
Knowledge Graph Enrichments for Credit Account Prediction
Michael Schulze
1,2
and Andreas Dengel
1,2
1
Computer Science Department, Rheinland-Pf
¨
alzische Technische Universit
¨
at Kaiserslautern-Landau (RPTU), Germany
2
Smart Data & Knowledge Services Departm., Deutsches Forschungszentrum f
¨
ur K
¨
unstliche Intelligenz (DFKI), Germany
fi
Keywords:
Knowledge Graphs, RDF, OWL, Rule-Based Link Prediction, Case-Based Reasoning.
Abstract:
For the problem of credit account prediction on the basis of received invoices, this paper presents a pipeline
consisting of 1) construction of an accounting knowledge graph, 2) enrichment algorithms, and 3), prediction
of credit accounts with methods of a) rule-based link prediction, b) case-based reasoning, and c) a combination
of both. Explainability and traceability have been key requirements. While preserving the order of invoices
in cross-fold validation, key findings in our scenario are: 1) using all enrichments from the pipeline increases
prediction performance up to 12.45 percent points, 2) single enrichments are useful on their own, 3) case-
based reasoning benefits most from having enrichments available, and 4), the combination of link prediction
and case-based reasoning yields best prediction results in our scenario.
Paper page: https://git.opendfki.de/michael.schulze/account-prediction.
1 INTRODUCTION
A typical task of accountants is the assignment of
accounts based on received invoice data. For exam-
ple, on an invoice where employees visited a restau-
rant for a business meeting, the accountant needs
to first assess the invoicing case correctly, and then
needs to find and choose the correct financial account.
Through interviews with accountants from our busi-
ness partner, we learnt that accountants in such situ-
ations face two major challenges: On the one hand,
as also reported by Bardelli et al. (Bardelli et al.,
2020), the search space regarding finding and choos-
ing accounts can be very high. For example, when ac-
countants are responsible for multiple company sub-
sidiaries, accountants need to tap into multiple ac-
counting handbooks where each handbook can be
several hundred pages long. On the other hand, to
assess the invoicing case correctly, accountants usu-
ally need to tap into several heterogeneous sources
of information. For instance, in the example of the
restaurant visit, the accountant may check a separate
participation list to decide whether guests have been
present or not. This would then result in different ac-
counts. This list may come from another ERP system
or, for example, by e-mail or some other intranet re-
source. Other sources of information can be, among
others, organizational policies (e.g., regarding han-
dling restaurant visits), accounting charts, tax regu-
lations, or other attachments. These challenges can
lead to long search times, especially for non-standard
cases, for novice accountants, and for new employees.
To tackle these challenges, this paper focuses on the
outlined problem of credit account prediction on the
basis of received invoices. The term credit account
is used here in accordance with related work, such
as in (Belskis et al., 2021) and (Belskis et al., 2020).
In line with insights gained from interviews with ac-
countants, and underlined by experiments reported in
Bardelli et al. (Bardelli et al., 2020), throughout ac-
count prediction literature (e.g. (Panichi and Lazzeri,
2023; Bardelli et al., 2020)), credit account predic-
tion is considered as especially challenging. How-
ever, current research focuses mainly on the goal of
automatizing account prediction (Bardelli et al., 2020;
Panichi and Lazzeri, 2023; Belskis et al., 2021); also
with the explicit goal to exclude knowledge work-
ers (e.g. (Belskis et al., 2021)). In contrast, but in
line with forecasts from Jain and Woodcock (Jain and
Woodcock, 2017), fully automatization is not seen
as realistic. This assessment is also underlined by
reported performance numbers in related work (e.g.
(Panichi and Lazzeri, 2023; Bardelli et al., 2020; Bel-
skis et al., 2021)), where results do not meet the level
of accuracy an automated system would require in
practice. Furthermore, through interviews with ac-
countants where guidelines from Lazar et al. (Lazar
et al., 2017) have been followed, explainability and
Schulze, M. and Dengel, A.
Knowledge Graph Enrichments for Credit Account Prediction.
DOI: 10.5220/0013181000003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 2, pages 441-452
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
441

traceability have been identified as key requirements.
While focusing on automatization, state-of-the-art lit-
erature does not consider these aspects as require-
ments in their approaches so far.
Therefore, a different perspective on account pre-
diction research is proposed: Instead of focusing
on the goal of full automatization, we propose fo-
cusing on the goal of assisting accountants in their
daily decision-making for the problem of account as-
signment. For credit account prediction, knowledge
graphs (Ehrlinger and W
¨
oß, 2016) can be on the one
hand useful to put prediction results as well as enti-
ties occurring in their explanations in the context of an
existing accounting knowledge graph (Schulze et al.,
2022), thus integrating them with other heterogenous
accounting resources, and on the other hand useful
to leverage the structure of knowledge graphs for ma-
chine learning approaches to predict accounts, such as
link prediction as proposed for future work by Panichi
and Lazzeri (Panichi and Lazzeri, 2023).
This paper aims to continue these lines of thought
in related work and addresses therefore the follow-
ing research questions: 1) how to predict credit ac-
counts using knowledge graphs with approaches that
can provide explanations and traceable predictions,
and 2), how to improve predictions by enriching such
knowledge graphs based on internal graph data avail-
able. Regarding explainability, the scope of the pa-
per is to consider these requirements in the prediction
approaches. Because the paper explores the feasibil-
ity and performance of such approaches, data-driven
evaluation will be conducted. Therefore, the quali-
tative assessment on the daily usability of different
explanation styles is beyond the paper’s scope.
Section 2 presents related work on credit account
prediction and Section 3 the pipeline to predict ac-
counts. Section 4 presents the evaluation setup and
evaluation results which are then compared and dis-
cussed in Section 5. Finally, Section 6 draws conclu-
sions and gives an outlook for future work.
2 RELATED WORK
The research field of credit account prediction is get-
ting more and more traction. One reason is the in-
creasing adoption of electronic invoices (Koch, 2019),
which is in Europe also politically enforced, and with
that the availability of invoice data in a digitized form.
With the goal of automatization, Bardelli et al.
(Bardelli et al., 2020) predicted accounts based on
electronic invoices. Available to the authors were two
datasets from accounting firms consisting of 32k and
34k invoice lines (not invoices) where 61% of invoice
lines have been used for account prediction. The rest
of the lines could not be assigned back to the respec-
tive entries in the account ledger. By considering ac-
count prediction for sent and received invoices, identi-
fying the latter as the more difficult case, best results
have been generated with decision-tree-based meth-
ods combined with Word2Vec (Mikolov et al., 2013).
Panichi and Lazzeri (Panichi and Lazzeri, 2023)
focused on the scenario of account prediction on re-
ceived invoices and presented a semi-supervised ap-
proach which manages to increase accuracy by 4%
compared to the approach of Bardelli et al. (Bardelli
et al., 2020) (with different data in a different setting).
The performance increase could be achieved by ap-
plying the A* search algorithm (Hart et al., 1968), re-
sulting in a loss of training data (because of the same
linkage problem) of only 14% compared to 39% as in
Bardelli et al. (Bardelli et al., 2020). Further charac-
terizations of the data used in the experiments were
not given except that it was much smaller than the
data used in Bardelli et al. (Bardelli et al., 2020).
In contrast, Belskis et al. (Belskis et al., 2021;
Belskis et al., 2020) built their approaches not on the
basis of invoice data but on postings in ledger ac-
counts. They employed natural language processing
classification algorithms and showed that the use of
comments in postings, which were manually created
by accountants, increased the performance of preci-
sion by 2.56 percent (Belskis et al., 2021) compared
to not using them (Belskis et al., 2020). The main goal
was also automatization without the consideration of
explainability.
Schulze et al. (Schulze et al., 2022) conducted
in the context of a knowledge service for accountants
credit account prediction as a side analysis. The ap-
proach was based on an accounting knowledge graph.
However, it was restricted to the scope of food- and
beverage-scenarios and required manually creation of
vocabulary for this particular scope. Still, by learning
decision trees, results indicated that knowledge graph
enrichments may increase prediction performance.
Table 1 summarizes the comparison of related
work. All the approaches use real-world data, which
is important for applying insights generated in ac-
count prediction research. The downside is that re-
sults are not reproducible with the very same data
because such data can reasonably not be published.
Therefore, no public benchmarks exist (Panichi and
Lazzeri, 2023). Given this situation, it is even more
important to provide all resources to enable reproduc-
tion of presented approaches and evaluations on own
invoice data. However, to the best of our knowledge,
none of the related work does this so far.
Furthermore, all approaches shuffle the training
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
442

Table 1: Comparison of related work on credit account prediction (? = not explicitly mentioned).
real in- domain number number consider source time-series
world voice inde- of of explain- code preserving
data based pendent invoices accounts ability public evaluation
(Belskis et al., 2021) yes no yes - ? no no no
(Bardelli et al., 2020) yes yes yes ?, 66k inv. lines 130-166 no no no
(Panichi and Lazzeri, 2023) yes yes yes ?, < 10k inv. lines ? no no no
(Schulze et al., 2022) yes yes no 1267 6 yes no no
(This paper) yes yes yes 7k 161 yes yes yes
and test data. This can be problematical because in-
voices are time dependent and thus can be seen as
time-series data as described in Bergmeir and Ben
´
ıtez
(Bergmeir and Ben
´
ıtez, 2012). For example, an event
such as a celebration may spawn particular types of
invoices that may have not been received in such
amounts in the training period when there was no
similar celebration before. Even when having invoice
data over longer periods, then still are business mod-
els and supplier relationships respect to change and
with this also received invoices. Also, the accounts to
predict are adapted over time.
Therefore, we argue that preserving the order of
received invoices is important when evaluating pre-
dictive models. This also means that reported num-
bers in related work on predictive performance might
be too optimistic. For example, on our data, we
reach an accuracy increase of 16.41 percent points
when not preserving the order but shuffling the data
in cross-validation. Without preserving the order in
evaluation, reported performance numbers in related
work range from 74% to 89% for invoice-based ap-
proaches. However, comparison of prediction perfor-
mances across approaches is difficult because of dif-
ferent used datasets and different numbers of accounts
to predict. The unavailability of open-source code to
use an account prediction approach as a baseline also
hinders the comparison. Finally, related work focuses
on automatization so that the aspects of explainability
and traceability are not considered or discussed so far.
This paper aims to address these aspects by 1)
focusing on explainable approaches by design using
knowledge graphs, 2) preserving the order of invoices
in evaluations, and 3) providing resources for apply-
ing the presented approach.
3 PIPELINE FOR CREDIT
ACCOUNT PREDICTION
Figure 1 summarizes the overall process for account
prediction with enriched knowledge graphs. Section
3.1 covers the construction of an accounting knowl-
edge graph from invoice data (Step 1). Section 3.2
elaborates on how the knowledge graph is enriched
with internal graph data (Step 2), and Section 3.3
elaborates on account prediction approaches (Step 3).
3.1 Accounting Knowledge Graph
Construction from Invoice Data
3.1.1 Invoice Data and Postings
Data used in this study comes from a holding com-
pany located in Germany and covers basic informa-
tion from received invoices and their related pro-
cesses. To illustrate how we come from invoice data
to account predictions with the proposed pipeline in
Figure 1, we will use the following fictive example
throughout the rest of the paper. The data process-
ing steps with this example including inputs and out-
puts can also be followed in the demo folder on the
paper page. Consider an accountant wants to pro-
cess an invoice to assign credit accounts. The start-
ing point is the invoice data already represented in an
ERP system with which the accountant works, so that
for the approach the data is available in the CSV for-
mat. This setting is comparable with experiment set-
tings reported in Bardelli et al. (Bardelli et al., 2020)
and Panichi and Lazzeri (Panichi and Lazzeri, 2023).
For every invoice, the ERP system creates one process
and attaches a process number to it. Therefore, when-
ever in the rest of the paper we speak of a process,
we mean this process where data from one invoice
is attached to. The booking area can be automati-
cally derived from the recipient listed on the invoice.
Let the example process number be 193224 and the
booking area 7467. Furthermore, our example invoice
comes from Chimney Sweep Mrs. Happy, which
is the invoice issuer. The service description on the in-
voice is Maintenance service baker street 4.
This is all the data required from the received invoice.
However, the approach requires also historical data
of booked invoices in form of postings, which is also
comparable to experiment settings in related work.
Knowledge Graph Enrichments for Credit Account Prediction
443

1. Construction of
Accounting KG
2. Enrichment of
Accounting KG
3. Credit Account
Prediction
Ontology for Account Prediction
(following the NeOn Methodology
(Su
´
arez-Figueroa et al., 2015))
Apache Jena
1
Semantic Layer:
Topic Recognition
(Algorithm 1)
KG Enrichment
(Figure 2)
Rule-based link prediction
Prediction with case-based-reasoning
Prediction with a combination of both
Figure 1: Overview of the pipeline for credit account prediction based on enriched accounting knowledge graphs.
There may be multiple similar invoices, however, for
illustration, for the rest of the paper consider the fol-
lowing fictive historic invoice with an assigned ac-
count (coming from the posting CSV). Process Num-
ber: 45564, Booking Area: 9874, Invoice Issuer:
Clean Chimney, Service Description: Maintenance
Service Stand. TI, Account: 5912.
The total data used in the experiments amounts to
7k invoices with 12k postings which have been re-
ceived in a couple of months within a year. In the
scope of this study, the 7k invoices represent the usual
scenario at the holding company where each invoice
has one account as the solution. By following a long-
tail distribution, 161 accounts could possibly be pre-
dicted. The service description typically consists of
one to seven words in German, comes usually from
a person who entered the service description manu-
ally, and often consists of organization- and business
domain-specific vocabulary including abbreviations.
3.1.2 Knowledge Graph Construction
RDF (World Wide Web Consortium, 2014b) was
used as the underlying data model of the knowledge
graph, SPARQL (Valle and Ceri, 2011) was used as
the query language, and OWL (Antoniou and van
Harmelen, 2004) was used as the ontology language.
This knowledge graph setup is in line with the notion
of a knowledge graph provided by Ehrlinger and
W
¨
oß (Ehrlinger and W
¨
oß, 2016), which also includes
an ontology. For the ontology development, the
NeOn Methodology Framework (Su
´
arez-Figueroa
et al., 2015) was followed which encompasses
the phases of specifying requirements, identifying
resources for the ontology, as well as restructuring
and evaluating the ontology (Su
´
arez-Figueroa et al.,
2015). The main requirement for the ontology
was to enable account prediction by downstream
prediction approaches. Examples for ’competency
questions’ (Gr
¨
uninger and Fox, 1995) serving this
goal which also cannot be answered without such
an ontology in place are: Show all processes
that have 5912 as an account and have at
least one service description topic in
common or Show all organizations that have
‘Chimney’ as an invoice issuer topic and
where the processes(invoices) where these
organizations are listed on as sellers
have been booked on the account 5912. For
the ontology development, non-ontological resources
were used. These were columns of the CSV file
where invoice data was contained (invoice issuer,
service description etc.), columns of the posting
CSV file (e.g., account number), and headings in
accounting handbooks (e.g., account number, short-
and long-description). In the restructuring phase,
existing vocabulary has been reused, for example the
P2P-O ontology (Schulze et al., 2021) for electronic
invoices and the Organization Ontology (World Wide
Web Consortium, 2014a). Finally, the ontology
was checked for consistency, and it was evaluated
regarding pitfall patterns from the Oops! (OntOlogy
Pitfall Scanner!) (Poveda-Villal
´
on et al., 2014)
(which resulted, for example, in more detailed license
information). Also, the pre-formulated ’competency
questions’ (Gr
¨
uninger and Fox, 1995) have been
tested. The ontology and accompanying resources
are available on our paper page for reuse.
Technically, by using this ontology, the account-
ing knowledge graph was constructed with the Java-
based framework Apache Jena
1
. With our input data,
the accounting knowledge graph had 102k triples.
Demo CSVs of the input data are also available on
the paper page to facilitate the preprocessing of own
invoice data.
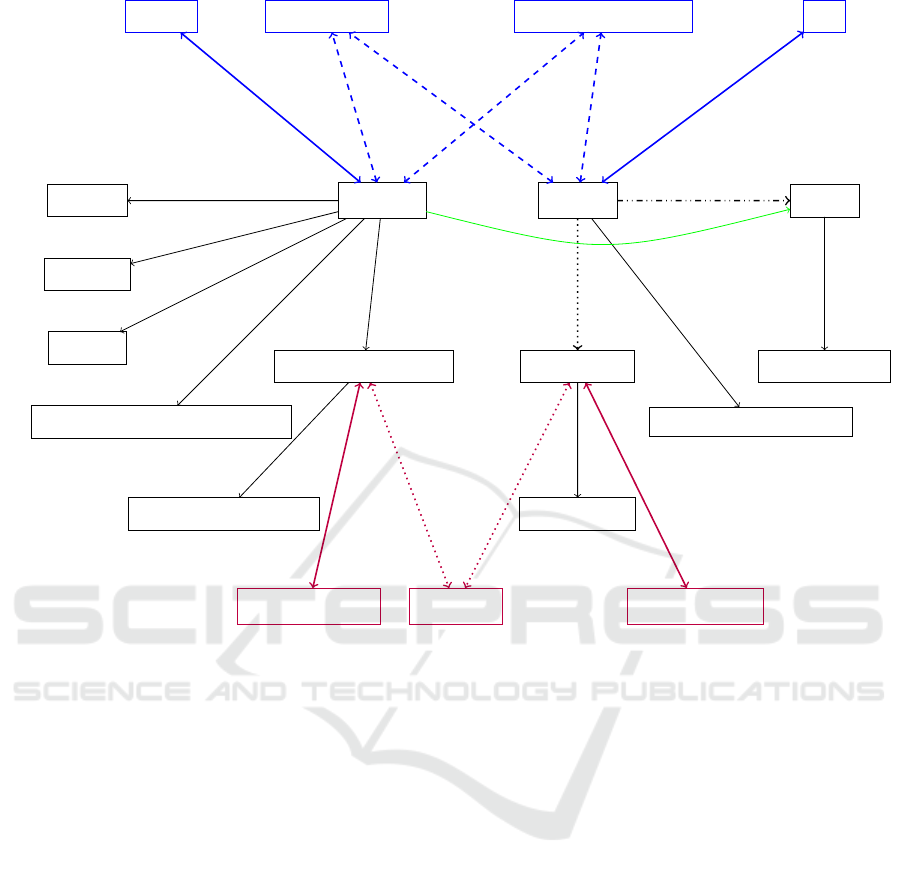
The black subgraphs a) and b) in Figure 2 il-
lustrate an excerpt of the constructed knowledge
graph with vocabulary from the developed ontol-
ogy. Subgraph a) shows parts of the example
process (invoice) at hand and subgraph b) rele-
vant parts of a similar historic process, which also
has a reference to the account :a5912. Note
that in this excerpt the black subgraphs a) and b)
are not connected. In fact, they are connected,
for example, with the expression that the instances
:oChimneySweepMrsHappy and :oCleanChimney
1
https://jena.apache.org
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
444

are both of the type org:FormalOrganization.
However, it is not shown in Figure 2 because every
organization has this relation. Consequently, down-
stream prediction approaches cannot make use of this
non-differentiating information.
3.2 Accounting Knowledge Graph
Enrichment
The goal of the enrichment step is to create the kind
of additional information in the knowledge graph that
downstream prediction approaches can use to make
better predictions. In the enrichment approach, such
information will be topics about service descriptions
of invoices and topics about invoice issuers. Further-
more, the enrichment approach should meet two ma-
jor requirements: First, the requirements of explain-
ability and traceability should also apply here to meet
these requirements throughout the pipeline. Second,
the enrichment process should be applicable across
domains and across invoice topics. Consequently,
the approach should be either unsupervised or semi-
supervised in order to manage the wide-ranging topics
of received invoices. The latter requirement is con-
trary to the requirements reported in the study con-
ducted by Schulze et al. (Schulze et al., 2022). There,
the domain was restricted to a food- and beverage-
scenario so that domain-specific vocabulary could be
created upfront. This is not feasible (or too costly)
when not restricting to a specific domain within a par-
ticular company.
First experimentations have been done with apply-
ing classical string-based similarity measures on ser-
vice descriptions which are implemented in the case-
based reasoning framework ProCAKE (Bergmann
et al., 2019), such as the Levenshtein-Distance (Lev-
enshtein, 1966). Groups of similar processes were
created which would then have been enriched to re-
spective processes. However, analysis of such groups
revealed that they had the tendency of being too big
with containing many unsimilar processes. One rea-
son may be that for this scenario, semantic similar-
ity cannot be implied by the similarity of the raw
strings. Also named entity recognition systems such
as RoBERTa (Liu et al., 2019) have been explored;
however, at least for German, only broad named entity
labels are supported (person, organization, location
and misc) which turned out not to be well suited for
the very domain specific language in received busi-
ness invoices.
The presented algorithm in Listing 1 for topic
recognition and the enrichment step illustrated with
the subgraphs c1) and c2) in Figure 2 are based on
the idea of the isolated mapping similarity introduced
in ProCAKE (Bergmann et al., 2019)
2
. However,
instead of directly comparing tokens of, for exam-
ple, two service descriptions with each other and then
computing a similarity value, as in the isolated map-
ping similarity, tokens are first gathered (Algorithm
1) and then matched and enriched on the accounting
knowledge graph (subgraphs c1) and c2) in Figure 2).
In this way, the similarity calculation is pushed down-
stream to the account prediction approaches.
Algorithm 1 shows how topics are gathered from
a set of given service description strings SD(AKG)
and invoice issuer names II(AKG) from an account-
ing knowledge graph AKG. Service descriptions
sd ∈ SD(AKG) and invoice issuer names ii ∈ II(AKG)
are first tokenized (including bi- and trigrams). Next,
they are added and counted into a set of tuples M
SDT
(for service descriptions) and M
IIT
(for invoice issuer
names), where M
SDT
= {⟨t
,
i⟩ : t ∈ T
SD
, i ∈ N with
i > 0} where T
SD
represents a set of tokens, and
where M
IIT
= {⟨t
′
,
i
′
⟩ : t
′
∈ T
II
, i
′
∈ N with i
′
> 0}
where T
II
also represents a set of tokens. However,
a tuple ⟨t
SD
∈ T
SD
, 1⟩ or a tuple ⟨t
II
∈ T
II
, 1⟩ is only
added when t
SD
meets given quality criteria Q
SD
and t
II
quality criteria Q
II
, which are given as an
input. By exploring meaningful topics in our data,
topics meet quality criteria Q
SD
and Q
II
when a)
they have more than one character because two
characters could already represent important business
specific abbreviations, b) they have more than three
digits when a topic consists only of numbers because
this could be an identifier, and finally c), they are
not a general language specific stop word. Finally,
Algorithm 1 returns with M
SDT
a set of counted
topics for service descriptions and returns with M
IIT
a set of counted topics for invoice issuer names.
Considering the service descriptions of the two
example processes (see also Figure 2), then topics in
M
SDT
would be {maintenance, service, baker,
str, maintenance service, service baker,
baker str, maintenance service baker,
service baker str, stand., ti, service
stand., stand. ti, service stand. ti}
(an excerpt is shown in Figure 2), and topics in
M
IIT
would be {chimney, sweep, mrs.,happy,
chimney sweep, sweep mrs., mrs. happy,
chimney sweep mrs., sweep mrs. happy,
clean, clean chimney}. An advantage of having
such separate sets is that they can be maintained
separately. For example, they can be sorted and
further refined regarding inappropriate topics. Also,
for experimentations with a fixed set, all topics that
occur only once can be removed because they do not
2
see https://procake.pages.gitlab.rlp.net/procake-
wiki/sim/collections/
Knowledge Graph Enrichments for Credit Account Prediction
445
a) b)
c1)
c2)
:p193224
:Process
’193224’
:oChimneySweepMrsHappy
:bk7467
’Maintenance service baker str 4’
:p45564
:a5912
’Misc. Service’
’Maintenance Service Stand. TI’
rdf:type
p2p-o:hasSeller
rdfs:label
p2p-o:serviceDescription
:hasBookingArea
:hasAccount
p2p-o:serviceDescription
:longDescription
:hasAccount
:oCleanChimney
p2p-o:hasSeller
’Chimney Sweep Mrs. Happy’ ’Clean Chimney’
rdfs:label
rdfs:label
’maintenance’
’maintenance service’
’baker’ ’ti’
’chimney’’chimney sweep’ ’clean chimney’
:serviceDescriptionTopic
:serviceDescriptionTopic
:serviceDescriptionTopic
:serviceDescriptionTopic
:serviceDescriptionTopic
:serviceDescriptionTopic
:invoiceIssuerTopic
:invoiceIssuerTopic
:invoiceIssuerTopic
:invoiceIssuerTopic
Figure 2: Excerpt of the accounting knowledge graph with fictive example data. The black subgraph a) represents the knowl-
edge graph constructed from the example invoice data at hand, the black subgraph b) represents the knowledge graph con-
structed from a prior invoice which has a reference to an account, the blue subgraph c1) represents examples for service
description enrichments, and the purple subgraph c2) represents examples for invoice issuer enrichments.
connect subgraphs.
The enrichment with the gathered topics from Al-
gorithm 1 is illustrated with the subgraphs c1) and
c2) in Figure 2: First, every service description string
and invoice issuer name in the accounting knowledge
graph is tokenized the same way as described in Al-
gorithm 1. Next, if a token equals a topic in M
SDT
or M
IIT
, it is added to the knowledge graph with
the predicate :serviceDescriptionTopic for ser-
vice descriptions and :invoiceIssuerTopic for in-
voice issuer names. With our data, 6k of such triples
have been enriched resulting in an enriched knowl-
edge graph with 108k triples.
3.3 Account Prediction
As depicted in Figure 1, Section 3.3.1 describes ac-
count prediction using a rule-based link prediction
(rule-based-LP) approach, Section 3.3.2 presents a
case-based reasoning (CBR) approach, and Section
3.3.3 elaborates on how expert knowledge from a
CBR System can be combined with rule-based-LP.
3.3.1 Account Prediction with Link Prediction
To enable the application of link prediction algo-
rithms for account prediction, the problem of account
prediction is first interpreted and formalized as a link
prediction problem: Given is an accounting knowl-
edge graph AKG
Train
, a test knowledge graph KG
Test
,
a set of nodes N, a set of edges E, and the spe-
cific edge {: hasAccount} that denotes which process
has which account as the solution. Then, AKG
Train
consists of a set of tuples ⟨n, e, n
′
⟩ where n, n
′
∈
N, e ∈ E and ∃⟨n, e, n
′
⟩|e = {: hasAccount}. Fur-
ther, KG
Test
= {⟨n
′′
, {: hasAccount}, n
′′′
⟩ : n
′′
, n
′′′
∈
N }. Then, AKG
′
Train
= AKG
Train
\ KG
Test
. With
AKG
′
Train
, the goal is to predict tuples of KG
Test
so
that AKG
Predicted
= AKG
′
Train
∪ KG
Test
.
The enrichment subgraphs c1) and c2) in Figure
2 enable new kinds of rules that rule learners can
calculate. With enrichments from the prior step,
the dashed and dotted edges can be leveraged by a
rule learner for generating new rules which connect
subgraphs a) and b). For example, in Figure 2, a
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
446

Data: SD(AKG),II(AKG), Q
SD
, Q
II
Result: M
SDT
, M
IIT
T
SD
=
/
0; T
II
=
/
0; M
SDT
=
/
0; M
IIT
=
/
0;
Service description strings:
foreach sd ∈ SD(AKG) do
T
SD
= tokenize(sd)
foreach t
SD
∈ T
SD
do
if Q
SD
(t
SD
) then
if ∃{⟨t, i⟩} ∈ M
SDT
with t = t
SD
then
{⟨t, i⟩} = {⟨t, i + 1⟩}
else
M
SDT
= M
SDT
∪ {⟨t
SD
, 1⟩}
end
end
end
end
Invoice issuer names:
foreach ii ∈ II(AKG) do
T
II
= tokenize(ii)
foreach t
II
∈ T
II
do
if Q
II
(t
II
) then
if ∃{⟨t
′
, i
′
⟩} ∈ M
IIT
with t
′
= t
II
then
{⟨t
′
, i
′
⟩} = {⟨t
′
, i
′
+ 1⟩}
else
M
IIT
= M
IIT
∪ {⟨t
II
, 1⟩}
end
end
end
end
Algorithm 1: Topic recognition given a set of service de-
scriptions, invoice issuer names, and quality criteria.
simple rule can be: :hasAccount(X,:a5912) ⇐=
:serviceDescriptionTopic(X,maintenance).
So, when a process X has the service description
topic maintenance, it is implied that process X has
the account :a5912, which is illustrated with the
green edge in Figure 2. Imagine that this was the case
in 9 out of 10 cases in AKG
′
Train
, then this particular
rule would have a confidence value of .90.
To implement this formalization, the bottom-up
rule learning algorithm of AnyBURL (Meilicke et al.,
2024) was used, which will be more detailed in the
Evaluation Setup Section 4.1.1. This state-of-the-
art algorithm was chosen because of its good perfor-
mance recently shown (Meilicke et al., 2024), and be-
cause it fulfills the requirements of explainability by
generating traceable rules with a symbolic approach.
3.3.2 Account Prediction with CBR
Because historic invoices can be seen as solved cases,
and because accountants often use historic cases as
the basis for a solution for a current task, case-based
reasoning (CBR) approaches (Kolodner, 2014) can
provide account predictions based on historic cases
where similarity functions can be used for explaining
and tracing back such predictions. As a CBR frame-
work, we used ProCAKE (Bergmann et al., 2019)
because this framework offers with its focus on pro-
cesses a suitable integration into the process-oriented
accounting domain. A process (with invoice data)
is seen as a case which is defined in an aggregate
class with the following set of attributes (which is
denoted as A): a process number p ∈ A, an invoice
issuer name iin ∈ A, a booking area ba ∈ A, an in-
voice service description sd ∈ A, a set of enriched
service description topics SD
enriched
∈ A, a set of en-
riched invoice issuer topics IIN
enriched
∈ A, and an
account solution acc ∈ A. Considering local cal-
culated similarities between attributes of two cases
s
local
(iin, iin
′
) ∈ R, s
local
(sd, sd
′
) ∈ R, . . . , the aggre-
gate similarity function s
aggregate
: A → R was defined
as follows:
s
aggregate
(s
local
(iin, iin
′
), s
local
(sd, sd
′
), s
local
(ba, ba
′
),
s
local
(SD
enriched
, SD
′
enriched
),
s
local
(IIN
enriched
, IIN
′
enriched
), w
1,2...5
∈ R : 0 ≤
w
1,2...5
≤ 3)
7→
(s
local
(iin, iin
′
) × w
1
) + (s
local
(sd, sd
′
) × w
2
) +
(s
local
(ba, ba
′
) × w
3
)
+(s
local
(IIN
enriched
, IIN
′
enriched
) × w
4
) +
(s
local
(SD
enriched
, SD
′
enriched
) × w
5
)
Note that the attributes process number p and ac-
count solution acc are not part of S
aggregate
. This
is because in the former case, it has no inherent
information value, and in the latter case, this is the
attribute to be predicted. However, when retrieving
similar cases, these attributes are of high value
for the accountant. Local similarity calculations
of s
local
(iin, iin
′
), s
local
(sd, sd
′
) and s
local
(ba, ba
′
)
were conducted using the string-equals similarity
measure in ProCAKE (Bergmann et al., 2019),
and calculations of s
local
(SD
enriched
, SD
′
enriched
) and
s
local
(IIN
enriched
, IIN
′
enriched
) using ProCAKES’s
(Bergmann et al., 2019) isolated mapping similarity
measure. Concrete weights w
1,2...5
∈ R were found by
applying hyperparameter optimization with ’random
search’ (Rastrigin, 1963), which will be covered in
more detail in the Evaluation Setup Section 4.1.2.
With respect to the example processes, by following
this approach, the attributes (invoice issuer name,
service descriptions (as well their topics), etc.) will
be compared as reported, and then an aggregate
similarity value will be calculated by applying the
weights from S
aggregate
. This similarity value indi-
cates the similarity between the process at hand (here
Knowledge Graph Enrichments for Credit Account Prediction
447

:p193224) and the historic process :p45564. These
calculations are conducted for every historic process
in the knowledge graph, and the accounts of the most
similar processes (here e.g. :a5912) are predicted
according to their aggregate similarity values.
3.3.3 Account Prediction with the Combination
of Expert Knowledge from CBR and
Rule-Based Link Prediction
A strength of rule-learners is that they are unsuper-
vised without hyperparameter optimization required
in case of AnyBURL (Meilicke et al., 2024). A
strength of CBR is the consideration of human-in-the
loop in the refinement phase bringing additional ex-
pert knowledge in (Kolodner, 2014). The basic idea
of combining these approaches is, on the one hand,
to make use of the predictive performance of rule-
learners, and on the other hand, to refine such pre-
dictions with expert knowledge from a CBR system.
Subsequently, in a refinement phase, the target ac-
counts where additional expert knowledge from CBR
should be tailored to, are the accounts where Any-
BURL (Meilicke et al., 2024) underperforms. For
each such account, the basis for analysis is, on the
one hand, the long description of the account in ac-
counting handbooks, and on the other hand, the reach-
able closure of all invoices in the training knowledge
graph AKG
′
Train
that should have yielded the correct
tuple in KG
Test
. On this basis, the expert defines ad-
ditional topics M
′
SDT
and M
′
IIT
as well as a respective
case which can be used for deriving the right account
solution. When now the service description or invoice
issuer name contains such topics in M
′
SDT
and M
′
IIT
,
the respective case and account solution is retrieved
and ranks higher than the predictions calculated with
S
aggregate
. Further, in the course of account predic-
tion with AnyBURL (Meilicke et al., 2024), when ex-
pert knowledge is available, then the account solution
coming from the CBR system is put at the first posi-
tion of the suggested predictions, and all other predic-
tions of AnyBURL (Meilicke et al., 2024) are moved
down by one position.
Imagine that in the example service description
Maintenance Service Stand. TI, the TI stands
for an abbreviation well-known within the organiza-
tion meaning a particular type of maintenance (e.g.,
with dust measurement) which is only typical for the
account :a5912. When this information is added in
the refinement phase of a CBR system, and when TI
occurs in a service description at hand, then :a5912
is suggested as the most likely account followed by
the predictions of AnyBURL.
1 2
3
4
5 6
7
8
9
10
2
3
4
5 6
7
8
9
10
11
3
4
5 6
7
8
9
10
11 12
4
5 6
7
8
9
10
11
12
13
4
5 6
7
8
9
10
11
12
13
5 6
7
8
9
10
11 1212
13
14
6
7
8
9
10
11 1212
13
14
15
7
8
9
10
11 12
13
14
15 16
8
9
10
11 12
13
14
15
16
17
Figure 3: Illustration of how 17 folds have been used
for cross-fold validation inspired by Bergmeir and Ben
´
ıtez
(Bergmeir and Ben
´
ıtez, 2012) considering the time-series
nature of invoice data where rectangles represent folds for
training, light circles folds for validation, and darker filled
circles folds for testing, resulting in eight datasets.
4 EVALUATION
Section 4.1 demonstrates the applied evaluation setup
and developed resources which make the different ap-
proaches comparable. Section 4.2 reports computing
performances, and Section 4.3 presents the results.
4.1 Evaluation Setup
Although rule-based-LP and CBR do not require mass
data for learning, 7k invoices and the resulting 108k
triples in the knowledge graph are still a medium-
sized sample for evaluation purposes. Therefore, in
line with best-practices in related work (e.g.(Panichi
and Lazzeri, 2023)), cross-fold validation was ap-
plied. However, as introduced in Related Work, in-
voices can relate to each other and can be time de-
pendent. Therefore, we argue to preserve the received
order of invoices in evaluations, also within the folds.
Figure 3 demonstrates in more detail how 17 folds of
the dataset have been used for training, validation, and
testing. As also depicted, this procedure resulted in
eight training-, valid- and test-datasets.
The code to enable cross-fold validation on in-
voice data where the order is preserved and the output
is consumable by AnyBURL (Meilicke et al., 2024)
and ProCAKE (Bergmann et al., 2019) is published
on the paper page. To enable comparative evaluation,
it is also considered that training-, valid- and test-
datasets can be built with different degrees of seman-
tic enrichment: 1) without any enrichment, 2) with
invoice issuer name enrichment, 3) with service de-
scription enrichment, and 4) with both, invoice issuer
name and service description enrichment (denoted as
full enrichment for short).
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
448

4.1.1 Evaluation Setup AnyBURL
Accordingly, with AnyBURL (Meilicke et al., 2024),
32 (4×8) models have been trained which then have
been evaluated on the 32 test datasets. Because Any-
BURL does not require any hyperparameter optimiza-
tion (Meilicke et al., 2024), and in line with the orig-
inal AnyBURL evaluation (Meilicke et al., 2019), the
valid datasets were also not used here. For experi-
ments, the latest version 2023 was applied
3
. Rules
have been learnt for 100 seconds because longer time
spans did not result in increased performance. All
default parameters have been applied except for the
maximum length of cyclic and acyclic rules. This
parameter was increased from 2 to 3 because enrich-
ments are this one hop deeper in the graph which oth-
erwise would not have been considered by the rule
learner. Furthermore, because we only want to pre-
dict :hasAccount relations, rules have been learnt
for this single relation. Finally, rules have been ap-
plied to predict hits @1 to hits @10 for each tuple
⟨n
′′
, {: hasAccount}, n
′′′
⟩ in KG
Test
.
4.1.2 Evaluation Setup ProCAKE
For ProCAKE (Bergmann et al., 2019) however, the
valid datasets have been used for optimizing hyper-
parameters. Here, hyperparameters are the weights
w
1,2...5
∈ R of the similarity function S
aggregate
as de-
scribed in Section 3.3.2. For optimization, ’random
search’ (Rastrigin, 1963) was applied where for each
training set models have been learnt and then have
been evaluated on the respective valid dataset. The
hyperparameter configuration with the best perfor-
mance on the valid dataset was then used for evaluat-
ing the trained model on the test dataset. Depending
on the enrichment level, weights of other enrichments
have been set to zero. Account solutions of the top 1
to top 10 most similar retrieved cases have then been
used to calculate hits @1 to hits @10.
4.1.3 Evaluation Setup Combination of
ProCAKE and AnyBURL
The evaluation setup of the approach where expert
knowledge from the CBR system is combined with
AnyBURL (Meilicke et al., 2024) was conducted
as follows. First, with custom evaluation code, the
performance of the AnyBURL-model of every fold
was evaluated on the valid dataset so that the per-
formance for each account was evaluated separately.
Then, the top 5 most frequently underperforming ac-
counts have been considered for increasing the per-
formance by integrating expert knowledge into Pro-
3
https://web.informatik.uni-mannheim.de/AnyBURL/
CAKE (Bergmann et al., 2019). This was done with
the procedure described in Section 3.3.3. Next, CBR
with additional expert knowledge was iteratively eval-
uated on the valid datasets, and with the final set of ex-
pert knowledge evaluated on the test datasets. Finally,
the predictions of AnyBURL on the test datasets have
been evaluated again but with consideration of expert
knowledge coming from the CBR system. Because
we were interested whether the combined approach is
on the one hand feasible and on the other hand is able
to increase the overall performance, and because of
higher manual effort in providing expert knowledge,
the presented procedure was conducted on the fully
enriched scenario but on all eight training,- valid- and
test-datasets. Also with this procedure, hits @1 to hits
@10 have been calculated.
4.2 Performance
All experiments were conducted with a laptop having
an Intel(R) Core(TM) i7-10750H CPU @2.60GHz
and 32GB RAM. As reported, rules have been learnt
by AnyBURL for 100 seconds. Applying the learnt
models which contained 34420 rules on average on
one test fold, which contained ca. 400 :hasAccount
relations, took on average 37211ms (full enrichment
scenario). For CBR, applying models with concrete
weights on one fold took on average 1257ms (also full
enrichment scenario). Enriching the whole account-
ing knowledge graph with service description topics
(as illustrated in Figure 2) took 3957ms and with in-
voice issuer topics 775ms. Applying Algorithm 1 for
topic extraction took 401ms for the whole knowledge
graph (351ms for service descriptions and 50ms for
invoice issuer names).
4.3 Evaluation Results
Table 2 summarizes the evaluation results. As shown
in Figure 3, eight models have been learnt and vali-
dated for each level of semantic enrichment (32 mod-
els AnyBURL (Meilicke et al., 2024) and 32 mod-
els ProCAKE (Bergmann et al., 2019)). Accordingly,
means for hits @1 to hits @5 and hits @10 are de-
picted. For the full enrichment scenario, results for in-
cluding expert knowledge from ProCAKE into Any-
BURL are depicted as well as the increase of percent
points when using full enrichments compared to no
enrichments.
Knowledge Graph Enrichments for Credit Account Prediction
449

Table 2: Evaluation results for credit account prediction with four different degrees of semantic enrichment.
hits@1 hits@2 hits@3 hits@4 hits@5 hits@10
Without Enrichment
ProCAKE (Bergmann et al., 2019) .4143 .4913 .5362 .5627 .5970 .6690
standard deviation .0686 .0561 .0464 .0470 .0428 .0380
AnyBURL (Meilicke et al., 2024) .4827 .5789 .6277 .6621 .6863 .7877
standard deviation .0284 .0291 .0379 .0361 .0376 .0403
Invoice Issuer Enrichment
ProCAKE (Bergmann et al., 2019) .4722 .5538 .5910 .6200 .6477 .7200
standard deviation .0660 .0544 .0498 .0508 .0451 .0329
AnyBURL (Meilicke et al., 2024) .5027 .6079 .6579 .6885 .7118 .8062
standard deviation .0414 .0306 .0329 .0435 .0487 .0435
Service Description Enrichment
ProCAKE (Bergmann et al., 2019) .5111 .5802 .6193 .6445 .6652 .7270
standard deviation .0516 .0455 .0465 .0444 .0446 .0408
AnyBURL (Meilicke et al., 2024) .5273 .6321 .6803 .7083 .7313 .8087
standard deviation .0368 .0438 .0448 .0478 .0486 .0419
Invoice Issuer Enrichment and
Service Description Enrichment
ProCAKE (Bergmann et al., 2019) .5387 .6145 .6464 .6786 .6977 .7528
standard deviation .0518 .0413 .0439 .0405 .0383 .0360
AnyBURL (Meilicke et al., 2024) .5333 .6462 .6956 .7243 .7446 .8231
standard deviation .0382 .0428 .0448 .0511 .0525 .0445
Expert Knowledge from ProCAKE
(Bergmann et al., 2019) combined with
AnyBURL (Meilicke et al., 2024) .5400 .6522 .7013 .7300 .7504 .8285
∆ percent points between no to
full enrichment for ProCAKE
(Bergmann et al., 2019) 12.45% 12.32% 11.02% 11.59% 10.07% 8.38%
∆ percent points between no to
full enrichment for AnyBURL
(Meilicke et al., 2024) 5.06% 6.73% 6.79% 6.21% 5.83% 3.54%
5 DISCUSSION
5.1 Comparison Between no and Full
Enrichment
According to Table 2, one key-finding is that for both,
ProCAKE (Bergmann et al., 2019) and AnyBURL
(Meilicke et al., 2024), applying both enrichments in-
creases the performance for hits @1 to hits @5 com-
pared to not having enrichments available. Overall,
the effect of using both enrichments is for ProCAKE
double as high as for AnyBURL. This may be due to
the comparable low performance of the CBR System
when having no enrichments available, and the bet-
ter capability of the rule learner to deal with less use-
ful information by generating still more fine-grained
rules. By looking at concrete predictions generated
by ProCAKE and AnyBURL in the no-enrichment
scenario, it is observable that big groups of three to
six accounts with the same confidence values are pre-
dicted. When enrichments come in, these big groups
disappear, and both approaches successfully handle to
make more fine-grained distinctions. This may also
explain why the effect of enrichments is less for hits
@10 compared to hits @1 to hits @5. However, con-
sidering our rationale of assisting accountants by sug-
gesting a range of predictions, especially hits @3 to
hits @5 are relevant.
5.2 Comparison Between Invoice Issuer
and Service Description Enrichment
As depicted in Table 2, another finding is that for both,
CBR and AnyBURL (Meilicke et al., 2024), also sin-
gle enrichments of invoice issuer names and service
descriptions result in a performance increase. This
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
450

indicates that these enrichments on their own are use-
ful. However, it is notable that service description en-
richments have a bigger impact on the performance
increase than invoice issuer enrichments. This is in-
teresting because during hyperparameter optimization
for the similarity function S
aggregate
in CBR (see Sec-
tion 4.1), we observed that when having no enrich-
ments available, then the invoice issuer name was
typically weighted higher than the service descrip-
tion, which implies that in this case the invoice issuer
name was more useful. However, in line with the ob-
served results, when having both enrichments avail-
able, then the service description enrichments typi-
cally have been weighted higher than invoice issuer
enrichments. The reason may lie on the one hand
in the higher variance of service description strings
compared to invoice issuer names, which implies that
service descriptions can be better used for making dis-
tinctions, and on the other hand, in the higher number
of tokens in service descriptions which results in more
enrichments. This indicates that when applying the
enrichments on invoice data, the usefulness may be
dependent on the variance of the set of strings, which
is typically higher for service descriptions and less
for invoice issuer names. In our data, there are twice
as many distinct service descriptions as invoice issuer
names. To conclude, considering the special charac-
teristics of such strings described in Section 3.1, re-
sults in Table 2 indicate that in such cases knowledge
graph enrichments may have an impact on predictive
performance.
5.3 Combining Expert Knowledge from
CBR with Rule-Based LP
By following the procedure described in Section
3.3.3, including expert knowledge in CBR and com-
bining this with AnyBURL (Meilicke et al., 2024)
yields overall the best results. With this, one find-
ing is that it is feasible to enhance rule-based-LP by
including expert knowledge in a way so that intended
account solutions are returned, and at the same time
false positives can be mostly avoided.
The following extensions may be beneficial to
increase the performance on KG
Test
further. First,
the integration of more fine-grained expert knowl-
edge which is contained in accounting handbooks. In
this way, more expert knowledge would be available
which may trigger on unseen invoicing cases. Sec-
ond, the consideration of not only top 5 underper-
forming accounts but more. Analogously, more ac-
counts would be covered by expert knowledge which
increases the chance of coverage on unseen data. We
restricted to top 5 underperforming accounts because
for cross-fold evaluation, the procedure of bringing in
expert knowledge needed to be manually executed 40
times (5 × 8 because of top five underperforming ac-
counts and eight training-, valid-, and test- datasets).
Third, the consideration of more dimensions from the
invoice data, such as individual invoice position lines,
in order to use them as information for applying ex-
pert knowledge.
6 CONCLUSION AND OUTLOOK
The research questions of this paper were how to pre-
dict credit accounts using knowledge graphs with ap-
proaches that can provide explanations and traceable
predictions, and how to improve such predictions by
enriching accounting knowledge graphs with internal
data. With a three main-step pipeline, it was shown
how accounting knowledge graphs can be constructed
and leveraged for predicting accounts by using rule-
based link prediction, case-based reasoning, and a
combination of both. Such approaches have in com-
mon that they can explain and trace back predictions.
Furthermore, it was shown how accounting knowl-
edge graphs can be enriched from internal data al-
ready available in the knowledge graph so that pre-
diction performance increases. Regarding evaluation,
it was highlighted to preserve the order of received in-
voices: on the one hand because of the time-series na-
ture of invoices, and on the other hand, to gain more
realistic insights when aiming to deploy such a sys-
tem. Furthermore, to apply the pipeline and the eval-
uation on own invoice data, all resources are available
at our paper page. Because related work did not pub-
lish source code of their approaches so far, with this
contribution it is now possible to use the provided re-
sources as a first baseline for future work. The usage
of basic invoice information and with that little pre-
processing necessary may facilitate this.
For future work, research on the perceived useful-
ness of different explanation styles provided by CBR
and rule-based-LP approaches can be fruitful. This is
particularly interesting considering the findings that
CBR and rule-based-LP produce similar prediction
results when having both enrichments available. Also,
while explanations in form of similar cases and corre-
sponding similarity values are in the context of CBR
conceptually rather straight forward, in the context of
rule learners it poses another challenge to aggregate
and represent a set of rules from a prediction in a
way so that they are meaningful and useful for daily
knowledge work.
Knowledge Graph Enrichments for Credit Account Prediction
451

ACKNOWLEDGEMENTS
We would like to thank our business partner for
the fruitful cooperation and all the support. We
thank Christian Zeyen for CBR-related discussions
and valuable feedback. We also thank Mahta
Bakhshizadeh, Desiree Heim, Christian Jilek, Heiko
Maus, and Markus Schr
¨
oder for fruitful discussions
and inspiration. Finally, we would like to thank
anonymous reviewers for their valuable feedback.
REFERENCES
Antoniou, G. and van Harmelen, F. (2004). Web ontology
language: OWL. In Handbook on Ontologies, Interna-
tional Handbooks on Information Systems, pages 67–
92. Springer.
Bardelli, C., Rondinelli, A., Vecchio, R., and Figini, S.
(2020). Automatic electronic invoice classification us-
ing machine learning models. Mach. Learn. Knowl.
Extr., 2(4):617–629.
Belskis, Z., Zirne, M., and Pinnis, M. (2020). Features
and methods for automatic posting account classifi-
cation. In Databases and Information Systems - 14th
Intern. Baltic Conf., volume 1243 of Communications
in Computer and Information Science, pages 68–81.
Springer.
Belskis, Z., Zirne, M., Slaidins, V., and Pinnis, M. (2021).
Natural language based posting account classification.
Balt. J. Mod. Comput., 9(2).
Bergmann, R., Grumbach, L., Malburg, L., and Zeyen, C.
(2019). Procake: A process-oriented case-based rea-
soning framework. In Workshops Proc. for (ICCBR
2019), Otzenhausen, Germany, September 8-12, 2019,
volume 2567 of CEUR Workshop Proceedings, pages
156–161. CEUR-WS.org.
Bergmeir, C. and Ben
´
ıtez, J. M. (2012). On the use of
cross-validation for time series predictor evaluation.
Inf. Sci., 191:192–213.
Ehrlinger, L. and W
¨
oß, W. (2016). Towards a definition of
knowledge graphs. In Joint Proc. of the Posters and
Demos Track of SEMANTiCS2016, Leipzig, Germany,
September 12-15, 2016, volume 1695 of CEUR Work-
shop Proceedings. CEUR-WS.org.
Gr
¨
uninger, M. and Fox, M. S. (1995). The role of compe-
tency questions in enterprise engineering. pages 22–
31. Springer US, Boston, MA.
Hart, P. E., Nilsson, N. J., and Raphael, B. (1968). A formal
basis for the heuristic determination of minimum cost
paths. IEEE Trans. Syst. Sci. Cybern., 4(2):100–107.
Jain, K. and Woodcock, E. (2017). A road map for digitiz-
ing source-to-pay. McKinsey.
Koch, B. (2019). The e-invoicing journey 2019-2025.
billentis GmbH.
Kolodner, J. L. (2014). Case-Based Reasoning. Morgan
Kaufmann.
Lazar, J., Feng, J., and Hochheiser, H. (2017). Research
Methods in Human-Computer Interaction, 2nd Edi-
tion. Morgan Kaufmann.
Levenshtein, V. I. (1966). Binary codes capable of cor-
recting deletions, insertions, and reversals. In Soviet
physics doklady, volume 10, pages 707–710.
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D.,
Levy, O., Lewis, M., Zettlemoyer, L., and Stoyanov,
V. (2019). Roberta: A robustly optimized BERT pre-
training approach. CoRR, abs/1907.11692.
Meilicke, C., Chekol, M. W., Betz, P., Fink, M., and
Stuckenschmidt, H. (2024). Anytime bottom-up rule
learning for large-scale knowledge graph completion.
VLDB J., 33(1):131–161.
Meilicke, C., Chekol, M. W., Ruffinelli, D., and Stucken-
schmidt, H. (2019). Anytime bottom-up rule learn-
ing for knowledge graph completion. In Proceedings
of IJCAI 2019, Macao, China, August 10-16, 2019,
pages 3137–3143. ijcai.org.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., and
Dean, J. (2013). Distributed representations of words
and phrases and their compositionality. In Proc. of
27th Annual Conference on Neural Information Pro-
cessing Systems 2013. Lake Tahoe, Nevada, United
States, pages 3111–3119.
Panichi, B. and Lazzeri, A. (2023). Semi-supervised classi-
fication with a*: A case study on electronic invoicing.
Big Data Cogn. Comput., 7(3):155.
Poveda-Villal
´
on, M., G
´
omez-P
´
erez, A., and Su
´
arez-
Figueroa, M. C. (2014). Oops! (ontology pitfall scan-
ner!): An on-line tool for ontology evaluation. Int. J.
Semantic Web Inf. Syst., 10(2):7–34.
Rastrigin, L. A. (1963). The convergence of the ran-
dom search method in the extremal control of a many
parameter system. Automaton & Remote Control,
24:1337–1342.
Schulze, M., Pelzer, M., Schr
¨
oder, M., Jilek, C., Maus, H.,
and Dengel, A. (2022). Towards knowledge graph
based services in accounting use cases. In Proceed-
ings of Poster and Demo Track of SEMANTiCS 2022,
Vienna, Austria, September 13th to 15th, 2022, vol-
ume 3235 of CEUR. CEUR-WS.org.
Schulze, M., Schr
¨
oder, M., Jilek, C., Albers, T., Maus,
H., and Dengel, A. (2021). P2P-O: A purchase-to-
pay ontology for enabling semantic invoices. In The
Semantic Web, ESWC 2021, Virt. Event, June 6-10,
2021, Proc., volume 12731 of LNCS, pages 647–663.
Springer.
Su
´
arez-Figueroa, M. C., G
´
omez-P
´
erez, A., and Fern
´
andez-
L
´
opez, M. (2015). The neon methodology framework:
A scenario-based methodology for ontology develop-
ment. Appl. Ontology, 10(2):107–145.
Valle, E. D. and Ceri, S. (2011). Querying the semantic
web: SPARQL. In Handbook of Semantic Web Tech-
nologies, pages 299–363. Springer.
World Wide Web Consortium (2014a). The organization
ontology, http://www.w3.org/tr/vocab-org/.
World Wide Web Consortium (2014b). Rdf 1.1 primer,
http://www.w3.org/tr/2014/note-rdf11-primer-
20140624/.
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
452
