
BiLSTM-Attention-Delta: A Novel Framework for Predicting Dropout in
MOOCs Within Big Data Environments
Thu Nguyen
1,2 a
, Hong-Tri Nguyen
3 b
and Tu-Anh Nguyen-Hoang
1,2 c
1
Faculty of Information Science and Engineering, University of Information Technology, Ho Chi Minh City, Vietnam
2
Vietnam National University, Ho Chi Minh City, Vietnam
3
Aalto University, Finland
fi
Keywords:
Predicting Dropout, MOOCs, Big Data Environments, Big Data Architecture, Neural Networks, AI.
Abstract:
The high dropout rate on online education platforms like MOOCs is a significant challenge for modern ed-
ucation systems. This wastes resources and diminishes the course’s credibility, impacting educational goals
and limiting learners’ personal development opportunities. Research on predicting dropout rates in MOOCs
has achieved significant milestones, with effective predictive models and analysis of influencing factors to re-
duce dropout rates. However, challenges remain in ensuring data quality, safeguarding personal information,
enhancing model interpretability, and addressing implementation difficulties, especially in the context of big
data. This study focuses on analyzing big data to develop an AI-powered intelligent education system capable
of monitoring and predicting student learning behavior to reduce dropout rates, while also personalizing the
learning process and improving the learner’s experience. However, the process of extracting big data from
MOOCs poses numerous challenges, including ensuring data quality, integrity, and the ability to handle di-
verse and massive data. Model interpretability and deployment are also complex, requiring rigorous technical
solutions and data management to optimize learning quality and experience. To tackle data processing and
deployment challenges, the study introduces the BiLSTM-Attention-Delta framework. This model improves
dropout prediction by over 10% compared to baselines, optimizes training and prediction times, and leverages
the Delta big data architecture (BDA) for effective deployment in MOOCs.
1 INTRODUCTION
Large-scale online learning platforms (MOOCs) have
grown rapidly, offering learning opportunities to mil-
lions worldwide (Rulinawaty et al., 2023). However,
the high dropout rate remains a significant challenge
(Wang et al., 2023; Mehrabi et al., 2022), as many
learners fail to complete the course or remain inac-
tive for extended periods. To address this, AI and big
data analytics offer promising solutions by monitor-
ing activities, predicting dropouts, and personalizing
learning (Younus et al., 2022; Cao et al., 2020; Zheng
et al., 2023). Challenges in extracting and processing
MOOC data persist, including ensuring data quality,
security, and managing large, diverse datasets (Ang
et al., 2020; Bai et al., 2021). Additionally, model in-
terpretability and deployment require advanced tech-
a
https://orcid.org/0000-0002-0571-2117
b
https://orcid.org/0000-0001-6483-0829
c
https://orcid.org/0000-0001-9283-769X
nical solutions to optimize the learning experience.
While AI and big data analytics show promising
results, challenges in data processing and sustainable
model deployment remain. To address these, this
study introduces the BiLSTM-Attention-Delta frame-
work for accurate and efficient dropout prediction in
big data environments. This framework offers a com-
prehensive solution to the dropout problem, enhanc-
ing the quality and efficiency of MOOC platforms.
This study is structured into five main sections.
Section 2 introduces related research on dropout rates
in MOOCs and unresolved challenges. Section 3 de-
scribes the BiLSTM-Attention-Delta framework and
its implementation in the MOOC context to enhance
performance. Section 4 provides experimental data
and analyzes model effectiveness, and Section 5 sum-
marizes key contributions and future directions for AI
applications in online education.
228
Nguyen, T., Nguyen, H.-T. and Nguyen-Hoang, T.-A.
BiLSTM-Attention-Delta: A Novel Framework for Predicting Dropout in MOOCs Within Big Data Environments.
DOI: 10.5220/0013202900003932
In Proceedings of the 17th International Conference on Computer Supported Education (CSEDU 2025) - Volume 2, pages 228-235
ISBN: 978-989-758-746-7; ISSN: 2184-5026
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

2 RELATED WORK
The problem of dropout prediction (binary classifica-
tion problem) in MOOCs has become a significant re-
search topic in the field of online education. MOOCs,
with their large-scale student population and high de-
gree of flexibility, often experience alarming dropout
rates, making prediction and intervention a top prior-
ity (Jeon et al., 2020). The goal of this problem is to
predict whether a learner is likely to drop out before
completing the course, thereby enabling timely sup-
port and intervention to reduce this rate. MOOCs at-
tract thousands to millions of participants per course,
yet most fail to complete them (Talebi et al., 2024;
Fu et al., 2021). The flexibility of learning often
leads to a loss of motivation, while the diverse cul-
tural and educational backgrounds of students add
complexity to predicting individual behavior. MOOC
platforms gather extensive data (Sakboonyarat and
Tantatsanawong, 2022), including interactions with
content (logins, video watch time, assignments sub-
mitted, materials downloaded), personal information
(age, gender, occupation), community engagement
(forum participation), and technical details (device,
study time). Leveraging this data is crucial for un-
derstanding dropouts and implementing effective in-
terventions.
Predicting student dropout is a critical challenge
as educational institutions increasingly use data an-
alytics to improve outcomes and completion rates.
Methods range from traditional techniques like deci-
sion trees (DT) (Pereira and Zambrano, 2017) and lo-
gistic regression (LR) (Cuji Chacha et al., 2020) to ad-
vanced models like CNN-LSTM (Talebi et al., 2024)
and Multi-layer Perceptron (MLP) (Jeon et al., 2020).
With growing datasets, selecting appropriate methods
for accurate predictions is crucial. While studies offer
diverse approaches, handling large, complex datasets
remains a key challenge requiring further research.
Our study addresses this issue, with the details sum-
marized in comparison to previous baseline methods
in Table 1.
Research on dropout prediction in large data envi-
ronments has made significant contributions but has
also revealed limitations that need to be addressed
to enhance practical application effectiveness. Tra-
ditional models, such as DT (Pereira and Zambrano,
2017) and LR (Cuji Chacha et al., 2020), offer in-
terpretability and ease of application but are inade-
quate for scaling with large and complex data, espe-
cially unstructured and time-series data. In contrast,
more complex models like CLSA (Fu et al., 2021) or
CNN-LSTM hybrid model (Talebi et al., 2024) bet-
ter leverage temporal and spatial information from
MOOCs data but face challenges related to computa-
tional complexity, requiring substantial resources and
lacking interpretability. (Jeon et al., 2020) introduced
a MLP learning model to efficiently process click-
stream data but still struggled with scalability for big
data. Notably, Apache Spark-based model (Sakboon-
yarat and Tantatsanawong, 2022) demonstrated po-
tential in handling large data efficiently but focused
on course recommendation rather than comprehen-
sively addressing dropout prediction.
Recognizing the lack of holistic features in related
works, this study focuses on resolving issues related
to scalability and computational resource optimiza-
tion in dropout prediction. To achieve this, the study
proposes the BiLSTM-Attention-Delta framework,
consisting of two main components: the BiLSTM-
Attention model and the Delta BDA. The BiLSTM-
Attention model, utilizing a sequential neural net-
work, predicts dropout behavior on MOOC platforms,
improving performance by over 10% compared to
baseline methods. Training time is reduced by 13
times, and prediction time by 5 times, making it suit-
able for large-scale data processing systems. The
Delta BDA supports large-scale model deployment
and optimizes data management, contributing to the
improvement of MOOC platforms’ quality and effi-
ciency.
3 BiLSTM-ATTENTION-DELTA
FRAMEWORK
3.1 The Proposed BiLSTM-Attention
Model for Dropout Prediction
The proposed BiLSTM-Attention model used for
dropout prediction in Figure 1 consists of three main
parts: preprocessing, BiLSTM layers, and the Bah-
danau Attention layer combined with a neural net-
work. In the preprocessing phase, the input data
is processed similarly to the previous study (Talebi
et al., 2024), with the addition of several elements,
such as integrating a vector representing the total time
for each behavior. Course duration data was collected
over a maximum period of 30 days, and dropout pre-
diction was performed at different time points. For
each registration with ID Q on day t ≤ T , there will be
a vector representing the learner’s behavior, as shown
in Equation 1.
x =
h
a
(1)
t
, a
(2)
t
, a
(3)
t
, . . . , a
(7)
t
i
(1)
In terms of dimensions, x ∈ R
7
, corresponding to
the number of behavior types a, representing the fre-
BiLSTM-Attention-Delta: A Novel Framework for Predicting Dropout in MOOCs Within Big Data Environments
229

Table 1: Comparison of Baseline Methods and Proposed Approach.
Research
studies
Scope Objectives Technology Data Contribution
(Pereira and
Zambrano,
2017)
The prediction
of student
dropout at the
University of
Nari
˜
no,
Colombia.
Identifying risk
factors
contributing to
student dropout.
DT Student profile
data from 2004
to 2006
includes
socioeconomic
and academic
information.
Providing
information to
develop
appropriate
intervention
policies.
(Cuji Chacha
et al., 2020)
The prediction
of student
dropout at the
Northern
Technical
University,
Ecuador.
Developing a
dropout
prediction model
based on LR.
LR Data from the
academic
information
system
(demographic
and academic).
Providing a
model to support
the identification
of students at
risk of dropping
out.
(Jeon et al.,
2020)
Predicting
dropout in
MOOCs based
on clickstream
data.
Weekly dropout
prediction in
MOOCs based
on interaction
data.
MLP learning:
Branch and
Bound.
Clickstream
data from
Coursera
courses.
The
representation
learning method
provides
interpretable and
efficient results.
(Fu et al.,
2021)
Predicting
MOOCs
dropout using
the CLSA
model.
Developing a
deep learning
model for
predicting
dropout in
MOOCs.
CNN, LSTM,
Self-Attention.
Data from the
XuetangX
platform
(interactions,
study time).
The proposed
CLSA
architecture is
more efficient
than traditional
models.
(Sakboonyarat
and Tantat-
sanawong,
2022)
Applying big
data technology
to propose
personalized
MOOCs.
Developing a
personalized
MOOC
recommendation
system based on
big data.
Apache Spark,
Kappa
Architecture,
Spark SQL,
Spark MLlib.
MOOCs data:
courses, user
profiles,
interaction
history.
A personalized
course
recommendation
system with the
capability to
handle large
volumes of data.
(Talebi et al.,
2024)
Predicting
dropout in
MOOCs using a
CNN-LSTM
model.
Developing an
accurate dropout
prediction model
from MOOCs
data.
CNN-LSTM
hybrid model.
Data from large
MOOCs
(interactions,
study time,
number of
clicks).
Combining
spatial and
temporal
information to
enhance
prediction
accuracy.
Our The research
focuses on the
issue of
predicting
student dropout
in MOOC
platforms.
Developing an
intelligent
system using AI
and big data
analytics to
predict and
reduce dropout
rates on MOOC
platforms.
The BiLSTM-
Attention-
Delta
framework
with the
BiLSTM-
Attention
Model and the
Delta BDA.
Big data from
MOOC
platforms,
including
student
interactions and
learning
behavior.
Providing a
comprehensive
solution, and
contributing to
the field of
online education.
CSEDU 2025 - 17th International Conference on Computer Supported Education
230

Figure 1: BiLSTM-Attention Model.
quency of each behavior recorded on that day. T is
the number of days in the weeks; for example, if the
number of weeks used for prediction is 3 weeks, then
T = 21, so T = 7, 14, 21, 28, 30.
The BiLSTM layers (Anand et al., 2023) pro-
cess data in two stages: the first layer captures daily
learning behaviors (timesteps), while the second ex-
tracts forward and backward hidden states from each
timestep. This information is then passed to the Bah-
danau Attention layer, which highlights the most im-
portant features in the time sequence. The Attention
layer (Itti et al., 1998; Bahdanau, 2014) computes at-
tention scores between BiLSTM input vectors at each
timestep and its final hidden state. The softmax func-
tion normalizes these scores into attention weights,
creating a weighted vector. The final output aggre-
gates weighted features across timesteps, enhancing
the model’s ability to identify key factors and predict
dropouts accurately. The attention calculation steps
are detailed in formulas 2, 3, 4, and 5.
score
i j
= tanh(W
i
h
i
+W
g
g) (2)
e
i
= v
T
a
· score
i
(3)
α
i
=
exp(e
i
)
∑
k
exp(e
k
)
(4)
c =
∑
i
α
i
h
i
(5)
Where: (1) score
i j
: The attention score between
input feature vector h
i
at timestep i and the final hid-
den state g of the BiLSTM. It assesses the relevance
between h
i
and g, using weight matrices W
i
, W
g
, and
the tanh function to normalize the output between −1
and 1. (2) e
i
: The unnormalized attention score for
each timestep i, representing the correlation between
the weight vector v
T
a
and score
i
. It is calculated be-
fore applying the softmax function, reflecting the pri-
ority of information from timestep i. (3) α
i
: The nor-
malized attention weight from the softmax function
of e
i
, indicating the importance of timestep i. α
i
val-
ues range from 0 to 1 and sum to 1, representing the
model’s focus on each timestep. (4) c: The context
vector, calculated as the weighted sum of feature vec-
tors h
i
using attention weights α
i
. It aggregates key
information from the input sequence and serves as in-
put for subsequent layers to make predictions.
The context vector is fed into a three-layer neu-
ral network, with the final layer using a sigmoid acti-
vation function (Equation 6) for binary classification:
dropouts (1) or retention (0). The sigmoid maps in-
put x to a probability between 0 and 1, predicting the
positive class if the probability exceeds 0.5, and the
negative class otherwise.
f (x) =
1
1 + e
−x
(6)
3.2 Our Framework
The BiLSTM-Attention-Delta framework (Figure 2)
addresses high dropout rates on MOOC platforms.
By integrating Delta BDA, this framework efficiently
manages and processes massive volumes of data de-
rived from users’ historical activities and real-time
interactions. It is particularly well-suited for educa-
tional data, encompassing both historical and real-
time datasets. This enables the BiLSTM-Attention
model to deliver fast, accurate predictions and real-
time solutions, optimizing learning processes and re-
ducing dropout rates. Deploying a BDA on a cloud
platform is essential for its scalability, cost-efficiency,
and support for distributed processing (Zbakh et al.,
2019). This study uses Microsoft Azure Cloud Ser-
vice, known for its high performance in handling
large-scale data processing and management (Ang
et al., 2020).
The Ingest component in the architecture (Fig-
ure 2) uses Azure Data Factory for batch processing
of historical data (e.g., learner profiles, course details)
and Azure Event Hubs for real-time streaming data
(e.g., activity logs). This setup ensures efficient in-
tegration and processing of diverse data types. The
Storage component in the architecture (Figure 2) uses
a Lakehouse architecture, combining Data Warehouse
BiLSTM-Attention-Delta: A Novel Framework for Predicting Dropout in MOOCs Within Big Data Environments
231

Figure 2: BiLSTM-Attention-Delta Framework.
and Data Lake strengths for centralized, reliable,
high-performance data storage. Delta Lake (Arm-
brust et al., 2020) is recommended, utilizing a Medal-
lion architecture with Bronze, Silver, and Gold layers:
(1) Bronze Layer: Stores raw, unprocessed data. (2)
Silver Layer: Cleans and transforms data, improving
quality. (3) Gold Layer: Contains high-quality, pro-
cessed data for analysis and decision-making. This
structure ensures efficient data management and sup-
ports diverse analytical needs. The Process compo-
nent (Figure 2) handles streaming data, scheduled
tasks, and event-based triggers. Pre-configured Azure
Databricks (Pala, 2021) jobs retrieve raw data from
the Bronze layer, perform integration, transformation,
and cleaning, and load refined datasets into the Sil-
ver and Gold layers using ACID transactions. Batch
data is processed via Azure Data Factory, which ex-
tracts, aggregates, and stores raw data in Delta Lake
tables. Streaming data from MOOC platforms is col-
lected via Event Hubs, secured with OAuth 2.0, and
processed using Azure Databricks with Delta Engine
and Spark Streaming (Armbrust et al., 2018). All data
is stored in Delta Lake for further processing. The En-
rich component (Figure 2) leverages AI and ML for
building, versioning, and deploying models, stream-
lining workflows while ensuring consistency and per-
formance. It deploys the BiLSTM-Attention model
using MLOps (Kreuzberger et al., 2023), which au-
tomates lifecycle management, including monitoring,
retraining, testing, and redeployment when perfor-
mance drops. The component integrates with MLOps
platforms like MLflow to handle experiment track-
ing, version control, automated deployment, and per-
formance monitoring, ensuring models remain up-to-
date, robust, and ready for real-time applications. The
Serve and Consumption component (Figure 2) pre-
pares processed data from the Bronze and Silver lay-
ers for analysis, storing it in the Gold layer in delta
format. This format supports version control, real-
time data handling, schema evolution, and audit log-
ging. A Databricks-based dashboard will visualize
near real-time data using Spark Structured Stream-
ing. Dropout predictions from the BiLSTM-Attention
model will integrate with BI tools and smart education
platforms, enabling activity monitoring, behavior pre-
diction, and personalized learning.
The BiLSTM-Attention-Delta framework offers a
powerful solution for reducing dropout rates on online
education platforms by leveraging the large-scale data
processing capabilities of the Delta architecture. By
combining historical and real-time data, the proposed
BiLSTM-Attention model enables accurate and effi-
cient early prediction of dropout risks. This allows
for the timely implementation of tailored strategies
to support learners and reduce dropout rates. This
framework represents a significant advancement in
enhancing the learning experience and addressing the
dropout challenge in MOOCs.
4 EXPERIMENTS
4.1 Experimental Setup
In dropout prediction, evaluation metrics are criti-
cal for ensuring model accuracy and suitability, espe-
cially with complex, imbalanced data. Most dropouts
occur in the first two weeks, requiring high sensitivity
to early signals. Key metrics include: (1) Recall: En-
sures the model identifies most dropouts, critical for
timely intervention. (2) F1-score: Balances Precision
and Recall, minimizing false alarms while accurately
detecting dropouts, especially with imbalanced data.
Additionally, training and prediction time are vital for
large-scale systems, ensuring the model is both ac-
CSEDU 2025 - 17th International Conference on Computer Supported Education
232

curate and efficient for real-time applications in dy-
namic educational environments.
The dataset used for dropout prediction in all
experiments of this study, collected from the Xue-
tangX MOOC platform (August 2015–August 2017)
(Feng et al., 2019), includes 89 million clickstream
records from 254,518 learners across 698 courses,
with 467,113 enrollments. It covers seven interac-
tion types: access, discussion, navigation, page close,
problem-solving, video viewing, and wiki search.
Among 225,642 labeled samples, 171,133 (dropouts,
“1”) and 54,509 (retained, “0”) highlight a dropout-
to-retention ratio of 3.4:1, reflecting significant data
imbalance. This dataset is vital for training pre-
diction models, requiring advanced methods to han-
dle its complexity and imbalance. Analyzing inter-
action trends over time provides insights into learn-
ing behaviors, improving course quality, personaliz-
ing learning, and identifying at-risk students, as illus-
trated in Figure 3.
The first chart in Figure 3 shows the highest in-
teraction levels in the first week for both groups. In
this week, the dropout group (“1”) had more interac-
tions than the completion group (“0”) due to a higher
number of users. From the second week, dropout
group interactions drop sharply, while the comple-
tion group declines by only 5–20% weekly, indicating
rapid disengagement among dropouts. The second
chart reveals that, despite more users in the dropout
group, the completion group averaged 3–10 times
more weekly actions during the first three weeks, em-
phasizing the importance of sustained engagement for
completion. Over 70% of dropouts occur within the
first two weeks, with engagement levels plummeting
thereafter. To predict dropouts effectively, models
must detect early warning signs, particularly within
the first two weeks. Techniques like Attention in
BiLSTM-Attention models can focus on critical early
behaviors to enhance accuracy. This analysis under-
scores the importance of capturing early trends, with
the BiLSTM-Attention model designed to leverage
these features for better predictions.
Details of the implementation of the proposed
method along with the baseline methods are presented
in Table 2. A summary of the key points and contri-
butions of these baseline methods is presented in Ta-
ble 1. Our experimental process was conducted in the
Google Colab environment, equipped with 2vCPU In-
tel(R) Xeon(R) @ 2.20GHz, 13GB RAM, and a Tesla
T4 GPU. The dataset was divided into three parts:
70% for the training set, 15% for the validation set,
and 15% for the test set. We applied the early stop-
ping technique to monitor and save the checkpoint
with the highest F1-score on the training set. The
training process was carried out over 20 epochs with a
batch size of 100, using the Adam optimizer. Notably,
the evaluation was performed over the first two weeks
of the course, as more than 70% of dropout cases oc-
cur during this period. Additionally, the Delta BDA
was implemented to facilitate the data collection and
processing on various MOOCs platforms. This archi-
tecture was deployed on Azure Cloud Services, lever-
aging cloud computing benefits such as flexible scal-
ability, automated workflows, high availability, and
reduced infrastructure costs compared to on-premise
deployment.
4.2 Results and Discussion
Table 3 compares various dropout prediction meth-
ods based on criteria such as Recall, F1-score, train-
ing time, prediction time, and deployment on a BDA.
Baseline methods like DT, LR, MLP, CNN,
CLSA, LSTM, and Bagging-CNN-LSTM struggle
with large-scale time-series data due to limitations
in handling temporal relationships and resource effi-
ciency. DT and LR face overfitting and linear assump-
tion challenges, while MLP and CNN fail to cap-
ture sequential patterns effectively. Advanced mod-
els like CLSA, LSTM, and Bagging-CNN-LSTM are
resource-intensive and prone to overfitting or opti-
mization issues. To address these, this study pro-
poses the BiLSTM-Attention-Delta method, combin-
ing BiLSTM and Attention to focus on key features,
reduce unnecessary data, minimize overfitting, and
optimize processing time.
The BiLSTM-Attention-Delta method outper-
forms others in dropout prediction with high accu-
racy and stability. It achieves the highest F1-score in
the first week (0.7344, over 10% improvement) and
a slight drop in the second week (0.7716), demon-
strating stability. Its recall is also among the highest,
particularly in the second week (0.8281), with consis-
tent performance across both weeks. In terms of time,
BiLSTM-Attention-Delta has a much faster training
speed compared to complex models like Bagging-
CNN-LSTM, taking only 171 seconds compared to
2324 seconds for the complex model, a reduction
in training time by more than 13 times. Addition-
ally, the model’s prediction time is 2.9 seconds com-
pared to 14.9 seconds, a reduction by more than 5
times. While the training time is longer compared
to simpler methods such as DT or LR, the predic-
tion performance is significantly higher. Addition-
ally, when compared to baseline methods such as
DT and Bagging-CNN-LSTM, BiLSTM-Attention-
Delta demonstrates superiority in both F1 and Re-
call, proving that the combination of Attention with
BiLSTM-Attention-Delta: A Novel Framework for Predicting Dropout in MOOCs Within Big Data Environments
233
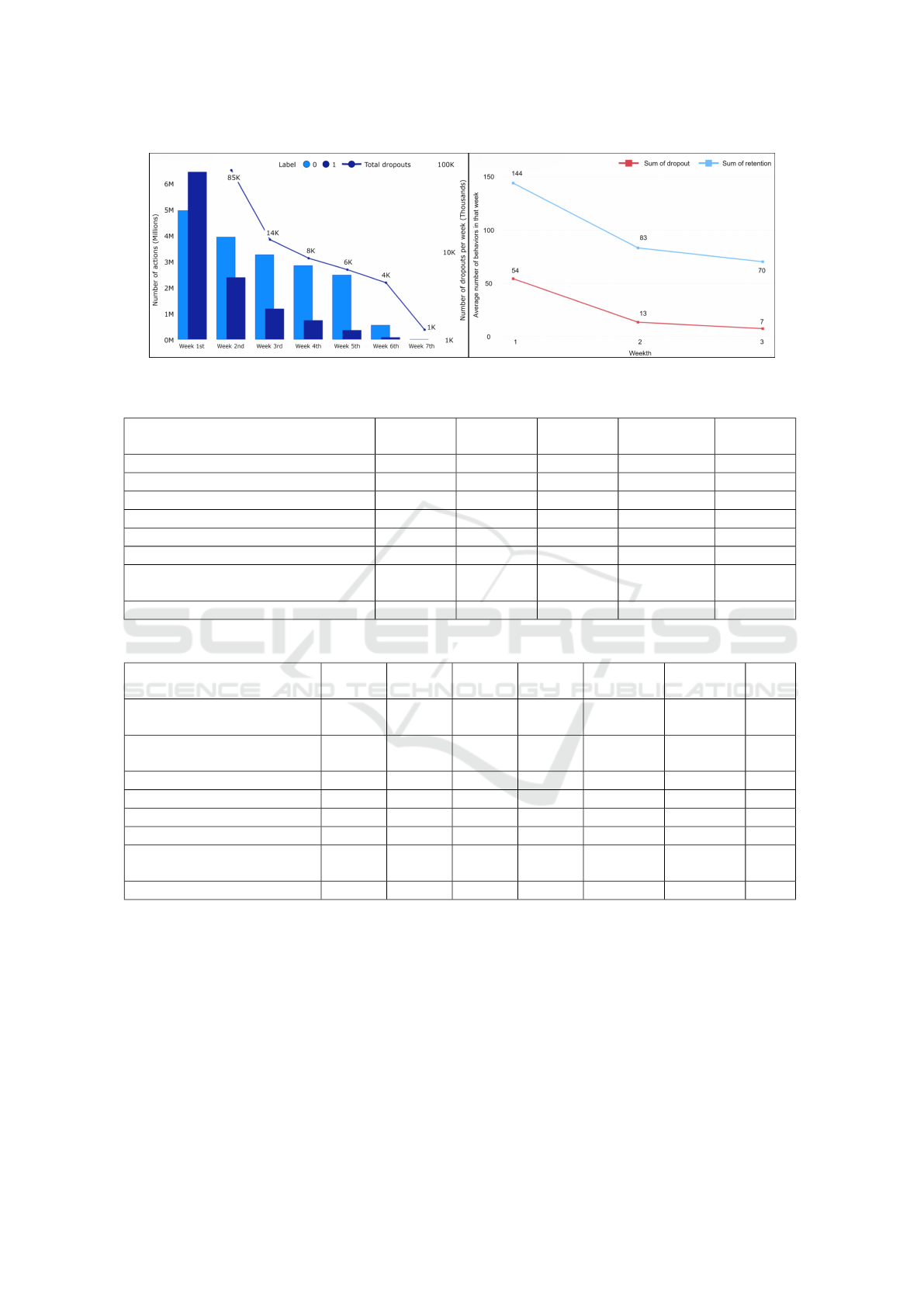
Figure 3: Statistical Results of Experimental Data.
Table 2: Experimental methods for the dropout prediction problem.
Methods Neural
network
CNN-
based
LSTM-
based
Attention
mechanism
BDA
DT (Pereira and Zambrano, 2017) No No No No No
LR (Cuji Chacha et al., 2020) No No No No No
MLP (Jeon et al., 2020) Yes No No No No
CNN (Talebi et al., 2024) Yes Yes No No No
CLSA (Fu et al., 2021) Yes Yes Yes Yes No
LSTM (Talebi et al., 2024) Yes No Yes No No
Bagging-CNN-LSTM (Talebi et al.,
2024)
Yes Yes Yes No No
BiLSTM-Attention-Delta Yes No Yes Yes Yes
Table 3: The experimental results for the dropout prediction problem in the first two weeks.
Methods Recall
(1st)
Recall
(2nd)
F1
(1st)
F1
(2nd)
Training
time (s)
Prediction
time (s)
BDA
DT (Pereira and Zambrano,
2017)
0.6605 0.6807 0.6394 0.6614 5 0.1 No
LR (Cuji Chacha et al.,
2020)
0.8250 0.8566 0.7189 0.7478 4 0.1 No
MLP (Jeon et al., 2020) 0.6947 0.7281 0.7039 0.7417 31 1.0 No
CNN (Talebi et al., 2024) 0.7942 0.8106 0.7290 0.7612 154 0.9 No
CLSA (Fu et al., 2021) 0.6979 0.8598 0.7112 0.7726 307 2.2 No
LSTM (Talebi et al., 2024) 0.7803 0.8335 0.7320 0.7699 573 4.3 No
Bagging-CNN-LSTM
(Talebi et al., 2024)
0.7090 0.7409 0.7183 0.7634 2324 14.9 No
BiLSTM-Attention-Delta 0.7906 0.8281 0.7344 0.7716 171 2.9 Delta
BiLSTM yields significant improvements in predic-
tion and accurate classification. Finally, BiLSTM-
Attention-Delta has been deployed on a BDA, ensur-
ing stability and the ability to handle large volumes
of data, further reinforcing the model’s feasibility in
practical applications. Thanks to its well-balanced
accuracy, stability, and processing speed, BiLSTM-
Attention-Delta stands out as the optimal method for
this problem.
5 CONCLUSION
The rapid growth of MOOCs and online educa-
tion platforms offers global learning opportunities
but faces the challenge of high dropout rates. This
study introduces the BiLSTM-Attention-Delta frame-
work, designed for accurate and efficient dropout
prediction in big data environments. The BiLSTM-
Attention model improves performance by over 10%
compared to baseline methods while significantly re-
CSEDU 2025 - 17th International Conference on Computer Supported Education
234

ducing training and prediction times, making it ideal
for large-scale data. Supported by the Delta BDA,
it ensures efficient deployment in MOOC environ-
ments. This research enhances online education and
big data analytics by addressing dropout issues and
improving the quality of MOOCs.
ACKNOWLEDGEMENTS
This research is funded by University of Informa-
tion Technology-Vietnam National University Ho Chi
Minh City under grant number D1-2024-69.
REFERENCES
Anand, G., Kumari, S., and Pulle, R. (2023). Fractional-
iterative bilstm classifier: A novel approach to pre-
dicting student attrition in digital academia. SSRG
International Journal of Computer Science and En-
gineering, 10(5):1–9.
Ang, K. L.-M., Ge, F. L., and Seng, K. P. (2020). Big ed-
ucational data & analytics: Survey, architecture and
challenges. IEEE access, 8:116392–116414.
Armbrust, M., Das, T., Sun, L., Yavuz, B., Zhu, S., Murthy,
M., Torres, J., van Hovell, H., Ionescu, A., Łuszczak,
A., et al. (2020). Delta lake: high-performance acid
table storage over cloud object stores. Proceedings of
the VLDB Endowment, 13(12):3411–3424.
Armbrust, M., Das, T., Torres, J., Yavuz, B., Zhu, S., Xin,
R., Ghodsi, A., Stoica, I., and Zaharia, M. (2018).
Structured streaming: A declarative api for real-time
applications in apache spark. In Proceedings of the
2018 International Conference on Management of
Data, pages 601–613.
Bahdanau, D. (2014). Neural machine translation by
jointly learning to align and translate. arXiv preprint
arXiv:1409.0473.
Bai, X., Zhang, F., Li, J., Guo, T., Aziz, A., Jin, A., and Xia,
F. (2021). Educational big data: Predictions, applica-
tions and challenges. Big Data Research, 26:100270.
Cao, W., Wang, Q., Sbeih, A., and Shibly, F. (2020). Artifi-
cial intelligence based efficient smart learning frame-
work for education platform. Inteligencia Artificial,
23(66):112–123.
Cuji Chacha, B. R., Gavilanes L
´
opez, W. L., Vicente Guer-
rero, V. X., and Villacis Villacis, W. G. (2020).
Student dropout model based on logistic regression.
In Applied Technologies: First International Con-
ference, ICAT 2019, Quito, Ecuador, December 3–
5, 2019, Proceedings, Part II 1, pages 321–333.
Springer.
Feng, W., Tang, J., and Liu, T. X. (2019). Understand-
ing dropouts in moocs. In Proceedings of the AAAI
conference on artificial intelligence, volume 33, pages
517–524.
Fu, Q., Gao, Z., Zhou, J., and Zheng, Y. (2021). Clsa:
A novel deep learning model for mooc dropout
prediction. Computers & Electrical Engineering,
94:107315.
Itti, L., Koch, C., and Niebur, E. (1998). A model of
saliency-based visual attention for rapid scene anal-
ysis. IEEE Transactions on pattern analysis and ma-
chine intelligence, 20(11):1254–1259.
Jeon, B., Park, N., and Bang, S. (2020). Dropout
prediction over weeks in moocs via interpretable
multi-layer representation learning. arXiv preprint
arXiv:2002.01598.
Kreuzberger, D., K
¨
uhl, N., and Hirschl, S. (2023). Ma-
chine learning operations (mlops): Overview, defini-
tion, and architecture. IEEE access, 11:31866–31879.
Mehrabi, M., Safarpour, A. R., and Keshtkar, A. (2022).
Massive open online courses (moocs) dropout rate in
the world: a protocol for systematic review and meta-
analysis. Interdisciplinary Journal of Virtual Learning
in Medical Sciences, 13(2):85–92.
Pala, S. K. (2021). Databricks analytics: Empowering data
processing, machine learning and real-time analytics.
Machine Learning, 10(1).
Pereira, R. T. and Zambrano, J. C. (2017). Application of
decision trees for detection of student dropout profiles.
In 2017 16th IEEE international conference on ma-
chine learning and applications (ICMLA), pages 528–
531. IEEE.
Rulinawaty, R., Priyanto, A., Kuncoro, S., Rahmawaty, D.,
and Wijaya, A. (2023). Massive open online courses
(moocs) as catalysts of change in education during un-
precedented times: A narrative review. Jurnal Peneli-
tian Pendidikan IPA, 9(SpecialIssue):53–63.
Sakboonyarat, S. and Tantatsanawong, P. (2022). Ap-
plied big data technique and deep learning for massive
open online courses (moocs) recommendation sys-
tem. ECTI Transactions on Computer and Informa-
tion Technology (ECTI-CIT), 16(4):436–447.
Talebi, K., Torabi, Z., and Daneshpour, N. (2024). Ensem-
ble models based on cnn and lstm for dropout pre-
diction in mooc. Expert Systems with Applications,
235:121187.
Wang, W., Zhao, Y., Wu, Y. J., and Goh, M. (2023). Factors
of dropout from moocs: a bibliometric review. Library
Hi Tech, 41(2):432–453.
Younus, A. M., Abumandil, M. S., Gangwar, V. P., and
Gupta, S. K. (2022). Ai-based smart education system
for a smart city using an improved self-adaptive leap-
frogging algorithm. In AI-Centric Smart City Ecosys-
tems, pages 231–245. CRC Press.
Zbakh, M., Essaaidi, M., Manneback, P., and Rong, C.
(2019). Cloud Computing and Big Data: Technolo-
gies, Applications and Security. Springer.
Zheng, L., Wang, C., Chen, X., Song, Y., Meng, Z.,
and Zhang, R. (2023). Evolutionary machine learn-
ing builds smart education big data platform: Data-
driven higher education. Applied Soft Computing,
136:110114.
BiLSTM-Attention-Delta: A Novel Framework for Predicting Dropout in MOOCs Within Big Data Environments
235
