
Rescuing Easy Samples in Self-Supervised Pretraining
Qin Wang
1 a
, Kai Krajsek
2 b
and Hanno Scharr
1 c
1
IAS-8: Data Analytics and Machine Learning, Forschungszentrum J
¨
ulich, Germany
2
J
¨
ulich Supercomputing Centre (JSC), Forschungszentrum J
¨
ulich, Germany
{qi.wang, k.krajsek, h.scharr}@fz-juelich.de
Keywords:
Self-Supervised Learning, Augmentation, Vision Transformer.
Abstract:
Many recent self-supervised pretraining methods use augmented versions of the same image as samples for
their learning schemes. We observe that ’easy’ samples, i.e. samples being too similar to each other after
augmentation, have only limited value as learning signal. We therefore propose to rescue easy samples and
make them harder. To do so, we select the top k easiest samples using cosine similarity, strongly augment
them, forward-pass them through the model, calculate cosine similarity of the output as loss, and add it to the
original loss in a weighted fashion. This method can be adopted to all contrastive or other augmented-pair
based learning methods, whether they involve negative pairs or not, as it changes handling of easy positives,
only. This simple but effective approach introduces greater variability into such self-supervised pretraining
processes, significantly increasing the performance on various downstream tasks as observed in our experi-
ments. We pretrain models of different sizes, i.e. ResNet-50, ViT-S, ViT-B, or ViT-L, using ImageNet with
SimCLR, MoCo v3, or DINOv2 training schemes. Here, e.g., we consistently find to improve results for Ima-
geNet top-1 accuracy with a linear classifier establishing new SOTA for this task.
1 INTRODUCTION
Self-supervised learning (SSL) from unlabeled data
is the most common approach for foundation model
pretraining (Chen et al., 2020a; He et al., 2020; Chen
et al., 2020b; Chen et al., 2021; Oquab et al., 2023;
Caron et al., 2021; He et al., 2022). Specifically, SSL
is a technique that, in the ideal case, learns a task ag-
nostic image feature representation on a pretext task
with unlabeled data that subsequently can be used on
other downstream tasks.
Some current SSL techniques like SimCLR (Chen
et al., 2020a), MoCo (He et al., 2020; Chen et al.,
2020b; Chen et al., 2021), and DINO (Oquab et al.,
2023; Caron et al., 2021) make use of image pairs.
For example, SimCLR (Chen et al., 2020a) allows to
derive image representations from unlabeled data by
contrasting the representations of augmented versions
of the same image, denoted ’positive pairs’ and of dif-
ferent images, denoted ’negative pairs’. A crucial step
in this process is to carefully craft positive as well as
negative pairs for meaningful comparisons. Specifi-
cally, positive pairs are formed by means of data aug-
a
https://orcid.org/0009-0002-1505-2455
b
https://orcid.org/0000-0003-3417-161X
c
https://orcid.org/0000-0002-8555-6416
mentation, i.e. a chain of image transformations, e.g.
geometrical transformations like cropping as well as
pixel wise transformations like color jitter, is applied
to an image to generate different ’views’ of the same
semantic content. It has been shown that the type of
augmentations plays a crucial role for the quality of
the learned image feature representation (Chen et al.,
2020b). If the hand-crafted augmentations are not suf-
ficiently diverse, the positive pairs may become too
alike, leading to the neural network training converg-
ing prematurely without learning valuable image rep-
resentations (Cai et al., 2020).
Consequently, it is crucial for SSL methods to be
robust against the effects of too-easy positive pairs.
To this end, we introduce a novel loss term L
topk
act-
ing on the top k easiest samples in a batch, only, by
strongly augmenting them. This constitutes a selec-
tive regularization ’rescuing’ these pairs for the pre-
training. To do so, we adopt RandAugment (Cubuk
et al., 2019b) to create strongly augmented views
in addition to the standard augmentation techniques
used in the baseline SSL methods.
In our experiments, we combine the SSL loss
of the baseline technique with our regularization
term L
topk
. This proposed approach has yielded
significant performance improvements, surpassing
400
Wang, Q., Krajsek, K. and Scharr, H.
Rescuing Easy Samples in Self-Supervised Pretraining.
DOI: 10.5220/0013167900003912
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 2: VISAPP, pages
400-409
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

Aug
Encoder
Loss
...
Common views
...
...
,
,
,
...
Top k
selector
Strong views
...
Strong
Aug
...
-th easiest samples indices,
easy samples
...
Features spaces
Figure 1: Illustration of rescuing easy samples self-
supervised pretraining framework. Top k easiest samples
are selected based on cosine similarity of features z
a
and
z
b
from common views. The selected samples are strongly
augmented, and input as additional strong views resulting
in features z
s
used for computing L
topk
(see (1)).
several established contrastive learning methods, not
only on benchmarks like ImageNet (Russakovsky
et al., 2015) but also across a range of downstream
tasks, including classification and dense prediction
tasks.
Our Contribution. We present
• a novel regularization term L
topk
suitable for all
augmented-views-based SSL methods,
• a sensitivity analysis of the involved hyperparam-
eters and recommendations how to select them,
• experiments based on the most recent versions of
SimCLR, MoCo, and DINO for a set of small to
medium-sized network architectures,
• new SOTA for various downstream tasks.
2 RELATED WORK
2.1 Self-Supervised Learning
SSL encompasses a wide spectrum of methods, in-
cluding information restoration (Larsson et al., 2016;
Pathak et al., 2016; He et al., 2022), spatial context in-
ference also denoted as pretext task learning(Doersch
et al., 2015; Gidaris et al., 2018; Noroozi et al., 2018),
canonical-correlation analysis methods(Andrew et al.,
2013; Zbontar et al., 2021; Bardes et al., 2021),
clustering methods, contrastive learning(Chen et al.,
2020a; He et al., 2020; Chen et al., 2020b; Chen et al.,
2021), self-distillation methods (Grill et al., 2020;
Oquab et al., 2023; Caron et al., 2021), instance dis-
crimination(Dosovitskiy et al., 2014; Wu et al., 2018)
as well as generative approaches(Bengio et al., 2006;
Springenberg, 2016; Donahue et al., 2017). Please
note that this classification of SSL methods is not ex-
clusive but might overlap. What all these methods
have in common is their ability to automatically de-
rive an objective from unlabelled data.
The SSL methods applied in this work belong all
to the group of multi-view invariance approaches that
further can be classified into contrastive learning and
self-distillation approaches. In order to define an ob-
jective for the learning process an image is trans-
formed in two or more augmented views such that
its semantic content is not changed. These different
views are then mapped to the feature space by either
the same or a different encoder for each view and an
objective is formulated such that the feature vectors
of the different views should be close in the feature
space. The different methods differ in how they gen-
erate the different views, in the chosen model archi-
tecture, the way the encoder(s) are learned as well as
the training objective.
One of the methods considered in this paper is the
Momentum Contrast version 3 (MoCo v3 (Chen et al.,
2021)) which has evolved from MoCo v2 (Chen et al.,
2020b) and MoCo (He et al., 2020). The main idea
of MoCo is the mapping of two different views by
two separate encoders to the feature space and a con-
trastive loss is computed from the two views whereas
the negative examples are obtained from a dynamic
dictionary with a queue making the number of nega-
tive examples independent of the batch size. Only one
encoder is updated using the contrastive loss whereas
the parameters of the second encoder follow a moving
average of the first one making it a self-distillation ap-
proach.
SimCLR (Chen et al., 2020a) proposed a simi-
lar idea but neglect the dynamic dictionary for neg-
ative examples but generated negative pairs from the
current batch as well as abandon self-distillation ap-
proach but consider the same encoder for both views
that are updated by means of gradient descent in each
step. In addition, SimCLR considers an additional
projection head before the contrastive loss and an ex-
tended data augmentation pipeline. MoCo v2(Bardes
et al., 2021) considered the extended data augmenta-
tion strategy as well as the projection head of Sim-
CLR while MoCo v3 abandons the memory queue
and replaces the convolution architecture by a Vision-
Transformer (ViT).
The third SSL method under consideration here is
DINOv2 (Oquab et al., 2023), which can be classified
both as a self-distillation and an information restora-
tion method. Its lineage can be traced back to the
work of (Grill et al., 2020; Chen and He, 2021; He
et al., 2022). The foundational idea from (Grill et al.,
2020) involves feeding two different views into two
decoders, a teacher and a student network and map-
ping the output of one encoder onto the output of the
Rescuing Easy Samples in Self-Supervised Pretraining
401

Method Architecture Top-1 accuracy
SimCLR (Chen et al., 2020a) ResNet-50 69.1
†
BarlowTwins (Zbontar et al., 2021) ResNet-50 73.5
†
MoCo v3(He et al., 2020) ResNet-50 73.8
†
MoCo v3(He et al., 2020) ViT-S 72.5
†
MoCo v3(He et al., 2020) ViT-B 76.7
†
Mugs(Zhou et al., 2022b) ViT-L 82.1
†
MAE-CT(Lehner et al., 2023) ViT-H 82.2
†
DINOv2(Oquab et al., 2023) ViT-L 82.6 ± 0.09
∗
Ours(SimCLR) ResNet-50 70.2
Ours(MoCo v3) ResNet-50 74.4
Ours(MoCo v3) ViT-S 73.1
Ours(MoCo v3) ViT-B 76.8
Ours(DINOv2) ViT-L 83.1 ± 0.02
Figure 2: Linear ImageNet top-1 accuracy. Top-1 accuracy for linear classifier trained on frozen features from different
SSL learning methods. Left: Model performance vs. number of parameters. We consistentlyimprove baseline SSL methods
(blue dots) with our adaptation (orange triangles). Grey dots are other SOTA SSL methods also not using additional training
data. Right: values with † are taken from the original literature. Values with ∗ are reproduced using their shared code. The
experiments for DINOv2 are conducted three times with different seeds; mean and standard deviation are given.
second one, all without requiring negative examples.
This process is safeguarded against collapsing due to
the asymmetry of the encoders. DINOv2 has evolved
from these approaches by incorporating a centering
and softmax operation in the feature space, as detailed
in (Caron et al., 2021). It also combines with masked
image modeling (Zhou et al., 2022a) and introduces
several techniques, such as regularizers, to stabilize
training at large scale on curated imaging data.
2.2 Data Augmentations
Today’s de facto standard to generate positive pairs
are data augmentation techniques, i.e. the original
image is processed by a image processing pipeline
where different geometric or pixelwise operations are
applied to generate two or more views of the same
semantic content. Consequently, applying objectives
that foster corresponding features to be as close as
possible to each other leads to image feature repre-
sentations that are (nearly) invariant with respect to
the transformations applied in the data augmentation
pipeline. In supervised learning the type and strength
of data augmentation has been vividly discussed as
well as methods for automatically generating opti-
mal data augmentation pipelines have been proposed
(Cubuk et al., 2019b; Cubuk et al., 2019a). Mostly,
in SSL the type and strength of the image transfor-
mations have not been focus of the publications until
Chen et al. (Chen et al., 2020a) firstly examine the
impact of different data augmentations in SimCLR,
proposing a richer data augmentation pipeline as pre-
vious approaches. They have been later adopted also
by others (Chen et al., 2020b; Zbontar et al., 2021;
Bardes et al., 2021). Poole et al. (Poole et al., 2020)
systematically studied the influence of data augmen-
tation both from a theoretical as well as from an
empirical view and derived unsupervised and self-
supervised approaches to synthesize optimal views
following the InfoMin principle. In (Bordes et al.,
2023) the influence of different data augmentations
on different downstream tasks have been studied. In
(Caron et al., 2020) more than two views have been
explored leading to a more robust representation.
Combining strong and weaker augmentations so
far got only little attention in the SSL literature.
Wang et al. (Wang and Qi, 2021) combined strong
and weaker augmentations and retrieved stronger
augmentations from a comprehensive pool of in-
stances by matching the distribution divergence be-
tween weakly and strongly augmented images. Un-
like our approach, their method applies strong aug-
mentation to all samples, potentially introducing a
negative training effect of too-hard samples. We pro-
pose the top-k selection as a countermeasure.
Adaptive augmentation selection for all image
pairs has been proposed by Zhang et al. (Zhang et al.,
2023). They sample augmentations by probabilities
that are derived from pretext task’s accuracies. In con-
trast to their approach, we apply strong augmentation
where needed, only, i.e. we select pairs that lead to
’too close’ features and therefore are to ‘too easy’, and
re-adds them after applying stronger data augmenta-
tions.
To the best of our knowledge, our approach is the
first one adapting augmentations for easy pairs, only,
thus ’rescuing’ them for training in a targeted fashion
avoiding negative effects of too-easy samples, while
also avoiding effects of too-hard samples.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
402

Input : Number of steps S, batch size N,
base encoder network f (·),
projection head g(·), loss scale
factor s, number k of images to
select for strong augmentation, SSL
loss function SSL.
Output: Trained encoder network f (·).
for steps = 1 to S do
Sample a minibatch x = {x
n
}
N
n=1
;
Draw 2 sets of augmentations t
a
∼ T ,
t
b
∼ T ;
y
a
← t
a
(x) ∈ R
N×3×X ×Y
;
y
b
← t
b
(x) ∈ R
N×3×X ×Y
;
Compute embeddings:
z
a
← g( f (y
a
)) ∈ R
N×D
;
z
b
← g( f (y
b
)) ∈ R
N×D
;
Compute SSL loss: L
SSL
← SSL(z
a
,z
b
);
Compute the cosine similarity C S;
sim ← CS(z
a
,z
b
) ∈ R
N
;
Get the top k indices:
i
topk
← topk(sim,k).indices ∈ N
k
;
z
s
← g( f (RandAugment(x
i
topk
))) ∈
R
k×D
;
L
topk
← −mean(CS(z
a
[i
topk
],z
s
));
Total loss: L ← L
SSL
+ sL
topk
;
Update networks f , g to minimize L;
end
return encoder network f (·), and discard
g(·).
Algorithm 1: Main Learning Algorithm.
3 METHOD
Pseudocode for our adaptive augmentation regular-
ization for SSL pretraining is shown as Algorithm 1.
Please note the symbols being defined there. A graph-
ical illustration of our method is shown in Figure 1.
Current SSL algorithms involve the joint embed-
ding of images distorted with common augmentations
T , following the contrastive learning framework of
SimCLR (Chen et al., 2020a). The self-supervised
loss SSL(z
a
,z
b
) is computed according to different
methods, given two (or more) image features z
a
and
z
b
, computed from two augmentations t
a
(x) and t
b
(x)
of each image in minibatch x ∈ R
N×3×X ×Y
. We con-
sider RGB color images of size X × Y and batch
size N. Our innovation lies in a regularization loss
term L
topk
incorporating RandAugment (Cubuk et al.,
2019b) to introduce an additional heavily augmented
view to the input images of the k most similar pos-
itive pairs according to sim = CS(z
a
,z
b
), where CS
is the cosine similarity. This allows us to introduce
L
topk
= −mean(CS (z
a
[i
topk
],z
s
)) weighted by a scale
Figure 3: Examples of common augmentation and strong
augmentation. The left image is a centercropped original
image, the middle three images are common views gener-
ated by common self-supervised learning augmentations,
and the right 3 images are distorted with RandAugment and
Cutout.
factor s, using heavily augmented views of the k im-
ages with index i
topk
according to sim. We elaborate
this method in the following sections in more detail.
Strong Augmentations. The amalgamation of
common augmentations for contrastive learning
encompasses random resized crop, horizontal flip,
color jitter, grayscale, Gaussian blur, solarization,
and equalization. While some methods(He et al.,
2020; Zbontar et al., 2021) employ asymmetric
augmentation strategies to encourage the learning
of more diverse features and prevent pretraining
collapse, our approach with RandAugment intro-
duces even more variant features. RandAugment
includes common augmentations such as contrast,
brightness, color jitter, equalization, sharpness, as
well as spatial augmentations like translation, shear,
rotation. Additionally, cutout is included in our
repertoire of strong augmentations. We follow the
augmentation strategy of RandAugment similar to
(Sohn et al., 2020) to randomly select transforma-
tions for each input. Specifically, we include 14
types of augmentations with different severity for
selecting randomly with pre-defined range as strong
augmentation. See Figure 3 for examples of common
views and strong views.
The strong augmentation pipeline is anticipated
to generate more diverse images for self-supervised
pretraining. To validate this assumption, we as-
sess the cosine similarity of features extracted from
a pre-trained neural network, specifically ResNet-50
trained on ImageNet, between common views and
strongly augmented views. The mean cosine similar-
ity score for common views over the entire dataset
is 0.7069, whereas for strongly augmented views, it
is 0.6690. Therefore, in this scenario, the strong
augmentation pipeline is expected to yield more di-
verse images compared to common augmentations.
Consequently, we can augment the dataset to include
more challenging positive examples by employing the
strong augmentation approach.
Top K Selector. Introducing strong augmentations
to a neural network training increases data variability,
Rescuing Easy Samples in Self-Supervised Pretraining
403

but this does not always yield positive effects (Wang
and Qi, 2021). When the input samples already ex-
hibit sufficient diversity, there may be no need to sub-
ject images to intense augmentation. In such cases,
preserving the diverse samples becomes crucial as
they play a vital role in enhancing the learning capa-
bilities of self-supervised learning (SSL) methods, fa-
cilitating the acquisition of improved representations
(Cai et al., 2020).
In our approach, we therefore refrain from uni-
formly applying strong augmentation to all images
within a mini-batch. Instead, we selectively em-
ploy strong augmentation on the top k most similar
views. The selection process is based on cosine sim-
ilarity, where each image sample x
i
in the mini-batch
x is individually evaluated with the cosine similar-
ity z
i
a
z
i
b
/(|z
i
a
||z
i
b
|) of its feature vectors z
i
a
∈ R
D
and
z
i
b
∈ R
D
of its two commonly augmented views y
i
a
and y
i
b
. D is the output dimension of the projection
head g(·). Cosine similarity is computed for the fea-
tures within the common positive pair, only, not for
negative pairs. Computing the cosine similarity score
vector sim ∈ R
N
therefore only adds linear complex-
ity in batch size N.
The cosine similarity scores vector serves as the
basis for selection. If the score for the cosine sim-
ilarity of the same image ranks within the top k in
the minibatch, we opt to heavily augment that partic-
ular image using RandAugment plus Cutout and input
it into the neural network. The features correspond-
ing to the top k strongly augmented views are sub-
sequently used for computing the regularization loss
L
topk
.
Consistency Regularization. To encourage the in-
variance of strong augmented views and common
augmented views, we introduce the regularization
term L
topk
to the loss function. The regularization
term is defined as follows,
L
topk
= −mean(CS(z
a
,z
s
)) (1)
Here, CS is cosine similarity, z
a
and z
s
denote the fea-
tures from common view and from strong augmented
view respectively.
We incorporate cosine similarity CS as a regu-
larization term in our approach. This choice aligns
with SimCLR and MoCo, where cosine similari-
ties are computed for subsequent use in contrastive
loss calculations. Additionally, in the case of DI-
NOv2, although cosine similarities are not explicitly
computed, the features are readily available for co-
sine similarity computation. Our objective, centered
on promoting invariances from multiple perspectives,
leads us to adopt the negative cosine similarity as the
loss function. In our implementation, we adapt the
SSL loss function by introducing the additional regu-
larization term
L = L
SSL
+ sL
topk
(2)
Here, L
SSL
denotes the SSL loss akin to SimCLR,
MoCo and DINOv2, while L
topk
represents the reg-
ularization term as shown in (1). The parameter s
scales the impact of L
topk
to balance between the
stronger augmentation and the original SSL loss. A
sensitivity analysis for hyperparameter s is shown in
Section 5.
4 EXPERIMENTAL RESULTS
Following the protocols from the previous work
(Chen et al., 2020a) (He et al., 2020) (Oquab et al.,
2023), we conduct the downstream experiments on
commonly used SSL evaluation datasets to evaluate
the performance of pretrained neural networks. We
show our results on ImageNet-1K (Deng et al., 2009),
classification datasets, as well as dense prediction
datasets.
Training Data. We pretrain the network with
ImagNet-1K train partition without labels. Labels are
only used for evaluation purposes in the downstream
tasks.
Baseline SSL Methods.. We incorporate our
method into a series of current state-of-the-art
(SOTA) self-supervised learning (SSL) techniques,
including SimCLR, MoCo v3, and DINOv2. For
SimCLR, we adhere to the ResNet-50 architecture
configuration. In the case of MoCo v3, our meth-
ods are implemented on various architectures, namely
ResNet-50, ViT-Small, and ViT-Base. In the context
of DINOv2, we follow the configuration for the ViT-
Large model, pretraining exclusively on ImageNet-
1K. This diverse set of SSL methods and architectures
allows us to comprehensively evaluate the effective-
ness of our approach across different self-supervised
learning frameworks.
In the results we name findings using our method
according to the underlying baseline SSL method,
e.g. ’Ours(SimCLR)’ or ’Ours(MoCo v3)’ etc. and
specify the network architecture in addition, where
needed.
Detailed Experiment Settings. We keep the same
settings as in the baseline publications wherever pos-
sible. Specifically, we apply the following settings:
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
404

• SimCLR We use ResNet-50 as the architecture of
the base encoder and optimize it using LARS(You
et al., 2017) with learning rate 4.8 (i.e. 0.3 ×
N/256) and weight decay of 10
−6
. We train at
batch size N = 4096 for 1000 epochs. Further-
more, we use linear warmup for the first 10 epochs
and decay the learning rate with cosine decay
schedule. All sensitivity experiments use the same
settings but train for 100 epochs, only.
• MoCo v3 We use ResNet-50, ViT-S and ViT-B
as architectures of the base encoder. For ResNet-
50, we use the same optimiser settings as above
for SimCLR. However, we follow the original lit-
erature to pretrain with 800 epochs. For ViT-S
and ViT-B, we use AdamW(Loshchilov and Hut-
ter, 2019) with learning rate 0.0024 and weight
decay 0.1. We train at batch size N = 4096 for
300 epochs. All sensitivity experiments use ViT-
S settings for 300 epochs.
• DINOv2 We use ViT-L as the architecture of the
base encoder. The specific version of ViT-L is
ViT-L/16. We train the base encoder with batch
size N = 2048 for 100 epochs (i.e. 12500 itera-
tions) with square rooted scale learning rate 0.004
and weight decay 0.04. All sensitivity experi-
ments use above settings.
Hyperparameters. We use different hyperparame-
ters for different baseline SSL methods according to
the sensitivity analysis given in Section 5. For Sim-
CLR we use k = 128 and s = 0.75, for MoCo v3
k = 64 and s = 0.05, and DINOv2 k = 16 and s = 1.
All other hyperparameters are selected as given in the
base SSLs publications, see paragraph above.
4.1 Linear Evaluations on ImageNet-1K
A common evaluation protocol for self-supervised
learning model is linear probing (Balestriero et al.,
2023). As usual, to evaluate the linear probing per-
formance on ImageNet-1K, we froze the respective
encoder f pretrained with our method, and finetune
a linear classifier on top of the encoder with the
ImageNet-1K training set. Then the results are eval-
uated with the validation set of ImageNet-1K. The
main results are shown in Figure 2. We observe
that our method based on MoCo v3 achieves the
highest top-1 accuracy (74.4%) among the ResNet-
50-based methods, outperforming SimCLR (69.1%)
and Ours(SimCLR) (70.2%). Our methods based on
DINOv2 achieves the best top-1 accuracy (83.1%)
among all the SSL methods establishing new SOTA
for this task. Our methods boost all the base SSL
algorithms we tested. It improved SimCLR by 1.1
%, MoCo v3(ResNet-50) by 0.6 % and DINOv2 by
0.5%. Besides, compared to DINOv2, our methods
exhibits a lower standard deviation (±0.02), indicat-
ing robustness in its performance across multiple ex-
periments.
4.2 Transfer Learning on Downstream
Tasks
Typical downstream tasks include augmentation in-
variant tasks (classification) and equivariant dense
prediction tasks (detection and segmentation). We test
our approach for both cases in the following.
Image Classification with Fixed Features. We fol-
low the experimental settings as given for SimCLR
(Chen et al., 2020a) and MoCo v3 (He et al., 2020).
To this end, we train a linear classifier g for each
task on frozen pretrained networks f . For evaluation,
we use a range of classification tasks given by the
datasets Food-101 (Bossard et al., 2014), CIFAR-10
and CIFAR-100 (Krizhevsky, 2009), SUN397 (Xiao
et al., 2010), FGVC Aircraft (Maji et al., 2013),
Describable Textures Dataset (DTD) (Cimpoi et al.,
2014), Oxford-IIIT Pets (Parkhi et al., 2012), Ox-
ford 102 Flowers (Nilsback and Zisserman, 2008) and
PASCAL VOC 2007 (Everingham et al., 2010).
The results for SimCLR vs. Ours(SimCLR) are
depicted in Figure 4a for ResNet-50, for MoCo v3 vs.
Ours(MoCo v3) in Figure 4b for ViT-B, and Figure 4c
shows the same plot for DINOv2 vs. Ours(DINOv2)
for ViT-L. The respective performance values are
shown in Table 1.
From the plots and table, we can infer that a net-
work pretrained with adaptive strong augmentations
outperforms baseline SSL methods across the major-
ity of downstream classification datasets. However,
the picture is not completely consistent across all base
SSL methods. While our method exhibits compa-
rable or improved performance to the SimCLR base
method on 9 out of the 10 tasks, it does not surpass it
on the VOC2007 dataset. Notably, our approach im-
proves the baseline on datasets such as Cifar, Caltech,
and Food101 by a significant margin (more than 1%).
In contrast to SimCLR, results for VOC2007 are im-
proved when using MoCo v3 or DINOv2, however, in
both cases results for DTD, SUN397, and Food-101
do not improve.
Transfer Learning on Dense Prediction. We eval-
uate transfer learning performance across multiple
dense prediction tasks. Specifically, we employ a lin-
ear classifier trained on a pre-trained network using
Rescuing Easy Samples in Self-Supervised Pretraining
405
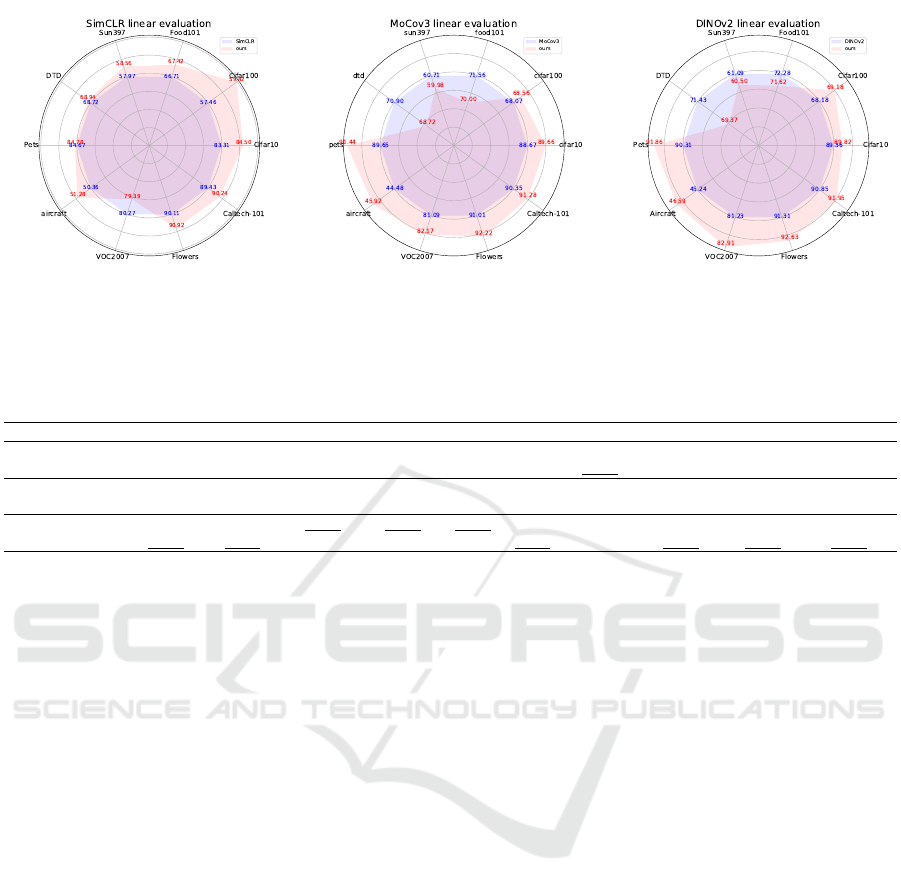
(a) SimCLR vs. Ours (SimCLR), ResNet-50. (b) MoCo v3 vs. Ours (MoCo v3), ViT-B. (c) DINOv2 vs. Ours (DINOv2), ViT-L.
Figure 4: Transfer learning on classification tasks. Radii are equally spaced to indicate performance differences clearly.
Numbers can also be found in Table 1.
Table 1: Transfer learning on classification tasks. Bold values indicate best results within direct comparison of Ours vs.
SSL methods, underlined values overall best.
Methods Cifar10 Cifar100 Food101 SUN397 DTD Pets Aircraft VOC2007 Flowers Caltech101
SimCLR 83.31 57.46 66.71 57.97 68.72 84.67 50.36 80.27 90.11 89.43
Ours(SimCLR) 84.50 59.42 67.42 58.56 68.94 84.78 51.28 79.39 90.92 90.24
MoCo v3 88.67 68.07 71.56 60.71 70.90 89.65 44.48 81.09 91.01 90.00
Ours(MoCo v3) 89.66 68.56 70.00 59.98 68.72 91.44 45.92 82.17 92.22 91.28
DINOv2 89.36 68.18 72.28 61.09 71.43 90.31 45.24 81.23 91.31 90.85
Ours(DINOv2) 89.82 69.18 71.62 60.50 69.37 91.86 46.59 82.91 92.63 91.95
both the PASCAL VOC dataset (Everingham et al.,
2010) and the MS-CoCo dataset (Lin et al., 2015).
Detailed results can be found in Table 2.
We observe for SimCLR and MoCo v3 that Ours
consistently outperforms baseline methods across
almost all evaluation metrics in tasks such as
VOC07+12 detection, COCO detection, and COCO
instance segmentation. In the domain of VOC07+12
detection, our adaptive augmentations self-supervised
learning (SSL) method exhibits a marginal yet dis-
cernible enhancement in AP
all
, AP
50
, and AP
75
com-
pared to the baseline SSL methods. This suggests that
Ours excels across various levels of precision. For DI-
NOv2 half of the measures were improved. The un-
derlined values in Table 2 reveal, that our method im-
proves the best seen values in 6 out of 9 performance
measures, where DINOv2 delivers the other 3 best or
on par results.
In conclusion, our approach improves upon the
baseline SSL methods in various dense prediction
tasks, showcasing superior performance in precision,
object detection, and instance segmentation tasks
across different datasets. The observed enhancements
are not only consistent but also statistically signif-
icant, underlining the effectiveness of our proposed
method.
5 SENSITIVITY ANALYSIS
Our methods needs two hyperparameters to be tuned
suitably, ’scale factor’ s and number k of strongly
augmented samples per mini-batch. We utilize the
ImageNet-1K linear probing assessment (see Sec-
tion 4.1) to report the efficacy of SSL methods. Given
that loss values vary across different SSL methods,
we conduct separate investigations per method.
Sensitivity to Scale Factor S. The scale factor s
serves to balance the SSL loss and our novel regu-
larization loss based on heavy augmentation (see (2)).
Naturally s ≥ 0 is a real positive number, where we
expect a break down of training performance for too
large s. We explore the impact of this hyperparameter
on SSL pretraining, keeping the other hyperparame-
ters fixed, specifically we set k = 64 for SimCLR and
MoCo v3 and k = 32 for DINOv2. In Figure 5 we
observe the expected decline for high s for all meth-
ods, however at quite different values of s. This is not
unexpected, as the base SSL losses are different in
their characteristics and amplitudes. For SimCLR we
get s = 0.75 for ResNet-50, for MoCo v3 s = 0.025
for ViT-S and s = 0.05 for ResNet-50 and ViT-B (not
shown), and for DINOv2 s = 1 (ViT-L) as best val-
ues. However, methods seem not to be too sensitive
to the exact values of s, as their performance influ-
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
406

Table 2: Transfer learning on dense prediction tasks. Bold values indicate best results within direct comparison of Ours
vs. baseline SSL methods, underlined values overall best. Hyperparameters have not been tuned for these tasks.
Method
VOC07+12 det CoCo det CoCo instance seg
AP
all
AP
50
AP
75
AP
bb
AP
bb
50
AP
bb
75
AP
mk
AP
mk
50
AP
mk
75
SimCLR 43.9 77.0 48.7 33.8 69.3 27.6 16.3 52.8 39.3
Ours(SimCLR) 46.4 77.9 43.9 34.7 69.9 29.5 16.4 53.5 38.9
MoCo v3 50.8 80.5 54.9 39.3 58.9 42.5 34.4 55.8 36.5
Ours(MoCo v3) 51.4 80.8 55.9 41.0 61.3 44.4 35.4 57.5 37.5
DINOv2 51.9 81.3 57.0 44.3 66.8 44.1 23.9 55.0 45.8
Ours(DINOv2) 52.2 81.1 57.3 43.9 66.9 43.9 24.2 54.5 45.8
(a) SimCLR. (b) MoCo v3. (c) DINOv2.
Figure 5: Sensitivity to scale factor s. Linear probing on
ImageNet-1K compared to SSL baseline (red dashed line
for 100 epochs and green dashed line for 200 epochs train-
ing, Our methods are trained for 100 epochs, only). The
grey shaded areas denote pretraining collapse here. We
evaluate the network three times, mean and standard devia-
tion are reported in the graph.
(a) SimCLR. (b) MoCo v3. (c) DINOv2.
Figure 6: Sensitivity analysis for hyperparameter k. Lin-
ear probing on ImageNet-1K. Red dashed lines indicate
baseline SSL performance. The grey shaded area indicates
pretraining collapse here.
ence remains positive, i.e. above the baseline indi-
cated as red dashed line, in a reasonably wide range
around the maximum. This allows for relatively wide-
spaced searches when trying to find the best s for a
new method.
Sensitivity to Top K Parameter K. We investigate
the sensitivity of our method to the hyperparameter
k, controlling the number of samples to be strongly
augmented. For the experiments we set s to the best
values we found in the respective sensitivity analysis,
above. From the plots in Figure 6 we see that the pa-
rameter k is best at k = 64 for SimCLR where training
batch size is N = 4096, for MoCo v3 best at k = 64
with N = 4096, and for DINOv2 it is k = 16, where
N = 2048. For DINOv2 also k = 32 performs almost
as good as k = 16, indicating that a ratio of N/k ≈ 64
may be a suitable rule of thumb.
6 CONCLUSIONS
Our novel strong-augmentation top k loss term is de-
signed to be easily included in training methods that
make use of augmented versions of the same sample.
To apply it properly, we observed that one needs to
tune two hyperparameters s and k, both being mildly
sensitive. However, we found quite different opti-
mal values for s for the investigated SSL methods
SimCLR, MoCo v3, and DINOv2. Simply selecting
some value that previously worked for an unrelated
method may therefore be inappropriate. The parame-
ter k seems to be better behaved and may be selected
as k = N/64 as a rule of thumb, where N is the batch-
size.
In this paper, we experiment with pretraining on
ImageNet-1K, only, in order to keep needed com-
pute (and CO
2
-footprint) within reasonable limits.
However, experiments show, that using our additional
loss term improves performance of most downstream
tasks, in some cases establishing new SOTA.
From Figure 2 we observe, that strongest improve-
ments are achieved on smallest models and that im-
provements on larger models are statistically signif-
icant but sometimes small. This opens the question
how well the found improvements transfer to larger
models trained on larger datasets. This question can-
not be answered by our current experiments and we
plan to address this in future studies.
ACKNOWLEDGEMENTS
The authors gratefully acknowledge the Gauss Cen-
tre for Supercomputing e.V. (www.gauss-centre.eu)
for funding this project by providing computing time
through the John von Neumann Institute for Comput-
ing (NIC) on the GCS Supercomputer JUWELS at
J
¨
ulich Supercomputing Centre (JSC).
Rescuing Easy Samples in Self-Supervised Pretraining
407

REFERENCES
Andrew, G., Arora, R., Bilmes, J., and Livescu, K. (2013).
Deep canonical correlation analysis. In Dasgupta,
S. and McAllester, D., editors, Proceedings of the
30th International Conference on Machine Learning,
volume 28 of Proceedings of Machine Learning Re-
search, pages 1247–1255, Atlanta, Georgia, USA.
PMLR.
Balestriero, R., Ibrahim, M., Sobal, V., Morcos, A.,
Shekhar, S., Goldstein, T., Bordes, F., Bardes, A., Mi-
alon, G., Tian, Y., Schwarzschild, A., Wilson, A. G.,
Geiping, J., Garrido, Q., Fernandez, P., Bar, A., Pir-
siavash, H., LeCun, Y., and Goldblum, M. (2023). A
cookbook of self-supervised learning.
Bardes, A., Ponce, J., and Vicreg, Y. L. (2021). Vi-
creg: Variance-invariance-covariance regularization
for self-supervised learning. In International Confer-
ence on Learning Representations.
Bengio, Y., Lamblin, P., Popovici, D., and Larochelle, H.
(2006). Greedy layer-wise training of deep networks.
In Sch
¨
olkopf, B., Platt, J., and Hoffman, T., editors,
Advances in Neural Information Processing Systems,
volume 19. MIT Press.
Bordes, F., Balestriero, R., and Vincent, P. (2023). Towards
democratizing joint-embedding self-supervised learn-
ing.
Bossard, L., Guillaumin, M., and Van Gool, L. (2014).
Food-101 – mining discriminative components with
random forests. In European Conference on Computer
Vision.
Cai, T. T., Frankle, J., Schwab, D. J., and Morcos, A. S.
(2020). Are all negatives created equal in contrastive
instance discrimination?
Caron, M., Misra, I., Mairal, J., Goyal, P., Bojanowski, P.,
and Joulin, A. (2020). Unsupervised learning of vi-
sual features by contrasting cluster assignments. In
Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.,
and Lin, H., editors, Advances in Neural Information
Processing Systems, volume 33, pages 9912–9924.
Caron, M., Touvron, H., Misra, I., J
´
egou, H., Mairal, J., Bo-
janowski, P., and Joulin, A. (2021). Emerging proper-
ties in self-supervised vision transformers.
Chen, T., Kornblith, S., Norouzi, M., and Hinton, G.
(2020a). A simple framework for contrastive learning
of visual representations.
Chen, X., Fan, H., Girshick, R., and He, K. (2020b). Im-
proved baselines with momentum contrastive learn-
ing.
Chen, X. and He, K. (2021). Exploring simple siamese rep-
resentation learning. In IEEE Conference on Com-
puter Vision and Pattern Recognition, CVPR 2021,
virtual, June 19-25, 2021, pages 15750–15758. Com-
puter Vision Foundation / IEEE.
Chen, X., Xie, S., and He, K. (2021). An empirical study of
training self-supervised vision transformers. In 2021
IEEE/CVF International Conference on Computer Vi-
sion (ICCV), pages 9620–9629, Los Alamitos, CA,
USA. IEEE Computer Society.
Cimpoi, M., Maji, S., Kokkinos, I., Mohamed, S., , and
Vedaldi, A. (2014). Describing textures in the wild.
In Proceedings of the IEEE Conf. on Computer Vision
and Pattern Recognition (CVPR).
Cubuk, E. D., Zoph, B., Mane, D., Vasudevan, V., and Le,
Q. V. (2019a). Autoaugment: Learning augmentation
policies from data. In IEEE Conference on Computer
Vision and Pattern Recognition, CVPR 2019.
Cubuk, E. D., Zoph, B., Shlens, J., and Le, Q. V. (2019b).
Randaugment: Practical automated data augmentation
with a reduced search space.
Deng, J., Socher, R., Fei-Fei, L., Dong, W., Li, K., and
Li, L.-J. (2009). Imagenet: A large-scale hierarchical
image database. In 2009 IEEE Conference on Com-
puter Vision and Pattern Recognition(CVPR), pages
248–255.
Doersch, C., Gupta, A., and Efros, A. A. (2015). Unsuper-
vised visual representation learning by context predic-
tion. In International Conference on Computer Vision
(ICCV).
Donahue, J., Kr
¨
ahenb
¨
uhl, P., and Darrell, T. (2017). Ad-
versarial feature learning. In 5th International Con-
ference on Learning Representations, ICLR 2017,
Toulon, France, April 24-26, 2017, Conference Track
Proceedings. OpenReview.net.
Dosovitskiy, A., Springenberg, J. T., Riedmiller, M., and
Brox, T. (2014). Discriminative unsupervised fea-
ture learning with convolutional neural networks. In
Ghahramani, Z., Welling, M., Cortes, C., Lawrence,
N., and Weinberger, K., editors, Advances in Neural
Information Processing Systems, volume 27. Curran
Associates, Inc.
Everingham, M., Van Gool, L., Williams, C. K. I., Winn,
J., and Zisserman, A. (2010). The pascal visual ob-
ject classes (voc) challenge. International Journal of
Computer Vision, 88(2):303–338.
Gidaris, S., Singh, P., and Komodakis, N. (2018). Unsu-
pervised representation learning by predicting image
rotations. CoRR, abs/1803.07728.
Grill, J.-B., Strub, F., Altch
´
e, F., Tallec, C., Richemond,
P. H., Buchatskaya, E., Doersch, C., Pires, B. A., Guo,
Z. D., Azar, M. G., Piot, B., Kavukcuoglu, K., Munos,
R., and Valko, M. (2020). Bootstrap your own latent:
A new approach to self-supervised learning.
He, K., Chen, X., Xie, S., Li, Y., Dollar, P., and Gir-
shick, R. (2022). Masked autoencoders are scalable
vision learners. In Proceedings - 2022 IEEE/CVF
Conference on Computer Vision and Pattern Recog-
nition, CVPR 2022, Proceedings of the IEEE Com-
puter Society Conference on Computer Vision and
Pattern Recognition, pages 15979–15988. IEEE Com-
puter Society. Publisher Copyright: © 2022 IEEE.;
2022 IEEE/CVF Conference on Computer Vision and
Pattern Recognition, CVPR 2022 ; Conference date:
19-06-2022 Through 24-06-2022.
He, K., Fan, H., Wu, Y., Xie, S., and Girshick, R. (2020).
Momentum contrast for unsupervised visual represen-
tation learning.
Krizhevsky, A. (2009). Learning multiple layers of features
from tiny images.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
408

Larsson, G., Maire, M., and Shakhnarovich, G. (2016).
Learning representations for automatic colorization.
In Computer Vision – ECCV 2016, pages 577–593.
Lehner, J., Alkin, B., F
¨
urst, A., Rumetshofer, E., Miklautz,
L., and Hochreiter, S. (2023). Contrastive tuning: A
little help to make masked autoencoders forget.
Lin, T.-Y., Maire, M., Belongie, S., Bourdev, L., Girshick,
R., Hays, J., Perona, P., Ramanan, D., Zitnick, C. L.,
and Doll
´
ar, P. (2015). Microsoft coco: Common ob-
jects in context.
Loshchilov, I. and Hutter, F. (2019). Decoupled weight de-
cay regularization.
Maji, S., Kannala, J., Rahtu, E., Blaschko, M., and Vedaldi,
A. (2013). Fine-grained visual classification of air-
craft.
Nilsback, M.-E. and Zisserman, A. (2008). Automated
flower classification over a large number of classes.
In Indian Conference on Computer Vision, Graphics
and Image Processing.
Noroozi, M., Vinjimoor, A., Favaro, P., and Pirsiavash, H.
(2018). Boosting self-supervised learning via knowl-
edge transfer. In Proceedings of the IEEE conference
on computer vision and pattern recognition.
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec,
M., Khalidov, V., Fernandez, P., Haziza, D., Massa,
F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W.,
Howes, R., Huang, P.-Y., Li, S.-W., Misra, I., Rab-
bat, M., Sharma, V., Synnaeve, G., Xu, H., Jegou, H.,
Mairal, J., Labatut, P., Joulin, A., and Bojanowski, P.
(2023). Dinov2: Learning robust visual features with-
out supervision.
Parkhi, O. M., Vedaldi, A., Zisserman, A., and Jawahar,
C. V. (2012). Cats and dogs. In IEEE Conference
on Computer Vision and Pattern Recognition.
Pathak, D., Kr
¨
ahenb
¨
uhl, P., Donahue, J., Darrell, T., and
Efros, A. A. (2016). Context encoders: Feature learn-
ing by inpainting. In 2016 IEEE Conference on Com-
puter Vision and Pattern Recognition (CVPR), pages
2536–2544.
Poole, B., Sun, C., Schmid, C., Krishnan, D., Isola, P., and
Tian, Y. (2020). What makes for good views for con-
trastive representation learning? In NeurIPS.
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh,
S., Ma, S., Huang, Z., Karpathy, A., Khosla, A.,
Bernstein, M., Berg, A. C., and Fei-Fei, L. (2015).
ImageNet Large Scale Visual Recognition Challenge.
International Journal of Computer Vision (IJCV),
115(3):211–252.
Sohn, K., Berthelot, D., Li, C.-L., Zhang, Z., Carlini, N.,
Cubuk, E. D., Kurakin, A., Zhang, H., and Raffel, C.
(2020). Fixmatch: Simplifying semi-supervised learn-
ing with consistency and confidence.
Springenberg, J. T. (2016). Unsupervised and semi-
supervised learning with categorical generative adver-
sarial networks. In Bengio, Y. and LeCun, Y., editors,
4th International Conference on Learning Represen-
tations, ICLR 2016, San Juan, Puerto Rico, May 2-4,
2016, Conference Track Proceedings.
Wang, X. and Qi, G.-J. (2021). Contrastive learning with
stronger augmentations. IEEE Transactions on Pat-
tern Analysis and Machine Intelligence, 45:5549–
5560.
Wu, Z., Xiong, Y., Yu, S. X., and Lin, D. (2018). Unsuper-
vised feature learning via non-parametric instance dis-
crimination. In 2018 IEEE Conference on Computer
Vision and Pattern Recognition, CVPR 2018, Salt
Lake City, UT, USA, June 18-22, 2018, pages 3733–
3742. Computer Vision Foundation / IEEE Computer
Society.
Xiao, J., Hays, J., Ehinger, K. A., Oliva, A., and Torralba,
A. (2010). Sun database: Large-scale scene recogni-
tion from abbey to zoo. 2010 IEEE Computer Society
Conference on Computer Vision and Pattern Recogni-
tion, pages 3485–3492.
You, Y., Gitman, I., and Ginsburg, B. (2017). Large batch
training of convolutional networks.
Zbontar, J., Jing, L., Misra, I., LeCun, Y., and Deny, S.
(2021). Barlow twins: Self-supervised learning via re-
dundancy reduction. In Meila, M. and Zhang, T., edi-
tors, Proceedings of the 38th International Conference
on Machine Learning, ICML 2021, 18-24 July 2021,
Virtual Event, volume 139 of Proceedings of Machine
Learning Research, pages 12310–12320. PMLR.
Zhang, Y., Zhu, H., and Yu, S. (2023). Adaptive data aug-
mentation for contrastive learning.
Zhou, J., Wei, C., Wang, H., Shen, W., Xie, C., Yuille,
A., and Kong, T. (2022a). iBOT: Image BERT Pre-
Training with Online Tokenizer. In International Con-
ference on Learning Representations (ICLR).
Zhou, P., Zhou, Y., Si, C., Yu, W., Ng, T. K., and Yan,
S. (2022b). Mugs: A multi-granular self-supervised
learning framework.
Rescuing Easy Samples in Self-Supervised Pretraining
409
