
Dynamic Obfuscation for Secure and Efficient Multi-Cloud Business
Processes
Amina Ahmed Nacer
1
and Mohammed Riyadh Abdmeziem
2
1
M’hamed Bougara University, 35000 Boumerdes, Algeria
2
National School of Computer Science, 16000 Oued Smar, Algiers, Algeria
Keywords:
Business Process, Cloud Computing, Data Obfuscation, Obfuscation Methods, Cost-Effective Solution.
Abstract:
Organizations increasingly outsource complex business processes to the cloud, but concerns about expos-
ing business strategies persist. While existing solutions split processes across multiple cloud providers, they
don’t fully address the risk of information leakage. Our approach leverages random obfuscation techniques
at each execution to safeguard sensitive data, offering a lightweight alternative to encryption. In multi-cloud
environments, where processes are distributed across providers, obfuscation reduces leakage risks with lower
computational overhead, making it ideal for resource-constrained scenarios compared to more expensive cryp-
tographic solutions.
1 INTRODUCTION
Cloud computing has become a dominant technol-
ogy, enabling organizations to minimize infrastruc-
ture costs and focus on core activities. This has
spurred interest in executing business processes (BP)
in the cloud, either by reusing BP fragments or de-
ploying proprietary ones. Business process outsourc-
ing, an advanced form of IT outsourcing, is increas-
ingly popular due to its advantages (Lynn et al., 2014;
Yang et al., 2007). However, security and strategic
risks remain significant barriers, particularly for BP
software, which encodes sensitive company know-
how (Aron et al., 2005; ENISA, 2009; Alliance,
2014).
One solution to mitigate these risks is obfuscating
BP models before cloud deployment. Works such as
(Jensen et al., 2011; Goettelmann et al., 2015; Rekik
et al., 2016) propose splitting BP models into frag-
ments, deploying them across multiple clouds, and
interconnecting them to form a choreography. While
this approach protects the logic of the BP, analyzing
input and output data of fragments could still expose
sensitive business activities and strategies.
To address this, we consider two cloud scenar-
ios: non-colluding clouds and potentially colluding
clouds. Building on (Nacer et al., 2016; Nacer et al.,
2018), this work focuses on enhancing data confi-
dentiality by dynamically obfuscating sensitive data.
Instead of transmitting unencrypted data, obfusca-
tion techniques are applied, selected randomly for
added security. Unlike encryption, obfuscation pre-
serves data utility and is less computationally inten-
sive, making it suitable for multi-cloud environments.
This approach ensures data privacy, compliance with
regulations, and process efficiency without compro-
mising functionality.
The remainder of this paper is organized as fol-
lows: Sections 1.1 and 1.2 present an attacker model
and the motivations, along with an overview of our
approach. The subsequent section details the pro-
posed data obfuscation method. Section 3 discusses
evaluation results, and Section 4 reviews related
works. Finally, the paper concludes with future re-
search directions.
1.1 Attacker Model
Different configurations can be used by a malicious
server or a coalition of providers (sharing their local
information) for mining valuable information about
the BP. In any case, we consider in this paper that
the malicious clouds cannot control the network, but
behave as honest but curious about the organization
deploying the process (see figure 1).
Assume that we have in this problematic a data set
D with n entries |D| = n. This data set is represented
by a set of labels L(D) and a set of values V (D). Each
data d ∈ D has a label L(d) and a value V (d).
We define F as a collection of fragments formed
Nacer, A. A. and Abdmeziem, M. R.
Dynamic Obfuscation for Secure and Efficient Multi-Cloud Business Processes.
DOI: 10.5220/0013192100003944
In Proceedings of the 10th International Conference on Internet of Things, Big Data and Security (IoTBDS 2025), pages 175-182
ISBN: 978-989-758-750-4; ISSN: 2184-4976
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
175

Label
of data
Value
D
1
V
1
D
2
V
2
D
3
V
3
D
4
V
4
D
5
V
5
D
6
V
6
Malicious cloud
Input data
Analyze labels-→ Mine information about business
activity of the organization
Analyze labels+ Values of data-→ Mine information
about business Know how and decision strategy
D
i
and V
I
: labels and values
on critical fragments
Figure 1: Attacker model.
by the division of the business process, where |F| =
m components. Each fragment f ∈ F has access to a
subset of L(D) named L
′
( f ) of labels.
We define S( f
i
) as a binary function that assigns a
value of 1 to sensitive fragment and 0 to non-sensitive
fragment
S( f
i
) =
{
0,1
}
where:
S( f
i
) =
(
1 i f f
i
issensitive
0 i f f
i
isnot sensitive
We consider that two types of attacks can occur:
• From Labels: having access to an important
amount of valuable labels can allow malicious
clouds to mine the business activity of the orga-
nization. Valuable labels are considered those la-
bels of data used by critical fragments. This can
be formalized as follows:
We define K as a collection of fragments that are
distributed on each cloud in C, where K ⊆ F.
K(c) =
{
f ∈ F : L
′
( f ) ⊆ L(D), f or d ∈ D
}
for
each cloud c ∈ C.
If any f ∈ F/S( f ) = 1, L
′
( f ) allows mining busi-
ness activities of the company.
• From Labels and Values: we argue that having
access to both labels and values of data of criti-
cal fragments can allow to mine information about
the business know-how and can give indicators on
its decision-making strategy. This can be formal-
ized as follows:
We define K as a collection of fragments that are
distributed on each cloud in C, where K ⊆ F.
For each cloud c ∈ C
K(c) =
f ∈ F : L
′
( f ) ⊆ L(D) ∧V
′
( f ) ⊆ V (D),
for d ∈ D
}
.
If any of the f ∈ F /S( f ) = 1, L
′
( f ) ∧V
′
( f ) en-
able mining information about the business know-
how and can provide indicators on its decision-
making approach.
1.2 Motivating Example
Figure 2 depicts a loan process in a bank using BPMN
(von Rosing et al., 2015) with the objective of accept-
ing or rejecting a loan request. The second part of
the figure illustrates a collaboration of BP fragments
of the same process, resulting from splitting the loan
BP logic using the BP Model obfuscator introduced
in (Nacer et al., 2018).
While splitting reduces the information managed
by each cloud, vulnerabilities persist. A malicious
cloud with access to critical data could infer pro-
cess logic. For example, analyzing labels like salary
with values such as salary 2000$, personal contri-
bution 100 000$, and loan amount 200 000$ might
reveal business strategies or decision rules, especially
in cases of cloud collusion.
1.3 General Overview of the Approach
Our methodology involves dynamically selecting ob-
fuscation techniques for each execution of an out-
sourced business process. Using the same obfuscation
algorithm repeatedly makes it easier for a malicious
cloud to infer process logic through input-output anal-
ysis.
To counter this, a random number is generated to
determine the obfuscation technique for each execu-
tion. The client obfuscates data using the selected
technique and sends it, along with the random num-
ber, to the required service for execution.
IoTBDS 2025 - 10th International Conference on Internet of Things, Big Data and Security
176

Cloud2
Get Loan
Application
(GLA)
Check
Customer
Credit (CCC)
Risk
Evaluation
(RE)
Risk
Capture (RC)
Hierarchy
Validation
(HV)
X
+
X
+
Cloud 1
Decision
Consolidation
(DC)
Final
Decision (FD)
X
+
X
+
Cloud 3
Loan
Reject (LR)
X
+
X
+
Direct Loan
Agreement
(DLA)
Receive
Receive
Receive
Fictive
Activity
Send
Send
Send
Receive
Receive
Send
Receive
Send
Fictive
Activity
Receive
Receive
Send
Receive
Salary 20 000$
Age 25
Amount of loan 200 000$
Guarantees yes
Personal contribution 100 000$
Real Data
Bank
Get Loan
Application
(GLA)
Chek Customer
Credit (CCC)
Risk Evaluation
(RE)
Risk Capture
(RC)
Direct Loan
Agreement
(DLA)
Loan Reject (LR)
Hierarchy
Validation (HV)
Decision
Consolidation
(DC)
Final
Decision (FD)
X
+
X
+
The fragmented bank process deployed on multiple clouds
A single cloud deploying the bank process
Figure 2: The Loan Process before and after cloud deployment.
The steps of the approach are as follows:
• The user generates a random number, selects an
obfuscation technique based on it, and sends the
obfuscated data and random number to the ser-
vice.
• The service uses the random number to select the
corresponding algorithm, processes the data, and
forwards the result and random number to the next
service.
• Subsequent services follow the same procedure,
ensuring consistent obfuscation handling across
the process.
This dynamic obfuscation approach adds an ex-
tra layer of security, reducing the risk of reverse-
engineering by attackers.
Next, we present the obfuscation techniques used
in this methodology.
2 DATA OBFUSCATION
APPROACH
This section introduces and explains the different ob-
fuscation techniques used in our approach for labels
and values obfuscation.
2.1 Labels and Values Obfuscation
2.1.1 Labels Obfuscation
We introduce in this section the different obfuscation
techniques used to obfuscate the labels of data.
• Randomized Label Obfuscation (RLO): is an
approach to conceal the semantic content of data
labels within organizational datasets. Unlike tra-
ditional methods, RLO relies on randomization to
assign labels to data points, aiming to eliminate
patterns and correlations that might compromise
data confidentiality. The technique provides an
advanced level of label concealment, reducing the
risk of reverse engineering and inference attacks.
Let L represent the set of original labels, and O
represent the set of obfuscated labels. The RLO
process is denoted by the function F
RLO
: L → O,
where F
RLO
(l) is the obfuscated label correspond-
ing to the original label l. The mapping between
original and obfuscated labels is maintained on
premise in a secure mapping table, denoted by T ,
where T [l] = F
RLO
(l).
• Contextual Embedding-Based Obfuscation
(CEO): this method involves transforming labels
into high-dimensional contextual embeddings,
making it extremely challenging to infer specific
details while preserving the richness of semantic
information. CEO focuses on transforming labels
into high-dimensional contextual embeddings
using pre-trained language models, enhancing
the confidentiality of label data. The approach
aims to provide a highly secure and versatile
solution for label obfuscation. Indeed, traditional
tokenization or semantic mapping may not
provide sufficient security for highly sensitive
labels. CEO addresses this by leveraging ad-
vanced natural language processing techniques to
embed labels into high-dimensional contextual
representations.
Let L represent the set of original labels, and E
represent the set of contextual embeddings. The
Contextual Embedding-based Obfuscation (CEO)
process is denoted by the function F
CEO
: L → E,
Dynamic Obfuscation for Secure and Efficient Multi-Cloud Business Processes
177

Table 1: Data order of magnitude modification.
Variables Range Max magnitude Min magnitude
[n,m]
n ≤ 10 and m ≤ 10 [2
n
,2
n+m
] /
n ≥ 10 and m < 1000
h
2
n
2
,2
m
2
i
/
n > 10000 /
h
n
10
nb−1
× 2
nb−1
,
m
10
nb−1
× 2
nb−1
i
n
n ≤ 10 2
n
/
n < 1000 2
n
2
/
n > 1000 /
n
10
nb−1
× 2
nb−1
Table 2: Data before and after obfuscation.
Variables Data Value Obfuscated value
V
1
Age [20 − 60] [1024 − 1073741824]
V
2
Monthly
salary
2000 16
V
3
Amount
of the loan
100000 32
where F
CEO
(l) = e
l
, signifying the transforma-
tion of each label l into its corresponding high-
dimensional contextual embedding e
l
.
It is noteworthy that in this paper, we used BERT
models (Devlin et al., 2018), as a pre-trained
language models, for the implementation of the
Contextual Embedding-based Obfuscation (CEO)
method.
2.1.2 Value Obfuscation
We present in this section the proposed approach used
to obfuscate values of data.
Data Range Modification. We change the order
of magnitude of a value of some sensitive data as
much as possible, in order to hide the information
which can be extracted from these values. Depend-
ing on the original value, the order of magnitude
can be maximized or minimized as depicted in table 1.
A malicious cloud analyzing the variables V
1
, V
2
and V
3
(see table 2) can mine their meaning from their
values and from the service executing it. Therefore to
avoid that, we changed their values. A variable having
a range of values [1024 − 1073741824] can hardly be
perceived as representing the age of the client. The
same reasoning is applied to variables V
2
and V
3
: an
amount of 16 for the salary and 32 for the loan.
Encoding Obfuscation. We use encoding obfusca-
tion to modify the representation of decision variables
(i.e. invert the logical values TRUE and FALSE). For
example, if a decision strategy is that a loan cannot
be attributed to a client which salary is not reach-
ing a certain threshold, and the amount of the loan
attributed cannot exceed 50 times the salary of the
client, the value of a decision variable of a client ful-
filling these criteria will be f alse.
Noise Data. We consider that the introduction of
noise data only affects sensitive information. Basi-
cally, using additional amount of data, we obfuscate
(cover, hide) meaningful information used by the ser-
vice. The additional data includes random values hav-
ing a magnitude that will be managed according to the
random values’ standard deviation.
To do so, we have to identify the statistical propri-
eties of the real data in terms of mean and variance.
These proprieties will be used to generate noise data
having proprieties that are different from the actual
ones.
We define X as the real data and E(X) = µ(X),
Var(X) = σ
2
(X) as the mean and the variance of X
respectively.
We define Z as the final set generated from adding
noise data Y to X: Z = X +Y . We decided to add at
the beginning only few data and to adapt it through
the different executions according to the risk related
to sensitive information. Moreover, the amount of
generated data must be adapted to the amount of real
ones. In fact, we consider that the more we have sen-
sitive data, the more we need to introduce noise ones.
IoTBDS 2025 - 10th International Conference on Internet of Things, Big Data and Security
178

3 EXPERIMENTATION
In this section, we conduct a comprehensive evalua-
tion of our approach through both security and per-
formance analyses. Firstly, we assess the security
aspect by comparing the effectiveness of our obfus-
cation technique through an analysis of obfuscated
and deobfuscated data. Subsequently, we evaluate the
performance of our approach by comparing it with
established cryptographic methods namely Rijndael
(Jamil, 2004) and Twofish (Schneier, 1998). The ex-
periments were conducted using business processes
of varying sizes to ensure a comprehensive assess-
ment. All experiments were performed on an In-
tel(R) Core(TM) i5-2310M 2.10 GHz processor run-
ning Windows 10
3.1 Security Analysis
This subsection analyzes the security of our obfus-
cation techniques by comparing obfuscated and de-
obfuscated data. The similarity serves as a metric to
assess their effectiveness in obscuring sensitive infor-
mation. Diverse deobfuscation algorithms were used,
tailored to the characteristics of the obfuscated data,
to evaluate robustness against unauthorized access.
• For label obfuscation, we applied techniques like
Randomized Label Obfuscation (RLO) and Con-
textual Embedding-based Obfuscation (CEO),
leveraging machine learning algorithms such as
k-Nearest Neighbors (k-NN) (Hastie et al., 2009)
and Decision Trees (Breiman, 2017). These al-
gorithms were selected for their ability to handle
categorical data and effectively reconstruct origi-
nal labels.
• For value obfuscation, including data range mod-
ification, encoding obfuscation, and noise addi-
tion, we used linear regression algorithms (Mont-
gomery et al., 2021) to estimate original values
from obfuscated data.
We used the Jaccard similarity measure (Mc-
Cormick et al., 1992) to evaluate the overlap between
original and deobfuscated data. This metric quantifies
similarity by comparing the intersection and union of
the two sets, providing a quantitative assessment of
our obfuscation methods’ accuracy. Figure 3 presents
the results across varying numbers of business process
activities.
The low similarity indices between obfuscated
and deobfuscated data (ranging from 0.1 to 0.4)
confirm the effectiveness of our obfuscation ap-
proach. Scores closer to 0.1 indicate significant di-
vergence, suggesting successful obfuscation, while
scores around 0.4 show partial similarity, which may
be due to the obfuscation technique’s complexity.
This implies that the method successfully obscures
sensitive data, making it difficult to fully reconstruct
the original values, even after deobfuscation attempts.
Our approach further strengthens security by dy-
namically selecting different obfuscation techniques
for each execution based on a random number.
This introduces unpredictability, making reverse-
engineering more difficult for potential attackers. The
variability in similarity scores across different busi-
ness processes emphasizes the importance of consid-
ering each process’s specific characteristics when im-
plementing obfuscation techniques.
3.2 Performance Analysis
To evaluate the performance of our approach, we
compare it with two well-known cryptographic al-
gorithms, Rijndael and Twofish (128-bit key size),
across business processes of varying scales. This
comparison provides insights into the efficiency and
effectiveness of our approach relative to these estab-
lished cryptographic methods. The analysis covers
key performance metrics, including execution time
(in milliseconds), memory usage (in kilobytes), and
CPU usage (as a percentage).
Figure 4 shows the execution times for Rijndael,
Twofish, and our approach across varying numbers
of activities. Both Rijndael and Twofish show in-
creased execution times as the number of activities
grows, reflecting their computational complexity. For
example, at 7 activities, the times are 10 milliseconds
for Rijndael, 8 milliseconds for Twofish, and 4 mil-
liseconds for our approach. At 8 activities, the times
are 10.5, 7.25, and 6 milliseconds, respectively. Ri-
jndael generally has slightly higher execution times
than Twofish, though the difference is minimal. In
contrast, our approach consistently performs faster,
suggesting less computationally intensive operations.
This likely results from focusing on data obfuscation
instead of cryptographic security, providing a quicker
alternative for situations where speed is crucial with-
out compromising security.
3.2.1 CPU Usage
Figure 5 shows the CPU usage of the three ap-
proaches. Rijndael and Twofish generally use more
CPU compared to our obfuscation approach, which
consistently demonstrates lower usage across differ-
ent numbers of activities. For instance, at 7 activi-
ties, the CPU usage for Rijndael, Twofish, and our
approach is 0.05%, 0.03%, and 0.01%, respectively.
At 8 activities, these are 0.06%, 0.05%, and 0.03%,
Dynamic Obfuscation for Secure and Efficient Multi-Cloud Business Processes
179
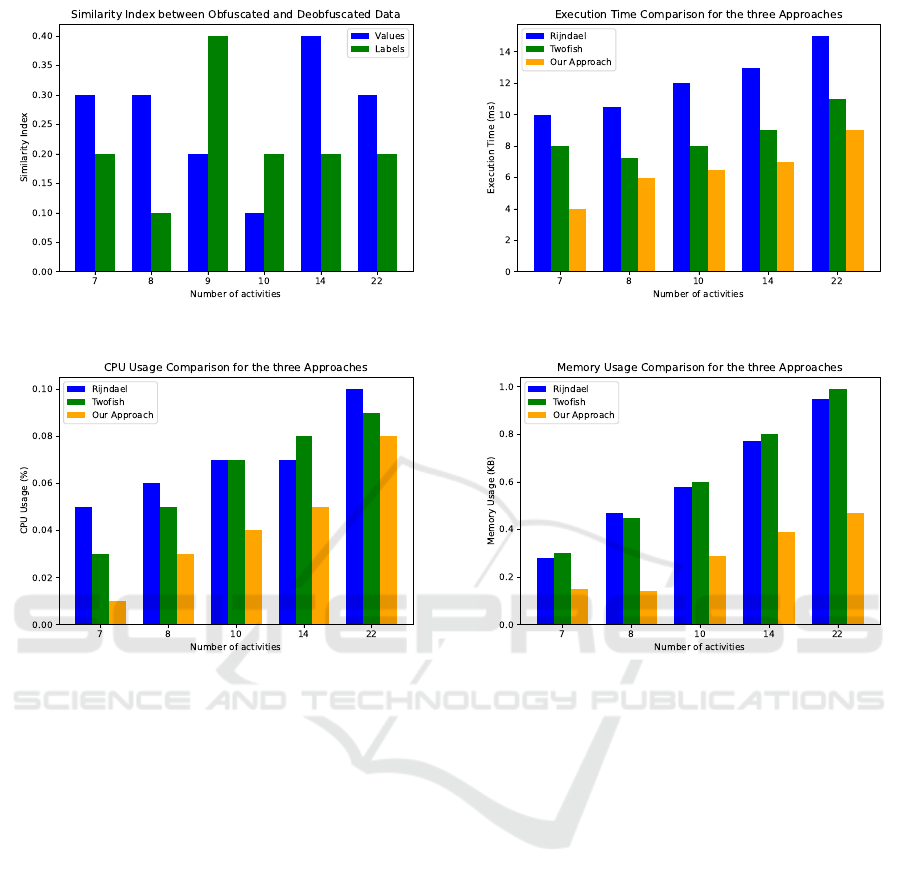
Figure 3: Index of similarity. Figure 4: Execution time.
Figure 5: CPU usage. Figure 6: Memory usage.
respectively. This pattern continues as the number of
activities increases, with our approach using signif-
icantly less CPU. The lower CPU usage can be at-
tributed to the obfuscation technique’s focus on pro-
tecting data without the complex computations in-
volved in cryptographic algorithms like Rijndael and
Twofish. This demonstrates the efficiency of our ap-
proach in terms of CPU utilization while maintaining
security and performance.
3.2.2 Memory Usage
Figure 6 shows the memory usage of the three ap-
proaches. Across varying numbers of activities, our
obfuscation approach consistently uses less memory
compared to Rijndael and Twofish. For example, at
7 activities, the memory usage for Rijndael, Twofish,
and our approach is 0.28 Kb, 0.3 Kb, and 0.15 Kb,
respectively. This trend continues as the number of
activities increases. The reduced memory usage high-
lights the efficient memory management of our obfus-
cation method. As the number of activities grows, our
approach’s advantage becomes more evident, demon-
strating scalability and resource efficiency, which is
particularly beneficial in resource-constrained envi-
ronments. Additionally, the smaller memory foot-
print may result in cost savings in hardware and in-
frastructure. This comparative analysis confirms the
effectiveness of our obfuscation approach in reducing
memory usage while maintaining security and perfor-
mance.
3.3 Discussion
Based on the comprehensive analysis conducted, our
obfuscation approach demonstrates robust security
measures and efficient performance metrics. The se-
curity analysis reveals the effectiveness of our tech-
niques in obscuring sensitive information within busi-
ness processes, as evidenced by low Jaccard similar-
ity indices between obfuscated and deobfuscated data.
This confirms the resilience of our obfuscation meth-
ods against unauthorized access.
In terms of performance, our approach consis-
tently outperforms established cryptographic algo-
rithms like Rijndael and Twofish in execution time,
CPU usage, and memory usage. This indicates that
IoTBDS 2025 - 10th International Conference on Internet of Things, Big Data and Security
180

our approach involves less computationally inten-
sive operations while still maintaining a high level
of security. Overall, our obfuscation approach of-
fers a balanced solution, prioritizing security without
compromising on performance or resource efficiency.
This makes it a viable alternative for various deploy-
ment scenarios, including resource-constrained envi-
ronments where minimizing computational and mem-
ory overhead is crucial.
4 RELATED WORKS
Several mechanisms for privacy-preserving data be-
fore cloud deployment are proposed in the literature,
often focusing on data encryption. However, encryp-
tion, including searchable and homomorphic encryp-
tion, can hinder cloud processing due to its perfor-
mance limitations and high computational cost. These
encryption techniques also require careful key man-
agement, which can introduce further complexity.
Alternatively, hybrid methods, such as the com-
bination of AES and FHE (Kumar and Badal, 2019),
offer data security while maintaining operational ef-
ficiency. Muralidhar et al. (Muralidhar and Sarathy,
2006) introduced data shuffling to mask confidential
numerical data, enhancing utility while minimizing
disclosure risks. Similarly, V Ciriani et al. (Ciriani
et al., 2010) proposed a method that combines data
fragmentation and encryption to protect sensitive in-
formation.
Other approaches focus on data partitioning and
distribution across multiple cloud providers. Jensen
et al. (Jensen et al., 2011) suggested using multiple
clouds to reduce the risk of data manipulation and
tampering. Zhang et al. (Zhang et al., 2013) and
Celesti et al. (Celesti et al., 2016) explored split-
ting data into parts and distributing them across dif-
ferent clouds, improving security by minimizing ex-
posure. However, these approaches often overlook the
potential for data reconstruction through conspiracies
among cloud providers.
5 CONCLUSION
To ensure the protection of business strategies and
sensitive data before cloud deployment, we intro-
duced an innovative approach that combines process
fragmentation with dynamic obfuscation. This sec-
ond level of obfuscation involves randomly selecting
techniques at each execution, making it harder for at-
tackers to reverse engineer the data.
Our evaluation demonstrates the effectiveness of
this approach in obscuring sensitive information,
as indicated by low similarity indices between ob-
fuscated and deobfuscated data. Additionally, our
method outperforms traditional cryptographic algo-
rithms in terms of execution time, CPU usage, and
memory usage, highlighting its efficiency.
Future work will focus on enhancing the adapt-
ability and resilience of our approach to emerging se-
curity threats and refining evaluation metrics to assess
obfuscation techniques more comprehensively.
DECLARATIONS
The authors have no competing interests to declare
that are relevant to the content of this article.
REFERENCES
Alliance, C. (2014). Csa security, trust & assurance registry
(star). visited on, pages 08–18.
Aron, R., Clemons, E. K., and Reddi, S. (2005). Just right
outsourcing: Understanding and managing risk. Jour-
nal of management information systems, 22(2):37–55.
Breiman, L. (2017). Classification and regression trees.
Routledge.
Celesti, A., Fazio, M., Villari, M., and Puliafito, A. (2016).
Adding long-term availability, obfuscation, and en-
cryption to multi-cloud storage systems. Journal of
Network and Computer Applications, 59:208–218.
Ciriani, V., Vimercati, S. D. C. D., Foresti, S., Jajodia,
S., Paraboschi, S., and Samarati, P. (2010). Combin-
ing fragmentation and encryption to protect privacy in
data storage. ACM Transactions on Information and
System Security (TISSEC), 13(3):1–33.
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K.
(2018). Bert: Pre-training of deep bidirectional trans-
formers for language understanding. arXiv preprint
arXiv:1810.04805.
ENISA, C. C. (2009). Benefits, risks and recommendations
for information security. European Network and In-
formation Security, 23.
Goettelmann, E., Ahmed-Nacer, A., Youcef, S., and Godart,
C. (2015). Paving the way towards semi-automatic
design-time business process model obfuscation. In
2015 IEEE International Conference on Web Services,
pages 559–566. IEEE.
Hastie, T., Tibshirani, R., Friedman, J. H., and Friedman,
J. H. (2009). The elements of statistical learning: data
mining, inference, and prediction, volume 2. Springer.
Jamil, T. (2004). The rijndael algorithm. IEEE potentials,
23(2):36–38.
Jensen, M., Schwenk, J., Bohli, J.-M., Gruschka, N., and
Iacono, L. L. (2011). Security prospects through
cloud computing by adopting multiple clouds. In 2011
Dynamic Obfuscation for Secure and Efficient Multi-Cloud Business Processes
181

IEEE 4th international conference on cloud comput-
ing, pages 565–572. IEEE.
Kumar, L. and Badal, N. (2019). A review on hybrid en-
cryption in cloud computing. In 2019 4th Interna-
tional Conference on Internet of Things: Smart Inno-
vation and Usages (IoT-SIU), pages 1–6. IEEE.
Lynn, T., O’carroll, N., Mooney, J., Helfert, M., Cor-
coran, D., Hunt, G., Van Der Werff, L., Morrison,
J., and Healy, P. . (2014). Towards a framework
for defining and categorising business process-as-a-
service (bpaas). (2014). In Proceedings of the 21st In-
ternational Product Development Management Con-
ference, page 65.
McCormick, W., Lyons, N., and Hutcheson, K. (1992).
Distributional properties of jaccard’s index of similar-
ity. Communications in Statistics-Theory and Meth-
ods, 21(1):51–68.
Montgomery, D. C., Peck, E. A., and Vining, G. G. (2021).
Introduction to linear regression analysis. John Wiley
& Sons.
Muralidhar, K. and Sarathy, R. (2006). Data shuffling—a
new masking approach for numerical data. Manage-
ment Science, 52(5):658–670.
Nacer, A. A., Goettelmann, E., Youcef, S., Tari, A., and
Godart, C. (2016). Obfuscating a business pro-
cess by splitting its logic with fake fragments for
securing a multi-cloud deployment. In 2016 IEEE
World Congress on Services (SERVICES), pages 18–
25. IEEE.
Nacer, A. A., Goettelmann, E., Youcef, S., Tari, A., and
Godart, C. (2018). A design-time semi-automatic ap-
proach for obfuscating a business process model in
a trusted multi-cloud deployment: A design-time ap-
proach for bp obfuscation. International Journal of
Web Services Research (IJWSR), 15(4):61–81.
Rekik, M., Boukadi, K., and Ben-Abdallah, H. (2016). A
comprehensive framework for business process out-
sourcing to the cloud. In 2016 IEEE international con-
ference on services computing (SCC), pages 179–186.
IEEE.
Schneier, B. (1998). The twofish encryption algorithm. Dr.
Dobb’s Journal: Software Tools for the Professional
Programmer, 23(12):30–34.
von Rosing, M., White, S., Cummins, F., and de Man, H.
(2015). Business process model and notation-bpmn.
Yang, D.-H., Kim, S., Nam, C., and Min, J.-W. (2007).
Developing a decision model for business process
outsourcing. Computers & Operations Research,
34(12):3769–3778.
Zhang, W., Sun, X., and Xu, T. (2013). Data privacy pro-
tection using multiple cloud storages. In Proceed-
ings 2013 International Conference on Mechatronic
Sciences, Electric Engineering and Computer (MEC),
pages 1768–1772. IEEE.
IoTBDS 2025 - 10th International Conference on Internet of Things, Big Data and Security
182
