
Data-Driven Fairness Generalization for Deepfake Detection
Uzoamaka Ezeakunne
1 a
, Chrisantus Eze
2 b
and Xiuwen Liu
1 c
1
Department of Computer Science, Florida State University, Tallahassee FL, U.S.A.
2
Department of Computer Science, Oklahoma State University, Stillwater OK, U.S.A.
Keywords:
Deepfake Detection, Image Manipulation Detection, Fairness, Generalization.
Abstract:
Despite the progress made in deepfake detection research, recent studies have shown that biases in the train-
ing data for these detectors can result in varying levels of performance across different demographic groups,
such as race and gender. These disparities can lead to certain groups being unfairly targeted or excluded.
Traditional methods often rely on fair loss functions to address these issues, but they under-perform when
applied to unseen datasets, hence, fairness generalization remains a challenge. In this work, we propose a
data-driven framework for tackling the fairness generalization problem in deepfake detection by leveraging
synthetic datasets and model optimization. Our approach focuses on generating and utilizing synthetic data
to enhance fairness across diverse demographic groups. By creating a diverse set of synthetic samples that
represent various demographic groups, we ensure that our model is trained on a balanced and representative
dataset. This approach allows us to generalize fairness more effectively across different domains. We employ
a comprehensive strategy that leverages synthetic data, a loss sharpness-aware optimization pipeline, and a
multi-task learning framework to create a more equitable training environment, which helps maintain fairness
across both intra-dataset and cross-dataset evaluations. Extensive experiments on benchmark deepfake detec-
tion datasets demonstrate the efficacy of our approach, surpassing state-of-the-art approaches in preserving
fairness during cross-dataset evaluation. Our results highlight the potential of synthetic datasets in achieving
fairness generalization, providing a robust solution for the challenges faced in deepfake detection.
1 INTRODUCTION
Deepfake technology, which combines ”deep learn-
ing” and ”fake,” represents a significant advancement
in media manipulation capabilities. Leveraging deep
learning techniques, it enables highly convincing fa-
cial manipulations and replacements in digital me-
dia. While technologically impressive, this capabil-
ity poses serious societal risks, particularly in spread-
ing misinformation and eroding public trust. In re-
sponse, researchers have developed various deepfake
detection techniques that have shown promising ac-
curacy rates in identifying manipulated content (Xu
et al., 2023; Zhao et al., 2021a; Ezeakunne and Liu,
2023; Guo et al., 2022; Pu et al., 2022b; Wang et al.,
2022).
However, a critical challenge has emerged in
the form of fairness disparities across demographic
groups as described in (Trinh and Liu, 2021; Xu
a
https://orcid.org/0009-0006-5524-5138
b
https://orcid.org/0000-0001-5440-4316
c
https://orcid.org/0000-0002-9320-3872
et al., 2022; Nadimpalli and Rattani, 2022; Masood
et al., 2023). Studies have revealed that current detec-
tion methods perform inconsistently across different
demographics, particularly showing higher accuracy
rates for individuals with lighter skin tones compared
to those with darker skin tones (Trinh and Liu, 2021;
Hazirbas et al., 2021). This bias creates a concern-
ing vulnerability where malicious actors could poten-
tially target specific demographic groups with deep-
fakes that are more likely to evade detection.
While recent algorithmic approaches have shown
promise in improving detection fairness when train-
ing and testing data use similar forgery techniques
(Ju et al., 2024), the real-world application presents
a more complex challenge. Deepfake detectors, typ-
ically developed and trained on standard research
datasets, must ultimately operate in diverse real-world
environments where they encounter deepfakes cre-
ated using various, potentially unknown forgery tech-
niques. This generalization capability is crucial for
practical deployment, particularly on social media
platforms where manipulated content proliferates.
582
Ezeakunne, U., Eze, C. and Liu, X.
Data-Driven Fairness Generalization for Deepfake Detection.
DOI: 10.5220/0013161000003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 3, pages 582-591
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
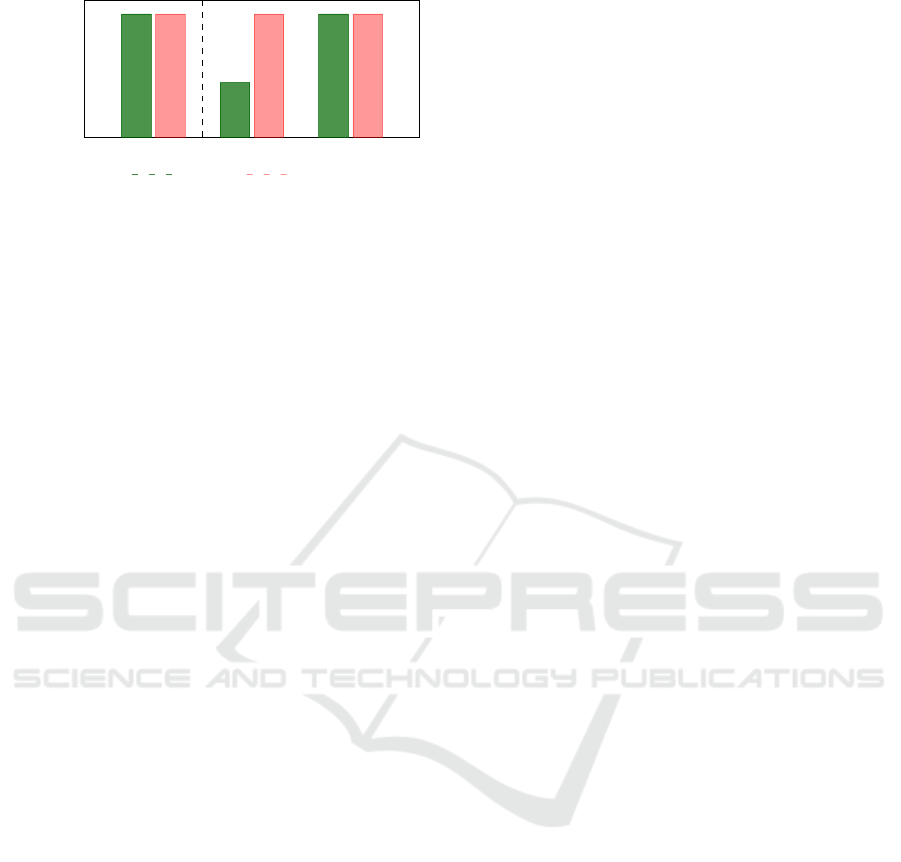
Train Set Test Set A Test Set B
0
50
100
Peformance (%)
Fairness Detection
Figure 1: Fairness Generalization Comparison: A detec-
tor’s accuracy can generalize well to unseen test sets A and
B, maintaining consistent detection performance. However,
while fairness metrics are preserved on test set B, they fail
to generalize to test set A, highlighting the challenge of
achieving consistent fairness across different datasets.
While current methods of deepfake detection fo-
cus almost entirely on detection accuracy, it is very
critical to also consider how well these approaches
generalize to fairness. As shown in Figure 1, if a de-
tector was trained on a dataset and its performance for
fairness and detection on the training set are shown
on the left bars, and the same detector is tested on
an unseen dataset (test set A) at the middle, the de-
tection performance, mostly in terms of model accu-
racy may generalize but fairness may fail to general-
ize. On the other hand, when tested on another un-
seen dataset (test set B), it can retain its fairness and
detection performance. As can be seen in Figure 1,
the detector’s detection performance can be general-
ized to both datasets but could fail to ensure fairness
generalization on test set A.
Our research addresses these challenges through
a comprehensive approach that combines data-centric
and algorithmic solutions. We propose a novel frame-
work that utilizes self-blended images (SBI) for syn-
thetic data generation to balance demographic repre-
sentation in the training data, addressing a key source
of fairness disparities. This is coupled with a multi-
task learning architecture that simultaneously opti-
mizes for both detection accuracy and demographic
fairness. The architecture employs an EfficientNet
backbone for feature extraction, with separate heads
for deepfake detection and demographic classifica-
tion.
To enhance generalization capabilities, we im-
plement Sharpness-Aware Minimization (SAM) op-
timization (Lin et al., 2024), which helps find more
robust solutions by flattening the loss landscape. Our
framework also incorporates a carefully designed loss
function that balances classification accuracy, demo-
graphic prediction, and fairness constraints. This ap-
proach represents a significant advancement in creat-
ing deepfake detection systems that are not only ac-
curate but also fair and generalizable across different
demographic groups and forgery techniques.
As demonstrated in our experimental results,
while traditional detectors may maintain detection ac-
curacy across different test sets, they often fail to
preserve fairness when encountering new data. Our
method addresses this limitation by specifically opti-
mizing for both performance metrics, ensuring con-
sistent fairness across different demographic groups
even when tested on previously unseen datasets.
Therefore, our contributions are as follows:
• We propose synthetic data balancing, to balance
training datasets across demographics to aid fair
learning in deepfake detection.
• Our framework introduces a multi-task architec-
ture, leveraging two classification heads; one for
deepfake detection and another for learning the
demographic features of the datasets. This en-
ables the system to not only detect forgery but
also ensure that it is aware of demographic biases,
making it more equitable across different groups.
• The multi-task learning approach, combined with
sharpness-aware loss optimization and robust fea-
ture extraction, makes the system more effective
at generalizing the fairness and detection perfor-
mances to unseen datasets.
• We performed intra-dataset and cross-dataset
evaluations to show the improved performance of
this method.
2 RELATED WORK
2.1 Deepfake Detection
To train deepfake detection models that perform well
during training and in practice; on unseen datasets,
several studies (Li et al., 2020a; Zhao et al., 2021b;
Guan et al., 2022; Li, 2018) have introduced novel
methods for manually synthesizing a variety of face
forgeries similar to deepfakes. These methods help
deepfake detection models learn more generalized
representations of artifacts, improving their ability to
identify deepfakes across different scenarios.
The authors in (Chen et al., 2022) proposed en-
hancing the diversity of forgeries through adversar-
ial training to improve the robustness of deepfake de-
tectors in recognizing various forgeries. FaceCutout
(Das et al., 2021) uses facial landmarks and ran-
domly cuts out different parts of the face (such as
the mouth, eye, etc.) to improve the robustness of
deepfake detection. Face-Xray (Li et al., 2020a) on
the other hand, involves generating blended images
Data-Driven Fairness Generalization for Deepfake Detection
583

(BI) by combining two different faces using a global
transformation and then training a model to distin-
guish between real and blended faces. The authors
in (Shiohara and Yamasaki, 2022) expanded on this
concept by creating a synthetic training dataset with
self-blended images (SBI), which are created by ap-
plying a series of data augmentation techniques to
real images. SBI has demonstrated even better gen-
eralization to previously unseen deepfakes compared
to Face-Xray (Li et al., 2020a). After synthesizing
forged images (i.e., pseudo deepfakes) using special-
ized augmentation techniques, they trained a binary
classification model to perform the detection task.
2.2 Fairness in Deepfake Detection
Despite efforts to enhance the generalization of deep-
fake detection to unseen data, limited progress has
been made in mitigating biased performance when
testing on both the same (intra-domain) and different
(cross-domain) dataset distributions.
Recent studies have highlighted significant fair-
ness issues in deepfake detection, revealing biases in
both datasets and detection models (Masood et al.,
2023). The work done by (Trinh and Liu, 2021)
and (Hazirbas et al., 2021) discovered substantial er-
ror rate differences across demographic groups, while
(Pu et al., 2022a) found that the MesoInception-4
model by (Afchar et al., 2018) was biased against
both genders. The authors in (Xu et al., 2022) advo-
cated for diverse dataset annotations to address these
biases, and (Nadimpalli and Rattani, 2022) introduced
a gender-balanced dataset to reduce gender-based per-
formance bias. However, these techniques led to only
modest improvements and required extensive data an-
notation. Furthermore, (Ju et al., 2024) worked to im-
prove fairness within the same dataset (intra-domain),
but did not address fairness generalization between
different datasets (cross-domain).
2.3 Fairness Generalization in Deepfake
Detection
Very little work has been done to achieve fairness
generation in deepfake detection. The recent work
done in (Lin et al., 2024) proposed a novel feature-
based technique to achieve fairness generalization and
preservation. They combine disentanglement learn-
ing, fairness learning, and loss optimization to pre-
serve fairness in deepfake detection. In the disen-
tanglement learning module, they utilized a disen-
tanglement loss to expose demographic and domain-
agnostic forgery features. While the fairness learn-
ing module fused the two features from the disentan-
glement learning module to obtain predictions for the
samples. Their framework, however, was trained on
a dataset with imbalanced demographic groups which
introduced some bias to their model.
Our framework approaches and solves fairness
generalization using a data-driven approach. Our
research prioritizes fairness and eliminates bias due
to dataset imbalance by using synthetic datasets to
balance the dataset distribution across the different
groups. We also used a multi-task learning approach,
combined with fairness and loss sharpness-aware op-
timization and robust feature extraction to achieve
significant performance improvements on both intra-
dataset evaluation and cross-dataset evaluation.
3 PROPOSED METHOD
Our method aims to enhance both the generalization
and fairness of deepfake detection models through a
data-centric strategy. This section provides a detailed
overview of the problem formulation, followed by the
process of generating our synthetic dataset. We then
outline our approach for addressing dataset imbal-
ance and conclude with a discussion of our multi-task
learning framework, designed to simultaneously op-
timize for accuracy and fairness across demographic
groups.
3.1 Problem Setup
Given an input face image I, the goal is to train a deep-
fake detection model g that classifies whether I is a
deepfake (fake) or a real face. The model g is defined
as:
g : I → {0, 1} (1)
where g(I) indicates the predicted label, with
g(I) = 1 denoting a deepfake and g(I) = 0 denoting a
real face.
Detection Accuracy: The primary goal is to max-
imize the detection accuracy. Given a set of face im-
ages {I
i
}
N
i=1
with true labels {y
i
}
N
i=1
, the overall accu-
racy of the model g is:
Accuracy =
1
N
N
∑
i=1
1(g(I
i
) = y
i
) (2)
where 1(·) is the indicator function that equals 1 if
the prediction matches the true label.
Fairness Constraint: The detector should per-
form fairly across different demographic groups. Let
D represent the demographic group associated with
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
584

an image, and D
k
be the set of images from the demo-
graphic group k. Define Accuracy
k
as the accuracy of
the detector on images from demographic group k:
Accuracy
k
=
1
|D
k
|
∑
i∈D
k
1(g(I
i
) = y
i
) (3)
The fairness of the detector is assessed by mini-
mizing the maximum disparity in accuracy across dif-
ferent demographic groups:
Fairness = max
k,l
|
Accuracy
k
− Accuracy
l
|
(4)
where k and l denote different demographic
groups. The objective is to minimize this fairness dis-
parity.
3.2 Synthetic Data Balancing
To enhance fairness in deepfake detection, we utilize
a technique based on self-blended images (SBI), as
proposed in (Shiohara and Yamasaki, 2022). This
technique involves generating synthetic images to
balance the demographic distribution of the dataset,
thereby improving fairness across various demo-
graphic groups. The dataset samples are shown in
Figure 2. Each real sample (upper row) has a cor-
responding fake sample (bottom row), so the dataset
is also balanced across real and fake classes. The pro-
cess of data balancing using a synthetic dataset is de-
tailed in the sections below.
Generation of Synthetic Images
Let I = {I
1
, I
2
, . . . , I
n
} represent the set of real face
images, where each I
i
belongs to a specific demo-
graphic group. The goal is to generate a set of self-
blended images S = {S
1
, S
2
, . . . , S
m
} using the follow-
ing steps:
Base Image Selection:
Select a diverse subset of
real face images, I
base
⊂ I , ensuring coverage across
demographic categories.
Augmentation Process: Apply a series of transfor-
mations to generate self-blended images. For a base
image I
i
, the synthetic image S
j
is generated using a
blend function B as follows:
S
j
= B(I
i
, T
k
(I
i
)) (5)
where T
k
represents a transformation operation such
as scaling, rotation, or color adjustment, and B is the
blending function that combines I
i
with T
k
(I
i
).
Dataset Balancing
To balance the dataset, we increase the representation
of underrepresented demographic groups:
Demographic Representation: Define the demo-
graphic groups D = {D
1
, D
2
, . . . , D
r
}. Let I
D
k
⊂ I
be the set of images belonging to demographic group
D
k
. To balance the dataset, we create synthetic im-
ages S
D
k
for each group D
k
:
B = I ∪ S (6)
where B is the balanced dataset and S =
S
r
k=1
S
D
k
.
This dataset B , is balanced across all the demo-
graphics, and also equal in terms of the number of
real and fake samples.
3.3 Multi-Task Learning
We propose a dual-task learning framework to en-
hance the fairness of deepfake detection models by
leveraging demographic information. The architec-
ture shown in Figure 3, is designed to improve the
generalization of deepfake detection across various
demographic groups, reducing bias in prediction ac-
curacy between these groups.
The input images are passed through the Effi-
cientNet encoder (Tan, 2019), which extracts high-
dimensional feature representations. These features
capture both low-level information (like textures and
edges) as well as high-level semantic features (such as
facial structure and potential tampering artifacts). The
extracted features serve as the input for the real/fake
classification head and the demographic head.
Real/Fake Classification Head: This head con-
sists of a Multi-Layer Perceptron (MLP) that pro-
cesses the extracted features and predicts whether the
input image is real or fake. The output of this MLP is
a probability score indicating the likelihood that the
image is a deepfake or a genuine one. This branch
focuses on learning the subtle cues and artifacts asso-
ciated with the deepfake generation, such as inconsis-
tencies in lighting, facial details, or blurring artifacts
around the face.
Demographic Head: In parallel to the real/fake
classification, the features are passed through a sec-
ond MLP for demographic group classification. This
MLP is designed to categorize the input into one of
eight demographic groups, such as Black-Male (B-
M), White-Female (W-F), Asian-Male (A-M), etc.
The purpose of this head is to ensure that the model
learns demographic-specific features that are indepen-
dent of deepfake artifacts. These features are crucial
for enhancing the fairness of the model across diverse
demographic groups.
Data-Driven Fairness Generalization for Deepfake Detection
585

Figure 2: Sample of Facial Images. The real images (top row) and their corresponding fake/synthetic image (bottom row).
Loss Function
We define the loss function to incorporate both the
standard classification loss and a fairness penalty.
Specifically, the total loss function L is composed of
three terms: the classification loss, the demographic
loss, and the fairness penalty.
Classification Loss: Let p = [p
1
, p
2
, . . . , p
N
] be
the predicted probabilities and y = [y
1
, y
2
, . . . , y
N
] be
the true binary labels. The binary cross-entropy loss
L
real
is defined as:
L
real
= −
1
N
N
∑
i=1
[y
i
log(p
i
) + (1 − y
i
)log(1 − p
i
)] (7)
where N is the number of samples, y
i
is the true
binary label (0 or 1) for the i-th sample, and p
i
is the
predicted probability for the positive class.
Demographic Loss: Let p
dem,i
=
[p
dem,i,1
, . . . , p
dem,i,8
] represent the predicted prob-
abilities for the i-th sample across 8 demographic
groups, and y
dem,i
= [y
dem,i,1
, . . . , y
dem,i,8
] be the
one-hot encoded true labels for those groups. The
demographic loss L
dem
is:
L
dem
= −
1
N
dem
N
dem
∑
i=1
8
∑
c=1
y
dem,i,c
log(p
dem,i,c
) (8)
where N
dem
is the number of samples in the demo-
graphic component, and the summation runs over the
8 demographic groups.
Fairness Penalty: To quantify fairness, we com-
pute the variance of the accuracy rates across differ-
ent demographic groups. Let a
k
denote the accuracy
for demographic group k. The variance of accuracies
Var
acc
is:
Var
acc
=
1
K
K
∑
k=1
Accuracy
k
−
¯
Accuracy
2
(9)
where K is the number of demographic groups,
Accuracy
k
is the accuracy for group k, and
¯
Accuracy
is the mean accuracy across all groups.
Total Loss: The total loss function L is a combi-
nation of the standard loss, the fairness penalty, and
the fairness loss. The total loss is defined as:
L = L
real
+ λ · Var
acc
+ L
dem
(10)
where λ is a hyperparameter controlling the
weight of the fairness penalty.
Optimization
We employ the Sharpness-Aware Minimization
(SAM) optimizer (Foret et al., 2020) as our optimizer.
SAM is designed to improve the generalization per-
formance of deep neural networks by encouraging the
model to find parameter spaces that are not only good
at minimizing the training loss but also robust to small
perturbations in the weight space. This results in a
flatter and smoother loss landscape, which has been
shown to correlate with better generalization.
The SAM optimizer modifies the traditional
gradient-based update by introducing a two-step pro-
cess that seeks to find parameters that minimize both
the loss and its sensitivity to perturbations. Let L(w)
denote the total loss function of the model, where w
represents the network’s parameters. SAM performs
the following steps:
Perturbation Step: SAM first finds a perturbation
ε that maximizes the loss function around the current
parameters. The perturbation ε is chosen to make the
loss worse within a neighborhood of the current pa-
rameter values:
ε(w) = arg max
∥ε∥≤ρ
L(w + ε) (11)
where ρ controls the size of the neighborhood in
which the optimizer searches for the sharpest direc-
tions.
Parameter Update Step: Once the worst-case
perturbation ε is found, the SAM optimizer updates
the parameters by minimizing the loss function at
w + ε:
w ← w − η∇L(w + ε) (12)
where η is the learning rate.
This two-step process leads to solutions in flat-
ter regions of the loss surface, improving the model’s
generalization and robustness.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
586

Figure 3: An overview of our proposed method. We utilize EfficientNet (Tan, 2019) to extract deep features from input images
for the feature extraction module. For the classification module, two heads are used: the real/fake head predicts whether the
input is real or fake, and the demographic head predicts the demographic group. The demographic classification head outputs
probabilities for one of eight demographic categories based on both gender and ethnicity. These categories include Black-Male
(B-M), Black-Female (B-F), White-Male (W-M), White-Female (W-F), Asian-Male (A-M), Asian-Female (A-F), Other-Male
(O-M), and Other-Female (O-F). We use SAM (Sharpness-Aware Minimization) for the optimization module to flatten the
loss landscape and enhance fairness generalization across demographic groups.
4 EXPERIMENTS
4.1 Experimental Settings
Dataset
To evaluate the fairness generalization capability of
our proposed approach, we train our model on the
widely used FaceForensics++ (FF++) dataset (Rossler
et al., 2019). For testing, we use FF++, Deepfake De-
tection Challenge (DFDC) (Dolhansky et al., 2020),
and Celeb-DF (Li et al., 2020b). We used the real im-
ages from these datasets and created synthetic images
as the fake images using the method in Section 3.2.
Since the original datasets do not include demo-
graphic information, we follow the approach in (Ju
et al., 2024) for data processing and annotation. The
datasets are categorized by race and gender, form-
ing the following intersection groups: Black-Male (B-
M), Black-Female (B-F), White-Male (W-M), White-
Female (W-F), Asian-Male (A-M), Asian-Female (A-
F), Other-Male (O-M), and Other-Female (O-F). The
Celeb-DF (Li et al., 2020b) does not contain the Asian
sub-group.
Evaluation Metrics
For evaluating our approach, we use several perfor-
mance metrics, including the Area Under the Curve
(AUC), Accuracy, and True Positive Rate (TPR).
These metrics allow us to benchmark our method
against previous works. To assess the degree of fair-
ness of the model, we analyze the accuracy gaps
across different races and genders.
Baseline Methods
For intra-dataset evaluation, we compare our ap-
proach against recent works in deepfake detection
fairness, specifically DAW-FDD (2023) (Ju et al.,
2024) and Lin et al. (2024) (Lin et al., 2024). For
cross-dataset evaluation, our method is compared to
the fairness generalization method proposed by Lin et
al. (2024) (Lin et al., 2024). To the best of our knowl-
edge, Lin et al. (2024) (Lin et al., 2024) is the prior
Data-Driven Fairness Generalization for Deepfake Detection
587
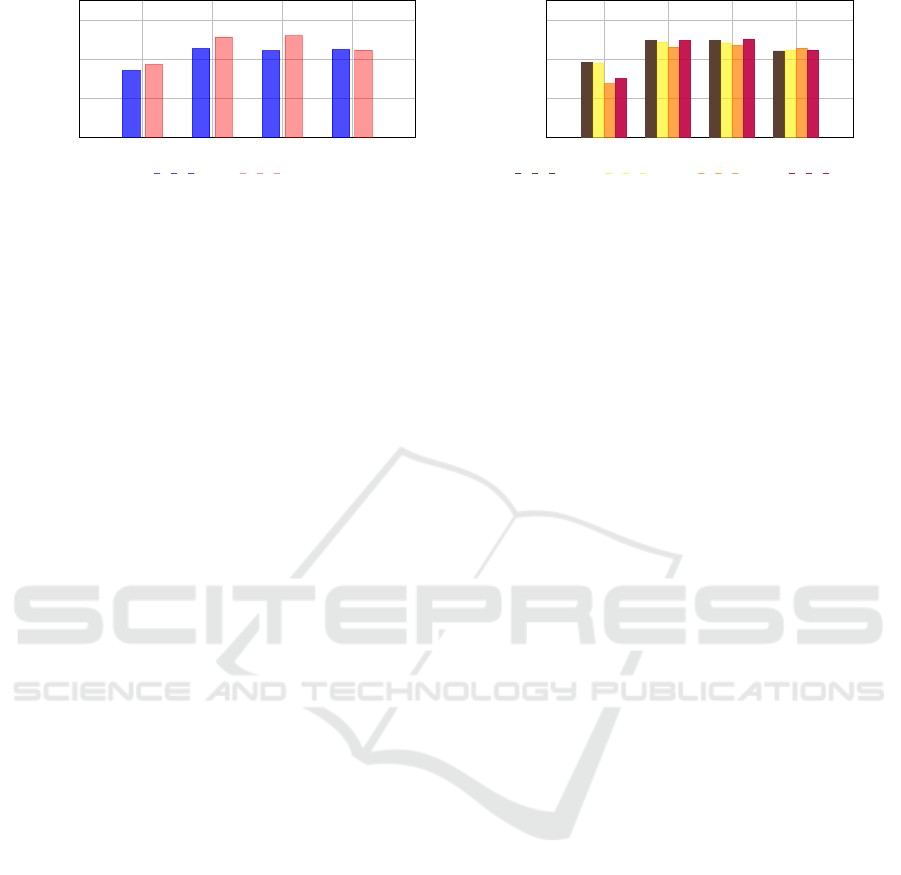
Xception
DAW-FDD
Lin et al. Ours
70
80
90
100
Accuracy (%)
Male Female
Figure 4: Intra-dataset evaluation across different methods.
Methods are trained and tested on the same distribution as
the training set (FF++ (Rossler et al., 2019)): Performance
comparison across gender. See Table 1 for exact numerical
values.
work addressing the fairness generalization problem.
We also used the Xception (Chollet, 2017) as a base-
line for comparison during both intra-dataset evalua-
tion and cross-dataset evaluation. The Xception net-
work (Chollet, 2017) was implemented using transfer
learning to perform the deepfake detection task.
Implementation Details
All experiments are conducted using PyTorch. For
our method, we set the batch size to 16 and train the
model for 100 epochs. To incorporate fairness, we use
a fairness penalty weight λ of 20 (See Eq. 10). For
optimization, we employ the SAM optimizer (Foret
et al., 2020). The learning rate is set to 5e-4, momen-
tum is configured at 0.9, and weight decay is set to
5 × 10
−3
.
4.2 Experimental Results
In this section, we discuss the results of our evalua-
tions and present our findings. We start by discussing
the results of our intra-dataset evaluations and then,
the results of the cross-dataset evaluations.
Intra-Dataset Evaluation Results
We perform intra-dataset evaluations to measure the
model’s performance on the same dataset distribution,
assessing its ability to fit the training data. As shown
in Table 1, our method achieves comparable perfor-
mance to baseline approaches in deepfake detection.
However, it demonstrates a significant improvement
over baseline methods in fairness preservation across
demographic groups. Figure 4 presents the evaluation
results for the gender demographic group, while Fig-
ure 5 illustrates the results for the racial demographic
group. As evidenced in these figures, the disparity
between the Male and Female subgroups is substan-
tially reduced in our approach with a 0.12% differ-
ence (in accuracy) between the subgroups, compared
Xception
DAW-FDD
Lin et al. Ours
70
80
90
100
Accuracy (%)
Black White Asian Others
Figure 5: Intra-dataset evaluation across different methods.
Methods are trained and tested on the same distribution as
the training set (FF++ (Rossler et al., 2019)): Performance
comparison across race. See Table 1 for exact numerical
values.
to the 1.58%, 2.90% and 3.87% differences between
the subgroups for the baseline approaches. Addition-
ally, the disparities among racial groups are signifi-
cantly lower with our approach with a 0.71% differ-
ence (which happens to be between asian and black -
considering minimum and maximum accuracies) be-
tween the subgroups, while the baselines had differ-
ences of 5.28%, 1.64% and 1.52%. These results
highlight the effectiveness and superiority of our ap-
proach in achieving fairness generalization.
4.2.1 Cross-Dataset Evaluation Results
We conducted cross-dataset evaluations to assess
our model’s performance on out-of-distribution data,
evaluating its ability to generalize to unseen datasets.
As recorded in Table 2, and visualized in Figures
6,7,8 and 9, our approach achieves comparable per-
formance to baseline methods in deepfake detection
while significantly outperforming them in fairness
generalization across demographic groups.
Figures 6 and 7 visualize the results of evaluations
from Table 2 where the model was trained on FF++
and tested on DFDC, while Figures 8 and 9 visual-
izes the results from Table 2 for training on FF++ and
testing on Celeb-DF. These figures demonstrate that
our approach exhibits minimal performance dispar-
ities across different gender and racial groups com-
pared to the baselines.
As shown in Table 2, on the DFDC dataset, the
Xception baseline has the lowest disparity in accuracy
across genders. The disparity in accuracy between
males and females is 1.85% for Xception, and then
4.5% (Lin et al., 2024) and 8.03% (Ours). Across race
on the DFDC dataset, our method has the lowest accu-
racy disparity across the races at 11.15% (which hap-
pens to be between Asian and white) with the baseline
recording accuracy disparities of 24.53% and 14.39%.
As shown in Table 2, on the Celeb-DF dataset,
our method has a minimal disparity in accuracy across
both gender and race. Across gender, we got 15.47%
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
588
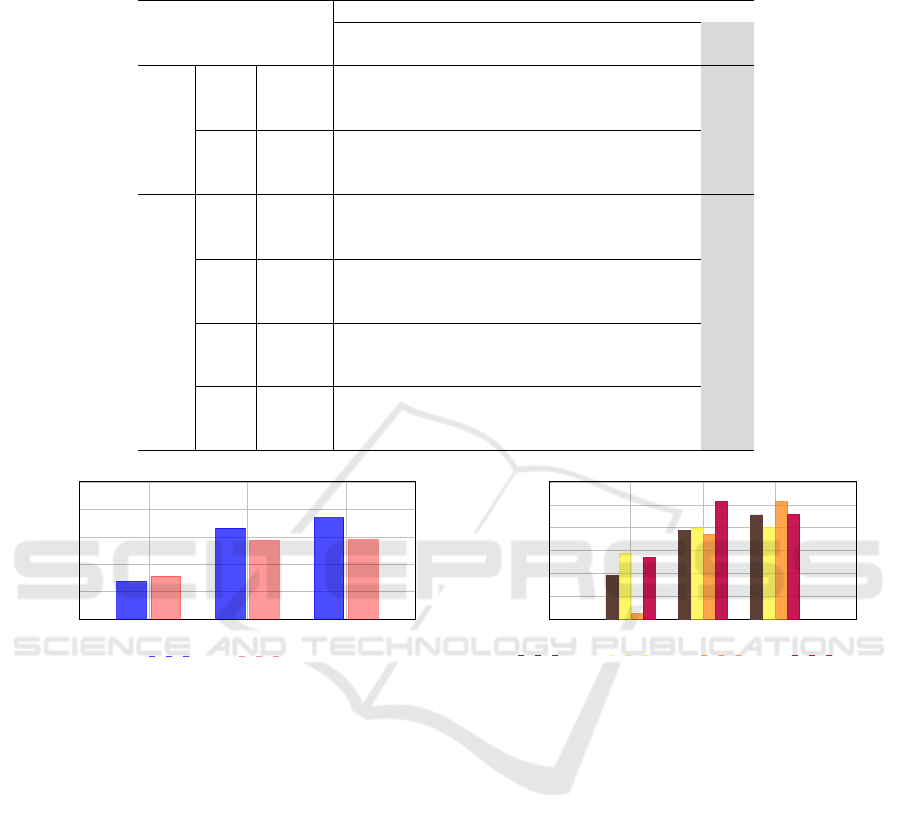
Table 1: Intra-dataset evaluation compares different deepfake detection approaches by training and testing on the same
dataset’s distribution. Results are computed on each dataset’s test set, with the best performance shown in bold.
FF++ (Rossler et al., 2019)
Xception DAW-FDD Lin et al. Ours
(Chollet, 2017) (Ju et al., 2024) (Lin et al., 2024)
Gender
Male
TPR (%) 98.62 93.48 92.13 91.91
AUC (%) 90.23 96.91 97.56 97.71
ACC (%) 87.03 92.65 92.07 92.39
Female
TPR (%) 98.85 97.15 98.02 91.89
AUC (%) 93.48 98.05 98.94 97.72
ACC (%) 88.61 95.55 95.94 92.27
Race
Black
TPR (%) 99.59 96.36 97.17 91.27
AUC (%) 95.85 97.92 98.22 97.57
ACC (%) 89.00 94.67 94.66 92.04
White
TPR (%) 98.71 95.47 94.81 91.88
AUC (%) 92.57 97.54 98.21 97.70
ACC (%) 88.84 94.29 94.09 92.28
Asian
TPR (%) 98.73 94.40 96.44 92.71
AUC (%) 89.40 96.39 97.54 97.91
ACC (%) 83.72 93.04 93.46 92.75
Other
TPR (%) 98.51 95.77 95.83 91.73
AUC (%) 89.87 98.23 98.58 97.66
ACC (%) 84.94 94.68 94.98 92.25
Xception Lin et al. Ours
30
40
50
60
70
80
Accuracy (%)
Male Female
Figure 6: Cross-dataset evaluation across different meth-
ods. Methods are trained on (FF++ (Rossler et al., 2019))
and tested on DFDC (Dolhansky et al., 2020). Performance
comparison is across gender. See Table 2 for exact numeri-
cal values.
disparity in accuracy, while the baselines recorded
wider disparities of 40.66% and 25.47% in accuracy.
Across race, our method recorded 11.54% as the max-
imum disparity in accuracy (which happens to be be-
tween white and black), the baselines recorded wider
disparities of 26.41% and 14.39%.
These results highlight the effectiveness of our ap-
proach in achieving fairness generalization in cross-
dataset scenarios, demonstrating improved consis-
tency across both racial and gender demographics
compared to baseline methods.
5 LIMITATIONS
The limitations of our method are:
Xception Lin et al. Ours
20
30
40
50
60
70
80
Accuracy (%)
Black White Asian Others
Figure 7: Cross-dataset evaluation across different meth-
ods. Methods are trained on (FF++ (Rossler et al., 2019))
and tested on DFDC (Dolhansky et al., 2020). Performance
comparison is across race. See Table 2 for exact numerical
values.
• Dependence on Demographically Annotated
Datasets: The effectiveness of our method relies
on the availability of detailed demographic anno-
tations. Such datasets are often difficult to obtain
and may not always be comprehensive enough,
potentially impacting the fairness assessment.
• Trade-Off Between Fairness and Detection Per-
formance: Improving fairness across demo-
graphic groups can result in a trade-off with over-
all detection performance. Enhancements aimed
at reducing demographic disparities may lead to
a decrease in the model’s overall accuracy in de-
tecting deepfakes.
These limitations highlight the need for further
research to address the challenges of dataset depen-
dency and the balance between fairness and detection
performance.
Data-Driven Fairness Generalization for Deepfake Detection
589
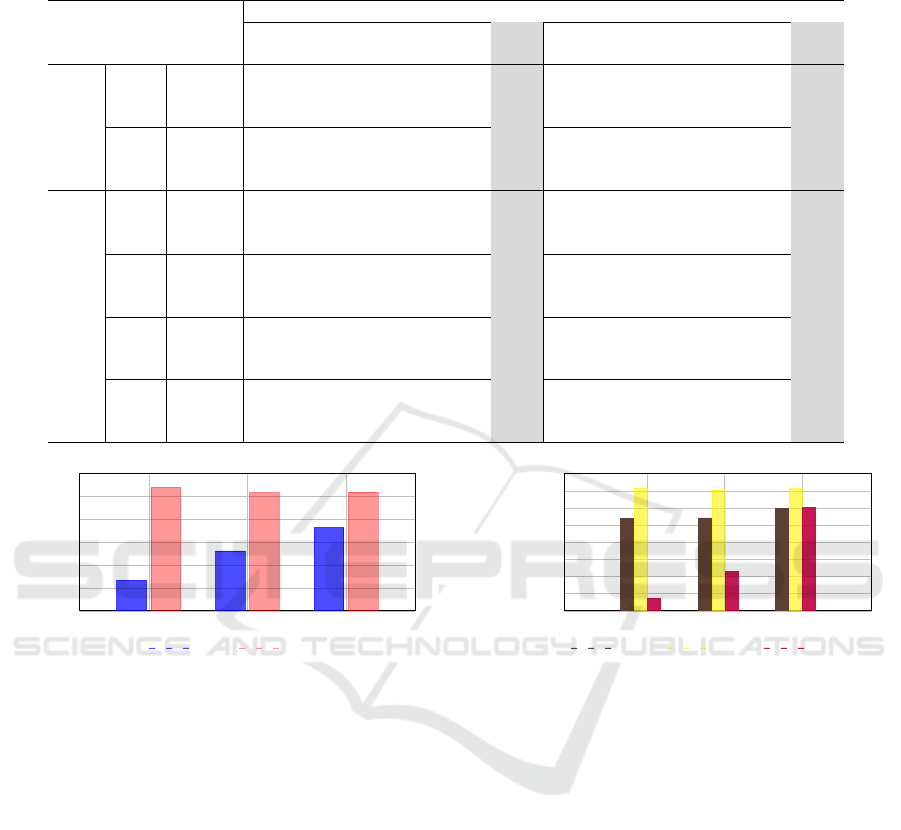
Table 2: Cross-dataset evaluation across different methods for deepfake detection. The methods were trained on (FF++
(Rossler et al., 2019)) and tested on DFDC (Dolhansky et al., 2020) and Celeb-DF (Li et al., 2020b).
DFDC (Dolhansky et al., 2020) Celeb-DF (Li et al., 2020b)
Xception Lin et al. Ours Xception Lin et al. Ours
(Chollet, 2017) (Lin et al., 2024) (Chollet, 2017) (Lin et al., 2024)
Gender
Male
TPR (%) 85.11 37.81 35.49 98.68 76.89 78.38
AUC (%) 59.97 60.08 63.30 36.97 66.93 75.44
ACC (%) 43.75 63.11 66.98 43.29 56.16 66.41
Female
TPR (%) 77.59 44.36 40.57 99.24 90.19 86.67
AUC (%) 50.70 60.06 59.12 53.26 75.83 82.09
ACC (%) 45.60 58.61 58.98 83.95 81.63 81.88
Race
Black
TPR (%) 76.28 45.14 57.58 98.68 76.89 78.38
AUC (%) 50.40 59.81 68.83 47.63 67.03 72.53
ACC (%) 39.23 58.66 65.54 63.99 64.10 69.61
White
TPR (%) 80.82 38.18 32.98 99.24 90.18 86.69
AUC (%) 56.45 60.14 60.18 53.58 77.02 82.20
ACC (%) 48.79 59.80 60.24 81.38 80.43 81.15
Asian
TPR (%) 82.50 42.50 19.16 - - -
AUC (%) 54.75 51.78 43.89 - - -
ACC (%) 22.38 57.04 71.39 - - -
Others
TPR (%) 87.68 55.93 36.18 100 96.66 73.33
AUC (%) 60.39 72.52 65.38 28.31 64.53 84.97
ACC (%) 46.91 71.43 65.82 17.22 32.78 70.00
Xception Lin et al. Ours
30
40
50
60
70
80
90
Accuracy (%)
Male Female
Figure 8: Cross-dataset evaluation across different methods.
Methods are trained on (FF++ (Rossler et al., 2019)) and
tested on Celeb-DF (Li et al., 2020b). Performance com-
parison is across gender. See Table 2 for exact numerical
values.
6 CONCLUSION
We have presented a novel approach to address the
critical challenge of fairness generalization in deep-
fake detection systems. Our method combines three
key innovations: a data-centric strategy using syn-
thetic image generation to balance demographic rep-
resentation, a multi-task learning architecture that si-
multaneously optimizes detection accuracy and de-
mographic fairness, and sharpness-aware optimiza-
tion to enhance generalization capabilities. Our com-
prehensive evaluations demonstrate the effectiveness
of this approach. In intra-dataset testing, our method
achieved comparable detection performance to exist-
ing approaches while significantly reducing demo-
graphic disparities - showing only 0.12% accuracy
difference between gender groups compared to up
Xception Lin et al. Ours
10
20
30
40
50
60
70
80
90
Accuracy (%)
Black White Others
Figure 9: Cross-dataset evaluation across different methods.
Methods are trained on (FF++ (Rossler et al., 2019)) and
tested on Celeb-DF (Li et al., 2020b). Performance com-
parison is across races. See Table 2 for exact numerical
values
to 3.87% in baseline methods, and 0.71% difference
across racial groups compared to up to 5.28% in
baselines. More importantly, in challenging cross-
dataset scenarios, our approach demonstrated supe-
rior fairness generalization. When tested on the
Celeb-DF dataset, our method reduced gender-based
accuracy disparities to 15.47% compared to up to
40.66% in baselines, while maintaining strong over-
all detection performance. These results suggest that
our integrated approach of balanced synthetic data,
demographic-aware learning, and robust optimization
provides a promising direction for developing deep-
fake detection systems that are both accurate and de-
mographically fair. Future work could explore ex-
tending these techniques to other domains where al-
gorithmic fairness and generalization are crucial con-
cerns.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
590

REFERENCES
Afchar, D., Nozick, V., Yamagishi, J., and Echizen, I.
(2018). Mesonet: a compact facial video forgery de-
tection network. In 2018 IEEE international work-
shop on information forensics and security (WIFS),
pages 1–7. IEEE.
Chen, L., Zhang, Y., Song, Y., Liu, L., and Wang, J. (2022).
Self-supervised learning of adversarial example: To-
wards good generalizations for deepfake detection.
Chollet, F. (2017). Xception: Deep learning with depthwise
separable convolutions. In Proceedings of the IEEE
conference on computer vision and pattern recogni-
tion, pages 1251–1258.
Das, S., Seferbekov, S., Datta, A., Islam, M. S., and Amin,
M. R. (2021). Towards solving the deepfake prob-
lem: An analysis on improving deepfake detection us-
ing dynamic face augmentation.
Dolhansky, B., Bitton, J., Pflaum, B., Lu, J., Howes, R.,
Wang, M., and Ferrer, C. C. (2020). The deepfake
detection challenge (dfdc) dataset. arXiv preprint
arXiv:2006.07397.
Ezeakunne, U. and Liu, X. (2023). Facial deepfake detec-
tion using gaussian processes.
Foret, P., Kleiner, A., Mobahi, H., and Neyshabur, B.
(2020). Sharpness-aware minimization for effi-
ciently improving generalization. arXiv preprint
arXiv:2010.01412.
Guan, J., Zhou, H., Gong, M., Ding, E., Wang, J., and Zhao,
Y. (2022). Detecting deepfake by creating spatio-
temporal regularity disruption.
Guo, H., Hu, S., Wang, X., Chang, M.-C., and Lyu, S.
(2022). Robust attentive deep neural network for de-
tecting gan-generated faces.
Hazirbas, C., Bitton, J., Dolhansky, B., Pan, J., Gordo, A.,
and Ferrer, C. C. (2021). Towards measuring fairness
in ai: the casual conversations dataset.
Ju, Y., Hu, S., Jia, S., Chen, G. H., and Lyu, S. (2024).
Improving fairness in deepfake detection.
Li, L., Bao, J., Zhang, T., Yang, H., Chen, D., Wen, F., and
Guo, B. (2020a). Face x-ray for more general face
forgery detection.
Li, Y. (2018). Exposing deepfake videos by detecting face
warping artif acts.
Li, Y., Yang, X., Sun, P., Qi, H., and Lyu, S. (2020b).
Celeb-df: A large-scale challenging dataset for deep-
fake forensics. In Proceedings of the IEEE/CVF con-
ference on computer vision and pattern recognition,
pages 3207–3216.
Lin, L., He, X., Ju, Y., Wang, X., Ding, F., and Hu, S.
(2024). Preserving fairness generalization in deepfake
detection.
Masood, M., Nawaz, M., Malik, K. M., Javed, A., Irtaza,
A., and Malik, H. (2023). Deepfakes generation and
detection: State-of-the-art, open challenges, counter-
measures, and way forward.
Nadimpalli, A. V. and Rattani, A. (2022). Gbdf: gender
balanced deepfake dataset towards fair deepfake de-
tection.
Pu, M., Kuan, M. Y., Lim, N. T., Chong, C. Y., and Lim,
M. K. (2022a). Fairness evaluation in deepfake detec-
tion models using metamorphic testing.
Pu, W., Hu, J., Wang, X., Li, Y., Hu, S., Zhu, B., Song,
R., Song, Q., Wu, X., and Lyu, S. (2022b). Learning a
deep dual-level network for robust deepfake detection.
Rossler, A., Cozzolino, D., Verdoliva, L., Riess, C., Thies,
J., and Nießner, M. (2019). Faceforensics++: Learn-
ing to detect manipulated facial images. In Proceed-
ings of the IEEE/CVF international conference on
computer vision, pages 1–11.
Shiohara, K. and Yamasaki, T. (2022). Detecting deepfakes
with self-blended images.
Tan, M. (2019). Efficientnet: Rethinking model scaling
for convolutional neural networks. arXiv preprint
arXiv:1905.11946.
Trinh, L. and Liu, Y. (2021). An examination of fairness of
ai models for deepfake detection.
Wang, J., Wu, Z., Ouyang, W., Han, X., Chen, J., Jiang,
Y.-G., and Li, S.-N. (2022). M2tr: Multi-modal multi-
scale transformers for deepfake detection.
Xu, Y., Raja, K., Verdoliva, L., and Pedersen, M. (2023).
Learning pairwise interaction for generalizable deep-
fake detection.
Xu, Y., Terh
¨
orst, P., Raja, K., and Pedersen, M. (2022). A
comprehensive analysis of ai biases in deepfake detec-
tion with massively annotated databases.
Zhao, H., Zhou, W., Chen, D., Wei, T., Zhang, W., and Yu,
N. (2021a). Multi-attentional deepfake detection.
Zhao, T., Xu, X., Xu, M., Ding, H., Xiong, Y., and Xia,
W. (2021b). Learning self-consistency for deepfake
detection.
Data-Driven Fairness Generalization for Deepfake Detection
591
