
Recommending Points of Interest with a Context-Aware Dual Recurrent
Neural Network
Lucas Silva Couto
a
, Gislaine Camila Lapasini Leal
b
and Marcos Aur
´
elio Domingues
c
State University of Maring
´
a, Department of Informatics, Maring
´
a, Brazil
Keywords:
Recurrent Neural Networks, Context-Aware Recommender Systems, Points of Interest, Context Acquisition,
Embeddings.
Abstract:
The advent of location-based social networks (LBSNs) has reshaped how users engage with their surroundings,
facilitating personalized connections with nearby points of interest (POIs) like restaurants, tourist attractions,
and so on. To help the users to find points that fit their interests, recommender systems can be used to filter a
large number of POIs according to the users’ preferences. However, the context in which the users make their
check-ins must be taken into account, which justifies the usage of context-aware recommender systems. The
goal of this work is to use a Context-Aware Dual Recurrent Neural Network to acquire contextual information
(represented by embeddings) for each POI, given the sequence of points that each user has checked-in. Then,
the contextual information (i.e. the embeddings) is used by context-aware recommenders to suggest POIs. We
evaluated the contextual information by using four context-aware recommender systems in two datasets. The
results showed that the contextual information obtained by our proposed method presents better results than
the state-of-the-art method proposed in the literature.
1 INTRODUCTION
In recent years, the proliferation of location-based
social networks (LBSNs), such as Yelp
1
, Gowalla
2
and Foursquare
3
has transformed how users interact
with their surroundings, leveraging geospatial infor-
mation to connect users with nearby points of interest
(POIs) tailored to their preferences, i.e. transporta-
tion, accommodation, tourism attraction, among other
places (Ding et al., 2018). This paradigm shift has
not only revolutionized the way people explore new
places but has also presented a fertile ground for re-
search aimed at refining POIs recommender systems
within LBSNs (Ding et al., 2018; S
´
anchez and Bel-
log
´
ın, 2022). Understanding the dynamics of user
preferences, spatial contexts, check-ins, and social in-
teractions is crucial for optimizing the recommenda-
tion process, thereby enhancing user experience and
engagement.
The effectiveness of POIs recommendations can
a
https://orcid.org/0009-0000-0641-8166
b
https://orcid.org/0000-0001-8599-0776
c
https://orcid.org/0000-0001-7195-0714
1
https://www.yelp.com
2
https://www.gowalla.com
3
https://foursquare.com
be obtained by the interplay between user prefer-
ences, geographical context, check-in patterns, and
context-aware recommender systems.
Users exhibit diverse preferences influenced by
various factors such as demographics, past behaviors,
and social connections, which demand personalized
recommendation strategies. Furthermore, geographi-
cal context adds another layer of complexity, as user
preferences for POIs are inherently tied to their spa-
tial proximity and accessibility. Check-in patterns, re-
flecting users’ historical interactions with POIs, pro-
vide valuable insights into their preferences and be-
havior trajectories, and facilitate the development of
context-aware recommender systems that adapt to
evolving user interests and spatial contexts.
Context-aware recommender systems are a kind
of recommendation algorithm designed to tailor sug-
gestions based on the specific contextual infor-
mation surrounding users and items (Adomavicius
et al., 2011). Unlike traditional recommender sys-
tems, which primarily rely on user-item interactions,
context-aware systems take into account additional
information such as time, location, device, social con-
text, and user activity. By incorporating contextual in-
formation, these systems are able to provide more rel-
evant and personalized recommendations to the users.
Couto, L. S., Leal, G. C. L. and Domingues, M. A.
Recommending Points of Interest with a Context-Aware Dual Recurrent Neural Networ k.
DOI: 10.5220/0013230000003929
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 27th International Conference on Enterprise Information Systems (ICEIS 2025) - Volume 1, pages 1061-1068
ISBN: 978-989-758-749-8; ISSN: 2184-4992
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
1061

Although there are several works about context-
aware recommender systems for POIs, there is a lack
of automatic techniques for extracting contextual in-
formation for such systems. To obtain such informa-
tion, we have proposed a Context-Aware Dual Re-
current Neural Network model that uses Long Short-
Term Memory (LSTM) networks to analyze the se-
quence of POIs that the users checked-in, and to pro-
duce an embedding vector (i.e. a contextual informa-
tion) for each POI. Embedding is a method to repre-
sent items using a real values vector that is obtained
by using a neural network trained to understand the
context of the items. LSTM is a kind of Recurrent
Neural Network (RNN) that was proposed with the
intent to solve problems with long term dependen-
cies (Hochreiter and Schmidhuber, 1997). The em-
bedding vectors contain the contextual information
that encircle the POIs for each user.
We evaluated our proposal by using four context-
aware recommender systems in two POIs datasets that
include the check-in history of thousands of users.
As a baseline, to compare our proposal against to,
we used the model proposed by (Wang et al., 2018).
That model was based on the Skip-Gram architec-
ture (Mikolov et al., 2013), a state-of-the-art embed-
ding model. The results showed that, in general, our
proposed model outperformed the baseline, indicat-
ing that it can capture better contextual information
through the embedding vectors.
The remaining of this paper is organized as fol-
lows: In Section 2, we describe some works that use
context-aware recommender systems and embedding
vectors for POIs. In Section 3, we present our pro-
posed model. Section 4 describes the empirical evalu-
ation, i.e. the datasets, the recommender systems, the
evaluation setup, and the results. Finally, in Section 5,
we present our conclusions and future directions.
2 RELATED WORK
In this section, we describe some works related to
context-aware POIs recommendations and embed-
ding vectors that we use to motivate our proposal.
2.1 Context-Aware POIs
Recommendations
POIs recommender systems have become essential in
enhancing user experiences across various domains.
Traditional approaches often overlook contextual in-
formation, which significantly influences user pref-
erences. Context-aware POIs recommender systems
dynamically integrate contextual factors such as time,
location, and user activities, to deliver tailored sug-
gestions.
There are many works about context-aware POIs
recommenders that use location-based data to obtain
user’s contextual information. For example, the work
proposed in (Wahurwagh and Chouragade, 2019) uses
POIs social networks to obtain users sentiment anal-
ysis as contextual information to recommend POIs.
Some works use other factors as contextual informa-
tion, such as weather conditions and spatio-temporal
contexts, to recommend POIs (Hossain et al., 2022;
Waga et al., 2011; Wang et al., 2021). In our work,
we focus on the sequences of check-ins in a session to
obtain embedding vectors as contextual information.
2.2 Embeddings
Embeddings represent data as a vector of real num-
bers, and has its origins in the area of distributed rep-
resentations (Hinton et al., 1986). In distributed rep-
resentations, an item is represented by a pattern of ac-
tivities in a set of computational elements, e.g. neu-
rons in neural networks, and each element can repre-
sent multiple items. There are many methods to ob-
tain those vectors, known as embedding vectors. One
of the most prominent method to obtain those vec-
tors was proposed by (Mikolov et al., 2013), and is
called Word2Vec. It is composed of two models that
are shallow neural networks that are trained on a cor-
pus of words and sentences.
There is a work proposed in the literature that is
related to our work and that uses an adaptation of the
Word2Vec method, as it can be extended to a lot of
domains. In the work of (Wang et al., 2018), the au-
thors use Skip-Gram, one of the models in Word2Vec,
for the song domain, intending to obtain embeddings
considering the songs that are around to a target song.
This idea can also be applied to POIs. In our pa-
per, we use the work proposed in (Wang et al., 2018)
as baseline, and we propose to use a Dual Recurrent
Neural Network (RNN) with Long Short Term Mem-
ory (LSTM) to obtain embedding vectors (i.e. con-
textual information) from sequences of check-ins in a
session.
3 PROPOSED WORK
In our work, we propose a Context-Aware Dual Re-
current Neural Network that is able to learn the gen-
eral and contextual preferences from the users in a
same model, generating embeddings that can be used
in context-aware recommender systems. The user’s
general preference can be inferred by its complete
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
1062
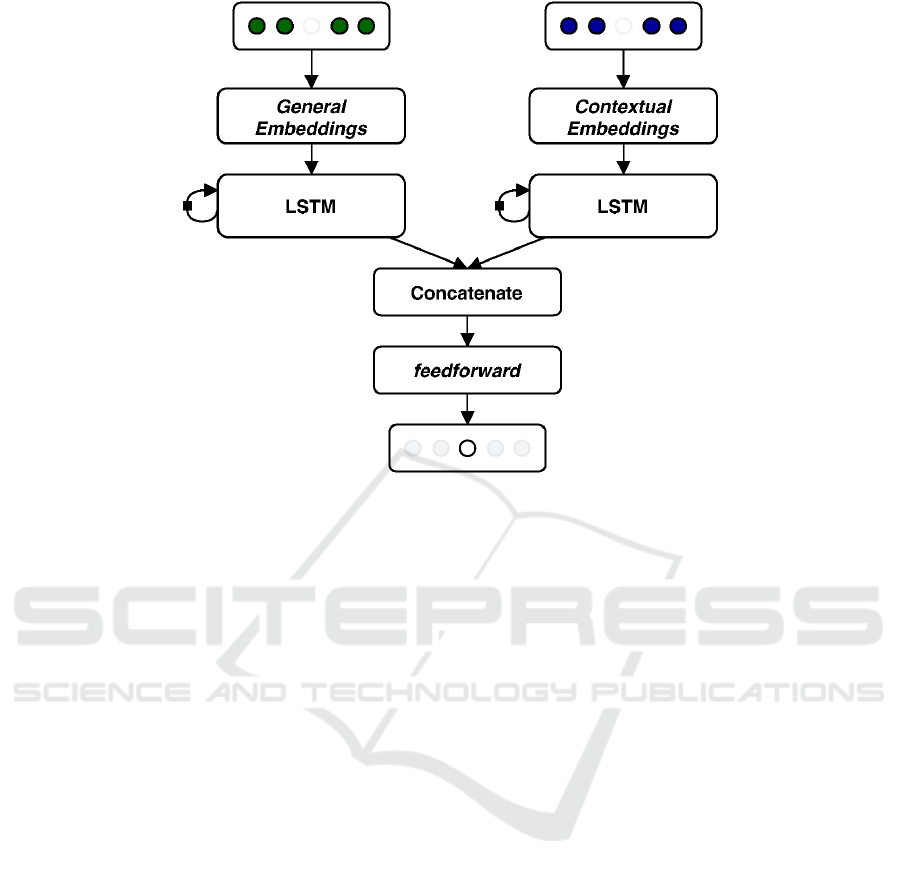
Figure 1: Overview of the proposed model.
check-in history and refers to the user’s specific pref-
erences for POIs. The contextual preference for POIs
indicates the recent preferences of the user in the cur-
rent session. Similar to the Context Bag-of-Words
model (CBOW) proposed by (Mikolov et al., 2013),
the goal of our model is to predict the center point in
the contextual window given its neighborhood POIs.
Figure 1 contains an overview of the proposed model
and its most important layers. However, in contrast
to the CBOW model, as we use a Recurrent Neural
Network (i.e. LSTM layers) to analyze the contex-
tual windows, the order in which the POIs are in the
window matter.
Long Short-Term Memory (LSTM) is a kind of
Recurrent Neural Networks that was proposed with
the intent to solve problems with long term depen-
dencies (Hochreiter and Schmidhuber, 1997). It uses
gated cells that are capable to forget information that
will no longer be useful, and keep information that
can be used later on the sequence (Goodfellow et al.,
2016). There are three gates in the LSTM cell: for-
get gate, input gate, and output gate. Through those
gates, the LSTM cell learns which information is use-
ful in a sequence and passes that information to make
predictions through the output gate, and the cell state
containing the relevant information is passed to the
next timestamp.
For our work, let U =
u
1
, u
2
, . . . , u
|U|
be the set
of users and P =
p
1
, p
2
, . . . , p
|P|
be the set of POIs,
in which |U | e |P| are the total number of unique
users and POIs, respectively. For each user u, their
check-in history are the POIs that were visited by
the user with its respective date and time, defined as
H
u
=
n
p
u
1
, p
u
2
, . . . , p
u
|
H
u
|
o
.
According to how much time has passed between
two points, the user’s check-in history can be divided
into sessions S
u
=
n
S
u
1
, S
u
2
, . . . , S
u
|
S
u
|
o
. A session n
from user u is defined as S
u
n
=
n
p
u
n,1
, p
u
n,2
, . . . , p
u
n,
|
s
′
n
|
o
,
in which p
u
n, j
∈ P.
As seen in Figure 1, our model receives streams of
data: the left one, which has as input the sliding win-
dow of a POI p
u
i
, taking into the complete check-in
history of a user H
u
, for all users. The right stream
has as input the sliding window of the same POI p
u
n,i
,
taking into account the session which the point is, in-
stead of the whole check-in history.
Those sliding windows are passed to the LSTM
layers, that are responsible to analyze the hidden rela-
tionships between the sequences of POIs in the win-
dows of both streams of data. Then, the cell state of
the last timestamp of both LSTMs are concatened in a
single vector. Finally, this vector is used as input by a
fully connected feedforward layer, that tries to predict
the POI that is in the center of both sliding windows,
using as input the concatenated vector.
Each part of the model has its own embedding ma-
trix that is initialized with all the POIs in the dataset
and, as the model learns through the forward and
back-propagation process, this matrix gets updated.
These embeddings will later be used in the context-
aware recommender systems. The result of this train-
Recommending Points of Interest with a Context-Aware Dual Recurrent Neural Network
1063

ing process is that each POI will have two embed-
ding vectors: one that refers to the general prefer-
ences from the users and another one that refers to
the contextual preferences from the users. Thus, we
can explore the flexibility of neural networks in a sin-
gle model to learn the two embedding vectors, instead
of two models as proposed in (Wang et al., 2018).
4 EMPIRICAL EVALUATION
In this section, we describe the empirical evaluation
carried out to evaluate our proposed model. In Sec-
tion 4.1, we present the datasets and their main statis-
tics. Section 4.2 introduces the context-aware recom-
mender systems proposed by (Wang et al., 2018) that
were used to evaluate our model against the baseline.
In Section 4.3, we present the baseline and the evalu-
ation setup. The results are discussed in Section 4.4.
4.1 Datasets
The two datasets used in the empirical evaluation con-
tain the check-in history for each user as well as the
timestamp for each check-in event, without any in-
formation about sessions. So, to generate the ses-
sions, we decided to split POIs that were checked-
in 30 minutes apart from each other. The Foursquare
dataset (Gao et al., 2012; Rossi and Ahmed, 2015) has
187,218 POIs, 11,326 users, and 2,290,997 check-ins.
The second dataset, called Gowalla (Cho et al., 2011),
has 697,606 POIs, 107,092 users, and 6,442,892
check-ins.
4.2 Context-Aware Recommender
Systems
To evaluate our proposed model against the one from
the baseline, we adapted the four context-aware rec-
ommender systems proposed by (Wang et al., 2018)
to recommend POIs. The recommenders make use
of a general preference and a contextual preference
for each user, which are built based on the learned
embeddings. The general preference for a user u
can be learned from its entire check-in history H
u
=
n
p
u
1
, p
u
2
, . . . , p
u
|
H
u
|
o
and is defined as:
p
u
g
=
1
|
H
u
|
∑
p
u
i
∈H
u
v
g2v
p
u
i
, (1)
where v
g2v
p
u
i
is defined as the general embedding vector.
The contextual preference for the user u, given their
current session S
u
n
=
p
u
n,1
, p
u
n,2
, . . . , p
u
n,
|
S
u
i
|
can be
defined as:
p
u
c
=
1
|
S
u
n
|
∑
p
u
n,i
∈S
u
n
v
c2v
p
u
n,i
, (2)
where v
c2v
p
u
n,i
corresponds to the contextual embedding
vector for the POI. As we can see in Equation 1, the
general preference is defined as an average of all the
general embedding vectors of the POIs in the user’s
check-in history. On the other hand, the contextual
preference, defined in Equation 2, is the average of
all the contextual embedding vectors of the POIs in
the user’s current session. Given the general and
contextual embedding vectors, we can use the four
context-aware recommender systems that were de-
fined in (Wang et al., 2018) to recommend POIs, as
they can be adapted to be used in different sequential
domains, including POIs: M-TN, SM-TN, CSM-TN
and CSM-UK.
Of all the context-aware recommender systems,
the M-TN is the only one that uses only the general
preference (i.e. the general embedding vector) to rec-
ommend POIs to the users. Given a user u and their
general preference p
u
g
for POIs, the recommender sys-
tem measures the cosine similarity between p
u
g
and the
general embedding vector of all the POIs in the set P.
The top-N POIs with the highest value of cosine sim-
ilarity are recommended to the user. Formally, the
predicted preference of the user u to the POI p can be
defined as:
pp
M−T N
(u, p) = cos
p
u
g
, v
g2v
p
. (3)
The SM-TN recommender system is similar to M-
TN, but it uses contextual information instead of the
general information. Given a user u and their contex-
tual preference p
u
c
, the SM-TN measures the cosine
similarity between the contextual embedding vector
v
c2v
p
u
n,i
of the POIs and the contextual preference of the
user. The top-N POIs with the highest cosine similar-
ity are then recommended to the user. Formally, the
preference can be defined as:
pp
SM−T N
(u, p) = cos
p
u
c
, v
c2v
p
. (4)
The CSM-TN recommender system is a combi-
nation of the previous recommender systems: M-
TN and SM-TN. After the similarity of each recom-
mender is calculated for each POI, they are summed
to obtain the most similar POIs according to both the
contextual and general preferences of the user. For-
mally, the preference is defined as:
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
1064

PP
CSM−T N
(u, p) = cos
p
u
g
, v
g2v
p
+ cos
p
u
c
, v
c2v
p
.
(5)
The last recommender system, CSM-UK, pro-
poses a combination of the traditional recommender
system, UserKNN (Resnick et al., 1994), with the
learned embedding vectors. The UserKNN recom-
mender system needs a similarity function to build a
neighborhood of similar users. In (Wang et al., 2018),
the similarity function between two users, u and v is
defined as follows:
sim(u, v) =
∑
p∈P
u
∩P
v
1
p
|
P
u
|
×
|
P
v
|
+ cos
p
u
g
, p
v
g
, (6)
where P
u
e P
v
are the set of POIs checked-in by the
users u and v, respectively. With the similarity func-
tion, the CSM-UK system recommends the top-N
most similar POIs for each user, given the user con-
textual preference and their most similar users. The
predicted preference for the target user u to a POI p
can be defined as:
pp
CSM−UK
(u, p) =
∑
v∈U
u,K
∩U
p
sim(u, v)
U
u,k
∩U
p
!
+ cos
p
u
c
, v
c2v
p
, (7)
where U
u,K
is the set with the K users more similar to
u, and U
p
is the set of users who have checked-in the
POI p.
4.3 Baseline and Evaluation Setup
Inspired by the Word2Vec model proposed in
(Mikolov et al., 2013), Wang et al. introduced a model
based on the Skip-Gram architecture to obtain embed-
ding vectors (Wang et al., 2018). The main idea of the
model is that the sequence of items accessed by a user
reflects its preferences during that period, and that co-
occurrence of items in a sequence indicates that those
items are similar. Embeddings of items that are close
in a sequence must appear close in a low dimensional
space.
The model consists of two methods that generate
embedding vectors with different goals: one to obtain
the general preference from the entire access history
of the user, and another one to obtain the contextual
preference from the user’s session. Thus, the method
has the contextual window slides through the sessions
instead of the entire access history. Here, we used the
work proposed in (Wang et al., 2018) as the baseline
to obtain embedding vectors from POIs.
To verify if our model is able of achieving bet-
ter results than the baseline, the context-aware recom-
mender systems were executed using the k-fold cross-
validation protocol. In this protocol, we split the users
of the datasets into k mutually exclusive partitions, in
which 1 of these partitions is chosen as the testing
partition and the remaining are chosen as the training
partition. We chose the testing partition k times, with-
out repeating the same partition, as described in (Al-
paydin, 2004). Figure 2 shows the process of splitting
the users into partitions, assuming k = 5 that is the
value used in our work.
Users that are in the training partition use all of
their POIs sessions to build their preferences (general
and contextual), as it can be seen in Figure 2. As for
the users that are in the testing partitions, they use
only the first part of their sessions to build their pref-
erences, and the second part for each session is used
as the testing POIs.
To evaluate the recommendations made by the rec-
ommender systems, we used five different metrics,
which three (Precision, Recall, and F-measure) are
commonly used to evaluate the accuracy of the rec-
ommendations, and two metrics that are used to eval-
uate if the ranking of the recommendations meets the
user’s preference, which are Mean Average Precision
(MAP) and Normalized Discounted Cumulative Gain
(NDCG) (J
¨
arvelin and Kek
¨
al
¨
ainen, 2002).
Precision, as described by (Chung et al., 2018),
is a metric that measures the proportion of satisfying
recommendations made by the recommender system,
indicating the quality of recommendations made with
an emphasis on the success of the recommendations.
Recall, on the other hand, measures the proportion of
the recommendations among the POIs that the user
is actually interested in. The F-measure metric is de-
fined as the harmonic mean between the Precision and
Recall metrics and as those metrics, its value varies
between 0 and 1.
The ranking metrics that were used in this work
have different goals. MAP, for instance, as described
in (Shani and Gunawardana, 2011), has as its main
focus to ensure that the first few items in the recom-
mendation list are in the correct order. If they are not,
the metric will penalize the recommendation list. The
MAP metric can be calculated as a mean of the Aver-
age Precision (AP) metric for each recommendation
made for a single user. The NDCG, in contrast to the
MAP metric, does not favor the items that appear first
in the recommendation list. Its goal, as defined by
(Shani and Gunawardana, 2011), is to offer a metric
that is appropriated to large recommendation lists in
which the penalty is applied to the items that are fur-
ther from the beginning of the list.
To optimize our model, we tested several param-
eters values by using Python and Keras. The best
values for both datasets consisted of 512 LSTM units
and embedding vectors of size 256. In both datasets,
Recommending Points of Interest with a Context-Aware Dual Recurrent Neural Network
1065
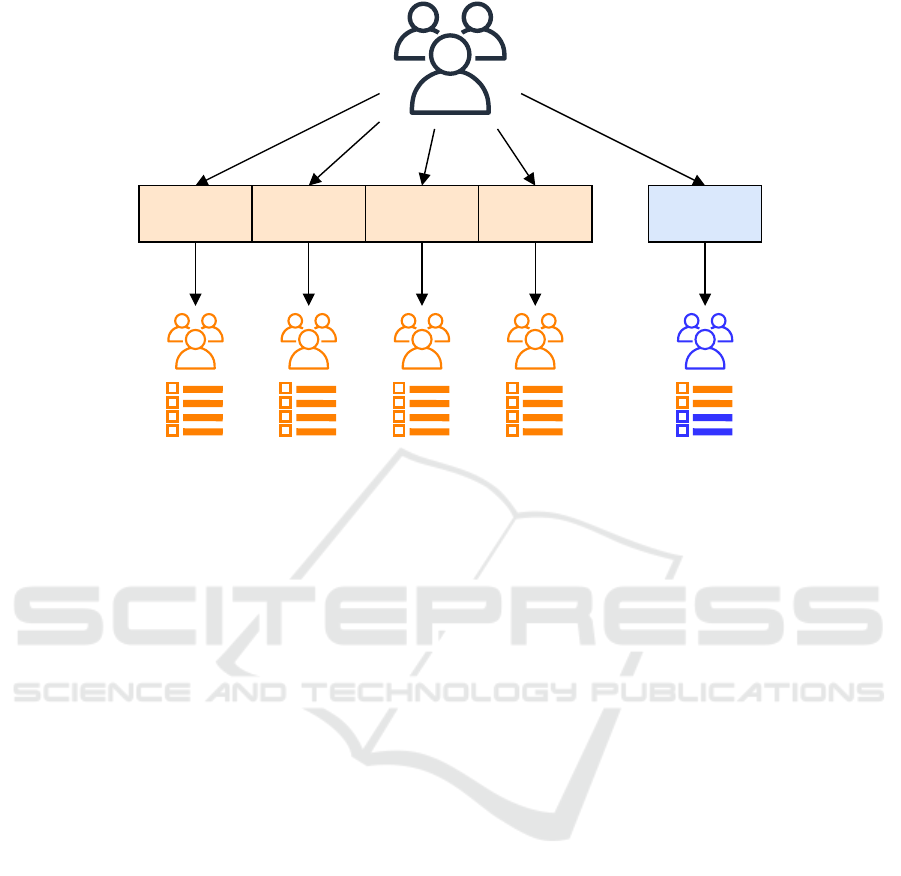
Figure 2: The k-fold cross-validation protocol with k = 5.
the Dropout was setup to 0.2, the Activation Function
adopted was tahn, and the Window Size was setup to
3.
Finally, to compare two context-aware recom-
mender systems, we applied the two sided paired t-
test with a 95% confidence level (Mitchell, 1997).
4.4 Results
In this section, we present the results for the top-5
recommendations generated by the recommender sys-
tems. As we can see in Figures 3 and 4, our proposed
model was able to outperform the baseline in most of
the context-aware recommender systems. The only
recommender systems that the baseline showed bet-
ter results than our proposed model were in SM-TN,
for both datasets, and in CSM-UK, for the Foursquare
dataset. The differences in Figures 3 and 4 are statis-
tically significant.
For the Foursquare dataset, there was an improve-
ment in M-TN and CSM-TN systems. This means
that, for general embedding vectors and the com-
bination of general and contextual embedding vec-
tors, our proposed model provides better recommen-
dations. The decrease for the CSM-UK algorithm is
similar to the decrease observed in the SM-TN, which
might indicates that the relationship between users are
not interfering in the final results. The most signif-
icant improvement in the Foursquare dataset, for the
NDCG metric, was in the CSM-TN, which combines
both embeddings (contextual and general), with an
improvement of 63.62%.
In the Gowalla dataset, the contextual embedding
vectors obtained by our model showed a big decrease
in comparison to the baseline, as we can see in the
metrics of the SM-TN recommender systems (Fig-
ure 4), which uses only the contextual embeddings.
Although there was no improvement in the contex-
tual embedding vectors, the general embeddings and
the combination embeddings (general and contex-
tual) showed a great improvement over the embed-
dings obtained by the baseline. The CSM-UK recom-
mender system, for example, showed an improvement
of 1625.93% in NDCG, and 1675.90% in Recall.
5 CONCLUSION AND FUTURE
WORK
In this work, we proposed a model that uses LSTM
units in a Context-Aware Dual Recurrent Neural Net-
work to learn both general and contextual embeddings
for POIs that can be used in context-aware recom-
mender systems.
The results obtained by our model in two datasets,
that contain the check-in history of users, showed
that our model can outperformed the baseline in both
datasets depending on the context-aware system used
to make the recommendations. This conclusion was
obtained by using metrics that measured how good the
recommendations are for the user, and if the recom-
mendations are ranked accordingly. This fact shows
that a Recurrent Neural Network can be used to cap-
ture the intrinsic relationship between the sequence of
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
1066

Figure 3: Results obtained by using the embeddings from the baseline and the proposed model in the Foursquare dataset.
Figure 4: Results obtained by using the embeddings from the baseline and the proposed model in the Gowalla dataset.
POIs that the user has checked-in, and generating con-
textual information for context-aware recommender
systems.
For future work, we plan to use different Recur-
rent Neural Networks such as Gated Recurrent Units
(GRU) (Cho et al., 2014), which has fewer parameters
as LSTM and can be used to decrease the training time
and memory consumption. Another possibility to im-
prove our model is to try different methods of initial-
izing the embedding matrices of the model. Finally,
we also intent to use Transformers (Vaswani et al.,
2017), which are network architectures that adopt the
mechanism of attention, differentially weighing the
significance of each part of the input data.
ACKNOWLEDGEMENTS
To NVIDIA Corporation for donation of a Titan V
GPU used in this work.
Recommending Points of Interest with a Context-Aware Dual Recurrent Neural Network
1067

REFERENCES
Adomavicius, G., Mobasher, B., Ricci, F., and Tuzhilin,
A. (2011). Context-aware recommender systems. AI
Magazine, 32(3):67–80.
Alpaydin, E. (2004). Design and Analysis of Machine
Learning Experiments. Introduction to Machine
Learning.
Cho, E., Myers, S. A., and Leskovec, J. (2011). Friendship
and mobility: user movement in location-based social
networks. In Proceedings of the 17th ACM SIGKDD
International Conference on Knowledge Discovery
and Data Mining, KDD’11, page 1082–1090.
Cho, K., van Merri
¨
enboer, B., Gulcehre, C., Bahdanau, D.,
Bougares, F., Schwenk, H., and Bengio, Y. (2014).
Learning phrase representations using RNN encoder–
decoder for statistical machine translation. In Pro-
ceedings of the 2014 Conference on Empirical Meth-
ods in Natural Language Processing (EMNLP), pages
1724–1734.
Chung, Y., Kim, N. R., Park, C. Y., and Lee, J. H. (2018).
Improved neighborhood search for collaborative filter-
ing. International Journal of Fuzzy Logic and Intelli-
gent Systems, 18(1):29–40.
Ding, Z., Li, X., Jiang, C., and Zhou, M. (2018). Objectives
and state-of-the-art of location-based social network
recommender systems. ACM Comput. Surv., 51(1).
Gao, H., Tang, J., and Liu, H. (2012). Exploring social-
historical ties on location-based social networks. In
Proceedings of the 6th International AAAI Conference
on Weblogs and Social Media.
Goodfellow, I., Bengio, Y., and Courville, A. (2016). Deep
Learning. The MIT Press.
Hinton, G. E., McClelland, J. L., and Rumelhart, D. E.
(1986). Distributed Representations. In Parallel Dis-
tributed Processing: Explorations in the Microstruc-
ture of Cognition, Vol. 1: Foundations, chapter Dis-
tribute Representations, pages 77–109. MIT Press,
Cambridge, MA, USA.
Hochreiter, S. and Schmidhuber, J. (1997). Long Short-
Term Memory. Neural Computation.
Hossain, M. B., Arefin, M. S., Sarker, I. H., Kowsher, M.,
Dhar, P. K., and Koshiba, T. (2022). Caran: A context-
aware recency-based attention network for point-of-
interest recommendation. IEEE Access, 10:36299–
36310.
J
¨
arvelin, K. and Kek
¨
al
¨
ainen, J. (2002). Cumulated gain-
based evaluation of ir techniques. ACM Trans. Inf.
Syst., 20(4):422–446.
Mikolov, T., Chen, K., Corrado, G., and Dean, J. (2013).
Efficient estimation of word representations in vector
space. In 1st International Conference on Learning
Representations, ICLR 2013 - Workshop Track Pro-
ceedings.
Mitchell, T. M. (1997). Machine Learning. McGraw-Hill,
Inc., New York, NY, USA, 1 edition.
Resnick, P., Iacovou, N., Suchak, M., Bergstrom, P., and
Riedl, J. (1994). GroupLens: An open architecture
for collaborative filtering of netnews. In Proceedings
of the 1994 ACM Conference on Computer Supported
Cooperative Work, CSCW 1994.
Rossi, R. A. and Ahmed, N. K. (2015). The network data
repository with interactive graph analytics and visual-
ization. In AAAI.
S
´
anchez, P. and Bellog
´
ın, A. (2022). Point-of-interest
recommender systems based on location-based social
networks: A survey from an experimental perspective.
ACM Comput. Surv., 54(11s).
Shani, G. and Gunawardana, A. (2011). Evaluating recom-
mendation systems. In Recommender Systems Hand-
book, chapter 8. Springer US, Boston, MA, 1 edition.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., Kaiser, L. u., and Polosukhin, I.
(2017). Attention is all you need. In Advances in
Neural Information Processing Systems, volume 30.
Curran Associates, Inc.
Waga, K., Tabarcea, A., and Fr
¨
anti, P. (2011). Context
aware recommendation of location-based data. In 15th
International Conference on System Theory, Control
and Computing, pages 1–6.
Wahurwagh, R. A. and Chouragade, P. M. (2019). Context
aware personalized poi recommendation with multi-
ple tourist information using hierarchical modeling. In
2019 3rd International Conference on Trends in Elec-
tronics and Informatics (ICOEI), pages 241–243.
Wang, C., Peng, C., Wang, M., Yang, R., Wu, W., Rui, Q.,
and Xiong, N. N. (2021). Cthgat: Category-aware and
time-aware next point-of-interest via heterogeneous
graph attention network. In 2021 IEEE International
Conference on Systems, Man, and Cybernetics (SMC),
pages 2420–2426.
Wang, D., Deng, S., and Xu, G. (2018). Sequence-based
context-aware music recommendation. Information
Retrieval Journal.
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
1068
