
DeepSpace: Navigating the Frontier of Deepfake Identification Using
Attention-Driven Xception and a Task-Specific Subspace
Ayush Roy
1 a
, Sk Mohiuddin
2 b
, Maxim Minenko
3 c
, Dmitrii Kaplun
4,3,∗ d
and Ram Sarkar
5 e
1
Jadavpur University, Department of Electrical Engineering, Kolkata, 700032, India
2
Asutosh College, Department of Computer Science, Kolkata, 700026, India
3
St. Petersburg Electrotechnical University ”LETI”, Dep. of Automation and Control Processes,
St. Petersburg, 197022, Russia
4
China University of Mining and Technology, Artificial Intelligence Research Institute, Xuzhou, 221116, China
5
Jadavpur University, Department of Computer Science and Engineering, Kolkata, 700032, India
{aroy80321, myselfmohiuddin}@gmail.com, {mvminenko, dikaplun}@etu.ru, ramjucse@gmail.com
Keywords:
Deepfake Detection, Subspace Optimization, Attention Mechanism.
Abstract:
The recent advancements in deepfake technology pose significant challenges in detecting manipulated media
content and preventing its malicious use in different areas. Using ConvNets feature spaces and fine-tuning
them for deepfake classification can lead to unwanted modifications and artifacts in the feature space. To
address this, we propose a model that uses Xception as the backbone and a Spatial Attention Module (SAM)
to leverage spatial information using shallower features like texture, color, and shape, as well as deeper fine-
grained features. We also create a task-specific subspace for projecting spatially enriched features, which
boosts the overall model performance. To do this, we utilize Gram-Smith orthogonalization on the flattened
features of real and fake images to produce the basis vectors for our subspace. We evaluate the proposed
method using two widely used and standard deepfake video datasets: FaceForensics++ and Celeb-DF (V2).
We conduct experiments following two different setups: intra-dataset (trained and tested on the same dataset)
and inter-dataset (trained and tested on separate datasets). The performance of the proposed model is compa-
rable to that of state-of-the-art methods, confirming its robustness and generalization ability. The code is made
available at https://github.com/AyushRoy2001/DeepSpace.
1 INTRODUCTION
The proliferation of deepfake technology, driven by
sophisticated machine learning algorithms, has ush-
ered in a new era of digital manipulation, where indi-
viduals can be convincingly portrayed saying or doing
things they never said or did. Face forgery, a subset
of deepfakes, involves the seamless alteration of facial
features in videos or images, presenting a formidable
challenge to the authenticity of visual content. As
this technology evolves, the need for robust detec-
tion mechanisms (Mohiuddin et al., 2023a) becomes
increasingly a necessity to safeguard against poten-
a
https://orcid.org/0000-0002-9330-6839
b
https://orcid.org/0000-0001-6411-4072
c
https://orcid.org/0000-0002-7334-7668
d
https://orcid.org/0000-0003-2765-4509
e
https://orcid.org/0000-0001-8813-4086
∗
Corresponding author
tial misuse, misinformation, and the erosion of trust.
Hence, improving deepfake detection can reduce mis-
information and protect individuals from harm, en-
hancing trust in digital content. However, it raises eth-
ical concerns, such as potential misuse for censorship
or unjust accusations, requiring careful regulation.
Deepfakes, created with machine learning like
Generative Adversarial Networks (GANs), produce
convincing synthetic media and raise misinforma-
tion concerns. Detecting them is essential, with AI-
based Counter-GANs distinguishing real from syn-
thetic content. Deep Convolutional Neural Networks
(CNNs), known for their ability to extract valuable
features from images, are effective in computer vi-
sion and have led to various models for detecting
deepfakes. For instance, the SiamNet model (Kingra
et al., 2023) leverages inconsistencies in source cam-
era noise patterns to identify artifacts in manipulated
videos. New methods (Raza and Malik, 2023; Lewis
et al., 2020) combine audiovisual learning to improve
Roy, A., Mohiuddin, S., Minenko, M., Kaplun, D. and Sarkar, R.
DeepSpace: Navigating the Frontier of Deepfake Identification Using Attention-Driven Xception and a Task-Specific Subspace.
DOI: 10.5220/0013173700003912
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 2: VISAPP, pages
163-172
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
163

deepfake detection, and the Xception network with
depth separable convolution layers has shown state-
of-the-art performance in this area. This is particu-
larly evident when employing a single CNN model,
as demonstrated by Li et al. (Li et al., 2020).
While deep CNN models excel at efficiently iden-
tifying local artifacts, contemporary deepfake genera-
tion techniques can produce a spectrum of artifacts,
ranging from localized distortions to those that en-
compass the entire image. In addition, the diverse
generation techniques contribute to a significant di-
versity in the types of artifacts generated. Existing
deep learning methods occasionally struggle to effec-
tively address this diversity, as evident in Li et al. (Li
et al., 2020). To address the extensive diversity ob-
served in the generation of fake content, numerous
researchers, exemplified by Yu et al. (Yu et al., 2022),
have integrated videos with distinctively manipulated
faces into their assessment procedures. Nevertheless,
this approach might not be sustainable given the broad
spectrum of faking methods. Consequently, there is a
pressing need to devise methods that can adeptly han-
dle the vast array of fraudulent artifacts.
CNNs with spatial attention focus on crucial re-
gions in an input image, improving feature recogni-
tion, performance, and interoperability. This prioriti-
zation aids robust feature extraction and enhances the
model’s decision-making. Some methods, reported in
(Mohiuddin et al., 2023b; Naskar et al., 2024), strive
to extract optimal features and strategically reduce
computations in deepfake detection. However, un-
necessary modifications in the feature subspace dur-
ing deep learning training can alter features and affect
performance. Robust models in other domains have
been achieved through proper feature subspace gen-
eration and optimization (Yin et al., 2023; Li et al.,
2023). A task-specific subspace aligns features in an
explainable manner while enhancing model robust-
ness. Limited research has explored the direction of
a task-specific subspace for deepfake detection, de-
spite its potential to address challenges in this field.
Therefore, the proposed model is designed to handle
the deepfake classification task.
The major contributions of our work are:
• We propose a methodology that incorporates the
projection of the spatially enriched feature from
Xception onto a task-specific subspace.
• A pivotal component of our model is the Spatial
Attention Module (SAM). SAM amalgamates the
shape, color, texture, etc. information from the
shallow features, and the fine-grained information
from the deep features to spatially enrich the out-
put features of the Xception model.
• The lack of exploration of task-specific subspace
for deepfake classification encourages us to for-
mulate one. We have utilized features of ’fake’
and ’real’ images to create the orthonormal ba-
sis vectors of our task-aware subspace using the
Gram-Smith orthogonalization. The features are
projected onto this subspace for an interpretable
boost in the model’s performance.
• Extensive experiments conducted on two chal-
lenging and popular deepfake datasets: Face-
Forensics++ (Rossler et al., 2019) and Celeb-
DF (Li et al., 2020), demonstrate that our model
achieves state-of-the-art (SOTA) results in terms
of both efficiency and resilience against known at-
tacks. Our approach substantially reduces false
positives, enhancing the accuracy and reliability
of the proposed model.
The paper is structured as follows: Section 2 pro-
vides an overview of past methods employed for de-
tecting deepfakes. The working principle of the pro-
posed model is detailed in Section 3. In 4, we as-
sess our method in extracting global inconsistencies,
presenting related datasets and the experimental pro-
tocol. Finally, 5 reports conclusive remarks on our
work.
2 RELATED WORK
In recent years, researchers have proposed deep
learning-based methods for detecting deepfakes, aim-
ing to enhance the robustness and accuracy of identi-
fying manipulated media content. The advanced tech-
niques, such as those utilizing GANs, challenge cur-
rent detection methods, making typical identification
methods less effective.
Earlier approaches primarily relied on deep learn-
ing architectures, especially CNNs, for detecting
deepfakes. For instance, pre-trained Xception and
Capsule Network models were used in Tolosana et
al. (Tolosana et al., 2021) to analyze full-face and
specific facial components. Studies such as those by
Rossler et al. (Rossler et al., 2019) demonstrated the
superior performance of XceptionNet across different
datasets. Meanwhile, Afchar et al. (Afchar et al.,
2018) utilized mesoscopic details with their Meso-4
and MesoInception-4 CNN architectures for forgery
detection. Amerini et al. (Amerini et al., 2019) ex-
plored unusual facial motion, using PWC-Net and
VGG16-based models to filter out authentic videos.
Despite their success, these deep CNN models face
limitations in capturing both local and global features
simultaneously, leading to challenges in accurately
identifying manipulation artifacts.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
164

In addition to the common challenges associated
with deep learning models, various studies (Ganguly
et al., 2022; Lu et al., 2023) propose incorporating at-
tention mechanisms into CNN models to broaden the
focus on facial image regions. For example, Nguyen
et al. (Nguyen et al., 2024) proposed an explicit
attention mechanism in a multi-task learning frame-
work (LAA-Net). By combining heatmap-based and
self-consistency attention, it focuses on artifact-prone
regions. Then, an Enhanced Feature Pyramid Net-
work (E-FPN) efficiently spreads low-level features,
limiting redundancy used for detection of deepfake.
Xia et al. (Xia et al., 2024) introduced the Multi-
Collaboration and Multi-Supervision Network (MM-
Net), addressing diverse spatial scales and sequential
permutations in manipulated face images, and achiev-
ing recovery without requiring knowledge of the spe-
cific manipulation method. Furthermore, these atten-
tion models primarily utilized convolution operations
across the entire image to generate the necessary at-
tention map, potentially emphasizing unimportant re-
gions. However, the presence of irrelevant features in
existing models can mislead classifiers during tasks,
leading to longer training times. Utilizing an effective
feature selection method may be helpful to overcome
this limitation by eliminating non-important features.
Many recent approaches emphasize ensemble
techniques, feature selection, and feature engineer-
ing. Some methods (Zhang et al., 2022; Hooda
et al., 2024) prioritize the selection of relevant fea-
tures through deep learning, while others (Mohiuddin
et al., 2023b; Naskar et al., 2024) rely on feature engi-
neering methods for deepfake detection. An alterna-
tive approach involves leveraging multiple modalities,
such as audio, video, and text, to enhance detection
accuracy and robustness against adversarial forgeries.
By combining complementary features from these
modalities, multimodal methods (Liz-Lopez et al.,
2024; Yu et al., 2023; Raza and Malik, 2023) can ef-
fectively capture inconsistencies across different in-
formation streams, which are often difficult for uni-
modal approaches to detect. As explored in other
domains, task-aware subspace learning offers several
advantages, capturing task-specific information to re-
duce unwanted changes and modifications of the fea-
tures (Zhou et al., 2023). Enhancing both local and
global correlation structures improves data affinity for
robust and applicable subspace clustering, preserves
global and local data structure, and extracts discrim-
inative features, thus improving classification perfor-
mance (Kou et al., 2023). Overall, the enhancement
in task performances by capturing task-specific infor-
mation, reducing interference, and improving the ro-
bustness of subspace clustering and feature extraction
can be seen in (Srirangarajan et al., 2022). These facts
motivate us to apply task-aware subspace learning for
deepfake detection.
3 METHODOLOGY
The method being proposed uses the features of
Xception to classify deepfake images. For effective
deep feature extraction, we utilized the fine-tuned
Xception due to its proven success in detecting face
manipulation (Li et al., 2020). The features from
Xception are spatially enriched by using the SAM
and then flattened using the Global Average Pooling
layer (GAP), followed by a dense layer consisting of
512 units and Rectified Linear Unit (ReLU) activa-
tion. These flattened features are then projected onto a
task-specific subspace to provide a better feature rep-
resentation, thus enhancing the overall performance
of the model. Finally, the classification layer utilizes
these projected flattened features to classify the deep-
fake images. A block diagram illustrating the overall
architecture of the proposed method is shown in Fig.
1.
3.1 Xception
Xception (Chollet, 2017) is a type of CNN architec-
ture that is well-known for its efficient and effective
feature extraction. It is achieved by using depth-wise
separable convolutions and residual connections. By
using depth-wise separable convolutions, Xception
reduces computational complexity while still main-
taining expressive power. This is done by applying
separate filters to each input channel followed by a
point-wise convolution that mixes and transforms the
output channels. This architectural choice enables ef-
ficient computation by reducing the number of param-
eters. Additionally, Xception incorporates residual
connections that help in the learning of complex fea-
tures and promote a better training of deep networks.
This has been demonstrated in the case of deepfakes
(Sahib and AlAsady, 2022).
3.2 Spatial Attention Module
Deepfake images can be identified by inconsistencies
in their spatial features such as lighting, texture, shad-
ing, and object relationships within the image. Some
common indicators of deepfakes are blurry edges, un-
natural skin tones, and misplaced shadows. How-
ever, these signs may not always be easy to detect.
To better detect deepfakes, we use both shallow and
deep features of images. The shallow features capture
DeepSpace: Navigating the Frontier of Deepfake Identification Using Attention-Driven Xception and a Task-Specific Subspace
165
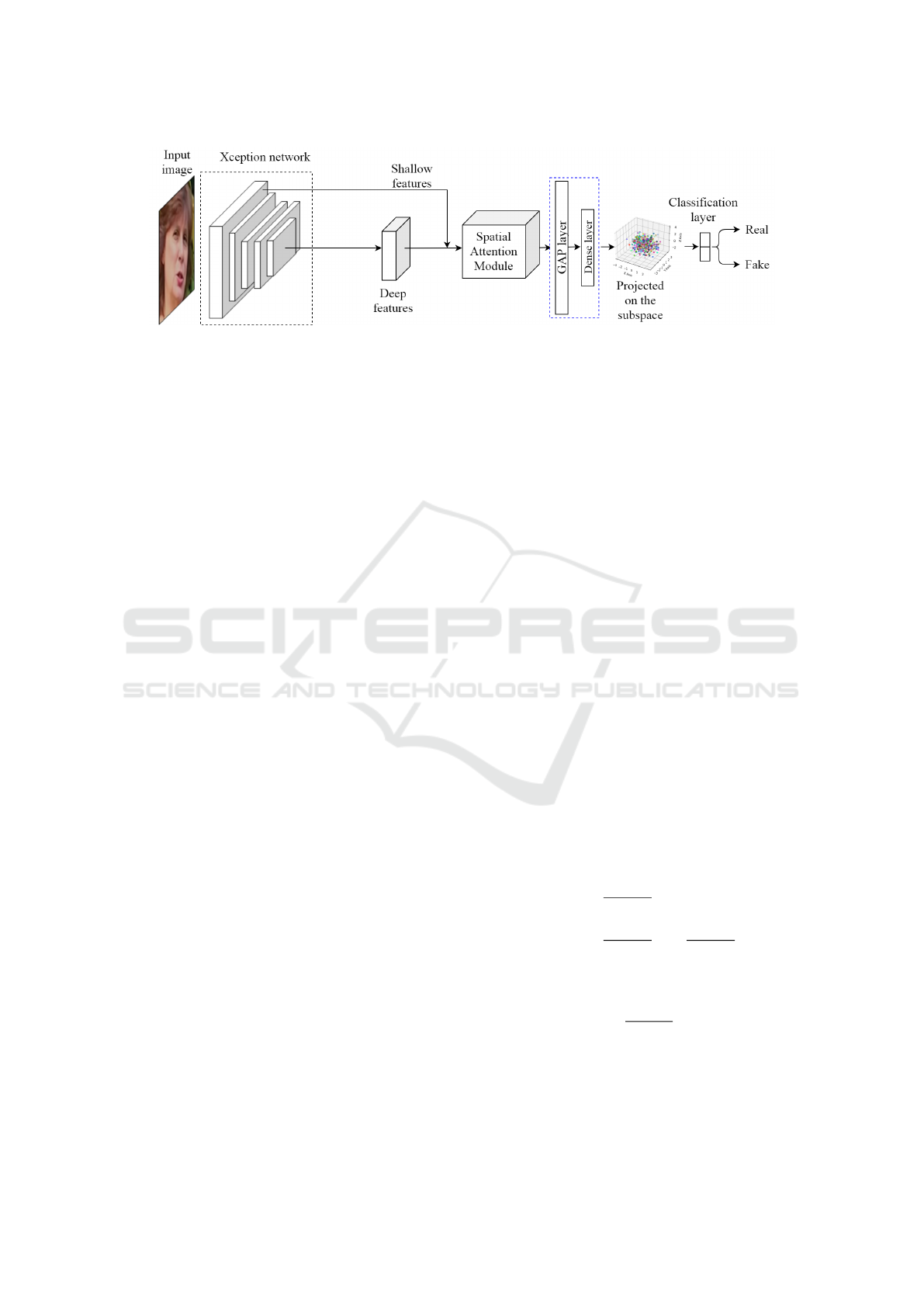
Figure 1: Overall workflow of the proposed deepfake detection method.
shape, edge, texture, and other information, while the
deeper features capture the fine-grain relationships of
the image. We use F
enc1
, the output feature from the
last layer of Xception, to capture these deep features,
and F
enc2
, the output feature from one of the initial
layers of Xception, to capture the shallow features.
The dimensions of F
enc1
and F
enc2
are H ×W ×C and
H × W ×C
′
, respectively. Using F
enc2
, we perform
average and max pooling across the channel dimen-
sion to capture spatial relationships. These features
are then concatenated and convoluted, followed by a
sigmoid activation function to produce F
attn
of dimen-
sion H ×W × 1. Eq. 1 shows the formation of F
attn
.
F
attn
= σ( f
1×1
[MaxPool(F
enc2
);AvgPool(F
enc2
)])
(1)
Here, MaxPool and AvgPool are average pooling
and max pooling across the channel dimension, re-
spectively, [] denotes concatenation, σ denotes sig-
moid activation, and f
1×1
is a convolution layer with
a kernel size of 1 × 1. F
attn
now consists of the spa-
tially enriched information based on texture, shape,
etc.
F
enc1
is processed by a convolution layer, followed
by a ReLU activation function. This produces a fea-
ture vector with dimensions H × W ×C
′
/2. To en-
hance the spatial information of this feature, it is
point-wise multiplied with F
attn
, which already con-
tains valuable spatial information. The resulting ten-
sor, denoted as F
eattn
, also has dimensions H ×W ×
C
′
/2 and is calculated as shown in Eq. 2.
F
eattn
= relu f
1×1
(F
enc1
) ⊗ F
attn
(2)
Here, ⊗ denotes point-wise multiplication.
To provide attention weights across the channel
dimension, a learnable weight α is multiplied across
the channel dimension of F
eattn
to produce F
SAM
. A
block diagram representation of SAM is shown in Fig.
2
3.3 Task-Aware Subspace
Deep learning often requires a fine-tuning of exist-
ing feature spaces for classification tasks. However,
this can sometimes cause unnecessary and undesired
modifications to feature spaces, leading to a less ex-
plainable model that performs poorly. To address this
issue, it is important to customize an optimal fea-
ture space for a particular classification task, which
can result in a more explainable and high-performing
model.
To classify deepfakes, we have created a task-
specific subspace by collecting flattened features from
a trained Xception model (without the SAM) on deep-
fake datasets. We have used the features from the
Dense layer, which consists of 512 units and ’relu’ ac-
tivation (as shown in Fig. 1), and randomly selected
features of 512 images (256 ’fake’ and 256 ’real’)
from all the collected features. With these selected
flattened features, we have created a subspace ori-
ented specifically towards classifying deepfakes. To
calculate the basis vectors for this subspace, we have
employed Gram-Schmidt orthogonalization, which is
a method frequently used in linear algebra and signal
processing to find an orthogonal basis for a subspace
spanned by a set of vectors in an inner product space.
Given a set of vectors {v
1
,v
2
,...,v
n
} (here,
v
1
,v
2
,... are the flattened features of the selected 512
images that we collected), the Gram-Schmidt orthog-
onalization process computes an orthogonal set of
vectors {u
1
,u
2
,...,u
n
} as follows:
u
1
= v
1
u
2
= v
2
−
⟨v
2
,u
1
⟩
⟨u
1
,u
1
⟩
u
1
u
3
= v
3
−
⟨v
3
,u
1
⟩
⟨u
1
,u
1
⟩
u
1
−
⟨v
3
,u
2
⟩
⟨u
2
,u
2
⟩
u
2
.
.
.
u
n
= v
n
−
n−1
∑
k=1
⟨v
n
,u
k
⟩
⟨u
k
,u
k
⟩
u
k
For our task, we normalize {u
1
,u
2
,...,u
n
}
(n=512) to create an orthonormal basis. We then
project the flattened features onto this subspace and
utilize the projected feature in the classification layer.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
166
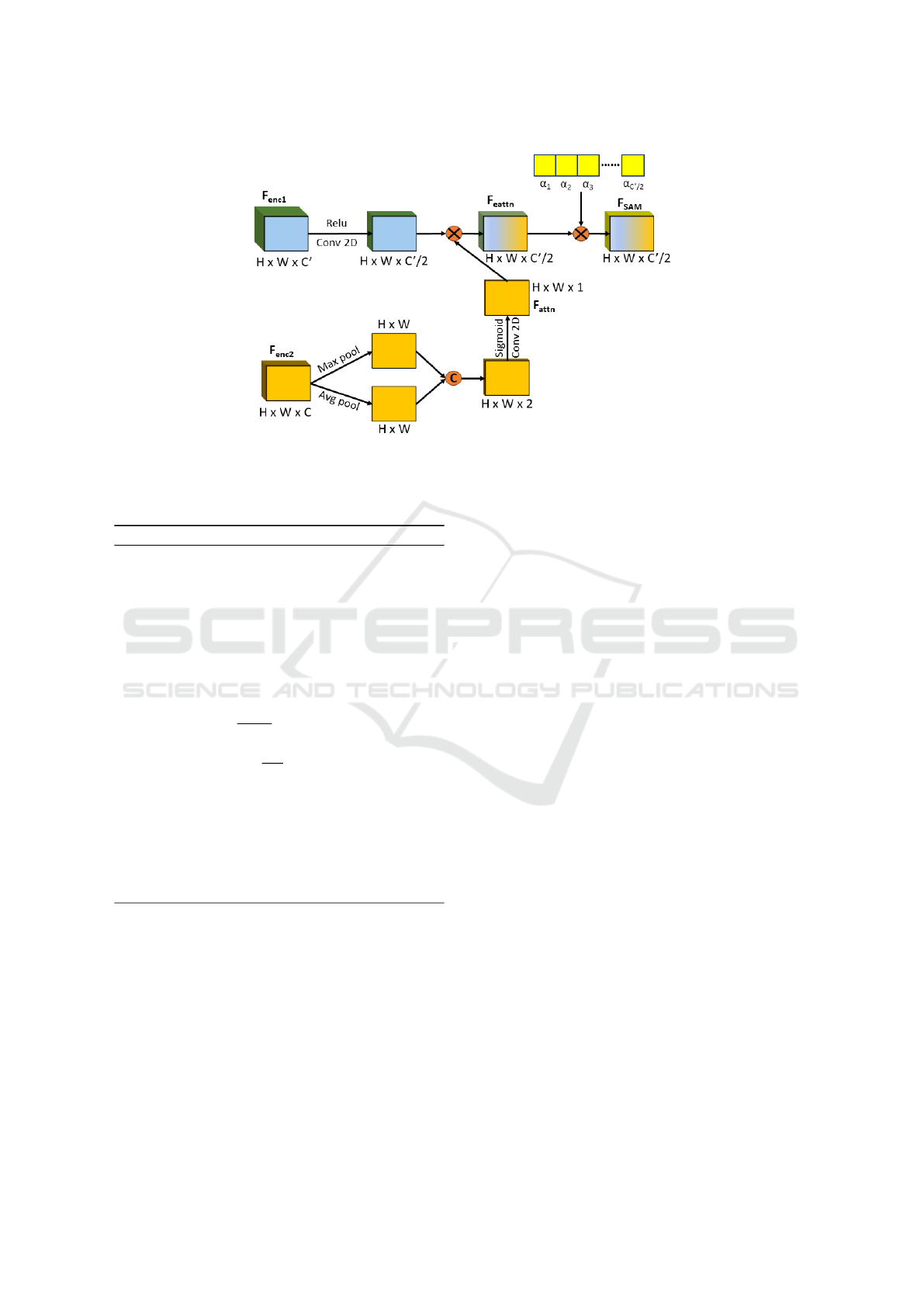
Figure 2: An illustration of the Spatial Attention Module (SAM).
For a detailed understanding, refer to the step-by-step
explanation outlined in Algorithm 1.
Algorithm 1: Constructing Task-aware Subspace.
1: Input: Flattened features V = {v
1
,v
2
,...,v
n
},
where v
i
∈ R
d
(collected from Dense layer of
Xception model)
2: Output: Orthonormal basis U = {u
1
,u
2
,...,u
n
}
3: Initialize U ← {} (empty set for orthogonal vec-
tors)
4: for i = 1 to n do
5: Compute u
i
← v
i
6: for j = 1 to i − 1 do
7: u
i
← u
i
−
⟨v
i
,u
j
⟩
⟨u
j
,u
j
⟩
u
j
8: end for
9: Normalize u
i
←
u
i
∥u
i
∥
10: Add u
i
to U
11: end for
12: Project Features: For each feature v
k
∈ V,
project onto the subspace:
13: p
k
←
∑
n
j=1
⟨v
k
,u
j
⟩u
j
14: Use the projected features {p
k
} for classification
tasks.
4 RESULTS
In this section, we discuss the effectiveness of our
proposed method for detecting deepfake videos. We
provide a detailed analysis of the results obtained
from our experiments. We have tested our method
against various challenges and perturbations to as-
sess its ability to maintain effectiveness in adverse
conditions. Furthermore, we have evaluated the per-
formance of our method on different datasets to en-
sure its robustness. The performance measure met-
rics used in our evaluation are the Area Under Curve
(AUC) score and accuracy.
4.1 Dataset Description
We have performed experiments to evaluate the effec-
tiveness of our proposed deepfake detection method-
ology. For this purpose, we have used two commonly
used public benchmark datasets: Celeb-DF (V2) (Li
et al., 2020), also known as ”CeDF”, and FaceForen-
sics++ (Rossler et al., 2019), abbreviated as ”FF++”.
CeDF Dataset. The dataset contains 5,639 high-
quality videos showcasing various celebrities. These
videos have been created from 590 original videos
that have been collected from YouTube and then fil-
tered to produce variations in age, gender, and back-
ground. The dataset includes a total of 518 videos,
consisting of 178 real videos and 340 fake ones. It
is an ideal resource for evaluating the effectiveness of
new deepfake detection techniques.
FF++ Dataset. The dataset is made up of four types
of mixed videos: Deepfakes, Face2Face, FaceSwap,
and NeuralTextures. Each category contains 1,000
videos that have been created using unique source
videos. For our experiments, we have focused on the
deepfake category, which we have considered as the
fake video class. Meanwhile, we have regarded the
original category videos as real videos. The FF++
dataset is available in different compression rates, but
we have used the c23 version.
Data Preparation for Experiments. To conduct ex-
periments, we have split both datasets into three sets:
train, validation, and test. For the training sets, we
have selected frames equidistant in the time domain
to extract frames from the train video sets. This has
DeepSpace: Navigating the Frontier of Deepfake Identification Using Attention-Driven Xception and a Task-Specific Subspace
167

been done to include the maximum variations in the
training image dataset. For the test and validation
sets, only the first I-frame from each video is con-
sidered. This means that the first I-frame in a video
decides the video’s authentication. While generating
cropped face images using the MTCNN algorithm,
we have extracted only one cropped face image with
the highest confidence score. Table 1 shows the de-
tailed distribution of video and image levels used in
our research.
4.2 Experimental Protocols
We have employed two evaluation setups to assess the
performance of our model on the two datasets:
Intra-Dataset Evaluation. In this particular setup,
the model has undergone training and testing on the
images collected from the same dataset. This means
that the same artifacts left by the generation meth-
ods of deepfakes are present in both the train and test
samples. Essentially, the model learns these artifacts
during training, which are present in the test sam-
ples as well. We represent the evaluation protocols
as FF++ FF++ and CeDF CeDF when the model is
trained and tested on the FF++ dataset and the CeDF
dataset, respectively. This evaluation setup allows us
to analyze the model’s performance within a single
dataset and assess its ability to differentiate between
real and fake videos within the same modality.
Inter-Dataset Evaluation. In this particular setup,
the model is trained on one dataset category and
later tested on the other. For instance, we have first
trained the model on the FF++ dataset and then val-
idated and tested it on the CeDF dataset, referred to
as FF++ CeDF. Similarly, we have trained the model
on the CeDF dataset and then validated and tested it
on the FF++ dataset, denoted as CeDF FF++. This
evaluation helps us to understand how well the model
performs on different datasets with varying modalities
and characteristics, and how robust it is across them.
For all our experiments, we have used a learn-
ing rate of 0.001, the Adam optimizer, and a batch
size of 32 for all of our experiments. We have ap-
plied the cross-entropy loss function for training the
model over 50 epochs and evaluated it using standard
metrics in TensorFlow on an NVIDIA TESLA P100
GPU. The training and validation curves of the pro-
posed model are shown in Fig. 3.
4.3 Ablation Studies
We have conducted a series of ablation experiments
on the CeDF dataset (CeDF CeDF setup) to deter-
mine the optimal architectural configuration and iden-
tify the improvements that each component brings.
All of these experiments have been conducted under
the same setup, including learning rate and epochs, as
mentioned in section 4.1.
In our first ablation experiment, we examine the
performance enhancement of a model using SAM. We
have used the output of the Xception layer with the di-
mensions of 19 × 19 × 728 as F
enc2
for SAM v-1. For
SAM v-2, we have used the output of the Xception
layer with the dimensions of 10 × 10 × 1024 as F
enc2
(as seen in Fig. 2). The results, shown in Table 2, indi-
cate that SAM v-2 performs significantly better than
SAM v-1, resulting in improved accuracy (+0.58%)
and AUC (+2.05%) scores for Xception.
We have conducted additional experiments to
demonstrate the significance of a task-specific sub-
space in projecting flattened features before classifi-
cation. By utilizing the best architectural configura-
tion from Table 2 and running ablation tests, we have
determined that the task-oriented subspace created us-
ing orthonormal basis vectors and normalizing the or-
thogonal vectors using the L2 norm yielded the best
results, as shown in Table 3. Additionally, we have
visualized the subspace representation of features be-
fore and after projection onto the task-aware subspace
in Fig. 4. To generate the subspace plots, we have re-
duced the features from the Global Average Pooling
(GAP) and the Dense layer using PCA to three dimen-
sions. The GAP layer features are the features before
projection onto the subspace, whereas the Dense fea-
tures are the projected features onto the subspace. It
can be seen in the plots that the organized orientation
after projecting onto the subspace helps in classifying
the real and fake images.
4.4 SOTA Comparison
We have conducted evaluations of different methods
to compare them fairly and meaningfully. To achieve
this, we have followed our established experimental
protocols as described earlier in subsection 4.2. This
approach has allowed us to assess and compare differ-
ent methods based on important factors such as their
detection performance, robustness, and generalization
ability. In this regard, we present the performance re-
sults of the deepfake detection methods on our exper-
imental setup, specifically on the two image datasets.
The corresponding performance metrics consid-
ered are the test accuracy and AUC score. We have
reported these results in Table 4, which shows the per-
formance against intra-dataset experiments and Ta-
ble 5, which exhibits the performance against inter-
dataset experiments. By examining the results, it be-
comes evident that our method outperforms most of
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
168
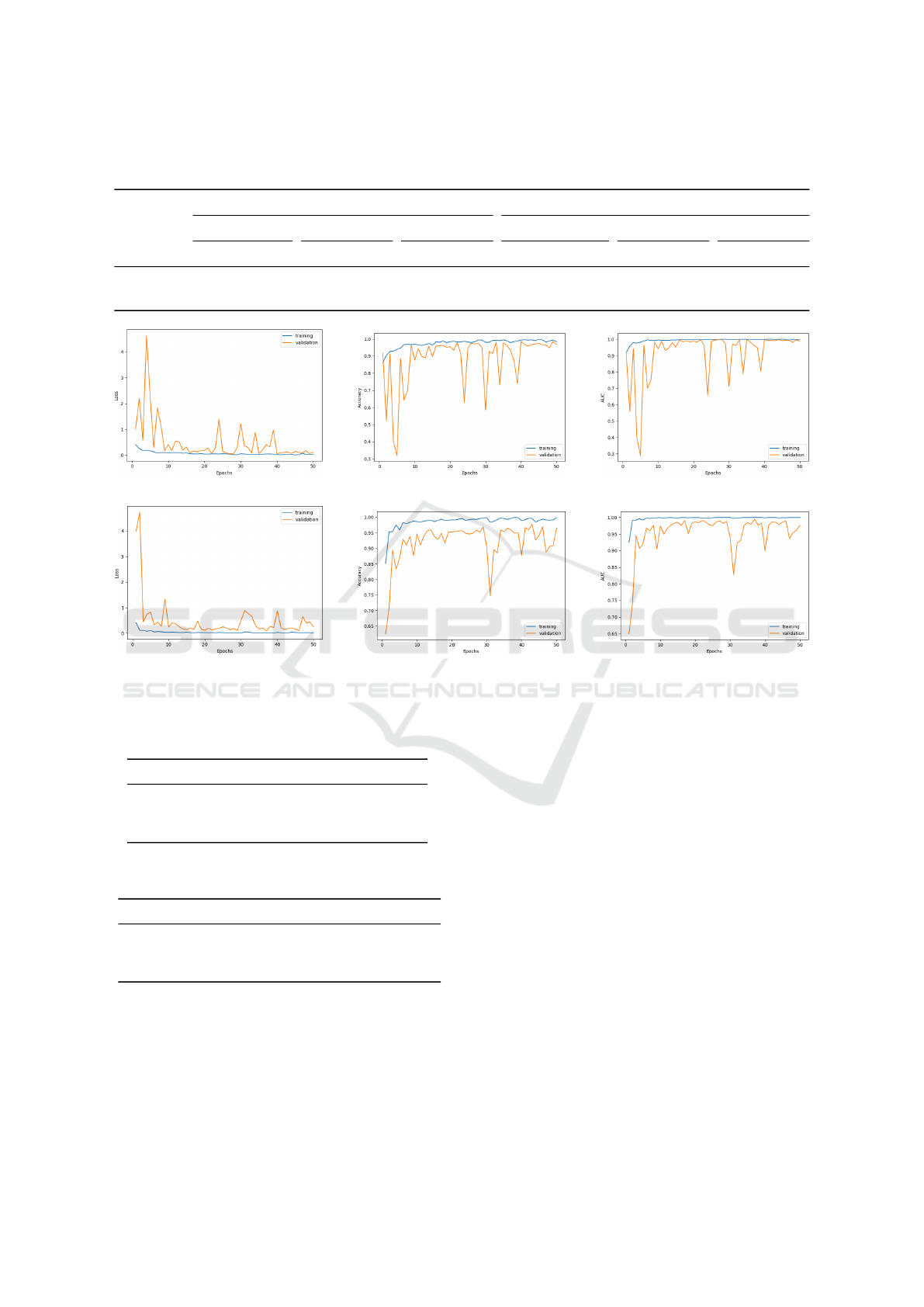
Table 1: The datasets used here exhibit the distribution of classes. The labels “Re” and “Fa” correspond to Real and Fake,
respectively.
#Video #image
Train Validation Test Train Validation Test
Dataset Re Fa Re Fa Re Fa Re Fa Re Fa Re Fa
Celeb-DF 612 4399 100 900 178 340 1130 8022 100 900 178 340
FF++ 700 700 200 200 100 100 2930 2946 200 200 100 100
(a) Loss curve for CEDF. (b) Accuracy curve for CEDF. (c) AUC curve for CEDF.
(d) Loss curve for FF++. (e) Accuracy curve for FF++. (f) AUC curve for FF++.
Figure 3: The loss, accuracy, and AUC curves of the proposed model for FF++ (bottom row) and CeDF (top row).
Table 2: Performance of Xception with and without the use
of SAM. All values are in %.
Model Accuracy AUC Score
Xception 93.63 90.73
Xception + SAM v-1 93.82 92.22
Xception + SAM v-2 94.21 92.78
Table 3: Analysis of the task-aware subspace using various
norms for the basis vectors. All values are in %.
Model Accuracy AUC Score
Orthogonal 93.63 91.40
Orthonormal (L1 norm) 94.21 91.71
Orthonormal (L2 norm) 95.17 93.25
the SOTA methods used in this comparison, particu-
larly in the context of intra-dataset experimental se-
tups. In other words, the proposed method demon-
strates superior performance when tested within the
same dataset.
Furthermore, when considering inter-dataset ex-
periments, which essentially evaluate the generaliza-
tion ability of a model, once again the current method
outperforms most of the other methods and achieves
competent results. This indicates that our method ex-
hibits high adaptability and effectiveness when faced
with different datasets. Overall, these findings un-
derscore the impressive performance of the current
method compared to other methods, both within and
across different datasets, confirming its superiority in
deepfake detection.
The confusion matrices obtained by evaluating
the proposed model using the intra-dataset and inter-
dataset experimental setup are shown in Fig. 5.
5 CONCLUSION
In this paper, we have developed a deep learning-
based approach to detect deepfake videos. Our ap-
proach initially employs Xception as the backbone to
extract deep learning features. We then use SAM to
spatially enrich the extracted features by leveraging
information from deeper features (fine-grained de-
DeepSpace: Navigating the Frontier of Deepfake Identification Using Attention-Driven Xception and a Task-Specific Subspace
169

(a) GAP layer of orthogonal basis. (b) GAP layer of orthonormal basis
(L1 norm).
(c) GAP layer of orthonormal basis
(L2 norm).
(d) Dense layer of orthogonal basis. (e) Dense layer of orthonormal basis
(L1 norm).
(f) Dense layer of orthonormal basis
(L2 norm).
Figure 4: An illustration of the subspace before projection (upper row) and after projection (lower row) onto the subspace.
Green is for real image features and yellow is for fake image features.
(a) FF++ FF++ (b) CeDF CeDF.
(c) FF++ CeDF (d) CeDF FF++
Figure 5: Confusion matrices obtained using intra-dataset
(a & b) and inter-dataset (c & d) experimental setups.
tailed features) and shallower features (shape, color,
texture, etc.). Additionally, we produce a task-
specific subspace for projecting the spatially enriched
features. We generate the basis vectors of this cus-
tomized subspace using the Gram-Smith orthogonal-
ization on the flattened features of ’fake’ and ’real’
images. Our experiments show that the projection of
the feature onto the subspace is particularly effective.
We evaluate our model’s effectiveness by conduct-
ing extensive experiments on two widely used pub-
lic deepfake forgery datasets: FF++ and CeDF. Our
method outperforms many SOTA methods used for
comparison in terms of classification accuracy and
AUC score. We assess the model’s performance in
two scenarios: intra-dataset and inter-dataset, to val-
idate its robustness and generalizability. However,
there is some room for improvement in the inter-
dataset experiments, indicating the need for a more
sophisticated task-related subspace to address such
challenges.
To the best of our knowledge, our paper pioneers
the exploration of task-specific customized subspace
for deepfake classification, with no prior research in
this area. Future research needs to be focused on in-
terpretable and customized subspace optimization to
achieve enhanced results.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
170

Table 4: Comparison with SOTA methods based on intra-dataset experiment.
Experiment Method Test accuracy AUC score
CeDF Li et al. (Li et al., 2020) 95.37 98.88
Afchar et al.(Afchar et al., 2018) 65.83 64.80
Qian et al. (Qian et al., 2020) 87.06 81.48
Guo et al. (Guo et al., 2021) 68.33 78.04
Wang et al.(Wang and Chow, 2023) 70.10 75.89
Proposed 95.17 93.25
FF++ Li et al. (Li et al., 2020) 96.00 98.34
Afchar et al. (Afchar et al., 2018) 65.00 66.93
Qian et al. (Qian et al., 2020) 95.50 96.52
Guo et al. (Guo et al., 2021) 78.50 87.62
Zhao et al. (Zhao et al., 2021) 96.00 98.97
Wang et al. (Wang and Chow, 2023) 84.36 93.99
Wang et al. (Wang et al., 2023) 92.11 97.66
Proposed 97.50 97.50
Table 5: Comparison with SOTA methods based on inter-dataset experiment.
Experiment Method Test accuracy AUC score
CeDF FF++ Li et al. (Li et al., 2020) 64.50 75.19
Afchar et al. (Afchar et al., 2018) 50.50 51.51
Qian et al. (Qian et al., 2020) 54.50 54.04
Ganguly et al. (Ganguly et al., 2022) 65.00 63.80
Mohiuddin et al. (Mohiuddin et al., 2021) 60.00 59.93
Mohiuddin et al. (Mohiuddin et al., 2023b) 66.50 76.72
Proposed 69.00 68.94
FF++ CeDF Li et al. (Li et al., 2020) 58.06 55.60
Afchar et al. (Afchar et al., 2018) 66.41 65.58
Qian et al. (Qian et al., 2020) 63.89 53.89
Ganguly et al. (Ganguly et al., 2022) 68.04 66.12
Mohiuddin et al. (Mohiuddin et al., 2021) 63.71 56.43
Zhao et al. (Zhao et al., 2021) - 67.44
Miao et al. (Miao et al., 2021) - 66.12
Wang et al. (Wang et al., 2023) 63.27 72.43
Proposed 68.53 65.06
ACKNOWLEDGEMENTS
This work was supported by the Russian Science
Foundation (project No. 22-76-10042).
REFERENCES
Afchar, D., Nozick, V., Yamagishi, J., and Echizen, I.
(2018). Mesonet: a compact facial video forgery de-
tection network. In 2018 IEEE international work-
shop on information forensics and security (WIFS),
pages 1–7. IEEE.
Amerini, I., Galteri, L., Caldelli, R., and Del Bimbo, A.
(2019). Deepfake video detection through optical flow
based cnn. In Proceedings of the IEEE/CVF inter-
national conference on computer vision workshops,
pages 0–0.
Chollet, F. (2017). Xception: Deep learning with depthwise
separable convolutions. In Proceedings of the IEEE
conference on computer vision and pattern recogni-
tion, pages 1251–1258.
Ganguly, S., Mohiuddin, S., Malakar, S., Cuevas, E., and
Sarkar, R. (2022). Visual attention-based deepfake
video forgery detection. Pattern Analysis and Appli-
cations, 25(4):981–992.
Guo, Z., Yang, G., Chen, J., and Sun, X. (2021). Fake face
detection via adaptive manipulation traces extraction
network. Computer Vision and Image Understanding,
204:103170.
Hooda, A., Mangaokar, N., Feng, R., Fawaz, K., Jha, S.,
and Prakash, A. (2024). D4: Detection of adversar-
ial diffusion deepfakes using disjoint ensembles. In
Proceedings of the IEEE/CVF Winter Conference on
DeepSpace: Navigating the Frontier of Deepfake Identification Using Attention-Driven Xception and a Task-Specific Subspace
171

Applications of Computer Vision, pages 3812–3822.
Kingra, S., Aggarwal, N., and Kaur, N. (2023). Siamnet:
Exploiting source camera noise discrepancies using
siamese network for deepfake detection. Information
Sciences, page 119341.
Kou, S., Yin, X., Wang, Y., Chen, S., Chen, T., and Wu,
Z. (2023). Structure-aware subspace clustering. IEEE
Transactions on Knowledge and Data Engineering.
Lewis, J. K., Toubal, I. E., Chen, H., Sandesera, V., Lom-
nitz, M., Hampel-Arias, Z., Prasad, C., and Palaniap-
pan, K. (2020). Deepfake video detection based on
spatial, spectral, and temporal inconsistencies using
multimodal deep learning. In 2020 IEEE Applied Im-
agery Pattern Recognition Workshop (AIPR), pages 1–
9. IEEE.
Li, T., Wang, Y., Liu, L., Chen, L., and Chen, C. P. (2023).
Subspace-based minority oversampling for imbalance
classification. Information Sciences, 621:371–388.
Li, Y., Yang, X., Sun, P., Qi, H., and Lyu, S. (2020).
Celeb-df: A large-scale challenging dataset for deep-
fake forensics. In Proceedings of the IEEE/CVF con-
ference on computer vision and pattern recognition,
pages 3207–3216.
Liz-Lopez, H., Keita, M., Taleb-Ahmed, A., Hadid, A.,
Huertas-Tato, J., and Camacho, D. (2024). Genera-
tion and detection of manipulated multimodal audio-
visual content: Advances, trends and open challenges.
Information Fusion, 103:102103.
Lu, W., Liu, L., Zhang, B., Luo, J., Zhao, X., Zhou, Y., and
Huang, J. (2023). Detection of deepfake videos using
long-distance attention. IEEE Transactions on Neural
Networks and Learning Systems.
Miao, C., Chu, Q., Li, W., Li, S., Tan, Z., Zhuang, W., and
Yu, N. (2021). Learning forgery region-aware and id-
independent features for face manipulation detection.
IEEE Transactions on Biometrics, Behavior, and Iden-
tity Science, 4(1):71–84.
Mohiuddin, S., Ganguly, S., Malakar, S., Kaplun, D., and
Sarkar, R. (2021). A feature fusion based deep learn-
ing model for deepfake video detection. In Interna-
tional conference on mathematics and its applications
in new computer systems, pages 197–206. Springer.
Mohiuddin, S., Malakar, S., Kumar, M., and Sarkar, R.
(2023a). A comprehensive survey on state-of-the-art
video forgery detection techniques. Multimedia Tools
and Applications, pages 1–41.
Mohiuddin, S., Sheikh, K. H., Malakar, S., Vel
´
asquez, J. D.,
and Sarkar, R. (2023b). A hierarchical feature se-
lection strategy for deepfake video detection. Neural
Computing and Applications, 35(13):9363–9380.
Naskar, G., Mohiuddin, S., Malakar, S., Cuevas, E., and
Sarkar, R. (2024). Deepfake detection using deep fea-
ture stacking and meta-learning. Heliyon.
Nguyen, D., Mejri, N., Singh, I. P., Kuleshova, P., Astrid,
M., Kacem, A., Ghorbel, E., and Aouada, D. (2024).
Laa-net: Localized artifact attention network for
high-quality deepfakes detection. arXiv preprint
arXiv:2401.13856.
Qian, Y., Yin, G., Sheng, L., Chen, Z., and Shao, J. (2020).
Thinking in frequency: Face forgery detection by min-
ing frequency-aware clues. In European conference
on computer vision, pages 86–103. Springer.
Raza, M. A. and Malik, K. M. (2023). Multimodaltrace:
Deepfake detection using audiovisual representation
learning. In Proceedings of the IEEE/CVF Conference
on Computer Vision and Pattern Recognition, pages
993–1000.
Rossler, A., Cozzolino, D., Verdoliva, L., Riess, C., Thies,
J., and Nießner, M. (2019). Faceforensics++: Learn-
ing to detect manipulated facial images. In Proceed-
ings of the IEEE/CVF international conference on
computer vision, pages 1–11.
Sahib, I. and AlAsady, T. A. A. (2022). Deep fake image
detection based on modified minimized xception net
and densenet. In 2022 5th International Conference
on Engineering Technology and its Applications (IIC-
ETA), pages 355–360. IEEE.
Srirangarajan, S. et al. (2022). Locality-aware discrimina-
tive subspace learning for image classification. IEEE
Transactions on Instrumentation and Measurement,
71:1–14.
Tolosana, R., Romero-Tapiador, S., Fierrez, J., and Vera-
Rodriguez, R. (2021). Deepfakes evolution: Analy-
sis of facial regions and fake detection performance.
In international conference on pattern recognition,
pages 442–456. Springer.
Wang, T., Cheng, H., Chow, K. P., and Nie, L. (2023). Deep
convolutional pooling transformer for deepfake detec-
tion. ACM Transactions on Multimedia Computing,
Communications and Applications, 19(6):1–20.
Wang, T. and Chow, K. P. (2023). Noise based deepfake
detection via multi-head relative-interaction. In Pro-
ceedings of the AAAI Conference on Artificial Intelli-
gence, volume 37, pages 14548–14556.
Xia, R., Liu, D., Li, J., Yuan, L., Wang, N., and Gao,
X. (2024). Mmnet: Multi-collaboration and multi-
supervision network for sequential deepfake detec-
tion. IEEE Transactions on Information Forensics and
Security.
Yin, W., Ma, Z., and Liu, Q. (2023). Discriminative sub-
space learning via optimization on riemannian mani-
fold. Pattern Recognition, 139:109450.
Yu, C.-M., Chen, K.-C., Chang, C.-T., and Ti, Y.-W.
(2022). Segnet: a network for detecting deepfake fa-
cial videos. Multimedia Systems, 28(3):793–814.
Yu, Y., Liu, X., Ni, R., Yang, S., Zhao, Y., and Kot, A. C.
(2023). Pvass-mdd: predictive visual-audio alignment
self-supervision for multimodal deepfake detection.
IEEE Transactions on Circuits and Systems for Video
Technology.
Zhang, D., Wu, P., Li, F., Zhu, W., and Sheng, V. S.
(2022). Cascaded-hop for deepfake videos detection.
KSII Transactions on Internet & Information Systems,
16(5).
Zhao, H., Zhou, W., Chen, D., Wei, T., Zhang, W., and
Yu, N. (2021). Multi-attentional deepfake detection.
In Proceedings of the IEEE/CVF conference on com-
puter vision and pattern recognition, pages 2185–
2194.
Zhou, C., Zhong, F., and
¨
Oztireli, C. (2023). Clip-pae:
Projection-augmentation embedding to extract rele-
vant features for a disentangled, interpretable and con-
trollable text-guided face manipulation. In ACM SIG-
GRAPH 2023 Conference Proceedings, pages 1–9.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
172
