
Effectiveness of Cross-Model Learning Through View-Model
Ensemble on Detection of Spatiotemporal EEG Patterns
Ömer Muhammet Soysal
1
, Iphy Emeka Kelvin
1
and Muhammed Esad Oztemel
2
1
Computer Science, Southeastern Louisiana University, Hammond, U.S.A.
2
Division of Electrical and Computer Engineering, Louisiana State University, Baton Rouge, U.S.A.
Keywords: Autoencoder, Biometric, Brain, Convolutional Neural Network, Electroencephalograph, Spatiotemporal,
Transfer Learning.
Abstract: Understanding the neural dynamics of human intelligence is one of the top research topics over the decades.
Advances in the computational technologies elevated the level of solving the complex problems by means of
the computational neuroscience approaches. The patterns extracted from neural responses can be utilized as
a biometric for authentication. In this study, we aim to explore cross-model transfer learning approach for
extraction of distinct features from Electroencephalography (EEG) neural signals. The discriminative features
generated by the deep convolutional neural network and the autoencoder machine learning models. In addition,
a 3D spatiotemporal View-matrix is proposed to search distinct patterns over multiple EEG channels, time,
and window segments. We proposed a View-model approach to obtain intermediate predictions. At the final
stage, these intermediate scores are ensembled through a majority-voting scheme to reach the final decision.
The initial results show that the proposed cross-model learning approach can outperform the regular
classification-based approaches.
1 INTRODUCTION
Machine learning has been utilized in different
electroencephalography- related research including
brain computer interface (Aggarwal, 2021), diagnosis
of neurological disorders (Oh, 2020), human
computer interaction (Zhao, 2020), development of
authentication systems (Fidas and Lyras, 2023) and
many others (Khosla, 2020). As non-invasively
collected data, EEG recordings exhibits both spatial
and temporal features for comprehensive analysis of
human brain characteristics.
Intra-subject characteristics of EEG signals
demonstrate similar patterns extracted over various
trials while they differ significantly among the
subjects (Mueller, 2013). This distinctiveness
property allows EEG patterns to be utilized as a
biometric for personal authentication. Various
advantages of identification based on brain signals
have been emphasized compared to traditional
personal verification methods (Bidgoly, 2020). For
example, fingerprint, retinal scan, voice recognition
and facial recognition systems may have
vulnerabilities in terms of data security and deception
attempts against these systems (Bharadwaj, 2014).
However, brain signals can provide a more secure
personal verification method against such threats
(Riera, 2007).
The fusion of multi-view predictions can improve
classification performance (Xu, 2013). Among
various fusion strategies, (Kuncheva, 2014) and
(Atrey, 2010) showed that the majority-voting
scheme performed better than single-view decision
making.
In this study, we explored effectiveness of cross-
model based learners that generate feature patterns
from proposed spatiotemporal View-matrix utilizing
a multi-view ensemble classifier system. The
proposed approach is unique in terms of introducing
1) a cross-model transfer learning framework that
employs the DCNN and the AE with widely used
regular classifiers and 2) testing the performance of
the proposed system using cross-session datasets. The
rest of the report is organized as follows: The method
section starts with describing the data acquisition and
preparation procedure. The section flows with
presenting the proposed View-Matrix data structure,
View-Model, and ensemble of these models. The
result section is discussing the effectiveness of the
proposed framework and hyperparameter scheme.
942
Soysal, Ö. M., Kelvin, I. E. and Oztemel, M. E.
Effectiveness of Cross-Model Learning Through View-Model Ensemble on Detection of Spatiotemporal EEG Patterns.
DOI: 10.5220/0013265300003912
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 2: VISAPP, pages
942-949
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

The conclusion summarizes outcomes and points to
limitations that can be improved.
1.1 Previous Work
Machine learning techniques are widely used for
verification of individuals based on EEG patterns.
Fidas et al. discussed the role of machine learning
techniques in personal verification applications. In
summary, wavelet transform, power spectral density,
autoregressive modelling and fast Fourier transform
are the main techniques used for feature extraction.
Support vector machine, hidden Markov models,
multilayer perceptron, recurrent neural networks
(RNN) and convolutional neural networks (CNN)
were used in the classification of the data obtained
from these features.
Autoencoders have been studied for different
purposes in analysis of brain signals (Weng, 2024).
As an example, AE mechanism can be used to remove
eye blink artifacts from EEG signals (Acharjee,
2024), to identify sleep stages (Dutt, 2022).
(Abdelhameed, 2018) utilized an AE network to
predict epileptic seizures. (Bandana, 2024) employed
a spatial AE network for personal verification. Latent
features obtained from the AE network trained a CNN
model. Ari et al. pointed out that AEs provide an ideal
solution for artificial data generation to increase the
amount of training data (Ari, 2022). Tian et al.
operated two encoders simultaneously (Tian, 2023).
Zhou and Wang utilize spatiotemporal AE, with
adaptive diffusion method, to obtain high resolution
EEG data from low-resolution data (Zhou, 2024).
Yao and Motani stated that the vital signs of the
patients contain both temporal and spatial
information. Therefore, they proposed a hybrid
learning mechanism for classification purposes. Their
system first extracts spatial features, and then
temporal patterns to determine if an individual is an
alcoholic or not. Support vector machine, gradient
boosting, random forest and decision tree algorithms
were applied for classification. Among these
classification techniques, SVM achieved the most
successful results (Yao, 2018).
On the other hand, multi-view fusion models
provide improved performance over single view-
based classification. Mane et al. examined multi-view
features obtained from different frequency bands to
train a CNN (Mane, 2020). Spyrou et al. applied
multi-view tensor factorization for detection of
epilepsy by means of a linear regression method
(Spyrou, 2015). (Gao, 2022) compared the multi-
view and single-view classification for emotion
recognition; it was found that the multi-view
classification is superior to single-view. (Emanet,
2024) employed multi-view hierarchical learning
model with 3D-CNN for classification of a stimulus
type. Jia et al. aimed to classify sleep stages utilizing
spatial-temporal graph convolutional network
through multiple views that are consisted of
functional connections and distance-based
connections (Jia, 2021).
Transfer learning techniques have been
successfully used in various EEG-related studies such
as motor imagery and evoked potential applications
(Wu, 2020). Waytowich et al. focused on
unsupervised spectral transfer learning and geometry-
based knowledge training for brain-computer
interface study examining subject independence
(Waytowich, 2016). Qi et al. used inter-subject
transfer learning to reduce the calibration time. A
small number of epochs for target subject is taken as
references and the Riemann distance metric was
calculated and applied to the most similar target
subject (Qi, 2018). Transfer learning can be applied
across devices as well as across subjects. Wu et al.
investigates how to improve the performance of
brain-computer interfaces (BCIs) by reducing the
amount of time needed to calibrate them for use with
different EEG headsets. The authors propose a new
method called active weighted adaptation
regularization (AwAR), which combines transfer
learning and active learning to facilitate the
calibration process. AwAR leverages data from
previously used EEG headsets to train a classifier for
a new headset, selecting only the most informative
data points for labelling. This significantly reduces
the amount of data required for calibration, ultimately
making BCI technology more user-friendly and
accessible (Wu, 2016). Additionally, Cimtay et al.
used a previously trained CNN model based on
Inception-ResNet in emotion recognition systems by
transferring its weights between subjects and datasets
(Cimtay, 2020).
2 METHOD
In this section, we describe the framework for
extraction of distinct patterns from spatio-temporal
EEG neural responses. The framework is composed
of the following main modules: 1) Preprocessing, 2)
feature extraction, 3) generating view-models, 4)
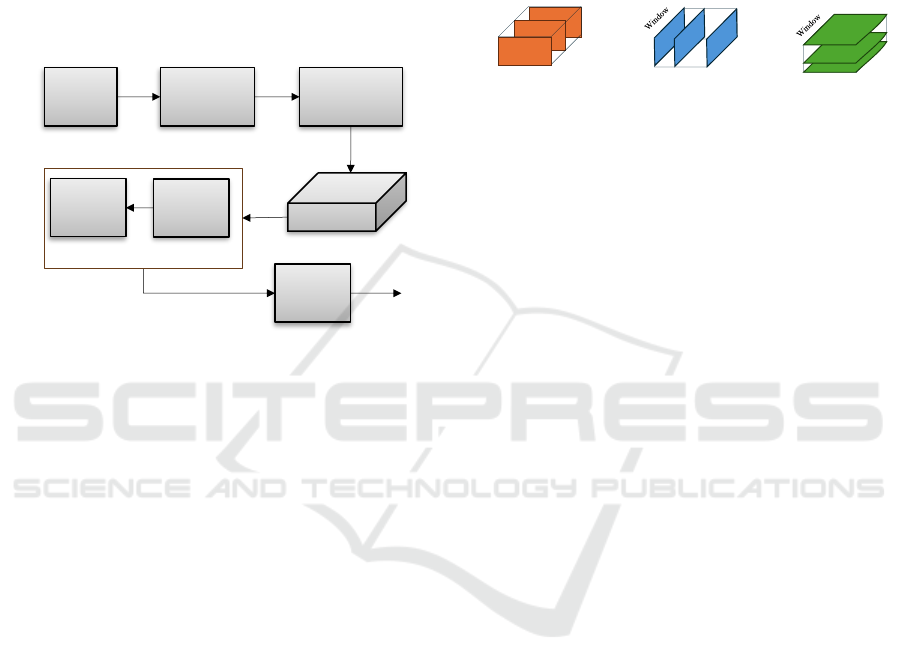
building fusion-model as illustrated in Figure 1.
Preprocessing is responsible for filtering artifacts
from the raw signal such as mean-line harmonics,
extraction of the spectrum of interest. The Laplacian
of Gaussian (LoG) is used as a signal conditioning
Effectiveness of Cross-Model Learning Through View-Model Ensemble on Detection of Spatiotemporal EEG Patterns
943
operator to enhance the signal. The View-Matrix
Generator formats the original 2D (channel, time)
data into a 3D spatiotemporal matrix. The View-
models are composed of the base learners, deep
convolutional neural network (DCNN) and AE, and
four regular classifiers namely k-nearest neighbours
(KNN), random forest (RF), support vector machines
(SVM), and artificial neural network to identify
participants. At the final stage, the fusion unit
ensembles View-model predictions to reach the final
decision.
Figure 1: Workflow.
The proposed method has been tested on EEG
data, which is composed of 7 subjects in 2 sessions,
10 days apart. We utilized the mBrain Smarting PRO
amplifier equipped with a 24-channel head cap. The
electrode locations on the head cap were designed
according to the 10-20 system. The amplifier was
configured at a sampling frequency of 500 Hz. We
designed and implemented several protocols using
the Presentation software: 1) Baseline, 2) inner voice-
audio, 3) shape-trace-audio, and 4) motion. Each
protocol is repeated for a total of 10 trials. In this
study, we presented results for the stimuli associated
with the resting state while eyes were open.
The EEG signal undergoes initial filtering with a
notch filter during the preprocessing stage. Next, a
band-pass filter is applied to focus on the 0.5 – 32 Hz
spectrum. The LoG operator described in (Oztemel,
2024) is then applied to enhance the signal. We
focused on trials with time duration of 0.5 seconds for
several stimuli. The EEG signal of a length L is
partitioned into different k segments of a length 𝑊 =
𝐿/(𝑝 𝑘)
with an overlap p.
2.2 3D Spatiotemporal Views
The proposed 3D Spatiotemporal View, named View-
Matrix, presented in Figure 3 combines the neural
dynamics over time for all EEG channels together
with cross-segment interactions. The neural activity
patterns are extracted from three views. View-1 is
composed of stacking the (channel, time) frames over
window segments. Similarly, View-2 enables
extraction of patterns in the stack of channel-window
frames over several periods and View-3 provides a
perspective from (window, time) frames across the
stack of channels.
Figure 2: 3D Spatiotemporal Views.
The descriptive feature patterns are generated
through a cross-model learning strategy. We explored
the effectiveness of the cross-model based transfer
learning over the regular classifiers (RC) ANN, KNN,
SVM, and RF. We utilized the DCNN and the AE as
base-learners. A View-model is generated by
employing an RC or combination of a base-learner
with an RC. Each View-model is constructed using its
designated View-matrix. When the training is
completed, the FC unit is dropped from the DCNN
model. Similarly, the decoder unit is discarded from
the AE model. The output of these models is utilized
to generate features passing through the flattening
unit F to train the regular classifiers. Figure 4
illustrates the training process flow. In the feature
extraction stage, a transfer-learning network model
generates features from the spatio-temporal set of
signals, named View-matrix. The fusion-model
combines predictions from multiple views to reach
the final decision.
2.3 Ensemble of View-Models
In the ensemble of intermediate predictions, we
utilized the idea of a voting classifier that produces
the final prediction from multiple opinions by
majority vote, i.e., the class with the highest
probability of being predicted by each classifier. The
fusion module yields the most frequently voted class
label together with the corresponding prediction
score. The mean prediction score is calculated when
more than one View-model predicts the same class.
When all three View-models disagree with each
other, a simple random selection determines the final
decision. Figure 5 illustrates the View-Model fusion
process.
View-1
(Channel, Time) → Window
Time
Channel
Channel
Time
View-2
(Channel, Window) → Time
View-3
(Window, Time) → Channel
Raw
Data
(Channel, Time)
View Matrix
Preproc
essing
View Matrix
Generator
Base-
Learner
RC
View-Models
Fusion
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
944
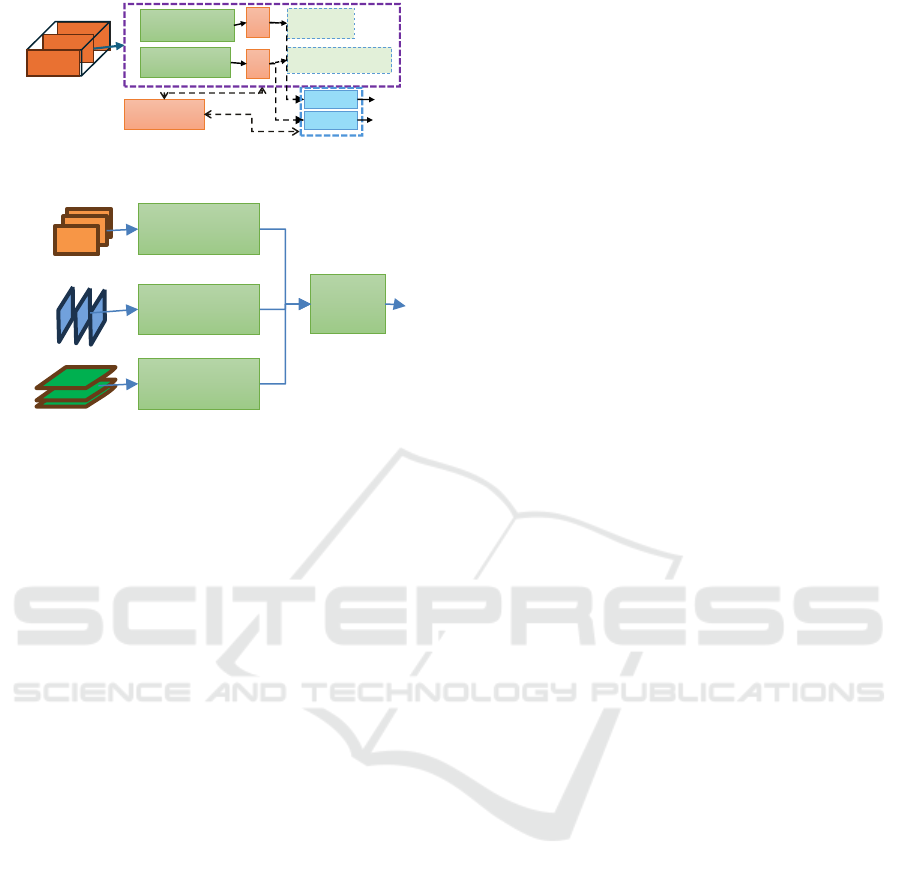
Figure 3: Training Process of View-Models.
Figure 4: View-Model Fusion Process.
3 RESULTS
In this section, we present our findings on the
effectiveness of the proposed framework. Two
performance measures, the accuracy (ACC) and the
area under the curve (AUC), were utilized for
evaluation of the proposed framework. We compared
the regular learning models with the cross-model
learning networks, DCNN and AE. We employed a
5-fold cross-validation strategy to measure the
stability of the proposed framework against the
uncertainty of the data distribution. At each fold, we
split the data into 80% for training and 20% for
validation. For the assessment of permanence, the
session-1 EEG recordings were utilized to generate
the models, and the session-2 recordings were used
for testing. Hyperparameter tuning was conducted at
each fold. The duration of a segment of Interest (SoI)
was 0.5 seconds. The EEG amplifier operated at a
sampling frequency of 500 Hz. The session-1 and
session-2 included 514 SoIs, making 1028 SoIs in
total. The size of the View-matrix per subject was
241632 (channel, time, window).
3.1 Effectiveness of Cross-Model Learning
Figure 6 presents the effect of each learning scheme
for extraction of distinct patterns from the 3D View-
matrix. The regular classifiers ANN, KNN, and SVM
trained by the features directly flattening of a View-
Matrix performed poorly compared to the RF as
Figure 6a shows. In addition, the RF classifier did not
show a stable performance as its distribution was
quite wide.
On the other hand, the DCNN and AE-based
cross-learner models outperformed the regular
classifiers as shown in Figure 6b and Figure 6c. The
distribution of the average prediction scores elevated
significantly. It should be noted that the predictions’
stability requires attention to improve the proposed
approach.
The analysis of Figure 7 clearly shows that the
proposed cross-model approach significantly
improved the learning performance. Overall, the
DCNN base learner showed slightly higher prediction
scores on average than the AE’s predictions. As a
remark, there is room to conduct research on the
stability of the base learners.
3.2 Identifiability of Individuals
In this study, we present outcomes from our in-house
dataset of EEG recordings from 7 individuals. It is
expected that individuals can be distinguished from
one another due to the unique characteristics of their
brain’s anatomical and functional differences. In
Figure 8, we presented AUC performance values of
the classification algorithms for each subject. The
performances of the KNN and SVM models provided
very similar results. However, the random forest and
ANN models showed performance improvement in
some cases, depending on the utilized learning
approach. These findings show that the cross-learner
model with DCNN and RF combination can be more
successful for certain subjects.
3.3 Comparison with the State of the
Art
Arnau pointed out a common mistake in EEG-based
biometric studies (Arnau, 2021). Surprisingly, few
studies have focused on the effects of time-dependent
changes in brain signals. In most studies, systems
developed for high-accuracy detection of subjects
were typically trained and tested on data collected in
the same session. Alternatively, data collected from
different sessions were combined; and then split into
learning and testing datasets. As a result, their
performance scores were reported as high. Being
aware of this situation, some studies performed the
learning and testing phases using data collected from
completely different sessions. Nakamura et al.
analysed two different scenarios in their study
focusing on this issue. In the first scenario, learning
and testing data were collected from the same session,
while in the second scenario, data were obtained from
DCNN layers
HP Tuning
FC
F
View
Encoder
Decoder
F
RC
RC
View-Model
(Channel, Time)
View-Model
(Channel, Window)
View-Model
(Window, Time)
Fusion
Model
Effectiveness of Cross-Model Learning Through View-Model Ensemble on Detection of Spatiotemporal EEG Patterns
945
different sessions. In the second scenario, the time
difference between the sessions varied from 5 to 15
days (Nakamura, 2017). As Arnau emphasized, it has
been proven that performance was higher when data
from the same session were used. It is worths
mentioning that one of the recent rare studies
(Plucińska, 2023), a spectral-based biometric
verification experiment, resulted in 75 to 96% ACC
depending on whether the cross-session data were
used for training and testing. A simple ANN classifier
was utilized to extract distinct features.
In this study, we used data from one session to
train the models and data from another session for
testing. The data collection sessions were completed
with a 10-day interval. Therefore, this study provides
one of the unique reports in the literature in terms of
isolating training and testing datasets. To the best of
our knowledge, this study is the first to propose a
multi-view cross-session framework for EEG-based
authentication utilizing a cross-session test dataset.
3.4 Hyperparameter Tuning
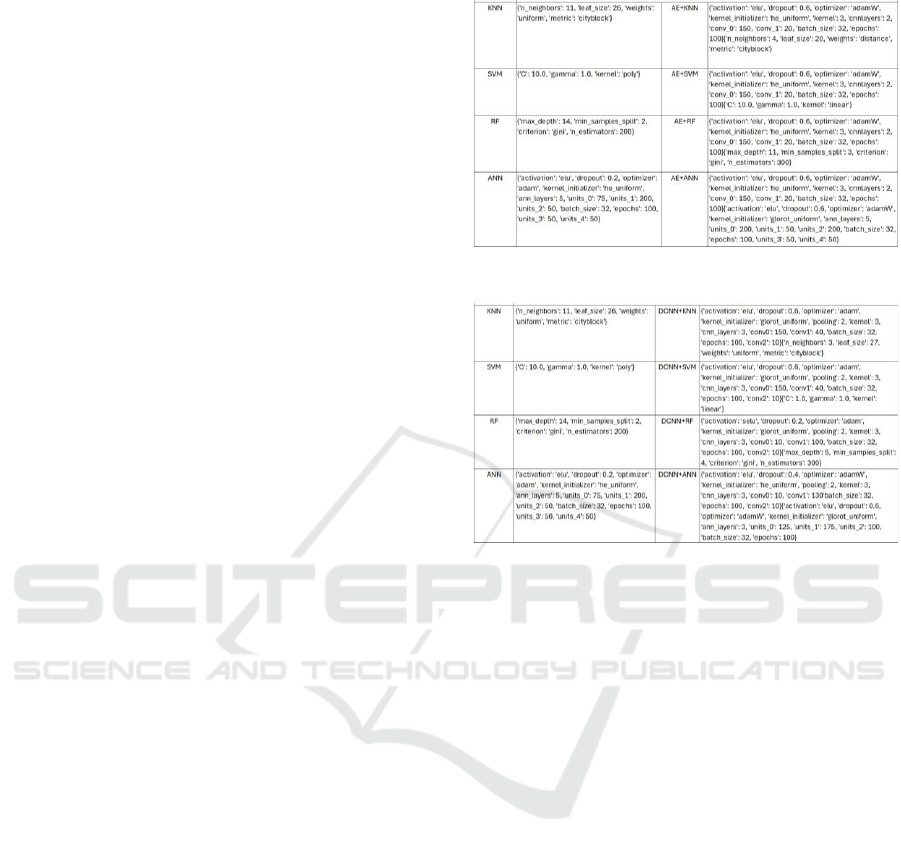
Table 1 and Table 2 provide insight into the
hyperparameters of each model. We utilized Bayesian
optimization in Keras Tuner to identify the best
parameters for our models. The KNN’s neighbour
parameter reduced from 11 to 4 (3) when trained by
the base-learner AE (DCNN). The SVM changed its
kernel type from polynomial to linear when used with
both base learners. The RF’s max_depth parameter
dropped from 14 to 5 and 11 when trained by the
DCNN and AE, respectively. The number of layers
remained the same when the AE was used while it
decreased from 5 to 3 when the DCNN was the base
trainer. The number of units at each layer showed a
variation. The DCNN’s number of layers remained
the same across RCs while the AE utilized 2 layers
with the same number of units at each layer for all
RCs.
Table 1: Best Parameters for RC and AE+RC models.
Table 2: Best Parameters for RC and DCNN+RC models.
4 CONCLUSIONS
In this research, we introduced our proposed 3D
spatiotemporal multi-view cross-learning framework
for the identification of individuals using EEG based
neural responses. We explored the effectiveness of
cross-model machine learning approaches compared
to regular classifiers. In addition, we investigated
individuals’ identifiability using the proposed
framework. The results indicate that the proposed
approach is promising, although more detailed
exploration is needed to achieve stable learning.
As an extension of this research, attention
mechanisms could be employed to enhance stability.
Furthermore, a longitudinal study involving data
collection over an extended period would help us
better understand the stability of EEG neural
responses.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
946
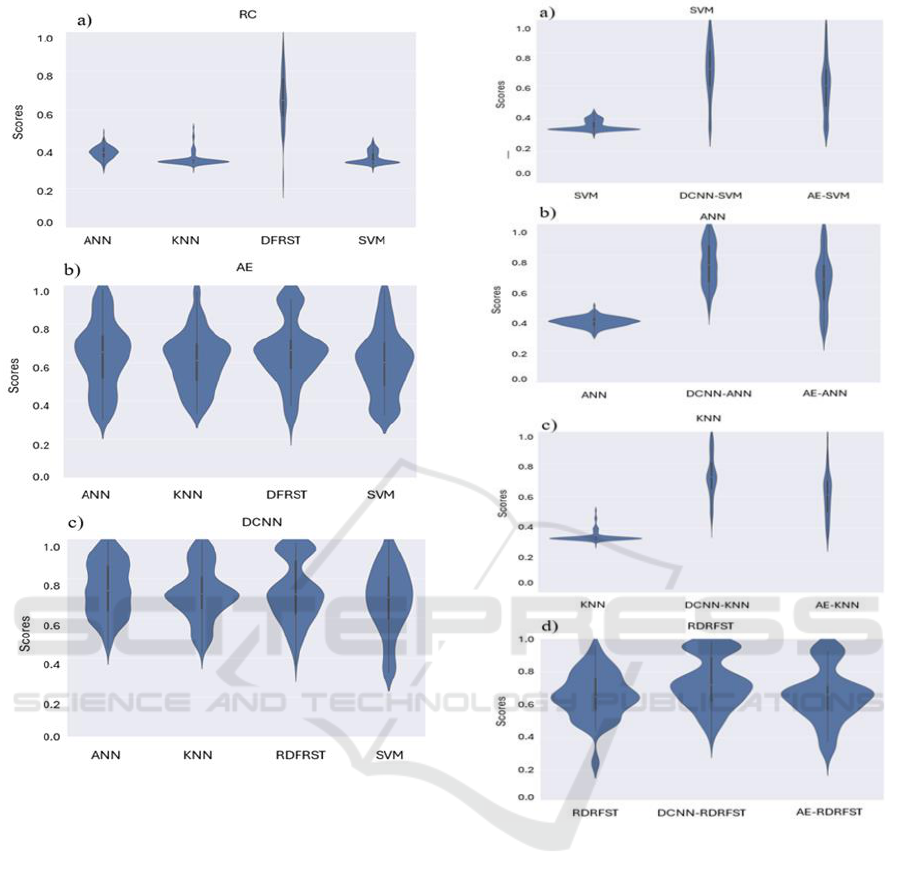
Figure 6: Comparison of RCs when trained by base
learners, a) Regular classifiers, b) AE, c) DCNN (ACC
scores).
ACKNOWLEDGEMENTS
Research reported in this publication was supported
by an Institutional Development Award (IDeA) from
the National Institute of General Medical Sciences of
the National Institutes of Health under grant number
P20GM103424-20 via Louisiana Biomedical
Research Network.
Author Contribution Statement:
All authors discussed the methods, results, and
commented on the manuscript. Major individual
contributions are as in the following.
Figure 7: Effectiveness of cross-model learners across RCs
(ACC scores).
Ömer M. Soysal: Supervising the project,
conceptualization, pipeline design, supervising the
data collection, implementing the pipeline, leading
the preparation of the manuscript.
Iphy E. Kelvin: Pipeline implementation,
debugging, testing the code, data structure design,
running the code, assisting in the data collection and
writing the method section.
Esad M. Oztemel: Implementation of the
autoencoder and signal conditioning functions,
assisting in conceptualization, writing the
introduction, and results section.
Effectiveness of Cross-Model Learning Through View-Model Ensemble on Detection of Spatiotemporal EEG Patterns
947
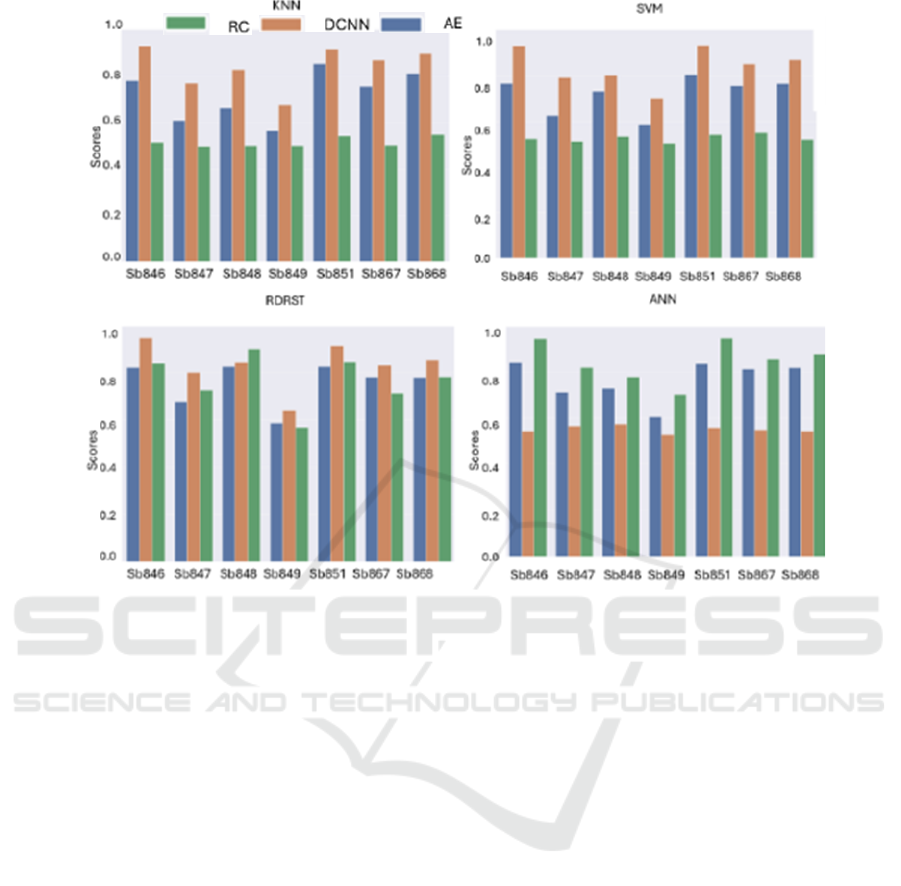
Figure 8: Identifiability of individuals (AUC scores).
REFERENCES
Abdelhameed, A. M., & Bayoumi, M. (2018, December).
Semi-supervised deep learning system for epileptic
seizures onset prediction. In 2018 17th IEEE
international conference on machine learning and
applications (ICMLA) (pp. 1186-1191). IEEE.
Acharjee, R., & Ahamed, S. R. (2024, February).
Automatic Eyeblink Artifact Removal from Single
Channel EEG Signals Using One-Dimensional
Convolutional Denoising AE. In 2024 International
Conference on Computer, Electrical & Communication
Engineering (ICCECE) (pp. 1-7). IEEE.
Aggarwal, S., & Chugh, N. (2022). Review of machine
learning techniques for EEG based brain computer
interface. Archives of Computational Methods in
Engineering, 29(5), 3001-3020.
Ari, B., Siddique, K., Alçin, Ö. F., Aslan, M., Şengür, A.,
& Mehmood, R. M. (2022). Wavelet ELM-AE based
data augmentation and deep learning for efficient
emotion recognition using EEG recordings. IEEE
Access, 10, 72171-72181.
Arnau-González, P., Katsigiannis, S., Arevalillo-Herráez,
M., & Ramzan, N. (2021). BED: A new data set for
EEG-based biometrics. IEEE Internet of Things
Journal, 8(15), 12219-12230.
Atrey, P. K., Hossain, M. A., El Saddik, A., & Kankanhalli,
M. S. (2010). Multimodal fusion for multimedia
analysis: a survey. Multimedia systems, 16, 345-379.
Bandana Das, B., Kumar Ram, S., Sathya Babu, K.,
Mohapatra, R. K., & Mohanty, S. P. (2024). Person
identification using AE-CNN approach with multitask-
based EEG biometric. Multimedia Tools and
Applications, 1-21.
Bidgoly, A. J., Bidgoly, H. J., & Arezoumand, Z. (2020). A
survey on methods and challenges in EEG based
authentication. Computers & Security, 93, 101788.
Bharadwaj, S., Vatsa, M., & Singh, R. (2014). Biometric
quality: a review of fingerprint, iris, and face. EURASIP
journal on Image and Video Processing, 2014, 1-28.
Cimtay, Y., & Ekmekcioglu, E. (2020). Investigating the
use of pretrained convolutional neural network on
cross-subject and cross-dataset EEG emotion
recognition. Sensors, 20(7), 2034.
Dutt, M., Redhu, S., Goodwin, M., & Omlin, C. W. (2022,
October). Sleep Stage Identification based on Single-
Channel EEG Signals using 1-D Convolutional AEs.
In 2022 IEEE International Conference on E-health
Networking, Application & Services (HealthCom) (pp.
94-99). IEEE.
Emanet, F. Y., & Sekeroglu, K. Decoding Visual Stimuli
and Visual Imagery Information from EEG Signals
Utilizing Multi-Perspective 3D-CNN Based
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
948

Hierarchical Deep-Fusion Learning Network.
Proceedings Copyright, 381, 388.
Fidas, C. A., & Lyras, D. (2023). A review of EEG-based
user authentication: trends and future research
directions. IEEE Access, 11, 22917-22934.
Gao, Y., Fu, X., Ouyang, T., & Wang, Y. (2022). EEG-
GCN: spatio-temporal and self-adaptive graph
convolutional networks for single and multi-view EEG-
based emotion recognition. IEEE Signal Processing
Letters, 29, 1574-1578.
Gopal, S. R. K., & Shukla, D. (2021, August). Concealable
biometric-based continuous user authentication system
an EEG induced deep learning model. In 2021 IEEE
International Joint Conference on Biometrics
(IJCB) (pp. 1-8). IEEE.
Jia, Z., Lin, Y., Wang, J., Ning, X., He, Y., Zhou, R., ... &
Li-wei, H. L. (2021). Multi-view spatial-temporal
graph convolutional networks with domain
generalization for sleep stage classification. IEEE
Transactions on Neural Systems and Rehabilitation
Engineering, 29, 1977-1986.
Khosla, A., Khandnor, P., & Chand, T. (2020). A
comparative analysis of signal processing and
classification methods for different applications based
on EEG signals. Biocybernetics and Biomedical
Engineering, 40(2), 649-690.
Kuncheva, L. I. (2014). Combining pattern classifiers:
methods and algorithms. John Wiley & Sons.
Mane, R., Robinson, N., Vinod, A. P., Lee, S. W., & Guan,
C. (2020, July). A multi-view CNN with novel variance
layer for motor imagery brain computer interface. In
2020 42nd annual international conference of the IEEE
engineering in medicine & biology society (EMBC)
(pp. 2950-2953). IEEE.
Mueller, S., Wang, D., Fox, M. D., Yeo, B. T., Sepulcre, J.,
Sabuncu, M. R., ... & Liu, H. (2013). Individual
variability in functional connectivity architecture of the
human brain. Neuron, 77(3), 586-595.
Nakamura, T., Goverdovsky, V., & Mandic, D. P. (2017).
In-ear EEG biometrics for feasible and readily
collectable real-world person authentication. IEEE
Transactions on Information Forensics and
Security, 13(3), 648-661.
Oh, S. L., Hagiwara, Y., Raghavendra, U., Yuvaraj, R.,
Arunkumar, N., Murugappan, M., & Acharya, U. R.
(2020). A deep learning approach for Parkinson’s
disease diagnosis from EEG signals. Neural Computing
and Applications, 32, 10927-10933.
Oztemel, M. E., & Soysal, Ö. M. (2024, April). Effect of
Signal Conditioning and Evoked-Potential Based
Representation on Stability and Distinctiveness of EEG
Brain Signatures. In 2024 12th International
Symposium on Digital Forensics and Security
(ISDFS) (pp. 1-7). IEEE.
Qi, H., Xue, Y., Xu, L., Cao, Y., & Jiao, X. (2018). A
speedy calibration method using Riemannian geometry
measurement and other-subject samples on a P300
speller. IEEE Transactions on Neural Systems and
Rehabilitation Engineering, 26(3), 602-608.
Plucińska, R.; Jędrzejewski, K.; Malinowska, U.; Rogala, J.
Leveraging Multiple Distinct EEG Training Sessions
for Improvement of Spectral-Based Biometric
Verification Results. Sensors 2023, 23, 2057.
Riera, A., Soria-Frisch, A., Caparrini, M., Grau, C., &
Ruffini, G. (2007). Unobtrusive biometric system based
on electroencephalogram analysis. EURASIP Journal
on Advances in Signal Processing, 2008, 1-8.
Spyrou, L., Kouchaki, S., & Sanei, S. (2015, September).
Multiview classification of brain data through tensor
factorisation. In 2015 IEEE 25th international
workshop on Machine Learning for Signal Processing
(MLSP) (pp. 1-6). IEEE.
Tian, C., Ma, Y., Cammon, J., Fang, F., Zhang, Y., & Meng,
M. (2023). Dual-encoder VAE-GAN with
spatiotemporal features for emotional EEG data
augmentation. IEEE Transactions on Neural Systems
and Rehabilitation Engineering, 31, 2018-2027.
Waytowich, N. R., Lawhern, V. J., Bohannon, A. W., Ball,
K. R., & Lance, B. J. (2016). Spectral transfer learning
using information geometry for a user-independent
brain-computer interface. Frontiers in neuroscience, 10,
430.
Weng, W., Gu, Y., Guo, S., Ma, Y., Yang, Z., Liu, Y., &
Chen, Y. (2024). Self-supervised Learning for
Electroencephalogram: A Systematic Survey. arXiv
preprint arXiv:2401.05446.
Wu, D., Lawhern, V. J., Hairston, W. D., & Lance, B. J.
(2016). Switching EEG headsets made easy: Reducing
offline calibration effort using active weighted
adaptation regularization. IEEE Transactions on
Neural Systems and Rehabilitation
Engineering, 24(11), 1125-1137.
Wu, D., Xu, Y., & Lu, B. L. (2020). Transfer learning for
EEG-based brain–computer interfaces: A review of
progress made since 2016. IEEE Transactions on
Cognitive and Developmental Systems, 14(1), 4-19.
Xu, C., Tao, D., & Xu, C. (2013). A survey on multi-view
learning. arXiv preprint arXiv:1304.5634.
Yao, J., & Motani, M. (2018). Deep spatio-temporal feature
learning using AEs.
Zhao, M., Gao, H., Wang, W., & Qu, J. (2020). Research
on human-computer interaction intention recognition
based on EEG and eye movement. IEEE Access, 8,
145824-145832.
Zhou, T., & Wang, S. (2024). Spatio-Temporal Adaptive
Diffusion Models for EEG Super-Resolution in
Epilepsy Diagnosis. arXiv preprint arXiv:2407.03089.
Effectiveness of Cross-Model Learning Through View-Model Ensemble on Detection of Spatiotemporal EEG Patterns
949
