
Metaheuristics Applied to Optimal Feature Selection for Accurate
Predictive Models in Smart Health: A Case Study on Hypotension
Prediction in Hemodialysis Patients
María Santamera-Lastras
1,2 a
, Felipe Cisternas-Caneo
3 b
, José Carlos Barrera-García
3 c
,
Broderick Crawford
3 d
, Alberto Garcés-Jiménez
2,4,5 e
, Diego Rodríguez-Puyol
1,5 f
and José Manuel Gómez-Pulido
2,4,5 g
1
Dept. of Medicine and Medical Specialties, Universidad de Alcalá, Madrid, Spain
2
Health Computing and Intelligent Systems Research Group (HCIS), Universidad de Alcalá, Madrid, Spain
3
Escuela de Ingeniería Informática, Pontificia Universidad Católica de Valparaíso, Valparaíso, Chile
4
Dept. of Computer Science, Universidad de Alcalá, Madrid, Spain
5
Ramón y Cajal Institute for Health Research (IRYCIS), Madrid, Spain
Keywords:
Intradialytic Hypotension, Metaheuristic, Predictive Learning, Dimensionality Reduction, Selection of
Characteristics.
Abstract:
Predicting potential hypotensive episodes in chronic kidney disease patients before dialysis is crucial for pre-
venting complications and ensuring effective treatment. This study explores the use of metaheuristic algo-
rithms to optimize the complex task of selecting the feature set needed to develop a highly accurate predictive
machine learning model for detecting hypotension, based on clinical parameters from the dialyzer and ana-
lytical data from blood tests. Metaheuristic algorithms offer a robust approach to optimal variable selection
and subsequent dimensionality reduction, leading to more accurate machine learning predictor models. In
this context, two relevant metaheuristic algorithms were employed: Particle Swarm Optimization (PSO) and
Grey Wolf Optimizer (GWO), along with the supervised machine learning algorithm XGBoost. The results
demonstrate that the application of metaheuristic techniques not only reduces the feature count from 67 to 36
variables but also improves classifier performance, thereby enhancing the prediction of hypotensive events.
Specifically, the optimized model achieved an Area Under the Curve (AUC) of 0.76 and a recall of 0.764 for
the minority class (hypotensive episodes) in chronic kidney disease patients prior to hemodialysis procedures.
1 INTRODUCTION
1.1 The Challenge of Early Detection of
Intradialytic Hypotension
Dialysis and transplantation have allowed many pa-
tients with advanced chronic kidney disease (CKD) to
live longer and maintain a good quality of life. Over
a
https://orcid.org/0009-0006-2323-192X
b
https://orcid.org/0000-0001-7723-7012
c
https://orcid.org/0009-0007-9934-5250
d
https://orcid.org/0000-0001-5500-0188
e
https://orcid.org/0000-0002-1365-9280
f
https://orcid.org/0000-0002-9125-9311
g
https://orcid.org/0000-0002-6897-8262
the last decade, the prevalence of advanced CKD has
increased by nearly 30% in Spain. As a result, in
2021, 65,740 patients required dialysis to stay alive,
with 26,690 of them undergoing hemodialysis (HD)
techniques (Sociedad Española de Nefrología, 2023).
Intradialytic hypotension (IDH) is one of the most
common adverse events during hemodialysis (HD)
sessions. Despite significant advances in HD tech-
niques in recent decades that have improved its man-
agement, IDH remains prevalent, occurring in 5-40%
of sessions (Flythe et al., 2020). This condition is as-
sociated with high morbidity and mortality rates, as
well as multiple complications. Currently, there are
no standardized guidelines or systematic treatments
for managing IDH; various maneuvers are employed
to control it (Furaz Czerpak et al., 2014). IDH is char-
Santamera-Lastras, M., Cisternas Caneo, F., Barrera García, J. C., Crawford, B., Garcéz-Jiménez, A., Rodríguez Puyol, D. and Gómez Pulido, J. M.
Metaheuristics Applied to Optimal Feature Selection for Accurate Predictive Models in Smart Health: A Case Study on Hypotension Prediction in Hemodialysis Patients.
DOI: 10.5220/0013164000003911
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 18th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2025) - Volume 1, pages 563-570
ISBN: 978-989-758-731-3; ISSN: 2184-4305
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
563

acterized by three essential components: a drop of
more than 20 mmHg in systolic blood pressure (SBP)
or more than 10 mmHg in mean arterial pressure
(MAP), the presence of ischemic symptoms in vari-
ous organs, and interventions by dialysis staff (Agar-
wal, 2012).
Identifying the occurrence of intradialytic hy-
potension (IDH) during hemodialysis (HD) treatment
is challenging due to the numerous variables involved,
including the type of dialyzer, dialyzer temperature,
patient characteristics, dialysis modality, and medical
criteria. Therefore, pinpointing the factors that most
significantly influence the occurrence of IDH and pre-
dicting its onset would provide valuable decision sup-
port for medical staff.
1.2 Prediction of IDH Using Machine
Learning Techniques
Determining whether a patient experiences intradia-
lytic hypotension (IDH) during hemodialysis (HD)
treatment is a complex task for traditional statistical
models. However, machine learning (ML) models
can effectively discover patterns in the data, making
them particularly well-suited for this problem (Nay-
yar et al., 2021). This work aims to identify an op-
timal ML-based model to predict the likelihood of
IDH at the start of HD treatment. To achieve this,
metaheuristic techniques will be employed to select
the best combination of variables from the patient’s
clinical and analytical blood records, which contain
numerous characteristics, to reduce noise, improve
model performance, and enhance the accuracy of the
ML model.
Recent research has developed predictive mod-
els that utilize machine learning algorithms and opti-
mization techniques to forecast intradialytic hypoten-
sion (IDH) episodes with high accuracy. These mod-
els empower healthcare professionals to anticipate
and prevent IDH, thereby enhancing patient safety
and well-being during hemodialysis treatments. By
combining machine learning with optimization tech-
niques, significant progress has been made in man-
aging and preventing health complications. Various
studies have proposed different methodologies to pre-
dict and manage IDH episodes, aiming to improve pa-
tient outcomes and enhance clinical decision-making.
For instance, Hong et al. (Hong et al., 2023) in-
troduced a software-based artificial intelligence alert
system to identify patients at high risk of IDH before
hemodialysis sessions. Similarly, Gervasoni et al.
(Gervasoni et al., 2023) developed and validated two
AI-based risk models to predict symptomatic IDH
at different time points. Othman et al. (Othman
et al., 2022) focused on early alert systems, employ-
ing AI and machine learning techniques for IDH pre-
diction prior to the initiation of hemodialysis. In an-
other approach, Yang et al. (Yang et al., 2022) pre-
sented a hybrid model, BSCWJAYA-KELM, which
integrates serum biomarkers with a novel optimiza-
tion algorithm to enhance prediction accuracy. Addi-
tionally, Chen et al. (Chen et al., 2020) investigated
clinical factors associated with IDH using deep learn-
ing, while Lee et al. (Lee et al., 2023) developed
a model based on pre-dialysis features for IDH pre-
diction. Zhang et al. (Zhang et al., 2023) utilized a
machine learning model to predict IDH in in-center
hemodialysis patients 15 to 75 minutes in advance.
Kim et al. (Kim et al., 2022) introduced a deep learn-
ing model that relies solely on monitoring measure-
ments from hemodialysis machines, and Mendoza-
Pittí et al. (Mendoza-Pittí et al., 2022) created a ma-
chine learning model capable of predicting IDH at the
start of hemodialysis sessions. Finally, Gómez-Pulido
et al. (Gómez-Pulido et al., 2021) predicted hypoten-
sion using models trained on a large dialysis database.
These studies collectively enhance the under-
standing of intradialytic hypotension (IDH) predic-
tion and management through the use of machine
learning algorithms and AI techniques. Their aim is
to identify high-risk patients early, facilitating timely
interventions to prevent acute hypotension during
hemodialysis and ultimately improving patient out-
comes.
1.3 Optimal Feature Selection
Technique Based on Metaheuristics
In the healthcare field, innovative and efficient so-
lutions to complex problems are crucial (Haupt and
Haupt, 2004). Metaheuristics, which include algo-
rithms such as genetic algorithms, particle swarm op-
timization, and ant colony optimization, have signif-
icant applications in this sector. These algorithms
iteratively search for optimal solutions by initializ-
ing a population of candidate solutions and evaluating
their fitness according to an objective function. Based
on this evaluation, they generate new populations by
modifying the existing ones to enhance overall fitness.
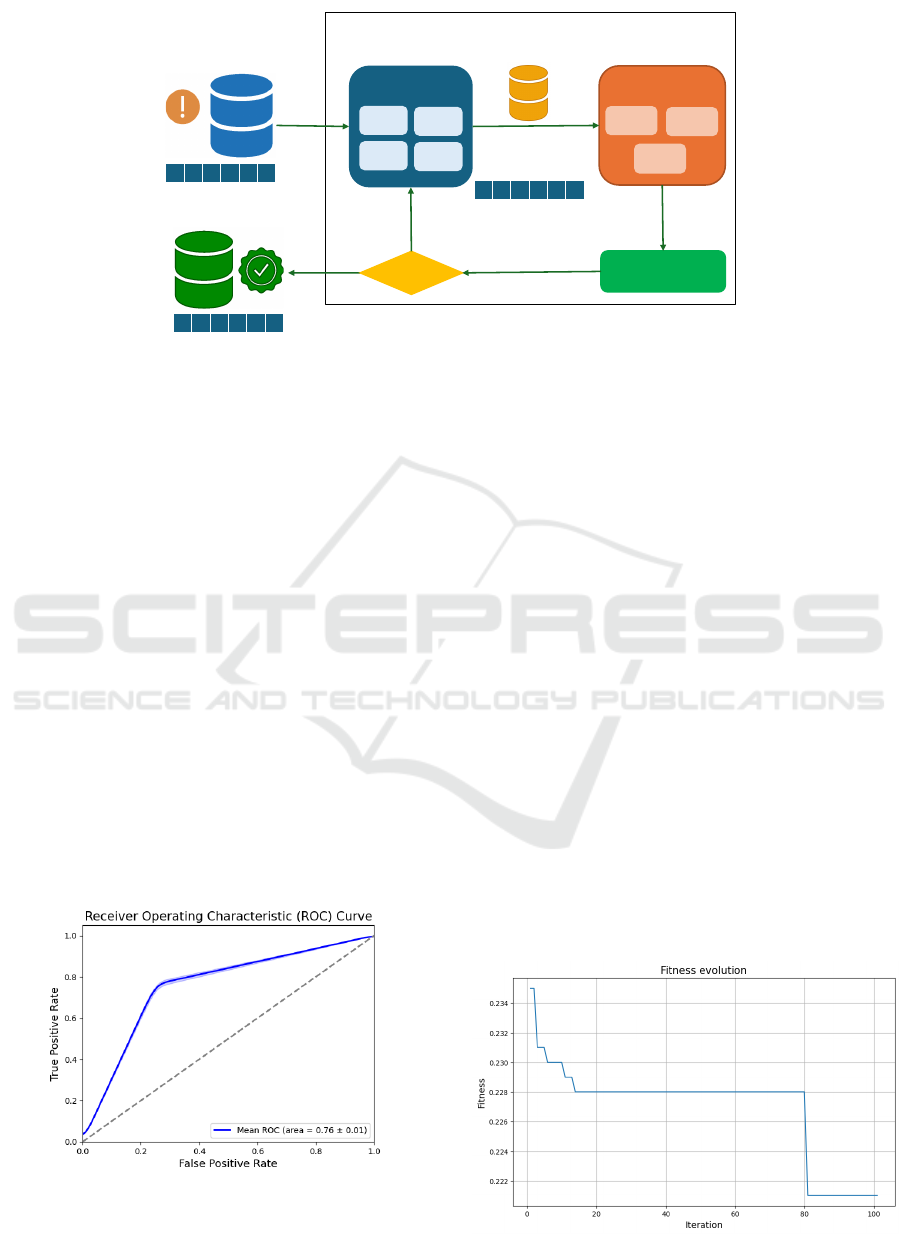
This process, illustrated in Fig. 1, continues until a
stopping criterion is met.
These techniques are employed to optimize medi-
cal treatments, enhance hospital scheduling, and facil-
itate the analysis of large medical datasets. The ability
of metaheuristics to identify near-optimal solutions
within a reasonable time frame makes them ideal for
addressing healthcare challenges, where swift and ac-
curate decisions can significantly impact patient out-
BIOINFORMATICS 2025 - 16th International Conference on Bioinformatics Models, Methods and Algorithms
564

comes (Rahul and Banyal, 2022; Aljohani, 2024).
The Feature Selection (FS) problem is a multi-
objective combinatorial optimization challenge that
arises from the need to eliminate irrelevant and redun-
dant information from datasets used in machine learn-
ing training. Such irrelevant information can hinder
the performance of prediction or classification algo-
rithms.
In its mathematics definition, FS assumes a
dataset O such as the original dataset, which con-
tains a o number of f features, such that O =
{ f
1
, f
2
, f
3
, ..., f
o
}. The objective of the prob-
lem is to select the best subset of features B =
{ f
1
, f
2
, f
3
, ..., f
b
} with b < o so that the features be-
longing to the selected subset are the most represen-
tative of the set of original data. (Ebiaredoh-Mienye
et al., 2022; Pudjihartono et al., 2022)
Internally, feature selection operates within a bi-
nary domain, where solutions are represented by ones
and zeros. A one indicates that a feature is included
in the data subset, while a zero signifies its exclu-
sion. Fig. 2 illustrates this representation for the fea-
ture selection problem. In this example, the original
dataset comprises six features, resulting in the solu-
tion [1, 1, 1,1, 1, 1]. After applying the metaheuristics,
the optimal subset of features, which includes fea-
tures f
1
, f
2
, and f
3
, is identified, yielding the solution
[1, 0, 1, 1, 0, 0].
The objective function to optimize within the
feature selection problem is represented in differ-
ent ways, but the most used is the weighted multi-
objective function (Barrera-García et al., 2023). In
this way, the objective function Z is calculated as the
following equation (1):
min Z = α · metric + β ·
|R|
|N|
(1)
where metric corresponds to a performance metric
obtained from the machine learning technique, |R| is
the number of selected features, and |N| the total num-
ber of features, with α ∈ [0, 1] and β = (1−α) param-
eters that regulate the importance of the quality of the
results and the size of the subset, respectively.
Figure 1: Flowchart of the metaheuristic algorithm process.
f
1
f
2
f
3
f
4
f
5
f
6
1 1 1 1 1 1
f
1
f
2
f
3
f
4
f
5
f
6
1 0 1 1 0 0
After Feature
Selection with
metaheuristics
Original Dataset Best Subset
Figure 2: Binary representation of vectors S and D.
1.4 Hypothesis
It is possible to detect an optimal combination of clin-
ical and analytical parameters associated with the de-
velopment of IDH.
By analyzing a patient’s previous analytical val-
ues and relevant data, along with measurements of
specific clinical parameters at the beginning of a
hemodialysis (HD) session, it may be possible to pre-
dict the occurrence of an intradialytic hypotension
(IDH) episode. This could help reduce its incidence
and enable early intervention by medical staff. The re-
search aims to extract and construct a subset of signif-
icantly relevant variables from a large database of HD
sessions and blood tests. This subset will be suitable
for processing with mass data tools and will facilitate
the prediction of IDH based on patterns derived from
an optimal and reduced set of clinical and analytical
parameters.
2 MATERIALS AND METHODS
2.1 Digitized Clinical Database of
Hemodialysis Patients
Our research is based on two extensive databases con-
taining medical information from 758 patients under-
going hemodialysis sessions at Hospital Príncipe de
Asturias in Madrid, Spain, over nearly four years,
from January 1, 2016, to October 30, 2019. The first
database includes clinical data for 98,015 hemodialy-
sis sessions, each lasting about five hours, and com-
prises patient and session identification data along
with 180 clinical parameters automatically recorded
by the dialyzer during the sessions. The second
database contains blood analysis data for the same pa-
tients and period, featuring 141 variables arising from
routine blood tests performed at varying intervals.
To create the dataset for this study, the two
databases were merged such that each hemodialysis
session was linked to both the session’s clinical data
and the results of the blood test closest in time—either
on the same date or immediately prior. In total, this
Metaheuristics Applied to Optimal Feature Selection for Accurate Predictive Models in Smart Health: A Case Study on Hypotension
Prediction in Hemodialysis Patients
565

merging process resulted in a new dataset contain-
ing 221 variables related to patient information, dial-
ysis sessions, and blood tests. The collection of these
records was approved by the hospital’s ethics commit-
tee, with all data fully anonymized.
2.2 Database of HD Sessions Indicating
IDH Events
In the integrated database, HD sessions in which
the IDH event is determined by medical criteria are
marked. For this purpose, it is determined from the
systolic arterial pressures measured in each of the 5
hours of the session whether the difference between
any of these pressures measured during the session
is at least 20 mmHg lower than the pressures mea-
sured at the beginning of the session and at the first
hour. Each HD session is assigned a new binary vari-
able, IDH, that takes the value of "1" if there is a hy-
potension event and "0" if there is not. Finally, a new
database, shown in Fig. 3, is formed containing the
analytical and clinical variables associated with each
session, keeping only the variables associated with the
start of the HD session, the so-called "Hour 0".
This new database supports the goal of developing
a predictive system that can accurately anticipate po-
tential hypotensive episodes during dialysis sessions.
2.3 Data Processing and Variables
Considered in the Clinical Study
After obtaining the integrated database, the medical
staff, using their experience and clinical knowledge,
determined a set of 67 variables to be considered for
the predictive model to be developed. Subsequently,
and as is usual in data science work, it is necessary
to pre-process the data before starting the modeling
phases. In the present case, after the tasks of integrat-
ing and combining data from different sources, clean-
ing tasks have been carried out, identifying and cor-
recting possible errors in the data. For this purpose,
an analysis of the variables to be analyzed was carried
out, detecting possible quality problems in the data,
and cleaning tasks were carried out in order to have
a set of consistent data, correcting incorrect, atypical,
or missing data. This data analysis process detected
that many dialysis sessions or analytical tests lacked
quality data. Therefore, the medical team opted to
keep the largest number of variables to be considered
for the models and to eliminate patients and dialy-
sis sessions that lacked quality data so that finally,
the data set used to run the predictive model consid-
ered 328 patients and a set of 68,574 sessions, which
constitutes 69.96% and of which 19,810 sessions had
IDH, representing 28.89% of the total number of HD
sessions considered after the data cleaning process
(Fig. 4). Both the patient cohort size and the number
of HD sessions are representative of the population
under study and allow for adequate modeling of the
predictor system to be developed.
2.4 Enhanced Prediction of IDH
Through Machine Learning and
Biomarker Analysis
2.4.1 Machine Learning Model
To predict IDH, an XGBoost model was employed,
selected for its superior performance in preliminary
experiments compared to various methods, including
KNN, Random Forest, and LGBM, as well as serving
as a representative example of decision tree-based ap-
proaches. Initial hyper-parameter tuning was tailored
to our dataset, which includes 67 features.
A 5-fold cross-validation technique was imple-
mented to validate the model, ensuring robust perfor-
mance evaluation.
Given the dataset’s class imbalance, with only
28.89% of sessions representing the minority class
(hypotensive patients), a data balancing technique
called RandomUnderSampler was employed. This
method was chosen based on previous experiments
that demonstrated its superiority over RandomOver-
Sampler and NearMiss techniques. The imbalance ra-
tio was adjusted to 1:1, equalizing the number of sam-
ples in both the majority and minority classes, thereby
improving the model’s predictive accuracy.
2.4.2 Feature Selection with Metaheuristics
For feature selection, two representative metaheuris-
tic algorithms were employed: Particle Swarm Op-
timization (PSO) and Grey Wolf Optimizer (GWO).
PSO was selected as a classic metaheuristic model
known for its effectiveness in solving optimization
problems by simulating social behavior patterns. In
contrast, GWO, inspired by the social hierarchy and
hunting behavior of grey wolves, is recognized for its
ability to balance exploration and exploitation during
the optimization process. Both algorithms were cho-
sen for their proven capability to efficiently navigate
large search spaces and identify relevant features, thus
enhancing the performance of the predictive model.
The binarization of solutions obtained from the
metaheuristics was necessary to convert continuous
variables into binary variables due to the discrete na-
ture of the feature selection optimization problem.
The S4 and STD transfer functions were employed
BIOINFORMATICS 2025 - 16th International Conference on Bioinformatics Models, Methods and Algorithms
566

Figure 3: Predictive model at the start of the hemodialysis session.
Figure 4: Number of HD sessions used to run the model.
for this process (Cisternas-Caneo et al., 2024).
The metaheuristic approach utilized two objective
functions (Eq. 2), both incorporating the number of
features in the model and various metrics to evaluate
the classifier’s performance, minimized over 100 iter-
ations. The first version aimed to maximize the recall
of the minority class (hypotensive patients) (Eq. 3),
while the second focused on maximizing the F1-score
of the minority class (Eq. 4). Additionally, the ob-
jective functions were weighted to favor performance
metrics over feature reduction, allowing flexibility in
adapting to the problem’s nature.
minz = 0.99 · Metric+ 0.01 ·
Selected features
Total features
(2)
Metric 1: 1 − Minority Class Recall
(3)
Metric 2: 1 − Minority Class F1-score
(4)
where F1-score and recall are defined as:
F1-Score =
T P
T P + 0.5(FP + FN)
Recall =
T P
T P + FN
and T P is true positives, FN is false negatives and FP
is false positives.
By iterating through these objectives, the meta-
heuristic algorithm effectively selected features that
enhanced the model’s predictive performance while
addressing the dataset’s class imbalance, as shown in
Figure 5. Feedback from the classifier’s performance
metrics guided the metaheuristic process, represent-
ing a novel approach where the selection module in-
tegrates performance testing with various sets of vari-
ables chosen by the metaheuristic.
3 EXPERIMENTAL RESULTS
3.1 Initial Model Performance
Before applying metaheuristics algorithms for feature
selection, the XGBoost model was trained using the
complete set of 67 features. The initial performance
metrics were as follows: an F1-score of 0.7172, pre-
cision of 0.7520, and recall of 0.7244. Given the na-
ture of the problem, accurately predicting the minor-
ity class, i.e., hypotensive episodes, is critical. There-
fore, the study primarily focused on metrics for the
minority class. Specifically, the recall for the mi-
nority class was emphasized to minimize false neg-
atives, which correspond to cases where hypotensive
episodes are not predicted when they should be. Thus,
the recall and F1-score for the minority class were
the key metrics of interest, with values of 0.7541 and
0.6373, respectively.
3.2 Feature Reduction
Table 1 compares the performance of the XGBoost
model using the original 67 features against the per-
Metaheuristics Applied to Optimal Feature Selection for Accurate Predictive Models in Smart Health: A Case Study on Hypotension
Prediction in Hemodialysis Patients
567
1
1
1
1
…
1
1
0
1
1
…
0
0
1
1
0
…
1
No
Yes
Feature Selection Module
Full Dataset
Best subset
Metaheuristic
Module
PSO
GWO
WOA
PSA
Machine Learning
Module
KNN
RF
XG
Subset with
some features
enabled
Performance
Metrics
finish?
Figure 5: Feature selection process.
formance after feature reduction using PSO and GWO
with both objective function metrics (Eq. 3, Eq. 4).
The best results for the minority class F1-score and
recall were achieved with the PSO algorithm using
the first objective function (Eq. 3). Specifically, the
minority class F1-score and recall values were 0.6419
and 0.7640, respectively. The feature selection pro-
cess reduced the number of features to 36. Also us-
ing PSO algorithm for feature reduction achieved a
46.27% decrease in the initially selected features by
the experts. Additionally, this process resulted in a
slight improvement in the XGBoost model’s perfor-
mance for predicting hypotensive episodes in dialysis
patients. Specifically, the F1-score for the minority
class increased from 0.6373 to 0.6419, and the re-
call for the minority class improved from 0.7541 to
0.7640.
Fig. 6 presents the Receiver Operating Character-
istic (ROC) curve for the IDH prediction model using
the 36 features selected by PSO algorithm. The Area
Under the Curve (AUC) value is 0.76.
Figure 6: Receiver Operating Characteristic (ROC) curve
and the area under the curve (AUC) for the XGBoost model
trained with the 36 features chosen by the PSO model.
Fig. 7 shows the fitness evolution of the best so-
lution over iterations for the PSO algorithm using the
objective function that included the minority class re-
call as a metric (Eq. 3). The plot illustrates a gradual
decrease in fitness, corresponding to an increase in the
minority class recall. This trend indicates a reduction
in false negatives and, consequently, an improvement
in the predictive performance of the model.
4 CONCLUSION
Predicting hypotensive episodes in chronic kidney
disease patients prior to dialysis is crucial for prevent-
ing complications and ensuring effective treatment.
This study employed the XGBoost machine learn-
ing model to predict such episodes, initially using a
dataset of 67 features selected by medical experts.
Subsequently, metaheuristic algorithms, specifically
PSO and GWO, were used to reduce the feature set
and enhance the model’s performance.
A key challenge in developing predictive mod-
els for medical applications is the large number of
Figure 7: Fitness evolution.
BIOINFORMATICS 2025 - 16th International Conference on Bioinformatics Models, Methods and Algorithms
568

Table 1: Classification results of models using Stratified k-fold cross-validation method.
Model FO IDH Patient Non-IDH Patient Accuracy Total
Metric Recall F1-score Precision Recall F1-score Precision Features
NO NO 0.7541 (0.007) 0.6373 (0.0060) 0.5518 (0.006) 0.7512 (0.004) 0.8116 (0.003) 0.8826 (0.003) 0.7520 (0.004) 67
PSO 1 0.7640 (0.015) 0.6419 (0.006) 0.5536 (0.005) 0.7497 (0.007) 0.8124 (0.003) 0.8867 (0.006) 0.7538 (0.004) 36
GWO 1 0.7617 (0.012) 0.6352 (0.006) 0.5448 (0.005) 0.7414 (0.006) 0.8067 (0.004) 0.8845 (0.005) 0.7473 (0.004) 38
PSO 2 0.7603 (0.008) 0.6422 (0.007) 0.5559 (0.007) 0.7532 (0.005) 0.8140 (0.004) 0.8855 (0.003) 0.7568 (0.006) 41
GWO 2 0.7560 (0.008) 0.6396 (0.009) 0.5527 (0.010) 0.7504 (0.009) 0.8119 (0.007) 0.8846 (0.004) 0.7547 (0.008) 38
NO, Without Metaheuristics; PSO, Particle Swarm Optimization; GWO, Grey Wolf Optimizer.
features, which can lead to increased computational
complexity and potential overfitting. Effective feature
reduction is essential to streamline the model, reduce
computational load, and eliminate irrelevant or redun-
dant information, thereby improving the model’s per-
formance and generalizability.
The study successfully developed a model capa-
ble of identifying IDH events in chronic kidney dis-
ease patients. By applying metaheuristic techniques,
the number of features was significantly reduced, and
the predictive accuracy of the model was improved.
The PSO algorithm, in particular, demonstrated a ro-
bust reduction in the number of features, decreasing
the feature set by 46.27% from the original 67 fea-
tures to 36. This substantial reduction in features not
only simplifies the model but also enhances its in-
terpretability and efficiency. Reducing the number
of features decreases the computational load, mak-
ing the model faster and more efficient in processing
data. Additionally, eliminating irrelevant and redun-
dant information helps to avoid overfitting, thereby
improving the model’s generalizability. This stream-
lined approach also facilitates easier interpretation of
the model’s results, allowing for more straightforward
insights into the key factors influencing IDH events.
This reduction in characteristics does not compro-
mise the model’s effectiveness. On the contrary, the
optimized model achieved an AUC of 0.76, demon-
strating its capability to distinguish between hypoten-
sive and non-hypotensive episodes. Additionally, it
achieved a recall of 0.764 for the minority class (hy-
potensive episodes) in chronic renal patients prior to
dialysis procedures. This high recall value signifies
a low number of false negatives, meaning that the
model effectively identifies patients with IDH who
might otherwise not be warned of such episodes. The
improvement of recall and F1-score for the minority
class, critical metrics for this medical prediction task,
underlines the effectiveness of using metaheuristics
and, in this case, PSO selects fewer significant fea-
tures. Consequently, the optimized model not only
provides reliable predictions of hypotensive episodes
but also operates with greater efficiency, facilitating
its potential integration into clinical practice.
In conclusion, this study highlights the importance
of feature reduction in predictive modeling for medi-
cal applications. The use of metaheuristic algorithms,
particularly PSO, has proven to be an effective strat-
egy for enhancing model performance while signifi-
cantly reducing the number of required features. This
approach offers a promising pathway for developing
efficient, accurate, and clinically applicable models
for predicting hypotensive episodes in chronic kidney
disease patients at the beginning of the HD session.
Looking ahead, there are several avenues for fu-
ture research. Our model could be further refined by
exploring additional machine learning techniques or
ensemble methods combining different approaches.
Extending the study to include predictions for other
pathological events during dialysis, such as thrombo-
sis and arrhythmias, could enhance its clinical utility.
Additionally, incorporating the full initial dataset of
200 variables—beyond those selected by medical ex-
perts—and addressing missing data through imputa-
tion techniques would provide a more comprehensive
analysis and potentially improve the model’s predic-
tive capabilities.
ACKNOWLEDGEMENTS
This work is part of the project "Prevention of seri-
ous pathological events in hemodialysis patients by
non-invasive continuous monitoring of vital signs and
analysis of circular biomarkers (ALLPREVENT)",
PMPTA23/00033, which has been funded by the In-
stituto de Salud Carlos III (ISCIII) within the pro-
gramme of R&D projects linked to personalised
medicine and advanced therapies. The authors would
like to thank Dr. Pablo Herrera, MSc. Melisa Granda
and MSc. Daniella Peña for their collaboration in the
study and the company Intelligent Data for their sup-
port and collaboration in research aimed at the design
and joint development of technological products in
the field of health. Felipe Cisternas-Caneo and Jose
Barrera-García are both supported by the National
Agency for Research and Development (ANID) un-
der the Doctorado Nacional Scholarship Program.
Metaheuristics Applied to Optimal Feature Selection for Accurate Predictive Models in Smart Health: A Case Study on Hypotension
Prediction in Hemodialysis Patients
569

REFERENCES
Agarwal, R. (2012). How can we prevent intradialytic hy-
potension? Current opinion in nephrology and hyper-
tension, 21(6):593–599.
Aljohani, A. (2024). Optimizing Patient Stratification in
Healthcare: A Comparative Analysis of Clustering
Algorithms for EHR Data. International Journal of
Computational Intelligence Systems, 17(1):173.
Barrera-García, J., Cisternas-Caneo, F., Crawford, B.,
Gómez Sánchez, M., and Soto, R. (2023). Feature se-
lection problem and metaheuristics: a systematic lit-
erature review about its formulation, evaluation and
applications. Biomimetics, 9(1):9.
Chen, J. B., Wu, K. C., Moi, S. H., Chuang, L. Y., and Yang,
C. H. (2020). Deep learning for intradialytic hypoten-
sion prediction in hemodialysis patients. IEEE Access,
8:82382–82390.
Cisternas-Caneo, F., Crawford, B., Soto, R., Giachetti, G.,
Paz, Á., and Peña Fritz, Á. (2024). Chaotic binariza-
tion schemes for solving combinatorial optimization
problems using continuous metaheuristics. Mathe-
matics, 12(2).
Ebiaredoh-Mienye, S. A., Swart, T. G., Esenogho, E., and
Mienye, I. D. (2022). A machine learning method
with filter-based feature selection for improved pre-
diction of chronic kidney disease. Bioengineering,
9(8):350.
Flythe, J. E., Chang, T. I., Gallagher, M. P., Lindley, E.,
Madero, M., Sarafidis, P. A., Unruh, M. L., Wang,
A. Y.-M., Weiner, D. E., Cheung, M., et al. (2020).
Blood pressure and volume management in dialysis:
conclusions from a kidney disease: Improving global
outcomes (kdigo) controversies conference. Kidney
international, 97(5):861–876.
Furaz Czerpak, K. R., Puente García, A., Corchete Prats,
E., Moreno de la Higuera, M., Gruss Vergara, E., and
Martín-Hernández, R. (2014). Estrategias para el con-
trol de la hipotensión en hemodiálisis. Nefrología,
6(1):1–14.
Gervasoni, F., Bellocchio, F., Rosenberger, J., Arkossy, O.,
Ion Titapiccolo, J., Kovarova, V., Larkin, J., Nikam,
M., Stuard, S., Tripepi, G. L., Usvyat, L. A., Winter,
A., Neri, L., and Zoccali, C. (2023). Development
and validation of ai-based triage support algorithms
for prevention of intradialytic hypotension. Journal of
Nephrology, 36(7):2001 – 2011. Cited by: 0.
Gómez-Pulido, J. A., Gómez-Pulido, J. M., Rodríguez-
Puyol, D., Polo-Luque, M. L., and Vargas-Lombardo,
M. (2021). Predicting the appearance of hypotension
during hemodialysis sessions using machine learning
classifiers. International Journal of Environmental
Research and Public Health, 18(5):2364.
Haupt, R. L. and Haupt, S. E. (2004). Practical Genetic
Algorithms. John Wiley & Sons.
Hong, D., Chang, H., He, X., Zhan, Y., Tong, R., Wu,
X., and Li, G. (2023). Construction of an early alert
system for intradialytic hypotension before initiating
hemodialysis based on machine learning. Kidney Dis-
eases, 9(5):433 – 442. Cited by: 2; All Open Access,
Gold Open Access.
Kim, H. W., Heo, S. J., Kim, M., Lee, J., Park, K. H., Lee,
G., and Kim, B. S. (2022). Deep learning model for
predicting intradialytic hypotension without privacy
infringement: a retrospective two-center study. Fron-
tiers in Medicine, 9:878858.
Lee, H., Moon, S. J., Kim, S. W., Min, J. W., Park,
H. S., Yoon, H. E., and Chung, B. H. (2023).
Prediction of intradialytic hypotension using pre-
dialysis features—a deep learning–based artificial in-
telligence model. Nephrology Dialysis Transplanta-
tion, 38(10):2310–2320.
Mendoza-Pittí, L., Gómez-Pulido, J. M., Vargas-Lombardo,
M., Gómez-Pulido, J. A., Polo-Luque, M.-L., and
Rodréguez-Puyol, D. (2022). Machine-learning
model to predict the intradialytic hypotension based
on clinical-analytical data. IEEE Access, 10:72065–
72079.
Nayyar, A., Gadhavi, L., and Zaman, N. (2021). Machine
learning in healthcare: review, opportunities and chal-
lenges. Machine Learning and the Internet of Medical
Things in Healthcare, pages 23–45.
Othman, M., Elbasha, A. M., Naga, Y. S., and Moussa,
N. D. (2022). Early prediction of hemodialysis com-
plications employing ensemble techniques. BioMedi-
cal Engineering Online, 21(1). Cited by: 1; All Open
Access, Gold Open Access, Green Open Access.
Pudjihartono, N., Fadason, T., Kempa-Liehr, A. W., and
O’Sullivan, J. M. (2022). A review of feature selec-
tion methods for machine learning-based disease risk
prediction. Frontiers in Bioinformatics, 2:927312.
Rahul, K. and Banyal, R. K. (2022). Metaheuristics ap-
proach to improve data analysis process for the health-
care sector. Procedia Computer Science, 215:98–
103. 4th International Conference on Innovative Data
Communication Technology and Application.
Sociedad Española de Nefrología (2023). La enfermedad
renal crónica en españa 2023. Accessed: 2024-07-12.
Yang, X., Zhao, D., Yu, F., Heidari, A. A., Bano, Y., Ibro-
himov, A., and Chen, X. (2022). Boosted machine
learning model for predicting intradialytic hypoten-
sion using serum biomarkers of nutrition. Computers
in Biology and Medicine, 147:105752.
Zhang, H., Wang, L. C., Chaudhuri, S., Pickering, A.,
Usvyat, L., Larkin, J., and Kotanko, P. (2023). Real-
time prediction of intradialytic hypotension using ma-
chine learning and cloud computing infrastructure.
Nephrology Dialysis Transplantation, 38(7):1761–
1769.
BIOINFORMATICS 2025 - 16th International Conference on Bioinformatics Models, Methods and Algorithms
570
