
Routine Pattern Learning and Anomaly Detection Applied to Lone
Workers Through Topic Modeling
Ana Cravid
˜
ao Pereira
1
, Mar
´
ılia Barandas
1
and Hugo Gamboa
1,2
1
Fraunhofer Portugal AICOS, Rua Alfredo Allen 455/461, 4200-135 Porto, Portugal
2
Laborat
´
orio de Instrumentac¸
˜
ao, Engenharia Biom
´
edica e F
´
ısica da Radiac¸
˜
ao (LIBPhys-UNL), Departamento de F
´
ısica,
Faculdade de Ci
ˆ
encias e Tecnologia da Universidade Nova de Lisboa, Monte da Caparica, 2829-516 Caparica, Portugal
Keywords:
Pattern Learning, Anomaly Detection, Topic Modeling, Incremental Learning, Lone Workers.
Abstract:
Learning routines and identifying anomalous behaviors play a critical role in worker safety. Identifying devia-
tions from normal patterns helps prevent accidents, ensuring enhanced safety in complex environments. Topic
modeling is frequently used to discover hidden semantics patterns and is well-suited to the complexity of rou-
tines in human behavior. However, its utility in complex time-series analysis and as a baseline for anomaly
detection has not been widely explored. This work proposes a novel solution to accurately model complex rou-
tines using topic modeling, enabling the identification of anomalies through a statistical approach. A dataset
of human movement recordings was collected over up to seven consecutive months, capturing the routines of
three lone workers, with each accumulating between 414 and 955 hours of recording time. This dataset served
as the basis for a comprehensive analysis of the results, showing strong alignment between visually observed
patterns in routines and the outcomes of the proposed method. Additionally, detecting anomalies across mod-
els with varying training days confirms that online learning enhances the accuracy and adaptability of routine
modeling. Topic modeling allows for in-depth learning of routines, capturing latent patterns undetectable to
humans. This capability prevents abnormal events, leading to a proactive approach to predictive risk assess-
ment.
1 INTRODUCTION
Working alone is a common practice across vari-
ous sectors, spanning from transport and logistics to
healthcare and the manufacturing industry. With the
intensification of remote working worldwide, it has
also become frequent in other fields. According to the
UK Ministry of Defence (2008), a lone worker is de-
fined as someone who cannot be immediately assisted
by another person during their working day, whether
for a short or extended period. The market for lone
worker safety solutions is growing as more organi-
zations recognize the need for comprehensive man-
agement policies and safety systems to ensure em-
ployee well-being. Current strategies primarily focus
on detecting falls or prolonged inactivity. However,
lone workers may also face other hazards, such as as-
sault or hostage situations, which are inadequately ad-
dressed by existing safety reactive measures.
To address these challenges, key methodologies
for a more proactive risk prediction and categoriza-
tion for lone workers in real-time include routine pat-
tern learning, anomaly detection tailored to individual
worker routines, and online learning to incorporate
new patterns and respond to previously unseen sce-
narios.
Contributions. This study proposes a framework that
learns and adapts to each worker’s unique routine pat-
terns, allowing it to identify deviations that may indi-
cate critical anomalies. The proposed solution was
evaluated in a real-world setting, involving three lone
workers from different sectors, ranging from office
work to the manufacturing industry. These workers
recorded their daily routines over 45 days across five
to seven consecutive months. Results demonstrated
the framework’s ability to learn routines and detect
anomalies in those routines. These contributions re-
sulted from a research path that addressed the follow-
ing research questions:
• RQ1. How can different worker routines be
learned in an unsupervised manner?
• RQ2. Are anomaly detection methods effective in
identifying deviations from an individual worker
routine?
• RQ3. How do different online learning tech-
niques impact routine pattern learning?
Pereira, A. C., Barandas, M. and Gamboa, H.
Routine Pattern Learning and Anomaly Detection Applied to Lone Workers Through Topic Modeling.
DOI: 10.5220/0013236600003911
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 18th International Joint Conference on Biomedical Engineering Systems and Technologies (BIOSTEC 2025) - Volume 1, pages 935-942
ISBN: 978-989-758-731-3; ISSN: 2184-4305
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
935

2 RELATED WORK
Over recent years, various strategies have been em-
ployed for pattern learning on human movement, uti-
lizing activity and spatial routines on daily or weekly
cycles. In the context of pattern learning, topic mod-
eling emerges as a relevant technique. Huynh et al.
(2008) contributed to the early application of topic
modeling for recognizing daily routines using time-
series activity data. Their approach begins by cluster-
ing features relevant to routines, followed by applying
Latent Dirichlet Allocation (LDA) to uncover hidden
topics within these routines. Similarly, a related study
from Tang (2021) explored the use of LDA to identify
location patterns in user trip behaviors using Global
Positioning System (GPS) coordinates. However, this
study did not consider the temporal factor of patterns.
Steinhauer et al. (2019) adopted a similar approach
in their study of telecommunication networks, inter-
preting run-time variable readings as words in LDA to
obtain representative topics. Furthermore, Seiter et al.
(2014) employed LDA to discover activity routines of
stroke rehabilitation patients, subsequently applying
KNN to map the discovered topics to specific rou-
tines. Sun et al. (2021) used a two-dimensional prob-
ability distribution, a variation of LDA, to discover
routine patterns in individual travel behavior. This
work does not consider the order of occurrences, es-
sential for routine comprehension.
In the context of anomaly detection in human rou-
tines, Sun et al. (2021) also explored the detection
of anomalies by using perplexity as a scoring func-
tion to assess whether new behaviors were predictable
(thus normal) or anomalous. Steinhauer et al. (2019)
also aimed to detect anomalies following topic mod-
eling by establishing a ”normal model” and relying
on an expert’s visual comparison to confirm the pres-
ence and nature of anomalies. In their study on de-
tecting patterns in anomalous clusters, Abraham and
Nair (2018) applied LDA to define the normal topics
within the data, subsequently using a statistical test
to detect anomalies. Similarly, Thornton et al. (2020)
used LDA to identify normal patterns in avionics net-
works and employed a combination of variational in-
ference and statistical analysis to detect anomalies.
Based on studies on routine pattern learning, topic
modeling has shown promising results for in-depth
analysis of human movement routines. This work will
therefore explore its potential in complex time series
analysis, focusing on a critical use case: lone worker
safety. Human routines are complex, and a few days
or weeks may be insufficient to capture them accu-
rately. To the best of our knowledge, no study has
addressed long-term routine learning in human move-
ment using both activity patterns and GPS data and
only a few have focused on anomaly detection within
individual routines, which is the aim of this study.
3 METHODS
The primary aim of this work is to develop a gener-
alized approach to predictive risk assessment based
on deviations from a user’s routine within the time-
series domain. To achieve this, a lone worker use
case was selected, and a general approach for rou-
tine learning, anomaly detection, and model updating
was developed. Figure 1 provides an overview of the
proposed approach. For the routine learning stage, a
topic modeling technique was applied, consisting of a
clustering step, document creation, LDA model train-
ing, and topic activation. For the anomaly detection
stage, a statistical approach was developed. Since the
solution is designed for real-life implementation, rou-
tine evolution was also considered. Therefore, model
updates were explored, using both retraining and In-
cremental Learning (IL) approaches.
3.1 Datasets and Preprocessing
For this study’s dataset, three lone workers volun-
teered to collect data on their daily work routines dur-
ing the first semester of 2024. The typical daily rou-
tine of LW1 includes a commuting period via sub-
way or car and a work period in an office. LW2 com-
mutes by car and has work periods that include being
in an office and walking outdoors within a specific re-
gion. Lastly, LW3 is a manufacturing worker who has
a long commuting period by car and spends part of
the workday walking through facilities.
The recording protocol involved installing a log-
ger Android application on the workers’ smartphones,
which was activated by the user at the beginning and
end of each workday. During the collection period,
the lone workers did not record data every weekday
due to holidays, application issues, battery drain, and
forgetfulness in activating the application. As a re-
sult, this led to a total of 45, 46, and 81 days of usable
data for routine learning for LW1, LW2, and LW3,
respectively. Additionally, the volunteers were asked
to annotate any days on which activities and/or loca-
tions occurred that were not part of their routine. This
request was made to prevent the contamination of rou-
tine learning with anomalous patterns. Therefore, the
test days were selected based on these annotations,
corresponding to a percentage between 23% and 34%
of all available days. Table 1 summarizes the dataset
details for the data collected from each lone worker.
BIOSIGNALS 2025 - 18th International Conference on Bio-inspired Systems and Signal Processing
936
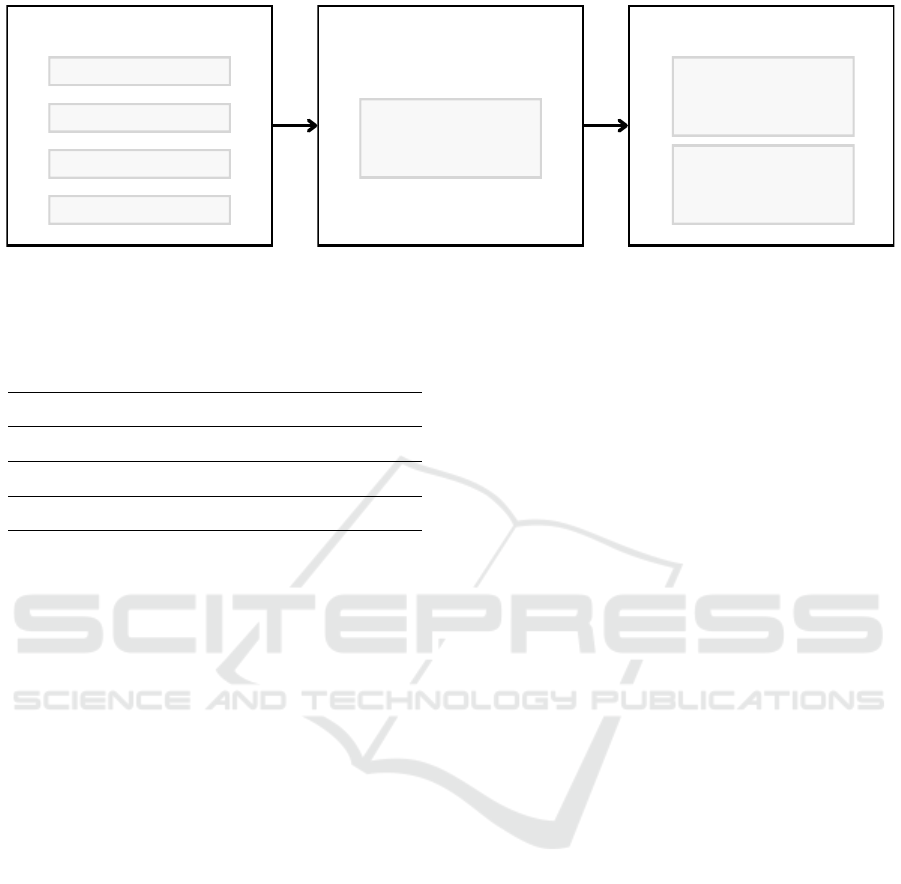
Clustering
ROUTINE LEARNING
Statistical
approach
ANOMALY DETECTION
Retrain
MODEL UPDATE
Document creation
LDA model
Topics
Incremental
Learning
Figure 1: Overview of the main stages of the proposed approach.
Table 1: Summary of data for lone workers. Mean day du-
ration and total duration are presented in hours
LW 1 LW 2 LW 3
Number of train days 30 35 62
Number of test days 15 11 19
Mean day duration 9,22 11,03 11,79
Total duration 414,69 507,43 955,37
The application recorded GPS information (lati-
tude, longitude, and accuracy), human activity data
(i.e., a set of pre-defined, automatically recognized
activities with associated confidence levels), and tem-
poral records. The activity data was obtained with the
Activity Recognition API from Google (2021), which
detects user activities through mobile device sensors.
The detected activities are in vehicle, on bicycle, on
foot, running, still, tilting, unknown, and walking.
For preprocessing the human activity data, low-
confidence activity labels were filtered out using a
threshold of 80%. For GPS information, only loca-
tions with an accuracy of up to 30 meters were con-
sidered. Finally, to align the time intervals for both
activities and locations, we applied linear interpola-
tion with a one-minute step, resulting in a data struc-
ture where each minute contains location data and a
confidence value for each activity label. The time of
day, weekday, and day of the month were added as
features in the final data structure.
3.2 Routine Learning
This section is divided into two subsections: the first
provides a brief overview of topic modeling, and the
second presents our proposed approach using topic
modeling for routine learning.
3.2.1 Topic Modeling
Topic modeling is a methodology mainly used in text
processing that allows the discovery of hidden pat-
terns and structures, i.e., topics, in collections of data.
In the case of a text document, topic modeling intents
to find common patterns across the document and to
understand how its words are associated to make up
the existing topics. As long as the elements that com-
pose the document can be processed into sequences
of characters, latent patterns can be discovered. Thus,
this methodology can also be applied to routine iden-
tification. The most common approach for topic mod-
eling is LDA, a generative probabilistic model devel-
oped by Blei et al. (2003). A graphical model repre-
sentation of LDA is presented in Figure 2, illustrating
how LDA transforms a collection of documents into
a probabilistic distribution of topics. Topic model-
ing assumes documents are formed by combining the
words from the existing topics in the correct propor-
tions - both the proportions of the words within the
topics and of the topics within the document. This
document is the input to train the model.
3.2.2 Proposed Approach
Before applying the LDA model, the input data struc-
ture is normalized, followed by the K-means cluster-
ing algorithm. The output clusters represent crucial
combinations of data elements that form the routine.
The elbow method was used to determine the opti-
mal number of clusters, having been chosen 7 clusters
for LW1 and LW3 and 8 clusters for LW2. Addition-
ally, one drawback of K-means is that it does not han-
dle points far from the centroids as outliers, assigning
them to one of the known clusters. To address this is-
sue, we adapted K-means by creating an ”outlier clus-
ter” for anomalous events. During the training phase,
no points are assigned to this outlier cluster. However,
in the testing phase, if the distance between the data
point and the cluster centroids exceeds three times the
Routine Pattern Learning and Anomaly Detection Applied to Lone Workers Through Topic Modeling
937

Topic 1 Topic 2 Topic 3
Doc 1 Doc 2 Doc 3 Doc 4
0
5
10
15
20
25
30
35
α
θ
z
w
Document
Collection of
documents
β
N
M
Topic distribution along
documents of a corpus
Figure 2: Graphical model representation of LDA. The outer plate, M, represents documents and the inner plate, N, represents
the words and topics within a document. Each word, w, is assigned to a topic, whose association is represented by z. Parameter
α defines the topic distribution within the corpus, θ defines the topic distribution within a document and β defines the word
distribution within topics. The diagram is presented in the work of Blei et al. (2003).
standard deviation of the training data, is assigned to
the outlier cluster.
Before creating the document, distances must be
transformed into probabilities so that shorter dis-
tances to a centroid correspond to higher association
probabilities with its cluster. This conversion was
done according to the following equation presented
in the work of Huynh et al. (2008):
ω
i
=
e
−d
i
/σ
∑
K
j=1
e
−d
j
/σ
, (1)
where ω
i
represents the weight, i.e., probability of a
cluster, σ denotes the standard deviation of the dis-
tances of all instances, d
i
is the distance of the in-
stance to the centroid of the cluster to which it be-
longs, d
j
is the distance of the instance to the centroid
of cluster j and K is the number of clusters.
Since an event spans several seconds rather than
a single point in time, a sliding window of ten min-
utes was defined. This window captures information
over intervals by summing the probabilities associ-
ated with each instance within that time frame and
normalizing the result. The window size was selected
considering the duration of the events targeted. For
each sliding window, it was produced a list whose el-
ements were the clusters, with their quantities propor-
tional to the probabilities obtained. The collection of
these lists forms the document used to train the model.
The LDA model trained outputs an activation
function that indicates the composition of the top-
ics, i.e., the contribution of each cluster to each topic,
which is illustrated by the following example:
Topic
1
= Cluster
1
× a
1,1
+ ...+ Cluster
K
× a
1,K
...
Topic
N
= Cluster
1
× a
N,1
+ ... + Cluster
K
× a
N,K
(2)
where N represents the number of topics, K the num-
ber of clusters and a
N,K
corresponds to the activation
value of Cluster
K
in Topic
N
. This function is used to
decode the latent structures in the test data, which un-
dergoes the same processing as the training data, by
multiplying the cluster probabilities by the activation
function factors.
Despite the creation of an outlier cluster, the num-
ber of topics remains unchanged, as topics are influ-
enced only by the clusters identified during training.
Therefore, this approach does not generate a topic that
detects anomalies. Instead, as highlighted by Equa-
tion 2, it minimizes the values of all other topics,
which might be an indicator of an anomaly.
3.3 Anomaly Detection
To the best of our knowledge, very few studies have
applied anomaly detection after pattern learning in
time series and no standard method exists. Therefore,
we implemented a statistical approach over the pat-
tern learning results to identify potential deviations.
This approach was applied to compare the behavior
of the topics in the training data with the activation of
the topics in the test data. For this purpose, the mean
value and corresponding standard deviation were cal-
culated for each topic and each timestamp across all
training days.
Let z be a set composed of N topics, z =
{z
1
,z
2
,...,z
N
}, which form a user’s routine. Let z
x,i
denote the topic z
x
at time instant i, and the mean and
standard deviation across all training days for z
x,i
be
represented by µ
z
x,i
and σ
z
x,i
, respectively. Given a test
instance where ˜z
x,i
represents the activation of z
x,i
, an
anomaly is detected through the following rule:
N
∑
x=1
˜z
x,i
− µ
z
x,i
> σ
z
x,i
>
N
2
(3)
where {.} is an indicator function that takes the
value 1 (anomaly) if the expression inside is true, and
0 (normal) otherwise. An anomaly is detected if more
BIOSIGNALS 2025 - 18th International Conference on Bio-inspired Systems and Signal Processing
938
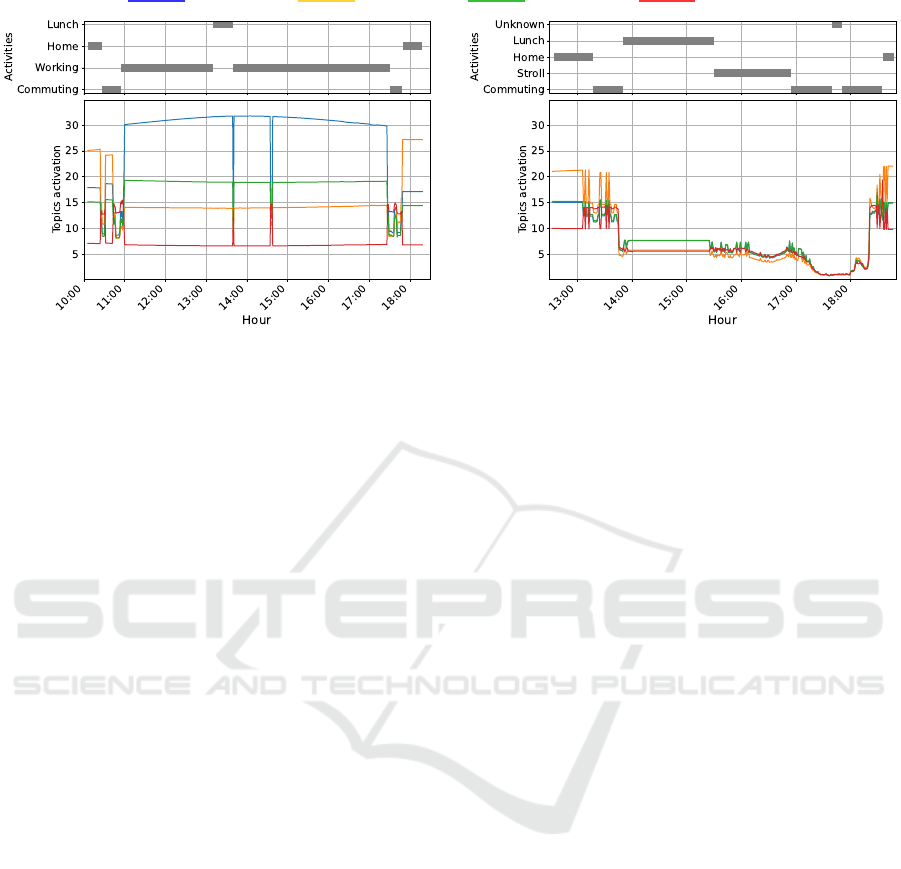
Topic 0 Topic 1 Topic 2 Topic 3
(a) Normal day. (b) Anomalous day.
Figure 3: Top: Annotation of activities performed along the complete workday of a normal and anomalous day. The annotated
activities are not exhaustively descriptive. For instance, Commuting includes walking to and from the train station, subway
travel, and car transportation. Bottom: Topic activations from the model selected, applied to the same test day.
than half of the topics at time instant i deviate from
their expected range, defined as µ
z
x,i
± σ
z
x,i
.
A post-processing technique was implemented to
require a minimum streak of samples flagged as
anomalies to confirm the detection, and a minimum
streak of normal samples to revert the status to nor-
mal. This safeguards the algorithm against inaccura-
cies and insignificant variations.
3.4 Model Update
Anomalies might be detected based on a pre-
established number of days. However, routine orig-
inally identified might have evolved. Therefore, it is
essential to maintain an updated routine baseline.
For the purpose of model updating, two ap-
proaches were studied: (a) Retraining the models
from scratch and (b) Applying Incremental Learning
(IL). While IL is computationally lighter but may re-
sult in catastrophic forgetting, model retraining con-
siders all data equally. In the case of the LDA model,
the implementation used supports incremental up-
dates and, therefore, both approaches were tested.
However, the approach of topic modeling includes
a preliminary step: the clustering algorithm before
the LDA model. In the IL approach, the clusters are
not updated with the new data, as it would demand
producing a new document for the LDA model and,
therefore, require retraining it instead of incremen-
tally updating it. Hence, it was assumed that the fea-
tures (i.e. clusters) are well-defined based on the ini-
tial training data.
4 RESULTS AND DISCUSSION
Regarding routine learning, it is difficult, if not im-
possible, to access all factors that compose a user’s
routine. Without a ground-truth routine, quantita-
tive evaluation is compromised, requiring relative
comparisons with other methods and the visualiza-
tion of semi-annotated data. Therefore, to evaluate
the model, we visualized topic activations across test
days, comparing them with the semi-annotated data.
The evaluation of anomaly detection was divided
into two phases. Firstly, it was hypothesized that
the number of detected anomalies decreases with the
number of training days, reflecting a stabilization
of the learned routine. Secondly, it was evaluated
whether the expected anomalies were being detected.
To achieve this, LW1 was asked to annotate perceived
anomalies in their routine, allowing for the applica-
tion of quantitative measures on the annotated data.
However, it is important to note that users’ percep-
tion of an anomaly is often limited compared to the
model’s considerations. As a result, these annotations
may be biased. For this reason, the evaluation focuses
exclusively on the limited set of annotated anomalies,
calculating the true positive rate for assessment pur-
poses.
Finally, for online learning evaluation, a compar-
ison was made between retraining the model from
scratch and applying incremental updates over dif-
ferent training days, using the number of detected
anomalies as a proxy for performance.
In summary, the performance evaluation com-
prised the following steps to address the previously
Routine Pattern Learning and Anomaly Detection Applied to Lone Workers Through Topic Modeling
939
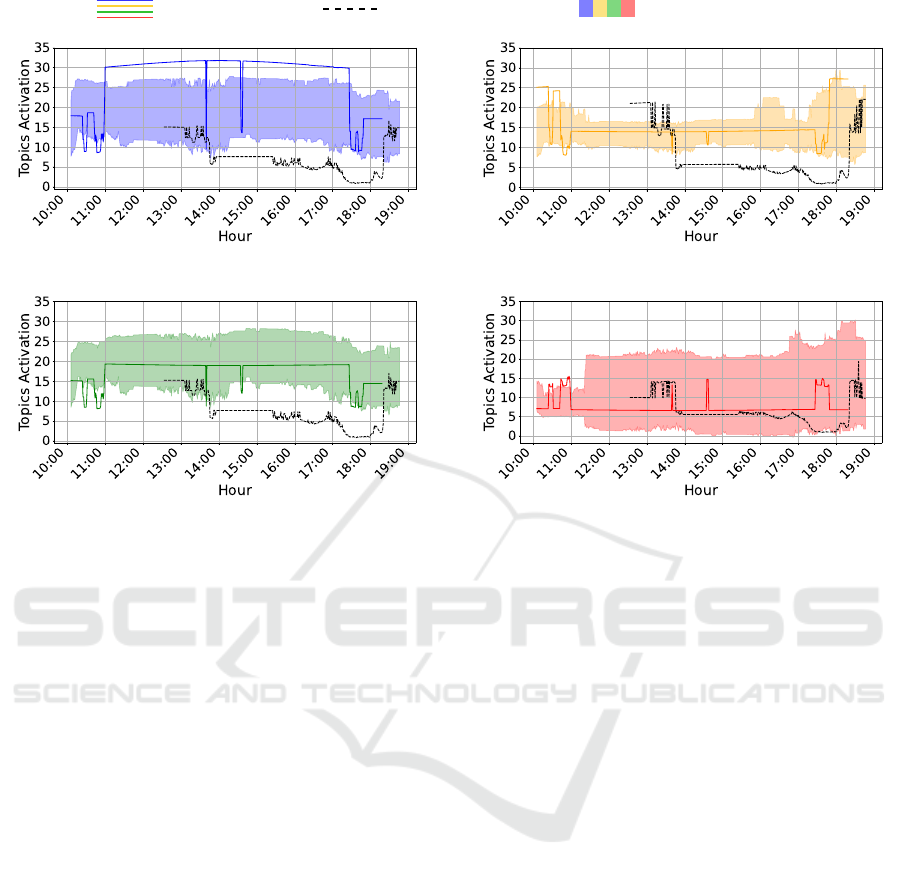
Normal day Anomalous day
Standard Deviation
(a) Topic 0. (b) Topic 1.
(c) Topic 2. (d) Topic 3.
Figure 4: Comparison of activated topics on a normal and an anomalous day, overlaid with the normality range obtained from
training days.
identified research questions:
1. Visual analysis of different test days compared to
the learned routine (RQ1).
2. Evaluation of the number of detected anomalies
as a function of the number of training days used
for routine learning (RQ2).
3. Comparison of the percentage of anomalies cor-
rectly detected (true positive rate) across the dif-
ferent tested models (RQ2).
4. Comparison of model updating strategies using
the number of detected anomalies as a proxy for
performance evaluation (RQ3).
4.1 Routine Learning: Visual Analysis
LW1 semi-annotated one typical and one anomalous
day from their routine to assess how well the model
learned the routine. Figure 3 illustrates the activa-
tion of topics throughout the workday, along with
semi-annotated labels for both days. On the normal
day (Figure 3a), it is observed that the topics acti-
vated by the model closely correspond to the annota-
tions shown on top. For example, the periods labeled
Home, Commuting and Working display a consistent
topic configuration within their respective pairs. This
alignment suggests that the model effectively extracts
meaningful information from the data, organizing it
into logical categories. On the anomalous day (Fig-
ure 3b), the topics do not align with the annotated
activities. While both Home periods display a con-
sistent topic configuration, all other periods exhibit
topics indicative of anomalous behavior. Throughout
most of the day, changes in annotated activities are
indistinguishable based on the activated topics, sug-
gesting that these activities are not recognized due to
their absence in the training data.
Another visualization uses the proposed approach
for anomaly detection. It is assumed that topics acti-
vated during the testing days should fall within each
topic’s mean ± standard deviation (referred to as the
normality range), to be considered normal. Thus,
each activated topic on both the normal and anoma-
lous days is shown in Figure 4, along with the cor-
responding normality range obtained during training.
For most of the normal day, Topics 1, 2 and 3 fall
within the normality range while Topic 0 does not. It
is important to note that even on training days, not all
topic activations consistently fall within the normality
range, emphasizing the importance of the combina-
tion of topics in routine formation. In contrast, on the
anomalous day, all topics except Topic 3 fall outside
the normality range for most of the day, confirming
its anomalous nature.
BIOSIGNALS 2025 - 18th International Conference on Bio-inspired Systems and Signal Processing
940

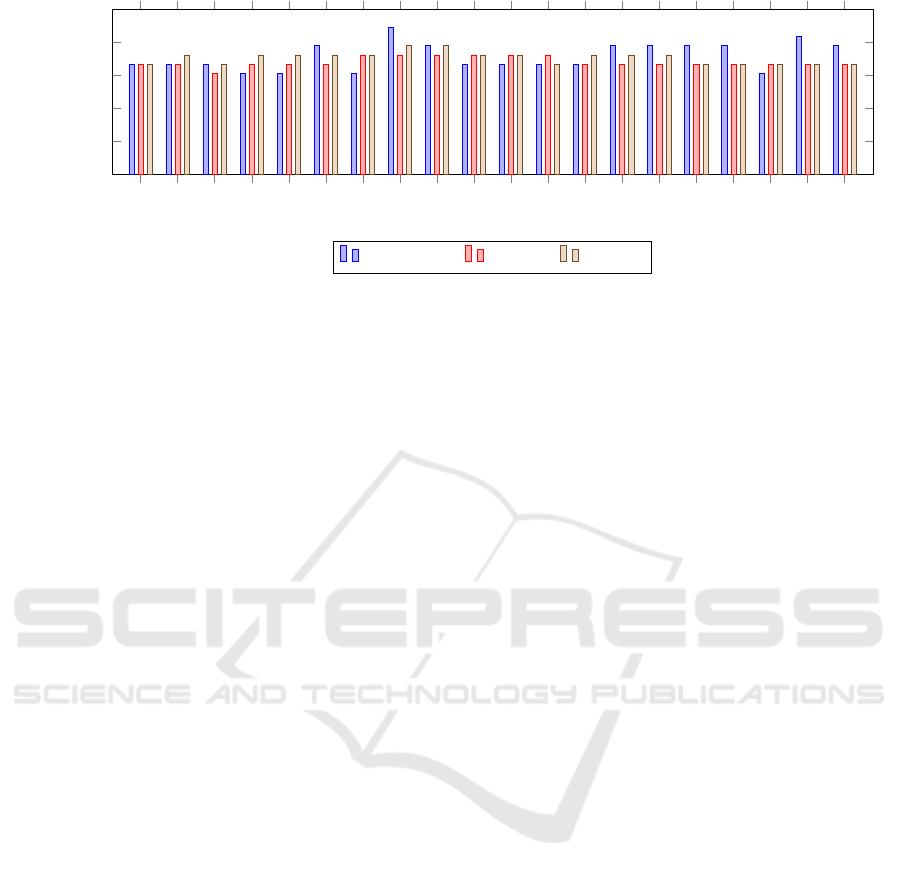
Model Retrain
Model IL5 Model IL10
(a) LW1 (b) LW2 (c) LW3
Figure 5: Number of anomalies detected with the increased number of training days for the three lone workers and three tested
approaches: Model Retrain, IL5, and IL10.
4.2 Anomaly Detection and Model
Updates
To evaluate anomaly detection performance and ad-
dress research questions RQ2 and RQ3, the topic
modeling technique was tested in the context of model
updating using the following approaches:
1. Model Retrain. Topic model retrained each time
new data is added to the training set.
2. Model IL5. Topic model trained with IL, starting
from a base model of five days and updating each
new day individually.
3. Model IL10. Topic model trained with IL, start-
ing from a base model of 10 days and updating
each new day individually.
As the number of training days grows, it is ex-
pected that the number of detected anomalies de-
creases, indicating that the routine is being bet-
ter learned and that instances previously considered
anomalous are now recognized by the model. This hy-
pothesis is confirmed in Figure 5. For all lone work-
ers’ routines, it is observed a decreasing trend in de-
tected anomalies across all models evaluated, with a
more pronounced drop during the first 10 days. These
results suggest that ten consecutive days are sufficient
for the model to learn a user’s routine. However, a
gradual decrease in detected anomalies is still evident
for LW1 and LW3, indicating that new data continues
to provide learnable information. In the case of LW2,
this decreasing pattern appears to plateau earlier, with
the Model Retrain approach even showing an increase
in detected anomalies toward the final days. It is ob-
served a more stable pattern in IL models, whereas
Model Retrain shows more fluctuation, with each new
day having a greater impact. Comparing the three ap-
proaches, no clear conclusions can be drawn from this
analysis, as the differences in anomalies detected be-
tween models do not appear to be significant across
users. More information about routine data would be
needed to determine which model performs best.
Regarding the correctly detected anomalies evalu-
ation, a rough annotation of anomalies was performed
for the test set of LW1 to serve as ground truth. It was
established that for an anomaly to be correctly de-
tected, the model must identify at least one instance
within the annotated anomaly. In Figure 6, the true
positive rate of annotated anomalies was evaluated
across the different models. This analysis reveals that
Model Retrain tends to outperformed both IL5 and
IL10 models with more training days, but there is
not a model that consistently produces a higher true
positive rate. Additionally, there does not appear to
be a significant difference between the performances
of Models IL5 and IL10, likely because the routine
learning stabilizes by day 10, as indicated in Figure 5.
5 CONCLUSIONS
In the context of lone workers, detecting anomalies
in their routines can help prevent risky situations and
promote preventive actions.
To discover the patterns that form the routines,
a topic modeling approach was implemented. This
method reveals hidden patterns, thereby identifying
relationships that, although coherent with annota-
tions, are not readily discernible to humans due to the
complexity of routines. Through visual inspection,
it was found that the LDA model identified routines,
and the derived topics accurately represented the hu-
man activities performed. Moreover, it was concluded
that the routine does not correspond to a single topic,
but rather to the combination of all topics activated.
Routine Pattern Learning and Anomaly Detection Applied to Lone Workers Through Topic Modeling
941
11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
0
20
40
60
80
100
Number of training days
True Positive Rate (%)
Retrain IL5 IL10
Figure 6: Comparison of correctly detected anomalies across different days for all models on data from Lone Worker 1.
The patterns identified were subsequently used as
the ground truth for defining the routine and detect-
ing any deviations from it. The anomaly detection
results were satisfactory, demonstrating effective per-
formance in detecting anomalies that had been anno-
tated. However, this evaluation is not straightforward,
as the annotated anomalies do not fully correspond to
the ground truth, due to their complex nature.
Finally, the routine’s continuous evolution was ad-
dressed using IL techniques. A comparison of the re-
sults between models updated with IL and those fully
retrained shows that the latter detected a higher num-
ber of anomalies when provided a higher number of
training days. However, further studies are necessary
to draw more definitive conclusions.
While the results presented are promising, there
are some limitations and future work to consider.
Firstly, parameters such as the number of topics need
further testing and optimization. Additionally, the sta-
tistical approach to anomaly detection does not con-
sider potential relationships between activated topics,
although the results indicate a strong inter-topic rela-
tionship. Thus, alternative anomaly detection meth-
ods should be explored, and more annotated data
should be collected to enhance the robustness and
generalizability of the methodologies. This would
also facilitate a more thorough comparison between
retraining and incremental learning.
ACKNOWLEDGMENTS
This work was supported by European funds through
the Recovery and Resilience Plan, project ”Center
for Responsible AI”, project number C645008882-
00000055.
REFERENCES
Abraham, B. L. and Nair, A. P. (2018). Anomalous topic
discovery based on topic modeling from document
cluster. International Research Journal of Engineer-
ing and Technology (IRJET), 5(2):966–972.
Blei, D. M., Ng, A. Y., and Jordan, M. I. (2003). La-
tent dirichlet allocation. J. Mach. Learn. Res.,
3(null):993–1022.
Google (2021). Google Activity Recognition API.
https://developers.google.com/location-context/
activity-recognition. [Accessed: November 4, 2024].
Huynh, T., Fritz, M., and Schiele, B. (2008). Discovery of
activity patterns using topic models. pages 10–19.
Seiter, J., Derungs, A., Schuster-Amft, C., Amft, O., and
Tr
¨
oster, G. (2014). Activity routine discovery in stroke
rehabilitation patients without data annotation. Pro-
ceedings - REHAB 2014, pages 270–273.
Steinhauer, H., Helldin, T., Mathiason, G., and Karlsson,
A. (2019). Topic modeling for anomaly detection in
telecommunication networks. Journal of Ambient In-
telligence and Humanized Computing, 14.
Sun, L., Chen, X., He, Z., and Miranda-Moreno, L. (2021).
Routine pattern discovery and anomaly detection in
individual travel behavior. Networks and Spatial Eco-
nomics, 23.
Tang, T. (2021). Characterizing shared mobility operator
and user behavior using big data analytics and ma-
chine learning. Master’s thesis, University of Virginia,
School of Engineering and Applied Science.
Thornton, A., Meiners, B., and Poole, D. (2020). La-
tent dirichlet allocation (lda) for anomaly detection in
avionics networks. In 2020 AIAA/IEEE 39th Digital
Avionics Systems Conference (DASC), pages 1–5.
UK Ministry of Defence (2008). JSP 375 Volume 1: Man-
agement of Health and Safety in Defence: Arrange-
ments. Last updated December 7, 2023.
BIOSIGNALS 2025 - 18th International Conference on Bio-inspired Systems and Signal Processing
942
