
Accuracy Improvement of Neuron Concept Discovery Using CLIP with
Grad-CAM-Based Attention Regions
Takahiro Sannomiya
a
and Kazuhiro Hotta
b
Meijo University, Nagoya, Japan
Keywords:
Explainable AI, CLIP, Concept of Neurons.
Abstract:
WWW is a method that computes the similarity between image and text features using CLIP and assigns a
concept to each neuron of the target model whose behavior is to be determined. However, because this method
calculates similarity using center crop for images, it may include features that are not related to the original
class of the image and may not correctly reflect the similarity between the image and text. Additionally, WWW
uses cosine similarity to calculate the similarity between images and text. Cosine similarity can sometimes
result in a broad similarity distribution, which may not accurately capture the similarity between vectors. To
address them, we propose a method that leverages Grad-CAM to crop the model’s attention region, filtering
out the features unrelated to the original characteristics of the image. By using t-vMF to measure the similarity
between the image and text, we achieved a more accurate discovery of neuron concepts.
1 INTRODUCTION
In recent years, image recognition models have been
used in a variety of fields, but the problem is that it is
unclear how the models are making decisions. To ad-
dress this issue, visualization methods such as Class
Activation Maps (CAM)(Wang et al., 2020; Zhou
et al., 2016) have been proposed, but they only show
the regions of interest and cannot explain what con-
cepts and features the model is learning. A method
was proposed to identify the concepts of the model’s
neurons using CLIP(Radford et al., 2021), which can
measure the similarity between images and text. This
method allows us to explain in concrete terms that hu-
mans can understand what concepts the model is bas-
ing its decisions on, and to deepen our understanding
of the model’s decision-making process and internal
behavior.
WWW(Ahn et al., 2024) is a method for identi-
fying neuron concepts. Since this method calculates
similarity using center crop for images, it includes
features that are not related to the original class of
the image and may not correctly reflect the similar-
ity between the image and the text. The WWW uses
cosine similarity in calculating the similarity between
images and text. Cosine similarity may not accurately
a
https://orcid.org/0009-0005-3644-381X
b
https://orcid.org/0000-0002-5675-8713
reflect the similarity between vectors due to the wide
similarity distribution. To address these issues, we
propose a method to more accurately discover neuron
concepts by using t-vMF similarity between images
and text, while using Grad-CAM to crop the regions
of interest in the model and eliminating features that
are not related to the original features of the image.
Experiments were conducted on ImageNet valida-
tion datasets consisting of 1000 classes, such as ani-
mals and vehicles, and text datasets such as Broaden
and WordNet. The results showed that the accuracy of
some evaluation metrics, such as CLIP cos, mpnet cos
and F1-score, exceeded that of conventional method.
The paper is organized as follows. Section 2 de-
scribes related works. Section 3 details the proposed
method. Section 4 presents experimental results. Sec-
tion 5 discusses the Ablation Study. Finally, Section
6 concludes our paper.
2 RELATED WORKS
We explain WWW, a method for identifying neuron
concepts. Figure 1 illustrates WWW. Let the i-th neu-
ron in layer l of the target model be denoted as (l, i).
We denote the number of text samples as j. First,
we crop a center region in each image in the prob-
ing dataset (evaluation data) D
probe
, and feed them
into the target model. We then select images where
Sannomiya, T. and Hotta, K.
Accuracy Improvement of Neuron Concept Discovery Using CLIP with Grad-CAM-Based Attention Regions.
DOI: 10.5220/0013247500003912
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 2: VISAPP, pages
497-502
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
497
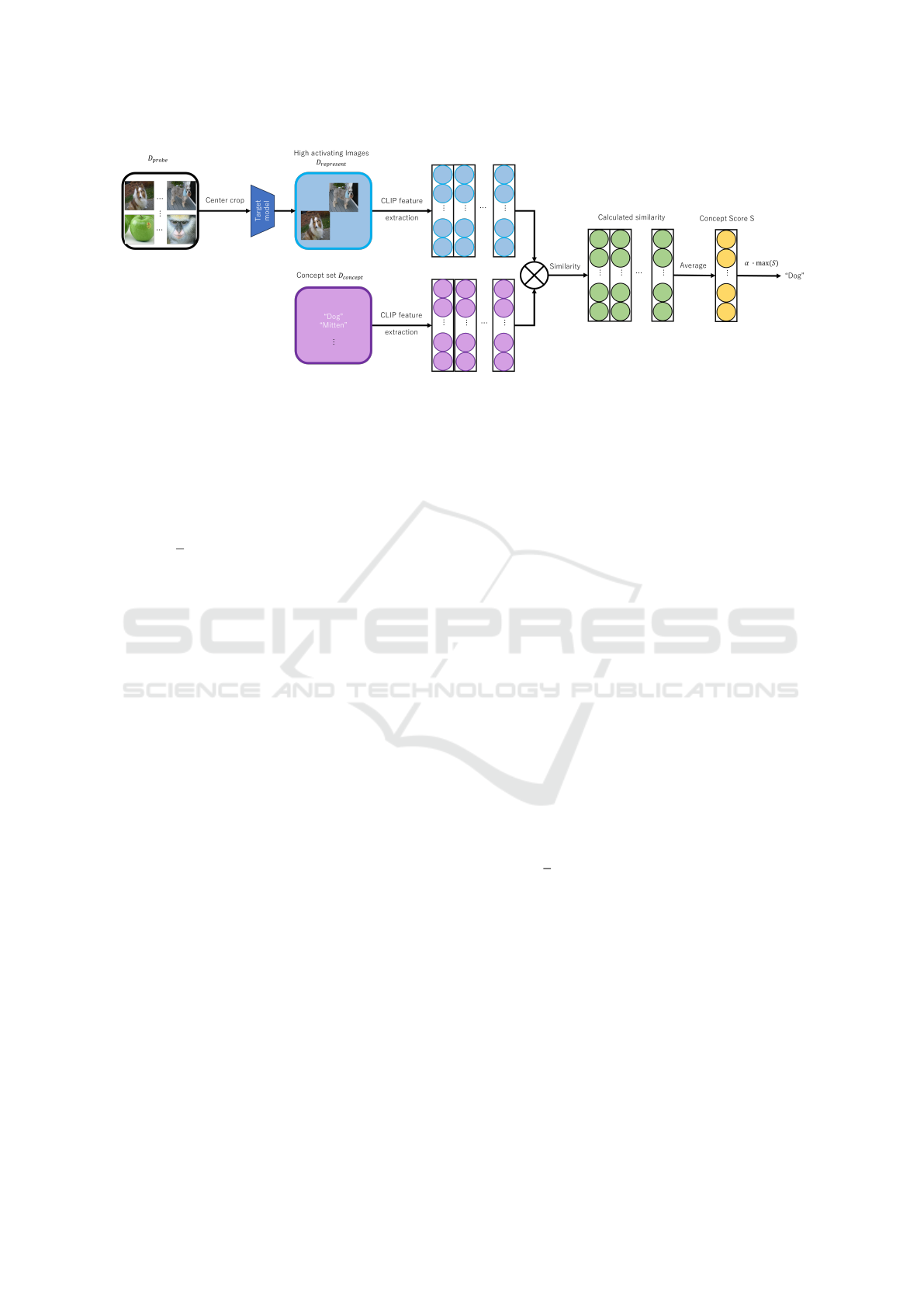
Figure 1: Overview of WWW.
the neuron exhibits a strong response (high activa-
tion) and denote this set as D
represent
. By feeding both
D
represent
and the text dataset D
concept
into CLIP, we
compute the concept score S
(l,i)
j
using the following
equation.
S
(l,i)
j
=
1
n
n
∑
o=1
n
cos
v
(l,i)
o
, t
j
− cos
v
(l,i)
o
, t
tem
o
,
(1)
where v
(l,i)
o
is the CLIP image feature vector, t
j
rep-
resents the CLIP text feature vector, and t
tem
is the
CLIP text feature vector of a base template word, such
as ”a photo of a,” which has similarity with any im-
age. In Equation (1), subtracting the cosine similarity
between v
(l,i)
o
and t
tem
from the cosine similarity be-
tween v
(l,i)
o
and t
j
removes the influence of the base
template, allowing us to focus solely on the similarity
between the image and the text itself. After calcu-
lating the concept score S
l,i
j
, the texts corresponding
to scores above the threshold δ
(l,i)
are considered as
concepts for the neuron (l, i). δ
(l,i)
is defined by the
following equation.
δ
(l,i)
= α × max(S
(l,i)
), (2)
where α is a hyper parameter representing concept
sensitivity.
This method reduces the influence of the base tem-
plate t
tem
, enabling the measurement of similarity be-
tween the image and text itself. However, since im-
ages in D
probe
are center-cropped and then passed
through the model to select high-activation images,
which are used as D
represent
for calculating similarity
with text, the unrelated features to the original class
of the image, such as background details, may be in-
cluded. This can prevent an accurate reflection of the
similarity between the image and text, potentially af-
fecting the identification of neuron concepts. Addi-
tionally, although WWW uses cosine similarity for
similarity calculations, this similarity measure has a
wide distribution, which may be insufficient for mea-
suring precise similarity.
3 PROPOSED METHOD
To solve this issue, we propose a method that com-
putes Grad-CAM on D
probe
, crops the attention re-
gion, and calculates the similarity using images that
retain class-relevant features. Additionally, to mea-
sure the similarity more accurately, we replace cosine
similarity with t-vMF similarity (Kobayashi, 2021),
which narrows the similarity distribution for more
precise measurement. As shown in Figure 2, the pro-
posed method feeds D
probe
into the target model and
computes Grad-CAM. The image is then cropped the
area centered on the highest Grad-CAM value. The
cropped image is fed into the target model, and im-
ages in which the i-th neuron in layer l (i.e., (l, i))
shows high activation are selected as D
represent
. The
concept score S
(l,i)
j
is then computed using the follow-
ing equation.
S
(l,i)
j
=
1
n
n
∑
o=1
n
t-vMF
v
′(l,i)
o
, t
j
−t-vMF
v
′(l,i)
o
, t
tem
o
(3)
where v
′(l,i)
o
is the image feature vector obtained
when high-activation images, determined using Grad-
CAM, are fed into CLIP. By calculating S
l,i
j
and se-
lecting texts corresponding to scores above the thresh-
old, as done in WWW, we can define these texts as the
concepts for the neuron (l, i). This approach allows
us to retain only the essential features of the image,
enabling a more accurate calculation of similarity be-
tween features related to the image class and the text.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
498
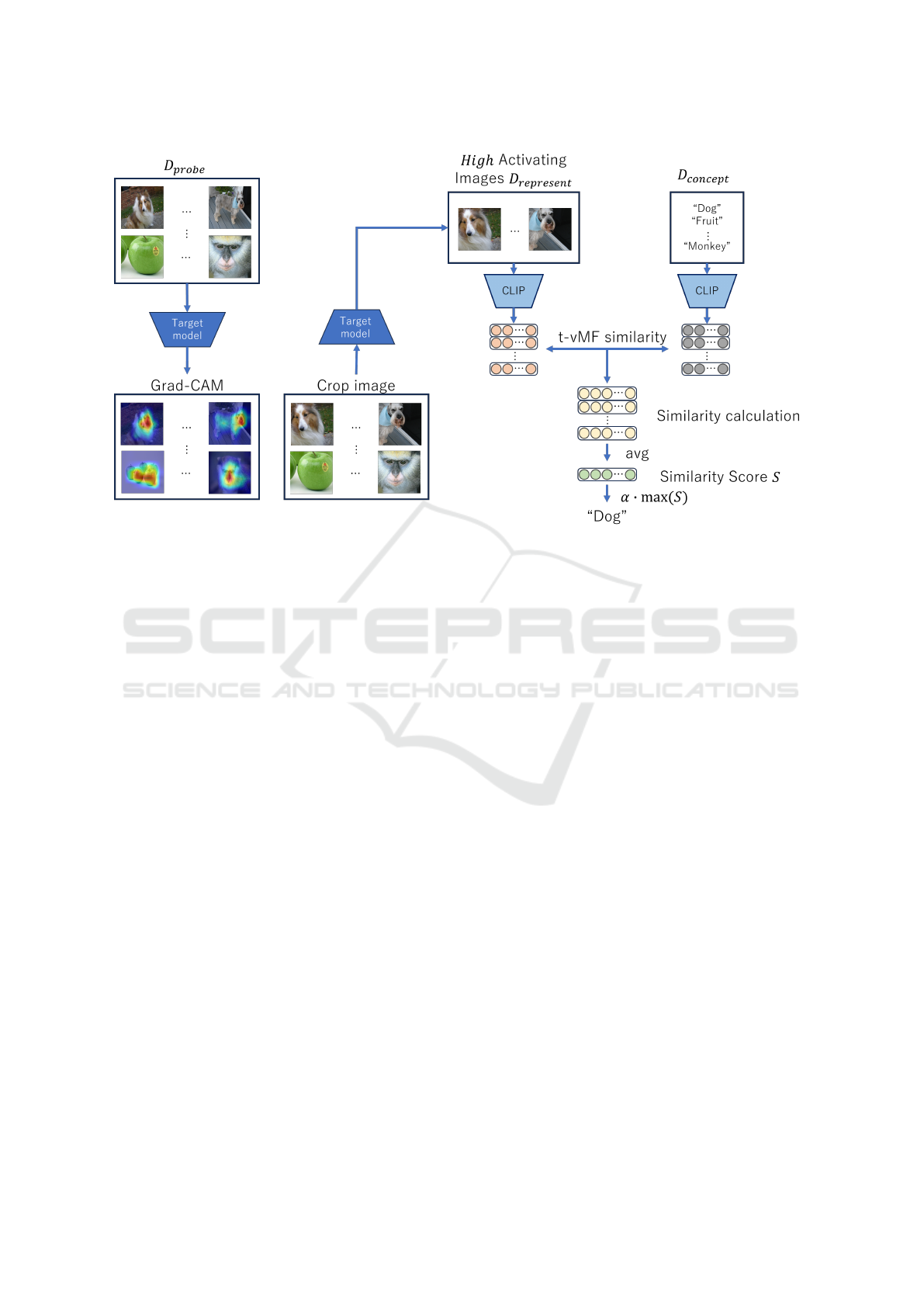
Figure 2: Overview of the proposed method.
4 EXPERIMENTS
In this section, we describe the experimental setup
and results. Section 4.1 describes the experimental
setup. Section 4.2 presents the results of the quali-
tative evaluation experiments. Section 4.3 shows the
results of the quantitative evaluation experiments.
4.1 Experimental Settings
Following the previous research, we use a ResNet-
50 model pre-trained on ImageNet-1k (Russakovsky
et al., 2015) as the target model. For D
probe
, we uti-
lize the validation images in the ImageNet-1k dataset,
while D
concept
includes ImageNet-1k, WordNet (Fell-
baum, 2005), and Broaden (Bau et al., 2017). We se-
lected 40 images from D
probe
that exhibited high ac-
tivation in the neurons to form D
represent
. Evaluation
metrics include CLIP cos, mpnet cos, F1-Score, and
Hit Rate, using CLIP and mpnet (Song et al., 2020).
CLIP cos and mpnet cos are metrics that measure co-
sine similarity by feeding class labels and selected
concepts into CLIP and mpnet, respectively. The F1-
score is an evaluation metric that measures the accu-
racy and flexibility of the discovered concepts, while
the Hit Rate is calculated based on the proportion of
selected concepts that match the class labels. Higher
values for any of these evaluation metrics indicate bet-
ter performance. The concept sensitivity α is set to
0.95 for both methods.
4.2 Qualitative Result
The results of the qualitative evaluation are shown in
Figure 3. WordNet is used for D
c
oncept, and im-
ages with each neuron in the final layer of ResNet-50
highly activated are compared. Below each image, the
proposed method and the concept identified in WWW
are shown. Figure 3 confirms the superiority of the
proposed method. For example, in Neuron 0, Neuron
10, Neuron 446, and Neuron 479, the concept identi-
fied by the proposed method matches the ground truth
of the image, while the concept identified by WWW
is similar to the ground truth but different. For Neu-
ron 296, Neuron 460, Neuron 671,Neuron 742, and
Neuron 850, the proposed method identifies concepts
that are consistent with ground truth, while WWW
identifies significantly different concepts. This may
be due to the fact that WWW uses center crop, which
includes unnecessary features in addition to the orig-
inal image features, making it easier to identify un-
related or similar concepts. This can be seen from
Figure 4. Figure 4 shows that if center crop is simply
used, the left side of the image contains many objects
unrelated to the ground truth, which may result in in-
correct similarity calculations. On the other hand, if
the image is cropped based on Grad-CAM, it is possi-
ble to remove the areas unrelated to the ground truth
Accuracy Improvement of Neuron Concept Discovery Using CLIP with Grad-CAM-Based Attention Regions
499

Figure 3: Qualitative evaluation of each method.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
500

Figure 4: Comparison of the proposed method and WWW crop images.
Table 1: Comparison results with Resnet-50 as target model.
Method D
probe
D
concept
CLIP cos mpnet cos F1-score Hit Rate
ImageNet val ImageNet(1k) 93.31 83.47 77.53 95.5
ImageNet val Broaden(1.2k) 77.79 44.47 6.6 9.3WWW
ImageNet val Wordnet(80k) 88.76 70.05 42.62 66.2
ImageNet val ImageNet(1k) 93.46 83.90 76.98 95.5
ImageNet val Broaden(1.2k) 78.31 45.45 6.73 9.3Ours
ImageNet val Wordnet(80k) 89.49 72.58 45.77 69.8
and keep many of the original features of the image.
we believe that the proposed method could more ac-
curately measure the relationship between image fea-
tures and text features by t-vMF similarity while ex-
cluding areas that are irrelevant to the original image
features using Grad-CAM.
4.3 Quantitative Results
From Table 1, it can be observed that the accuracy has
improved for almost all evaluation metrics. The max-
imum improvements are 0.73% for CLIP cos, 2.53%
for mpnet cos, 3.15% for F1-score, and 3.6% for Hit
Rate. This improvement is believed to result from the
use of Grad-CAM to remove non-essential features of
the images while accurately calculating the similar-
ity between image features and text features using t-
vMF similarity. Additionally, regarding Broaden and
WordNet, both methods show an increase in accuracy
as the size of D
concept
increases. This improvement is
considered to arise from the enhanced expressiveness
of the concepts that can be assigned to the neurons
as D
concept
grows. The proposed method can reflect
the similarity between image features and text fea-
tures more accurately, which likely leads to a greater
increase in the accuracy of evaluation metrics when
D
concept
is changed from Broaden to WordNet com-
pared to existing methods.
Table 2: Results of Ablation Study.
Grad-CAM t-vMF CLIP cos mpnet cos F1-score
88.76 70.05 42.62
✓ 88.89 70.45 42.42
✓ 89.43 72.42 45.83
✓ ✓ 89.49 72.58 45.77
5 ABLATION STUDY
In this section, we discuss the contributions of Grad-
CAM and t-vMF to the improvements in accuracy.
The experimental results are presented in Table 2.
From Table 2, it can be inferred that WWW uses
center-cropped images, which contain a significant
amount of redundant features, leading to relatively
low accuracy. Furthermore, when we use t-vMF, a
slight improvement in accuracy is observed in CLIP
cos and mpnet cos. In contrast, when Grad-CAM is
used, improvements in accuracy are confirmed across
all evaluation metrics. Additionally, when both Grad-
CAM and t-vMF are used together, the maximum ac-
curacy is achieved for two evaluation metrics: CLIP
cos and mpnet cos. This is believed to be due to
the elimination of redundant features by Grad-CAM
while allowing for accurate similarity calculations
through t-vMF.
Accuracy Improvement of Neuron Concept Discovery Using CLIP with Grad-CAM-Based Attention Regions
501

6 CONCLUSION
In this paper, we proposed a method that utilizes
Grad-CAM and t-vMF similarity to accurately mea-
sure the similarity between the intrinsic features of
images and text for improving the discovery accuracy
of neuron concepts. As a result, we achieved more
accurate identification of neuron concepts across var-
ious datasets.
REFERENCES
Ahn, Y. H. et al. (2024). WWW: A unified framework for
explaining what, where and why of neural networks
by interpretation of neuron concepts. In Proceedings
of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition, pages 10968–10977.
Bau, D., Zhou, B., Khosla, A., Oliva, A., and Torralba,
A. (2017). Network dissection: Quantifying inter-
pretability of deep visual representations. In Proceed-
ings of the IEEE conference on computer vision and
pattern recognition, pages 6541–6549.
Fellbaum, C. (2005). Wordnet and wordnets. encyclopedia
of language and linguistics.
Kobayashi, T. (2021). T-vMF similarity for regularizing
intra-class feature distribution. In Proceedings of the
IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition, pages 6616–6625.
Radford, A. et al. (2021). Learning transferable visual mod-
els from natural language supervision. In Interna-
tional Conference on Machine Learning, pages 8748–
8763.
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S.,
Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bern-
stein, M., et al. (2015). Imagenet large scale visual
recognition challenge. International journal of com-
puter vision, 115:211–252.
Song, K., Tan, X., Qin, T., Lu, J., and Liu, T.-Y. (2020). Mp-
net: Masked and permuted pre-training for language
understanding. Advances in neural information pro-
cessing systems, 33:16857–16867.
Wang, H., Wang, Z., Du, M., Yang, F., Zhang, Z., Ding, S.,
Mardziel, P., and Hu, X. (2020). Score-cam: Score-
weighted visual explanations for convolutional neu-
ral networks. In Proceedings of the IEEE/CVF con-
ference on computer vision and pattern recognition
workshops, pages 24–25.
Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., and Tor-
ralba, A. (2016). Learning deep features for discrim-
inative localization. In Proceedings of the IEEE con-
ference on computer vision and pattern recognition,
pages 2921–2929.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
502
