
Towards Multi-View Hand Pose Recognition Using a Fusion of Image
Embeddings and Leap 2 Landmarks
Sergio Esteban-Romero
1 a
, Romeo Lanzino
2 b
, Marco Raoul Marini
2 c
and Manuel Gil-Mart
´
ın
1 d
1
Grupo de Tecnolog
´
ıa del Habla y Aprendizaje Autom
´
atico, ETSI Telecomunicaci
´
on, Universidad Polit
´
ecnica de Madrid,
Av. Complutense 30, 28040, Madrid, Spain
2
VisionLab, Department of Computer Science, Sapienza University of Rome, Via Salaria 113, Rome 00198, Italy
Keywords:
Multi-View Hand Pose Recognition, Leap Motion Controller 2, Multimodal Data, Multimodal Fusion, Deep
Learning.
Abstract:
This paper presents a novel approach for multi-view hand pose recognition through image embeddings and
hand landmarks. The method integrates raw image data with structural hand landmarks derived from the
Leap Motion Controller 2. A Vision Transformer (ViT) pretrained model was used to extract visual features
from dual-view grayscale images, which were fused with the corresponding Leap 2 hand landmarks, creating
a multimodal representation that encapsulates both visual and landmark data for each sample. These fused
embeddings were then classified using a multi-layer perceptron to distinguish among 17 distinct hand poses
from the Multi-view Leap2 Hand Pose Dataset, which includes data from 21 subjects. Using a Leave-One-
Subject-Out Cross-Validation (LOSO-CV) strategy, we demonstrate that this fusion approach offers a robust
recognition performance (F1 Score of 79.33 ± 0.09 %), particularly in scenarios where hand occlusions or
challenging angles may limit the utility of single-modality data.
1 INTRODUCTION
Non-verbal communication is a crucial component in
human interactions, playing a crucial role in express-
ing emotions, attitudes and intentions beyond words
and it represents approximately 65% of human mes-
sages (Shin et al., 2024). Besides its human nature, it
is also a key element for human-computer interaction
(HCI) to make more accessible systems that leverage
communicating with electronic devices or with other
humans, e.g. via sign language (Miah et al., 2024).
In this context, enhancing user interaction in immer-
sive technologies like virtual reality and augmented
reality could enable more intuitive and accessible ex-
periences.
The proper recognition of hand poses is challeng-
ing due to the numerous joints of the hands, which
enable a wide variety of positions and because of oc-
clusions, consequence of the viewpoint, among others
(Lee et al., 2024). Consequently, such inconveniences
a
https://orcid.org/0009-0008-6336-7877
b
https://orcid.org/0000-0003-2939-3007
c
https://orcid.org/0000-0002-2540-2570
d
https://orcid.org/0000-0002-4285-6224
are also present in some of the datasets that have
been traditionally used to design hand pose recogni-
tion systems.
The existing solutions to capture dynamics of the
human body can be divided into device-based and
vision-based systems (Rahim et al., 2020). Device-
based solutions often employ wristbands or gloves to
track the position of key points that are representa-
tive enough of the hand (Lee et al., 2024)(Wang et al.,
2023). Analogously, vision-based systems, such as
MediaPipe (Zhang et al., 2020) (Chen et al., 2022)
aim to capture the most representative positions of the
hand by replicating the functioning of device-based
systems using only images.
In this work, we present a baseline result using
the Multi-view Leap2 Hand Pose Dataset (ML2HP
Dataset) (Gil-Mart
´
ın et al., 2024) on the hand pose
recognition task. The dataset includes real images
recorded from two different angles to mitigate hand
occlusion phenomena alongside landmark coordi-
nates, velocities, orientations, and finger widths rela-
tive to the hand. To the best of our knowledge, it is the
first result achieved using this dataset. To obtain the
baseline result, we first processed the images using
a pre-trained Vision Transformer (ViT) (Dosovitskiy
918
Esteban-Romero, S., Lanzino, R., Marini, M. R. and Gil-Martín, M.
Towards Multi-View Hand Pose Recognition Using a Fusion of Image Embeddings and Leap 2 Landmarks.
DOI: 10.5220/0013234300003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 3, pages 918-925
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

et al., 2020) to be used as input features alongside
the raw landmarks. Finally, a multilayer perceptron
(MLP) with 17 outputs, equal to the number of poses
in the dataset, provides the final probability distribu-
tion.
The remainder of this paper is organized as fol-
lows. Section 2 briefly describes works focused on
the recognition of poses and gestures using differ-
ent sources. Section 3 provides a description of the
dataset, the required data cleaning procedures, the
model architecture used to construct the presented
baseline and the followed evaluation methodology.
Section 4 provides a discussion of the results obtained
when validating our model. Section 5 highlights our
conclusions and also points towards future lines of re-
search.
2 RELATED WORKS
Hand Gesture Recognition (HGR) has become a cru-
cial area in human-computer interaction, enabling
more natural communication with devices through
gestures. In the literature, most solutions include a
feature extraction method, which can be either man-
ual or based in Artificial Neural Networks (ANN),
and a classifier adapted to decode such information
(Tan et al., 2023).
Histograms of Oriented Gradients (HOG) and
wavelet transforms have been widely used for HGR
over the years because of their ability to cap-
ture edge and frequency features (Dalal and Triggs,
2005)(Agarwal et al., 2015). However, these tech-
niques often introduce biases stemming from the ex-
pert’s choices during feature extraction, as they rely
on handcrafted parameters and may not generalize
well to diverse datasets. This can limit their effec-
tiveness compared to more modern, data-driven ap-
proaches such as deep learning (Tan et al., 2023).
Later, the feature extraction problem has also been
addressed using machine learning (ML) strategies to
extract features such as convolutional neural networks
(Tao et al., 2018) (CNN) or Principal Component
Analysis (PCA) (Oliveira et al., 2017) with a specific
focus on sign language. Moreover, improvements
in the field were achieved for Chinese, Arabic, and
Japanese using Deep Learning methods (Yuan et al.,
2021)(Aly and Aly, 2020).
Other lines of research explore more complex ar-
chitectures based on a multi-stage deep learning so-
lution that achieves state-of-the-art results in various
HGR datasets such as the creative senz3D dataset
(Creative Senz3D) or the Kinetic and Leap Motion
Gestures dataset (Kinetic and Leap Motion Gestures)
which comprises RGB images and depth maps.
The latest advances in vision-based RGB systems
use Vision Transformers (ViT) (Dosovitskiy et al.,
2021) to leverage the capabilities of HGR systems.
Current challenges in RGB still image-based hand
gesture recognition (HGR) include limited model per-
formance in addressing orientation changes, partial
occlusions, and accurately capturing depth and spatial
details. Furthermore, the scarcity of diverse datasets
and the demand for more computationally efficient
models further complicate the development of effec-
tive solutions (Shin et al., 2024).
Moreover, other works have been focused on
landmark-based approaches for hand pose and ges-
ture recognition. These methods detect key points
such as finger joints to capture the structure of the
hand and feed deep learning architectures to model
and classify hand gestures or poses. For example,
previous works used MediaPipe landmarks to feed a
transformer and perform a sign language recognition
task (Luna-Jim
´
enez et al., 2023), or used several li-
braries to extract landmarks and perform human pose
estimation (Chung et al., 2022).
A promising future direction would be to integrate
both image-based and landmark-based modalities.
While images capture detailed spatial information,
landmarks provide a simplified, efficient hand struc-
ture representation. Combining these two sources
could enhance model accuracy and generalization, ad-
dressing challenges like partial occlusions and orien-
tation changes.
3 MATERIALS AND METHODS
In this section, we describe the dataset that has been
used to obtain the baseline result presented in this pa-
per, the data cleaning process, the model architecture
and the evaluation methodology followed to train and
evaluate the proposed system.
3.1 Dataset
The Multi-view Leap2 Hand Pose Dataset (ML2HP
Dataset) (Gil-Mart
´
ın et al., 2024) is a comprehen-
sive and meticulously curated dataset designed to
address the challenges of hand pose recognition in
multi-view settings. Captured using two Leap Mo-
tion Controller 2 devices, the dataset provides a rich
source of real-world data that enables accurate and re-
liable hand pose recognition models, particularly for
human-computer interaction applications.
This dataset comprises 714,000 instances, col-
lected from 21 subjects performing 17 distinct hand
Towards Multi-View Hand Pose Recognition Using a Fusion of Image Embeddings and Leap 2 Landmarks
919
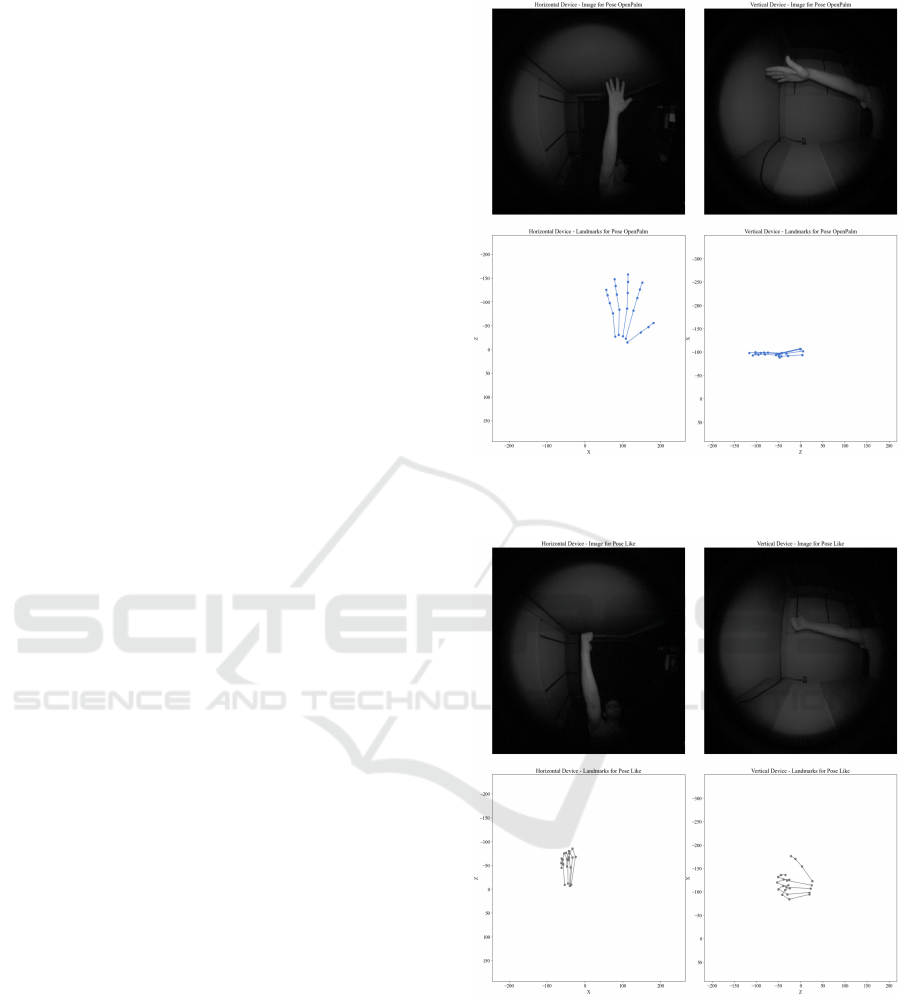
poses, such as ”Open Palm”, ”Closed Fist”, ”Like”
and ”OK Sign”. The subjects’ ages range from 22 to
68 years, with a diverse gender distribution, making
the dataset suitable for generalization across different
demographic groups. Each instance in the dataset in-
cludes real images along with 247 hand properties,
such as landmark coordinates, palm velocity, finger
orientations, and finger widths. The dataset is also
balanced across different hand poses, and hand usage
(right or left), ensuring robustness in training machine
learning models.
A key feature of the ML2HP dataset is its multi-
view recording setup, which employs two Leap Mo-
tion Controller 2 devices positioned at complemen-
tary angles (Horizontal and Vertical viewpoints), cor-
responding to a dual-camera setup. This dual-camera
configuration mitigates occlusion issues, ensuring
that hand poses are captured accurately even when
parts of the hand are obscured from one camera’s
view.
This dataset presents instances where the orien-
tation of the hand relative to each device can influ-
ence hand pose detection when using a single device.
When the hand faced directly toward the horizontal
device, the vertical device often struggled with ac-
curate hand pose detection due to occlusion and lim-
ited visibility of the fingers, as illustrated in the Open
Palm example of Figure 1. Similarly, when the hand
was oriented toward the vertical device, the horizon-
tal device faced comparable challenges, resulting in
incomplete landmark representation, as seen in the
Like hand pose of Figure 2. However, in certain cases
where the hand was positioned diagonally, both de-
vices successfully captured the hand pose accurately,
as demonstrated in the Four hand pose of the Figure
3.
This way, this dataset composed of multi-view and
multimodal (images and landmarks) information pro-
vides a particularly valuable set for developing and
testing hand-tracking models that can generalize well
across different subjects, and hand usage. Moreover,
to the best of our knowledge, no baseline perfor-
mance metrics exist for this dataset, allowing us to
explore and establish an initial benchmark for hand
pose recognition task using the available data.
3.2 Data Cleaning
When exploring the dataset we encounter some is-
sues coming from the official acquisition program
provided to operate Leap Motion Controller 2. In par-
ticular, we identified two different types of issues:
• Missing Values: in one specific frame out of the
714,000 available, we find missing values in 29
Figure 1: Images and 2D landmark representations for
OpenPalm class from both viewpoint devices (Gil-Mart
´
ın
et al., 2024).
Figure 2: Images and 2D landmark representations for Like
class from both viewpoint devices (Gil-Mart
´
ın et al., 2024).
columns for the horizontal device and 55 for the
vertical device recordings. The specific metadata
associated with the frame can be found in Table
1. We assigned the mean value of the column to
those missing values. No further exploration of
which value to assign has been carried out.
• Non Printable Characters: some float values
include ”non-printable” characters which lead to
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
920

Figure 3: Images and 2D landmark representations for Four
class from both viewpoint devices (Gil-Mart
´
ın et al., 2024).
Table 1: Metadata associated to the frame containing miss-
ing values in the dataset.
Property Value
frame id 232
subject id 19
which hand Left Hand
pose OpenPalm
device Horizontal
errors in the system as they were recognized as
strings. We hypothesize that this issue may also
come from the official acquisition system pro-
vided or from the usage of different encodings
when processing the files. However, we did not
conduct further investigation on the matter. To
overcome that difficulty, we used regular expres-
sions to isolate those specific values for their con-
venient cleansing and casting into actual float
numbers.
3.3 Model Architecture
Our approach tackles some of the most concern-
ing problems associated to HGR using the ML2HP
Dataset. Specifically, we propose a solution that for
every sample integrates the information of both view-
points including the image and the hand landmark in-
formation. The architecture is illustrated in Figure 4.
Specifically, we use a pretrained Vision Trans-
former (ViT) model
1
from Huggingface as the feature
1
https://huggingface.co/google/vit-base-patch16-384
Table 2: Dimensions corresponding to each of the variables
involved in the proposed model architecture, where C is the
number of channels, H and W correspond to the height and
width of the image, N
vertical
and N
horizontal
correspond to
the ViT output for each viewpoint image, N
landmarks
is the
number of available landmarks per viewpoint, and N
classes
corresponds to the number of hand poses.
Variable Dim
C 3
H 512
W 512
N
vertical
768
N
horizontal
768
N
landmarks
242
N
classes
17
extractor. The ViT model is designed to process only
images with three channels, which presents a lim-
itation when working with single-channel grayscale
images. To address this, we replicated the intensity
values of the grayscale images across the remaining
two channels, effectively converting them into three-
channel images.
Then, we extract the Classification (CLS) token
from the model’s final hidden state, which serves as
a compact representation of the entire image (Doso-
vitskiy et al., 2020). This representation is then con-
catenated with the extracted landmarks, resulting in a
multimodal embedding that encapsulates all the rele-
vant information for each sample.
Finally, to classify each sample into one out of the
17 possible classes we use the multimodal embedding
as input for a MLP that will be adapted throughout the
training process. The layers in the MLP have the fol-
lowing dimensionality: input dim → 1, 024 → 512 →
256 → 128 → 17, where input dim = N
horizontal
+
N
vertical
+ 2 ∗ N
landmarks
. The specific dimensions of
each variable are presented in Table 2. We used
CrossEntropyLoss Pytorch implementation as loss
function to optimize throughout the training process.
For our model, we used Adam optimizer (Kingma
and Ba, 2017) and set the learning rate to 10
−5
to en-
sure gradual and stable updates during training. The
batch size was set to 256, balancing memory us-
age and training efficiency. Training was conducted
for a maximum of 3 epochs to prevent overfitting
and reduce computational time considering the large
amount of samples available. No validation of the
selected hyperparameters has been performed in this
study.
Arguably, there might be some over-
representation as well as dependencies between
the input features since the landmarks are descriptors
of the hands that appear in the images. However, we
consider both modalities can complement each other,
Towards Multi-View Hand Pose Recognition Using a Fusion of Image Embeddings and Leap 2 Landmarks
921
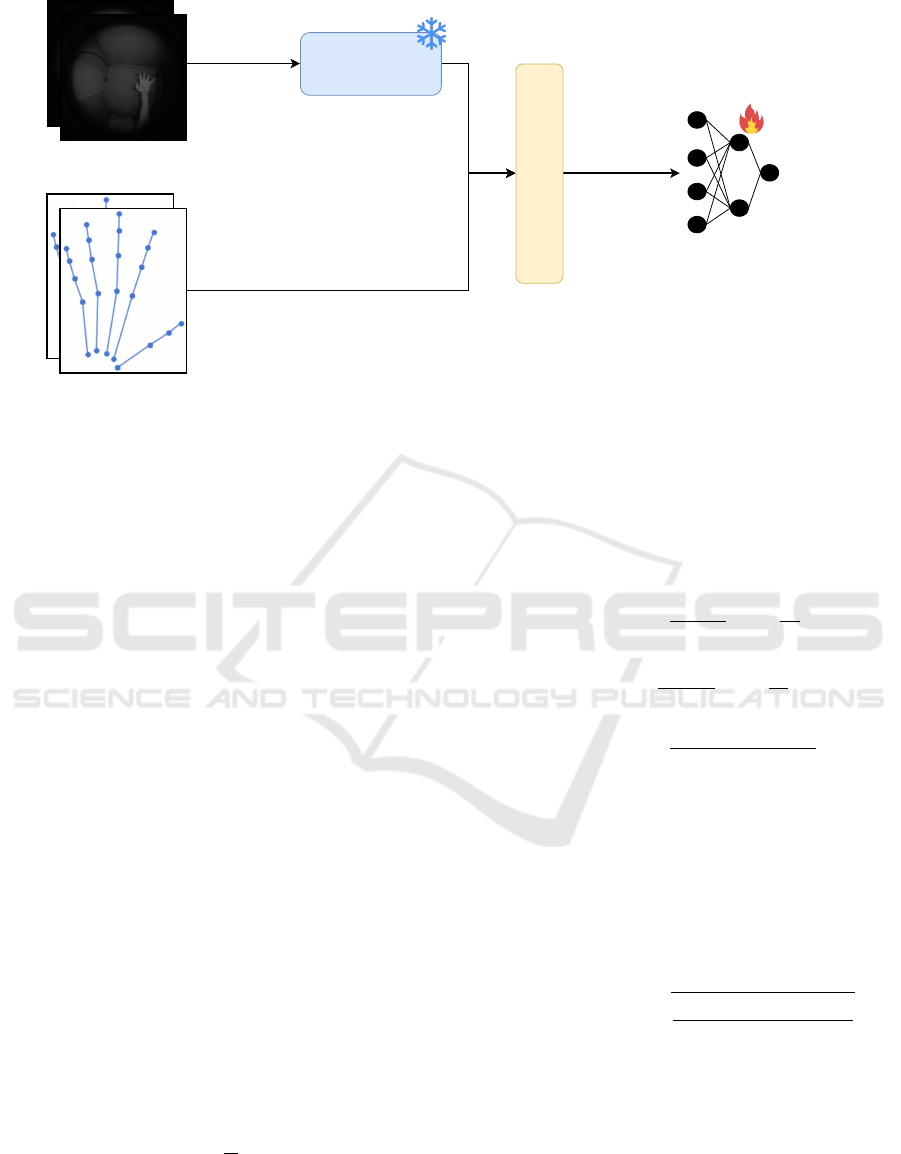
ViT
Horizontal and vertical
viewpoint
( || )
Horizontal and vertical
viewpoint landmarks
2xCxHxW
2xN
landmarks
1xN
horizontal
1xN
vertical
1xN
classes
MLP
Concatenate
and reshape
1x input_dim
Figure 4: Architecture used to create the baseline result for ML2HP Dataset where a pretrained ViT is used as feature extractor
for images. Then, in combination with the raw landmark values, the MLP is fine-tuned to solve the task. The snowflake
indicates those parts that remain frozen and the flame those fine-tuned throughout the training process.
specially in those situations where we experience
hand occlusions or there is not a clear view of the
hand from any viewpoint. Besides this hypothesis,
we encourage researchers to further investigate the
relevance of each modality as well as the existing
correlation between features.
3.4 Evaluation Methodology
To evaluate the system using the whole dataset in a
subject-independent scenario, we employed a Leave-
One-Subject-Out Cross-Validation (LOSO-CV) ap-
proach as the data distribution strategy. In this
methodology, data from all subjects except one are
used to train the system, while the data from the left-
out subject are used to test it. This process is repeated,
with each subject being left out in turn, and the results
are averaged across all iterations. This approach sim-
ulates a realistic scenario where the system is eval-
uated with recordings from subjects not used in the
training phase.
As evaluation metrics, we used accuracy, which is
defined as the ratio between the number of correctly
classified samples and the total number of samples.
For a classification problem with N testing examples
and N
classes
classes, accuracy is defined in Equation 1:
Accuracy =
1
N
N
classes
∑
i=1
P
ii
(1)
Considering R
i
as the sum of all examples in the
i-th column of the confusion matrix and S
i
as the sum
of all examples in the i-th row, the precision (Equa-
tion 2), recall (Equation 3), and F1-score (Equation
4) metrics are defined as follows:
Precision =
1
N
classes
N
classes
∑
i=1
P
ii
R
i
(2)
Recall =
1
N
classes
N
classes
∑
i=1
P
ii
S
i
(3)
F1-score = 2 ·
Precision · Recall
Precision + Recall
(4)
To show statistical significance, we used confi-
dence intervals, which represent plausible values for
a specific metric. A significant difference between
the results of two experiments is established when
their confidence intervals do not overlap. Equation
5 shows the computation of confidence intervals as-
sociated with a specific metric value and N samples
for a 95% confidence level:
CI(95%) = ±1.96 ·
r
metric · (100 − metric)
N
(5)
4 RESULTS AND DISCUSSION
Table 3 shows the results for the LOSO-CV evalua-
tion, with an F1 Score of 79.33 ± 0.09 %. This score
reflects a robust performance, indicating a strong bal-
ance between precision and recall, which is essential
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
922

for reliable classification outcomes. However, con-
sidering the substantial sample size of 714,000 exam-
ples, there exists still work for improvement in overall
performance.
Table 3: Performance metrics with 95% confidence inter-
vals for the LOSO-CV evaluation.
Metric Value (%)
Accuracy 79.65 ± 0.09
Precision 80.63 ± 0.09
Recall 79.65 ± 0.09
F1 Score 79.33 ± 0.09
The confusion matrix related to the results is
shown in Figure 5 and highlights some of the best and
worst classified hand poses.
Considering that there are 42,000 examples per
class, One hand pose is the best classified, achieving
39,719 correct predictions with minimal misclassifi-
cation. Spiderman also performs well, with 36,827
correctly identified instances, although it is occasion-
ally confused with Stop (2,886 times). This confu-
sion likely arises from their similar configurations,
both involving extended fingers, making them harder
to distinguish when occluded or viewed from certain
angles. Open Palm is another well-recognized pose,
with 36,685 correct classifications, though some in-
stances are misclassified as Tiger (3,359 times), re-
flecting the slight overlap in appearance when fingers
are not fully straightened or curled.
On the other hand, some poses show poor per-
formance, with quite misclassifications. OK is one
of the worst classified, with 28,770 correct predic-
tions. It is frequently confused with OpenPalm (3,735
times), likely because both involve the extension of
several fingers, and the circular thumb-index gesture
in OK can sometimes appear flattened or ambiguous
from certain angles. Rock also struggles, achieving
only 28,910 correct classifications. It is often con-
fused with Tiger (6,574 times) and Spiderman (2,279
times), as these poses share similar elements, such as
the partial extension of specific fingers, which can be
difficult to distinguish under certain viewpoints.
These results indicate that subtle differences in
finger arrangements and slight variations in curva-
ture contribute to misclassifications. For example, the
similarity between Rock and Spiderman, with their
partially extended fingers, highlights the difficulty of
accurately distinguishing between such poses. Like-
wise, OpenPalm being misclassified as Tiger suggests
that some pose may lack enough distinct visual cues
when viewed from certain perspectives.
These findings suggest future research directions,
including the need to explore the impact of camera
perspective. Identifying which camera—horizontal or
vertical—provides the clearest view of each instance
may improve recognition by leveraging the most in-
formative viewpoint.
5 CONCLUSIONS
In order to establish a baseline for future research,
we evaluated our proposed method on the Multi-view
Leap2 Hand Pose Dataset using a LOSO-CV strategy
in order to provide an accurate system capable to gen-
eralize across different individuals. To the best of our
knowledge, this is the first result achieved using this
dataset. The proposed architecture used ViT to extract
features from images, demonstrating the advantages
of a multimodal approach that combines image data
with hand landmark information. This integration of-
fers a robust performance, even when in some cases
hand pose may be occluded. The system offers a F1
Score of 79.33 ± 0.09 %, which indicates strong clas-
sification performance across the dataset. In particu-
lar, the confusion matrix reveals specific poses that
are frequently misclassified, such as Tiger and Open
Palm, suggesting a need for enhanced strategies o dis-
tinguish between similar poses.
Future work could explore alternative partitioning
strategies for the ML2HP dataset, such as separating
training and testing based on distinct camera orien-
tations or hand dominance. Additionally, detecting
which camera (horizontal or vertical) the hand is pri-
marily oriented towards for each instance and evaluat-
ing performance using data from only that viewpoint
would provide insights into how much information
can be effectively extracted from a single perspec-
tive. In addition, it could be possible to investigate
the impact of using only one modality—either the
image data or the hand landmarks—rather than both.
This would help determine whether the visual features
alone or the landmark information is enough for ac-
curate hand pose recognition in certain scenarios. Ex-
ploring these configurations would provide a clearer
understanding of the individual contributions of each
modality and help develop more efficient models that
optimize either visual or landmark-based recognition.
Furthermore, applying the proposed model to new
datasets will provide deeper insights into its function-
ality and improve the understanding of its practical
performance.
ACKNOWLEDGEMENTS
Sergio Esteban-Romero research was supported
by the Spanish Ministry of Education (FPI grant
Towards Multi-View Hand Pose Recognition Using a Fusion of Image Embeddings and Leap 2 Landmarks
923
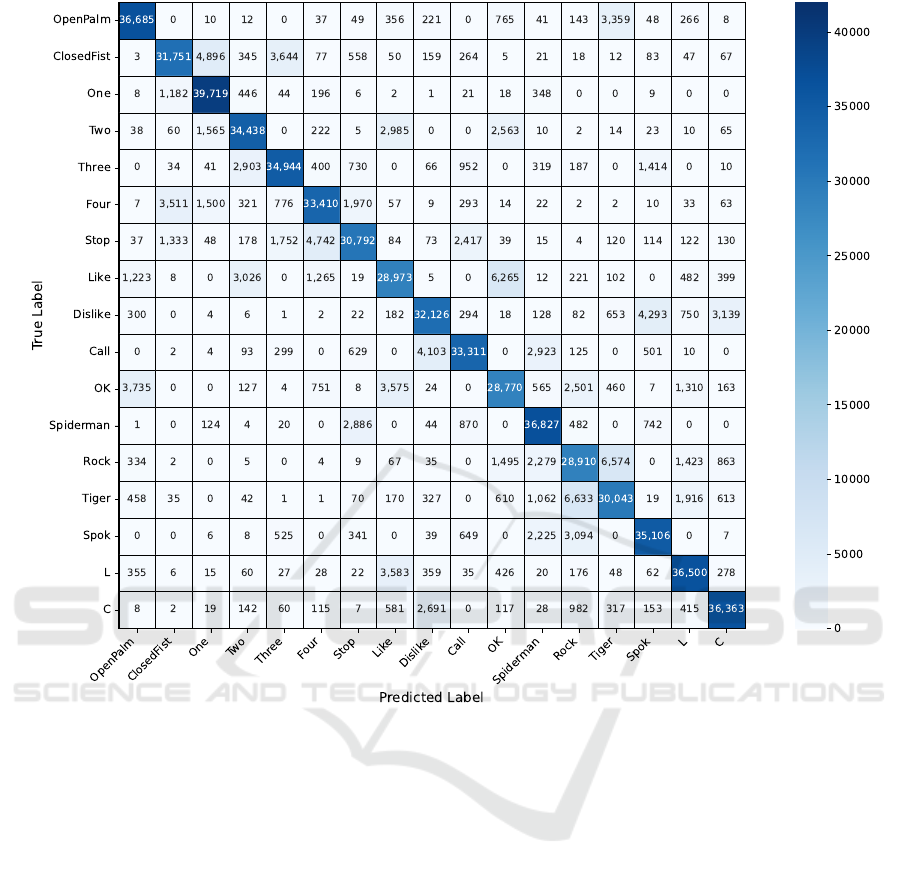
Figure 5: Confusion matrix for the baseline system using a LOSO-CV.
PRE2022-105516). This work was funded by
Project ASTOUND (101071191 — HORIZON-
EIC-2021-PATHFINDERCHALLENGES-01) of the
European Commission and by the Spanish Ministry
of Science and Innovation through the projects
TRUSTBOOST (PID2023-150584OB-C21 and
PID2023-150584OB-C22), GOMINOLA (PID2020-
118112RB-C21 and PID2020-118112RB-C22) and
BeWord (PID2021-126061OB-C43), funded by
MCIN/AEI/10.13039/501100011033 and by the
European Union “NextGenerationEU/PRTR”.
REFERENCES
Agarwal, R., Raman, B., and Mittal, A. (2015). Hand ges-
ture recognition using discrete wavelet transform and
support vector machine. In 2015 2nd International
Conference on Signal Processing and Integrated Net-
works (SPIN), pages 489–493.
Aly, S. and Aly, W. (2020). Deeparslr: A novel signer-
independent deep learning framework for isolated ara-
bic sign language gestures recognition. IEEE Access,
8:83199–83212.
Chen, R.-C., Manongga, W. E., and Dewi, C. (2022). Recur-
sive feature elimination for improving learning points
on hand-sign recognition. Future Internet, 14(12).
Chung, J.-L., Ong, L.-Y., and Leow, M.-C. (2022). Com-
parative analysis of skeleton-based human pose esti-
mation. Future Internet, 14(12).
Dalal, N. and Triggs, B. (2005). Histograms of oriented gra-
dients for human detection. In 2005 IEEE Computer
Society Conference on Computer Vision and Pattern
Recognition (CVPR’05), volume 1, pages 886–893
vol. 1.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn,
D., Zhai, X., Unterthiner, T., Dehghani, M., Min-
derer, M., Heigold, G., Gelly, S., Uszkoreit, J., and
Houlsby, N. (2020). An image is worth 16x16 words:
Transformers for image recognition at scale. CoRR,
abs/2010.11929.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn,
D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer,
M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby,
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
924

N. (2021). An image is worth 16x16 words: Trans-
formers for image recognition at scale.
Gil-Mart
´
ın, M., Marini, M. R., San-Segundo, R., and
Cinque, L. (2024). Dual leap motion controller 2: A
robust dataset for multi-view hand pose recognition.
Sci. Data, 11(1).
Kingma, D. P. and Ba, J. (2017). Adam: A method for
stochastic optimization.
Lee, C.-J., Zhang, R., Agarwal, D., Yu, T. C., Gunda,
V., Lopez, O., Kim, J., Yin, S., Dong, B., Li, K.,
et al. (2024). Echowrist: Continuous hand pose track-
ing and hand-object interaction recognition using low-
power active acoustic sensing on a wristband. In Pro-
ceedings of the CHI Conference on Human Factors in
Computing Systems, pages 1–21.
Luna-Jim
´
enez, C., Gil-Mart
´
ın, M., Kleinlein, R., San-
Segundo, R., and Fern
´
andez-Mart
´
ınez, F. (2023). In-
terpreting sign language recognition using transform-
ers and mediapipe landmarks. In Proceedings of the
25th International Conference on Multimodal Interac-
tion, ICMI ’23, page 373–377, New York, NY, USA.
Association for Computing Machinery.
Miah, A. S. M., Hasan, M. A. M., Tomioka, Y., and Shin,
J. (2024). Hand gesture recognition for multi-culture
sign language using graph and general deep learning
network. IEEE Open Journal of the Computer Society.
Oliveira, M., Chatbri, H., Ferstl, Y., Farouk, M., Little, S.,
O’Connor, N. E., and Sutherland, A. (2017). A dataset
for irish sign language recognition.
Rahim, M. A., Miah, A. S. M., Sayeed, A., and Shin,
J. (2020). Hand gesture recognition based on opti-
mal segmentation in human-computer interaction. In
2020 3rd IEEE International Conference on Knowl-
edge Innovation and Invention (ICKII), pages 163–
166. IEEE.
Shin, J., Miah, A. S. M., Kabir, M. H., Rahim, M. A., and
Al Shiam, A. (2024). A methodological and structural
review of hand gesture recognition across diverse data
modalities. IEEE Access.
Tan, C. K., Lim, K. M., Chang, R. K. Y., Lee, C. P., and
Alqahtani, A. (2023). Hgr-vit: Hand gesture recogni-
tion with vision transformer. Sensors, 23(12).
Tao, W., Leu, M. C., and Yin, Z. (2018). American sign lan-
guage alphabet recognition using convolutional neural
networks with multiview augmentation and inference
fusion. Engineering Applications of Artificial Intelli-
gence, 76:202–213.
Wang, H., Ru, B., Miao, X., Gao, Q., Habib, M., Liu, L.,
and Qiu, S. (2023). Mems devices-based hand gesture
recognition via wearable computing. Micromachines,
14(5).
Yuan, G., Liu, X., Yan, Q., Qiao, S., Wang, Z., and Yuan,
L. (2021). Hand gesture recognition using deep fea-
ture fusion network based on wearable sensors. IEEE
Sensors Journal, 21(1):539–547.
Zhang, F., Bazarevsky, V., Vakunov, A., Tkachenka, A.,
Sung, G., Chang, C.-L., and Grundmann, M. (2020).
Mediapipe hands: On-device real-time hand tracking.
Towards Multi-View Hand Pose Recognition Using a Fusion of Image Embeddings and Leap 2 Landmarks
925
