
Segmentation-Guided Neural Radiance Fields
for Novel Street View Synthesis
Yizhou Li
1 a
, Yusuke Monno
1 b
, Masatoshi Okutomi
1 c
, Yuuichi Tanaka
2
, Seiichi Kataoka
3
and Teruaki Kosiba
4
1
Institute of Science Tokyo, Tokyo, Japan
2
Micware Mobility Co., Ltd., Hyogo, Japan
3
Micware Automotive Co., Ltd., Hyogo, Japan
4
Micware Navigations Co., Ltd, Hyogo, Japan
{yli, ymonno}@ok.sc.e.titech.ac.jp, mxo@ctrl.titech.ac.jp, {tanaka yuu, kataoka se, kosiba te}@micware.co.jp
Keywords:
Neural Radiance Fields (NeRF), Novel View Synthesis, Street Views, Urban Scenes.
Abstract:
Recent advances in Neural Radiance Fields (NeRF) have shown great potential in 3D reconstruction and
novel view synthesis, particularly for indoor and small-scale scenes. However, extending NeRF to large-scale
outdoor environments presents challenges such as transient objects, sparse cameras and textures, and varying
lighting conditions. In this paper, we propose a segmentation-guided enhancement to NeRF for outdoor street
scenes, focusing on complex urban environments. Our approach extends ZipNeRF and utilizes Grounded
SAM for segmentation mask generation, enabling effective handling of transient objects, modeling of the sky,
and regularization of the ground. We also introduce appearance embeddings to adapt to inconsistent lighting
across view sequences. Experimental results demonstrate that our method outperforms the baseline ZipNeRF,
improving novel view synthesis quality with fewer artifacts and sharper details.
1 INTRODUCTION
Neural Radiance Fields (NeRF) (Mildenhall et al.,
2020) have emerged as a powerful tool for recon-
structing 3D scenes and generating novel view im-
ages with impressive quality, offering significant po-
tential for applications such as autonomous driving
and augmented reality. Although NeRF performs well
in bounded scenes, extending it to unbounded outdoor
scenes such as urban street scenes presents unique
challenges. While various methods have been pro-
posed to tackle different challenges in outdoor scenes
(Zhang et al., 2020; Barron et al., 2022; Tancik et al.,
2022; Rematas et al., 2022; Turki et al., 2023), a uni-
fied framework to address these challenges is still in
the developing phase.
In this paper, we present an enhanced method of
NeRF specifically tailored for novel view synthesis
(NVS) of street views. Our method is based on Zip-
NeRF (Barron et al., 2023), one of the grid-based
variants of NeRFs (Barron et al., 2023; M
¨
uller et al.,
a
https://orcid.org/0000-0002-7122-2087
b
https://orcid.org/0000-0001-6733-3406
c
https://orcid.org/0000-0001-5787-0742
2022; Sun et al., 2022) known for its improved effi-
ciency and quality. We extend it to address the chal-
lenges associated with outdoor scenarios.
Specifically, we focus on NVS of outdoor street
scenes using monocular video clips captured by a
video recorder mounted on a car. This is inherently
challenging due to the dynamic nature of transient ob-
jects such as vehicles and pedestrians, the presence
of sparse textures in certain regions such as the sky
and the ground, and the variations in lighting con-
ditions across different video clips. We summarize
these challenges as follows.
First, transient objects such as vehicles and pedes-
trians present significant challenges, as they disrupt
the consistency across video frames required for ac-
curate NeRF learning. Second, the sky often results
in erroneous near-depth estimation due to the lack of
textures and defined features, which leads to float-
ing artifacts during NVS. Third, limited textures in
the ground often lead to poor geometry estimation,
producing noticeable artifacts during NVS. Finally,
street view videos captured at different times intro-
duce inconsistent lighting conditions, which contra-
dict NeRF’s assumption of consistent colors across
Li, Y., Monno, Y., Okutomi, M., Tanaka, Y., Kataoka, S. and Kosiba, T.
Segmentation-Guided Neural Radiance Fields for Novel Street View Synthesis.
DOI: 10.5220/0013244200003912
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 2: VISAPP, pages
591-597
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
591

Drive Recorder Images
“sky”
“road”
“car. truck. bus.
bike. bicycle.
vehicle. people.”
Segmentation with
Grounded SAM
Masked Part Exclusion
Separate MLP + Sky Decay Loss
1
2
n
3
n-1
Decay volume density towards sky
Ground Plane Fitting
(, ℛ
)
= +
Figure 1: The overview of our approaches for different segmentation regions.
views. These inconsistencies result in blurry and in-
accurate NVS.
To overcome these challenges, we leverage the se-
mantic information from Grounded SAM (Ren et al.,
2024), a semantic segmentation model based on
SAM (Liu et al., 2023) and Grounding DINO (Liu
et al., 2023) that utilizes text prompts, to obtain pre-
cise segmentation masks for each target. Concretely,
we obtain the masks of transient objects, sky, and
ground using Grounded SAM, as shown in Fig. 1. We
then apply different techniques to handle each seg-
mented region as follows.
• Transient Objects. We mask them out during
the training, effectively excluding them from con-
tributing to the learned densities and colors, which
reduces NVS artifacts.
• Sky. We utilize a separate sky-specific hash
representation (Turki et al., 2023) that estimates
the sky’s appearance based solely on view di-
rection, ensuring accurate background representa-
tion without causing erroneous density in the fore-
ground. Additionally, we implement a sky decay
loss to further suppress artifacts resulting from the
sky region.
• Ground. We introduce a plane-fitting regulariza-
tion loss in PlaNeRF (Wang et al., 2024) that en-
courages the ground surface to conform to a pla-
nar geometry, thus enhancing the reconstruction
quality of ground areas.
• Inconsistent Lighting. We adopt an appearance
embedding strategy inspired by BlockNeRF (Tan-
cik et al., 2022) and URF (Rematas et al., 2022).
This allows us to learn an image-wise appearance
embedding that captures different lighting condi-
tions, enabling our model to disentangle irradi-
ance from appearance and produce consistent col-
ors across the scene.
We evaluate our improved method to our real data,
consisting of 12 video clips entering and exiting an
intersection from different directions. The results
demonstrate substantial improvements over the base-
line ZipNeRF, particularly in reducing artifacts.
2 METHODOLOGY
In this section, we describe our methodology, includ-
ing the definitions of symbols and the processes ap-
plied to handle different segmented regions in our
segmentation-guided NeRF enhancement.
2.1 NeRF Formulation
Let {I
1
, I
2
, . . . , I
N
} represent a set of input images cap-
tured from different viewpoints using a monocular
camera, where N is the total number of images. Our
goal is to reconstruct a 3D scene representation and
generate novel view images of the scene. The neural
radiance field is represented as a combination of grid-
based features and a Multi-Layer Perceptron (MLP).
The output of our method can be represented by the
following function:
f (x, d) → (c, σ), (1)
where f (x, d) takes a 3D point x ∈ R
3
and a view di-
rection d ∈ R
3
as the inputs, and returns the corre-
sponding color c ∈ R
3
and density σ ∈ R.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
592
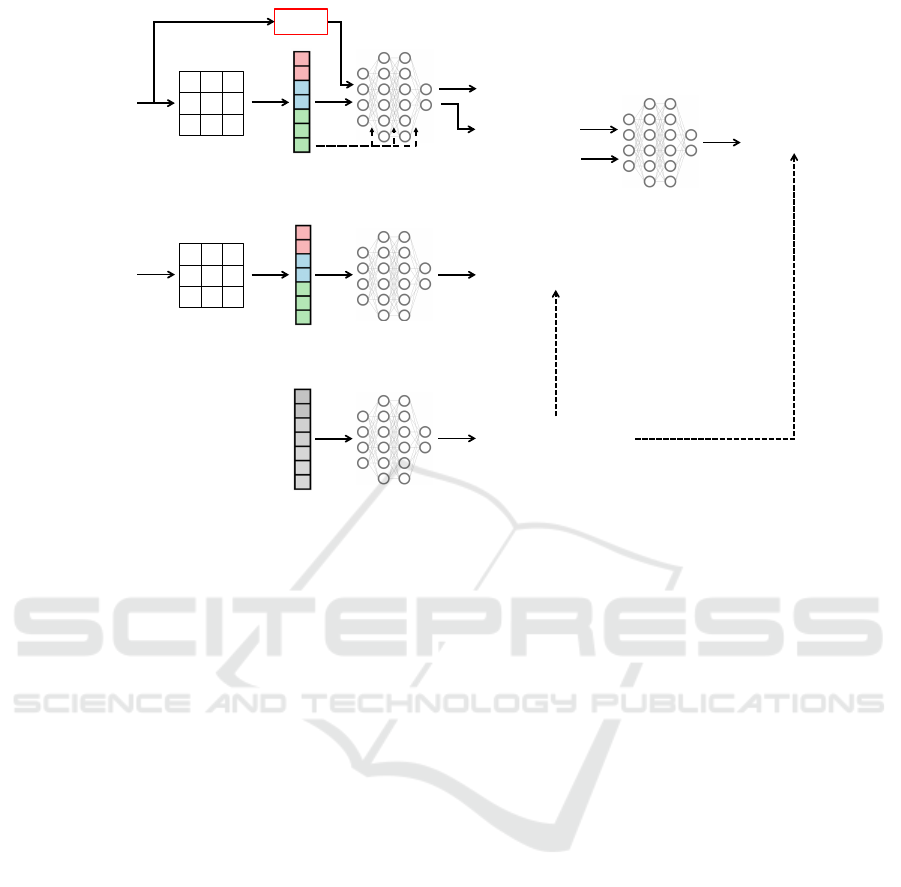
Color
View direction
Color
MLP
Sky
hash
View
direction
Feature
Sky color
MLP
Sky color
Feature
Foreground
hash
Density
MLP
New feature
IPE
Image-wise
appearance
embedding
β
Appearance
MLP
Color transformation
,
Applying
Applying
3D position
Density σ
Figure 2: The overview of our network architecture.
2.2 Segmentation Masks
We utilize Grounded SAM (Ren et al., 2024) to seg-
ment the input images and obtain three regions: tran-
sient objects, sky, and ground. For the segmentation
of each region, we use specific text prompts, as shown
in Fig. 1, and obtain the following masks:
• M
t
: Mask for transient objects,
• M
s
: Mask for the sky region,
• M
g
: Mask for the ground region,
where each mask M ∈ {0, 1} is a binary mask that in-
dicates whether a pixel belongs to the specified region
(M = 1) or not (M = 0).
2.3 Handling Different Regions
2.3.1 Transient Objects
For the transient objects, represented by the mask M
t
,
we exclude their contributions during the NeRF train-
ing phase. Specifically, we set the loss contribution
from the rays reaching the transient objects to zero.
The color reconstruction loss L
rgb
is defined as
L
rgb
(θ) =
∑
i
E
r∼I
i
h
(1 −M
t
(r)) ·
C(r; β
i
) −C
gt,i
(r)
2
2
i
,
(2)
where θ is the network parameters, C(r; β
i
) is the pre-
dicted color of ray r with appearance compensation
parameter β
i
(detailed in Sec. 2.4), and C
gt,i
(r) is the
ground truth color of ray r in image i.
2.3.2 Sky Region
For the sky region, represented by the mask M
s
, we
adopt a separate sky-specific representation for mod-
eling the sky’s appearance as shown in Fig. 2. The
sky’s color is estimated based solely on the view di-
rection d, as the sky can be considered infinitely far
away. We blend the sky representation with the fore-
ground using an alpha map derived from the accumu-
lated density along each ray:
C(r; β
i
) =
Z
t
f
t
n
w(t) · Γ(β
i
) · c(t)dt + c
sky
(d), (3)
where Γ(β
i
) is the appearance compensation transfor-
mation, c
sky
(d) is the sky color predicted by the sky
network, and w(t) represents the volume rendering
weight defined as
w(t) = exp
−
Z
t
t
n
σ(s)ds
· σ(t). (4)
We then introduce the sky decay loss L
sky
to both
suppress density estimates in the sky region and en-
hance the accumulated density of rays not marked by
the sky mask. This approach helps to prevent the gen-
eration of artifacts such as floaters and ensures a more
accurate representation of non-sky regions. The sky
Segmentation-Guided Neural Radiance Fields for Novel Street View Synthesis
593

decay loss is defined as
L
sky
(θ) =
∑
i
E
r∼I
i
M
s
(r)
Z
t
f
t
n
w(t)
2
dt
−
∑
i
E
r∼I
i
(1 − M
s
(r))
Z
t
f
t
n
w(t)
2
dt
,
(5)
where the first term suppresses the density estimates
for rays marked by the sky mask (M
s
(r) = 1), and
the second term enhances the accumulated density for
rays not marked by the sky mask (M
s
(r) = 0).
While applying the sky decay loss, we observed
unintended side effects, particularly due to hash colli-
sions inherent in the grid-based ZipNeRF. These col-
lisions could cause the decay of densities in non-sky
foreground regions where suppression is not intended.
To mitigate these negative effects, we incorporate po-
sitional embeddings of 3D point coordinates x as ad-
ditional inputs to the MLP, as shown in Fig. 2. This
ensures that the density estimation relies not only on
the hash features but also on accurate spatial informa-
tion from x. To prevent the MLP from over-relying
on the 3D coordinates, we also add residual connec-
tions (He et al., 2016), allowing the hash features to be
directly fed into the intermediate layers of the MLP.
The final MLP input is given by
z = [ f
hash
(x), γ(x)], (6)
where f
hash
(x) is the feature obtained from the
hash, and γ(x) is the integrated positional embedding
(IPE) (Barron et al., 2021) of x.
2.3.3 Ground Region
For the ground region, represented by the mask M
g
,
we adopt a plane regularization method based on Sin-
gular Value Decomposition (SVD) following PlaN-
eRF (Wang et al., 2024) as shown in Fig. 1. We apply
this regularization to ensure that the predicted points
on the ground conform to a planar structure, which
helps in achieving a more consistent reconstruction
of the ground surface.
Given a patch of rays R
g
for the ground region, we
define the predicted point cloud
P = {p
r
= o
r
+ z
r
d
r
| r ∈ R
g
} (7)
where o
r
is the ray origin, z
r
is the rendered depth, and
d
r
is the ray direction of ray r. The least-squares plane
defined by a point
ˆ
p
c
and a normal unitary vector n is
obtained by solving the following optimization prob-
lem:
min
ˆ
p
c
,n
∑
r∈R
((p
r
−
ˆ
p
c
) · n)
2
, (8)
where the point
ˆ
p
c
is the barycenter of the point cloud:
ˆ
p
c
=
1
N
p
∑
r∈R
g
p
r
, (9)
where N
p
is the number of points in the patch. We
form a matrix A from the differences between each
point and the barycenter as
A =
p
0
−
ˆ
p
c
p
1
−
ˆ
p
c
··· p
N
p
−
ˆ
p
c
T
. (10)
The plane normal n is given by the right singular
vector corresponding to the smallest singular value of
A, which can be found using SVD. We regularize the
NeRF-rendered points to this plane by minimizing the
smallest singular value σ
3
of A as
L
ground
(θ, R
g
) = σ
3
(θ, R
g
). (11)
This regularization encourages the points in the
ground region to lie on a plane, thereby improving
the geometry of the reconstructed ground.
2.4 Appearance Embedding for
Lighting Inconsistencies
To address lighting inconsistencies across video clips,
we follow URF (Rematas et al., 2022) to perform an
affine mapping of the radiance predicted by the shared
network as shown in Fig. 2. This affine transforma-
tion is represented by a 3 × 3 matrix and a 1 × 3 shift
vector, both of which are decoded from a per-image
latent code β
i
∈ R
B
as
Γ(β
i
) = (T
i
, b
i
) : R
B
→ (R
3×3
, R
1×3
), (12)
where T
i
represents the color transformation matrix
and b
i
represents the shift vector.
The color transformation for the radiance c pre-
dicted by the network is then performed as
c
′
= T
i
c + b
i
, (13)
where c ∈ R
3
is the original radiance, and c
′
∈ R
3
is
the transformed color.
This affine mapping models lighting and exposure
variations with a more restrictive function, thereby
reducing the risk of unwanted entanglement when
jointly optimizing the scene radiance parameters θ
and the appearance mappings β.
2.5 Overall Loss Function
The complete loss function L
total
is a weighted com-
bination of the above-mentioned components, which
is described as
L
total
= L
rgb
+ λ
sky
L
sky
+ λ
ground
L
ground
. (14)
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
594

6
Dataset Sample
Figure 3: (Left) Sample images of our dataset for an intersection. Each image is from each of 12 video clips. (Right) Estimated
camera poses by using COLMAP.
4
Comparison between ZipNeRF [1] and Our Method
ZipNeRF
Ours
Figure 4: Comparison of ZipNeRF and the proposed method for novel view synthesis.
3 EXPERIMENTS
In this section, we present the experimental setups,
including implementation and dataset details. Then,
we present a quantitative comparison of our proposed
method with the baseline ZipNeRF to demonstrate the
effectiveness of our segmentation-guided NeRF en-
hancement for outdoor street scenes.
3.1 Dataset
We collected our dataset using an iPhone 15, captur-
ing video footage of the Sannomiya intersection in
Kobe, Japan. The dataset includes a total of 12 video
clips, as shown in Fig. 3: four straight directions
(South to North, North to South, West to East, and
East to West) and eight turning directions (e.g., South
to West, South to East, etc.). As shown in Fig. 3, each
video clip was captured throughout different times of
the day, thus with varying lighting conditions.
After capturing the videos, we extracted a total of
1,112 frames from the 12 video clips. The original
frames are in 4K resolution (3840 × 2160). Since the
videos were recorded from inside a car, we cropped
out the windshield area, resulting in a reduced reso-
lution of 3376 × 1600. To make the data more man-
ageable for processing, we further resized the frames
to 2110 × 1100, which were then used for COLMAP
and NeRF training.
After resizing, we used COLMAP (Sch
¨
onberger
and Frahm, 2016), an open-source Structure-from-
Motion (SfM) tool, to obtain the camera poses and
intrinsic parameters for each frame. The estimated
intrinsic parameters and camera poses were then used
for our NeRF training.
This dataset presents significant challenges, in-
cluding changing lighting conditions, transient ob-
jects (e.g., pedestrians and vehicles), and sparse tex-
tures in the sky and ground regions, making it ideal
for evaluating the robustness of our proposed method.
3.2 Implementation Details
Our implementation is based on PyTorch and an
NVIDIA RTX 4090 GPU. The total training time for
our data was approximately 6 hours. We used the
Adam optimizer for parameter updates, with a batch
size of 4096 rays per iteration. The initial learning
rate was set to 0.01 and gradually decayed to 0.001
using a cosine annealing schedule over a maximum
of 50, 000 iterations. The loss weights were set as
λ
sky
= λ
ground
= 0.0001.
3.3 Qualitative Comparison
We conducted a quantitative comparison between our
proposed method and the baseline ZipNeRF. Fig-
ure 4 shows the visualization of the results, where we
Segmentation-Guided Neural Radiance Fields for Novel Street View Synthesis
595

Without ground plane regularization
With ground plane regularization
Figure 5: Comparison of the cases without and with ground plane regularization.
Before diffusion-based image enhancement After diffusion-based image enhancement
Figure 6: Comparison of the results before and after our diffusion-based image enhancement.
compare the novel view images of the reconstructed
scenes in terms of visual quality and the presence of
artifacts. The proposed method demonstrates notable
improvements over ZipNeRF, particularly in handling
challenging outdoor conditions.
In the images produced by ZipNeRF, we observed
significant blurring, color artifacts, and floating arti-
facts in areas with sparse textures, such as the sky
and the ground. In contrast, our method effectively
mitigates these issues. By employing segmentation-
guided enhancements such as sky-specific modeling,
transient object masking, and ground plane regular-
ization, our approach produces clearer details, fewer
artifacts, and sharper details in the novel view images.
Figure 5 shows the detailed comparison of rendered
images and depth maps in the cases without and with
ground plane regularization. We can clearly observe
that the plane regularization helps to generate more
reliable depth maps, reducing floating artifacts in the
ground regions. The above results highlight the effec-
tiveness of our segmentation-guided NeRF enhance-
ments in addressing the unique challenges posed by
outdoor street environments.
Even though our method generates appealing re-
sults, it still generates artifacts if the rendered novel
view is far from the training views, as exemplified
in the left image of Fig. 6. To enhance the re-
sults for those views, we apply our previously pro-
posed diffusion-based image restoration method (Li
et al., 2025), where we restore the rendered images
with artifacts based on the pre-trained stable diffu-
sion model (Rombach et al., 2022) and a fine-tuned
ControlNet (Zhang et al., 2023). The right image of
Fig. 6 shows the result after our diffusion-based en-
hancement, demonstrating a visually pleasing result
by utilizing the power of a diffusion model.
4 CONCLUSION
In this paper, we have presented a segmentation-
guided NeRF enhancement for novel street view syn-
thesis. Building on ZipNeRF, we have introduced
techniques to address challenges like transient ob-
jects, sparse textures, and lighting inconsistencies. By
utilizing Grounded SAM for segmentation and intro-
ducing appearance embeddings, our method effec-
tively handles these challenges. Qualitative results
have demonstrated that our method outperforms the
baseline ZipNeRF, producing fewer artifacts, sharper
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
596

details, and improved geometry, especially in chal-
lenging areas like the sky and the ground.
REFERENCES
Barron, J. T., Mildenhall, B., Tancik, M., Hedman, P.,
Martin-Brualla, R., and Srinivasan, P. P. (2021).
Mip-NeRF: A multiscale representation for anti-
aliasing neural radiance fields. In Proceedings of the
IEEE/CVF International Conference on Computer Vi-
sion (ICCV), pages 5855–5864.
Barron, J. T., Mildenhall, B., Verbin, D., Srinivasan, P. P.,
and Hedman, P. (2022). Mip-NeRF 360: Unbounded
anti-aliased neural radiance fields. In Proceedings of
the IEEE/CVF Conference on Computer Vision and
Pattern Recognition (CVPR), pages 5470–5479.
Barron, J. T., Mildenhall, B., Verbin, D., Srinivasan, P. P.,
and Hedman, P. (2023). Zip-NeRF: Anti-aliased grid-
based neural radiance fields. In Proceedings of the
IEEE/CVF International Conference on Computer Vi-
sion (ICCV), pages 19697–19705.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
ual learning for image recognition. In Proceedings of
the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), pages 770–778.
Li, Y., Liu, Z., Monno, Y., and Okutomi, M. (2025).
TDM: Temporally-consistent diffusion model for all-
in-one real-world video restoration. In Proceedings
of International Conference on Multimedia Modeling
(MMM), pages 155–169.
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J.,
Li, C., Yang, J., Su, H., Zhu, J., et al. (2023).
Grounding DINO: Marrying DINO with grounded
pre-training for open-set object detection. arXiv
preprint 2303.05499.
Mildenhall, B., Srinivasan, P. P., Tancik, M., Barron, J. T.,
Ramamoorthi, R., and Ng, R. (2020). NeRF: Repre-
senting scenes as neural radiance fields for view syn-
thesis. In Proceedings of European Conference on
Computer Vision (ECCV), pages 405–421.
M
¨
uller, T., Evans, A., Schied, C., and Keller, A. (2022).
Instant neural graphics primitives with a multiresolu-
tion hash encoding. ACM Transactions on Graphics
(TOG), 41(4):1–15.
Rematas, K., Liu, A., Srinivasan, P. P., Barron, J. T.,
Tagliasacchi, A., Funkhouser, T., and Ferrari, V.
(2022). Urban radiance fields. In Proceedings of the
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition (CVPR), pages 12932–12942.
Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J.,
Huang, X., Chen, Y., Yan, F., Zeng, Z., Zhang, H., Li,
F., Yang, J., Li, H., Jiang, Q., and Zhang, L. (2024).
Grounded SAM: Assembling open-world models for
diverse visual tasks. In arXiv preprint 2401.14159.
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and
Ommer, B. (2022). High-resolution image synthesis
with latent diffusion models. In Proceedings of the
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition (CVPR), pages 10684–10695.
Sch
¨
onberger, J. L. and Frahm, J.-M. (2016). Structure-
from-motion revisited. In Proceedings of IEEE Con-
ference on Computer Vision and Pattern Recognition
(CVPR), pages 4104–4113.
Sun, C., Sun, M., and Chen, H.-T. (2022). Direct voxel
grid optimization: Super-fast convergence for radi-
ance fields reconstruction. In Proceedings of the
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition (CVPR), pages 5459–5469.
Tancik, M., Casser, V., Yan, X., Pradhan, S., Mildenhall,
B., Srinivasan, P. P., Barron, J. T., and Kretzschmar,
H. (2022). Block-NeRF: Scalable large scene neural
view synthesis. In Proceedings of the IEEE/CVF Con-
ference on Computer Vision and Pattern Recognition
(CVPR), pages 8248–8258.
Turki, H., Zhang, J. Y., Ferroni, F., and Ramanan, D. (2023).
SUDS: Scalable urban dynamic scenes. In Proceed-
ings of the IEEE/CVF Conference on Computer Vi-
sion and Pattern Recognition (CVPR), pages 12375–
12385.
Wang, F., Louys, A., Piasco, N., Bennehar, M., Rold
˜
aao,
L., and Tsishkou, D. (2024). PlaNeRF: SVD unsu-
pervised 3D plane regularization for NeRF large-scale
urban scene reconstruction. In Proceedings of Inter-
national Conference on 3D Vision (3DV), pages 1291–
1300.
Zhang, K., Riegler, G., Snavely, N., and Koltun, V. (2020).
NeRF++: Analyzing and improving neural radiance
fields. arXiv preprint 2010.07492.
Zhang, L., Rao, A., and Agrawala, M. (2023). Adding con-
ditional control to text-to-image diffusion models. In
Proceedings of the IEEE/CVF International Confer-
ence on Computer Vision (ICCV), pages 3836–3847.
Segmentation-Guided Neural Radiance Fields for Novel Street View Synthesis
597
