
An Approach for Product Record Linkage Using Cross-Lingual Learning
and Large Language Models
Andre Luiz Firmino Alves
1
, Cl
´
audio de Souza Baptista
2
, Jos
´
e Itallo Martins Silva Diniz
2
,
Francisco Igor de Lima Mendes
2
and Mateus Queiroz Cunha
2
1
Federal Institute of Para
´
ıba, Brazil
2
Federal University of Campina Grande, Brazil
andre.alves@ifpb.edu.br, baptista@computacao.ufcg.edu.br, {jose.diniz, francisco.mendes, mateus.cunha}@ccc.ufcg.edu.br
Keywords:
Cross-Lingual Learning, Record Linkage, Product Matching, Information Retrieval.
Abstract:
Organizations increasingly rely on data for the decision-making process. Nevertheless, significant challenges
arise from poor data quality, leading to incomplete, inconsistent, and redundant information. As dependency
on data grows, it becomes essential to develop techniques that integrate information from various sources while
dealing with these challenges in the context of product matching. Our work investigates information retrieval
and entity resolution approaches to product matching problems related to short and varied product descriptions
in commercial data, such as those found in electronic invoices. Our proposed approach, STEPMatch, employs
deep learning models alongside cross-lingual learning techniques, enhancing adaptability in contexts with
limited or incomplete data, effectively identifying products accurately and consistently.
1 INTRODUCTION
The internet has become a vast repository of infor-
mation about real-world entities, such as products,
people, and organizations, described heterogeneously
across distinct platforms (Han et al., 2023). The rise
of such unstructured data has made it essential to de-
velop solutions that integrate this information effec-
tively. The task of Entity Resolution (ER) emerges
as an effective technique for identifying and linking
these different representations, ensuring data consis-
tency and quality, which are critical aspects in a myr-
iad of applications, from business decision-making
to government oversight (Christophides et al., 2020;
Christen, 2012).
Product matching, a subset of Entity Resolution,
aims to identify similar products even when described
in varying ways. This task poses unique challenges in
e-commerce and government procurement, where in-
complete descriptions, spelling variations, and incon-
sistencies complicate the data linkage. Prior research
on product matching has predominantly focused on e-
commerce data with detailed and structured descrip-
tions, primarily in English (G
¨
oz
¨
ukara and
¨
Ozel, 2021;
Barlaug and Gulla, 2021; Christophides et al., 2020).
However, this focus does not reflect the characteris-
tics of sales records from electronic invoices. Further-
more, much of the research has been limited to pair-
wise product matching, neglecting record linkage ap-
proaches that could integrate products within broader
and more diverse datasets. This restriction limits the
application of the previous research in more complex
data integration scenarios (K
¨
opcke et al., 2010; Tracz
et al., 2020; Peeters and Bizer, 2022; de Santana et al.,
2023; Traeger et al., 2024).
Product data obtained from electronic invoices
often includes brief and unclear descriptions and a
lack of standardized information. Consequently, sig-
nificant challenges arise for product matching ap-
proaches that aim to manage these documents. Ad-
ditionally, the limited availability of annotated data
in low-resource languages, such as Portuguese, hin-
ders the effectiveness of traditional supervised entity
resolution methods. This situation presents an oppor-
tunity for cross-lingual learning (CLL) approaches,
which transfer knowledge from annotated corpora
in other languages to contexts with limited annota-
tions (Peeters and Bizer, 2022; Pikuliak et al., 2021;
De Oliveira et al., 2024). This method offers a vi-
able alternative for product matching in low-resource
languages, mainly when dealing with short and low-
quality descriptions.
In this work, we propose STEPMatch, derived
from a methodology based on cross-lingual learning
for product matching in short descriptions. We evalu-
ate our model’s effectiveness in retrieving and linking
Alves, A. L. F., Baptista, C. S., Diniz, J. I. M. S., Mendes, F. I. L. and Cunha, M. Q.
An Approach for Product Record Linkage Using Cross-Lingual Learning and Large Language Models.
DOI: 10.5220/0013285000003929
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 27th International Conference on Enterprise Information Systems (ICEIS 2025) - Volume 1, pages 63-74
ISBN: 978-989-758-749-8; ISSN: 2184-4992
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
63

products from textual descriptions, utilizing informa-
tion retrieval techniques and semantic refinement to
overcome the limitations of keyword-based methods,
such as TF-IDF and BM25, which do not adequately
capture the semantics of short descriptions (Rateria
and Singh, 2024; Hambarde and Proenc¸a, 2023). Our
proposal aims to enhance the performance in entity
resolution for products and contribute a solution ap-
plicable to scenarios with scarce and noisy data typi-
cal of tax and e-commerce.
We highlight the following contributions of our
work:
• An Approach for Product Record Linkage Us-
ing Cross-Lingual Learning and Large Language
Models;
• Assessment of Cross-Lingual Learning for Prod-
uct Matching;
• An Analysis of Lexical, Semantic, and Hybrid
Methods for Searching Products with Short De-
scriptions; and
• A novel reranking approach for Information Re-
trieval Systems using Cross-Lingual Learning and
Large Language Models to enhance the ranking of
search results.
The remainder of this work is structured as fol-
lows: section 2 discusses the related work; section
3 details the designs of the algorithms that compose
STEPMatch, as well as an overview of the steps uti-
lized to achieve effective product matching; section 4
focuses on the experiments we conducted; section 5
discusses our findings and what those findings mean
for the effectiveness of STEPMatch; and lastly, sec-
tion 6 encompasses our conclusions, pointing out our
contributions followed by future work to be under-
taken.
2 RELATED WORK
Entity resolution, also known as record linkage, du-
plicate detection, or reference reconciliation, aims to
identify different representations of the same real-
world entity, promoting consistent data integration
across various applications (K
¨
opcke et al., 2010; Bar-
laug and Gulla, 2021; Christen, 2012). The entity
resolution task typically comprises two main steps:
1) Blocking, which reduces the number of neces-
sary comparisons, and 2) Matching, which determines
whether a pair of entities refers to the same object.
Product matching is a particular application of
Record Linkage that aims to identify equivalent prod-
ucts across different data sources. Various ap-
proaches, such as probabilistic models, rule-based al-
gorithms, and machine learning techniques, are em-
ployed for this task. Deep learning and large language
models are currently considered state-of-the-art prod-
uct matching solutions (Barlaug and Gulla, 2021).
Researchers have extensively studied the opti-
mization of entity-matching techniques for large data
volumes. Xiao et al. (2011) developed a filter to
avoid calculations between all possible pairs using to-
ken ordering. Ristoski et al. (2018) proposed a prod-
uct matching approach based on Natural Language
Processing (NLP) and deep learning, combining tex-
tual and visual features extracted with Conditional
Random Field (CRF) and Convolutional Neural Net-
work (CNN) for classification with traditional ma-
chine learning algorithms. Barbosa (2019) utilized
diverse textual representations and a deep learning-
based binary classifier to capture similarity patterns
in product matching. To overcome the lack of anno-
tated data in a specific language, leveraging available
data in other languages to train and optimize machine
learning models, Peeters and Bizer (2022) employ
Cross-Lingual Learning in product matching classi-
fication.
Various Entity Resolution frameworks stand out
for their diverse approaches. Christen (2008) and
Bilenko and Mooney (2003) apply blocking and clas-
sification with algorithms such as Support Vector Ma-
chines (SVM) to identify duplicate records. Konda
(2018) offers a comprehensive solution for ER, in-
cluding pre-processing, data analysis, and machine
learning-based blocking. Meanwhile, DeepER (Ebra-
heem et al., 2017) and DeepMatcher (Mudgal et al.,
2018) utilize vector representations and embeddings
to capture semantic similarities. Finally, Ditto (Li
et al., 2020) employs pre-trained language models to
perform contextualized classification of product pairs.
At the time of this writing, Ditto currently represents
the state-of-the-art in entity matching (Peeters and
Bizer, 2022; Barlaug and Gulla, 2021).
This work distinguishes itself by addressing the
challenge of matching product descriptions found
in electronic invoices, which are typically shorter
and less structured than those commonly used in e-
commerce. While most existing entity recognition
and product matching approaches have focused on
structured data, our study proposes a comprehensive
solution that includes blocking techniques and in-
novative re-ranking methods within information re-
trieval systems. To the best of our knowledge, this
approach is novel as it explores cross-lingual learning
and information retrieval methods as effective strate-
gies to improve product linkage precision, especially
in fragmented data and multiple languages.
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
64
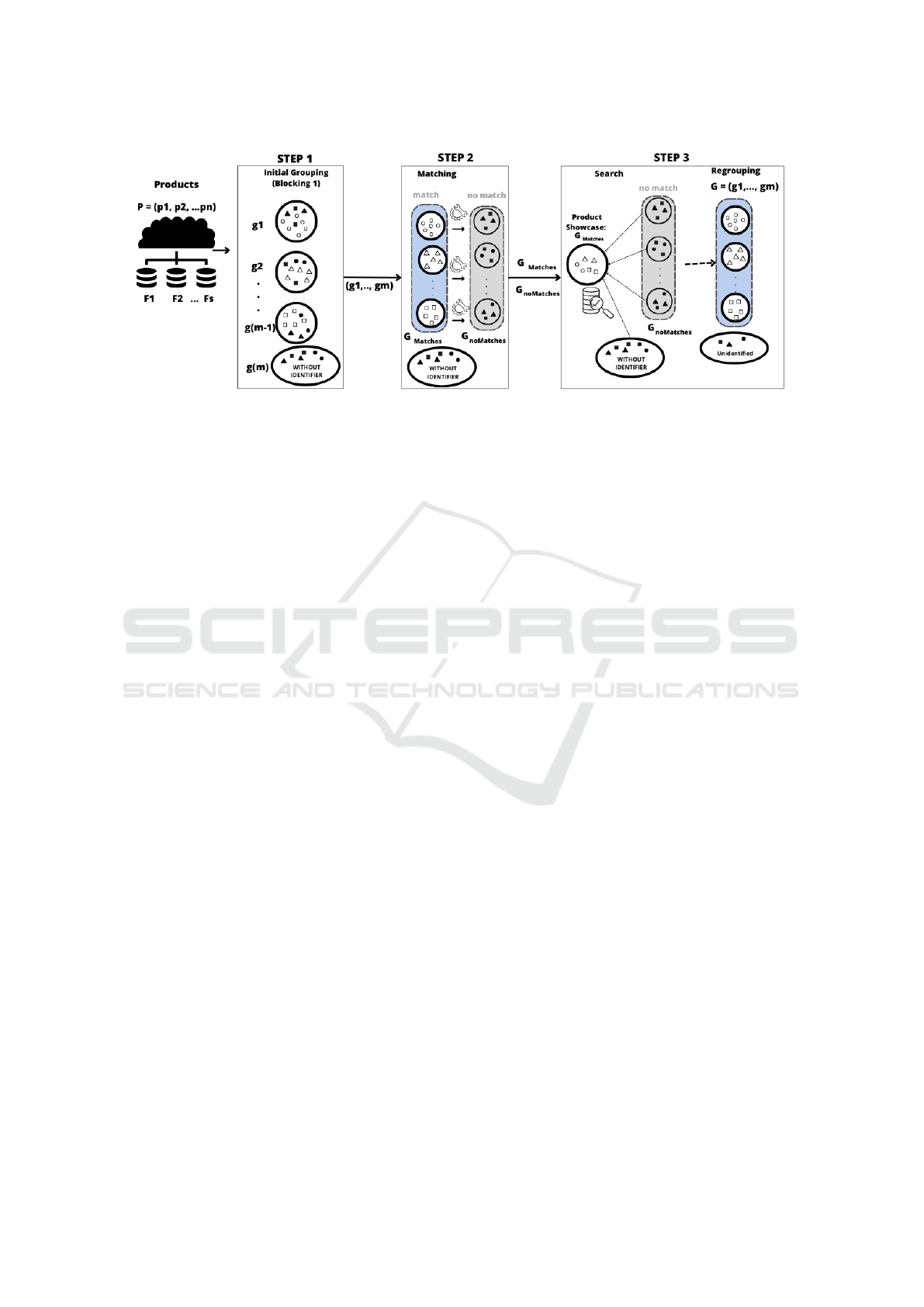
Figure 1: STEPMatch general overview.
3 STEPMatch: SHORT TEXT
PRODUCT MATCHING
This section introduces the STEPMatch approach
proposed in our work to perform record linkage on
short texts. We present the key components and
methods involved in addressing the product match-
ing problem, particularly emphasizing the Informa-
tion Retrieval (IR) mechanisms proposed to retrieve
the associations of product identifiers.
3.1 Overview
In electronic invoices, a single product identifier
may refer to multiple distinct descriptions of the
same item, and errors can occur in the association
between product codes and descriptions. We aim
to correctly associate the product descriptions with
their respective identifiers, resolving record inconsis-
tency issues. Our approach includes discovering non-
corresponding products with the same identifiers and
correcting them with the most appropriate ones, es-
pecially for products with inconsistent records. Our
work serves as a solution to address data inconsis-
tency problems in this type of scenario.
Figure 1 provides an overview of STEPMatch.
The process begins in step 1 with an initial clustering
of products, denoted as the set P = {p
1
, p
2
, . . . , p
n
},
sourced from various data sources. This step groups
products with similar attribute values into G =
{g
1
, g
2
, . . . , g
m
}. Each group g
i
∈ G contains a sub-
set of similar products, defined as g
i
= { p
j
∈ P | j =
1, . . . , k}, where 1 ≤ k ≤ n, with g
i
⊂ P.
In step 2, the product groups g
i
∈ G undergo pro-
cessing, and matching verification is carried out in-
ternally among the products within each group. This
results in two types of groups: matching groups
(G
Matches
) and non-matching groups (G
noMatches
).
Finally, in step 3, the focus is on identifying prod-
uct matches that were not detected in the previous
step, specifically targeting the products in G
noMatches
.
Figure 2 illustrates an example of the operations
performed in the steps of STEPMatch. The pro-
cess begins given a set of products from various data
sources: in Step 1 the algorithm identifies two groups
of products right after analyzing the input data; in
Step 2, products that do not belong to any of the
groups are detected; these mismatched products are
therefore forwarded to Step 3, which is responsible
for correctly associating them with their respective
groups. Products that remain unassociated with any
group are set aside and, along with future data loads,
will be reprocessed by STEPMatch.
Similarity functions are used to define product
groups at different steps of STEPMatch. These func-
tions analyze each pair of products by processing data
based on the current step. Typically, the similarity be-
tween any two products, p
i
and p
j
, is determined by
a function F
Sim
(p
i
, p
j
) ≥ θ, where θ represents a sim-
ilarity threshold.
The following subsections describe the steps of
STEPMatch, emphasizing step 3, which focuses on
this work’s main contribution.
3.1.1 Step 1: Blocking
The blocking step adopted by STEPMatch involves
dividing the product dataset into blocks or smaller
groups based on specific criteria. These groups were
designed to select products that could be potential
candidates for comparison during the matching step.
We seek to limit comparisons to entities within each
block, avoiding the algorithmic complexity of O(N
2
)
An Approach for Product Record Linkage Using Cross-Lingual Learning and Large Language Models
65

Figure 2: Illustrative example of the operation of STEPMatch.
during the matching phase (Papadakis et al., 2021;
Christophides et al., 2020).
The Standard Blocking (SB) is a hash-based strat-
egy for entity resolution. It generates blocking keys
by concatenating parts of selected attributes, form-
ing groups of entities with identical keys (Papadakis
et al., 2021). The initial clustering of products uses
the SB method, in which the attribute product iden-
tifier, present in the data, was used to represent the
blocking key. At this stage, the similarity function
F
Sim
(p
i
, p
j
) ≥ θ used to group two products p
i
and
p
j
∈ P based on the unique identifier of each product,
defined by id(p
j
). Thus, the similarity function for
product clustering, F
SB
Sim
, based on the SB method, can
be defined as:
F
SB
Sim
(p
i
, p
j
) =
(
1 if id(p
i
) = id(p
j
)
0 if id(p
i
) ̸= id(p
j
)
In our experiment, the similarity defined by the
threshold θ is equal to 1. Two products are considered
similar if and only if their identifiers are equal.
3.1.2 Step 2: Match Verification
This step verifies matches between product descrip-
tions and their respective identifiers. To carry out
this task, we defined the Algorithm 1, implemented
to check the matches of the products within the pro-
vided groups. The GroupProducts function receives
the initial grouping of products G = {g
1
, . . . , g
m
} de-
fined in step 1 as input.
Upon receiving the product groups as input, our
algorithm checks the product matches for each re-
ceived group and returns two sets with the same num-
ber of products per group. The first set represents the
groups of intrinsically matched products, while the
second set represents those that did not match the ini-
tial grouping.
Let G = {g
1
, g
2
, . . . , g
m
} be the set of prod-
uct groups, the function GroupProducts processes
Algorithm 1: Group Products Function.
Input : G = {g
1
, .., g
m
};
Output: G
Matches
= {g
′
1
, .., g
′
m
},
G
noMatches
= {g
′′
1
, .., g
′′
m
};
1 foreach g in G do
2 g.canonDesc ← f indCanonDesc(g);
3 end
4 G
noMatches
←
/
0;
5 G
Matches
← copy(G);
6 foreach g in G
Matches
do
7 P
noMatches
←
/
0;
8 foreach p in g.products do
9 if not isMatch(p.desc, g.canonDesc)
then
10 P
noMatches
.add(p) ;
11 g.delete(p);
12 end
13 G
noMatches
[g.id].add(P
noMatches
);
14 end
15 return (G
Matches
, G
noMatches
);
each group g
i
∈ G and returns two sets G
Matches
=
{g
′
1
, . . . , g
′
m
} and G
noMatches
= {g
′′
1
, . . . , g
′′
m
}, where
G
Matches
represents the products of group g
i
that have
intrinsic matches, and G
noMatches
represents the prod-
ucts of group g
i
that do not have matches in the ini-
tial grouping. Thus, for each group g
i
∈ G, it holds
that g
i
= g
′
i
∪ g
′′
i
and g
′
i
∩ g
′′
i
=
/
0, where g
′
i
∈ G
Matches
and g
′′
i
∈ G
noMatches
, ensuring that all products are ex-
clusively categorized in one of the two sets, preserv-
ing the structure of the initial grouping G. In other
words, G
Matches
∪ G
noMatches
= G and G
Matches
∩
G
noMatches
=
/
0.
To avoid the O(N
2
) complexity in the compar-
isons of all products in the formed groups, a valid de-
scription for each group is initially defined, referred
to here as the canonical description (line 2 of Algo-
rithm 1). The matching verification of the products
in the group is performed only with this canonical
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
66

description, resulting in a complexity of O(N) per
grouping. The canonical group description was estab-
lished through a majority voting approach, whereby
we selected the description with the highest number
of occurrences. In the case of a tie, when multiple
descriptions have the same number of occurrences, a
secondary criterion for breaking the tie is proposed,
such as choosing the description with the most words
or characters.
Once the canonical description of each product
group is defined, our algorithm identifies and sep-
arates incorrect associations of products, maintain-
ing groups whose products are indeed corresponding
(G
Matches
) and creating groups of non-corresponding
products (G
noMatches
) (lines 6 to 14). This identifica-
tion of products is carried out through the similarity
function F
Sim
(p
i
, p
j
) ≥ θ, where {p
i
, p
j
} ∈ g
i
, p
i
is
the product that contains the canonical description of
group g
i
, and θ represents the similarity threshold.
Formally, we have:
g
′
i
= {p
j
| F
Sim
(p
i
, p
j
) ≥ θ}
g
′′
i
= {p
j
| F
Sim
(p
i
, p
j
) < θ},
where g
′
i
∈ G
Matches
and g
′′
i
∈ G
noMatches
. Then, these
two sets of product groups, G
Matches
and G
noMatches
,
are returned to the main algorithm (Algorithm 2).
The similarity function F
Sim
(p
i
, p
j
) is defined
in the function isMatch() (line 9, Algorithm 1).
The techniques for implementing the function is-
Match() can explore lexical approaches (Christen,
2008; Konda, 2018) or advanced machine learning
techniques (Li et al., 2020; Peeters et al., 2020;
de Santana et al., 2023; Primpeli et al., 2019; Barlaug
and Gulla, 2021), including Cross-Lingual Learning
(Peeters and Bizer, 2022).
3.1.3 Search for Matching Products: Step 3
While step 2 identifies products with invalid matches
(G
noMatches
) in the initial grouping (G), our step 3 aims
to associate the products identified as non-matching
(G
noMatches
) with other products that represent the
same entity, establishing the matches correctly.
Initially, the products with valid matches
(G
Matches
) are used to create a showcase of indexed
products in an Information Retrieval system. Subse-
quently, the products contained in G
noMatches
are used
as search keys to find index matches. This search
process enables the identification of the most suitable
products to make the correct associations.
The process carried out in step 3 can be formally
described as follows:
1. Indexing: products p ∈ G
Matches
are indexed in the
IR system to enable more efficient retrieval;
2. Searching: for each product p
′′
∈ G
noMatches
, a
search is conducted in the IR system using p
′′
as
the key;
3. Matching: the IR system returns a set of prod-
ucts {p
i
} for each p
′′
searched, where {p
i
} =
findSimilarity(p
′′
); and
4. Linkage: the correct correspondence between
p
′′
and {p
i
} is determined based on similarity,
F
Sim
(p
′′
, {p
i
}) ≥ θ. The linkage is carried out
by considering the highest value of the similarity
function F
Sim
. That is, for each p
′′
∈ G
noMatches
,
p
∗
is found such that:
p
∗
= arg
p
i
∈G
Matches
max F
Sim
(p
′′
, {p
i
}).
In this case, the product p
∗
is the one that maxi-
mizes the similarity function F
Sim
between p
′′
and
the products G
Matches
.
The function findSimilarity(p
′′
) aims to locate the
most suitable products for making the most appropri-
ate associations. For that purpose, two mechanisms
for retrieving and classifying relevant documents are
used:
1. Search Algorithm:
• Initially, the search algorithm is used to cal-
culate the relevance of the indexed products
(p
i
∈ G
Matches
) in relation to the query product
(p
′′
∈ G
noMatches
);
• The similarity function F
f ind
Sim
(p
′′
, p
i
) is then
used to rank the candidate products based on
textual similarity.
The initial search can be formally depicted as:
{p
i
} = findSimilarity(p
′′
),
where p
i
∈ G
Matches
e F
Search
Sim
(p
′′
, p
i
) > θ
2. Reordering with Cross-Encoder:
• The reordering is carried out using a cross-
encoder language model.
• The language model evaluates the relevance of
the pairs (p
′′
, p
i
) more accurately, generating
a refined similarity score F
Cross-Encoder
Sim
(p
′′
, p
i
).
We calculate the similarity score consider-
ing the semantics associated with the prod-
uct name. Thus, the reordering of the pairs
(p
′′
, p
i
) is carried out in such a way that
F
Cross-Encoder
Sim
(p
′′
, p
i
) is greater than or equal to
F
Search
Sim
(p
′′
, p
i
).
• Formally, this reordering can be represented as:
{p
i
}
final
= Reorder
Cross−Encoder
({p
i
}, p
′′
),
where F
Cross-Encoder
Sim
(p
′′
, p
i
) =
Cross-Encoder(p
′′
, p
i
) and Cross-Encoder
represents a language model trained to
calculate the similarity between two products.
An Approach for Product Record Linkage Using Cross-Lingual Learning and Large Language Models
67
For each product p
′′
∈ G
noMatches
, the function
findSimilarity(p
′′
) performs an initial search and a
subsequent reordering with cross-encoder, returning
the most relevant products {p
i
}
final
for each product
p
′′
.
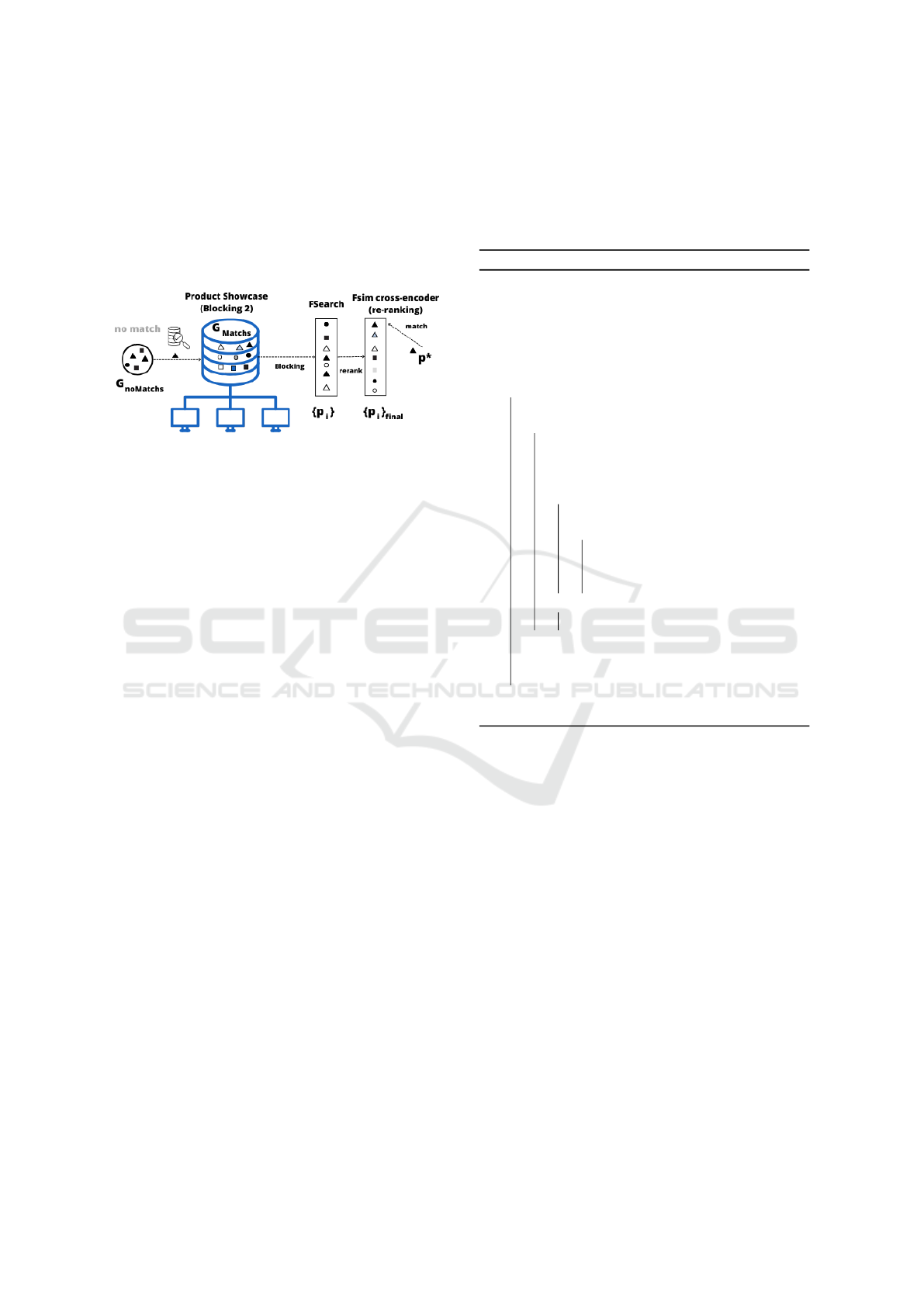
Figure 3 illustrates this process of searching for
corresponding products implemented in STEPMatch.
Figure 3: Search for product matches.
We indexed the products in STEPMatch using a
blocking strategy to avoid the complexity O(N
2
) in
reordering with Cross-Encoder.
The design of step 3 is detailed in the Algorithm
2, where it takes the following parameters as input:
• G
noMatches
: a set of product groups without
matches, identified in the Matching Stage (step 2)
using the Algorithm 1; and
• G
Matches
: a showcase of products matching set by
the Algorithm 1. This showcase represents the
products that are indexed in the IR system.
Two empty sets are instantiated at line 2 of the Al-
gorithm 2: G
newMatch
and G
unknown
. The set G
newMatch
represents the groups of products for which new
matches with products from the showcase were pos-
sible, while G
unknown
represents a set of products for
which matches could not be determined. These sets
constitute the final result of the algorithm.
The Algorithm 2 iterates over each product in ev-
ery group of G
noMatches
to perform searches within the
showcase G
Matches
(lines 3-18). The function find-
Similarity (line 6) is responsible for returning a list
ordered by relevance, considering the degree of sim-
ilarity of the searched item p
j
∈ G
noMatches
with the
products p
i
∈ G
Matches
. The first element of the list,
p
∗
, represents the product p
i
with the highest degree
of similarity, matching it with the searched product
p
j
(line 9). The function isMatch() (Algorithm 1) is
used again to verify if there is indeed a match between
p
j
and the first element of the list p
∗
(line 10). Once
the matching of the items is confirmed, the product
p
j
is added to the same group as the p
∗
element at
the top of the search results (lines 11-13). If the func-
tion isMatch() does not confirm the match, the item
p
j
is added to the set Products
unknown
of unmatched
products (line 15). Finally, the sets G
newMatch
, which
include groups of matching products, and G
unknown
,
with unmatched products (line 17), represent the fi-
nal result of the processing of Algorithm 2 and are
returned.
Algorithm 2: Matching Locator.
Input : G
Matches
= {g
′
1
, .., g
′
m
},
G
noMatches
= {g
′′
1
, .., g
′′
m
};
Output: G
newMatch
= {g
1
, g
2
, ..., g
n
},
G
unknown
= {g
unknown
};
1 G
newMatch
←
/
0 ;
2 G
unknown
←
/
0 ;
3 foreach g
aux
in G
noMatches
do
4 Products
unknown
←
/
0 ;
5 foreach p
j
in g
aux
.products do
6 products
result
←
f indSimilarity(p
j
, G
Matches
);
7 f lag
match
← False ;
8 if products
result
.size() > 0 then
9 p
∗
= products
result
[0];
10 if isMatch(p
∗
.desc, p
j
.desc) then
11 p
j
.id ← p
∗
.id;
12 f lag
match
= True;
13 G
newMatch
[p
j
.id].add(p
j
) ;
14 if (not f lag
match
then
15 Products
unknown
.add(p
j
)
16 end
17 G
unknown
[
′
unknown
′
].add(Products
unknown
);
18 end
19 return (G
newMatch
, G
unknown
);
3.2 Cross-Encoder Model with
Cross-Lingual Learning
The STEPMatch uses the similarity function F
Sim
to
perform product matching. We employed this func-
tion in both of the presented algorithms. Our ap-
proach aims to apply transfer learning, enhancing our
model by fine-tuning it with task-specific inputs. For
product matching, the model receives two product
descriptions P
i
and P
j
as input, classifying them as
Matched (y = 1) or Not Matched (y = 0). The clas-
sification is achieved through a probability P
m
(y
i j
=
1 | (p
i
, p
j
)) that indicates the confidence of a match
occurring between p
i
and p
j
. Formally, the output of
our model is represented by:
ˆ
P
m
= f
m
(M
θ∗
(p
i
, p
j
))
ˆy =
(
1 se M
θ∗
(p
i
, p
j
) ≥ τ
0 se M
θ∗
(p
i
, p
j
) < τ,
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
68

where
ˆ
P
m
represents the similarity index, quantifying
the degree of correspondence or similarity between
products p
i
and p
j
. This index is calculated from the
similarity function f
m
, which receives the value re-
turned from the softmax activation function used in
the output layer of the LLM M
θ∗
. Finally, ˆy represents
the binary classification (0 or 1) predicted through a
threshold τ. By default, the threshold τ is set to 0.5
and may be adjusted according to the desired opti-
mization.
In the context of product matching, our work also
contributes to the state of the art by evaluating transfer
learning techniques between languages by exploring
distinctive CLL strategies. In this approach, several
LLMs are evaluated, including both monolingual and
multilingual models. Our goal with CLL is to enhance
the performance of LLMs by using annotated corpora
from a high-resource specific language to build classi-
fication models applicable to a different low-resource
language through transfer learning. This process re-
volves around training classification models from a
source language and fine-tuning with a smaller por-
tion of data from the target language. This approach
allows for using learning models in languages with
limited resources, maximizing efficiency and accu-
racy in the product matching task.
The use of CLL strategies (Pikuliak et al., 2021;
De Oliveira et al., 2024) assumes the use of at least
two distinct language corpora to develop, with a trans-
fer learning method, where the classification model
uses data from a source language D
s
to improve prod-
uct matching classification in a target language D
t
.
The trained model M
CLL
θ
is fine-tuned using a combi-
nation of data from the corpora D
s
and D
t
, controlled
by the parameters α and β, which adjust the propor-
tion of data from each language in the fine-tuning pro-
cess. Formally, we have:
D = αD
s
+ βD
t
,
where α and β control the amount of data from the
source and target languages, respectively.
Our study used data in English as the source lan-
guage (D
s
) and Brazilian Portuguese as the target lan-
guage (D
t
). Inspired by the works of Alves et al.
(2024); De Oliveira et al. (2024), this research ex-
plored the combined strategy of Joint-Learning (JL)
and Cascade-Learning (CL) in refining the model.
The JL technique uses corpora from specific lan-
guages during training, including a subset of data
from the target language as part of the training corpus.
On the other hand, in the CL technique, the model un-
dergoes fine-tuning exclusively using the training lan-
guage corpora and then further fine-tuning utilizing a
subset of the target language data. In the combined
strategy, referred to as JL/CL, the trained model un-
derwent two refinements, wherein the first phase, a
fraction of 50% of the source language data (α = 0.5),
as well as 50% of the target language data (β = 0.5),
and then in the second adjustment, we only used the
remaining 50% of the target language data (β = 0.5).
4 EXPERIMENTAL SETUP
This section provides an overview of the dataset and
LLMs comprising STEPMatch and details of our ex-
periments.
4.1 Dataset
This work utilizes CLL approaches that adopt a la-
beled product corpus from a source language to train
models capable of evaluating products in a target
language. For the source language, we used the
WDC Product corpus (Web Data Commons Train-
ing and Test Sets for Large-Scale Product Matching),
which contains paired product annotations in English
and has been used in other product matching stud-
ies.Peeters et al. (2020); Primpeli et al. (2019)
For the target language, we used data in Brazil-
ian Portuguese from products derived from Electronic
Fiscal Invoices (NFe-BR) issued in a Brazilian state.
The data was collected over a three-month period,
from May to July 2023, totaling approximately 6.6
million records. The database includes information
such as the identification code (GTIN), a short de-
scription of the product, and the price. This dataset
encompasses many products, accounting for 578,640
distinct barcodes (GTIN) and 942,447 unique descrip-
tions.
To construct the NFe-BR corpus containing pairs
of products labeled as “match” and “no match” we
adopted a contrastive approach to obtain a diverse
and representative set of product pairs, similar to the
methodology in Peeters et al. (2020); Embar et al.
(2020); de Santana et al. (2023). Positive pairs were
formed by grouping products with identical GTINs.
We employed the BM25 algorithm via ElasticSearch
1
for negative pairs to find similar product descriptions.
For each positive pair, k negative pairs were gener-
ated, resulting in a 1:k ratio. In our experiments, we
set k=5 to create a dataset with a higher proportion
of negative instances. Furthermore, a subset of cate-
gories was selected, prioritizing those with the highest
representation in terms of product quantity.
The WDC Products corpus includes product pairs
1
https://www.elastic.co/elasticsearch
An Approach for Product Record Linkage Using Cross-Lingual Learning and Large Language Models
69

Table 1: Product Corpora.
Train Valid Test
Corpora Match
No
Match
Match
No
Match
Match
No
Match
WDC 1410 5065 352 1267 300 800
NF BR 1419 6.946 281 1511 298 1493
designated for training, validation, and testing. For
the NFe-BR, we randomly divided the annotated
product pairs into 70%, 15%, and 15% for training,
validation, and testing, respectively. Table 1 presents
the quantitative details for each corpus.
4.2 Information Retrieval
Our trained models are not limited to classification
tasks but can also return the probabilities of match be-
tween pairs of products. These probabilities are used
as criteria to determine the relevance of a search result
in the reordering process. In other words, the higher
the probability of a match between a searched product
and the retrieved items, the greater the result’s rele-
vance for the model.
In our experiments, the function findSimilarity(p”)
of the algorithm 2 was implemented through vari-
ous approaches, including lexical, semantic, and hy-
brid search methods. Initially, these techniques were
evaluated without our re-ranking method, establish-
ing baselines for comparison with the STEPMatch ap-
proach, which presents the reordering using a cross-
encoder language model.
For conducting the searches, we indexed the dis-
tinct descriptions of the products from the electronic
invoices dataset in ElasticSearch, including both the
textual descriptions and their vector representations,
generated from pre-trained models from the Sentence-
Transformers
2
, which we used to generate semantic
embeddings.
In our experiments, the methods were applied to
retrieve the top-k products most similar to the item of
interest. Next, we describe the search methods used
in our work.
4.2.1 Search Methods Without Re-Ranking
To implement the function F
Search
Sim
(p
′′
, p
i
) > θ, we ex-
plored lexical, semantic, and hybrid approaches. In
the lexical search, we used the BM25 algorithm, im-
plemented in Elasticsearch
3
. In the semantic search,
the vector search algorithm Approximate Nearest
Neighbor (ANN) was applied to identify the prod-
ucts with the highest similarity. This approach effec-
tively navigates the high-dimensional space of doc-
2
https://www.sbert.net/
3
https://www.elastic.co/pt/blog/practical-bm25-part-2-
the-bm25-algorithm-and-its-variables
ument embeddings, identifying the subset of docu-
ments most similar to the query based on their co-
sine distance. We evaluated three embedding models
based on SBERT (Reimers and Gurevych, 2019):
• all-MiniLM-L6-v2: Offers high performance and
compact embeddings in a dense vector space of
384 dimensions, making it suitable for large-scale
query processing;
• LaBSE: With 768-dimensional embeddings, this
language-agnostic cross-encoder model supports
various languages;
• quora-distilbert-multilingual: With 768-
dimensional embeddings, it is designed to
work with multiple languages.
The hybrid search approach we adopted in this
work was based on the Reciprocal Rank Fusion (RRF)
technique (Cormack et al., 2009), which allows for
combining the results of different types of queries,
such as those retrieved by lexical and semantic ap-
proaches, into a single ranking as shown in the fol-
lowing equation:
RRFscore(d ∈ D) =
∑
r∈R
1
k +r(d)
where D is the set of documents to be classified, R is
the set of rankings from different information retrieval
systems, and r(d) represents the position of document
d in ranking r.
4.2.2 Search Methods with Re-Raking
To implement the reordering with the adopted Cross-
Encoder, we trained our models to perform the func-
tion F
Cross-Encoder
Sim
(p
′′
, p
i
) which evaluates the rele-
vance of the products p
i
compared to the product
p
′′
. For this, we selected the best methods from the
search without re-ranking in section 4.2.1 and carried
out the reordering using the BERT-multilingual model
trained precisely for product matching.
To evaluate the effectiveness of the Cross-lingual
Learning technique, we trained a model based on
the LLM BERT-Multilingual. We compared its per-
formance with a baseline, in which the same LLM
was trained without the CLL approach, meaning the
model was adjusted exclusively with product descrip-
tions in Portuguese.
4.3 Evaluation Metrics
We classified relevant documents as positive, while
non-relevant ones were considered negative. Based
on this classification, it was possible to calculate the
percentage of relevant documents retrieved using the
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
70

recall metric. Additionally, the NDCG (Normalized
Discounted Cumulative Gain) metric, widely used
in information retrieval (IR), was employed to eval-
uate the effectiveness of search algorithms by con-
sidering the relevance of documents and applying a
discount factor according to the ranking. This fac-
tor reflects user behavior, prioritizing documents with
higher rankings, making NDCG an essential quantita-
tive measure for assessing algorithm performance.
5 RESULTS AND DISCUSSION
The experiments in this section aim to evaluate the
search mechanism implemented by the function find-
Similarity(), presented in step 3. The main focus is
to analyze the relevance of search results in identify-
ing corresponding products in an information retrieval
environment.
Our objective with this analysis is to evaluate the
search methods that retrieve relevant items for a spe-
cific product from the test corpus of electronic in-
voices. An item returned in a search is seen as relevant
when it has the same GTIN as the searched item, even
if it has alternative descriptions.
The order of the relevant retrieved items is not cru-
cial in searching for corresponding products, as all
descriptions refer to the same product, represented
by the same GTIN. What is most important is that
all variations of the product description are present at
the beginning of the search results, regardless of their
ranking position.
For example, if the product ”Skim Milk XYZ”
is registered in the system with three distinct de-
scriptions: ”Skim Milk XYZ 1L”, ”XYZ Skim Milk
1000ml”, and ”Skim Milk 1L”, we consider all these
descriptions relevant. Thus, it does not matter if
”XYZ Skim Milk 1000ml” appears in the first posi-
tion and ”Skim Milk XYZ 1L” in the third; the main
point is that both descriptions are retrieved as varia-
tions of the same product.
This way, the information retrieval system
searched for each item in the test set, computing the
evaluation metrics for the Top 500 items returned by
the search methods. These results were analyzed con-
sidering the average of all the queries made.
We evaluated the results using recall and Normal-
ized Discounted Cumulative Gain (NDCG) metrics,
which were considered appropriate for the product
matching context. Recall assesses the system’s abil-
ity to retrieve all relevant matches for a given query,
where, in this context, a high recall value indicates
that the model was able to recover most of the rele-
vant products from the dataset. In contrast, NDCG
measures the quality of the ranking of the retrieved
documents, assigning higher scores to the most rele-
vant documents located at the top of the results list.
The Figures 4 and 5 show the results of the exper-
iments conducted with lexical and semantic searches
for the function F
Search
Sim
(p
′′
, p
i
) > θ. The lexical
search is labeled as ”bm25,” while the semantic
searches, based on the vectors generated by the mod-
els all-MiniLM-L6-v2, LaBSE, and quora-distilbert-
multilingual, are labeled as ”semantic all minilm,”
”semantic labase,” and ”semantic quora,” respec-
tively. Among the approaches tested, ”bm25” and
”semantic all minilm” stood out with the best recall
and NDCG metrics, indicating that these methods re-
trieved more relevant documents and positioned them
more accurately in the top ranks. These results en-
couraged the development of a hybrid search, com-
bining the features of both approaches.
Figure 4: Recall for Lexical and Semantic search methods.
Figure 5: NDCG for Lexical and Semantic search methods.
The Figures 6 and 7 show the results after the
introduction of hybrid search (“bm25 all minilm”),
through the combination of lexical (“bm25”) and se-
mantic (“semantic all minilm”) methods using the
RRF technique. We observed that the recall achieved
by the hybrid method is comparable to that of the best
lexical and semantic methods, demonstrating the ef-
fectiveness of combining the approaches for retriev-
ing relevant items. However, the NDCG was lower,
indicating that the relevance of the retrieved items was
inferior to that of the other methods.
An Approach for Product Record Linkage Using Cross-Lingual Learning and Large Language Models
71
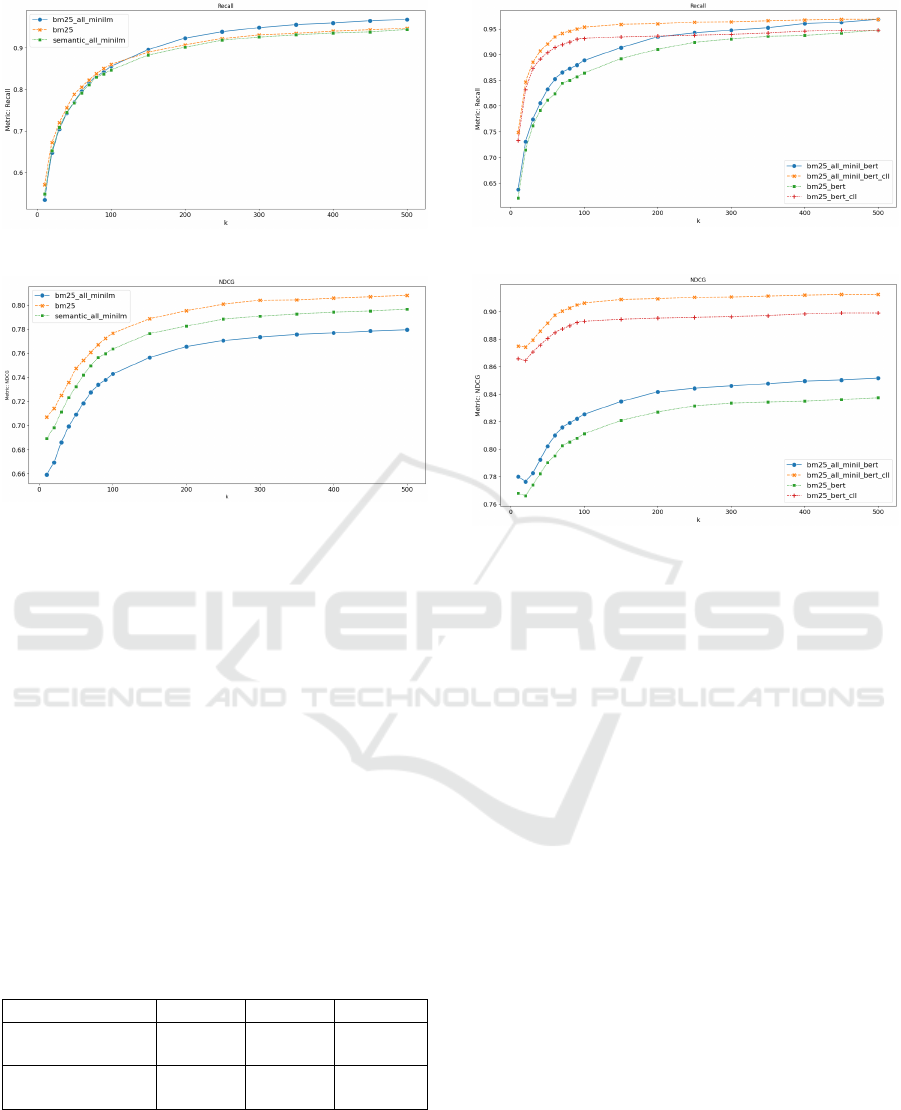
Figure 6: Recall including a hybrid approach.
Figure 7: NDCG including a hybrid approach.
For the implementation of the function
F
Cross-Encoder
Sim
(p
′′
, p
i
) we trained a model from
the BERT family, specifically the BERT-Multilingual,
which calculates a similarity value between the
product p
′′
and p
i
, where p
i
represents each element
retrieved in the initial search (lexical or semantic).
For comparison, we used a baseline model trained
exclusively with data from Brazilian electronic
invoices and a second model trained using the CLL
approach. Table 2 presents the metrics f1-score,
recall, and precision of the models for the similarity
classification task. We used a bootstrapping strategy,
training and evaluating the model over ten repetitions
to estimate its uncertainty. The results in the table in-
dicate that the model trained with CLL outperformed
the baseline.
Table 2: Baseline vs. CLL - Scores for BERT-Multilingual
Models Trained Mean Value and Standardized Error (95%
Confidence Level) Calculated from 10 Samples.
Strategy F1 Recall Precision
baseline
(without CLL)
94.3
±0.0053
94.2
±0.0049
94.3
±0.0052
CLL
JL 50%+CL 50%
98.6
±0.0064
98.2
±0.0060
98.9
±0.0062
With the trained models and evaluated search
methods, we implemented the findSimilarity(p”)
function with reordering applied by the models. The
results, presented in Figures 8 and 9, demonstrate an
improvement both in the number of retrieved items
Figure 8: Recall with re-ranking using BERT.
Figure 9: NDCG with re-ranking using BERT.
and the quality of the ranking when using reordering
with CLL, compared to reordering with the baseline
model.
The results show that the reordering strategy us-
ing a cross-encoder model trained with CLL demon-
strated superior performance compared to traditional
information retrieval (IR) approaches, such as lexi-
cal, semantic, and hybrid searches. This advantage
arises from using the cross-encoder, which compares
pairs of descriptions more accurately, enabling a more
contextualized and detailed assessment of the simi-
larity between products. Furthermore, transfer learn-
ing, made possible by data from products annotated
in another language, improved the performance of our
adopted model.
From Figure 10, it is possible to compare the
NDCG obtained by the different search approaches
evaluated in this study. The strategies that use reorder-
ing with cross-encoder models, adjusted with prod-
uct data, stand out from the others, retrieving relevant
items more accurately. These results mainly highlight
the potential of the reordering strategy with Cross-
lingual Learning to improve the retrieval of relevant
products in product matching applications.
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
72

Figure 10: NDCG comparison of the best approaches.
6 CONCLUSION
Our work proposed an approach to product match-
ing in short descriptions, focusing on electronic in-
voices issued in Brazil. The scenario is character-
ized by short, unstructured, and often inconsistent
descriptions, making product matching challenging.
To tackle these challenges, we developed the STEP-
Match approach (Short Text Product Matching), in-
tegrating information retrieval techniques and super-
vised machine learning, aiming for effective matching
of products in the context of invoice product data. The
proposed approach promotes integrating and enrich-
ing product data from diverse sources to provide con-
sistent information to support management processes
that depend on accurate product data.
We used machine learning techniques in an In-
formation Retrieval (IR) environment to search for
matching products. Initially, we apply lexical search
techniques, such as the BM25 algorithm, in con-
junction with semantic searches to retrieve a set of
candidate products. Subsequently, a cross-encoder
language model, trained specifically for the product
matching task, reorders these candidates, prioritizing
the matching products at the top of the list.
The main contribution of this work was the use of
Large Language Models with Cross-lingual Learning
strategies, which improved the relevance of the items
retrieved in the search for corresponding products.
The research demonstrated the effectiveness of model
adjustment in scenarios with scarce annotated data.
The experiments revealed that a model trained with
the JL/CLL strategy, initially with 50% of the train-
ing data from products in English and Portuguese and
then adjusted with the remaining 50% of the data in
Portuguese, outperformed the reference model, which
was trained exclusively with data in Portuguese. This
experiment confirmed the capability of CLL to pro-
mote model generalization across different languages
and domains, optimizing classification and retrieval
methods for corresponding products. Furthermore,
the techniques applied for reordering search results
surpassed traditional approaches for this application.
We intend to evaluate other CLL strategies for
model adjustment for future work, exploring different
LLMs, languages, and product categories. Addition-
ally, we aim to explore hybrid search techniques fur-
ther to enhance accuracy and effectiveness in product
matching. Lastly, we plan to make a direct compar-
ison of STEPMatch with state-of-the-art approaches
in the field of Entity Resolution.
ACKNOWLEDGEMENTS
The authors would like to thank the Brazilian Na-
tional Council for Scientific and Technological De-
velopment (CNPq) for partially funding this research.
REFERENCES
Alves, A. L. F., Baptista, C. d. S., Barbosa, L., and Araujo,
C. B. M. (2024). Cross-lingual learning strategies
for improving product matching quality. In Proceed-
ings of the 39th ACM/SIGAPP Symposium on Applied
Computing, SAC ’24, page 313–320, New York, NY,
USA. Association for Computing Machinery.
Barbosa, L. (2019). Learning representations of Web enti-
ties for entity resolution. International Journal of Web
Information Systems, 15(3):346–358.
Barlaug, N. and Gulla, J. A. (2021). Neural networks for
entity matching: A survey. ACM Transactions on
Knowledge Discovery from Data (TKDD), 15(3):1–
37.
Bilenko, M. and Mooney, R. J. (2003). Adaptive duplicate
detection using learnable string similarity measures.
In Proceedings of the Ninth ACM SIGKDD Interna-
tional Conference on Knowledge Discovery and Data
Mining, KDD ’03, page 39–48, New York, NY, USA.
Association for Computing Machinery.
Christen, P. (2008). Febrl: A freely available record linkage
system with a graphical user interface. In Proceedings
of the Second Australasian Workshop on Health Data
and Knowledge Management - Volume 80, HDKM
’08, page 17–25, AUS. Australian Computer Society,
Inc.
Christen, P. (2012). Data matching systems. In Data Match-
ing, pages 229–242. Springer Berlin Heidelberg.
Christophides, V., Efthymiou, V., Palpanas, T., Papadakis,
G., and Stefanidis, K. (2020). An overview of end-
to-end entity resolution for big data. ACM Computing
Surveys, 53(6):1–42.
Cormack, G. V., Clarke, C. L. A., and Buettcher, S. (2009).
Reciprocal rank fusion outperforms condorcet and in-
dividual rank learning methods. In Proceedings of
An Approach for Product Record Linkage Using Cross-Lingual Learning and Large Language Models
73

the 32nd International ACM SIGIR Conference on Re-
search and Development in Information Retrieval, SI-
GIR ’09, page 758–759, New York, NY, USA. Asso-
ciation for Computing Machinery.
De Oliveira, A. B., Baptista, C. d. S., Firmino, A. A., and
De Paiva, A. C. (2024). A large language model ap-
proach to detect hate speech in political discourse us-
ing multiple language corpora. In Proceedings of the
39th ACM/SIGAPP Symposium on Applied Comput-
ing, SAC ’24, page 1461–1468, New York, NY, USA.
Association for Computing Machinery.
de Santana, M. A., de Souza Baptista, C., Alves, A.
L. F., Firmino, A. A., da Silva Janu
´
ario, G., and
da Silva Caldera, R. W. (2023). Using machine
learning and NLP for the product matching problem.
In Intelligent Sustainable Systems, pages 439–448.
Springer Nature Singapore.
Ebraheem, M., Thirumuruganathan, S., Joty, S. R., Ouz-
zani, M., and Tang, N. (2017). Deeper - deep entity
resolution. CoRR, abs/1710.00597.
Embar, V., Sisman, B., Wei, H., Dong, X. L., Faloutsos,
C., and Getoor, L. (2020). Contrastive entity linkage:
Mining variational attributes from large catalogs for
entity linkage. In Automated Knowledge Base Con-
struction.
G
¨
oz
¨
ukara, F. and
¨
Ozel, S. A. (2021). An incremental
hierarchical clustering based system for record link-
age in e-commerce domain. The Computer Journal,
66(3):581–602.
Hambarde, K. A. and Proenc¸a, H. (2023). Information re-
trieval: Recent advances and beyond. IEEE Access,
11:76581–76604.
Han, J., Pei, J., and Tong, H., editors (2023). Data Mining:
Concepts and Techniques. Morgan Kaufmann, fourth
edition edition.
Konda, P. V. (2018). Magellan: Toward building entity
matching management systems. The University of
Wisconsin-Madison.
K
¨
opcke, H., Thor, A., and Rahm, E. (2010). Evaluation
of entity resolution approaches on real-world match
problems. Proceedings of the VLDB Endowment, 3(1-
2):484–493.
Li, Y., Li, J., Suhara, Y., Doan, A., and Tan, W.-C. (2020).
Deep entity matching with pre-trained language mod-
els. Proceedings of the VLDB Endowment, 14(1):50–
60.
Mudgal, S., Li, H., Rekatsinas, T., Doan, A., Park, Y., Kr-
ishnan, G., Deep, R., Arcaute, E., and Raghavendra,
V. (2018). Deep Learning for Entity Matching. In
Proceedings of the 2018 International Conference on
Management of Data, pages 19–34, New York, NY,
USA. ACM.
Papadakis, G., Skoutas, D., Thanos, E., and Palpanas, T.
(2021). Blocking and Filtering Techniques for Entity
Resolution. ACM Computing Surveys, 53(2):1–42.
Peeters, R. and Bizer, C. (2022). Supervised contrastive
learning for product matching. In Companion Pro-
ceedings of the Web Conference 2022, WWW ’22,
page 248–251, New York, NY, USA. Association for
Computing Machinery.
Peeters, R., Bizer, C., and Glava
ˇ
s, G. (2020). Interme-
diate training of bert for product matching. small,
745(722):2–112.
Pikuliak, M.,
ˇ
Simko, M., and Bielikova, M. (2021). Cross-
lingual learning for text processing: A survey. Expert
Systems with Applications, 165:113765.
Primpeli, A., Peeters, R., and Bizer, C. (2019). The WDC
training dataset and gold standard for large-scale prod-
uct matching. In Companion Proceedings of The 2019
World Wide Web Conference. ACM.
Rateria, S. and Singh, S. (2024). Transparent, low resource,
and context-aware information retrieval from a closed
domain knowledge base. IEEE Access, 12:44233–
44243.
Reimers, N. and Gurevych, I. (2019). Sentence-bert: Sen-
tence embeddings using siamese bert-networks.
Ristoski, P., Petrovski, P., Mika, P., and Paulheim, H.
(2018). A machine learning approach for prod-
uct matching and categorization. Semantic web,
9(5):707–728.
Tracz, J., W
´
ojcik, P. I., Jasinska-Kobus, K., Belluzzo, R.,
Mroczkowski, R., and Gawlik, I. (2020). BERT-based
similarity learning for product matching. Proceedings
of Workshop on Natural Language Processing in E-
Commerce, pages 66–75.
Traeger, L., Behrend, A., and Karabatis, G. (2024). Scop-
ing: Towards streamlined entity collections for multi-
sourced entity resolution with self-supervised agents.
In Proceedings of the 26th International Conference
on Enterprise Information Systems - Volume 1: ICEIS,
pages 107–115. INSTICC, SciTePress.
Xiao, C., Wang, W., Lin, X., Yu, J. X., and Wang, G. (2011).
Efficient similarity joins for near-duplicate detection.
ACM Trans. Database Syst., 36(3).
ICEIS 2025 - 27th International Conference on Enterprise Information Systems
74
