
Enhanced Generative Data Augmentation for Semantic Segmentation
via Stronger Guidance
Quang-Huy Che
1,2
, Duc-Tri Le
1,2
, Bich-Nga Pham
1,2
,
Duc-Khai Lam
1,2
and Vinh-Tiep Nguyen
1,2∗
1
University of Information Technology, Ho Chi Minh City, Vietnam
2
Vietnam National University, Ho Chi Minh City, Vietnam
Keywords:
Data Augmentation, Stable Diffusion, Semantic Segmentation, Controllable Model.
Abstract:
Data augmentation is crucial for pixel-wise annotation tasks like semantic segmentation, where labeling re-
quires significant effort and intensive labor. Traditional methods, involving simple transformations such as
rotations and flips, create new images but often lack diversity along key semantic dimensions and fail to alter
high-level semantic properties. To address this issue, generative models have emerged as an effective solution
for augmenting data by generating synthetic images. Controllable Generative models offer data augmentation
methods for semantic segmentation tasks by using prompts and visual references from the original image.
However, these models face challenges in generating synthetic images that accurately reflect the content and
structure of the original image due to difficulties in creating effective prompts and visual references. In this
work, we introduce an effective data augmentation pipeline for semantic segmentation using Controllable Dif-
fusion model. Our proposed method includes efficient prompt generation using Class-Prompt Appending and
Visual Prior Blending to enhance attention to labeled classes in real images, allowing the pipeline to generate
a precise number of augmented images while preserving the structure of segmentation-labeled classes. In
addition, we implement a class balancing algorithm to ensure a balanced training dataset when merging the
synthetic and original images. Evaluation on PASCAL VOC datasets, our pipeline demonstrates its effective-
ness in generating high-quality synthetic images for semantic segmentation. Our code is available at this https
URL.
1 INTRODUCTION
Semantic segmentation is a fundamental computer vi-
sion task that involves classifying each pixel in an
image. Deep learning models have significantly ad-
vanced semantic segmentation methods. These mod-
els are usually trained on large-scale datasets with
dense annotations, such as PASCAL VOC (Evering-
ham et al., 2015), MS COCO (Lin et al., 2014),
BDD100K (Yu et al., 2020), and ADE20K (Zhou
et al., 2019). It is often necessary to re-label the
data to address a specific task. However, labeling a
new dataset to enable accurate model learning is time-
consuming and costly, particularly for semantic seg-
mentation tasks that require pixel-level labeling.
An alternative to enhancing data diversity without
annotating a new dataset is data augmentation, which
creates more training examples by leveraging an ex-
isting dataset. Commonly used data augmentation
∗
Corresponding author.
methods in semantic segmentation include rotating,
scaling, flipping, and other manipulations of individ-
ual images. These techniques encourage the model
to learn more invariant features, thereby improving
the robustness of the trained model. However, ba-
sic transformations do not produce novel structural
elements, textures, or changes in perspective. Con-
sequently, more advanced data augmentation meth-
ods utilize generative models for different tasks (Tra-
bucco et al., 2024; Azizi et al., 2023; He et al., 2023;
Fang et al., 2024; Wu et al., 2024). Generative models
leverage the ability to create new images based on in-
puts such as text, semantic maps, and image guidance
to specific tasks and data augmentation needs. No-
tably, Stable Diffusion (SD) models (Rombach et al.,
2022; Podell et al., 2024) propose a method for condi-
tional image generation that fusions textual informa-
tion, bounding boxes, or segmentation masks to gen-
erate or inpaint images. Controllable Models (Zhang
et al., 2023; Mou et al., 2023) further enhance the
Che, Q.-H., Le, D.-T., Pham, B.-N., Lam, D.-K. and Nguyen, V.-T.
Enhanced Generative Data Augmentation for Semantic Segmentation via Stronger Guidance.
DOI: 10.5220/0013175900003905
In Proceedings of the 14th International Conference on Pattern Recognition Applications and Methods (ICPRAM 2025), pages 251-262
ISBN: 978-989-758-730-6; ISSN: 2184-4313
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
251
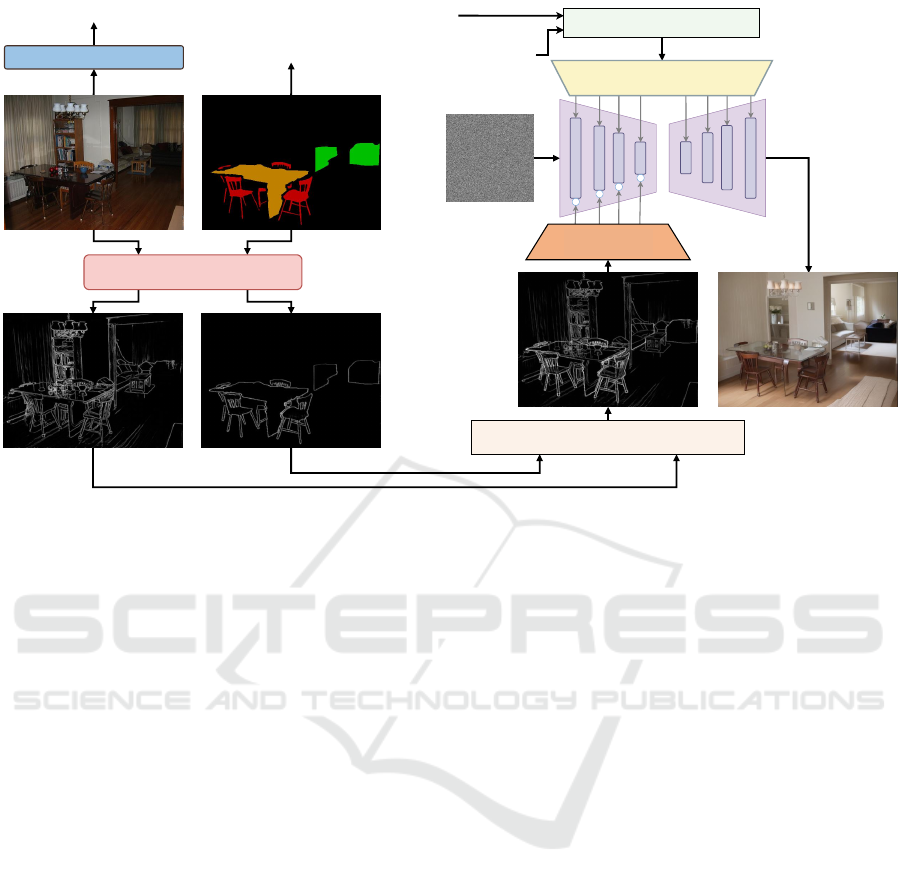
Caption:
Class labels:
a dining room table and chairs in a room
Prior Detector
sofa, chair, dining table
Class-Prompt Appending
+
+
+
+
Noise
Adapter
Visual Prior Blending
CLIP Text Encoder
Image Captioning Model
Figure 1: The controllable data augmentation pipeline for the semantic segmentation task combines our proposed methods:
Class-Prompt Appending and Visual Prior Blending.
guided image generation capability by utilizing visual
priors such as edges, depth, segmentation mask, hu-
man poses, etc.
The segmentation mask annotation can be easily
computed in data augmentation using simple trans-
formations (e.g. translation, scaling, flip). How-
ever, with generative models, data augmentation is
more problematic as it requires generating new im-
ages while still matching the ground truth annota-
tions. A straightforward approach to this challenge
is to utilize the Inpainting model (Rombach et al.,
2022) to change the labeled regions in the images
while keeping the rest of the remaining information.
Although this method can enhance the diversity of
labeled data, it does not ensure that the newly gen-
erated object matches the original structure, and the
surrounding elements may lack diversity since they
are left unchanged. Additionally, (Mou et al., 2023;
Zhang et al., 2023; Chae et al., 2023) propose image
generation models that can be controlled via segmen-
tation masks, making these methods highly suitable
for efficient data augmentation in semantic segmenta-
tion tasks. However, generative models require train-
ing on semantic segmentation datasets, which lim-
its their capacity to provide information beyond the
scope of the training dataset.
To address the issue of data augmentation for se-
mantic segmentation using generative models, we can
leverage a deep understanding of generative models
to identify their strengths, such as their broad knowl-
edge base, generalization capabilities, and structural
control. In this paper, we propose using Controllable
Generative models with prior visual without training
on semantic segmentation datasets to augment data
for semantic segmentation. However, utilizing Con-
trollable Generative models directly may present
challenges, such as generated objects not strictly
adhering to their original structure or a lack of la-
beled classes in the generated images. So, how can
we overcome these limitations? In this work, we
propose Visual Prior Blending to enhance the visual
representation of labeled classes and Class-Prompt
Appending to construct text prompts that generate im-
ages containing all labeled classes. The combination
of these two proposed methods, as shown in Figure 1,
enables more effective data augmentation when utiliz-
ing Controllable Generative models, resulting in im-
proved performance.
In this work, we analyze and propose methods to
address these challenges when generating images us-
ing controllable generative models.
Our main contributions are:
• Class-Prompt Appending: By combining “gener-
ated caption” and “labeled classes”, we use this
method to construct text prompts containing com-
prehensive information about the image and its
classes. This ensures that all labeled classes are
fully represented in the synthesized image.
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
252

• Visual Prior Blending: This method blends the vi-
sual priors from the original image and the seg-
mentation masks. It aims to balance the informa-
tion between the original image and the labeled
objects, ensuring that the generated objects main-
tain the structure defined by the segmentation la-
bels.
• In addition, we also use a class balancing algo-
rithm to control the number of classes during im-
age generation so that when combining the syn-
thetic dataset and the original data, the classes in
the extended dataset are more balanced.
• We evaluate our proposed method on the
VOC7/VOC12 datasets with various settings. The
results demonstrate the effectiveness of the pro-
posed approach, particularly in scenarios with
limited data samples.
2 RELATED WORK
Data augmentation using generative models is com-
monly applied in classification tasks (Trabucco et al.,
2024; Azizi et al., 2023; He et al., 2023). Unlike clas-
sification tasks, to augment data for Segmentation or
Object Detection tasks, where the synthetic images
must ensure the location of the objects. Inpainting
model (Rombach et al., 2022; Podell et al., 2024;
Yang et al., 2023) is considered an option because it
allows to specify what to edit as a mask. However,
using an off-the-shelf inpainting model for data aug-
mentation in semantic segmentation tasks may lead to
shortcomings. There is no guarantee that the newly
created objects align with the ground truth annota-
tions, and the model may also tend to replace smaller
objects with background elements.
Early studies in synthetic data generation (Mou
et al., 2023; Zhang et al., 2023; Chae et al., 2023)
propose using semantic segmentation maps to guide
image generation and create an efficient solution for
data augmentation for semantic segmentation. Label-
ing each pixel to show which class it belongs to helps
to create accurate images with correct object locations
and details. However, these methods require train-
ing on specific segmentation datasets, which limits
the generation of synthetic images for classes not in-
cluded in the training data. For example, (Mou et al.,
2023; Zhang et al., 2023) propose models trained on
the ADE20K dataset (Zhou et al., 2019), which has
various images from different contexts like indoor,
outdoor, industrial, and natural scenes. When gener-
ating synthetic images based on segmentation masks
from the BDD100K dataset (Yu et al., 2020), which
consists of images captured from car dashcams in
self-driving scenarios, the model is unable to gener-
ate classes not present in the ADE20K dataset. These
missing classes include traffic signs, traffic lights, and
lane markings. Due to this limitation, we avoid using
models guided by semantic segmentation maps in this
study to maintain the generality of our method.
Instead of directly selecting synthetic images to
train the model, some studies (Fang et al., 2024; Wu
et al., 2024) propose using post-filtering techniques
to choose the best synthetic images. However, select-
ing one high-quality image from many can be time-
consuming, and imperfect filtering can lead to a low-
quality synthetic dataset. In addition, with the abil-
ity to generate different images from the same input
and change the random seeds, selecting the best ones
based on multiple results does not accurately reflect
the image generation ability. Therefore, in this paper,
we directly use the generated images without going
through any post-filtering techniques to demonstrate
the effectiveness of the proposed method. In addi-
tion, in Section 4.3.1, we also integrate the filter using
CLIP Encoder (Fang et al., 2024) to demonstrate the
compatibility of the proposed method when applying
filters.
3 METHOD
Our proposed image data augmentation pipeline is
shown in Figure 1, which consists of three main
components: (1) Text prompt construction, (2) Vi-
sual Prior Blending, and (3) Controllable Diffusion
Generation. Class-Prompt Appending append “class
prompt” including the classes visible in the image
with “caption” generated from the Image Captioning
model. Visual Prior Blending method combines the
visual pre-information of the real image and the seg-
mentation map. The results of the above two methods
are fed into the Controllable Steady Diffusion model
to generate the synthetic image. In addition, to gener-
ate synthetic data from a given dataset, we use class
balancing algorithm to generate data with even dis-
tribution among classes. Next, we provide a detailed
description of each component.
3.1 Preliminary
Diffusion models comprise both forward and reverse
processes (Ho et al., 2020). In the forward process,
a Markovian chain is defined with noise added to the
clean image x
0
:
x
t
=
√
¯
α
t
x
0
+
p
1 −
¯
α
t
ε, ε ∼ N (0, I) (1)
Enhanced Generative Data Augmentation for Semantic Segmentation via Stronger Guidance
253

Caption: a living room with a
fireplace and a couch
Class labels: chair, sofa
Caption + Class label: a living room
with a fireplace and a couch; chair,
sofa
Caption: a room with a table and a
laptop on it
Class labels: sofa, chair, dining table
Caption + Class label: a room with a
table and a laptop on it; sofa, chair,
dining table
Caption: a pink airplane on the tarmac
Class label: aeroplane, person
Caption + class labels: a pink airplane on the tarmac;
aeroplane, person
Caption: a living room with
green and blue walls
Class label: sofa, chair,
potted plant
Caption + class labels: a
living room with green and
blue walls; sofa, chair, potted
plant
aeroplane
aeroplane
person
person
sofa
chair
chair
sofa
sofa
chair chair
dining table
chair
chair
chair
sofa
potted plant
Figure 2: Classes missing in the generated prompts: Red describes the missing classes in the generated prompt while blue
marks the ones appearing in the sentence.
A field of
green grass
Generated caption:
Simple text prompt: A photo
of cow
A street
with cars parked on it at night
Generated caption:
Simple text prompt: A photo
of car, person
Guidance
Simple text prompt
Generated caption
Figure 3: Common issues of using generated captions and simple text prompts: In addition to generated prompts and
simple text prompts, the four visualizations include: original images with labeled classes, guidance images (line art), images
generated by simple text prompts, and images generated by generated prompts.
where x
t
is the noise image at time step t, ε is a
noise map sampled from a Gaussian distribution, and
¯
α
t
denotes the corresponding noise level. The neural
network ε
t
is parameterized by θ, which is optimized
to predict the noise added to ε
t
in the reverse process.
A classical Diffusion model is typically optimized by:
L
DDPM
= E
x
0
,t,ε
t
∥
ε
t
−ε
θ
(x
t
,t)
∥
2
2
(2)
In the context of controllable generation (Zhang
et al., 2023; Mou et al., 2023), when given a condition
image c
v
and a text prompt c
t
, the diffusion training
loss function at time t can be re-written as:
L = E
x
0
,c
v
,c
t
,t,ε
t
∥
ε
t
−ε
θ
(x
t
,t, c
v
, c
t
)
∥
2
2
(3)
3.2 Generative Data Augmentation
Pipeline
3.2.1 Text Prompt Construction
To generate an image containing the labeled classes
as in the original image, we need a robust prompt
that describes the original image well to serve as in-
put to the SD model. A simple way to do this is by
constructing a prompt based on the labeled classes.
For example, if image I
i
contains target classes C
i
= [c
1
,..., c
M
], where M is the number of classes in
image I
i
, we can construct a simple prompt such as:
“c
1
,..., c
M
” or “A photo of c
1
,..., c
M
”. However, using
a prompt that only lists target classes may not clearly
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
254

Image Label Line Art
(a) An example of information loss occurs when using Line Art Detection, particularly in the reddish areas, where
information is lacking.
Prior Detector
Visual Prior Blending
(b) The results of the Visual Prior Blending method demonstrate that previously edge-deficient objects are now
fully detailed, and the edge features of the labeled classes are more prominent compared to the background,
thereby enhancing the generative model’s attention capability.
Figure 4: The edge feature results before (a) and after (b) using the Visual Prior Blending method.
describe the original image’s layout. To improve this,
we can use the existing or generated captions from
the training images in these datasets as text prompts
for SD. For example, we can use the provided cap-
tions when using the COCO dataset (Lin et al., 2014).
However, most datasets, such as PASCAL VOC (Ev-
eringham et al., 2015), BDD100K (Yu et al., 2020),
and ADE20K (Zhou et al., 2019), do not have cap-
tions, while annotating captions for images also re-
quires intensive labor. Therefore, we propose using
an Image Captioning model such as BLIP-2 (Li et al.,
2023) to generate captions for each image. However,
image captions have limitations compared to simple
prompts, as they often omit some of the actual classes
present in the image (as shown in Figure 2). This issue
results in missing class names in the captions when
using generated descriptions.
Illustrated in Figure 3, some examples demon-
strate using simple text prompts and generated cap-
tions to create synthetic images through the Control-
lable SD model. The results indicate that using sim-
ple text prompts produces images with messy lay-
outs that do not match the original while using gen-
erated prompts leads to missing classes in the gener-
ated images due to their absence in the generated cap-
tions. However, we observe that these two methods
can complement each other’s weaknesses. Therefore,
we propose combining generated captions with the
image’s class labels to address these limitations. With
an image I
i
, we append the generated captions P
g
i
with the class labels P
c
i
to generate new text prompts
P
∗
i
. This process, known as Class-Prompt Appending
(Nguyen et al., 2023), can be represented as: P
∗
i
=
“P
g
i
; P
c
i
”. For example, in the sub-figure in the top-
right corner of Figure 2, the prompt generated by our
proposed method would be “a pink plane on the tar-
mac; aeroplane, person”. Our method ensures that
new text prompts include both general information
and the target classes of the original image. This tech-
nique helps the synthetic image to have a clear layout
similar to the original one and also addresses the prob-
lem of missing labeled classes in the synthetic image.
3.2.2 Visual Prior Blending
Unlike Stable Diffusion models that typically only
use text prompts to generate images, Controllable
Generation models require additional input guid-
ance (Canny Edge (Canny, 1986), Sketch-Guided (Su
et al., 2021), Line-Art Edge (Chan et al., 2022), Depth
Map (Ranftl et al., 2022), HED soft edge (Xie and Tu,
2015)) generated from the visual prior detector to de-
termine the image layout. Canny, Line-Art Edge, and
Enhanced Generative Data Augmentation for Semantic Segmentation via Stronger Guidance
255

Algorithm 1: Class balancing algorithm for dataset
generation.
Input: Original dataset D
origin
; Target
images per class n
balance
Output: Balanced dataset D
f inal
1 Stage 1: Initialization /* Storing
images per class */
2 M ←
/
0
3 for I in D do
4 for C in I do
5 M [C ] ← M [C ] ∪{I }
6 Stage 2: Sorting /* Sorting by number
of classes */
7 for C in M do
8 Sort M [C ]
9 Stage 3: Balancing /* Generating
additional images */
10 D
gen
←
/
0
11 for C in M do
12 while len(M [C ]) < n
balance
do
13 for I in M [C ] do
14 Generate I
gen
based on I
15 M [C ] ← M [C ] ∪{I
gen
}
16 D
gen
← D
gen
∪{I
gen
}
17 if len(M [C ]) ≥ n
balance
then
18 break
19 D
f inal
← D
gen
∪D
origin
20 return D
f inal
Sketch are the visual priors we propose using to bal-
ance the diversity of the image and the precise struc-
ture of the generated classes in the image. Our default
visual prior is Line-Art Edge to generate visual guid-
ance. In Section 4.3.5, we also discuss other types
of visual priors to see how effectively they augment
the data. Using the T2I-Adapter (Mou et al., 2023)
model, the Line Art Detector converts the image into
visual prior in-line drawings for each input image.
Then, the Adapter generates different resolution fea-
tures, performing conditional operations at each time
step with the UNet denoiser’s features.
In general, methods such as Line-Art Edge, Canny
Edge, or HED soft edge all suffer from the limitation
that the labeled classes in the image may be blurred
or small in size, leading to inaccuracies in describing
the structure of the labeled classes within the condi-
tional image. Figure 4a shows an image produced
using Line Art Detection. However, the edge re-
sults in this case are missing some details of the per-
son, and the TV monitor is almost absent. The red
shapes indicate the missing details in the image. This
loss of information also occurs when using HED or
Canny Edge. These weaknesses result in mislabel-
ing in the synthetic image compared to the original
image. We observed that although the segmentation
labels of real images cannot fully describe an image’s
content, they provide accurate information about the
labeled classes. Based on this observation, we pro-
pose combining the real image’s prior visualization
with the labels before feeding them into the controlled
image generation model. The blending of the prior vi-
sual image I
i
(V
I
i
) and prior visual segmentation label
S
i
(V
S
i
) ensures that the generated image has a clear
layout and well preserves structures the class labeled
information. Our proposed blends V
I
i
and V
S
i
by a
weighted sum:
V
∗
i
= ω
1
V
I
i
+ ω
2
V
S
i
(4)
With ω
1
, ω
2
being the trade-off scales when com-
bining V
I
i
and V
S
i
. This blending results in a prior
visual that is clear in content and complete informa-
tion about labeled classes. Figure 4b shows how the
Visual Prior Blending method can preserve the struc-
ture labeled classes in an image.
3.3 Create Class-Balancing Dataset
To address the issue of class imbalance during model
training, we aim for the final dataset D
f inal
, which
merges the original dataset D
origin
and the synthetic
dataset D
gen
, to have a balanced distribution among
classes. To create a balanced dataset from the original
dataset D
origin
, we use the class balancing algorithm
to generate the dataset D
gen
based on the balancing
factor n
balance
, as presented in Algorithm 1. The al-
gorithm consists of three main stages: Initialization,
Sorting, and Balancing. In Stage 1, a dictionary M is
initialized to map each class to its associated images.
Each image I is linked to a list of classes it contains.
In the next stage, images are arranged in ascending
order based on the number of classes they represent,
prioritizing those with fewer classes to be generated
to maintain the balance. In the final stage, additional
images are generated for each class until they reach
n
balance
, ensuring an even distribution among classes.
This process ensures the dataset is balanced, prevent-
ing the overrepresentation of any class and promoting
more robust model training.
After generating high-quality training samples,
the synthetic dataset D
gen
and the original dataset
D
origin
are merged into an extended dataset D
f inal
for
training:
D
f inal
= D
gen
∪D
origin
(5)
In the default setting, we choose an appropriate
n
balance
such that |D
gen
| ≈ |D
origin
| where | . | is the
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
256
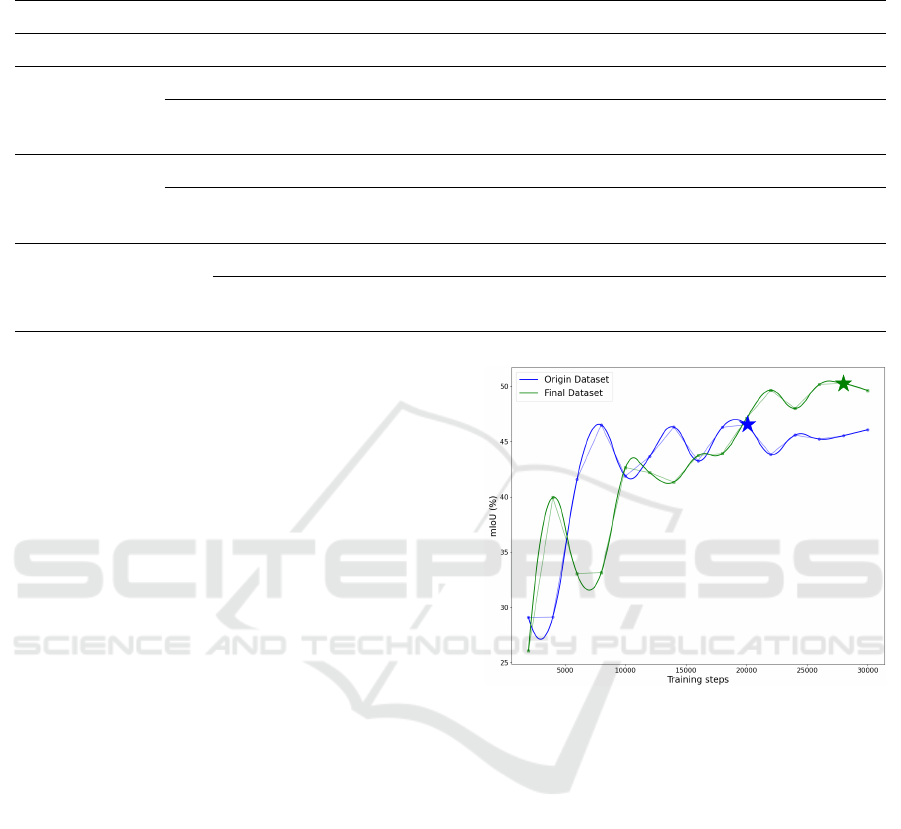
Table 1: Semantic Segmentation Evaluation: Comparison in mIoU (%) on val set between models’ training on the original
training set (D
origin
) and the extended training set (D
f inal
).
Dataset VOC7 VOC12
Number images 209 92 183 366 732 1464
DeepLabV3+
Resnet50
D
origin
46.54 29.91 38.21 49.40 58.20 61.84
D
gen
∪D
origin
△
50.27
↑ 3.73
33.87
↑ 3.96
41.45
↑ 3.24
52.22
↑ 2.78
60.11
↑ 1.91
63.06
↑ 1.22
PSPNet
Resnet50
D
origin
47.04 31.87 38.96 46.62 57.48 62.39
D
gen
∪D
origin
△
50.01
↑ 2.97
34.67
↑ 2.80
41.46
↑ 2.50
49.34
↑ 2.72
61.09
↑ 3.61
63.78
↑ 1.39
Mask2Former
Resnet50
D
origin
48.28 34.85 39.63 51.37 59.94 63.65
D
gen
∪D
origin
△
49.69
↑ 1.41
35.53
↑ 0.68
40.29
↑ 0.66
51.77
↑ 0.40
60.02
↑ 0.08
62.56
↓ 1.09
number of images in the dataset. In Section 4.3.2, we
further discuss the impact of varying the number of
generated synthetic images.
4 RESULTS
4.1 Experiment Details
4.1.1 Dataset
In this section, we evaluate our method on the seg-
mentation datasets VOC7 and VOC12 (Everingham
et al., 2015). PASCAL VOC 2007 has 422 im-
ages annotated for semantic segmentation, split into
209 training and 213 validation images. Meanwhile,
VOC12 has training and validation sets, including
1.464 and 1.449 images. In addition to training on
the entire VOC12 dataset (1.464 images), we also
train our model using 1/2 (732 images), 1/4 (366 im-
ages), 1/8 (183 images), and 1/16 (92 images) parti-
tion protocols (Wang et al., 2022). These evaluations
on smaller subsets demonstrate the effectiveness of
our method in real-world, limited-data scenarios.
4.1.2 Implementation Details
We construct our framework on the deep learning
PyTorch framework (Paszke et al., 2019) and T2I-
Adapter (Mou et al., 2023) using Stable Diffusion XL
1.0 (Podell et al., 2024) with 30 time steps. We gen-
erate data using values for ω
1
and ω
2
, as defined in
Section 4.3.4. For semantic segmentation, we em-
ploy the DeepLabV3+ (Chen et al., 2018), PSPNet
(Zhao et al., 2017), and Mask2Former (Cheng et al.,
2022) with segmenters implemented in the MMSeg-
Figure 5: The mIoU (%) of the DeepLabV3+ model over
30k training steps. The star symbol indicates the point of
convergence, where the model achieves its highest perfor-
mance on the validation set.
mentation framework (MMSegmentation Contribu-
tors, 2020). We utilize the SGD optimizer with stan-
dard settings in MMSegmentation. We train our mod-
els with an input image size of 512×512 with 30k
steps on the Pascal VOC datasets, including VOC7
and VOC12. During training, we only apply sim-
ple transformation methods to augment data, such as:
RandomResize, RandomCrop, RandomFlip. The per-
formance of the trained model on the applied data
is assessed using the Mean Intersection over Union
(mIoU) metric.
Enhanced Generative Data Augmentation for Semantic Segmentation via Stronger Guidance
257

Table 2: Evaluation results of the DeepLabV3+ model on the PASCAL VOC7 dataset trained on D
origin
and D
f inal
.
D
origin
89.32 75.35 43.90 53.95 38.03 51.72 50.81 67.41 72.0 7.77 24.61
D
f inal
88.69 67.67 45.35 57.00 38.07 56.08 70.14 70.67 73.46 28.81 45.45
mIoU (%)
D
origin
41.67 45.16 42.29 66.08 72.71 42.00 14.07 24.68 40.74 12.96 46.54
D
f inal
39.48 36.27 50.10 55.80 71.49 40.29 21.91 18.10 48.13 32.72 50.27
Table 3: Impact of Class-Prompt Appending (1), Visual
Prior Blending (2), Class balancing algorithm (3), and Post
Filter (Fang et al., 2024) (4).
(1) (2) (3) (4) mIoU (%)
42.15
✓ 47.60
✓ 47.25
✓ ✓ 48.98
✓ ✓ ✓ 50.27
✓ ✓ ✓ ✓ 52.23
Table 4: Effect of the number of synthetic data generated on
data balance and performance.
n
gen
R/S Entropy ↑ ClR ↓ mIoU (%)
- 209/0 3.944 0.253 46.54
27 209/216 4.044 0.231 50.27
41 209/425 4.042 0.231 50.37
55 209/634 4.059 0.224 49.25
69 209/845 4.057 0.225 47.32
4.2 Main Results
4.2.1 Quantitative Results
The results presented in Table 1 demonstrate that
combining augmented data (D
gen
) with the original
dataset (D
origin
) improves the performance of vari-
ous segmentation models on the VOC7 and VOC12
datasets. All models, including DeepLabV3+, PSP-
Net, and Mask2Former, significantly improve when
augmented data. DeepLabV3+ consistently performs
the best across different dataset sizes. We note that
as the amount of real-world data increases, the accu-
racy of the generated images and labels becomes cru-
cial. Mismatched generated images in the synthetic
data can lead to performance degradation; this is ob-
served in Mask2Former when trained on the VOC12
dataset with 1464 images.
Figure 5 visualizes the validation set accuracy on
the PASCAL VOC7 dataset over 30,000 steps using
the DeepLabV3+ model. The results show that train-
ing the model on the D
f inal
achieves 50.27% mIoU,
3.73% higher than training solely on the D
origin
. The
visualization also indicates that the model converges
earlier when trained on the D
origin
compared to the
D
f inal
. Additionally, the detailed performance for
each class in the PASCAL VOC dataset provided
in Table 2 demonstrates that most classes show im-
proved accuracy when trained on the D
f inal
dataset.
Notably, some classes, such as “bus”, “cow”, “chair”,
and “TV monitor”, exhibit significant improvements.
4.2.2 Qualitative Results
In Figure 6, each row presents three images: the
original image, the image generated by the Control-
lable Generation model (using prompts generated by
BLIP-2), and the image produced by the generation
model with our proposed. For the images generated
by the SD model without our method, the first two
rows illustrate cases where labeled classes in the im-
age are missing in the generated description, causing
the model to fail in accurately generating all those
classes. In the third row, the image contains objects
belonging to the “cow” class with smaller sizes, which
prevents the Image Captioning Model from includ-
ing “cow” in the description, resulting in an inaccu-
rate generated image without cows. In the last row,
although the case is relatively simple and the prompt
includes all the labeled classes, the generated image
still fails to depict the structure of both “bird” ob-
jects accurately. All four images are significantly im-
proved with our proposed pipeline, with the labeled
objects entirely generated and their structure well pre-
served. This demonstrates that our method effectively
addresses the limitations of directly using Control-
lable Image Generation models.
4.3 Ablation Study
We conduct all ablation study experiments using the
DeepLabV3+ model, backbone Resnet50 with train-
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
258

A man and his dog
are walking through a field
Caption:
Class labels: sheep,
person, dog
w/o ours w/ ours
Two parrots are sitting
on a branch
Caption:
Class labels: bird
A field of green grassCaption:
Class labels: cow
A street with cars
parked on it at night
Caption:
Class labels: car, person
Figure 6: Some results show the limitations of direct generation and the effectiveness of our method to overcome them.
ing and evaluation details described in Section 4.1.2.
The model is trained on the PASCAL VOC7 dataset,
and the results are evaluated on the val set.
4.3.1 Effects of Different Methods
The performance of the proposed methods is sum-
marized in Table 3. When using the Baseline with
generated prompts, the performance is only as low
as 42.15% mIoU, which is lower than when train-
ing on the original data. This demonstrates the es-
sential nature of the proposed methods when gener-
ating synthetic data. Our method yields a 50.27%
mIoU, showing its effectiveness. Additionally, we ex-
perimented with combining the Post Filter with the
Category-Calibrated CLIP Rank (Fang et al., 2024)
for generating synthetic data. The result of this blend-
ing is higher, which shows that our method can com-
bine filters from previous studies (Fang et al., 2024;
Wu et al., 2024) to improve the performance.
4.3.2 Effect of Number of Synthetic Data
The results of the proposed method’s experiments
with different amounts of generated synthetic data are
summarized in Table 4, R/S refers to the number of
real/synthetic images. The metrics we use to evaluate
data imbalance include Entropy, and Class Imbalance
Ratio (CIR). Initially, without using synthetic data,
the model achieves an mIoU of 46.54. When train-
ing with synthetic data in quantities of approximately
|D
origin
|, 2 ×|D
origin
|, and 3 ×|D
origin
|, the data bal-
ance metrics stabilize at a better level, and model per-
formance improves. However, we observed that us-
ing synthetic data around 3 ×|D
origin
| negatively im-
pacts performance, resulting in a decrease compared
to training with 1 ×|D
origin
| and 2 ×|D
origin
| of syn-
thetic data.
4.3.3 Text Prompt Selection
Table 5 compares different text prompt selection
methods for generative modeling. We compare the
performance of three prompt types: Generated cap-
tion generated from the Image Captioning model,
Simple text prompt listing the classes in the image,
and Class-Prompt Appending, a combination of the
two prompt types. Class-Prompt Appending outper-
forms the other two methods by 50.27 mIoU (%),
precisely 3.03 and 2.06 better than generated cap-
tion and simple text prompt, respectively, in mIoU.
These results show that the Class-Prompt Appending
text prompt selection method can support SD in gen-
Enhanced Generative Data Augmentation for Semantic Segmentation via Stronger Guidance
259

Table 5: Performance of different text prompt selections.
Method Example mIoU (%)
Generated caption A room with a table and a laptop on it 47.24
Simple text prompt A photo of sofa, chair, dining table 48.21
Class-Prompt Appending
A room with a table and a laptop on it;
sofa, chair, dining table
50.27
T2I Adapter Canny T2I Adapter Sketch ControlNet CannyT2I Adapter LineArt Inpainting
Caption a room with a table and a laptop on it
Caption:
Class labels:
sofa, chair, dining table
Real Image
Figure 7: Some image generation results from various Controllable models when combined with our proposed approach.
Table 6: Different visual priors controlled the enhancement results. All used the Stable Diffusion XL version.
T2I-Adapter ControlNet
Inpainting
LineArt Canny Sketch Canny
mIoU (%) 50.27 48.95 47.52 48.95 47.56
Table 7: Study on different trade-off scales.
ω
2
ω
1
0.6 0.7 0.8 0.9 1.0
0.7 47.12 47.32 46.42 45.36 45.38
0.8 48.51 48.93 48.32 47.09 46.79
0.9 49.13 50.27 49.11 48.79 48.36
1.0 48.13 49.32 48.91 48.33 47.03
erating diverse datasets and ensuring accurate atten-
tion.
4.3.4 Effect of Different Trade-Off Scales
Trade-off scales are utilized to blend the visual prior
of the image with the semantic segmentation map pre-
sented in Section 3.2.2. We tested various scales and
documented the results in Table 7. The outcomes in-
dicate that the scale ω
1
=0.7 and ω
2
=0.9 yields the best
results, with ω
2
enabling proper localization of the la-
beled classes. On the other hand, the scale ω
1
=0.7
retains the general content of the image without need-
ing to be as detailed as the original image.
4.3.5 Other Visual Priors
We compare using different visual priors for both T2I-
Adapter (Mou et al., 2023) and ControlNet (Zhang
et al., 2023): Line Art (Chan et al., 2022), Canny
(Canny, 1986), Sketch (Su et al., 2021). We also com-
bine Inpainting (Rombach et al., 2022) with our meth-
ods (excluding Visual Prior Blending). Although the
T2I-Adapter combined with Line Art gives the best
result at 50.27% mIoU, other visual priors also show
competitive performance, especially Canny on both
T2I-Adapter and ControlNet. Figure 7 shows some
image results with Controllable Diffusion model.
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
260

5 DISCUSSION AND
CONCLUSION
5.1 Limitations
While our approach effectively generates synthetic
images to augment data for semantic segmentation,
there are certain limitations to consider. First, the re-
sults in Tables 1 and 4 show that the model’s perfor-
mance may decrease when the number of synthetic
images is large or more significant than the number
of original real images. This may be because the syn-
thetic images do not completely guarantee the origi-
nal images’ location and quantity of labels. Addition-
ally, as the images produced by the Stable Diffusion
(Podell et al., 2024) model are trained on the LION-
5B dataset (Schuhmann et al., 2022), the resulting
images do not share the same distribution as the tar-
get dataset. So, the synthetic data cannot completely
replace the original training dataset used to train the
model.
5.2 Conclusion
In this study, we introduced a novel data augmenta-
tion pipeline for semantic segmentation tasks based
on Controllable Diffusion models. Our proposed
methods, including Class-Prompt Appending, Visual
Prior Blending, and a class-balancing algorithm, ef-
fectively address challenges associated with generat-
ing synthetic images while preserving the structure
and class balance of labeled datasets. By combining
synthetic and real-world data, we demonstrated im-
provements in segmentation performance on the PAS-
CAL VOC datasets in terms of mIoU, compared to
training on original datasets alone. These results val-
idate the effectiveness of our approach, particularly
in scenarios with limited data availability. Further-
more, our method can be seamlessly combined with
other augmentation methods to further enhance per-
formance. Through extensive experiments, we have
demonstrated the versatility and robustness of our ap-
proach, providing a strong foundation for future re-
search in data augmentation.
ACKNOWLEDGMENTS
This research is funded by University of Information
Technology-Vietnam National University of Ho Chi
Minh city under grant number D1-2024-76.
REFERENCES
Azizi, S., Kornblith, S., Saharia, C., Norouzi, M., and Fleet,
D. J. (2023). Synthetic data from diffusion models im-
proves imagenet classification. Transactions on Ma-
chine Learning Research.
Canny, J. (1986). A computational approach to edge de-
tection. IEEE Transactions on Pattern Analysis and
Machine Intelligence, PAMI-8(6):679–698.
Chae, J., Cho, H., Go, S., Choi, K., and Uh, Y. (2023). Se-
mantic image synthesis with unconditional generator.
In Thirty-seventh Conference on Neural Information
Processing Systems.
Chan, C., Durand, F., and Isola, P. (2022). Learning to
generate line drawings that convey geometry and se-
mantics. In 2022 IEEE/CVF Conference on Computer
Vision and Pattern Recognition (CVPR), pages 7905–
7915.
Chen, L.-C., Zhu, Y., Papandreou, G., Schroff, F., and
Adam, H. (2018). Encoder-decoder with atrous sepa-
rable convolution for semantic image segmentation. In
Ferrari, V., Hebert, M., Sminchisescu, C., and Weiss,
Y., editors, Computer Vision – ECCV 2018, pages
833–851, Cham.
Cheng, B., Misra, I., Schwing, A. G., Kirillov, A., and Gird-
har, R. (2022). Masked-attention mask transformer
for universal image segmentation. In 2022 IEEE/CVF
Conference on Computer Vision and Pattern Recogni-
tion (CVPR).
Everingham, M., Eslami, S. M. A., Gool, L. V., Williams,
C. K. I., Winn, J., and Zisserman, A. (2015). The pas-
cal visual object classes challenge: A retrospective.
International Journal of Computer Vision, 111(1):98–
136.
Fang, H., Han, B., Zhang, S., Zhou, S., Hu, C., and Ye, W.-
M. (2024). Data augmentation for object detection
via controllable diffusion models. In 2024 IEEE/CVF
Winter Conference on Applications of Computer Vi-
sion (WACV), pages 1246–1255.
He, R., Sun, S., Yu, X., Xue, C., Zhang, W., Torr, P.,
Bai, S., and QI, X. (2023). IS SYNTHETIC DATA
FROM GENERATIVE MODELS READY FOR IM-
AGE RECOGNITION? In The Eleventh International
Conference on Learning Representations.
Ho, J., Jain, A., and Abbeel, P. (2020). Denoising diffusion
probabilistic models. In Advances in Neural Infor-
mation Processing Systems, volume 33, pages 6840–
6851.
Li, J., Li, D., Savarese, S., and Hoi, S. (2023). Blip-
2: bootstrapping language-image pre-training with
frozen image encoders and large language models. In
Proceedings of the 40th International Conference on
Machine Learning, ICML’23.
Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P.,
Ramanan, D., Doll
´
ar, P., and Zitnick, C. L. (2014).
Microsoft coco: Common objects in context. In Com-
puter Vision – ECCV 2014, pages 740–755, Cham.
Springer International Publishing.
MMSegmentation Contributors (2020). OpenMMLab Se-
mantic Segmentation Toolbox and Benchmark.
Enhanced Generative Data Augmentation for Semantic Segmentation via Stronger Guidance
261

Mou, C., Wang, X., Xie, L., Wu, Y., Zhang, J., Qi, Z., Shan,
Y., and Qie, X. (2023). T2i-adapter: Learning adapters
to dig out more controllable ability for text-to-image
diffusion models.
Nguyen, Q. H., Vu, T. T., Tran, A. T., and Nguyen, K.
(2023). Dataset diffusion: Diffusion-based synthetic
data generation for pixel-level semantic segmentation.
In Thirty-seventh Conference on Neural Information
Processing Systems.
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J.,
Chanan, G., Killeen, T., Lin, Z., Gimelshein, N.,
Antiga, L., Desmaison, A., Kopf, A., Yang, E., De-
Vito, Z., Raison, M., Tejani, A., Chilamkurthy, S.,
Steiner, B., Fang, L., Bai, J., and Chintala, S. (2019).
Pytorch: An imperative style, high-performance deep
learning library. In Advances in Neural Information
Processing Systems, volume 32.
Podell, D., English, Z., Lacey, K., Blattmann, A., Dock-
horn, T., M
¨
uller, J., Penna, J., and Rombach, R.
(2024). Sdxl: Improving latent diffusion models for
high-resolution image synthesis. In The Twelfth Inter-
national Conference on Learning Representations.
Ranftl, R., Lasinger, K., Hafner, D., Schindler, K., and
Koltun, V. (2022). Towards robust monocular depth
estimation: Mixing datasets for zero-shot cross-
dataset transfer. IEEE Transactions on Pattern Analy-
sis and Machine Intelligence, 44(3).
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and
Ommer, B. (2022). High-resolution image synthesis
with latent diffusion models. In Proceedings of the
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition (CVPR), pages 10684–10695.
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C. W.,
Wightman, R., Cherti, M., Coombes, T., Katta, A.,
Mullis, C., Wortsman, M., Schramowski, P., Kun-
durthy, S. R., Crowson, K., Schmidt, L., Kaczmar-
czyk, R., and Jitsev, J. (2022). LAION-5b: An open
large-scale dataset for training next generation image-
text models. In Thirty-sixth Conference on Neural
Information Processing Systems Datasets and Bench-
marks Track.
Su, Z., Liu, W., Yu, Z., Hu, D., Liao, Q., Tian, Q.,
Pietik
¨
ainen, M., and Liu, L. (2021). Pixel differ-
ence networks for efficient edge detection. In 2021
IEEE/CVF International Conference on Computer Vi-
sion (ICCV), pages 5097–5107.
Trabucco, B., Doherty, K., Gurinas, M. A., and Salakhut-
dinov, R. (2024). Effective data augmentation with
diffusion models. In The Twelfth International Con-
ference on Learning Representations.
Wang, Y., Wang, H., Shen, Y., Fei, J., Li, W., Jin, G., Wu,
L., Zhao, R., and Le, X. (2022). Semi-supervised se-
mantic segmentation using unreliable pseudo labels.
In Proceedings of the IEEE/CVF International Con-
ference on Computer Vision and Pattern Recognition
(CVPR).
Wu, W., Dai, T., Huang, X., Ma, F., and Xiao, J.
(2024). Gpt-prompt controlled diffusion for weakly-
supervised semantic segmentation.
Xie, S. and Tu, Z. (2015). Holistically-nested edge detec-
tion. In 2015 IEEE International Conference on Com-
puter Vision (ICCV), pages 1395–1403.
Yang, B., Gu, S., Zhang, B., Zhang, T., Chen, X., Sun, X.,
Chen, D., and Wen, F. (2023). Paint by example:
Exemplar-based image editing with diffusion mod-
els. In 2023 IEEE/CVF Conference on Computer Vi-
sion and Pattern Recognition (CVPR), pages 18381–
18391.
Yu, F., Chen, H., Wang, X., Xian, W., Chen, Y., Liu, F.,
Madhavan, V., and Darrell, T. (2020). Bdd100k: A
diverse driving dataset for heterogeneous multitask
learning. In IEEE/CVF Conference on Computer Vi-
sion and Pattern Recognition (CVPR).
Zhang, L., Rao, A., and Agrawala, M. (2023). Adding con-
ditional control to text-to-image diffusion models. In
2023 IEEE/CVF International Conference on Com-
puter Vision (ICCV), pages 3813–3824.
Zhao, H., Shi, J., Qi, X., Wang, X., and Jia, J. (2017).
Pyramid scene parsing network. In Proceedings of
the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR).
Zhou, B., Zhao, H., Puig, X., Xiao, T., Fidler, S., Barriuso,
A., and Torralba, A. (2019). Semantic understanding
of scenes through the ade20k dataset. International
Journal of Computer Vision, 127(3):302–321.
ICPRAM 2025 - 14th International Conference on Pattern Recognition Applications and Methods
262
