible
AI dimensions in terms of data quality, privacy, re-
producibility and explainability to enable a well gov-
erned AI agent platform.
3 STATEFUL AGENT
MONITORING
Stateful execution (Lu et al., 2024) is an inherent char-
acteristic of any distributed systems platform, and can
be considered as a critical requiremen t to materialize
the orchestration layer of an AI agent platform. Given
this, we envision that agent monitor ing together with
failure recovery will become more and more criti-
cal as AI agent platforms become enterprise ready,
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
394
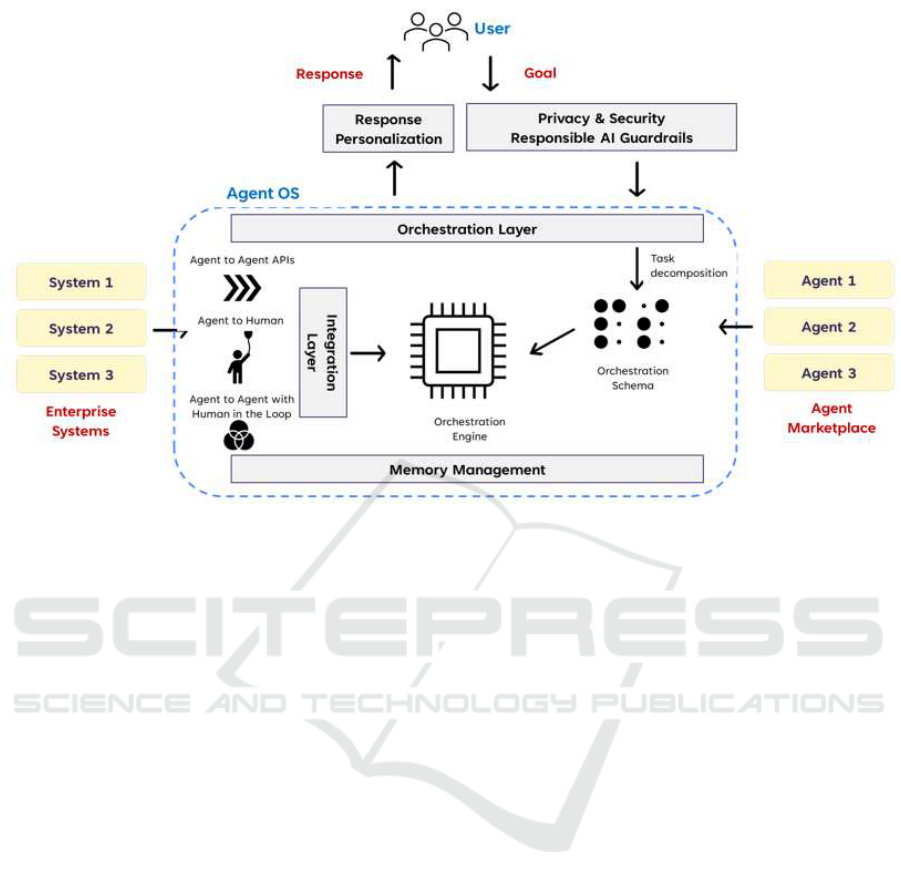
Figure 1: AI agent platform reference architecture.
and start supporting productionized deployments of
AI agents.
However, monitoring AI agents (similar to moni-
toring large-scale distributed systems) is challengin g
because of the following reaso ns:
• No global observer: Due to the ir distributed na-
ture, we c annot assume th e existence of an entity
having visibility over the entire execution. In fact,
due to their privacy and autonomy requirements,
even the composite agent may not have visibil-
ity over the internal processing of its component
agents.
• Non-determinism: AI agents allow parallel com-
position of processes. Also, AI agents usually de-
pend on external factors for their execution. As
such, it may n ot be possible to predict their be-
havior before the actual execution. For example,
whether a flight booking will succeed or not de-
pends on the number of available seats (at the time
of bo oking) and cannot be predicted in advance.
• Communication delays: Communication delays
make it impossible to record the states of all the
involved agents instantaneously. For example,
let us assume that age nt A initiates an attempt to
record the state of the composition. Then, by the
time the request (to record its state) reaches agent
B and B records its state, ag ent A’s state might
have changed.
• Dynamic configuration: The agents are selected
incrementa lly as the execution progresses (dy-
namic binding). Thus, the “comp onents” of the
distributed system may not be known in ad vance.
To summar ize, agent monitoring is c ritical given
the complexity and long running n ature of AI agents.
We define agent monitoring as the a bility to find out
where in the process the execution is and whether any
unanticipated glitches have appeared. We discuss the
capabilities and limitations of acqu iring age nt execu-
tion snapshots with respect to answering the follow-
ing typ es of qu eries:
• Local qu e ries: Queries which can be answer e d
based on the local state information of an agent.
For example, queries such as “What is the curre nt
state of agent A’s execution?” or “Has A reached a
specific state?”. Local queries can be answered by
directly querying the concerned agent provider.
• Composite queries: Queries expressed over the
states of several agents. We assume that any query
related to the status of a composition is expressed
as a conjunction of the states of individual agent
executions. Examples of status queries: “Have
agents A, B and C reached states x, y and z r espec-
tively ?” Such queries have be en referred to as sta-
ble predicates in literature. Stable pre dicates are
defined as predicates which do not become false
once they have become true.
• Histor ical qu eries: Queries re late d to the execu-
tion history of the composition. For example,
Stateful Monitoring and Responsible Deployment of AI Agents
395

“How many times have agents A and B been sus-
pended?”. If the query is answered usin g an ex-
ecution snap shot algorithm, then it needs to be
mentioned that the results are with respect to a
time in the past.
• Relationship quer ie s: Queries based on the re-
lationship between states. For example, “What
was the state of agent A when agent B was in
state y?” Unfortun ately, execution snapshot based
algorithm s do not guarantee answers for such
queries. For example, we would not be able to an-
swer the query unless we have a snapshot whic h
captures the state of agent B when it was in state y.
Such predicates have been referred to as unstable
predicates in literature. Unstable predicates keep
alternating their va lues between true and false -
so are difficult to answer based on snapshot algo-
rithms.
We outline the AI agent monitoring approach and
solution architecture in the next section.
3.1 Agent Snapshot Monitoring
We assume the existence of a coordinator and log
manager corresponding to each agent as shown in
Fig. 2. We also assume that e a ch agent is responsi-
ble for executing a single task.
The coordinator is responsible for all non-
functional aspects related to the exec ution o f the agent
such as monitoring, transactions, etc. The log man-
ager logs information about any state transitions as
well as any messages sent/received by the ag ent. The
state transitions and messages considered are as out-
lined in Fig. 3 :
• Not - E xecuting (NE): T he agent is waiting for an
invocation.
• Executing (E): On receiving an invocation mes-
sage (IM), the agent changes its state from NE to
E.
• Suspended (S) and suspended by invo ker (IS): An
agent, in state E, may chang e its state to S due to
an internal event (suspend) or to IS on the receipt
of a suspend message (SM). Conversely, the tran-
sition from S to E occurs due to an internal event
(resume) and f rom IS to E on re ceiving a resume
message (RM).
• Canceling (CI), canceling due to invoker (ICI)
and canceled (C): An agen t, in state E/S/I S, may
change its state to CI due to an internal event (can-
cel) or ICI on the receipt of a c a ncel message
(CM). Once it finishes cancellation, it changes its
state to C and sends acCanceled message (CedM)
to its parent. Note that cancellation may require
canceling the effects of some of its comp onent
agents.
• Terminated (T) and compensating (CP): The
agent changes its state to T once it has finished ex-
ecuting the task. On termination, the agent sends
a terminated message (TM) to its parent. An agent
may be required to cance l a task even after it has
finished executing the task (compensation). An
agent, in state T, changes its state to CP on re-
ceiving the CM. Once it finishes compensation, it
moves to C and sends a CedM to its parent agent.
We assume that the composition schema (static
composition) specifies a partial order for agent tasks.
We define the happened-before relation b etween
agent tasks as follows:
A task a happen e d-before task b (a → b) if and
only if one of the following holds:
1. there exists a control / data dependency between
tasks a and b such that a needs to terminate before
b ca n start executing.
2. there exists a task c such that a → c and c → b.
A task, on failure, is retried with the same or dif-
ferent agents until it completes successfully (termi-
nates). Note that each (retrial) attemp t is considered
as a new invocation and would be logged accordingly.
Finally, to accommodate asynchro nous commu nica-
tion, we assume the presence of input/output (I/O)
queues. Basically, each agent ha s an I/O qu eue with
respect to its parent and component agents - as shown
in Fig. 3.
Given synchronized clocks and logging (as dis-
cussed above), a snapshot of the hierarchical compo-
sition at time t would consist of the logs of all the
“relevant” agents until time t.
The relevan t agents can b e determined in a recur-
sive manner (starting from the ro ot agent) by consid-
ering the agents of the invoked tasks recorded in the
parent agent’s log un til time t. If message timestamps
are used then we ne e d to con sider the skew while
recording the logs, i.e., if a parent agent’s log was
recorde d until time t then its component agents’ logs
need to be recorded until (t + skew). The states of the
I/O queues can be dete rmined from the state transition
model.
4 RESPONSIBLE AGENTS
The growing adoption of generative AI, esp. with
respect to the adoption of large langu a ge models
(LLMs), has reignited the discu ssion around responsi-
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
396
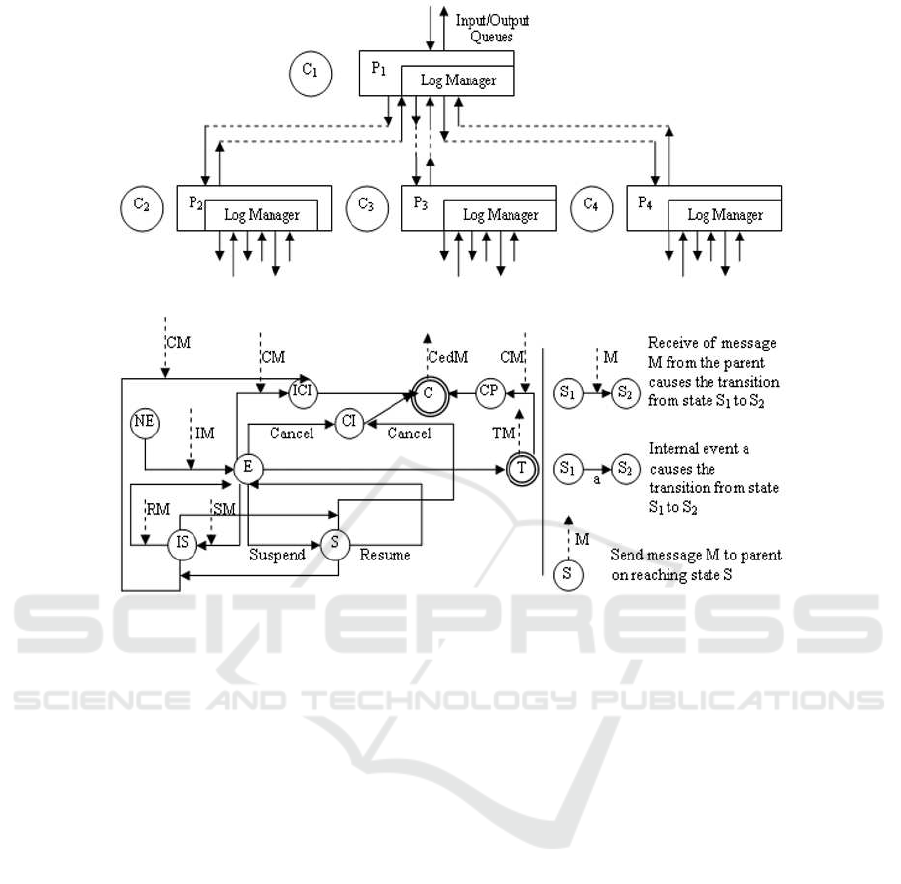
Figure 2: Agent monitoring i nfrastructure.
Figure 3: Agent execution lifecycle.
ble AI - to ensure that AI/ML systems are responsibly
trained and deployed.
The table in Fig. 4 sum marizes the key challenges
and solutions in implementing responsible AI for AI
agents in comparison to
• ChatGPT style large language model (LLM) APIs
• LLM fine-tuning: LLMs are generic in nature.
To realize the full po tential of LLMs for enter-
prises, they need to be contextua lize d with enter-
prise knowledge c a ptured in terms of documents,
wikis, business processes, etc. This is achieved
by fine-tuning an LLM with enterprise knowledge
/ embeddings to develop a context-specific small
languag e model (SLM)
• Retrieval-augmented-genera tion (RAG): Fine-
tuning is a computationally intensive process.
RAG provides a viable alternative by providing
additional context with the prompt, grounding the
retrieval and responses to the given context. The
prompts can be relatively long, so it is possible to
embed enterprise context within th e prompt itself.
We expand on the above points in the re st of the
paper to enable an integrated Ag e ntOps pipeline with
responsible AI governance.
Data consistency: The data used f or training (esp.,
fine-tunin g) the L LM should be accurate and precise,
which mean s the relevant data pertaining to the spe-
cific use-case should be used to train the LLMs, e.g.
if the use case is to generate summary of a medi-
cal prescription - the user should not use other data
like Q&A of a diag nosis; user must use only medical
prescriptions and corresponding summarization of th e
prescription. Many a times, da ta pipelines need to be
created to ingest the data and feed that to LLMs. In
such scenarios, extra caution needs to be exercised to
consume the running text fields a s these fields hold
mostly inconsistent a nd incorrect data.
Bias/Fairness: With re spect to model perfor mance
and reliability, it is difficult to control undesired bi-
ases in black-bo x LLMs, thoug h it can be controlled
to some extent by using unif orm and unbiased data to
fine-tune the LLMs and/or contextualize the LL Ms in
a RAG architecture.
Accountability: To make LLMs more reliable,
it is rec ommended to have manual validation o f the
LLM’s outpu ts. Involving humans ensures if LLMs
hallucinate or provide wrong response, a human can
evaluate and make the necessary corrections.
Hallucination: In case of using LLM APIs or or-
chestrating multiple AI agents, hallucination likeli-
hood increases with the in crease in the number of
Stateful Monitoring and Responsible Deployment of AI Agents
397
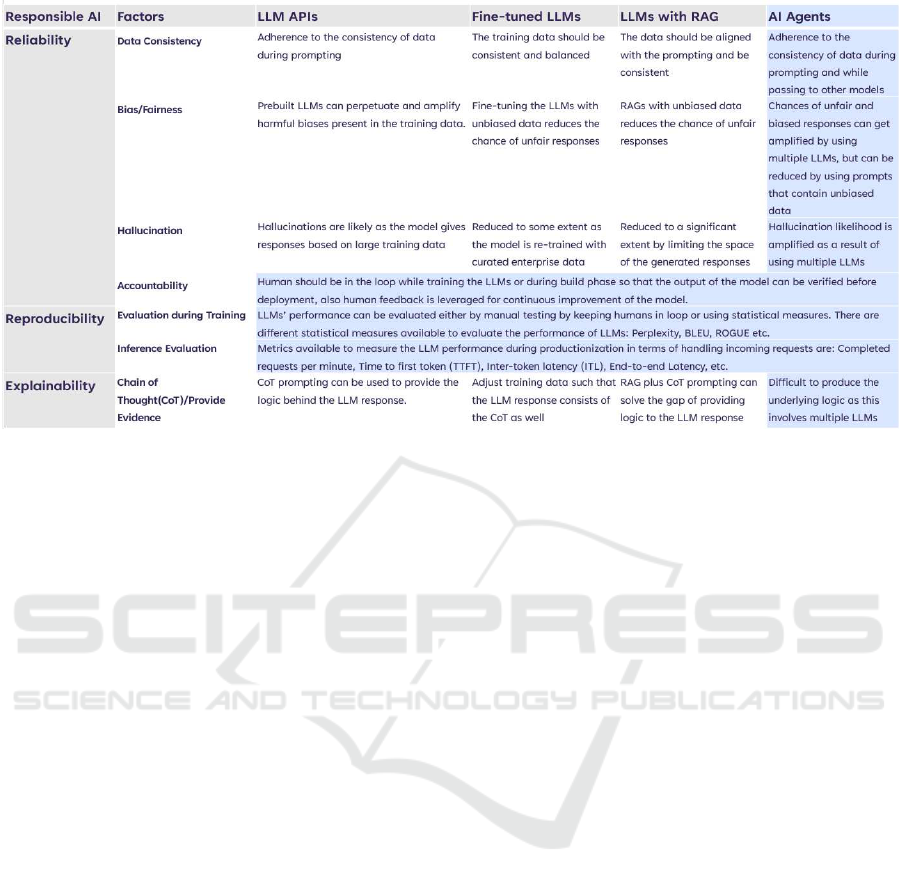
Figure 4: Responsible AI challenges for Agentic AI.
agents involved. The right promp ts can help but only
to a limited extent. To further limit the hallucination,
LLMs need to be fine-tuned with cura te d data and/or
limit the search space of r esponses to r e levant and re-
cent enterprise data.
Data Privacy: With respect to conversational pri-
vacy (Biswas, 2020), we need to consider the privacy
aspects of enter prise data provided as context (RAGs)
and/or enterprise data used to fine-tune the LLMs. In
addition, the novel privacy asp ect here is to consider
the privacy risks of data (prompts) provided voluntar-
ily b y the end-users, which can potentially be u sed as
training data to re-train / fine-tune the LLMs.
5 CONCLUSION
Agentic AI is a disruptive technology, and there is
currently a lot of interest a nd focus in making the
underlying agent platforms ready for enterprise adop-
tion. Towards this end, we outlined a reference a rchi-
tecture for AI agent platforms. We primarily focused
on two aspects critical to enable scalable and respon-
sible ado ption of A I agents - an AgentOps pipeline
integrated with monitoring and responsible AI princi-
ples.
From an agent monitoring perspective, we focused
on the challenge of capturing the state of a (hierar-
chical) multi-agent system at any give n point of time
(snapshot) . Snapshots usually reflect a state of a dis-
tributed system which “might have occurred”. To-
wards this end, we discussed the different types of
agent execution related queries and showed how we
can answer them using the ca ptured snapshots.
To enable responsible deployment of agents, we
highlighted the responsible AI dimensions relevant to
AI agents; and showed how they can be integrated
in a seamless fashion with the underlying Agen-
tOps pipelines. We believe that these will effectively
future- proof agentic AI investments and ensur e that
AI agents are able to cope as the AI agent platfor m
and regulatory landscap e evolves with time.
REFERENCES
Biswas, D. (2020). Privacy Preserving Chatbot Conver-
sations. In IEEE Third International Conference
on Artificial Intelli gence and Knowledge Engineering
(AIKE), pages 179–182.
Biswas., D. (2024). Constraints Enabled Autonomous
Agent Marketplace: Discovery and Matchmaking. In
Proceedings of the 16th International Conference on
Agents and Artificial Intelligence (ICAART ) , pages
396–403.
Bordes, A., B oureau, Y.-L., and Weston, J. (2017). Learning
End-to-End Goal-Oriented Dialog.
Capezzuto, L., Tarapore, D., and Ramchurn, S. D. ( 2021).
Large-Scale, Dynamic and Distributed Coalition For-
mation with Spatial and Temporal Constraints. In
Multi-Agent Systems, pages 108–125. Springer Inter-
national Publishing.
Lu, J., Holleis, T., Zhang, Y., Aumayer, B., Nan, F., Bai, F.,
Ma, S., Ma, S., Li, M., Yi n, G., Wang, Z., and Pang,
R. (2024). ToolSandbox: A Stateful, Conversational,
Interactive Evaluation Benchmark for LLM Tool Use
Capabilities.
Park, J. S., O’Brien, J. C., Cai, C. J., Morris, M. R., Liang,
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
398

P., and Bernstein, M. S. (2023). Generative Agents:
Interactive Simulacra of Human Behavior.
Significant Gravitas (2023). AutoGPT. https://github.com/
Significant-Gravitas/Auto-GPT.
Trabelsi, Y., Adiga, A., Kraus, S., and Ravi, S. S. (2022).
Resource All ocation to Agents with Restrictions:
Maximizing Likelihood with Minimum Compromise.
In Multi-Agent Systems, pages 403–420. Springer In-
ternational Publishing.
Vei t, D., M¨uller, J. P., Schneider, M., and Fiehn, B. (2001).
Matchmaking for Autonomous Agents i n Electronic
Marketplaces. In Proceedings of the Fifth Inter-
national Conference on Autonomous Agents, page
65–66. Association for Computing Machinery.
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E. H.,
Le, Q., and Zhou, D. (2022). Chain of Thought
Prompting Elicits Reasoning in Large Language Mod-
els. CoRR, abs/2201.11903.
Weiss, G. (2016). Multiagent Systems, Second Edition.
Intelligent Robotics and Autonomous Agents. MIT
Press, 2nd edition.
Yan, J., Hu, D., Liao, S. S., and Wang, H. (2015). Mining
Agents’ Goals in Agent-Oriented Business Processes.
ACM Trans. Manage. Inf. Syst., 5(4).
Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T. L., Cao,
Y., and Narasimhan, K. (2023). Tree of Thoughts: De-
liberate Problem Solving with Large Language Mod-
els.
Zhang, Z., Zhang, A., Li, M., and Smola, A. (2022). Auto-
matic Chain of Thought Prompting in Large Language
Models.
Stateful Monitoring and Responsible Deployment of AI Agents
399
