
Combining Supervised Ground Level Learning and Aerial Unsupervised
Learning for Efficient Urban Semantic Segmentation
Youssef Bouaziz
1,2 a
, Eric Royer
1
and Achref Elouni
2
1
Institut Pascal, Universit
´
e Clermont Auvergne, Clermont-Ferrand, France
2
LIMOS, Universit
´
e Clermont Auvergne, Clermont-Ferrand, France
{first name.last name}@uca.fr
Keywords:
Semantic Segmentation, Aerial Imagery, 3D Point Clouds, Label Propagation.
Abstract:
Semantic segmentation of aerial imagery is crucial for applications in urban planning, environmental monitor-
ing, and autonomous navigation. However, it remains challenging due to limited annotated data, occlusions,
and varied perspectives. We present a novel framework that combines 2D semantic segmentation with 3D
point cloud data using a graph-based label propagation technique. By diffusing semantic information from
2D images to 3D points with pixel-to-point and point-to-point connections, our approach ensures consistency
between 2D and 3D segmentations. We validate its effectiveness on urban imagery, accurately segmenting
moving objects, structures, roads, and vegetation, and thereby overcoming the limitations of scarce annotated
datasets. This hybrid method holds significant potential for large-scale, detailed segmentation of aerial im-
agery in urban development, environmental assessment, and infrastructure management.
1 INTRODUCTION
Semantic segmentation of aerial imagery is crucial in
fields such as urban planning, environmental mon-
itoring, and autonomous navigation. By assign-
ing semantic labels to every pixel, valuable insights
into spatial patterns and functional elements can be
derived, enabling large-scale analysis and decision-
making. However, aerial photos pose unique chal-
lenges due to varying perspectives, occlusions, and
the need to integrate multiple data sources. A signif-
icant limitation is the lack of annotated ground-truth
data, which impedes training high-performing super-
vised models and benchmarking new approaches.
The scarcity of comprehensive ground-truth
datasets forces reliance on alternative methods that
integrate additional data sources. Most available
datasets cover limited areas or lack sufficient resolu-
tion and detail, reducing their utility for precise seg-
mentation. Consequently, there is a growing need for
methods that leverage diverse data types to overcome
these constraints and improve segmentation accuracy.
To address these challenges, we present a novel
methodology that fuses 2D semantic segmentation
with 3D point cloud data. Building on the graph-
based label propagation technique in (Mascaro et al.,
a
https://orcid.org/0000-0003-3257-6859
2021), we transfer semantic information from 2D im-
ages to 3D points. Edges between 2D pixels and 3D
points enable label diffusion, incorporating geometric
scene information. Once diffused in 3D, these labels
are then projected back onto 2D aerial imagery, en-
suring geometrically consistent and detailed segmen-
tations. This approach preserves alignment between
the 2D and 3D domains, resulting in accurate and re-
fined labels.
To further enhance the quality of 2D segmenta-
tions, we integrate MaskFormer (Cheng et al., 2021),
an advanced semantic segmentation algorithm, into
our pipeline. MaskFormer excels at segmenting com-
plex scenes, making it ideal for producing high-
quality 2D segmentations, which are then used as
input for the label diffusion process. We segment
the ground-level images into five key classes: mov-
ing object, structure, road, vegetation, and other.
These classes capture the essential elements com-
monly found in aerial and urban scenes, providing a
comprehensive understanding of the environment.
Our methodology overcomes the limitations of
traditional approaches by combining powerful 2D
segmentation with graph-based label propagation to
achieve accurate and detailed 3D semantic segmenta-
tion of aerial photos. This hybrid approach addresses
the challenge of limited ground-truth data by lever-
aging the geometric relationships between 2D and
434
Bouaziz, Y., Royer, E. and Elouni, A.
Combining Supervised Ground Level Learning and Aerial Unsupervised Learning for Efficient Urban Semantic Segmentation.
DOI: 10.5220/0013162600003912
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 3: VISAPP, pages
434-441
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

3D data, allowing us to transfer labels efficiently and
consistently. The proposed method has wide-ranging
potential for applications in urban development, en-
vironmental assessment, and infrastructure manage-
ment, where large-scale and accurate segmentation of
aerial imagery is critical.
2 RELATED WORK
Supervised semantic segmentation from ground-level
images is a critical task in autonomous driving and
remains an active research area. Early deep learning-
based approaches, such as fully convolutional net-
works (FCN) (Simonyan and Zisserman, 2015)
and GoogLeNet (Szegedy et al., 2015), paved the
way. Subsequent architectures, like Segnet (Badri-
narayanan et al., 2017) and HRNet (Yuan et al., 2020),
addressed limitations such as high computational
cost, achieving impressive results like 85.1% mIoU
on CityScapes. UNet (Ronneberger et al., 2015), ini-
tially for medical segmentation, and Deeplab (Liang-
Chieh et al., 2015; Chen et al., 2018) introduced in-
novations to improve efficiency and preserve detail.
Recent self-supervised methods like
DINO (Caron et al., 2021) demonstrate poten-
tial by learning from unlabeled data, offering viable
solutions for scenarios with scarce annotations,
such as aerial segmentation. Annotated datasets
like CityScapes (Cordts et al., 2016) (5000 images)
and Mapillary Vistas (Neuhold et al., 2017) (25,000
images) remain essential for training and advancing
segmentation models.
For remote sensing tasks, datasets vary signif-
icantly in annotations, spectral bands, and resolu-
tion (Schmitt et al., 2021). Unlike ground-level
datasets, there is no equivalent comprehensive dataset
for aerial images. The ISPRS Vaihingen and Pots-
dam dataset (Rottensteiner et al., 2012) has supported
many advancements in urban aerial image segmen-
tation. Recent methods like RS-Dseg (Luo et al.,
2024) address challenges by using diffusion mod-
els with spatial-channel attention to enhance seman-
tic information extraction, achieving state-of-the-art
results on Potsdam. The labor-intensive nature of
labeling aerial datasets has led to interest in semi-
supervised techniques. These methods use a small set
of labeled data to generate pseudo-labels for larger
unlabeled datasets, augmenting training. For exam-
ple, (Desai and Ghose, 2022) successfully trained a
land use classification network using just 2% labeled
data. To address the lack of labeled data, unsuper-
vised approaches (Ji et al., 2019; Caron et al., 2018;
Cho et al., 2021; Hamilton et al., 2022) have been ex-
plored. While their accuracy lags behind supervised
and semi-supervised methods, they remain practical
when no labeled data is available. For example, on
CityScapes, unsupervised methods improved from an
mIoU of 7.1 in 2018 (MDC (Caron et al., 2018)) to
21.0 in 2022 (STEGO (Hamilton et al., 2022)).
The fusion of heterogeneous methods and data
sources offers promising solutions to segmentation
challenges. For instance, (Genova et al., 2021) trans-
fers semantic labels from 2D street-level images to
3D point clouds, bridging modality gaps. Graph-
based methods encode semantic relationships across
modalities. The scene graph concept (Krishna et al.,
2017) has been adapted for semantic segmentation
of building interiors (Armeni et al., 2019). Mascaro
et al. (Mascaro et al., 2021) introduced ”Diffuser,” a
graph-based label diffusion approach that refines 3D
segmentations by leveraging multi-view 2D semantic
information. This method avoids 3D training data and
integrates effectively with existing 2D segmentation
frameworks, broadening its applicability.
3 METHODOLOGY
This section outlines our methodology for semantic
segmentation of aerial photos using 2D segmentations
and 3D point cloud data. Our approach builds on
a label propagation technique (Mascaro et al., 2021)
for transferring labels from 2D to 3D domains and
incorporates MaskFormer, an open-source segmenta-
tion algorithm, to improve 2D segmentation accuracy.
By combining these methods, we transfer semantic la-
bels from 2D images to a 3D segmented point cloud,
enhancing the accuracy and consistency of labels ap-
plied to aerial photos.
The process utilizes two data sources: an aerial
image and a set of ground-level images I
k
. Ground
images are processed with a structure-from-motion
algorithm to generate a sparse 3D point cloud, which
is georeferenced to associate each point with a pixel in
the aerial image (using Meshroom). Ground images
are also segmented with a semantic segmentation al-
gorithm trained on manually labeled data, assigning
semantic labels to each pixel. Each 3D point in the
point cloud is linked to the pixels used in its trian-
gulation, forming associations between ground image
pixels, 3D points, and aerial image pixels. These re-
lationships are then encoded into a graph as described
in the following paragraphs.
Combining Supervised Ground Level Learning and Aerial Unsupervised Learning for Efficient Urban Semantic Segmentation
435

3.1 2D-to-3D Label Diffusion
To summarize, the methodology leverages the output
of a 2D semantic segmentation framework to prop-
agate class labels through the point cloud, generat-
ing a refined 3D semantic map. The algorithm uses a
graph structure comprising nodes that represent both
2D pixels and 3D points. The graph incorporates
pixel-to-point and point-to-point edges to enable la-
bel diffusion.
Pixel-to-point edges are constructed by creating
a subgraph G
I
k
→X
for each ground image I
k
, where
I
k
is the k-th image and X represents all 3D points
in the scene. Represented as an adjacency matrix,
this subgraph facilitates information flow from 2D to
3D. Edges between pixels and points are determined
by projecting the 3D points back to the 2D image
plane using camera projection matrices from Mesh-
room. This process links the 2D semantic labels to
their corresponding 3D points. The adjacency matrix
G
I
k
→X
is defined as:
G
I
k
→X
i j
=
1 if pixel p
i
projects to 3D point x
j
in
frame I
k
0 otherwise
Additionally, point-to-point edges are created by
connecting each point to its K nearest neighbors based
on Euclidean distance. This step ensures that the sub-
graph G
X →X
encodes the 3D geometry of the scene
point cloud. The adjacency matrix G
X →X
is defined
as:
G
X →X
i j
=
w
i j
= exp
−
∥
x
i
−x
j
∥
2
2
0.05
if point x
i
is
among the K
nearest neigh-
bors of point x
j
0 otherwise
The label diffusion graph, denoted as G, combines
the pixel-to-point and point-to-point edges. The adja-
cency matrix G is obtained by concatenating the pre-
viously defined adjacency matrices as follows:
G =
G
X →X
G
I
1
→X
··· G
I
N
f
→X
0 I
I
1
··· 0
.
.
.
.
.
.
.
.
.
.
.
.
0 0 ··· I
I
N
f
where N
f
is the total number of frames, I
I
k
is the
identity matrix of size N
I
k
× N
I
k
, and N
I
k
represents
the total number of pixels in image I
k
. The identity
matrices preserve the structure of the point cloud and
ground image pixels in the graph representation dur-
ing iterations.
To propagate class labels through the graph, a
probabilistic transition matrix P is computed by nor-
malizing each row of the adjacency matrix G. The
transition matrix P is defined as:
P
i j
=
G
i j
∑
N
k=1
G
ik
where N is the total number of nodes in the graph.
In order to accumulate the likelihood of each node
belonging to each class during the iterative propaga-
tion, a label matrix Z is defined. The label matrix Z
has dimensions N × C, where N represents the total
number of nodes in the graph G, and C represents the
number of classes.
The label matrix Z incorporates the semantic la-
bels for both the 3D points and the pixels in each
ground image. Z is defined as:
Z =
Z
X
Z
I
1
Z
I
2
.
.
.
Z
I
N
f
where:
• Z
X
is a matrix with dimensions N
X
×C, where N
X
is the total number of 3D points in the point cloud.
It represents the initial semantic labels for the 3D
points, initialized to zeros due to the absence of
prior knowledge about their class labels at the start
of the diffusion process.
• Z
I
1
, Z
I 2
, ..., Z
I N
f
are the initial semantic labels for
the pixels in each ground image I
1
, I 2, ..., I N
f
.
Each Z
I
k
is a matrix with dimensions N
I
k
× C,
where each row corresponds to a pixel in image
I
k
and contains the likelihood of that pixel belong-
ing to different classes, based on the 2D semantic
segmentation framework’s output.
The label diffusion process iteratively multiplies
the transition matrix P with the label matrix Z un-
til convergence or a maximum number of iterations
is reached. This iterative operation propagates class
probabilities through the graph, capturing contextual
information across both 2D and 3D domains. The up-
date equation for the label matrix Z is:
Z
(t+1)
= P · Z
(t)
where Z
(t)
represents the label matrix at iteration
t. The label diffusion process continues until con-
vergence or the maximum number of iterations is
reached.
Finally, the likelihood values in the label matrix
Z are converted to 3D point labels by assigning each
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
436

point the class with the highest accumulated proba-
bility. This is achieved by finding the index j
∗
that
maximizes the likelihood in the i-th row of Z:
j
∗
= argmax
j
Z
i j
Once the index j
∗
is determined, the correspond-
ing class label is assigned to the i-th point, making it
the most likely class based on the accumulated prob-
abilities. Repeating this for all points in the 3D se-
mantic map yields a refined representation where each
point is labeled according to the likelihood values in
Z.
In summary, the proposed methodology integrates
2D semantic segmentation results with geometric in-
formation from the 3D point cloud, refining seman-
tic labels through a label diffusion process. The 3D
label matrix Z
X
iteratively accumulates class likeli-
hoods for each node using propagated information
from neighbors. The final 3D semantic map offers
a more accurate and consistent classification of object
classes in the scene.
3.2 Semantic Segmentation of Aerial
Photos
The methodology for semantic segmentation of aerial
photos involves applying a label diffusion process
similar to Section 3.1, but adapted for a 3D-to-2D La-
bel Diffusion process.
This approach transfers labels from a labeled 3D
point cloud to 2D unlabeled orthophotos, leverag-
ing the rich semantic information in the 3D point
cloud. Additionally, an unsupervised segmentation
network (Kim et al., 2020) identifies similarities be-
tween orthophoto regions, refining label propagation
and aligning semantically similar regions for more ac-
curate segmentation.
The matrices used in this process differ from those
in 2D-to-3D diffusion. The label matrix Z
′
is initial-
ized using the 3D semantic segmentation results from
the point cloud (Z
X
). It consists of two blocks: the 2D
label matrix Z
′O
, corresponding to orthophoto pixels,
initially set to zeros; and the 3D label matrix Z
′X
, con-
taining class probabilities from the segmented point
cloud (Z
X
). The structure of Z
′
is:
Z
′
=
Z
′O
Z
X
In this representation, Z
′O
is a matrix with dimen-
sions N
O
×C, where N
O
is the total number of pixels
in the aerial photos, and C is the number of seman-
tic classes. Similarly, Z
X
has dimensions N
X
× C,
where N
X
is the total number of 3D points in the point
cloud. The label matrix Z
′
initializes semantic proba-
bilities for 3D points, while Z
′O
, representing the 2D
orthophoto pixels, is filled with zeros. This provides
the starting point for the label diffusion process.
To represent connectivity between orthophoto pix-
els and 3D points in the graph, we construct the ad-
jacency matrix G
′
, which includes the pixel-to-pixel
adjacency matrix G
′O→O
and the point-to-pixel adja-
cency matrix G
′X →O
.
To establish these connections, we define a sliding
window S W around each pixel p
i
in the aerial photo.
For each pixel p
j
within this window, we compute a
score combining a semantic similarity score (S
i j
) and
a neighborhood score (W
i j
).
The neighborhood score (W
i j
) is computed using
a Gaussian filter centered at p
i
, defined within the
sliding window. This filter assigns weights to neigh-
boring pixels based on their spatial proximity to p
i
,
following a Gaussian distribution. Closer pixels re-
ceive higher weights, while farther ones receive lower
weights, thus measuring the spatial relationship be-
tween p
i
and p
j
.
To compute the semantic similarity score (S
i j
), we
use an unsupervised segmentation algorithm based on
differentiable feature clustering (Kim et al., 2020).
The number of classes generated by the algorithm is
fixed to a maximum of C, aligning with the classes
used in Section 3.1. The segmented aerial photo is
utilized to assign semantic similarity scores between
p
i
and p
j
. Pixels belonging to the same class are as-
signed a score of 1, reflecting strong semantic simi-
larity. For pixels in different classes, a small non-zero
score (e.g., 1e-9) is assigned to allow slow label prop-
agation.
By combining W
i j
and S
i j
, we construct the pixel-
to-pixel adjacency matrix G
′O→O
, encoding spatial
and semantic relationships between pixels. It is de-
fined as:
G
′O→O
i j
= W
i j
× S
i j
where G
′O→O
i j denotes the element at the ith row
and jth column of the matrix, W i j is the neighbor-
hood score between pixels p
i
and p
j
, and S
i j
repre-
sents their unsupervised semantic similarity.
To link the 3D points in the point cloud with the
corresponding pixels in the aerial photos, a manual
alignment of the point cloud with the orthophoto is
performed. This ensures that each 3D point is ac-
curately projected onto its respective pixel in the or-
thophoto.
After alignment, the point-to-pixel adjacency ma-
trix G
′X →O
is constructed. For each pixel in the or-
thophoto, the matrix assigns a score of 1 if a 3D point
Combining Supervised Ground Level Learning and Aerial Unsupervised Learning for Efficient Urban Semantic Segmentation
437
projects onto that pixel, indicating a connection in the
graph representation.
By linking the nodes representing 3D points to
the pixels in the aerial photos, the point-to-pixel ad-
jacency matrix facilitates the label diffusion process,
propagating semantic labels from the 3D point cloud
to corresponding pixels. This propagation leverages
the graph structure, enabling the transfer of semantic
information for the segmentation of aerial photos.
To construct the adjacency matrix G
′
, we concate-
nate the pixel-to-pixel adjacency matrix G
′O→O
with
the point-to-pixel adjacency matrix G
′X →O
. The iden-
tity matrix I
O
is added to preserve the structure of the
point cloud and the aerial photo in the graph represen-
tation during the multiplication of G
′
with Z
′
.
G
′
=
G
′O→O
G
′X →O
0 I
O
The resulting adjacency matrix G
′
encodes the
connectivity between pixels and 3D points, enabling
the propagation of semantic labels from the 3D point
cloud to the aerial photo.
The label diffusion process iteratively updates the
label matrix Z
′
by multiplying it with the transition
matrix P
′
, which is derived by normalizing G
′
as de-
scribed in Section 3.1.
This 3D-to-2D label diffusion process enhances
the semantic segmentation of aerial photos by lever-
aging the geometric context and rich information
from the 3D point cloud. The result is more accurate
and detailed class labeling, supporting various appli-
cations in aerial image analysis and scene understand-
ing.
4 EXPERIMENTS AND RESULTS
In this section, we evaluate our proposed methodol-
ogy, including the 2D-to-3D and 3D-to-2D label dif-
fusion processes detailed in Section 3. Our experi-
ments demonstrate the effectiveness of the semantic
segmentation pipeline through qualitative and quan-
titative analyses. Performance is assessed using the
Mean Intersection over Union (mIoU) metric against
a manually labeled ground-truth orthophoto. We also
investigate the impact of key parameters, such as the
sliding window size S W , on the label diffusion pro-
cess.
4.1 Dataset and Experimental Setup
We conducted experiments using ground-level images
and a corresponding aerial photo. The ground images
were segmented into 66 object categories (Neuhold
et al., 2017), which were remapped into five classes:
moving object, structure, road, vegetation, and other.
These classes are well-suited for urban environments
and cover the key semantic elements of the scene.
The ground photos were processed with Mesh-
room to generate a 3D point cloud, forming the ba-
sis for the 2D-to-3D label diffusion process. The 3D
point cloud was then manually aligned with the aerial
orthophotos to enable the 3D-to-2D label diffusion
process. A manually labeled ground-truth orthophoto
was created to compute the Mean Intersection over
Union (mIoU), serving as a benchmark for evaluation.
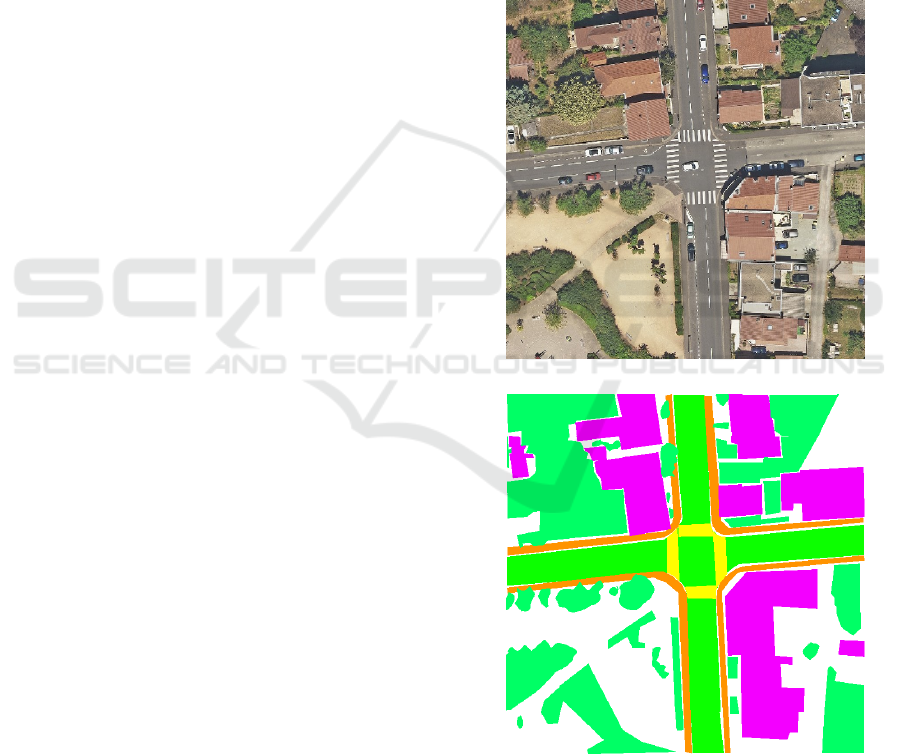
Figure 1 shows the manually labeled ground-truth or-
thophoto used in our analysis.
(a) Orthophoto
(b) Ground-truth orthophoto
Figure 1: Manually labeled ground-truth orthophoto used
for mIoU calculation.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
438

4.2 Qualitative Analysis
4.2.1 2D Semantic Segmentation Results
Figure 2 illustrates the 2D semantic segmentation re-
sults of the ground-level photos. Using MaskFormer,
the model effectively labeled pixels into the prede-
fined 66 object categories, providing the input for the
subsequent 2D-to-3D label diffusion process.
Figure 2: Examples of segmented ground photos.
4.2.2 3D Point Cloud Generation and Labeling
Initially, the ground images were processed with
Meshroom to generate an unlabeled 3D point cloud,
as shown in Figure 3. This reconstruction captures the
scene’s geometric structure and serves as the basis for
the 2D-to-3D label diffusion process, though it lacks
semantic information.
Figure 3: Unlabeled 3D point cloud generated from ground
images using Meshroom.
Following the 2D-to-3D label diffusion, the unla-
beled 3D point cloud was enriched with semantic la-
bels, as shown in Figure 4. Each point was assigned
one of five class labels based on the diffusion pro-
cess, demonstrating the successful transfer of labels
from 2D images to 3D space using pixel-to-point and
point-to-point constraints.
Figure 4: Labeled 3D point cloud after applying the 2D-to-
3D label diffusion process.
4.2.3 Orthophoto Segmentation
After aligning the 3D point cloud with the aerial or-
thophotos, we performed the 3D-to-2D label diffu-
sion to transfer the labels to the 2D orthophoto. As
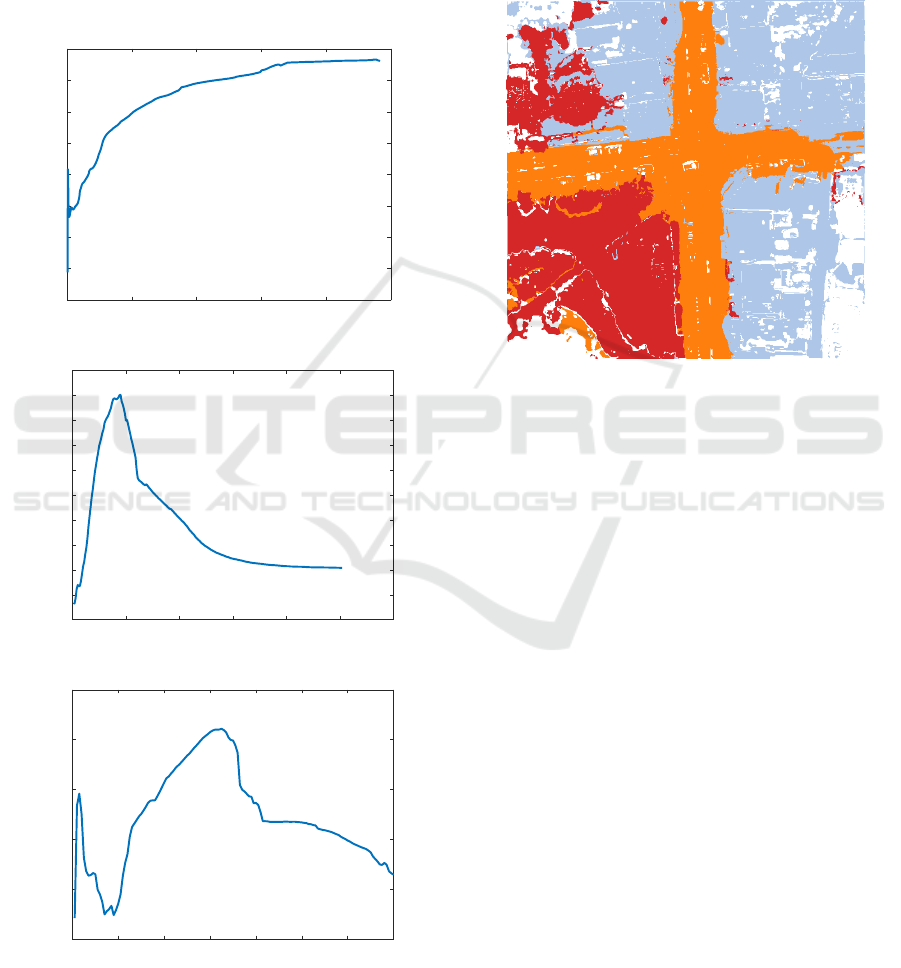
a first step, the orthophoto underwent unsupervised
segmentation, shown in Figure 5, which structured the
diffusion process by integrating similarity constraints
based on feature clustering.
Figure 5: Result of unsupervised segmentation on the or-
thophoto.
4.3 Quantitative Analysis
Comparing our results with other state-of-the-art
methods presents challenges due to the scarcity of
works focusing on orthophoto semantic segmentation.
Moreover, our approach relies on orthophotos linked
to ground-level images, making direct comparisons
with existing methodologies difficult. Nonetheless,
our results, measured against the manually labeled
ground-truth orthophoto, highlight the robustness and
Combining Supervised Ground Level Learning and Aerial Unsupervised Learning for Efficient Urban Semantic Segmentation
439
effectiveness of our method in urban environments.
To evaluate the impact of local constraints, we
tested our 3D-to-2D label diffusion algorithm with
different sliding window sizes (S W ): 9 × 9, 25 × 25,
and 65 × 65 pixels. The sliding window determines
the neighboring pixels considered during label propa-
gation in the orthophoto.
Figure 6 shows the mIoU progression across label
diffusion iterations, calculated against the manually
labeled ground-truth orthophoto. The results indicate
0 2000 4000 6000 8000 10000
iteration
0.4
0.41
0.42
0.43
0.44
0.45
0.46
0.47
0.48
mIoU
S W = 9 × 9
0 500 1000 1500 2000 2500 3000
iteration
0.465
0.47
0.475
0.48
0.485
0.49
0.495
0.5
0.505
0.51
0.515
mIoU
S W = 25 × 25
0 200 400 600 800 1000 1200 1400
iteration
0.465
0.47
0.475
0.48
0.485
0.49
mIoU
S W = 65 × 65
Figure 6: Evolution of mIoU across iterations with different
sliding window sizes.
that a sliding window size of S W = 25 × 25 achieves
the best balance, avoiding the limitations of too few
constraints or excessive noise from larger windows.
The best segmentation result was achieved after
500 iterations with a 25×25 sliding window. Figure 7
illustrates the final segmented orthophoto. This con-
figuration balanced local and global context, yielding
the highest mIoU score of 0.51.
Figure 7: Final semantic segmentation of the orthophoto
with S W = 25 × 25.
5 CONCLUSION
In this paper, we introduced a novel methodology for
semantic segmentation of aerial photos by leveraging
2D segmentations and 3D point cloud data. Our ap-
proach employs a graph-based label diffusion algo-
rithm to propagate semantic labels from 2D images to
a 3D point cloud and subsequently transfer them to
aerial photos. The ”Meshroom” algorithm was used
for 3D reconstruction, providing precise camera poses
and accurate geometry from ground-level photos.
By integrating 2D and 3D spatial information,
our method achieves accurate and detailed segmen-
tation of aerial photos, effectively capturing intricate
scene details. Experimental results validate the pro-
posed framework’s effectiveness in urban environ-
ments. The optimal configuration (SW = 25 × 25)
highlighted the importance of balancing neighbor-
hood constraints to minimize noise and enhance ac-
curacy.
Future work will focus on improving the unsuper-
vised segmentation stage to better align semantic re-
gions within orthophotos, further enhancing segmen-
tation performance.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
440

REFERENCES
Armeni, I., He, Z.-Y., Gwak, J., Zamir, A. R., Fischer, M.,
Malik, J., and Savarese, S. (2019). 3d scene graph: A
structure for unified semantics, 3d space, and camera.
In Proceedings of the IEEE International Conference
on Computer Vision.
Badrinarayanan, V., Kendall, A., and Cipolla, R. (2017).
Segnet: A deep convolutional encoder-decoder ar-
chitecture for image segmentation. IEEE Transac-
tions on Pattern Analysis and Machine Intelligence,
39(12):2481–2495.
Caron, M., Bojanowski, P., Joulin, A., and Douze, M.
(2018). Deep clustering for unsupervised learning of
visual features. In European Conference on Computer
Vision.
Caron, M., Touvron, H., Misra, I., J
´
egou, H., Mairal, J., Bo-
janowski, P., and Joulin, A. (2021). Emerging prop-
erties in self-supervised vision transformers. In Pro-
ceedings of the IEEE/CVF international conference
on computer vision, pages 9650–9660.
Chen, L.-C., Zhu, Y., Papandreou, G., Schroff, F., and
Hartwig, A. (2018). Encoder-decoder with atrous sep-
arable convolution for semantic image segmentation.
In European Conference on Computer Vision, pages
801–818.
Cheng, B., Schwing, A. G., and Kirillov, A. (2021). Per-
pixel classification is not all you need for semantic
segmentation.
Cho, J. H., Mall, U., Bala, K., and Hariharan, B. (2021).
Picie: Unsupervised semantic segmentation using
invariance and equivariance in clustering. 2021
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition (CVPR), pages 16789–16799.
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler,
M., Benenson, R., Franke, U., Roth, S., and Schiele,
B. (2016). The cityscapes dataset for semantic urban
scene understanding. In Proc. of the IEEE Conference
on Computer Vision and Pattern Recognition (CVPR).
Desai, S. M. and Ghose, D. (2022). Active learning for
improved semi-supervised semantic segmentation in
satellite images. 2022 IEEE/CVF Winter Conference
on Applications of Computer Vision (WACV), pages
1485–1495.
Genova, K., Yin, X., Kundu, A., Pantofaru, C., Cole,
F., Sud, A., Brewington, B., Shucker, B., and
Funkhouser, T. (2021). Learning 3d semantic seg-
mentation with only 2d image supervision. In 2021
International Conference on 3D Vision (3DV), pages
361–372.
Hamilton, M., Zhang, Z., Hariharan, B., Snavely, N., and
Freeman, W. T. (2022). Unsupervised semantic seg-
mentation by distilling feature correspondences. In In-
ternational Conference on Learning Representations.
Ji, X., Henriques, J. F., and Vedaldi, A. (2019). Invariant
information clustering for unsupervised image clas-
sification and segmentation. In Proceedings of the
IEEE/CVF International Conference on Computer Vi-
sion (ICCV).
Kim, W., Kanezaki, A., and Tanaka, M. (2020). Unsuper-
vised learning of image segmentation based on dif-
ferentiable feature clustering. IEEE Transactions on
Image Processing, 29:8055–8068.
Krishna, R., Zhu, Y., Groth, O., Johnson, J., Hata, K.,
Kravitz, J., Chen, S., Kalan-tidis, Y., Li, L.-J.,
Shamma, D. A., Bernstein, M., and Fei-Fei, L. (2017).
Visual genome: Connecting language and vision us-
ing crowdsourced dense image annotations. Interna-
tional Journal of Computer Vision, (123):32–73.
Liang-Chieh, C., Papandreou, G., Kokkinos, I., Murphy, K.,
and Yuille, A. (2015). Semantic Image Segmentation
with Deep Convolutional Nets and Fully Connected
CRFs. In International Conference on Learning Rep-
resentations, San Diego, United States.
Luo, Z., Pan, J., Hu, Y., Deng, L., Li, Y., Qi, C., and Wang,
X. (2024). Rs-dseg: semantic segmentation of high-
resolution remote sensing images based on a diffusion
model component with unsupervised pretraining. Sci-
entific Reports, 14(1):18609.
Mascaro, R., Teixeira, L., and Chli, M. (2021). Dif-
fuser: Multi-view 2d-to-3d label diffusion for se-
mantic scene segmentation. In 2021 IEEE Inter-
national Conference on Robotics and Automation
(ICRA), pages 13589–13595.
Neuhold, G., Ollmann, T., Rota Bul
`
o, S., and Kontschieder,
P. (2017). The mapillary vistas dataset for semantic
understanding of street scenes. In International Con-
ference on Computer Vision (ICCV).
Ronneberger, O., Fischer, P., and Brox, T. (2015). U-
net: Convolutional networks for biomedical im-
age segmentation. In Medical Image Computing
and Computer-Assisted Intervention – MICCAI 2015,
pages 234–241. Springer International Publishing.
Rottensteiner, F., Sohn, G., Jung, J., Gerke, M., Baillard,
C., B
´
enitez, S., and Breitkopf, U. (2012). The is-
prs benchmark on urban object classification and 3d
building reconstruction. ISPRS Annals of Photogram-
metry, Remote Sensing and Spatial Information Sci-
ences, I-3.
Schmitt, M., Ahmadi, S., and H
¨
ansch, R. (2021). There
is no data like more data – current status of machine
learning datasets in remote sensing. In International
Geoscience and Remote Sensing Symposium.
Simonyan, K. and Zisserman, A. (2015). Very deep con-
volutional networks for large-scale image recognition.
In International Conference on Learning Representa-
tions.
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S.,
Anguelov, D., Erhan, D., Vanhoucke, V., and Rabi-
novich, A. (2015). Going deeper with convolutions. In
2015 IEEE Conference on Computer Vision and Pat-
tern Recognition (CVPR), pages 1–9.
Yuan, Y., Chen, X., and Wang, J. (2020). Object-contextual
representations for semantic segmentation.
Combining Supervised Ground Level Learning and Aerial Unsupervised Learning for Efficient Urban Semantic Segmentation
441
