
Solving Monge Problem by Hilbert Space Embeddings of Probability
Measures
Takafumi Saito
a
and Yumiharu Nakano
b
Department of Mathematical and Computing Science, Institute of Science Tokyo, Tokyo, Japan
Keywords:
Monge Problem, Maximum Mean Discrepancy, Deep Learning.
Abstract:
We propose deep learning methods for classical Monge’s optimal mass transportation problems, where where
the distribution constraint is treated as a penalty term defined by the maximum mean discrepancy in the theory
of Hilbert space embeddings of probability measures. We prove that the transport maps given by the proposed
methods converge to optimal transport maps in the problem with L
2
cost. Several numerical experiments
validate our methods. In particular, we show that our methods are applicable to large-scale Monge problems.
1 INTRODUCTION
Our aim in this paper is to propose numerical methods
for Monge’s mass transportation problem, described
as follows: given two Borel probability measures µ,
ν on R
d
and a cost function c : R
d
× R
d
→ [0,∞], to
minimize Our problem is to minimize
M(T ) :=
Z
R
d
c(x,T (x))dµ(x)
over all Borel measurable mapping T : R
d
→ R
d
such
that µ ◦ T
−1
= ν. Here, µ ◦ T
−1
denotes the pushfor-
ward of µ with T , i.e., µ ◦ T
−1
(A) = µ(T ∈ A) for any
Borel set A.
We shall briefly describe the background of the
Monge problem. Monge problem was proposed by
Gaspagnol Monge in 1781 (Monge, 1781). In the
20th century, this problem was expanded by Kan-
torovich to make it mathematically easier to handle,
and is now called the Monge-Kantrovich problem
(Kantrovich, 1942), (Kantrovich, 1948).
The Monge problem, as extended by Kantrovich,
is called the Monge-Kantrovich problem. The first
existence and uniqueness result was established by
Brein, (Breiner, 1987), (Breiner, 1991). Gangbo and
McCann further developed the generalized problem
(Gangbo and McCann, 1996). Mikami also provided
a probabilistic proof of Breiner’s result (Mikami,
2004).
Algorithms for solving the Monge-Kantrovich
problem can be traced back nearly 100 years (Tolstoi,
a
https://orcid.org/0009-0007-0598-0238
b
https://orcid.org/0000-0002-5723-4444
1930). Since the advent of mathematical program-
ming, these algorithms have been a field of signifi-
cant interest (Dantzig, 1951). This is largely because
Dantzig’s initial motivation for developing mathe-
matical programming was related to solving trans-
portation problems (Dantzig, 1949), and it was later
discovered that optimal transportation problems and
minimum cost flow problems are equivalent (Korte
and Vygen, 2012). Research has advanced in the
development of solvers that apply mathematical pro-
gramming to machine learning (Bauschke and Com-
bettes, 2011), as well as in solvers used in dynamic
optimal transport (OT) (Papadakis et al., 2014). To-
day, it remains one of the most actively researched
fields.
We describe recent solvers developed to address
the Monge-Kantrovich problem. In recent years, the
Monge-Kantrovich problem has been actively applied
in machine learning. One prominent approach in-
volves solving the entropy optimization problem by
introducing an entropy regularization term, using the
Sinkhorn algorithm (Peyr
´
e and Cuturi, 2019). The
Python library POT (Flamary et al., 2021) provides a
solver for various optimal transport problems, includ-
ing entropy-regularized optimal transport.
When solving the optimal transport problem,
computations can scale with the cube of the input
data size. Therefore, it is crucial to support large-
scale computations and to leverage GPUs for numeri-
cal calculations. Optimal transport solvers designed
for large-scale computations include the Python li-
brary Geomloss (Feydy et al., 2019). Another tool,
the Python library KeOps (Charlier et al., 2021), opti-
294
Saito, T. and Nakano, Y.
Solving Monge Problem by Hilbert Space Embeddings of Probability Measures.
DOI: 10.5220/0013167600003893
In Proceedings of the 14th International Conference on Operations Research and Enterprise Systems (ICORES 2025), pages 294-300
ISBN: 978-989-758-732-0; ISSN: 2184-4372
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

mizes the reduction of large arrays using neural net-
works and kernel formulas.
Additionally, the OTT library (Cuturi et al., 2022),
based on the high-performance JAX library for nu-
merical calculations, offers implementations that can
solve problems such as the Monge-Kantrovich prob-
lem.
Our aim is to derive a numerical solution for the
basic mathematical analysis of the original Monge
problem, rather than the Monge-Kantrovich problem.
In particular, the goal is to develop algorithns capable
of performing GPU-based numerical computations
and handling large-scale calculations. The method for
deriving the numerical solution primarily utilizes the
embedding theory of probability measures, which was
previously applied by Nakano (Nakano, 2024) to ob-
tain a numerical solution for the Schr
¨
odinger bridge
problem. In this study, we also apply this theory to
derive a numerical solution for the Monge problem.
The penalty method is employed to find the optimal
solution, with the use of Maximum Mean Discrep-
ancy (MMD) as the penalty function being a novel
approach. Unlike existing methods, this method is in-
dependent of input data size. We also confirm this
through numerical experiments.
This paper is structured as follows. In the next
section, we review some basic results on the theory of
Hilbert space embedding of probability measures and
describe a numerical method that describes a theo-
retical approximation solution to the Monge problem
with L
2
cost. Section 3 gives numerical experiments.
2 PENALTY METHOD
2.1 Hilbert Space Embeddings of
Probability Measures
We shall give a quick review of theory of Hilbert
space embeddings of probability measures, as devel-
oped in Sriperumbudur et al. (Sriperumbudur et al.,
2010). Denote by P (R
d
) the set of all Borel probabil-
ity measures on R
d
. Let K be a symmetric and strictly
positive definite kernel on R
d
, i.e., K(x, y) = K(y,x)
for x,y ∈ R
d
and for any positive distinct x
1
,...,x
N
∈
R
d
and α = (α
1
,...,α
N
)
T
∈ R
N
\{0},
N
∑
j,ℓ=1
α
j
α
ℓ
K(x
j
,x
ℓ
) > 0.
Assume further that K is bounded and continuous on
R
d
×R
d
. Then, there exists a unique Hilbert space H
such that K is a reproducing kernel on H with norm
∥ · ∥ (Wendland, 2010). Then consider the maximum
mean discrepancy (MMD) γ
K
defined by, for µ
0
,µ
1
∈
P (R
d
),
γ
K
(µ
0
,µ
1
) : = sup
f ∈H ,∥ f ∥≦1
Z
R
d
f dµ
0
−
Z
R
d
f dµ
1
=
Z
R
d
K(·,x)µ
0
(dx)
−
Z
R
d
K(·,x)µ
1
(dx)
H
It is known that if K is an integrally strictly positive
definite then γ
K
defines a metric on P (R
d
). Examples
of integrally strictly positive definite kernels include
the Gaussian kernel K(x,y) = e
−α|x−y|
2
, x,y ∈ R
d
,
where α > 0 is a constant, and the Mat
´
ern kernel
K(x, y) = K
α
(|x − y|), x,y ∈ R
d
, where K
α
is the mod-
ified Bessel function of order α > 0. It is also known
that Gaussian kernel as well as Mat
´
ern kernel metrize
the weak topology on P (R
d
) (Sriperumbudur et al.,
2010), (Nakano, 2024).
Define
K
1
(x,y) : = K(x, y) −
Z
R
d
K(x, y
′
)µ
1
(dy
′
)
−
Z
R
d
K(x
′
,y)µ
1
(dx
′
).
Then,
γ
K
(µ
0
,µ
1
)
2
=
Z
R
d
Z
R
d
K
1
(x,y)µ
0
(dx)µ
0
(dy)
+
Z
R
d
×R
d
K(x
′
,y
′
)µ
1
(dx
′
)µ
1
(dy
′
).
(1)
2.2 Proposed Methods
Let γ = γ
K
be as in Section 2.1. We proposed a penalty
method for Monge problem by Hilbert space embed-
dings of probability measures, described as follows:
inf
T
M
λ
(T ) := inf
T
M(T ) + λγ
2
(µ ◦T
−1
,ν)
.
Note that the second term penalizes the distance be-
tween the laws of T (x) and ν. Moreover, the second
term in the above formula can be expressed discretely
as follows: given IID samples X
1
,··· ,X
M
∼ µ
0
and
Y
1
,··· ,Y
M
∼ µ
1
, an unbiased estimator of γ
k
(µ
0
,µ
1
)
2
is given by
¯
γ
K
(µ
0
,µ
1
)
2
:=
1
M(M − 1)
∑
i
∑
j̸=i
K(X
i
,X
j
)
−
2
M
2
∑
i, j
K(X
i
,Y
j
)
+
1
M(M − 1)
∑
i
∑
j̸=i
K(Y
i
,Y
j
)
(2)
Solving Monge Problem by Hilbert Space Embeddings of Probability Measures
295

(Gretton et al., 2006). Then, we approxiate T by
a class {T
θ
}
θ∈Θ
of deep neural networks. Each T
θ
can be given by a multilayer perception with input
layer g
0
, L − 1 hidden layer g
1
,...,g
L−1
, and output
layer g
L
, where L ≧ 1 and for ξ ∈ R
1+m
, g
0
(ξ) = ξ,
g
ℓ
(ξ) = φ
ℓ−1
(w
ℓ
g
ℓ−1
(ξ) + β
ℓ
) ∈ R
m
ℓ
,ℓ = 1,.. . , L, for
some matrices w
ℓ
and vectors β
ℓ
,ℓ = 1,...,L. Here
m
ℓ
denotes the number of units in the layer ℓ, and φ
ℓ−
is an activation function. Then the parameter θ is de-
scribed by θ = (w
ℓ
,β
ℓ
)
ℓ=1,...,L
and T
θ
(x) = g
L
(x) ∈
R
d
. For λ > 0, the integral term in (1) is replaced
by (2) and T
θ
(x) as follows: by Subsetcion 3.2. in
(Nakano, 2024),
F
1
(θ) =
1
λM
M
∑
i=1
C(X
i
,T
θ
(X
i
))
+
1
M(M − 1)
∑
i
∑
j̸=i
K(T
θ
(X
i
),T
θ
(X
j
))
−
2
M
2
K(T
θ
(X
i
),Y
j
)
(3)
The algorithm is described below and we test our one
algorithm thorough a numerical experiment.
Algorithm 1: Deep learning algorithm with empirical
MMD.
Data: The number n of the iterations, the
batch size M, weight parameter λ > 0
Result: transport map T
initialization
X
1
,...,X
M
← IID samples from µ,
Y
1
,··· ,Y
M
← IID samples from ν.
for k=1,2,...,n do
Compute F
1
(θ) in (3) using {X
j
,Y
j
}
M
j=1
.
Take the gradient step on ∇
θ
F
1
(θ).
2.3 Theoretical Result
For given λ > 0 consider the minimization problem
M
λ
(T ) := M(T )+ λγ
2
(µ ◦T
−1
,ν)
over all Borel measurable mappings T . Take arbitrary
positive sequences {ε
n
}
∞
n=1
and {λ
n
}
∞
n=1
such that
ε
n
→ 0, λ
n
→ +∞ (n → ∞).
Then take T
n
: R
d
→ R
d
such that
M
λ
n
(T
n
) −ε
n
≤ M
∗
λ
n
:= inf
T
M
λ
n
(T ).
Then we have the following:
Theorem 2.1. Let c(x,y) = |x − y|
2
. Suppose that µ
is absolutely continuous with respect to the Lebesgue
measure and that
Z
R
d
|x|
2
µ(dx) +
Z
R
d
|y|
2
ν(dy) < ∞.
Suppose moreover that γ metrizes the weak topology
on P (R
d
). Then,
lim
n→∞
p
λ
n
γ(µ ◦T
−1
n
,ν) = 0, (4)
lim
n→∞
M
λ
n
(T
n
) = M(T
∗
), (5)
where T
∗
is the unique optimal transport map. In par-
ticular, {T
n
}
∞
n=1
converges to T
∗
in law under µ.
Proof . First, note that under our assumption, an opti-
mal transport map does exist uniquely (see, e.g., The-
orem 2.12 in (Villani, 2021) and Theorem 1.25 in
(Santambrogio, 2015)).
Step (i). We will show (4). This claim can be
proved by almost the same argument as that given in
the proof of Theorem 3.1 in (Nakano, 2024), but we
shall give a proof for reader’s convenience. Assume
contrary that
limsup
n→∞
λ
n
γ
2
(µ ◦T
−1
n
,ν) = 3δ
for some δ > 0. Then there exists a subsequence {n
k
}
such that
lim
k→∞
λ
n
k
γ
2
(µ ◦T
−1
n
k
,ν) = 3δ.
Since γ is a metric, we have γ(µ ◦ (T
∗
)
−1
,ν) = 0,
whence M
∗
λ
≤ M(T
∗
) for any λ. This means
M
λ
n
(T
n
) ≤ M
∗
λ
n
+ ε
n
≤ M(T
∗
) +ε
n
.
Thus, the sequence {M
λ
n
(T
n
)}
∞
n=1
is bounded, and so
there exists a further subsequence {n
k
m
} such that
lim
m→∞
M
¯
λ
m
(
¯
T
m
) = κ := sup
k
M
λ
n
k
(T
n
k
) < ∞,
where
¯
λ
m
= λ
n
k
m
and
¯
T
m
= T
n
k
m
. Now choose m
0
and
m
1
such that
κ < M
¯
λ
m
0
(
¯
T
m
0
) +δ,
¯
λ
m
1
> 4
¯
λ
m
0
, 2δ <
¯
λ
m
1
¯
γ
2
m
1
< 4δ,
where
¯
γ
m
= γ(µ ◦ T
n
k
m
,ν). With these choices it fol-
lows that
κ < M
¯
λ
m
0
(
¯
T
m
0
) +δ ≤ M
∗
¯
λ
m
0
+ δ ≤ M
¯
λ
m
0
(
¯
T
m
1
) +δ
= M(
¯
T
m
1
) +
¯
λ
m
0
¯
λ
m
1
¯
λ
m
1
¯
γ
2
m
1
+ δ
< M(
¯
T
m
1
) +
1
4
¯
λ
m
1
¯
γ
2
m
1
+ δ < M(
¯
T
m
1
) +2δ
< M(
¯
T
m
1
) +
¯
λ
m
1
¯
γ
2
m
1
= M
¯
λ
m
1
(
¯
T
m
1
) ≤ κ,
which is impossible.
Step (ii). Next we will show (5). Let ε
′
> 0. For
ICORES 2025 - 14th International Conference on Operations Research and Enterprise Systems
296

R > 0 we have
µ ◦T
n
(|x| > R) ≤
1
R
2
Z
R
d
|T
n
(x)|
2
µ(dx)
≤
2
R
2
Z
R
d
|x −T
n
(x)|
2
µ(dx)
+
2
R
2
Z
R
d
|x|
2
µ(dx)
≤
2
R
2
(M(T
∗
) +ε
n
) +
C
R
2
for some constant C > 0. Thus we can take a suffi-
ciently large R
′
such that µ
n
◦ T
n
(|x| > R
′
) ≤ ε
′
. This
means that {µ◦T
−1
n
}
∞
n=1
is tight, whence there exists a
subsequence {n
k
} such that µ ◦T
−1
n
k
converges weakly
to some µ
∗
. Since we have assumed that γ metrizes the
weak topology, we get
lim
k→∞
γ(µ ◦T
−1
n
k
,µ
∗
) = 0.
This together with the step (i) yields
γ(µ
∗
,ν) ≤ γ(µ
∗
,µ◦T
−1
n
k
)+γ(µ◦T
−1
n
k
,ν) → 0, k → ∞,
whence µ
∗
= ν. Hence we have shown that each
subsequence {µ ◦ T
−1
n
j
} contain a further subsequence
{µ ◦ T
−1
n
j
m
} that converges weakly to ν. Then, by The-
orem 2.6 in Billingsley (Billingsley, 2013), we de-
duce that {µ ◦ T
−1
n
} converges weakly to ν. Denote
by W
2
(µ
1
,µ
2
) the 2-Wasserstein distance between µ
1
and µ
2
. Then we have W
2
2
(µ,ν) = M(T
∗
) and the du-
ality formula
W
2
2
(µ,ν) = sup
Z
ϕdµ +
Z
ψdν
,
where the supremum is taken over all bounded con-
tinuous functions ϕ and ψ such that ϕ(x) + ψ(y) ≤
|x − y|
2
, x,y ∈ R
d
. See, e.g., Proposition 5.3 in Car-
mona and Delarue (Carmona and Delarue, 2018). Let
ε
′′
> 0 be arbitrary. Then there exist ϕ
′
and ψ
′
such
that
W
2
2
(µ,ν)
≤
Z
R
d
ϕ
′
(x)dµ(x) +
Z
R
d
ψ
′
(y)dν(y) + ε
′′
.
Further, since ψ
′
is bounded and continuous, there ex-
ists n
0
∈ N such that ϕ
′
(x) +ψ(y) ≤ |x − y|
2
and
Z
R
d
ψ
′
(T
∗
(x))dµ(x) ≤
Z
R
d
ψ
′
(T
n
(x))dµ(x) + ε
′′
for n ≥ n
0
. With these choices it follows that for n ≥
n
0
,
M(T
∗
) = W
2
2
(µ,ν)
≤
Z
R
d
ϕ
′
(x)dµ(x) +
Z
R
d
ψ
′
(T
∗
(x))dµ(x) + ε
′′
≤
Z
R
d
ϕ
′
(x) +ψ
′
(T
n
(x))
dµ(x) + 2ε
′′
≤
Z
R
d
|x −T
n
(x)|
2
dµ(x) + 2ε
′′
≤ M
λ
n
(T
n
) +2ε
′′
.
Then letting n → ∞ we get
M(T
∗
) ≤ lim inf
n→∞
M
λ
n
(T
n
) +2ε
′′
.
Since ε
′′
is arbitrary, we deduce M(T
∗
) ≤
liminf
n→∞
M
λ
n
(T
n
). On the other hand, (4) im-
mediately leads to lim sup
n→∞
M
λ
n
(T
n
) ≤ M(T
∗
).
Therefore, lim
n→∞
M
λ
n
(T
n
) = M(T
∗
), as wanted.
3 NUMERICAL EXPERIMENTS
Here we test our two algorithms through several nu-
merical experiments.
3.1 Interpolation of Synthetic Datasets
All of numerical examples below are implemented in
PyTorch on a Core(TM) i7-13700H with 32GB mem-
ory in this subsection. In these experiments, we de-
scribe three experiments on synthetic datasets. Date
size is set to be 500 for each experiment. The Gaus-
sian kernel K(x, y) = e
−|x−y|
2
, cost function c(x,y) =
|x − y|
2
and the Adam optimizer with learning late
0.0001 is used. Here, the function T (x) is described
by a multi-layer perception with 1 hidden layer. These
result that obtained after about 3000 epochs. Penalty
parameter λ defined by 1/λ = 0.000001.
3.1.1 From Moon to Circle
In this experiment, the initial distribution is the well-
known synthetic dataset generated by two “moons”
(Figure 1), and the target distribution is the one gen-
erated by two “circles” (Figure 2).
Figure 1: Initial distribution.
Solving Monge Problem by Hilbert Space Embeddings of Probability Measures
297
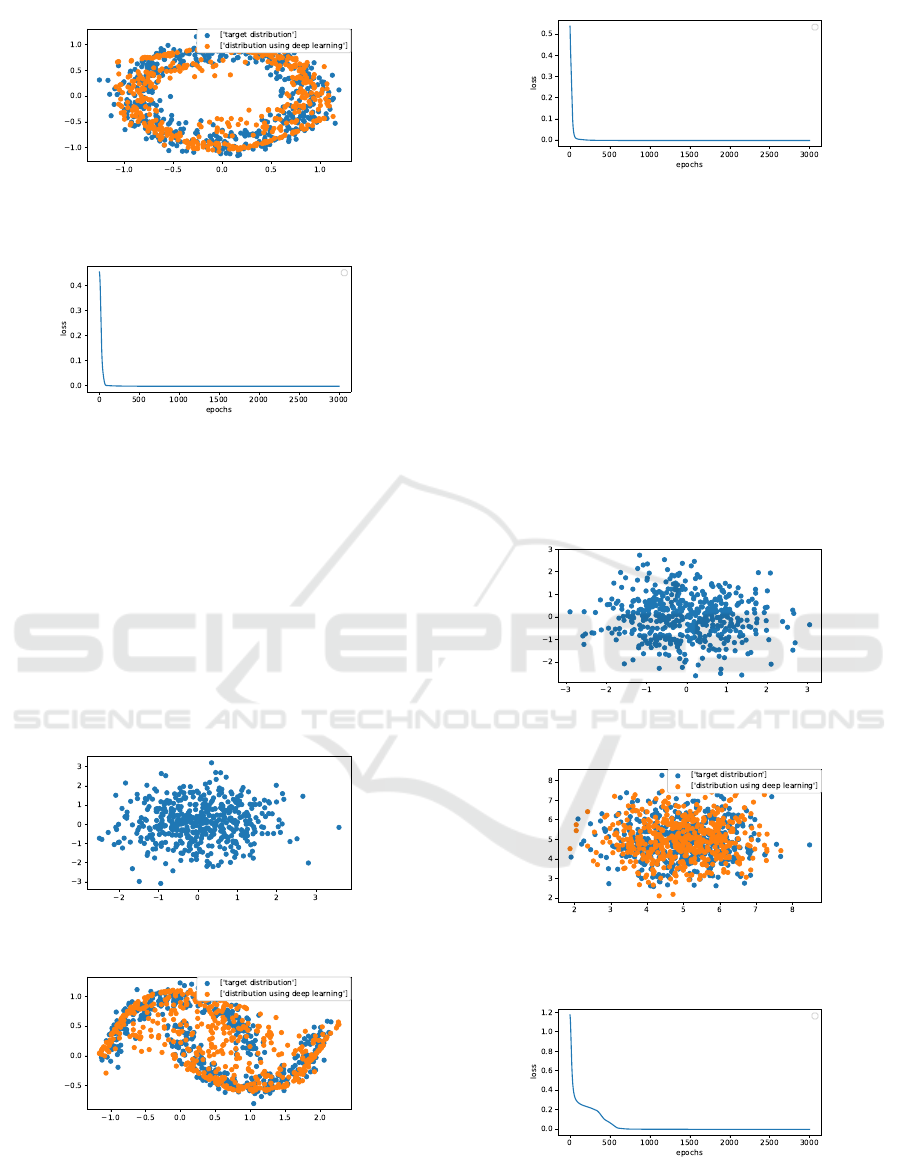
Figure 2: Target distribution (blue) and generated samples
(orange).
Figure 3: Loss curve.
We can see from Figure 2 that the proposed
method faithfully generates the target distribution.
Figure 3 shows the change in loss, and the loss con-
verges in the first 500 epochs.
3.1.2 From Normal Distribution to Moon
In this experiment, the initial distribution is a two-
dimensional uncorrelated normal distribution with
mean 0 and variance 1 (Figure 4), and the final dis-
tribution is the synthetic dataset generated by the two
moons as in Section 3.1.1 (Figure 5).
Figure 4: Initial distribution.
Figure 5: Target distribution (blue) and generated samples
(orange).
Figure 6: Loss curve.
We can see from Figure 5 that the proposed
method again generates the target distribution cor-
rectly with a small variance. Figure 6 shows the
change in loss. We can see that the loss converges
in the first 500 epochs.
3.1.3 From Normal Distribution to Normal
Ditribution
In this experiment, the initial distribution is a two-
dimensional uncorrelated normal distribution with
mean 0 and variance 1, and the target distribution
is a two-dimensional uncorrelated normal distribution
with mean 5 and variance 1.
Figure 7: Initial distribution.
Figure 8: Target distribution (blue) and generated samples
(orange).
Figure 9: Loss curve.
For normal distributions, we see from Figures 7-9
that stable generation is achieved as in Sections 3.1.1
and 3.1.2.
ICORES 2025 - 14th International Conference on Operations Research and Enterprise Systems
298

3.2 Comparison with POT
We compared the performance with POT, the exist-
ing Python library as mentioned in Section 1. Here,
the initial distribution is a two-dimensional uncorre-
lated normal distribution with mean 0 and variance 1,
and the target distribution is a two-dimensional un-
correlated normal distribution with mean 5 and vari-
ance 1. The Gaussian kernel K(x,y) = e
−|x−y|
2
, cost
function c(x, y) = |x − y|
2
and the Adam optimizer
with learning late 0.0001 is used. Here, the func-
tion T (x) is described by a multi-layer perception
with 2 hidden layer. Penalty parameter λ defined by
1/λ = 0.000001. In this experiment, we compare the
number of points that can be calculated, the num-
ber of times the calculation can be run, and the ac-
curacy achieved when using an AMD EPYC 9654
with 768GB of memory. The experimental result is
described in Table 1, where SD stands for standard
deviation. Here, we set the number of batch size to
Table 1: The proposed method with CPU.
Data size epochs expectation, SD
600000 3 5.03, 0.99
be 10000 and so the number of iterations is 60. Table
1 shows that the proposed method is able to compute
accurately even for large data sizes of 600000.
Next, we perform a similar experiment on
NVIDIA H100. The experimental result is described
in Table 2, where SD again stands for standard de-
viation. Here we set the number of batch size to be
Table 2: The proposed method with GPU.
Data size epochs expectation, SD
600000 10 4.97, 1.01
10000 and so the number of iterations is 60. We can
see from Table 2 that our method is able to compute
accurately even for large data sizes of 600000 as in
the CPU case.
Then, we use the solver ot.sinkhorn() in POT
to compare the performance of POT with that of
our algorithm on a Core(TM) i7-13700H with 32GB
memory. The computational complexity of this solver
is known to be O(n
2
), where n is the input data size.
Table 3 shows that a stable result is obtained when
Table 3: Python Optimal Transport.
Data size expectation, SD
1000 5.00, 0.97
the data size is 1000. When the data size exceeded
2000, the solver is unstable due to the computational
limitations mentioned above.
Numerical experiments in this subsection show
that our proposed method is a promising option for
solving large-scale Monge problems.
4 CONCLUSION
In this paper, we derive an approximate solution to the
Monge problem by using the embeddings of probabil-
ity measures and a deep learning algorithm. Through
several numerical experiments, we confirmed that
our method produces accurate approximate solutions
and is efficiently computable on a GPU. In future
work, we aim to extend our research to handle larger
datasets, explore the Monge problem with alternative
cost functions, and investigate numerical solutions for
multi-marginal transport problems.
REFERENCES
Bauschke, H. H. and Combettes, P. L. (2011). Convex anal-
ysis and monotone operator theory in Hilbert spaces.
Springer-Verlag.
Billingsley, P. (2013). Convergence of probability mea-
sures. John Wiley & Sons.
Breiner, Y. (1987). D
´
ecomposition polaire et
r
´
earrangement monotone des champs de vecteurs.
C. R. Acad. Sci. Paris S
´
erie I, 305(19):805–808.
Breiner, Y. (1991). Polar factorization and monotone re-
arrangement of vecto-valued fanctions. Comm. Pure
Appl. Math., 44(4):375–417.
Carmona, R. and Delarue, F. (2018). Probabilistic theory of
mean field games with applications I. Springer.
Charlier, B., Feydy, J., Glaun
`
es, J. A., Collin, F. D., and
Durif, G. (2021). Kernel operations on the GPU, with
autodiff, without memory overflows. Journal of Ma-
chine Learning Research, 22(74):1–6.
Cuturi, M., Meng-Papaxanthos, L., Tian, Y., Bunne, C.,
Davis, G., and Teboul, O. (2022). Optimal transport
tools (ott): A jax toolbox for all things wasserstein.
arXiv:2201.12324.
Dantzig, G. B. (1949). Programming of interdependent
activities: Ii mathematical model. Econometrican,
17(3/4):200–211.
Dantzig, G. B. (1951). Application of the simplex method
to a transportation problem. Activity Analysis of Pro-
duction and Allocation, 13:359–373.
Feydy, J., S
´
ejourn
´
e, T., Vialard, F. X., Amari, S., Trouve,
A., and Peyr
´
e, G. (2019). Interpolating between Opti-
mal Transport and MMD using Sinkhorn Divergences.
In The 22nd International Conference on Artificial In-
telligence and Statistics, pages 2681–2690.
Flamary, R., Courty, N., Gramfort, A., Alaya, M. Z., Bois-
bunon, A., Chambon, S., Chapel, L., Corenflos, A.,
Fatras, K., Fournier, N., Gautheron, L., Gayraud, N.
Solving Monge Problem by Hilbert Space Embeddings of Probability Measures
299

T. H., Janati, H., Rakotomamonjy, A., Redko, I., Ro-
let, A., Schutz, A., Seguy, V., Sutherland, D. J., Tave-
nard, R., Tong, A., and Vayer, T. (2021). POT: Python
Optimal Transport. Journal of Machine Learning Re-
search, 22(78):1–8.
Gangbo, W. and McCann, R. J. (1996). The geometry of
optmal transportation. Acta Math., 177:113–161.
Gretton, A., Borgwardt, K., Rasch, M., Sch
¨
olkopf, B., and
Smola, A. (2006). A kernel method for the two-
sample-problem. Advances in neural information pro-
cessing systems, 19.
Kantrovich, L. V. (1942). On mass transportation. (Rus-
sian) Reprinted from C. R. (Doklady) Acad.Sci. URSS
(N. S.), 37:199–201.
Kantrovich, L. V. (1948). On a problem of monge. (Rus-
sian) Reprinted from C. R. (Doklady) Acad.Sci. URSS
(N. S.), 3:225–226.
Korte, B. and Vygen, J. (2012). Combinatorial Optimiza-
tion. Springer.
Mikami, T. (2004). Monge’s problem with a quadratic
cost by the zero-noize limit of h-path process.
Probab. Theory Related Fields, 129:245–260.
Monge, G. (1781). M
´
emoiresur la th
´
eorie des d
´
eblais et des
remblais. De l’Imprimerie Royale.
Nakano, Y. (2024). A kernel-based method for Schr
¨
odinger
bridges. arXiv:2310.14522.
Papadakis, N., Peyr
´
e, G., and Oudet, E. (2014). Optimal
transport with proximal splitting. SIAM Journal on
Imaging Sciences, 7:212–238.
Peyr
´
e, G. and Cuturi, M. (2019). Computional Optimal
Transport. Now Publishers.
Santambrogio, F. (2015). Optimal Transport for Applied
Mathematicians Calculus of Variations, PDEs, and
Modeling. Springer.
Sriperumbudur, B. K., Gretton, A., Fukumizu, K.,
Schr
¨
olkopf, B., and Lanckriet, G. R. G. (2010).
Hilbert space embeddings and metrics on probability
measures. J. Mach. Learn. Res., 11:1517–1561.
Tolstoi, A. N. (1930). Metody nakhozhdeniya naimen’
shego summovogo kilome-trazha pri planirovanii
perevozok v prostranstve (russian; methods of finding
the minimal total kilometrage in cargo transportation
planning in space). TransPress of the National Com-
missariat of Transportation, pages 23–55.
Villani, C. (2021). Topics in optimal transportation. Amer-
ican Mathematical Soc.
Wendland, H. (2010). Scattered data approximation. Cam-
bridge University Press, Cambridge.
ICORES 2025 - 14th International Conference on Operations Research and Enterprise Systems
300
