
Using Machine Learning to Analyze the Impact of Lifestyle and
Socioeconomic Factors on the Incidence of Depression Among Young
Brazilians
Thayris G. F. Rodrigues
a
, Ariane C. B. da Silva
b
and Cristiane N. Nobre
c
Institute of Exact Sciences and Informatics, Pontifical Catholic University of Minas Gerais,
Dom Jos
´
e Gaspar, Belo Horizonte, Brazil
Keywords:
Depression, Adolescence, Children, Machine Learning, Instance Selection.
Abstract:
Depression is a growing mental health problem among young people in Brazil, with factors such as socioe-
conomic and lifestyle conditions influencing its prevalence. This study investigates how variables such as
education, family situation, and access to services impact the incidence of depression, using data from the
National Health Survey (PNS) of the Brazilian Institute of Geography and Statistics (IBGE). Using machine
learning algorithms such as Random Forest, XGBoost, SVM, and MLP, the analysis identified patterns among
the factors, highlighting sleep problems and depressive feelings as the main determinants, with Recall above
70%. These results support the creation of more inclusive mental health policies.
1 INTRODUCTION
Depression is one of the most prevalent mental dis-
orders worldwide, representing a significant concern
in the Brazilian context, especially among young peo-
ple, which saw an increase of 11.1.
In Brazil, depression is a public health concern.
The World Health Organization (WHO) estimates that
350 million people live with the disease, with Brazil
being the second country with the highest prevalence
in the Americas (Abelha, 2014), affecting a signif-
icant portion of the population. However, accord-
ing to estimates from the United Nations Children’s
Fund (UNICEF), the understanding of the specific de-
terminants of depression among Brazilian youth is
still limited, and the number of these young people
is very high, with almost 16 million between the ages
of 10 and 19 having some mental disorder (UNICEF,
2022).
The central problem motivating this research is
the high prevalence of depression among Brazilian
youth and the lack of comprehensive understanding
of the factors contributing to this condition (Fonseca
et al., 2008). Depression not only affects the mental
and emotional health of young people but can also
a
https://orcid.org/0009-0008-2380-9634
b
https://orcid.org/0000-0003-2477-4433
c
https://orcid.org/0000-0001-8517-9852
have significant impacts on their personal relation-
ships, academic and professional performance. Addi-
tionally, the stigma surrounding depression often hin-
ders access to proper treatment and the necessary sup-
port for those suffering from this condition. These
factors can be observed in the works of (Santos and
Kassouf, 2007) and (Brito, 2011).
This study aims to investigate the relationship be-
tween depression and socioeconomic and lifestyle
factors among Brazilian youth aged 15 to 29, a demo-
graphic defined as youth by the Youth Statute (da Ju-
ventude, 2015). Using data from the National Health
Survey (PNS) by the Brazilian Institute of Geogra-
phy and Statistics (IBGE), the research seeks to un-
derstand how variables such as residence, education,
family situation, ethnicity, and access to public health
services influence the prevalence of depression. By
focusing specifically on the Brazilian context, this
study aims to contribute to mental health policies and
preventive interventions targeted at this population.
This work is organized as follows: Section 2
presents the theoretical framework, addressing the
main concepts and studies on depression in Brazil and
worldwide, and on depression among young people.
Section 3 discusses related works, highlighting re-
search focusing on depression among Brazilian youth.
Section 4 provides a description of the methodology
used, including the data source and the criteria for
variable selection. Section 5 presents the results of
Rodrigues, T. G. F., B. da Silva, A. C. and Nobre, C. N.
Using Machine Learning to Analyze the Impact of Lifestyle and Socioeconomic Factors on the Incidence of Depression Among Young Brazilians.
DOI: 10.5220/0013185600003911
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 18th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2025) - Volume 2: HEALTHINF, pages 639-646
ISBN: 978-989-758-731-3; ISSN: 2184-4305
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
639

the analysis, followed by the discussion of these re-
sults. Finally, in Section 6, the study concludes, sug-
gesting directions for future research and implications
for public policies.
2 THEORETICAL FRAMEWORK
2.1 Depression in Brazil and the World
Depression is a mental illness characterized by per-
sistent sadness, loss of interest in activities once en-
joyed, and a range of emotional and physical symp-
toms. According to the World Health Organization
(WHO), Brazil stands out with one of the highest de-
pression prevalence rates in the world, being the fifth
country with the most cases of the disease. It is esti-
mated that about 5.8% of the Brazilian population suf-
fers from depression, which represents approximately
11.7 million people, showing that Brazil is above the
global average of around 4.4% (World Health Orga-
nization, 2017).
According to this same study, in the context of the
Americas, Brazil holds an alarming position, being
behind only the United States, where 5.9% of the pop-
ulation is affected by depression. These data highlight
the severity of the situation and the urgent need for ef-
fective public policies to tackle depression.
Moreover, in this same WHO study, it is empha-
sized that depression is one of the leading causes of
disability worldwide and has profound impacts on
productivity and economic costs due to lost workdays
and associated disabilities. The lack of proper treat-
ment and its consequences are also recurring themes
in this research (World Health Organization, 2017).
Furthermore, the article by Rakel (1999) discusses
the prevalence and challenges in treating depression
in primary care. It emphasizes that depression is often
underdiagnosed and undertreated. Patients with de-
pression frequently present physical symptoms, such
as fatigue, insomnia, and unexplained pain, which can
hinder the correct diagnosis. The author also high-
lights that the longer a depressive episode lasts, the
greater the likelihood of recurrence, underscoring the
importance of appropriate and early treatment.
2.2 Depression Among Young People
Depression is one of the most prevalent mental disor-
ders among young people, with a significant increase
in incidence rates during adolescence and early adult-
hood. This stage of life is marked by various transi-
tions and challenges that can make young individu-
als particularly vulnerable to mental health problems
(Thapar et al., 2022).
Several risk factors contribute to the development
of depression in this age group, with psychosocial
stress playing a central role. Experiences such as diffi-
culties in social relationships are particularly impact-
ful (Smith and Blackwood, 2004). These risk factors
not only increase the likelihood of developing depres-
sion but can also exacerbate the condition in already
vulnerable individuals.
The impacts of depression on young people are
extensive and profound, affecting various aspects of
their lives. Depression can compromise academic
performance, leading to educational difficulties that,
in turn, increase the risk of reliance on social assis-
tance and unemployment in adulthood (Thapar et al.,
2022). Beyond the direct effects on mental health,
these challenges can hinder individuals’ social and
economic development, creating a cycle of adversity
that is difficult to break.
A particularly concerning aspect of depression in
young people is its tendency to recur. While many
young individuals may recover from a depressive
episode within a year, depression often becomes a
chronic condition with high relapse rates. Factors
such as comorbidities and social adversity are predic-
tors of a worse prognosis, complicating full recovery
and increasing the need for continuous interventions
(Carr, 2008).
Moreover, the growing prevalence of depression,
both in its milder forms and in Major Depressive Dis-
order (MDD), during adolescence and early adult-
hood underscores the need for more effective preven-
tion and treatment strategies. Studies indicate that
the global prevalence of MDD among children and
adolescents is approximately 1.3%, though this figure
tends to be higher in the older age groups within this
population (Thapar et al., 2022).
3 RELATED WORK
Depression is an extremely relevant topic and, accord-
ing to Barbosa et al. (2011), still faces resistance in
debate and knowledge production. Healthcare pro-
fessionals often lack adequate information for the de-
tection and management of depression, especially in
severe cases.
The increasing rates of depression among young
adults, as noted by Barbosa et al. (2011), are alarm-
ing. Studies such as Carneiro Pinto (2015) indi-
cate that factors like gender, age, and education level
may not result in significant differences in emo-
tional symptoms related to depression, highlighting
HEALTHINF 2025 - 18th International Conference on Health Informatics
640

the importance of comprehensive analyses. In Brazil,
Gonc¸alves et al. (2018) found that low education lev-
els and physical inactivity are associated with depres-
sion in women, while living with a partner and engag-
ing in physical exercise act as protective factors. Ad-
ditionally, Emerson and Llewellyn (2023) point out
that about 20
Furthermore, Maia et al. (2023) demonstrate that
Machine Learning techniques can identify risk fac-
tors for depression among Brazilian youth, provid-
ing support for public policies. However, they high-
light ethical challenges in using such technologies.
Therefore, policies that consider the social determi-
nants of depression and train healthcare professionals
for proper interventions are essential (Santos and Kas-
souf, 2007). Early intervention programs and contin-
uous support are crucial, especially for young people
(Brito, 2011).
After reviewing related studies, it is essential to
acknowledge that each offers valuable insights into
youth depression. However, it is important to high-
light that these studies have certain limitations that
our work can address more comprehensively. It is
necessary to recognize limitations such as small sam-
ple sizes, specific focuses, or the absence of longitudi-
nal data. Table 1 presents comparisons and limitations
of each study.
This study’s proposal stands out by specifically
addressing depression among Brazilian youth and
identifying specific factors that may cause this con-
dition. It aims to contribute to the field by broadening
existing perspectives, overcoming the limitations of
related works, and exploring new aspects of youth de-
pression, such as violence, socioeconomic conditions,
and access to mental health services.
4 MATERIALS AND METHODS
4.1 Database Description
The research was based on the National Health Sur-
vey (PNS) Database, a nationwide household sur-
vey conducted by the Ministry of Health (MS) and
the Brazilian Institute of Geography and Statistics
(IBGE). For this study, the most recent version of the
PNS, from the year 2019, was utilized. This version
offers comprehensive information on various sociode-
mographic, behavioral, and health characteristics, in-
cluding data related to depression. The original 2019
PNS database comprises 1,087 attributes and 293,726
instances.
The primary objective of this study is to analyze
the occurrence of depression among Brazilian youth.
For this purpose, the central attribute used for filtering
the instances was Q092, which indicates whether a
physician or mental health professional has ever diag-
nosed the respondent with depression. All instances
where this attribute was absent were excluded from
the analysis. Additionally, the attribute C008, which
refers to the age of the household member on the ref-
erence date, was used as a filtering criterion to restrict
the analysis to youth aged 15 to 29 years, as defined
by the Statute of Youth (da Juventude, 2015).
From the original 1,087 attributes, the most rel-
evant ones were selected based on the risk factors
associated with depression, as identified in previous
studies such as Sim
˜
oes (2021). After filtering the
instances and selecting the attributes of interest, the
resulting dataset contained 63,260 instances (62,334
without a depression diagnosis and 926 with a depres-
sion diagnosis) and 32 attributes. Table 2 provides a
detailed breakdown of these attributes and their re-
spective descriptions.
4.2 Methodology
During Step 0, we performed several preprocessing
steps to reduce noise in the database, including han-
dling duplicates, removing outliers, and managing
missing values. We also analyzed the correlation of
attributes with the class to eliminate redundancies.
These actions were carried out carefully to ensure that
the database was clean and organized before applying
machine learning algorithms. This ensured that the
models were trained on more representative and ro-
bust data, minimizing distortions.
In Step 1, we further analyzed the dataset and
made additional adjustments by removing attributes
with incomplete information or few responses. We
also merged some attributes and their responses to ob-
tain more consistent variables, improving the quality
of the data. By the end of this step, the dataset con-
tained 27,701 instances, of which 26,775 had no de-
pression diagnosis, 926 had a positive diagnosis, and
24 attributes.
After preprocessing, we split the dataset into 80%
for training and 20% for testing, with stratification to
maintain the correct proportion between cases with
and without a depression diagnosis. We applied strat-
ified cross-validation with 10 iterations (StratifiedK-
Fold), using the average of the results to represent
model performance. This process was essential for
a more reliable evaluation of the models during hy-
perparameter tuning, improving the robustness of the
results.
Additionally, we used the Ant Colony-based in-
stance and attribute selection technique (RantIFS). In-
Using Machine Learning to Analyze the Impact of Lifestyle and Socioeconomic Factors on the Incidence of Depression Among Young
Brazilians
641

Table 1: Comparison of related works.
Reference Main Contributions Limitations
Santos and
Kassouf (2007)
Need for comprehensive mental health policies that include social
determinants
Broad focus, with little em-
phasis on specific strategies for
young people
Fonseca et al.
(2008)
Gender differences in the perception of depression and the influence
of the socio-affective context
Focus on reactive depression
and limited sample; suggests
broader scope in future studies
Barbosa et al.
(2011)
Identification of resistance in the debate on depression and the
alarming increase in depression rates among young adults
General approach, without a
specific focus on Brazilian
youth or cultural/regional
factors
Carneiro Pinto
(2015)
Study in Portugal showing that gender, age, and education do not
significantly influence emotional symptoms
Study conducted in another
country; results may not be di-
rectly applicable to the Brazil-
ian context
Gonc¸alves et al.
(2018)
Identification of specific risk factors for depression in Brazilian
women
Limited focus on women aged
20 to 59 years and specific geo-
graphic area
Emerson and
Llewellyn
(2023)
Detailed analysis of the relationship between depression, disability,
and lifestyle factors in young people from low and middle-income
countries.
The study presents a global
approach, without an analy-
sis focused on the cultural
and socioeconomic specifics of
Brazilian youth.
Maia et al.
(2023)
Use of Machine Learning to identify profiles and key factors of de-
pression in Brazil.
Ethical challenges and limi-
tations in data interpretation;
no specific focus on Brazilian
youth
stances from the majority class were selected with
a 70% probability to ensure representative samples,
and attribute selection was performed after combining
the selected instances. This approach helped reduce
the impact of class imbalance. The use of the Ant
Colony was crucial for optimizing the most relevant
instances and features. After this step, the database
contained 16,723 instances (15,797 without depres-
sion diagnosis and 926 with a positive diagnosis) and
15 attributes. Table 3 shows the number of instances
per class for training/validation and testing.
In Step 2, we trained various machine learning
algorithms, including Decision Tree Classifier, Ran-
dom Forest Classifier, Gradient Boosting Classifier,
XGBoost Classifier, MLPClassifier, and SVM (Sup-
port Vector Machine). To optimize performance,
we applied advanced hyperparameter tuning tech-
niques such as GridSearchCV combined with strat-
ified cross-validation (StratifiedKFold). These tech-
niques ensured an efficient search for the best hy-
perparameters, significantly improving model perfor-
mance.
Additionally, we addressed class imbalance us-
ing a combination of Undersampling and Oversam-
pling. First, we applied Random Undersampling
to reduce the majority class samples without exces-
sive loss of relevant information. Then, we used
the G SM1 method to generate synthetic samples for
minority classes, considering nearby neighbors and
adding controlled noise for diversity.
After balancing, we normalized the data with
StandardScaler to standardize the variable scales,
promoting better convergence of the models during
training.
Step 3 consisted of evaluating the trained classi-
fiers using metrics such as Precision
1
, Recall
2
and F1-
Score
3
to assess model performance. Precision is the
proportion of instances correctly classified as positive
out of all predicted as positive, assessing the model’s
precision in predictions. Recall measures the percent-
age of positive instances correctly identified by the
model, indicating its ability to detect relevant exam-
ples. F1-Score is the harmonic mean between Pre-
cision and Recall, balancing these metrics, especially
when there is a trade-off between them. These metrics
provided a detailed analysis of the algorithms’ effec-
tiveness in correctly predicting the classes.
Finally, in Step 4, we focused on interpreting
the generated models, analyzing the results obtained.
This phase was crucial for evaluating the performance
of the algorithms after applying data preprocessing
and balancing techniques. We examined the impact
of these techniques on performance metrics such as
precision, recall, and F1-score. The analysis allowed
us to identify the best model and understand the in-
fluence of each technique, enabling adjustments for
future iterations.
1
Precision =
T P
T P+FP
2
Recall =
T P
T P+FN
3
F1-Score = 2 ×
Precision×Recall
Precision+Recall
HEALTHINF 2025 - 18th International Conference on Health Informatics
642

Table 2: Description of Attributes.
Attribute Description Reference
Individual Characteristics
Age Refers to the chronological age of individuals. C008
Race Refers to the racial identification of individuals. C009
Gender Refers to the gender of the individual, which can be male or female. C006
Marital Status Indicates the current marital status of the individual (single, married, divorced,
widowed, etc.).
C011
Socioeconomic Conditions
Literacy Indicates whether the individual is literate, that is, whether they can read and
write.
D001
Education Level Refers to the highest level of formal education achieved by the individual. VDD004A
Health Insurance Indicates whether the individual has health insurance. I00102
Lifestyle
Frequency of Sluggish-
ness or Agitation
Refers to the frequency with which the individual feels sluggish or agitated in
their daily life.
N015
Sleep Problems Refers to difficulties in falling asleep or maintaining continuous sleep. N010, N011
Depressive Feelings Indicates the presence of feelings related to depression, such as persistent sad-
ness.
N016, N017,
N018
Screen Time Refers to the amount of time the individual spends using electronic devices with
screens (cell phone, computer, television, etc.).
P04501, P04502
Alcohol Consumption Refers to the frequency and quantity of alcohol consumed by the individual. P02801
Smoking Indicates whether the individual is a smoker and the frequency of tobacco con-
sumption.
P050
Health Conditions
Disabilities Refers to the presence of any type of physical, sensory, or mental disability. G033, G048,
G066
Mental Health Indicates the general mental health condition of the individual. Q092
General Health Condi-
tion
Refers to the individual’s perception of their own health, both physical and men-
tal.
J001, J00101,
J001
Violence
Insults or Threats Refers to the frequency with which the individual experiences verbal insults or
threats.
V00201,
V00202
Intimidation or Aggres-
sion
Indicates the frequency of intimidation or physical aggression experienced by
the individual.
V00204,
V01401,
V01402,
V01403
Sexual Aggression Refers to the occurrence of any type of sexual violence experienced by the indi-
vidual.
V02801,
V02802
Table 3: Dataset at different processing stages.
Class Original Dataset Filtered by Age Post Preprocessing Unbalanced Training Balanced Training Test Set
Diagnosed 8,332 926 926 741 1,895 185
Not Diagnosed 82,514 62,334 26,775 12,637 1,895 3,160
Total 90,846 63,260 27,701 13,378 3,790 3,345
4.3 ML Algorithms
As for the ML algorithms, after the preprocessing
stage, the training set was used for the training of six
classification algorithms: DT (criterion: entropy, max
depth: 4, max features: None, min samples leaf: 14,
min samples split: 14); XGBoost (colsample bytree:
0.54, gamma: 0.1, learning rate: 0.04, max depth: 5,
min child weight: 1, n estimators: 300, reg alpha:
0.01, reg lambda: 1, subsample: 0.631); Gradient-
Boost (learning rate: 0.01, max depth: 12, n estima-
tors: 300, subsample: 0.9, min samples leaf: 5, min
samples split: 20); SVM (C: 0.502, class weight: bal-
anced, degree: 2, gamma: auto, kernel: rbf); MLP
(activation: relu, alpha: 0.1, hidden layer sizes: 512,
learning rate: adaptive, max iter: 500, solver: adam).
All of them were built using the Scikit-learn library
version 1.0.2 (Pedregosa et al., 2011). The experi-
ments were conducted on the Windows 11 operating
system using an Intel(R) Core(TM) i5-1035G1 pro-
cessor, 1.00 GHz, 8 GB of RAM, and the Jupyter tool
v2022.1.3
Using Machine Learning to Analyze the Impact of Lifestyle and Socioeconomic Factors on the Incidence of Depression Among Young
Brazilians
643

5 RESULTS AND DISCUSSIONS
The results presented in Table 4 show that almost all
the Machine Learning algorithms achieved more than
70% in the Recall metric, indicating significant effi-
ciency in detecting individuals with a depression di-
agnosis. The high Recall, especially in algorithms
such as Random Forest (90%), SVM (85%), and XG-
Boost (77%), suggests that these models were effec-
tive in correctly identifying depression cases based on
the provided socioeconomic, lifestyle, and health at-
tributes.
On the other hand, when observing precision, the
models displayed behavior that suggests a high rate of
false positives, with low values such as 16% in Ran-
dom Forest and 19% in SVM. This means that while
the models correctly identify many true depression
cases (high recall), a significant number of individ-
uals without depression are incorrectly classified as
positive for the condition.
Table 4: Performance of ML Algorithms (in percentage).
Algorithm Precision Recall F1 Class
DT 98 86 91 No diagnosis
AUC 0.86 22 68 33 With diagnosis
RF 99 72 84 No diagnosis
AUC 0.88 16 90 27 With diagnosis
GradientBoost 98 88 92 No diagnosis
AUC 0.85 23 63 33 With diagnosis
XGBoost 98 83 90 No diagnosis
AUC 0.89 21 77 33 With diagnosis
SVM 99 79 88 No diagnosis
AUC 0.87 19 85 31 With diagnosis
MLP 98 85 91 No diagnosis
AUC 0.85 22 73 34 With diagnosis
In studies on depression in young people, sensi-
tivity (Recall) is one of the most important metrics,
as the primary goal is to minimize the number of in-
dividuals incorrectly diagnosed as not having depres-
sion. Failing to identify a depression case can worsen
the patient’s condition, negatively affecting treatment
success. Therefore, it is essential for the model to
have a high Recall rate, ensuring that most individu-
als with a depression diagnosis are detected.
Additionally, discrepancies between Recall and
Precision may be related to the complexity of the
dataset. Depression analysis involves various factors,
such as socioeconomic and health conditions, which
can be difficult to distinguish clearly. The presence
of overlapping attributes may have made it challeng-
ing for the models to differentiate between individuals
with and without a depression diagnosis, resulting in
false positives.
Figure 1 illustrates the instances from the dataset
after dimensionality reduction to 2 dimensions us-
ing the non-linear reduction technique t-distributed
stochastic neighbor embedding (t-SNE). Even after
data balancing, the plots show that the two classes
(with and without a depression diagnosis) still signif-
icantly overlap. This indicates that the separability
between the classes in the represented dimensions is
not very clear, which contributes to the difficulty in
the classification task, directly affecting the models’
performance in terms of Recall and Precision.
5.1 SHAP Chart Analysis
In addition to the quantitative metrics, we performed
an analysis using SHAP (SHapley Additive exPlana-
tions) plots on the model with the best performance
(XGBoost) to interpret the individual impact of each
variable on the model’s predictions. This interpreta-
tive approach was important for understanding how
the features influence the model’s decisions at differ-
ent levels. Figure 2 presents this analysis visually,
showing the relative impact of the variables.
The SHAP graphs showed that the most important
variables for prediction are related to mental health
aspects, especially depression. They played a cen-
tral role in the model’s results, helping identify fac-
tors influencing the classification between diagnosed
and undiagnosed cases. This provided a deeper un-
derstanding of the model’s behavior.
• Sleep Problem Frequency: This variable has a
significant impact on the model’s prediction. Indi-
viduals who report a high frequency of sleep prob-
lems (values in red) are strongly associated with a
higher likelihood of belonging to the positive class
(depression diagnosis). This relationship aligns
with the study by M
¨
uller and Guimar
˜
aes (2007),
which indicates that sleep disturbances are impor-
tant markers of mental health conditions.
• Frequency of Feeling Depressed: Individuals
who frequently report feeling depressed showed
a clear correlation with the positive class (diag-
nosed with depression), confirming that this is one
of the most important indicators.
• Frequency of Slowness or Agitation: This vari-
able also stands out as a strong predictor. Be-
havioral rhythm changes, such as extreme slow-
ness or episodes of agitation, are often associated
with depressive disorders. High frequency (in red)
greatly increases the probability of classification
as positive for depression.
Other variables also played a relevant role in the
model’s prediction. The variable ”Hours on Devices
for Leisure” showed an ambiguous impact: exces-
sive use may be linked to isolation and emotional de-
cline, while moderate use can promote socialization
HEALTHINF 2025 - 18th International Conference on Health Informatics
644
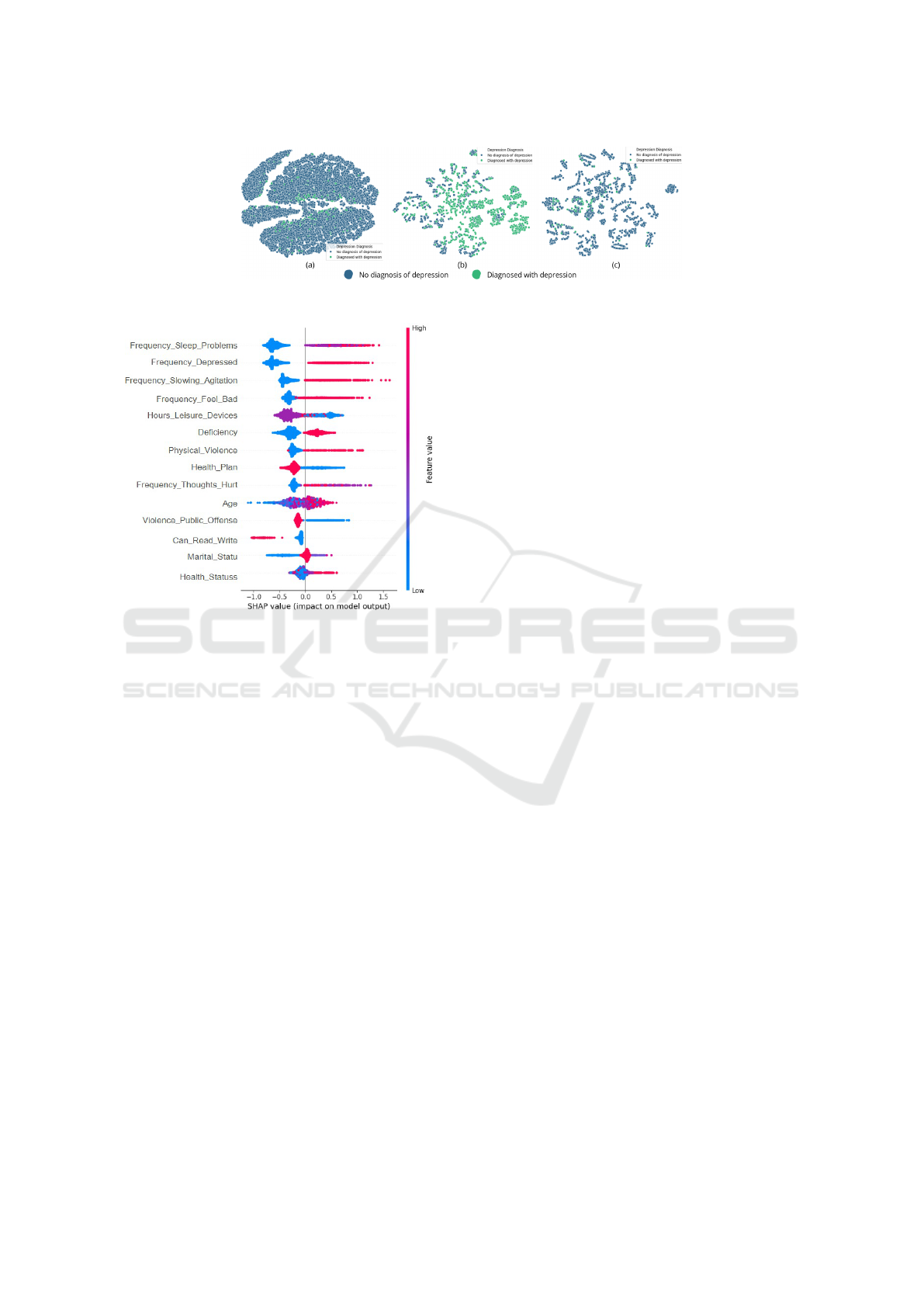
Figure 1: Spatial representation of training and testing sets. (a) Unbalanced database. (b) Balanced database. c) Test Set.
Figure 2: SHAP explanations for the XGBoost model.
and leisure, highlighting that context matters.
Experiences of Physical Violence” showed high
positive SHAP values, indicating an increased prob-
ability of depression in individuals who experienced
physical violence. Such traumas are recognized as
risk factors for mental health issues, with studies
like Bontempo and Pereira (2012) and Pedrosa de
Medeiros (2018) exploring how violence can impact
mental health, particularly in adolescents and Brazil-
ian women, leading to depression.
Finally, variables like ”Health Plan” and ”Disabil-
ity” reflect socioeconomic conditions and personal
challenges that can influence depressive symptoms,
albeit with a subtler impact on the model. These find-
ings underline the importance of considering both in-
dividual and contextual aspects in the interpretation
of results.
6 CONCLUSION
This study investigated the prevalence of depression
among young Brazilians aged 15 to 29, along with
the socioeconomic and lifestyle factors that influence
this condition. Using data from the 2019 National
Health Survey (PNS) and various machine learning
techniques, it was possible to identify relevant pat-
terns among the analyzed variables.
Although the machine learning models performed
well in correctly classifying both young individuals
diagnosed with depression and those without a di-
agnosis, they still faced challenges in identifying all
cases accurately, as reflected in the low Precision val-
ues for undiagnosed cases. However, nearly all mod-
els consistently showed Recall values above 70%,
suggesting that these algorithms were relatively ef-
fective in identifying the majority of diagnosed cases
based on socioeconomic, lifestyle, and health at-
tributes provided as input.
The low Accuracy indicates a higher rate of false
positives, which can be attributed to the complex-
ity of the dataset and the overlap between the ”diag-
nosed” and ”undiagnosed” classes. This overlap com-
promised the algorithms’ ability to clearly distinguish
between individuals with and without a depression di-
agnosis. Furthermore, contextual and subjective fac-
tors influencing the diagnosis may not have been fully
captured by the quantitative variables used, suggest-
ing that more comprehensive data or refined model-
ing techniques are necessary to improve the balance
between Recall and Precision.
The SHAP plot analysis was essential for inter-
preting the importance of variables in the model,
highlighting that factors such as the frequency of
sleep problems and the frequency of feeling depressed
showed a strong correlation with the depression diag-
nosis. On the other hand, variables such as the time
spent on leisure activities with devices showed a more
ambiguous impact, suggesting that contextual and en-
vironmental factors influence the diagnosis in a more
complex manner. These results emphasize the im-
portance of interpretable methods and improving data
quality to more accurately capture the psychological,
social, and contextual aspects that affect depression
diagnosis.
The results of this study highlight the importance
of public policies that expand access to education and
mental health services for young people, especially in
vulnerable areas. Preventive programs and interven-
tions that promote mental well-being are essential to
Using Machine Learning to Analyze the Impact of Lifestyle and Socioeconomic Factors on the Incidence of Depression Among Young
Brazilians
645

reduce depression rates and their impacts.
Future studies should investigate factors such as
culture and social support in youth depression, as well
as use longitudinal data to better understand the evo-
lution of mental health over time. It is also impor-
tant for future work to analyze cases that were in-
correctly classified as positive by the algorithms but
officially do not have the diagnosis. This process
could reveal patterns and characteristics present in
the database that make it difficult to correctly sepa-
rate cases, paving the way for adjustments in models
or data preprocessing, improving the balance between
Recall and Precision.
ACKNOWLEDGMENTS
The authors would like to thank the National Coun-
cil for Scientific and Technological Development of
Brazil (CNPq – Code: 311573/2022-3), the Co-
ordination for the Improvement of Higher Educa-
tion Personnel - Brazil (CAPES - Grant PROAP
88887.842889/2023-00 - PUC/MG, Grant PDPG
88887.708960/2022-00 - PUC/MG - Informatics and
Finance Code 001), the Foundation for Research
Support of Minas Gerais State (FAPEMIG – Codes:
APQ-03076-18 and APQ-05058-23).
REFERENCES
Abelha, L. (2014). Depress
˜
ao, uma quest
˜
ao de sa
´
ude
p
´
ublica. Cadernos Sa
´
ude Coletiva, 22(3):223–223.
Barbosa, F. d. O., Macedo, P. C. M., and Silveira, R. M.
C. d. (2011). Depress
˜
ao e o suic
´
ıdio. Revista da
SBPH, 14:233–243.
Bontempo, K. d. S. and Pereira, A. R. (2012). Sa
´
ude mental
de crianc¸as e adolescentes v
´
ıtimas de viol
ˆ
encia: uma
revis
˜
ao cr
´
ıtica da literatura. Revista de Terapia Ocupa-
cional da Universidade de S
˜
ao Paulo, 23(2):130–136.
Brito, I. (2011). Ansiedade e depress
˜
ao na adolesc
ˆ
encia.
Revista Portuguesa de Medicina Geral e Familiar,
27(2):208–14.
Carneiro Pinto, Joana Martins, P. B. P. T. C. O. A. (2015).
Ansiedade, depress
˜
Ao e stresse: Um estudo com
jovens adultos e adultos portugueses. Psicologia,
Sa
´
ude e Doenc¸as.
Carr, A. (2008). Depression in young people: Descrip-
tion, assessment and evidence-based treatment. De-
velopmental Neurorehabilitation, 11(1):3–15. PMID:
17943506.
da Juventude, E. (2015). Perfil da juventude de ribeir
˜
ao
preto 2015. https://www.ribeiraopreto.sp.gov.br/port
al/pdf/2015-jovem-04202109.pdf. Acesso em: 23 de
maio de 2024.
Emerson, E. and Llewellyn, G. (2023). Parental report of
signs of anxiety and depression in children and adoles-
cents with and without disability in middle- and low-
income countries: Meta-analysis of 44 nationally rep-
resentative cross-sectional surveys. Child Psychiatry
& Human Development.
Fonseca, A. A. d., Coutinho, M. d. P. d. L., and Azevedo, R.
L. W. d. (2008). Representac¸
˜
oes sociais da depress
˜
ao
em jovens universit
´
arios com e sem sintomas para de-
senvolver a depress
˜
ao. Psicologia: Reflex
˜
ao e Cr
´
ıtica,
21:492–498.
Gonc¸alves, A. M. C., Teixeira, M. T. B., Gama, J. R.
d. A., Lopes, C. S., Silva, G. A. e., Gamarra, C. J.,
Duque, K. d. C. D., and Machado, M. L. S. M. (2018).
Preval
ˆ
encia de depress
˜
ao e fatores associados em mul-
heres atendidas pela estrat
´
egia de sa
´
ude da fam
´
ılia.
Jornal Brasileiro de Psiquiatria, 67:101–109.
Maia, C., Nobre, C., Gomes, M., and Z
´
arate, L. (2023).
Using machine learning to identify profiles of indi-
viduals with depression. In Anais do XI Symposium
on Knowledge Discovery, Mining and Learning, pages
105–112, Porto Alegre, RS, Brasil. SBC.
M
¨
uller, M. R. and Guimar
˜
aes, S. S. (2007). Impacto dos
transtornos do sono sobre o funcionamento di
´
ario e a
qualidade de vida. Estudos de Psicologia (Campinas),
24(4):519–528.
Pedrosa de Medeiros, Mariana Zanello, V. (2018). Relac¸
˜
ao
entre a viol
ˆ
encia e a sa
´
ude mental das mulheres no
brasil: an
´
alise das pol
´
ıticas p
´
ublicas. Estudos e
Pesquisas em Psicologia.
Rakel, R. E. (1999). Depression. Primary Care, 26(2):211–
224.
Santos, M. J. d. and Kassouf, A. L. (2007). Uma
investigac¸
˜
ao dos determinantes socioecon
ˆ
omicos da
depress
˜
ao mental no brasil com
ˆ
enfase nos efeitos da
educac¸
˜
ao. Economia Aplicada, 11(1):5–26.
Sim
˜
oes, R. F. (2021). Preval
ˆ
encia de sintomas depressivos
e fatores associados em usu
´
arios da atenc¸
˜
ao prim
´
aria
`
a sa
´
ude de belo horizonte. Dissertac¸
˜
ao de mestrado,
Universidade Federal de Minas Gerais, Belo Hori-
zonte, MG, Brasil. Dispon
´
ıvel no Reposit
´
orio Insti-
tucional da UFMG, http://hdl.handle.net/1843/44207.
Smith, D. J. and Blackwood, D. H. R. (2004). Depression
in young adults. Advances in Psychiatric Treatment,
10(1):4–12.
Thapar, A., Eyre, O., Patel, V., and Brent, D.
(2022). Depression in young people. The Lancet,
400(10352):617–631.
UNICEF (2022). Sa
´
ude mental de adolescentes.
World Health Organization (2017). Depression and other
common mental disorders: Global health estimates.
Accessed: 2024-05-17.
HEALTHINF 2025 - 18th International Conference on Health Informatics
646
